数据结构大作业(建立英文字典)
数据结构与算法(Python版)《数据结构》参考答案(A卷)

数据结构与算法(Python版)《数据结构》参考答案(A卷)数据结构与算法是计算机科学中非常重要的基础知识,它们在软件开辟中起着至关重要的作用。
在Python编程语言中,数据结构与算法同样扮演着重要的角色。
本文将介绍数据结构与算法在Python中的应用,匡助读者更好地理解和运用这些知识。
一、数据结构1.1 列表(List)Python中最常用的数据结构之一是列表,它可以存储任意类型的数据,并且支持增删改查等操作。
1.2 字典(Dictionary)字典是另一个常用的数据结构,它以键值对的形式存储数据,可以快速查找和修改数据。
1.3 集合(Set)集合是一种无序且不重复的数据结构,可以进行交集、并集、差集等操作,非常适合处理数学运算。
二、算法2.1 排序算法Python中有多种排序算法可供选择,如冒泡排序、快速排序、归并排序等,每种算法都有其适合的场景和特点。
2.2 查找算法查找算法用于在数据集中查找指定的元素,常见的查找算法有线性查找、二分查找等,可以提高查找效率。
2.3 图算法图算法是一类特殊的算法,用于解决图结构中的问题,如最短路径、最小生成树等,在网络分析和路由规划中有广泛应用。
三、应用实例3.1 数据处理数据结构与算法在数据处理中有着重要的应用,可以匡助我们高效地处理大量数据,如数据清洗、分析和建模等。
3.2 网络编程在网络编程中,我们时常需要使用数据结构与算法来处理网络数据包、路由信息等,确保网络通信的稳定和高效。
3.3 人工智能在人工智能领域,数据结构与算法也扮演着重要的角色,如机器学习算法中的数据预处理、特征选择等。
四、优化技巧4.1 空间复杂度优化在编写代码时,我们应该尽量减少空间复杂度,避免不必要的内存占用,提高程序的运行效率。
4.2 时间复杂度优化算法的时间复杂度直接影响程序的运行速度,我们可以通过选择合适的算法和数据结构来优化时间复杂度。
4.3 算法优化技巧除了选择合适的数据结构和算法外,我们还可以通过优化代码逻辑、减少循环嵌套等方式来提高程序的性能。
mysql 中英文对照字典表设计

mysql 中英文对照字典表设计一、**引言**在MySQL数据库设计中,字典表是一种常用的数据结构,主要用于存储特定的、非结构化的信息。
中英文对照字典表是一种特殊类型的字典表,它将中文词汇与对应的英文词汇进行对照存储。
这种设计在需要中英文互译的应用场景中非常有用。
二、**设计考虑**1. **表结构**:中英文对照字典表通常包含三个主要字段:`word_id`(词目字段),`english_word`(英文词字段)和`chinese_word`(中文词字段)。
这些字段的类型应选择适当的数据类型,以确保存储和查询的效率。
2. **数据导入**:可以考虑使用CSV文件或其他数据导入工具将现有的中英文词汇对照数据导入到字典表中。
3. **查询功能**:字典表应提供基本的查询功能,以便用户可以搜索特定的中文词汇或英文词汇,得到对应的词汇。
三、**表结构设计示例**表名:`dictionary`1. `word_id` (INT, 主键)2. `english_word` (VARCHAR, 最大长度根据实际需求设定)3. `chinese_word` (VARCHAR, 最大长度根据实际需求设定)4. **其他可能字段**:如创建时间、更新时间、词频等,视具体需求而定。
四、**存储与查询方法**MySQL提供了丰富的查询语言(如SELECT, WHERE, JOIN等)以及索引技术,可以有效地查询和检索字典表中的数据。
同时,考虑到大数据量的存储和查询,可以使用分区表、分片集群等技术提高查询性能。
五、**维护与更新**字典表的设计应考虑到其维护和更新的需求。
通常,可以通过触发器或程序定期自动更新字典表,以保证数据的准确性。
同时,用户反馈或需求变化时,也应提供相应的更新机制。
六、**总结**中英文对照字典表在MySQL数据库设计中是一种非常实用的数据结构。
通过合理的设计和存储方式,可以实现高效的数据存储和查询。
数据结构课程设计大作业

课程设计(数据结构)一、题目的目的和要求1.设计目的巩固和加深对数据结构的理解,通过上机实验、调试程序,加深对课本知识的理解,最终使学生能够熟练应用数据结构的知识写程序。
(1)通过本课程的学习,能熟练掌握几种基本数据结构的基本操作。
(2)能针对给定题目,选择相应的数据结构,分析并设计算法,进而给出问题的正确求解过程并编写代码实现。
2.设计题目要求设计内容:本系统应完成以下几方面的功能:学生信息的建立:create();学生信息的插入:insert();学生信息的查询:search();学生信息的修改:change();学生信息的删除:delete();学生信息的输出:print()。
设计要求:(1)每条记录至少包含:姓名(name )、(xuehao),(kemu),(chengji)属性。
(2)作为一个完整的系统,应具有友好的界面和较强的容错能力(3)程序能正常运行,并写出课程设计报告二、设计进度及完成情况三、主要参考文献及资料[1] 叶核亚编著. 数据结构(Java版)(第3版). 北京:电子工业出版社,2011[2] 施平安等译. JAVA程序设计教程(第5版). 北京:清华大学出版社,2007[3] Java相关资料四、成绩评定设计成绩:(教师填写)指导老师:(签字)目录第一章系统概述 (1)第二章系统分析 (1)第三章系统设计 (1)第四章系统实现 (10)第五章系统运行与测试 (11)第六章总结与心得 .............................................. 错误!未定义书签。
参考文献 ................................................................ 错误!未定义书签。
第一章系统概述在这次的课程设计中我们选择的题目是:学生信息系统,能够添加、删除、查询联系人等。
由于自己的知识有限,程序可能不是太完美,但是我会认真对待,尽自己最大女里去完成此次任务!!!第二章系统分析学生信息系统主要用于帮助用户保存学生信息,方便用户查询联系人的相关信息。
python大作业80个

python大作业80个Python大作业80个:创意与实现Python是一种功能强大的编程语言,被广泛应用于各个领域。
在学习Python的过程中,大作业是一个很好的机会来展示你的技能和创意。
下面列举了80个Python大作业的主题,可以供你选择并创造属于自己的项目。
1. 制作一个简单的计算器,支持基本的数学运算。
2. 基于Python的文字冒险游戏,玩家通过选择不同的选项来推动剧情发展。
3. 创建一个简单的日历程序,可以查看某个日期的特定信息。
4. 制作一个密码生成器,可以生成随机的强密码。
5. 用Python实现一个简单的天气预报程序,根据用户输入的位置显示当地的天气情况。
6. 创建一个自动化批量重命名文件的工具,可以按照指定的命名规则对文件进行批量重命名。
7. 开发一个简单的网页爬虫,可以从指定的网页中提取信息。
8. 实现一个迷宫游戏,玩家通过键盘输入控制角色在迷宫中移动。
9. 创建一个简单的电子邮箱客户端,可以发送和接收电子邮件。
10. 制作一个简单的音乐播放器,可以播放本地存储的音乐文件。
11. 开发一个简单的人脸识别程序,可以识别照片中的人脸并进行标记。
12. 创建一个简单的文件压缩工具,可以将文件或文件夹压缩成zip 格式。
13. 实现一个简单的聊天机器人,可以回答用户提出的问题。
14. 制作一个简单的文字编辑器,可以打开、编辑和保存文本文件。
15. 创建一个简单的画图程序,可以实现基本的画图功能。
16. 开发一个简单的音频处理工具,可以对音频进行剪切、合并或转码。
17. 实现一个简单的网页游戏,玩家通过鼠标点击进行游戏操作。
18. 制作一个简单的日记本应用,可以记录和管理用户的日记。
19. 创建一个简单的文件搜索工具,可以根据关键词快速搜索文件。
20. 开发一个简单的计算器应用,可以进行科学计算和统计分析。
21. 实现一个简单的图像处理工具,可以对图像进行滤镜、调色和裁剪等操作。
