语义分析与中间代码生成程序的设计原理与实现技术__实验报告与源代码_北京交通大学
中间代码生成实验报告

一、实验目的1. 理解编译原理中中间代码生成的基本概念和作用。
2. 掌握中间代码生成的常用算法和策略。
3. 提高对编译器构造的理解和实际操作能力。
二、实验环境1. 操作系统:Windows 102. 编程语言:Java3. 开发工具:Eclipse三、实验内容1. 中间代码生成的基本概念2. 中间代码的表示方法3. 中间代码生成算法4. 实现一个简单的中间代码生成器四、实验步骤1. 了解中间代码生成的基本概念中间代码生成是编译过程中的一个重要环节,它将源程序转换成一种中间表示形式,便于后续的优化和目标代码生成。
中间代码生成的目的是提高编译器的灵活性和可维护性。
2. 研究中间代码的表示方法中间代码通常采用三地址代码(Three-Address Code,TAC)表示。
TAC是一种低级表示,由三个操作数和一个操作符组成,例如:(t1, t2, t3) = op,其中t1、t2、t3为临时变量,op为操作符。
3. 学习中间代码生成算法中间代码生成算法主要包括以下几种:(1)栈式中间代码生成算法(2)归约栈中间代码生成算法(3)递归下降中间代码生成算法4. 实现一个简单的中间代码生成器本实验采用递归下降中间代码生成算法,以一个简单的算术表达式为例,实现中间代码生成器。
(1)定义语法规则设表达式E由以下语法规则表示:E → E + T | E - T | TT → T F | T / F | FF → (E) | i(2)设计递归下降分析器根据语法规则,设计递归下降分析器,实现以下功能:①识别表达式E②识别项T③识别因子F(3)生成中间代码在递归下降分析器中,针对不同语法规则,生成相应的中间代码。
例如:当遇到表达式E时,生成以下中间代码:(t1, t2, t3) = op1(t1, t2) // op1表示加法或减法(t4, t5, t6) = op2(t4, t5) // op2表示乘法或除法(t7, t8, t9) = op3(t7, t8) // op3表示赋值(4)测试中间代码生成器编写测试用例,验证中间代码生成器的正确性。
语义分析与中间代码生成

语法分析程序
ifs( ) { token = getnexttoken(); If(token!="if") error; token= getnexttoken(); bexp(); token = getnexttoken(); If(token!="then") error; token = getnexttoken(); ST_SORT();//调用函数处理then后的可 执行语句 token = getnexttoken(); If(token!= "else") error;
语法分析程序 语法制导的翻译 token = getnexttoken(); { q = nxq; gencode(j, —, —, 0); ST_SORT();//处理else后 backpatch(e.fc, nxq); //已知假出 口e.fc 的可执行语句 t.chain = merg(s1.chain, q); } getnexttoken(token);
语义分析与中间代码生成
实验目的:通过本实验,加深对语法分析 作用的理解,掌ห้องสมุดไป่ตู้语义分析和中间代码生 成的方法并编程实现语义分析以及生成中 间代码!
实验内容:根据语义分析和中间代码生成 的原理,设计并实现实现语义分析以及生 成中间代码!
原理概述
语义分析是以语法分析的结果———语法树为输入,产生 与源程序功能等价的中间代码。中间代码的形式可以是三 元式,间接三元式,四元式等。 语义分析的任务包括:(1)静态语义检查:如:类型、 运算、数组维数、越界等的检查;(2)语义的处理:如: 变量的存储分配、表达式的求值、语句的翻译(生成中间 代码) 语义分析可以采用多种分析技术,如语法制导的翻译。语 法制导的翻译实际上就是在语法分析的基础上,当分析完 一个正确的语法单位后,添加相应的语义信息,直接生成 相应的四元式表。因此,本部分的程序可以和语法分析程 序合为一体,在语法分析得到正确的语法成分的基础上, 在适当的位置添加语义成分。
北京交通大学 编译原理

北京交通大学编译原理2021级《编译原理》实验教学内容一、学习目标编译系统是计算机系统重要的系统软件之一,编译原理课程主要讲授编译系统重要组成部分程序设计语言编译程序的设计原理和实现技术,是计算机科学与技术专业学生的必修专业课程,也是每个优秀的计算机专业人员必修的一门课程,更重要的是,编译原理课程中蕴含着计算机科学中解决问题的思路、抽象问题和解决问题的方法,其内容可让计算机专业学生“享用一辈子”。
本课程开展研究性教学的目是,在教师的引导下以问题回朔与思维启发的方式,使学生在不断的探究过程中掌握编译程序设计和构造的基本原理和实现技术,启迪学生的抽象思维、激发学生的学习兴趣、培养学生的探究精神和专业素养,从而提高学生发现问题、分析问题和解决问题的能力。
二、学习任务1、学习内容以理论与教学紧密结合的五个研究性学习专题作为教学载体,这五个研究专题是:专题1_词法分析程序构造原理与实现技术专题2_递归下降语法分析设计原理与实现技术专题3_LL(1)语法分析设计原理与实现技术专题4_算符优先语法分析设计原理与实现技术专题5_语义分析及中间代码生成程序设计原理与实现技术2、任务要求1)以上内容专题1必做,专题2、3、4选择二个必做;专题5选做;实验占总成绩的20%,完成选做部分在总成绩中将获得加分。
2)实验要求设计并完成所做专题,同时又能将专题完成从源程序的输入,经过词法分析、语法分析的过程,或者(选做专题5)从词法分析、语法制导翻译生成中间代码的过程。
程序应能查看到词法分析的输出二元式序列,词法分析和语法分析得的输出结果。
或者中间代码序列,还能给出简单的错误提示。
3)编写符合实验语言词法和语法规则的源程序进行测试,须给出尽可能完备的测试用例。
4)能力培养:深入理解理论对实践的指导作用;基本原理、实现技术和方法的正确运用;编译程序本身的系统性。
鼓励同学扩充语言的功能,如增加单词符号的种类,增加赋值语句、条件语句等。
实验三语义分析及中间代码生成

