software
SOFTWARE ERROR故障的处理

SOFTWARE ERROR故障的处理当系统出现software error 告警时,通常是系统软件有问题不能释放造成的。
建议对这个故障采取下面方法检查系统。
1、检查该时间有无其他告警:ALLIP;2、检查该网元FORLOPP有无开启:SYFSP;“Forlopp handling”为ONSYRAP;“Forlopp release”为ON开启后会增加系统负荷。
如果没有开启,建议开启,指令为:SYFSC:FLSTATUS=ACTIVE;3、检查系统不能释放FORLOPP的数量:SYELP;爱立信系统默认值为1000,看CURRENT ERROR INTENSITY: 这个值有无在继续增涨,如果继续增涨,达到门限值将产生立即RESTARTCURRENT ERROR INTENSITY: 如果达到一定数量将产生PENDING RESTARTSYRTP;看PENDING RESTART时间,系统默认凌晨3:00<SYFSP;FORLOPP EXECUTION STATUSFORLOPP HANDLINGACTIVEFORLOPP EXECUTION CONTROL FUNCTION (ECF)OFFFORLOPP ERROR FUNCTION (FLERROR)ONFORLOPP MODE SUBMODE LIMITOPERATION REDUCED LOAD NO LIMITEND<SYRAP;SYSTEM RECOVERY ACTIONSFORLOPP RELEASEACTIVESELECTIVE RESTARTACTIVESELECTIVE RESTART TYPE SMALLDELAYEDSIGNALLING ERRORSPASSIVESMALL SYSTEM RESTART ESCALATION WINDOW 4LARGE SYSTEM RESTART ESCALATION WINDOW 4NUMBER OF SMALL SYSTEM RESTARTS1NUMBER OF LARGE SYSTEM RESTARTS2SYREI EXPLANATION PARAMETER MANDATORYSYFRI EXPLANATION PARAMETER OPTIONALFORLOPP HANDLING LOCKED ACTIVEYESSUSPENDED FORLOPPS AFTER RESTARTNO ACTIONEND<SYRTP;TIME FOR PENDING RESTARTNO RESTART IS PENDINGEND<SYELP;LIMITS FOR SOFTWARE ERROR INTENSITYDCAT TIME LIMIT0 0000 - 2359 10001 0000 - 2359 10002 0000 - 2359 10003 0000 - 2359 10004 0000 - 2359 10005 0000 - 2359 10006 0000 - 2359 10007 0000 - 2359 10008 0000 - 2359 10009 0000 - 2359 100010 0000 - 2359 100011 0000 - 2359 100012 0000 - 2359 100013 0000 - 2359 100014 0000 - 2359 100015 0000 - 2359 1000CURRENT ERROR LIMIT: 1000CURRENT ERROR INTENSITY: 0FORLOPP RELEASE DELAY LIMIT: 30DELAY FOR LAST FORLOPP RELEASE: 0 NUMBER OF FORLOPPS DURING RELEASE: 0END。
SoftwareComponents

7
The role of system software
System software servers as the interface between the user, the application software, and the computer’s hardware.
System software is a collection of programs that control and maintain the operations of the computer and its devices.
Uses can modify the software and share their improvements with others Customers can personalize the software to meet their needs.
Investigate the application of open source software.( exercise )
What are the categories of software?
2
Categories of software
operating system (OS) System software
software
utility software
Business application software Applications software Graphical and multimedia Internet software
14
Disk Defragmenter (P414)
How is a file fragmented ?
SmacqDAQSoftware快速使用指南
Smacq DAQ Software 快速使用指南关于Smacq DAQ SoftwareSmacq DAQ Software是Smacq为USB-3000和USB-5000系列数据采集卡开发的数据采集软件。
Smacq DAQ Software可以帮助没有编程经验的用户快速获取实验数据。
Smacq DAQ Software的设计主要是针对基础应用,对于复杂应用需要用户根据实际情况选择合适的开发环境,编程实现相关功能。
Smacq提供多种环境的开发范例和说明文档,如有需要请到自行下载或与service@取得联系。
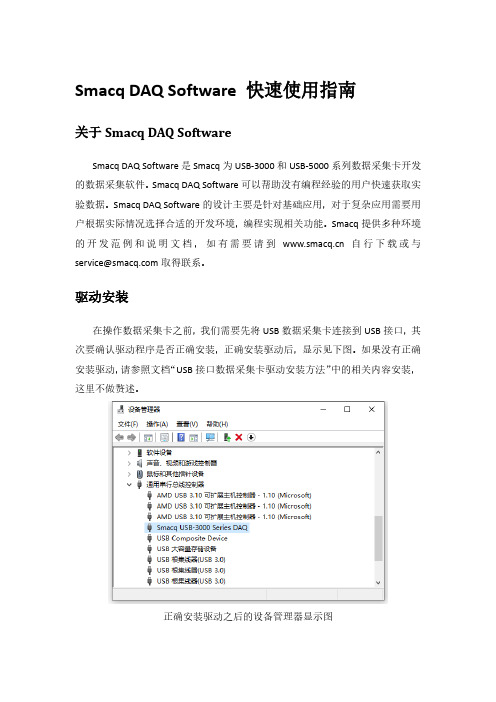
驱动安装在操作数据采集卡之前,我们需要先将USB数据采集卡连接到USB接口,其次要确认驱动程序是否正确安装,正确安装驱动后,显示见下图。
如果没有正确安装驱动,请参照文档“USB接口数据采集卡驱动安装方法”中的相关内容安装,这里不做赘述。
正确安装驱动之后的设备管理器显示图软件安装找到Smacq DAQ Softwave所在文件夹,双击运行setup.exe文件,一直下一步即可完成安装。
软件安装完成安装完成后,会在桌面创建快捷方式Smacq DAQ Softwave。
打开软件双击Smacq DAQ Software快捷方式打开软件。
打开软件后,点击Device List 按键,会在界面左侧显示连接到该电脑上的所有USB-3000和USB-5000系列数据采集卡的信息。
选择数据采集卡系列连接数据采集卡在设备选择列表中选择需要操作的采集卡,然后点击连接按键后,采集卡可以使用功能会激活。
连接数据采集卡功能说明Smacq DAQ Software有多种功能,详见下表。
YT模式采集卡连接后,点击YT按键,进入到YT模式。
YT模式是使用最多的功能,在YT模式中显示电压随时间变化的曲线。
在进行数据采集之前,需要选对采集卡进行设置。
YT模式模拟采集设置在YT模式中,点击设置进入YT-Config界面。
首先设置模拟输入的通道模式,根据硬件连接的方式进行选择,如果不清楚如果连接,可参考用户手册中3.2章节信号连接方式。
课程介绍1.软件工程的研究领域和组成要素 软件工程(Software ...

