lab11 自底向上的语法分析技术1
5第五章 自底向上语法分析法1

• 总结: 采用图的遍历完成自底向上的分析。
分析过程中有个急需解决的问题:谁先规约?
解决方法:通过比较终结符号之间的优先关系来确定谁 先规约。 由于自底向上的分析过程就是一个图的遍历过程,因此 分析程序通常会使用一个分析栈来辅助分析。 自底向上的分析开始时栈是空的,在成功分析的末尾就 只有开始符号。
文法G[A]={A→(A) | a}分隔如下:
A→.(A)
表示正准备开始分析
A→(.A)
表示(已被吸收,准备吸收A
A→(A.)
表示(A已被吸收,准备吸收)
A→(A).
表示(A)已被吸收,可以归约了
A→.a
表示正准备开始分析
A→a.
表示a已被吸收,可以归约了
有两个开始的地方,到底从谁开始? 解决方法:引入新的开始符号,扩充文法。
• LR(0)文法(LR(0) grammar): LR(0) 项DFA图的 所有状态均不存在移进-归约冲突(shift-reduce conflict) 和归约-归约冲突(reduce-reduce conflict) 。
移进-归约冲突:即某个状态不能既包含一个“移 进的”项目A→.X (X是一个终结符),又包含 一个如B→.的归约项。
$V+V *n
$V+V* n
$V+V*n
$V+V*V
$V+V
$V
• 试分析文法G[A]={A→(A) | a}所对应的串((a))。
(1)构造终结符优先关系表 (2)分析过程
分析栈 $ $( $(( $((a $((A $((A) $(A $(A) $A
输入串 ((a)) (a)) a)) )) )) ) )
主要内容
自底向上的语法分析解读

程序4-4 简单优先分析驱动程序
int parser(void){ int i=0,k=0,r;stack[0]='#'; r=a[k++]; do{ int j,LeftSide; while(!IsHigherThan(stack[i],r)) {stack[++i]=r;r=a[k++];} j=i; while(! IsLowerThan (stack[j-1], stack[j])) j--; LeftSide= RightSideOfAProduction (stack[j],stack[i],i-j+1); if(LeftSide){ /*LeftSide!=0 means the production exists */ i=j;stack[i]=LeftSide; }else /* There is no production which matches the right side */ if(i==2 && r=='#' && stack[i] == STARTSYSBOL) return SUCCESS; else return ERROR; } while (1); } /* end of parser */
与的句柄之间的关系必有下述情况之一: A A
A
… … s t ... … … s t … ... … … s t … ... 1. s在句柄中, 3. s不在句柄中,而t 2. s与t均在句 而t不在句柄中 在句柄中 柄中 对于上述情况,我们规定, 情况1: s>t; 情况2: s=t; 情况3: s<t 另外,还有一种情况,就是s和t均不在句柄中,那么一定存在某句 型使得它们进入上述三种情况之一.
编译原理之自底向上的优先分析法(40页)

2021/8/25
int * int +
int
8
A Shift-Reduce Parse in Detail (3)
|int * int + int int | * int + int int * | int + int
2021/8/25
文法G[E]:E→E+E|E-E|E*E|E/E|EE|(E)|i
(1)i的优先级最高 (1) 优先级次于i,右结合 (2)*和/优先级次之,左结合
+ -*/ ( ) i# +>><<<<><> ->><<<<><> *> > > > < < > < >
(3)+和-优先级最低,左结合
/>>>><<><>
|int * int + int int | * int + int int * | int + int int * int | + int int * T | + int
T
2021/8/25
int * int +
int
11
A Shift-Reduce Parse in Detail (6)
|int * int + int int | * int + int int * | int + int int * int | + int int * T | + int T | + int
语法分析--自底向上分析技术

