C-词法扫描器及语法分析器实现
简单C语言编译器

简单C语言编译器编译器是一种将高级语言转换为机器语言的软件工具。
它是编译原理中的一个重要概念,负责将程序源代码转换成可执行文件。
在这个过程中,编译器会对源代码进行词法分析、语法分析、语义分析和代码优化等操作。
一个简单的C语言编译器包含以下主要组件:1. 词法分析器(Lexer):词法分析器将源代码分割成一个个词素(token),例如关键字、标识符、运算符和常量等。
它可以通过有限自动机(DFA)来实现,也可以使用现有的词法分析工具如Lex。
2. 语法分析器(Parser):语法分析器根据对应的语法规则,将一系列的词素组合成语法树。
它可以通过上下文无关文法(CFG)来实现,例如使用自顶向下的递归下降分析法或自底向上的移入-规约分析法。
3. 语义分析器(Semantic Analyzer):语义分析器对语法树进行语义检查,例如检查变量的声明和使用是否匹配、类型转换是否合法、函数调用是否正确等。
它还可以生成符号表,用于存储程序中的变量、函数和类型等信息。
4. 中间代码生成器(Intermediate Code Generator):中间代码生成器将语法树转换成一种中间表示形式,通常是三地址码、虚拟机指令或者抽象语法树。
该中间表示形式能够方便后续的代码优化和目标代码生成。
5. 代码优化器(Code Optimizer):代码优化器对中间代码进行优化,以提高目标代码的性能。
常见的优化技术包括常量折叠、复写传播、循环展开、函数内联等。
优化器的目标是在不改变程序行为的前提下,尽可能地减少执行时间和存储空间。
6. 目标代码生成器(Code Generator):目标代码生成器将优化后的中间代码转换成机器语言代码。
它可以根据目标平台的特点选择合适的指令集和寻址方式,并生成可以被计算机硬件执行的程序。
7. 符号表管理器(Symbol Table Manager):符号表管理器负责管理程序中的符号表,其中包含了变量、函数和类型等信息。
词法分析器的实现与设计

题目:词法分析器的设计与实现一、引言................................ 错误!未定义书签。
二、词法分析器的设计 (3)2.1词的内部定义 (3)2.2词法分析器的任务及功能 (3)32.2.2 功能: (4)2.3单词符号对应的种别码: (4)三、词法分析器的实现 (5)3.1主程序示意图: (5)3.2函数定义说明 (6)3.3程序设计实现及功能说明 (6)错误!未定义书签。
77四、词法分析程序的C语言源代码: (7)五、结果分析: (12)摘要:词法分析是中文信息处理中的一项基础性工作。
词法分析结果的好坏将直接影响中文信息处理上层应用的效果。
通过权威的评测和实际应用表明,IRLAS是一个高精度、高质量的、高可靠性的词法分析系统。
众所周知,切分歧义和未登录词识别是中文分词中的两大难点。
理解词法分析在编译程序中的作用,加深对有穷自动机模型的理解,掌握词法分析程序的实现方法和技术,用c语言对一个简单语言的子集编制一个一遍扫描的编译程序,以加深对编译原理的理解,掌握编译程序的实现方法和技术。
Abstract:lexical analysis is a basic task in Chinese information processing. The results of lexical analysis will directly affect the effectiveness of the application of Chinese information processing. The evaluation and practical application show that IRLAS is a high precision, high quality and high reliability lexical analysis system. It is well known that segmentation ambiguity and unknown word recognition are the two major difficulties in Chinese word segmentation. The understanding of lexical analyse the program at compile, deepen of finite automata model for understanding, master lexical analysis program implementation method and technology, using C language subset of a simple language compilation of a scanned again compiler, to deepen to compile the principle solution, master compiler implementation method and technology.关键词:词法分析器?扫描器?单词符号?预处理Keywords: lexical analyzer word symbol pretreatment scanner一、引言运用C语言设计词法分析器,由指定文件读入预分析的源程序,经过词法分析器的分析,将结果写入指定文件。
编译原理实验报告(词法分析器语法分析器)

编译原理实验报告实验一一、实验名称:词法分析器的设计二、实验目的:1,词法分析器能够识别简单语言的单词符号2,识别出并输出简单语言的基本字.标示符.无符号整数.运算符.和界符。
三、实验要求:给出一个简单语言单词符号的种别编码词法分析器四、实验原理:1、词法分析程序的算法思想算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
2、程序流程图(1(2)扫描子程序3五、实验内容:1、实验分析编写程序时,先定义几个全局变量a[]、token[](均为字符串数组),c,s( char型),i,j,k (int型),a[]用来存放输入的字符串,token[]另一个则用来帮助识别单词符号,s用来表示正在分析的字符。
字符串输入之后,逐个分析输入字符,判断其是否‘#’,若是表示字符串输入分析完毕,结束分析程序,若否则通过int digit(char c)、int letter(char c)判断其是数字,字符还是算术符,分别为用以判断数字或字符的情况,算术符的判断可以在switch语句中进行,还要通过函数int lookup(char token[])来判断标识符和保留字。
2 实验词法分析器源程序:#include <stdio.h>#include <math.h>#include <string.h>int i,j,k;char c,s,a[20],token[20]={'0'};int letter(char s){if((s>=97)&&(s<=122)) return(1);else return(0);}int digit(char s){if((s>=48)&&(s<=57)) return(1);else return(0);}void get(){s=a[i];i=i+1;}void retract(){i=i-1;}int lookup(char token[20]){if(strcmp(token,"while")==0) return(1);else if(strcmp(token,"if")==0) return(2);else if(strcmp(token,"else")==0) return(3);else if(strcmp(token,"switch")==0) return(4);else if(strcmp(token,"case")==0) return(5);else return(0);}void main(){printf("please input string :\n");i=0;do{i=i+1;scanf("%c",&a[i]);}while(a[i]!='#');i=1;j=0;get();while(s!='#'){ memset(token,0,20);switch(s){case 'a':case 'b':case 'c':case 'd':case 'e':case 'f':case 'g':case 'h':case 'i':case 'j':case 'k':case 'l':case 'm':case 'n':case 'o':case 'p':case 'q':case 'r':case 's':case 't':case 'u':case 'v':case 'w':case 'x':case 'y':case 'z':while(letter(s)||digit(s)){token[j]=s;j=j+1;get();}retract();k=lookup(token);if(k==0)printf("(%d,%s)",6,token);else printf("(%d,-)",k);break;case '0':case '1':case '2':case '3':case '4':case '5':case '6':case '7':case '8':case '9':while(digit(s)){token[j]=s;j=j+1;get();}retract();printf("%d,%s",7,token);break;case '+':printf("('+',NULL)");break;case '-':printf("('-',null)");break; case '*':printf("('*',null)");break;case '<':get();if(s=='=') printf("(relop,LE)");else{retract();printf("(relop,LT)");}break;case '=':get();if(s=='=')printf("(relop,EQ)");else{retract();printf("('=',null)");}break;case ';':printf("(;,null)");break;case ' ':break;default:printf("!\n");}j=0;get();} }六:实验结果:实验二一、实验名称:语法分析器的设计二、实验目的:用C语言编写对一个算术表达式实现语法分析的语法分析程序,并以四元式的形式输出,以加深对语法语义分析原理的理解,掌握语法分析程序的实现方法和技术。
C语言词法分析器和C-语言语法分析器编译原理课程设计

