第2章 SAS语言入门-正式课件
sas课件

Chapter 2 Data Summary and Other RelatedProcedures2.1 PROC MEANSThe MEANS procedure provides data summarization tools to compute descriptive statistics for variables across all observations and within groups of observations. For example, PROC MEANS•calculates descriptive statistics based on moments•estimates quantiles, which includes the median•calculates confidence limits for the mean•identifies extreme values•performs a t test.You have a SAS data set called blood which includes the variables Subject, Gender, AgeGroup, RBC (red blood cells), WBC (white blood cells) and Chol (Cholesterol). This data set has already been created and must be in your SASdata folder. Let us create another SAS program called blood.sas1.DATA STEP!*The following title will appear as the first line of every page in the output window;title1'STAT 6360';*Input data;data sasdata.blood;infile'K:\6360\SASdata\blood.txt';length Gender $ 6 BloodType $ 2 AgeGroup $ 5;input SubjectGenderBloodTypeAgeGroupWBCRBCChol;label Gender = "Gender"BloodType = "Blood Type"AgeGroup = "Age Group"Chol = "Cholestrol";run;2.PROC MEANSa.This gives more than just means!b.This procedure is a very good example of common statements found in allSAS procedures!c.Basic use of PROC MEANSi.DATA=____ – specify the data setii.VAR statement – specifies the variablesiii.Following is the example SAS code and output:title2'PROC MEANS summary statistics for blood data set';proc means data=SASdata.blood;run;STAT 6360PROC MEANS summary statistics for blood data setThe MEANS ProcedureVariable Label N Mean Std Dev Minimum--------------------------------------------------------------------------Subject 1000 500.5000000 288.8194361 1.0000000WBC 908 7042.97 1003.37 4070.00RBC 916 5.4835262 0.9841158 1.7100000Chol Cholesterol 795 201.4352201 49.8867157 17.0000000--------------------------------------------------------------------------Variable Label Maximum-------------------------------------Subject 1000.00WBC 10550.00RBC 8.7500000Chol Cholesterol 331.0000000-------------------------------------d.Other options in the PROC MEANS linei.There are specific statistic keywords; for example:(1)N – number of non-missing values(2)NMiss – number of missing values(3)Mean(4)Sum(5)Median(6)Std – Standard deviation(7)Var – Variance(8)Clm – confidence limit for the mean(9)alpha – significance level used in confidence intervals(10)probt – p-value for t-test used in H o:μ=0 vs. H a:μ≠0(11)t – test statistic for t-test used in H o:μ=0 vs. H a:μ≠0(12)To perform the above test with the hypothesized value not equalto 0, create a new data set with a new variable:new_variable = old_variable – hyp_valueand use PROC MEANS with the new variable.ii.NOPRINT – no results are printed to the OUTPUT window; may be useful if only want to create an OUTPUT data set only (see below) iii.SAS codes and output to calculate just the specified statistics next:title2'PROC MEANS - just the mean and the median';proc means data=SASdata.blood mean median;run;STAT 6360PROC MEANS - just the mean and the medianThe MEANS ProcedureVariable Label Mean Median-------------------------------------------------------Subject 500.5000000 500.5000000WBC 7042.97 7040.00RBC 5.4835262 5.5200000Chol Cholesterol 201.4352201 202.0000000-------------------------------------------------------title2'PROC MEANS - adding a VAR statement and requestingspecific statistics';proc means data=SASdata.blood n nmiss mean median min max;var RBC WBC;run;STAT 6360PROC MEANS - adding a VAR statement and requesting specific statisticsThe MEANS ProcedureNVariable Label N Miss Mean Median Minimum---------------------------------------------------------------------------WBC 908 92 7042.97 7040.00 4070.00RBC 916 84 5.4835262 5.5200000 1.7100000---------------------------------------------------------------------------Variable Label Maximum-----------------------------------WBC 10550.00RBC 8.7500000-----------------------------------iv.Example code and output – calculate 95% confidence interval for μRBC, μWBC:title2'PROC MEANS confidence interval for population means';proc means data=SASdata.blood alpha=0.05clm;var RBC WBC;run;STAT 6360PROC MEANS confidence interval for population meansThe MEANS ProcedureLower 95% Upper 95%Variable CL for Mean CL for Mean----------------------------------------RBC 5.4197114 5.5473410WBC 6977.62 7108.32----------------------------------------v.SAS code and output for testing hypothesis μRBC = 0 with α = 0.05:title2'PROC MEANS hypothesis test for mu_RBC=0';proc means data=SASdata.blood std mean alpha=0.05t probt;var RBC;r un;STAT 6360PROC MEANS hypothesis test for mu_RBC=0The MEANS ProcedureAnalysis Variable : RBCStd Dev Mean t Value Pr > |t|---------------------------------------------------0.9841158 5.4835262 168.64 <.0001---------------------------------------------------vi.Example code and output – hypothesis test for μRBC = 5.0 with α=0.05:*Change data for hypothesis test of mu_RBC=5';data blood;set SASdata.blood;RBC2 = RBC - 5;run;title2'PROC MEANS hypothesis test for muRBC=5.0';proc means data=blood std mean alpha=0.05t probt;var RBC2;run;PROC MEANS hypothesis test for muRBC=5.0The MEANS ProcedureAnalysis Variable : RBC2Std Dev Mean t Value Pr > |t|---------------------------------------------------0.9841158 0.4835262 14.87 <.0001---------------------------------------------------proc ttest data=blood h0=5alpha=.05;var RBC;run;e.CLASS statement – specifies a variable for which summary statistics areproduced for each of the variables in the VAR statementi.SAS code and output are given below:title2'PROC MEANS - using