(1)与软件本身的特点有关 )
缺乏“可见性” 缺乏“可见性” 管理和控制软件开发过程相当困难 软件较难维护。 软件较难维护。 规模庞大 为了在预定时间内开发出规模庞大的软件, 为了在预定时间内开发出规模庞大的软件,必须 由许多人分工合作,然而, 由许多人分工合作,然而,如何保证每个人完成的工作合 在一起确实能构成一个高质量的大型软件系统,不仅涉及 在一起确实能构成一个高质量的大型软件系统, 许多技术问题,更重要的是必须有严格而科学的管理。 许多技术问题,更重要的是必须有严格而科学的管理。
(3) 软件产品质量靠不住。 软件产品质量靠不住。 (4) 软件可维护性差。 软件可维护性差。
开发过程没有统一的、公认的规范,软件开发人员按各自的风格 开发过程没有统一的、公认的规范, 工作,各行其事。开发过程无完整、规范的文档, 工作,各行其事。开发过程无完整、规范的文档,发现问题后进行 杂乱无章的修改。程序结构不好,运行时发现错误也很难修改, 杂乱无章的修改。程序结构不好,运行时发现错误也很难修改,导 致维护性差。 致维护性差。
6. 编码和单元测试
数据模型 功能模型 行为模型
必须准确完整地体现用户的要求。 必须准确完整地体现用户的要求。
联系图) (实体-联系图) 实体 联系图 数据流图) (数据流图) 状态转换图) (状态转换图)
. 书写规格说明书
用正式文档准确地记录对目标系统的需求。 用正式文档准确地记录对目标系统的需求。
4. 总体设计 概要设计 总体设计(概要设计 概要设计)
(2)与软件开发与维护的方法不正确有关 )
在不同时期引入一个变动需 要付出的代价的变化趋势。 要付出的代价的变化趋势。
忽视软件需求分析的重要性 作好软件定义时期的工作, 作好软件定义时期的工作, 是降低软件成本提高软件质 量的关键。 量的关键。
软件工程第01章

教学目的:1. 了解软件、软件危机等概念2. 掌握软件工程的定义、原理、目标和原则教学重点:软件工程的定义、原理、目标和原则教学难点:软件工程的目标和原则第一章软件与软件工程1.1 软件(Software)1.1.1 软件与软件的组成程序设计语言三种类型:1.机器语言、汇编语言:依赖于机器,面向机器2.高级语言:独立于机器,面向过程或面向对象3.面向问题语言:独立于机器,非过程式语言(4GL)文档(document)—一种数据媒体和其上所记录的数据。
文档记录软件开发活动和阶段成果,具有永久性,可供人或机器阅读。
文档可用于专业人员和用户之间的通信和交流;软件开发过程的管理;运行阶段的维护。
1. 软件的特点软件是逻辑产品,硬件是物理产品。
特点:(1)软件开发更依赖于开发人员的业务素质、智力、人员的组织、合作和管理。
软件开发、设计几乎都是从头开始,成本和进度很难估计。
(2)软件存在潜伏错误,硬件错误一般能排除。
(3)软件开发成功后,只需对原版进行复制。
(4)软件在使用过程中维护复杂:1)纠错性维护—改正运行期间发现的潜伏错误;2)完善性维护—提高或完善软件的性能;3)适应性维护—修改软件,以适应软硬件环境的变化;4)预防性维护—改进软件未来的可维护性和可靠性。
(5)软件不会磨损和老化。
2. 软件的发展第一阶段——20世纪60年代中期以前,软件开发处于个体化生产状态。
在这一阶段中,软件还没有系统化的开发方法。
目标主要集中在如何提高时空效率上。
第二阶段——从20世纪60年代中期到70年代末期。
软件开发已进入了作坊式生产方式,即出现了“软件车间”。
软件开发开始形成产品。
到20世纪60年代末,“软件危机”变得十分严重。
第三阶段——从20世纪70年代中期到20世纪80年代末期。
软件开发进入了产业化生产,即出现了众多大型的“软件公司”。
在这一阶段,软件开发开始采用了“工程”的方法,软件产品急剧增加,质量也有了很大的提高。
计算机专业英语单词

17.track 磁道
18.video disk 视盘
19.airfoil 机翼,螺旋桨
20.airtight 密封的
21.concentric 同圆心的,共轴的
22.consecutive 相邻的,连接的
23.cushion 缓冲气垫
24.eliminate 删去,省略,排除,消除
mand processor 命令处理程序
5.input/output control system or IOCS I/O控制系统
6.operating system 操作系统
7.primitive command 原始命令
8.prompt 提示
9.protocol 协议
10.system software 系统软件
35.mouse 鼠标
36.mundane 现世的,世界的,世俗的
37.medium 介质 media
38.plamsized 手掌大的
39.plotter 绘图仪
40.peripheral 外部(围)的
41.solid 固体的,实心的
42.table 小平板
43.Universal Product Code (UPC) 通用商品代码
3.debug 调试
4.documentation 文档
5.interpreter 解释程序,翻译员
6.library 库
7.load module 装入模块
8.machine language 机器语言
9.maintenance 维护
10.nonprocedural language 非过程语言
Unit4-Software Development解读