实验三语义分析及中间代码生成一、实验目的通过上机实习,加深对语法制导翻译原理的理解,掌握将语法分析所识别的语法范畴变换为某种中间代码的语义翻译方法。
二、实验内容实现简单的高级语言源程序的语义处理过程。
三试验要求(一)程序设计要求(1)目标机:8086及其兼容处理器(2)中间代码:三地址码或者四元式(3)设计结果:语法分析树(节点具有属性)、三地址码表、符号表、TOKEN串表(4)语义分析内容要求:1)变量说明语句2)赋值语句3)控制语句(任选一种)(5)其它要求:1)将词法分析(扫描器)作为子程序,供语法语义程序调用;2)使用语法制导的语义翻译方法;3)编程语言自定;4)最好提供源程序输入界面;5)目标代码生成暂不做;6)编译后,可查看TOKEN串、语法分析树、符号表、三地址码表;7)主要数据结构:产生式表、符号表、语法分析树、三地址码表。
四、实验设计(1)系统功能(包括各个子功能模块的功能说明);可对一段包含加减乘除括号的赋值语句进行语法分析,其必须以$为终结符,语句间以;隔离,判断其是否符合语法规则,依次输出判断过程中所用到的产生式,并输出最终结论,若有错误可以报错并提示错误所在行数及原因(2)开发平台(操作系统、设计语言);Windows 7,Microsoft Visual C++ 6.0(Dos),C++。
(3) 数据结构struct token//词法 token结构体{int code;//编码int num;//递增编号token *next;};token *token_head,*token_tail;//token队列struct str//词法 string结构体{int num;//编号string word;//字符串内容str *next;};str *string_head,*string_tail;//string队列struct ivan//语法产生式结构体{char left;//产生式的左部string right;//产生式的右部int len;//产生式右部的长度};ivan css[20];//语法 20个产生式struct pank//语法 action表结构体{char sr;//移进或归约int state;//转到的状态编号};pank action[46][18];//action表int go_to[46][11];//语法 go_to表struct ike//语法分析栈结构体,双链{ike *pre;int num;//状态int word;//符号编码ike *next;};ike *stack_head,*stack_tail;//分析栈首尾指针struct L//语义四元式的数据结构{int k;string op;//操作符string op1;//操作数string op2;//操作数string result;//结果L *next;//语义四元式向后指针L *Ltrue;//回填true链向前指针L *Lfalse;//回填false链向前指针};L *L_four_head,*L_four_tail,*L_true_head,*L_false_head;//四元式链,true链,false链struct symb//语义输入时符号表{string word;//变量名称};(4)五、实验结果六、实验总结通过本次实验,我了解了当我编写的代码在经过编译过程中所进行的处理,分为词法分析,语法分析,语义分析和中间代码生成,生成的中间代码经过代码生成器变形成了我们常提到的目标程序.语义分析和中间代码生成会有静态检查:包括类型检查、控制流检查、唯一性检查和关联名字检查等等一判断源程序是否符合语言规定的语法和语义要求。
编译原理 第4章 语义分析和中间代码生成

第4章 语义分析和中间代码生成
文法符号的属性可分为继承属性与综合属性两类。
继承属性用于“自上而下”传递信息。继承属性 由相应语法树中结点的父结点属性计算得到,即沿语 法树向下传递,由根结点到分枝(子)结点,它反映了 对上下文依赖的特性。继承属性可以很方便地用来表 示程序语言上下文的结构关系。 综合属性用于“自下而上”传递信息。综合属性 由相应语法分析树中结点的分枝结点(即子结点)属性
了一个操作过程并同时描述了源程序的层次结构。
第4章 语义分析和中间代码生成
注意,语法规则中包含的某些符号可能起标点符
号作用也可能起解释作用。 如赋值语句语法规则: S→V=e 其中的赋值号“=”仅起标点符号作用,其目的是
把V与e分开;
第4章 语义分析和中间代码生成
而条件语句语法规则: S→if(e)S1; else S2 其中的保留字符号if和else起注释作用,说明当布 尔表达式e为真时执行S1,否则执行S2;而“;”仅起 标点符号作用。
计算得到,其传递方向与继承属性相反,即沿语法分
析树向上传递,从分枝结点到根结点。
第4章 语义分析和中间代码生成
4.2.2 属性文法
属性文法是一种适用于定义语义的特殊文法,即 在语言的文法中增加了属性的文法,它将文法符号的 语义以“属性”的形式附加到各个文法的符号上(如上 述与变量X相关联的属性X.type、X.place和X.val等), 再根据产生式所包含的含义,给出每个文法符号属性 的求值规则,从而形成一种带有语义属性的上下文无 关文法,即属性文法。
G[D]:D→int L∣float L L→L, id∣id
其对应的属性文法为:
产生式 (1) D→TL 语义规则 L.in=T.type
第7章 语义分析和中间代码生成

规约过程
树
15
图 x:=(a+b)*(a+b)图形表示的中间代码 (a) 树表示;(b) DAG表示
16
(1)E E(1) OP E(2) (2)E(E(1))
函数过程,建立一个以OP为 结点,E(1).optr和 E(2).optr为左右枝的子树, 回送新子树根的指针
{ E.nptr:= makenode (OP,E(1).optr,E(2).optr)} { E.optr:= E(1).optr } (3)E-E(1) { E.nptr := makenode (‘uminus’,E(1).optr)}
E→E1+E2 E. nptr:= mknode('+', E1. nptr, E2. nptr)
E. nptr:= mknode('*', E1. nptr, E2. nptr)
E. nptr:= mknode('-', 0, E1. nptr) E. nptr:= E1. nptr E. nptr:= mkleaf(id, id. place) E. nptr:=mkleaf(num,num.val)
30
(3)
x=y形式的赋值语句,将y的值赋给
χ。 (4) 无条件转移语句goto L,即下一个将 被执行的语句是标号为L的语句。 (5) 条件转移语句if x rop y goto L,其 中rop为关系运算符,如<、<=、==、!=、 >、>=等。若x和y满足关系rop就转去执 行标号为L的语句,否则继续按顺序执行 本语句的下一条语句。
47作用说明语句declarations用于对程序中规定范围内使用的各类变量常数过程进行说明编译要完成的工作在符号表中记录被说明对象的属性为执行做准备计算要占的存储空间计算相对地址48简单声明句的翻译程序中的每个名字如变量名都必须在使用之前进行说明而说明语句的功能就是为编译程序说明源程序中的每一个名字及其性质
LL(1)语法分析设计原理与实现技术实验 实验报告及源代码 北京交通大学