CLASS';proc means data=SASdata.blood;class Gender;var RBC WBC Chol;run;STAT 6360PROC MEANS - using CLASSThe MEANS ProcedureNGender Obs Variable Label N Mean Std Dev---------------------------------------------------------------------------Female 440 RBC 409 5.4984841 0.9823118WBC 403 7112.43 997.8255175Chol Cholesterol 349 202.4985673 47.7061542Male 560 RBC 507 5.4714596 0.9863729WBC 505 6987.54 1005.31Chol Cholesterol 446 200.6031390 51.5666201---------------------------------------------------------------------------NGender Obs Variable Label Minimum Maximum---------------------------------------------------------------------Female 440 RBC 1.7100000 8.7500000WBC 4620.00 10260.00Chol Cholesterol 56.0000000 331.0000000Male 560 RBC 2.3300000 8.4300000WBC 4070.00 10550.00Chol Cholesterol 17.0000000 328.0000000---------------------------------------------------------------------f.BY statement – specifies a variable for which summary statistics areproduced for each of the variables in the statement “by”i.Works very similar to the CLASS statement!ii.However, the output will be summarized differentlyiii.If the data is not sorted by the “BY” variable, it needs to be done before running the PROC MEANS with the BYiv.Make sure data sorted by BY variable (Data don’t have to be sorted if you use the CLASS statement)v.SAS codes and output are given below:*Sort data by Gender;proc sort data=SASdata.blood out =blood_sort;by Gender;run;title2'PROC MEANS - using BY';proc means data=blood_sort;var RBC WBC Chol;by Gender;run;PROC MEANS - using BY------------------------------ Gender=Female ------------------------------The MEANS ProcedureVariable Label N Mean Std Dev Minimum--------------------------------------------------------------------------RBC 409 5.4984841 0.9823118 1.7100000WBC 403 7112.43 997.8255175 4620.00Chol Cholesterol 349 202.4985673 47.7061542 56.0000000--------------------------------------------------------------------------Variable Label Maximum-------------------------------------RBC 8.7500000WBC 10260.00Chol Cholesterol 331.0000000-------------------------------------------------------------------- Gender=Male -------------------------------Variable Label N Mean Std Dev Minimum--------------------------------------------------------------------------RBC 507 5.4714596 0.9863729 2.3300000WBC 505 6987.54 1005.31 4070.00Chol Cholesterol 446 200.6031390 51.5666201 17.0000000--------------------------------------------------------------------------Variable Label Maximum-------------------------------------RBC 8.4300000WBC 10550.00Chol Cholesterol 328.0000000-------------------------------------g.OUTPUT statement – puts information calculated in the procedure intoanother data seti.OUT= specifies the data setii.See SAS help for statistics-keywords that you can specify in anOUTPUT statement. We will indicate some statistics-keywords below iii.Notice the difference between outputting the means for one and two variables!iv.SAS codes and output are given below. In this we have specified the‘Mean’ of sugar and ‘First-Quartile’ of sugar.title2'PROC MEANS - using output STATEMENT and only onevariable';proc means data=SASdata.blood;class gender;var RBC;output out=out_RBC mean=mean_RBC p25=p25_RBC;run;title2'The output data set out_RBC';proc print data=out_RBC;run;The output data set out_RBCObs Gender _TYPE_ _FREQ_ mean_RBC p25_RBC1 0 1000 5.48353 4.842 Female 1 440 5.49848 4.893 Male 1 560 5.47146 4.79h.More SAS codes and output are given below:*The noprint option is used just to demonstrate it;title2'PROC MEANS - using output STATEMENT and 3 variables';proc means data=SASdata.blood noprint;class gender;var RBC WBC;output out=out_setall mean(RBC WBC)=mean_RBC mean_WBC p25(RBC WBC)=p25_RBC p25_WBC;run;Note: The noprint option suppresses all the output from the PROC MEANS.title2'The output data set out_setall';proc print data=out_setall;run;The output data set out_setallObs Gender _TYPE_ _FREQ_ mean_RBC mean_WBC p25_RBC p25_WBC1 0 1000 5.48353 7042.97 4.84 63752 Female 1 440 5.49848 7112.43 4.89 64603 Male 1 560 5.47146 6987.54 4.79 6350i.The order of statements inside of PROC MEANS does not matter (at least, Ican not find any documentation or examples where it does). See myexamples of how I generally order the statements.2.2 PROC UNIVARIATELet us recall the Cereal data set. This SAS data set has already been created and must be in your SASdata folder.PROC UNIVARIATE – This helps find a variety of summary statistics for each adjusted nutritional variablea.Basic use of PROC UNIVARIATEi.VAR statement – specifies the variablesii.SAS codes and output:*Find summary statistics using PROC UNIVARIATE;title2'PROC UNIVARIATE - summary statistics for each variable';proc univariate data=SASdata.Adjcereal;var sugar fat sodium;run;PROC UNIVARIATE - summary statistics for each variableThe UNIVARIATE ProcedureVariable: sugarMomentsN 40 Sum Weights 40Mean 0.28941556 Sum Observations 11.5766223Std Deviation 0.14955987 Variance 0.02236815Skewness -0.4267097 Kurtosis -0.8076909Uncorrected SS 4.2228126 Corrected SS 0.87235798Coeff Variation 51.6765118 Std Error Mean 0.02364749Basic Statistical MeasuresLocation VariabilityMean 0.289416 Std Deviation 0.14956Median 0.333333 Variance 0.02237Mode 0.345455 Range 0.55556Interquartile Range 0.22258Tests for Location: Mu0=0Test -Statistic- -----p Value------Student's t t 12.23874 Pr > |t| <.0001Sign M 19.5 Pr >= |M| <.0001Signed Rank S 390 Pr >= |S| <.0001Quantiles (Definition 5)Quantile Estimate100% Max 0.555555699% 0.555555695% 0.501041790% 0.449944475% Q3 0.400000050% Median 0.333333325% Q1 0.177419410% 