《编译原理课程设计》课程报告题目 C语言词法分析器和C-语言语法分析器学生姓名学生学号指导教师提交报告时间 2019 年 6 月 8 日C语言词法分析器1 实验目的及意义1.熟悉C语言词法2.掌握构造DFA的过程3.掌握利用DFA实现C语言的词法分析器4.理解编译器词法分析的工作原理2 词法特点及正则表达式2.1词法特点2.1.1 保留字AUTO, BREAK , CASE , CHAR , CONST , CONTINUE , DEFAULT , DO , DOUBLE , ELSE,ENUM , EXTERN , FLOAT , FOR , GOTO,IF , INT , LONG , REGISTER , RETURN,SHORT , SIGNED , SIZEOF , STATIC , STRUCT ,SWITCH , TYPEDEF , UNION , UNSIGNED , VOID,VOLATILE , WHILE,2.1.2 符号+ - * / ++ -- += -= *= < <= > >= == != = ; , ( ) [ ] { } /* */ :2.2 正则表达式whitespace = (newline|blank|tab|comment)+digit=0|..|9nat=digit+signedNat=(+|-)?natNUM=signedNat(“.”nat)?letter = a|..|z|A|..|ZID = letter(letter|digit|“_”)+CHAR = 'other+' STRING = “other+”3 Token定义3.2 tokenType类型代码4 DFA设计4.1 注释的DFA设计注释的DFA如下所示,一共分为5个状态,在开始状态1时,如果输入的字符为/, 则进入状态2,此时有可能进入注释状态,如果在状态2时,输入的字符为*,则进入注释状态,状态将转到3,如果在状态3时,输入的字符为*,则有可能结束注释状态,此时状态将转到状态4,如果在状态4时输入的字符为/,则注释状态结束,状态转移到结束状态。
用C语言实现简单的词法分析器

⽤C语⾔实现简单的词法分析器词法分析器⼜称扫描器。
词法分析是指将我们编写的⽂本代码流解析为⼀个⼀个的记号,分析得到的记号以供后续语法分析使⽤。
词法分析器的⼯作是低级别的分析:将字符或者字符序列转化成记号.。
要实现的词法分析器单词符号及种别码对照表:单词符号#begin if then while do End+-*/:: =种别码0123456131415161718单词符号<<><=>>==;()Letter(letter|digit)digit digit*种别码2021222324252627281011#include<stdio.h>#include<string.h>char input[200];//存放输⼊字符串char token[5];//存放构成单词符号的字符串char ch; //存放当前读⼊字符int p; //input[]下标int fg; //switch标记int num; //存放整形值//⼆维字符数组,存放关键字char index[6][6]={"begin","if","then","while","do","end"};main(){p=0;printf("please intput string(End with '#'):\n");do{ch=getchar();input[p++]=ch;}while(ch!='#');p=0;do{scaner();switch(fg){case 11:printf("( %d,%d ) ",fg,num);break;case -1:printf("input error\n"); break;default:printf("( %d,%s ) ",fg,token);}}while(fg!=0);getch(); //⽤于让程序停留在显⽰页⾯}/*词法扫描程序:*/scaner(){int m=0;//token[]下标int n;//清空token[]for(n=0;n<5;n++)token[n]=NULL;//获取第⼀个不为0字符ch=input[p++];while(ch==' ')ch=input[p++];//关键字(标识符)处理流程if((ch<='z'&&ch>='a')||(ch<='Z'&&ch>='A')){while((ch<='z'&&ch>='a')||(ch<='Z'&&ch>='A')||(ch<='9'&&ch>='0')){token[m++]=ch;ch=input[p++];}token[m++]='\0';ch=input[--p];fg=10;for(n=0;n<6;n++)if(strcmp(token,index[n])==0)//strcmp()⽐较两个字符串,相等返回0{fg=n+1;break;}}//数字处理流程else if((ch<='9'&&ch>='0')){num=0;while((ch<='9'&&ch>='0')){num=num*10+ch-'0';ch=input[p++];}ch=input[--p];fg=11;}//运算符界符处理流程elseswitch(ch){case '<':m=0;token[m++]=ch;ch=input[p++];if(ch=='>') //产⽣<>{fg=21;token[m++]=ch;}else if(ch=='=') //产⽣<={fg=22;token[m++]=ch;}else{fg=20;ch=input[--p];}break;case '>':token[m++]=ch;ch=input[p++];if(ch=='=') //产⽣>={fg=24;token[m++]=ch;}else //产⽣>{fg=23;ch=input[--p];}break;case ':':token[m++]=ch;ch=input[p++];if(ch=='=') //产⽣:={fg=18;token[m++]=ch;}else //产⽣:{fg=17;ch=input[--p];}break;case '+':fg=13;token[0]=ch;break; case '-':fg=14;token[0]=ch;break; case '*':fg=15;token[0]=ch;break; case '/':fg=16;token[0]=ch;break; case ':=':fg=18;token[0]=ch;break; case '<>':fg=21;token[0]=ch;break; case '<=':fg=22;token[0]=ch;break; case '>=':fg=24;token[0]=ch;break; case '=':fg=25;token[0]=ch;break; case ';':fg=26;token[0]=ch;break; case '(':fg=27;token[0]=ch;break; case ')':fg=28;token[0]=ch;break; case '#':fg=0;token[0]=ch;break; default:fg=-1;}}。
词法分析器实验报告

