PeerDB A P2P-based 讲义System for Distributed Data S
密码学的基础知识英文翻译

密码学的基础知识在公钥加密系统中,为了保障加密操作的便捷,产生了密钥技术.目前, 公钥加密系统都使用两个不同的密钥,其中一个密钥是私有的,另一个是公有的.根据不同的应用要求,发送方可使用其私钥或者接收方的公钥或同时使用二者来执行密码加密功能。
密钥体制的应用一般可分为三类; (1)加密/解密:发送方用接收方的公钥对消息加密; (2) 数字签名:发送方用自己的私钥对消息“签名”,可以对整条消息或者对消息的一个小的数据块来产生,接受方利用公钥验证数据源; (3) 密钥交换:通信双方交换会话密钥,一般都要借用通信第三方的私钥。
非对称加密算法进行数字签名时使用两个密钥:公开密钥(public key)和私有密钥(private key),分别用于对数据的加密和解密,即如果使用公开密钥对数据进行加密,只有用对应的私有密钥才能进行解密;如果用私有密钥对数据进行加密,则只有用对应的公开密钥才能解密。
任何拥有发送方公开密钥的人都可以通过密钥验证明文来源的正确性。
由于发送方私有密钥的保密性,使得接收方可以根据验证结果来拒收该报文,也能使其他人无法伪造报文。
密钥密钥是一个数值,它和加密算法一起生成特别的密文。
密钥本质上是非常非常大的数。
密钥的尺寸用位(bit)来衡量,1024 位密钥代表的数是非常巨大的. 在公开密钥加密方法中,密钥的尺寸越大,密文就越安全. 然而,公钥的尺寸和传统加密方法中密钥的尺寸是不相关的.传统 80 位密钥的强度等同于 1024 位的公钥,传统 128 位密钥的强度等同于 3000 位的公钥。
在同种加密算法中,密钥越大越安全。
但是传统方法和公开密钥方法所用的加密算法不一样,因此它们的密钥尺寸不能直接比较公钥和私钥是算术相关的,仅凭公钥推算出私钥是非常困难的。
然而如果有足够的时间和计算能力,总是可能导出私钥的。
这使得选择合适尺寸的密钥变得非常重要。
为了安全需要足够大的密钥,为了速度有要足够小的密钥。
p2p对等通信方式的概念 -回复

p2p对等通信方式的概念-回复P2P对等通信方式的概念:构建去中心化网络的传输方式引言:随着互联网的快速发展,人们对于数据传输的需求也日益增加。
而传统的中心化服务器架构虽然功能强大,但仍然存在一些问题,如单点故障、性能瓶颈和易受攻击等。
为了解决这些问题,人们开始探索一种去中心化的通信模式,即P2P对等通信方式。
本文将从对P2P对等通信方式的定义开始,逐步解释其工作原理和优势,以及在不同领域中的应用。
最后,我们还将讨论当前存在的挑战和未来的发展方向。
一、P2P对等通信方式的定义P2P (Peer-to-Peer) 对等通信方式是一种在网络中直接连接两个或多个终端设备,让它们能够以点对点的方式进行数据传输和资源共享的方式。
在这种通信方式中,每个终端设备都既是客户端,又是服务器,即可以发送和接收数据。
二、P2P对等通信方式的工作原理P2P对等通信方式的工作原理可以简单概括为四个步骤:发现、连接、通信和资源共享。
1. 发现:在P2P网络中,每个终端设备都需要通过一种发现机制找到其他设备。
常见的发现机制有基于中心服务器的发现、基于广播的发现和基于DHT (分布式哈希表) 的发现。
2. 连接:一旦发现了其他设备,终端之间就可以建立直接连接。
这种连接可以是点对点的,也可以是多对多的。
3. 通信:一旦连接建立,设备之间可以通过直接交换数据包来进行通信。
这种通信方式可以是对称式的,即每个设备都既是发送方,也是接收方;也可以是非对称式的,即设备之间的角色分工不同。
4. 资源共享:P2P对等通信方式的一个重要特点是可以实现资源共享。
通过直接连接,终端设备可以共享自己的计算、存储和带宽等资源,从而提高整个网络的效率和可扩展性。
三、P2P对等通信方式的优势相比于传统的中心化服务器架构,P2P对等通信方式具有以下几个优势:1. 去中心化:P2P对等通信方式不依赖于中心服务器的存在,每个设备都可以直接与其他设备进行通信和资源共享。
网络管理课程设计(BER编解码,报文构造与解析)

计算机网络管理课程设计1.引言简单网络管理协议(SNMP)首先是由Internet工程任务组织(Internet Engineering Task Force)(IETF)的研究小组为了解决Internet上的路由器管理问题而提出的。
SNMP被设计成与协议无关,所以它可以在IP,IPX,AppleTalk,OSI以及其他用到的传输协议上被使用。
它具有简单性,易于扩展性的特点。
SNMP是一系列协议组和规范(见下表),它们提供了一种从网络上的设备中收集网络管理信息的方法。
SNMP也为设备向网络管理工作站报告问题和错误提供了一种方法。
名字说明MIB 管理信息库SMI 管理信息的结构和标识SNMP 简单网络管理协议从被管理设备中收集数据有两种方法:一种是只轮询(polling-only)的方法,另一种是基于中断(interrupt-based)的方法。
Snmp发展到现在共有三个版本,本课程设计是基于snmpv1版本。
2.设计任务及思想2.1任务:设计一个Manager。
Manager可以向华为网络设备发送get和set报文,并获得有效操作结果,实现版本为SNMPv1.开发工具:VC++(Win32)内容: Socket网络通信、 BER编码、BER解码、SNMP报文构造、SNMP报文解析、用户输入/输出。
2.2思想:根据snmp协议,分析抓包软件抓出的结果。
Manager在进行操作时,先对要发送的报文进行构造,然后对要发送的报文各数据类型依据asn.1进行编码再发送。
agent接收到报文后,进行报文解析,再解码。
看manager的要求是什么,然后回应一个报文,即response 报文,manager即对回应的报文进行解析解码,整个过程由socket通信完成,snmp报文封装在udp中发送。
3设计过程2.1 BER编码和解码Ber编码是整个设计过程中的极为重要的部分,一个报文有很多段组成,每段的数据类型都不尽相同。
PeerIS基于Peer-to-Peer的信息检索系统

