常用数据库的保留关键字列表
Oracle数据库中关键字

Oracle数据库中关键字在 Oracle 数据库中有一些单词具有特定的意思,也许不是提供给你的,但是使用它们你就可以不必解析、执行和获取你所编写的代码。
为了更准确,在第一句话中的一些单词可以归类为保留字和关键字。
在关键字的分类中,上下文起到了作用,因为一个单词不总是保留字。
例如,在Oracle数据库中有一些单词具有特定的意思,也许不是提供给你的,但是使用它们你就可以不必解析、执行和获取你所编写的代码。
为了更准确,在第一句话中的“一些单词”可以归类为保留字和关键字。
在关键字的分类中,上下文起到了作用,因为一个单词不总是保留字。
例如,单词COMMIT 本身可以触发很多事件,所以你可能要假设COMMIT 是Oracle密切使用的一个关键字。
从Oracle 的角度看,就是只有它可以使用这个单词。
但结果是,COMMIT 并没有如它希望的那样。
如果你想的话你可以创建一个叫做COMMIT 的表,因为COMMIT 是一个关键字,这比保留字的级别要低。
保留字是被锁定的,而关键字在某些条件下可以使用。
审查是一个有用的工具或功能,那么如果你想创建你自己的审查表,你是否可以使用“create table audit (...)”语句呢?至少在SQL中是不行的,你不能通过这种方法使用“audit”。
既然你不想使用这些特殊单词,那么你怎样能知道(或者你能从哪找到)特殊单词有哪些呢? 在文档库(在一个索引中)中的几个指导包括了这个列表,但是权威的和一站式的来源是V$RESERVED_WORDS 数据字典视图。
视图的名称表示这只是关于保留字的;但是描述视图的时候,重要的主键列被称为KEYWORD。
这使得当我要了解关键字和保留字的区别时把我搞糊涂了。
它使得视图中的第二列也很重要:RESERVED。
因此V$RESERVED_WORDS 的解码环如下所示:数据库参考指导在对V$RESERVED_WORDS的描述中准确地表达了这个意思。
数据库——单表查询、多表查询的常用关键字

数据库——单表查询、多表查询的常⽤关键字数据库——单表查询、多表查询的常⽤关键字⼀单表查询1、前期表与数据准备# 创建⼀张部门表create table emp(id int not null unique auto_increment,name varchar(20) not null,sex enum('male','female') not null default 'male', #⼤部分是男的age int(3) unsigned not null default 28,hire_date date not null,post varchar(50),post_comment varchar(100),salary double(15,2),office int, # ⼀个部门⼀个屋⼦depart_id int);# 插⼊记录# 三个部门:教学,销售,运营insert into emp(name,sex,age,hire_date,post,salary,office,depart_id) values('tank','male',17,'20170301','张江第⼀帅形象代⾔部门',7300.33,401,1), # 以下是教学部('egon','male',78,'20150302','teacher',1000000.31,401,1),('kevin','male',81,'20130305','teacher',8300,401,1),('jason','male',73,'20140701','teacher',3500,401,1),('owen','male',28,'20121101','teacher',2100,401,1),('jerry','female',18,'20110211','teacher',9000,401,1),('⼤饼','male',18,'19000301','teacher',30000,401,1),('sean','male',48,'20101111','teacher',10000,401,1),('歪歪','female',48,'20150311','sale',3000.13,402,2),# 以下是销售部门('丫丫','female',38,'20101101','sale',2000.35,402,2),('丁丁','female',18,'20110312','sale',1000.37,402,2),('星星','female',18,'20160513','sale',3000.29,402,2),('格格','female',28,'20170127','sale',4000.33,402,2),('张野','male',28,'20160311','operation',10000.13,403,3), # 以下是运营部门('程咬⾦','male',18,'19970312','operation',20000,403,3),('程咬银','female',18,'20130311','operation',19000,403,3),('程咬铜','male',18,'20150411','operation',18000,403,3),('程咬铁','female',18,'20140512','operation',17000,403,3);# PS:如果在windows系统中,插⼊中⽂字符,select的结果为空⽩,可以将所有字符编码统⼀设置成gbk插⼊表数据2、语法书写与执⾏顺序# 在写SQL命令是注意两点:- 书写顺序# 查询id是4-5记录的id与名字- select id, name from emp where id > 3 and id < 6;# PS: 根据现实⽣活中图书馆管理员找书的过程: 先知道书在哪个位置,然后再判断要找的是什么书,最后再找书本中的第⼏页;- 执⾏顺序- from # 找图书馆- where # 书在图书馆中的位置- select # 查找书中的某⼀页内容# 注意: 执⾏顺序必须要清楚# 查询数据量⼤时,可以在表后⾯ + \G,修改显⽰格式;select * from emp\G # 不要加分号3、where约束条件# PS: 根据执⾏顺序来书写 SQL语句,⼀步⼀步来写;# 1.查询id⼤于等于3⼩于等于6的数据select * from emp where id >= 3 and id <= 6;# between: 两者之间# and: 与select * from emp where id between 3 and 6;# 2.查询薪资是20000或者18000或者17000的数据# or: 或者select * from emp where salary=20000 or salary=18000 or salary=17000;# in: 在什么⾥select * from emp where salary in (20000, 18000, 17000);# 3.查询员⼯姓名中包含o字母的员⼯姓名和薪资# like: 模糊匹配# %: 匹配0个或多个任意字符# _: 匹配⼀个任意字符select name, salary from emp where name like "%o%";# 4.查询员⼯姓名是由四个字符组成的员⼯姓名与薪资select name, salary from emp where name like "_____";# char_length(字段): 获取字段长度select name, salary from emp where char_length(name) = 4;# 5.查询id⼩于3或者⼤于6的数据select * from emp where id < 3 or id > 6;select * from emp where id not between 3 and 6;# 6.查询薪资不在20000,18000,17000范围的数据select * from emp where salary not in (20000, 18000, 17000);# 7.查询岗位描述为空的员⼯名与岗位名# 注意: 针对null不能⽤等号,只能⽤isselect name, post from emp where post_comment = null;select name, post from emp where post_comment is null;select name,post from emp where post_comment is not null;4、group by# group by: 分组# ⽐如: ⼀张员⼯表中有性别字段,可以根据性别分组,⼀组是男性,⼀组是⼥性,或者是根据部门分组,有教学部、销售部等... # 1.按部门分组# 严格模式下只能获取分组字段post数据, ⽆法获取其他字段信息,就好⽐是进程之间数据隔离,但是可以使⽤聚合函数来获取'''聚合函数: max, min, sum, avg, count'''# ⾮严格模式下不报错select * from emp group by post; # 报错select id, name from emp group by post; # 报错select post from emp group by post;# 严格模式设置"""设置sql_mode为only_full_group_by,意味着以后但凡分组,只能取到分组的依据,不应该在去取组⾥⾯的单个元素的值,那样的话分组就没有意义了,因为不分组就是对单个元素信息的随意获取"""show variables like "%mode%";set global sql_mode="strict_trans_tables,only_full_group_by";# 2.获取每个部门的最⾼⼯资 ----> 画图,讲述数据分组后,发⽣了什么事情select post, max(salary) from emp group by post;# as: 起别名; 给获取出来的数据字段名,设置别名select post as '部门', max(salary) as '薪资' from emp group by post;# 可简写, 但不推荐select post '部门', max(salary) '薪资' from emp group by post;# 每个部门的最低⼯资select post, min(salary) from emp group by post;# 每个部门的平均⼯资select post, avg(salary) from emp group by post;# 每个部门的⼯资总和select post, sum(salary) from emp group by post;# 每个部门的⼈数: count() 中传任意参数都没问题select post, count(id) from emp group by post;select post, count(post) from emp group by post;# 3.查询分组之后的部门名称和每个部门下所有员⼯的姓名# group_concat(name): 不仅可以获取分组后的某⼀个字段,并且可以对字符串进⾏拼接select post, group_concat(name) from emp group by post;# 给每个部门的员⼯名字前 + NB_select post, group_concat('NB_', name) from emp group by post;# 拼接部门员⼯名字+薪资select post, group_concat(name, ":", salary) from emp group by post;# 4.补充concat(不分组时⽤)拼接字符串达到更好的显⽰效果 as语法使⽤select concat('Name: ', name) as '名字', concat('Sal: ', salary) as '薪资' from emp;# 5.补充as语法即可以给字段起别名也可以给表起select as '名字', emp.salary as '薪资' from emp;# 6.查询四则运算# 求各部门所有员⼯的年薪select name, salary * 12 as annual_salary from emp;5、练习题# 写查询语句的步骤: 先看需要查哪张表,然后看有没有什么限制条件, 再看需要根据什么分组,最后再看需要查看什么字段!执⾏顺序:from --> where --> group by --> select# 注意: 聚合函数:1、只能在group by后(执⾏顺序)使⽤2、若查询语句没有group by,则默认整张表就是⼀个分组。
sql常用关键字