词法分析器实验报告词法分析器实验报告一、引言词法分析器是编译器中的重要组成部分,它负责将源代码分解成一个个的词法单元,为之后的语法分析提供基础。
本实验旨在设计和实现一个简单的词法分析器,以深入理解其工作原理和实现过程。
二、实验目标本实验的目标是设计和实现一个能够对C语言代码进行词法分析的程序。
该程序能够将源代码分解成关键字、标识符、常量、运算符等各种词法单元,并输出其对应的词法类别。
三、实验方法1. 设计词法规则:根据C语言的词法规则,设计相应的正则表达式来描述各种词法单元的模式。
2. 实现词法分析器:利用编程语言(如Python)实现词法分析器,将源代码作为输入,根据词法规则将其分解成各种词法单元,并输出其类别。
3. 测试和调试:编写测试用例,对词法分析器进行测试和调试,确保其能够正确地识别和输出各种词法单元。
四、实验过程1. 设计词法规则:根据C语言的词法规则,我们需要设计正则表达式来描述各种词法单元的模式。
例如,关键字可以使用'|'操作符将所有关键字列举出来,标识符可以使用[a-zA-Z_][a-zA-Z0-9_]*的模式来匹配,常量可以使用[0-9]+的模式来匹配等等。
2. 实现词法分析器:我们选择使用Python来实现词法分析器。
首先,我们需要读取源代码文件,并将其按行分解。
然后,针对每一行的代码,我们使用正则表达式进行匹配,以识别各种词法单元。
最后,我们将识别出的词法单元输出到一个结果文件中。
3. 测试和调试:我们编写了一系列的测试用例,包括各种不同的C语言代码片段,以测试词法分析器的正确性和鲁棒性。
通过逐个测试用例的运行结果,我们可以发现和解决词法分析器中的问题,并进行相应的调试。
五、实验结果经过多次测试和调试,我们的词法分析器能够正确地将C语言代码分解成各种词法单元,并输出其对应的类别。
例如,对于输入的代码片段:```cint main() {int a = 10;printf("Hello, world!\n");return 0;}```我们的词法分析器将输出以下结果:```关键字:int标识符:main运算符:(运算符:)运算符:{关键字:int标识符:a运算符:=常量:10运算符:;标识符:printf运算符:(常量:"Hello, world!\n"运算符:)运算符:;关键字:return常量:0运算符:;```可以看到,词法分析器能够正确地将代码分解成各种词法单元,并输出其对应的类别。
编译原理课程设计报告C语言词法与语法分析器的实现

编写原理课程设计报告题目:编译原理课程设计C语言词法和语法分析器的实现C-词法和语法分析器的实现1.课程设计目标(1)题目的实用性C语言具有完整语言的基本属性,写C语言的词法分析和语法分析对理解编译原理的相关理论和知识会起到很大的作用。
通过编写C语言词法和语法分析程序,可以对编译原理的相关知识:正则表达式、有限自动机、语法分析等有一个清晰的认识和掌握。
(2)C语言的词法描述①语言的关键词:else if int返回void while的所有关键字都是保留字,必须小写。
②特殊符号:+ - * / < <= > >= == != = ;, ( ) [ ] { } /* */③其他标记是ID和NUM,它们由以下正则表达式定义:ID =字母字母*NUM =数字数字*字母= a|..|z|A|..|Zdigit = 0|..|9注:ID表示标识符,NUM表示数字,letter表示字母,digit表示数字。
小写字母和大写字母是有区别的。
④它由空格、换行符和制表符组成。
空格通常会被忽略。
⑤用常用的C语言符号/*将注释括起来...*/.注释可以放在任何空白位置(也就是注释不能放在标记上),可以多行。
注释不能嵌套。
(3)规划目标能够正确分析程序的词法和语法。
2.分析和设计(1)设计理念a.词汇分析词法分析的实现主要使用有限自动机理论。
有限自动机可以用来描述识别输入字符串中模式的过程,因此也可以用来构造扫描程序。
词法分析器可以很容易地用有限自动机理论来设计。
b.语法分析语法分析采用递归下降分析法。
递归下降法是语法分析中最容易理解的方法。
其主要原理是根据每个非终结符的产生式结构为其构造相应的解析子程序,其中终结符生成匹配命令,非终结符生成过程调用命令。
这种方法被称为递归子例程下降法或递归下降法,因为语法递归的相应子例程也是递归的。
子程序的结构与产生式的结构几乎相同。
(2)程序流程图主程序流程图:词法分析:语法分析:词汇分析子流程图:语法分析子流程图:3.程序代码实现整个词法与语法程序设计在同一个项目中,包含八个文件,分别是main.cpp、parse.cpp、scan.cpp、util.cpp、scan.h、util.h、globals.h和parse.h,其中scan.cpp和scan.h是词法分析程序。
C语言编译原理词法分析和语法分析

C语言编译原理词法分析和语法分析编程语言的编写和使用离不开编译器的支持,而编译器的核心功能之一就是对代码进行词法分析和语法分析。
C语言作为一种常用的高级编程语言,也有着自己的词法分析和语法分析规则。
一、词法分析词法分析是编译器的第一阶段,也是将源代码拆分为一个个独立单词(token)的过程。
在C语言中,常见的单词包括关键字(如if、while等)、标识符(如变量名)、常量(如数字、字符常量)等。
词法分析器会根据预定义的规则对源代码进行扫描,并将扫描到的单词转化为对应的符号表示。
词法分析的过程可以通过有限自动机来实现,其中包括各种状态和状态转换规则。
词法分析器通常会使用正则表达式和有限自动机的方法来进行实现。
通过词法分析,源代码可以被分解为一个个符号,为后续的语法分析提供基础。
二、语法分析语法分析是编译器的第二阶段,也是将词法分析得到的单词序列转换为一棵具有语法结构的抽象语法树(AST)的过程。
在C语言中,语法分析器会根据C语言的文法规则,逐句解析源代码,并生成相应的语法树。
C语言的语法规则相对复杂,其中包括了各种语句、表达式、声明等。
语法分析的过程主要通过递归下降分析法、LR分析法等来实现。
语法分析器会根据文法规则建立语法树的分析过程,对每个语法结构进行逐步推导和分析,最终生成一棵完整的语法树。
三、编译器中的词法分析和语法分析在编译器中实现词法分析和语法分析是一项重要的技术任务。
编译器通常会将词法分析和语法分析整合在一起,形成一个完整的前端。
在C语言编译器中,词法分析和语法分析器会根据C语言的词法规则和文法规则,对源代码进行解析,并生成相应的中间表示形式,如语法树或者中间代码。
词法分析和语法分析的结果会成为后续编译器中各个阶段的输入,如语义分析、中间代码生成、目标代码生成等。
编译器的优化和错误处理也与词法分析和语法分析有密切关系。
因此,对词法分析和语法分析的理解和实现对于编译器开发者而言是非常重要的。
编译-词法分析器-语法分析器实验报告

