图解Hadoop生态系统
【PPT培训课件】hadoop生态圈

zookeeper
概 念
iSend
iReceive iSend iReceive
Zookeeper典型应用-工作过程
Zookeeper
架构
工作原理:Paxos算法
z3 z1
架 构
z2
iSend
iReceive
Zookeeper
实例
cSlave0 cSlave1 cSlave2
部 署
yum install zookeeper-server
cMaster
cSlave0
现 实 需 求 2006年谷歌发表论文BigTable, 年末、微软旗下自然语言搜索 公司Powerset出于处理大数据 的需求,按论文思想,开启了 HBase项目 在 线 访 问 在线 实时 服务
例 题
cMaster
cSlave0
cSlave2
iClient
cProxy
cSlave1
Zookeeper
为什么
部 分 失 败 现 实 需 求
zookeeper
当一条消息在网络中的两个节点之间传送时,由于可能会出现各 种问题,发送者无法知道接收者是否已经接收到这条消息,比如 在接收者还未接收到消息前,发生网络中断,再比如接收者接收 到消息后发生网络中断,甚至是接收进程死掉。发送者能够获取 真实情况的唯一途径是重新连接接收者,并向它发出询问。
例 题
①分别使用命令行接口和API接口向zookeeper存储树中新建一 节点并存入信息 ②假设机器cSlave0上有进程Pa,机器cSlave2上有进程Pb,使 用zookeeper实现进程Pa与Pb相互协作
HBase
为什么
cSlave2
客户欲实 时读HDFS 里数据
hadoop生态系统及简介
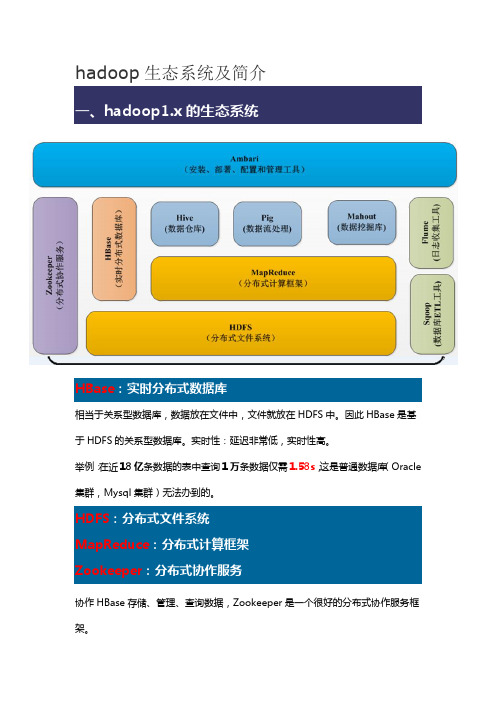
hadoop生态系统及简介HBase:实时分布式数据库相当于关系型数据库,数据放在文件中,文件就放在HDFS中。
因此HBase是基于HDFS的关系型数据库。
实时性:延迟非常低,实时性高。
举例:在近18亿条数据的表中查询1万条数据仅需1.58s,这是普通数据库(Oracle 集群,Mysql集群)无法办到的。
HDFS:分布式文件系统MapReduce:分布式计算框架Zookeeper:分布式协作服务协作HBase存储、管理、查询数据,Zookeeper是一个很好的分布式协作服务框架。
Hive数据仓库:比如给你一块1000平方米的仓库,让你放水果。
如果有春夏秋冬四季的水果,让你放在某一个分类中。
但是水果又要分为香蕉、苹果等等。
然后又要分为好的水果和坏的水果。
因此数据仓库的概念也是如此,他是一个大的仓库,然后里面有很多格局,每个格局里面又分小格局等等。
对于整个系统来说,比如文件系统。
文件如何去管理?Hive 就是来解决这个问题。
Hive:分类管理文件和数据,对这些数据可以通过很友好的接口,提供类似于SQL语言的HiveQL查询语言来帮助你进行分析。
其实Hive底层是转换成MapReduce的,写的HiveQL进行执行的时候,Hive提供一个引擎将其转换成MapReduce再去执行。
Hive设计目的:方便DBA很快地转到大数据的挖掘和分析中。
Pig基于MapReduce的,基于流处理的。
写了动态语言之后,也是转换成MapReduce 进行执行。
和Hive类似。
Mahout基于图形化的数据碗蕨。
SqoopELT:提取--> 转换--> 加载。
从数据库中获取数据,并进行一系列的数据清理和清洗筛选,将合格的数据转换成一定格式的数据进行存储,将格式化的数据存储到HDFS文件系统上,以供计算框架进行数据分析和挖掘。
格式化数据:TSV 格式:每行数据的每列之间以制表符(tab \t)进行分割CVS 格式:每行数据的每列之间以逗号进行分割Sqoop:将关系型数据库中的数据与HDFS(HDFS 文件,HBase中的表,Hive 中的表)上的数据进行相互导入导出。
Hadoop生态体系简介

资源调度系统YARN
资源调度系统YARN
• Resource Manager (RM)负责管理集群的container分 配 • Node Manager管理每个节点上的资源和任务,主要有 两个作用,定期向RM汇报该节点的资源使用情况和各 个container的运行状态,接收并处理AM的任务启动、 停止等请求 • Application Master (AM),每个应用专属,负责该应用 下任务的调度和协调 • 每个container可看做是一个资源的封装实体,包括 CPU资源和内存资源
Hive优化技巧
原语句:SELECT COUNT( DISTINCT id ) FROM TABLE_NAME 由于语句没有group by,hive只在一个reduce处理数据 改写为:SELECT COUNT(*) FROM (SELECT DISTINCT id FROM TABLE_NAME) T