0.06350815% 0.04030301% 0.0000000Extreme Observations-------Lowest------ ------Highest-----Value Obs Value Obs0.0000000 35 0.448276 60.0200000 11 0.451613 220.0606061 9 0.468750 230.0625000 14 0.533333 260.0645161 37 0.555556 24The output for fat and sodium is EXCLUDED to save space!b.There are several options one can use in the PROC UNIVARIATE linei.Plot – produces a stem-and-leaf (or histogram), box-plot, and normalprobability plot; BETTER quality plots are possible!ii.mu0=___ - tests H o:μ=___ vs. H a:μ≠__iii.alpha = ___ - significance level for confidence intervalsiv.cibasic - (1-α)100% confidence intervals for μ and σv.SAS codes and partial output are given below:title2'PROC UNIVARIATE - Illustrating options in the procunivariate statement';proc univariate data=SASdata.Adjcereal alpha=0.05cibasicmu0=0.1plots;var sugar fat sodium;run;PROC UNIVARIATE - Illustrating options in the proc univariate statementThe UNIVARIATE ProcedureVariable: sugarMomentsN 40 Sum Weights 40Mean 0.28941556 Sum Observations 11.5766223Std Deviation 0.14955987 Variance 0.02236815Skewness -0.4267097 Kurtosis -0.8076909Uncorrected SS 4.2228126 Corrected SS 0.87235798Coeff Variation 51.6765118 Std Error Mean 0.02364749Basic Statistical MeasuresLocation VariabilityMean 0.289416 Std Deviation 0.14956Median 0.333333 Variance 0.02237Mode 0.345455 Range 0.55556Interquartile Range 0.22258Basic Confidence Limits Assuming NormalityParameter Estimate 95% Confidence LimitsMean 0.28942 0.24158 0.33725Std Deviation 0.14956 0.12251 0.19204Variance 0.02237 0.01501 0.03688Tests for Location: Mu0=0.1Test -Statistic- -----p Value------Student's t t 8.009964 Pr > |t| <.0001Sign M 12 Pr >= |M| 0.0001Signed Rank S 339 Pr >= |S| <.0001PROC UNIVARIATE - Illustrating options in the proc univariate statement The UNIVARIATE ProcedureVariable: sugarQuantiles (Definition 5)Quantile Estimate100% Max 0.555555699% 0.555555695% 0.501041790% 0.449944475% Q3 0.400000050% Median 0.333333325% Q1 0.177419410% 0.06350815% 0.04030301% 0.00000000% Min 0.0000000Extreme Observations-------Lowest------ ------Highest-----Value Obs Value Obs0.0000000 35 0.448276 60.0200000 11 0.451613 220.0606061 9 0.468750 230.0625000 14 0.533333 260.0645161 37 0.555556 24PROC UNIVARIATE - Illustrating options in the proc univariate statementThe UNIVARIATE ProcedureVariable: sugarStem Leaf # Boxplot5 6 1 |5 3 1 |4 557 3 |4 001334 6 +-----+3 5555678 7 | |3 0011334 7 *-----*2 5563 | + |2 0 1 | |1 692 +-----+1 002 |0 66677 5 |0 02 2 |----+----+----+----+Multiply Stem.Leaf by 10**-1Normal Probability Plot0.575+ +++ *| ++*| ++*+*| *******| ****+| *******+| ***+++| *+++| ++**| +++**| +*+****0.025+ * ++*+----+----+----+----+----+----+----+----+----+----+-2 -1 0 +1 +2a.CLASS and BY statements – these options have a similar effect on theoutput as in PROC MEANStitle2'PROC UNIVARIATE - Illustrating the class statement';proc univariate data=SASdata.Adjcereal alpha=0.05cibasicmu0=0.1;class shelf;var sugar;run;2.3 PROC FREQYou have a SAS data set called survey which includes the variables ID, Gender, Age, Salary, Quest1- Quest5.Here is a listing of this data set.1.DATA STEP!a.Input this dataset to sas.*Data set SURVEY;data sasdata.survey;infile'K:\6360\SASdata\survey.txt';input @1 ID $3.@5 Gender $ 1.@7 Age 2.@10 Salary dollar7.0@17 Ques1 $1.@19 Ques2 $1.@21 Ques3 $1.@23 Ques4 $1.@25 Ques5 $1.;label ID = 'Subject ID'Gender = 'Gender'Age = 'Age as of 1/1/2006'Salary = 'Yearly Salary'Ques1 = 'The governor doing a good job?'Ques2 = 'The property tax should be lowered'Ques3 = 'Guns should be banned'Ques4 = 'Expand the Green Acre program'Ques5 = 'The school needs to be expanded';run;b.You can use Formats to enhance your output.i.You can also create your own formats.ii.For example, if you have variable called Gender with values F and M, you can format these values so that they print as Male and Female.iii.Many SAS procedures use formatted values of variables in theirprocessing. For example, proc means, proc print, proc freq, etc.iv.You create user-defined formats with PROC FORMAT; you associate your formats with one or more variables in a FORMAT statement. Weuse the above sasdata.survey data set to show how formats can beused.v.For example, suppose you want to compute frequencies on age groups, but your data set contains the variable age. Rather than create a newvariable representing age groups, you can simply write a format anduse proc freq with the format statement like this:* Using PROC FORMAT to create user-defined formats;proc format;value $gender 'M' = 'Male''F' = 'Female'' ' = 'Not entered'other = 'Miscoded';value age low-29 = 'Less than 30'30-50 = '30 to 50'51-high = '51+';value $likert '1' = 'Strongly disagree''2' = 'Disagree''3' = 'No opinion''4' = 'Agree''5' = 'Strongly agree';run;*Adding a FORMAT statement in PROC PRINT;title"Data Set SURVEY with Formatted Values";proc print data=sasdata.survey;id ID;var Gender Age Salary Ques1-Ques5;format Gender $gender.Age age.Ques1-Ques5 $likert.Salary dollar8.0;run;Data Set SURVEY with Formatted ValuesID Gender Age Salary Ques1 Ques2001 Male Less than 30 $28,000 Strongly disagree Disagree002 Female 51+ $76,123 Agree Strongly agree003 Male 30 to 50 $36,500 Disagree Disagree004 Female 51+ $128,000 Strongly agree No opinion005 Male Less than 30 $23,060 No opinion No opinion006 Male 51+ $90,000 Disagree No opinion007 Female 30 to 50 $76,100 Strongly agree No opinionID Ques3 Ques4 Ques5001 Strongly disagree Disagree No opinion002 Disagree Strongly disagree Strongly disagree003 Disagree Disagree Strongly disagree004 Disagree Disagree Agree005 No opinion Agree Disagree006 