kettle使用手册
kettle使用手册

kettle使用手册Kettle使用手册一、Kettle简介1.1 Kettle概述Kettle(也被称为Pentaho Data Integration)是一款开源的ETL(Extract, Transform, Load)工具,它能够从各种数据源中提取数据,并进行各种转换和加工,最后将数据加载到指定的目的地中。
Kettle具有强大的数据处理功能和友好的图形化界面,使得数据集成和转换变得简单而高效。
1.2 功能特点- 数据抽取:从多种数据源中提取数据,包括关系型数据库、文件、Web服务等。
- 数据转换:支持多种数据转换操作,如字段映射、类型转换、数据清洗等。
- 数据加载:将转换后的数据加载到不同的目的地,如数据库表、文件、Web服务等。
- 调度管理:支持定时调度和监控,可自动执行数据集成任务。
二、安装与配置2.1 系统要求在安装Kettle之前,请确保满足以下系统要求: - 操作系统:Windows、Linux、Unix等。
- Java版本:JDK 1.8及以上。
- 内存:建议至少4GB的可用内存。
2.2 安装Kettle最新版本的Kettle安装包,并按照安装向导进行安装。
根据系统要求和个人需求进行相应的配置选项,完成安装过程。
2.3 配置Kettle在安装完成后,需要进行一些配置以确保Kettle正常运行。
具体配置步骤如下:- 打开Kettle安装目录下的kettle.properties文件。
- 根据实际需要修改配置项,如数据库连接、日志路径、内存分配等。
- 保存修改并重启Kettle。
三、Kettle基础操作3.1 数据抽取3.1.1 创建数据源连接打开Kettle,左上角的“新建连接”按钮,在弹出的窗口中选择待抽取的数据源类型(如MySQL、Oracle等),填写相关参数并测试连接。
3.1.2 设计数据抽取作业- 打开Kettle中的“转换”视图。
- 从左侧的工具栏中选择适当的输入组件(如“表输入”或“文件输入”),将其拖拽到设计区域中。
kettle使用手册
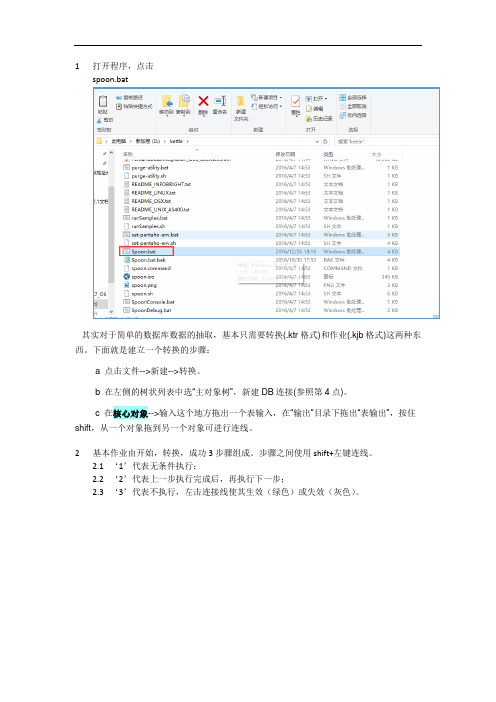
1打开程序,点击spoon.bat其实对于简单的数据库数据的抽取,基本只需要转换(.ktr格式)和作业(.kjb格式)这两种东西。
下面就是建立一个转换的步骤:a 点击文件-->新建-->转换。
b 在左侧的树状列表中选“主对象树”,新建DB连接(参照第4点)。
c 在核心对象-->输入这个地方拖出一个表输入,在“输出”目录下拖出“表输出”,按住shift,从一个对象拖到另一个对象可进行连线。
2基本作业由开始,转换,成功3步骤组成。
步骤之间使用shift+左键连线。
2.1‘1’代表无条件执行;2.2‘2’代表上一步执行完成后,再执行下一步;2.3‘3’代表不执行,左击连接线使其生效(绿色)或失效(灰色)。
3打开具体步骤中的转换流程,点击‘Transformation’跳转至相应具体转换流程,编辑此转换具体路径,双击转换,弹出窗口,‘1’为相对路径,点击‘2’选择具体Visit.ktr 转换,为绝对路径。
4建立数据库连接,输入相应信息测试,成功即可图45转换具体设置,如图4,‘表输出’至‘文本文件输出’流程跳接线为错误处理步骤,当输出格式不能满足表输出的目的表结构类型时,将会将记录输出到‘文本文件输出’中的记录中。
5.1双击‘表输入’,输入相应的SSQL语句,选择配置数据库连接,或新增,预览查询生成的结果(如果数据库配置中使用变量获取,此处预览生成错误)。
5.2双击‘表输出’,选择数据库连接,‘浏览’选择相应目标表,(此处‘使用批量插入’勾选去除,目的是在错误处理步骤中无法使用批量处理,可能是插件兼容问题)6表输出插件定义a) Target Schema:目标模式。
要写数据的表的Schema的名称。
允许表明中包含“。
”对数据源来说是很重要的b) 目标表:要写数据的表名。
c) 提交记录数量:在数据表中用事物插入行。
如果n比0大,每n行提交一次连接。
否则不使用事务,速度会慢一些。
d) 裁剪表:在第一行数据插入之前裁剪表。
Kettle开发使用手册