一、目的编译技术是理论与实践并重的课程,而其实验课要综合运用一、二年级所学的多门课程的内容,用来完成一个小型编译程序。
从而巩固和加强对词法分析、语法分析、语义分析、代码生成和报错处理等理论的认识和理解;培养学生对完整系统的独立分析和设计的能力,进一步培养学生的独立编程能力。
二、任务及要求基本要求:1.词法分析器产生下述小语言的单词序列这个小语言的所有的单词符号,以及它们的种别编码和内部值如下表:单词符号种别编码助记符内码值DIMIFDO STOP END标识符常数(整)=+***,()1234567891011121314$DIM$IF$DO$STOP$END$ID$INT$ASSIGN$PLUS$STAR$POWER$COMMA$LPAR$RPAR------内部字符串标准二进形式------对于这个小语言,有几点重要的限制:首先,所有的关键字(如IF﹑WHILE等)都是“保留字”。
所谓的保留字的意思是,用户不得使用它们作为自己定义的标示符。
例如,下面的写法是绝对禁止的:IF(5)=x其次,由于把关键字作为保留字,故可以把关键字作为一类特殊标示符来处理。
也就是说,对于关键字不专设对应的转换图。
但把它们(及其种别编码)预先安排在一张表格中(此表叫作保留字表)。
当转换图识别出一个标识符时,就去查对这张表,确定它是否为一个关键字。
再次,如果关键字、标识符和常数之间没有确定的运算符或界符作间隔,则必须至少用一个空白符作间隔(此时,空白符不再是完全没有意义的了)。
例如,一个条件语句应写为IF i>0 i= 1;而绝对不要写成IFi>0 i=1;因为对于后者,我们的分析器将无条件地将IFI看成一个标识符。
这个小语言的单词符号的状态转换图,如下图:2.语法分析器能识别由加+ 减- 乘* 除/ 乘方^ 括号()操作数所组成的算术表达式,其文法如下:E→E+T|E-T|TT→T*F|T/F|FF→P^F|Pp→(E)|i使用的算法可以是:预测分析法;递归下降分析法;算符优先分析法;LR分析法等。
编译原理c语言编译器的设计与实现
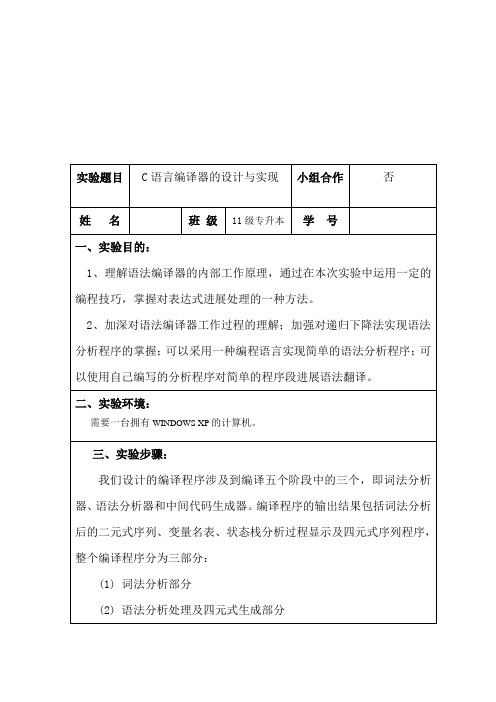
经编译程序运行后得到的输出结果如下:
1〕词法分析得出的相应的名字的号码和他的值2〕列举程序中所有的变量
3〕状态栈的移进-归约过程1.
4〕最后产生的四元式中间代码
一、实验总结:
通过此次实验,让我知道了词法分析的功能是输出把它组织成单个程序,让我理解到如何设计、编制并调试词法分析程序,加深对词法分析原理的理解;对语法规那么有明确的定义;编写的分析程序可以进展正确的语法分析;对于遇到的语法错误,可以做出简单的错误处理,给出简单的错误提示,保证顺利完成语法分析过程;实验报告要求用文法的形式对语法定义做出详细说明,说明语法分析程序的工作过程,说明错误处理的实现。
通过该实验的操作,我理解编译原理课程兼有很强的理论性和理论性,是计算机专业的一门非常重要的专业根底课程,它在系统软件中占有非常重要的地位,是计算机专业学生的一门主修课。
为了让学生可以更好地掌握编译原理的根本理论和编译程序构造的根本方法和技巧,融会贯穿本课程所学专业理论知识,进步他们的软件设计才能,。
词法分析器的实现与设计

词法分析器的实现与设计Company Document number:WUUT-WUUY-WBBGB-BWYTT-1982GT题目:词法分析器的设计与实现摘要:词法分析是中文信息处理中的一项基础性工作。
词法分析结果的好坏将直接影响中文信息处理上层应用的效果。
通过权威的评测和实际应用表明,IRLAS是一个高精度、高质量的、高可靠性的词法分析系统。
众所周知,切分歧义和未登录词识别是中文分词中的两大难点。
理解词法分析在编译程序中的作用,加深对有穷自动机模型的理解,掌握词法分析程序的实现方法和技术,用c语言对一个简单语言的子集编制一个一遍扫描的编译程序,以加深对编译原理的理解,掌握编译程序的实现方法和技术。
Abstract:lexical analysis is a basic task in Chinese information processing. The results of lexical analysis will directly affect the effectiveness of the application of Chinese information processing. The evaluation and practical application show that IRLAS is a high precision, high quality and high reliability lexical analysis system. It is well known that segmentation ambiguity and unknown word recognition are the two major difficulties in Chinese word segmentation. The understanding of lexical analyse the program at compile, deepen of finite automata model for understanding, master lexical analysis program implementation method and technology, using C language subset of a simple language compilation of a scanned again compiler, to deepen to compile the principle solution, master compiler implementation method and technology.关键词:词法分析器扫描器单词符号预处理Keywords: lexical analyzer word symbol pretreatment scanner一、引言运用C语言设计词法分析器,由指定文件读入预分析的源程序,经过词法分析器的分析,将结果写入指定文件。
编译原理课程设计c语言编译器

