计量经济学一元回归实验
计量经济学实验一 一元回归模型
实验二一元回归模型【实验目的】掌握一元线性、非线性回归模型的建模方法【实验内容】建立我国税收预测模型【实验步骤】【例1】建立我国税收预测模型。
表1列出了我国1985-1998年间税收收入Y和国内生产总值(GDP)x的时间序列数据,请利用统计软件Eviews建立一元线性回归模型。
一、建立工作文件⒈菜单方式在录入和分析数据之前,应先创建一个工作文件(Workfile)。
启动Eviews软件之后,在主菜单上依次点击File\New\Workfile(菜单选择方式如图1所示),将弹出一个对话框(如图2所示)。
用户可以选择数据的时间频率(Frequency)、起始期和终止期。
图1 Eviews菜单方式创建工作文件示意图图2 工作文件定义对话框本例中选择时间频率为Annual(年度数据),在起始栏和终止栏分别输入相应的日期85和98。
然后点击OK,在Eviews软件的主显示窗口将显示相应的工作文件窗口(如图3所示)。
图3 Eviews工作文件窗口一个新建的工作文件窗口内只有2个对象(Object),分别为c(系数向量)和resid(残差)。
它们当前的取值分别是0和NA(空值)。
可以通过鼠标左键双击对象名打开该对象查看其数据,也可以用相同的方法查看工作文件窗口中其它对象的数值。
⒉命令方式还可以用输入命令的方式建立工作文件。
在Eviews软件的命令窗口中直接键入CREATE命令,其格式为:CREATE 时间频率类型起始期终止期本例应为:CREATE A 85 98二、输入数据在Eviews软件的命令窗口中键入数据输入/编辑命令:DA TA Y X此时将显示一个数组窗口(如图4所示),即可以输入每个变量的数值图4 Eviews数组窗口三、图形分析借助图形分析可以直观地观察经济变量的变动规律和相关关系,以便合理地确定模型的数学形式。
⒈趋势图分析命令格式:PLOT 变量1 变量2 ……变量K作用:⑴分析经济变量的发展变化趋势⑵观察是否存在异常值本例为:PLOT Y X⒉相关图分析命令格式:SCAT 变量1 变量2作用:⑴观察变量之间的相关程度⑵观察变量之间的相关类型,即为线性相关还是曲线相关,曲线相关时大致是哪种类型的曲线说明:⑴SCAT命令中,第一个变量为横轴变量,一般取为解释变量;第二个变量为纵轴变量,一般取为被解释变量⑵SCAT命令每次只能显示两个变量之间的相关图,若模型中含有多个解释变量,可以逐个进行分析⑶通过改变图形的类型,可以将趋势图转变为相关图本例为:SCA T Y X图5 税收与GDP趋势图图5、图6分别是我国税收与GDP时间序列趋势图和相关图分析结果。
计量经济学:一元线性回归模型

一、变量间的关系及研究方法基本概念
1. 变量间的关系
(1)确定性关系或函数关系:研究的是确定现 象非随机变量间的关系。
圆面积 f ,半径 半径2
(2)统计依赖或相关关系:研究的是非确定现 象随机变量间的关系。
农作物产量 f 气温, 降雨量, 阳光, 施肥量
2、研究方法
对变量间统计依赖关系的考察主要是通过 相关分析(correlation analysis)或回归分析 (regression analysis)来完成的
称为(双变量)总体回归函数(population regression function, PRF)。
三、随机扰动项与总体回归模型
❖ 总体回归函数说明在给定的收入水平Xi下,该社 区家庭平均的消费支出水平。
❖ 但对某一个别的家庭,其消费支出可能与该平均 水平有偏差。
1、随机干扰项
(1) i Yi E(Y | X i )
935 1012 1210 1408 1650 1848 2101 2354 2860 968 1045 1243 1474 1672 1881 2189 2486 2871
1078 1254 1496 1683 1925 2233 2552 1122 1298 1496 1716 1969 2244 2585 1155 1331 1562 1749 2013 2299 2640 1188 1364 1573 1771 2035 2310 1210 1408 1606 1804 2101
§2.2 一元线性回归模型的参数估计
一、线性回归模型的基本假设 二、参数的普通最小二乘估计(OLS) 三、参数估计的最大或然法(ML)* 四、最小二乘估计量的性质 五、参数估计量的概率分布及随机干扰 项方差的估计
计量经济学【一元线性回归模型——回归分析概述】

