201412203102016-毛伟-数据结构与算法作业-基 于 C 语 言 的 关 键 路 径 算 法
数据结构与算法(C语言篇)第4章 习题答案[2页]
![数据结构与算法(C语言篇)第4章 习题答案[2页]](https://img.taocdn.com/s3/m/33724e1ceffdc8d376eeaeaad1f34693daef10d1.png)
习题答案1.填空题(1)非线性、一对多(2)前驱(3)叶结点(叶子结点)(4)度数(5)两(6)满二叉(7)从根结点到该结点之间的路径长度与该结点的权值的乘积(8)树中所有叶结点的带权路径长度之和(9)递增(10)平衡因子(11)B树的阶2.选择题(1)B (2)D (3)A (4)C (5)B (6)A (7)D (8)D3.思考题(1)如果i=1,则结点i无双亲,为根结点。
如果i>1,则结点i的双亲结点是结点i/2。
如果2i≤n,则结点i的左孩子是结点2i,否则结点i为叶结点。
如果2i+1≤n,则结点i的右孩子是结点2i+1,否则结点i无右孩子。
(2)非叶结点最多只有M个孩子,且M>2。
除根结点以外的非叶结点都有k个孩子和k-1个数据元素,k值满足[M/2]≤k≤M。
每一个叶结点都有k-1个数据元素,k值满足[M/2]≤k≤M。
所有叶结点都在同一层次。
所有分支结点的信息数据一致(n,A0,K1,A1,K2,A2……K n,A n),其中:K i(i=1,2……n)为关键字,且K i<K i+1(i=1,2……n-1);A i为指向孩子结点的指针,且指针A i−1指向子树中的所有结点均小于K i,A n所指子树中的所有结点的关键字均大于K n;n为关键字的个数([M/2]-1≤n≤M-1)。
(3)B+树是B树的升级版,区别在于叶结点在B+树的最底层(所有叶结点都在同一层),叶结点中存放索引值、指向记录的指针、指向下一个叶结点的指针。
叶结点按照关键字的大小,从小到大顺序链接。
分支结点不保存数据,只用来作索引,所有数据都保存在叶结点。
B*树是B+树的变体,B*树不同于B+树的是:其非根和非叶子结点上增加了指向兄弟结点的指针。
4.编程题(1)1//参数1为树的结点个数,参数2起始结点编号2btree_t *btree_create(int n, int i){3 btree_t *t;4 //使用malloc函数为结点申请内存空间5 t = (btree_t *)malloc(sizeof(btree_t));6 //将结点编号作为数据,保存至data中7 t->data = i;89 if(2 * i <= n){ //满足条件,说明结点有左孩子,编号为2i10 //递归调用,为左孩子的创建申请空间11 t->lchild = btree_create(n, 2 * i);12 }13 else{ //不满足条件,则没有左孩子14 t->lchild = NULL;15 }1617 if(2 * i + 1 <= n){ //满足条件,说明结点有右孩子,编号为2i+118 //递归调用,为右孩子的创建申请空间19 t->rchild = btree_create(n, 2 * i + 1);20 }21 else{ //不满足条件,则没有右孩子22 t->rchild = NULL;23 }2425 return t;26}。
数据结构_(严蔚敏C语言版)_学习、复习提纲.
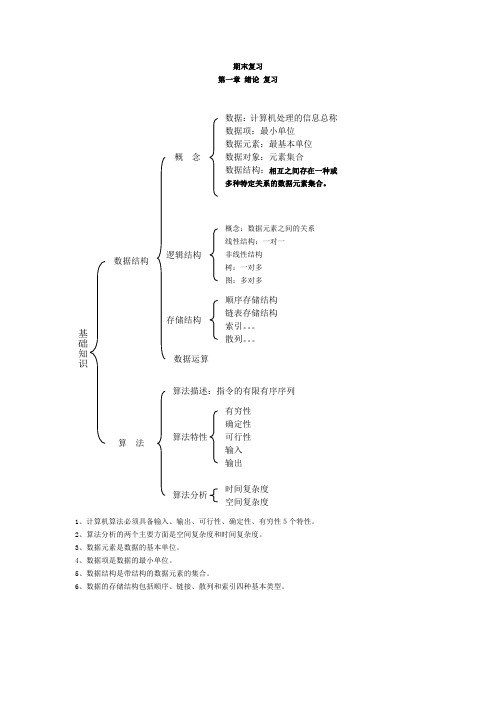
期末复习 第一章 绪论 复习1、计算机算法必须具备输入、输出、可行性、确定性、有穷性5个特性。
2、算法分析的两个主要方面是空间复杂度和时间复杂度。
3、数据元素是数据的基本单位。
4、数据项是数据的最小单位。
5、数据结构是带结构的数据元素的集合。
6、数据的存储结构包括顺序、链接、散列和索引四种基本类型。
基础知识数据结构算 法概 念逻辑结构 存储结构数据运算数据:计算机处理的信息总称 数据项:最小单位 数据元素:最基本单位数据对象:元素集合数据结构:相互之间存在一种或多种特定关系的数据元素集合。
概念:数据元素之间的关系 线性结构:一对一非线性结构 树:一对多 图:多对多顺序存储结构 链表存储结构 索引。
散列。
算法描述:指令的有限有序序列算法特性 有穷性 确定性 可行性 输入 输出 算法分析时间复杂度 空间复杂度第二章 线性表 复习1、在双链表中,每个结点有两个指针域,包括一个指向前驱结点的指针 、一个指向后继结点的指针2、线性表采用顺序存储,必须占用一片连续的存储单元3、线性表采用链式存储,便于进行插入和删除操作4、线性表采用顺序存储和链式存储优缺点比较。
5、简单算法第三章 栈和队列 复习线性表顺序存储结构链表存储结构概 念基本特点基本运算定义逻辑关系:前趋 后继节省空间 随机存取 插、删效率低 插入 删除单链表双向 链表 特点一个指针域+一个数据域 多占空间 查找费时 插、删效率高 无法查找前趋结点运算特点:单链表+前趋指针域运算插入删除循环 链表特点:单链表的尾结点指针指向附加头结点。
运算:联接1、 栈和队列的异同点。
2、 栈和队列的基本运算3、 出栈和出队4、 基本运算第四章 串 复习栈存储结构栈的概念:在一端操作的线性表 运算算法栈的特点:先进后出 LIFO初始化 进栈push 出栈pop队列顺序队列 循环队列队列概念:在两端操作的线性表 假溢出链队列队列特点:先进先出 FIFO基本运算顺序:链队:队空:front=rear队满:front=(rear+1)%MAXSIZE队空:frontrear ∧初始化 判空 进队 出队取队首元素第五章 数组和广义表 复习串存储结构运 算概 念顺序串链表串定义:由n(≥1)个字符组成的有限序列 S=”c 1c 2c 3 ……cn ”串长度、空白串、空串。
数据结构与算法分析c语言描述中文答案

数据结构与算法分析c语言描述中文答案一、引言数据结构与算法是计算机科学中非常重要的基础知识,它们为解决实际问题提供了有效的工具和方法。
本文将以C语言描述中文的方式,介绍数据结构与算法分析的基本概念和原理。
二、数据结构1. 数组数组是在内存中连续存储相同类型的数据元素的集合。
在C语言中,可以通过定义数组类型、声明数组变量以及对数组进行操作来实现。
2. 链表链表是一种动态数据结构,它由一系列的节点组成,每个节点包含了数据和一个指向下一个节点的指针。
链表可以是单链表、双链表或循环链表等多种形式。
3. 栈栈是一种遵循“先进后出”(Last-In-First-Out,LIFO)原则的数据结构。
在C语言中,可以通过数组或链表实现栈,同时实现入栈和出栈操作。
4. 队列队列是一种遵循“先进先出”(First-In-First-Out,FIFO)原则的数据结构。
在C语言中,可以通过数组或链表实现队列,同时实现入队和出队操作。
5. 树树是一种非线性的数据结构,它由节点和边组成。
每个节点可以有多个子节点,其中一个节点被称为根节点。
在C语言中,可以通过定义结构体和指针的方式来实现树的表示和操作。
6. 图图是由顶点和边组成的数据结构,它可以用来表示各种实际问题,如社交网络、路网等。
在C语言中,可以通过邻接矩阵或邻接表的方式来表示图,并实现图的遍历和查找等操作。
三、算法分析1. 时间复杂度时间复杂度是用来衡量算法的执行时间随着问题规模增长的趋势。
常见的时间复杂度有O(1)、O(log n)、O(n)、O(n^2)等,其中O表示“量级”。
2. 空间复杂度空间复杂度是用来衡量算法的执行所需的额外内存空间随着问题规模增长的趋势。
常见的空间复杂度有O(1)、O(n)等。
3. 排序算法排序算法是对一组数据按照特定规则进行排序的算法。
常见的排序算法有冒泡排序、插入排序、选择排序、快速排序、归并排序等,它们的时间复杂度和空间复杂度各不相同。