编译原理课程设计 c语言编译器一、教学目标本课程的目标是让学生掌握C语言编译器的基本原理和实现方法。
通过本课程的学习,学生应能够理解编译器的主要组成部分,如词法分析器、语法分析器、中间代码生成器、优化器和目标代码生成器等;掌握编译器的设计方法和实现技巧,如有限自动机、递归下降分析和代码优化等;能够独立设计和实现一个小型的C语言编译器。
二、教学内容本课程的教学内容主要包括C语言编译器的基本原理、编译器的设计方法和实现技巧。
具体包括以下几个部分:1.C语言编译器的概述:介绍编译器的作用、编译过程和编译器的种类等。
2.词法分析:介绍词法分析器的原理和实现方法,包括正则表达式、有限自动机等。
3.语法分析:介绍语法分析器的原理和实现方法,包括递归下降分析、LL分析、LR分析等。
4.中间代码生成:介绍中间代码生成器的原理和实现方法,包括三地址码、静态单赋值码等。
5.代码优化:介绍代码优化的原理和实现方法,包括常数折叠、死代码消除等。
6.目标代码生成:介绍目标代码生成器的原理和实现方法,包括机器码生成、寄存器分配等。
三、教学方法本课程的教学方法采用讲授法、讨论法和实验法相结合的方式。
在讲授基本原理和方法的同时,通过案例分析和讨论,让学生更好地理解和掌握相关知识。
同时,通过实验环节,让学生亲手设计和实现C语言编译器的基本模块,提高学生的实践能力和创新能力。
四、教学资源本课程的教学资源包括教材、参考书、多媒体资料和实验设备。
教材主要包括《编译原理》、《C语言编译器》等;参考书包括《编译原理学习指导》、《编译器设计实践》等;多媒体资料包括教学PPT、视频讲座等;实验设备包括计算机、编程环境等。
教学资源将全程支持教学内容和教学方法的实施,丰富学生的学习体验。
五、教学评估本课程的评估方式包括平时表现、作业、考试等多个方面,以全面客观地评价学生的学习成果。
平时表现主要考察学生的出勤、课堂参与度和团队协作能力;作业分为课后练习和实验报告,用以巩固和检验学生的学习效果;考试包括期中考试和期末考试,全面测试学生的知识掌握和应用能力。
编译原理名词解释

编译原理名词解释1. 词法分析器(Lexer):也称为扫描器(Scanner),用于将源代码分割成一个个单词(Token)。
2. 语法分析器(Parser):将词法分析器生成的单词序列转换成语法树(Parse Tree)或抽象语法树(Abstract Syntax Tree)。
3. 语法树(Parse Tree):表示源代码的语法结构的树状结构,它由语法分析器根据语法规则生成。
4. 抽象语法树(Abstract Syntax Tree):比语法树更加简化和抽象的树状结构,用于表示源代码的语义结构。
5. 语义分析器(Semantic Analyzer):对抽象语法树进行语义检查,并生成中间代码或目标代码。
6. 中间代码(Intermediate code):一种介于源代码和目标代码之间的中间表示形式,可以被不同的优化器和代码生成器使用。
7. 目标代码生成器(Code Generator):将中间代码转换成特定目标平台的机器代码。
8. 优化器(Optimizer):用于对中间代码进行优化,以提高代码的执行效率和资源利用率。
9. 符号表(Symbol Table):用于存储程序中的标识符(变量、函数等)的信息,包括名称、类型等。
10. 语言文法(Grammar):定义了一种语言的语法规则,常用的形式包括上下文无关文法和正则文法。
11. 上下文无关文法(Context-free Grammar):一种形式化的语法表示方法,由产生式和非终结符组成,描述一种语言的句子结构。
12. 语言解释器(Interpreter):将源代码逐行解释执行的程序,不需要生成目标代码。
13. 回溯法(Backtracking):一种递归式的算法,用于在语法分析过程中根据产生式进行选择。
14. 正则表达式(Regular Expression):用于描述一类字符串的表达式,可以用于词法分析中的模式匹配。
15. 自顶向下分析(Top-down Parsing):从文法的起始符号开始,按照语法规则逐步构建语法树的过程。
基于C语言子系统的词法分析器计与实现

基于C语言词法分析器的设计与实现摘要:算法实现是学生学习过程中的难点,编译器是程序员使用的关键工具,程序员每天都在使用编译器,依赖于其正确性和可靠性。
编译器作为广大IT从业者必须接触的系统软件,它的设计本身又是一个极其庞大的工程。
首先介绍了C 语言及C 语言编译器的发展历程,其次对本次开发所用到的工具Visual Studio C++2005 以及面向对象的程序设计方法做一下简单介绍。
最后重点介绍了编译器的详细开发过程,分为四个部分分别阐述:词法分析器的设计,语法分析器的设计,语义分析,以及系统的用户界面部分。
每个部分又分别从总体框架,详细流程,重点数据结构和函数,以及与其他部分的接口等方面予以阐述。
本次设计只象征性的选择部分具有代表性的功能。
在本文的第四章详细给出了此次设计所实现的功能和语法规范,同时也给出了编译器的运行方式。
关键词:编译器;C语言程序;面向对象程序设计方法;VC++,引言: 词法分析是编译过程中的基础阶段。
开发程序设计语言词法分析器的方法主要有两种;一种是手工编写;另一种借助与辅助工具。
本文在研究基于windows平台的基础上,设计并实现啦编译器的词法分析模块。
绪论1.1 C语言及编译器概述C语言是在70年代初问世的。
C语言是一种结构化语言。
它层次清晰,便于按模块化方式组织程序,易于调试和维护。
C语言的表现能力和处理能力极强。
它不仅具有丰富的运算符和数据类型,便于实现各类复杂的数据结构。
它还可以直接访问内存的物理地址,进行位(bit)一级的操作。
由于C语言实现了对硬件的编程操作,因此C语言集高级语言和低级语言的功能于一体。
既可用于系统软件的开发,也适合于应用软件的开发。
此外,C语言还具有效率高,可移植性强等特点。
因此广泛地移植到了各类各型计算机上,从而形成了多种版本的C语言。
编译是从源代码(通常为高阶语言)到能直接被计算机或虚拟机执行的目标代码(通常为低阶语言或机器语言)的翻译过程。
编译原理课程设计报告C-语言词法与语法分析器的实现