• 质短语 • 算符优先识别算法
第五章 语法分析----自底向上分析技术
5.3算符优先分析技术
5.3.4算符优先文法句型的识别
• 质短语 • 算符优先识别算法
例 文法G[Z]: Z∷=E E∷=T|E+T T∷=F|T*F F∷=(E)|i 设有输入符号串i+(i+i)*i, 试识别它是否是文法的句子。
第五章 语法分析----自底向上分析技术
5.2 简单优先分析技术
5.2.1 优先关系与优先文法
5.2.2 简单优先分析技术的实现 5.2.3 简单优先分析技术的局限性及克服
第五章 语法分析----自底向上分析技术
5.2 简单优先分析技术
5.2.1优先关系与优先文法
• 寻找句柄的基本思想 • 优先关系及其应用 • 简单优先文法
5.3.1算符优先分析技术的引进 Tj<Ti 当且仅当文法G中存在形如U∷=…TjV…的规则,其中V=>Ti…或V=>WTi…;
+
Tj >Ti 当且仅当文法G中存在形如U∷=…VTi…的规则,其中V=>…Tj 或V=>…TjW。
+ 5.3.2算符文法 Z∷=E E∷=T|E+T T∷=F|T*F F∷=(E)|i 例 设有文法G[Z]:
例5.1
步骤 ( 1) ( 2) ( 3) ( 4) ( 5) ( 6) ( 7) ( 8) ( 9) ( 10) ( 11)
设有文法G[E]:E∷=E+E|E*E|(E)|i
栈 # #i #E #E* #E*i #E*E #E #E+ #E+i #E+E #E 输入 i*i+i# *i+i# *i+i# i+i# +i# +i# +i# i# # # # 动作 移入 归约 移入 移入 归约 归约 移入 移入 归约 归约 接受 E∷ =i E∷ =E+E E∷ =i E∷ =E*E E∷ =i 规则
语法分析最常用的两类方法

LL分析法和LR分析法。
1、自上而下语法分析方法(LL分析法)
给定文法G和源程序串r。
从G的开始符号S出发,通过反复使用产生式对句型中的非终结符进行替换(推导),逐步推导出r 。
是一种产生的方法,面向目标的方法。
分析的主旨为选择产生式的合适的侯选式进行推导,逐步使推导结果与r匹配。
2、自下而上语法分析方法(LR分析法)
从给定的输入串r开始,不断寻找子串与文法G中某个产生式P的候选式进行匹配,并用P的左部代替(归约)之,逐步归约到开始符号S。
是一种辨认的方法,基于目标的方法。
分析的主旨为寻找合适的子串与P的侯选式进行匹配,直到归约到G的S为止。
扩展资料
LALR分析器可以对上下无关文法进行语法分析。
LALR即“Look-AheadLR”。
其中,Look-Ahead为“向前看”,L代表对输入进行从左到右的检查,R代表反向构造出最右推导序列。
LALR分析器可以根据一种程序设计语言的正式语法的产生式而对一段文本程序输入进行语法分析,从而在语法层面上判断输入程序是否合法。
实际应用中的LALR分析器并不是由人手工写成的,而是由类似于yacc和GNU Bison之类的LALR语法分析器生成工具构成。
由机器自动生成的代码相比较于程序员手工的代码,拥有更好的运行效率而且减少了程序员的工作量。
在自底向上的语法