《数据结构》课后答案(C语言版)(严蔚敏_吴伟民著)

第1章 绪论1.1 简述下列术语:数据,数据元素、数据对象、数据结构、存储结构、数据类型和抽象数据类型。
解:数据是对客观事物的符号表示。
在计算机科学中是指所有能输入到计算机中并被计算机程序处理的符号的总称。
数据元素是数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理。
数据对象是性质相同的数据元素的集合,是数据的一个子集。
数据结构是相互之间存在一种或多种特定关系的数据元素的集合。
存储结构是数据结构在计算机中的表示。
数据类型是一个值的集合和定义在这个值集上的一组操作的总称。
抽象数据类型是指一个数学模型以及定义在该模型上的一组操作。
是对一般数据类型的扩展。
1.2 试描述数据结构和抽象数据类型的概念与程序设计语言中数据类型概念的区别。
解:抽象数据类型包含一般数据类型的概念,但含义比一般数据类型更广、更抽象。
一般数据类型由具体语言系统内部定义,直接提供给编程者定义用户数据,因此称它们为预定义数据类型。
抽象数据类型通常由编程者定义,包括定义它所使用的数据和在这些数据上所进行的操作。
在定义抽象数据类型中的数据部分和操作部分时,要求只定义到数据的逻辑结构和操作说明,不考虑数据的存储结构和操作的具体实现,这样抽象层次更高,更能为其他用户提供良好的使用接口。
1.3 设有数据结构(D,R),其中{}4,3,2,1d d d d D =,{}r R =,()()(){}4,3,3,2,2,1d d d d d d r =试按图论中图的画法惯例画出其逻辑结构图。
解:1.4 试仿照三元组的抽象数据类型分别写出抽象数据类型复数和有理数的定义(有理数是其分子、分母均为自然数且分母不为零的分数)。
解:ADT Complex{ 数据对象:D={r,i|r,i 为实数} 数据关系:R={<r,i>} 基本操作: InitComplex(&C,re,im)操作结果:构造一个复数C ,其实部和虚部分别为re 和imDestroyCmoplex(&C)操作结果:销毁复数CGet(C,k,&e)操作结果:用e返回复数C的第k元的值Put(&C,k,e)操作结果:改变复数C的第k元的值为eIsAscending(C)操作结果:如果复数C的两个元素按升序排列,则返回1,否则返回0IsDescending(C)操作结果:如果复数C的两个元素按降序排列,则返回1,否则返回0Max(C,&e)操作结果:用e返回复数C的两个元素中值较大的一个Min(C,&e)操作结果:用e返回复数C的两个元素中值较小的一个}ADT ComplexADT RationalNumber{数据对象:D={s,m|s,m为自然数,且m不为0}数据关系:R={<s,m>}基本操作:InitRationalNumber(&R,s,m)操作结果:构造一个有理数R,其分子和分母分别为s和m DestroyRationalNumber(&R)操作结果:销毁有理数RGet(R,k,&e)操作结果:用e返回有理数R的第k元的值Put(&R,k,e)操作结果:改变有理数R的第k元的值为eIsAscending(R)操作结果:若有理数R的两个元素按升序排列,则返回1,否则返回0IsDescending(R)操作结果:若有理数R的两个元素按降序排列,则返回1,否则返回0Max(R,&e)操作结果:用e返回有理数R的两个元素中值较大的一个Min(R,&e)操作结果:用e返回有理数R的两个元素中值较小的一个}ADT RationalNumber1.5 试画出与下列程序段等价的框图。
《数据结构与算法》习题与答案

《数据结构与算法》习题与答案(解答仅供参考)一、名词解释:1. 数据结构:数据结构是计算机存储、组织数据的方式,它不仅包括数据的逻辑结构(如线性结构、树形结构、图状结构等),还包括物理结构(如顺序存储、链式存储等)。
它是算法设计与分析的基础,对程序的效率和功能实现有直接影响。
2. 栈:栈是一种特殊的线性表,其操作遵循“后进先出”(Last In First Out, LIFO)原则。
在栈中,允许进行的操作主要有两种:压栈(Push),将元素添加到栈顶;弹栈(Pop),将栈顶元素移除。
3. 队列:队列是一种先进先出(First In First Out, FIFO)的数据结构,允许在其一端插入元素(称为入队),而在另一端删除元素(称为出队)。
常见的实现方式有顺序队列和循环队列。
4. 二叉排序树(又称二叉查找树):二叉排序树是一种二叉树,其每个节点的左子树中的所有节点的值都小于该节点的值,而右子树中的所有节点的值都大于该节点的值。
这种特性使得能在O(log n)的时间复杂度内完成搜索、插入和删除操作。
5. 图:图是一种非线性数据结构,由顶点(Vertex)和边(Edge)组成,用于表示对象之间的多种关系。
根据边是否有方向,可分为有向图和无向图;根据是否存在环路,又可分为有环图和无环图。
二、填空题:1. 在一个长度为n的顺序表中,插入一个新元素平均需要移动______个元素。
答案:(n/2)2. 哈希表利用______函数来确定元素的存储位置,通过解决哈希冲突以达到快速查找的目的。
答案:哈希(Hash)3. ______是最小生成树的一种算法,采用贪心策略,每次都选择当前未加入生成树且连接两个未连通集合的最小权重边。
答案:Prim算法4. 在深度优先搜索(DFS)过程中,使用______数据结构来记录已经被访问过的顶点,防止重复访问。
答案:栈或标记数组5. 快速排序算法在最坏情况下的时间复杂度为______。
数据结构课后习题答案详解C语言版严蔚敏

数据结构习题集答案(C语言版严蔚敏)第2章线性表2.1描述以下三个概念的区别:头指针,头结点,首元结点(第一个元素结点)。
解:头指针是指向链表中第一个结点的指针。
首元结点是指链表中存储第一个数据元素的结点。
头结点是在首元结点之前附设的一个结点,该结点不存储数据元素,其指针域指向首元结点,其作用主要是为了方便对链表的操作。
它可以对空表、非空表以及首元结点的操作进行统一处理。
2.2填空题。
解:(1)在顺序表中插入或删除一个元素,需要平均移动表中一半元素,具体移动的元素个数与元素在表中的位置有关。
(2)顺序表中逻辑上相邻的元素的物理位置必定紧邻。
单链表中逻辑上相邻的元素的物理位置不一定紧邻。
(3)在单链表中,除了首元结点外,任一结点的存储位置由其前驱结点的链域的值指示。
(4)在单链表中设置头结点的作用是插入和删除首元结点时不用进行特殊处理。
2.3在什么情况下用顺序表比链表好?解:当线性表的数据元素在物理位置上是连续存储的时候,用顺序表比用链表好,其特点是可以进行随机存取。
2.4对以下单链表分别执行下列各程序段,并画出结果示意图。
解:2.5画出执行下列各行语句后各指针及链表的示意图。
L=(LinkList)malloc(sizeof(LNode)); P=L;for(i=1;i<=4;i++){P->next=(LinkList)malloc(sizeof(LNode));P=P->next; P->data=i*2-1;}P->next=NULL;for(i=4;i>=1;i--)Ins_LinkList(L,i+1,i*2);for(i=1;i<=3;i++)Del_LinkList(L,i);解:2.6已知L是无表头结点的单链表,且P结点既不是首元结点,也不是尾元结点,试从下列提供的答案中选择合适的语句序列。
a.在P结点后插入S结点的语句序列是__________________。
(完整版)计算机科学记忆口诀

(完整版)计算机科学记忆口诀计算机科学记忆口诀计算机科学是现代社会中不可或缺的一部分。
为了帮助研究者更好地掌握计算机科学的基本概念和原理,下面是一份计算机科学的记忆口诀,供大家参考和使用。