四、随机误差项的涵义
随机误差项是在模型设定中省略下来而又集体的
影响着被解释变量 Y 的全部变量的替代物。涵义如
下: 1、在解释变量中被忽略的因素的影响; 2、变量观测值观测误差的影响; 3、模型关系的设定误差的影响; 4、其它随机因素的影响。 设定随机误差项的主要原因: 1、理论的含糊性; 2、数据的欠缺; 3、节省的原则。
➢ 例如:
二、总体回归函数(方程)PRF Population regression function
由于变量间统计相关关系的随机性(非确定性),回归 分析关心的是根据解释变量的已知或给定值,考察被解 释变量的总体均值,即当解释变量取某个确定值时,与 之统计相关的被解释变量所有可能出现的对应值的平均 值。
样本回归函数的随机形式:
其中 为(样本)残差(Residual),可看成是随机误差项 的 的具体估计值。由于引入随机项,称为样本回归 模型。
总体回归线与样本回归线的基本关系
例2.1:一个假想的社区是由60户家庭组成的总体,要
研究该社区每月家庭消费支出Y 与每月家庭可支配收入 X 的关系;即知道了家庭的每月收入,预测该社区家庭
每月消费支出的 (总体) 平均水平。为达到此目的,将该 60户家庭划分为组内收入差不多的10组,以分析每一收 入组的家庭消费支出。
表2.1 某社区家庭每月收入与消费支出调查统计表
回归分析是研究因果相关,也就是有因果关系的相关关 系;既然回归分析是研究变量之间的因果关系,因此回归 分析对变量的处理方法存在不对称性,也就是说,回归分 析将变量区分为被解释变量和解释变量,其中被解释变量 是“结果”,解释变量是“原因”,并且回归分析方法认为作 为“原因”的解释变量属于非随机变量,作为“结果”的被解 释变量为随机变量;也就是说,作为“原因”的解释变量取 确定值时,作为“结果”的被解释变量取值是随机的。
计量经济学4_一元线性回归

min m ∑ (Yi − m )
i =1
n
2
∑ (Y − b
i =1 i
n
0
− bi X i ) 2
4.6
称最小化 4.6 式中误差平方和的截距和斜率估计量为β0 和β1 的普通最小二乘(OLS)估计量。
7 8
OLS估计量、预测值和残值
斜率β1和截距β 0的OLS估计量分别为 ˆ β1 =
OLS预测值和残值
TestScore = 698.9 – 2.28×STR
ˆ YAntelope = 698.9 – 2.28×19.33 = 654.8
ˆ u Antelope = 657.8 – 654.8 = 3.0
13 14
拟合优度( Measures of Fit )
所得到的回归线描述数据的效果如何评价? 回归变量说明了大部分还是极少部分的因变量变化? 观测值是紧密地聚集在回归线周围还是很分散? • 回归的 R2 是指可由 Xi 解释(或预测)的 Yi 样本方差的 比例。回归的 R2 的取值范围为 0 到 1.
——普通最小二乘估计量
前面讨论过,Y 是总体均值μY 的 最小二乘估计量,即在所有 可能的估计量 m 中, Y 使估计误差总平方和最小:
将 OLS 估计量这种思想应用于线性回归模型。令 b0 和 b1 分 别表示β0 和β1 的某个估计量,则基于这些估计量的回归线 为:b0+b1X,于是由这条线得到 Yi 的预测值为:b0+b1Xi。 因而,第 i 个观测的观测误差为:Yi-b0-biXi,n 个观测的观测 误差平方和为:
Yi = β0 + β1Xi + ui, i = 1,…, n 不太可能出现大异常值 Xi 和(或)Yi 的观测中远落在一般数据范围 之外的大异常值是不大可能出现的。 • 表述为:X 和 Y 具有非零有限四阶距: 即 0 < E ( X ) < ∞, 0 < E (Y ) < ∞ • 或表述为:X 和 Y 具有有限峰度。 • 该假设说明 OLS 对异常值是很敏感 的。
计量经济学一元线性回归作业

