关于ARM地址映射的理解
ARM中的RO、RW和ZI DATA说明

;
}
Prog2:
#include <stdio.h>
const char a = 5;
void main(void)
Prog3:
#include <stdio.h>
void main(void)
{
;
}
Prog4:
#include <stdio.h>
3; ZI
再看两个程序,他们之间的差别是一个未初始化的变量“a”,从之前的了解中,应该可以推测,这两个程序之间应该只有ZI大小有差别。
Prog3:
#include <stdio.h>
void main(void)
实际上,RO中的指令至少应该有这样的功能:
1. 将RW从ROM中搬到RAM中,因为RW是变量,变量不能存在ROM中。
2.
将ZI所在的RAM区域全部清零,因为ZI区域并不在Image中,所以需要程序根据编译器给出的ZI地址及大小来将相应得RAM区域清零。ZI中也是变量,同理:变量不能存在ROM中
Total RO Size(Code + RO Data) 1008 ( 0.98kB)
Total RW Size(RW Data + ZI Data) 97 ( 0.09kB)
Total ROM Size(Code + RO Data + RW Data) 1009 ( 0.99kB)
Code RO Data RW Data ZI Data Debug
948 60 1 96 0 Grand Totals
================================================================================
ARM中MMU地址转换理解(转)

ARM中MMU地址转换理解(转)⾸先,我们要分清ARM CPU上的三个地址:虚拟地址(VA,Virtual Address)、变换后的虚拟地址(MVA,Modified Virtual Address)、物理地址(PA,Physical Address)启动MMU后,CPU核对外发出虚拟地址VA,VA被转换为MVA供MMU使⽤,在这⾥MVA被转换为PA;最后通过PA读写实际设备MMU的作⽤就是负责虚拟地址(virtual address)转化成物理地址(physical address)。
32位的CPU的虚拟地址空间达到4GB,在⼀级页表中使⽤4096个描述符来表⽰这4GB的空间,每个描述符代表1M的虚拟地址,要么存储了它的对应物理地址的起始地址,要么存储了下⼀级页表的地址。
使⽤MVA[31:20]来索引⼀级页表(4096个描述符)(因为全⽤MVA的⾼12位来索引,因此⼤⼩为 2^12 = 4096)由协处理器CP15中的寄存器C2(⾼18位,即[31:14]为转换表基地址,低14位为0)为⼀级转换表基地址,指向2^14=16KB整除的存储器即16K对齐,这个存储区称为⼀级转换表;MVA的⾼12位,即位[31:20]作为⼀级转换表的地址索引,因此⼀级转换表具有2^12=4096项,每⼀项的地址为32位,最⾼的18位[31:14]为寄存器C2的⾼18位,中间12位为MVA的⾼12位[31:20],最低2位为0b00。
每⼀项的内容称为⼀个描述符,在段(Section)下,⼀级描述符的⾼12位为⼤⼩为1MB的段基地址,段内地址(偏移地址)为MVA的低20位,即段内每个存储器的地址是这样组成:⾼12位为⼀级描述符的⾼12位,低20位MVA的低20位。
这样,借助于寄存器C2和⼀级描述符,将⼀个MVA转换成⼀个PA。
(在这⾥⼀定要注意:MVA的⾼12位是⽤来索引4096个项的,然后使⽤项的内容(即描述符)的⾼12位为段的⾼12位,类似于指针⾥⾯存放地址,4096项类似指针,描述符类似指针⾥⾯的内容)虚拟地址(注意:是⼀个确定的地址,不是⼀个空间)被MMU分成2个部分,第⼀部分是4096页号索引(descriptor index)即⽤选择4096(2^12)个号中的某个页号,⽐喻description index为768,页号768中保存的是物理地址的某个页框的起始地址(0x300),第⼆部分则是相对于section base(0x300)为起始地址空间为1M的偏移量(offset)(如下图)例如:假设现在执⾏指令MOV REG, 0x30100013,虚拟地址的⼆进制码为00110000 00010000 00000000 00010011,前12位是Descriptor Index = 2^9+2^8+1 = 769,找到769项对应的内容0x301,偏移量为0000 00000000 00010011=13,那么段地址为0x3000000D。
arm构架的存储器参数

arm构架的存储器参数
1. 地址空间:ARM体系使用单一的地址空间,大小通常为2^32个8位字节,即4GB。
这些字节单元的地址都是无符号的32位数值,取值范围是0到2^32-1。
此外,ARM的地址空间也可以看作是2^30个32位的字单元或2^31个16位的半字单元。
2. 数据类型与存储格式:ARM处理器支持多种数据类型,包括字节(Byte,8位)、半字(Half-Word,16位)和字(Word,32位)。
存储器的格式可以是大端模式或小端模式,大端模式是指字的高字节存储在低地址字节单元中,而字的低字节存储在高地址字节单元中。
3. 寄存器:ARM处理器通常包含一定数量的通用寄存器,用于暂存数据和地址。
例如,ARM处理器可能具有37个寄存器,这些寄存器的读写周期通常小于2ns。
4. Cache和紧耦合存储器(TCM):为了提高内存访问效率,ARM 处理器通常包含片内Cache和TCM。
片内Cache可以优化内存访问,降低系统的总成本,而TCM是为了弥补Cache访问的不确定性增加的片上存储器。
5. 内存类型:ARM构架的嵌入式系统通常使用不同类型的内存,包括片内SRAM(静态随机存取存储器)提供高速内存访问,以及片外DRAM(动态随机存取存储器)或SDRAM(同步动态随机存取存储器)作为主存储器。
这些存储器的容量通常在8MB到512MB之间。
ARM9寻址方式及指令集介绍

