第13讲 中间代码生成_3
07-第7章-中间代码生成-编译原理PDF精讲课件-中国科技大学(共13讲)

中国科学技术大学 计算机科学与技术学院 陈意云
第七章 中间代码生成
记号 分析 流 器 本章内容
–介绍几种常用的中间表示:后缀表示、图形表示 和三地址代码 –用语法制导定义和翻译方案来说明源语言的各种 构造怎样被翻译成中间形式
静态 检查 器
中间 代码 中间 代码 生成 代码 生成 器 器
7.1 中 间 语 言
7.1.2 图形表示 • 语法树是一种图形化的中间表示 • 有向无环图也是一种中间表示
assign a + + a assign +
+ c uminus d uminus c c d d b b (b) DAG (a) 语法树 a = (b + cd) + cd的图形表示
7.1 中 间 语 言
7.1.4 静态单赋值形式 • 一种便于某些代码优化的中间表示 • 和三地址代码的主要区别
– 所有赋值指令都是对不同名字的变量的赋值 – 一个变量在不同路径上都定值的解决办法 if (flag) x = 1; else x = 1; y = x a; 改成 if (flag) x1 = 1; else x2 = 1; x3 = (x1, x2); //由flag的值决定用x1还是x2
E E1 E2 E.nptr = mkNode( ‘’, E1.nptr, E2.nptr) E.nptr = mkUNode( ‘uminus’, E1.nptr) E E1 E (E1) F id E.nptr = E1.nptr E.nptr = mkLeaf (id, id.entry)
符号表实例
7.2 声 明 语 句
• 符号表的特点
–各过程有各自的符号表 –符号表之间有双向链 –构造符号表时需要符号表栈 –构造符号表需要活动记录栈 sort var a:…; x:…; readarray var i:…; exchange quicksort var k, v:…; partition var i, j:…;
编译原理语义分析与中间代码生成

编译原理语义分析与中间代码生成在编译原理中,语义分析是编译器的重要组成部分之一,它负责验证和处理源代码中的语义信息,为后续的中间代码生成做准备。
本文将介绍语义分析的基本概念和流程,并探讨中间代码生成的相关技术。
一、语义分析的基本概念和流程语义分析是指对源代码进行语义检查和语义信息提取的过程。
其主要目标是确保源代码在语义上是正确的,并从中提取出各种语义信息,以便后续阶段使用。
语义分析的基本流程如下:1. 词法分析和语法分析:在进行语义分析之前,需要先对源代码进行词法分析和语法分析,以便将代码转化为具有结构的中间表示形式(如抽象语法树)。
2. 符号表的构建:符号表是语义分析的重要数据结构,用于存储程序中出现的各种标识符及其相关信息,如类型、作用域等。
在语义分析阶段,需要构建符号表并实时更新。
3. 类型检查:类型检查是语义分析的核心任务之一。
它通过对表达式、赋值语句、函数调用等进行类型推导和匹配,来验证程序是否存在类型错误。
4. 语义规则检查:除了类型检查外,语义分析还需要检查程序是否符合语言规范中的其他语义规则,如变量是否已声明、函数调用是否正确等。
5. 语义信息提取:语义分析还负责提取源代码中的各种语义信息,如函数调用关系、变量的定义和引用关系、控制流信息等。
这些信息将为后续的代码优化和代码生成提供依据。
二、中间代码生成的相关技术中间代码是指某种形式的中间表示形式,通常与源代码和目标代码之间存在一定的映射关系。
它在编译过程中起到连接前后两个阶段的桥梁作用,并且可以进行一些优化。
常见的中间代码形式之一是三地址码。
三地址码是一种低级的代码表示形式,每条指令最多包含三个操作数。
它具有简洁明了的特点,适合进行后续的优化工作。
在进行中间代码生成时,需要考虑以下几个方面的技术:1. 表达式的翻译:在将源代码转化为中间代码时,需要将源代码中的表达式进行翻译。
这包括对表达式的计算顺序、运算符优先级等方面的处理。
2. 控制流的处理:在编译过程中,需要将源代码中的控制流转化为中间代码中的条件分支和循环结构。
编译原理中间代码生成

编译原理中间代码生成在编译原理中,中间代码生成是编译器的重要阶段之一、在这个阶段,编译器将源代码转换成一种中间表示形式,这种中间表示形式通常比源代码抽象得多,同时又比目标代码具体得多。
中间代码既能够方便地进行优化,又能够方便地转换成目标代码。
为什么需要中间代码呢?其一,中间代码可以方便地进行编译器优化。
编译器优化是编译器的一个核心功能,它能够对中间代码进行优化,以产生更高效的目标代码。
在中间代码生成阶段,编译器可以根据源代码特性进行一些优化,例如常量折叠、公共子表达式消除、循环不变式移动等。
其二,中间代码可以方便地进行目标代码生成。
中间代码通常比较高级,比目标代码更具有表达力。
通过中间代码,编译器可以将源代码转换成与目标机器无关的形式,然后再根据目标机器的特性进行进一步的优化和转换,最终生成目标代码。
中间代码生成的过程通常可以分为以下几步:1.词法分析和语法分析:首先需要将源代码转换成抽象语法树。
这个过程涉及到词法分析和语法分析两个步骤。
词法分析将源代码划分成一个个的词法单元,例如标识符、关键字、运算符等等。
语法分析将词法单元组成树状结构,形成抽象语法树。
2.语义分析:在语义分析阶段,编译器会对抽象语法树进行静态语义检查,以确保源代码符合语言的语义规定。
同时,还会进行类型检查和类型推导等操作。
3.中间代码生成:在中间代码生成阶段,编译器会将抽象语法树转换成一种中间表示形式,例如三地址码、四元式、特定的中间代码形式等。