Strongly agree Agree No opinion007 Agree No opinion No opinion2. PROC FREQa.This can be used to count frequencies of both character and numericvariables in one-way, two-way, and three-way tables!title"PROC FREQ with all the Defaults";proc freq data=sasdata.survey;format Gender $gender.Age age.Ques1-Ques5 $likert.Salary dollar8.2;run;STAT 6360PROC FREQ with all the DefaultsThe FREQ ProcedureSubject IDCumulative CumulativeID Frequency Percent Frequency Percentƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒ001 1 14.29 1 14.29002 1 14.29 2 28.57003 1 14.29 3 42.86004 1 14.29 4 57.14005 1 14.29 5 71.43006 1 14.29 6 85.71007 1 14.29 7 100.00GenderCumulative CumulativeGender Frequency Percent Frequency PercentƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒFemale 3 42.86 3 42.86Male 4 57.14 7 100.00Age as of 1/1/2006Cumulative CumulativeAge Frequency Percent Frequency PercentƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒLess than 30 2 28.57 2 28.5730 to 50 2 28.57 4 57.1451+ 3 42.86 7 100.00The FREQ ProcedureYearly SalaryCumulative CumulativeSalary Frequency Percent Frequency Percentƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒ$23,060.33 1 14.29 1 14.29$28,000.12 1 14.29 2 28.57$36,500.22 1 14.29 3 42.86$76,100.53 1 14.29 4 57.14$76,123.45 1 14.29 5 71.43$90,000.23 1 14.29 6 85.71$128,000.53 1 14.29 7 100.00The governor doing a good job?Cumulative CumulativeQues1 Frequency Percent Frequency PercentƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒStrongly disagree 1 14.29 1 14.29Disagree 2 28.57 3 42.86No opinion 1 14.29 4 57.14Agree 1 14.29 5 71.43Strongly agree 2 28.57 7 100.00The output for other Ques2-5 is EXCLUDED to save space!b.You may include a TABLES statement to list the variables you want tocompute frequencies. The following programs select Gender and Ques1 andeliminates the cumulative statistics as well. The SAS code and output are:title"Adding a TABLES statement to PROC FREQ";proc freq data=sasdata.survey;tables Gender Ques1 / nocum;run;STAT 6360Adding a TABLES statement to PROC FREQThe FREQ ProcedureGenderGender Frequency PercentƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒFemale 3 42.86Male 4 57.14The governor doing a good job?Ques1 Frequency PercentƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒStrongly disagree 1 14.29Disagree 2 28.57No opinion 1 14.29Agree 1 14.29Strongly agree 2 28.57c.Basic use of PROC FREQ to create a 2×2 tablei.TABLES statement –variables to be summarized; notice the use of “*”ii.The row variable goes first and the column variable goes second.iii.For example, to see a table of gender by blood type in the Blood data set, you would write the following:title2"A Two-way Table of Gender by Blood Type";proc freq data=sasdata.blood;tables Gender * BloodType;run;STAT 6360A Two-way Table of Gender by Blood TypeThe FREQ ProcedureTable of Gender by BloodTypeGender BloodTypeFrequency|Percent |Row Pct |Col Pct |A |AB |B |O | Total---------+--------+--------+--------+--------+Female | 178 | 20 | 34 | 208 | 440| 17.80 | 2.00 | 3.40 | 20.80 | 44.00| 40.45 | 4.55 | 7.73 | 47.27 || 43.20 | 45.45 | 35.42 | 46.43 |---------+--------+--------+--------+--------+Male | 234 | 24 | 62 | 240 | 560| 23.40 | 2.40 | 6.20 | 24.00 | 56.00| 41.79 | 4.29 | 11.07 | 42.86 || 56.80 | 54.55 | 64.58 | 53.57 |---------+--------+--------+--------+--------+Total 412 44 96 448 100041.20 4.40 9.60 44.80 100.00iv.The highlighted cell above gives a key to what is in each cell. For example, the Gender = Female and BloodType = A cell contains 40.45as its third number. This is found by taking the cell count 178 dividedby the row total of 440. Thus, 40.45% of Gender=Female has bloodtype A.d.Options in the PROC FREQ line – NOPRINTe.TABLES statementi.Multiple tables can be createdii.More than two variables can be represented in a table.iii.NOROW – no row percentage given in each celliv.NOCOL – no column percentage given in each cellv.NOPERCENT - no table percentage in each cellvi.CHISQ – Performs the Pearson chi-square test for independence.(1)H o: Two variables are independentH a: Two variables are dependent(2)Let o ij denote the (i,j) cell observed counts, e ij denote theestimated expected cell counts under independence for the (i,j)cell(3)e ij= (i th row total)(j th column total) / (sample size)(4)Let r denote the number of rows and c denote the number ofcolumns for a contingency table with two variables.(5)The test statistic is2 r c ij iji1j1ij(o e)e==−∑∑(6)Under H o, the test statistic’s probability distribution can beapproximated by a χ2 distribution with (r-1)(c-1) degrees offreedom.(7)For more information, take STAT 8620 (categorical dataanalysis) class!vii.CELLCHI2 – prints each cell’s contribution to the Pearson chi-square test statisticviii.OUT=___ - creates a data set that includes the cell frequencies for the last table specified in the TABLES statementix.LIST – each cell frequency is put into one row (similar to the OUT data set) instead of a r×c tablex.ALPHA and BINOMIAL – use with one variable with two possible responses; finds the confidence interval for a proportionf.OUTPUT statementi.OUT=____ - specifies data setii.The CHISQ option gives many test results in the data set; the _PCHI_ variable is the Pearson chi-square test statistic, DF_PCHI is the degreesof freedom, and P_PCHI is the p-value.g.WEIGHT statement – use if each row of the data set gives the frequency ofa variable combination (previously each row represented only ONEobservation)h.Example SAS code and output are given below:title2'Examples of options in the TABLES statement';proc freq