sql_常用关键字SQL(Structured Query Language)是一种用于管理关系型数据库的标准化语言,它有许多常用的关键字和命令。
以下是一些常用的SQL关键字和命令:1.SELECT:用于从数据库表中检索数据。
2.FROM:用于指定要检索数据的表。
3.WHERE:用于过滤满足特定条件的数据。
4.GROUP BY:用于将数据按照指定的列进行分组。
5.HAVING:用于过滤组内的数据,与WHERE类似,但是作用于分组后的数据。
6.ORDER BY:用于对检索的数据进行排序。
7.ASC:用于指定升序排序。
8.DESC:用于指定降序排序。
9.LIMIT:用于限制检索结果的数量。
10.OFFSET:用于指定从哪一行开始检索。
11.INNER JOIN:用于将两个表通过一个或多个相等的列进行连接。
12.LEFT JOIN:用于将左表中的所有记录与右表中相匹配的记录连接。
13.RIGHT JOIN:用于将右表中的所有记录与左表中相匹配的记录连接。
14.FULL JOIN:用于将左表和右表中的所有记录连接。
15.INSERT INTO:用于向表中插入新的行。
16.UPDATE:用于修改表中已有的数据。
17.DELETE FROM:用于从表中删除行。
18.CREATE TABLE:用于创建一个新的表。
19.ALTER TABLE:用于修改现有表的结构。
20.DROP TABLE:用于删除表。
21.TRUNCATE TABLE:用于删除表中的所有行,但不删除表结构。
22.SELECT DISTINCT:用于检索唯一不重复的值。
23.COUNT:用于计算符合条件的行数。
24.SUM:用于计算数值列的总和。
25.AVG:用于计算数值列的平均值。
26.MIN:用于找出一列的最小值。
27.MAX:用于找出一列的最大值。
28.CASE:用于根据条件执行不同的操作。
29.COALESCE:用于返回参数列表中的第一个非空值。
MySQL关键字及保留字