这种中间表示形式通常比较高级,能够方便进行编译器的优化和转换。
4.中间代码优化:中间代码生成的结果通常不是最优的,因为生成中间代码时考虑的主要是功能的正确性,并没有考虑性能的问题。
在中间代码生成之后,编译器会对中间代码进行各种优化,以产生更高效的代码。
例如常量折叠、循环优化、死代码删除等等。
5.中间代码转换:在完成了中间代码的优化之后,编译器还可以对中间代码进行进一步的转换。
这个转换的目的是将中间代码转换成更具体、更低级的形式,例如目标机器的汇编代码。
编译原理与中间代码生成技术

编译原理与中间代码生成技术编译原理是计算机科学中的重要理论基础,它研究的是将高级语言翻译成机器语言的转换过程。
而中间代码生成技术则是编译原理中的一个关键环节,它负责将源代码转换为中间表示形式,为后续的优化和目标代码生成做准备。
本文将介绍编译原理的基本概念和中间代码生成技术的原理与应用。
一、编译原理基础编译原理是计算机科学中的一个重要分支,它研究的是高级语言程序如何转换为机器语言的过程。
编译原理包括词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等多个阶段。
其中,中间代码生成是编译原理的一个关键环节,它将源代码转换为中间表示形式,以便后续的优化和目标代码生成。
二、中间代码生成技术的原理中间代码是源代码与目标代码之间的一种中间表示形式。
它既比源代码更容易理解,又比目标代码更容易生成和优化。
中间代码生成技术的目的是将源代码转换为中间代码,为后续的优化和目标代码生成做准备。
中间代码生成技术的原理可以用以下步骤来描述:1. 词法分析:将源代码分割成一个个语法单元,比如标识符、关键字、操作符等。
词法分析器会根据事先定义好的词法规则,将源代码转换为词法单元序列。
2. 语法分析:将词法单元序列转换为抽象语法树(AST)。
语法分析器会根据事先定义好的语法规则,分析词法单元序列所组成的语法结构,并构建出相应的抽象语法树。
3. 语义分析:对抽象语法树进行语义检查和类型推断。
语义分析器会检查语法结构中是否存在语义错误,并为表达式推导出对应的类型信息。
4. 中间代码生成:将语法树转换为中间代码表示形式。
中间代码生成器会根据语义信息和事先定义好的转换规则,将语法树转换为中间代码表示形式。
三、中间代码生成技术的应用中间代码生成技术广泛应用于编译器、解释器和虚拟机等领域。
以下是中间代码生成技术在这些领域的具体应用场景:1. 编译器:编译器是将高级语言程序转换为机器语言的工具。
中间代码生成技术在编译器中起到了至关重要的作用,它能够将源代码转换为中间代码表示形式,为后续的代码优化和目标代码生成做准备。
编译原理中的中间代码生成

编译原理中的中间代码生成编译原理是计算机科学中非常重要的一门课程,它研究的是将高级语言程序转化为低级语言程序,实现计算机能够理解和运行的目的。
但是高级语言相较于机器语言更为抽象和复杂,所以需要经过多个步骤的处理,其中中间代码生成就是其中的一个重要环节。
中间代码是指一种介于高级语言和机器语言之间的表示方式,它的作用是将高级语言程序转化为更容易被计算机处理的形式,同时它也提供了一种通用的平台,可以将同一份高级语言程序转化为多种低级语言程序,如汇编语言、机器语言等。
如今,多数编译器都采用中间代码进行转化和优化,它不仅可以提高代码执行效率,还可以提高程序的可移植性和可维护性。
那么,中间代码的生成是如何进行的呢?和编译器的其它部分一样,中间代码生成也是经过多个步骤的处理,其中最主要的步骤包括词法分析、语法分析、语义分析和中间代码生成。
词法分析的作用是将源程序的字符序列转换为单词序列。
它依靠的是正则表达式的特性,对源程序进行识别和划分,得到一系列单词。
这些单词包括关键字、标识符、常数、字符等,在很大程度上决定了接下来的语法分析和语义分析。
语法分析是将单词序列转化为抽象语法树的过程,它将程序以树的形式进行表示,更为直观和容易理解。
通过对抽象语法树的遍历,可以得到程序的各种信息,如变量名、函数名、常量、运算符和控制语句等。
对于每个节点,编译器会根据其语义和上下文信息,进行类型检查、错误检测和决策生成等操作,最终得到一个可运行的程序。
语义分析是识别程序中不符合语言规范或逻辑错误的部分,它是整个编译过程中最为复杂的一个环节。
在这个过程中,编译器需要根据程序的上下文信息,判断其意义和合理性,并进行正确的处理。
例如,当编译器遇到一个未定义的变量或函数时,它将会报错并停止编译。
语义分析可以避免很多程序运行时的错误,同时也是编译器优化的重要基础。
当编译器通过词法分析、语法分析和语义分析,得到一个完整、正确的程序后,就可以进行中间代码生成了。
中间代码生成

三地址中间代码
三元式:i:(ω 三元式:i:(ω,op1,op2) 四元式: ,op1,op2, 四元式:( ω,op1,op2,result) b×c+b× 如:a:= b×c+b×d
三元式 (×, b, c) × (×, b, d) × (+, (1), (2)) (:=, (3), a) 四元式 (×, b, c, t1) × (×, b, d, t2) × (+, t1, t2, t3) (:=, t3, a, -)
第八章 中间代码生成
中间语言 简单表达式的中间代码生成 原子语句的中间代码生成 结构语句的中间代码生成 声明的中间代码
中间语言
后缀式----逆波兰式 后缀式----逆波兰式 ---三地址中间代码(三元式、四元式) 三地址中间代码(三元式、四元式) 图结构中间代码(语法树、 图结构中间代码(语法树、DAG)
变量中间代码结构
V ≡ id V ≡ V1.id V ≡ V1[E]