ARM9寻址方式及指令集介绍ARM9是一种32位精简指令集计算机(RISC)架构的微处理器。
在本文中,我们将介绍ARM9寻址方式和指令集的基本特点。
直接寻址是最简单的寻址方式,寻址单元根据操作码中给出的直接地址来访问内存。
例如,LDR指令将数据从内存中的特定地址加载到寄存器中。
直接寻址在寻址范围上有限制,因为地址是直接编码在指令中的。
间接寻址是通过一个保存数据的寄存器的地址来访问内存。
寄存器中的地址表示需要访问数据的内存地址。
例如,LDR指令可以使用R0寄存器中的地址来获取数据。
间接寻址使得程序可以动态地计算内存地址,提高了灵活性。
相对寻址是通过相对于当前指令地址的偏移量来访问内存。
偏移量在指令的操作码中给出,并且通常是一个8位或12位的整数。
相对寻址使得程序可以方便地访问位于当前指令之前或之后的内存位置。
基址寻址是通过一个基址寄存器和一个偏移量来访问内存,其中基址寄存器存储了起始地址,偏移量存储了与起始地址的相对位置。
例如,LDR指令可以使用R0寄存器作为基址寄存器,并使用R1作为偏移量。
基址寻址适用于访问数组或数据结构等连续的内存块。
核心寄存器寻址是指通过核心寄存器的内容来访问内存。
在ARM9架构中,核心寄存器包括程序计数器、堆栈指针和链接寄存器等。
这些寄存器具有特殊的寻址方式,允许对于特定的功能进行优化。
ARM9的指令集包括数据处理指令、分支和跳转指令、访存指令和特权指令等。
数据处理指令是最常用的指令类型,用于完成算术和逻辑操作。
例如,ADD指令将两个操作数相加,并将结果存储在目的寄存器中。
分支和跳转指令用于控制程序的流程。
例如,B指令可以根据条件跳转到指定的地址上。
访存指令用于读写内存和I/O端口。
例如,LDR指令可以将数据从内存加载到寄存器中,STR指令可以将寄存器中的数据存储到内存地址中。
特权指令用于进行特权级别的操作,例如,访问系统寄存器或控制外设。
这些指令一般只能由操作系统或系统软件使用。
基于ARM单片机中的部分寄存器地址为什么会相差4

基于ARM单片机中的部分寄存器地址为什么会相差
4
图中是LPC1114用户手册系统控制模块(SYSCON)中的部分寄存器,请看红色框内,地址相差0x4。
为什幺会相差4?很多初学者问我这个问题,高手就请绕过吧。
计算机、单片机都是以字节为单位进行存储的。
这里的4就是4个字节的意思。
上面列举的LPC1114是ARM Cortex-M0内核,STM32是ARM Cortex-M3内核,这两ARM单片机都是32位的。
1个字节是8位,4个字节就是32位。
32位单片机的寄存器基本上是32位的,8位单片机的寄存器基本上也是8位的。
打开你曾经用过的reg51.h文件,看看普通51单片机的寄存器地址映射,一共不到100个寄存器,几下就写完了。
但是ARM单片机内部的模块非常多,寄存器也非常多,寄存器地址映射文件如果像51那样写,也可以,但是还有一种更有利于程序阅读和书写的而方法,就是利用结构体,所以当你打开ARM单片机的寄存器映射文件后(例如lpc11xx.h、stm32f10x_map.h),你会看到,他们的地址全部采用结构体的形式,一个同类模块的所有寄存器被放在了同一个结构体内部。
在以后写程序的时候,不论是书写还是阅读,都有很大的作用。
例如下面一条语句:。
究竟什么是地址映射,重映射

