历年链表考题及答案
C程序设计(链表)习题与答案

一、单选题1、链表不具有的特点是()。
A.不必事先估计存储空间B.插入、删除不需要移动元素C.可随机访问任一元素D.所需空间与线性表长度成正比正确答案:C2、链接存储的存储结构所占存储空间()。
A.分两部分,一部分存放结点值,另一部分存放结点所占单元数B.只有一部分,存放结点值C.分两部分,一部分存放结点值,另一部分存放表示结点间关系的指针D.只有一部分,存储表示结点间关系的指针正确答案:C3、链表是一种采用()存储结构存储的线性表。
A.网状B.星式C.链式D.顺序正确答案:C4、有以下结构体说明和变量的定义,且指针p指向变量a,指针q指向变量b,则不能把结点b连接到结点a之后的语句是()。
struct node {char data;struct node *next;} a,b,*p=&a,*q=&b;A.(*p).next=q;B.p.next=&b;C.a.next=q;D.p->next=&b;正确答案:B5、下面程序执行后的输出结果是()。
#include <stdio.h>#include <stdlib.h>struct NODE {int num; struct NODE *next;};int main(){ struct NODE *p,*q,*r;p=(struct NODE*)malloc(sizeof(struct NODE));q=(struct NODE*)malloc(sizeof(struct NODE));r=(struct NODE*)malloc(sizeof(struct NODE));p->num=10; q->num=20; r->num=30;p->next=q;q->next=r;printf("%d",p->num+q->next->num);return 0;}A.30B.40C.10D.20正确答案:B6、下面程序执行后的输出结果是()。
第08章指针和链表真题
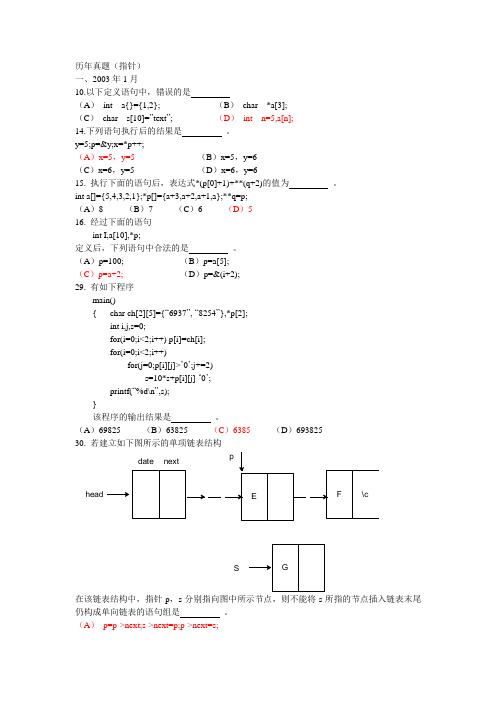
历年真题(指针)一、2003年1月10.以下定义语句中,错误的是(A ) int a{}={1,2}; (B ) char *a[3];(C ) char s[10]=”text ”; (D ) int n=5,a[n];14.下列语句执行后的结果是 。
y=5;p=&y;x=*p++;(A )x=5,y=5 (B )x=5,y=6(C )x=6,y=5 (D )x=6,y=615. 执行下面的语句后,表达式*(p[0]+1)+**(q+2)的值为 。
int a[]={5,4,3,2,1};*p[]={a+3,a+2,a+1,a};**q=p;(A )8 (B )7 (C )6 (D )516. 经过下面的语句int I,a[10],*p;定义后,下列语句中合法的是 。
(A )p=100; (B )p=a[5];(C )p=a+2; (D )p=&(i+2);29. 有如下程序main(){ char ch[2][5]={“6937”, “8254”},*p[2];int i,j,s=0;for(i=0;i<2;i++) p[i]=ch[i];for(i=0;i<2;i++)for(j=0;p[i][j]>‟0‟;j+=2)s=10*s+p[i][j]-…0‟;printf(“%d\n ”,s);}该程序的输出结果是 。
(A )69825 (B )63825 (C )6385 (D )69382530. 若建立如下图所示的单项链表结构date nextheadS在该链表结构中,指针p ,s 分别指向图中所示节点,则不能将s 所指的节点插入链表末尾仍构成单向链表的语句组是 。
(A ) p=p->next;s->next=p;p->next=s;(B)p=p->next;s->next=p->next;p->next=s;(C)s->next=NULL;p =p->next;p->next=s;(D)p=(*p).next;(*s).next=(*p).next; (*p).next=s;试卷二试题二:把下列程序补充完整实现两个字符串的比较,即自己写个strcmp函数,函数原型为:int strcmp(char *p1,char *p2)设p1指向字符串s1,p2指向字符串s2,要求:当s1=s2时,返回值为0。
C、C++程序设计:链表单元测试与答案

一、单选题1、在一个单链表中,已知q所指结点是p所指结点的前驱结点,若在q和p之间插入结点s,则执行()。
A.s->next=p->next;p->next=s;B.p->next=s->next; s->next=p;C.p->next=s;s->next=q;D.q->next=s;s->next=p;正确答案:D2、在一个表头指针为HL单链表中,若要向表头插入一个由指针p 指向的结点,则执行( )。
A.p一>next=HL;HL=p;B.HL=p; p一>next=HL;C.p一>next=Hl; p=HL;D.p一>next=HL一>next; HL=p;正确答案:A3、在单链表指针为p的结点之后插入指针为s的结点,正确的操作是:()。
A.p->next=s->next;p->next=s;B.p->next=s;s->next=p->next;C.p->next=s;p->next=s->next;D.s->next=p->next;p->next=s;正确答案:D4、在表尾指针为rs的链表的后面插入指针为p的结点的正确语句为()。
A.p->next=NULL; rs=p;B.rs->next=p; p->next=NULL;C.rs->next=p; rs->next=NULL;D.p->next=rs; rs->next=NULL;正确答案:B5、假设p为表尾指针rs的前驱指针,则删除表尾结点的正确语句为()。
A.p->next=NULL; delete p;B.p->next=NULL; delete rs;C.p=NULL; delete rs;D.rs=NULL; delete rs;正确答案:B二、判断题1、链表存储时,各结点的存储空间可以是不连续的。
第2章习题(带答案)

第2章习题(带答案)1.链表不具有的特点是A.可随机访问任一个元素B.插入删除不需要移动元素C.不必事先估计存储空间D.所需空间与线性表长度成正比2.在一个具有n个结点的单链表中查找值为某的某结点,若查找成功,则平均比较个结点。
A.nB.n/2C.(n-1)/2D.(n+1)/23.在单链表中P所指结点之后插入一个元素某的主要操作语句序列是=(node某)malloc(izeof(node));、->data=某;、->ne某t=p->ne某t、p->ne某t=。
4.在单链表中查找第i个元素所花的时间与i成正比。
(√)5.在带头结点的双循环链表中,任一结点的前驱指针均不为空。
(√)6.用链表表示线性表的优点是()。
A.便于随机存取C.便于插入与删除B.花费的存储空间比顺序表少D.数据元素的物理顺序与逻辑顺序相同7.在双向链表中删除P所指结点的主要操作语句序列是p->prior->ne某t=p->ne某t;、p->ne某t->prior=p->prior;、free(p);8.下述哪一条是顺序存储结构的优点?()A.存储密度大B.插入运算方便C.删除运算方便D.可方便地用于各种逻辑结构的存储表示9.若某表最常用的操作是在最后一个结点之后插入一个结点或删除最后一个结点。