LL(1)语法分析设计原理与实现技术实验计科100X班 10284XXX程序设计功能实现LL(1)分析中控制程序(表驱动程序);完成以下描述算术表达式的LL(1)文法的LL(1)分析程序。
G[E]: E→TE′E′→ATE′|εT→FT′T′→MFT′|εF→(E)|iA→+|-M→*|/说明:终结符号i 为用户定义的简单变量,即标识符的定义。
主要数据结构描述由文法可得:对于E:FIRST( E )= {(, i }对于E’: FIRST( E’ ) ={+,−,ε}对于T: FIRST( T )= ={(, i }对于T’: FIRST( T’)= ={*,∕,ε}对于F: FIRST( F )= ={(, i }对于A: FIRST( A )= ={+, - }对于M: FIRST(M)= ={*, / }由此我们容易得出各非终结符的FOLLOW集合如下:FOLLOW( E )= { ),#}FOLLOW(E’) ={ ),#}FOLLOW( T ) ={+,−,),#}FOLLOW( T’ ) = FOLLOW( T ) ={+,−,),#}FOLLOW( F )=FIRST(T’)\ε∪FOLLOW(T’)={*,∕,+,−,),#}FOLLOW( A )= { (, i }FOLLOW( M )= { (, i}文法LL(1)的预测分析表(表1):表1. LL(1)预测分析表注:为编程方便,在程序中,将E’、T’改为G、S程序结构描述1.设计方法:程序通过从文本文档读入数据,将所读数据以空格、回车或者退格为标示符,分为字符串,对字符串进行词法分析,最后将所有字符串按序输出到结果文档中,并在结果文档中标明每个字符串的类别序号。
2、程序中主要函数定义和调用关系如下:函数:void print()作用:输出分析栈void print1();作用:输出剩余串int main();作用:主要逻辑功能程序执行图如下:实验结果测试用例1:i+i*i#测试用例2:i-i++#实验总结相对于递归下降分析法,LL(1)分析法更为有效.采用此种方法的分析器由一张预测分析表(LL(1)分析表)、一个控制程序(表驱动程序)和一个分析栈组成,预测分析表中个元素的含义是:或者指出当前推到所应使用过的产生式,或者指出输入符号串中存在语法错误.LL(1)分析法的局限在于:只能分析LL(1)文法或者某些非LL(1)文法,但需先将其改造成LL(1)文法。
语义分析及中间代码生成程序设计原理与实现技术--实验报告及源代码-北京交通大学

语义分析及中间代码生成程序设计原理与实现技术XXX 1028XXX2 计科1XXX班1.程序功能描述完成以下描述赋值语句和算术表达式文法的语法制导生成中间代码四元式的过程。
G[A]:A→V:=EE→E+T∣E-T∣T→T*F∣T/F∣FF→(E)∣iV→i说明:终结符号i 为用户定义的简单变量,即标识符的定义。
2. 设计要求(1)给出每一产生式对应的语义动作;(2)设计中间代码四元式的结构(暂不与符号表有关)。
(3)输入串应是词法分析的输出二元式序列,即某算术表达式“实验项目一”的输出结果。
输出为输入串的四元式序列中间文件。
(4)设计两个测试用例(尽可能完备),并给出程序执行结果四元式序列。
3.主要数据结构描述:本程序采用的是算符优先文法,文法以及算符优先矩阵是根据第四次实验来修改的,所以主要的数据结构也跟第四次差不多,主要为文法的表示,FirstVT集和LastVT集以及算符优先矩阵:算符优先矩阵采用二维字符数组表示的:char mtr[9][9]; //算符优先矩阵4.程序结构描述:本程序一共有8功能函数:void get(); //获取文法void print(); //打印文法void fun(); //求FirstVT 和 LastVTvoid matrix(); //求算符优先矩阵void test(); //测试文法int cmp(char a,char b); 比较两个运算符的优先级 1 0 -1void out(char now,int avg1,int avg2); //打印四元式int ope(char op,int a,int b); //定义四元式计算方法5.实验代码详见附件6.程序测试6.1 功能测试程序运行显示如下功能菜单:选择打印文法:选择构造FirstVt集和LastVT集:选择构造算符优先矩阵:6.2 文法测试测试1:1+2*3测试2:2+3+4*5+(6/2)7.学习总结本次实验完成了语义及中间代码生成的设计原理与实现,所采用的方法为算符优先分析方法,首先根据文法求出此文法的FirstVT集和LastVT集,然后根据他们求出此文法的算符优先矩阵。
编译原理实验四语义分析及中间代码生成

编译原理实验四语义分析及中间代码⽣成⼀、实验⽬的(1)通过上机实验,加深对语法制导翻译原理的理解,掌握将语法分析所识别的语法范畴变换为某种中间代码的语义翻译⽅法。
(2)掌握⽬前普遍采⽤的语义分析⽅法─语法制导翻译技术。
(3)给出 PL/0 ⽂法规范,要求在语法分析程序中添加语义处理,对于语法正确的表达式,输出其中间代码;对于语法正确的算术表达式,输出其计算值。
⼆、实验内容(1)语义分析对象重点考虑经过语法分析后已是正确的语法范畴,本实验重点是语义⼦程序。
已给 PL/0 语⾔⽂法,在实验⼆或实验三的表达式语法分析程序⾥,添加语义处理部分,输出表达式的中间代码,⽤四元式序列表⽰。
(2) PL/0 算术表达式的语义计算:PL/0 算术表达式,例如:2+35 作为输⼊。
输出: 17PL/0 表达式的中间代码表⽰:PL/0 表达式,例如: a(b+c)。
输出: (+,b,c,t1)(,a,t1,t2)三、设计思想1.原理属性⽂法:是在上下⽂⽆关⽂法的基础上为每个⽂法符号(终结符或⾮终结符)配备若⼲个相关的“值”(称为属性)。
属性:代表与⽂法符号相关的信息,和变量⼀样,可以进⾏计算和传递。
综合属性:⽤于“⾃下⽽上”传递信息。
在语法树中,⼀个结点的综合属性的值,由其⼦结点的属性值确定。
S—属性⽂法:仅仅使⽤综合属性的属性⽂法。
语义规则: 属性计算的过程即是语义处理的过程。
对于⽂法的每⼀个产⽣式配备⼀组属性的计算规则,则称为语义规则。
(1)终结符只有综合属性,它由词法分析器提供。
(2)⾮终结符既可以有综合属性也可以有继承属性,⽂法开始符号的所有继承属性作为属性计算前的初始值。
(3)产⽣式右边符号的继承属性和产⽣式左边符号的综合属性都必须提供⼀个计算规则。
(4)产⽣式左边符号的继承属性和产⽣式右边符号的综合属性由其它产⽣式的属性规则计算。
⼀遍扫描的处理⽅法: 与树遍历的属性计算⽅法不同,⼀遍扫描的处理⽅法是在语法分析的同时计算属性值,⽽不是语法分析构造语法树之后进⾏属性的计算,⽽且⽆需构造实际的语法树。
编译原理中的语法分析与中间代码生成