Hadoop发行版本
• • • • Cloudera Hadoop (CDH) Hortonworks Data Platform (HDP) MapR Intel
Hadoop生态体系结构
分布式文件系统HDFS
客户端读取HDFS中的数据
客户端将数据写入HDFS
HDFS复本如何存放
• 在运行客户端的节点上放第一个复本 • 第二个复本放在与第一个不同且随机另外选择 的机架中的节点上 • 第三个复本与第二个复本放在同一个机架上, 且随机选择另一个节点
Reduce阶段
• • • • Reduce通过http从NodeM输出到磁盘 最后把接收到的文件合并起来输入reduce 执行用户reducer方法,结果输出到hdfs
Hadoop简介

fileSystem.mkdirs(new Path("/test"));
} //上传本地文件到HDFS
fileSystem.copyFromLocalFile(src, dst);
fileSystem.copyFromLocalFile(delSrc, src, dst); fileSystem.copyFromLocalFile(delSrc, overwrite, src, dst); fileSystem.copyFromLocalFile(delSrc, overwrite, srcs, dst);
HDFS JAVA API
//重命名HDFS文件 fileSystem.rename(src, dst); //删除文件, True 表示递归删除
fileSystem.delete(new Path("/d1"), true);
//查找某个文件在HDFS集群的位置 FileStatus fs = fileSystem.getFileStatus(new Path("/data")); BlockLocation[] bls=fileSystem.getFileBlockLocations(fs, 0, fs.getLen()); for (int i = 0,h=bls.length; i < h; i++) { String[] hosts= bls[i].getHosts(); System.out.println("block_"+i+"_location: "+hosts[0]); } //获取HDFS集群上所有节点名称信息 DistributedFileSystem hdfs = (DistributedFileSystem) fileSystem; DatanodeInfo[] dns=hdfs.getDataNodeStats(); for (int i = 0,h=dns.length; i < h; i++) {
Hadoop生态系统基本介绍

基于QJM的HDFS HA架构概述
• 在HA模式的HDFS有如下的守护进程
a. Active NameNode(主) b. standby NameNode(主) c. DataNode(从) d. JournalNode(奇数个) e. ZKFC(主备)
写文件流程
HDFS client
1:create 3:write
• 2007年1月 研究集群增加到900个节点 • 2007年4月 研究集群增加到两个集群1000个节点 • 2008年4月 在900个节点上运行1TB的排序测试集仅需要209秒,成为全球最快 • 2008年10月 研究集群每天状态10TB的数据 • 2009年3月 17个集群共24000个节点 • 2009年4月 在每分钟排序中胜出,59秒内排序500GB(1400个节点上)和173分钟
Data store n
map
(Key 1, Values…)
Байду номын сангаас
(Key 2, Values…)
(Key 3, Values…)
==Barrier== : Aggregates intermediate values by output key
Key 1, Intermediate Values
Key 2, Intermediate Values
the aardvark sat on the sofa
• Intermediate data produced:
(the, 1), (cat, 1), (sat, 1), (on, 1), (the, 1) (mat, 1), (the, 1), (aardvark, 1), (sat, 1) (on, 1), (the, 1), (sofa, 1)
把 Hadoop 生态的核心讲明白了!