则采用()存储方式最节省运算时间。
A.单链表B.双链表C.单循环链表D.带头结点的双循环链表10.对任何数据结构链式存储结构一定优于顺序存储结构。
(某)11.对于双向链表,在两个结点之间插入一个新结点需修改的指针共4个,单链表为____2___个。
12.以下数据结构中,()是非线性数据结构A.树B.字符串C.队列D.栈13.若某线性表最常用的操作是存取任一指定序号的元素和在最后进行插入和删除运算,则利用()存储方式最节省时间。
A.顺序表B.双链表C.带头结点的双循环链表D.单循环链表14.“线性表的逻辑顺序和物理顺序总是一致的。
java链表面试题

java链表面试题链表是一种常见的数据结构,面试中经常会涉及到与链表相关的问题。
以下是一些常见的Java链表面试题,希望能够帮助你更好地准备面试。
1. 反转链表题目描述:给定一个单向链表的头节点,将该链表反转,返回反转后的链表头节点。
解题思路:使用三个指针pre、cur、next来实现链表的反转。
初始时pre为null,cur为头节点,next为cur的下一个节点。
通过迭代遍历链表,将cur的next指向pre,然后将pre、cur、next都向后移动一个位置。
直到遍历到链表的最后一个节点,最后将cur指向的节点作为新的链表头,并返回该节点。
示例代码:```javapublic Node reverseList(Node head) {Node pre = null;Node cur = head;while (cur != null) {Node next = cur.next;cur.next = pre;pre = cur;cur = next;}return pre;}```2. 链表中环的检测题目描述:给定一个单向链表的头节点,判断该链表中是否存在环。
解题思路:使用快慢指针的方法来判断链表中是否存在环。
定义两个指针fast和slow,开始时都指向链表的头节点。
fast指针每次移动两个节点,slow指针每次移动一个节点。
如果链表中存在环,则fast指针最终会追赶上slow指针;如果链表中不存在环,则fast指针会先到达链表尾部,即fast指针为null。
示例代码:```javapublic boolean hasCycle(Node head) {Node fast = head;Node slow = head;while (fast != null && fast.next != null) {fast = fast.next.next;slow = slow.next;if (fast == slow) {return true;}}return false;}```3. 合并两个有序链表题目描述:给定两个有序链表的头节点,将两个链表合并为一个新的有序链表,并返回新链表的头节点。
python链表试题

python链表试题含解答共5道1. 试题:反转链表编写一个函数,反转一个单链表。
```pythonclass ListNode:def __init__(self, value=0, next=None):self.value = valueself.next = nextdef reverse_linked_list(head):prev = Nonecurrent = headwhile current is not None:next_node = current.nextcurrent.next = prevprev = currentcurrent = next_nodereturn prev```2. 试题:检测环编写一个函数,检测一个链表是否有环。
```pythondef has_cycle(head):slow = headfast = headwhile fast is not None and fast.next is not None:slow = slow.nextfast = fast.next.nextif slow == fast:return Truereturn False```3. 试题:合并两个有序链表编写一个函数,合并两个有序链表为一个新的有序链表。
```pythondef merge_two_lists(l1, l2):dummy = ListNode()current = dummywhile l1 is not None and l2 is not None:if l1.value < l2.value:current.next = l1l1 = l1.nextelse:current.next = l2l2 = l2.nextcurrent = current.nextif l1 is not None:current.next = l1else:current.next = l2return dummy.next```4. 试题:移除链表元素编写一个函数,移除链表中所有值为给定值的节点。
链表练习题及答案

1、已知L是带表头的单链表,其P结点既不是首元结点,也不是尾元结点,a.删除p结点的直接后继的语句是11,3,14b.删除p结点的直接前驱的语句是10,12,8,11,3,14c.删除p结点的语句序列是10,7,3,14d.删除首元结点的语句序列是12,10,13,14e.删除尾元结点的语句序列是9,11,3,14(1)p=p->next;(2) p->next=p;(3)p->next=p->next->next;(4)p=p->next->next;(5)while(p)p=p->next;(6)whlie(Q->next){p=Q;Q=Q->next;}(7)while(p->next!=Q)p=p->next;(8)while(p->next->next!=Q)p=p->next;(9)while(p->next->next)p=p->next;(10)Q=p;(11)Q=p->next;(12)p=L;(13)L=L->next;(14)free(Q);2、已知L是带表头的单链表,其P结点既不是首元结点,也不是尾元结点,a.在p结点后插入s结点的语句序列是4,1b.在p结点前插入s结点的语句序列是7,11,8,4,1c.在表首插入s结点的语句序列是5,12d.在表尾插入s结点的语句序列是7,9,4,1或11,9,1,61.p-> next =s;2.p-> next=p-> next-> next;3.p->next=s->next;4.s->next=p-> next;5.s-> next=L;6.s->next=NULL;7.q=p ;8.while(p->next!=q) p=p->next;9.while(p->next!=NULL) p=p->next;10.p =q;11.p=L;12.L=s;13.L=P;3、已知P结点是某双向链表的中间结点,从下列提供的答案中选择合适的语句序列a.在P结点后插入S结点的语句序列是12,7,3,6b.在P结点前插入S结点的语句序列是13,8,5,4c.删除p结点的直接后继结点的语句序列是15,1,11,18d.删除p结点的直接前驱结点的语句序列是16,2,10,18e.删除p结点的语句序列是9,14,171.P->next=P->next->next;2.P->priou=P->priou->priou;3.P->next=S;4.P->priou=S;5.S->next=P;6.S->priou=P;7.S->next=P->next;8.S->priou=P->priou;9.P->priou->next=P->next;10.P->priou->next=P;11.P->next->priou=P;12.P->next->priou=S;13.P->priou->next=S;14.P->next->priou=P->priou;15.Q=p->next;16.Q=P->priou;17.free(P);18.free(Q);。