数据结构样卷3(英文)

重庆大学 《数据结构》 课程样卷 3开课学院: 计算机学院 课程号: 18001035 考试日期:考试方式:考试时间: 120 分钟一、 Single choice1. Merge two ordered list, both of them contain n elements, the least timesof comparison is ( ).A. nB. 2n-1C. 2nD. n-12. Sequential stored linear list with the length of 1000, if we insertan element into any position, the possibility is equal, when we insert a new element, the average number of removing elements is ( ). A. 1000 B. 1001 C. 500 D. 4993. Assume that the initial status of stack S and queue Q are both NULL,push elements e1,e2,e3,e4,e5,e6 into the stack S one by one, an element pops from stack, then enter into queue Q. If the sequence which the six elements in the dequeue is e2,e4,e6,e5,e3,e1, the capacity of stack S is at least ( ).A. 6B. 4C. 3D. 24. Two-dimensional array A [10 .. 20,5 .. 10] stores in line sequence,each element occupies 4 storage location, and the memory address of A[10,5] is 1000, then the address of A[20,9] is ( ). A. 1212 B. 1256 C. 1368 D. 13645. A tree with degree 3, it has 2 nodes with the degree 3, one node withthe degree 2, and 2 nodes with the degree 1, so the number of nodes with degree 0 is ( ).A. 4.B. 5.C. 6.D. 76. The inorder sequence of a binary tree is ABCDEFG, and its postordersequence is BDCAFGE, so its pre-order sequence is ( ) A. EGFACDB B. EACBDGF C. EAGCFBD D. EGAFCDB7. A Huffman tree with n leaf nodes, its total number of nodes is ( )A. n-1B. n+1C. 2n-1D. 2n+18. In an adjacency list of undirected graph with n vertexes and e edges,the number of edge node is ( ).A. nB. neC. eD. 2e9. The degree (sum of in-degree and out-degree) of a directed graph isk1, and the number of out-degree is k2. Therefore, in its adjacency list, the number of edge nodes in this singly linked list is ( ). A. k1 B. k2 C. k1-k2 D. k1+k210. If the graph has n vertexes is a circle, so it has ( ) spanning tree.A. nB. 2nC. n-1D.n+111. When look up a sequential list with the length 3, the possibility thatwe find the first element is 1/2, and the possibility that we find the second element is 1/3, the possibility that we find the third element is 1/6, so the average searching length to search any element (find it successfully and the sentry is at the end of the list) is ( ) A. 5/3 B.2 C. 7/3 D.4/312. There is an ordered list {3,5,7,8,11,15,17,22,23,27,29,33}, by binarysearch to search 27, so the number of comparison is ( ) A. 2 B. 3 C. 4 D. 513. Sort the following keyword sequences by using Quicksort, and theslowest one is ( )A. 19,23,3,15,7,21,28B. 23,21,28,15,19,3,7C. 19,7,15,28,23,21,3D. 3,7,15,19,21,23,28 14. Heapsort needs additional storage complexity is ( )A. O(n)B. O(nlog 2n)C. O(n 2) D. O(1)15. If we sort an array within the time complexity of O(nlog2n), needingsort it stably, the way that we can choose is ( )A. Merge sortB. Direct insertion sortC. Heap sortD. Quicksort二、 Fill the blanks1.Assume that the structure of the nodes in doubly circular linked list is (data,llink,rlink), without a head node in the list, if we want命题人:组题人:审题人:命题时间: 教务处制学院 专业、班 年级 学号 姓名公平竞争、诚实守信、严肃考纪、拒绝作弊封线密to insert the node which pointer s points after the node pointer ppoints, then execute as the following statements:; ; ___ _; ;2.Both stack and queue are _______linear structure.3.The four leaf nodes with the weight 9,2,5,7 form a Huffman tree, itsweighted path length is ________.4.In order to ensure that an undirected graph with six vertexes isconnected, need at least ______ edges.5.An n-vertex directed graph, if the sum of all vertices’ out-degreeis