V.tuple=空 V.tuple=空 V1.tuple (AADD,V1.Arg,offset(id),V.Arg) V1.tuple E.tuple (SUBI, E.Arg, low, t1) (MULTI, t1, size, t2) (AADD, V1.Arg, t2, V.Arg) V1.tuple (ASSIGN,V1.Arg, V信息:
表达式种类: 表达式种类:E.kind 表达式的类型:E.type 表达式的类型: 表达式的结果值ARG ARG: 表达式的结果值ARG:E.Arg 或 ARG(E) 标号L LabelForm’(L) 标号L:ARG(L)= LabelForm (L) 整数C ValueForm’(C) 整数C:ARG(C)= ValueForm (C) 源程序变量X AddrForm’(L,Off, 源程序变量X:ARG(X)= AddrForm (L,Off, Mode) 临时变量T AddrForm’( 临时变量T:ARG(T)= AddrForm (-1, off, Mode) 表达式的中间代码: 表达式的中间代码:E.tuple
编译原理中的语法分析与中间代码生成

编译原理中的语法分析与中间代码生成编译原理是计算机科学中一门非常重要的学科,主要研究将高级语言翻译成机器语言的方法和技术。
其中,语法分析和中间代码生成是编译器实现的两个重要步骤。
一、语法分析语法分析是编译器将源代码转换成抽象语法树的过程。
在这个阶段,编译器会检查源代码的语法是否符合语言规范,并将代码转化为一系列的语法结构。
一个好的语法分析器能够快速准确地识别代码中的语言结构,同时能够在出现语法错误的时候给出有意义的错误报告。
常见的语法分析方法包括LL(1)分析、LR分析等。
LL(1)分析器通过构造预测分析表来实现分析,而LR分析器则采用自底向上的分析方法,通过状态迁移来实现分析。
在语法分析的过程中,编译器还需要处理语法的优先级,如算术运算符的优先级,逻辑运算符的优先级等。
对于不同的语言规范,将有不同的算法来处理语法。
例如,C语言中的运算符优先级和结合性与其他语言不同,因此需要特殊的处理方式。
二、中间代码生成中间代码生成是语法分析后的下一步,它的作用是将抽象语法树转化为中间表示,通常是三地址码或四地址码。
中间代码可以看作是目标代码的前一步,它是一种更加抽象的代码形式,方便后续的优化和翻译。
中间代码的生成方法有很多种,最常用的是遍历抽象语法树并根据语法结构生成中间代码。
不同的语言规范会对中间代码的生成方式有不同的要求。
例如,Java语言规范对着重于类型检查和异常处理的中间代码生成,而C语言的中间代码生成则着重于指针和数组的处理等。
在生成中间代码的过程中,编译器还需要考虑优化问题。
编译器能够在生成中间代码的时候进行一些基本的优化,例如删除冗余代码、常量合并等等,这样可以减少目标代码的大小和程序的运行时间。
总之,语法分析和中间代码生成是编译器实现的两个关键步骤。
它们需要一个好的算法和优秀的实现方式,以便在编译过程中产生高效、可靠的目标代码。
中间代码生成实验报告

中间代码生成实验报告中间代码生成实验报告一、引言在计算机编程领域中,中间代码生成是编译器的一个重要阶段。
它将源代码转化为一种中间表示形式,以便于后续的优化和目标代码生成。
本实验旨在通过实现一个简单的中间代码生成器,深入理解编译器的工作原理和中间代码的作用。
二、实验背景中间代码是一种介于源代码和目标代码之间的表示形式。
它通常是一种抽象的、与机器无关的形式,具有较高的可读性和可维护性。
中间代码生成是编译器的一个重要阶段,它将源代码转化为中间代码,为后续的优化和目标代码生成提供基础。
三、实验目的本实验的主要目的是通过实现一个简单的中间代码生成器,加深对编译器工作原理的理解,并掌握中间代码的生成过程。
具体目标包括:1. 学习使用编程语言实现中间代码生成算法;2. 理解中间代码的数据结构和语义;3. 掌握将源代码转化为中间代码的过程;4. 分析和优化生成的中间代码。
四、实验设计与实现本实验采用C++语言实现一个简单的中间代码生成器。
具体步骤如下:1. 词法分析:使用词法分析器对输入的源代码进行扫描,将其划分为一个个的词法单元。
2. 语法分析:使用语法分析器对词法单元进行解析,构建语法树。
3. 语义分析:对语法树进行语义分析,检查语法的正确性,并生成中间代码。
4. 中间代码生成:根据语义分析的结果,生成对应的中间代码。
5. 中间代码优化:对生成的中间代码进行优化,提高执行效率和代码质量。
6. 目标代码生成:将优化后的中间代码转化为目标代码。
五、实验结果与分析经过实验,我们成功实现了一个简单的中间代码生成器,并生成了相应的中间代码。
通过对生成的中间代码进行分析,我们发现其中存在一些冗余和不必要的指令,可以进一步进行优化。
例如,可以通过常量折叠、死代码删除等技术,减少中间代码的长度和执行时间。
六、实验总结通过本次实验,我们深入理解了中间代码生成的过程和作用,并通过实践掌握了中间代码生成器的实现方法。
在实验过程中,我们遇到了一些困难和挑战,但通过不断的学习和尝试,最终取得了满意的结果。
编译原理语义分析和中间代码生成

在语义分析阶段,编译器会检查源代 码中是否存在类型错误、未定义的变 量和函数、不符合控制流规则的语句
等。
语义分析的主要任务包括类型检查、 函数和变量的解析、控制流的检查等。
如果发现错误,编译器会报错并停止 编译过程;如果没有发现错误,编译 器将继续生成中间代码。
02 中间代码生成
中间代码生成概述
中间代码是源代码和目标代码之间的代 码形式,用于表示源程序的结构和语义
信息。
中间代码生成是编译过程的一个重要阶 中间代码生成可以提高编译器的灵活性