V ol.15, No.9 ©2004 Journal of Software 软 件 学 报 1000-9825/2004/15(09)1375 PeerIS :基于Peer -to -Peer 的信息检索系统∗凌 波1,2+, 陆志国1, 黄维雄3, 钱卫宁1, 周傲英11(复旦大学 计算机科学与工程系,上海 200433) 2(中国浦东干部学院,上海 200233) 3(新加坡国立大学 新加坡-麻省理工联盟,新加坡)PeerIS : A Peer -to -Peer Based Information Retrieval SystemLING Bo 1,2+, LU Zhi-Guo 1, Ng Wee-Siong 3, QIAN Wei-Ning 1, ZHOU Ao-Ying 11(Department of Computer Science and Engineering, Fudan University, Shanghai 200433, China) 2(China Executive Leadership Academy Pudong, Shanghai 200233, China) 3(Singapore-MIT Alliance, National University of Singapore, Singapore)+ Corresponding author: Phn: +86-21-65643024, E-mail: lingbo@, /wplReceived 2003-11-29; Accepted 2004-02-03Ling B, Lu ZG, Ng WS, Qian WN, Zhou AY. PeerIS : A peer-to-peer based information retrieval system. Journal of Software , 2004,15(9):1375~1384. /1000-9825/15/1375.htmAbstract : In this paper, the emerging P2P computing is first briefly introduced, including its distinct features, potential merits and applications, and the problems from which the existing P2P-based data sharing systems are suffering are further point out. To address these problems, the concept of P2P-based information retrieval is proposed, which can not only exploit the potential merits of P2P to overcome the problems of traditional information retrieval systems (e.g., lacking of scalability), but also achieve fully semantic retrieval and sharing in the context of P2P systems. Based on the ideology, PeerIS, a P2P-based information retrieval system is developed. Then, the architecture of PeerIS and its peers’ components are presented. The key issues of implementation are described, including communication, semantics-based self-reconfiguration, query processing and self-adaptive routing mechanisms, are also described. Finally, an experimental study is used to verify the advantages of PeerIS. Key words : peer-to-peer; information retrieval摘 要: 介绍了对等计算(peer-to-peer,简称P2P)的特征、潜在优势和应用范围,指出了当前P2P 数据共享系统∗ Supported by the National Nature Science Foundation of China under Grant No.60373019 (国家自然科学基金); the High Education Doctorial Subject Research Program of MoE of China under Grant No.20030246023 (国家教育部博士点基金资助); the Science and Technology Commission of Shanghai Municipal Government of China under Grant No.03DZ15028 (上海市科委重大研究 项目)作者简介: 凌波(1974-),男,江西赣州人,博士,主要研究领域为P2P 计算,分布式数据库,信息检索,信息经济;陆志国(1978-)男,硕士,主要研究领域为P2P 计算,数据库系统实现技术;黄维雄(1973-),男,马来西亚人,博士,主要研究领域为数据库性能,P2P 计算,基于Internet 的应用;钱卫宁(1976-),男,博士,主要研究领域为P2P 计算,海量数据挖掘,流数据管理与分析;周傲英(1965-),男,博士,教授,博士生导师,主要研究领域为对等计算,Web 数据管理,数据挖掘,流数据管理与分析.1376 Journal of Software软件学报 2004,15(9)存在仅支持弱语义(甚至缺乏语义)和粗粒度(文件水平)共享等局限性.针对这种现状,提出了基于P2P的信息检索,既可充分发掘P2P技术的潜在优势,克服传统信息检索系统的可伸缩瓶颈等问题,又可实现P2P数据共享系统语义丰富和细粒度的信息检索与共享;并开发出PeerIS:基于P2P的信息检索系统.描述了PeerIS的整体构架与节点的内部结构;重点阐述了PeerIS的通信机制、自配置机制、查询机制以及自适应路由机制等实现关键技术;并用实验证明了PeerIS的优异性.关键词: peer-to-peer;信息检索中图法分类号: TP311 文献标识码: A对等计算(peer-to-peer,简称P2P)已经成为计算技术研究热点.虽然P2P目前还没有被人们广泛接受的定义,但以下特征使其明显区别于传统的计算模式:(1)P2P系统是自组织的、非集中式的,各节点(peer)是自治的、动态的;(2) 节点在P2P系统中同时承担客户机与服务器两位一体的角色;(3) 各个节点功能与职责相同,它们之间的交互直接而对等;(4) 纯粹的P2P系统不存在集中式机制.这种新型的体系结构具备许多潜在的优势有待于发掘:首先,非集中式体系结构不但消除了系统的单点出错和可伸缩性瓶颈等局限性,而且使得系统的鲁棒性、可用性和性能可随节点数目的增加而提高;其次,系统的信息、带宽与计算资源随着节点的加入而不断丰富,因而系统的能力随之不断增强;并且,由于各节点之间的交互直接而对等,可以高效地利用系统的资源;另外,P2P还能够很好地提供匿名等特殊服务.因此,P2P被认为是未来重构分布式体系结构的关键技术[1].已有的研究成果表明,P2P可以应用于许多领域:如CPU周期共享[2]、及时信息传输[3]、协同工作组件[4]和数据共享[5~10]等.其中,数据共享已经成为当前P2P研究与开发的主流.简而言之,基于P2P的数据共享系统大致可分为3类:混合型、结构化和非结构化P2P系统,如图1所示.混合型P2P数据共享系统用一个或数个服务器维护所有在线节点的共享数据索引.对等节点(peer)提交的查询首先被发送到服务器,服务器处理后把要查找文件的维护节点的IP地址返回给查询节点,最后,查询节点与维护节点建立直接连接并下载查找到的文件,如图1(a)所示.然而,由于这类系统存在集中式机制(如Napster的中心索引服务器),系统存在可伸缩性瓶颈和单点出错等局限性.近期开发出的结构化P2P数据共享系统,如PAST[7,8],数据在系统的放置是严格控制的.基于分布式哈希函数,数据严格地映射到节点,即如果一个文件f的标识符的哈希值与某个节点P的标识符的哈希值最相近,则由节点P维护文件f,如图1(b)所示.这类系统的查询消息能在具有上限的跳数(hops)内到达答案所在节点,因而这类系统的查询路由比较高效.但是这类系统存在以下局限性:(1) 不支持非精确匹配的查询;(2) 系统中数据的放置严格控制,这就意味着在动态的P2P环境中维护系统拓扑结构的代价极其昂贵.非结构化P2P系统既不存在任何集中式机制,也不存在数据放置控制机制;节点独立自治,虽然一个节点不但可以为其他节点提供信息与服务,而且可以享用其他节点提供的信息与服务,但每个节点只需维护自己关注的文件;查询一旦提交,提交节点立即搜索本地文件库,并把查询转发给其所有邻居,这些邻居也依次进行类似的操作,直到查询消息的存活期(time-to-live,简称TTL)减少到0为止,所有查询结果(包括击中与失败)沿途返回给提交节点,如图1(c)所示.显然,相对于其他两类数据共享系统,非结构化系统更具有可伸缩性、灵活性和自治性等优良特性.因此,我们不把混合型和结构化系统列入研究范畴,而着重研究非结构化系统.然而,当前数据共享系统存在仅支持弱语义(甚至缺乏语义)和粗粒度(文件水平)共享等局限性,用户通过文件的标识符进行查找(如Past用文件名的哈希值查找).在这种模式下,一方面,用户很难设想出一个文件标识符来表达信息需求,因而很难找到自己真正需要的文件;另一方面,许多标识符相近、但语义不相干的答案却被返回给用户,造成了大量的带宽与计算资源的浪费,极大地限制了P2P潜能的发挥.显然,这种缺乏语义的共享既不能很好地满足用户的需求,也不能有效地利用系统的资源.凌波 等:PeerIS:基于Peer-to-Peer 的信息检索系统1377针对这种现状,我们提出基于P2P 的信息检索,把语义丰富的信息检索技术与P2P 系统相集成,既可充分发掘P2P 技术的潜在优势,克服传统信息检索系统存在的可伸缩瓶颈等局限性;又可克服现有P2P 数据共享系统仅支持弱语义(甚至缺乏语义)和粗粒度(文件水平)的共享等问题,实现P2P 系统语义丰富的信息检索与共享.基于此理念,我们在BestPeer [1]平台上开发出PeerIS:基于P2P 的信息检索系统.相对于现有的类似系统,PeerIS 有以下优点:• 保持节点(peer)的自治性,系统中的各个节点只需维护和查找自己关注的文件,独立自主地设定共享文件范围以及共享权限,完全消除了结构化P2P 系统忽略节点自治性和数据严格放置的局限性;• 节点在不同的环境中可以承担不同的角色工作,既可作为P2P 系统的peer(数据服务器与客户机两位一体),又可用作独立自治的信息检索系统,还可作为其他网络(如Internet)的节点,这与现有的结构化与非结构化文件共享系统节点功能单一有明显的区别;• 支持不同粒度、语义丰富的信息检索与共享,节点不仅可以处理本地提交的查询,还可以完成远程查询,而与现有的P2P 文件共享系统(包括非结构化系统)仅支持文件水平和缺乏语义的共享有明显的区别;• 支持基于语义的动态自配置策略,节点可以根据查询历史、相互间的兴趣偏好与行为相似度动态地调整邻居关系,这明显有别于典型的非结构化P2P 系统(如Gnutella)的节点随机和静态地选择邻居节点的机制,自配置机制的优异性已在文献[1]中得以证明.总之,本文的主要贡献如下:(1) 提出了基于P2P 的信息检索,并开发出PeerIS:基于P2P 的信息检索系统;(2) 介绍了系统的整体构架,系统中节点的相互关系以及节点的内部构成;(3) 论述了系统实现的关键技术;(4) 用实验证明了PeerIS 的优良特性.本文第1节介绍PeerIS 的体系结构.第2节论述PeerIS 实现的关键技术.第3节进行系统测试与性能分析.第4节总结全文并指出今后的工作方向.1 PeerIS 体系结构本节首先介绍PeerIS 系统的整体构架和peer 之间的相互关系,然后描述peer 的内部结构.1.1 PeerIS 系统体系结构PeerIS 是建立在BestPeer 平台上的一种新型的基于P2P 的信息检索系统,系统由两类节点构成:数目甚少的位置独立全局名称服务器LIGLO(location independent global names lookup server)和为数众多的对等节点(peer,用BPID 标识)[1].LIGLO 之间都相互联系并以P2P 方式交互,并且每个LIGLO 都与其所管辖的peer 相联;ComputerS o f t w a r e H a r d w a r e … S e c u r i t y Art M u s i cM o v i e… B r o a d c a s t1378 Journal of Software 软件学报 2004,15(9) 每个peer 都是一个自治的信息检索系统,并一起构成P2P 系统,由于受到自身的带宽与计算资源等条件的限制,每个peer 在某时刻只能与有限的peer 相互联系和交互.PeerIS 中peer 之间的两类重要关系定义如下:邻居节点.如果两个peer 直接相联,那么它们互为邻居.相关节点.如果一个peer P i 通过其他peer 与另一个peer P j 相联并交互,那么P j 被定义为P i 的一个相关 节点.显然,邻居节点是相关节点的一种特例,可以把这两类节点统称为重要节点.在PeerIS 中,每个peer 用一个重要节点管理器(important peer manager,简称IPM)来管理邻居节点和相关节点.通过系统的基于语义的自配置机制(见第2.2节),每个peer 根据其自身资源条件,尽可能地把与自己具有最相似偏好(用本地文件的语义类别分布定义)和行为的peer 保持为邻居节点和相关节点.这样,在PeerIS 中,peer 将基于不同的偏好和行为形成不同的簇,如图1中虚线所示;并且在同一簇内,两个peer 的偏好和行为越相似,则逻辑距离越近,反之亦然.这样,对于某个给定的查询,它的答案只在特定的节点簇(称为该查询的目标簇),只需在该节点簇处理.1.2 Peer 结构及工作流程PeerIS 系统的每个peer 均由6个组件耦合而成,如图2所示.Fig.2 Architecture of PeerIS node图2 PeerIS 节点结构示意图(1) 用户界面(user interface).友好的用户界面便于用户管理和维护本地文件,设置文件共享范围及其共享权限,产生和提交查询.如图3所示.Fig.3 User interface of PeerIS图3 PeerIS 用户界面PeerIS 节点的用户界面是在IE 的基础上加ToolBand 插件开发而成的.用户的查询(关键词)直接输入插件中,查询结果则以Html 的形式返回给IE 显示.显然,peer 的用户界面也可以用作普通浏览器,这种实现体现了凌波等:PeerIS:基于Peer-to-Peer的信息检索系统1379peer在不同的环境下可以充当不同角色的设计理念.(2) 重要节点管理器(important peer manager,简称IPM)有3种功能:(a) 管理重要节点(邻居节点和相关节点)的标识符、当前IP地址以及兴趣偏好以及查询历史统计信息等;另外,反映本地节点的兴趣的统计信息也由IPM管理,该设计技巧的优点是可以迅速判断本地是否可能有查询答案、查询是否落到其目标节点簇;(b) 基于重要节点的查询统计信息,应用基于语义的自配置机制(见第2.2节),动态地调整重要节点;(c) 截取IE插件的输入,生成相应的查询,基于本地节点和重要节点的兴趣偏好信息,判断本地是否可能有答案、查询是否落到了目标节点簇,并决定把查询转发给哪些重要节点.(3) BestPeer平台.提供最基本的P2P系统功能,包括消息传递、移动Agent克隆与转发以及数据传输等底层功能[1].Peer在线时,BestPeer周期性地发出(Active)消息探测邻居节点在线与否或应答这类探测(Active_Ok);查询时,把查询嵌在Agent中,并根据IPM的处理结果转发给相应的重要节点.(4) 信息检索模块(IR module)有3大功能:(a) 预处理本地文件(如去虚词、提取词根)以获取文件的索引项及其词频和初始反比文档频数等统计信息,并为本地文件建立索引[11];(b) 确定文件的语义类别;(a)与(b)的处理结果将存储于字典(dictionary)中;(c) 检索信息,一旦接收到由本地IPM(或远程转发)而来的查询,信息检索模块从字典中提取相关文件的统计信息并计算查询与文件的语义相关程度(见第2.3节),排序后把合格结果返回给IPM(转发查询的邻居节点),通过界面展现给用户.