Kettle开发使用手册Kettle开发使用手册4月版本历史说明1.Kettle介绍1.1.什么是KettleKettle是纯Java编写的、免费开源的ETL工具,主要用于抽取(Extraction)、转换(Transformation)、和装载(Loading)数据。
Kettle中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
在这种思想的设计下,Kettle广泛用于不同数据库之间的数据抽取,例如Mysql 数据库的数据传到Oracle,Oracle数据库的数据传到Greenplum数据库。
1.2.Kettle的安装Kettle工具是不需要安装的,直接网上下载解压就能够运行了。
不过它依赖于Java,需要本地有JDK环境,如果是安装4.2或5.4版本,JDK需要1.5以上的版本,推荐1.6或1.7的JDK。
运行Kettle直接双击里面的批处理文件spoon.bat就行了,如图 1.1所示:图1.12.Kettle脚本开发2.1.建立资源库(repository仓库)Repository仓库是用来存储所有kettle文件的文件系统,由于数据交换平台服务器管理kettle文件也是用Repository仓库,因此我们这边本地的kettle开发环境也是要用到该资源库。
建立资源库的方式是工具 --> 资源库- -> 连接资源库,这时候弹出一个窗口,我们点击右上角的“+”号,跟着点击下面的kettle file repository选项,按确定,如图2.1所示:图2.1跟着在右上角选择一个目录,建议在kettle路径下新建repository文件夹,再选择这个文件夹作为根目录,名称和描述能够任意写,如图2.2所示:。
kettle的使用方法

kettle的使用方法Kettle是一种用于数据集成和转换的开源工具,也被称为Pentaho Data Integrator(PDI)。
它提供了一套功能强大的工具,可以帮助用户从不同的数据源中提取、转换和加载数据。
本文将介绍Kettle 的使用方法,帮助读者快速上手使用该工具。
一、安装Kettle您需要从Kettle官方网站下载最新版本的安装包。
安装包通常是一个压缩文件,您可以将其解压到您选择的目录中。
然后,通过运行解压后的文件夹中的启动脚本来启动Kettle。
二、连接数据源在使用Kettle之前,您需要先连接到您的数据源。
Kettle支持多种类型的数据源,包括关系型数据库、文件、Web服务等。
您可以使用Kettle提供的连接器来连接到您的数据源,或者根据需要自定义连接器。
连接成功后,您可以在Kettle中查看和操作您的数据。
三、创建转换在Kettle中,数据转换是通过创建转换作业来实现的。
转换作业是由一系列的转换步骤组成的,每个步骤都执行特定的数据操作。
您可以使用Kettle提供的各种转换步骤,如数据提取、数据过滤、数据转换、数据加载等,来构建您的转换作业。
四、配置转换步骤在创建转换作业后,您需要配置每个转换步骤的参数和选项。
例如,在数据提取步骤中,您需要指定要提取的数据源和查询条件。
在数据转换步骤中,您可以定义数据的转换逻辑,如数据清洗、数据合并、数据计算等。
在数据加载步骤中,您需要指定目标数据表和加载方式。
五、运行转换作业完成转换步骤的配置后,您可以运行整个转换作业,将数据从源数据源提取、转换和加载到目标数据源。
在运行转换作业之前,您可以选择性地预览转换结果,以确保数据操作的准确性和一致性。
Kettle还提供了调试功能,可以帮助您快速定位和解决转换作业中的问题。
六、调度转换作业除了手动运行转换作业之外,Kettle还支持将转换作业安排为定期执行的任务。
您可以使用Kettle提供的调度功能,根据您的需求设置转换作业的执行时间和频率。
kettle使用方法

kettle使用方法一、什么是kettle?Kettle是一款功能强大的开源ETL (Extract, Transform, Load) 工具,用于处理各种数据的抽取、转换和加载。
它提供了可视化的界面,使用户能够轻松地创建和管理数据流程。
二、kettle的安装和配置1.下载kettle安装包,并解压到指定目录。
2.进入kettle目录,在终端中运行spoon.sh (Linux/Mac) 或spoon.bat(Windows) 启动kettle。
3.在弹出的窗口中,点击”File”菜单,选择”Preferences”打开配置页面。
4.在配置页面中,设置kettle的选项,如数据连接、插件路径等。
三、kettle中的数据流程1.创建一个新的数据流程:点击工具栏上的”新建”按钮,在弹出的对话框中选择”Transformation”创建一个新的转换,或选择”Job”创建一个作业。
2.在数据流程中,可以拖拽各种组件来构建转换或作业,如数据输入、数据输出、转换、聚合等。
3.连接组件:使用鼠标拖拽连线工具,连接各个组件,定义数据的流向。
4.配置组件:双击组件,如数据输入组件,可以配置数据源的连接信息、查询语句等。
5.定义转换规则:在转换组件中,根据需要配置字段映射、条件过滤、转换函数等。
6.运行数据流程:点击工具栏上的”运行”按钮,运行数据流程并查看结果。
四、kettle的常用组件和功能1.数据输入:用于读取数据源的组件,支持多种数据源,如数据库、文件、Web服务等。
2.数据输出:用于将数据写入目标的组件,支持多种输出格式,如数据库表、文件、Web服务等。
3.转换组件:用于对数据进行转换的组件,如字段映射、类型转换、条件过滤、聚合等。
4.调度和监控:kettle提供了作业调度和监控的功能,可以定时执行作业、生成报表等。
5.插件扩展:kettle支持插件扩展,用户可以根据需要开发自己的插件,用于处理特定的数据源或转换规则。
Kettle的使用说明