段,它把源代码转换成一种更接近于机 和可移植性,因为中间代码与具体的机
器语言的代码形式,以便进行后续的优 器语言无关,可以在不同的平台上使用
代码优化
编译器通过优化技术 对源代码进行优化, 以提高生成代码的执 行效率,减少运行时 间。
代码分析
编译原理还可以用于 代码分析,检查代码 的语法、语义和结构, 发现潜在的错误和漏 洞。
程序理解
编译原理可以帮助理 解程序的内部结构和 行为,为程序修改、 重构和优化提供支持。
编译原理的发展趋势
静态分析
在语法分析阶段,编译器根据 语言的语法规则将词素或标记 组合成一个个的语法结构,如 表达式、语句、程序等。
语义分析阶段是在语法分析的 基础上,对这些语法结构进行 语义检查和语义处理。
语义分析的例子
01
02
假设有以下C语言代码 ```c
03
int a = "hello";
04
```
05
在语义分析阶段,编译 器会发现变量a被赋值为 一个字符串字面量,而 字符串字面量是字符数 组类型的值,因此会报 错,因为整型变量不能 赋值为字符数组类型的 值。
中间代码生成
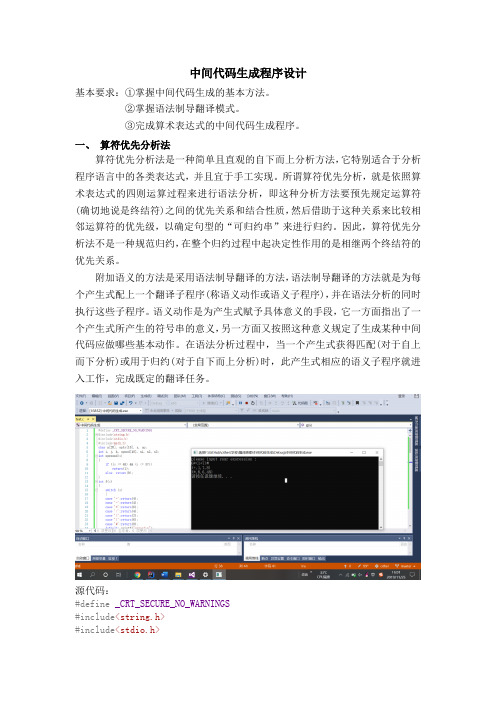
中间代码生成程序设计基本要求:①掌握中间代码生成的基本方法。
②掌握语法制导翻译模式。
③完成算术表达式的中间代码生成程序。
一、算符优先分析法算符优先分析法是一种简单且直观的自下而上分析方法,它特别适合于分析程序语言中的各类表达式,并且宜于手工实现。
所谓算符优先分析,就是依照算术表达式的四则运算过程来进行语法分析,即这种分析方法要预先规定运算符(确切地说是终结符)之间的优先关系和结合性质,然后借助于这种关系来比较相邻运算符的优先级,以确定句型的“可归约串”来进行归约。
因此,算符优先分析法不是一种规范归约,在整个归约过程中起决定性作用的是相继两个终结符的优先关系。
附加语义的方法是采用语法制导翻译的方法,语法制导翻译的方法就是为每个产生式配上一个翻译子程序(称语义动作或语义子程序),并在语法分析的同时执行这些子程序。
语义动作是为产生式赋予具体意义的手段,它一方面指出了一个产生式所产生的符号串的意义,另一方面又按照这种意义规定了生成某种中间代码应做哪些基本动作。
在语法分析过程中,当一个产生式获得匹配(对于自上而下分析)或用于归约(对于自下而上分析)时,此产生式相应的语义子程序就进入工作,完成既定的翻译任务。
源代码:#define_CRT_SECURE_NO_WARNINGS#include<string.h>#include<stdio.h>#include<math.h>char a[20], optr[10], s, op;int i, j, k, opond[10], x1, x2, x3;int operand(s){if ((s >= 48) && (s <= 57))return(1);else return(0);}int f(s){switch (s){case'+':return(4);case'-':return(4);case'*':return(6);case'/':return(4);case'(':return(2);case')':return(6);case'#':return(0);default: printf("error!\n");}}int g(s){switch (s){case'+':return(3);case'-':return(3);case'*':return(5);case'/':return(5);case'(':return(7);case')':return(2);case'#':return(0);default:return (0); printf("error!\n");}}void get(){s = a[i];i = i + 1;}int main(){printf("please input your exoression : \n");i = 0;do{i = i + 1;scanf("%c", &a[i]);} while (a[i] != '#');i = 1; j = k = 1;optr[j] = '#';get();while (!((optr[j] == '#' && (s == '#')))){if (operand(s)){opond[k] = s - 48;k = k + 1;get();}else if (f(optr[j]>g(s))){op = optr[j];j = j - 1;x1 = opond[k - 1];x2 = opond[k - 1];k = k - 1;switch (op){case'+':x3 = x1 + x2; break;case'*':x3 = x1*x2; break;case'-':x3 = x1 - x2; break;case'/':x3 = x1 / x2; break;}opond[k] = x3;k++;printf("%c, %d, %d, %d)\n", op, x1, x2, x3);}else if (f(optr[j]<g(s))){j = j + 1;optr[j] = s;get();}else if (f(optr[j] == g(s))){if (optr[j] == '('&&')'){j = j - 1;get();}else printf("error!!!\n");}else printf("error!!!\n");}}。
编译原理课件-中间代码生成

(3) E→not E1 { E.true:= E 1.false; E.Codebegin:= E 1.codebegin; E.false:= E 1.true