Hadoop是一个由Apache基金会开发的分布式系统基础架构。
开发人员可以在不了解分布式底层细节的情况下开发分布式程序,充分利用集群的威力进行高速并行运算以及海量数据的分布式存储。
Hadoop大数据技术架构如图1所示。
图1Hadoop大数据技术架构然而,Hadoop不是一个孤立的技术,而是一套完整的生态圈,如图2所示。
在这个生态圈中,Hadoop最核心的组件就是分布式文件系统HDFS和分布式计算框架MapReduce。
HDFS为海量的数据提供了存储,是整个大数据平台的基础,而MapReduce则为海量的数据提供了计算能力。
在它们之上有各种大数据技术框架,包括数据仓库Hive、流式计算Storm、数据挖掘工具Mahout和分布式数据库HBase。
此外,ZooKeeper为Hadoop集群提供了高可靠运行的框架,保证Hadoop集群在部分节点宕机的情况下依然可靠运行。
Sqoop与Flume分别是结构化与非结构化数据采集工具,通过它们可以将海量数据抽取到Hadoop平台上,进行后续的大数据分析。
图2Hadoop大数据生态圈Cloudera与Hortonworks是大数据的集成工具,它们将大数据技术的各种组件集成在一起,简化安装、部署等工作,并提供统一的配置、管理、监控等功能。
Oozie是一个业务编排工具,我们将复杂的大数据处理过程解耦成一个个小脚本,然后用Oozie组织在一起进行业务编排,定期执行与调度。
01分布式文件系统过去,我们用诸如DOS、Windows、Linux、UNIX等许多系统来在计算机上存储并管理各种文件。
与它们不同的是,分布式文件系统是将文件散列地存储在多个服务器上,从而可以并行处理海量数据。
Hadoop的分布式文件系统HDFS如图3所示,它首先将服务器集群分为名称节点(NameNode)与数据节点(DataNode)。
名称节点是控制节点,当需要存储数据时,名称节点将很大的数据文件拆分成一个个大小为128MB的小文件,然后散列存储在其下的很多数据节点中。
Hadoop生态系统概述以及版本演化

Hadoop构成 YARN(资源管理系统)
Hadoop构成 YARN(资源管理系统)
Hadoop构成 MapReduce(分布式计算框架)
源自于Google的MapReduce论文
发表于2004年12月 Hadoop MapReduce是Google MapReduce克隆版
MapReduce特点
Spark …
(内存计算)
YARN
(分布式计算框架)
HDFS
(分布式存储系统)
Flume (日志收集 )
Hadoop构成 Hive(基于MR的数据仓库)
由facebook开源,最初用于解决海量结构化的日志数据统 计问题;
ETL(Extraction-Transformation-Loading)工具
Hadoop构成 YARN(资源管理系统)
YARN是什么
Hadoop 2.0新增系统 负责集群的资源管理和调度 使得多种计算框架可以运行在一个集群中
YARN的特点
良好的扩展性、高可用性 对多种类型的应用程序进行统一管理和调度 自带了多种多用户调度器,适合共享集群环境
Hadoop构成 YARN(资源管理系统)
Hadoop介绍 概述
分布式存储系统HDFS(Hadoop Distributed File System)
分布式存储系统 提供了高可靠性、高扩展性和高吞吐率的数据存储服务
资源管理系统YARN(Yet Another Resource Negotiator)
负责集群资源的统一管理和调度
分布式计算框架MapReduce
构建在Hadoop之上的数据仓库;
数据计算使用MR,数据存储使用HDFS
Hive 定义了一种类 SQL 查询语言——HQL;
搞懂Hadoop生态系统

01Hadoop概述Hadoop体系也是一个计算框架,在这个框架下,可以使用一种简单的编程模式,通过多台计算机构成的集群,分布式处理大数据集。
Hadoop是可扩展的,它可以方便地从单一服务器扩展到数千台服务器,每台服务器进行本地计算和存储。
除了依赖于硬件交付的高可用性,软件库本身也提供数据保护,并可以在应用层做失败处理,从而在计算机集群的顶层提供高可用服务。