Unit 4 Software Development
7
A programmer uses another type of program called a text editor to write the new program in a special notation called a programming language. text editor文本编辑程序,文本编辑器 notation[nəʊ’teɪʃn] n.记号,符号,标记法 程序员还使用另一种称为文本编辑器的程序来编写新程 序,新程序是用称为程序设计语言的特殊符号来编写的。
Unit 4 Software Development 6
定语从句
Ⅱ. Program Development (程序开发) Software designers create new programs by using special applications, often called utility programs or development programs.
Unit 4 Software Development
2
For the instructions to be carried out, a computer must execute a program, that is, the computer reads a program, and then follows the steps encoded in the program in a precise order until completion. carry out执行;进行;完成 encode[ɪn'kəʊd] vt.(将文字材料)译成密码;编码,编 制成计算机语言 要使程序中的指令得到执行,计算机必须执行该程序, 也就是说,计算机要读取该程序,然后按确切的顺序执 行程序中编码的步骤,直至程序结束。
自由软体介绍与应用(Open Source Software).

更多相關資源
教育部自由軟體應用諮詢中心
.tw/
自由軟體技術交流網
.tw/
澎湖人NO1影音教學網
http://203.68.253.130/~huang/video/#
web
下課囉~~!
謝謝大家的聆聽!
自由軟體v.s.商業軟體(A)
自由軟體不但將程式原始碼開放,並授權您 對它改良及散佈;而相對我們在網路上常見 的免費軟體及共享軟體,雖然一樣可以免費 的下載使用,但卻無法看到它的程式原始碼, 更不可能也不可以對它的程式進行修改,而 且即使是免費,也不可以任意的拷貝給您的 朋友。
自由軟體v.s.商業軟體(A)
Picasa(B) <<軟體畫面>>
Picasa(C)
<<軟體下載>> 以下連結來自此官方網站: /
/picasa/picasa2-
current.exe
其他好用軟體
何謂自由軟體(OSS)?(A)
自由軟體是指可以讓您自由
的使用、研究、散佈、改良 的軟體。
何謂自由軟體(OSS)?(B)
使用的自由: 可以不受任何限制地來使 用軟體。 研究的自由: 可以研究軟體運作方式、 並使其適合個人需要。 散佈的自由: 可以自由地複製此軟體並 散佈給他人。 改良的自由: 可以自行改良軟體並散佈 改良後的版本以使全體社群受益。
應用類別 辦公室應用 電子郵件 影像處理 向量繪圖 多媒體播放 網頁瀏覽器 商業軟體 MS Office MS Outlook Adobe Photoshop CorelDRAW Windows Media Player Internet Explorer 自由軟體 Thunderbird GIMP Inkscape mplayer Firefox
计算机软件

2.操作系统的启动
•自举:装载操作系统软件并启动执行的过程。计算机的ROM
中固化了一小部分操作系统指令(基本I/O系统,又称BIOS),
计算机加电后,自动执行BIOS, BIOS先把一部分程序从磁盘 读入内存,然后再由读入的这部分程序装载其他所需的操作系
统软件。这个过程称作为“自举”或“引导”。
•命令:操作系统功能的表现形式。
– 计算机软件(Computer Software):包含与数据
处理系统操作有关的程序、规程、规则以及相关 文档的智力创作。(ISO的定义)
什么是计算机软件
• 软件的三层含义(从科学概念上讲):
–个体含义,即上面所说的计算机系统中的程序、 规程、规则及其文档 –整体含义,指在特定计算机系统中所有个体含 义下的软件的总体
3.1.2 计算机软件的发展
计算机软件的发展
计算机软件的发展与计算机应用和硬件的发展互 (1)第一阶段(1940年代到1950年代中期) • 从第一台计算机上的第一个程序开始到实用的高级语 言程序出现以前,是计算机软件发展初期。 • 应用领域较窄:主要是科学与工程计算。处理对象:
相推动和制约。软件的发展大致经历了三个主要阶段:
3.2.5 设备管理
• 设备管理:对计算机系统中除了CPU和内存以外的所 有I/O设备的管理。进而言之,设备管理的对象除了 进行实际I/O操作的设备外,还包括诸如控制器、通
道等支持设备。
• 设备管理任务:外部设备的分配、启动和故障处理, 用户不必详细了解设备及接口的技术细节,就可以 利用驱动程序对相应的设备进行操作。 • 采用技术:中断技术、通道技术、虚拟设备技术和
数值数据
• 工作方式:个体;编程语言:使用低级语言编程 • 人们对和程序有关的文档的重要性认识不足,重视编 程技巧
注册表大全

一、什么是注册表注册表是2000/XP操作系统、硬件设备以及客户应用程序得以正常运行和保存设置的核心“数据库”,也可以说是一个非常巨大的树状分层结构的数据库系统。
注册表记录了用户安装在计算机上的软件和每个程序的相互关联信息,它包括了计算机的硬件配置,包括自动配置的即插即用的设备和已有的各种设备说明、状态属性以及各种状态信息和数据利用一个功能强大的注册表数据库来统一集中地管理系统硬件设施、软件配置等信息,从而方便了管理,增强了系统的稳定性。
二、注册表的功能刚才我们看到了,注册表中记录了用户安装在计算机上的软件和每个程序的相关信息,通过它可以控制硬件、软件、用户环境和操作系统界面的数据信息文件。
相关知识:注册表文件的数据信息保存在system.dat和user.dat中、利用regedit.exe 程序能够存取注册表文件(其实大家可能也知道regedt32.exe,这两个程序是一样的)三、编辑器说明:别说你不知道怎么进注册表啊(哈,在运行里键入regedit就可以了)根键:这个称为HKEY…………,某一项的句柄项:附加的文件夹和一个或多个值子项:在某一个项(父项)下面出现的项(子项)值项:带有一个名称和一个值的有序值,每个项都可包括任何数量的值项,值项由三个部分组成:名称、数据类型和数据。
说明:1、名称:不包括反斜线的字符、数字、代表符和空格的任意组合。
同一键中不可有相同的名称2、数据类型:包括字符串、二进制和双字节等3、数据:值项的具体值,它的大小可以占用64KB第二课总体结构分析注册表包括以下5个根键1.HKEY_CLASSES_ROOT说明:该根键包括启动应用程序所需的全部信息,包括扩展名,应用程序与文档之间的关系,驱动程序名,DDE和OLE信息,类ID编号和应用程序与文档的图标等。
2.HKEY_CURRENT_USER说明:该根键包括当前登录用户的配置信息,包括环境变量,个人程序以及桌面设置等3.HKEY_LOCAL_MACHINE说明:该根键包括本地计算机的系统信息,包括硬件和操作系统信息,安全数据和计算机专用的各类软件设置信息4.HKEY_USERS说明:该根键包括计算机的所有用户使用的配置数据,这些数据只有在用户登录系统时才能访问。
计算机专业英语Unit05_SectionA_Software_Process_Models