data=sasdata.blood;tables Gender * BloodType / chisq fisher norow nopercentnocol cellchi2out=out_set1;output out=out_test chisq;*NOTE: out data set contains the table for the LAST table inthe table statement!;run;proc print data=out_set1;run;proc print data=out_test;run;STAT 6360Examples of options in the TABLES statementThe FREQ ProcedureTable of Gender by BloodTypeGender BloodTypeFrequency |Cell Chi-Square|A |AB |B |O | Total---------------+--------+--------+--------+--------+Female | 178 | 20 | 34 | 208 | 440| 0.0593 | 0.0212 | 1.6074 | 0.6005 |---------------+--------+--------+--------+--------+Male | 234 | 24 | 62 | 240 | 560| 0.0466 | 0.0166 | 1.263 | 0.4718 |---------------+--------+--------+--------+--------+Total 412 44 96 448 1000Statistics for Table of Gender by BloodTypeStatistic DF Value Prob------------------------------------------------------Chi-Square 3 4.0865 0.2523Likelihood Ratio Chi-Square 3 4.1389 0.2469Mantel-Haenszel Chi-Square 1 0.5828 0.4452Phi Coefficient 0.0639Contingency Coefficient 0.0638Cramer's V 0.0639Fisher's Exact Test----------------------------------Table Probability (P) 7.587E-05Pr <= P 0.2516Sample Size = 1000Examples of options in the TABLES statementBloodObs Gender Type COUNT PERCENT1 Female A 178 17.82 Female AB 20 2.03 Female B 34 3.44 Female O 208 20.85 Male A 234 23.46 Male AB 24 2.47 Male B 62 6.28 Male O 240 24.0Examples of options in the TABLES statementObs N _PCHI_ DF_PCHI P_PCHI _LRCHI_ DF_LRCHI P_LRCHI _MHCHI_ 1 1000 4.08651 3 0.25227 4.13889 3 0.24685 0.58276 Obs DF_MHCHI P_MHCHI XP2_FISH _PHI_ _CONTGY_ _CRAMV_1 1 0.44523 0.25156 0.063926 0.063796 0.063926i.Example code and output showing the LIST statement:title2'List option in the TABLES statement';proc freq data=sasdata.blood;tables Gender * BloodType / list;run;List option in the TABLES statementThe FREQ ProcedureCumulative Cumulative Gender BloodType Frequency Percent Frequency Percent ------------------------------------------------------------------------ Female A 178 17.80 178 17.80Female AB 20 2.00 198 19.80Female B 34 3.40 232 23.20Female O 208 20.80 440 44.00Male A 234 23.40 674 67.40Male AB 24 2.40 698 69.80Male B 62 6.20 760 76.00Male O 240 24.00 1000 100.00 j.Example code and output showing the WEIGHT statement:*Show how to use the weight statement;*First, create a new data set;data GB_new;input Gender $ Bloodtype $ frequency;。
第02章_SAS语言的基本概念

SAS 语言概述 §2.1 SAS语言概述 §2.2 SAS常量 常量 §2.3 SAS变量 变量 §2.4 SAS函数 函数 §2.5 SAS表达式 表达式 语句与程序 §2.6 SAS语句与程序
语言概述 §2.1 SAS语言概述
SAS SAS提供了一种完善的编程语言。如同大多数 提供了一种完善的编程语言。 提供了一种完善的编程语言 计算机高级语言一样, 计算机高级语言一样,SAS用户只须要熟悉其 用户只须要熟悉其 命令、 命令、语句及简单的语法规则就可进行数据管 理和分析处理工作。因此,掌握SAS编程技术 理和分析处理工作。因此,掌握 编程技术 是学习SAS的关键环节。 的关键环节。 是学习 的关键环节
变量 §2.3 SAS变量
SAS
1、变量的取值范围: 、变量的取值范围: 数值型变量的值是数值,数值的范围是: 数值型变量的值是数值,数值的范围是:±10-307 到±10+308。 。 字符型变量的值是字符串,其取值范围最多为200 字符型变量的值是字符串,其取值范围最多为 个字符。 个字符。 2、变量长度: 、变量长度: 变量长度是指SAS数据集中存储它的每一个值的字 变量长度是指 数据集中存储它的每一个值的字 节数。 节数。 数值型变量长度为: 个字节, 个字节。 数值型变量长度为:3~8个字节,默认为 个字节。 个字节 默认为8个字节 个字节, 字符型变量长度为: 字符型变量长度为:1~200个字节,默认为 个字 个字节 默认为8个字 节。
语言概述 §2.1 SAS语言概述
SAS data student; input xh$ xm$ yy gs; p=yy+gs; cards; 001 aaa 89 91 002 bbb 70 88 003 ccc 90 92 004 ddd 70 87 005 eee 85 83 一个简单的 SAS程序 SAS程序
SAS课件讲义

★第一章:SAS系统简介SAS文件及命名1、SAS数据集文件(后缀为sas7bdat)2、SAS程序文件(后缀为sas)3、SAS日志文件(后缀为log)4、SAS输出文件(后缀为list)★第二章:SAS数据集的分类临时数据集和永久数据集(一)临时数据集存放在work数据库中(二)永久数据集存放在永久数据库中,除了work数据库之外,其他的数据库都是永久数据库。
1、SAS文件的2级命名方式:目录.文件名2、使用Libname语句创建永久数据集,libname 自建目录名‘目录地址’;Libname例创建与读取永久数据库1、创建永久数据集永久数据集的扩展名是sas7bdat。
libname例:libname sasroom "d:\sasdata"; data sasroom.data1; input y $ x1 x2 x3@@; cards; run; proc print; run;2、读取永久数据集 read例libname sasroom "d:\sasdata"; data sasroom.data1; input y $ x1 x2 x3@@; cards;run;建立SAS数据集的5种方法1、用data步输入数据建立。
newdata例data newdata; input group $ x1 x2 x3; cards;2、利用infile语句从外部调入数据文件建立SAS数据集,注意:infile语句必须放在input语句的前面。
(Infile例)3、利用“导入数据”功能建立。
(Excel例)4、利用EFI(external file interface)功能导入(classifydata例)。
5、data步利用set 语句建立。
(Set1例)查看SAS数据集的内容1、使用contents过程查看数据的相关信息。
Contents例proc contents data=数据集名 position;2、用print过程来显示数据。
《SAS基础教程》课件

THANKS
感谢观看
点图
用于展示大量数据 点,常用于散点图 和热力图等。
柱状图
用于比较不同类别 之间的数据,直观 展示数据差异。
饼图
用于展示各部分在 整体中所占的比例 。
箱线图
用于展示数据的分 布和异常值。
图表制作与美化
01
色彩搭配
选择合适的颜色,使图表更加美观 和易于理解。
图表布局
合理安排图表元素的位置,使其更 加紧凑和有序。
03
02
字体和标签
使用清晰易读的字体,添加必要的 标签和说明。
数据标记和提示
使用数据标记和提示,帮助读者更 好地理解数据。
04
动态图表与交互式图表
动态图表
通过动画效果展示数据随时间或其他变量的 变化过程。
交互式图表
允许用户通过交互操作来筛选和查看特定数 据。
可视化交互性
提供交互式控件,使用户能够与图表进行互 动,探索数据。
SAS的发展历程
总结词
SAS经历了从简单统计分析工具到复杂数据管理、分析平台的演变。
详细描述
SAS最初是一个简单的统计分析工具,用于处理和分析数据。随着技术的发展和用户需求的增加,SAS不断扩展 和改进,逐渐发展成为一个功能强大的数据管理、分析和可视化平台。
SAS的应用领域
总结词
SAS广泛应用于各个领域,如金融、医疗 、市场调研等。
数据驱动的动态可视化பைடு நூலகம்
根据实时数据动态更新图表,展示数据的实 时变化。
05
SAS编程基础
SAS编程语言简介
要点一
总结词
SAS编程语言是一种用于数据管理、分析和报表生成的高 级编程语言。
《SAS软件入门教程》课件

高级统计分析
总结词
高级统计分析是在描述性统计分析和推论性统计分析基础上,运用更为复杂和高级的统 计模型和技术,对数据进行深入分析和挖掘的方法。
SAS软件开始商业化,推出 SAS/ETS、SAS/STAT等模块 。
1990年代
SAS软件开始支持互联网和分 布式计算,推出 SAS/CONNECT、 SAS/INSIGHT等模块。
1960年代
SAS软件由美国北卡罗来纳大 学开发,最初主要用于统计分 析。
1980年代
SAS软件不断扩展,推出 SAS/BASE、SAS/EIS、 SAS/IMAGE等模块。
THANKS
THE FIRST LESSON OF THE SCHOOL YEAR
宏变量和宏程序
了解宏变量的定义和使用方法,掌握宏程序 的编写和调用。
自定义过程
了解自定义过程的概念和语法,掌握如何创 建和使用自定义过程。
宏编程和自定义过程的应用
通过案例演示宏编程和自定义过程在数据处 理和分析中的应用。
01
SAS软件实战案例
案例一:数据探索和可视化
总结词
通过SAS软件进行数据探索和可视化,帮助用户更好地理解数据。
使用动态图表
通过动画效果展示数据随时间的变化,使数据变化更加直观。
使用3D图表
在二维图表的基础上增加高度维度,展示更丰富的数据信息。
01
SAS编程技巧
变量处理和数据转换
变量类型
了解和正确使用不同类型的变量,如数值型、字符型 、日期型等。
第二章、SAS编程基础 第一节、SAS语言的基本规定

第二章、SAS编程基础
5
3、函数
大约有13类,140多种。 统计软件所特有的几种函数:
1)随机函数:产生随机数 RANUNI()、RANNOR()RANEXP()、
RANBIN()等,其中()中的参数应为0或5位、 6位、7位奇数。 2)概率(分布)函数: PROBNORM(x) PROBBNML(p,n,m) POISSON(a,m)等, 注:函数名大小写无影响。
第二章、SAS编程基础
15
二、输出语句(PUT语句)
一般与FILE语句配合使用,将内容输出到File 指定的文件中或Log 、Output 窗口中.