编译原理中的语法分析与中间代码生成编译原理是计算机科学中一门非常重要的学科,主要研究将高级语言翻译成机器语言的方法和技术。
其中,语法分析和中间代码生成是编译器实现的两个重要步骤。
一、语法分析语法分析是编译器将源代码转换成抽象语法树的过程。
在这个阶段,编译器会检查源代码的语法是否符合语言规范,并将代码转化为一系列的语法结构。
一个好的语法分析器能够快速准确地识别代码中的语言结构,同时能够在出现语法错误的时候给出有意义的错误报告。
常见的语法分析方法包括LL(1)分析、LR分析等。
LL(1)分析器通过构造预测分析表来实现分析,而LR分析器则采用自底向上的分析方法,通过状态迁移来实现分析。
在语法分析的过程中,编译器还需要处理语法的优先级,如算术运算符的优先级,逻辑运算符的优先级等。
对于不同的语言规范,将有不同的算法来处理语法。
例如,C语言中的运算符优先级和结合性与其他语言不同,因此需要特殊的处理方式。
二、中间代码生成中间代码生成是语法分析后的下一步,它的作用是将抽象语法树转化为中间表示,通常是三地址码或四地址码。
中间代码可以看作是目标代码的前一步,它是一种更加抽象的代码形式,方便后续的优化和翻译。
中间代码的生成方法有很多种,最常用的是遍历抽象语法树并根据语法结构生成中间代码。
不同的语言规范会对中间代码的生成方式有不同的要求。
例如,Java语言规范对着重于类型检查和异常处理的中间代码生成,而C语言的中间代码生成则着重于指针和数组的处理等。
在生成中间代码的过程中,编译器还需要考虑优化问题。
编译器能够在生成中间代码的时候进行一些基本的优化,例如删除冗余代码、常量合并等等,这样可以减少目标代码的大小和程序的运行时间。
总之,语法分析和中间代码生成是编译器实现的两个关键步骤。
它们需要一个好的算法和优秀的实现方式,以便在编译过程中产生高效、可靠的目标代码。
第4章 语义分析和中间代码生成(新)-sxw

第4章 语义分析和中间代码生成
4.3 几种常见的中间语言
4.3.1 抽象语法树 抽象语法树也称图表示,是一种较为流行的中间语言 抽象语法树 表示形式.在抽象语法树表示中,每一个叶结点都表示诸 如常量或变量这样的运算对象,而其它内部结点则表示运 算符. 注意 语法规则中包含的某些符号可能起标点符号作用也 可能起解释作用.如赋值语句语法规则:S→V=e 其中的 赋值号"="仅起标点符号作用,其目的是把V与e分开 条件语句语法规则:S→if(e)S1; else S2其中的保留字符号if 和else起注释作用,说明当布尔表达式e为真时执行S1,否 则执行S2;而";"仅起标点符号作用.
第4章 语义分析和中间代码生成
当把语法规则中本质部分抽象出来而将非本质部分 去掉后,便得到抽象语法规则.这种去掉不必要信息的 做法可以获得高效的源程序中间表示.上述语句的抽象 语法规则为: (1) 赋值语句:左部 表达式 (2) 条件语句:表达式 语句1 语句2
第4章 语义分析和中间代码生成
与抽象语法相对应的语法树称为抽象语法树或抽象树, 如赋值语句x=ab*c的抽象语法树如图4–4(a)所示,而图 4–4(b)则是该赋值语句的普通语法树.
第4章 语义分析和中间代码生成
Eval=52
Eval=7
+
Eval=45
7
Eval=9
*
Eval=5
9
图4–2 语法制导翻译计算表达式 7+9*5#的语法树
5
第4章 语义分析和中间代码生成
表4.1 表达式7+9*5#的语义分析和计值过程
步骤 1 2 3 4 5 6 7 8 9 10 11 状态栈 0 03 01 014 0143 0147 01475 014753 014758 0147 01 符号栈 # #7 #E # E+ # E+9 # E+E # E+E* # E+E*5 # E+E*E # E+E #E 语义栈 _ __ _7 _7_ _7_ _ _7_9 _7_9_ _7_9_ _ _7_9_5 _7_45 _52 输入串 7+9*5# +9*5# +9*5# 9*5# *5# *5# 5# # # # # 主要动作 s3 r4 s4 s3 r4 s5 s3 r4 r2 r1 acc
第七章语义分析和中间代码生成
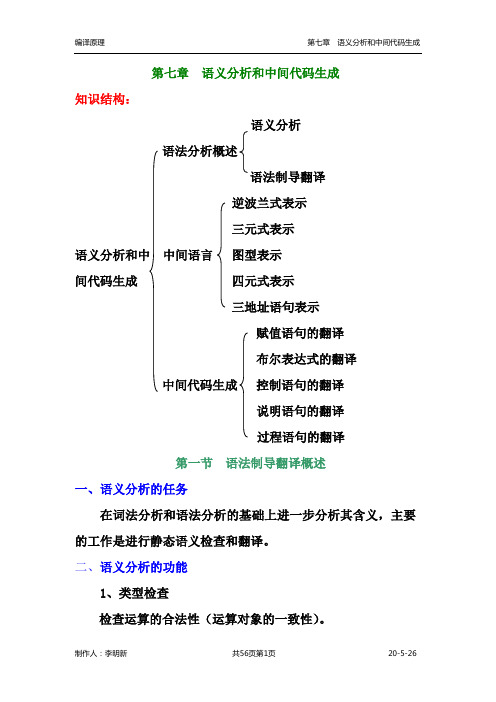
第七章语义分析和中间代码生成知识结构:语义分析语法分析概述语法制导翻译逆波兰式表示三元式表示语义分析和中中间语言图型表示间代码生成四元式表示三地址语句表示赋值语句的翻译布尔表达式的翻译中间代码生成控制语句的翻译说明语句的翻译过程语句的翻译第一节语法制导翻译概述一、语义分析的任务在词法分析和语法分析的基础上进一步分析其含义,主要的工作是进行静态语义检查和翻译。
二、语义分析的功能1、类型检查检查运算的合法性(运算对象的一致性)。
2、一致性检查一个对象(标识符等)在一个分程序中只能被定义一次。
3、相关名字检查如果一个名字必须出现多次,检查使用的名字是否相同的。
4、控制流检查控制流语句必须使控制转移到合法的地方。
5、确定类型确定标识符所关联得数据类型。
6、识别含义确认程序中各种成分组合到一起的含义,并作相应的语义处理,对可执行的语句生成中间语言或目标语言。
三、生成的语言1、直接生成目标语言根据源程序中各语法成分的语义,直接生成机器语言或汇编语言。
其特点:⑴编译时间较短;⑵存储空间较大;⑶目标语言的质量较差。
2、生成中间语言介于源程序语言和机器语言之间的机内表示形式。
其特点:⑴编译程序的逻辑结构简单;⑵有利于编译程序的移植;⑶便于目标语言的优化。
四、语义分析方法1、语法制导翻译方法在语法分析过程中,使用语法规则进行归约的同时,根据每个产生式的语义动作进行翻译(在语法规则的制导下,通过对语义规则的计算,完成对输入字符串的翻译)的方法。
2、属性翻译方法指明语义规则的计算次序,陈述一些实现细节,以表达语义动作在语法分析过程中的执行时刻。
五、语义规则为文法中的每一条产生式配置计算属性的计算规则。
六、语法制导翻译为文法中每个产生式配备一组语义规则。
1、语义规则语义规则计算包括:产生代码、在符号表中存放信息、在分析工作栈中填写语义值(属性值),并生成相应的中间代码。
2、自上而下分析用一条产生式与输入符号匹配成功时, 执行相应语义子程序生成中间代码。
编译原理课件07语义分析和中间代码产生