KETTLE使用说明简介Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
Kettle可以在/网站下载到。
注:ETL,是英文Extract-Transform-Load 的缩写,用来描述将数据从来源端经过萃取(extract)、转置(transform)、加载(load)至目的端的过程。
ETL 一词较常用在数据仓库,但其对象并不限于数据仓库。
下载和安装首先,需要下载开源免费的pdi-ce软件压缩包,当前最新版本为5.20.0。
下载网址:/projects/pentaho/files/Data%20Integration/然后,解压下载的软件压缩包:pdi-ce-5.2.0.0-209.zip,解压后会在当前目录下上传一个目录,名为data-integration。
由于Kettle是使用Java开发的,所以系统环境需要安装并且配置好JDK。
žKettle可以在/网站下载ž 下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可。
运行Kettle进入到Kettle目录,如果Kettle部署在windows环境下,双击运行spoon.bat 或Kettle.exe文件。
Linux用户需要运行spoon.sh文件,进入到Shell提示行窗口,进入到解压目录中执行下面的命令:# chmod +x spoon.sh# nohup ./spoon.sh & 后台运行脚本这样就可以打开配置Kettle脚本的UI界面。
Kettle配置使用说明

Kettle配置使用说明Kettle配置使用说明1.文件结构1.1 kettle4.0.1该文件夹存放的是kettle4.0.1的桌面应用程序,/kettle4.0.1/Spoon.bat是运行软件的一个批处理文件,双击运行。
1.2 workspace该文件夹存放的是以各个警种总队全拼命名的分别存放.ktr文件和.job文件的文件夹。
Start.job是一个启动总纲。
1.3 script该文件夹是存放的数据库建库脚本,目前是oracle10g版本1.4 model存放的是powerDesign的cdm概念模型文件用于根据需要生成pdm和script。
2.文件路径配置本系统使用的都是系统所在路径的相对路径,不管处于什么目录下都请将kettle4.0.1和workspace的文件夹放在同一目录之下。
当然你可以随意改变文件夹的名称。
3.运行环境配置先运行一次/kettle4.0.1/Spoon.bat,Linux就不说了,如果你用的是windows系统,那么你可以在/${userhome}/.kettle下找到一个.kettle的文件夹主要说下:Response.xml-记录资源库信息(自己去勾)Kettle.property-这是好东西,可以让你在软件中任何可以使用到环境变量的地方使用到里面的配置信息(键-值对配置),类似全局变量。
当然是有利有弊,配置点什么数据库连接和一些常用的东西之外别把那里当仓库,想下全局变量定义的多了会给系统带来什么风险。
A_fileInput=file:///E:/Test_Server/srcFile/A_fileOutput=file:///E:/Test_Server/errFile/这2个属性是配置读取的Excel文件和输出错误的Excel文件用到的路径配置。
由于文件名命名的差异和存放位置的不同需要使用者自行配置。
有在系统内修改文件路径的风险,当然这是没有办法避免的,只能在项目初期和用户有这方面的约定俗成。
Kettle使用手册

Kettle培训手册Etl介绍ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程),对于金融IT来说,经常会遇到大数据量的处理,转换,迁移,所以了解并掌握一种etl工具的使用,必不可少。
Kettle是一款国外开源的etl工具,纯java编写,绿色无需安装,数据抽取高效稳定。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
kettle部署运行将kettle2.5.1文件夹拷贝到本地路径,例如D盘根目录。
双击运行kettle文件夹下的spoon.bat文件,出现kettle欢迎界面:稍等几秒选择没有资源库,打开kettle主界面创建transformation,job点击页面左上角的解并到本地路径,例如保存到D:/etltest下,保存文件名为EtltestTrans,kettle默认transformation 文件保存后后缀名为ktr点击页面左上角的解并到本地路径,例如保存到D:/etltest下,保存文件名为EtltestJob,kettle默认job文件保存后后缀名为kjb创建数据库连接在transformation页面下,点击左边的【Main Tree】,双击【DB连接】,进行数据库连接配置。
Connection name自命名连接名称Connection type选择需要连接的数据库Method of access选择连接类型Server host name写入数据库服务器的ip地址Database name写入数据库名Port number写入端口号Username写入用户名Password写入密码例如如下配置:点击【test】,如果出现如下提示则说明配置成功点击关闭,再点击确定保存数据库连接。
一个简单的ktr例子目标:从交易表(trade),帐户表(account),客户表(cust)抽数交易相关的所有信息,并判断对公对私分别进行处理,输出到文本文件中。
Kettle用户操作手册1

Kettle用户操作手册1.kettle介绍1.1 什么是kettleKettle是“Kettle E.T.T.L. Envirnonment”只取首字母的缩写,这意味着它被设计用来帮助你实现你的ETTL 需要:抽取、转换、装入和加载数据;它的名字起源正如该项目的主程序员MATT所说:希望把各种数据放到一个壶里然后以一种指定的格式流出。
Spoon是一个图形用户界面,它允许你运行转换或者任务。
1.2 Kettle 的安装要运行此工具你必须安装 Sun 公司的JAVA 运行环境1.4 或者更高版本,相关资源你可以到网络上搜索JDK 进行下载,Kettle 的下载可以到取得最新版本。
1.3 运行SPOON下面是在不同的平台上运行Spoon 所支持的脚本:Spoon.bat: 在windows 平台运行Spoon。
Spoon.sh: 在Linux、Apple OSX、Solaris 平台运行Spoon。
1.4 资源库一个Kettle资源库可以包含那些转换信息,这意味着为了从数据库资源中加载一个转换就必须连接相应的资源库。
在启动SPOON的时候,可以在资源库中定义一个数据库连接,利用启动spoon时弹出的资源库对话框来定义,如图所示:单击加号便可新增;关于资源库的信息存储在文件“reposityries.xml”中,它位于你的缺省home 目录的隐藏目录“.kettle”中。
如果是windows 系统,这个路径就是c:\Documents and Settings\<username>\.kettle。
如果你不想每次在Spoon 启动的时候都显示这个对话框,你可以在“编辑/选项”菜单下面禁用它。
admin 用户的缺省密码也是admin。
如果你创建了资源库,你可以在“资源库/编辑用户”菜单下面修改缺省密码。
1.5 定义1.5.1 转换主要用来完成数据的转换处理。
转换步骤,可以理解为将一个或者多个不同的数据源组装成一条数据流水线。
KETTLE简单使用说明文档