在自底向上的语法一、什么是自底向上的语法自底向上的语法(Bottom-Up Parsing)是一种常用的语法分析方法,用于将一个字符串根据给定语法规则转化为语法分析树。
与之相对的是自顶向下的语法分析方法,自顶向下的语法分析从根节点开始,逐步将输入的字符串分解为非终结符和终结符,直到得到语法分析树。
而自底向上的语法分析则相反,它从叶子节点开始,逐步合并成非终结符,直到得到语法分析树。
自底向上的语法分析方法通常采用的是操作符优先分析法(Operator Precedence Parsing),也称为算符优先文法。
这种分析方法可以通过构造一个算符优先关系表来进行分析,从而判断字符串是否符合给定的语法规则。
自底向上的语法分析方法适用于各种类型的语言和文法,包括正则文法、上下文无关文法等。
这种方法具有较高的灵活性和适应性,并且能够处理大型复杂的文法和语言。
二、自底向上的语法分析步骤自底向上的语法分析过程可以分为以下步骤:1. 词法分析首先,将输入的字符串进行词法分析,将其划分为一个个单词或记号(Token)。
每个单词或记号都具有一个特定的含义,表示了输入字符串中的一个基本语义单元。
2. 初始化构建一个栈(Stack)用于保存已识别的单词或记号,并初始化一个语法分析表(Parsing Table)用于记录语法规则和操作符的优先级关系。
3. 移入操作从输入的字符串中读取一个未处理的单词或记号,并将其压入栈中。
4. 归约操作不断检查栈中的记号序列是否满足某一语法规则,如果满足,则将该记号序列替换为相应的非终结符,并执行相应的语义动作。
重复这个过程,直到不能再进行归约操作。
5. 接受或错误处理如果最终栈中只剩下一个元素,且该元素为起始符号,则语法分析成功,接受输入的字符串。
如果栈中无法进行归约操作,或者最终栈中还有多余的元素,或者无法匹配到输入字符串的所有部分,则语法分析失败,进行错误处理。
三、算符优先文法算符优先文法是自底向上分析方法的代表,它以操作符的优先级和关联性为基础,构造一个优先关系表来进行分析。
编译原理讲义(第五章语法分析--自底向上分析技术)

优先关系
• 和书上的写法不一样,凑合用。 SiSj Si Sj Si Sj • 注意: , , 之间不同于=,>和<。 由Si Sj不能导出Sj Si。
优先关系的例子
• 文法:Z::=bMb M::=(L|a L::=Ma) • 语言:{bab, b(aa)b, b((aa)a)b, …} • 可以从语法树里面导出部分优先关系。
关系闭包和Warshall算法
• Warshall算法是利用矩阵计算关系传递闭包的方法。计 算B的传递闭包的算法伪代码如下: 对于外层循环,当 A = B; i=K的循环结束的时 for (i = 1; i<=n; i++) 候,满足:如果Si和 for (j=1; j<=n; j++) Sj满足Si R Si1, Si1 R { Si2, … Sin R Sj, 并 if (A[j,i]==1) 且im<K, 那么现在 for(k=1; k<=n; k++) A[i,j] = 1; A[j,k] = A[j,k]+A[i,k] }
基本方法(续)
• 归约中的动作有4类
– 移入:读入一个符号并把它归约入栈。 – 归约:当栈中的部分形成一个句柄(栈顶的 符号序列)时,对句柄进行归约。 – 接受:当栈中的符号仅有#和识别符号的时 候,输入符号也到达结尾的时候,执行接受 动作。 – 当识别程序觉察出错误的时候,表明输入符 号串不是句子。进行错误处理。
计算优先关系的例子P136
• 文法:S::=Wa W::=Wb W::=a • 将文法中的符号按照S,W,a,b排列。
0100 BHEAD= 0110 0000 0000
0010 0011 0000 0000
编译原理自底向上的语法分析

规范前缀
或者终极符串
规范句型
一些相关概念
规范活前缀:满足如下条件之一的规范前缀称为规范 活前缀:
该规范前缀不包含简单短语;
该规范前缀只包含一个简单短语,而且是在该规范前缀的最 后(这个简单短语就是句柄);
Z ABb 规范活前缀:
规范前缀为 AB, ABb AB(不包含简单短语) , ABb(包含一个简单短语且在最后)
自顶向下语法分析回顾 自底向上语法分析的例子 自底向上语法分析的主要思想 自底向上语法分析的关键问题 一些相关概念
自顶向下分析例
自顶向下分析过程是从文法开始符出发,为所给输入串构造
最左推导的过程。
输入
句型
动作
P: (1) Z aBeA (2) A Bc (3) B d (4) B bB (5) B
移入型规范活前缀
归约:规范活前缀只包含一个简单短语,而且是在该规范
活前缀的最后;
可归约规范活前缀 :归约规范活前缀
Z ABb
规范前缀为 AB, ABb
规范活前缀: AB(不包含简单短语) --- 移入型规范活前缀
ABb(包含一个简单短语) --- 归约规范活前缀
自底向上分析知识关系图
推导(*)
句型(S *)
( E) E +T
每棵简单子树(只有一层的子树)的叶子节 点构成简单短语:T、E+T、i
最左简单子树的叶子节点构成句柄: T
一些相关概念
自顶向下的语法分析方法中曾介绍过: 推导:对句型中的非终极符用产生式右部替换
推导的逆过程称为归约
规范推导:一个句型的最右推导称为该句型的 规范推导; 规范推导的逆过程称为规范归约(最左归约)
分析动作:移入(shift),归约(reduce) 包含以下方法:
编译原理 语法分析—自底向上分析技术