语义分析阶段中的关键问题和 挑战
语义分析阶段面临着许多关键问题和挑战,例如识别复杂的语义错误、处理 不完整的代码等。
在处理大型程序时,编译器需确保语义分析的效率和准确性,并能处理各种 语法结构。
中间代码的定义和作用
中间代码是一种介于高级语言和底层机器代码之间的形式,它是一种可读性 较强且易于生成和优化的表示。
语义分析的基本任务和目标
语义分析的主要任务是识别和验证程序中的语义错误,例如类型不匹配、变量未定义等。 它的目标是确保程序的语义是一致的,以便于理解和执行。语义语义分析使用了各种技术和方法,包括符号表、类型检查、控制流分析等。 符号表用于记录变量和函数的信息,类型检查用于比较表达式和操作数的类 型是否一致。 控制流分析用于检测条件语句、循环语句和函数调用等代码块的流程。
编译原理课件07语义分析 和中间代码产生
在这一节中,我们将学习关于语义分析和中间代码产生的定义、概述以及它 们在编译过程中的作用。我们将探讨语义分析的任务、方法和挑战,以及中 间代码产生的基本原理和实际应用。
语义分析和中间代码产生的定义和概述
语义分析是编译过程中的重要阶段,用于分析程序的意义和语法结构,并生成中间代码。中间代码产生是将高 级语言代码转换为更低级的可执行形式的过程。 在这一阶段,编译器将检查语法的正确性和静态语义的正确性,以确保程序在执行时没有语法错误。 语义分析和中间代码产生是编译器的核心部分,它们直接影响了程序的性能和可读性。
中间代码作为编译器和解释器的输入,是程序在执行前的一个中间阶段,并 可用于代码优化和跨平台编译。
中间代码产生的基本原理和方法
中间代码产生的基本原理是将程序的语义结构转换为一系列指令序列,这些指令不依赖于具体的计算机体系结 构。 中间代码生成的方法包括源代码到抽象语法树的转换、语法树到中间代码的转换等。
编译原理教程04语义分析和中间代码生成

在本教程中,我们将探讨编译原理中的两个重要主题:语义分析和中间代码 生成。了解它们的定义、步骤、技术和应用,提升编译器质量和效率。
语义分析的定义和作用
1 作用
确保源代码符合语法和语义规则,并检测隐藏的错误和不一致性。
中间代码的定义和作用
1 作用
在后续编译过程中提供统一的中间表示,方便目标代码生成和优化。
常见的语义分析和中间代码生成技术
1 语义分析器的类型和实现方法
包括语法制导翻译、类型检查和静态分析等不同技术。
拟机代码和抽象语法树转换。
语义分析和中间代码生成的应用和意义
1 提高编译器的效率和质量
2 支持
通过优化和错误检测,生成更高效和可靠 的目标代码。
语义分析的步骤
词法分析
将源代码转换为单词流。
语法分析
根据语法规则构建语法树。
语义处理
对语法树执行语义规则验 证和错误检测。
中间代码生成的步骤
生成语法树
通过语法分析构建抽象语法树或其他中间表示。
生成中间代码
将抽象语法树转换为可执行的中间代码。
语义分析和中间代码生成的关系
1 重要性
语义分析的准确性和质量对中间代码生成阶段至关重要。
帮助开发人员开发更强大和易于维护的程 序。
编译原理教程实验报告