(翻譯不是最優)
語句 if a<b or c<d and e<f then S1 else S2 的四元式
(1) if a<b goto (7) //轉移至(E.true )
(2) goto (3)
(3) if c<d goto (5)
(4) goto (p+1)
//轉移至(E.false)
(5) if e<f goto (7) (6) goto (p+1) (7)( S1的四元式
不同層次的中間代碼
源語言
中間代碼
(高級語言) (高級)
中間代碼 (中級)
中間代碼 (低級)
float a[10][20]; a[i][j+2];
t1 = a[i, j+2]
t1 = j + 2 t2 = i * 20 t3 = t1 + t2 t4 = 4 * t3 t5 = addr a t6 = t5 + t4 t7 = *t6
語義描述使用的變數和過程:
E.true : “真”鏈, E.false : “假”鏈
E.codebegin : E 的第一個四元式
Nextstat: 下一四元式地址
中间代码生成

中间代码生成计算机科学与工程学院课程设计报告题目全称:常用边缘算法的实现学生学号: 2506203010 姓名:王嘉指导老师:职称:指导老师评语:签字:课程设计成绩:设计过程表现设计报告质量总分编译器中间代码生成的研究与实现作者:王嘉学号:2506203010 指导老师:吴洪摘要:在编译器的翻译流水线中,中间代码生成是处于核心地位的关键步骤。
它的实现基于语法分析器的框架,并为目标机器代码的实现提供依据。
虽然在理论上没有中间代码生成器的编译器也可以工作,但这将会带来编译器的高复杂度,低稳定性和难移植性。
现代编译理论不仅要求中间代码的生成,还要求基于中间代码的优化。
本文研究并实现了一个轻量级类C语言的中间代码生成器,并就中间代码生成的原理进行了细致的阐述。
关键字:中间代码生成、语法制导翻译、翻译模式、语法树、三地址码一、目的及意义在编译器的分析综合模型中,前端将源程序翻译成一种中间表示,后端根据这个中间表示生成目标代码。
目标语言的细节要尽可能限制在后端。
尽管源程序可以直接翻译成目标语言,但使用与机器无关的中间形式具有以下优点:1.重置目标比较容易:不同机器上的编译器可以在已有前端的基础上附近一个适合这台新机器的后端来生成。
2.可以在中间表示上应用与机器无关的代码优化器。
本文介绍如何使用语法制导方法,基于一种轻量级的类C语言FineC的词法分析器和语法分析器,一遍地将源程序翻译成中间形式的编程语言结构,如声明、赋值及控制流语句。
为简单起见,我们假定源程序已经经过一遍扫描,生成了相应的词法记号流和符号表、词素表结构。
基于FineC语法标准的语法分析器框架也已经能够正常工作。
我们的任务就是补充这个框架,使其在语法分析的过程中生成相应的中间代码,并将必要的变量和函数声明存放在一个符号表链中。
二、目标语言词法和语法标准:这里定义一个编程语言称作FineC(“fine”指代轻量、精妙)。
它是一种适合编译器设计方案的语言。
编译原理-中间代码生成程序解析

实验报告课程名称实验学期学生所在系部编译原理至学年第学期年级专业班级学生姓名学号任课教师实验成绩计算机学院制、实验目的分析PL/O编译程序的总体结构、代码生成的方法和过程;具体写出一条语句的{参数:id:要找的符号}{返回值:要找的符号在符号表中的位置,如果找不到就返回0 }function positi on (id: alfa): in teger;vari: in teger;beg in { find ide ntifier in table }table[0].name := id; {先把id放入符号表0号位置}i := tx; {从符号表中当前位置也即最后一个符号开始找}while table[i].name <> id do {如果当前的符号与要找的不一致}i := i - 1; {找前面一个}position := i {返回找到的位置号,如果没找到则一定正好为0 }end{ positi on };(二)过程说明说明入口参数,返回值和过程的功能1、入口参数:过程体入口时的处理code[table[tx0].adr].a:=cx; (cx 为过程入口地址,填写在code中)with table[tx0] dobegi nadr:=cx;(过程的入口填写在table表的过程名中)size:=dx;(过程需要的空间填写在table中)end;cxo:=cx;(保留过程在code中的入口地址在输出目标代码时用)gen (i nt,0,dx); (生成过程入口指令)2、返回值:(*通过静态链求出数据区基地址的函数base *)(*参数说明:I:要求的数据区所在层与当前层的层差*)(*返回值:要求的数据区基址*)fun cti on base(l: in teger): in teger;varb1: in teger;beg inbl := b; (* find base 1 level down *)(* 首先从当前层开始*)while l > 0 do (*如果l大于0,循环通过静态链往前找需要的数据区基址*)beg inb1 := s[b1]; (*用当前层数据区基址中的内容(正好是静态链SL数据,为上一层的基址)的作为新的当前层,即向上找了一层*)l := l - 1 (* 向上了一层,l 减一*)end;base := b1 (*把找到的要求的数据区基址返回*)en d(* base *);(三)程序静态结构图源程序输入主程序程序运行输出出错处理程序表格管理程序退出数据段SYM 为语句后继符?PCODE 码输出结束(四)PL0文法描述在计算机科学中,文法是编译原理的基础,是描述一门程序设计语言和实现其 编译器的方法。