(5) 字典(dictionary)管理本地文件的索引(倒排文件)、索引项的词频和反比文档频数、文件的语义类别以及文件的共享权限等信息.(6) 文件库(corpus)存储本地所有的文本文件.2 实现技术本节论述系统的通信机制、自配置机制、查询机制以及自适应路由机制.2.1 通信机制PeerIS系统采用两种通信机制:消息传递和移动Agent机制,以更好地满足不同的处理需求.移动Agent机制与消息机制有许多共同点,可以把移动Agent机制看做是消息机制的智能化高级形式.因此,我们在论述消息机制时也论述移动Agent的相关之处.2.1.1 消息机制PeerIS的peer周期性地产生消息,探测其邻居节点在线与否.消息头如图4所示.UUID Descriptor-ID Payload-Descriptor Group-ID TTL Hops Playload-LengthFig.4 Message header of PeerIS图4 PeerIS消息头示意图 •UUID.消息标识符,用于唯一地标识任意一个消息;在移动Agent机制中,唯一地标识Agent.•Descriptor-ID.一个16位的字符串,用于标识消息的发送者.在移动Agent机制中,它是指最后一个转发Agent的节点.•Playload-Descriptor.用于标识消息的种类.纯消息机制中,消息有两类:Active和Active_Ok,前者用于节点探测其邻居节点在线与否,后者是前者的应答.PeerIS采用区别于其他P2P系统单向消息策略,即消息接受者并不向对应消息的发送者发送消息;如果一个节点向其一个邻居节点发出一条Active消息后,在预定的时间间隔内收到Active_Ok应答,则认为该邻居节点在线,否则,认为该邻居节点离线.这种策略有助于减少带宽消耗,提高系统的可扩充性和性能.在移动Agent机制中,Playload-Descriptor有两对:Connection与Connection_Proved以及Query与QueryHits,分别表示连接请求和连接确认、查询与查询击中.•Group_ID.用于确定消息或移动Agent发往何处,该机制支持自适应路由机制.•TTL(time-to-live).生命周期,即消息能够转发的次数.在移动Agent机制中,TTL用于确定Agent能够克隆的次数.1380Journal of Software 软件学报 2004,15(9)• Hops.消息(Agent)已经转发(克隆)的次数.• Playload_length:消息头中内容的大小.2.1.2 移动Agent 机制 移动Agent 机制用于peer 初始化、调整邻居节点和查询处理.任何一个Agent 都有一个类似于消息机制“消息头”,各条目的作用已提前在消息机制中加以论述,以下仅阐述不同于消息机制的工作内容:• Connection.当一个节点向其他节点请求建立新连接时就向其发出Connection.该机制主要用于新节点的初始化和一个节点调整和优化其邻居节点过程.• Connection_Proved 是Connection 的应答.当一个节点(如P i )收到另一个节点(如P j )的Agent 带来的Connection 请求时,它首先从该移动Agent 中提取相关数据,用以计算请求节点P j 与自己的偏好和行为相似度.根据计算结果,P i 做出相应的决策:接受请求和回复Connection_Proved 并推荐给自己相关的邻居节点或根本不作应答.如果P j 在预定时间内没收到P i 的应答,则认为请求失败.• Query.移动Agent 把查询约束条件(如关键词和语义类别等)运送到相关节点.如果节点拥有结果,就以QueryHits 应答.• QueryHits 是相应Query 的应答,与QueryHits 一道,移动Agent 把该应答peer 的相关信息返回给查询者,满足当前查询以及优化节点的邻居节点和查询.2.2 基于语义的自配置机制基于语义的自配置机制是PeerIS 的peer 能够根据信息偏好、行为和查询统计数据综合地确定和调整自己的重要节点的机制,使自己能以较小的代价检索到所需的数据.2.2.1 自配置基础对于每个peer 而言,重要节点的选择至关重要.由于理性用户的兴趣总有一定的偏好.比如,对于计算技术研究人员而言,有的更关注对等计算,有的则专注于索引研究;而对于医学专家而言,有的专心攻克肝类病,有的则潜心发现提高免疫能力的机理等.显然,由于他们的兴趣各异,维护的信息也不同.peer 的兴趣偏好可以用本地文件的语义类别分布来定义,语义类别由类似于文本分类法[12]来确定,并用向量模型表达.这样,每个peer 为每类兴趣维护数个具有高度相似的peer 为重要节点,并且,兴趣相似度越高,成为重要节点的优先权也越高.确定优先权的公式为 ∑∑∑===××=ו=t s j s t s i s t s j s i s j i j i j i w w w w P C P C P C P C P P SimIn 1,21,21,,|)(||)(|)()(),(ρρρρ (1)其中),(j i P P SimIn 为peer i P 与j P 的兴趣相似度,)(i P C ρ与)(j P C ρ分别为两个peer 的兴趣特征向量,而|)(|i P C ρ与|)(|j P C ρ则分别为两个向量的模,若是分子与分母同时为0,则),(j i P P SimIn 取零值.i s w ,和j s w ,非负,表示i P 与j P 节点中对应于第s 个特征词的权值.另外,行为相似性也是决定重要节点优先权的关键因素之一.即使两个节点的兴趣偏好非常类似,但它们如果不能同时在线,它们成为邻居则没有任何意义.行为相似性的计算公式为 360024)()(),(××∩=N P Con P Con P P SimBe j i j i (2) 其中),(j i P P SimBe 为两个peer 的行为相似度,)()(j i P Con P Con ∩为N 天中两peer 同时在线的时间.360024××N 是以秒为单位计量的N 天的时间.在PeerIS 中,peer 在初次加入网络或系统崩溃而再次加入网络时,就是基于兴趣和行为相似度来决定其重要节点的.2.2.2 动态自配置策略相对于其他P2P 系统,PeerIS 的一大特征和优点是每个peer 能够动态地配置自己的重要节点.PeerIS 的动态自配置机制以兴趣与行为相似性为基础,并综合了peer 间交互的历史统计数据、时间因素以及网络因子.其公式如下:凌波 等:PeerIS:基于Peer-to-Peer 的信息检索系统1381∗+∗∗=∑∑−1)()()()(),(t j j t j j j i P Hop P Hit P Hop P Hit P P AP βαω (3) 其中),(j i P P AP 为peer i P 在动态自配置过程中,j P 成为i P 的重要节点的优先权;∑tj j P Hop P Hit )()(为当前配置周期内j P 所提供合格答案与逻辑距离之商的总和,而∑−1)()(t j j P Hop P Hit 则为上一次自配置周期所得的该值;á,â为递进系数,且á+â=1,á>â,用户的兴趣偏好越不稳定,则á越大,这两个系数可以根据peer 的统计数据来确定;ω是取值范围为[0,1]的网络因子,它考虑了WAN 与LAN 之分、peer 的带宽与计算资源利用状况.在PeerIS 中,如果peer 在同一Intranet 且带宽与计算资源负荷小于阈值的80%,则ω取值为1.其他情况可以通过配置系统的移动Agent 来确定.基于该自配置机制,PeerIS 中的节点周期性地利用空闲时间动态地调整自己的邻居节点和重要节点,这样,系统中的节点基于兴趣与行为相似性形成不同的簇,并且在同一簇内,两个peer 的偏好和行为越相似,两者的逻辑距离越近,反之亦然.用户提交的查询往往在重要节点获得答案,因而系统的性能很好.2.3 查询机制为了支持语义丰富的信息检索与共享,PeerIS 中的每个peer 维护的文件和用户提交的查询均用向量空间模型[12]来表达.在向量空间模型中,peer 维护的文件和用户提交的查询的索引项都用权重来表达,这些权重不仅用于确定文件和查询之间的相似程度,而且用于计算被检索出的文件排序.在向量空间模型中,索引项i k 在文件j d 的重要程度),(j i d k 用一权重j i ,ω来表达.类似地,索引项i k 在用户提交的查询中,q 的重要程度),(q k i 也用一权重q i ,ω来表达.这样,文件j d 的向量定义为,,...,,,,2,1)(j t j j j w w w d =ρ其中,t 为该文件的索引项的数目.类似地,用户提交的查询的向量定义为 .,...,,,,2,1)(q t q q w w w q =ϖ 因此,查询q 和peer 维护的文件d j 的相似度sim (d j ,q )可由以下公式计算:∑∑∑===××=ו=t i q i t i j i t i q i j i j j j w w w w q d q d q d Sim 1,21,21,,||||),(ρρρρ (4) 上式中,||j d ρ和||q ρ分别表示查询与文件的各向量的模.用户提交的查询首先由本地peer P i 解析后以并行的方式进行处理:如果本地可能有答案,则搜索本地文件库(否则不查本地文件库),同时把该查询发送到相关重要节点,并在这些节点进行类似的处理.对于远程查询,PeerIS 采用两步处理策略.第1步,远程peer 的QueryHits 先返回给查询peer,并由Master Agent 根据sim (d j ,q )进行排序后展现给用户选择;第2步,被选中的QueryHits 被送回到相关peer,并把最终结果从这些peer 返回给查询peer.这种处理策略有两个优点:(1) 最终查询结果经过用户的语义过滤,可以减少信息处理和传输负荷,更高效地利用带宽;(2) 关于相关远程peer 的元数据(如文件类别分布和QueryHits 数目等)也返回给查询peer,这些信息是peer 优化其重要节点组成和优化查询处理的基础.2.4 自适应路由机制大多数非结构化P2P 系统(如Gnutella)采用广播路由策略.为防止以指数增长的查询消息在P2P 网络中泛滥,每个查询都预先设定了一个存活周期(time-to-live,简称TTL),当消息转发的累计跳数达到TTL 时被注销.这种过于简单的策略面临两难抉择:如果TTL 设得太小,则查询只能在网络的小范围内处理,导致系统的查全率低下(如Gnutella,见实验);如果TTL 设得过大,查询消息洪泛系统.为了克服上述挑战,我们以PeerIS 的拓扑特征(节点簇)为基础,提出了自适应的查询路由策略.这种策略首先根据节点的兴趣偏好把查询转发到目标节点簇;在目标簇,查询尽量只访问能够提供语义相似度大于阈值答案的节点.大致过程如下:• 查询-提交,就在本地节点解析,并根据IMP 中本地节点与重要节点的兴趣统计信息来判定该查询是否已1382 Journal of Software软件学报 2004,15(9)经落在了目标节点簇,并根据判断结果分别进行以下两种处理;•如果该查询没有落在目标节点簇,则节点根据邻居节点的兴趣偏好统计信息,把查询向最可能导向目标节点簇的路径转发,所有接收到该查询的节点都进行同样的决策,直到查询落到目标簇节点或TTL为0为止;•查询一旦落在目标点簇,如果不能立即获得合格答案,当前节点可以根据本次路由的历史记录,把查询向可能提供最相关语义答案的节点转发;当查询经过那个节点后,如果处理节点不能提供满足语义要求(SR(d j,q)≤ threshold),查询终止.3 系统性能实验分析本节对PeerIS进行实验性能分析.首先,我们简要说明实验设置,然后从网络传输时间、查全率和带宽利用效率3个方面对比PeerIS与Gnutella(经典非结构化P2P系统).我们将看到,实验结果证明了PeerIS的优良特性.3.1 实验设置实验环境由在同一LAN的66台PC构成,每台PC配置为Intel Pentium 1.7(或1.8)G处理器、128RAM和Windows 2000 Professional操作系统,并安装PeerIS系统.我们产生一批每个大约10KB的文件,这些文件分属于4个语义类别.每个节点管理1 000个文件,分别属于两个语义类别,比例为80%:20%.这样,整个P2P信息检索系统有4个语义簇,每个节点同时属于两个簇.另外,我们也用这些节点随机分布成一个Gnutella系统.Gnutella实际上是一个典型的非结构化P2P的文件共享的协议,代表了现有非结构化P2P文件共享系统的特征:(1) Gnutella随机且静态地选择邻居节点;(2) 采用非选择性的广播式的搜索策略,即查询发起节点把查询消息广播给它的所有邻居节点,并把查询消息的TTL值减1,而这些邻居节点也把查询消息广播给它们的所有邻居节点和减少TTL的值,查询广播直到TTL等于0为止;(3) 另外,Gnutella仅支持基于文件名的粗粒度的搜索.但是在本实验中,我们也把IR技术在Gnutella的节点中实现,但考虑到现实中的Gnutella和其他非结构化P2P文件共享系统没有基于语义和不同粒度的检索与共享功能,因而它们的节点在处理查询机制与PeerIS时有所不同,查询时间也不具有可比性.所以我们仅比较了网络传输时间.为了使实验结果具有可比性,实验在可控的环境内进行,并以同一个节点集为评价基准.我们设计了3种评价方案:(1) 查找用户偏好的文件,即查找占提交节点80%的那个语义类的文件,用Favorite表示;(2) 查找非偏好文件,即查找不属于本地节点那两类的文件,用Non-Favorite表示;(3) 在Gnutella上查找文件,用Gnutella表示.方案(1)与方案(2)全面地刻画了PeerIS检索面临的情形.3种方案中执行相同的查询,方案(2)的查询提交节点与方案(1)的提交节点分别属于不同的节点簇,而方案(3)的提交节点与方案(1)相同.3.2 网络传输时间由于PeerIS与Gnutella节点处理查询的机制不同,两者的处理速度不具有可比性,因而我们用网络传输时间来比较两种P2P协议的效率.网络传输时间是查询从提交节点路由到答案维护节点所耗费的时间与答案从维护节点返回到提交节点的所耗费的时间之和.图5展示了查询执行10次各个答案传输时间的平均值.从下面图5可知,Favorite的网络传输时间最短;对于前6个答案,Gnutella的传输时间比查找Non-Favorite 所消耗的时间要短,而此后,两者相近甚至Non-Favorite的传输时间比Gnutella要短.导致这种结果的原因是网络拓扑结构以及数据的分布.在检索Favorite文件时,答案集中在查询提交节点所在的簇,距离提交节点很近,因而网络传输时间短.Gnutella的答案散布在整个网络,所以传输时间呈线性增长;Non-Favorite的答案集中在远离查询提交节点的节点簇,它们距提交节点的距离相近,并且比Gnutella的有些答案更近,因而所有答案的传输时间很相近,并且,从第7个答案开始就优于Gnutella.因为用户在一般情况下是查找Favorite文件的,并且即使用户的兴趣发生改变,随着节点本地新数据的积累和查询统计数据的更新,系统的自配置机制也会使节点加入到响应的节点簇,即后续查询就在本节点簇完成.因而,PeerIS整体上优于Gnutella.。
Internet原理与技术第8章P2P技术课件
➢ 磁头读写盘片上的磁道,由于网络吞吐量低于磁盘吞吐量, 持续低速下载(上传)带来频繁的读写操作,盘片可能会由 于过热而损坏
磁盘缓存技术
➢ 使用内存缓存数据 ➢ 写数据时,仅当缓存满后再整体写入硬盘(下载) ➢ 读数据时,仅当缓存中没有时才从硬盘读数据,且整块读入,
减少磁盘操作(上传)
➢ Gnutella不是特指某一款软件,而是指遵守Gnutella协议的 网络以及客户端软件的统称。
➢ 基于Gnutella协议的客户端软件有Shareaza、LimeWire和 BearShare等
➢ Gnutella协议0.6版加入了超级结点Ultrapeer
GNUTELLA运行原理
24
GNUTELLA洪泛问题
Internet: Supporting Netork
A Generic Topological Model of P2P Systems
6
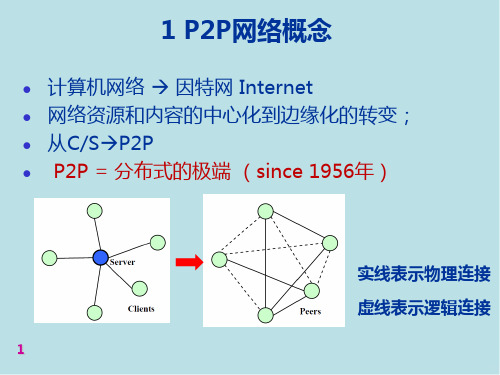
P2P网络特点
P2P:Peer to Peer对等网络 ➢ peer结点(对等机)在行为上是自由的——任意 加入、退出,不受其它结点限制, ➢ 功能上是平等的——不管实际能力的差异 ➢ 连接上是互联的——直接/间接,任两结点可建立 逻辑链接,对应物理网上的只是一条IP
32
Chord:简单、优美的带弦环形P2P网络,结构化P2P领域最著名的 理论模型,MIT与Berkeley的研究者于2001年正式发表;
Chord使用安全散列函数(如SHA-1)为每个网络结点和数据对象分 配唯一的ID
➢ nodeID=H(node属性),属性可以是结点IP、port、公钥、随机 数或它们的组合
Pastry 著名学术团体与技术组织成立专门的P2P研究组,如
DistributedSystemsPrinciplesandParadigms中文版书名分布