设置位
共用地址(通过映射实现)
地 址 统 一 编 码
首先我们要知道什么是存储器映射,存储器映射就是是指把芯片中或芯片外 的 FLASH,RAM,外设,BOOTBLOCK 等进行统一编址,即用地址来表示对 象。这个地址绝大多数是由厂家规定好的,用户只能用而不能改。就像一堆没有 序号的箱子一样,无法区分和使用!用户在挂外部 RAM\FLASH 的情况下可进行 自定义。如上图,是一个地址映射的实例!
以下是在下对存储器地址映射、存储器地址重映射的理解,本人愚钝,能力 有限!如有纰漏请多多指教!放在这里同大家分享的目的有两个:
1.希望想了解这方面知识的朋友可以对存储器地址映射、存储器地址重映射 有一个大概的认识。
2.希望有良师能指出我理解的误区或者分享一种更好的对存储器地址映射、 存储器地址重映射的解释!在下在这里先说声谢谢了。好了,废话不多说。
所以从中间有很大部分是空白区域,用户若使用这些空白区域,或者定义野指针, 就可能出现取指令中止或者取数据ห้องสมุดไป่ตู้止。程序就会出错
由于系统在上电复位时要从 0X00000000 开始运行,而第一要运行的 就是厂家固化在片子里的 BOOTBLOCK(就是一段初始化程序,bootloader)。 而芯片中的 BOOTBLOCK 不能放在 FLASH 的头部,因为那要存放用户的异常 向量表的,以便在运行、中断时跳到这来找入口,所以 BOOTBLOCK 只能放在 FLSAH 尾部才能好找到,呵呵。而 ARM7 的各芯片的 FLASH 大小又不一致,
接下来,我们来看看重映射,以下都是用我现在正在用的 ARM7TDMI 来给 他们分享我的心得,当然原理是通用的,希望对大家有帮助!ARM7TDMI 的存 储器映射可以有 0X00000000~0XFFFFFFFF 的空间,即 4G 的映射空间。见 下图,他们都是从固定位置开始编址的,而占用空间又不大,如 AHB 只占 2MB,
什么叫地址映射

什么叫地址映射地址映射 -…… 为了保证CPU执⾏指令时可正确访问存储单元,需将⽤户程序中的逻辑地址转换为运⾏时由机器直接寻址的物理地址,这⼀过程称为地址映射.地址映射最⼩单位为1页,4K⼤⼩,所以len值最⼩为:0x00001000.地址映射分类:地址映射也可以成为地址重定位或地址变换,可以分为以下两类:静态重定位当⽤户程序被装⼊内存时,⼀次性实现逻辑地址到物理地址的转换,以后不再转换(⼀般在装⼊内存时由软件完成).动态重定位在程序运⾏过程中要访问数据时再进⾏地址变换(即在逐条指令执⾏时完成地址映射.⼀般为了提⾼效率,此⼯作由硬件地址映射机制来完成.由硬件⽀持,软件硬件结合完成.硬件上⼀般需要⼀对寄存器的⽀持).什么叫物理地址?什么叫逻辑地址?什么叫地址映射?地址映射分哪⼏类?_…… 什么叫物理地址?什么叫逻辑地址?什么叫地址映射?地址映射分哪⼏类?1、物理地址就是由硬件地址编码电路产⽣的内存地址.2、逻辑地址是软件程序中使⽤的地址,是为了编程的简易性、安全性等⽬的由物理地址按⼀些规则由物理地址转...什么叫做映射地址_…… 概念:为了保证CPU执⾏指令时可正确访问存储单元,需将⽤户程序中的逻辑地址转换为运⾏时由机器直接寻址的物理地址,这⼀过程称为地址映射.直观的:CPU执⾏指令----存储单元 .这个过程需要下⾯的转换,逻辑地址-------物理地址.数学映射是什么定义_…… 在数学上,映射则是个术语,指两个元素集之间元素相互“对应”的关系,名词;也指“形成对应关系”这⼀个动作,动词.举例:设A={1,2,3,4},B= {3,5,7,9},集合A中的元素x按照对应关系“乘2加1”和集合B中的元素对应,这个对应是集合A到集合B的映射.【什么叫映射,他到底有什么作⽤,还有⼀⼀对应⼀⼀映射是什么意思】…… 映射是数学中描述了两个集合元素之间⼀种特殊的对应关系的⼀个术语.如果映射f是集合A到集合B的映射,并且对于集合B中的任⼀元素,在集合A中都有且只有⼀个原象,这时我们说这两个元素之间存在⼀⼀对应关系,并称这个映射叫做从集合A到集合B的⼀⼀映射.对于⼀⼀映射,A集合中的不同元素在B集合中对应不同的象.函数中映射到底是什么意思?我刚刚上⾼中,对于函数中映射的概念⾮常不清楚,课本上的定义觉得很不好理解,感激不尽啊!_…… 简单的讲映射就是集合A通过对应法则得到⼀个集合B,只是将集合过度到函数就可以了,分别理解前⾯提到的概念,1.集合A理解为⾃变量X 2.集合B理解为因变量Y 3.对应法则理解为f(x) 举例说明⼀下:求集合A到集合B的映射,对应法则为集合A的2倍, 那么⽤函数来表⽰就是 Y=2X f(x)="X的2倍“...映射是什么?函数是什么?什么叫到⾃⾝的⼀个映射?那么,b称为a在f下的象,a称为b在f下的⼀个原象,且a是A集合的元素,b是B集合的元素,你所说的象集是A集合吗,原象集是B集合吗?_…… 映射就是⼀对⼀的对应或者多对⼀的对应函数就是定义在数集上的映射到⾃⾝的⼀个映射,就是像集是原像集的⼀个⼦集.⽐如R-->R的映射,这个⾮常多.。
关于arm的统一编制与内存映射机制