MySQL关键字及保留字在SQL语句中出现的关键字和保留字如果要使⽤⼈他们的字符意思⽽不是作为关键字、保留字使⽤,关键字可以正常使⽤,但是保留字必须使⽤`(键盘tab键上⾯,数字1左边的那个按键)来分割。
这个在SQLServer⾥⾯是使⽤[]中括号实现的。
所以我们要尽量避免使⽤关键字和保留字来作为表明和字段名。
下⾯是mysql 5.7的关键字和保留字:官⽅⽂档地址Table 1 Keywords and Reserved Words in MySQL 5.7ACCESSIBLE (R)ACCOUNT ACTIONADD (R)AFTER AGAINSTAGGREGATE ALGORITHM ALL (R)ALTER (R)ALWAYS ANALYSEANALYZE (R)AND (R)ANYAS (R)ASC (R)ASCIIASENSITIVE (R)AT AUTOEXTEND_SIZEAUTO_INCREMENT AVG AVG_ROW_LENGTHBACKUP BEFORE (R)BEGINBETWEEN (R)BIGINT (R)BINARY (R)BINLOG BIT BLOB (R)BLOCK BOOL BOOLEANBOTH (R)BTREE BY (R)BYTE CACHE CALL (R)CASCADE (R)CASCADED CASE (R)CATALOG_NAME CHAIN CHANGE (R)CHANGED CHANNEL CHAR (R)CHARACTER (R)CHARSET CHECK (R)CHECKSUM CIPHER CLASS_ORIGINCLIENT CLOSE COALESCECODE COLLATE (R)COLLATIONCOLUMN (R)COLUMNS COLUMN_FORMATCOLUMN_NAME COMMENT COMMITCOMMITTED COMPACT COMPLETIONCOMPRESSED COMPRESSION CONCURRENTCONDITION (R)CONNECTION CONSISTENTCONSTRAINT (R)CONSTRAINT_CATALOG CONSTRAINT_NAMECONSTRAINT_SCHEMA CONTAINS CONTEXTCONTINUE (R)CONVERT (R)CPUCREATE (R)CROSS (R)CUBECURRENT CURRENT_DATE (R)CURRENT_TIME (R)CURRENT_TIMESTAMP (R)CURRENT_USER (R)CURSOR (R)CURSOR_NAME DATA DATABASE (R)DATABASES (R)DATAFILE DATEDATETIME DAY DAY_HOUR (R)DAY_MICROSECOND (R)DAY_MINUTE (R)DAY_SECOND (R)DEALLOCATE DEC (R)DECIMAL (R)DECLARE (R)DEFAULT (R)DEFAULT_AUTHDEFINER DELAYED (R)DELAY_KEY_WRITEDELETE (R)DESC (R)DESCRIBE (R)DES_KEY_FILE DETERMINISTIC (R)DIAGNOSTICS DIRECTORY DISABLE DISCARDDISK DISTINCT (R)DISTINCTROW (R)DIV (R)DO DOUBLE (R)DROP (R)DUAL (R)DUMPFILE DUPLICATE DYNAMIC EACH (R)ELSE (R)ELSEIF (R)ENABLE ENCLOSED (R)ENCRYPTION ENDENDS ENGINE ENGINESENUM ERROR ERRORSESCAPE ESCAPED (R)EVENTEVENTS EVERY EXCHANGE EXECUTE EXISTS (R)EXIT (R) EXPANSION EXPIRE EXPLAIN (R)EXPORT EXTENDED EXTENT_SIZEFALSE (R)FAST FAULTSFETCH (R)FIELDS FILEFILE_BLOCK_SIZE FILTER FIRSTFIXED FLOAT (R)FLOAT4 (R)FLOAT8 (R)FLUSH FOLLOWSFOR (R)FORCE (R)FOREIGN (R) FORMAT FOUND FROM (R)FULL FULLTEXT (R)FUNCTION GENERAL GENERATED (R)GEOMETRY GEOMETRYCOLLECTION GET (R)GET_FORMAT GLOBAL GRANT (R)GRANTSGROUP (R)GROUP_REPLICATION HANDLERHASH HAVING (R)HELPHIGH_PRIORITY (R)HOST HOSTSHOUR HOUR_MICROSECOND (R)HOUR_MINUTE (R) HOUR_SECOND (R)IDENTIFIED IF (R)IGNORE (R)IGNORE_SERVER_IDS IMPORTIN (R)INDEX (R)INDEXESINFILE (R)INITIAL_SIZE INNER (R)INOUT (R)INSENSITIVE (R)INSERT (R)INSERT_METHOD INSTALL INSTANCEINT (R)INT1 (R)INT2 (R)INT3 (R)INT4 (R)INT8 (R)INTEGER (R)INTERVAL (R)INTO (R)INVOKER IO IO_AFTER_GTIDS (R)IO_BEFORE_GTIDS (R)IO_THREAD IPCIS (R)ISOLATION ISSUERITERATE (R)JOIN (R)JSONKEY (R)KEYS (R)KEY_BLOCK_SIZEKILL (R)LANGUAGE LASTLEADING (R)LEAVE (R)LEAVESLEFT (R)LESS LEVELLIKE (R)LIMIT (R)LINEAR (R)LINES (R)LINESTRING LISTLOAD (R)LOCAL LOCALTIME (R) LOCALTIMESTAMP (R)LOCK (R)LOCKSLOGFILE LOGS LONG (R) LONGBLOB (R)LONGTEXT (R)LOOP (R)LOW_PRIORITY (R)MASTER MASTER_AUTO_POSITION MASTER_BIND (R)MASTER_CONNECT_RETRY MASTER_DELAY MASTER_HEARTBEAT_PERIOD MASTER_HOST MASTER_LOG_FILE MASTER_LOG_POS MASTER_PASSWORD MASTER_PORT MASTER_RETRY_COUNT MASTER_SERVER_ID MASTER_SSLMASTER_RETRY_COUNT MASTER_SERVER_ID MASTER_SSLMASTER_SSL_CA MASTER_SSL_CAPATH MASTER_SSL_CERTMASTER_SSL_CIPHER MASTER_SSL_CRL MASTER_SSL_CRLPATH MASTER_SSL_KEY MASTER_SSL_VERIFY_SERVER_CERT (R)MASTER_TLS_VERSION MASTER_USER MATCH (R)MAXVALUE (R)MAX_CONNECTIONS_PER_HOUR MAX_QUERIES_PER_HOUR MAX_ROWSMAX_SIZE MAX_STATEMENT_TIME MAX_UPDATES_PER_HOUR MAX_USER_CONNECTIONS MEDIUM MEDIUMBLOB (R) MEDIUMINT (R)MEDIUMTEXT (R)MEMORYMERGE MESSAGE_TEXT MICROSECONDMIDDLEINT (R)MIGRATE MINUTEMINUTE_MICROSECOND (R)MINUTE_SECOND (R)MIN_ROWSMOD (R)MODE MODIFIES (R)MODIFY MONTH MULTILINESTRING MULTIPOINT MULTIPOLYGON MUTEXMYSQL_ERRNO NAME NAMESNATIONAL NATURAL (R)NCHARNDB NDBCLUSTER NEVERNEW NEXT NONODEGROUP NONBLOCKING NONENOT (R)NO_WAIT NO_WRITE_TO_BINLOG (R) NULL (R)NUMBER NUMERIC (R)NVARCHAR OFFSET OLD_PASSWORDON (R)ONE ONLYOPEN OPTIMIZE (R)OPTIMIZER_COSTS (R) OPTION (R)OPTIONALLY (R)OPTIONSOR (R)ORDER (R)OUT (R)OUTER (R)OUTFILE (R)OWNERPACK_KEYS PAGE PARSERPARSE_GCOL_EXPR PARTIAL PARTITION (R) PARTITIONING PARTITIONS PASSWORDPHASE PLUGIN PLUGINSPLUGIN_DIR POINT POLYGONPORT PRECEDES PRECISION (R)PREPARE PRESERVE PREVPRIMARY (R)PRIVILEGES PROCEDURE (R) PROCESSLIST PROFILE PROFILESPROXY PURGE (R)QUARTERQUERY QUICK RANGE (R)READ (R)READS (R)READ_ONLYREAD_WRITE (R)REAL (R)REBUILDRECOVER REDOFILE REDO_BUFFER_SIZE REDUNDANT REFERENCES (R)REGEXP (R)RELAY RELAYLOG RELAY_LOG_FILERELAY_LOG_POS RELAY_THREAD RELEASE (R)RELOAD REMOVE RENAME (R) REORGANIZE REPAIR REPEAT (R) REPEATABLE REPLACE (R)REPLICATE_DO_DB REPLICATE_DO_TABLE REPLICATE_IGNORE_DB REPLICATE_IGNORE_TABLE REPLICATE_REWRITE_DB REPLICATE_WILD_DO_TABLE REPLICATE_WILD_IGNORE_TABLE REPLICATION REQUIRE (R)RESETRESIGNAL (R)RESTORE RESTRICT (R)RESUME RETURN (R)RETURNED_SQLSTATE RETURNS REVERSE REVOKE (R)RIGHT (R)RLIKE (R)ROLLBACKROLLUP ROTATE ROUTINEROW ROWS ROW_COUNTROW_FORMAT RTREE SAVEPOINTSCHEDULE SCHEMA (R)SCHEMAS (R)SCHEMA_NAME SECOND SECOND_MICROSECOND (R) SECURITY SELECT (R)SENSITIVE (R) SEPARATOR (R)SERIAL SERIALIZABLESERVER SESSION SET (R)SHARE SHOW (R)SHUTDOWNSIGNAL (R)SIGNED SIMPLESLAVE SLOW SMALLINT (R) SNAPSHOT SOCKET SOMESONAME SOUNDS SOURCESPATIAL (R)SPECIFIC (R)SQL (R) SQLEXCEPTION (R)SQLSTATE (R)SQLWARNING (R)SQL_AFTER_GTIDS SQL_AFTER_MTS_GAPS SQL_BEFORE_GTIDS SQL_BIG_RESULT (R)SQL_BUFFER_RESULT SQL_CACHESQL_CALC_FOUND_ROWS (R)SQL_NO_CACHE SQL_SMALL_RESULT (R) SQL_THREAD SQL_TSI_DAY SQL_TSI_HOURSQL_TSI_MINUTE SQL_TSI_MONTH SQL_TSI_QUARTER SQL_TSI_SECOND SQL_TSI_WEEK SQL_TSI_YEARSSL (R)STACKED STARTSTARTING (R)STARTS STATS_AUTO_RECALC STATS_PERSISTENT STATS_SAMPLE_PAGES STATUSSTOP STORAGE STORED (R) STRAIGHT_JOIN (R)STRING SUBCLASS_ORIGIN SUBJECT SUBPARTITION SUBPARTITIONS SUPER SUSPEND SWAPSSWITCHES TABLE (R)TABLES TABLESPACE TABLE_CHECKSUM TABLE_NAMETEMPORARY TEMPTABLE TERMINATED (R) TEXT THAN THEN (R)TIME TIMESTAMP TIMESTAMPADDTIMESTAMPDIFF TINYBLOB (R)TINYINT (R) TINYTEXT (R)TO (R)TRAILING (R) TRANSACTION TRIGGER (R)TRIGGERSTRUE (R)TRUNCATE TYPETYPES UNCOMMITTED UNDEFINEDUNDO (R)UNDOFILE UNDO_BUFFER_SIZE UNICODE UNINSTALL UNION (R)UNIQUE (R)UNKNOWN UNLOCK (R) UNSIGNED (R)UNTIL UPDATE (R) UPGRADE USAGE (R)USE (R)USER USER_RESOURCES USE_FRMUSING (R)UTC_DATE (R)UTC_TIME (R)UTC_TIMESTAMP (R)VALIDATION VALUEVALUES (R)VARBINARY (R)VARCHAR (R) VARCHARACTER (R)VARIABLES VARYING (R)VIEW VIRTUAL (R)WAITWARNINGS WEEK WEIGHT_STRING WHEN (R)WHERE (R)WHILE (R)WITH (R)WITHOUT WORKWRAPPER WRITE (R)X509XA XID XMLXOR (R)YEAR YEAR_MONTH (R) ZEROFILL (R)ACCOUNT: added in 5.7.6 (nonreserved)ALWAYS: added in 5.7.6 (nonreserved)CHANNEL: added in 5.7.6 (nonreserved)COMPRESSION: added in 5.7.8 (nonreserved)ENCRYPTION: added in 5.7.11 (nonreserved)FILE_BLOCK_SIZE: added in 5.7.6 (nonreserved)FILTER: added in 5.7.3 (nonreserved)FOLLOWS: added in 5.7.2 (nonreserved)FOLLOWS: added in 5.7.2 (nonreserved)GENERATED: added in 5.7.6 (reserved)GROUP_REPLICATION: added in 5.7.6 (nonreserved)INSTANCE: added in 5.7.11 (nonreserved)JSON: added in 5.7.8 (nonreserved)MASTER_TLS_VERSION: added in 5.7.10 (nonreserved)MAX_STATEMENT_TIME: added in 5.7.4 (nonreserved); removed in 5.7.8NEVER: added in 5.7.4 (nonreserved)NONBLOCKING: removed in 5.7.6OLD_PASSWORD: removed in 5.7.5OPTIMIZER_COSTS: added in 5.7.5 (reserved)PARSE_GCOL_EXPR: added in 5.7.6 (reserved); became nonreserved in 5.7.8 PRECEDES: added in 5.7.2 (nonreserved)REPLICATE_DO_DB: added in 5.7.3 (nonreserved)REPLICATE_DO_TABLE: added in 5.7.3 (nonreserved)REPLICATE_IGNORE_DB: added in 5.7.3 (nonreserved)REPLICATE_IGNORE_TABLE: added in 5.7.3 (nonreserved)REPLICATE_REWRITE_DB: added in 5.7.3 (nonreserved)REPLICATE_WILD_DO_TABLE: added in 5.7.3 (nonreserved)REPLICATE_WILD_IGNORE_TABLE: added in 5.7.3 (nonreserved)ROTATE: added in 5.7.11 (nonreserved)STORED: added in 5.7.6 (reserved)VALIDATION: added in 5.7.5 (nonreserved)VIRTUAL: added in 5.7.6 (reserved)WITHOUT: added in 5.7.5 (nonreserved)XID: added in 5.7.5 (nonreserved)Table 2 New Keywords and Reserved Words in MySQL 5.7 compared to MySQL 5.6ACCOUNT ALWAYS CHANNELCOMPRESSION ENCRYPTION FILE_BLOCK_SIZEFILTER FOLLOWS GENERATED (R)GROUP_REPLICATION INSTANCE JSONMASTER_TLS_VERSION NEVER OPTIMIZER_COSTS (R)PARSE_GCOL_EXPR PRECEDES REPLICATE_DO_DBREPLICATE_DO_TABLE REPLICATE_IGNORE_DB REPLICATE_IGNORE_TABLE REPLICATE_REWRITE_DB REPLICATE_WILD_DO_TABLE REPLICATE_WILD_IGNORE_TABLE ROTATE STACKED STORED (R)VALIDATION VIRTUAL (R)WITHOUTXID。
SQL保留字词汇一览表
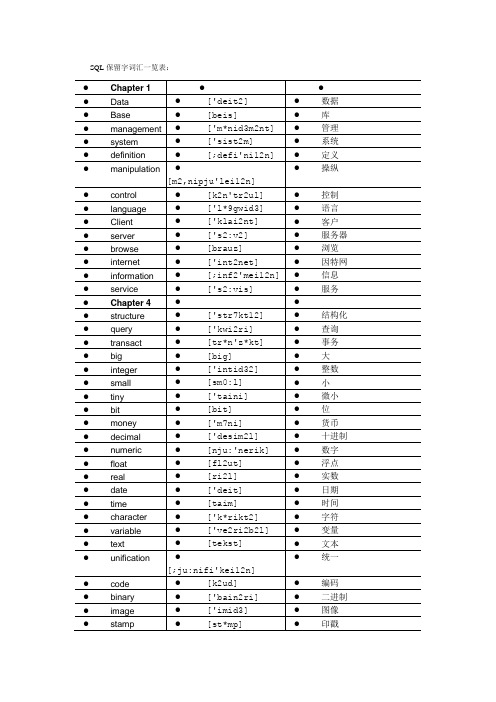
十进制
numeric
[nju:'nerik]
数字
float
[fl2ut]
浮点
real
[ri2l]
实数
date
['deit]
日期
time
[taim]
时间
character
['k*rikt2]
字符
variable
['ve2ri2b2l]
变量
text
[tekst]
文本
unification
创建
alter
['0:lt2]
修改
drop
[dr0p]
删除
help
[help]
帮助
add
[*d]
增加
remove
[ri'mu:v]
移除
modify
['m0difai]
修改
insert
[in's2:t]
插入
update
[;7p'deit]
修改
delete
[di'li:t]
删除
as
[*z]
与…一样
into
procedure
[pr2'si:d32]
过程
output
['autput]
输出
execute
['eksikju:t]
执行
for
[f0:]
对
after
['4:ft2]
之后
instead
[in'sted]
代替
of
Oracle数据库中关键字