计量经济学实验报告姓名孙晓晗学号0842226 班级经济管理学院上机时间:2010-10-19 上机地点:实验楼A105上机目的:熟悉EVIEWS的基本操作,以及学习一元线形回归模型的简单建立标题一、研究的问题研究随着GDP的变化国家财政收入会如何变化,从而研究GDP 与国家财政收入的关系。
二、对问题的经济理论分析、所涉及的经济变量财政收入是政府部门的公共收入,是国民收入分配中用于保证政府行使其公共职能、实施公共政策及提供公共服务的资金需求。
其主要有资源配置、收入再分配和宏观经济调控三大职能。
财政收入的增长情况关系着一个国家经济的发展和社会的进步。
因此,研究财政收入的增长就显得尤为必要。
财政收入的增长受到多方面因素的影响,但最根本的原因是经济的总体发展态势,即GDP的增长。
因此,此次分析涉及到GDP和国家财政收入两个经济变量。
三、理论模型的建立以财政收入(CZSR)为被解释释变量,GDP为解释变量,构造回归模型:Y i=b0+b1X i+u i四、相关变量的数据收集及数据来源说明数据来源于中华人民共和国国家统计局,网址为:/五、数据的计算机输入及运行过程、模型的结果1.数据输入,给变量赋值2.获得X与Y的散点图3.建立一元线性回归方程六、模型检验、对结果的解释及说明1.检验(1)经济模型意义检验由建立一元线性回归方程结果可得:Y i=389.5147+0.116157Xa.正负号由建立回归方程结果可得b1=0.116157,为正值,说明国家财政收入按照小于1的正比例随GDP增长,因此此值在经济学上有意义。
b.斜率大小由建立回归方程结果可得b0=389.5147,有较好的经济学含义。
(2)统计学检验a.拟合优度检验R2=1.94,说明回归方程与样本观察值拟合优度很好。
b.T检验Prob(t-Statistic)=0.45〉5%,不通过检验c.F检验Prob(F-Statistic)=0.00001〈5%,通过检验七、用模型就现实问题进行分析(一)财政收入占GDP的比重低且比重总体呈下降的趋势从世界各国的情况分析,财政收入占GDP的比重随经济发展而渐渐提高。
一元回归及检验实验报告

竭诚为您提供优质文档/双击可除一元回归及检验实验报告篇一:一元线性回归模型的参数估计实验报告山西大学实验报告实验报告题目:计量经济学实验报告学院:专业:课程名称:计量经济学学号:学生姓名:教师名称:崔海燕上课时间:一、实验目的:掌握一元线性回归模型的参数估计方法以及对模型的检验和预测的方法。
二、实验原理:1、运用普通最小二乘法进行参数估计;2、对模型进行拟合优度的检验;3、对变量进行显著性检验;4、通过模型对数据进行预测。
三、实验步骤:(一)建立模型1、新建工作文件并保存打开eviews软件,在主菜单栏点击File\new\workfile,输入startdate1978和enddate20XX并点击确认,点击save 键,输入文件名进行保存。
2输入并编辑数据在主菜单栏点击Quick键,选择empty\group新建空数据栏,先输入被解释变量名称y,表示中国居民总量消费,后输入解释变量x,表示可支配收入,最后对应各年分别输入数据。
点击name键进行命名,选择默认名称group01,保存文件。
得到中国居民总量消费支出与收入资料:xY年份19786678.83806.719797551.64273.219807944.24605.5198 184385063.919829235.25482.4198310074.65983.21984115 656745.7198511601.77729.2198613036.58210.9198714627 .788401988157949560.5198915035.59085.5199016525.994 50.9199118939.610375.8199222056.511815.3199325897.3 13004.7199428783.413944.2199531175.415467.919963385 3.717092.5199735956.218080.6199838140.919364.119994 027720989.3200042964.622863.920XX20XX20XX20XX20XX20XX46385.45127457408.164623.17 4580.485623.124370.126243.22803530306.233214.436811 .2注:y表示中国居民总量消费x表示可支配收入3、画散点图,判断被解释变量与解释变量之间是否为线性关系在主菜单栏点击Quick\graph出现对话框,输入“xy”,点击确定。
计量经济学实验二-一元线性回归模型的估计、检验和预测