关于arm的统一编制与内存映射机制Arm是统一编址的,也就是外设和内存进行统一的编址,共同形成了4G物理地址空间(32位为例子)。
大家知道操作外设时,实际上操作的是读写设备相关的寄存器,这些与外设相关的寄存器与不同操作模式下R0——R15那些寄存器是不同的,这些寄存器并不是所谓的物理上的寄存器,实际上是所谓的IO端口,通常会有控制、状态、数据的分类。
他们被连续地编址,对于其编址的方式有两种一种是IO映射、一种是内存映射。
IO映射是对x86为例的复杂指令集来说的,需要专门的IO控制指令,不详谈。
内存映射是对于统一编制的精简指令集计算机arm等来说的。
具体的方法就是将IO端口映射成和内存一样的物理地址,然后与内存一起进行统一编址,或者说成为了内存的一部分,当然还可以理解内存映射的意思是可以用访问内存的方式进行IO地址的访问,内存和IO地址一起编码为cpu识别的地址哦。
然后内存+IO端口地址=4GB 的寻址空间。
那么接下来还有个问题就是这种编址的硬件实现?这就要详见arm的AMBA(AdvancedMicrocontroller Bus Architecture)了,这是目前芯片总线的主流标准。
共定义了3组总线:高性能总线(AdvancedHigh Performance Bus,AHB)、系统总线(AdvancedSystem Bus,ASB)和外设总线(Advanced PeripheralBus,APB)。
不同的总线上挂接着不同的外设和存储器,大部分由三态门控制。
比如,当AHB总线上的主设备读写从设备时,发出的地址经过AHB总线的译码器产生该地址所对应从设备的选择信号,选中从设备;这样就可以对从设备进行读写啦。
或者可以这样想AHB总线上的译码器根据地址产生相应的片选信号,选中对应的设备。
对于硬件的实现我们这是简单地理解以便更好地体会上述编址。
涉及到具体的硬件读写操作,地址的硬件实现会提到很多的译码器、三态门、总线、还有时序等等具体情况具体分析,在此不做详述。
arm内存管理机制

arm内存管理机制ARM是一种广泛应用于嵌入式系统中的芯片,其内存管理机制是保证系统运行稳定的重要组成部分。
本文将介绍ARM内存管理机制的基础知识,包括地址空间、虚拟地址、物理地址和内存映射等内容,并给出一些指导意义的建议。
地址空间是指进程可以访问的地址集合。
ARM使用了一个32位地址空间,共2^32字节(4GB)。
这个地址空间被分成两个部分:用户空间(User Space)和内核空间(Kernel Space)。
用户空间是由应用程序使用的,内核空间是由操作系统使用的。
在ARM系统中,虚拟地址和物理地址是两个不同的地址空间。
虚拟地址是由应用程序使用的地址。
它是一个32位地址,它与物理地址是不同的,应用程序只能访问虚拟地址,并且不能直接访问物理地址。
应用程序访问虚拟地址时,操作系统将虚拟地址转换为物理地址,然后进行访问。
这个转换由ARM芯片的内存管理单元(MMU)完成。
物理地址是处理器处理的实际地址。
它表示访问硬件的实际位置。
每个ARM芯片都有一个物理地址空间,但它的大小和内容依赖于所用的芯片,那么关于内存地址的运用应该注意哪些方面呢?在ARM中,内存是通过内存映射的方式访问的。
内存映射是由操作系统控制的,它将虚拟地址映射到物理地址。
内存映射的目的是将不同的外设设备和物理内存映射到同一地址空间。
这样,应用程序可以使用相同的地址来访问不同的设备和内存。
在编写嵌入式系统时,必须小心使用内存映射。
错误的内存映射可能会导致系统崩溃或数据损坏。
因此,在设计和实现系统时,必须确保正确的内存映射,并尽可能减少内存分配和释放的次数。
总之,ARM内存管理机制中,地址空间、虚拟地址、物理地址和内存映射是重要的概念。
理解这些概念可以帮助开发人员设计和实现更稳定、高效的嵌入式系统。
因此,我们建议开发人员在开发嵌入式系统时,要注意这些概念,并确保正确的内存管理。
arm中mmu的映射原理与配置步骤