KETTLE简单使用说明文档1. 下载和安装要运行此工具你必须安装SUN 公司的JAVA 运行环境 1.4 或者更高版本,相关资源你可以到网络上搜索JDK 进行下载。
设置JAVA 运行环境变量,JAVA_HOME 和PATHKETTLE 的下载可以到/取得最新版本,下载后解压,就可以直接运行。
2.kettle主要有两部分组成,主对象树,核心对象,3.新建一个kettle文件(数据库之间做处理)1)转换右键点击新建,如图所示2) 设置数据库连接,上图DB连接右键新建(支持多库连接): 如图:3)核心对象里面有很多组件,通过拖拽来供给我们做操作,如图4)添加一个源输入,打开输入文件夹,可以看到各种输入类型,支持文件,数据库等。
如图5)这里通过数据库操作,那我们这里拖拽一个表输入组件6)双击打开,可以看到你可以选择上面连接的数据库,然后通过获取sql语句来选择你要输入的源表进行操作。
并且sql语句支持传递变量参数和占位符参数,以及多表关联sql。
如下图7)输入表已经OK,那输出表呢,那我看下输出组件。
如图8)选中两个组件,右键新建节点连接。
如下图9)双击打开表输出,选择输出的数据库,以及目标表和输入表与目标表的字段映射10)映射选择以及匹配11)点击箭头弹出启动界面,点击启动,该kettle文件即可执行数据的迁移了12)上面是一个简单的数据库转换操作。
在表输入和表输出直接可以加不同组件对数据进行筛选过滤。
通过转换文件夹下的组件。
如图转换可以处理中文乱码,字段数字的计算,值的转换,序列的生成等等脚本可以用java代码,javascript,sql脚本等等查询支持调用存储过程,两个表直接关联查询等等以上只是针对kettle工具的简单实用介绍。
kettle使用教程(超详细)

01
3. 运行Kettle启动脚本(spoon.sh或 spoon.bat),启动Kettle图形化界面。
03
02
2. 配置Java环境变量,确保系统中已安装Java 并正确配置了JAVA_HOME环境变量。
04
4. 在Kettle界面中,配置数据源和数据目标 连接信息。
5. 创建ETL任务,拖拽组件进行连接和配置。
实战演练
以一个具体的数据迁移任务为例,详细介绍如 何使用Kettle实现ETL过程的自动化。
案例二:数据仓库建设实践
数据仓库概念介绍
数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支 持管理决策。
Kettle在数据仓库建设中的应用
Kettle提供了丰富的数据转换和处理功能,可以方便地实现数据仓库的建模、数据抽取、 清洗和加载等任务。
它支持多种数据源和数据目标,包括关系型数据库、文 件、API等。
Kettle提供了图形化界面和易用的组件,使得用户可以方 便地进行数据集成和处理。
Kettle特点与优势
图形化界面
Kettle提供了直观的图形化界 面,使得用户可以轻松地构建 ETL任务。
灵活性
Kettle支持自定义组件和插件, 用户可以根据自己的需求进行 扩展。
03
实战演练
以一个具体的实时数据处理任务为例, 介绍如何使用Kettle设计实时数据处理 流程。
案例四:Kettle在数据挖掘中应用
数据挖掘概念介绍
01
数据挖掘是指从大量数据中提取出有用的信息和知识的
过程,包括分类、聚类、关联规则挖掘等任务。
Kettle在数据挖掘中的应用
02
Kettle提供了丰富的数据处理和转换功能,可以方便地
Kettle使用手册及测试案例

一、【kettle】window安装与配置1、下载kettle包,并解压2、安装jdk,并配置java环境a).打开我的电脑--属性--高级--环境变量b).新建系统变量JA V A_HOME和CLASSPATH变量名:JA V A_HOME变量值:C:\Program Files\Java\jdk1.7.0[具体路径以自己本机安装目录为准]变量名:CLASSPATH变量值:.;%JA V A_HOME%\lib\dt.jar;%JA V A_HOME%\lib\tools.jar;c). 选择“系统变量”中变量名为“Path”的环境变量,双击该变量,把JDK安装路径中bin目录的绝对路径,添加到Path变量的值中,并使用半角的分号和已有的路径进行分隔。
变量名:Path变量值:%JA V A_HOME%\bin;%JA V A_HOME%\jre\bin;3、配置kettle环境在系统的环境变量中添加KETTLE_HOME变量,目录指向kettle的安装目录:D:\kettle\data-integration4、启动spoonWindows直接双击批处理文件Spoon.bat具体路径为:kettle\data-integration\Spoon.batLinux 则是执行spoon.sh,具体路径为:~/kettle/data-integration/spoon.sh二、使用Kettle同步数据同步数据常见的应用场景包括以下4个种类型:➢ 只增加、无更新、无删除➢ 只更新、无增加、无删除➢ 增加+更新、无删除➢ 增加+更新+删除只增加、无更新、无删除对于这种只增加数据的情况,可细分为以下2种类型:1) 基表存在更新字段。
通过获取目标表上最大的更新时间或最大ID,在“表输入”步骤中加入条件限制只读取新增的数据。
2) 基表不存在更新字段。
通过“插入/更新”步骤进行插入。
插入/更新步骤选项:只更新、无增加、无删除通过“更新”步骤进行更新。
KETTLE使用说明(中文版)