目录一、加载工作文件 (7)二、选择方程 (7)1.作散点图 (7)2.进行因果关系检验 (9)三、一元线性回归 (10)四、经济检验 (12)五、统计检验 (13)六、回归结果的报告 (15)七、得到解释变量的值 (15)八、预测应变量的值 (17)实验二一元线形回归模型的估计、检验和预测实验目的:掌握一元线性回归模型的估计、检验和预测方法。
实验要求:选择方程进行一元线性回归,进行经济、拟合优度、参数显著性和方程显著性等检验,预测解释变量和应变量。
实验原理:普通最小二乘法,拟合优度的判定系数R2检验和参数显著性t检验等,计量经济学预测原理。
实验步骤:已知广东省宏观经济部分数据如表2-1所示,要根据这些数据研究和分析广东省宏观经济,建立宏观计量经济模型,从而进行经济预测、经济分析和政策评价。
实验二~实验十二主要都是用这些数据来完成一系列工作。
表2-1 广东省宏观经济数据续上表续上表一、加载工作文件广东省宏观经济数据已经制成工作文件存在盘中,命名为GD01.WF1,进入EViews后选择File/Open打开GD01.WF1。
二、选择方程根据广东数据(GD01.WF1)选择收入法国国内生产总值(GDPS)、财政收入(CS)、财政支出(CZ)和社会消费品零售额(SLC),分别把①CS作为应变量,GDPS作为解释变量;②CZ作为应变量,CS作为解释变量;③SLC作为应变量,GDPS作为解释变量进行一元线性回归分析。
1.作散点图从三个散点图(图2-1~图2~3)可以看出,三对变量都呈现线性关系。
图2-1 图2-2图2-3 2.进行因果关系检验从三个因果关系检验可以看出,GDPS是CS的因;CS不是CZ 的因;GDPS不是SLC的因。
但根据理论CS是CZ的因,GDPS是SLC的因,可能是由于指标设置问题。
所以还是把CS作为应变量,GDPS作为解释变量;CZ作为应变量,CS作为解释变量;SLC作为应变量,GDPD作为解释变量进行一元线性回归分析。
计量经济学实验一一元线性回归完成版
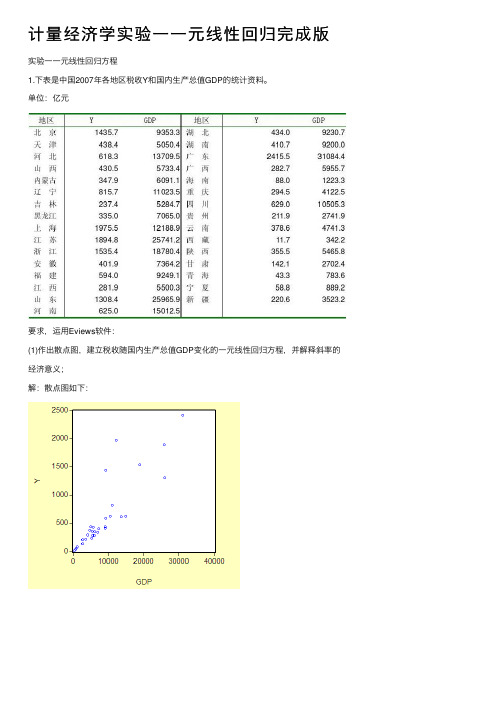
计量经济学实验⼀⼀元线性回归完成版实验⼀⼀元线性回归⽅程1.下表是中国2007年各地区税收Y和国内⽣产总值GDP的统计资料。
单位:亿元要求,运⽤Eviews软件:(1)作出散点图,建⽴税收随国内⽣产总值GDP变化的⼀元线性回归⽅程,并解释斜率的经济意义;解:散点图如下:得到估计⽅程为:0.07104710.62963=-y x这个估计结果表明,GDP 每增长1亿元,各地区税收将增加0.071047亿元。
(2) 对所建⽴的回归⽅程进⾏检验;解:从回归的估计的结果来看,模型拟合得较好。
可决系数20.7603R =,表明各地区税收变化的76.03%可由GDP 的变化来解释。
从斜率项的t 检验值看,⼤于5%显著性⽔平下⾃由度为229n -=的临界值0.025(29) 2.05t =,且该斜率满⾜0<0.071047<1,表明2007年,GDP 每增长1亿元,各地区税收将增加0.071047亿元。
(3) 若2008年某地区国内⽣产总值为8500亿元,求该地区税收收⼊的预测值及预测区间。
解:由上述回归⽅程可得地区税收收⼊的预测值:0.0710********.62963593.3Y =-= 下⾯给出税收收⼊95%置信度的预测区间:由于国内⽣产总值X 的样本均值与样本房差为()8891.126()57823134E X Var X ==于是,在95%的置信度下,0()E Y 的预测区间为593.3 2.045±593.3113.4761=±或(479.8239,706.7761)当GDP 为8500亿元时地区的税收收⼊的个值预测值仍为593.3。
同样的,在95%的置信度下,该地区的税收收⼊的预测区间为593.3 2.045593.3641.0421±=±或(-47.7,1234.3)。
资料来源:《深圳统计年鉴2002》,中国统计出版社解:(1)建⽴深圳地⽅预算内财政收⼊对GDP 的回归模型;得到回归⽅程:?0.134582 3.611151yx =-(2)估计所建⽴模型的参数,解释斜率系数的经济意义;X 的系数为0.314582,常数项为-3.611151。
计量经济学实验一