Oracle数据库中关键字在 Oracle 数据库中有一些单词具有特定的意思,也许不是提供给你的,但是使用它们你就可以不必解析、执行和获取你所编写的代码。
为了更准确,在第一句话中的一些单词可以归类为保留字和关键字。
在关键字的分类中,上下文起到了作用,因为一个单词不总是保留字。
例如,在Oracle数据库中有一些单词具有特定的意思,也许不是提供给你的,但是使用它们你就可以不必解析、执行和获取你所编写的代码。
为了更准确,在第一句话中的“一些单词”可以归类为保留字和关键字。
在关键字的分类中,上下文起到了作用,因为一个单词不总是保留字。
例如,单词COMMIT 本身可以触发很多事件,所以你可能要假设COMMIT 是Oracle密切使用的一个关键字。
从Oracle 的角度看,就是只有它可以使用这个单词。
但结果是,COMMIT 并没有如它希望的那样。
如果你想的话你可以创建一个叫做COMMIT 的表,因为COMMIT 是一个关键字,这比保留字的级别要低。
保留字是被锁定的,而关键字在某些条件下可以使用。
审查是一个有用的工具或功能,那么如果你想创建你自己的审查表,你是否可以使用“create table audit (...)”语句呢?至少在SQL中是不行的,你不能通过这种方法使用“audit”。
既然你不想使用这些特殊单词,那么你怎样能知道(或者你能从哪找到)特殊单词有哪些呢? 在文档库(在一个索引中)中的几个指导包括了这个列表,但是权威的和一站式的来源是V$RESERVED_WORDS 数据字典视图。
视图的名称表示这只是关于保留字的;但是描述视图的时候,重要的主键列被称为KEYWORD。
这使得当我要了解关键字和保留字的区别时把我搞糊涂了。
它使得视图中的第二列也很重要:RESERVED。
因此V$RESERVED_WORDS 的解码环如下所示:数据库参考指导在对V$RESERVED_WORDS 的描述中准确地表达了这个意思。
MySQL5.7中的关键字与保留字详解