5.4 输出:插入/更新
插入/更新:若流里的数据在目标表中不存在,执行插入,否则执行更新, 数据量不大的情况下,一般采用插入/更新操作。
5.5 输出:更新
这个步骤类似于插入/更新步骤,除了对数据不作插入操作之外。它仅仅 执行更新操作。
5.6 输出:删除
这个步骤类似于更新步骤,除了不更新操作之外,其他的行均被删除。
选择表输入, excel 输出,建立节点 连接。右击连接线,可编辑连线属 性。
5.1常用输入:
表输入 Excel 输入 文本文件输入 XML 文件输入 CUBE 输入(多维数据集) 获取系统信息
5.2输入:表输入
选择表输入,点击鼠标右键,选择编辑步骤。 步骤名称可以更改,一般更改为和输入表相关的名称。 数据库连接 : 选择一个已建好的数据库连接,也可以新建一个。 点击”获取SQL查询语句”,可弹出数据库浏览器,选择自己需要的表或视图。 选择好表或视图后,SQL 区域会显示相应的SQL,如选择在SQL里包含字段名,你 所选择的表的所有字段均会显示. 在SQL区域用户可手动修改SQL语句。
7.3 Flow :Blocking Step(被冻结的步骤)
这是一个非常简单的步骤,它冻结所有的输出,直到从上一个步骤来的最后一行 数据到达,最后 一行数据将发送到下一步。 你可以使用这个步骤触发常用插件、 存储过程和js等等。
8.0 连接 :Merge Join(合并排序)
这个步骤将来自两个不同的步骤输 入的数据执行一个高效的合并。合 并选项包括INNER ,LEFT OUTER , RIGHT OUTER, FULL OUTER. 这个步骤将输入的行按照指定的字 段存储 被合并的两个步骤,必须按照相同 的段进行排序。
Kettle开发使用手册

Kettle开发使用手册2017年4月版本历史说明1.Kettle介绍1.1.什么是KettleKettle是纯Java编写的、免费开源的ETL工具,主要用于抽取(Extraction)、转换(Transformation)、和装载(Loading)数据。
Kettle中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
在这种思想的设计下,Kettle广泛用于不同数据库之间的数据抽取,例如Mysql数据库的数据传到Oracle,Oracle数据库的数据传到Greenplum数据库。
1.2.Kettle的安装Kettle工具是不需要安装的,直接网上下载解压就可以运行了。
不过它依赖于Java,需要本地有JDK环境,如果是安装4.2或5.4版本,JDK需要1.5以上的版本,推荐1.6或1.7的JDK。
运行Kettle直接双击里面的批处理文件spoon.bat就行了,如图1.1所示:图1.12.Kettle脚本开发2.1.建立资源库(repository仓库)Repository仓库是用来存储所有kettle文件的文件系统,由于数据交换平台服务器管理kettle文件也是用Repository仓库,因此我们这边本地的kettle 开发环境也是要用到该资源库。
建立资源库的方式是工具 --> 资源库- -> 连接资源库,这时候弹出一个窗口,我们点击右上角的“+”号,跟着点击下面的kettle 选项,按确定,如图2.1所示:图2.1跟着在右上角选择一个目录,建议在kettle路径下新建repository文件夹,再选择这个文件夹作为根目录,名称和描述可以任意写,如图2.2所示:图2.2建完后会kettle工具会自动连接到repository资源库,每次打开kettle 也会弹出一个窗口让你先连接到资源库。
在连接到资源库的情况下打开文件就是资源库所在目录了,如图2.3所示。
Kettle开发使用手册

Kettle 开发使用手册Kettle 开发使用手册2 0 1 7 年 4 月版本历史说明版本作者日期备注1.0彭伟峰2017.04.111. Kettle 介绍1.1. 什么是 KettleKettle 是纯 Java编写的、免费开源的 ETL工具,主要用于抽取 (Extraction)、转换 (Transformation)、和装载(Loading)数据。
Kettle中文名称叫水壶,该项目的主程序员 MATT希望把各种数据放到一个壶里,然后以一种指定的格式流出。
在这种思想的设计下,Kettle 广泛用于不同数据库之间的数据抽取,例如Mysql 数据库的数据传到 Oracle ,Oracle 数据库的数据传到 Greenplum数据库。
1.2. Kettle的安装Kettle 工具是不需要安装的,直接网上下载解压就可以运行了。
不过它依赖于Java,需要本地有 JDK环境,如果是安装 4.2 或 5.4 版本, JDK需要 1.5 以上的版本,推荐 1.6 或 1.7 的 JDK。
运行 Kettle直接双击里面的批处理文件spoon.bat 就行了,如图 1.1 所示:图1.12. Kettle 脚本开发2.1. 建立资源库( repository 仓库)Repository仓库是用来存储所有kettle文件的文件系统,由于数据交换平台服务器管理 kettle文件也是用Repository仓库,因此我们这边本地的kettle开发环境也是要用到该资源库。
建立资源库的方式是工具-->资源库- ->连接资源库,这时候弹出一个窗口,我们点击右上角的“+”号,跟着点击下面的kettlefile repository选项,按确定,如图 2.1 所示:图2.1跟着在右上角选择一个目录,建议在kettle路径下新建repository文件夹,再选择这个文件夹作为根目录,名称和描述可以任意写,如图 2.2 所示:图2.2建完后会 kettle工具会自动连接到repository资源库,每次打开kettle 也会弹出一个窗口让你先连接到资源库。
Kettle使用+说明