c++数据结构链表的选择题

c++数据结构链表的选择题(最新版)目录1.链表的概述2.链表的优缺点3.链表的基本操作4.链表的选择题解答正文一、链表的概述链表是一种常见的数据结构,主要用于存储一系列有序的数据元素。
链表由若干个节点组成,每个节点包含两个部分:数据部分和指针部分。
数据部分用于存储实际数据,指针部分用于存储下一个节点的地址。
链表的第一个节点称为头节点,最后一个节点称为尾节点。
链表的头节点和尾节点通常会用哨兵节点(dummy node)表示,以方便编程操作。
二、链表的优缺点链表的优点主要有以下几点:1.灵活性高:链表可以根据需要动态创建和删除节点,因此适合存储动态数据。
2.插入和删除操作简便:在链表中插入和删除节点不需要移动后续节点,因此时间复杂度较低。
链表的缺点主要有以下几点:1.空间开销大:链表需要额外的空间来存储节点之间的指针。
2.访问节点较慢:链表需要遍历整个链表才能访问指定位置的节点,因此时间复杂度较高。
三、链表的基本操作链表的基本操作包括创建节点、插入节点、删除节点、遍历链表等。
下面分别介绍这些操作:1.创建节点:使用 malloc 或其他分配内存的方式分配一个新节点,并初始化节点的数据部分和指针部分。
2.插入节点:将新节点的指针部分指向原链表的尾节点,然后将新节点的数据部分与原链表的尾节点数据部分连接。
3.删除节点:遍历链表,找到待删除节点的前一个节点,将待删除节点的指针部分从原链表中删除,然后将待删除节点的数据部分和指针部分都设置为 NULL。
4.遍历链表:使用指针或迭代器遍历链表,访问链表中的每个节点。
四、链表的选择题解答以下是一些关于链表的选择题及其答案:1.链表中第一个节点称为?答:头节点。
2.链表中最后一个节点称为?答:尾节点。
3.链表中哨兵节点的作用是什么?答:用于区分链表的头部和尾部,方便编程操作。
4.在链表中插入一个新节点,需要修改的指针有哪些?答:需要修改新节点的指针部分,使其指向原链表的尾节点;同时需要修改原链表尾节点的指针部分,使其指向新节点。
C语言链表题目及答案

下面哪种选项描述了链表的特点?A) 可以随机访问元素B) 拥有固定大小的内存空间C) 元素之间通过指针连接D) 可以自动调整大小答案: C在链表中,头节点的作用是什么?A) 存储链表的长度B) 存储链表的最后一个节点C) 存储链表的第一个节点D) 存储链表的中间节点答案: C下面哪种选项描述了双向链表的特点?A) 每个节点只有一个指针指向下一个节点B) 每个节点只有一个指针指向上一个节点C) 每个节点同时拥有指向前一个节点和后一个节点的指针D) 只能从链表的一端进行操作答案: C在链表中,删除一个节点的操作涉及修改哪些指针?A) 只需要修改被删除节点的前一个节点的指针B) 只需要修改被删除节点的后一个节点的指针C) 需要修改被删除节点的前一个节点和后一个节点的指针D) 不需要修改任何指针答案: C在链表的尾部添加一个新节点的操作复杂度是多少?A) O(1)B) O(n)C) O(log n)D) O(n^2)答案: A如何遍历链表的所有节点?A) 使用for循环B) 使用while循环C) 使用递归函数D) 使用if语句答案: B在链表中,如何找到特定值的节点?A) 使用线性搜索B) 使用二分搜索C) 使用递归搜索D) 使用栈搜索答案: A链表和数组相比,哪个更适合频繁插入和删除操作?A) 链表B) 数组C) 二叉树D) 堆栈答案: A在链表中,如何在指定位置插入一个新节点?A) 修改前一个节点的指针B) 修改后一个节点的指针C) 修改当前节点的指针D) 不需要修改任何指针答案: A链表的头指针指向什么?A) 链表的第一个节点B) 链表的最后一个节点C) 链表的中间节点D) 链表的空节点答案: A链表中节点的个数称为什么?A) 链表的长度B) 链表的高度C) 链表的宽度D) 链表的容量答案: A在链表中,如何删除指定值的节点?A) 修改前一个节点的指针B) 修改后一个节点的指针C) 修改当前节点的指针D) 不需要修改任何指针答案: A单链表的最后一个节点指向什么?A) 链表的第一个节点B) 链表的最后一个节点C) NULLD) 链表的中间节点答案: C双向链表相比于单向链表的优势是什么?A) 占用更少的内存空间B) 遍历速度更快C) 可以从任意方向遍历D) 插入和删除操作更快答案: C在链表中,如何找到倒数第n个节点?A) 遍历整个链表B) 使用递归函数C) 使用栈数据结构D) 使用双指针技巧答案: D链表的删除操作和数组的删除操作的时间复杂度分别是什么?A) 链表的删除操作为O(1),数组的删除操作为O(n)B) 链表的删除操作为O(n),数组的删除操作为O(1)C) 链表的删除操作为O(n),数组的删除操作为O(n)D) 链表的删除操作为O(1),数组的删除操作为O(1)答案: A在链表中,如何判断链表是否为空?A) 检查头指针是否为NULLB) 检查尾指针是否为NULLC) 检查链表的长度是否为0D) 检查链表的第一个节点是否为NULL答案: A链表的逆序操作是指什么?A) 删除链表中的节点B) 反转链表中节点的顺序C) 插入节点到链表的尾部D) 在链表中查找指定值的节点答案: B在链表中,如何查找指定值的节点?A) 使用线性搜索B) 使用二分搜索C) 使用递归搜索D) 使用栈搜索答案: A在双向链表中,如何删除指定值的节点?A) 修改前一个节点的指针B) 修改后一个节点的指针C) 修改当前节点的指针D) 不需要修改任何指针答案: A链表的插入操作和数组的插入操作的时间复杂度分别是什么?A) 链表的插入操作为O(1),数组的插入操作为O(n)B) 链表的插入操作为O(n),数组的插入操作为O(1)C) 链表的插入操作为O(n),数组的插入操作为O(n)D) 链表的插入操作为O(1),数组的插入操作为O(1)答案: A如何删除单向链表中的重复节点?A) 使用递归算法B) 使用双指针技巧C) 使用栈数据结构D) 不需要额外操作,链表会自动去重答案: B链表的优势之一是什么?A) 随机访问速度快B) 占用内存空间少C) 插入和删除操作高效D) 支持高级操作如排序和搜索答案: C在链表中,如何找到中间节点?A) 遍历整个链表B) 使用递归函数C) 使用栈数据结构D) 使用快慢指针技巧答案: D在链表中,如何在尾部添加一个新节点?A) 修改前一个节点的指针B) 修改后一个节点的指针C) 修改当前节点的指针D) 创建一个新节点并更新尾指针答案: D链表的查找操作的时间复杂度是多少?A) O(1)B) O(log n)C) O(n)D) O(n^2)答案: C在双向链表中,如何找到倒数第n个节点?A) 从头节点开始遍历B) 从尾节点开始遍历C) 使用递归函数D) 使用双指针技巧答案: B链表的删除操作的时间复杂度是多少?A) O(1)B) O(log