Marcus,Sten : Blueprints for High Availablity
Birman, Reliable Distributed Systems
Byzantine Failure问题:
Pease,M., “Reaching Agreement in the Presence of Faults” J.ACM,1980
Lamport,L.: “Byzantine Generals Problem. ” ACM T ng.syst. 1982
Shooman,M.L: Reliability of Computer Systems and Networks :Fault Tolerance, Analysis, and Design. 2002
Tanisch,P., “Atomic Commit in Concurrent Computing. ” IEEE Concurrency,2000
集中式体系结构:C/S
分布式体系结构:
点对点系统(peer-peer system):DHT(distributed hash table),例如Chord
随机图(random map)
混合体系结构:
协作分布式系统BitTorrent、Globule
自适应软件技术:
①要点分离
②计算映像
③基于组件的设计
Henning,M., “A New Approach to Object-Oriented Middleware”
第11章分布式文件系统
NFS (Network File System):远程访问模型
2024年电信5G基站建设理论考试题库(附答案)

2024年电信5G基站建设理论考试题库(附答案)一、单选题1.在赛事保障值守过程中,出现网络突发故障,需要启用红黄蓝应急预案进行应急保障,确保快速处理和恢复。
红黄蓝应急预案的应急逻辑顺序为()A、网络安全->用户感知->网络性能B、网络性能->用户感知->网络安全C、用户感知->网络安全->网络性能D、用户感知->网络性能->网络安全参考答案:D2.2.1G规划,通过制定三步走共享实施方案,降配置,省TCO不包含哪项工作?A、低业务小区并网B、低业务小区关小区C、低业务小区拆小区D、高业务小区覆盖增强参考答案:D3.Type2-PDCCHmonsearchspaceset是用于()。
A、A)OthersysteminformationB、B)PagingC、C)RARD、D)RMSI参考答案:B4.SRIOV与OVS谁的转发性能高A、OVSB、SRIOVC、一样D、分场景,不一定参考答案:B5.用NR覆盖高层楼宇时,NR广播波束场景化建议配置成以下哪项?A、SCENARTO_1B、SCENARIO_0C、SCENARIO_13D、SCENARIO_6参考答案:C6.NR的频域资源分配使用哪种方式?A、仅在低层配置(非RRC)B、使用k0、k1和k2参数以实现分配灵活性C、使用SLIV控制符号级别的分配D、使用与LTE非常相似的RIV或bitmap分配参考答案:D7.SDN控制器可以使用下列哪种协议来发现SDN交换机之间的链路?A、HTTPB、BGPC、OSPFD、LLDP参考答案:D8.NR协议规定,采用Min-slot调度时,支持符号长度不包括哪种A、2B、4C、7D、9参考答案:D9.5G控制信道采用预定义的权值会生成以下那种波束?A、动态波束B、静态波束C、半静态波束D、宽波束参考答案:B10.TS38.211ONNR是下面哪个协议()A、PhysicalchannelsandmodulationB、NRandNG-RANOverallDescriptionC、RadioResourceControl(RRC)ProtocolD、BaseStation(BS)radiotransmissionandreception参考答案:A11.在NFV架构中,哪个组件完成网络服务(NS)的生命周期管理?A、NFV-OB、VNF-MC、VIMD、PIM参考答案:A12.5G需要满足1000倍的传输容量,则需要在多个维度进行提升,不包括下面哪个()A、更高的频谱效率B、更多的站点C、更多的频谱资源D、更低的传输时延参考答案:D13.GW-C和GW-U之间采用Sx接口,采用下列哪种协议A、GTP-CB、HTTPC、DiameterD、PFCP参考答案:D14.NR的频域资源分配使用哪种方式?A、仅在低层配置(非RRC)B、使用k0、k1和k2参数以实现分配灵活性C、使用SLIV控制符号级别的分配D、使用与LTE非常相似的RIV或bitmap分配参考答案:D15.下列哪个开源项目旨在将电信中心机房改造为下一代数据中心?A、OPNFVB、ONFC、CORDD、OpenDaylight参考答案:C16.NR中LongTruncated/LongBSR的MACCE包含几个bit()A、4B、8C、2D、6参考答案:B17.对于SCS120kHz,一个子帧内包含几个SlotA、1B、2C、4D、8参考答案:D18.SA组网中,UE做小区搜索的第一步是以下哪项?A、获取小区其他信息B、获取小区信号质量C、帧同步,获取PCI组编号D、半帧同步,获取PCI组内ID参考答案:D19.SA组网时,5G终端接入时需要选择融合网关,融合网关在DNS域名的'app-protocol'name添加什么后缀?A、+nc-nrB、+nr-ncC、+nr-nrD、+nc-nc参考答案:A20.NSAOption3x组网时,语音业务适合承载以下哪个承载上A、MCGBearB、SCGBearC、MCGSplitBearD、SCGSplitBear参考答案:A21.5G需要满足1000倍的传输容量,则需要在多个维度进行提升,不包括下面哪个()A、更高的频谱效率B、更多的站点C、更多的频谱资源D、更低的传输时延参考答案:D22.以SCS30KHz,子帧配比7:3为例,1s内调度次数多少次,其中下行多少次。
p2p协议原理

p2p协议原理一、P2P协议的基本原理P2P(Peer-to-Peer)是一种通信模式,它没有中央服务器,所有节点对等连接。
它是指一种计算机网络技术,其中每个节点都可以是服务请求者、服务提供者或者两者兼备,良好的P2P系统可以优化网络带宽并提高性能,它能使用户更加直接地分享文件和应用程序,特别是在大型文件传输时它的好处非常明显。
P2P协议的基本原理可以分为以下几个方面:1. 去中心化服务P2P网络没有统一的控制中心,又称之为去中心化服务。
每个节点都可以独立地提供或者接受服务,可以随时加入或者离开网络,并各自掌握着一部分数据和计算资源。
因此,P2P网络不存在单个点的故障,对节点数量不敏感,对规模不限制,也不需要专业的数据中心来维护。
2. 分布式数据存储P2P网络的数据都是存储在各个节点上的,通过节点之间的互联形成了一个分布式的存储系统。
每个节点都是其他节点的数据中心,存储若干个副本,确保数据不会因为某个节点的故障而丢失。
当有新的数据添加到网络中时,P2P协议自动将数据复制到一定数量的节点上,同时也会自动清除不需要的过期数据,确保数据的完整性和可用性。
3. 动态网络拓扑P2P网络的拓扑结构是动态的。
任何一个节点都可以加入或者离开网络,也可以随时和其他节点建立或者断开连接。
当节点加入网络时,P2P协议会自动在已有的节点中选择最优的节点,建立P2P连接。
这个连接不仅可以传输数据,还可以共享网络资源,比如CPU、带宽等。
当节点离开网络时,P2P协议会自动结束连接并将数据复制到其他节点上,确保数据的下传速度和可靠性。
4. 去重复下载P2P协议可以去除已经存在的数据,在进行下载时先获取早已下载过的数据块,这样可以省去下载时间和带宽资源的浪费,同时也减少了网络占用带宽,提高了整个P2P 系统的效率。
二、P2P协议的流程P2P协议的工作流程包括了搜索、连接、数据块传输、退出等多个步骤。
下面将对P2P协议的流程进行简要介绍:1. 搜索在P2P协议中,搜索是指向其他节点获取需要的数据块。
网络系统建设与运维(高级)电子教案全书教案完整版精选全文
可编辑修改精选全文完整版教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)
教学流程设计(理实一体化)。
Pearson BTEC International Level 2 计算机网络简介指导手册说明书

Unit 4: Introduction to Computer NetworkingDelivery guidanceApproaching the unitThis unit explores how computer networks are used to meet the needs of businesses and individuals. Learners will explore how they are used in real-world, vocational scenarios and how to analyse user requirements to design, create, and test a network.In the first learning aim learners will explore existing networks and their components to gain an understanding of how they are used to meet a range of needs. They will explore the potential security risks when using a network, and ways that these risks can be reduced. In the second and third learning aims learners will study how to design, implement, and test a network to meet identified needs in response to a client brief.Learners should understand the importance of computer networks, and that without them, many of the things we do both personally and professionally, such as surfing the web, watching a film on a streaming service, or calling and messaging friends and relatives, would not be possible. Delivering the learning aimsLearning aim A: This provides core knowledge about the use of networks, including individual components that form a network, and how networks meet the needs of organisations and users. This unit is focused on how networks are used in the real world to meet a range of needs. It would be beneficial to learners to provide opportunities to consider the use of networks in a range of different contexts. The use of high-quality case studies or visits and guest speakers would all provide opportunities for engaging learners with the content, and would allow learners to consider a range of different uses of networks in order to develop a wider understanding of their uses and components, as well as security implications.Given the widespread use of networks in our everyday lives, the unit also provides opportunities for learners to draw on their own experiences when taking part in class discussions.Learning aim B: Delivery should focus on practical and engaging tasks and, where possible, learners should be provided with a scenario or brief for which they will design a network. This will help them focus on the aims of the organisation and the activities that must be facilitated to meet those aims, which will better prepare them for the requirements of the assignment. Producing high-quality design documentation for a network requires a sound understanding of both the hardware and software components that form the network. Where needed, recap knowledge covered, in learning aim A. It may also be beneficial to overlap delivery of learning aims B and C, so that learners can produce a design, and then apply that design to the practical network building activities in learning aim C.Learning aims C: This learning aim focuses on the development of practical computer network building skills. Learners should be provided with opportunities to connect a range of physical devices and components to form networks for different purposes. They should explore how to test a network and, where required, identify and fix any issues.It would be beneficial for learners to use actual, physical components to build networks when completing tasks. However, for some scenarios that use larger business contexts, this may not be plausible. In these situations, learners can make use of simulated network software such as Cisco Packet Tracer.Assessment modelAssessment guidanceThis unit is internally assessed. There is a maximum number of two summative assignments for this unit. Tutors should refer to the assessment guidance in the specification for specific detail, particularly in relation to the requirements for the Pass, Merit and Distinction grades. Learning aim A is assessed by a written report or presentation. In their report, learners must consider how two different networks are used, in different contexts, to meet organisation and user needs. They should explore the potential security threats to the networks and how these threats are mitigated. Learners should consider the good, and not so good, features of the network and consider how effective the network is in meeting the aims and objectives of the organisation and intended users.For learning aim B, learners will respond to a given scenario to design a network solution. Learners will be expected to produce an initial user requirements specification, detailed network designs (including a network diagram), and a test plan for the network. These design documents should be sufficiently clear and detailed to enable a third party to use them to create the intended network.For learning aim C,learners will produce and test their planned network to meet the given brief. They should demonstrate the ability to connect and configure components to form a networkensuring that the devices and software are correctly configured to ensure that the network is functional and secure.Learners should perform systematic testing, applying their test plan, to ensure any potential issues are identified and rectified.Learners will produce a supporting document which outlines the approaches that they took when designing and building the network, and which justifies any choices made in relation to the design and build of the network (e.g. the topology used, chosen devices, network settings, user permissions etc.). Any justifications made should be directly related to the requirements of the scenario.Getting startedThis gives you a starting place for one way of delivering the unit, based around the recommended assessment approach in the specification.Details of links to other BTEC units and qualifications, and to other relevant units/qualificationsThis unit links to:•Unit 1: Using IT to Support Information and Communication in Organisations•Unit 6: Introduction to Digital Graphics and Animation•Unit 7: Introduction to Website Development•International GCSE/core curriculum in Information Technology.ResourcesIn addition to the resources listed below, publishers are likely to produce Pearson-endorsed textbooks that support this unit of the BTEC International Level 2 Qualifications in Information Technology. Check the Pearson website at: (/endorsed-resources) for more information as titles achieve endorsement.VideosWhat is OSI Model? - YouTube Provides an introduction and overview to theOSI network model[HOWTO] Test My Network Speed?! [iPerf & JPerf] - YouTube Tutorial on how to use iperf tools to test the speed of data over a networkNetwork Troubleshooting using the IPCONFIG Command - YouTube Tutorial on how to use command tools to test a networkNetwork Troubleshooting using PING, TRACERT, IPCONFIG, NSLOOKUP COMMANDS - YouTube Tutorial on how to use command tools to test a networkPING Command - Troubleshooting - YouTube Tutorial on ping command tool WebsitesEthernet Standards - IEEE 802.3 »Electronics Notes ()An overview of ethernet standardsLesson 6 Network protocols ()Information about a range of protocols used to control data over a networkLesson 7 The IP suite and packet switching ()An introduction to, and overview of, data packets and packet switchingThe 15 biggest data breaches of the 21st century | CSO Online A collection of examples of prominent data breachesPearson is not responsible for the content of any external internet sites. It is essential for teachers to preview each website before using it in class so as to ensure that the URL is still accurate, relevant, and appropriate. We suggest that teachers bookmark useful websites and consider enabling learners to access them through the school/college intranet.。
《基于SIP的P2P通信及其防火墙穿越的研究》