一、实验目的本次实验旨在使学生通过编译原理的学习,了解编译程序的设计原理及实现技术,掌握编译程序的各个阶段,并能将所学知识应用于实际编程中。
二、实验内容1. 词法分析2. 语法分析3. 语义分析4. 中间代码生成5. 代码优化6. 目标代码生成三、实验步骤1. 词法分析(1)设计词法分析器,识别输入源代码中的各种词法单元;(2)使用C语言实现词法分析器,并进行测试。
2. 语法分析(1)根据文法规则设计语法分析器,识别输入源代码的语法结构;(2)使用C语言实现语法分析器,并进行测试。
3. 语义分析(1)设计语义分析器,检查语法分析后的语法树,确保语义正确;(2)使用C语言实现语义分析器,并进行测试。
4. 中间代码生成(1)设计中间代码生成器,将语义分析后的语法树转换为中间代码;(2)使用C语言实现中间代码生成器,并进行测试。
5. 代码优化(1)设计代码优化器,对中间代码进行优化,提高程序性能;(2)使用C语言实现代码优化器,并进行测试。
6. 目标代码生成(1)设计目标代码生成器,将优化后的中间代码转换为特定目标机的汇编语言;(2)使用C语言实现目标代码生成器,并进行测试。
四、实验结果与分析1. 词法分析实验结果:成功识别输入源代码中的各种词法单元,包括标识符、关键字、运算符、常量等。
2. 语法分析实验结果:成功识别输入源代码的语法结构,包括表达式、语句、程序等。
3. 语义分析实验结果:成功检查语法分析后的语法树,确保语义正确。
4. 中间代码生成实验结果:成功将语义分析后的语法树转换为中间代码,为后续优化和目标代码生成提供基础。
5. 代码优化实验结果:成功对中间代码进行优化,提高程序性能。
6. 目标代码生成实验结果:成功将优化后的中间代码转换为特定目标机的汇编语言,为程序在目标机上运行做准备。
五、实验心得1. 编译原理是一门理论与实践相结合的课程,通过本次实验,我对编译程序的设计原理及实现技术有了更深入的了解。
编译原理语义分析和中间代码生成