1)自由格式输出 格式:Put 变量[$] ; 例如: Data new; Input name$ sex $ age; File “c:\dat.txt”; Put name$ sex$ age; Cards; Wang f 18 Liu m 16 ;
格式:INPUT[@][#] 变量 [@][@@]; @表示把控制指针保持在当前行,下一
个input语句仍在当前行读数。例1:
data marks; Input grade @; If grade=1 then input math phys chem; Else input hist geog Chinese; Cards; 1 80 90 78 2 79 93 87 Proc print ; run;
第二章、SAS编程基础
14
@@表示当前数据行含有多个观察值,input读 完一个观察后,控制指针仍保持在当前行,接 着读下一个数据。例2:
Data product; Input year x1 x2; Cards; 1997 50 60 1998 70 75 1999 80 87 Pro,还有算术函数、截取函数、数学函数、 三角函数、字符函数、日期与时间函数,这些 函数的用法与其它软件大致相同等等。
SAS简单介绍.ppt

15 /共127页
程序说明
数据步:将数据读入系统,建立数据集。
以DATA语句开始 INPUT语句描述数据变量, 用$表示变量是字符型 CARDS语句指示后面是数据
每行为一个观测数据,数据间无分号, 数据最后以“;”开头的空行结束
统计计算 Statistical Computation
16 /共127页
(8) Investment Analysis 投资分析
(9) Market Research 市场调查
统计计算 Statistical Computation
24 /共127页
(10) Project Management 计划安排--打开 PROJMAN 模块 (11) Quality Improvement 统计质量控制--打开 SQC 模块,提供了不需编程的质量管理图表和分析
•方 式 四 : 在 命 令 框 输 入 SUBMIT 命 令并执行
统计计算 Statistical Computation
19 /共127页
输出窗口
查看结果 ➢激活OUTPUT窗口( F7 ) ➢注意:没有正确结果,可能是:
• 程序语法错误:→ 查看日志窗口错误信息 • 程序逻辑错误:→ 分析源程序 • 没有调用能输出结果的过程
10 /共127页
SAS 的启动和退出
启动SAS
➢双击桌面SAS图标
➢开始菜单 程序 The SAS System
The SAS System for Windows V8(或9.0)
退出SAS
➢标题栏关闭按钮
➢菜单栏 File Exit
➢在命令框键入“Bye”或 “Endsas” 统计计算 Statistical Computation
Chapter2 SAS软件入门PPT课件

2020/11/24
第7页,共37页
Data LearnSAS.exam2;
input name $ 1-11 sex $12-17 year 24-27 month 28-29 day
30-31;
date=MDY(month,day,year);
如有空白则被忽略; ④ 在Input语句中必须列出观测中每一项数据对应的变量名,而
不能省略中间的某一个。
2020/11/24
第5页,共37页
Data LearnSAS.exam1;
input var1 var2;
var3=dif1(var2);
time=intnx('month','01jul2005'd,_n_-1);
第10页,共37页
2. 读入其他微机文件 如“读入D盘--->Teaching文件夹--->课 程讲义文件夹--->金融建模与计算2010 文件夹---> SAS基础程序文件夹下的 stud.xls文件”
2020/11/24
第11页,共37页
Proc Import out=LearnSAS.Exam4 DataFile='D:\Teaching\课程讲义\金融建模与计算 2010\SAS基础程序\stud.xls'
/*InFile语句应该放在Input语句前面*/ DBMS=Excel2000 Replace; GetNames=Yes; Run;
2020/11/24
第12页,共37页
3. 与大型数据库接口 如在数据库服务器Server_SFS中有一个数据 库 Finance , 其 中 有 一 个 表 Sales , 用 户 名 Guest,密码anyone
lesson02 SAS英文教程

* List Directed Input: Reading data values separated by tabs (.txt files); DATA bp; INFILE DATALINES DLM = '09'x DSD; INPUT clinic $ dbp6 sbp6 dbpbl sbpbl; DATALINES; C 84 138 93 143 D 89 150 91 140 A 78 116 100 162 A 86 155 C 81 145 86 140 ; TITLE 'Reading in Data separated by a tab'; PROC PRINT DATA=bp; RUN;
* Reading data using Pointers and Informats DATA bp; INFILE DATALINES ; INPUT @1 clinic $1. @2 dbp6 3. Informats must end with a @5 sbp6 3. period. @8 dbpbl 3. @11 sbpbl 3. ; DATALINES; C084138093143 D089150091140 A078116100162 A 086155 C081145086140 ; Title 'Reading in Data using Point/Informats'; PROC PRINT DATA=bp;
Lesson 2
Raw Data
Read in Data Process Data (Create new variables) Output Data (Create SAS Dataset)
Data Step
SAS基础教程ppt课件

SAS系统是一个模块化、集成化的应用软件系统,使 用SAS系统可以实现对数据的完全控制和充分利用。 SAS系统主要完成以数据为中心的四大任务: 数据访问. 数据管理. 数据呈现. 数据分析. (所有的工作在一个平台内完成)
5
SAS的核心任务(从数据到信息) 数据采集 管理 组织 利用 查看及改变功能键的设置; OPTIONS窗口: 查看及改变SAS的系统设置; LIBNAME窗口: 查看已存在的SAS数据库; DIR窗口:查看某个SAS数据库的内容; VAR窗口:查看SAS数据集的有关信息;
19
每个窗口都有自己相应的菜单选项; 可通过点击窗口条或在查看菜单打开不同的窗口; 在工具菜单可以调用一些实用的工具以及定制系统的属性;
OLAP系列: SAS/MDDB,Open OLAP Server, SAS/EIS
10
表现工具: 前端开发工具:SAS/AF 图形表现工具:SAS/GRAPH,可制作出各种二维和三维图形,如柱 状图,散点图,饼图等等; 地理信息表现工具:SAS/GIS
Web产品: SAS/Intrnet: SAS/StoredProcess SAS/WebEIS: SAS/Portal SAS/Web Report Studio …… SAS/WebAF
6
SAS系统的核心: Base SAS模块,用于管理并呈现数据,包含有一套编程语言以及一系列 过程,是其它模块的基础:
SAS数据的存储: 关系型数据存储:data set,data view;完全支持SQL标准的数据结 构和数据处理. 多维数据存储:MDDB/Cube;没有结构性冗余的有效存储. 数据挖掘库:DMDB;针对数据挖掘特点的数据存储. 并行处理数据引擎:智能数据切分功能,优化的索引结构.
sas讲义1-2

第二章 SAS软件对数据文件变量的读取原始数据指的是录入存贮在计算机硬盘,卡片,磁盘或磁带等信息载体上的已编码数据。
在绝大多数情况下,这些数据是以数字符号编码的,有时也用“字符串”来编码。
我们在本章中,将介绍SAS软件对一个原始数据文件里变量的读取方式以及相关变量的建立方法。
我们先介绍SAS对一个数据文件定义变量的方法和要求。
一、SAS软件对数据文件读取变量的方法:INPUT指令是用来说明原始数据读取的先后顺序,并定义相应的变量的,如同我们前面讲过的那样,这是一个属于DATA类型的指令。
一个变量的读取和识别是通过标注与定义这个变量的名字来完成的,变量名最多只能占八个字符(字母或符号)的位置,而且第一个字符必须是一个字母或一个下横短线“_”的符号。
SAS程式中的变量名单是由一串连续的变量名所组成的,在每两个变量名之间必须到少要留有一个空格的空间。
如果变量数很多,而且在数据文件(矩阵)中他们是按逻辑顺序排列的(如姓名,性别,年龄,出生年月,地址,职业,身高,体重,受教育程度……),那么可以最后用数字来区分并定义变量名,其优点是仅使用一个(或多个)字母,后面加数字即可,便于在程式下面的读取与识别。
如:V1 V2 V3 V4 (V50)VAR1 VAR2 VAR3……VAR50等等。
更多简单及概括的方法是,我们仅“写”下首尾两端的两个变量名,并在中间用一个短横线把它们间隔开即可。
如:V1—V50VAR1—VAR50 等等。
如果变量名不是用数字来定义识别的,而是用字母组成的单词来命名的,我们在第一次读取及命名这些变量的时候,没有简写的方法,每一个变量要用一个单词或“字符串”来命名。
但在完成初次的定义之后,如果变量是在“SAS数据文件”中按其名字的先后顺序排列的,我们则可以在后面的重复读取时“写下”首尾两端的两个变量的名字,在两个变量名之间,再加上两道短横线“--”把它们分隔开即可。
如:我们初次定义以下变量:A name address revenue PROF(profession)在下次重新读取这些变量时,我们仅写下“A--PROF”即可。
SAS编程简介PPT课件

数据类型转换
使用`PROC FORMAT`过程,将数值型数 据转换为字符型数据,或将字符型数据转 换为数值型数据。
数据排序
使用`PROC SORT`过程,根据指定的列对 数据进行排序。
数据合并
使用`PROC SQL`过程,通过`UNION`语 句将两个或多个数据集合并为一个新的数 据集。
使用PROC SQL对数据集进行高级操作
THANKS
感谢您的观看
SAS程序通常由数据步和过程步组成,数据步用于读取和操作数据 ,过程步用于执行统计分析或数据挖掘任务。
SAS语法规则
SAS编程语言遵循严格的语法规则,包括变量声明、赋值、循环、 条件语句等。
SAS函数和宏
SAS提供了大量的内置函数和宏,用于执行各种数据处理和统计分 析任务。
SAS编程的应用领域
数据分析
SAS编程语法及语 句
数据步基本语法及语句
数据步定义
数据步是SAS程序中最基本的单元,用于 创建、操作和管理数据。
数据筛选和排序
在数据步中,可以对数据进行筛选和排序 ,以便后续的数据分析。
数据步语句
数据步语句包括变量声明、数据输入和转 换、数据筛选和排序等。
数据输入和转换
在数据步中,可以通过读入外部数据文件 或使用已有的数据集,进行数据转换和清 洗。
SAS编程简介PPT课 件
汇报人:
日期:
目录
CONTENTS
• SAS编程概述 • SAS编程语法及语句 • SAS编程实战案例 • SAS编程进阶内容 • SAS编程常见问题及解决方案 • SAS编程未来发展趋势和展望
01
SAS编程概述
SAS简介
SAS公司概况
SAS是一家总部位于美国北卡罗来纳州的公 司,专门从事统计分析软件的开发和销售。
SAS课件-2
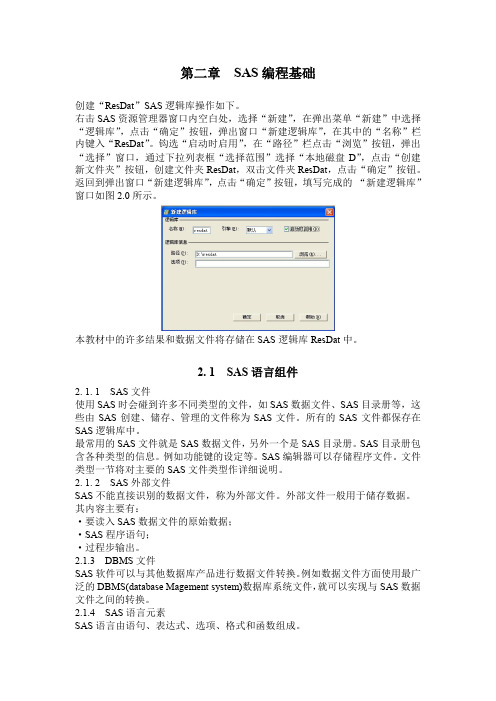
第二章SAS编程基础创建“ResDat”SAS逻辑库操作如下。
右击SAS资源管理器窗口内空白处,选择“新建”,在弹出菜单“新建”中选择“逻辑库”,点击“确定”按钮,弹出窗口“新建逻辑库”,在其中的“名称”栏内键入“ResDat”。
钩选“启动时启用”,在“路径”栏点击“浏览”按钮,弹出“选择”窗口,通过下拉列表框“选择范围”选择“本地磁盘D”,点击“创建新文件夹”按钮,创建文件夹ResDat,双击文件夹ResDat,点击“确定”按钮。
返回到弹出窗口“新建逻辑库”,点击“确定”按钮,填写完成的“新建逻辑库”窗口如图2.0所示。
本教材中的许多结果和数据文件将存储在SAS逻辑库ResDat中。
2. 1 SAS语言组件2. 1. 1 SAS文件使用SAS时会碰到许多不同类型的文件,如SAS数据文件、SAS目录册等,这些由SAS创建、储存、管理的文件称为SAS文件。
所有的SAS文件都保存在SAS逻辑库中。
最常用的SAS文件就是SAS数据文件,另外一个是SAS目录册。
SAS目录册包含各种类型的信息。
例如功能键的设定等。
SAS编辑器可以存储程序文件。
文件类型一节将对主要的SAS文件类型作详细说明。
2. 1. 2 SAS外部文件SAS不能直接识别的数据文件,称为外部文件。
外部文件一般用于储存数据。
其内容主要有:·要读入SAS数据文件的原始数据;·SAS程序语句;·过程步输出。
2.1.3 DBMS文件SAS软件可以与其他数据库产品进行数据文件转换。
例如数据文件方面使用最广泛的DBMS(database Magement system)数据库系统文件,就可以实现与SAS数据文件之间的转换。
2.1.4 SAS语言元素SAS语言由语句、表达式、选项、格式和函数组成。
SAS有两种语句:·数据步;·过程步。
在SAS中,通过数据步和过程步来使用SAS语言的元素。
这两种语句在后面都将详细地介绍。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第3节 SAS系统数据集的建立
上述程序INPUT语句中,变量Y后面的@@表示数据可以在一行里连续读 入,即在一行内连续读入x和y,直到本行结束后,再转到下一行继续读入, 直至分号(数据块结束)。如果去掉@@,则每行只能读入两个数据,即 一个x和一个y,然后再转入下一行继续读;如果读入的数据为字符型变量, 则在INPUT语句中应在相应的变量名后加上“$”符号。如上例中如果x为 字符型变量,y为数值型变量,则INPUT语句应为:
第3节 SAS系统数据集的建立
一、SAS数据集与数据库
任何统计分析都需要对数据进行操作,在SAS系统中,只能 对SAS数据集进行处理和分析。SAS数据集存储在SAS数据库的文 件集中,SAS数据库与某一个文件夹相对应,因此,要为每一个 数据库指定一个库标记(即库名)来识别该库,SAS中指定库标 记用LIBNAME命令实现,其一般格式为: LIBNAME 库标记 ‘文件夹位置’ 例如要指定目录‘c:\course’为库标记SP, 建立永久数据库, 则可用如下语句来实现:
SAS程序包括了:
数据步:数据准备部分, 过程步:数据分析部分, 数据步和过程步均由一个语句或几个 语句组成,每个语句都以一个关键词 开始,以分号结束。
第1节 SAS程序结构与编写
【例2-2】某医院分别调查了11例克山病患者和健康人的血磷值(mmol/L), 如表2-2所示,试求两组的平均血磷值和标准差。
第2节 程序运行与结果解释
程序2-1运行结果如下:
DATA EX2_1; INPUT X1 X2@@; CARDS; 35 60 40 74 40 64 42 71 37 72 45 68 43 78 37 68 44 70 42 65 41 73 39 75 ; PROC MEANS; RUN;