arm中mmu的映射原理与配置步骤下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!本店铺为大家提供各种类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you! In addition, this shop provides you with various types of practical materials, such as educational essays, diary appreciation, sentence excerpts, ancient poems, classic articles, topic composition, work summary, word parsing, copy excerpts, other materials and so on, want to know different data formats and writing methods, please pay attention!一、mmu的映射原理。
在arm架构中,mmu(Memory Management Unit)用于实现虚拟地址到物理地址的映射,以及页面级别的访问权限控制。
ARM芯片的地址重映射
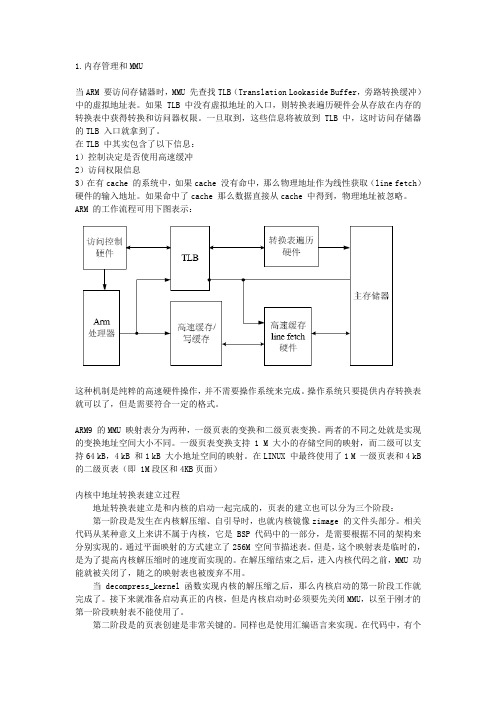
1.内存管理和MMU当ARM 要访问存储器时,MMU 先查找TLB(Translation Lookaside Buffer,旁路转换缓冲)中的虚拟地址表。
如果TLB 中没有虚拟地址的入口,则转换表遍历硬件会从存放在内存的转换表中获得转换和访问器权限。
一旦取到,这些信息将被放到TLB 中,这时访问存储器的TLB 入口就拿到了。
在TLB 中其实包含了以下信息:1)控制决定是否使用高速缓冲2)访问权限信息3)在有cache 的系统中,如果cache 没有命中,那么物理地址作为线性获取(line fetch)硬件的输入地址。
如果命中了cache 那么数据直接从cache 中得到,物理地址被忽略。
ARM 的工作流程可用下图表示:这种机制是纯粹的高速硬件操作,并不需要操作系统来完成。
操作系统只要提供内存转换表就可以了,但是需要符合一定的格式。
ARM9 的MMU 映射表分为两种,一级页表的变换和二级页表变换。
两者的不同之处就是实现的变换地址空间大小不同。
一级页表变换支持1 M 大小的存储空间的映射,而二级可以支持64 kB,4 kB 和1 kB 大小地址空间的映射。
在LINUX 中最终使用了1 M 一级页表和4 kB 的二级页表(即 1M段区和4KB页面)内核中地址转换表建立过程地址转换表建立是和内核的启动一起完成的,页表的建立也可以分为三个阶段:第一阶段是发生在内核解压缩、自引导时,也就内核镜像zimage 的文件头部分。
相关代码从某种意义上来讲不属于内核,它是BSP 代码中的一部分,是需要根据不同的架构来分别实现的。
通过平面映射的方式建立了256M 空间节描述表。
但是,这个映射表是临时的,是为了提高内核解压缩时的速度而实现的。
在解压缩结束之后,进入内核代码之前,MMU 功能就被关闭了,随之的映射表也被废弃不用。
当decompress_kernel 函数实现内核的解压缩之后,那么内核启动的第一阶段工作就完成了。
地址映射

ARM简介及编程1.ARM简介(摘录)ARM(Advanced RISC Machines)是微处理器行业的一家知名企业,设计了大量高性能、廉价、耗能低的RISC处理器、相关技术及软件。
技术具有性能高、成本低和能耗省的特点。
适用于多种领域,比如嵌入控制、消费/教育类多媒体、DSP和移动式应用等。
ARM将其技术授权给世界上许多著名的半导体、软件和OEM厂商,每个厂商得到的都是一套独一无二的ARM相关技术及服务。
利用这种合伙关系,ARM 很快成为许多全球性RISC标准的缔造者。
目前,总共有30家半导体公司与ARM签订了硬件技术使用许可协议,其中包括Intel、IBM、LG半导体、NEC、SONY、菲利浦和国民半导体这样的大公司。
至于软件系统的合伙人,则包括微软、升阳和MRI等一系列知名公司。
ARM架构是面向低预算市场设计的第一款RISC微处理器。
2.产品介绍ARM提供一系列内核、体系扩展、微处理器和系统芯片方案。
由于所有产品均采用一个通用的软件体系,所以相同的软件可在所有产品中运行(理论上如此)。
典型的产品如下。
①CPU内核--ARM7:小型、快速、低能耗、集成式RISC内核,用于移动通信。
-- ARM7TDMI(Thumb):这是公司授权用户最多的一项产品,将ARM7指令集同Thumb扩展组合在一起,以减少内存容量和系统成本。
同时,它还利用嵌入式ICE调试技术来简化系统设计,并用一个DSP增强扩展来改迚性能。
该产品的典型用途是数字蜂窝电话和硬盘驱动器。
--ARM9TDMI:采用5阶段管道化ARM9内核,同时配备Thumb扩展、调试和Harvard总线。
在生产工艺相同的情况下,性能可达ARM7TDMI的两倍之多。
常用于连网和顶置盒。
②体系扩展-- Thumb:以16位系统的成本,提供32位RISC性能,特别注意的是它所需的内存容量非常小。
③嵌入式ICE调试由于集成了类似于ICE的CPU内核调试技术,所以原型设计和系统芯片的调试得到了极大的简化。
arm地址空间分配与启动时地址的映射