s, then the sum of all vertices’ degree is__ ___.6.The Depth-First traversal of a graph is similar to the binarytree_______ traversal; the Breadth-first graph traversal algorithmis similar to the binary tree ______traversal.7. A connected graph with n vertexes and e edges has ____ edges of itsspanning tree.8.The time complexity of binary searching is _____; if there are 100elements, the maximum number of comparisons by binary searching is____.9.Sort n elements by merge sort, the requiring auxiliary space is _____.10.Sort a linear list with 8 elements by Quicksort, at the best, thecomparison time is ______.三、 Application1. Begin from the vertex A, seek the minimum spanning tree by using Primalgorithms2. The following is AOE network:(1) How much time does it take to complete the whole project?(2) Find out all of the critical path.(9 points)3. Assume that a set of keywords is {1,12,5,8,3,10,7,13,97},tryto complete the following questions:(9 points)(1) Choose the keywords in sequence to build a binary sort tree Bt;(2) Draw the structure of the tree after deleting node “12”from thebinary tree Bt.4. The keyword sequence is {503,87,512,61,908,170,897,275,653,462}, usingradix sorting method to sort them in ascending order, try to write every trip results of sort. (9 points)四、 Algorithm1.The following algorithm execute on a singly linked list without headnode, try to analyze and write its function.(5 points)void function(LinkNode *head){LinkNode *p,*q,*r;p=head;q=p->next;while(q!=NULL){r=q->next;q->next=p;p=q;q=r;}head->next=NULL;head=p;}2.Design an algorithm to divide a singly linked list ‘A’ with a headpointer ‘a’ into two singly linked list ‘A’ and ‘B’, whose head pointers are ‘a’and ‘b’, respectively. On the condition that linked list A has all elements of odd serial number in the previous linked listA and linked listB has all elements of even serial number in the previouslinked list A, in addition, the relative order of the original linked list are maintained.(7 points)3. The type of binary tree is defined as follows:typedef struct BiTNode {char data;struct BiTNode *lchild,*rchild;}BiTNode, *BiTree;Please design an algorithm to count how many leaf nodes the binary tree have. (8 points)。
数据结构与算法常用英语词汇

数据结构与算法常用英语词汇.txt 女人谨记:一定要吃好玩好睡好喝好。
一旦累死了,就别的女人花咱的钱,住咱的房,睡咱的老公,泡咱的男朋友,还打咱的娃。
第一部份计算机算法常用术语中英对照Data Structures 基本数据结构Dictionaries 字典Priority Queues 堆Graph Data Structures 图Set Data Structures 集合Kd-Trees 线段树Numerical Problems 数值问题Solving Linear Equations 线性方程组Bandwidth Reduction 带宽压缩Matrix Multiplication 矩阵乘法Determinants and Permanents 行列式Constrained and Unconstrained Optimization 最值问题Linear Programming 线性规划Random Number Generation 随机数生成Factoring and Primality Testing 因子分解/质数判定Arbitrary Precision Arithmetic 高精度计算Knapsack Problem 背包问题Discrete Fourier Transform 离散 Fourier 变换Combinatorial Problems 组合问题Sorting 排序Searching 查找Median and Selection 中位数Generating Permutations 罗列生成Generating Subsets 子集生成Generating Partitions 划分生成Generating Graphs 图的生成Calendrical Calculations 日期Job Scheduling 工程安排Satisfiability 可满足性Graph Problems -- polynomial 图论-多项式算法Connected Components 连通分支Topological Sorting 拓扑排序Minimum Spanning Tree 最小生成树Shortest Path 最短路径Transitive Closure and Reduction 传递闭包Matching 匹配Eulerian Cycle / Chinese Postman Euler 回路/中国邮路Edge and Vertex Connectivity 割边/割点Network Flow 网络流Drawing Graphs Nicely 图的描绘Drawing Trees 树的描绘Planarity Detection and Embedding 平面性检测和嵌入Graph Problems -- hard 图论-NP 问题Clique 最大团Independent Set 独立集Vertex Cover 点覆盖Traveling Salesman Problem 