在语义分析阶段,编译器会检查源代 码中是否存在类型错误、未定义的变 量和函数、不符合控制流规则的语句
等。
语义分析的主要任务包括类型检查、 函数和变量的解析、控制流的检查等。
如果发现错误,编译器会报错并停止 编译过程;如果没有发现错误,编译 器将继续生成中间代码。
02 中间代码生成
中间代码生成概述
中间代码是源代码和目标代码之间的代 码形式,用于表示源程序的结构和语义
信息。
中间代码生成是编译过程的一个重要阶 中间代码生成可以提高编译器的灵活性
段,它把源代码转换成一种更接近于机 和可移植性,因为中间代码与具体的机
器语言的代码形式,以便进行后续的优 器语言无关,可以在不同的平台上使用
代码优化
编译器通过优化技术 对源代码进行优化, 以提高生成代码的执 行效率,减少运行时 间。
代码分析
编译原理还可以用于 代码分析,检查代码 的语法、语义和结构, 发现潜在的错误和漏 洞。
程序理解
编译原理可以帮助理 解程序的内部结构和 行为,为程序修改、 重构和优化提供支持。
编译原理的发展趋势
静态分析
在语法分析阶段,编译器根据 语言的语法规则将词素或标记 组合成一个个的语法结构,如 表达式、语句、程序等。
语义分析阶段是在语法分析的 基础上,对这些语法结构进行 语义检查和语义处理。
语义分析的例子
01
02
假设有以下C语言代码 ```c
03
int a = "hello";
04
```
05
在语义分析阶段,编译 器会发现变量a被赋值为 一个字符串字面量,而 字符串字面量是字符数 组类型的值,因此会报 错,因为整型变量不能 赋值为字符数组类型的 值。
lab14语义分析与中间代码生成

实验报告封面课程名称:编译原理课程代码: SS2027任课老师:彭小娟实验指导老师: 彭小娟实验报告名称:实验十四:语义分析与中间代码生成1学生姓名:学号:教学班:递交日期:签收人:我申明,本报告内的实验已按要求完成,报告完全是由我个人完成,并没有抄袭行为。
我已经保留了这份实验报告的副本。
申明人(签名):实验报告评语与评分:评阅老师签名:彭小娟一、实验名称:语义分析与中间代码生成1二、实验日期: 年 月 日三、实验目的:1. 理解相关概念:中间代码、三地址码,各种语句的目标代码结构2. 掌握三地址码(三元式、四元式、DAG 图),3. 理解赋值语句三地址代码的翻译模式四、实验用的仪器和材料:(操作系统:CPU :内存:硬盘:软件:)硬件:PC 人手一台软件:office五、实验的步骤和方法:1. 给出下面中缀式的逆波兰表示(后缀式),后缀式的中缀式表示/*)(*)/(*++-+-+-++e d c ab d c b a e d c b anot A or not (C or not D)2. 请将表达式-(a+b)*(c+d)-(a+b+c)分别表示成三元式、四元式序列。
3. 按7.3节所说的方法,写出下面赋值句)(*:D C B A +-=的自下而上语法制导翻译过程。
给出所产生的三地址代码。
六、数据记录和计算:七、实验结果或结论:(总结)八、备注或说明:可写上实验成功或失败的原因,实验后的心得体会、建议等。
九、引用参考文献:即在本实验中所引用的之資料。
友情提示:范文可能无法思考和涵盖全面,供参考!最好找专业人士起草或审核后使用,感谢您的下载!。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
语义分析及中间代码生成程序设计原理与实现技术XXX 1028XXX2 计科1XXX班1.程序功能描述完成以下描述赋值语句和算术表达式文法的语法制导生成中间代码四元式的过程。
G[A]:A→V:=EE→E+T∣E-T∣T→T*F∣T/F∣FF→(E)∣iV→i说明:终结符号i 为用户定义的简单变量,即标识符的定义。
2. 设计要求(1)给出每一产生式对应的语义动作;(2)设计中间代码四元式的结构(暂不与符号表有关)。
(3)输入串应是词法分析的输出二元式序列,即某算术表达式“实验项目一”的输出结果。
输出为输入串的四元式序列中间文件。
(4)设计两个测试用例(尽可能完备),并给出程序执行结果四元式序列。
3.主要数据结构描述:本程序采用的是算符优先文法,文法以及算符优先矩阵是根据第四次实验来修改的,所以主要的数据结构也跟第四次差不多,主要为文法的表示,FirstVT集和LastVT 集以及算符优先矩阵:算符优先矩阵采用二维字符数组表示的:char mtr[9][9]; //算符优先矩阵4.程序结构描述:本程序一共有8功能函数:void get(); //获取文法void print(); //打印文法void fun(); //求FirstVT 和LastVTvoid matrix(); //求算符优先矩阵void test(); //测试文法int cmp(char a,char b); 比较两个运算符的优先级 1 0 -1void out(char now,int avg1,int avg2); //打印四元式int ope(char op,int a,int b); //定义四元式计算方法5.实验代码详见附件6.程序测试6.1 功能测试程序运行显示如下功能菜单:选择打印文法:选择构造FirstVt集和LastVT集:选择构造算符优先矩阵:6.2 文法测试测试1:1+2*3测试2:2+3+4*5+(6/2)7.学习总结本次实验完成了语义及中间代码生成的设计原理与实现,所采用的方法为算符优先分析方法,首先根据文法求出此文法的FirstVT集和LastVT集,然后根据他们求出此文法的算符优先矩阵。
由于此文法和第四次文法基本相同,只是多了一条赋值语句,所以采用的规则和第四次基本相同。
在分析阶段,每当遇到有规约的项目,判断一下,打印出此部运算的四元式,这样一步一步分析,知道输入的算术表达式计算分析完毕。
由于本次实验部分代码和第四次实验的代码比较相似,只需增加一点四元式的分析计算打印过程,就能够顺利完成本次实验。
通过这次实验,我对语义分析以及中间代码部分有了一定的提高,对以后的学习有了一定程度上的帮助。
// lb6.cpp : 定义控制台应用程序的入口点。
//#include "stdafx.h"#include <iostream>#include <string>#include <VECTOR>#include <stack>using namespace std;struct info{char left;vector<string> right;vector<char> first;vector<char> last;};vector<info> lang;char mtr[9][9]; //算符优先矩阵stack<char> sta;void get(); //获取文法void print(); //打印文法void fun(); //求FirstVT 和LastVTvoid matrix(); //求算符优先矩阵void test(); //测试文法int cmp(char a,char b); //比较两个运算符的优先级 1 0 -1void out(char now,int avg1,int avg2); //打印四元式int ope(char op,int a,int b); //定义四元式计算方法int main(){int choose;while(1){cout << "****************************************" << endl;cout << " 获取文法请按1" << endl;cout << " 打印文法请按2" << endl;cout << " 构造FirstVT集和LastVT集请按3" << endl;cout << " 构造优先关系矩阵请按4" << endl;cout << " 文法测试请按5" << endl;cout << " 结束请按0" << endl;cout << "****************************************" << endl;cout << endl;cin >> choose;if(choose == 0)break;switch(choose){case 1: get(); break;case 2: print(); break;case 3: fun(); break;case 4: matrix(); break;case 5: test(); break;default:break;}}return 0;}void get(){info temp,temp1,temp2;temp.left = 'E';temp.right.push_back("E+T");temp.right.push_back("E-T");temp.right.push_back("T");temp.right.push_back("i");temp1.left = 'T';temp1.right.push_back("T*F");temp1.right.push_back("T/F");temp1.right.push_back("F");temp2.left = 'F';temp2.right.push_back("(E)");temp2.right.push_back("i");lang.push_back(temp);lang.push_back(temp1);lang.push_back(temp2);cout << "****************************************" << endl;cout << " 文法获取完成" << endl; cout << "****************************************" << endl;cout << endl;}void print(){cout << "****************************************" << endl; for(int i = 0;i < lang.size();i ++){for(int j = 0;j < lang[i].right.size();j ++){cout << lang[i].left << " --> ";cout << lang[i].right[j] << endl;}}cout << "****************************************" << endl; cout << endl;}void fun(){int i,j,sign = 0,sign1 = 0;for(i = 0;i < lang.size();i ++){for(j = 0;j < lang[i].right.size();j ++){string temp = lang[i].right[j]; //获取右部if(temp[0] > 'Z' || temp[0] < 'A'){ //终结符lang[i].first.push_back(temp[0]);}else if(temp.length() >= 2){ //终结符if(temp[1] > 'Z' || temp[1] < 'A'){lang[i].first.push_back(temp[1]);}}}}for(i = 0;i < lang.size();i ++){for(j = 0;j < lang[i].right.size();j ++){string temp = lang[i].right[j]; //获取右部if((temp[0] > 'Z' || temp[0] < 'A') && temp.length() == 1){ //终结符lang[i].last.push_back(temp[0]);}else if(temp.length() >= 3){ //终结符if(temp[1] > 'Z' || temp[1] < 'A')lang[i].last.push_back(temp[1]);else if(temp[2] > 'Z' || temp[2] < 'A') //终结符lang[i].last.push_back(temp[2]);}}}while(sign == 0){ //迭代FirstVTsign = 1;for(i = 0;i < lang.size();i ++){for(j = 0;j < lang[i].right.size();j ++){string temp = lang[i].right[j]; //获取右部if(temp.length() == 1 && (temp[0] <= 'Z' && temp[0] >= 'A')){//可以迭代for(int k = 0;k < lang.size();k ++){if(lang[k].left == temp[0]){ //找到了,添加元素for(int p = 0;p < lang[k].first.size();p ++){sign1 = 0;char ch = lang[k].first[p];for(int q = 