2014/10/06
设置和坑[1]
• 需要配置pentaho-big-data-plugin 目录中的plugin.properties文件
▫ 把active.hadoop.configuration = 的值改成 hadp20
• mysql貌似连不上,需要把mysql-connector-java-***-bin.jar 放到lib目录中
Transformation举例二:支持hive表操作
• 支持Hive的表操作,结合使用hadoop file output 可以支持从关系型 数据库向hive表中导入数据
Transformation举例三:数据同步
Hyperbase 外表
改表的列的 顺序和类型
• 支持数据更新和同步
▫ 两张表的列的顺序和数据格式必须一模一样 ▫ 注意hyperbase id 为字典序,但RDB id则不一定
combined with transactions: This status table holds for all jobs/transformations all tables that need to be in a consistent state. For all tables the last processed keys (source/target) and the status is saved. Some tables might need compound keys depending on the ER-design. It is also possible to combine this approach with the own Kettle transformation log tables and the Dates and Dependencies functionality. There is an extended example in the Pentaho Data Integration for Database Developers (PDI2000C) course in module ETL patterns (Patterns: Batching, Transaction V - Status Table) • Snapshot-Based CDC • When no suitable time stamps or IDs are available or when some records might have been updated, you need the snapshot-based approach. Store a copy of the loaded data (in a table or even a file) and compare record by record. It is possible to create a SQL statement that queries the delta or use a transformation. Kettle supports this very comfortable by the Merge rows (diff) step. There is an extended example in the Pentaho Data Integration for Database Developers (PDI2000C) course in module ETL patterns (Pattern: Change Data Capture) • Trigger-Based CDC • Kettle does not create triggers in a database system and some (or most?) people don't like the trigger-based CDC approach because it introduces a further layer of complexity into another system. Over time it is hard to maintain and keep in sync with the overall architecture. But at the end, it depends on the use case and might be needed in some projects. There are two main options: • Create a trigger and write the changed data to a separate table • This table has a time stamp or sequenced ID that can be used to select the changed data rows. • Create a trigger and call Kettle directly via the Kettle API • This scenario might be needed in real-time CDC needs, so a Kettle transformation might be called directly from the trigger. Some databases support Java calls from a trigger (e.g. PL/Java for PostgreSQL or Oracle, see References below). • If you are using Hibernate to communicate with the database, you can use Hibernate event listeners as triggers (package summary). That way it would work with every database when you use standard SQL queries or HQL queries in the triggers. • Database Log-Based CDC • Some databases allow own CDC logs that can be analyzed. • Real-time CDC • So in case you need Real-time CDC, some of the above solutions will solve this need. Depending on the timing (how real-time or near-time) your needs are, you may choose the best suitable option. The trigger based call of Kettle is the most real-time solution. It is also possible to combine all of the above solutions with a continuously executed transformation (e.g. every 15 minutes) that collects the changed data.
kettle操作步骤

目录一、Kettle简介 (1)二、Kettle的使用 (1)2.1启动kettle (1)2.2创建转换(transformation) (2)2.3表输入详解: (6)2.4插入/更新详解: (10)三、创建作业(job) (11)一、Kettle简介Kettle是一款开源纯java编写的数据抽取工具,高效稳定、绿色无需安装,可以在Window、Linux、Unix上运行。
二、Kettle的使用2.1启动kettle无需安装,直接双击pdi_kettle中的“Kettle.exe”即可;如果提示输入用户名密码,可以直接点击“没有资源库”按钮,等稍后再建立资源库;如下次打开不希望启动此欢迎页面可将“启动时显示这个对话框”前的勾选去掉2.2创建转换(transformation)1、如下图,先创建一个转换,名称默认为“转换1”,可以在保存时选择保存路径并修改其名称2、选择输入,最常用的输入是“表输入”、“文本文件输入”和“Excel输入”;直接将需要的输入拖拽到右侧的转换中3、选择输出,常用的输出有“插入/更新”、“文本文件输出”、“表输出”和“Excel Output”,同样是以拖拽的方式将选择的输出放到右侧合适的位置4、建立节点连接(hops)可以同时按着shift和鼠标左键在图形界面上拖拉,也可以同时选中需要建立连接的两个步骤右键新建连接、确定即可5、异常处理,有时候在执行某些步骤如插入、删除操作时会出错,这时候需要异常处理;一般会选择调用存储过程来记录异常定义过“错误处理”后可以进行“调用DB存储过程”所需要连的数据库、调用的存储过程、参数以及返回值的设置注意:参数的顺序必须与调用的存储过程或函数的顺序一致2.3表输入详解:至此一个简单的转换已经搭起来了,其中表输入是用来从数据库中抽取数据的,里面主要是查询数据的SQL,尽量给每个字段取别名,别名与将要插入的表中的字段名对应。
由于要读取数据库所以首先要与资源库建立连接1、如下图所示,创建资源库连接:在主对象树中双击DB连接,根据具体情况选择合适的数据库和连接方式并填写连接名、IP、端口、用户名、密码等信息2、表输入,注意事项如下图所示3、给表输入的SQL传参,可用输入中的“文本文件输入”或“生成记录”进行传参“文本文件输入”需要将参数和值写入文本文档中,然后通过浏览找到该文档并增加到选中的文件中;文本文件输入一定不要忘了获取字段另外有时候还要对内容进行设置,比如是否包含头部等下面是包含头部时文本的写法“生成记录”可直接将需要的参数作为字段填入其中,注意”限制”可理解为”字段”的重复使用次数(待确认)2.4插入/更新详解:插入/更新,顾名思义,就是用来执行插入或更新操作的,我们可以通过设置来只执行插入或执行插入和更新,由于只更新有单独的一个控件可以完成,故这个控件无此功能。
Kettle使用手册及测试案例