旅行商问题Hamiltonian Cycle Hamilton 回路Graph Partition 图的划分Vertex Coloring 点染色Edge Coloring 边染色Graph Isomorphism 同构Steiner Tree Steiner 树Feedback Edge/Vertex Set 最大无环子图Computational Geometry 计算几何Convex Hull 凸包Triangulation 三角剖分Voronoi Diagrams Voronoi 图Nearest Neighbor Search 最近点对查询Range Search 范围查询Point Location 位置查询Intersection Detection 碰撞测试Bin Packing 装箱问题Medial-Axis Transformation 中轴变换Polygon Partitioning 多边形分割Simplifying Polygons 多边形化简Shape Similarity 相似多边形Motion Planning 运动规划Maintaining Line Arrangements 平面分割Minkowski Sum Minkowski 和Set and String Problems 集合与串的问题Set Cover 集合覆盖Set Packing 集合配置String Matching 模式匹配Approximate String Matching 含糊匹配Text Compression 压缩Cryptography 密码Finite State Machine Minimization 有穷自动机简化Longest Common Substring 最长公共子串Shortest Common Superstring 最短公共父串DP——Dynamic Programming——动态规划recursion ——递归第二部份数据结构英语词汇数据抽象 data abstraction数据元素 data element数据对象 data object数据项 data item数据类型 data type抽象数据类型 abstract data type逻辑结构 logical structure物理结构 phyical structure线性结构 linear structure非线性结构 nonlinear structure基本数据类型 atomic data type固定聚合数据类型 fixed-aggregate data type可变聚合数据类型 variable-aggregate data type 线性表 linear list栈 stack队列 queue串 string数组 array树 tree图 grabh查找,线索 searching更新 updating排序(分类) sorting插入 insertion删除 deletion前趋 predecessor后继 successor直接前趋直接后继双端列表循环队列immediate predecessor immediate successor deque(double-ended queue) cirular queue指针 pointer先进先出表(队列) first-in first-out list 后进先出表(队列) last-in first-out list栈底栈定压入弹出队头bottom top push pop front队尾 rear上溢 overflow下溢 underflow数组 array矩阵 matrix多维数组 multi-dimentional array以行为主的顺序分配 row major order以列为主的顺序分配 column major order 三角矩阵 truangular matrix对称矩阵 symmetric matrix稀疏矩阵 sparse matrix转置矩阵 transposed matrix链表 linked list线性链表 linear linked list单链表 single linked list多重链表 multilinked list循环链表 circular linked list双向链表 doubly linked list十字链表 orthogonal list广义表 generalized list链 link指针域 pointer field链域 link field头结点 head 头指针 head 尾指针 tail 串 string node pointer pointer空白(空格)串blank string 空串(零串) null string子串 substring树 tree子树 subtree森林 forest根 root叶子结点深度层次双亲孩子leaf node depth level parents children兄弟 brother祖先 ancestor子孙 descentdant二叉树 binary tree平衡二叉树 banlanced binary tree 满二叉树 full binary tree彻底二叉树 complete binary tree遍历二叉树 traversing binary tree 二叉排序树 binary sort tree二叉查找树 binary search tree线索二叉树 threaded binary tree 哈夫曼树 Huffman tree有序数 ordered tree无序数 unordered tree判定树 decision tree双链树 doubly linked tree数字查找树 digital search tree树的遍历 traversal of tree先序遍历 preorder traversal中序遍历 inorder traversal后序遍历 postorder traversal图 graph子图 subgraph有向图无向图彻底图连通图digraph(directed graph) undigraph(undirected graph) complete graphconnected graph非连通图 unconnected graph强连通图 strongly connected graph 弱连通图 weakly connected graph 加权图 weighted graph有向无环图 directed acyclic graph 稀疏图 spares graph稠密图 dense graph重连通图 biconnected graph二部图 bipartite graph边 edge顶点 vertex弧 arc路径 path回路(环) cycle弧头弧尾源点终点汇点headtailsource destination sink权 weight连接点 articulation point 初始结点 initial node终端结点 terminal node相邻边 adjacent edge相邻顶点 adjacent vertex 关联边 incident edge入度 indegree出度 outdegree最短路径 shortest path有序对 ordered pair无序对 unordered pair简单路径简单回路连通分量邻接矩阵simple pathsimple cycle connected component adjacency matrix邻接表 adjacency list邻接多重表 adjacency multilist遍历图 traversing graph生成树 spanning tree最小(代价)生成树 minimum(cost)spanning tree生成森林 spanning forest拓扑排序 topological sort偏序 partical order拓扑有序 topological orderAOV 网 activity on vertex networkAOE 网 activity on edge network关键路径 critical path匹配 matching最大匹配 maximum matching增广路径 augmenting