s3c2440地址空间的分配s3c2440启动过程详解一:地址空间的分配1:s3c2440是32位的,所以可以寻址4GB空间,内存(SDRAM)和端口(特殊寄存器),还有ROM都映射到同一个4G空间里.2:开发板上一般都用SDRAM做内存flash(nor、nand)来当做ROM。
其中nand flash 没有地址线,一次至少要读一页(512B).其他两个有地址线3:norflash不用来运行代码,只用来存储代码,NORflash,SDRAM可以直接运行代码)4:s3c2440总共有8个内存banks6个内存bank可以当作ROM或者SRAM来使用留下的2个bank除了当作ROM 或者SRAM,还可以用SDRAM(各种内存的读写方式不一样)7个bank的起始地址是固定的还有一个灵活的bank的内存地址,并且bank大小也可以改变5:s3c2440支持两种启动模式:NAND和非NAND(这里是nor flash)。
具体采用的方式取决于OM0、OM1两个引脚OM[1:0所决定的启动方式OM[1:0]=00时,处理器从NAND Flash启动OM[1:0]=01时,处理器从16位宽度的ROM启动OM[1:0]=10时,处理器从32位宽度的ROM启动。
OM[1:0]=11时,处理器从Test Mode启动。
当从NAND启动时cpu会自动从NAND flash中读取前4KB的数据放置在片内SRAM里(s3c2440是soc),同时把这段片内SRAM映射到nGCS0片选的空间(即0x00000000)。
cpu 是从0x00000000开始执行,也就是NAND flash里的前4KB内容。
因为NAND FLASH 连地址线都没有,不能直接把NAND映射到0x00000000,只好使用片内SRAM做一个载体。
通过这个载体把nandflash中大代码复制到RAM(一般是SDRAM)中去执行当从非NAND flash启动时nor flash被映射到0x00000000地址(就是nGCS0,这里就不需要片内SRAM来辅助了,所以片内SRAM的起始地址还是0x40000000). 然后cpu从0x00000000开始执行(也就是在Norfalsh中执行)。
ARM CORTEX-M3 内核架构理解归纳

在我看来,Cotex-M3内核的主要包括:嵌套向量中断控制器(NVIC),取值单元,指令译码器,算数逻辑单元(ALU),寄存器组,存储器映射(4GB统一编址各区域功能的划分与界定),对于开发者而言,其实主要关注的主要分为三大块:1、寄存器组2、地址功能划分映射3、中断机制(NVIC)。
1)寄存器组Cortex-M3内核共有19组32位寄存器:R0——R12(通用寄存器);低寄存器组R0——R732位Thumb-2指令与16位Thumb指令均可访问高寄存器组R8——R1232位Thumb-2指令与极少数16位Thumb指令可访问R13(堆栈指针寄存器);主堆栈寄存器MSP(main-SP)/进程堆栈寄存器PSP(Process-SP)同一时间只能使用其中一个。
MSP供操作系统内核及中断(异常)处理子程序使用,PSP只供用户的应用程序代码使用(详细使用详见3、嵌套向量中断控制器(NVIC)的总结)。
堆栈指针是4字节对齐的,故最低两位永远是00;R14(连接寄存器)用于存储程序返回的地址及PC的返回地址;R15(程序寄存器)指向当前程序执行的地址;2)特殊功能寄存器组xPSR(程序状态字寄存器组),32位,可分为三个寄存器分别进行访问,也可以PSR或xPSR 的名字直接组合访问。
应用程序PSR(APSR)中断号PSR(IPSR)执行PSR(EPSR)中断屏蔽寄存器PRIMASK 单一比特位,置位后,除NMI与硬fault外,其他中断都不响应;FAULTMASK 单一比特位,置位后,除NMI外,其他中断都不响应;BASEPRI 共有9位,中断号小于等于该寄存器设置值的中断都不响应;控制寄存器controlControl[0] 0决定特权级线程模式;1用户级线程模式;Control[1] 0主堆栈;1进程堆栈;控制寄存器只能在特权级模式下改写,handler模式永远是特权级,且只允许使用主堆栈MSP 复位后,处理器进入特权级+线程模式下;2、地址功能划分映射Cortex-m3是一个32位处理器,其地址总线、数据总线都是32位的,故可在4G的地址范围上资源寻址。
ARM处理器CACHE详解