2017—2018第二学期计量经济学实验报告实验(一):一元回归模型实验学号:姓名:专业:经济学类选课班级: A01 实验日期:2018/05/07 实验地点: 05021、家庭消费支出(Y )、可支配收入(2X )、个人个财富(2X )设定模型如下:i i i i X X Y μβββ+++=22110 回归分析结果为:LS // Dependent Variable is Y Date: 18/4/02 Time: 15:18 Sample: 1 10Included observations: 10Variable Coefficient Std. Error T-Statistic Prob. C 24.40706.9973 ___3.4881_____ 0.01012X - 0.3401 0.4785 ___-_0.7108____ 0.5002 2X 0.0823 0.0458 1.7969 0.1152 R-squared ___0.9615_____ Mean dependent var111.1256Adjusted R-squared0.9504S.D. dependent var 31.4289S.E. of regression ___6.5436____ Akaike info criterion4.1338Sum squared resid 342.5486 Schwartz criterion 4.2246 Log likelihood- 31.8585 F-statistic 87.3339Durbin-Watson stat2.4382Prob(F-statistic)0.0001补齐表中划线部分的数据(保留四位小数);并写出回归分析报告。
2、根据有关资料完成下列问题: LS // Dependent Variable is Y Date: 11/12/02 Time: 10:18 Sample: 1978 1997 Included observations: 20Variable Coefficient Std. Error T-Statistic Prob. C 858.310867.12015 _____12.7877___0.0000X 0.100031 _____0.0022___ 46.04788 0.0000R-squared __0.9916__ Mean dependent var 3081.157Adjusted R-squared0.991115 S.D. dependent var 2212.591S.E. of regression __202.9982_ Akaike info criterion10.77510Sum squared resid 782956.8 Schwartz criterion 10.87467 Log likelihood- 134.1298F-statistic ___21230.46934_____Durbin-Watson stat 0.859457 Prob(F-statistic) 0.000000(其中:X —国民生产总值;Y —财政收入)(1) 补齐表中的数据(保留四位小数),并写出回归分析报告;(2)解释模型中回归系数估计值的经济含义;答:C=858.3108表示当国民生产总值等于0时,财政收入等于858.3108。
计量经济学实验二 一元线性回归模型

实验二一元线性回归模型2.1 实验目的掌握一元线性回归模型的基本理论,一元线性回归模型的建立、估计、检验及预测的方法,以及相应的EViews软件操作方法。
2.2 实验内容建立中国消费函数模型。
以表2.1中国的收入与消费的总量数据为基础,建立中国消费函数的一元线性回归模型。
表2.1数据来源:2004年中国统计年鉴,中国统计出版社2.3 实验步骤2.3.1 散点相关图分析将表1.1的GDP设为变量X,总消费设为Y,建立变量X和Y的相关图,如图2.1所示。
可以看X和Y之间呈现良好的线性关系。
可以建立一元线性回归模型。
2.3.2 估计线性回归模型在数组窗口中点击Proc\Make Equation ,如果不需要重新确定方程中的变量或调整样本区间,可以直接点击OK 进行估计。
也可以在EViews 主窗口中点击Quick\Estimate Equation ,在弹出的方程设定框(见图2.2)内输入模型:Y C X 或 Y = C (1) + C (2) * X图2.2图2.3还可以通过在EViews 命令窗口中键入LS 命令来估计模型,其命令格式为:LS 被解释变量 C 解释变量系统将弹出一个窗口来显示有关估计结果(如图2.3 所示)。
因此,我国消费函数的估计式为:ˆY2329.4010.547*X =+St 1191.923 0.014899t 1.95 36.71R 2=0.99 s.e.=2091s.e .是回归函数的标准误差,即σˆ=)216(ˆ2-∑t u。
R 2是可决系数。
R 2 = 0.99,说明上式的拟合情况好,y t 变差的99%由变量x t 解释。
因为t = 36.71> t 0.05 (15) = 2.13,所以检验结果是拒绝原假设β1 = 0,即总消费和GDP 之间存在线性回归关系。
上述模型的经济解释是,GDP 每增长1 亿元,我国消费将总额将增加0.547亿元。
图2.42.3.3 残差图在估计方程的窗口选择View\ Actual, Fitted,Residual\Actual, Fitted,Residual Table,得到相应的残差图2.4。
实验3计量经济学实验一元线性回归模型

ˆ1 ~N(1,,
2
) (Xi X)2
三、知识点回顾
n 4、最小二乘估计量的性质及分布
随机干扰项 i 的方差 2 的估计 ˆ 0 和 ˆ 1 的方差表达式中都包含随机干扰项 i 的方差 2
,由于随机干扰项 i 实际上是无法观察测量的,因此其
量 Y 的平均值。
三、知识点回顾
1、四种重要的关系式
(2)总体回归函数(方程): E(YXi)01Xi
其中总体回归参数真值 0 , 1 是未知的;总体回归方程也是 未知的。
(3)样本回归函数(方程): Yˆi ˆ0 ˆ1Xi
在实际应用中,从总体中抽取一个样本,进行参数估计,从 而获得估计的回归方程,系数 ˆ 0 , ˆ1 为估计的回归系数;用 这个估计的回归方程近似替代总体回归方程,其中估计的回 归系数 ˆ 0 , ˆ1 是总体参数真值 0 , 1 的估计值;基于估计方程 计算的 Y ˆ i 就为 E (Y X i ) 的估计值; 由于我们从来就无法知道真实的回归方程,因此计量经济学 分析注重的是这个估计的回归方程和估计的回归系数;
据;普通最小二乘法给出的判断拟合程度的标准是:残差平
方和最小,即:m in Q ne i2n(Y i Y ˆi)2n Y i (ˆ0ˆ1 X i) 2
i 1
i 1
i 1
最小二乘法就是:在使上述残差平方和Q 达到最小时,确定
模型中的参数 ˆ 0 和 ˆ 1 的值,或者说在给定观测值之下,选
择出 ˆ 0 , ˆ1 的值,使残差平方和Q 达到最小。
接近,这也说明OLS估计值是非常有价值的。
三、知识点回顾
n 4、最小二乘估计量的性质及分布
计量经济学试验完整版--李子奈