path增广路径图 augmenting path graph查找 searching线性查找(顺序查找) linear search (sequential search)二分查找 binary search分块查找 block search散列查找 hash search平均查找长度 average search length散列表 hash table散列函数 hash funticion直接定址法 immediately allocating method 数字分析法 digital analysis method平方取中法 mid-square method折叠法 folding method除法 division method随机数法 random number method排序 sort内部排序 internal sort外部排序 external sort插入排序 insertion sort随小增量排序 diminishing increment sort 选择排序 selection sort堆排序 heap sort快速排序归并排序基数排序外部排序quick sort merge sortradix sort external sort平衡归并排序 balance merging sort二路平衡归并排序 balance two-way merging sort 多步归并排序 ployphase merging sort置换选择排序 replacement selection sort文件 file主文件 master file顺叙文件 sequential file索引文件 indexed file索引顺叙文件 indexed sequential file索引非顺叙文件 indexed non-sequential file直接存取文件 direct access file多重链表文件 multilist file倒排文件 inverted file目录结构 directory structure树型索引 tree index。
Python数据结构——练习题及答案

Python数据结构——练习题及答案Python是一种强大的编程语言,具备丰富的数据结构和内置函数,用于处理和操作数据。
本文将提供一些有关Python数据结构的练习题及其答案,帮助读者进一步巩固和理解相关知识。
一、列表(List)相关练习题1. 创建一个空列表,并将元素1、2、3依次添加到列表中。
答案:```pythonmy_list = []my_list.append(1)my_list.append(2)my_list.append(3)```2. 将列表`[1, 2, 3, 4, 5]`按逆序输出。
答案:```pythonmy_list = [1, 2, 3, 4, 5]reversed_list = my_list[::-1]print(reversed_list)```3. 判断列表`[1, 2, 3, 4, 5]`中是否存在数字3。
答案:```pythonmy_list = [1, 2, 3, 4, 5]if 3 in my_list:print("数字3存在于列表中")else:print("数字3不存在于列表中")```二、字典(Dictionary)相关练习题1. 创建一个字典,包含以下键值对:`'name': 'John', 'age': 25, 'city': 'New York'`。
答案:```pythonmy_dict = {'name': 'John', 'age': 25, 'city': 'New York'}```2. 在字典`{'name': 'John', 'age': 25, 'city': 'New York'}`中添加键值对`'gender': 'Male'`。
创建字典的五种方法

创建字典的五种方法创建字典的五种方法字典是Python中非常重要的数据类型之一,它可以用于存储键值对,是一种无序的数据结构。
在Python中,有多种方法可以创建字典,下面将介绍五种常用的方法。
1. 直接赋值法直接赋值法是最简单也是最常用的创建字典的方法。
它通过将键值对写在花括号内,并以冒号分隔键和值来创建一个字典。
例如:```my_dict = {'apple': 1, 'banana': 2, 'orange': 3}print(my_dict)```输出结果为:```{'apple': 1, 'banana': 2, 'orange': 3}```2. dict()函数法dict()函数可以将其他数据类型转换为字典类型。
当传入一个包含键值对元组的列表时,dict()函数会自动将其转换为一个字典。
例如:```my_list = [('apple', 1), ('banana', 2), ('orange', 3)]my_dict = dict(my_list)print(my_dict)```输出结果为:```{'apple': 1, 'banana': 2, 'orange': 3}```3. fromkeys()方法法fromkeys()方法可以用于创建一个新字典,并设置所有键的默认值。
它接收两个参数:第一个参数是包含所有键的可迭代对象;第二个参数是所有键对应的默认值。
例如:```my_keys = ['apple', 'banana', 'orange']my_dict = dict.fromkeys(my_keys, 0)print(my_dict)```输出结果为:```{'apple': 0, 'banana': 0, 'orange': 0}```4. zip()函数法zip()函数可以将多个可迭代对象打包成元组序列。
python字典实训题目

python字典实训题目这里有一个关于Python字典(dictionary)的实训题目:实训题目:作为一个图书管理员,需要创建一个图书馆的书籍目录。
使用Python字典来管理这个图书目录,能够进行以下操作:1.添加书籍:将书名作为键,书籍信息(如作者、出版日期等)作为值添加到图书目录中。
2.检查书籍是否存在:输入书名,检查该书是否在图书目录中。
3.获取书籍信息:输入书名,获取对应书籍的信息(如作者、出版日期等)。
4.删除书籍:输入书名,从图书目录中删除对应的书籍信息。
示例:●创建一个空的图书目录library_catalog={}●添加书籍信息def add_book(title,author,published_date):library_catalog[title]={"Author":author,"Published Date":published_date}print(f"Added'{title}'to the library catalog.")●检查书籍是否存在def check_book(title):if title in library_catalog:print(f"'{title}'exists in the library catalog.")else:print(f"'{title}'does not exist in the library catalog.")●获取书籍信息def get_book_info(title):if title in library_catalog:info=library_catalog[title]print(f"Information for'{title}':")for key,value in info.items():print(f"{key}:{value}")else:print(f"'{title}'does not exist in the library catalog.")●删除书籍信息def remove_book(title):if title in library_catalog:del library_catalog[title]print(f"Removed'{title}'from the library catalog.")else:print(f"'{title}'does not exist in the library catalog.")●示例操作add_book("Python Crash Course","Eric Matthes","November 2019")check_book("Python Crash Course")get_book_info("Python Crash Course")remove_book("Python Crash Course")这个实训题目可以帮助练习使用字典来创建一个简单的图书目录,并进行书籍的添加、检查、获取信息和删除操作。
