kafka配置
Kafka安装配置及其使用说明

Kafka安装配置及使用说明(铁树2018-08-08)(Windows平台,5个分布式节点,修改消息大小,调用程序范例)1安装配置采用5台服务器作为集群节点,IP地址为:XX.XX.0.12-XX.XX.0.16.每台机器依次安装配置JDK zookeeper、kafka,先安装完一台机器,然后拷贝到其他机器,再修改配置文件。
1.1 JDK安装配置JDK版本:jdk1.7.0_51_x64 解压版(jdk1.7.0_51_x64.rar )解压到C盘kafka目录下,如图所示首特KtBAHXJ'.bin2010.1/30 王币K =S h db2013/7/3V 七比5:件耒.incbde2018/7/30 £36上沁201^7/® 2^36h瞬了20147/30 2\36.[ih201^7/30 J5 3-B11 CQPvwGHrr2013/1^15 2CTO1文件 4K@LKtN$E Wli/4/10 *141KB 丄和d] README201V4/10M4HTML 応1KB理|即■艸2QW4/10 中141呵.ire2013/12/1B 7002iMnRSf? J1P 尹也珈u计刖...TM [RDP4HraECEN^r R EADME2014/4^10 tU17] KB & =堆址H {3□ THLRO^ftRIVUCENSEREADWt-JAVA-FX2014/4/10 RL4123K£lID 宓亍2S .tic设置环境变量:JAVA_HOMEC:\kafka\jdk1.7.0_51_x64PATH C:\kafka\jdk1.7.0_51_x64\bin麥毘名型):jm_HONE妄重值也): C:莎毎i\j dkl. 7.0_51_1«64|1.2 zookeeper 安装配置1.2.1解压安装zookeeper 版本:3412 (zookeeper-3412.tar.gz )詞匸F 2仝召耳丰” U卡话諮文弍矣解压到C盘kafka目录下,如图所示计垃巧■衣抽剧&隹;]* ki祖亓* 5-4.121.2.2创建zookeeper数据目录和日志目录zkdata #存放快照C:\kafka\zookeeper-3412\zkdatazkdatalog#存放日志C:\kafka\zookeeper-3412\zkdatalog1.2.3修改配置文件进入到“C:\kafka\zookeeper-3412 ”目录下的conf目录中,复制zoo_sample.cfg (官方提供的zookeeper的样板文件),重命名为zoo.cfg (官方指定的文件命名规则)« 本為iE 誣心)►ksika Ik ipolcwpe—3 <112 conf■- it itciad默认内容:1 t Th 电 r.umber af niLLisecnnds of 色亀亡h 1 ick2 iLclriijie^SOljJ t Ihe ruFibor of t £cks that tho iruit ial 4 * jyncbut cnizat i on pharc ca- tak?4 Ihe hunbBi : of ticts that can pajs belvten7 $ sendw a request 吐id. eettinz © icknovl^dgement 耳 syricLlJiitsBq i 十h* di reetery whfrp +t.n im 现i 雪hat is licr^ri ・t do net 工令 /tup for stor^c^ /tup htre is jurt 11 t spikes ida"t i :3Qkc?pcr# the port 可t which -the clients 呼ill coimcrtU cLientFort^2131f the jisKimum minbeT of client co?mecT laris.£ zncresse this i_£ you r.eEd to hand L e no re clxent^ 17tnsjcCl ier±Cra:n3= 5 □IS # 車 fie sure to rsal the nLiirtenan.es scctzon cf tlie20 幸 atLnirjLEtratej 匚 ^ULde bef 匚工匕 tijrnj.n^ on aut'Opurge»2144 him :77盘口或&女口空匚.ZLDAC 上已・ ot 色FdtoiCL"i :iii 工亡!IT /®□亡X BE □色血二n ・htilflsc^niaiiiT enance24 t 7h# r.ujTibsr af snap shots ta- retain tn dli+dJirtau't&pujEge ・ snapR*t a.inCanmt-3# Pur co tack. intocTral in hour 口27 t Set tc *0* ts 11 fable aute p>jrgs f oMure# ant op ILL 宦口 pux < s Int erv 41= 129修改后配置文件为:if The nuff.her cf ticks that tho uii"t ial 巾 即 cyriehecnLEa'tici^ phsso aan tdc« LnL^LinitsLDH Thp iriur.hPT of tick? Th 献 EWI hpiv^pnH s^niiing a QH ^SI 釧d t inj 砒 a^nnwlertg^ngrit synGLiinit=5 #t he direertcry the snapshoot LS siored. 常 dn not USB /i up DE storagBj /tup here is jusl 0 ezsnpLe srakes.dal iDi r=C : /kaf k 3 o oke epei^ 3k . 12/' sk Jai adat aLui-EDAi-C^k afls^zookEepejD-O.. 4. 12 ■''zld -atalDE :* t hs port at vhich the clieEirts wllL eoni^ct cli«YtPort=l2]81. nrwr, l?10. 99. D. 12s 12838: 13S8$ s«rwr. 2x10. SS. D. 13:12SB8:138BSserver. XI0.9現 0.14H2888:13838 mF 4F 10. 99« DL 15; 128BB; 13338 骂”兀T 甲 6^10- 99w 0-16: 12SS3;]33S$ I0 The 丁Lssiirm nixTiter of clzerrt cor_neztLons B星 inciease this if you used to hardlm note cLients ftnirCl:. erACrutr.s-SO 律律 sure to resd ths mwJtDnan©白 section of tho 0sliriinifflr iter 事二日暂 befcr? turning cn aurt operg :#・ 9 hrm ; f/r i)応总吕ac 直吐凶..o E " dou/cun:程nt/医U okE BnmrAitiiiiL htnlg 呂 c ;_maint Eaaric 甘# The niff-.bc-r of snapshots 十 0 rFt»n ui dstaPix'au.1 3pnTge ・ sTiSf Est aLnCount - J □□ 0 P -irg :€i tasjE int=r^al IZI hours■ J 堆 Set 1 D *0* 1 □ disable aut D purge fea1 LLITEorpij r 牴》r ・ pur 百 e Irrt e 匚晴呂 1 二24367 691011坨|14 161 ie n IF is卑21 22 23 ■£■?乔齐# The nwiiber of ffiillisecoads (of each tick £ tjckTjjir-20D0# The number of milliseconds of each tick tickTime=2000# The nu mber of ticks that the in itial# synchroni zati on phase can takeini tLimit=10# The nu mber of ticks that can pass betwee n# sending a request and gett ing an ack no wledgeme nt syncLimit=5# the directory where the sn apshot is stored.# do not use /tmp for storage, /tmp here is just# example sakes.dataDir二C:/kafka/zookeeper-3.4.12/zkdatadataLogDir二C:/kafka/zookeeper-3.4.12/zkdatalog# the port at which the clie nts will connectclie ntPort=12181server. 1=XX.XX.0.12:12888:13888server.2=XX.XX.0.13:12888:13888server.3=XX.XX.0.14:12888:13888server.4=XX.XX.0.15:12888:13888server.5=XX.XX.0.16:12888:13888# the maximum nu mber of clie nt conn ecti ons.# in crease this if you n eed to han dle more clie nts#maxClie ntCnxn s=60## Be sure to read the maintenance secti on of the# adm ini strator guide before tur ning on autopurge.##/doc/curre nt/zookeeperAdmi n.html#sc_mai nte nance## The nu mber of sn apshots to reta in in dataDirautopurge.s napRetai nCoun t=100# Purge task in terval in hours# Set to "0" to disable auto purge featureautopurge.purgeI nterval=24配置文件解释:#tickTime :这个时间是作为Zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime 时间就会发送一个心跳。
kafka jvm参数