Hadoop核心生态圈组件如图1所示。
图1Haddoop开源生态02Hadoop生态圈Hadoop包括以下4个基本模块。
1)Hadoop基础功能库:支持其他Hadoop模块的通用程序包。
2)HDFS:一个分布式文件系统,能够以高吞吐量访问应用中的数据。
3)YARN:一个作业调度和资源管理框架。
4)MapReduce:一个基于YARN的大数据并行处理程序。
除了基本模块,Hadoop还包括以下项目。
1)Ambari:基于Web,用于配置、管理和监控Hadoop集群。
支持HDFS、MapReduce、Hive、HCatalog、HBase、ZooKeeper、Oozie、Pig和Sqoop。
Ambari还提供显示集群健康状况的仪表盘,如热点图等。
Ambari以图形化的方式查看MapReduce、Pig和Hive应用程序的运行情况,因此可以通过对用户友好的方式诊断应用的性能问题。
2)Avro:数据序列化系统。
3)Cassandra:可扩展的、无单点故障的NoSQL多主数据库。
4)Chukwa:用于大型分布式系统的数据采集系统。
5)HBase:可扩展的分布式数据库,支持大表的结构化数据存储。
6)Hive:数据仓库基础架构,提供数据汇总和命令行即席查询功能。
7)Mahout:可扩展的机器学习和数据挖掘库。
8)Pig:用于并行计算的高级数据流语言和执行框架。
9)Spark:可高速处理Hadoop数据的通用计算引擎。
Spark提供了一种简单而富有表达能力的编程模式,支持ETL、机器学习、数据流处理、图像计算等多种应用。
Hadoop技术介绍PPT课件

精选ppt2021最新
8
数据存取策略
HDFS上的最小数据单元为Block。原始文件被分成1个或者多个Block,默认 Block大小为64M,默认存储3份Block。
由NameNode决定三份Block分别存放在哪些DataNode上。根据散列算法出第一份 数据的存放节点,在同一机架(Rack)中的另一个DataNode保存第二份数据,在不同 机架的另一个DataNode保存第三份数据。NameNode记录了数据的所有位置信息。
精选ppt2021最新
16
精选ppt2021最新
17
相关框架
ZooKeeper
Zookeeper是Google的Chubby一个开源的实现,是高有效和可靠的协同工作系统, Zookeeper能够用来Leader选举,配置信息维护等。
Sqoop
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一 个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中, 也可以将HDFS的数据导进到关系型数据库中。
对指定列根据列值进行分区,每个区一个目录。 Bucket
对指定列进行Hash分区,每个区一个目录。 External Table
对应HDFS一个目录路径,删除表,数据不会删除
精选ppt2021最新
15
Hbase (Hadoop DataBase) HBase是一个分布式的、面向列的开源数据库。Hbase依托于Hadoop的HDFS
精选ppt2021最新
11
Hadoop不是万能的
✓ 离线海量数据分析 一次写入,多次读取 海量历史数据统计分析
✓ 非结构化数据处理
Hadoop家族以及环境搭建(附图解)

Hadoop家族以及环境搭建(附图解)来源:ITSTAR回顾上次课内容,上一次课首先我们就给大家介绍了项目如何去安装Linuxp环境,这个步骤我们写得非常的清楚和详细,建议大家下来以后一定要按照我们的文档一步一步的进行操作,所以我们提供了一个word的文档,这个文档大家可以从我们这个实验介质当中可以找到这个文档,那这里实际上就列出来了你在安装这个Linux的时候需要注意哪些具体的问题。
前面的这些步骤都比较简单,咱们就看一看就可以了。