一、【kettle】window安装与配置1、下载kettle包,并解压/projects/data-integration/2、安装jdk,并配置java环境a).打开我的电脑--属性--高级--环境变量b).新建系统变量JA V A_HOME和CLASSPATH变量名:JA V A_HOME变量值:C:\Program Files\Java\jdk1.7.0[具体路径以自己本机安装目录为准]变量名:CLASSPATH变量值:.;%JA V A_HOME%\lib\dt.jar;%JA V A_HOME%\lib\tools.jar;c). 选择“系统变量”中变量名为“Path”的环境变量,双击该变量,把JDK安装路径中bin目录的绝对路径,添加到Path变量的值中,并使用半角的分号和已有的路径进行分隔。
变量名:Path变量值:%JA V A_HOME%\bin;%JA V A_HOME%\jre\bin;3、配置kettle环境在系统的环境变量中添加KETTLE_HOME变量,目录指向kettle的安装目录:D:\kettle\data-integration4、启动spoonWindows直接双击批处理文件Spoon.bat具体路径为:kettle\data-integration\Spoon.batLinux 则是执行spoon.sh,具体路径为:~/kettle/data-integration/spoon.sh二、使用Kettle同步数据同步数据常见的应用场景包括以下4个种类型:➢ 只增加、无更新、无删除➢ 只更新、无增加、无删除➢ 增加+更新、无删除➢ 增加+更新+删除只增加、无更新、无删除对于这种只增加数据的情况,可细分为以下2种类型:1) 基表存在更新字段。
通过获取目标表上最大的更新时间或最大ID,在“表输入”步骤中加入条件限制只读取新增的数据。
2) 基表不存在更新字段。
通过“插入/更新”步骤进行插入。
kettle操作手册