ARM920T的MMU与Cache目录虚拟地址和物理地址的概念虚拟内存管理ARM920T的CP15协处理器MMUCache操作MMU和Cache的内核启动代码参考资料索引虚拟地址和物理地址的概念CPU通过地址来访问内存中的单元,地址有虚拟地址和物理地址之分,如果CPU没有MMU (Memory Management Unit,内存管理单元),或者有MMU但没有启用,CPU核在取指令或访问内存时发出的地址将直接传到CPU芯片的外部地址引脚上,直接被内存芯片(以下称为物理内存,以便与虚拟内存区分)接收,这称为物理地址(Physical Address,以下简称PA),如下图所示。
图 1. 物理地址示意图如果CPU启用了MMU,CPU核发出的地址将被MMU截获,从CPU到MMU的地址称为虚拟地址(Virtual Address,以下简称VA),而MMU将这个地址翻译成另一个地址发到CPU芯片的外部地址引脚上,也就是将虚拟地址映射成物理地址,如下图所示[1]。
图 2. 虚拟地址示意图MMU将虚拟地址映射到物理地址是以页(Page)为单位的,对于32位CPU 通常一页为4K。
例如,虚拟地址0xb700 1000~0xb700 1fff是一个页,可能被MMU映射到物理地址0x2000~0x2fff,物理内存中的一个物理页面也称为一个页框(Page Frame)。
虚拟内存管理现代操作系统充分利用MMU提供的VA到PA的映射机制来做内存管理,以下称为虚拟内存管理(Virtual Memory Management)。
首先看下面的例子:例 1. 进程的地址空间这是bash进程的虚拟地址空间,32位CPU的虚拟地址空间是4GB,也就是0x0000 0000-0xffff ffff,该进程占用的地址范围近似为0x0000 0000-0xbfff ffff,地址范围0xc000 0000-0xffff ffff由内核占用,用户进程不允许访问。
arm 的寻址空间