kafka jvm参数摘要:1.Kafka简介2.JVM参数的作用3.Kafka JVM参数优化建议正文:Kafka是一款高性能、可扩展的分布式消息队列系统,广泛应用于大数据处理、实时数据流分析和日志收集等场景。
Kafka在运行时,JVM参数的设置对系统的性能和稳定性有着重要影响。
本文将详细介绍Kafka JVM参数的相关知识。
JVM参数是Java虚拟机参数的简称,它影响Java程序运行时的性能和稳定性。
对于Kafka这样的Java应用程序来说,合理调整JVM参数可以提高资源利用率、提高系统性能,同时避免一些潜在的稳定性问题。
以下是一些建议的Kafka JVM参数优化设置:1.调整堆大小(-Xms和-Xmx)堆大小是JVM分配给应用程序的最大内存。
Kafka作为大数据处理系统,需要大量的堆内存来存储消息数据和元数据。
通常,可以将Kafka的堆大小设置为服务器总内存的50%-70%。
具体数值需要根据服务器实际硬件资源和Kafka的负载情况来调整。
2.启用压缩指针(-XX:+UseCompressedOops)启用压缩指针可以减少堆内存的使用,提高堆内存的利用率和垃圾回收效率。
对于Kafka这种大数据处理系统来说,可以显著减少内存消耗。
3.调整垃圾回收器(G1和CMS)Kafka在生产环境中,可以根据服务器的硬件资源和负载情况,选择合适的垃圾回收器。
G1垃圾回收器适用于大内存、高吞吐量的场景,而CMS垃圾回收器适用于对低延迟要求不高的场景。
4.调整新生代与老年代的比例(-XX:NewRatio和-XX:SurvivorRatio)调整新生代与老年代的比例可以影响垃圾回收的频率和性能。
通常,可以将新生代与老年代的比例设置为1:2,以平衡垃圾回收的性能和内存占用。
5.启用类数据共享(-XX:+UseClassDataSharing)启用类数据共享可以减少垃圾回收时的内存访问开销,提高垃圾回收性能。
对于Kafka这种大数据处理系统来说,可以显著提高性能。
kafka 做为存储的用法

kafka 做为存储的用法Kafka 是一种基于流处理的数据传输和存储系统,广泛应用于实时数据流处理和大数据分析。
它提供了一个高效、可扩展和容错的消息队列,用于存储和传输数据。
本篇文章将详细介绍 Kafka 作为存储的用法,包括其优势、使用场景、配置和使用方法。
一、Kafka 优势Kafka 具有以下优势:1. 高性能:Kafka 提供了高性能的流处理能力,能够处理大量的数据流,并保持较高的吞吐量。
2. 可扩展性:Kafka 支持横向扩展,可以通过添加更多的节点来提高处理能力,具有良好的可扩展性。
3. 容错性:Kafka 具有强大的容错机制,能够自动处理节点故障,保证系统的稳定运行。
4. 易用性:Kafka 提供了简单易用的 API,方便用户进行数据传输和存储。
二、使用场景Kafka 适用于以下场景:1. 数据流处理:Kafka 适用于实时数据流处理,可以用于实时分析、数据挖掘、日志收集等场景。
2. 大数据存储:Kafka 可以作为大数据系统的一部分,用于存储大量的数据,并提供高效的检索和分析功能。
3. 消息队列:Kafka 可以作为消息队列使用,用于异步通信、事件分发、服务间通信等场景。
4. 流式 API:Kafka 可以作为流式 API 提供商,为应用程序提供实时数据访问能力。
三、配置在使用 Kafka 作为存储时,需要进行以下配置:1. 选择合适的数据格式:Kafka 支持多种数据格式,如 JSON、AVRO、Protobuf 等,根据实际需求选择合适的格式。
2. 选择集群节点数和存储容量:根据实际需求配置 Kafka 集群的节点数和存储容量。
3. 设置分区数和副本数:合理设置分区数和副本数,以提高数据的可用性和容错能力。
4. 配置网络通信参数:根据实际网络环境配置网络通信参数,如网络接口、传输协议等。
5. 配置安全机制:根据实际需求配置安全机制,如身份认证、访问控制等。
四、使用方法使用 Kafka 作为存储,需要按照以下步骤进行操作:1. 安装和部署 Kafka 集群。
kafka入门教程