python制作英文学习字典案列

python制作英⽂学习字典案列def rdic():fr = open('dic.txt','r')for line in fr:line = line.replace("\n",'')v = line.split(':')dic[v[0]] = v[1]keys.append(v[0])fr.close()def centre():n = input("请输⼊进⼊相应模块(添加、查询、退出):")if n =="添加":key = input("请输⼊英⽂单词:")if key not in keys:value = input("请输⼊中⽂单词:")dic[key] = valuekeys.append(key)print("单词已经添加成功")else:print("该单词已经添加⾄字典库")elif n =="查询":key = input("请输⼊英⽂单词:")if key in keys:print("中⽂意思为:"+dic[key])else:print("字典中未找到这个单词")elif n =="退出":return 1else:print("输⼊有误")return 0def wdic():#写⼊⽂件代码通过keys的顺序写⼊with open('dic.txt','w') as fw:for k in keys:fw.write(k+':'+dic[k]+'\n')if __name__=="__main__":keys = [] #⽤来存储读取的顺序dic = {}while True:rdic()n = centre()wdic()if n == 0:continueelif n == 1:break。
python字典练习题

python字典练习题Python中的字典(Dictionary)是一种可变容器,可以存储、索引和排序键值对。
字典通过使用键来访问值,而不是使用位置索引。
本篇文章将为您提供一些Python字典的练习题,帮助您提高对字典的理解和运用。
1. 创建字典首先,我们需要学会如何创建一个字典。
请按照以下要求创建一个字典,并将其存储在变量`my_dict`中:- 键-值对包括键`name`和相应的值`"Tom"`;- 键`age`和相应的值`25`;- 键`city`和相应的值`"New York"`。
2. 访问字典中的值现在,我们要学习如何访问字典中的值。
请完成以下任务:- 打印输出字典中`name`对应的值;- 打印输出字典中`age`对应的值;- 打印输出字典中`city`对应的值。
3. 修改字典中的值字典是可变的,允许我们随时修改键对应的值。
请完成以下任务:- 将字典中`name`对应的值修改为`"Jerry"`;- 将字典中`age`对应的值增加`5`;- 打印输出被修改后的字典。
4. 添加键值对如果需要,在字典中添加键值对也是非常简单的。
请按照以下要求向字典中添加一个键值对:- 键为`"gender"`,值为`"male"`。
5. 删除键值对有时,我们需要删除字典中的某个键值对。
请完成以下任务:- 删除字典中键为`"city"`的键值对;- 打印输出被删除键值对后的字典。
6. 遍历字典遍历字典是十分常见的操作,它让我们能够同步访问字典中的键和值。
请完成以下任务:- 使用循环遍历并打印输出字典中的所有键;- 使用循环遍历并打印输出字典中的所有值;- 使用循环遍历并打印输出字典中的所有键值对。
7. 获取字典长度有时,我们需要知道字典中包含多少个键值对。
请找到并使用一个函数,打印输出字典中键值对的个数。
python我的英文字典案例

python我的英文字典案例如果你想要创建一个Python程序,这个程序可以作为一个英文字典使用,那么下面是一个简单的示例。
这个程序使用字典数据结构来存储单词和它们的定义。
```python创建一个字典,键是单词,值是定义dictionary = {"apple": "A fruit that is round and red and has a yellow pit.","banana": "A long curved fruit which is yellow when ripe.","cherry": "A small red or black sweet fruit.","dog": "A domesticated mammal that is a member of the canine family.","cat": "A domesticated mammal that is a member of the cat family."}用户输入一个单词,程序查找并打印出该单词的定义word = input("请输入一个单词: ")if word in dictionary:print(dictionary[word])else:print("该单词不在字典中.")```在这个程序中,我们首先创建了一个字典,其中包含了一些单词和它们的定义。
然后,我们使用`input`函数来获取用户输入的单词,并使用`if`语句来检查这个单词是否在我们的字典中。
如果单词在字典中,我们就打印出它的定义。
如果单词不在字典中,我们就打印出一条错误消息。
创建字典的五种方法

创建字典的五种方法一、使用{}创建字典在Python中,我们可以使用一对花括号{}来创建一个空的字典。
然后,我们可以通过指定键值对的方式来添加元素到字典中。
例如,我们可以用以下代码创建一个包含两个键值对的字典:my_dict = {}my_dict['apple'] = 1my_dict['banana'] = 2这样,我们就创建了一个名为my_dict的字典,其中键'apple'对应的值是1,键'banana'对应的值是2。
二、使用dict()函数创建字典除了使用{}来创建字典之外,我们还可以使用内置的dict()函数来创建字典。
通过传入以键值对形式表示的可迭代对象,我们可以快速地创建一个字典。
以下是使用dict()函数创建字典的示例代码:my_dict = dict([('apple', 1), ('banana', 2)])通过这个代码,我们同样创建了一个包含两个键值对的字典,其中键'apple'对应的值是1,键'banana'对应的值是2。
三、使用fromkeys()方法创建字典fromkeys()方法是字典对象的一个方法,它可以创建一个新的字典,其中包含指定的键以及对应的默认值。
以下是使用fromkeys()方法创建字典的示例代码:keys = ['apple', 'banana']default_value = 0my_dict = dict.fromkeys(keys, default_value)通过这段代码,我们创建了一个包含两个键值对的字典,其中键'apple'和'banana'都对应着值0。
四、使用zip()函数创建字典在Python中,我们可以使用zip()函数将两个可迭代对象合并成一个新的可迭代对象。
python字典部分练习题

python字典部分练习题字典作为Python中一种重要的数据结构,能够高效地存储和检索键值对。
在本文中,我们将介绍一些Python字典的基本用法,并提供一些练习题供读者实践。
一、字典的基本操作字典的创建和初始化:d = {} # 创建一个空字典d = {'apple': 1, 'banana': 2, 'orange': 3} # 创建一个带初始键值对的字典字典中添加或修改键值对:d['apple'] = 5 # 添加键值对'apple': 5,或修改已有键'apple'的值为5字典中删除键值对:del d['banana'] # 删除键为'banana'的键值对字典中检索键值对:value = d['apple'] # 根据键'apple'检索对应的值判断键是否存在:key_exists = 'banana' in d # 判断键'banana'是否存在于字典d中二、练习题1. 题目描述:给定一个字典my_dict,请尝试输出该字典的所有键。