是算符优先文法。 + * ( + > < < * > > < ( < < < ) > > i > >
) i > < > < ═ < > >
5.2.4 算符优先文法句型的识别
1.质短语 质短语:句型中至少包含一个终结符号,且除它自 身外不再包含其他质短语的短语。 如文法 G[E]:E::=E+T|T T::=T*F|F F::=(E)|i 的句型E+T*F*i+i中的T*F和 i 是质短语。如何人工寻找 句型中的质短语?先找出一切短语,再从最短的找起。
1 2 3 4 5 6 7 8
i+(i+i)*i F+(i+i)*i F+(F+i)*i F+(F+F)*i F+(E)*i F+F*i F+F*F F+T
#< i >+ #< + < ( < i > + #< + < ( <+< i >) #< + < ( <+> ) #< + < ( = ) > * #< + <* < i > # #< + <* ># #< + >#
E+T*F*i+i中的短语和质短语? 句型分析中自动寻找质短语的思路: 先从左向右寻找质短语的尾终结符号, 再从右向左寻找质短语的头终结符号,
即,先找优先关系
(?) 再找优先关系
(?)
2.句型的识别 关于文法G[E],对输入符号串i+(i+i)*i句型分析
步骤 句 型 关 系 最左质短语 归约到符号
按自底向上分析技术,句型分析的过程是一个不断 从语法分析树中剪去分支的过程。
Part5语法分析自底向上的语法分析(1)解读

Part5.语法分析——自底向上的语法分析(1)作业1.对于文法S→A A→BA A→εB→aB B→b(1) 构造LR(1)分析表;(2) 给出用LR(1)分析表对输入符号串abab的分析过程。
2.设已给文法(1)G1[S]:S→Aa|bAc|dc|bdaA→d(2)G2[S]:S→Aa|bAc|Bc|bBaA→dB→d试证明:G1是LALR(1)文法但不是SLR(1)文法;G2是LR(1)文法但不是LALR(1)文法。
3.试为如下的文法构造LALR(1)分析表。
E→E+T|T T→TF|F F→F*|a|b4.给出下面二义文法的语法分析表:E→E sub E sup EE→E sub EE→E sup EE→{E}E→c1.1自底向上分析的基本问题自底向上的语法分析方法,也称为移动归约分析法。
最易于实现的一种移动归约分析方法,叫做算符优先分析法,而更一般的移动归约分析方法叫做LR分析法,LR分析法可以用作许多自动的语法分析器的生成器。
移动归约分析法为输入串构造分析数时是从叶结点(底端)开始,向根结点(顶端)前进。
我们可以把该过程看成是把输入串ω“归约”成文法开始符号的过程。
在每一步归约中,如果一个子串和某个产生式的右部匹配,则用该产生式的左部符号代替该子串。
如果每一步都能恰当的选择子串,我们就可以得到最右推导的逆过程。
在实现上,就是说用一个寄存符号的先进后出栈,把输入符号一个一个的移进到栈里,当栈顶形成某个产生式的一个候选式时,即把栈顶的这一部分替换(归约)为该产生式的左部符号。
所有不同的自底向上分析法的一个共同特点就是,便输入单词符号(移进符号栈),边归约。
也就是从左到右移进输入串的过程中,一旦发现栈顶符号呈现可归约串就立即进行归约。
1.1.1句柄和归约非形式的,一个符号串的“句柄”是和一个产生式右部匹配的子串,而且把它归约到该产生式左部的非终结符代表了最右推导逆过程的一步。
形式的说,右句型(最右推导可得到的句型)γ的句柄是一个产生式A→β以及γ的一个位置,在该位置可以找到串β,而且用A代替β可以得到γ的最右推导的前一个右句型,即如果S=>*αAω=>αβω,其中ω全部由终结符构成,那么我们就说β是句型αβω的句柄。
编译原理-自下而上的语法分析