前面的这些都是比较简单,我们把重点的几个步骤给大家再说一下,我们往下看其中一个非常重要的步骤就是,你要选择你的网卡类型,我们在这里推荐大家去选择这个仅主机模式的这X网卡,它就能够保证我们的本机和虚拟机能够进行通信,这样我们在本机上通过Putty就能连接到虚拟机Linux上,但是你选择仅主机模式的时候,在安装Linux的时候就需要设置它的ip地址,而这个ip地址咱们的笔记上面是写得很清楚的,那么我们可以看到当你设置ip地址的时候,你需要跟你本机上VMware net1的这个网卡在同一个网段上,这个咱们可以来确定下,因为我们抓好了这个VMware以后我们可以打开我们的这个命令行的窗口,我们可以执行ip这个config -all列出来所有的ip的地址,我们应该看这个就是VMware net1的这个网卡,他锁定的ip地址是192.168.157注意,这个地址是网关地址,网关就是windows,然后在安Linux的时候,你指的ip地址需要跟这个ip地址在一个网段也就是说在这个157的这个上所以呢我们一共会安装5台的Linux,那么ip地址大家设置的时候要设是192.168.157.111,192.168.157.112,192.168.157.113和192.168.157.114和192.168.157.115这样,通过这些ip地址就可以从windows 上连接到Linux上,这个问题大家一定不要设置错了。
大数据学习之路(1)Hadoop生态体系结构
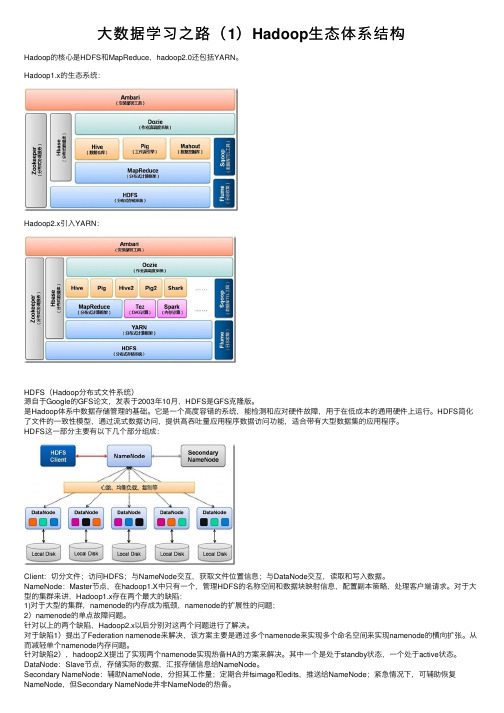
⼤数据学习之路(1)Hadoop⽣态体系结构Hadoop的核⼼是HDFS和MapReduce,hadoop2.0还包括YARN。
Hadoop1.x的⽣态系统:Hadoop2.x引⼊YARN:HDFS(Hadoop分布式⽂件系统)源⾃于Google的GFS论⽂,发表于2003年10⽉,HDFS是GFS克隆版。
是Hadoop体系中数据存储管理的基础。
它是⼀个⾼度容错的系统,能检测和应对硬件故障,⽤于在低成本的通⽤硬件上运⾏。
HDFS简化了⽂件的⼀致性模型,通过流式数据访问,提供⾼吞吐量应⽤程序数据访问功能,适合带有⼤型数据集的应⽤程序。
HDFS这⼀部分主要有以下⼏个部分组成:Client:切分⽂件;访问HDFS;与NameNode交互,获取⽂件位置信息;与DataNode交互,读取和写⼊数据。
NameNode:Master节点,在hadoop1.X中只有⼀个,管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户端请求。
对于⼤型的集群来讲,Hadoop1.x存在两个最⼤的缺陷:1)对于⼤型的集群,namenode的内存成为瓶颈,namenode的扩展性的问题;2)namenode的单点故障问题。
针对以上的两个缺陷,Hadoop2.x以后分别对这两个问题进⾏了解决。
对于缺陷1)提出了Federation namenode来解决,该⽅案主要是通过多个namenode来实现多个命名空间来实现namenode的横向扩张。
从⽽减轻单个namenode内存问题。
针对缺陷2),hadoop2.X提出了实现两个namenode实现热备HA的⽅案来解决。
其中⼀个是处于standby状态,⼀个处于active状态。
DataNode:Slave节点,存储实际的数据,汇报存储信息给NameNode。
Secondary NameNode:辅助NameNode,分担其⼯作量;定期合并fsimage和edits,推送给NameNode;紧急情况下,可辅助恢复NameNode,但Secondary NameNode并⾮NameNode的热备。
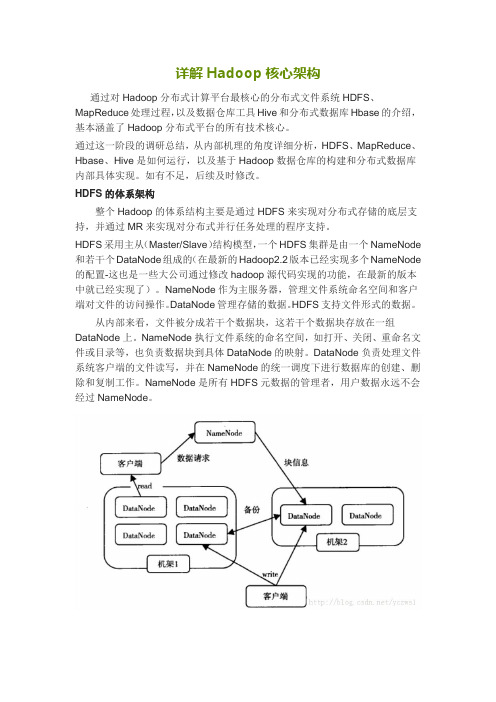
详解Hadoop核心架构
详解Hadoop核心架构通过对Hadoop分布式计算平台最核心的分布式文件系统HDFS、MapReduce处理过程,以及数据仓库工具Hive和分布式数据库Hbase的介绍,基本涵盖了Hadoop分布式平台的所有技术核心。
通过这一阶段的调研总结,从内部机理的角度详细分析,HDFS、MapReduce、Hbase、Hive是如何运行,以及基于Hadoop数据仓库的构建和分布式数据库内部具体实现。
如有不足,后续及时修改。
HDFS的体系架构整个Hadoop的体系结构主要是通过HDFS来实现对分布式存储的底层支持,并通过MR来实现对分布式并行任务处理的程序支持。