II. The Waterfall Model
3. Implementation and unit testing. During this stage, the software design is realized as a set of programs or program units. Unit testing involves verifying that each unit meets its specification. 4. Integration and system testing. The individual program units or programs are integrated and tested as a complete system to ensure that the software requirements have been met. After testing, the software system is delivered to the customer.
7/38
II. The Waterfall Model
1. Requirements analysis and definition. The system’s services, constraints and goals are established by consultation with system users. They are then defined in detail and serve as a system specification. 2. System and software design. The systems design process partitions the requirements to either hardware or software systems. It establishes an overall system architecture. Software design involves identifying and describing the fundamental software system abstractions and their relationships.
SOFTWARE—PRACTICE AND EXPERIENCE

SOFTWARE—PRACTICE AND EXPERIENCESoftw.Pract.Exper.2003;33:885–899(DOI:10.1002/spe.532)Substituting outline fonts forbitmap fonts in archivedPDF filesS.G.Probets ‡and D.F.Brailsford ∗,†School of Computer Science,University of Nottingham,Jubilee Campus,Nottingham NG81BB,U.K.SUMMARYAs collections of archived digital documents continue to grow the maintenance of an archive,and the quality of reproduction from the archived format,become important long-term considerations.In particular,Adobe’s portable document format (PDF)is now an important ‘final form’standard for archiving and distributing electronic versions of technical documents.It is important that all embedded images in the PDF,and any fonts used for text rendering,should at the very minimum be easily readable on screen.Unfortunately,because PDF is based on PostScript technology,it allows the embedding of bitmap fonts in Adobe Type 3format as well as higher-quality outline fonts in TrueType or Adobe Type 1formats.Bitmap fonts do not generally perform well when they are scaled and rendered on low-resolution devices such as workstation screens.The work described here investigates how a plug-in to Adobe Acrobat enables bitmap fonts to be substituted by corresponding outline fonts using a checksum matching technique against a canonical set of bitmap fonts,as originally distributed.The target documents for our initial investigations are those PDFfiles produced by (L A )T E X systems when set up in a default (bitmap font)configuration.For all bitmap fonts where recognition exceeds a certain confidence threshold replacement fonts in Adobe Type 1(outline)format can be substituted with consequent improvements in file size,screen display quality and rendering speed.The accuracy of font recognition is discussed together with the prospects of extending these methodsto bitmap-font PDF files from sources other than (L A )T EX.Copyright c 2003John Wiley &Sons,Ltd.KEY WORDS :PDF;(L A )T EX;bitmap fonts;outline fonts INTRODUCTIONOver the past 10years Adobe’s portable document format (PDF)has become extremely popular as an archiving format,largely because of its PostScript-based architecture which allows complex material ∗Correspondence to:D.F.Brailsford,School of Computer Science,University of Nottingham,Jubilee Campus,Nottingham NG81BB,U.K.†E-mail:dfb@ ‡Present address:Department of Information Science,Loughborough University,Loughborough,Leicestershire LE113TU,U.K.Published online 25June 2003Copyright c 2003John Wiley &Sons,Ltd.Received 27June 2002Revised 27February 2003Accepted 28February 2003886S.G.PROBETS AND D.F.BRAILSFORDto be rendered at very high quality on page and on screen.A second important consideration is that PDF can give an accurate rendering of exactly what was published in hard-copy format with all layout, including page breaks,line breaks and so on,kept intact.PDFfiles are viewed in the Acrobat viewer software and can either have all the required fonts embedded in thefile or can rely onfinding the fonts in the system environment where the Acrobat viewer is running.The option of embedding all fonts,to maximize portability of the PDF,is becoming increasingly popular.When a PDFfile is the only archived form of a document it is important that it be of high quality. Unfortunately there are many examples of PDF documents available on the Web where the quality of fonts and diagrams is so bad that the screen display is almost indecipherable.If a corpus of PDF documents is to be properly maintained then,in an ideal world,any upgrading of the PDF should be achieved by completely reprocessing the enhanced and amended source material. To this end,the publisher should also archive all the sourcefiles together with all the processing software needed to transform the source to the PDF.This is a very severe requirement and one that few organizations would be prepared to undertake.Note that,in extreme cases,it would be necessary to retain the precise release of Acrobat Distiller(to create the PDF)and all the system fonts that were used.More importantly,it would be vital to keep the exact correct release of the text processing software,since important algorithms such as hyphenation and diagram placement can vary greatly from release to release.In practice many publishers of scientific material now archive PDFfiles together with some XML metadata about each article.If the publisher’s workflow starts with full-text SGML or XML then this may well be archived also,but what will almost always be missing are the sourcefiles for the‘typesetting middleware’that lies between the abstract XML document and thefinal PDF form. Indeed,many of the preservation schemes for maintaining digital resources,especially ones based on the Open Archival Information System(OAIS)model[Copyright c 2003John Wiley&Sons,Ltd.Softw.Pract.Exper.2003;33:885–899SUBSTITUTING FONTS IN PDF FILES887 These two software systems have a loyal following within the academic community and in the STM (Scientific,Technical and Medical)segment of journal and book publishing.In what follows we trace the processing of T E X and L A T E X to PostScript via a common program called dvips and thence to Adobe’s PDF format.When discussing possible source texts for dvips we use the logo(L A)T E X to mean‘T E X or L A T E X’.Knuth’s original T E X not only made technical typesetting software freely available but it also provided a free set of bitmap fonts at various resolutions.These fonts implemented a typeface design called Computer Modern(CM),loosely based on Victorian‘Schoolbook’designs.The CM fonts,in bitmap or outline forms,are an important part of the look and feel of most(L A)T E X-created material. The CM fonts were designed with a program called METAFONT[Copyright c 2003John Wiley&Sons,Ltd.Softw.Pract.Exper.2003;33:885–899888S.G.PROBETS AND D.F.BRAILSFORDType3fonts can be based on a character cell of arbitrary size and the units into which the cell is subdivided can be chosen by the font designer.By contrast,Type1font programs have an implicit BuildChar procedure;fonts of this sort must be outlines rather than bitmaps and they must be based on a1point character cell employing units of1/1000point.The subset of PostScript that is used by the Type1buildchar is carefully optimized,within the interpreter,for good performance.Type1fonts are also capable of carrying hinting information.In the early days of PostScript,Type1format was used solely by professional type designers;the details of the format were confidential and the character outlines were encrypted. But since1990the format specification has been publicly available[Copyright c 2003John Wiley&Sons,Ltd.Softw.Pract.Exper.2003;33:885–899SUBSTITUTING FONTS IN PDF FILES889 The dvi-to-PostScript translator most commonly used is dvips developed by Tomas Rokicki[Copyright c 2003John Wiley&Sons,Ltd.Softw.Pract.Exper.2003;33:885–899890S.G.PROBETS AND D.F.BRAILSFORD(L A)T E X source codelatexcommanddvidvips(bitmap fonts)PostScript(bitmap fonts)distill PDF(bitmap fonts)PDF(outline fonts)PostScript(outline fonts)distillFixFontprogramBdvips(outline fonts)A FontReppluginCpdflatex(Type1fonts)Figure1.Processing(L A)T E X to PDF.which outputs PDF directly and uses Type1outline fonts.Although this route is gaining in popularity, and has the advantage that its default font set is of high quality,it requires that all inserted diagrams be prepared as PDFfiles with an origin of coordinates at(0,0);it therefore lacks theflexibility of the traditional dvips route(see upper part of FigureCopyright c 2003John Wiley&Sons,Ltd.Softw.Pract.Exper.2003;33:885–899SUBSTITUTING FONTS IN PDF FILES891 Type1Outlineparison of bitmap and outline CM fonts.source and to introduce outline fonts at point A.Indeed,it is the best way to proceed provided one accepts that the re-processing may not be entirely straightforward.If the source code is several years old,and if it is important to recreate the exact page layout and line breaks of material currently archived as PDF(say),then one has to recreate as exactly as possible the entire original processing environment, i.e.there is a need to archive the exact release of(L A)T E X and its styles,the exact version of dvips and the exact fonts that were used.If this is not done then the old source code has to be processed with more recent releases of the processing software and this leads,all too easily,to frustrating problems where the processing software crashes because the source text is using‘legacy’features no longer supported;or newfigure placement routines cause line breaks and page breaks to change in the output; or mysterious gaps appear due to exotic characters being chosen from fonts that are no longer available. Putting these problems right can take an astonishing amount of effort.For all these reasons,and in circumstances where the(L A)T E X source