kafka入门教程
Kafka是一个分布式流处理平台,被广泛应用于大数据处理和
实时数据流处理的场景。
它具有高吞吐量、可扩展性强、持久性和容错能力、以及多种数据处理模式等特点。
本教程将引导你进入Kafka的世界,教你如何安装、配置和使
用Kafka。
下面是教程内容概述:
1. 下载和安装Kafka
首先,你需要从Kafka的官方网站上下载最新版本的Kafka。
接下来,我们将介绍如何在不同操作系统上进行安装和配置。
2. 配置Kafka
在安装完成后,你需要对Kafka进行一些必要的配置。
这包
括设置Zookeeper连接、主题(Topic)的配置、分区(Partition)的配置等。
3. 创建生产者和消费者
一旦配置完成,你就可以创建Kafka的生产者和消费者实例了。
生产者可将消息发送到指定的主题,消费者则可以订阅特定的主题并消费其中的消息。
4. 发送和接收消息
通过创建生产者并将消息发送至主题,你可以实现向Kafka
集群发送消息的功能。
消费者可以通过订阅主题并接收消息来完成消息消费的功能。
5. Kafka的高级特性
在熟悉基本使用后,你还可以学习一些更高级的Kafka特性,如消息分区、消息持久化、消息的顺序性等。
6. 故障处理和调优
正确处理故障和进行性能优化是使用Kafka的关键。
我们将
介绍一些常见的故障处理和性能优化技巧。
通过本教程,你将能够迅速上手使用Kafka,并了解它的基本
概念和常用功能。
希望这对你入门Kafka有所帮助!。
kafka topic参数

kafka topic参数Kafka Topic参数详解Kafka是一种高性能、分布式、可扩展的消息系统,被广泛应用于大数据领域。
在Kafka中,Topic是消息的逻辑分类,类似于数据库中的表,它定义了一组具有相同特征的消息。
本文将详细介绍Kafka Topic的参数及其含义,帮助读者更好地理解和使用Kafka。
一、分区数(partitions)分区数是指一个Topic被划分为多少个分区,每个分区对应一个独立的消息队列。
分区数的设置对于Kafka的性能和可伸缩性具有重要影响。
较少的分区数可能导致单个分区的负载过重,而较多的分区数可能增加了系统的复杂性和管理难度。
合理设置分区数可以根据实际需求来保证系统的高性能和可扩展性。
二、副本数(replication factor)副本数是指每个分区在集群中的复制个数。
副本数的设置对于Kafka的高可用性和容错性具有重要意义。
通常建议将副本数设置为大于等于3,以保证即使某个Broker节点发生故障,仍能保证数据的可用性。
需要注意的是,副本数的设置会影响存储空间和网络带宽的消耗,需要根据实际情况进行权衡。
三、清理策略(cleanup.policy)清理策略是指Kafka在磁盘空间不足时如何处理旧的消息。
Kafka 提供了两种清理策略:删除策略(delete)和压缩策略(compact)。
删除策略会删除旧的消息,释放磁盘空间;压缩策略会保留所有消息的最新版本,并删除重复的消息,以减少磁盘空间的占用。
根据业务需求和磁盘空间的限制,选择合适的清理策略可以有效管理消息的存储和清理。
四、消息保留时间(retention time)消息保留时间是指消息在Topic中保留的时间长度。
Kafka提供了两种设置消息保留时间的方式:基于时间(time-based)和基于大小(size-based)。
基于时间的保留策略可以根据时间间隔来删除旧的消息;基于大小的保留策略可以根据消息的字节数来删除旧的消息。
kafkatemplate参数

kafkatemplate参数Kafka是一个分布式流处理平台,被广泛应用于各种实时数据处理场景。
而在Kafka中,KafkaTemplate是一个核心的组件,用于发送消息到Kafka集群。
本文将对KafkaTemplate的参数进行详细介绍,包括参数的作用、使用方法以及常见的配置示例。
一、KafkaTemplate概述KafkaTemplate是Spring Kafka提供的一个高级别的模板类,它封装了Kafka Producer的API,提供了一系列简化发送消息的方法。
通过KafkaTemplate,开发人员可以方便地在Spring应用中与Kafka交互,实现消息的发送与消费。
二、KafkaTemplate参数说明1. defaultTopic- 数据类型:String- 默认值:null- 说明:指定默认的主题(topic),当发送消息时没有指定主题时将使用该默认主题发送消息。
2. messageConverter- 数据类型:MessageConverter- 默认值:DefaultKafkaMessageConverter- 说明:指定消息转换器,用于将应用程序的消息对象转换为Kafka消息。
3. producerListener- 数据类型:ProducerListener- 默认值:null- 说明:指定生产者监听器,用于在消息发送过程中监听并处理相关事件,如发送成功、发送失败等。
4. producerFactory- 数据类型:ProducerFactory- 默认值:null- 说明:指定生产者工厂,用于创建Kafka Producer实例。
5. sendCallback- 数据类型:ListenableFutureCallback- 默认值:null- 说明:指定发送回调,用于在发送消息成功或失败后进行回调处理。
6. closeTimeout- 数据类型:Long- 默认值:null- 说明:指定关闭Kafka Producer的超时时间(毫秒),超时后将强制关闭Producer。
kafka安装及配置过程