计量经济学试验完整版--李子奈计量经济学试验??李子奈目录实验一一元线性回归5一实验目的 5二实验要求 5三实验原理 5四预备知识 5五实验内容 5六实验步骤 51.建立工作文件并录入数据 52.数据的描述性统计和图形统计: 73.设定模型,用最小二乘法估计参数: 84.模型检验: 85.应用:回归预测: 9实验二可化为线性的非线性回归模型估计、受约束回归检验及参数稳定性检验12一实验目的: 12二实验要求12三实验原理12四预备知识12五实验内容12六实验步骤13实验三多元线性回归14一实验目的14三实验原理15四预备知识15五实验内容15六实验步骤156.1 建立工作文件并录入全部数据 15 6.2 建立二元线性回归模型156.3 结果的分析与检验166.4 参数的置信区间166.5 回归预测176.6 置信区间的预测18实验四异方差性20一实验目的20二实验要求20三实验原理20四预备知识20五实验内容20六实验步骤206.1 建立对象: 206.2 用普通最小二乘法建立线性模型216.3 检验模型的异方差性216.4 异方差性的修正24实验五自相关性28一实验目地28二实验要求28三实验原理28四预备知识28五实验内容28六实验步骤286.1 建立Workfile和对象 296.2 参数估计、检验模型的自相关性296.3 使用广义最小二乘法估计模型 336.4 采用差分形式作为新数据,估计模型并检验相关性35 实验六多元线性回归和多重共线性37一实验目的37二实验要求37三实验原理37四预备知识37五实验内容37六实验步骤376.1 建立工作文件并录入数据386.2 用OLS估计模型386.3 多重共线性模型的识别386.4 多重共线性模型的修正39实验七分布滞后模型与自回归模型及格兰杰因果关系检验 41 一实验目的41二实验要求41三实验原理41四预备知识41五实验内容41六实验步骤426.1 建立工作文件并录入数据426.2 使用4期滞后2次多项式估计模型426.3 格兰杰因果关系检验45实验八联立方程计量经济学模型49一实验目的49二实验要求49三实验原理49四预备知识49五实验内容49六实验步骤506.1 分析联立方程模型。
计量经济学的2.3 一元线性回归模型的统计检验

ˆ ˆ P( ) 1
如果存在这样一个区间,称之为置信区间 (confidence interval); 1-称为置信系数(置信度) (confidence coefficient), 称为显著性水平(level of significance)(或犯第I类错误的概率,即拒真的概 率);置信区间的端点称为置信限(confidence limit) 或临界值(critical values)。置信区间以外的区间称 4 为临界域
由于置信区间一定程度地给出了样本参数估计 值与总体参数真值的“接近”程度,因此置信区间 越小越好。 (i t s , i t s )
2 i 2 i
要缩小置信区间,需要减小 (1)增大样本容量n,因为在同样的置信水平 下, n越大,t分布表中的临界值越小;同时,增大样本 容量,还可使样本参数估计量的标准差减小;
5
如何构造参数值的估计区间? 通过构造已知分布的统计量
6
构造统计量(1)
回顾: 在正态性假定下
以上统计量服从自由度为n-2的x2分布,n为样本量
7
构造统计量(2)
ˆ ˆ 0 和 1 服从正态分布
ˆ E ( 0 )= 0
ˆ E ( 1 )=1
Var 0) (ˆ
X
i 1 n i 1
§2.3 一元线性回归模型的统 计检验
一、参数的区间估计 二、拟合优度检验 三、参数的假设检验 (对教材内容作了扩充)
1
一、参数的区间估计
参数的两种估计:点估计和区间估计
点估计
通过样本数据得到参数的一个估计值。
(如:最小二乘估计、最大似然估计)
点估计不足:
(1)点估计给出在给定样本下估计出的参数的可能取值,但 它并没有指出在一次抽样中样本参数值到底离总体参数的真 值有多“近”。 (2)虽然在重复抽样中估计值的均值可能会等于真值,但由 于抽样波动,单一估计值很可能不同于真值。 2
计量经济学 第二章 一元线性回归模型