1. 数据结构- 数组:连续空间,随机访问数组:连续空间,随机访问- 链表:非连续空间,顺序访问链表:非连续空间,顺序访问- 队列:先进先出,尾部入队,头部出队队列:先进先出,尾部入队,头部出队- 栈:后进先出,顶部入栈,顶部出栈栈:后进先出,顶部入栈,顶部出栈- 树:分层结构,有根节点和子节点树:分层结构,有根节点和子节点- 图:节点和边的集合,可以有环图:节点和边的集合,可以有环2. 算法- 递归:自我调用,需有终止条件递归:自我调用,需有终止条件- 排序:冒泡、选择、插入、快速、归并、堆排序等排序:冒泡、选择、插入、快速、归并、堆排序等- 查找:二分查找、散列表等查找:二分查找、散列表等- 动态规划:将问题分解为相似子问题的组合动态规划:将问题分解为相似子问题的组合- 贪心算法:每步都选择当前最优解贪心算法:每步都选择当前最优解- 回溯算法:通过试错的方式寻找解决方案回溯算法:通过试错的方式寻找解决方案3. 编程语言- Python:简洁、易读、易学Python:简洁、易读、易学- Java:跨平台、面向对象Java:跨平台、面向对象- C:高性能、可移植、低级别C:高性能、可移植、低级别- C++:C语言的扩展,支持面向对象和泛型编程C++:C语言的扩展,支持面向对象和泛型编程- JavaScript:用于前端开发和浏览器脚本JavaScript:用于前端开发和浏览器脚本- Ruby:简洁、优雅、动态类型Ruby:简洁、优雅、动态类型以上口诀是计算机科学中的一些基本概念和原理的简单总结。
希望通过这些口诀,大家能更好地理解和记忆计算机科学的知识,为学习和实践提供帮助。
数据结构与算法课程标准

《数据结构与算法》课程标准主编:张扬主审:梁平职业教育及专业拓展平台: 职业技术课课程编码: 1102203 是否专业核心课程: 是总学时: 64 适用专业: 计算机应用技术实践比例(%): 15.6%课程类型: (理论+实践)课学分: 4精品课程: 有考核方式: 考试开设学期: 第二学期制(修)订日期: 2010年6月一、课程描述随着计算机软件和硬件的发展,计算机的应用已经深入到社会的各个领域,各行各业都需要对大量的非数值数据进行存储、加工和管理。
如何根据实际应用研究的要求,对这些大量的表面上杂乱无章的数据进行有效地组织、存储和处理,编制出相应的高效算法,这就是《数据结构与算法》这门课程所要研究并加以解决的问题。
《数据结构与算法》是计算机科学中一门综合性的专业技术基础课,也是计算机科学技术应用专业的必修课程,为计算机专业技术人员提供必要的专业基础知识和技能训练,同时也是计算机应用相关学科所必须掌握的课程。
通过本课程的学习,使学生熟练掌握计算机程序设计中常见的各种数据的逻辑结构、存储结构及相应的运算,初步掌握算法的时间分析和空间分析的技术,并能根据计算机加工的数据特性运用数据结构的知识和技巧设计出更好的算法和程序,并进一步培养基本的良好的程序设计能力。
《数据结构与算法》课程适用于三年制计算机应用技术专业,在第二学期开设。
二、课程培养目标本课程以培养学生的数据抽象能力和复杂程序设计的能力为总目标。
通过本课程的学习,学生可以学会分析研究计算机加工的数据结构的特性,以便为应用涉及的数据选择适当的逻辑结构、存储结构及其相应的运算,并初步掌握算法的时间分析和空间分析的技术;另一方面,本课程的学习过程也是复杂程序设计的训练过程,要求学生编写的程序结构清楚和正确易读,符合软件工程的规范。
1.专业能力目标(1)掌握各种主要数据结构的特点、计算机内的表示方法,以及处理数据的算法实现。
(2)使学生学会分析研究计算机加工的数据结构的特性,以便为应用涉及的数据选择适当的逻辑结构、存储结构及相应的算法,并初步了解对算法的时间分析和空间分析技术。
《数据结构与算法实验》课程教学大纲
3
实验
/
/
四、考核方式
序号
考核环节
操作细节
总评占比
1
实验
1.本课程36个学时实验,共12次实验。
2.成绩采用百分制,根据实验完成情况评分。
3.考核学生对数据结构与算法知识的应用能力,针对12个独立的问题,能够根据题目功能和性能要求确定设计目标,从技术角度优选解决方案获得有效结果。
90%
2
考勤
随机点名、刷卡点名等
实验
/
/
11
第11题
11.任务调度(Schedule)
根据初始优先级设置,按照调度原则,预测一批计算任务的执行序列。
/
3
实验
/
/
12
第12题
12.循环移位(Cycle)
所谓循环移位是指。一个字符串的首字母移到末尾,其他字符的次序保持不变。比如ABCD经过一次循环移位后变成BCDA
给定两个字符串,判断它们是不是可以通过若干次循环移位得到彼此
/
3
实验
/
/
10
第10题
10.玩具(Toy)
ZC神自小就是这方面的天才,他往往是一只手还没揩干鼻涕,另一只手已经迅速地将处于任意状态的玩具复原至如图(a)所示的初始状态。物质极其匮乏的当年,ZC神只有一个这样的玩具;物质极大丰富的今天,你已拥有多个处于不同状态的玩具。现在,就请将它们全部复原吧。
/
3
《数据结构与算法实验》教学大纲
一、课程基本信息
课程名称
数据结构与算法实验
Data Structure and Algorithm Experiment
课程编码
CST310411015
严蔚敏数据结构(C语言版)知识点总结笔记课后答案

第1章绪论1.1复习笔记一、数据结构的定义数据结构是一门研究非数值计算的程序设计问题中计算机的操作对象以及它们之间的关系和操作等的学科。
二、基本概念和术语数据数据(data)是对客观事物的符号表示,在计算机科学中是指所有能输入到计算机中并被计算机程序处理的符号的总称,它是计算机程序加工的“原料”。
2.数据元素数据元素(data element)是数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理。
3.数据对象数据对象(data object)是性质相同的数据元素的集合,是数据的一个子集。
4.数据结构数据结构(data structure)是相互之间存在一种或多种特定关系的数据元素的集合。
(1)数据结构的基本结构根据数据元素之间关系的不同特性,通常有下列四类基本结构:① 集合。
数据元素之间除了“同属于一个集合”的关系外,别无其它关系。
② 线性结构。
数据元素之间存在一个对一个的关系。
③ 树形结构。
数据元素之间存在一个对多个的关系。
④ 图状结构或网状结构。
数据元素之间存在多个对多个的关系。
如图1-1所示为上述四类基本结构的关系图。
图1-1 四类基本结构的关系图(2)数据结构的形式定义数据结构的形式定义为:数据结构是一个二元组Data_Structure==(D,S)其中:D表示数据元素的有限集,S表示D上关系的有限集。
(3)数据结构在计算机中的表示数据结构在计算机中的表示(又称映象)称为数据的物理结构,又称存储结构。
它包括数据元素的表示和关系的表示。
① 元素的表示。
计算机数据元素用一个由若干位组合起来形成的一个位串表示。
② 关系的表示。
计算机中数据元素之间的关系有两种不同的表示方法:顺序映象和非顺序映象。
并由这两种不同的表示方法得到两种不同的存储结构:顺序存储结构和链式存储结构。
a.顺序映象的特点是借助元素在存储器中的相对位置来表示数据元素之间的逻辑关系。
b.非顺序映象的特点是借助指示元素存储地址的指针(pointer)表示数据元素之间的逻辑关系。
严蔚敏《数据结构》(C语言版)笔记和习题(含考研真题)详解