0;q < lang[i].first.size();q ++){if(lang[i].first[q] == ch){ //包含了sign1 = 1;}}if(sign1 == 0){lang[i].first.push_back(ch);sign = 0;}}}}}}}}sign = 0;while(sign == 0){ //迭代LastVTsign = 1;for(i = 0;i < lang.size();i ++){for(j = 0;j < lang[i].right.size();j ++){string temp = lang[i].right[j]; //获取右部if(temp.length() == 1 && (temp[0] <= 'Z' && temp[0] >= 'A')){//可以迭代for(int k = 0;k < lang.size();k ++){if(lang[k].left == temp[0]){ //找到了,添加元素for(int p = 0;p < lang[k].last.size();p ++){sign1 = 0;char ch = lang[k].last[p];for(int q = 0;q < lang[i].last.size();q ++){if(lang[i].last[q] == ch){ //包含了sign1 = 1;}}if(sign1 == 0){lang[i].last.push_back(ch);sign = 0;}}}}}}}}cout << "****************************************" << endl;cout << "FirstVT:" << endl;for(i = 0;i < lang.size();i ++){cout << lang[i].left << " : ";for(j = 0;j < lang[i].first.size();j ++){cout << lang[i].first[j] << " ";}cout << endl;}cout << endl;cout << "LasttVT:" << endl;for(i = 0;i < lang.size();i ++){cout << lang[i].left << " : ";for(j = 0;j < lang[i].last.size();j ++){cout << lang[i].last[j] << " ";}cout << endl;}cout << "****************************************" << endl; cout << endl;}void matrix(){int i,j;for(i = 0;i < 9;i ++){ //初始化for(j = 0;j < 9;j ++){mtr[i][j] = 'n';}}string temp = "+-*/()i#";for(i = 1;i < 9;i ++){mtr[i][0] = temp[i - 1];mtr[0][i] = temp[i - 1];}vector<string> str;for(i = 0;i < lang.size();i ++){ //aU a < FirstVT(U)for(j = 0;j < lang[i].right.size();j ++){string ss = lang[i].right[j];string ok = "";if(ss.length() > 2){if((ss[0] > 'Z' || ss[0] < 'A') && (ss[1] <= 'Z' && ss[1] >= 'A')){ //aUok = "";ok += ss[0];ok += ss[1];str.push_back(ok);}if((ss[1] > 'Z' || ss[1] < 'A') && (ss[2] <= 'Z' && ss[2] >= 'A')){ //aUok = "";ok += ss[1];ok += ss[2];str.push_back(ok);}}}}for(i = 0;i < str.size();i ++){for(j = 1;j < 9;j ++){if(mtr[j][0] == str[i][0]){ //Find a Then Find FirstVt(U) for(int k = 0;k < lang.size();k ++){if(lang[k].left == str[i][1]){ //Find Ufor(int p = 0;p < lang[k].first.size();p ++){for(int q = 1;q < 9;q ++){if(mtr[q][0] == lang[k].first[p]){mtr[j][q] = '<';}}}}}}}}str.clear();for(i = 0;i < lang.size();i ++){ //Ua LastVT(U) > afor(j = 0;j < lang[i].right.size();j ++){string ss = lang[i].right[j];string ok = "";if(ss.length() > 2){if((ss[1] > 'Z' || ss[1] < 'A') && (ss[0] <= 'Z' && ss[0] >= 'A')){ //Uaok = "";ok += ss[0];ok += ss[1];str.push_back(ok);}if((ss[2] > 'Z' || ss[2] < 'A') && (ss[1] <= 'Z' && ss[1] >= 'A')){ //Uaok = "";ok += ss[1];ok += ss[2];str.push_back(ok);}}}}for(i = 0;i < str.size();i ++){for(j = 1;j < 9;j ++){if(mtr[0][j] == str[i][1]){ //Find a Then Find LastVt(U) for(int k = 0;k < lang.size();k ++){if(lang[k].left == str[i][0]){ //Find Ufor(int p = 0;p < lang[k].last.size();p ++){for(int q = 1;q < 9;q ++){if(mtr[0][q] == lang[k].last[p]){mtr[q][j] = '>';}}}}}}}}str.clear();for(i = 0;i < lang.size();i ++){ //ab aUb a = bfor(j = 0;j < lang[i].right.size();j ++){string ss = lang[i].right[j];string ok = "";if(ss.length() > 2){if((ss[1] > 'Z' || ss[1] < 'A') && (ss[0] > 'Z' || ss[0] < 'A')){ //aa ok = "";ok += ss[0];ok += ss[1];str.push_back(ok);}if((ss[2] > 'Z' || ss[2] < 'A') && (ss[1] > 'Z' || ss[1] < 'A')){ //aa ok = "";ok += ss[1];ok += ss[2];str.push_back(ok);}if((ss[2] > 'Z' || ss[2] < 'A') && (ss[0] > 'Z' || ss[0] <'A')){ //aUaok = "";ok += ss[0];ok += ss[2];str.push_back(ok);}}}}for(i = 0;i < str.size();i ++){for(j = 1;j < 9;j ++){if(str[i][0] == mtr[j][0]){for(int k = 1;k < 9;k ++){if(mtr[0][k] == str[i][1]){mtr[j][k] = '=';}}}}}for(i = 0;i < lang[0].first.size();i ++){ //#for(j = 1;j < 9;j ++){if(lang[0].first[i] == mtr[0][j]){mtr[8][j] = '<';}}}for(i = 0;i < lang[0].first.size();i ++){ //#for(j = 1;j < 9;j ++){if(lang[0].first[i] == mtr[j][0]){mtr[j][8] = '>';}}}mtr[8][8] = '=';cout << "****************************************" << endl; for(i = 0;i < 9;i ++){for(j = 0;j < 9;j ++){if(mtr[i][j] != 'n')cout << mtr[i][j] << " ";elsecout << " ";}cout << endl;}cout << "****************************************" << endl; cout << endl;}void test(){cout << "****************************************" << endl; cout << "请输入算术表达式:" << endl;string str;cin >> str;str += '#';int i,j,k;stack<int> data;stack<char> op;op.push('#');char now = 'n'; //记录当前栈顶操作符int sign = 0;for(i = 0;i < str.length();i ++){sign = 0;if(str[i] >= '0' && str[i] <= '9'){ //操作数int temp = str[i] - '0';data.push(temp);}else{ //运算符op.push(str[i]);sign = 1;}if(now != 'n' && sign == 1){ //有可比性,并且操作符栈有更新if(!op.empty()){char top = op.top(); //栈顶元素while(cmp(now,top) == 1){ //需要规约int avg1 = data.top();data.pop();int avg2 = data.top();data.pop();out(now,avg2,avg1); //打印四元式data.push(ope(now,avg2,avg1));op.pop();op.pop();if(!op.empty()){now = op.top();}else{now = 'n';}op.push(top);}if(cmp(now,top) == 0){op.pop();op.pop();if(!op.empty()){now = op.top();}else{char temp = '=';if(!data.empty()){int da = data.top();out(temp,da,0);}}}}}else{ //不需要比较if(!op.empty()){now = op.top();}}}}int cmp(char a,char b){int i,j;for(i = 1;i < 9;i ++){if(mtr[i][0] == a){for(j = 1;j < 9;j ++){if(mtr[0][j] == b){if(mtr[i][j] == '>'){return 1;}else if(mtr[i][j] == '='){return 0;}else if(mtr[i][j] == '<'){return -1;}}}}}return 2;}void out(char now,int avg1,int avg2){cout << "****************************************" << endl;cout << now << " ," << avg1 << " ," << avg2 << " ," << ope(now,avg1,avg2) << endl;cout << "****************************************" << endl;cout << endl;}int ope(char op,int a,int b){if(op == '+'){return a + b;}if(op == '-'){return a - b; }if(op == '*'){return a * b; }if(op == '/'){return a / b; }if(op == '='){return a;}return 0;}。