text is not available,the next best alternative—point B in FigureCopyright c 2003John Wiley&Sons,Ltd.Softw.Pract.Exper.2003;33:885–899892S.G.PROBETS AND D.F.BRAILSFORDfile.Because of the need for careful analysis of the original PostScript,FixFont is designed to workonly with PostScript produced by Tomas Rokicki’s dvips program,in its configuration as constituted around1995(release5.495).In addition to the bitmap font-scaling strategies attempted by dvips,its generated PostScript hasanother major drawback when attempting font substitution:the release5.495dvips software does notname the Type3fonts it embeds with their usual T E X name but instead it generates its own name for the fonts such as Fa,Fb etc.When the font is embedded the bits making up each character within the fontare included as a hexadecimal string in PostScript image format.Because of this font name problem,it is necessary to try to recognize what the font actually is,before substitution can occur.This is done byanalysing the actual bitmaps of the characters within the font.Once it has been determined that Fa is,for example,CM Roman at10points(CMR10)and that Fb is CM Math Italic at10points(CMMI10) then substitution can be performed safely.However life isn’t quite that simple.Most(L A)T E X installations contain different versions of eachbitmap font for various resolutions.Standard resolutions in early(L A)T E X releases were300,329,360, 432,518,622,746,896,1075,1290and1548dpi.More recently these have been supplemented witha new set at600,657,720,864,1037,1244,1493,1792,2150,2580and3096dpi.So not onlydoes the CM typeface have a different bitmap font for many different point sizes(6,8,9,10,12, etc.),it also has a different pk font for each different resolution at every point size.This can leadto(L A)T E X installations having hundreds of these fonts,with names like CMR10.300,CMR10.329,CMR10.360,CMR12.300etc.In creating the PostScript,dvips might pick any one of these fonts, as described later,to minimize the scaling required.The FixFont softwareFixFont was developed in1996or thereabouts and although released via Emerge,there is a distinctimpression that it has its roots in work started at Adobe Systems Inc.somewhat earlier.FixFontcompares the CM bitmap Type3fonts in a PostScriptfile with the characteristics of the standard METAFONT CM bitmap fonts contained in a database.It works in two stages.Thefirst stage is to generate a database of checksums for all the characters in all possible CM fonts,once they have beenconverted to Adobe Type3format.This stage only needs to be performed once.Once the software has knowledge of these checksums,the second stage of the process can occur.In this stage the characteristics of bitmap fonts within legacy PostScriptfiles can be compared with the database,in an attempt to recognize the fonts included in thefile.If recognition is successful then font replacement can occur.The second stage takes the PostScriptfile in which font substitution is required,and analyses allthe bitmap Type3fonts within it.The same algorithm that was used to generate the database is used to generate checksums for all the characters in all the embedded fonts.For example,the checksums for fonts Fa,Fb,Fc etc.are calculated.These checksums can then be compared with the database generated in step one,and if all the checksums match,then it can be assumed that font Fa is actually CMR10.300etc.The details of the algorithm for generating the checksums do not matter too much, so long as the algorithm is fast and leads to a distinct checksum for every character in the database. This same algorithm is then used to analyse the bitmap fonts within the PostScriptfile.For interest, FixFont generates its checksum by cycling through the bitmap character data in4-byte segments,and keeps a running total of the summed values of each32-bit segment as thefinal checksum.Copyright c 2003John Wiley&Sons,Ltd.Softw.Pract.Exper.2003;33:885–899SUBSTITUTING FONTS IN PDF FILES893 Thefirst of the two FixFont programs is called makedb;it is a Unix shell script and it is responsible for creating the font database.It works by creating a L A T E Xfile for every font on the system.Thus,for example,afile named CMR10.300.tex is created which contains ASCII characters0–127for the CMR10.300font.Similarfiles are created for all other fonts in the(L A)T E X installation.Eachfile is then processed by L A T E X and dvips to generate a‘font-sampler’PostScriptfile which contains a hexadecimal string representation of the bitmaps for thefirst128characters in the font.The resulting PostScriptfile is analysed by makedb and used to generate a checksum for all the character glyphs. Although the fonts in the intermediate PostScript will be called Fa(or similar),the makedb script will have created the original L A T E Xfile and named it CMR10.300.tex.Therefore the resulting PostScript file will be named CMR10.300.ps.The makedb script can now relate the glyph checksums to the original METAFONTfile name in order to build up a list of checksums for CMR10.300. Similar information is collected for all fonts on the system and stored in a simple datafile.Although FixFont refers to this as a‘database’it lacks the internal structure of a conventional database;the term datafile would be a more accurate description.Once the database has been created,the second FixFont utility can be used to perform the substitution.This second utility is a C program called substitute which modifies an existing PostScriptfile by replacing the embedded CM Type3fonts with their Type1equivalents. The PostScriptfile is analysed by substitute and,using the same algorithm as makedb,it creates a checksum for all the bitmap Type3characters within it.These are then compared against the database on a font-by-font basis,and,if there is a match,the Type3font is removed from the PostScriptfile and replaced by its corresponding Type1font.If the Type1fonts are already present on the system running substitute,then the bitmap fonts are replaced by embedded Type1fonts.If the Type1fonts are not present on the system,then the bitmapped fonts are replaced by references to the Type1fonts(which must then be available at the time the new PostScriptfile is printed,displayed or distilled).If an exact match is not attainable across all the characters in any particular font then the substitute program can be configured to perform fuzzy matching.Configuration options include performing substitutions only when a given percentage of glyphs appears to match a given font,or only when a given number of glyphs match the database.A pre-made database is distributed with FixFont.FixFont’s outputThe PostScriptfile generated by substitute,containing Type1outline fonts,must,aside from an obvious improvement in font quality,render the page identically to the original bitmap-font PostScript file.To achieve this,a simple Type3for Type1font substitution is insufficient;it is also necessary to make additional alterations to the output PostScript.Suppose,for example,that the initial(L A)T E Xfile had used CMR10at10point.The CMR10.300font would have been embedded into the PostScript. However,this font has been designed to display at a point size of10on a300dpi device,without the need for scaling.PostScript,however,uses a coordinate system with72dpi,so to make the font display at the correct size a scale factor of72/300is applied to the glyphs by dvips in the original Type3 PostScriptfile.If we now replace the Type3font with a Type1font we must scale the new font to make it appear at the same size.Firstly,it must be scaled by300/72(i.e.4.16)to counteract the factor of72/300originally applied to the Type3font.Secondly,it needs to be scaled up by a factor of10to account for the fact that Type1fonts are designed to display glyphs at point size1,whereas the Type3 font CMR10.300is designed to display characters at point size10.Thefirst of these scaling factors is Copyright c 2003John Wiley&Sons,Ltd.Softw.Pract.Exper.2003;33:885–899894S.G.PROBETS AND D.F.BRAILSFORDapplied via a PostScript Font Matrix and the second via the scalefont operator.As an example,if the Type3font CMR10.300is replaced by the Type1font CMR10the following lines would need to be included in the new PostScript:/DvipsFontMatrix[ 4.1600-4.1600]def/Fa{/cmr10findfont10.00scalefont DvipsFontMatrix makefont setfont}def In common with many other typesetting systems(L A)T E X works on a coordinate system with origin at the top left-hand corner and where y is positive as one goes down the page.PostScript,by contrast, uses classic Cartesian coordinates with(0,0)at the bottom left-hand corner and where y is positive upwards.It is perfectly possible,in PostScript,to set up a transformation for it to use a typesetting coordinate system,but the only problem is that the characters themselves will then render upside down if,internally to the character cell,they are using the conventional Cartesian system.Things can be put to rights very easily by applying a Font Matrix to the bitmap font,which reverses the y direction;this explains why the fourth value in the above font matrix is−4.16rather than4.16.Occasionally a point size will be requested that is not in the commonly occurring range from about 6to20point.Under these circumstances many(L A)T E X systems will try to activate METAFONT to create a new bitmap font‘on thefly’.If this fails for any reason then dvips has to decide which of the available CM point sizes,and at which resolution,would scale most elegantly to give the desired output.The PostScript code for the correct scaling must then be generated.For example,if thefile requires CMR output at point size37,one way to do this would be to specify CMR10at37point. In this case let us suppose,hypothetically,that dvips chooses to use the CMR10.432font and scales it by a factor of2.57.If this were the case then when