n)C) O(n)D) O(n^2)答案: A链表和数组相比,哪个更适合频繁插入和删除操作?A) 链表B) 数组C) 哈希表D) 栈答案: A如何判断链表是否有环?A) 使用线性搜索B) 使用递归算法C) 使用快慢指针技巧D) 使用栈数据结构答案: C在链表中,如何反转链表的顺序?A) 使用递归算法B) 使用栈数据结构C) 使用双指针技巧D) 使用循环迭代答案: D在链表中,如何删除所有节点?A) 依次删除每个节点B) 修改头指针为NULLC) 修改尾指针为NULLD) 不需要额外操作,链表会自动清空答案: A链表的头节点是什么?A) 链表的第一个节点B) 链表的最后一个节点C) 链表的中间节点D) 链表的空节点答案: A在链表中,如何插入一个新节点到指定位置之前?A) 修改前一个节点的指针B) 修改后一个节点的指针C) 修改当前节点的指针D) 不需要修改任何指针答案: A在链表中,如何删除指定位置的节点?A) 修改前一个节点的指针B) 修改后一个节点的指针C) 修改当前节点的指针D) 不需要修改任何指针答案: A单向链表和双向链表的区别是什么?A) 单向链表只有一个指针指向下一个节点,双向链表有两个指针分别指向前一个节点和后一个节点B) 单向链表只能从头到尾遍历,双向链表可以从头到尾或者从尾到头遍历C) 单向链表只能在尾部添加节点,双向链表可以在头部和尾部都添加节点D) 单向链表只能包含整型数据,双向链表可以包含任意类型的数据答案: A链表的删除操作和数组的删除操作的时间复杂度分别是什么?A) 链表的删除操作为O(1),数组的删除操作为O(n)B) 链表的删除操作为O(n),数组的删除操作为O(1)C) 链表的删除操作为O(n),数组的删除操作为O(n)D) 链表的删除操作为O(1),数组的删除操作为O(1)答案: A如何判断两个链表是否相交?A) 比较链表的长度是否相等B) 比较链表的头节点是否相等C) 比较链表的尾节点是否相等D) 比较链表中的所有节点是否相等答案: B链表和数组的主要区别是什么?A) 链表是一种线性数据结构,数组是一种非线性数据结构B) 链表的长度可变,数组的长度固定C) 链表支持随机访问,数组只能顺序访问D) 链表的插入和删除操作效率高,数组的访问效率高答案: B在链表中,如何找到倒数第k个节点?A) 从头节点开始遍历,直到倒数第k个节点B) 从尾节点开始遍历,直到倒数第k个节点C) 使用递归函数查找倒数第k个节点D) 使用双指针技巧,一个指针先移动k步,然后两个指针同时移动直到第一个指针到达链表末尾答案: D在链表中,如何判断是否存在环?A) 使用线性搜索,检查是否有重复的节点B) 使用递归算法,判断节点是否已经访问过C) 使用栈数据结构,检查节点是否已经入栈D) 使用快慢指针技巧,如果两个指针相遇,则存在环答案: D如何将两个有序链表合并成一个有序链表?A) 创建一个新链表,依次比较两个链表的节点并插入新链表中B) 将第一个链表的尾节点指向第二个链表的头节点C) 将第二个链表的尾节点指向第一个链表的头节点D) 使用递归算法,依次比较两个链表的节点并合并答案: A在链表中,如何删除重复的节点?A) 使用递归算法,遍历链表并删除重复的节点B) 使用双指针技巧,依次比较相邻节点并删除重复的节点C) 使用栈数据结构,检查节点是否已经入栈并删除重复的节点D) 不需要额外操作,链表会自动去重答案: B链表的优点是什么?A) 占用内存空间少B) 插入和删除操作高效C) 支持高级操作如排序和搜索D) 可以随机访问任意位置的元素答案: B。
历年链表考题与答案

历年链表考题及答案[2005秋II.14]设已建立了两条单向链表,这两链表中的数据已按从小到大的次序排好,指针h1和h2分别指向这两条链表的首结点。
链表上结点的数据结构如下:structnode{intdata;node*next;};以下函数node*Merge(node*h1,node*h2)的功能是将h1和h2指向的两条链表上的结点合并为一条链表,使得合并后的新链表上的数据仍然按升序排列,并返回新链表的首结点指针。
算法提示:首先,使newHead和q都指向首结点数据较小链表的首结点,p指向另一链表首结点。
其次,合并p和q所指向的两条链表。
在q不是指向链尾结点的情况下,如果q 的下一个结点数据小于p指向的结点数据,则q指向下一个结点;否则使p1指向q的下一个结点,将p指向的链表接到q所指向的结点之后,使q指向p所指向的结点,使p指向p1所指向的链表。
直到p和q所指向的两条链表合并结束为止。
注意,在合并链表的过程中,始终只有两条链表。
[函数](4分)node*Merge(node*h1,node*h2){node*newHead,*p,*p1;//使newHead和q指向首结点数据较小链表的首结点,p指向另一链表首结点if((27)){newHead=h1;p=h2;}//h1->data<h2->dataelse{newHead=h2;p=h1;}node*q=newHead;//合并两条链表while(q->next){if(q->next->data<p->data)(28);//q=q->nextelse{(29);//p1=q->nextq->next=p;q=p;p=p1;}}q->next=p;(30);//returnnewNead}[2005春II.11]设已建立一条单向链表,指针head指向该链表的首结点。
java链表算法面试题

java链表算法面试题面试题一:反转链表给定一个单链表的头节点head,请完成反转链表的函数。
例如,输入:1->2->3->4->5->NULL,输出:5->4->3->2->1->NULL。
解题方法:反转链表可以使用迭代或递归的方式实现。
方法一:迭代1. 定义三个指针prev、curr和next,分别指向前一个节点、当前节点和下一个节点。
2. 初始化prev为null,curr为head。
3. 遍历链表,每次将当前节点的next指针指向prev,然后更新prev、curr和next指针。
4. 当遍历完链表后,返回prev作为反转后的链表头节点。
方法二:递归1. 使用递归的方式,从头节点开始反转链表。
2. 若当前节点或下一个节点为null,直接返回当前节点作为反转后的链表头节点。
3. 否则,递归调用反转函数,以当前节点的下一个节点为头节点,获得反转后的链表头节点newHead。
4. 将当前节点的next指针指向null,并将当前节点的next节点的next指针指向当前节点。
5. 返回newHead作为反转后的链表头节点。
面试题二:删除链表倒数第K个节点给定一个单链表的头节点head和一个正整数K,删除链表倒数第K 个节点并返回新的头节点。
例如,输入:1->2->3->4->5->NULL,K=2,输出:1->2->3->5->NULL。
解题方法:可以使用双指针法来解决该问题。
1. 初始化两个指针fast和slow均指向头节点head。
2. 将fast指针向前移动K个节点,使fast与slow之间相隔K个节点。
3. 同时移动fast和slow指针,直到fast指针到达链表末尾。
4. 此时slow指针指向倒数第K个节点的前一个节点。
5. 将slow指针的next指针指向倒数第K个节点的后一个节点,即删除了倒数第K个节点。
结构体与链表习题附答案