编译原理之中间代码生产、词法优化与代码生成

编译原理之中间代码⽣产、词法优化与代码⽣成
中间代码⽣成
在把⼀个源程序翻译成⽬标代码的过程中,⼀个编译器可能构造出⼀个或多个中间表⽰。
这些中间表⽰可以有多种形式。
语法树是⼀种中间表⽰形式,它们通常在语法分析和语义分析中使⽤。
在源程序的语法分析和语义分析完成之后,很多编译器⽣成⼀个明确的低级的或类机器语⾔的中间表⽰。
我们可以把这个表⽰看作是某个抽象机器的程序。
该中间表⽰应该具有两个重要的性质:它应该易于⽣成,且能够被轻松地翻译为⽬标机器上的语⾔。
代码优化
机器⽆关的代码优化步骤试图改进中间代码,以便⽣成更好的⽬标代码。
“更好”通常意味着更快,但是也可能会有其他⽬标,如更短的或能耗更低的⽬标代码
代码⽣成
代码⽣成器以源程序的中间表⽰形式作为输⼊,并把它映射到⽬标语⾔。
如果⽬标语⾔是机器代码,那么就必须为程序使⽤的每个变量选择寄存器或内存位置。
然后,中间指令被翻译成为能够完成相同任务的机器指令序列。
代码⽣成的⼀个⾄关重要的⽅⾯是合理分配寄存器以存放变量的值。
(这⾥我觉得还存疑因为书本上下下段还说了⼀句话,上⾯对代码⽣成的讨论忽略了对源程序中的标识⾏进⾏存储分配的重要问题。
) 不过总之,运⾏时刻的存储组织⽅法依赖于被编译的语⾔。
编译器在中间代码⽣成或代码⽣成阶段做出有关存储分配的决定。
中间代码生成

陈林第六章中间代码生成本章内容中间代码表示 抽象语法树 三地址代码 中间代码生成 表达式类型检查控制流编译器前端的逻辑结构静态类型检查和中间代码生成的过程都可以用语法制导的翻译来描述和实现对于抽象语法树这种中间表示的生成,第五章已经介绍过表达式的有向无环图语法树中,公共子表达式每出现一次,就有一个对应的子树表达式的有向无环图(Directed Acyclic Graph,DAG)能够指出表达式中的公共子表达式,更简洁地表示表达式构造DAG可以用和构造抽象语法树一样的SDD来构造DAG构造不同的处理在函数Leaf和Node每次被调用时,构造新节点前先检查是否已存在同样的节点,如果已经存在,则返回这个已有的节点构造过程示例三地址代码(1)每条指令右侧最多有一个运算符一般情况可以写成x=y op z允许的运算分量名字:源程序中的名字作为三地址代码的地址 常量:源程序中出现或生成的常量编译器生成的临时变量三地址代码(2)指令集合(1)运算/赋值指令:x=y op z x=op y复制指令:x=y无条件转移指令:goto L条件转移指令:if x goto L if False x goto L 条件转移指令:if x relop y goto L三地址代码(3)•指令集合(2)–过程调用/返回•param x1//设置参数•param x2•…•param xn•call p, n//调用子过程p,n为参数个数–带下标的复制指令:x=y[i]x[i]=y•注意:i表示离开数组位置第i个字节,而不是数组的第i个元素–地址/指针赋值指令:•x=&y x=*y*x=y语句do i = i + 1; while (a[i]<v);三地址代码实例三地址指令的四元式表示方法在实现时,可以使用四元式/三元式/间接三元式来表示三地址指令四元式:可以实现为纪录(或结构)格式(字段):op arg1arg2resultop: 运算符的内部编码arg1,arg2,result是地址x=y+z+ y z x单目运算符不使用arg2param运算不使用arg2和result条件转移/非条件转移将目标标号放在result字段四元式的例子赋值语句:a=b* -c + b* -c三元式表示•三元式(triple)op arg1arg2•使用三元式的位置来引用三元式的运算结果•x[i]=y需要拆分为两个三元式–求x[i]的地址,然后再赋值•x=y op z需要拆分为(这里?是编号)–(?)op y z–=x?•问题:在优化时经常需要移动/删除/添加三元式,导致三元式的移动三元式的例子 a=b*-c + b * -c包含了一个指向三元式的指针的列表 我们可以对这个列表进行操作,完成优化功能;操作时不需要修改三元式中的参数间接三元式静态单赋值(SSA)SSA中的所有赋值都是针对不同名的变量对于同一个变量在不同路径中定值的情况,可以使用φ函数来合并不同的定值if (flag) x=-1; else x = 1;y = x*aif (flag) x1=-1; else x2= 1;x3=φ(x1,x2); y = x3*a类型和声明•类型检查(Type Checking)–利用一组规则来检查运算分量的类型和运算符的预期类型是否匹配•类型信息的用途–查错、确定名字需要的内存空间、计算数组元素的地址、类型转换、选择正确的运算符•主要内容–确定名字的类型–变量的存储空间布局(相对地址)类型表达式•类型表达式(type expression):表示类型的结构–基本类型–类名–类型构造算子作用于类型•array[数字,类型表达式]•record[字段/类型对的列表](可以用符号表表示)–函数类型构造算子→:参数类型→结果类型–笛卡尔积:s X t–可以包含取值为类型表达式的变量类型表达式的例子类型例子元素个数为3X4的二维数组数组的元素的记录类型该记录类型中包含两个字段:x和y,其类型分别是float和integer类型表达式array[3,array[4,record[(x,float),(y,integer)]]]类型等价不同的语言有不同的类型等价的定义结构等价或者它们是相同的基本类型或者是相同的构造算子作用于结构等价的类型而得到的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