FixFont replaces CMR10.432by the Type1font CMR10,the latter needs to be scaled by(300×10)/72×(432/300)×2.57.Although FixFont manages the rewriting of PostScript very adroitly,its total dependence on a release of dvips which is now7years old illustrates the general difficulty of having to archive appropriate intermediate processing software if one wishes to regenerate a PDF from any of the intermediate processing stages shown in FigureCopyright c 2003John Wiley&Sons,Ltd.Softw.Pract.Exper.2003;33:885–899SUBSTITUTING FONTS IN PDF FILES895 embedded bitmap fonts,it will only occasionally be the case that the original(L A)T E X source,dvi and PostScriptfiles are also available.Our motivation in writing an Acrobat plug-in,which we call FontRep,to perform a similar job to FixFont,was prompted by the prospect of eventually developing a general method for replacing bitmap fonts within PDFfiles.But there are other clear advantages to be gained from creating such a plug-in.PDF is based on Level2PostScript and the way PDF is used in output from Acrobat Distiller relies on a set of procedure definitions and dictionary entries that correspond closely to those used by Adobe Illustrator.Thus,the conversion of PostScript to PDF,by Distiller,effectively‘normalizes’the PostScript.By analysing this more standardized output format it should be possible to perform the font replacement operation,initially,on a wider variety of(L A)T E X-generated documents and eventually to generalize the methods to cope with bitmap font replacement in PDFfiles generated from sources other than(L A)T E X.The FontRep plug-in for AcrobatThe FontRep plug-in,for the full MS-Windows version of the Adobe Acrobat viewer(release5.0) works in a similar manner to the FixFont application for PostScript described above.The database must be generated in the same way as before,but font substitution occurs on PDFfiles rather than PostScript files.As with FixFont,once the database has been created thefirst step in the substitution process is to locate every Type3bitmap font in the PDF document.As each font is encountered,the bitmaps for every character in the font are extracted.If necessary,filter decoding and bit manipulation are applied to each character to obtain a hexadecimal representation of the bitmaps.From here,generation of a checksum,and comparison against the database,takes place very much as with FixFont.It is worth noting that when PDF is generated by Acrobat Distiller it changes dvips’s obscure font names such as Fa,Fb to the equally obscure T1,T2etc.The result,therefore,of comparing these embedded fonts to the canonical ones encapsulated within the database is the knowledge that the bitmap font T1equates to CMR10,say,or that T2is CMBX12.Acrobat API(Application Programming Interface)calls can then be used from within the plug-in to search the system fonts on the host machine and,if a matching Type1font is present,it can be embedded into the PDF and the corresponding bitmap font removed.Unfortunately,as with FixFont,identifying and replacing fonts is only a part of the problem. As before,the Type1font’s innate font dimensions and units cause PDF content streams to render at a very different size to that seen with the bitmap Type3font being replaced.This was overcome in FixFont’s regenerated PostScript by including font matrices to scale the Type1character widths. Sadly it is not so easy in PDF,which has only a subset of PostScript’s capabilities and which,in particular,does not permit a non-standard font matrix to be associated with a PDF Type1font object. There are two initially obvious strategies for overcoming this problem:thefirst is to scale the glyphs within the font itself before embedding;the second is to rewrite the content streams within the PDF, scaling the characters as required.The former method has the advantage of leaving the PDF content streams untouched and so it was attemptedfirst,but it was foiled by the internal design of Acrobat. Scaling the glyphs within a font,by using a font matrix prior to embedding,means that the width of each glyph increases.Glyph widths in Type1fonts are specified in units of1/1000th pt,and so widths are in the region of100–1000units for commonly occurring characters.Scaling these by a factor of300×10/72(for CMR10)or300×12/72(for CMR12)means that the widths of the Copyright c 2003John Wiley&Sons,Ltd.Softw.Pract.Exper.2003;33:885–899896S.G.PROBETS AND D.F.BRAILSFORDglyphs are transformed to a region between4000and40000units for CMR10,and even higher for fonts designed at larger point sizes.Now the PDF font format requires an array of character widthsto be populated for all fonts,but the internal type used by Acrobat is an array of signed16-bit integers,meaning that the maximum possible width for a glyph in Acrobat is215−1(32767). Trying to input character widths greater than this causes overflow,leaving a residue that is an apparentlynegative quantity.This,in turn,causes the PDF to render incorrectly,with the most noticeable effect being that wide characters such as‘M’can shift a few centimetres to the left of where they ought to be.The second possibility,of doing the scaling via a rewriting of PDF content streams,was attempted next.With the use of API calls a scaling matrix could be applied to text runs within the PDF content stream.Unfortunately,some minor bugs in certain API calls resulted in badly formatted content. The only solution to the problem was for the plug-in to rewrite the content streams itself,without relying on the API calls.To do this the plug-in had to decompose the PDF content stream into tokens, with each token consisting of a single content object,operator or argument.The tokens could then be analyzed,added to or altered,for example a scaling factor could be applied,or existing matrices altered,before the revised PDF content stream was output.This latter approach has the added benefit that more control is available over the output.It becomeseasier to create an option whereby users are asked what action should be taken in the case of uncertain glyph matches.For example,suppose53out of54glyphs in font T1are recognized as being from the Type3bitmap font CMR10.300.In this case the Type1CMR10is embedded and the user is asked whether the one remaining glyph should be left as a Type3,or mapped to a Type1glyph on the assumption that it is the standard character at that font position in T E X encoding.The release of Acrobat5.0appears to havefixed some of the problems with the API,but the success of the tokenizing approach has meant that this is still a very promising strategy.Other font replacement strategiesThe font replacement strategies described in the previous sub-section involve the creation of reconfigured Type1fonts,for the entire CM family,in Adobe.pfa format.The reconfiguration involves adjusting the font matrix within the fontfile to account for the various scalings and axis inversions that have already been described.Once this has been done the fonts are installed as system fonts and the Acrobat API for Windows has a method which imports a system font and allows it to replace the corresponding Type3bitmap font already present.Although the strategy of rewriting the text streams has met with some success there are still some niggling problems with character positioning and the rather worrying prospect that the tokenizer has to be100%accurate in recognizing the intended point size of each component in the text stream before a correct text matrix can be applied.From almost every viewpoint a solution where simple font substitution can be performed,with no rewriting of text streams,is greatly preferred.We have already discussed earlier,that a Type3font is not constrained to having bitmap character glyphs;it could equally be an unhinted set of outlines for drawing the character shapes.Thus,if the CM Type1fonts could be regenerated as Type3outline fonts,directly from METAFONT or via reconfiguring a Type1CMR font in a tool such as Macromedia Fontographer,then it might be possible to substitute a Type3bitmap font with an equivalent Type3 outline.Copyright c 2003John Wiley&Sons,Ltd.Softw.Pract.Exper.2003;33:885–899SUBSTITUTING FONTS IN PDF FILES897 Initial testing of this idea is underway and early results seem promising.Although Type3fonts are not allowable as system fonts under Windows,it turns out that an API call of CosObjCopy allows an object to be copied over from a given PDFfile to replace an object in another PDF.By creating a PDF consisting entirely of embedded PDF Type3CM outline fonts,we thereby create a resource from which the different fonts(complete with the appropriate font scaling matrices)can be abstracted,for use as bitmap Type3font replacements within the target PDF.The appearance of the PDF once Type3outline fonts have been substituted for Type3bitmaps, is certainly improved.This is helped in large part by a new feature in the Acrobat5viewer software that allows line art to be smoothed.One has to remember,here,that the drawing routines for character shapes in a Type3font charproc entry are not interpreted in a specialized way,as they would be in a Type1font.They are simply treated as vector drawing(i.e.line art)routines.However,this smoothing of the character shapes cannot call on the hinting information of Type1fonts.Perhaps for this reason,and to avoid delicate hairline strokes disappearing altogether,the smoothing errs on the side of‘rounding up’rather than‘rounding down’.The overall effect of this is that text in outline Type3CMR appears‘bolder’than its Type1equivalent.Prior to afirst release of FontRep we are evaluating the replacement accuracy and the glyph quality offered by this alternative approach as opposed to the text stream rewriting described earlier. The FontRep home page[Copyright c 2003John Wiley&Sons,Ltd.Softw.Pract.Exper.2003;33:885–899。
Open Source Software