编译原理课程设计报告课题名称:编译原理课程设计C-语言词法与语法分析器的实现提交文档学生姓名:提交文档学生学号:同组成员名单:指导教师姓名:指导教师评阅成绩:指导教师评阅意见:..提交报告时间:年月日C-词法与语法分析器的实现1.课程设计目标(1)题目实用性C-语言拥有一个完整语言的基本属性,通过编写C-语言的词法分析和语法分析,对于理解编译原理的相关理论和知识有很大的作用。
通过编写C-语言词法和语法分析程序,能够对编译原理的相关知识:正则表达式、有限自动机、语法分析等有一个比较清晰的了解和掌握。
(2)C-语言的词法说明①语言的关键字:else if int return void while所有的关键字都是保留字,并且必须是小写。
②专用符号:+ - * / < <= > >= == != = ; , ( ) [ ] { } /* */③其他标记是ID和NUM,通过下列正则表达式定义:ID = letter letter*NUM = digit digit*letter = a|..|z|A|..|Zdigit = 0|..|9注:ID表示标识符,NUM表示数字,letter表示一个字母,digit表示一个数字。
小写和大写字母是有区别的。
④空格由空白、换行符和制表符组成。
空格通常被忽略。
⑤注释用通常的c语言符号/ * . . . * /围起来。
注释可以放在任何空白出现的位置(即注释不能放在标记内)上,且可以超过一行。
注释不能嵌套。
(3)程序设计目标能够对一个程序正确的进行词法及语法分析。
2.分析与设计(1)设计思想a.词法分析词法分析的实现主要利用有穷自动机理论。
有穷自动机可用作描述在输入串中识别模式的过程,因此也能用作构造扫描程序。
通过有穷自动机理论能够容易的设计出词法分析器。
b.语法分析语法分析采用递归下降分析。
递归下降法是语法分析中最易懂的一种方法。
它的主要原理是,对每个非终结符按其产生式结构构造相应语法分析子程序,其中终结符产生匹配命令,而非终结符则产生过程调用命令。
编译原理中的词法分析与语法分析

编译原理中的词法分析与语法分析在编译原理中,词法分析和语法分析是构建编译器的两个关键步骤。
词法分析器和语法分析器被称为编译器前端的两个主要组成部分。
本文将分别介绍词法分析和语法分析的定义、作用、实现方法以及它们在编译过程中的具体应用。
词法分析词法分析是编译器的第一个阶段,也叫扫描器(Scanner)或词法扫描器。
它的主要任务是将输入的字符流(源代码)转换为一系列的单词或词法单元(Token),词法单元是编译器在后续分析中使用的最小有意义的单位,如关键字、标识符、运算符和常量等。
词法分析器的作用是将源代码分解成一个个词法单元,并对这些词法单元进行分类和标记。
常用的实现方法是有限自动机(DFA)或正则表达式,他们通过模式匹配来识别和处理词法单元。
在词法分析的过程中,我们可以排除源代码中不需要的信息,例如空格、注释等,只保留有实际意义的词法单元。
词法分析的结果是一个词法单元序列,它作为语法分析的输入。
词法分析器还可以进行错误检查,如识别出非法的标识符或操作符等。
语法分析语法分析是编译器的第二个阶段,也称为解析器(Parser)。
它的主要任务是将词法分析阶段产生的词法单元序列转换为一个抽象语法树(Abstract Syntax Tree,AST)或语法分析树,并根据语法规则检查源代码的语法正确性。
语法分析器的作用是根据预先定义的文法规则,对词法单元序列进行推导和匹配,并构建一个代表源代码结构的语法树。
常用的实现方法有LR分析器和LL分析器,它们通过构建状态转换图和预测分析表来确定下一步的推导动作。
语法分析的结果是一个表示源代码结构的语法树,它为后续的语义分析和代码生成提供了便利。
语法分析器还可以检测和报告语法错误,如不匹配的括号或缺失的分号等。
词法分析与语法分析在编译过程中的应用词法分析和语法分析是编译器的两个关键阶段,它们完成了源代码解析和结构分析的任务,为后续的语义分析和代码生成提供了基础。
词法分析的结果是一个词法单元序列,它提供了源代码中最小有意义的单位,为语法分析提供了输入。
语法分析器实验报告

杭州电子科技大学班级: 12052312 专业: 计算机科学与技术实验报告【实验名称】实验二语法分析一. 实验目的编写一个语法分析程序, 实现对词法分析程序所提供的单词序列的语法检查和结构分析。
二. 实验内容利用编程语言实现语法分析程序, 并对简单语言进行语法分析。
2.1 待分析的简单语言的语法用扩充的BNF表示如下:⑴<程序>: : =begin<语句串>end⑵<语句串>: : =<语句>{;<语句>}⑶<语句>: : =<赋值语句>⑷<赋值语句>: : =ID: =<表达式>⑸<表达式>: : =<项>{+<项> | -<项>}⑹<项>: : =<因子>{*<因子> | /<因子>⑺<因子>: : =ID | NUM | (<表达式>)2.2 实验要求说明输入单词串, 以“#”结束, 如果是文法正确的句子, 则输出成功信息, 打印“success”, 否则输出“error”。
例如:输入begin a:=9; x:=2*3; b:=a+x end #输出success!输入x:=a+b*c end #输出error测试以上输入的分析, 并完成实验报告。
2.3 语法分析程序的算法思想(1)主程序示意图如图2-1所示。
图2-1 语法分析主程序示意图(2)递归下降分析程序示意图如图2-2所示。
(3)语句串分析过程示意图如图2-3所示。
图2-3 语句串分析示意图图2-2 递归下降分析程序示意图(4)statement 语句分析程序流程如图2-4.2-5.2-6.2-7所示。
图2-4 statement 语句分析函数示意图 图2-5 expression 表达式分析函数示意图图2-7 factor 分析过程示意图三.个人心得一、 通过该实验, 主要有以下几方面收获: 二、 对实验原理有更深的理解。
C语言解释器源码剖析