结构体与链表习题附答案一、选择题1、在说明一个结构体变量时系统分配给它的存储空间是().A)该结构体中第一个成员所需的存储空间B)该结构体中最后一个成员所需的存储空间C)该结构体中占用最大存储空间的成员所需的存储空间D)该结构体中所有成员所需存储空间的总和。
2.设有以下说明语句,则以下叙述不正确的是()tructtu{inta;floatb;}tutype;A.truct是结构体类型的关键字B.tructtu是用户定义的结构体类型C.tutype是用户定义的结构体类型名D.a和b都是结构体成员名3、以下对结构体变量tu1中成员age的合法引用是()#includetructtudent{intage;intnum;}tu1,某p;p=&tu1;A)tu1->ageB)tudent.ageC)p->ageD)p.age4、有如下定义:Structdate{intyear,month,day;};Structworklit{Charname[20];Chare某;Structdatebirthday;}peron;对结构体变量peron的出生年份进行赋值时,下面正确的赋值语句是()Aworklit.birthday.year=1978Bbirthday.year=1978Cperon.birthday .year=1958Dperon.year=19585、以下程序运行的结果是()#include”tdio.h”main(){tructdate{intyear,month,day;}today;printf(“%d\\n”,izeof(truct date));}A.6B.8C.10D.126、对于时间结构体tructdate{intyear,month,day;charweek[5];}则执行printf(“%d\\n”,izeof(tructdate))的输出结果为(A.12B.17C.18D.207、设有以下语句:tructt{intn;charname[10]};tructta[3]={5,“li”,7,“wang”,9,”zhao”},某p;p=a;则以下表达式的值为6的是()A.p++->nB.p->n++C.(某p).n++D.++p->n8、设有以下语句,则输出结果是()tructLit{intdata;tructLit某ne某t;};tructLita[3]={1,&a[1],2,&a[2],3,&a[0]},某p;p=&a[1];printf(\printf(\printf(\}A.131B.311C.132D.2139、若有以下语句,则下面表达式的值为1002的是()tructtudent{intage;intnum;};tructtudenttu[3]={{1001,20},{1002,19},{1003,21}};)tructtudent某p;p=tu;A.(p++)->numB.(p++)->ageC.(某p).numD.(某++p).age10、下若有以下语句,则下面表达式的值为()tructcmpl某{int某;inty;}cnumn[2]={1,3,2,7};cnum[0].y/cnum[0].某某cnum[1].某;A.0B.1C.3D.611、若对员工数组进行排序,下面函数声明最合理的为()。
链表常见面试题

链表是一种常见的数据结构,它由一系列节点组成,每个节点包含数据和指向下一个节点的指针。
链表在面试中经常被问到一些问题,以下是一些常见的问题及其回答:问题1:什么是链表?回答:链表是一种线性数据结构,它由一系列节点组成,每个节点包含数据和指向下一个节点的指针。
链表的特点是每个节点都有自己的数据,而不需要像数组那样通过索引访问元素。
问题2:链表的优点和缺点是什么?回答:链表的优点包括:* 空间利用率高,因为每个节点都可以存储更多的数据。
* 插入和删除操作的时间复杂度较低,因为只需要修改指针即可。
* 可以实现动态内存分配,可以根据需要动态地添加或删除节点。
然而,链表的缺点包括:* 访问链表中的元素时需要遍历链表,时间复杂度较高。
* 内存管理比较复杂,需要手动管理节点和指针。
问题3:链表的种类有哪些?回答:链表可以按照不同的方式进行分类,例如单向链表、双向链表、循环链表等。
其中单向链表是最常用的类型,因为它简单且易于实现。
双向链表和循环链表也经常被用于需要双向或循环访问的场景。
问题4:如何实现链表?回答:实现链表需要定义一个节点类,该类包含数据和指向下一个节点的指针。
然后可以使用这个节点类来创建链表对象,并使用指针来添加和删除节点。
问题5:如何遍历链表?回答:遍历链表通常使用迭代器或指针来实现。
可以使用指针从头节点开始遍历链表,直到到达尾节点。
也可以使用迭代器来遍历链表中的元素。
问题6:如何反转链表?回答:反转链表可以使用迭代器或递归来实现。
使用迭代器时,可以从头节点开始遍历链表,并在遍历过程中修改指针以反转链表的方向。
使用递归时,可以将头节点移到下一个节点,然后将该节点作为新的头节点重复此过程,直到最后一个节点被反转。
问题7:如何在链表中查找元素?回答:在链表中查找元素通常使用线性搜索或二分搜索。
线性搜索是从头节点开始遍历链表,直到找到要查找的元素或到达尾节点为止。
二分搜索可以在链表的子集中快速查找元素,但需要额外的空间和时间复杂度。
链表习题——精选推荐

一选择题1.下述哪一条是顺序存储结构的优点?(a )A.存储密度大B.插入运算方便C.删除运算方便D.可方便地用于各种逻辑结构的存储表示2.下面关于线性表的叙述中,错误的是哪一个?(b )A.线性表采用顺序存储,必须占用一片连续的存储单元。
B.线性表采用顺序存储,便于进行插入和删除操作。
C.线性表采用链接存储,不必占用一片连续的存储单元。
D.线性表采用链接存储,便于插入和删除操作。
3.线性表是具有n个(c)的有限序列(n>0)。
A.表元素B.字符C.数据元素D.数据项E.信息项4.若某线性表最常用的操作是存取任一指定序号的元素和在最后进行插入和删除运算,则利用(a )存储方式最节省时间。
A.顺序表B.双链表C.带头结点的双循环链表D.单循环链表5.某线性表中最常用的操作是在最后一个元素之后插入一个元素和删除第一个元素,则采用(d )存储方式最节省运算时间。
A.单链表B.仅有头指针的单循环链表C.双链表D.仅有尾指针的单循环链表6.设一个链表最常用的操作是在末尾插入结点和删除尾结点,则选用( d )最节省时间。
A. 单链表B.单循环链表C. 带尾指针的单循环链表D.带头结点的双循环链表//双循环链表处理所有问题要比其他链表更方便7. 静态链表中指针表示的是(c ). A.内存地址B.数组下标C.下一元素地址D.左、右孩子地址8. 链表不具有的特点是(b )A.插入、删除不需要移动元素B.可随机访问任一元素C.不必事先估计存储空间D.所需空间与线性长度成正比9. 下面的叙述不正确的是(b,c )A.线性表在链式存储时,查找第i个元素的时间同i的值成正比B. 线性表在链式存储时,查找第i个元素的时间同i的值无关C. 线性表在顺序存储时,查找第i个元素的时间同i 的值成正比D. 线性表在顺序存储时,查找第i个元素的时间同i的值无关10.非空的循环单链表head的尾结点p↑满足(a )。
A.p↑.link=head B.p↑.link=NIL C.p=NIL D.p= head 11.循环链表H的尾结点P的特点是(a )。
链表练习题及答案