There are different business models associated with OSS, and confusion continues to reign over their relative strengths and weaknesses.
Vendors often market proprietary approaches as "open," which can lead to vendor lock-in and high switching costs
The best support comes from developers who built the software. Increases the overall operational costs when compared with self-support.
Recommendations:
Open as free Open as in access Open as over time Open as not close Open as in reuse and change Open as in any place and for anyone
Should company use OSS?
• Commercial Support is the most widely adopted form of OSS • offering flexibility to customers in balancing costs versus risks
-- Chandrasekaran & Lerner (2015)
It include two products: an open source & a proprietary non-free version. (Proffitt, 2010)
03计算机专业英语- Software

Text
• 系统软件包括 构成计算机操作 系统(OS)的所 有内容,包括设 备驱动程序、配 置文件和其他关 键系统组件
What Is Application Software?
Computer software is the set of instructions and data that tells a computer what to do and how to do it. Software provides instructions to your computer’s hardware. Without it, your PC or Mac would be little more than a large paper weight. But software actually comes in three main types: system, programming and application software. System software includes all the stuff that make up a computer's operating system (OS),including device drivers, configuration files and other key system components
Text
• 软件实际上有 三种主要类型: 系统软件、编程 软件和应用软件。
What Is Application Software?
Computer software is the set of instructions and data that tells a computer what to do and how to do it. Software provides instructions to your computer’s hardware. Without it, your PC or Mac would be little more than a large paper weight. But software actually comes in three main types: system, programming and application software. System software includes all the stuff that make up a computer's operating system (OS),including device drivers, configuration files and other key system components
software的中文是什么意思