自上而下的语法分析
特点
从高层次的文法规则开始,通过不断展开和推导,直到生成目标字符串。
优点
易于理解和实现,可以生成详细的错误报告。
自下而上的语法分析
1
自底向上的语法分析方法概述
通过以输入的标记为起点,逐步推导文法规则,直到生成目标字符串。
2
LR语法分析
一种常用的自底向上的语法分析方法,通过构建一个LR分析表进行推导。
3
LALR语法分析
是LR语法分析的一种变体,通过合并相同状态来降低分析表的复杂度。
自下而上的语法分析的优点和局限性
优点
适用于大型文法,能够处理更广泛的语言结构。
局限性
分析过程复杂,容易产生冲突,需要较大的存储空 间。
自下而上的语法分析的实现
词法分分析器的生成
根据文法规则,构建分析表或语法分析器的数据结构。
语法制导翻译的实现
在语法分析过程中,将源代码转换为目标代码。
自下而上的语法分析的应用
1
编译器中的语法分析
语法分析是编译器中的重要组成部分,用于将源代码转换为中间代码或目标代码。
2
解析器生成器
自下而上的语法分析技术被广泛应用于解析器生成器中,用于自动生成语法分析 器。
结论
自下而上的语法分析是编译原理中重要的一环,虽然实现复杂,但却具有广 泛的应用价值。
编译原理-自下而上的语 法分析
编译原理是研究程序在计算机上的自动翻译过程,语法分析是其中的重要步 骤。自下而上的语法分析是一种常用的语法分析方法。
语法分析的定义和目的
1 定义
语法分析是编译器中的一个阶段,用于验证 和分析程序语法的正确性。
2 目的
语法分析的目的是将源代码转换为语法树, 为后续的编译过程提供基础。
编译原理自底向上优先分析法

其他领域中的应用实例
形式语言理论
自底向上优先分析法在形式语言理论中可用于研究语言的性质和结构,如文法分类、自动机理论等。
人工智能
自底向上优先分析法在人工智能领域中可用于知识表示、推理和问题求解等方面,如专家系统、智能 规划等。
06 总结与展望
总结
01
优先分析法是一种编译原理中的语法分析方法,它按照一 定的优先级规则,从左到右、从底向上地构建语法树。这 种方法在编译器设计中具有广泛的应用,能够有效地处理 表达式的语法和语义问题。
其他领域
除了编译器设计和自然语言处理领域,自底向上 优先分析法还可以应用于其他需要处理和分析语 法结构的领域。
03 自底向上优先分析法实现
构建抽象语法树(AST)
抽象语法树(AST)是源代码的抽象 语法结构的树状表现形式,树上的每 个节点都表示源代码中的一种结构。
在构建AST时,需要遵循源代码的语 法规则,将源代码中的各个元素(如 变量、操作符、语句等)按照其语法 关系组织成树状结构。
02
自底向上优先分析法是优先分析法的一种,它从输入的字 符串开始,逐步向上构建语法树,直到达到抽象语法树的 根节点。这种方法在处理复杂的表达式时具有较高的效率 和准确性。
03
优先分析法在编译原理中具有重要的地位,它不仅能够帮 助编译器正确地处理表达式的语法和语义问题,还能够提 高编译器的性能和可维护性。
语义分析
对AST进行语义检查,确保代码符合 语言的语义规则。
中间代码生成
将AST转换成中间代码,通常是三地 址码。 Nhomakorabea代码优化
对中间代码进行优化,提高执行效 率。
代码生成
将中间代码转换成机器码,生成可 执行文件。
编译原理自底向上优先分析法