MySQL5.7中的关键字与保留字详解前⾔MySQL和Oracle的关键字还是不尽相同的,在Oracle数据库中,我们的数据表中定义了⼤量的code字段⽤来表⽰主键,但是在MySQL中code是关键字,使⽤以前的处理⽅法就有些“⽔⼟不服”。
下⾯我们来了解⼀下MySQL中的关键字和保留字。
什么是关键字和保留字关键字是指在SQL中有意义的字。
某些关键字(例如SELECT,DELETE或BIGINT)是保留的,需要特殊处理才能⽤作表和列名称等标识符。
这⼀点对于内置函数的名称也适⽤。
如何使⽤关键字和保留字⾮保留关键字允许作为标识符,不需要加引号。
如果您要适⽤保留字作为标识符,就必须适⽤引号。
举个例⼦,BEGIN和END是关键字,但不是保留字,因此它们⽤作标识符不需要引号。
INTERVAL是保留关键字,必须加上引号才能⽤作标识符。
mysql>mysql> use hoegh;Database changedmysql>mysql> CREATE TABLE interval (begin INT, end INT);ERROR 1064 (42000):mysql>mysql> CREATE TABLE `interval` (begin INT, end INT);Query OK, 0 rows affected (0.42 sec)mysql>mysql> show create table `interval`;+----------+---------------------------------------------------------| Table | Create Table+----------+---------------------------------------------------------| interval | CREATE TABLE `interval` (`begin` int(11) DEFAULT NULL,`end` int(11) DEFAULT NULL) ENGINE=InnoDB DEFAULT CHARSET=latin1 |+----------+---------------------------------------------------------1 row in set (0.00 sec)mysql>我们看到,第⼀条语句中表名使⽤了保留字interval,执⾏失败;第⼆条语句对interval加了引号,执⾏成功。
Java关键字(keyword)和保留字(reserved word)的用法

Java关键字(keyword)和保留字(reserved word)的用法在java中有48个关键字和2个保留字。
经过学习,借助了谷歌的力量我将这些关键字和保留字整理如下。
一.访问限定。
1.public关键字: public的意思是公有的,public作为关键字可以放在类前,表示这个类可以被其他包中的类的对象所访问。
Public限定的类在文件中只允许有一个,且类名必须与文件名相同。
如果public用来修饰方法,表示方法可以被其他包中的类调用。
如果public用来修饰属性,则可直接通过对象名.属性来访问对象的属性。
2.private关键字: private的意思是私有的,其可调用性范围最小。
在方法的前面加上private,则方法只能由内部的方法或者构造器调用,通常,属性都是用private限定的,而一般的类前,都不加private限定。
在类继承时,父类中的private方法将不能被子类继承。
当我们给某个构造器加上private修饰符时,则不能创建某个类的对象。
3.protected关键字:protected限定符界于public和private之间。
被protected限定的方法,子类可以继承,在同一个包内可以访问,在不同的包内不可以访问。
这些关键字的用法如上所述,但为了更好的理解一些细节的问题,大家可以看一下我对下面这些问题的总结。
那么,一个类中是否可以定义两个或者两个以上的public类?我们可以在eclipse 中运行一下,结果如下:由上可见,在一个类中,Public限定的类在文件中只允许有一个,且类名必须与文件名相同。
若在类里面还要创建一个类的话,那就只能是默认的,不可以加其他访问修饰符,或者,可以在已有的类的内部,再创建一个类,但名字必须不同与文件名。
若属性使用public进行修饰,就可以直接通过对象·属性来访问对象的属性。
输出结果是name=向聘。
这里就是直接通过创建的对象来访问st对象的name属性的。
数据库关键字汇总

数据库关键字汇总---by julseSELECT查找,选择from从...中INTO将查询结果保存起来,插入新表或临时表DISTINCT去重。
清除重复的行。
在select的后面,目标列的前面,top的后面(如果有top)ALL全部,与distinct相反GROUPBY分组。
GROUP BY子句:对查询结果按指定列的值分组,该属性列值相等的元组为一个组。
通常会在每组中作用集函数HAVING用于分组语句之后,表示对组的条件要求ORDERBY排序ASC升序(默认的排序方式)DESC降序top 5 [percent]前5个[前百分之5个]对记录的数量进行具体限定between 5 and 15 在5和15之间,确定范围in('',''),notin()确定集合,在集合中null,isnull空值and,or连接多重条件like模糊查询[NOT]BETWEEN...AND...(不在)在什么与什么值之间,包含边界值exists,notexists判断是不是存在子查询返回逻辑值时:用EXISTS/NOTEXISTSleft[outer]join...on..,right[outer]join..on..左外连接,left左,right右,outer外join连接UNION联合查询。
即并集INTERSECT相交查询。
即交集EXCEPT差查询。
即差集聚合函数:count(*)计数min(<列名>)本列最小值max(<列名>)本列最大值sum(<列名>)本列求和CREATE创建。
用于建表、建库、建函数、存储过程、触发器ALTER修改。
修改CREATE创建的东西DROP删除。
删除CREATE创建的东西EXEC运行。
执行存储过程的关键字DATABASE数据库table表ADD添加notnull非空constraint约束primarykey主键FOREIGNKEY外键REFERENCES提及用于创建外键check检查。
数据库常用关键字