《基于SIP的P2P通信及其防火墙穿越的研究》一、引言随着互联网技术的飞速发展,P2P(Peer-to-Peer)通信技术已成为现代通信领域的重要研究方向。
SIP(Session Initiation Protocol)作为一种重要的通信协议,被广泛应用于P2P通信中。
然而,在防火墙普及的今天,如何实现基于SIP的P2P通信及其防火墙穿越成为了研究的热点问题。
本文旨在探讨基于SIP的P2P通信技术及其在防火墙穿越方面的应用。
二、SIP协议及其在P2P通信中的应用SIP协议是一种用于建立、修改和终止多媒体会话的协议,其应用领域包括语音、视频会议、即时消息等。
在P2P通信中,SIP协议被广泛应用于信令传输,实现用户间的通信连接。
通过SIP协议,用户可以发起呼叫、交换媒体信息、处理呼叫状态等,从而建立起稳定的P2P通信链路。
三、P2P通信的技术原理与挑战P2P通信技术的原理是通过在网络中的各个节点之间建立直接的通信链路,实现信息交换和资源共享。
然而,在实际应用中,P2P通信面临着诸多挑战。
其中之一便是防火墙的穿越问题。
由于防火墙的存在,很多节点的通信被限制在局域网内,导致P2P 通信链路无法建立。
此外,网络地址转换(NAT)等技术也增加了P2P通信的复杂性。
四、基于SIP的P2P通信的防火墙穿越技术为了解决P2P通信中的防火墙穿越问题,研究者们提出了多种技术方案。
其中,基于SIP的防火墙穿越技术是一种有效的解决方案。
该方案利用SIP协议的信令功能,通过信令交互实现节点间的通信连接。
具体而言,当两个节点需要进行通信时,它们通过SIP协议进行信令交互,获取对方的公网地址和端口信息,从而建立起稳定的P2P通信链路。
此外,该方案还可以利用中继服务器等技术手段,提高防火墙穿越的成功率。
五、实验与分析为了验证基于SIP的P2P通信及其防火墙穿越技术的有效性,我们进行了实验分析。
实验结果表明,该方案在信令传输、媒体交换等方面均表现出良好的性能。
一种基于Peer_to_Peer技术的Web缓存共享系统研究