kafka安装及配置过程⼀、安装kafka根据Scala版本不同,⼜分为多个版本,我不需要使⽤Scala,所以就下载官⽅推荐版本kafka_2.12-2.4.0.tgz。
使⽤tar -xzvf kafka_2.12-2.4.0.tgz 解压为了使⽤⽅便,可以创建软链接kafka0⼆、Zookeeper配置当前下载的kafka程序⾥⾃带Zookeeper,可以直接使⽤其⾃带的Zookeeper建⽴集群,也可以单独使⽤Zookeeper安装⽂件建⽴集群。
1. 单独使⽤Zookeeper安装⽂件建⽴集群Zookeeper的安装及配置可以参考另⼀篇博客,⾥⾯有详细介绍2. 直接使⽤其⾃带的Zookeeper建⽴集群kafka⾃带的Zookeeper程序脚本与配置⽂件名与原⽣Zookeeper稍有不同。
kafka⾃带的Zookeeper程序使⽤bin/zookeeper-server-start.sh,以及bin/zookeeper-server-stop.sh来启动和停⽌Zookeeper。
⽽Zookeeper的配制⽂件是config/zookeeper.properties,可以修改其中的参数(1)启动Zookeeperbin/zookeeper-server-start.sh -daemon config/zookeeper.properties加-daemon参数,可以在后台启动Zookeeper,输出的信息在保存在执⾏⽬录的logs/zookeeper.out⽂件中。
对于⼩内存的服务器,启动时有可能会出现如下错误os::commit_memory(0x00000000e0000000, 536870912, 0) failed; error='Not enough space' (errno=12)可以通过修改bin/zookeeper-server-start.sh中的参数,来减少内存的使⽤,将下图中的-Xmx512M -Xms512M改⼩。
springboot之kafka配置参数

springboot之kafka配置参数在Spring Boot中使用Kafka,需要配置一些参数来连接和配置Kafka集群。
下面是一些常用的Kafka配置参数的详细解释。
1. spring.kafka.bootstrap-servers: 指定Kafka集群的地址,多个地址用逗号分隔。
例如:spring.kafka.bootstrap-servers=localhost:90922. spring.kafka.client-id: 指定Kafka客户端的唯一标识符。
3. spring.kafka.consumer.group-id: 指定消费者组的唯一标识符。
消费者组用于分配消息到不同的消费者实例。
4. spring.kafka.consumer.auto-offset-reset: 指定消费者在启动时的初始偏移量。
可选值为earliest(从最早的偏移量开始消费)或latest(从最新的偏移量开始消费)。
7. spring.kafka.consumer.max-poll-records: 指定每次拉取的最大记录数。
8. spring.kafka.consumer.key-deserializer: 指定键的反序列化器。
常用的反序列化器有StringDeserializer、IntegerDeserializer等。
9. spring.kafka.consumer.value-deserializer: 指定值的反序列化器。
10. spring.kafka.producer.key-serializer: 指定键的序列化器。
11. spring.kafka.producer.value-serializer: 指定值的序列化器。
12. spring.kafka.producer.acks: 指定生产者要求的确认模式。
可选值为all(所有副本都确认)、-1(所有副本都确认)或0(不需要确认)。
13. spring.kafka.producer.retries: 指定生产者在发生错误时的重试次数。
kafka消息序列化配置参数

kafka消息序列化配置参数Kafka消息序列化配置参数是指在Kafka消息系统中,用于配置消息的序列化和反序列化的参数。
在Kafka中,消息的序列化是指将消息对象转换为字节流的过程,而反序列化则是将字节流转换回消息对象的过程。
以下是一些常见的Kafka消息序列化配置参数:1. key.serializer,这个参数指定了用于序列化消息键的序列化器类。
在生产者端,当发送消息时,会使用这个序列化器将消息键序列化为字节流。
常见的序列化器类包括StringSerializer和IntegerSerializer等。
2. value.serializer,这个参数指定了用于序列化消息值的序列化器类。
类似地,在生产者端,当发送消息时,会使用这个序列化器将消息值序列化为字节流。
常见的序列化器类也包括StringSerializer和IntegerSerializer等。
3. key.deserializer,在消费者端,这个参数指定了用于反序列化消息键的反序列化器类。
当消费者从Kafka中获取消息时,会使用这个反序列化器将消息键的字节流反序列化为对象。
4. value.deserializer,在消费者端,这个参数指定了用于反序列化消息值的反序列化器类。
类似地,当消费者从Kafka中获取消息时,会使用这个反序列化器将消息值的字节流反序列化为对象。
5. serializer.class,在旧版本的Kafka中,这个参数用于指定消息键和值的序列化器类,而在新版本中已经被key.serializer和value.serializer取代。
这些参数可以通过Kafka的配置文件或者编程方式进行设置,以满足不同场景下的消息序列化需求。
正确配置这些参数可以确保消息在生产者和消费者之间的正确序列化和反序列化,从而保证消息在Kafka系统中的可靠传输和处理。
需要根据具体的业务需求和数据类型选择合适的序列化器类,并合理配置序列化参数,以提高系统的性能和可靠性。
kafka常用配置参数

kafka常用配置参数Kafka作为一个分布式流处理平台,有许多常用的配置参数,这些参数可以用来配置Kafka集群的行为,包括性能、可靠性、安全性等方面。
以下是一些常用的Kafka配置参数:1. broker.id,每个Kafka broker的唯一标识。
2. zookeeper.connect,用于连接Zookeeper集合的主机和端口列表。
3. work.threads,处理网络请求的线程数。
4. num.io.threads,处理磁盘IO的线程数。
5. socket.send.buffer.bytes和socket.receive.buffer.bytes,分别用于控制网络发送和接收数据的缓冲区大小。
6. num.partitions,每个主题的默认分区数。
7. default.replication.factor,每个主题的默认副本数。
8. log.retention.hours,消息日志文件保留时间。
9. offsets.topic.replication.factor,偏移量主题的副本数。
10. group.initial.rebalance.delay.ms,消费者组在重新平衡之前等待的时间。
11. fetch.min.bytes和fetch.max.wait.ms,控制消费者从服务器获取消息的最小字节数和最大等待时间。
12. max.poll.records,每次调用消费者的poll方法能够返回的最大记录数。
13. security.protocol,用于指定Kafka集群的安全协议,如PLAINTEXT、SSL、SASL_PLAINTEXT、SASL_SSL等。
14. ssl.keystore.location和ssl.truststore.location,SSL连接所需的密钥库和信任库的位置。
15. sasl.mechanism和sasl.jaas.config,用于配置SASL认证机制和相应的参数。
kafka调优参数