C语言解释器源码剖析概述C语言是一门广泛应用于系统开发、嵌入式设备以及高性能计算等领域的编程语言。
在C语言的开发和使用过程中,解释器起着重要的作用。
本文将深入剖析C语言解释器的源码,分析其原理和实现方式。
引言解释器是将高级语言程序逐行解析并执行的工具。
C语言解释器的源码包含了解析C语言程序,将其转换为可执行指令的过程。
通过深入分析C语言解释器的源码,我们能够了解其内部的工作原理和核心算法。
解析过程C语言解释器的源码主要包含了以下几个模块:词法分析器、语法分析器、语义分析器和解释器核心。
词法分析器负责将C语言程序的源代码分割成一个个的记号,如关键字、标识符、运算符等。
语法分析器将这些记号组合成语法树,用于表达程序的结构。
语义分析器进行语义检查,如类型检查、作用域检查等。
解释器核心则负责执行语法树上的指令,实现C语言程序的功能。
核心算法C语言解释器的源码中使用了一些核心算法,如递归下降法、LL(1)分析法、符号表等。
递归下降法是一种自顶向下的语法分析方法,通过递归地展开非终结符号来构建语法树。
在识别语法错误时,递归下降法能够提供有关错误种类和位置的准确信息。
LL(1)分析法是一种基于输入流的预测性语法分析方法,只需预读一个输入记号即可判断下一个正确的语法规则。
LL(1)分析法在编写语法分析器时具有简单和高效的特点。
符号表是解释器执行过程中存储变量和函数信息的数据结构。
通过符号表,解释器能够正确地访问和管理程序中的变量和函数。
源码剖析在源码中,词法分析器使用正则表达式来识别C语言程序中的关键字、标识符和运算符。
语法分析器使用递归下降法来生成语法树,并通过LL(1)分析法进行语法分析。
语义分析器使用符号表来进行语义检查,并生成中间代码。
解释器核心通过解释执行中间代码,实现C语言程序的功能。
总结C语言解释器源码的剖析深入分析了解释器内部的工作原理和核心算法。
通过对词法分析、语法分析、语义分析和解释器核心的剖析,我们能够更好地理解C语言解释器的实现方法。
计算机编译的名词解释