第28卷 第2期2005年2月计 算 机 学 报C HIN ESE J OU RNAL OF COM PU TERSVol.28No.2Feb.2005一种基于Peer 2to 2Peer 技术的W eb 缓存共享系统研究凌 波1) 王晓宇2) 周傲英2) Ng Wee 2Siong3)1)(中国浦东干部学院 上海 200233)2)(复旦大学计算机科学与工程系 上海 200433)3)(新加坡国立大学计算机科学系 新加坡 117576)收稿日期:2003204224;修改稿收到日期:2004210208.凌 波,男,1974年生,博士,主要研究兴趣包括对等计算、基于对等计算的数据管理和信息检索、信息经济和领导科学等.E 2mail :bling @.王晓宇,男,1975年生,博士,主要研究兴趣包括Web 数据管理、对等计算和嵌入式系统等.周傲英,男,1965年生,博士,教授,博士生导师,主要研究兴趣包括Web 数据管理、数据挖掘、数据流管理与分析、对等计算、金融数据管理与分析等.N g Wee 2Siong ,男,1973年生,马来西亚人,2004年在新加坡国立大学获得计算机科学专业理学博士学位,主要研究兴趣包括数据库性能、对等计算和基于Internet 的应用等.摘 要 提出了一种基于peer 2to 2peer 技术的分布式Web 缓存共享系统:BuddyWeb.该系统的核心理念是让企业网络中的所有PC 能够相互共享浏览器中的本地缓存,从而形成一个高效的、大规模的分布式缓存共享系统,并使系统具备易管理、易实现、低成本等优点;接着详细阐述了BuddyWeb 的工作原理和算法策略;然后,针对Buddy 2Web 系统的特性提出了仿真实验模型和评估方法.实验结果证明了BuddyWeb 在命中率、网络通信流量负荷、系统响应延迟等诸方面均能取得令人满意的效果.关键词 peer 2to 2peer Web 缓存;动态自配置;自适应跳步中图法分类号TP303A Collaborative Web C aching SystemB ased on Peer 2to 2Peer ArchitectureL IN G Bo 1) WAN G Xiao 2Yu 2) ZHOU Ao 2Y ing 2) Ng Wee 2Siong 3)1)(China Executive L eadershi p A cadem y Pu dong ,S hanghai 200233)2)(Depart ment of Com p uter Science &Engineering ,Fu dan Universit y ,S hanghai 200433)3)(Depart ment of Com puter Science ,N ational Universit y of S ingapore ,S ingapore 117576)Abstract In t his paper ,a collaborative P2P 2based Web caching system ,named BuddyWeb ,has been p roposed ,whose underlying ideology is t hat all t he PCs in an Int ranet are able to share t heir local caching to constit ute a large 2scale ,effective collaborative Web caching system.BuddyWeb distinguishes it self from ot hers wit h t he advantages of scalability ,effectiveness and low cost.Furt hermore ,t he working mechanism and t he algorit hm of t he system have also been detailed.In addition ,a simulation model has been devised to evaluate such a system.And t he evaluation re 2sult s show BuddyWeb achieves a satisfied performance in hit s 2ratio ,t raffic 2load and latency of re 2sponse.K eyw ords peer 2to 2peer Web caching ;dynamic self 2reco nfiguration ;self 2adaptive hopping1 引 言Peer 2to 2Peer (简称P2P )计算模型正越来越广泛地应用于数据挖掘、资源交换、数据管理、文件共享等领域.P2P 技术得以风行的最初动机是人们希望创建属于自己的在线通信通道,以实时地访问和交换信息,典型的P2P 系统有Napster 和Gnutella 等.本文提出了一种新型的P2P 应用:Web 缓存共享.不同于以往基于proxy 端的Web 缓存技术,本文着眼于如何在一个企业局域网环境中利用所有节点(PC) (浏览器中)的本地缓存.企业环境P2P模型与互联网资源共享模型的主要区别为:(1)连结节点(peer)间的带宽不同,企业局域网的带宽比广域网带宽高得多;(2)企业局域网的安全性好,因为局域网中的所有节点都受防火墙保护;(3)企业环境中整个网络都是可控制和可管理的.为了更好地阐述本文的研究背景和动机,让我们考虑复旦大学校园网这样一个企业级局域网.在这类网络中,有成千台PC相互连接在一起,每台PC都有一个Web浏览器.这里,防火墙把校园网与“外面的世界”隔离开,任何进入和外出的请求都要通过一个中心p roxy;另外,中心proxy还承担数据流量“计费器”的角色,每个通过它出入的字节都要收费.在当前的计算模式下,用户不能相互共享节点浏览器中的缓存内容,即使正查找的信息已缓存在校园网(L AN)内的其它节点,也不能在L AN内获得.所有查询不得不通过中心proxy发送到远程服务器,这样既导致了较长的响应时间,又增加了额外的费用.相反,如果能利用P2P技术使L AN内所有PC共享本地缓存,则不但能缩短响应时间,而且能节省费用.带着这样的动机,本文设计了基于P2P技术的Web缓存共享系统:BuddyWeb.在BuddyWeb中,所有参与节点的本地缓存都可共享,在触发外部(到Int ranet之外的)访问之前,首先搜索L AN内节点的缓存.总之,BuddyWeb具有以下独特性:(1)网络的拓扑结构可以依据节点的兴趣而自调整.运行一段时间后,网络中将形成不同兴趣的虚拟社区.例如,数据库研究社区,生物信息研究社区等.(2)采用了基于节点缓存内容相似度的路由策略.基于相似度的判断,查询将从一个节点路由到和该节点具有较高相似度的相邻节点.(3)实现了基于兴趣相似度的自适应跳步策略(self2adaptive hopping st rategy),每个查询消息的T TL值(Time2To2Live,生命周期)会自动调整,从而实现最大化搜索结果和最小化带宽消耗的优化目标.本文第2节介绍BuddyWeb的体系结构,首先回顾实现系统的P2P系统平台Best Peer,然后描述BuddyWeb节点的体系结构;第3节介绍Buddy2 Web的特性和算法,包括基于兴趣相似度的动态自配置策略以及基于兴趣相似度的路由策略与自适应跳步机制;第4节提出仿真实验模型并展示实验结果;第5节讨论相关的工作;第6节总结全文.2 BuddyWeb系统体系结构本节首先介绍实现BuddyWeb系统的P2P平台,以更好地理解系统的工作机制,然后详细描述BuddyWeb节点的体系结构和工作流程.2.1 B estPeer平台BuddyWeb是在Best Peer[1]平台上实现的. Best Peer是集成了移动Agent技术的通用P2P平台,可以在它上面有效地开发各种P2P应用.平台系统由两类实体组成:大量的对等节点和少量的位置独立全局名查找服务器(L IG LO).每个对等节点都运行一个基于J ava的Best Peer软件,并能互相通信和共享资源.L IG LO服务器是有固定IP地址并运行着L IG LO软件的特殊节点,主要有两个功能: (1)为每个对等节点分配全局唯一的标识符(BPID),即使一个节点以不同IP地址登录,也能被唯一地识别出来;(2)维护自己所管辖的对等节点的当前状态信息,包括在线与否及当前IP地址等元数据.图1 Best Peer节点自配置过程在传统的P2P系统(如Gnutella)中,邻居节点(直接相连的节点)一般是人工静态指定或随机决定的,而Best Peer的节点可以动态地重新配置自己的邻居.该机制基于以下简单假设:对于任意一个给定的节点,曾经对它有益的节点,在以后的查询中很可能仍然有益.因此,Best Peer的节点会把曾经对自己最有益的节点维护成直接邻居;由于自身资源的限制,每个节点的邻居数量受限.图1展示了节点重新配置邻居的过程.在图1(a)中,Peer X发出的请求直接发送给Peer B和Peer A.但是,只有Peer C和Peer E才有Peer X当前请求的对象.那么Peer X 从Peer C和Peer E获得结果;并且,Peer X发现虽然Peer C和Peer E对它有益,却不是直接邻居,因此,Peer X重新配置自己的邻居节点,将Peer C和Peer E节点加入自己的邻居列表中,结果网络拓扑1712期凌 波等:一种基于Peer2to2Peer技术的Web缓存共享系统研究结构如图1(b ).自配置策略的实质就是将最有益的节点保持在近邻位置上,以便为自己提供更好的服务.Best Peer 支持两种缺省动态自配置策略[1]:(1)MaxCount ,以提供有效查询结果数最大化为基准;(2)Min Hop ,以获得相同查询结果所历经的跳数(hop )最少为基准.2.2 BuddyWeb 节点体系结构BuddyWeb 节点的体系结构如图2所示.Web 浏览器充当前端用户界面,采用Microsoft Internet Explorer (IE ).在BuddyWeb 支持的浏览器中由一个本地proxy 来操纵本地Web 缓存;用一个H T TP 后台线程支持H T TP 请求.底层数据通信由Best Peer 平台管理.BuddyWeb 节点正是借助于Best Peer 平台与其它节点共享缓存内容.对用户而言,这种设置是透明的,用户觉察不到BuddyWeb 浏览器和普通浏览器的差别.图2 BuddyWeb 节点体系结构当用户从浏览器提交一个U RL 查询,本地p roxy 将其改写成Best Peer 平台可以接受的输入形式并传送给底层Best Peer 平台.接着,Best Peer 产生一个移动Agent 并将其派到BuddyWeb 网络中搜寻匹配结果.一旦查找到匹配结果,Best Peer 将结果的位置等元数据返回给发出查询的本地p roxy ;本地p roxy 立刻使H T TP 后台线程直接向存有匹配文档的节点发出H T TP 连接请求;一旦收到H T TP 连接请求,被请求节点上的H T TP 后台线程立即处理该请求,并传送被请求的结果.3 BuddyWeb 的特性与算法本节详细介绍BuddyWeb 的特性与算法,包括基于兴趣相似度的自配置策略、基于兴趣相似度路由策略和自适应跳步,并展示了L IG LO 和对等节点的工作算法.3.1 基于兴趣相似度的动态自配置策略由于Best Peer 的缺省自配置策略是基于查询行为的,不能有效利用共享内容的语义信息.在BuddyWeb 中,我们提出了一种基于兴趣(或内容语义)相似度的动态配置策略.该策略充分利用了Best Peer 中的L IG LO 服务器.即每个注册的节点不仅要将当前IP 地址传送给管辖它的L IG LO 服务器,同时还要定期向L IG LO 发送关于自己浏览兴趣的信息.节点浏览兴趣是通过它浏览过的网页信息来提取的.虽然具体方法很多,但抽取的浏览兴趣信息必须同时满足代表性和简练性的要求.BuddyWeb 通过节点浏览过网页的部分元数据(meta 2data ,例如〈TITL E 〉〈/TITL E 〉)来定义节点的浏览兴趣.每个节点的浏览兴趣会在管辖它的L IG LO 服务器用一组词列表的形式来表示.本文提出的动态自配置策略就是基于这些词列表进行的.我们可以把所有词列表中的词看作一个词袋(wordbag ),并用这个词袋构造一个向量空间.基于向量空间,每个词列表可以依据某种权重方案映射为该向量空间中的向量,最简单的权重方案是布尔权重.这样,每个节点的浏览兴趣就由向量表示.由于BuddyWeb 有多个L IG LO 服务器,每个L IG LO 服务器中仅保存了在它登记的节点浏览兴趣词列表.因此,所有L IG LO 必须相互协商,从而决定由谁接收其它L IG LO 所保存的兴趣词列表信息.解决该问题的另一种方法是通过哈希影射的方法,这样可以避免所有的向量计算在一个服务器上进行.但由于在企业网环境中,BuddyWeb 的L IG LO 服务器数量有限,而且L IG LO 服务器间传输的词列表只是一些“轻量级”文件,因此采用协商方法.基于上述定义的向量空间,节点可以采用余弦相似度函数来计算它们之间的兴趣相似度.为了使浏览兴趣最相近的节点直接连接在一起,每个节点都仅将跟自己具有最高相似度的数个节点维护为邻居.当网络中很多节点时,计算节点浏览兴趣向量的两两相似度非常耗时.解决这个问题的简单方法是将相似度的计算分布到每个节点.这样,负责计算的L IG LO 服务器只要计算向量空间及每个节点在该空间中的向量.计算完成后,这些向量会传发网络中的所有L IG LO 服务器.基于兴趣相似度的动态自配置的具体过程如下:(1)经过一个指定的时间周期(如一天)后,L IG LO 在特定时间(如午夜)相互协商并推举一台L IG LO 计算向量空间和所有登记节点的向量.(2)当一个节点登陆时,首先跟它登记的L IG LO 通信,上传其当前IP 地址,并接收当前网络中所有271计 算 机 学 报2005年节点(包括该登陆节点本身)的浏览兴趣向量.该节点与其它节点间的两两相似度就在登陆节点本地计算出来,并按由高到低排序.(3)k个具有最高相似度的节点将保持为直接连接邻居,k是一个指定的系统参数.采用基于兴趣的自配置策略,BuddyWeb系统运行一段时间后,会形成特定的(节点)虚拟社区. 3.2 基于兴趣相似度的路由与自适应跳步目前,大多数P2P系统(如Gnutella)的查询采用广播路由策略,即查询节点把查询广播给所有邻居,邻居收到查询后在本地检索的同时,继续把查询转发给它们的所有邻居,直到查询转发次数达到限制值(T TL).这种广播路由策略导致了很高的网络通信流量负担.在BuddyWeb中,每个节点都保存自配置过程中计算得到的节点间兴趣相似度值.由于该值实际上是节点缓存内容的相似度,因而,当节点转发查询时,只需转发至和该节点具有很高相似度值的邻居,而不是转发给所有邻居.注意,查询提交节点将查询传播给所有邻居.利用节点间的兴趣相似性度,BuddyWeb还实现了一种自适应查询跳步策略.以往的P2P系统(包括Best Peer)都预先设定查询跳数(T TL值).如果T TL值设得太小,那么查询处理被限制在很小范围,查全率低;反之,如果T TL设得过大,网络的通信流量负担非常沉重.因此,不可能事先为不同的查询设定一个相同的T TL值,并同时达到上面两种考虑的折衷.BuddyWeb充分利用了Best Peer提供的Agent 机制,所有查询被封装在Agent中,Agent在路由途中记录一些“历史”信息.为了更直观地阐述自适应跳步策略,我们用距离(跟相似度本质相同)来描述节点间的关系.在网络中,两节点间最长的距离被看作BuddyWeb概念空间的直径,即所有节点的兴趣所覆盖范围.自适应跳步策略的具体工作过程如下:(1)节点发起一个携带一个参数s(而不是T TL 定值)的查询Agent.这里参数s是一个由P2P网络预先设定值,称为概念空间参数.网络直径用D表示,其值在动态自配置的过程中计算出.(2)当查询Agent被转发到邻居节点,Agent记录下当前节点与其邻近节点间的“距离”.并且,该距离跟以前路由路径上的距离值累加.(3)如果累加值超过s・D的值,那么查询路由终止(查询Agent不再被转发).否则,节点继续将查询Agent向其直接相连的节点转发.采用该策略,每个查询的T TL会依据它所搜索的概念空间范围而自适应调整.概念空间参数s 反映了系统希望节点在概念空间中搜索的范围.通过设定参数s可以使BuddyWeb在通信量和查全率两方面动态实现折衷.BuddyWeb系统中的L IG LO服务器和对等节点的工作算法分别如算法1与算法2所示.算法1. L IG LO工作算法.For L IG LO server:void ProcessPeerLogin() //等待Peer登陆{while(true){if(AnyPeerRequest ToLogin())//是否有Peer请求登陆{Accept PeerRequest();//接受登陆请求Get PeerIP();//获得登陆节点IPSendCurrent RegisteredPeersInterest();//将当前所有登陆节点的兴趣向量发给请求节点}else{Sleep(WA IT_IN TERVAL);}}}算法2. 对等节点的工作算法.For each peer:bool Login(){bool bRet=Connect ToL IG LOServer();//请求连接到L IG LO服务器if(bRet){SendCurrent IPAddress();//将当前IP地址发送给L IG LO服务器G et RegisteredPeer Interests();//获得当前登记的所有节点的兴趣向量ComputeSimlarities();//计算同其它节点的相似度RankSimilarities();//对兴趣相似度排序Connet To KNeighbors();//同相似度最高的k个节点建立连接}return bRet;}//发起查询void Query(StringList str Keys,float s)//StringList为关键字组,s为概念空间参数3712期凌 波等:一种基于Peer2to2Peer技术的Web缓存共享系统研究{int D=G etCurrentNetworkDiameter();//获得或者计算当前网络的近似直径int T TL=D×s;SendCurrentQueryToNeibs(str Keys,T TL,0);//将当前查询发送到邻居节点开始查询,0表示当前查询经过的距离为0int i Total W ait Time=0;while(i Total W ait Time<MAX_WA IT_TIM E){G otQueryResult();//取得当前返回的查询结果DisplayResults();//将查询结果显示给用户Sleep(WA IT_IN TERVAL);i Total W ait Time+=WAIT_IN TERVAL;}}//收到查询请求的节点处理查询void ProcessQuery(StringList str Keys,int T TL,intcurS te ps){Result Info result=SearchIn ThisPeer(str Keys);//在当前节点上查找查询结果ReturnResults To InitialPeer(result);//将查询结果返回给查询节点if(curS teps<T TL)SendCurrentQueryT oNeibs(str K eys,T TL,curSteps+1);//将当前查询发送到邻居节点开始查询}4 系统评估4.1 仿真评估模型Web缓存系统的性能很大程度上取决于实际环境的工作负荷.因此,为了比较客观地评估Bud2 dyWeb系统算法的有效性,本文采用仿真模拟的方法,并建立一个可控的仿真环境.并且,可假设Bud2 dyWeb节点所请求的都是静态可缓存对象.虽然这和实际环境存在差异,但由于不可缓存的对象对于任何缓存方法的影响都是同样的(H T TP请求都被直接发至原始站点),所以并不影响仿真的有效性.实际上,仿真实验的目的是验证BuddyWeb在一般情况下的行为特征,而不是具体模拟某种现实的Web缓存实例.4.1.1 仿真模型初始数据集的构造假设在某段时间内BuddyWeb所有节点所请求的Internet对象集合为Q={q1,q2,…,q n},被定义为仿真试验对象全集.设对象集合Q一共包含u 个不同的主题,每个主题的对象集合用Q T表示.为简化仿真过程,可假设不同主题的对象集合间不存在交集,即Q T1∪Q T2∪…∪Q T u=Q;Q T i∩Q T j= ,其中i,j∈{1,2,…,u}.因为仿真过程并不需要真实存在可缓存对象集合Q,因而可用一组映射关系来模拟从对象的元数据中抽取关键词的过程.设从每个主题集中的对象的元数据中抽取的关键词集为T,那么,对象主题集Q T 与其相应的关键词集T之间的抽取关系可以通过一个映射来表达,F(Q T i)→T i,其中i∈{1,2,…,u}.通过映射F可以为每个主题对象集Q T与其相应的关键词集T之间建立一个一一对应的关系.为简化仿真过程,可设每个关键词集T中含有同样数目的关键词m个,且T i∩T j= ,其中i,j∈{1,2,…,u}.另外,对于Internet对象实验全集Q中的对象,我们将为其中每一个对象的大小分配一个值.其分布符合在[1K,1M]上的正态分布.4.1.2 BuddyWeb仿真网络节点的构造创建一个BuddyWeb的仿真网络,设网络一共有w个节点,每个节点由一个BuddyWeb本地proxy操纵该节点的缓存、发送H T TP请求及响应其它节点的H T TP请求.每个节点的本地缓存能保存k兆的可缓存静态对象.在仿真实验之前,首先为每个节点初始化本地缓存内容,具体过程如下:从u个主题对象集合{Q T1,Q T2,…,Q T u}中随机地挑选1~p个主题集合(p为仿真实验参数,称为最大主题浏览数).然后从挑中的主体集合中随机选取其中的静态可缓存对象,直至达到该节点本地缓存容量,即k MB.BuddyWeb仿真网络的每个节点在选择了x(1ΦxΦp)个主题对象集合后,就依据映射F得到x个相应的关键词集合.按照该节点从这x个不同的主题对象集合中随机选取的对象数目的比例,可从相应的x个关键词集合中随机地挑选出q个不同的关键词构成该节点的浏览兴趣词列表.如果该节点的本地缓存中存有y个对象,则q=Δ・y,Δ是仿真实验参数,该参数定义为节点浏览兴趣词列表生成系数. 4.1.3 BuddyWeb网络行为的模拟为了比较全面模拟BuddyWeb网络的实际运作过程,仿真模型需要确定以下两个因素:(1)每个节点发出的H T TP所请求的对象;(2)每个节点发出H T TP请求的时间间隔.设节点i为BuddyWeb中的任意一个节点,它本地缓存中的Internet对象所涉及的主题对象集合的并集为N Q T i.节点的浏览过程(发出H T TP请求的过程)直接受到浏览者浏览兴趣的影响.浏览者既会保持一定的浏览兴趣连续性(继续浏览和其缓471计 算 机 学 报2005年存中对象主题相同的主题),也会浏览一些以前没有浏览过的主题,后一种现象称为浏览者的浏览兴趣漂移.因此,仿真模型引入了浏览兴趣飘移系数μ来刻画这种现象.μ=1表示节点浏览的Internet对象和它本地缓存中的对象完全没有重合的主题,μ=0表示节点浏览的Internet对象和它本地缓存中对象的主题完全重合.节点i所产生的H TTP请求对象有100μ%从集合N Q T i中随机地产生,有1-100μ%从Q-NQ T i中随机产生.节点产生H T TP请求的时间间隔直接影响整个BuddyWeb网络中通信流量的负荷.如果节点发出请求的时间间隔很短,那么网络的信息流量负荷就会很重,否则,流量负荷就很轻.为此,仿真模型引入请求间隔参数t,节点产生H T TP请求的时间间隔将从[0,t]范围内随机地产生一个值来确定.由于实验对象全集是所有网络中的节点所发出的H TTP 请求对象,因此实验结束时,实验对象全集Q中所有对象都被仿真网络的节点请求过.最后,因为每个节点的缓存容量都是有限的,所以仿真实验还要为网络节点所缓存的对象确定替换策略,本研究采用L RU缓存替换策略.表1展示了仿真模型参数的预设定值.表1 仿真模型参数缺省值仿真模型参数代表符号设定值BuddyWeb网络中的节点数目w2000实验对象全集Q中的对象数目n1000000实验对象中包含的主题数目u20每个节点本地缓存中包括的最大主题数目p8节点浏览兴趣词列表生成系数Δ3每个主题关键词集合中含有的关键词数目m500表1中未被列出的参数为评估实验参变量,用于研究BuddyWeb网络的行为特征.参变量的具体设定将在评估实验过程中详细说明.4.2 仿真实验评估本节评估BuddyWeb系统的基于相似度的动态自配置策略以及路由与自适应动态跳步方法的有效性.实验评估主要基于以下度量指标:系统性能(外部带宽或命中率,系统响应延迟或跳步数)和网络通信流量负荷.实验比较了加入动态自配置策略的BuddyWeb系统和没有自配置的策略的静态BuddyWeb系统,评估了自适应动态跳步算法对系统性能和网络通信负荷的影响.实验结果表明了基于兴趣相似度的动态自配置策略的优越性;同时也证明了自适应动态跳步算法在没有牺牲系统性能的前提下,有效地降低了网络的通信流量负荷.4.2.1 命中率与外部带宽命中率定义为网络中所有节点发出的请求被BuddyWeb网络中缓存所响应的百分比.本小节首先研究基于相似度的动态自配置策略对BuddyWeb 命中率的影响以及节点缓存对提高整个系统命中率的贡献;接着研究浏览者行为(不同的浏览兴趣漂移系数)对整个系统的命中率的影响;最后比较自适应跳步算法与路对系统命中率的影响.未加入动态自配置策略的BuddyWeb系统等同于一个传统的静态P2P系统,称为静态Buddy2 Web系统(简称SBW);采用了动态自配置策略的BuddyWeb系统称为动态BuddyWeb系统(简称DBW).为了研究自适应跳步算法与路由策略的影响,动态BuddyWeb系统分为加入自适应跳步算法与路由策略的动态BuddyWeb系统(简称ADBW)和未加入的动态BuddyWeb系统(DBW).DBW采用传统P2P系统的广播策略,每个消息的T TL=7.图3横坐标为每个节点的本地缓存的容量,纵坐标为系统的命中率.实验结果表明采用动态配置策略的BuddyWeb系统(DBW)的命中率明显高于静态BuddyWeb系统(SBW).并且,随着本地缓存容量的增加,DBW越来越优于SBW.这充分说明了动态自配置策略对有效利用本地缓存的作用.图3 加入动态自配置策略前后系统的命中率另外,由图3可知,在较为合理的缓存容量上(例如100MB),动态自配置的BuddyWeb系统能获得满意的命中率,这说明有基于兴趣相似的动态自配置策略的BuddyWeb系统能有效利用网络中每个节点的本地缓存.所以随着每个本地节点本地缓存的增加,命中率得到了极大的提高.注意到水平坐标的刻度是对数级的.这也说明即使每个节点的本地缓存容量很小,大量节点的协作能够取得较高较好的命中率.图4展示了在不同浏览兴趣漂移系数下,Buddy2 Web的命中率(节点缓存容量为100MB).5712期凌 波等:一种基于Peer2to2Peer技术的Web缓存共享系统研究图4 不同浏览兴趣漂移系数下的命中率 由图4可见,无动态自配置策略的BuddyWeb系统几乎不受浏览漂移系数变化的影响,而动态自配置系统则随着浏览漂移系数增加,系统的命中率呈下降趋势,并且浏览漂移系数超过0.6时,动态自配置策略下的BuddyWeb 系统的命中率开始低于不采用自配置策略的系统.接下来评价自适应跳步算法与路由策略.加入自适应跳步算法与路由算法后,BuddyWeb 可以依据预设定的概念空间参数s 自适应地决定跳步的数目.实验中,s =0.7.图5 加入自适应跳步算法与路由策略前后DBW 系统的命中率由图5可见在较小的节点本地缓存容量下,ADBW 系统的命中率较低于DBW 系统.当节点本地缓存达到或超过10MB 时,ADBW 系统的命中率开始接近甚至优于DBW 系统.该结果说明了自适应跳步算法与路由策略在本地缓存达到一定的容量时,不会降低系统命中率,但有效地下降了整个网络的通信流量负荷(见4.2.2节).现在研究概念空间参数s 对于系统命中率的影响,实验结果如图6所示.由图6可知,随着概念空间参数s 的增加,系统的命中率得到了显著的提高,但s 超过017时,它对系统命中率的提高作用开始减缓.但随着s 的增大,网络的通信流量负荷也会相应地增加.4.2.2节将图6 概念空间参数s 在ADBW 系统中对于命中率的影响会进一步研究概念空间参数s 对网络流量负荷的影响.并且,由上述实验结果可知,BuddyWeb 系统的缓存命中率已经和集中式的proxy 缓存系统相当.4.2.2 网络通信流量负荷网络通信流量负荷定义为单位时间内Buddy 2Web 网络中传输字节数量的总和.表2列出了估算通信流量参数.表2 通信流量相关信息字节数的估计值请求头(Request headers )信息字节数350字节(估计值)响应头(Response headers )信息字节数150字节(估计值)传输的对象字节数在实验对象全集中相应对象的大小接下来研究自适应跳步算法与路由策略对减轻BuddyWeb 网络通信流量负荷的作用以及参数s 对网络通信流量负荷的影响.图7给出了在不同的请求间隔参数t 下,ADBW 与DBW 系统在单位时间内的通信流量.实验随机地选取了10个单位采样时间段,每个采样时间段设为1min.实验中节点本地缓存容量设为100MB ,DBW 的T TL =7,ADBW 系统的概念空间参数s 设为017.图7 不同请求间隔参数下,BuddyWeb 网络通信流量负荷由图7可知,采用自适应跳步算法和路由策略的BuddyWeb 系统的网络通信流量负荷得到了极大的改善,而传统的P2P 系统的广播式路由机制导671计 算 机 学 报2005年。
ccnp学习资料大全教程文件