HDFS采用主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode 和若干个DataNode组成的(在最新的Hadoop2.2版本已经实现多个NameNode 的配置-这也是一些大公司通过修改hadoop源代码实现的功能,在最新的版本中就已经实现了)。
NameNode作为主服务器,管理文件系统命名空间和客户端对文件的访问操作。
DataNode管理存储的数据。
HDFS支持文件形式的数据。
从内部来看,文件被分成若干个数据块,这若干个数据块存放在一组DataNode上。
NameNode执行文件系统的命名空间,如打开、关闭、重命名文件或目录等,也负责数据块到具体DataNode的映射。
DataNode负责处理文件系统客户端的文件读写,并在NameNode的统一调度下进行数据库的创建、删除和复制工作。
NameNode是所有HDFS元数据的管理者,用户数据永远不会经过NameNode。
如图:HDFS体系结构图图中涉及三个角色:NameNode、DataNode、Client。
NameNode是管理者,DataNode是文件存储者、Client是需要获取分布式文件系统的应用程序。
文件写入:1) Client向NameNode发起文件写入的请求。
云计算平台架构图

Hadoop生态系统数据流程图及架构图
1、mysql、oracle、sql server等关系型数据库的结构化数据通过sqoop2工具导入到hive、hdfs中,通过hive、mapreduce等工具进行过虑、清洗、统计、分析、计算等操作,将操作后的数据放到hdfs云存储里面,或者再通过sqoop2工具导回到关系型数据库。
2、日志、文档、图片、小视频等半结构化数据及非结构化数据通过flume或者其他数据采集工具采集,采集的数据可以放到hdfs云存储、hbase分布式数据库等。
3、通过hbase api的接口将各类数据组织之后放到hbase分布式数据库中。
4、数据采集工具采集到的一部分数据可以进行流式计算,即数据先缓存到kafka等消息队列,然后实时传送给storm系统进行数据挖掘,数据分析等,将所得结果放到关系型或非关系型数据库。
5、spark系统和hadoop系统结合使用,spark系统读取hdfs,hbase上的数据通过其高效率的内存计算功能进行计算,挖掘,分析等操作,将所得结果存放到关系型或非关系型数据库。
欢迎您的下载,
资料仅供参考!
致力为企业和个人提供合同协议,策划案计划书,学习课件等
等
打造全网一站式需求。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
[转载]图解Hadoop生态系统
修订记录
文档版本时间修订说明修订人
虽然Hortonworks和Cloudera在Apache Hadoop统治力排行榜上分列一、二,但在整理Hadoop生态系统中,他们还只能算作初创公司,仍然可能被大鳄们扼杀或收购。
图:Hadoop生态系统。
(供图:GigaOM,原图可以点击查看公司信息。
)
GigaOM将Hadoop生态圈的公司分为11种,分别是:
·Hadoop即服务(基础设施:这些服务与IaaS服务关系紧密,包括Amazon Elastic MapReduce、GoGrid Big Data Solution、Windows Azure HD Insights等等。
·Hadoop即服务(应用/分析)
·Hadoop即应用/平台
·数据库
·SQL接口:Hive是名副其实的主流,还包括Cloudera Impala、Hortonworks Stinger Initiative、EMC Greenplum这些号称提升几十到上百倍Hive效率的工具,但这还需要更多的应用场景的实践才能让人信服。
·编程框架/语言
·第三方管理平台
·发行版
·二次销售商:第二种是将Hortonworks或Cloudera的Hadoop发行版打包在自己已有的产品或服务中,他们本身并不具备开发Hadoop的能力。
·竞争平台
·HDFS替代品。