计算机编译的名词解释计算机编译是指将人类编写的高级语言程序翻译成计算机能够理解和执行的机器语言的过程。
在计算机科学中,编译器是实现这个过程的关键工具。
本文将对计算机编译的相关名词进行解释,以帮助读者更好地理解这一概念。
一、编译器(Compiler)编译器是一种程序,它将高级语言的源代码转换为目标代码,使计算机能够直接执行。
编译器通常包含以下几个主要的组件:1. 词法分析器(Lexer):也称为扫描器,负责将源代码分解成一个个记号(Token)。
记号是语言中的最小单位,例如关键字、标识符、运算符等。
2. 语法分析器(Parser):语法分析器根据语言的语法规则,将记号组织成一棵由语法构成的语法树(Parse Tree)。
语法树表示了源代码的结构。
3. 语义分析器(Semantic Analyzer):语义分析器对语法树进行检查,以确保源代码的语义正确。
它会检查变量的声明与使用是否匹配、类型转换是否正确等。
4. 目标代码生成器(Code Generator):目标代码生成器将语法树转换为计算机能够执行的目标代码。
目标代码可以是二进制文件、字节码或其他形式的中间表示。
二、解释器(Interpreter)解释器是一种执行高级语言程序的程序。
与编译器不同,解释器不会直接将源代码转换为目标代码,而是逐行解释并执行源代码。
解释器通常包含以下几个主要的组件:1. 词法分析器(Lexer):与编译器的词法分析器相同,将源代码分解成记号。
2. 语法分析器(Parser):解释器的语法分析器根据语言的语法规则,将源代码解析为语法树。
但与编译器不同,解释器不会生成目标代码。
3. 解释器核心(Interpreter Core):解释器核心逐行读取语法树,并实时解释和执行源代码。
它会根据不同的语法规则执行相应的操作。
三、即时编译(Just-in-Time Compilation)即时编译是一种将高级语言程序动态转换为机器代码的技术。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
编译原理课程设计报告课题名称: C-词法扫描器及语法分析器实现目录1 课程设计目标 (2)2 分析与设计 (3)2.1 程序结构 (3)2.2 程序流程 (4)3 词法分析 (5)3.1 代码结构分析 (5)3.2 Token定义 (6)3.2.1 Token的定义和类型 (6)3.2.2 Token的种别码 (6)3.3 DAF分析 (7)3.3.1 删除注释DFA (7)3.3.2 词法分析DFA (9)4 语法分析 (13)4.1 代码结构分析 (13)4.2 节点定义 (14)4.2.1 节点定义和类型 (14)4.2.2 各类型节点的描述 (15)4.3 递归向下语法分析 (15)4.3.1 C-文法 (15)4.3.2 递归向下分析过程 (16)5 测试结果 (33)5.1 流程 (33)5.2 词法分析结果 (33)5.3 词法分析出错 (37)5.4 语法分析结果 (38)5.5 语法分析出错 (40)6 总结 (41)6.1 词法分析编写过程 (41)6.2 语法分析编写过程 (42)6.3 成果和收获 (42)7 附录 (43)7.1 scanner.h源文件 (43)7.2 scanner.cpp源文件 (44)7.3 parser.h源文件 (53)7.4 parser.cpp源文件 (55)1 课程设计目标学生在学习《编译原理》课程过程中,结合各章节的构造编译程序的基本理论,要求用C或C++语言描述及上机调试,实现一个C-Minus 小编译程序(包括词法分析,语法分析等重要子程序),使学生将理论与实际应用结合起来,受到软件设计等开发过程的全面训练,从而提高学生软件开发的能力。
要求:(1)设计词法分析器设计各单词的状态转换图,并为不同的单词设计种别码。
将词法分析器设计成供语法分析器调用的子程序。
功能包括:a. 具备预处理功能。
将不翻译的注释等符号先滤掉,只保留要翻译的符号串,即要求设计一个供词法分析调用的预处理子程序;b. 能够拼出语言中的各个单词;c. 返回(种别码,属性值)。
(2)语法分析要求用学习过的自底向上或自顶向下的分析方法等,实现对表达式、各种说明语句、控制语句进行语法分析。
若语法正确,则用语法制导翻译法进行语义翻译;生成并打印出语法树;若语法错误,要求指出出错性质和出错位置(行号)。
2 分析与设计2.1 程序结构本节主要分析程序的代码结构和代码工程文件的划分。
(程序由两个类组成: Scanner类和Parser类,分别为词法分析和语法分析类。
工程分为四个文件:scanner.h、scanner.cpp、parser.h、parser.cpp,分别对应Scanner类和Parser类的声明和实现文件)。
本程序采用C++语言以面向对象的思想编写,程序分为两部分:词法分析(Scanner)和语法分析(Parser),分别将两个处理阶段封装成Scanner类和Parser类,两个类各司其职,分别完成词法分析和语法分析的任务。
Scanner类主要的工作是过滤注释、词法分析获取Token。
Parser类的主要工作是根据Scanner类词法分析之后的Token进行语法分析,生成语法树,最后并输出语法树。
在处理过程中,Scanner类的对象作为Parser类的一个成员变量,配合Parser类进行语法分析。
工程文件总体上是按照两个类的格局分为四个文件,分别是两个类的声明文件和实现文件。
四个文件分别为scanner.h和scanner.cpp以及parser.h和parser.cpp,他们分别是Scanner类声明文件、Scanner类实现文件、Parser类声明文件、Parser类实现文件。
词法分析scanner.h:与词法分析相关的类(Scanner类)的声明scanner.cpp:词法分析阶段类(Scanner类)的实现语法分析parser.h:与语法分析相关的类(Parser类)的声明parser.cpp:语法分析阶段类(Parser类)的实现2.2 程序流程在程序中,Scanner 类的对象(scanner)作为Parser 类中的一个成员变量,配合Parser 类进行语法分析。
它们的关系是这样的:Parser 类的一个成员变量scanner 首先对源程序删除注释,然后进行词法分析获取所有Token ,并将获取的Token 存储在scanner 对象的tokenList (vector 类型)中。
然后Parser 类的语法分析程序就根据tokenList 中的Token 进行语法分析,生成语法树,最后打印语法树。
同时,这也是程序的流程。
整体程序流程图开始删除注释出错词法分析TF 结束语法分析出错 出错 输出出错信息TF F T从文件获取源代码3 词法分析3.1 代码结构分析词法分析阶段的代码被封装成一个类——Scanner,scanner.h中主要是Scanner类的声明代码,scanner.cpp中主要是Scanner类的实现代码。
Scanner类对外提供的函数主要有:getSourseStringFromFile(string s)(从文件中获取待分析的源代码)、deleteComments()(过滤注释)、scan()(词法分析主程序)。
词法分析的过程主要是:●Scanner调用getSourseStringFromFile(string s),从文件中获取待分析的源代码●Scanner调用deleteComments(),将注释过滤掉,如果注释出错,则不进行词法分析●Scanner调用scan(),进行词法分析,将分析得到的所有Token保存在Scanner类的成员变量tokenList中,以备语法阶段调用,并将Token输出到文件Token.txt中以上三个函数构成了词法分析的骨架,在Scanner类中还有其他成员变量和函数,主要作为这三个函数处理过程的中间步骤,为这三个函数服务。
Scanner类的代码结构和主要的成员变量和函数如下图所示:其他函数和成员变量的作用和含义:●void backToLastChar():在词法分析过程中,回退一个字符●DFAState charType(char):返回字符的类型(按状态分),如white space返回START,0-9返回NUM●char getNextChar():获取到下一个字符●Token getTokenAt(int):根据下标从tokenList数组中获取词法分析后所保存的Token(供语法分析阶段调用)●void printToken():将词法分析好的Token输出到文件Token.txt中●TokenType returnTokenType(string s):根据字符串返回对应的31种Token类型,如字符串"int"将返回INT,"var"将返回ID●int charIndex:配合getNextChar()和backToLastChar()使用(分别自增和自减1),用以指示当前待分析的char在源代码中的位置●bool commentFlag:标注注释开始的标志,为true时表示正在注释体内,即源代码进入"/*"之后且"*/"之前的状态●int lineCount:对行号计数,表示当前词法分析在源代码的行位置(每次获取到的char为'/n'就自增1)●bool scanSuccess:词法分析是否成功的标志●string sourseString:获取源代码的字符串●string str:在分析过程中保存Token对应的串●vector<Token> tokenList:保存Token序列3.2 Token定义3.2.1 Token的定义和类型Token定义://定义的Token结构体,包括类型、对应的串、所在代码的行号struct Token{TokenType tokenType;string tokenString;int lineNo;};Token类型(TokenType):程序中,将Token的类型分为31种,分别对应于else、if、int、return、void、while、+、-、*、/、<、<=、>、>=、==、!=、=、;、,、(、)、[、]、{、}、/*、*/、num、id、错误、文件结束,TokenType的定义和种别码分别如下所示://定义的Token的类型(31种),分别对应于else、if、int、return、void、while、+、-、*、/、<、<=、>、>=、==、!=、=、;、,、(、)、[、]、{、}、/*、*/、num、id、错误、结束typedef enum{ELSE = 1,IF,INT,RETURN,VOID,WHILE,PLUS,MINUS,TIMES,OVER,LT,LEQ,GT,GEQ,EQ,NEQ,ASSIGN,SEMI,COMMA,LPAREN,RPAREN,LMBRACKET, RMBRACKET,LBBRACKET,RBBRACKET,LCOMMENT,RCOMMENT,NUM,ID,ERROR,ENDFILE} TokenType;3.2.2 Token的种别码TokenType的种别码如下表所示,共31种单词符号种别码Value 单词符号种别码Valueelse ELSE 1 = ASSIGN 17if IF 2 ; SEMI 18int INT 3 , COMMA 19return RETURN 4 ( LPAREN 20void VOID 5 ) RPAREN 21while WHILE 6 [ LMBRACKET 22+ PLUS 7 ] RMBRACKET 23 - MINUS 8 { LBBRACKET 24 * TIMES 9 } RBBRACKET 25 / OVER 10 /* LCOMMENT 26 < LT 11 */ RCOMMENT 27 <= LEQ 12 num NUM 28 > GT 13 id ID 29 >= GEQ 14 错误 ERROR 30 == EQ 15 结束 ENDFILE31 !=NEQ163.3 DAF 分析由于词法分析程序分为两个步骤处理:删除注释和词法分析获取Token 。
所以对应有两个DFA ,程序分别根据这两个DFA 进行编写,现根据DFA 分析两程序deleteComments()和scan()如下:3.3.1 删除注释DFA删除注释的DFA 描述:删除注释的DFA 如下所示,一共分为5个状态,在开始状态1时,如果输入的字符为/,则进入状态2,此时有可能进入注释状态,如果在状态2时,输入的字符为*,则进入注释状态,状态将转到3,如果在状态3时,输入的字符为*,则有可能结束注释状态,此时状态将转到状态4,如果在状态4时输入的字符为/,则注释状态结束,状态转移到结束状态。