Vty
二、 IOS 的基本配置 具体的基本配置: 基本路由器的检验命令: show version show processes show protocols show mem show ip route show startup‐config show running‐config show flash show interfaces
ARP(Address Resolution Protocol):地址解析协议,是一种将 IP 地址转化成物理地址的 协议。
ARP 原理:某机器 A 要向主机 B 发送报文,会查询本地的 ARP 缓存表,找到 B 的 IP 地址对应的 MAC 地址后,就会进行数据封装和传输。如果未找到,则广播 A 一个 ARP 请求报文(携带主机 A 的 IP 地址 Ia——物理地址 Pa),请求 IP 地址为 Ib 的主机 B 回答 物理地址 Pb。网上所有主机包括 B 都收到 ARP 请求,但只有主机 B 识别自己的 IP 地址, 于是向 A 主机发回一个 ARP 响应报文。其中就包含有 B 的 MAC 地址,A 接收到 B 的应 答后,就会更新本地的 ARP 缓存。接着使用这个 MAC 地址发送数据(由网卡附加 MAC 地址)。因此,本地高速缓存的这个 ARP 表是本地网络流通的基础,而且这个缓存是动 态的。
保留:127.0.0.1 0.0.0.0 私有地址:10.0.0.0/8 172.16.0.0/12 192.168.0.0/16 可用地址:能够在设备上和主机上配置的地址 不可用地址:主机位全 0 的表示网络本身;主机位全 1 表示该网络内的所有主机 网关地址:需要提取一个地址用来作网关,实现不同网段的主机通信
CCNP-BSCI课堂笔记