链表练习题及答案1、已知L是带表头的单链表,其P结点既不是首元结点,也不是尾元结点,a.删除p结点的直接后继的语句是11,3,14b.删除p结点的直接前驱的语句是10,12,8,11,3,14c.删除p结点的语句序列是10,7,3,14d.删除首元结点的语句序列是12,10,13,14e.删除尾元结点的语句序列是9,11,3,14(1)p=p->next;(2) p->next=p;(3)p->next=p->next->next;(4)p=p->next->next;(5)while(p)p=p->next;(6)whlie(Q->next){p=Q;Q=Q->next;}(7)while(p->next!=Q)p=p->next;(8)while(p->next->next!=Q)p=p->next;(9)while(p->next->next)p=p->next;(10)Q=p;(11)Q=p->next;(12)p=L;(13)L=L->next;(14)free(Q);2、已知L是带表头的单链表,其P结点既不是首元结点,也不是尾元结点,a.在p结点后插入s结点的语句序列是4,1b.在p结点前插入s结点的语句序列是7,11,8,4,1c.在表首插入s结点的语句序列是5,12d.在表尾插入s结点的语句序列是7,9,4,1或11,9,1,61.p-> next =s;2.p-> next=p-> next-> next;3.p->next=s->next;4.s->next=p-> next;5.s-> next=L;6.s->next=NULL;7.q=p ;8.while(p->next!=q) p=p->next;9.while(p->next!=NULL) p=p->next;10.p =q;11.p=L;12.L=s;13.L=P;3、已知P结点是某双向链表的中间结点,从下列提供的答案中选择合适的语句序列a.在P结点后插入S结点的语句序列是12,7,3,6b.在P结点前插入S结点的语句序列是13,8,5,4c.删除p结点的直接后继结点的语句序列是15,1,11,18d.删除p结点的直接前驱结点的语句序列是16,2,10,18e.删除p结点的语句序列是9,14,171.P->next=P->next->next;2.P->priou=P->priou->priou;3.P->next=S;4.P->priou=S;5.S->next=P;6.S->priou=P;7.S->next=P->next;8.S->priou=P->priou;9.P->priou->next=P->next;10.P->priou->next=P;11.P->next->priou=P;12.P->next->priou=S;13.P->priou->next=S;14.P->next->priou=P->priou;15.Q=p->next;16.Q=P->priou;17.free(P);18.free(Q);。
2024-2025学年高二上学期浙教版(2019)选修一 2.2 链表 同步练习(含答案)

2023-2024学年高二上学期浙教版(2019)选修一2.2 链表一、选择题1.如下图所示的链表:假如要查找元素11,共需遍历的次数为()A.5B.6C.7D.82.寻宝游戏中通过一个线索找到下一个线索,最好用下列数据组织形式中的()来表示。
A.数组B.链表C.栈D.队列3.小张准备去多个城市旅游,他设计的行程若采用链表结构表示,如图a所示。
若行程有变,需在“上海”与“成都”之间增加一站“杭州”,链表修改为如图b所示,有以下可选操作:①“上海”所在节点的next值赋为“杭州”所在节点的next值①“上海”所在节点的next值赋为5①“杭州”所在节点的next值赋为“上海”所在节点的next值①“杭州”所在节点的next值赋为-1链表更新顺序正确的是()A.①①B.①①C.①①D.①①4.把单向链表第1个节点的位置口叫奇数位置,第2个节点的位置叫偶数位置,以此类推。
现将所有偶数位置的节点依次取出后,放在所有奇数位置节点的后面。
实现该功能的Python 代码段如下,方框中应填入的正确代码为()a=[['a',1],['b',2]. ['c',3],['d',4],[ 'e',-1]]head=odd=0 #链表a头节点指针是headevenhead=even=a[head][1]while even!=-1 and a[even][1]!=-1:a[odd][1]=evenhead #将链表连接在奇数链表之后A.B.C.D.5.链表中的节点通常包含哪两部分()A.数据域和控制域B.数据域和指针域C.指令域和地址域D.标志域和内容域6.有如下Python程序,用于判断链表是否为回文链表(回文链表是指正序遍历和逆序遍历得到的结点顺序一致的链表),则划线处代码是()a=[[1,1],[2,2],[8,3],[2,4],[1,-1]]st=[];head=0;flag=Trueslow, fast=head, headwhile ① :st.append (a[slow][o])slow=a[slow][1]fast=a[a[fast][1]][1]if ① :slow=a[slow][1]while slow!=-1:if st.pop () !=a[slow][0]:flag=Falseslow=a[slow][1]if flag:print("是回文链表!")else:print("不是回文链表!")A.①fast!=-1 or a[fast][1]!=-1①fast!=-1B.①fast!=-1 or a[fast][1]!=-1①a[fast][1]!=-1 C.①fast!=-1 and a[fast][1]!=-1①fast!=-1D.①fast!=-1 and a[fast][1]!=-1①a[fast][1]!=-1 7.有如下图所示的单向链表:从头指针head指向的节点开始查找数据元素“5”,并删除该节点,下列说法正确的是()A.共需查找3次B.删除数据元素“5”的节点,后续节点需要移动3次C.头指针head将指向数据元素“7”的节点D.操作完成后,链表中数据元素的个数为6个8.创建一个空链表时,通常会设置什么来表示链表的起始()A.尾指针B.头指针指向一个空节点C.头指针指向NULL或-1D.无需设置特殊标记9.一头指针head=2 的单向链表L=[[30,4], [10,-1], [20,0], [15,1],[21,3]]通过以下Python 程序段,转换为原链表的逆序链表,即头指针head=1,L=[[30,2], [10,3], [20,-1], [15,4],[21,0]]。
单链表题目和答案

第2章自测卷答案一、 填空1•顺序表中逻辑上相邻的元素的物理位置相互相邻。
单链表中逻辑上相邻的元素的物理位置丕相邻。
2. 在单链表中,除了首元结点外,任一结点的存储位宜由其直接前驱结点值域指示。
3. 在n 个结点的单链表中要删除已知结点*p,需找到它的地址。
二、 判断正误(在正确的说法后面打勾,反之打叉)1. 链表的每个结点中都恰好包含一个指针。
X2. 链表的物理存储结构具有同链表一样的顺序。
X3. 链表的删除算法很简单,因为当删除链中某个结点后,il •算机会自动地将后续的各个单元向前移动。
X4. 线性表的每个结点只能是一个简单类型,而链表的每个结点可以是一个复杂类型。
Y5. 顺序表结构适宜于进行顺序存取,而链表适宜于进行随机存取。