第 1 章 绪 论............................................................................................................................................... 4 1.1 复习笔记 .......................................................................................................................................... 4 1.2 强化习题详解 ................................................................................................................................... 7 1.3 考研真题与典型题详解 ................................................................................................................... 22
第 4 章 串................................................................................................................................................... 114 4.1 复习笔记 ....................................................................................................................................... 114 4.2 强化习题详解 ................................................................................................................................ 118 4.3 考研真题与典型题详解 ..................................................................................................................138
《数据结构与算法》课程教学大纲

《数据结构与算法》课程教学大纲课程代码:12281030适用专业:计算机应用技术总学时数: 68学时,其中:理论教学34学时,实践教学34学时。
学分:4.5先修课程:《C语言程序导论》、《程序设计导论》考核方式:机试一、制订大纲的依据本大纲根据2013年软件技术专业教学计划制订。
二、课程简介数据结构是介于数学、计算机硬件和计算机软件之间的一门计算机科学与技术专业的核心课程,是高级程序设计语言、编译原理、操作系统、数据库等课程的基础。
同时,数据结构技术也广泛应用于信息科学、系统工程、应用数学以及各种工程技术领域。
数据结构课程集中讨论软件开发过程中的设计阶段、同时设计编码和分析阶段的若干基本问题。
此外,为了构造出好的数据结构及其实现,还需考虑数据结构及其实现的评价与选择。
因此,数据结构的内容包括抽象、实现和评价三个层次,从数据表示和数据处理上看有五个基本组成“要素”分别是逻辑结构,存储结构、基本运算、算法及不同数据结构的比较与算法分析。
三、课程性质、教育目标(一)性质:本课程为计算机系软件技术专业的专业课。
(二)教育目标:通过本课程的学习,使学生深透地理解数据结构的逻辑结构和物理结构的基本概念以及有关算法,培养基本的、良好的程序设计技能,编制高效可靠的程序,为学习操作系统、编译原理和数据库等课程奠定基础。
四、课程教学内容与基本要求第一部分绪论(一)教学内容数据结构的基本概念和术语;抽象数据类型的表示;算法和算法分析。
(二)重点、难点重点:数据结构的基本概念及相关术语。
难点:算法的时间复杂度分析。
(三)教学基本要求知识要求:了解:抽象数据类型及面向对象概念;理解:算法的定义及算法的特性;掌握:数据结构的基本概念、算法的性能分析与度量方法。
第二部分线性表(一)教学内容1.线性表的定义及操作;2.线性表的顺序存储定义及操作实现;3.单链表的定义;单链表中的插入与删除;带表头结点的单链表;静态链表;4.循环链表的类定义及运算;5.双向链表的类定义及运算;6.线性表的应用:多项式及其相加。
数据结构与算法习题册参考答案

数据结构与算法习题册(课后部分参考答案)《数据结构与算法》课程组目录目录课后习题部分第一章绪论 (1)第二章线性表 (3)第三章栈和队列 (5)第四章串 (8)第五章数组和广义表 (10)第六章树和二叉树 (13)第七章图 (16)第九章查找 (20)第十章排序 (23)第一章绪论一. 填空题1. 从逻辑关系上讲,数据结构的类型主要分为集合、线性结构、树结构和图结构。
2. 数据的存储结构主要有顺序存储和链式存储两种基本方法,不论哪种存储结构,都要存储两方面的内容:数据元素和数据元素之间的关系。
3. 算法具有五个特性,分别是有穷性、确定性、可行性、输入、输出。
4. 算法设计要求中的健壮性指的是算法在发生非法操作时可以作出处理的特性。
二. 选择题1. 顺序存储结构中数据元素之间的逻辑关系是由 C 表示的,链接存储结构中的数据元素之间的逻辑关系是由 D 表示的。
A 线性结构B 非线性结构C 存储位置D 指针2. 假设有如下遗产继承规则:丈夫和妻子可以相互继承遗产;子女可以继承父亲或母亲的遗产;子女间不能相互继承。
则表示该遗产继承关系的最合适的数据结构应该是B 。
A 树B 图C 线性表D 集合3. 算法指的是 A 。
A 对特定问题求解步骤的一种描述,是指令的有限序列。
B 计算机程序C 解决问题的计算方法D 数据处理三. 简答题1. 分析以下各程序段,并用大O记号表示其执行时间。
(1) (2)i=1;k=0; i=1;k=0;While(i<n-1) do{ {k=k+10*i; k=k+10*i;i++; i++;} }while(i<=n)⑴基本语句是k=k+10*i,共执行了n-2次,所以T(n)=O(n)。
⑵基本语句是k=k+10*i,共执行了n次,所以T(n)=O(n)。
2. 设有数据结构(D,R),其中D={1, 2, 3, 4, 5, 6},R={(1,2),(2,3),(2,4),(3,4),(3,5),(3,6),(4,5),(4,6)}。
数据结构C语言版(第2版)严蔚敏人民邮电出版社课后习题答案

数据结构(C语言版)(第2版)课后习题答案李冬梅2015.3目录第1章绪论 (1)第2章线性表 (5)第3章栈和队列 (13)第4章串、数组和广义表 (26)第5章树和二叉树 (33)第6章图 (43)第7章查找 (54)第8章排序 (65)第1章绪论1.简述下列概念:数据、数据元素、数据项、数据对象、数据结构、逻辑结构、存储结构、抽象数据类型。
答案:数据:是客观事物的符号表示,指所有能输入到计算机中并被计算机程序处理的符号的总称。
如数学计算中用到的整数和实数,文本编辑所用到的字符串,多媒体程序处理的图形、图像、声音、动画等通过特殊编码定义后的数据。
数据元素:是数据的基本单位,在计算机中通常作为一个整体进行考虑和处理。
在有些情况下,数据元素也称为元素、结点、记录等。
数据元素用于完整地描述一个对象,如一个学生记录,树中棋盘的一个格局(状态)、图中的一个顶点等。
数据项:是组成数据元素的、有独立含义的、不可分割的最小单位。
例如,学生基本信息表中的学号、姓名、性别等都是数据项。
数据对象:是性质相同的数据元素的集合,是数据的一个子集。