计量经济学第二章一元线性回归模型第二章一元线性回归模型第一节一元线性回归模型及其古典假定第二节参数估计第三节最小二乘估计量的统计特性第四节统计显著性检验第五节预测与控制第一节回归模型的一般描述(1)确定性关系或函数关系:变量之间有唯一确定性的函数关系。
其一般表现形式为:一、回归模型的一般形式变量间的关系经济变量之间的关系,大体可分为两类:(2.1)(2)统计关系或相关关系:变量之间为非确定性依赖关系。
其一般表现形式为:(2.2)例如:函数关系:圆面积S =统计依赖关系/统计相关关系:若x和y之间确有因果关系,则称(2.2)为总体回归模型,x(一个或几个)为自变量(或解释变量或外生变量),y为因变量(或被解释变量或内生变量),u为随机项,是没有包含在模型中的自变量和其他一些随机因素对y的总影响。
一般说来,随机项来自以下几个方面:1、变量的省略。
由于人们认识的局限不能穷尽所有的影响因素或由于受时间、费用、数据质量等制约而没有引入模型之中的对被解释变量有一定影响的自变量。
2、统计误差。
数据搜集中由于计量、计算、记录等导致的登记误差;或由样本信息推断总体信息时产生的代表性误差。
3、模型的设定误差。
如在模型构造时,非线性关系用线性模型描述了;复杂关系用简单模型描述了;此非线性关系用彼非线性模型描述了等等。
4、随机误差。
被解释变量还受一些不可控制的众多的、细小的偶然因素的影响。
若相互依赖的变量间没有因果关系,则称其有相关关系。
对变量间统计关系的分析主要是通过相关分析、方差分析或回归分析(regression analysis)来完成的。
他们各有特点、职责和分析范围。
相关分析和方差分析本身虽然可以独立的进行某些方面的数量分析,但在大多数情况下,则是和回归分析结合在一起,进行综合分析,作为回归分析方法的补充。
回归分析(regression analysis)是研究一个变量关于另一个(些)变量的具体依赖关系的计算方法和理论。
一元线性回归模型(计量经济学)

回归分析是一种统计方法,用于研究变量之间的关系。它基于最小二乘法,寻找最合适的直线来描述变 量间的线性关系。通过回归分析,我们可以理解变量之间的因果关系和预测未知数据。
一元线性回归模型的假设
1 线性关系
2 独立误差
一元线性回归模型假设自变量和因变量之 间存在线性关系。
模型的残差项是独立的,不受其他因素的 影响。
3 常数方差
4 正态分布
模型的残差项具有恒定的方差,即方差齐 性。
模型的残差项服从正态分布。
一元线性回归模型的估计和推断
1
模型估计
使用最小二乘法估计模型的回归系数。
2
参数推断
进行参数估计的显著性检验和置信区间估计。
3
模型拟合程度
使用残差分析和R平方评估模型的拟合程度。
模型评估和解释结果
通过残差分析和R平方等指标评估模型的拟合程度,并解释模型中回归系数的 含义。了解如何正确使用模型的结果,并识别异常值和离群点对模型的影响。
一元线性回归模型(计量 经济学)
在本节中,我们将介绍一元线性回归模型,探讨回归分析的基本概念和原理, 了解一元线性回归模型所做的假设,并学习模型的估计和推断方法。我们还 将探讨模型评估和解释结果的技巧,并通过实例应用和案例分析进一步加深 对该模型的理解。最后,我们将总结和得出结论。
回归分析的基本概念和原理
实例应用和案例分析
汽车价格预测Байду номын сангаас
使用一元线性回归模型预 测汽车价格,考虑车龄、 里程等因素。
销售趋势分析
通过一元线性回归模型分 析产品销售的趋势,并预 测未来销售。
学术成绩预测
应用一元线性回归模型预 测学生的学术成绩,考虑 学习时间、背景等因素。
计量经济学实验报告一元线性回归模型实验