学习目标: • 掌握:构造算符优先关系表,进行算符
优先分析,构造优先函数 • 理解:算符优先文法,最左素短语 • 了解:简单优先分析法
2020/12/4
1 自底向上分析方法概述 2 自底向上优先分析方法概述 3 算符优先分析法
2020/12/4
1 自底向上分析方法概述
1. 基本思想 ➢ 从输入符号串开始,利用文法的产生式逐步进行
其中a∈VT, B,C∈VN ➢ 直观上说LASTVT(B)是由B推导出的最右终
结符(允许右边有一非终结符)的集合。 ➢例文法:
E→E+T|T T→T×F|F F→(E)|i
LASTVT(F)={),i} LASTVT(T)={×,),i} LASTVT(E)={+,×,),i}
2020/12/4
构造LASTVT(A)的算法与构造FIRSTVT(A)算 法相似 根据下面两条规则 a) 若产生式A→…a,或A→…aB,则 a∈LASTVT(A) b) 若有产生式A→…B,且a∈LASTVT(B),则 a∈LASTVT(A)
包含优先级和结合性的表达式文法是算符优先文法
E→E+T|T T→T×F|F F→(E)|i
2020/12/4
3.3 算符优先关系表的构造
1. 最左终结符集FIRSTVT ➢ FIRSTVT(B)={b|B=>+ b… 或 B=>+ Cb… }
其中b∈VT, B,C∈VN ➢ 直观上说FIRSTVT(B)是由B推导出的最左终结
自底向上分析的过程为:
abbcde|-aAbcde|-aAcde|-aAcBe|-S
2020/12/4
例 文法: (1) S→aAcBe (2) A→b
编译原理实验2-自底向上语法分析算法程序设计
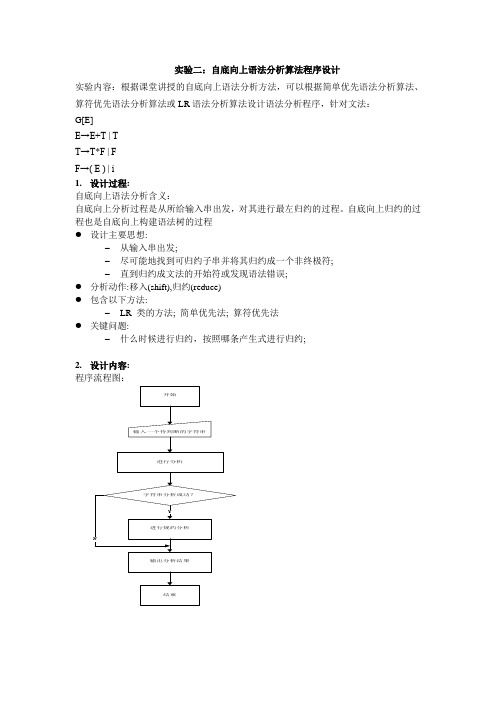
实验二:自底向上语法分析算法程序设计实验内容:根据课堂讲授的自底向上语法分析方法,可以根据简单优先语法分析算法、算符优先语法分析算法或LR语法分析算法设计语法分析程序,针对文法:G[E]E→E+T | TT→T*F | FF→( E ) | i1.设计过程:自底向上语法分析含义:自底向上分析过程是从所给输入串出发,对其进行最左归约的过程。
自底向上归约的过程也是自底向上构建语法树的过程●设计主要思想:–从输入串出发;–尽可能地找到可归约子串并将其归约成一个非终极符;–直到归约成文法的开始符或发现语法错误;●分析动作:移入(shift),归约(reduce)●包含以下方法:–LR 类的方法; 简单优先法; 算符优先法●关键问题:–什么时候进行归约,按照哪条产生式进行归约;2.设计内容:程序流程图:3. 程序关键代码:#include <stdio.h>int flag;//初始化变量char m[20]={'+','*','^','i','(',')','#'};chart[20][20]={{'>','<','<','<','<','>','>'},{'>','>','<', '<','<','>','>'},{'>','>','<','<','<','>','>'},{'>','>',' >','n','n','>','>'},{'<','<','<','<','<','=','n'},{'>','>' ,'>','n','n','>','>'},{'<','<','<','<','<','n','='}};int termin(char arr[20],char c); //函数:判断是否终结符char compare(char xarr[20][20],char c1,char c2); //函数:比较两个终结符之间的优先关系void error();main (){printf("请输入字符串并以#结束\n:");char str[50];char a,q;char s[50];int k,j,n;scanf("%s",str);s[0]='n';flag=0;n=0;k=1;s[k]='#';do //读取输入的字符串到#号结束{a=str[n];if (termin(m,a)>=0)n++;else{error();return(0);}if (termin(m,s[k])>=0)j=k;elsej=k-1;while (compare(t,s[j],a)=='>'){do{q=s[j];if ((j-1)<=0){error();return(0);}if (termin(m,s[j-1])>=0){j=j-1;}elsej=j-2;}while (compare(t,s[j],q)!='<');k=j+1;s[k]='N';}if((compare(t,s[j],a)=='<')||(compare(t,s[j],a)= ='=')){k=k+1;s[k]=a;}elseerror();}while (a!='#');if (!flag)printf("The sentence is legal!\n");}int termin(char arr[20],char c){int i=0;int l=0;while (arr[i]!='\0'){if (arr[i]==c){l=1;break;}i=i+1;}if (l==1)return(i);elsereturn(-1);}char compare(char xarr[20][20],char c1,char c2)//比较两个终结符之间的优先关系{int i,j;char r;i=termin(m,c1);j=termin(m,c2);r=xarr[i][j];return(r);}void error() //通过flag来判断字符串是否非法{flag=1;printf("The sentence is not legal\n!");}4.实验结果:上图输入的字符串虽符合要求,但是进行运行分析是发现不能进行规约,结果错误非法.5.实验总结:通过实验知道了采用自底向上分析方法对输入的字符串进行语法分析,进一步掌握最左归约的过程.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验报告封面
课程名称:编译原理课程代码: SS2027
任课老师:彭小娟实验指导老师: 彭小娟
实验报告名称:实验十一:自底向上的语法分析技术
学生姓名:
学号:
教学班:
递交日期:
签收人:
我申明,本报告内的实验已按要求完成,报告完全是由我个人完成,并没有抄袭行为。
我已经保留了这份实验报告的副本。
申明人(签名):
实验报告评语与评分:
评阅老师签名:彭小娟
一、实验名称:自底向上的语法分析
二、实验日期: 年 月 日
三、实验目的:
1. 理解相关概念:自底向上分析方法的基本思想;FIRSTVT 集合,LASTVT 集合,算符优先文法的定义,
2. 掌握FIRSTVT 集合,LASTVT 集合的计算以及算符优先关系表的构造
四、实验用的仪器和材料:(操作系统:CPU :内存:硬盘:软件:) 硬件:PC 人手一台
软件:office
五、实验的步骤和方法:
1. 对于文法G(S):
S
S L L a aS L S |,||)(>->- (1) 画出句型(S,(a))的语法树
(2) 写出上述句型的所有短语、直接短语、句柄和素短语
2. 给定文法G(S):
S
S T T T a S |,)(||→Λ>- (1) 计算该文法的FIRSTVT 集合和LASTVT 集合
(2) 计算该文法的优先关系。
该文法是一个算符优先文法吗?
(3) 计算该文法的优先函数
(4) 给出输入串 (a,a)的算符优先分析过程。
3. 书133页第二题
六、数据记录和计算:
七、实验结果或结论:(总结)
八、备注或说明:可写上实验成功或失败的原因,实验后的心得体会、建议等。
九、引用参考文献:即在本实验中所引用的之資料。