输入:my_dict = {'apple': 1, 'banana': 2, 'orange': 3}输出:apple, banana, orange解答:```pythonmy_dict = {'apple': 1, 'banana': 2, 'orange': 3}keys = my_dict.keys()keys_str = ', '.join(keys)print(keys_str)```2. 题目描述:给定一个字典my_dict,请尝试输出该字典的所有值。
数据结构上机作业——顺序表
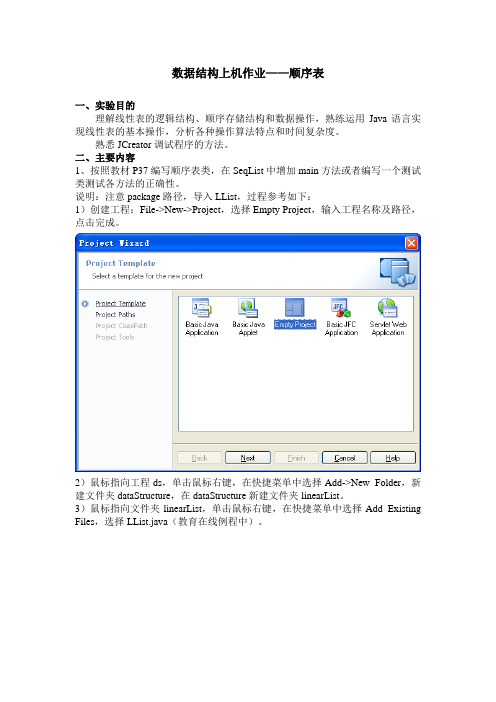
数据结构上机作业——顺序表一、实验目的理解线性表的逻辑结构、顺序存储结构和数据操作,熟练运用Java语言实现线性表的基本操作,分析各种操作算法特点和时间复杂度。
熟悉JCreator调试程序的方法。
二、主要内容1、按照教材P37编写顺序表类,在SeqList中增加main方法或者编写一个测试类测试各方法的正确性。
说明:注意package路径,导入LList,过程参考如下:1)创建工程:File->New->Project,选择Empty Project,输入工程名称及路径,点击完成。
2)鼠标指向工程ds,单击鼠标右键,在快捷菜单中选择Add->New Folder,新建文件夹dataStructure,在dataStructure新建文件夹linearList。
3)鼠标指向文件夹linearList,单击鼠标右键,在快捷菜单中选择Add Existing Files,选择LList.java(教育在线例程中)。
4)鼠标指向文件夹linearList,单击鼠标右键,,在快捷菜单中选择New Class,在Class Wizard中输入相关内容,类名:SeqList。
5)程序编辑结束后,执行Build->Build File菜单命令,编译Java程序,系统在Build Output区域输出错误信息,编译通过后将生成字节码文件(.class)。
6)测试:方法1 在SeqList类中增加main方法,例如public static void main(String args[]){SeqList<String> list=new SeqList<String>(7);list.add("");list.add("");list.add("");list.add("");System.out.println(list.toString());list.add(2,"");System.out.println(list.toString());list.remove(3);System.out.println(list.toString());}修改main方法,完成相应测试。
重庆科技学院-linus期末大作业

重庆科技学院《数据结构》课程设计专业班级:计科2012级3班学号: 2012442084 姓名:赵弈胰成绩:摘要设计一些简单的程序,来实现屏幕输出,约瑟夫问题,单词的拼写检查,非递减有序集合合并,括号匹配,排队优化,快速排序等功能。
我们首先应该想到设计需要的知识点,比如:链表、数组等方法,赋值运算、逻辑运算、括号运算等运算,还有循环等。
数据结构是计算机存储、组织数据的方式。
数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。
通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。
数据结构往往同高效的检索算法和索引技术有关。
关键字:数据结构、数组、链表、算法目录摘要 (I)目录 (II)1需求分析 (1)1.1功能需求 (1)1.2系统运行环境 (2)2开发环境...................................................................................................... 错误!未定义书签。
2.1 QT简介............................................................................................ 错误!未定义书签。
2.2开发环境搭建.................................................................................. 错误!未定义书签。
2.1.1安装g++ ................................................................................................ 错误!未定义书签。
2.1.2安装QT5.0 ............................................................................................ 错误!未定义书签。
Python字典(Dictionary)操作全解【创建、读取、修改、添加、删除、有序字典、。。。

Python字典(Dictionary)操作全解【创建、读取、修改、添加、删除、有序字典、。
字典是“键-值”对的⽆序可变序列,字典中的每个元素可以分为两部分,“键”和“值”。
定义字典时,每个元素的“键”和“值”⽤冒号分隔,相邻元素之间⽤逗号分隔,所有元素放在⼀对⼤括号”{“和”}“中。
字典中的“键”可以是Python 中任意不可变数据,例如整数,实数,复数,字符串,元组等等,但不能使⽤列表、集合、字典作为字典的“键”,因为这些对象是可变的。
另外,字典中的“键”不允许重复,⽽值是可以重复的。
by《董付国Python程序设计基础》注意:Python中字典的键必须是⼀个具体的数,或者是⼀个不可变序列。
List是⼀个可变序列,提供了插⼊删除修改操作,⽽tuple属于不可变序列,没有append()、extend()和insert()这些可以对序列进⾏修改的函数。
具体内容可参考⽬录。
不保证⽆差错,以具体代码结果为准。
⽬录1 字典的创建1.1⼿动创建使⽤等号直接⼿动创建字典。
a_dict={'DXY':"19950819" , 'HJL':"19960424"}print(a_dict) #{'HJL': '19960424', 'DXY': '19950819'}print(type(a_dict)) #<class 'dict'> 为字典类型1.2 使⽤内置函数dict()创建dictionary=dict( [["a",1],["b",2],["c",3]] )print(dictionary) #{'b': 2, 'a': 1, 'c': 3}print( type(dictionary )) #<class 'dict'>将 “'键'='值'”作为dict()的参数来创建字典。
创建字典的语句

创建字典的语句1. 创建一个包含城市名称和对应人口的字典:```pythoncity_population = {'北京': 2154, '上海': 2424, '广州': 1490, '深圳': 1303}```2. 创建一个包含水果名称和对应颜色的字典:```pythonfruit_colors = {'苹果': '红色', '香蕉': '黄色', '葡萄': '紫色', '橙子': '橙色'}```3. 创建一个包含学科名称和对应学分的字典:```pythonsubject_credits = {'数学': 4, '英语': 3, '化学': 2, '物理': 3}```4. 创建一个包含汽车品牌和对应价格范围的字典:```pythoncar_prices = {'丰田': '10万-50万', '本田': '8万-40万', '奥迪': '30万-200万', '特斯拉': '50万-300万'}```5. 创建一个包含动物名称和对应食物的字典:```pythonanimal_food = {'狮子': '肉', '大熊猫': '竹子', '鹦鹉': '水果', '金鱼': '鱼食'}```这些语句演示了如何使用Python 中的字典数据类型创建不同类型的字典。