kafka调优参数Kafka调优参数是为了优化Kafka的性能和稳定性,以下是一些常用的Kafka 调优参数:1. work.threads:定义用于处理网络请求的线程数量,默认值是3。
可以根据实际情况增加该值来提高网络处理能力。
2. num.io.threads:定义用于处理磁盘IO的线程数量,默认值是8。
可以根据实际情况增加该值来提高磁盘IO能力。
3. socket.send.buffer.bytes 和socket.receive.buffer.bytes:定义客户端和服务器之间网络通信的缓冲区大小,默认值是64KB。
可以根据集群规模和网络带宽调整这两个参数。
4. socket.request.max.bytes:定义单个请求的最大字节数,默认值是100MB。
可以根据实际需求调整该值,例如当需要发送大量数据时可以增大该值。
5. log.segment.bytes 和log.segment.ms:定义日志分段的大小和时间,默认值分别是1GB和7天。
可以根据数据量和频率来调整这两个参数,以免产生过多的小日志段。
6. num.partitions:定义每个主题的分区数,默认值是1。
可以根据负载均衡和并行处理的需求来调整分区数,例如可以增加分区数以提高并发性能。
7. log.retention.bytes 和log.retention.ms:定义日志保留的大小和时间,默认值分别是无限制和7天。
可以根据数据量和存储空间来调整这两个参数,以避免无限制的保存大量过期数据。
8. replica.fetch.max.bytes:定义当副本从主分区拉取数据时的最大字节数,默认值是1MB。
可以根据网络带宽和副本数量来调整该值,以避免拉取数据过慢。
9. fetch.message.max.bytes:定义消费者从服务器拉取消息时的最大字节数,默认值是1MB。
可以根据消息大小和网络带宽来调整该值,以避免消息拉取过大。
logstash kafka output参数

logstash kafka output参数Logstash是一个开源的日志收集、解析和传输工具,广泛应用于大数据处理和实时数据分析领域。
Kafka作为Logstash的输出插件,可以将处理后的数据发送到Kafka集群,以便进行进一步的分析和处理。
本文将详细介绍Logstash Kafka输出插件的参数配置,帮助读者更好地应用到实际项目中。
1.Logstash简介Logstash是一个开源的日志处理工具,具有如下特点:- 高度可扩展:支持处理大量日志数据。
- 灵活的插件系统:可以方便地集成各种数据处理和传输插件。
- 易于配置:通过简单的配置文件即可实现复杂的日志处理流程。
2.Kafka输出插件的作用Kafka输出插件主要用于将Logstash处理后的数据发送到Kafka集群。
这使得Logstash具备了实时数据传输的能力,可以满足各类实时数据处理场景的需求。
3.Logstash Kafka输出参数详解Logstash Kafka输出插件的配置文件中,主要包含以下几个参数:- topic:指定发送到Kafka的主题。
- bootstrap_servers:Kafka集群的地址,多个地址用逗号分隔。
- codec:指定输出数据的编码格式,如“json”,“json_lines”等。
- group_id:指定消费者组ID,用于区分不同的消费者。
- consume_threads:指定消费线程数,用于并行处理Kafka消息。
- offset_storage:指定offset存储方式,如“文件”,“扎堆”等。
- offset_file:offset存储文件的路径。
- key_field:指定发送到Kafka的消息中的键字段。
- json_fields:指定JSON格式的消息中的字段。
4.配置示例以下是一个Logstash Kafka输出插件的配置示例:```input {stdin {}}output {kafka {bootstrap_servers => "localhost:9092"codec => "json"group_id => "logstash-consumer"consume_threads => 1offset_storage => "file"offset_file => "/var/log/logstash/kafka-offset.log"key_field => "@metadata[logstash_grok]"json_fields => ["message"]}}```5.总结Logstash Kafka输出插件为实时数据处理提供了强大的支持,通过灵活配置插件参数,可以满足各类场景的需求。
kafka bootstrap-server参数

Kafka是一种由Apache开发的分布式流处理评台,它具有高吞吐量、持久性、可伸缩性和容错特性。
在Kafka中,bootstrap-server参数被用来指定Kafka集群中用于启动客户端连接的主机和端口号。
它是Kafka客户端连接到Kafka集群的入口点,因此对于配置Kafka客户端非常重要。
在本文中,我们将深入探讨Kafka bootstrap-server参数的作用、用法和配置方式,帮助读者更好地理解和掌握Kafka的使用。
一、作用bootstrap-server参数的主要作用是告诉Kafka客户端在哪里找到Kafka集群。
当客户端启动时,它会使用bootstrap-server参数指定的主机和端口号来建立与Kafka集群的初始连接。
一旦建立了初始连接,客户端就可以获取Kafka集群的元数据信息,并开始进行消息的生产和消费操作。
二、用法在Kafka中,bootstrap-server参数可以通过两种方式进行配置:一种是通过配置文件,另一种是通过命令行参数。
1. 配置文件方式在Kafka的配置文件(通常是server.properties)中,可以通过以下方式配置bootstrap-server参数:```yamlbootstrap.servers=hostname1:port1,hostname2:port2,hostname 3:port3```其中,hostname1:port1,hostname2:port2,hostname3:port3是Kafka集群中的多个Broker节点的主机和端口号。
2. 命令行参数方式在启动Kafka客户端时,可以通过命令行参数来指定bootstrap-server参数,例如:```bash--bootstrap-serverhostname1:port1,hostname2:port2,hostname3:port3```这样,客户端就会使用命令行中指定的主机和端口号来连接到Kafka集群。
kafka,filebeat配置