NP BSCI 课程 (3)1.1.EIGRP 增强型内部网关路由协议 (3)1.1.1.EIGRP的特性: (3)1.1.2.EIGRP的关键技术 (3)1.1.3.EIGRP的术语 (3)1.1.4.EIGRP的包的类型 (3)1.1.5.EIGRP metric值的计算 (4)1.1.6.EIGRP的配置 (4)1.1.7.路由汇总 (6)1.1.8.非等价负载均衡 (6)1.1.9.基于MD5的认证加密 (7)1.2.OSPF 开放式最短路径优先协议 (8)1.2.1.工作的过程 (8)1.2.2.OSPF的区域划分 (8)1.2.3.关于OSPF的邻居关系与邻接关系 (9)1.2.4.OSPF包的类型 (9)1.2.5.DR和BDR的选举 (9)1.2.6.OSPF的实验配置 (10)1.2.7.Router-id 的选举 (11)1.2.8.OSPF网络类型 (11)1.2.9.Virtual-Link 虚链路 (12)1.2.10.LSA(链路状态通知) 的类型 (14)1.2.11.路由的类型 (16)1.2.12.修改OSPF接口COST值和路由器的带宽值 (16)1.2.13.OSPF的特殊区域 (17)1.2.14.OSPF的邻居认证 (19)1.2.15.OSPF的路由汇总 (20)1.3.IS-IS(中间系统) 路由协议 (21)1.3.1.基本概念 (21)1.3.2.相关术语 (21)1.3.3.相关特性 (21)1.3.4.Level-1 和Level-2 以及Level-1-2 (21)1.3.5.NSAP地址 (21)1.3.6.IS-IS的邻居建立条件 (22)1.3.7.纯IS-IS的实验配置 (22)1.3.8.集成IS-IS的实验配置 (24)1.4.BGP 边界网关协议 (26)1.4.1.何时使用BGP (26)1.4.2.满足以下条件之一时,不要使用BGP (26)1.4.3.BGP的特性 (27)1.4.4.BGP的数据库 (27)1.4.5.BGP的消息类型 (27)1.4.6.关于IBGP与EBGP之间的关系 (27)1.4.7.基本BGP邻居建立的实验 (29)1.4.8.高级的BGP(属性)实验 (30)1.4.9.BGP的路径属性 (33)1.4.10.BGP路由选择决策过程 (33)1.4.11.使用Route-map操纵BGP路径实验(Local_prefence As-path) (33)1.5.过滤路由的更新 (36)1.6.路由重分发(Redistribution) (37)1.6.1.将RIPv2路由重分发进OSPF 中 (37)1.6.2.将OSPF路由重分发进RIPv2中 (38)1.6.3.将EIGRP 100 重分发进OSPF 中 (38)1.6.4.将OSPF重分发进EIGRP 100中 (39)1.6.5.将RIP v2重分发进EIGRP 100 中 (39)1.6.6.将EIGRP 100 重分发进RIPv2中 (39)1.6.7.将EIGRP 100 重分发进EIGRP 10 (40)1.6.8.将EIGRP 100重分发进集成ISIS中 (40)1.6.9.将ISIS 重分发进EIGRP 100 (41)1.6.10.将ISIS重发分进OSPF中 (41)1.6.11.将OSPF 重分发进ISIS中 (42)1.7.各种路由协议的管理距离值 (42)1.8.(MultiCast)组播 (43)1.8.1.单播数据流 (43)1.8.2.广播数据流 (43)1.8.3.组播数据流 (44)1.8.4.组播的缺点: (44)1.8.5.IP的组播地址(3层地址) (45)1.8.6.数据链路层的2层组播地址 (45)1.8.7.IGMP互联网组管理协议 (46)1.8.8.第2层组播帧交换 (47)1.8.9.组播路由协议 (47)1.8.10.带有RP的稀疏密集的实验配置 (48)1.9.IPV6 (48)1.9.1.IPV6的特性 (48)1.9.2.地址空间 (49)1.9.3.IPv6的地址格式 (49)1.9.4.IPv6地址类型 (49)1.9.5.组播地址Multicast (50)1.9.6.任意播地址Anycast (51)1.9.7.EUI(扩展全局标识)地址格式 (51)1.9.8.IPv6与OSPFv3的实验配置 (52)NP BSCI 课程1.1.EIGRP 增强型内部网关路由协议1.1.1.EIGRP的特性:属CISCO私有协议高级的距离矢量路由协议实现网络的快速收敛支持变长子网掩码和不连续的子网路由更新时发送变化部分的更新内容路由更新采用触发更新机制,只当网络发生变化的时候,才会发送路由更新支持多个网络层的协议(IP、IPX、Novell协议)使用组播和单播技术代替了广播(组播地址:224.0.0.10)在网络的任意点可方便的创建手动路由汇总实现100%无环路(基于DUAL(弥散更新算法))支持等价的和非等价的负载均衡1.1.2.EIGRP的关键技术邻居的发现和恢复使用Hello包来建立,高速链路5秒发送Hello包,低速链路是60秒发送Hello包是一个RTP(可靠的传输协议)协议,能够保证所有的更新数据包能被邻居路由器接受到使用DUAL算法机制,选择一个低代价、无环路的路径到达每一个目标段1.1.3.EIGRP的术语1、Successor 后继路由\\ 主路由2、Feasible Successor (FS)可行后继路由\\备用路由3、Feasible Distance (FD)可行距离\\指从源到达目标段的路径距离值4、Advertised Distance (AD)通告距离\\是指通告路由器到达目标段的距离值1.1.4.EIGRP的包的类型HelloUpdate 更新包Query 查询包Reply 应答包ACK 确认包Router# debug eigrp packet //关闭debug使用undebug all1.1.5.EIGRP metric值的计算K1= 带宽1 BWK2= 负载0 txload(发送) 1/255 rxload(接收) 1/255 255代表固定参考值 K3= 延迟1 DLY 100M=100 10M=1000 1.544M=20000K4= 可靠性0 Reliability 255/255 (最可靠)K5= 最大传输单元0 MTU 1500注:1代表使用, 0代表未被使用Router# show interface E0/0计算公式Metric= [ 107/最小带宽(k) + (延迟)/10]×256说明:最小带宽:指从源到达目的网段链路中的最小带宽延迟:指每段链路的延迟总和1.1.6.EIGRP的配置R1(config)# router eigrp 100R1(config-router)# no auto-summaryR1(config-router)# network 12.0.0.0 0.0.0.3R1(config-router)# network 13.0.0.0 0.0.0.3R1(config-router)# endR2(config)# router eigrp 100R2(config-router)# no auto-summaryR2(config-router)# network 12.0.0.0 0.0.0.3R2(config-router)# network 23.0.0.0 0.0.0.3R2(config-router)# endR3(config)# router eigrp 100R3(config-router)# no auto-summaryR3(config-router)# network 13.0.0.0 0.0.0.3R3(config-router)# network 23.0.0.0 0.0.0.3R3(config-router)# endR1#show ip routeCodes: C - connected, S - static, R - RIP, M - mobile, B - BGPD - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter areaN1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2E1 - OSPF external type 1, E2 - OSPF external type 2i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2ia - IS-IS inter area, * - candidate default, U - per-user static routeo - ODR, P - periodic downloaded static routeGateway of last resort is not set23.0.0.0/30 is subnetted, 1 subnetsD 23.0.0.0 [90/2681856] via 13.0.0.2, 00:00:12, Serial0/1[90/2681856] via 12.0.0.2, 00:00:12, Serial0/012.0.0.0/30 is subnetted, 1 subnetsC 12.0.0.0 is directly connected, Serial0/013.0.0.0/30 is subnetted, 1 subnetsC 13.0.0.0 is directly connected, Serial0/1说明:[90/2681856] [协议管理距离/Metric度量值]R1#show interfaces s0/0Serial0/0 is up, line protocol is upHardware is M4TInternet address is 12.0.0.1/30MTU 1500 bytes, BW 1544 Kbit, DLY 20000 usec,reliability 255/255, txload 1/255, rxload 1/255Metric= [ 107/最小带宽(k) + (延迟+延迟)/10]×256Metric= [ 107/1544 + 4000] ×256Metric= [ 6476 + 4000] ×256Metric= 2681856说明:当107/1544 时候,会出现小数点,立即取整数位,舍弃小数点。
原理与技术专题培训

–实时消息:Yahoo!、AOL和Jabber已在多种计算机 顾客之间广泛使用
–同行共享:Buzzpad,分布式Power Point异地同步 互动评审、编辑同一信息
–P2P游戏:NetZ 1.0 ,Scour Exchange,Cybiko游戏 运营在全部Peer旳计算机上,更新也分布在全部 Peer端,不需要中心服务器
–对等端向组给出某些资源,并从组取得某些资源 –Napster:把音乐供给组内其别人,并从其别人取得音乐 –捐赠计算资源用于外星生命旳搜索或战胜癌症,取得帮
助其别人旳满足
另一种应用模式选择:
–相对集中式、和C/S模式 –纯P2P:没有服务器旳概念,全部组员都是对等端
并不是全新旳概念
–早期分布式系统:如UUCP和互换网络 –电话通信 –计算机网络中旳通信、网络游戏中旳诸玩家 –自助餐,志愿组活动…
2024/10/12
•Napster •Gnutella •Freenet •Publius •Free Haven
•Magi •Groove •Jabber
•JXTA •.NET •.NETMyServices
20
P2P 多维视图
通信与协同-带宽
Centerspan Jabber Cybiko AiMster
Cn2
Cnn-1 Cn3
Cn2 C: Reed ’law:规模是O(2n)
➢Sarnoff ’law:效 益规模是O(n):网络 是广播媒介,任1发送 者(设备)和多种(n1)接受者(设备)。
➢Reed ’law:效益规 模是O(2n):网络是群 组媒介。网络可建立 Cn2+Cn3+…Cnn-1+Cnn = 2n-n-1 个小组
外文参考文献译文及原文下一代信息共享网络结构

下一代信息共享网络结构涂古芳张灿张毅刘德荣摘要在这篇文章里,我们介绍下一代信息共享网络结构,这通过建立访问网络协议栈和多协议标签交换技术(MPLS)的IP服务质量(QoS)模型去实现异机种网络交互操作,可能被不同操作者或在各种领域中运行的。
这个网络结构是纯IP基准的。
通过在现存网的顶部增加建立一个覆盖网络层,它合并了各种类型网络,有线的或无线电的,固定的或移动的,支柱,本地区的或个人的。
它被称为知识管理层。
知识管理层是由存在于IP边缘路由器或媒体网关型网点顶端的新硬件和软件组成的端对端网络设备。
这个结构提供纯IP基准信息共享。
通过以最优化方法来管理和控制网络状态、行为和资源,它增强了服务质量支持、安全性和灵活性,以及网络构成。
在这里,我们给出各种网络结构的概述,趋向纯IP基准灵活信息共享网络的网络结构演化,然后介绍下一代网络结构,使下一代网络概念成为可能的主要特征和访问网络协议栈。
将详细介绍下一代网络控制的可扩展译码和服务质量。
关键词:下一代,共享,网络,MPLS,QoS。
目录1 引言 (1)2 NGN结构的演化 (3)因特网结构 (3)趋向UMTS全IP结构的GSM/GPRS网络演化 (3)WLAN/3G整合结构 (4)3信息共享NGN结构 (5)4 访问网络协议栈结构和下一代网络MPLS模式服务质量 (7)访问下一代网络网络协议栈结构 (7)下一代网络中MPLS模式上的IP服务质量 (7)5 可扩展代码和NGN服务质量控制 (9)结论 (10)致谢 (10)附录原文 (12)1 引言信息共享的下一代网络(简称为NGN)是以纯IP基准为基础的移动网络,那是合并了固定的、移动的、有线的、无线电网络以及增加了建立在现存网顶端的覆盖网络层。
覆盖网络层是由在一些IP边缘路由器或媒体网关型网点顶端的新软件和新硬件调度的端对端网络。
它能实现信息共享和合作性工作,以及任何时间、任何地点、任何人的通信请求。
传统电信网总是利用由基于线路转接的存储程序控制(SPC,Stored Program Control)交换机组成的电话网络,但是下一代网络电信网是以封装交换为基础。
P2P环境下文件共享的信任建立博弈模型及稳态分析

机制通过反复博弈和演化稳定策略实现动态
策略调整及其演化稳定性 。 P2P 用户节点信任的建立是网络 节点之间交互合作的重要内容, 演化博弈与稳定策略为研究 P2P 网络的信任机制提供了新思路 。 本文试图从演化博弈论的角度来解决 P2P 环境下文件共
i =1 n
根据以上假设, 信任建立的演化博弈模型可描述为一个四 H, S, U) 。其具体含义如下: 元组 DTG = ( user, ( a) user = ( SP, SR) 为博弈的局中人, 每个 P i 有两个属性, SP SR 即 为文件服务提供上传者, 为文件服务请求下载者 。 ( b) S 为博弈的策略组合。ψi ( t) 为节点 SR 选择信任对方 节点 SP 的次数, i ( t ) 为节点 SP 选择合作的次数。 在 t 阶段 的 P i 效用值取决于此阶段所有 P - i 的策略组合 S( t) = ( ψi ( t) , i ( t) ) , 在历史信息的基础上选择行为策略, 根据决策函数确 定策略。 ( c) H 为历史信息。 节点 i 所获取的历史信息 h i ( t ) 是( S ( 1) , S( 2 ) , …, S( t) ) 的函数, 那么
Abstract: In the P2P filesharing environment the securing cooperation is based on the trust between the strangers node. Current establishment of trust relationship depends on the credible third party. But there is no central server and the trusted thirdparty guarantees in P2P networks,so it’ s very difficult to establish the trust relationship of the nodes. This paper proposed a game model of trust establishment based on the evolutionary game theory,in order to provide trust assurance for the strange nodes in the P2P filesharing environment. Used the dynamic replication to analyze the trust establishment game model and also the steadystate of the P2P filesharing systems. In the last,gave a preliminary simulation results. Key words: P2P filesharing; trust establishing; replicator dynamic mechanism; stable evolutionary strategy