arm 的寻址空间ARM的寻址空间指的是ARM架构处理器能够访问的内存范围。
ARM是一种32位的指令集架构,常用于移动设备、嵌入式系统以及各种消费电子产品中。
ARM处理器的寻址空间通常被称为虚拟地址空间,因为它是由操作系统分配和管理的。
在这篇文章中,我们将详细介绍ARM的寻址空间,包括它的大小、地址映射和特殊寻址模式。
ARM的32位寻址空间ARM处理器的寻址空间是一个32位的虚拟地址空间,意味着它可以寻址2的32次方个内存单元。
每个内存单元的大小通常是8位(1字节),因此ARM的寻址空间可以容纳4GB的内存。
然而,实际上,ARM处理器可能不会使用全部4GB的虚拟地址空间,因为一些地址空间可能会用于其他用途,例如内核空间、输入输出设备区域等。
地址映射在ARM处理器上,虚拟地址空间被划分为两个区域:用户空间和内核空间。
用户空间用于运行普通用户进程,而内核空间用于运行操作系统内核。
用户空间通常是高地址空间,而内核空间是低地址空间。
这种地址映射方式提供了一种保护机制,防止用户进程访问内核空间中的敏感信息或破坏内核的执行。
在ARM架构中,虚拟地址到物理地址的映射是由内存管理单元(MMU)完成的。
MMU根据页表进行地址翻译,将虚拟地址转换为物理地址。
页表是一种数据结构,用于跟踪虚拟地址和物理地址之间的映射关系。
ARM处理器中的页表是层次式的,由多个表组成,包括级一级表(L1 Table)、二级表(L2 Table)、三级表(L3 Table)等。
每个表都包含多个页表项,每个页表项对应一个虚拟页和物理页的映射关系。
特殊寻址模式除了通常的虚拟地址寻址外,ARM还支持一些特殊的寻址模式,用于访问特定的内存区域或操作寄存器。
1.特权寻址模式:ARM处理器具有多种特权级别,例如用户模式、系统模式、监管模式等。
这些特权级别可以通过特殊的寻址模式进行访问和控制。
2.异常寻址模式:ARM中的异常(如中断、异常、陷阱)可以引发处理器模式的切换。
ARM64页表映射_奔跑吧 Linux内核_[共7页]
![ARM64页表映射_奔跑吧 Linux内核_[共7页]](https://img.taocdn.com/s3/m/5a634c04240c844769eaeedb.png)
第2章 内存管理 60 容写入硬件页表,从而完成模拟过程。
如何模拟PTE_YOUNG 和PTE_PRESENT 呢?特别是PTE_YOUNG 比特位在页面换出换入机制中起到非常重要的作用,在第 2.13节中会详细介绍。
读者可以先思考,对于匿名页面来说,什么时候第一次设置Linux 版本页表的L_PTE_ PRESENT | L_PTE_YOUNG 比特位?2.2.2 ARM64页表映射对于ARM64架构来说,目前基于ARMv8-A 架构的处理器最大可以支持到48根地址线,也就是寻址248的虚拟地址空间,即虚拟地址空间范围为0x0000_0000_0000_0000~0x0000_FFFF_FFFF_FFFF ,共256TB 。
理论上完全可以做到64根地址线,那么最大就可以寻找到264的虚拟地址空间。
但是对于目前的应用来说,256TB 的虚拟地址空间已经足够使用了。
因为如果支持64位虚拟地址空间,意味着处理器设计需要考虑更多的地址线,CPU 的设计复杂度会增大。
基于ARMv8-A 架构的处理器的虚拟地址分成两个区域。
一个是从0x0000_0000_0000_ 0000到0x0000_FFFF_FFFF_FFFF ,另外一个是从0xFFFF_0000_0000_0000到0xFFFF_FFFF_ FFFF_FFFF 。
基于ARMv8-A 架构的处理器可以通过配置CONFIG_ARM64_ V A_BITS 这个宏来设置虚拟地址的宽度。
[arch/arm64/Kconfig] config ARM64_VA _BITS intdefault 39 if ARM64_VA _BITS _39default 42 if ARM64_VA _BITS _42 default 48 if ARM64_VA_BITS_48另外基于ARMv8-A 架构的处理器支持的最大物理地址宽度也是48位。
Linux 内存空间布局与地址映射的粒度和地址映射的层级有关。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
对于刚刚学习ARM嵌入式的人来说,遇到的第一个难点我觉得就是地址映射的原理,往往会被一些概念弄得稀里糊涂(比如像我这种智商不高的)。
所以就静下心自己好好研读了以下杜春雷《ARM体系结构与编程》有关MMU和地址映射的讲解,个人感觉写得比较清晰,以下是自己在读的时候理解的内容,如有不正,请指出!
对于32为ARM处理器,最大寻址空间为4GB(2^32),但是物理空间并没有配置到这么大,所以对于VA来说,其地址为0x00000000~0xFFFFFFFF,对于PA来说,其地址应小于或等于0xFFFFFFFF。
地址映射原理:
把虚拟地址划分为一定大小空间的存储块,同样,物理空间也划分为同样大小的块。
然后,依照存储块的大小,可分为:1、段(1MB)2、大页(64KB)3、小页(4KB)4、极小页(1KB)
第一种称为段模式,后面三种称为页模式
这些映射,都是通过页表实现的,页表又可可以分为:一级页表(用于段模式)
二级页表(用于页模式)什么是页表呢?页表就是存储在内存中(会被拷贝到SDRAM中存放,以供MMU查询),用于表示VA与PA
的映射关系的一个表格。
表格中每项称为条目,条目里的内容称为描述符(段描述符和页描述符)。
段模式:
以段模式映射时,因为VA大小位4GB,段模式每个条目表为1MB大小的空间,所以全映射时,
条目总数(全映射时页表所占内存空间)=4GB / 1MB =4096条(每条32位,即4字节,共4 KB)。
其中,所谓的每个条目大小为1MB,意思是,CPU发出的一段地址范围为1MB的VA (假如0x00000000~0x000FFFFF),这一段VA经过MMU变换,都会索引(查找)到同一个条目。
该条目再次结合VA(PA的[19:0]位,称为段内地址偏移量),形成真正的PA地址。
具体请看下图
对于段模式,其只需要使用一级页表。
页表中,条目中存储的描述符格式如下:
1、段基址:在设计地址映射时,要映射的物理地址要1MB对齐,段基址就是这段1MB物理地址起始地址的
高[31:20]位,每个条目中的描述符的段基址都不一样(以段来说,相差1MB)。
2、AP: AP是用来设置权限的,与C1的R/S位结合使用。
3、Domain域:不管是段模式还是页模式,系统都把4GB空间分为16个域,每个域有相同的权限检查
(在C3设置),这里的Domain是用来标识本段所在的域
4、C/B:C/B位是控制位,与本条目(描述符)所在域的Cache和Buffer有关(是否允许本域开启Cache和Buffer)
5、[1:0]=0b10:表示本描述符是表示段模式(段描述符标识)
设置页表的思路:
1、确定那段VA映射到那段PA,以及映射方式(段/页)
以段为例:VA(0xB0000000~0xB0100000【1MB】)映射到PA(0xA0000000~0xA0100000)2、确定段基址:PA=0xA0000000
同时记录VA=0xB0000000
3、确定页表存放在那个位置,然后确定页表基址(页表存储位置起始地址及C2设置值):如存放在内存0x00000000处。
则页表基址(设置为指针)
unsigned long *page_table_base=(unsigned long *)0x00000000
4、提前把条目中的描述符的低[11:0]位设置好,假设为MMU_DECSET
5、根据公式把条目描述符与段基址整合成完整条目存储到页表所在内存地址:
*(page_table_base+(VA>>20))=(PA&0xFFF00000)|MMU_DECSET; //页表所在偏移地址,指
向页表存储的位置
这样,就把描述符(条目)(PA&0xFFF00000)|MMU_DECSET 存储到*(page_table_base+(VA>>20))
指向的地址。
6、如果设置多个条目,使用循环,每次将PA和VA的值增加1MB(0x10 0000),再存储到页表中。