kafka,filebeat配置1. zookeeper配置kafka是依赖zookeeper的,所以先要运⾏zookeeper,下载的tar包⾥⾯包含zookeeper需要改⼀下dataDir ,放在/tmp可是⾮常危险的dataDir=/data/zookeeper# the port at which the clients will connectclientPort=2181# disable the per-ip limit on the number of connections since this is a non-production configmaxClientCnxns=0maxClientCnxns可以限制每个ip的连接数。
可以适当开。
2. kafka 配置可配置项还是挺多的,总结⼏个must配置的地⽅。
# The address the socket server listens on. It will get the value returned from# .InetAddress.getCanonicalHostName() if not configured.# FORMAT:# listeners = listener_name://host_name:port# EXAMPLE:# listeners = PLAINTEXT://:9092#listeners=PLAINTEXT://:9092# Hostname and port the broker will advertise to producers and consumers. If not set,# it uses the value for "listeners" if configured. Otherwise, it will use the value# returned from .InetAddress.getCanonicalHostName().#advertised.listeners=PLAINTEXT://:9092这个listeners 很多地⽅都能⽤到。
kafka 面试题

kafka 面试题Kafka作为一种高性能的分布式消息系统,近年来在大数据领域受到了广泛的应用和关注。
对于准备参加Kafka相关岗位面试的求职者来说,熟悉Kafka的原理和技术细节是非常重要的。
本文将就Kafka面试中常见的一些问题做一些详细的解答,帮助读者更好地准备和应对Kafka面试。
1. 什么是Kafka?Kafka是一种开源的、分布式的发布-订阅消息系统,最初由LinkedIn公司开发。
它主要用于高容量的实时日志聚合、数据管道以及流式处理应用。
2. Kafka的工作原理是什么?Kafka采用了分布式提交日志的架构,可以将消息以多个topic进行分类,每个topic又可以分为多个partition。
Producer将消息写入指定topic的partition,而Consumer则订阅一个或多个topic的partition并消费其中的消息。
3. Kafka的主要组件有哪些?Kafka的主要组件包括以下几个:- Producer:负责将消息写入Kafka集群。
- Consumer:负责从Kafka集群中读取消息。
- Broker:Kafka集群中的一个节点,负责消息的存储、转发和复制。
- Topic:消息的类别或主题。
- Partition:一个topic可以分为多个partition,每个partition是一个有序的消息队列。
- Offset:消息在partition中的唯一标识,Consumer可以通过指定offset来消费特定位置的消息。
- ZooKeeper:Kafka使用ZooKeeper来进行集群管理和协调。
4. Kafka有哪些重要的配置参数?Kafka的配置参数非常丰富,以下是一些重要的配置参数示例:- broker.id:每个Broker在集群中的唯一标识。
- log.dirs:指定存储消息日志的目录。
- num.partitions:每个topic的partition数量。
kafka linux参数

kafka linux参数Kafka Linux参数详解Kafka是一种高性能、分布式的消息队列系统,常用于构建实时流数据处理平台。
在Linux环境下,为了保证Kafka的正常运行和提高性能,我们可以通过配置参数来调整其行为和性能。
本文将详细介绍几个常用的Kafka Linux参数。
一、Kafka配置文件Kafka的配置文件位于Kafka安装目录下的config文件夹中,主要包括server.properties和producer.properties两个文件。
其中server.properties是Kafka服务端的配置文件,包含了Kafka的核心参数;producer.properties是生产者客户端的配置文件,主要用于配置生产者相关的参数。
二、Kafka核心参数1. broker.idbroker.id是Kafka集群中每个broker的唯一标识,用于在集群中唯一标识每个broker。
在配置文件中,可以通过设置broker.id参数来指定broker的ID。
2. listenerslisteners参数用于配置Kafka服务端监听的端口和协议。
默认情况下,Kafka使用9092端口,并支持PLAINTEXT、SSL、SASL_PLAINTEXT等协议。
可以通过修改listeners参数来指定监听的端口和协议。
3. log.dirslog.dirs参数用于配置Kafka存储日志文件的目录。
Kafka使用日志文件来存储消息,每个分区对应一个日志文件。
可以通过修改log.dirs参数来指定存储日志文件的目录。
4. num.partitionsnum.partitions参数用于指定一个主题(topic)的分区数。
Kafka 将消息分发到不同的分区中,以实现消息的并行处理和负载均衡。
可以通过修改num.partitions参数来增加或减少分区的数量。
5. message.max.bytesmessage.max.bytes参数用于限制Kafka接收的单个消息的最大字节数。
kafka配置参数详解
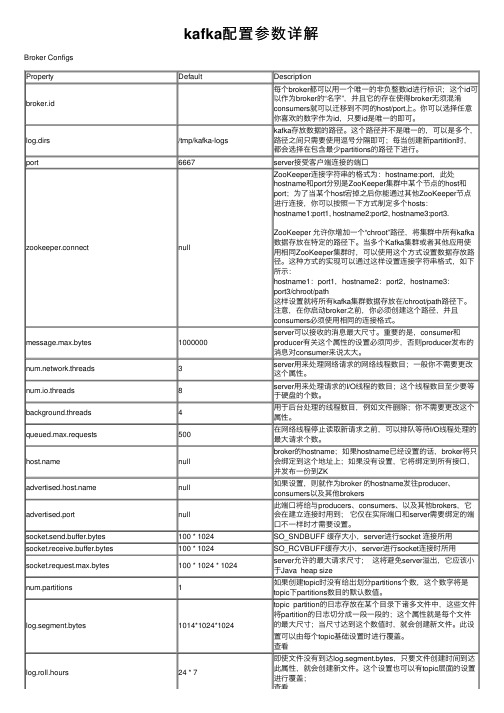
kafka配置参数详解Broker ConfigsProperty Default Descriptionbroker.id 每个broker都可以⽤⼀个唯⼀的⾮负整数id进⾏标识;这个id可以作为broker的“名字”,并且它的存在使得broker⽆须混淆consumers就可以迁移到不同的host/port上。
你可以选择任意你喜欢的数字作为id,只要id是唯⼀的即可。
log.dirs/tmp/kafka-logs kafka存放数据的路径。
这个路径并不是唯⼀的,可以是多个,路径之间只需要使⽤逗号分隔即可;每当创建新partition时,都会选择在包含最少partitions的路径下进⾏。
port6667server接受客户端连接的端⼝zookeeper.connect null ZooKeeper连接字符串的格式为:hostname:port,此处hostname和port分别是ZooKeeper集群中某个节点的host和port;为了当某个host宕掉之后你能通过其他ZooKeeper节点进⾏连接,你可以按照⼀下⽅式制定多个hosts:hostname1:port1, hostname2:port2, hostname3:port3. ZooKeeper 允许你增加⼀个“chroot”路径,将集群中所有kafka 数据存放在特定的路径下。
当多个Kafka集群或者其他应⽤使⽤相同ZooKeeper集群时,可以使⽤这个⽅式设置数据存放路径。
这种⽅式的实现可以通过这样设置连接字符串格式,如下所⽰:hostname1:port1,hostname2:port2,hostname3:port3/chroot/path这样设置就将所有kafka集群数据存放在/chroot/path路径下。
注意,在你启动broker之前,你必须创建这个路径,并且consumers必须使⽤相同的连接格式。
message.max.bytes1000000server可以接收的消息最⼤尺⼨。
kafka配置文件详解