数据库常用关键字adoquery1.Fielddefs[1].Name;字段名dbgrid1.columns[0].width:=10;dbgrid的字段宽度adoquery1.Fields[i].DataType=ftString字段类型updatejb_spzlsetkp_item_name=upper(kp_item_name)修改数据库表中某一列为大写selectfrommaster.dbo.sysobjects,jm_ers多库查询adotable1.sort:=''字段名称ASC''adotable排序SQL常用语句一览sp_passwordnull,''新密码'',''sa''修改数据库密码(1)数据记录筛选:sql="selectfrom数据表where字段名=字段值orderby字段名[desc]"sql="selectfrom数据表where字段名like''%字段值%''orderby 字段名[desc]"sql="selecttop10from数据表where字段名orderby字段名[desc]"sql="selectfrom数据表where字段名in(''值1'',''值2'',''值3'')"sql="selectfrom数据表where字段名between值1and值2"(2)更新数据记录:sql="update数据表set字段名=字段值where条件表达式"sql="update数据表set字段1=值1,字段2=值2……字段n=值nwhere条件表达式"(3)删除数据记录:sql="deletefrom数据表where条件表达式"sql="deletefrom数据表"(将数据表所有记录删除)(4)添加数据记录:sql="insertinto数据表(字段1,字段2,字段3…)values(值1,值2,值3…)"sql="insertinto目标数据表selectfrom源数据表"(把源数据表的记录添加到目标数据表)(5)数据记录统计函数:AVG(字段名)得出一个表格栏平均值COUNT(|字段名)对数据行数的统计或对某一栏有值的数据行数统计MAX(字段名)取得一个表格栏最大的值MIN(字段名)取得一个表格栏最小的值SUM(字段名)把数据栏的值相加引用以上函数的方法:sql="selectsum(字段名)as别名from数据表where条件表达式"setrs=conn.excute(sql)用rs("别名")获取统的计值,其它函数运用同上。
数据库中常用的一些关键字

数据库中常⽤的⼀些关键字1.distinct ⽤来查询不重复记录的条数,可以是单个字段去重、也可以是多个字段去重,但是不能与all同时使⽤并且不能在insert、delete、update中使⽤select distinct column1 from table_name;2.where ⼦句⽤于提取那些满⾜指定条件的记录select column1,column2,... from table_name where column_name .....有⼀些常⽤运算符=等于、<>不等于、>⼤于、 <⼩于、 >=⼤于等于、 <=⼩于等于、 between在某个范围内、 like搜索某种模式、 in指定针对某个列的多个可能值3.and & orselect * from table_name where column1=value1 and column2=value2;select * from table_name where column1=value1 or column2=value2;4.order by ⽤于对结果集进⾏排序,默认为ASC升序,DESC降序5.insert into语句⽤于向表中插⼊新纪录insert into table_name(column1,column2,...) values(value1,value2,...);6.update语句⽤于更新表中的记录update table_name set column1=value1,... where some_column=some_value;7.delete语句⽤于删除表中的记录delete from table_name where some_column=some_value;8.top、limit、rownumselect top number|percent column_name from table_name where [condition];例如:==SQL server/Acess中== select top 2 * from student; ==等价于mysql中== select * from student limit 2; ==等价于oracle中== select * from student where rownum<=2;9.like操作符⽤于在where⼦句中搜索列中的指定模式select column_name(s) from table_name where column_name like pattern; 注意需要⽤到%10.in操作符⽤于在where⼦句中规定多个值select column_name(s) from table_name where column_name in (value1,value2,...);11.between⽤于选取介于两个值之间的数据范围内的值select column_name(s) from table_name where column_name between value1 and value2;12.inner join在表中存在⾄少⼀个匹配时返回⾏=========等同于joinselect column_name(s) from table1 inner join table2 on table1.column_name=table2.column_name;13.left join关键字从左表返回所有的⾏,即使右表中没有匹配,结果以nul显⽰=========也可以称为left outer joinselect column_name(s) from table1 left join table2 on table1.column_name=table2.column_name;14.right join关键字从右表返回所有的⾏,即使左表没有匹配,结果以null显⽰=========也可以称为right outer joinselect column_name(s) from table1 right join table2 on table1.column_name=table2.column_name;15.full outer join关键字只要左表和右表其中⼀个表中存在匹配,则返回⾏select column_name(s) from table1 full outer join table2 on table1.column_name=table2.column_name;16.union操作符合并两个或多个select语句的结果**********union只会选取不同的值,union all会选取所有的值,包括重复的值select column_name(s) from table1union/union allselect column_name(s) from table2;//******两个select语句必须有相同数量的列,列也必须有相似的数据类型,⽽且列的顺序也必须相同****// 17.select into语句从⼀个表复制数据,然后插⼊到另⼀个表中******但是两个表的结构和数据类型完全⼀致select column_name(s) into new_table from old_table;18.insert into select语句从⼀个表复制数据,把数据插⼊到⼀个已存在的表中,⽬标表中任何已存在的⾏都不会受影响insert into table2(column_name(s)) select column_name(s) from table1;19.create database语句⽤于创建数据库create database dbname;20.create table语句⽤于创建数据库中的表create table table_name{column_name1 data_type(size),column_name2 data_type(size),...};21.constraints约束⽤于规定表中的数据规则约束类型not null(指⽰某列不能存储null值)、unique(保证某列的每⾏必须有唯⼀的值)、primary key(not null和unique的结合)、foreign key(保证⼀个表中的数据匹配另⼀个表中的值的参照完整性)check(保证列中的值符合指定的条件)、default(规定没有给列赋值时的默认值)create table table_name{column_name1 data_type(size) constraints_name,column_name2 data_type(size) constraints_name,...};22.index索引:以便于更加快速⾼效的查询数据create index index_name on table_name(column_name);23.drop⽤于删除索引、表和数据库drop index index_name on table_name;drop table table_name;drop database database_name;删除表内的数据,不删除表本⾝,使⽤truncate table table_name;24.alter table ⽤于在已有的表中添加、删除、修改列alter table table_name add column_name datatype;//添加alter table table_name drop column column_name;//删除alter table table_name modify column_name datatype;//更新25.auto increment会在新纪录插⼊表中时⽣成⼀个唯⼀的数字CREATE TABLE Persons(ID int NOT NULL AUTO_INCREMENT,LastName varchar(255) NOT NULL,FirstName varchar(255),PRIMARY KEY (ID))在Oracle中必须通过sequence对象创建CREATE SEQUENCE seq_personMINVALUE 1START WITH 1INCREMENT BY 1CACHE 10insert into Persons(ID,FirstName,LastName) values(seq_person.nextval,'Lars','Monsen');26.view视图:是可视化的表,包含⾏和列,视图中的字段来⾃⼀个或多个数据库中的真实的表中的字段create view view_name AS select column_name(s) from table_name where condition ;create or replace view view_name as select column_name(s) from table_name where condition;drop view view_name;//删除视图27.date函数now() 返回当前的⽇期和时间、curdate()当前的⽇期、curtime()当前的时间、date()提取⽇期或时间表达式的⽇期部分、extract()返回⽇期/时间的单独部分、datediff()返回两个⽇期之间的天数、date_format()⽤不同的格式显⽰⽇期/时间28.avg()函数:返回数值列的平均值select avg(column_name) from table_name;29.count()函数:返回匹配指定条件的⾏数select count(column_name) from table_name;select count(distinct column_name) from table_name;30.first()函数:返回指定的列中第⼀个记录的值select first(column_name) from table_name;//只有MS Access⽀持first()函数select top 1 column_name from table_name order by column_name asc;//sql server⽤法select column_name from table_name order by column_name asc limit 1;//mysql⽤法select column_name from table_name order by column_name asc where rownum <=1;//oracle⽤法st()函数:返回指定列中最后⼀个记录的值select last(column_name) from table_name;//只有MS Access⽀持last()函数select top 1 column_name from table_name order by column_name desc;//sql server⽤法select column_name from table_name order by column_name desclimit 1;//mysql⽤法select column_name from table_name order by column_name desc where rownum <=1;//oracle⽤法32.max()函数:返回指定列中最⼤值select max(column_name) from table_name;33.min()函数:返回指定列中最⼩值select min(column_name) from table_name;34.sum()函数:返回数值列的总数select sum(column_name) from table_name;//理解为求和35.having⼦句可以筛选分组后的各组数据select column_name,aggregate_function(column_name) from table_name where column_name operator value group by column_name having aggregate_function(column_name) operator value;35.exists运算符⽤于判断查询⼦句是否有记录,如果有⼀条或多条返回true,否则falseselect column_name(s) from table_name where exists (select column_name from table_name where condition);36.ucase()函数:把字段的值转换为⼤写////upper()函数select ucase(column_name) from table_name;37.lcase()函数:把字段的值转换为⼩写/////lower()函数select lcase(column_name) from table_name;38.mid()函数:⽤于从⽂本字段中提取字符select mid(column_name,start[,length]) from table_name;39.len()函数:返回⽂本字段中值的长度select len(column_name) from table_name;select length(column_name) from table_name;//MySQL中的函数名称及⽤法40.round()函数:⽤于把数值字段舍⼊为指定的⼩数位数select round(column_name,decimals) from table_name;***********round(x):返回参数x的四舍五⼊的⼀个整数***********round(x,d):返回参数x的四舍五⼊的有d位⼩数的⼀个数字。
数据库---查询所用的关键字汇总