例如:整数数据对象是集合N={0,±1,±2,…},字母字符数据对象是集合C={‘A’,‘B’,…,‘Z’,‘a’,‘b’,…,‘z’},学生基本信息表也可是一个数据对象。
数据结构:是相互之间存在一种或多种特定关系的数据元素的集合。
换句话说,数据结构是带“结构”的数据元素的集合,“结构”就是指数据元素之间存在的关系。
逻辑结构:从逻辑关系上描述数据,它与数据的存储无关,是独立于计算机的。
因此,数据的逻辑结构可以看作是从具体问题抽象出来的数学模型。
存储结构:数据对象在计算机中的存储表示,也称为物理结构。
抽象数据类型:由用户定义的,表示应用问题的数学模型,以及定义在这个模型上的一组操作的总称。
具体包括三部分:数据对象、数据对象上关系的集合和对数据对象的基本操作的集合。
严蔚敏数据结构c语言版习题集全答案

说明: 1. 本文是对严蔚敏?数据构造(c语言版)习题集?一书中所有算法设计题目的解决方案,主要作者为kaoyan.计算机版版主一具.以下网友:siice,龙抬头,iamkent,zames,birdthinking等为答案的修订和完善工作提出了珍贵意见,在此表示感;2. 本解答中的所有算法均采用类c语言描述,设计原那么为面向交流、面向阅读,作者不保证程序能够上机正常运行(这种保证实际上也没有任何意义);3. 本解答原那么上只给出源代码以及必要的注释,对于一些难度较高或思路特殊的题目将给出简要的分析说明,对于作者无法解决的题目将给出必要的讨论.目前尚未解决的题目有: 5.20, 10.40;4. 请读者在自己已经解决了某个题目或进展了充分的思考之后,再参考本解答,以保证复习效果;5. 由于作者水平所限,本解答中一定存在不少这样或者那样的错误和缺乏,希望读者们在阅读中多动脑、勤思考,争取发现和纠正这些错误,写出更好的算法来.请将你发现的错误或其它值得改良之处向作者报告: 第一章绪论1.16void print_descending(int x,int y,int z)//按从大到小顺序输出三个数{scanf("%d,%d,%d",&x,&y,&z);if(x<y) x<->y; //<->为表示交换的双目运算符,以下同if(y<z) y<->z;if(x<y) x<->y; //冒泡排序printf("%d %d %d",x,y,z);}//print_descending1.17Status fib(int k,int m,int &f)//求k阶斐波那契序列的第m项的值f{int tempd;if(k<2||m<0) return ERROR;if(m<k-1) f=0;else if (m==k-1) f=1;else{for(i=0;i<=k-2;i++) temp[i]=0;temp[k-1]=1; //初始化for(i=k;i<=m;i++) //求出序列第k至第m个元素的值{sum=0;for(j=i-k;j<i;j++) sum+=temp[j];temp[i]=sum;}f=temp[m];}return OK;}//fib分析:通过保存已经计算出来的结果,此方法的时间复杂度仅为O(m^2).如果采用递归编程(大多数人都会首先想到递归方法),那么时间复杂度将高达O(k^m).1.18typedef struct{char *sport;enum{male,female} gender;char schoolname; //校名为'A','B','C','D'或'E'char *result;int score;} resulttype;typedef struct{int malescore;int femalescore;int totalscore;} scoretype;void summary(resulttype result[ ])//求各校的男女总分和团体总分,假设结果已经储存在result[ ]数组中{scoretype score;i=0;while(result[i].sport!=NULL){switch(result[i].schoolname){case 'A':score[ 0 ].totalscore+=result[i].score; if(result[i].gender==0) score[ 0 ].malescore+=result[i].score; else score[ 0 ].femalescore+=result[i].score;break;case 'B':score.totalscore+=result[i].score;if(result[i].gender==0) score.malescore+=result[i].score;else score.femalescore+=result[i].score;break;……………… }i++;}for(i=0;i<5;i++){printf("School %d:\n",i);printf("Total score of male:%d\n",score[i].malescore);printf("Total score of female:%d\n",score[i].femalescore);printf("Total score of all:%d\n\n",score[i].totalscore);}}//summary1.19Status algo119(int a[ARRSIZE])//求i!*2^i序列的值且不超过maxint{last=1;for(i=1;i<=ARRSIZE;i++){a[i-1]=last*2*i;if((a[i-1]/last)!=(2*i)) reurn OVERFLOW;last=a[i-1];return OK;}}//algo119分析:当某一项的结果超过了maxint时,它除以前面一项的商会发生异常.1.20void polyvalue(){float ad;float *p=a;printf("Input number of terms:");scanf("%d",&n);printf("Input the %d coefficients from a0 to a%d:\n",n,n);for(i=0;i<=n;i++) scanf("%f",p++);printf("Input value of x:");scanf("%f",&x);p=a;xp=1;sum=0; //xp用于存放x的i次方for(i=0;i<=n;i++){sum+=xp*(*p++);xp*=x;}printf("Value is:%f",sum);}//polyvalue第二章线性表2.10Status DeleteK(SqList &a,int i,int k)//删除线性表a中第i个元素起的k个元素{if(i<1||k<0||i+k-1>a.length) return INFEASIBLE;for(count=1;i+count-1<=a.length-k;count++) //注意循环完毕的条件a.elem[i+count-1]=a.elem[i+count+k-1];a.length-=k;return OK;}//DeleteK2.11Status Insert_SqList(SqList &va,int x)//把x插入递增有序表va中{if(va.length+1>va.listsize) return ERROR;va.length++;for(i=va.length-1;va.elem[i]>x&&i>=0;i--)va.elem[i+1]=va.elem[i];va.elem[i+1]=x;return OK;}//Insert_SqList2.12int Listp(SqList A,SqList B)//比拟字符表A和B,并用返回值表示结果,值为正,表示A>B;值为负,表示A<B;值为零,表示A=B {for(i=1;A.elem[i]||B.elem[i];i++)if(A.elem[i]!