kettle操作⼿册1.什么Kettle?Kettle是⼀个开源的ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程)项⽬,项⽬名很有意思,⽔壶。
按项⽬负责⼈Matt的说法:把各种数据放到⼀个壶⾥,然后呢,以⼀种你希望的格式流出。
Kettle包括三⼤块:Spoon——转换/⼯作(transform/job)设计⼯具(GUI⽅式)Kitchen——⼯作(job)执⾏器(命令⾏⽅式)Span——转换(trasform)执⾏器(命令⾏⽅式)Kettle是⼀款国外开源的etl⼯具,纯java编写,绿⾊⽆需安装,数据抽取⾼效稳定。
Kettle中有两种脚本⽂件,transformation和job,transformation完成针对数据的基础转换,job则完成整个⼯作流的控制。
2.Kettle简单例⼦2.1下载及安装Kettle下载地址:/doc/209c62d476a20029bd642d26.html /projects/pentaho/files现在最新的版本是 3.6,为了统⼀版本,建议下载 3.2,即下载这个⽂件pdi-ce-3.2.0-stable.zip。
解压下载下来的⽂件,把它放在D:\下⾯。
在D:\data-integration⽂件夹⾥,我们就可以看到Kettle的启动⽂件Kettle.exe或Spoon.bat。
2.2 启动Kettle点击D:\data-integration\下⾯的Kettle.exe或Spoon.bat,过⼀会⼉,就会出现Kettle的欢迎界⾯:稍等⼏秒,就会出现Kettle的主界⾯:2.3 创建kettle后台管理点击【新建】,新建资源库信息这⾥我们选择KETTLE 后台管理数据库的类型,以及配置JDBC设置完成后,点击【创建或更新】,将会在指定的数据库⾥⾯新建KETTLE的后台管理数据表。
再设置【名称】,点击【确定】。
回到登陆界⾯,选择新建的【资源库】,输⼊⽤户账号密码(默认账号:admin,密码:admin)进⼊KTETTLE 的开发界⾯2.4 kettle说明主对象树:转换(任务),作业(JOB)核⼼对象:主对象中可⽤的组件2.5 值映射组件使⽤的字段名:源字段⽬标字段名:⽬标字段源值:源数据的值⽬标值:替换的值注:最好先将源值去空格,再进⾏替换2.6 增加常量组件名称:映射字段类型:字段类型格式:数据格式长度:值:常量的值2.7计算器组件新字段:映射字段计算:计算类型字段A,B,C:需计算的字段值类型:数据的类型2.8获取系统信息组件名称:显⽰的名称类型:显⽰的类型(系统时间,IP,指令等等)2.9增加序列组件值的名称:映射值的名称起始值:序列的初始值增加值:设置增加的值最⼤值:设置最⼤值2.10 表输出组件数据库连接:设置数据库⽬标表:设置⽬标的表提交记录数量:设置提交数量忽略插⼊错误:跳过错误,继续执⾏指定库字段:数据库字段:选择插⼊的字段2.11 多路选择(Switch/Case) 组件更多路选择的字段:设置Switch的字段分⽀值的数据类型:设置值的类型分⽀值:值:设置case的值⽬标步骤:跳过的操作步骤缺省的⽬标步骤:未通过的操作步骤2.12 Null if... 组件名称:选择替换的字段需要转换成NULL的值:需要转换成NULL的值2.12 执⾏SQL脚本组件数据库连接:选择数据库SQL script :输⼊要执⾏的SQL语句参数:设置要替换的参数字段2.13 Modified Java Script Value 组件Java Script:脚本的输⼊:输⼊字段:输出字段字段名称:定义的字段名改成为:新的字段名类型:字段类型Replace Value:是否替换的值2.14 合并记录组件旧数据源:输⼊数据源新数据源:输⼊数据源匹配关键字段:匹配关键字段数据字段:数据字段2.15 记录关联(笛卡尔输出) 组件条件:输⼊关联的条件2.16 Merge Join 组件第⼀个步骤:第⼀个操作的步骤第⼆个步骤:第⼆个操作的步骤步骤选择的字段:步骤关联的字段2.17 ⾏转列组件关键字:选择表的关键字分组字段:分组的字段⽬标字段:选择⽬标在字段VALUE:值字段名称关键字值:关键字值类型:数据类型2.18 ⽣成随机值组件名称:新⽣成字段名类型:随机数的类型2.19 去除重复⾏组件字段名称:关键字的字段忽略⼤⼩写:是否忽略⼤⼩写注意:去掉重复⾏需先排序2.20 插⼊/ 更新组件数据库连接:选择数据库⽬标表:选择⽬标表不执⾏任何更新:是否执⾏更新操作查询的关键字:关键字更新字段:选择要插⼊更新的字段2.21 表输⼊组件数据库连接:选择数据库SQL:输⼊SQL语句预览:数据预览获得SQL查询语句:获得SQL查询语句2.22 排序记录组件字段名称:选择排序的字段名称升序:是否升序⼤⼩写敏感:是否区分⼤⼩写2.23 XML输出组件⽂件名称:输出⽂件的名称跟路径扩展:扩展名2.24 ⽂本⽂件输出组件⽂件名称:输出⽂件的名称跟路径扩展:扩展名2.25 Write to log 组件⽇志级别:选择⽇志级别字段:选择打印的字段2.26 过滤记录组件条件:输⼊条件。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Spoon.bat修改
在set opt=*最后"-Dfile.encoding=UTF-8",解决乱码问题表输入
替换SQL语句中的变量:变量用‘?’ 表示
从步骤中插入数据:这个组件之前的流程名称
新建/编辑
Wizard(向导)
填写数据库连接名称(选择数据库连接类型和数据库访问类型)NEXT
端口号默认NEXT
点击测试数据库连接
获取SQL查询语句
选择表或者视图,确定也可以自定义SQL语句.
预览
查询
查询所需关键字:字段1为流入字段
查询返回的值:字段为数据库表字段,可以起个别名,类型不选可能导致跨库乱码获取查询关键字:流入的所有字段
获取返回字段:所选数据库表所有字段
Switch/Case
Switch字段:流入的字段
Case值数据类型:视情况而定
Case值:此处为空时-转到-查询DEPT_CODE 默认目标步骤(default):自定义流程,如图
字段选择
移除:移除流入字段
元数据:修改元数据字段
选择和修改:
如果指定了移除和元数据就不能选择列映射
增加常量
添加一列到元数据流中
设置字段值替换流字段的值
表输出
主选项默认
不是临时表的话,千万不要选中剪裁表,这个用于删除表中的数据勾选’指定数据库字段’后才能操作’数据库字段面板’
提交记录数量:每次批处理的数量,一批对应一个事务
输入字段映射
不要随便点’猜一猜’
空操作
什么也不做
删除
查询所需的关键字:删除的条件
插入/更新
不推荐使用
比较流中和数据库表的值,不同则更新编辑映射:同表输出
字符串替换
过滤两个或以上中文并设置为空串
去除重复记录
注意:去除的记录要排序,否则只去除连续的值
行扁平化
详解:
/Document/detail/tid/73025
Access输入
选择mdb格式文件,支持正则过滤
Kettle增量更新
/s/blog_6d35752501015dtm.html 获取系统信息
类型
预览记录
计算器
如下是移除元数据流字段,新数据流加负号
Kettle变量
(1)名称对应参数
值:可以写SQL函数,比如sysdate+1,to_date()等
相对应的变量名
(2)位置对应参数
获取系统信息
此处添加两个变量作为增量的值
设置变量
变量活动类型:
2)通过属性文件(常用)
在C:\Users\${userName}\.kettle\kettle.properties中添加变量(key=value)
Java Virtual Machine:S系统级作用域,凡是在一个java虚拟机下运行的线程都受其影响。
parent job:在当前作业下是生效的。
grand-parent job:在当前作业的父作业下是生效的。
the root job:R级作用域,凡是在跟作业下运行的都是生效的
变量替换SQL语句
勾选“替换SQL语句里的变量“和”执行每一行“
合并记录
比较两个数据源数据
关键字段:用于定位两个数据源中的同一记录
数据字段:比较的字段
标志字段:用于保存比较的结果
1. “identical”–旧数据和新数据一样
2. “changed”–数据发生了变化;
3. “new”–新数据中有而旧数据中没有的记录
4. “deleted”–旧数据中有而新数据中没有的记录
过滤记录
过滤后的数据发送到false步骤。