数据库---查询所⽤的关键字汇总--1、查询Student表中的所有记录的Sname、Ssex和Class列。
select Sname,Ssex,class from Student--2、查询教师所有的单位即不重复的Depart列。
select distinct depart from teacher--3、查询Student表的所有记录。
select *from student--4、查询Score表中成绩在60到80之间的所有记录。
select *from Score where degree between 60 and 80--5、查询Score表中成绩为85,86或88的记录。
select *from Score where degree in (85,86,88)--6、查询Student表中“95031”班或性别为“⼥”的同学记录。
select *from student where class='95031' or ssex='⼥'--7、以Class降序查询Student表的所有记录。
select *From student order by class desc--8、以Cno升序、Degree降序查询Score表的所有记录。
select *from score order by Cno,Degree desc--9、查询“95031”班的学⽣⼈数。
--聚合函数:针对数据列,计算求和或者计数等⼀系列算术性操作select count(*) from student where class='95031'--sum(),avg(),max(),min()select MAX(Degree) as maxfen,MIN(Degree) minfen from Score where Cno='3-105'--10、查询Score表中的最⾼分的学⽣学号和课程号。
mysql常用语句及关键字

mysql常⽤语句及关键字⼀、常⽤sql语句注意,关键字和函数最好⼤写,字段和表名⼩写,这样很容易区分。
1.创建数据库t_userCREATE DATABASE t_user;2.删除数据库t_userDROP DATABASE t_user;3.使⽤数据库t_userUSE t_user;显⽰数据库中的表SHOW TABLES;4.创建数据表 t_order表名的命名规范为表名必须⽤ t_ 、tb_的前缀,或者是业务模块前缀。
⽐如t_orderCREATE TABLE t_order (id INT(11) NOT NULL AUTO_INCREMENT COMMENT '主键,⾃增id',order_id VARCHAR(25) NOT NULL COMMENT '订单号,唯⼀',pay_status TINYINT(2) UNSIGNED DEFAULT 0 COMMENT '1:未⽀付,2:⽀付成功,3:⽀付失败, 4:已下单,5:申请退款,6:退款成功,7:退款失败 ',user_id INT(11) NOT NULL COMMENT '⽤户id',total_price DECIMAL(25,2) NOT NULL DEFAULT 0.00 COMMENT '交易⾦额',result TEXT COMMENT '结果',order_desc VARCHAR(128) NOT NULL DEFAULT '' COMMENT '订单描述',is_overtime TINYINT(1) DEFAULT 0 COMMENT '是否超时,0表⽰否,1表⽰是',create_date DATE DEFAULT NULL COMMENT '购买⽇期',create_time TIMESTAMP COMMENT '创建时间',update_time TIMESTAMP COMMENT '更新时间',PRIMARY KEY (id),UNIQUE KEY uk_order_id (order_id),INDEX idx_order (order_id,pay_status,user_id)) ENGINE=INNODB DEFAULT CHARSET=utf8AUTO_INCREMENT 表⽰⾃增,UNSIGNED 表⽰⽆符号,UNIQUE 表⽰唯⼀约束,COMMENT为字段描述。
oracle数据库常用关键字以及写法

oracle数据库常⽤关键字以及写法数据库常⽤关键字:create table---创建⼀个表创建⼀个表带表名(列名列的类型,列名列的类型……)create table Z_COURSE(id NUMBER, cour_code VARCHAR2(20), cour_name VARCHAR2(20), p_cour_code VARCHAR2(20));insert into---插⼊数据插⼊数据表名(表的列类型)要插⼊的值(符合列的类型的数据,有⼏列就写⼏条⽽且要符合列的类型)insert into Z_COURSE (id, cour_code, cour_name, p_cour_code)values (1, 'LAU-100', '汉语⾔⽂学专业', null);delete---删除数据删除表名限制条件当条件为什么,对表进⾏数据删除delete emp e where e.empname='jjj';update---更新⼀条数据更改表名设置某个属性为什么当条件是什么,对表进⾏数据更改update emp e set e.empname='qqqq' where e.id=4;select---查询数据(实际⼯作中尽量不要写*,*代表全部,对于数据较⼤的会影响运⾏速度,可以给表加变量名,由⼀个字母代表,然后字母. 就可以得到表内需要显⽰的列,多列可以由逗号隔开)查询全部列(*)from表名select * from z_student;查询表内名字的⼀列select from z_student s;where---给执⾏的语句加限制条件set---设置某些属性。
MySQL关键字