=B.elem[i]) return A.elem[i]-B.elem[i];return 0;}//Listp2.13LNode* Locate(LinkList L,int x)//链表上的元素查找,返回指针{for(p=l->next;p&&p->data!=x;p=p->next);return p;}//Locate2.14int Length(LinkList L)//求链表的长度{for(k=0,p=L;p->next;p=p->next,k++);return k;}//Length2.15void ListConcat(LinkList ha,LinkList hb,LinkList &hc)//把链表hb接在ha后面形成链表hc{while(p->next) p=p->next;p->next=hb;}//ListConcat2.16见书后答案.2.17Status Insert(LinkList &L,int i,int b)//在无头结点链表L的第i个元素之前插入元素b{p=L;q=(LinkList*)malloc(sizeof(LNode));q.data=b;if(i==1){q.next=p;L=q; //插入在链表头部}else{while(--i>1) p=p->next;q->next=p->next;p->next=q; //插入在第i个元素的位置}}//Insert2.18Status Delete(LinkList &L,int i)//在无头结点链表L中删除第i个元素{if(i==1) L=L->next; //删除第一个元素else{p=L;while(--i>1) p=p->next;p->next=p->next->next; //删除第i个元素}}//Delete2.19Status Delete_Between(Linklist &L,int mink,int maxk)//删除元素递增排列的链表L中值大于mink且小于maxk的所有元素{p=L;while(p->next->data<=mink) p=p->next; //p是最后一个不大于mink的元素if(p->next) //如果还有比mink更大的元素{q=p->next;while(q->data<maxk) q=q->next; //q是第一个不小于maxk的元素p->next=q;}}//Delete_Between2.20Status Delete_Equal(Linklist &L)//删除元素递增排列的链表L中所有值一样的元素{p=L->next;q=p->next; //p,q指向相邻两元素while(p->next){p=p->next;q=p->next; //当相邻两元素不相等时,p,q都向后推一步}else{while(q->data==p->data){free(q);q=q->next;}p->next=q;p=q;q=p->next; //当相邻元素相等时删除多余元素}//else}//while}//Delete_Equal2.21void reverse(SqList &A)//顺序表的就地逆置{for(i=1,j=A.length;i<j;i++,j--)A.elem[i]<->A.elem[j];}//reverse2.22void LinkList_reverse(Linklist &L)//链表的就地逆置;为简化算法,假设表长大于2{p=L->next;q=p->next;s=q->next;p->next=NULL;while(s->next){q->next=p;p=q;q=s;s=s->next; //把L的元素逐个插入新表表头}q->next=p;s->next=q;L->next=s;}//LinkList_reverse分析:本算法的思想是,逐个地把L的当前元素q插入新的链表头部,p为新表表头.2.23void merge1(LinkList &A,LinkList &B,LinkList &C)//把链表A和B合并为C,A和B的元素间隔排列,且使用原存储空间{p=A->next;q=B->next;C=A;while(p&&q){s=p->next;p->next=q; //将B的元素插入if(s){t=q->next;q->next=s; //如A非空,将A的元素插入}p=s;q=t;}//while}//merge12.24void reverse_merge(LinkList &A,LinkList &B,LinkList &C)//把元素递增排列的链表A和B合并为C,且C中元素递减排列,使用原空间{pa=A->next;pb=B->next;pre=NULL; //pa和pb分别指向A,B的当前元素while(pa||pb){pc=pa;q=pa->next;pa->next=pre;pa=q; //将A的元素插入新表}else{pc=pb;q=pb->next;pb->next=pre;pb=q; //将B的元素插入新表}pre=pc;}C=A;A->next=pc; //构造新表头}//reverse_merge分析:本算法的思想是,按从小到大的顺序依次把A和B的元素插入新表的头部pc处,最后处理A或B的剩余元素.2.25void SqList_Intersect(SqList A,SqList B,SqList &C)//求元素递增排列的线性表A和B的元素的交集并存入C中{i=1;j=1;k=0;while(A.elem[i]&&B.elem[j]){if(A.elem[i]<B.elem[j]) i++;if(A.elem[i]>B.elem[j]) j++;if(A.elem[i]==B.elem[j]){C.elem[++k]=A.elem[i]; //当发现了一个在A,B中都存在的元素,i++;j++; //就添加到C中}}//while}//SqList_Intersect2.26void LinkList_Intersect(LinkList A,LinkList B,LinkList &C)//在链表构造上重做上题{p=A->next;q=B->next;pc=(LNode*)malloc(sizeof(LNode));while(p&&q){if(p->data<q->data) p=p->next;else if(p->data>q->data) q=q->next;else{s=(LNode*)malloc(sizeof(LNode));s->data=p->data;pc->next=s;pc=s;p=p->next;q=q->next;}}//whileC=pc;}//LinkList_Intersect2.27void SqList_Intersect_True(SqList &A,SqList B)//求元素递增排列的线性表A和B的元素的交集并存回A中{i=1;j=1;k=0;while(A.elem[i]&&B.elem[j]){if(A.elem[i]<B.elem[j]) i++;else if(A.elem[i]>B.elem[j]) j++;A.elem[++k]=A.elem[i]; //当发现了一个在A,B中都存在的元素i++;j++; //且C中没有,就添加到C中}}//whilewhile(A.elem[k]) A.elem[k++]=0;}//SqList_Intersect_True2.28void LinkList_Intersect_True(LinkList &A,LinkList B)//在链表构造上重做上题{p=A->next;q=B->next;pc=A;while(p&&q){if(p->data<q->data) p=p->next;else if(p->data>q->data) q=q->next;else if(p->data!