kafka配置⽂件详解kafka的配置分为 broker、producter、consumer三个不同的配置⼀、BROKER 的全局配置最为核⼼的三个配置 broker.id、log.dir、zookeeper.connect 。
------------------------------------------- 系统相关 -------------------------------------------每⼀个broker在集群中的唯⼀标⽰,要求是正数。
在改变IP地址,不改变broker.id的话不会影响consumersbroker.id =1kafka数据的存放地址,多个地址的话⽤逗号分割 /tmp/kafka-logs-1,/tmp/kafka-logs-2log.dirs = /tmp/kafka-logs提供给客户端响应的端⼝port =6667消息体的最⼤⼤⼩,单位是字节message.max.bytes =1000000broker 处理消息的最⼤线程数,⼀般情况下不需要去修改work.threads =3broker处理磁盘IO 的线程数,数值应该⼤于你的硬盘数num.io.threads =8⼀些后台任务处理的线程数,例如过期消息⽂件的删除等,⼀般情况下不需要去做修改background.threads =4等待IO线程处理的请求队列最⼤数,若是等待IO的请求超过这个数值,那么会停⽌接受外部消息,算是⼀种⾃我保护机制queued.max.requests =500broker的主机地址,若是设置了,那么会绑定到这个地址上,若是没有,会绑定到所有的接⼝上,并将其中之⼀发送到ZK,⼀般不设置打⼴告的地址,若是设置的话,会提供给producers, consumers,其他broker连接,具体如何使⽤还未深究⼴告地址端⼝,必须不同于port中的设置advertised.portsocket的发送缓冲区,socket的调优参数SO_SNDBUFFsocket.send.buffer.bytes =100*1024socket的接受缓冲区,socket的调优参数SO_RCVBUFFsocket.receive.buffer.bytes =100*1024socket请求的最⼤数值,防⽌serverOOM,message.max.bytes必然要⼩于socket.request.max.bytes,会被topic创建时的指定参数覆盖socket.request.max.bytes =10010241024------------------------------------------- LOG 相关 -------------------------------------------topic的分区是以⼀堆segment⽂件存储的,这个控制每个segment的⼤⼩,会被topic 创建时的指定参数覆盖log.segment.bytes =102410241024这个参数会在⽇志segment没有达到log.segment.bytes设置的⼤⼩,也会强制新建⼀个segment 会被 topic创建时的指定参数覆盖log.roll.hours =24*7⽇志清理策略选择有:delete和compact 主要针对过期数据的处理,或是⽇志⽂件达到限制的额度,会被 topic创建时的指定参数覆盖log.cleanup.policy = delete数据存储的最⼤时间超过这个时间会根据log.cleanup.policy设置的策略处理数据,也就是消费端能够多久去消费数据log.retention.bytes和log.retention.minutes任意⼀个达到要求,都会执⾏删除,会被topic创建时的指定参数覆盖log.retention.minutes=7days指定⽇志每隔多久检查看是否可以被删除,默认1分钟log.cleanup.interval.mins=1topic每个分区的最⼤⽂件⼤⼩,⼀个topic的⼤⼩限制 = 分区数*log.retention.bytes 。
kafka内存设置原则