2013-2014第1学期计量经济学实验报告实验(一):一元线性回归模型实验学号姓名:专业:国际经济与贸易选课班级:实验日期:2013年12月2日实验地点:K306实验名称:一元线性回归模型实验【教学目标】《计量经济学》是实践性很强的学科,各种模型的估计通过借助计算机能很方便地实现,上机实习操作是《计量经济学》教学过程重要环节。
目的是使学生们能够很好地将书本中的理论应用到实践中,提高学生动手能力,掌握专业计量经济学软件EViews的基本操作与应用。
利用Eviews做一元线性回归模型参数的OLS估计、统计检验、点预测和区间预测。
【实验目的】使学生掌握1.Eviews基本操作:(1)数据的输入、编辑与序列生成;(2)散点图分析与描述统计分析;(3)数据文件的存贮、调用与转换。
2. 利用Eviews做一元线性回归模型参数的OLS估计、统计检验、点预测和区间预测【实验内容】1.Eviews基本操作:(1)数据的输入、编辑与序列生成;(2)散点图分析与描述统计分析;(3)数据文件的存贮、调用与转换;2. 利用Eviews做一元线性回归模型参数的OLS估计、统计检验、点预测和区间预测。
实验内容以下面1、2题为例进行操作。
1、为了研究深圳地方预算中财政收入与国内生产总值关系,运用以下数据:(1)建立深圳的预算内财政收入对GDP的回归;(2)估计模型的参数,解释斜率系数的意义;(3)对回归结果进行检验;(4)若2002年的国内生产总值为3600亿元,试确定2002年财政收入的预测值和预α=)。
测区间(0.052、在《华尔街日报1999年年鉴》(The Wall Street Journal Almanac 1999)上,公布有美国各航空公司业绩的统计数据。
航班正点准时到达的正点率和此公司每10万名乘客中投诉1(1)做出上表数据的散点图(2)依据散点图,说明二变量之间存在什么关系?(3)描述投诉率是如何根据航班正点率变化,并求回归方程。
计量经济学eviews一元线性回归模型实验指导

第二章 一元线性回归模型一、 实验目的掌握EViews 软件的基本功能,理解一元线性回归模型及最小二乘估计的基本原理。
二、 基本知识点:样本回归方程与总体回归方程的联系与区别;满足古典假设的前提,一元线性回归模型的最小二乘法参数估计,一元线性回归模型的检验以及均值与个值预测。
三、 实验内容及要求:依据经济学理论,以实际数据为基础,建立经济数学模型,分析经济变量之间的数量关系。
以本章所学内容,研究2012年中国各地区农村家庭人均生活消费支出与人均纯收入之间关系,数据来源于《2013年中国统计年鉴》。
要求:在认真理解本章内容的基础上,通过实验掌握一元线性回归模型的实际应用方法,并熟悉EViews 软件的基本使用方法。
四、 实验指导:由经济学理论知,收入是影响消费的主要因素,二者之间有密切关系。
二者之间关系的散点图如图2.4.1所示。
图2.4.1说明,各地区农村居民家庭人均生活消费支出与家庭人均纯收入大致呈现出线性相关关系。
(CD 表示农村居民家庭人均生活消费支出,RD 农村居民家庭人均纯收入)图2.4.1 RD —CD 散点图故假设二者之间关系设定为一元线性回归模型:i i i rd cd μββ++=10,其中cd i 各地区农村居民家庭人均生活消费支出,rd i 为各地区农村居民家庭人均纯收入,μi 为随机误差项,即除人均收入外,影响农村居民家庭人均生活消费支出的其他因素。
假设该模型满足古典假设,可运用OLS 方法估计模型的参数。
利用计量经济学软件EViews5.0。
建立工作文件STEP1:进入EViews 目录,然后双击EViews 程序图标,进入EViews 主页见图2.4.2。
图2.4.2 EViews工作界面STEP2:点击Eviews主页面菜单\Workfile见图2.4.3,弹出work对话框(图2.4.4)。
在work type中选择Unsteuctured/Undated【由于本例是截面数据】,并在observation中输入观察值得个数,本例为31(图2.4.4),点击OK出现数据编辑窗口(图2.4.5)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
案例一:用回归模型预测木材剩余物
伊春林区位于黑龙江省东北部。
全区有森林面积218.9732万公顷,木材蓄积量为2.324602亿m3。
森林覆盖率为62.5%,是我国主要的木材工业基地之一。
1999年伊春林区木材采伐量为532万m3。
按此速度44年之后,1999年的蓄积量将被采伐一空。
所以目前亟待调整木材采伐规划与方式,保护森林生态环境。
为缓解森林资源危机,并解决部分职工就业问题,除了做好木材的深加工外,还要充分利用木材剩余物生产林业产品,如纸浆、纸袋、纸板等。
因此预测林区的年木材剩余物是安排木材剩余物加工生产的一个关键环节。
,利用一元线性回归模型预测林区每年的木材剩余物。
显然引起木材剩余物变化的关键因素是年木材采伐量。
表1.1 年剩余物y t和年木材采伐量x t数据
林业局名年木材剩余物y t(万m3)年木材采伐量x t(万m3)
乌伊岭26.13 61.4
东风23.49 48.3
新青21.97 51.8
红星11.53 35.9
五营7.18 17.8
上甘岭 6.80 17.0
友好18.43 55.0
翠峦11.69 32.7
乌马河 6.80 17.0
美溪9.69 27.3
大丰7.99 21.5
南岔12.15 35.5
带岭 6.80 17.0
朗乡17.20 50.0
桃山9.50 30.0
双丰 5.52 13.8
合计202.87 532.00。