=pc->data){pc=pc->next;pc->data=p->data;p=p->next;q=q->next;}}//while}//LinkList_Intersect_True2.29void SqList_Intersect_Delete(SqList &A,SqList B,SqList C){i=0;j=0;k=0;m=0; //i指示A中元素原来的位置,m为移动后的位置while(i<A.length&&j<B.length&& k<C.length){if(B.elem[j]<C.elem[k]) j++;else if(B.elem[j]>C.elem[k]) k++;else{same=B.elem[j]; //找到了一样元素samewhile(B.elem[j]==same) j++;while(C.elem[k]==same) k++; //j,k后移到新的元素while(i<A.length&&A.elem[i]<same)A.elem[m++]=A.elem[i++]; //需保存的元素移动到新位置while(i<A.length&&A.elem[i]==same) i++; //跳过一样的元素}}//whilewhile(i<A.length)A.elem[m++]=A.elem[i++];//A的剩余元素重新存储。
算法与数据结构C语言习题参考答案1-5章,DOC

1.绪论1.将下列复杂度由小到大重新排序:A.2n B.n! C.n5D.10000 E.n*log2(n) 【答】10000<n*log2(n)<n5<2n<n!2.将下列复杂度由小到大重新排序:A.n*log2(n) B.n+n2+n3C.24D.n0.5【答】24<n0.5<n*log2(n)<n+n2+n3{intj=1;while(j<=n){intk=1;while(k<=n){printf(“i=%d,j=%d,k=%d\n”,I,j,k);k=k+1;}j=j+1;}i=i+1;}【答】循环控制变量i从1增加到n,最外层循环体执行n次,循环控制变量j从1增加到n,中间层循环体执行n次,循环控制变量k从1增加到n,最内层循环体执行n次,所以该程序段总的时间代价为:T(n)=1+n+n{1+n+n[1+n+2n+1]+1+1}+1=3n3+3n2+4n+2=O(n3)2.线性表1.试写一个插入算法intinsertPost_seq(palist,p,x),在palist所指顺序表中,下标为p的元素之后,插入一个值为x的元素,返回插入成功与否的标志。
【答】数据结构{的元素之后插入元素/*intp,q;for(p=0;p<n;p++)/*查找值为x的元素的下标*/if(x==palist->element[p]){for(q=p;q<palist->n-1;q++)/*被删除元素之后的元素均前移一个位置*/palist->element[q]=palist->element[q+1];palist->n=palist->n-1; /*元素个数减1*/return1;}return0;}3.设有一线性表e=(e0,e1,e2,…,e n-1),其逆线性表定义为e'=(e n-1,…,e2,e1,e0)。
026-算法与数据结构+高中起点专科期末试卷A答案
H3=(0+3) mod 12=3,不冲突,关键字24放入3号单元。
H(key)=key mod 12=47 mod 12=11,不冲突,关键字47放入11号单元,
H(key)=key mod 12=29 mod 12=5,不冲突,关键字29放入5号单元,
H(key)=key mod 12=16 mod 12=4,不冲突,关键字16放入4号单元,
}
printf("\n");
SelectLa(La,Lb,Lc);……………………………(1分)
printf("\n");
return 0;
}
2、void conversion()…………………………….(共10分)
{ //对于输入的任意一个非负十进制整数,打印输出与其等值的八进制数
SqStack s;……………………………(2分)
H6=(0+6) mod 12=6,不冲突,关键字36放入6号单元。
最后建成的哈希表如表所示。
采用线性探测法处理冲突的哈希表
0 1 2 34 5 6 7 8 9 10 11
12
25
38
24
16
29
36
22
47
四、编程题(共2题,共30分)(根据学生编程掌握情况,酌情给分)
1.……………………………(共20分
{
scanf("%d",&x);
ListInsert(La,i,x);//构造n个元素的顺序表LA=( )
}
La_len=ListLength(La);
for(i=1; i<=La_len; i++ )……………………………(3分)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据结构与算法报告名称:基于 C 语言的关键路径算法作者:毛伟学号: 201412203102016 班级:计算机专升本 <2> 班学院:医学技术学院专业:计算机科学与技术指导老师:汤琼职务:2015 年 5 月浙江.杭州摘要目录第一章概论 (1)1.1报告背景 (1)1.2什么是关键路径 (2)1.3关键路径法起源 (3)1.4关键路径分类 (3)1.4.1箭线图 (4)1.4.2前导图 (5)1.5关键路径的特点 (5)第二章关键路径的意义 (6)2.1研究意义 (6)2.2关键路径的算法思想 (6)2.3关键路径的算法 (7)2.4关键路径的作用 (7)第三章关键路径的内容及核心算法 (8)3.1关键路径的内容 (8)3.2算法分析 (9)3.1核心算法 (10)参考文献 (11)附录 (12)C语言代码及运行截图 (12)第一章概论1.1报告背景背景:了解到关键路径之前,先了解一下什么是图。
图(Graph)是一种较线性表和树更为复杂的数据结构。
在线性表中,数据元素之间仅有线性关系,每个数据元素只有一个直接前驱和一个直接后续;在树形结构中,数据元素之间有着明显的层次关系,并且每一层上的数据元素可能和下一层中多个元素(即其孩子结点)相关,但只能和上一层中一个元素(即其双亲结点)相关;而在图形结构中,结点之间的关系可以是任意的,图中任意两个数据元素之间都可能相关。
由此,图的应用极为广泛,特别是近年来迅速发展,已渗入到诸如语言学、逻辑学、物理、化学、电讯工程、计算机科学以及数学的其他分支中。
而关键路径法(Critical Path Method, CPM)是一种基于数学计算的项目计划管理方法,是网络图计划方法的一种,属于肯定型的网络图。
关键路径法将项目分解成为多个独立的活动并确定每个活动的工期,然后用逻辑关系(结束-开始、结束-结束、开始-开始和开始结束)将活动连接,从而能够计算项目的工期、各个活动时间特点(最早最晚时间、时差)等。
在图中的数据元素通常称做顶点(Vertex),V是顶点的有穷非空集合;VR是两个顶点之间的关系的集合。
若,v w VR<>∈,则,v w<>表示从v到w的一条弧(Arc),且称v为弧尾(Tail)或初始点(Initial node),称w为弧头(Head)或终端点(Terminal node),此时的图称为有向图(Digraph)。
若,v w VR<>∈即VR是对称的,则以无序对,v w<>∈必有,w v VR<>代替这两个有序对,表示v和w之间的一条边(Edge),此时,的图称为无向图(Undigraph)。
如下图所示:如图1所示是一个假想的有11项活动的A0E-网。
其中有9个事件v1,v2......,v9,每个事件表示在它之前的活动一完成,在它之后的活动可以开始。