Y6. 顺序存储方式的优点是存储密度大,且插入、删除运算效率高。
X7. 线性表在物理存储空间中也一定是连续的。
X&线性表在顺序存储时,逻辑上相邻的元素未必在存储的物理位置次序上相邻。
X9. 顺序存储方式只能用于存储线性结构。
X10. 线性表的逻辑顺序与存储顺序总是一致的。
X三、 单项选择题(A ) 1.链接存储的存储结构所占存储空间:(A ) 分两部分,一部分存放结点值,另一部分存放表示结点间关系的指针(B ) 只有一部分,存放结点值(C ) 只有一部分,存储表示结点间关系的指针(D ) 分两部分,一部分存放结点值,另一部分存放结点所占单元数(B ) 2.链表是一种采用存储结构存储的线性表:(A )顺序 (B )链式 (C )星式 (D )网状(D ) 3.线性表若采用链式存储结构时,要求内存中可用存储单元的地址:(A )必须是连续的 (B )部分地址必须是连续的(C ) 一定是不连续的 (D )连续或不连续都可以(B ) 4.线性表L 在情况下适用于使用链式结构实现。
(A )需经常修改L 中的结点值 (C )L 中含有大量的结点 C ) 5.单链表的存储密度(A )大于1: (B )等于1: A ) 6、在单链表的一个结点中有个指针。
数据结构:链表单元测试与答案

一、单选题1、线性表采用链式存储时,其地址______。
A.部分地址必须是连续的B.一定是不连续的C.连续与否均可以D.必须是连续的正确答案:C2、从一个具有n个结点的单链表中查找值等于x的结点时,在查找成功的情况下,需要平均比较______个结点。
A.(n-1)/2B.(n+1)/2C.nD.n/2正确答案:B3、能够满足快速完成插入和删除运算的线性表存储结构是____。
A.有序存储B.链式存储C.顺序存储D.散列存储正确答案:B4、已知单向链表中指针p指向结点A,______表示删除A的后继结点(若存在)的链操作(不考虑回收)。
A.p—>next=pB.p=p—>next—>nextC.p=p—>nextD.p—>next=p—>next—>next正确答案:D5、在一个单向链表中,已知结点*q是*p的前趋结点,若在*q和*p 之间插入*s结点,则须执行_____。
A. p—>next= s—>next;s—>next= p;B.s—>next= p—>next;p—>next=s;C.p—>next=s; s—>next=q;D. q—>next=s; s—>next= p;正确答案:D6、已知h是指向单向加头链表的头指针,删除首元结点(第1个实际元素)的操作是_____。
A.p=h->next;free(p);h=h->next;B.p=h,h=p->next;free(p);C.p=h->next,h->next=p->next;free(p);D.free(h->next);h=h->next;正确答案:C7、就单一的____运算来说,线性表采用顺序存储比采用链式存储好(n是表长)。
A.输出所有结点B.查找结点x在表中的序号C.存取任意第i(0≤i≤n-1)个结点D.交换前两个结点的值正确答案:C8、判定以head为头指针的单向简单链表为空的条件是 ______。
第三章 链表 基本题

第三章链表基本题3.2.1单项选择题1.不带头结点的单链表head为空的判定条件是A.head=NULLB.head->next=NULLC.head->next=headD.head!=NULL2.带头接待点的单链表head为空的判定条件是A.head=NULLB.head->next=NULLC.head->next=headD.head!=NULL3.非空的循环单链表head的尾结点(由p所指向)满足A.p->head=NULLB.p=NULLC.p->next=headD.p=head4.在循环双链表p的所指结点之后插入s所指结点的操作是A.p->right=s; s->left=p; p->right->lefe=s; s->right=p->right;B.p->right=s; p->right->left=s; s->lefe=p; s->right=p->right;C.s->lefe=p; s->right=p->right; p->right=s; p->right->left=s;D.s->left=p; s->right=p->right; p->right->left=s; p->right=s;5.在一个单链表中,已知q所指结点是所指结点p的前驱结点,若在q和p之间插入结点S,则执行A.s->next=p->next; p->next=s;B.p->next=s->next; s->next=p;C.q->next=s; s->next=p;D.p->next=s; s->next=q;6.在一个单链表中,若p所指结点不是最后结点,在p之后插入s所指结点,则执行A.s->next=p; p->next=s;B.s->next=p->next; p->next=s;C.s->next=p->next; p=s;D.p->next=s; s->next=p;7.在一个单链表中,若删除p所指结点的后续结点,则执行A.p->next=p->next->next;B.p=p->next; p->next=p->next->next;C.p->next=p->nextD.p=p->next->next8.假设双链表结点的类型如下:typedef struct linknode{int data; /*数据域*/Struct linknode *llink; /*llink是指向前驱结点的指针域*/Struct linknode *rlink; /*rlink是指向后续结点的指针域*/}bnode下面给出的算法段是要把一个所指新结点作为非空双向链表中的所指结点的前驱结点插入到该双链表中,能正确完成要求的算法段是A.q->rling=p; q->llink=p->llink; p->llink=q;p->llink->rlink=q;B.p->llink=q; q->rlink=p; p->llink->rlink=q; q->llink=p->llink;C.q->llink=p->llink; q->rlink=p; p->llink->rlink=q; p->llink=q;D.以上都不对9.从一个具有n个结点的有序单链表中查找其值等于x结点时,在查找成功的情况下,需平均比较()个结点。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
[2005秋II.14]设已建立了两条单向链表,这两链表中的数据已按从小到大的次序排好,指针h1和h2分别指向这两条链表的首结点。链表上结点的数据结构如下:
struct node{
int data;
node *next;
};
以下函数node *Merge(node *h1, node *h2)的功能是将h1和h2指向的两条链表上的结点合并为一条链表,使得合并后的新链表上的数据仍然按升序排列,并返回新链表的首结点指针。
{p1 = p2 ;
p2=p2->next;
}
if ((30))//(30)p2->num < p->num或p->num>p2->num
{p2->next = p;
p->next =0;
}
else
{p->next = p2;
p1->next = p;
}
}
}
return (h);