控制流语句及其SDT哈尔滨工业大学陈鄞第六章中间代码生成P →S S →S 1S 2S →id =E ; | L = E ; S →if B then S 1| if B then S 1else S 2| while B do S 1控制流语句的基本文法例控制流语句的代码结构S if B then S 1else S 2布尔表达式B 被翻译成由跳转指令构成的跳转代码继承属性S.next :是一个地址,该地址中存放了紧跟在S 代码之后的指令(S 的后继指令)的标号B.true :是一个地址,该地址中存放了当B 为真时控制流转向的指令的标号B.false :是一个地址,该地址中存放了当B 为假时控制流转向的指令的标号用指令的标号标识一条三地址指令S 1.next S 2.next S.nextif B.trueB.falsethen goto S.nextelse B.code S 1.codeS 2.codeS.codeP →{ S.next = newlabel (); }S { label (S.next );} S →{ S 1.next = newlabel (); } S 1{ label (S 1.next ); S 2.next = S.next ; } S 2S →id =E ; | L = E ; S →if B then S 1| if B then S 1else S 2| while B do S 1控制流语句的SDTlabel (L ): 将下一条三地址指令的标号赋给Lnewlabel ( ): 生成一个用于存放标号的新的临时变量L ,返回变量地址S →if B then S 1else S 2S →if {B.true =newlabel ();B.false =newlabel ();}Bthen {label (B.true );S 1.next =S.next ;}S 1{gen (‘goto ’S.next )}else {label (B.false );S 2.next =S.next ;}S 2if -then -else 语句的SDT if B.trueB.falseS.nextthen goto S.next else S 1.nextS 2.next B.code S 1.code S 2.codeS.codeif-then语句的SDTS→if B then S1S→if{B.true=newlabel();B.false=S.next;}Bthen{label(B.true);S1.next=S.next;}S1ifB.true B.falseS.next thenS1.next B.codeS1.codeS.codeS →while B do S 1S →while {S.begin =newlabel ();label (S.begin );B.true =newlabel ();B.false =S.next ;}Bdo {label (B.true );S 1.next =S.begin ;}S 1{gen (‘goto ’S.begin );}while -do 语句的SDTwhile B.true B.falseS.begin do goto S.beginS 1.nextB.code S 1.code S.next S.code控制流语句及其SDT哈尔滨工业大学陈鄞第六章中间代码生成布尔表达式及其SDT哈尔滨工业大学陈鄞第六章中间代码生成B → B or B | B and B | not B | (B )| E relop E | true | false布尔表达式的基本文法优先级:not > and >orrelop (关系运算符):<, <=, >, >=,==, ! =关系表达式在跳转代码中,逻辑运算符&&、|| 和! 被翻译成跳转指令。
运算符本身不出现在代码中,布尔表达式的值是通过代码序列中的位置来表示的 例语句三地址代码if x <100 goto L2goto L 3L 3: if x >200 goto L 4goto L 1L 4: if x !=y goto L 2goto L 1L 2:x =0L 1:if ( x <100 || x >200 &&x !=y )x =0;B → E 1relop E 2{ gen (‘if ’ E 1.addr relop E 2.addr ‘goto ’ B.true );gen (‘goto ’ B.false ); }B → true { gen (‘goto ’ B.true ); } B → false { gen (‘goto ’ B.false ); }B → ( {B 1.true =B.true ; B 1.false =B.false ; } B 1) B → not { B 1.true = B.false ; B 1.false = B.true ; } B 1布尔表达式的SDTB →B 1or B 2B → { B 1.true = B.true ; B 1.false = newlabel (); }B 1or { label (B 1.false ); B 2.true = B.true ; B 2.false = B.false ; }B 2B →B 1or B 2的SDTB.falseB 1.false B 2.false B 1.true B 2.true B.trueor B 1.codeB 2.codeB.codeB →B 1and B 2B → { B 1.true = newlabel (); B 1.false = B.false ; } B 1and { label (B 1.true ); B 2.true = B.true ; B 2.false = B.false ; }B 2B.falseB 1.false B 2.false B 1.true B 2.true B.trueand B 1.codeB 2.codeB.code B →B 1and B 2的SDT布尔表达式及其SDT哈尔滨工业大学陈鄞第六章中间代码生成控制流翻译的例子哈尔滨工业大学陈鄞第六章中间代码生成P →{a}S {a} S →{a}S 1{a}S 2S →id=E ;{a}| L =E ;{a}E →E 1+E 2{a}|-E 1{a}|(E 1){a}|id {a}| L {a} L →id[E ]{a}| L 1[E ]{a} S →if {a}B then {a}S 1| if {a}B then {a}S 1else {a}S 2| while {a}B do {a}S 1{a}B → {a}B or {a}B | {a}B and {a}B | not {a}B | ({a}B )| E relop E {a}| true {a}| false {a}控制流语句的SDT任何SDT 都可以通过下面的方法实现首先建立一棵语法分析树,然后按照从左到右的深度优先顺序来执行这些动作SDT 的通用实现方法P →{a}S {a} S →{a}S 1{a}S 2S →id=E ;{a}| L =E ;{a}E →E 1+E 2{a}|-E 1{a}|(E 1){a}|id {a}| L {a} L →id[E ]{a}| L 1[E ]{a} S →if {a}B then {a}S 1| if {a}B then {a}S 1else {a}S 2| while {a}B do {a}S 1{a}B → {a}B or {a}B | {a}B and {a}B | not {a}B | ({a}B )| E relop E {a}| true {a}| false {a}控制流语句的SDTwhile a < b do if c < d then x = y + z ;elsex = y –z ;S 1S 3S 2BB 1例do then S 3else S P B 1c<dS 1x =y +zifa <b B whileS 2x=y-zP { S.next = newlabel ( ); }S { label (S.next );}do then S 3else S B 1c<dS 1x =y +zP例S.n=L 1whileifa <b B S 2x=y-zS while {S.begin =newlabel ();label (S.begin );B.true =newlabel ();B.false =S.next ;}B do {label (B.true );S 1.next =S.begin ;}S 1{gen (‘goto ’S.begin );}S 3.n=L 2S.begin =L 2=1B → E 1relop E 2{ gen (‘if ’ E 1.addr relop E 2.addr ‘goto ’ B.true );gen (‘goto ’ B.false ); }dowhile then S 3else S B 1c<dS 1x =y +zP 例1:if a <b goto L 32: goto L 1goto L 2S.n=L 1S 2x=y-zif a <b B.t =L 3B.f =L 1=3BS if {B.true =newlabel ();B.false =newlabel ();}Bthen {label (B.true );S 1.next =S.next ;}S 1{gen (‘goto ’S.next );}else {label (B.false );S 2.next =S.next ;}S 2B 1.t =L 4B 1.f =L 5S 1.n=L 2S 2.n=L 2= 5= 8S 3.n=L 2S.n=L 1doif then S 3else SB a <b B 1c<dS 1x =y +z S2x=y-z P例1: if a < b goto L 32: goto L 13: if c < d goto L 44: goto L 55: t 1= y + z 6: x = t 17: goto L 28: t 2= y -z 9: x = t 210:11:goto L 2=11while B.t =L 3B.f =L 1=33115811S.begin =L 2=11: if a < b goto 32: goto 113: if c < d goto 54: goto 85: t 1= y + z6: x = t 17: goto 18: t 2= y -z9: x = t 210: goto 111:语句“while a <b do if c <d then x=y+z else x=y-z ”的三地址代码1: ( j <,a , b , 3)2:( j , -, -, 11 )3:( j <, c , d , 5 )4:( j , -, -, 8 ) 5:( + , y , z , t 1 ) 6:( = , t 1, -, x ) 7:( j , -, -, 1 )8:( -, y , z , t 2 ) 9:( = , t 2, -, x ) 10:( j , -, -, 1 )11:控制流翻译的例子哈尔滨工业大学陈鄞第六章中间代码生成。