在这些例子中,字典用于存储不同种类的信息,并通过键值对的形式进行组织。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
{
int i,j=0,mid;
PTrie_Node ph=Head1,ph1;
i=*word-'a';
int sign3=0;
这个单词总共出现的次数。否则输出NO
2)扩展型问题
(3) 给定一个单词,按字典序输出字典 Dictionary 中所有以这个单词为前缀的单词。
例如,如果字典T={a,aa, aaa, b, ba}, 如果你输入a,那么输出应该为{a, aa, aaa}。
(4) 给定一个单词,输出在 Dictionary 中以这个单词为前缀的单词的出现频率最高的
Init_WordMid();
Search_TopTen_word(Head); //查找字典里最多的十个单词
PriTopTen_word(fp8);
printf("--------第五题完成,结果写入文件MostFrequenceWord.txt中--------");
return 1;
}
}
else if(*(word+j)=='\0' && ph1->DisplayNum(mid) && ph1!=0 && ph1->ele[mid].next==0)
{
fprintf(fp2,"%d\n",ph1->ele[mid].num);
《数据结构》实验报告
实验题目: 现在有一个英文字典(每个单词都是由小写的'a'-'z'组成),单词量很大,达到120 多万的单词,而且还有很多重复的单词。此外,我们现在还有一些 Document,每个Document 包含一些英语单词。针对这个问题,请你选择合适的数据结构,组织这些数据,使时间复杂度和空间复杂度尽可能低,并且解决下面的问题和分析自己算法的时间复杂度。
return 1;
}
fprintf(fp2,"NO\n");
return 0;
}
(4)查找以既定字串为前缀的所有字串
PTrie_Node Search_Trie_1(PTrie_Node &Head1,char *word) //字符串前缀匹配搜索
sign3=1;
break;
}
}
if(sign3!=1)
{
if(*(word+j)=='\0' && ph1->DisplayNum(mid) && ph1!=0)
{
fprintf(fp2,"%d\n",ph1->ele[mid].num);
可以检索多个word(即连续的k 个word,其中k>=2),检索出同时包含k 个连续word 的DocumentID。
一、需求分析
1、本程序无需输入,通过文件的打开与读写得到最终结果。
2、输出形式诸如“第 步已完成,结果写入文件 中”。
3、建立字典树,对Trie_Node *next;
int sign;
char *word; //指向查询后的单词
}Ele,*Ele1;
2.(1)主函数模块
void main() //主函数
(6)查找出现频率最高前十单词模块
三 详细设计
1. 元素类型,结点类型和指针类型:
struct Trie_Node;
int sign1,sign2=0,sign3=1,sign4=1;
typedef struct Node_ele
{
int sign4; //用于表示插入时的优先级
while(*(word +j)!='\0' && ph->DisplaySign(i) && ph!=NULL)
{
j++;
ph1=ph;
ph=ph->ele[i].next;
mid=i;
i=*(word+j)-'a';
if(ph==0)
{
sign2=0;
}
else
{
fprintf(fp7,"CASE %d:\n",z++);
TopWord[0]=&ph->ele[sign1];
Search_TopTen_word(Search_Trie_1(Head,word1));//查找字符串为前缀的前十多单词
如同搜索引擎一样,即输入一些关键字,然后检索出和这些关键字相关的文档)。
(7) 在第(6)问中,我们只考虑了一个word 在哪些Document 中的情况,我们进一
步考虑2 个相邻word 的情况,检索出同时包含这两个相邻word 的DocumentID。
4)挑战型问题
(8) 现在我们再对(7)的问题进行扩展,把(7)中的只检索相邻2 个word 推广到
printf("\n");
FILE *fp6=fopen("PrefixFrequence.txt","r");
FILE *fp7=fopen("PrefixFrequence_Result.txt","w");
int z=1;
while(fscanf(fp6,"%s",word1)!=EOF)
Search_Trie(Head,word1,fp2);
}
printf("--------第二题完成,结果写入文件SearchWordInVocabulary_Result.txt中--------");
printf("\n");
FILE *fp3=fopen("TotPrefixWord.txt","r");
{
Init_WordMid();
ph=Search_Trie_2(Head,word1); //第二个查找函数 返回当前节点的指针
if(sign2==1 && sign3==0)
{
fprintf(fp7,"CASE %d:\n",z++);
sign2=0;
if(strcmp(word1,"nq") && strcmp(word1,"gyps"))
{
fprintf(fp4,"%s\n",word1);
}
Search_Think(ph,fp4); //搜索字符串前缀匹配单词
}
}
printf("--------第三题完成,结果写入文件TotPrefixWord_Result.txt中-------- ");
FILE *fp4=fopen("TotPrefixWord_Result.txt","w");
PTrie_Node ph;
int j=1;
while(fscanf(fp3,"%s",word1)!=EOF)
{
ph=Search_Trie_1(Head,word1);
FILE *fp2=fopen("SearchWordInVocabulary_Result.txt","w"); //打开“写”文件
int i=1;
while(fscanf(fp1,"%s",word1)!=EOF)
{
fprintf(fp2,"CASE %d:\n",i++);
◎实验目的:在本次课程设计中,希望同学们根据自己所学的知识,查找相关的资料,构造合适的数据结构,尽自己最大的努力解决这些问题,从而使自己学到更多新的知识。
◎实验内容:
1)基本型问题
(1) 选择合适的数据结构,将所有的英文单词生成一个字典 Dictionary。
(2) 给定一个单词,判断这个单词是否在字典 Dictionary 中。如果在单词库中,输出
10 个单词,对于具有相同出现次数的情况,按照最近(即最后)插入的单词优先级比较高
的原则输出。
(5) 输出 Dictionary 中出现次数最高的10 个单词。
3)高级型问题
(6) 现在我们有一些 Document,每个Document 由一些单词组成,现在的问题就是给
你一个word,检索出哪些Document 包含这个word,输出这些Document 的DocumentID(就
printf("\n");
}
(2)字典树建立模块
int Creat_Trie(PTrie_Node &Head) //建立字典树
{
FILE *f1=fopen("vocabulary.txt","r");
二 概要设计
为实现要求,应以字典树为存储结构。
1.基本操作
初始条件:字典树存在
操作结果:建立其他数据结构,实现对字典树的查找及对结果的保存
2.本程序包括六个模块
(1)主函数模块