MySQL关键字EXPLAINexplain模拟优化器执⾏SQL语句,在5.6以及以后的版本中,除过select,其他⽐如insert,update和delete均可以使⽤explain查看执⾏计划,从⽽知道mysql是如何处理sql语句,分析查询语句或者表结构的性能瓶颈。
作⽤1. 表的读取顺序2. 数据读取操作的操作类型3. 哪些索引可以使⽤4. 哪些索引被实际使⽤5. 表之间的引⽤6. 每张表有多少⾏被优化器查询执⾏计划包含的信息如下信息描述id查询的序号,包含⼀组数字,表⽰查询中执⾏select⼦句或操作表的顺序。
ID相同:执⾏顺序从上往下。
ID不同:id值越⼤,优先级越⾼,越先执⾏select_type 查询类型,主要⽤于区别普通查询,联合查询,⼦查询等的复杂查询simple ——简单的select查询,查询中不包含⼦查询或者UNIONprimary ——查询中若包含任何复杂的⼦部分,最外层查询被标记subquery——在select或where列表中包含了⼦查询derived——在from列表中包含的⼦查询被标记为derived(衍⽣),MySQL会递归执⾏这些⼦查询,把结果放到临时表中union——如果第⼆个select出现在UNION之后,则被标记为UNION,如果union包含在from⼦句的⼦查询中,外层select被标记为derivedunion result——UNION 的结果table输出的⾏所引⽤的表type 显⽰联结类型,显⽰查询使⽤了何种类型,按照从最佳到最坏类型排序system——表中仅有⼀⾏(=系统表)这是const联结类型的⼀个特例。
const——表⽰通过索引⼀次就找到,const⽤于⽐较primary key或者unique索引。
因为只匹配⼀⾏数据,所以如果将主键置于where列表中,mysql能将该查询转换为⼀个常量eq_ref——唯⼀性索引扫描,对于每个索引键,表中只有⼀条记录与之匹配。
(整理)JAVA的保留(53个)关键字_v1.1.
密级:【中密】版本:【1.0】文档作者:【陈联聪】提交时间:【2013-6-6】【JAVA的保留关键字说明】1 概述在java中保留关键字是被java本身定义使用的字母组合,具有特殊意义,所以不能用作变量名、方法名以及包名。
Java共有53个关键字,中const和goto虽然被保留但未被使用。
2 详述保留关键字分为9大类:一、访问控制修饰符的关键字(共3个):四、异常处理(共5个)九、枚举和断言(共2个):3 附加说明说明:1、使用volatile关键字修饰的为“容易失去”的变量,即为该变量可能同时被多个线程所控制和修改,在程序执行过程中该变量可能被其它的程序所修改,通常volatile用来修饰接受外部输入的变量。
如表示当前系统时间的变量。
2、使用native修饰的方法为其它(C、C++等)语言的特殊方法。
3、使用synchronized声明的方法为同步方法,即在多线程中该方法调用时会把当前的对象“加锁”,从而达到同步的目的。
以上中需要注意对于不在同一个包中的子类在使用父类的protected的成员时,只能通过继承的方式调用而不能使用父类的引用来调用。
附二、this与super的区别:附三、方法重载与重写(重点)附四、final关键字的使用:附五、接口的特性:1、所有接口方法隐含都是公共的和抽象的。
2、接口中定义的所有变量必须是公共的、静态的和最终的。
3、接口方法一定不能使静态的。
4、因为接口中的方法是抽象的,所以不能将其标示为final、strictfp、native。
5、接口可以扩展一个或多个接口6、接口不能扩展除了其它接口之外的任何内容7、接口不能实现另一个接口或类。
附六、static 例子:[java] view plaincopyprint?1.public class Test{2.class A{} //内部类3.ActionListener al=new ActionListener(···){}//匿名内部类4.5.<SPAN style="FONT-SIZE: 14pt"><SPAN style="FONT-SIZE: 16px"> </SPAN></SPAN>public class Test{class A{} //内部类ActionListener al=new ActionListener(···){}//匿名内部类}静态块优先于其他方法/类的执行附七、throw是你执行的动作。
数据库关键字,和依赖集

数据库关键字,和依赖集数据库关键字总结1.wherewhere常在数据库中用来进行条件筛选,如 select xx from xx where id=xx;这就是筛选出id字段=xx的所有记录2.select用于查询数据表里的数据select 查询的字段名(*代表全部数据) from 表名 where [条件表达式]3.insert用于新增数据库里新的字段和数据,insert into 表名 (字段名1,字段名2,字段名3) values("字段名1的值","字段名2的值","字段名3的值"),可以利用insert关键字将已有的表中数据复制到另一张新表中。
4.update用来修改数据库里的数据,update 表名 set 值1=xx,值2=xx where [条件表达式]5.delete用来删除数据库中的某个字段,delete from 表名 where [条件表达式]6.distinct用来去除数据库中重复的数据,select distinct 字段名(*) from 表名7.order by用于查询的时候可以对数据进行升序/降序排列,select 字段名from 表名 order by desc(降序)/asc(升序) 默认升序。
8.group by用于数据库查询的时候对数据进行分组,select 字段名 from 表名group by 字段名1 按照字段名1进行分组9.having和where一样是进行条件筛选的,但是区别是where是先把所有符合条件的数据进行筛选,筛选之后再进行分组操作,而having是先进行分组操作,分组之后再对分组后的数据进行筛选,关于数据库中having和where的区别:1.首先用having条件来查询的语句是先分组再判断的2.having可以使用统计函数,where不可以3.having可以指定查询的字段别名,where不可以4.关于关键字执行顺序 where, group by, having, order by, limit 10.limitlimit是常用于分类查询的一个关键字select 字段名 from 表名 limit 1 , 5;这是从第二条数据开始查,查询五条数据,第一个参数是从第几行开始查,第二个关键字是查询几条数据,select 字段名 from 表名 limit 5; 这是默认从第一行开始查,查询5条数据,当默认第一行开始的时候是limit 0 , 5所以可以省略第一个参数11.offset这个关键字常用于limit中表示跳过几条数据select 字段名 from 表名 limit 1 , 5 offset 3;这是从第二条数据开始查,查询五条数据,跳过3条数据,也就是说查询第5,6条数据,与select 字段名 from 表名 limit 5,2; (从第五条数据开始查询,查询两条数据)查询结果是一样的12.and常用于条件筛选中,表示同时满足and前后的条件select 字段名 from 表名 where 字段名1>xx and 字段名2=yy; 筛选出既满足字段名1>xx的记录和字段名2=yy的记录取两者的交集13.or常用于条件筛选中,表示or前后的条件满足其一即可,select 字段名 from 表名字段名1>xx or字段名2=yy;筛选出满足字段名1>xx 的记录或者是字段名2=yy的记录14.like常用于数据库中模糊查询,select 字段名 from 表名 where name="刘%";查询name中刘是第一个字的所有数据,select 字段名 from 表名 where name="刘_"查询name中刘是第一个字,一共2个字的所有数据;_代表匹配一个任意字符,%表示匹配多个任意字符15.union常用于数据库中的组合查询SELECT 字段名 FROM 表名1UNIONSELECT 字段名 FROM 表名2;如果表1有a,b,c,d四条数据,表二有a,e,f,g四条数据,那么查询结果就是a,b,c,d,e,f,g,是会去掉相同的数据的16.union all常用于数据库中的组合查询SELECT 字段名 FROM 表名1UNION ALLSELECT 字段名 FROM 表名2;如果表1有a,b,c,d四条数据,表二有a,e,f,g四条数据,那么查询结果就是a,b,c,d,a,e,f,g,是不会去掉相同的数据的17.left join左连接查询,常用于多表联查,将两个表联合查询,查询出来的结果会包括左表的全部记录和右表表中符合左表字段的记录,如果左表中对应的数据在右表查不到的话在右表中对应字段的值会显示为NULL select 字段名 from 表名1 left join 表名2 on 表名1.字段名=表名2.字段名;18.right join右连接查询,常用于多表联查,将两个表联合查询,查询出来的结果会包括右表的全部记录和左表中符合右表字段的记录,如果右表中对应的数据在左表查不到的话在左表中对应字段的值会显示为NULLselect 字段名 from 表名1 right join 表名2 on 表名1.字段名=表名2.字段名;19.inner join内连接查询,常用于多表联查,会把两个表中共有的字段名及数据显示出来select * from 表名1 inner join 表名2 on 表名1.字段名=表名2.字段名;20.Alter修改字段长度常用语句alter table 表名 modify 字段名字段类型;依赖集分类1平凡函数依赖还是在自己这圈子里晃悠,就像学号还是依赖于学号和课程号,说了等于白说(没用)。