kafka内存设置原则Kafka 是一个高性能分布式消息传递系统,广泛应用于实时数据处理等场景中。
如何设置 Kafka 的内存是一个很重要的问题,可以影响到其性能和稳定性。
本文将为大家介绍 Kafka 内存设置的原则和步骤。
1. 确定 JVM 参数Kafka 运行在 Java 虚拟机(JVM)中,因此内存设置需要通过JVM 参数的方式进行。
JVM 参数主要包括两种:堆参数和非堆参数。
堆参数用于控制 Java 程序的堆内存大小,非堆参数用于控制 Java 程序中的非堆内存大小。
Kafka 中常用的 JVM 参数如下:- Xms:堆内存的初始大小。
- Xmx:堆内存的最大大小。
- Xmn:新生代内存大小。
- XX:MaxDirectMemorySize:Direct Memory 的最大大小。
- XX:MaxPermSize:永久代的最大大小。
- XX:MaxMetaspaceSize:元空间的最大大小。
2. 确定 Kafka 参数除了 JVM 参数,Kafka 自身也有一些参数需要设置。
Kafka 中常用的参数如下:- message.max.bytes:单个消息的最大大小。
- replica.fetch.max.bytes:从副本获取消息的最大大小。
- socket.receive.buffer.bytes:socket 接收缓冲区的大小。
- socket.request.max.bytes:请求的最大大小。
- log.retention.bytes:日志文件的最大大小。
3. 分配内存比例在确定了 JVM 和 Kafka 的参数之后,需要合理设置内存的分配比例。
Kafka 的内存主要分为堆内存和 Direct Memory。
堆内存用于存储 Kafka 的 metadata、消息日志和索引数据等,而 DirectMemory 用于提高数据读写的效率。
通常情况下,建议将堆内存和 Direct Memory 的比例设置为1:1,即堆内存占总内存的一半,Direct Memory 也占总内存的一半。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1配置jdk8
假设安装(解压)路径:jdk1.8.0
修改/etc/profile,增加以下设置并保存
Export JAVA_HOME=jdk1.8.0
Export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
Export CLASSPATH=$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$CLASSPATH
命令行中执行source /etc/profile
2Zookeeper centos7 虚拟机群部署
假设目录结构为
/opt/zookeeper/ #zookeeper存放目录
/opt/zkdata#快照日志的存储路径
/opt/zklog#事物日志的存储路径
2.1在每台机器上修改配置文件
(1)进入/opt/zookeeper/conf,建立配置文件并修改。
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改内容如下:
tickTime=2000
#这个时间是作为Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime 时间就会发送一个心跳。
initLimit=10
#这个配置项是用来配置Zookeeper 接受客户端(这里所说的客户端不是用户连接Zookeeper 服务器的客户端,而是Zookeeper 服务器集群中连接到Leader 的Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。
当已经超过5个心跳的时间(也就是tickTime)长度后Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。
总的时间长度就是5*2000=10 秒
syncLimit=5
#这个配置项标识Leader 与Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个tickTime 的时间长度,总的时间长度就是5*2000=10秒
dataDir=/opt/zkdata
#快照日志的存储路径
dataLogDir=/opt/zklog
#事物日志的存储路径,如果不配置这个那么事物日志会默认存储到dataDir制定的目录,这样会严重影响zk的性能,当zk吞吐量较大的时候,产生的事物日志、快照日志太多
clientPort=12181
#这个端口就是客户端连接Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
修改他的端口改大点
server.1=192.168.7.100:12888:13888
server.2=192.168.7.101:12888:13888
server.3=192.168.7.107:12888:13888
#server.1 这个1是服务器的标识也可以是其他的数字,表示这个是第几号服务器,用来标识服务器,这个标识要写到快照目录下面myid文件里
#192.168.7.107为集群里的IP地址,第一个端口是master和slave之间的通信端口,默认是2888,第二个端口是leader选举的端口,集群刚启动的时候选举或者leader 挂掉之后进行新的选举的端口默认是3888
(2)在每台机器创建myid文件
#server1
echo "1" > /opt/zookeeper/zkdata/myid
#Echo “”中的整数要与zoo.cfg文件中server. 后面的数字相同
(3)启动zookeeper
/opt/zookeeper/bin/zkServer.sh start
(4)查看服务状态
/opt/zookeeper/bin/zkServer.sh status
正常应显示如下信息:
JMX enabled by default
Using config: /opt/zookeeper/zookeeper-3.4.6/bin/../conf/zoo.cfg #配置文件Mode: follower #是否为领导
2.2Zookeeper常见启动错误排查
排查方法:启动时打开日志./zkServer.sh start-foreground并观察
常见原因及解决方法:
(1)zookeeper配置错误
检查各项配置即可,例如路径、端口号等
(2)检查是否存在myid文件,内容是否正确
(3)出现“no route to host”
关闭防火墙即可:systemctl stop firewalld.service
systemctl disable firewalld.service
(4)”bindException”
查看端口占用
Lsof -i:12181#zoo.cfg中的clientPort
若有其他程序占用则考虑终止该进程
Kill -9 PID
常用命令:
Uname -a 查看位数
Cat /etc/os-release 查看系统版本
3K afka分布式部署
下载kafka二进制包并解压,假设解压路径:kafka
注意:zookeeper-server与kafka-server的启动需root用户权限
(1)修改kafka配置
vim kafka/config/server.properties
修改内容如下:
broker.id=1 # 每台服务器的broker.id都不能相同
#hostname
=192.168.7.100
#在log.retention.hours=168 下面新增下面三项
message.max.byte=5242880
default.replication.factor=2
replica.fetch.max.bytes=5242880
#设置zookeeper的连接端口
zookeeper.connect=192.168.7.100:12181,192.168.7.101:12181,192.168.7.107:12181
(2)在每台机器上启动kafka
Kafka/bin/kafka-server-start.sh kafka/config/server.properties
利用Jps检查kafka服务是否启动
(3)创建、发布、订阅消息
a)创建Topic
kafka/bin/kafka-topics.sh --create --zookeeper IP:12181 --replication-factor 2 --partitions
1 --topic testtopic
b)创建一个发布者
kafka/bin/kafka-console-producer.sh --broker-list IP:9092 --topic testtopic
c)创建一个订阅者
bin/kafka-console-consumer.sh --bootstrap-server IP:9092 --from-beginning --topic testtopic
4Centos 虚拟集群网络配置
(1)首先查看网卡设备是否为eth0,若不是转至步骤2,否则转至步骤4
ifconfig -a
(2)修改网卡配置
vim /etc/sysconfig/grub
找到“GRUB_CMDLINE_LINUX”,增加net.ifnames=0 biosdevname=0并保存
(3)执行grub2-mkconfig -o /boot/grub2/grub.cfg
(4)更改/etc/sysconfig/network-scripts/目录下的ifcfg-eno16777736为ifcfg-eth0,并修改里面内容。
如下:
1.DEVICE=eth0
2.BOOTPROTO=static
3.IPADDR=192.168.17.100
MASK=25
5.255.255.0
5.HWADDR=00:0C:29:9C:48:B4
6.IPV6INIT=no
7.NM_CONTROLLED=yes
8.ONBOOT=yes
9.TYPE=Ethernet
10.UUID=35d96ab0-4a6a-4cca-b6c9-fbe24003a44d
11.DNS1=192.168.17.2
12.GATEWAY=192.168.17.2
其中地址在VM的“虚拟网络编辑器”中查看或修改,并设置虚拟机的网络设置,如下图
(5)重启,ifconfig查看是否成功。
(6)在每台机器上完成以上步骤
(7)Ping 其他机器IP,若ping成功则集群网络配置成功。