}
[2004春II.11]输入一行字符串,用单向链表统计该字符串中每个字符出现的次数。方法是:对该字符串中的每个字符,依次查找链表上的结点。若链表结点上有该字符,则将该结点的count值加1;否则产生一个新结点,存放该字符,置count为1,并将该结点插入链首。最后,输出链表上的每个结点的字符及出现次数。链表的结构如下图所示。
if(head==0) //空表,插入第1个结点
{head=new Node;
strcpy(head->name, name);
head->count=1;
head->next=0;
}
else//不是空表,进行结点数值查找
{while(p1)
{if((27))//找到了// strcmp(p1->name, name)==0
print(h); dele(h);
}
[2003秋II.12]用链表实现对候选人的得票进行统计。函数Statistic的输入参数:head指向链首,name存放候选人的姓名。该函数的功能为:若在链表的结点上找到name,则将姓名为name的结点上得得票数加1;否则新建一个结点,初始化其姓名和的票数,并将新结点插入链尾。最后返回链表的首指针。链表的结构如下图所示。
[程序](4分)
Node *sort(Node *head)
{Node *p=head, *p1,*p2;
if(p==NULL) return head;
while(p->next!=NULL)
{ p1=p;
p2=p->next;
while(p2!=NULL)
{if()// p2->data < p1->d>next);
}
void DeleteChain(node *head)//依次删除链表上的每一个结点
{ node *p=head;
if(p)
{ head=____________ ;// head->next
delete p;
if(head) DeleteChain(head);
#include <iostream.h>
struct Node{
int x; //围成一圈时,人的序号
Node *next;
};
Node *DelNode(Node *head, int m) //依次输出环形链表中凡报到m者的序号
{ Node *p;
int count;
if(head==NULL) return _____________ ;// head
(30);// (30) head=p
}
return head;
}
void main(void)
{ char s[300], *p=s;
node *h=0;
char c;
cout<<"请输入一行字符串:";
cin.getline(s,300);
while(c=*p++) h=search(h, c);
}
[2005春II.11]设已建立一条单向链表,指针head指向该链表的首结点。结点的数据结构如下:
struct Node{
int data;
Node *next;
};
以下函数sort(Node *head)的功能是:将head所指向链表上各结点的数据按data值从小到大的顺序排序。
算法提示:初始时,使p指向链表的首结点,从p之后的所有结点中找出data值最小的结点,让p1指向该结点。将p指向的结点的data值与p1指向的结点的data值进行交换。让p指向下一个结点,依此类推,直至p指向链表的最后一个结点为止。
{ if(head)
{ cout<<head->data<<endl;
if(head->next) ShowChain(_____________);//head->next
}
}
void AddNode(node *p, node *&head) //将p所指向的结点插入链尾
{ if(head==NULL) head=___________ ;// p
cout<<"输入得票候选人的姓名:";
cin>>name;
while( strcmp(name,"0")!=0 )
{head = Statistic(head,name);
cout<<"输入得票候选人的姓名:";
cin>>name;
}
cout<<"统计得票结果:\n姓名得票数\n";
List(head);
head=head->next;
}
}
void dele(node *head)
{ node *p;
while(head!=NULL)
{ p=head;
head=(27);//(27) head->next
delete p;
}
}
node *search(node *head, char ch)
{ node *p;
Node *sort(Node *head)
{if (head== 0 ) return head;
Node *h,*p;
h=0;
while(head)
{p=head;
(27);//(27)head = head->next或head =p->next
Node *p1,*p2;
if (h == 0 )
Free(head);
}
[2003春II.14]以下程序使用递归函数实现单向链表操作,完成链表的创建、显示、释放链表的结点。
#include <iostream.h>
struct node
{ float data;
node *next;
};
void ShowChain(node *head) //依次输出每一个结点上的数据
[函数](4分)
node * Merge(node *h1, node *h2)
{node *newHead, *p, *p1;
//使newHead和q指向首结点数据较小链表的首结点,p指向另一链表首结点
if((27)){newHead=h1;p=h2;}// h1->data<h2->data
else{newHead=h2;p=h1;}
node *q=newHead;
//合并两条链表
while( q->next)
{if( q->next->data < p->data )
(28);// q=q->next
else
{(29);// p1=q->next
q->next=p;
q=p;
p=p1;
}
}
q->next=p;
(30);// return newNead
#include <iostream.h>
#include <string.h>
struct Node
{char name[12]; //候选人姓名
int count; //计数候选人的得票
Node * next;
};
Node *Statistic(Node *head, char *name)
{Node *p1=head,*p2;
p=head;
while(p)
{ if(p->c==ch)
{ p->count++; break; }
(28);//(28) p=p->next
}
if(p==0)
{ p=new node;
p->c=ch;
p->count=1;
if(head)(29);//(29) p->next=head
else p->next=0;
p1->next=0;
(30);// p2->next=p1
}
}
return head;
}
void List(Node *head) //输出结果
{while(head)
{cout<< head->name <<" :\t"<< head->count <<endl;
head=head->next;