如v1表示整个工程的开始,v9表示整个工程结束,v5表示a4和a5已完成,a7和a8可以开始。
与每个活动相联系的数是执行该活动所需的时间。
比如,活动a1需要6天,a2需要4天。
由于整个工程只有一个开始点和一个完成点,故在正常情况(无环)下,网中只有一个入度为零的点(称作源点)和一个出度为零的点(叫做汇点)。
那么该工程待研究的问题是:1.完成整项工程至少需要多少时间?2.哪些活动是影响工程进度的关键?由于在AOE-网中有些活动可以并行进行,所以完成工程的最短时间是从开始点到完成点的最长路径的长度(这里所说的路径长度是指路径上各活动持续时间之和,不是路径上弧的数目)。
路径长度最长的路径叫做关键路径(Critical path)。
假设开始点是v1,从v1到vi的最长路径叫做时间vi的最早发生时间。
这个时间决定了所有以vi为尾的弧所表示的活动的最早开始时间。
我们用e(i)表示活动ai的最早开始时间。
还可以定义一个活动开始的最迟时间l(i),这是在不推迟整个工程完成的前提下,活动ai最迟必须开始进行的时间。
两者之差l(i)-e(i)意味着完成活动ai的时间余量。
当这个时间余量等于0的时候,也即是l(i)=e(i)的活动,我们称其为关键活动。
显然,关键路径上的所有活动都是关键活动,因此提前完成非关键活动并不能加快工程的进度。
因此,分析关键路径的目的是辨别哪些是关键活动,以便争取提高关键活动的功效,缩短整个工期。
关键路径法(CPM)最早出现于1956年,当时美国杜邦(Du Pont)公司拥有一台UNⅣAC 1 计算机,他们使用这台计算机进行他们公司几乎所有的数据处理工作,但是仍然还有大量的剩余时间,杜邦(Du Pont)公司的管理层开始研究计算机在其它方面使用的可能性,因为当时电脑的费用是非常高昂的,他们考虑工程计划可能是应用电脑的一个方向。
他们联系了雷明顿兰德(Remington Rand)公司的Macuchy 博士,帮他们解决计算机使用的问题,后者派出了年轻的数学家James E. Kelly去协助杜邦(Du Pont)公司解决问题,杜邦公司方面的负责人是Morgan Walker。
他们要解决的问题是在工程项目中工期和费用之间的关系,他们研究的是如何能够采取正确的措施,在减少工期的情况下能尽可能少的增加费用。
1957年5月7日,在特拉华州内瓦克召开的一个会议正式确定开始新计划技术的开发。
Kelly借用了线性规划的概念来解决项目计划自动计算的问题,简单的说就是确定了每个活动的工期和活动间的逻辑关系,输入电脑后就能自动计算项目的工期,为了电脑的计算,Kelly在活动间使用了i,j这样的节点来表示活动间的前后逻辑关系。
当时遇到的一个问题是,杜邦公司的管理层并不理解Kelly所使用的方法,为了让其他人能够理解所使用方法的原理,Kelly就绘制了图形来解释电脑所作的工作,图形以箭线表示活动,以节点表示活动间的逻辑关系,这就是最早的箭线图(ADM)。
前面提到过,Kelly和Walker最初研究的目的是为了解决项目中工期和费用之间关系的问题,所以在Kelly和Walker最初提出的方法中,也包括费用的计划方法,其做法是,在每个活动上加载其相应的费用,从而得到整个项目的费用,就能分析与进度相关的费用问题,这种做法与现用的方法没有太大差别。
但在当时的情况下,项目收集费用并分解到各个活动上存在较大困难。
所以,在之后的很长时期内,关键路径法主要还是用于进度的计划和控制方面。
Kelly和Walker还提出了资源加载和分配的方法,当然也存在和费用分析一样的问题。
1.4关键路径分类根据绘制方法的不同,关键路径法可以分为两种:即箭线图(ADM)和前导图(PDM)。
关键路径法箭线图(ADM)法又称为双代号网络图法,它是以横线表示活动而以带编号的节点连接活动,活动间可以有一种逻辑关系,结束-开始型逻辑关系。
在箭线图中,有一些实际的逻辑关系无法表示,所以在箭线图中需要引入虚工作的概念。
1.4.1箭线图箭线图(ADM)要表示的是一个项目的计划,所以其清晰的逻辑关系和良好的可读性是关键路径法非常重要的,除了箭线图(ADM)本身具有正确的逻辑性,良好的绘图习惯也是必要的。
因此在绘图时遵守上面的这些规则就是非常重要的,另外,在绘图时,一般尽量使用直线和折线,在不可避免的情况下可以使用斜线,但是要注意逻辑方向的清晰性。
绘制箭线图时主要有以下一些规则:⒈在箭线图(ADM)中不能出现回路。
如上文所述,回路是逻辑上的错误,不符合实际的情况,而且会导致计算的死循环,所以这条规则是必须的要求。
⒉箭线图(ADM)一般要求从左向右绘制。
这虽然不是必须的要求,但是符合人们阅读习惯,可以增加箭线图(ADM)的可读性。
⒊每一个节点都要编号,号码不一定要连续,但是不能重复,且按照前后顺序不断增大。
这条规则有多方面的考虑,在手工绘图时,它能够增加图形的可读性和清晰性,另外,在使用计算机运行箭线图(ADM)这一条就非常重要,因为在计算机中一般通过计算节点的时间来确定各个活动的时间,所以节点编号不重复是必须的。
⒋一般编号不能连续,并且要预留一定的间隔。
主要是为了在完成的箭线图(ADM)中可能需要增加活动,如果编号连续,新增加活动就不能满足编号由小到大的要求。
⒌表示活动的线条不一定要带箭头,但是为了表示的方便,一般推荐使用箭头。
这一条主要是绘制箭线图(ADM)时可以增加箭线图(ADM)的可读性。
⒍一般要求双代号网络图要开始于一个节点,并且结束于一个节点。
此要求可以在手工绘图增加可读性,而在计算机计算时,可以增加效率和结果的清晰性。
⒎在绘制网络图时,一般要求连线不能相交,在相交无法避免时,可以采用过桥法或者指向法等方法避免混淆。
此要求主要是为了增加图形的可读性。
1.4.2前导图前导图(PDM)法又称为单代号网络图法,它是以节点表示活动而以节点间的连线表示活动间的逻辑关系,活动间可以有四种逻辑关系,结束-开始、结束-结束、开始-开始和开始-结束。
1.5关键路径的特点1)关键路径上的活动持续时间决定了项目的工期,关键路径上所有活动的持续时间总和就是项目的工期。
2)关键路径上的任何一个活动都是关键活动,其中任何一个活动的延迟都会导致整个项目完工时间的延迟。
3)关键路径上的耗时是可以完工的最短时间量,若缩短关键路径的总耗时,会缩短项目工期;反之,则会延长整个项目的总工期。
但是如果缩短非关键路径上的各个活动所需要的时间,也不至于影响工程的完工时间。
4)关键路径上活动是总时差最小的活动,改变其中某个活动的耗时,可能使关键路径发生变化。
5)可以存在多条关键路径,它们各自的时间总量肯定相等,即可完工的总工期。
关键路径是相对的,也可以是变化的。
在采取一定的技术组织措施之后,关键路径有可能变为非关键路径,而非关键路径也有可能变为关键路径。
第二章关键路径的意义2.1研究意义关键路径可以很方便的让我们估算出某个工程最短时间的开销,同时,可以挺高项目的整体优势,分析出最佳的工程项目实施。
以及知道这个工程中哪些活动,即哪些项目是主要的,哪些项目是影响工程进度的关键,从而使我们对工程实施作出更好的时间安排,并且可以分清主次,抓住核心工程,做到最佳效果。
总体来说,正因为关键路径可以帮助我们对工程进行非常好的估算,使得我们在未进行项目的实施时,就已经总体的了解到项目的关键点,从而作出有必要的安排。
提高项目的进度。
2.2关键路径的算法思想我们用有向网络来表示某一工程, 用有向网络的弧来表示某个子工程( 活动) , 顶点表示某个事件, 弧上的权来表示子工程或( 活动) 持续的时间, 这样的有向网络称为AOE( ActivityOn Edge) 一网。
由于整个工程只有一个开始点和一个完成点, 故在正常情况( 无回路) 下, 网中只有一个入度为零的点( 对称源点) 和一个出度为零的点( 汇点) 。