LIBNAME SP‘c:\course’ DATA SP.EX2_1; INPUT X Y @@; CARDS; 1 3 5 7 9 21 54 76 ; RUN;
第3节 SAS系统数据集的建立
二、数据库的种类
1、永久性数据库(SASUSER) 2、临时性数据库(WORK) 临时性数据库只有一个,它在每次启动SAS系统后自 动生成,关闭SAS时库中的数据集被自动删除。 永久库可以有多个,用户可以用LIBNAME语句指定永 久的库标记,永久库中的文件将被保留。但库标记仍然是 临时的,每次启动SAS系统后都要重新指定。为了方便用 户,SAS在每次启动时都会自动指定两个库标记。
第二章 SAS语言入门
第1节 SAS语言的程序结构与编写 第2节 SAS的程序运行结果与解释
第3节 SAS系统数据集的建立
第4节 SAS系统对数据的管理 第5节 SAS 结构化语句 第6节 常用的SAS运算符和SAS函数
第1节 SAS程序结构与编写
一个简单的SAS程序
【例 2-1】 某学校测得 12 名女生体重 X1(kg) 和胸围 X2(cm) 资料 表2-1,试计算体重与胸围的均数和标准差。
在程序编辑窗口逐行编写完程序2_1后,在窗口命令框中键入“submit” 或点击快捷工具栏中的“小人图标”按钮 ,程序即被提交给SAS系 统运行,在标题栏中会看到相应的系统信息不断刷新,如程序无误且 有运算结果,则最后OUTPUT窗口弹出成为当前窗口,显示程序运行结 果。如程序有误,则窗口不做改变,按LOG窗口中的相应提示,查看 错误所在,再在编辑窗口中把出错部分改正,再运行程序。
第1节 SAS程序结构与编写
二、 SAS程序的书写
SAS功能的实现是通过由SAS语句组成的程序来完成的,每一条 语句指定SAS完成特定的操作。 1. 语句的第一个词一般为SAS关键字,指定系统执行某一操作。语 句的其他部分说明如何执行这一操作,描述操作所需的信息。 2. 语句从上一个语句结束处开始,每个语句必须以一个分号结束。 程序的末尾用RUN;语句结束。 3. 语句的输入格式相当自由。 ① 一个SAS语句可以从一行的任一列开始输入。 ② 一行中可以输入任意多条语句,一条语句也可以占用多行。 ③ 语句中间还可以空行。 ④ 语句对字母的大小写不加区分,输入语句时可以用大写字母,也 可以用小写字母,或大小写混合使用,但要求语句中的各项之间至少 有一个空格分隔。 为了便于阅读和检查,建议开始学习时每行只写一个语句。
表2-2 11名克山病与健康人的血磷值
患者组 正常组
0.84 0.54
1.05 0.64
1.20 1.20 1.39 0.64 0.75 0.76
1.53 1.67 1.80 1.87 2.07 2.11 0.81 1.16 1.20 1.34 1.35 1.48
程序2_2 DATA EX2_2; INPUT GRP X @@; CARDS; 1 0.84 1 1.05 1 1.20 1 1.67 1 1.80 1 1.87 2 0.54 2 0.64 2 0.75 2 1.20 2 1.34 2 1.35 ;
第3节 SAS系统数据集的建立
② 利用菜单方式建立数据集
当数据量很大时,用户可以把数据用数据管理软件如FOXPRO或DBASE等 来创建数据库文件以及EXCEL工作表,导入SAS系统中,从而创建SAS数据集。 该操作是对话式的,界面友好,简单实用。
【例2-3】调查10名糖尿病人的血糖(Y,mmol/L)、胰岛素(X1,mU/L)及生长 素(X2,ug/L)的测定值列于下表,将该表数据建立成SAS数据集。 患者编号(ID) 血糖(Y) 胰岛素(X1) 生长素(X2) 1 10.43 13.2 9.63 2 13.41 15.6 11.42 3 11.07 10.9 6.98 4 12.52 14.1 10.69 5 8.96 16.5 5.63 6 15.21 11.0 12.51 7 9.64 15.2 7.35 8 12.16 18.4 6.43 9 10.61 17.4 9.86 10 8.49 20.6 5.73
数据步 PROC MEANS DATA = EX2_2; CLASS GRP; VAR X; 过程步 RUN;
1 1 2 2
1.20 1 1.39 1 1.51 2.07 1 2.11 0.76 2 0.81 2 1.16 1.48
第1节 SAS程序结构与编写
一、 SAS程序的结构 1、数据步
作用:输入数据并建立SAS数据集。 DATA语句 表示数据步开始并指明要建立的SAS数据集的文件名。
第1节 SAS程序结构与编写
BY语句 若要对数据进行分组处理,比如当我们要按性别或品种等分组输出 统计结果时,可采用BY语句来实现。如果我们想按不同的X值输出其他变 量的值,则加入的BY语句如下: BY X; 注意:使用BY语句要求数据集事先已经按BY语句中指定的变量进行了排 序,否则程序将无法正确运行。在应用时,可以先用SORT过程来进行排 序,格式如下: PROC SORT [D据集按X变量进行排序,则可加入语句: PROC SORT; BY X;
值得注意的是:
1. INPUT语句中列出变量的顺序与数据块中输入数据的顺序 必须一致;
2. 数据块中的每一数据行上数据与数据间至少用一个空格隔 开;
3. 每个观测占一行,如为了输入方便,需要在一个数据行中 输入多个观测,可在INPUT语句结尾加上续航符@@
第1节 SAS程序结构与编写
2、过程步
① 作用:对已建立的SAS数据集通过调用SAS系统中的各种现成的过程 进行统计分析、打印等处理(一个过程代表一种、一类统计方法、 一类操作或处理)。 ② 格式: PROC 过程名 [DATA=数据集名] [选项];
第1节 SAS程序结构与编写
DATA=[数据集名] 该选项用于指明所需处理的数据集名。 例如用于分析的数据集名为TEMP,则应写为DATA=TEMP。
程序2-2(克山病调查案例) PROC MEANS DATA=EX2_2; CLASS GRP; VAR X; RUN;
VAR语句 按用户需要指定要分析的变量。PROC PRINT;语句输出的是系统默 认的变量,即输出全部变量。若只想显示其中的X变量的列表,则 PRINT过程应为: PROC PRINT; VAR X; WHERE语句 用于给定处理的条件。比如我们只想显示小于15的X变量的值,则 应在PRINT过程中加入WHERE语句以对条件进行限制,即: PROC PRINT; VAR X; WHERE X<15;
第3节 SAS系统对数据集的建立
需要注意的是:
1、SAS数据库对应的是文件夹 SASUSER对应 D:\SAS\SASUSER WORK对应 D:\SAS\SASWORK;
2、SAS数据集对应文件,
每个数据集实际上是在相应的文件夹内产生一个文件名为数 据集名,扩展名为.SD2的文件。每一个数据集都有一个两级名, 第一级是库标记,第二级是数据集名,中间用“.”号隔开,在程序 中通过指定两级名来识别文件。文件两级名的一般形式如下: 库标记.数据集名 例如,在引用A库中的数据集DATA01时,应写为:A.DATA01。
三、数据的两种输入方式
SAS程序中,数据的输入方式主要有直接输入和从外部文件读人两种方式。
1、 通过INPUT和CARDS语句建立数据集(直接输入方式)
Data temp; /*建立临时数据集WORK.TEMP*/ Input x y@@; /*输入的变量为X、Y,且是连续输入*/ Cards; /*直接输入数据,数据块开始*/ 12 14 20 21 14 16 13 15 /*数据块*/ ; /*数据块结束*/ Proc print; /*显示数据集内容*/ Run; /*程序结束,且运行*/ SAS数据集可以是永久的 也可是临时的。当原始数 程序运行在结果 据不多,可通过DATA步中 OBS X Y INPUT和CARDS语句创建 1 12 14 零时数据集。 2 20 91 3 14 16 4 13 15