software的中文是什么意思software的中文意思英 [ˈsɒftweə(r)] 美 [ˈsɔ:ftwer]software 基本解释名词软件; 软体; 软设备software 相关例句名词1. My job is writing the software.我的工作是写软件。
情景对话求职面试B:Give me a summary of your current job description.对你目前的工作,能否做个概括的说明。
A:I have been working as a computer programmer for five years. To be specific, I do system analysis, trouble shooting and provide software support.我干了五年的`电脑程序员。
具体地说,我做系统分析,解决问题以及软件供应方面的支持。
B:Why did you leave your last job?你为什么离职呢?A:Well, I am hoping to get an offer of a better position. If opportunity knocks, I will take it./I feel I have reached the "glass ceiling" in my current job. / I feel there is no opportunity for advancement.我希望能获得一份更好的工作,如果机会来临,我会抓住。
/我觉得目前的工作,已经达到顶峰,即�]有升迁机会。
software的单语例句1. The demand for business software among Chinese SMEs is growing as more and more of them seek to boost their efficiency.2. A senior business intelligence manager with Microsoft Corp locates authenticity markers on a box of genuine Microsoft software.3. Paying the costs for legally purchased software is necessary for business operations to be legitimate.4. Authorities moved against Tomato Garden after receiving complaints from the Business Software Alliance, it said.5. Now, clients for his business software are several wineries in the region.6. She cited a 2003 estimate by The Business Software Alliance which claimed that the piracy rate in China was as high as 92 percent.7. Analysts had widely expected thousands of Sun employees to lose their jobs, but not until No 2 business software maker Oracle closes the deal.software的双语例句1. The kernel in design and realization of virtual instrument is the software development.虚拟仪器设计及实现的核心是软件的开发。
Fleet Manager II Software说明书

Fleet Manager II SoftwareWear yellow. Work safe.Corporate Headquarters2840 - 2 Avenue S.E.USA 1.888.749.8878 Europe +44 (0)1295 700 300 China +86 10 6786 7305Calgary, AB, Canada T2A 7X9 Canada 1.800.663.4164 France +33 (0) 442 98 17 70 S.E. Asia +65 6748 4915Phone: +1-403-248-9226Australia +61.3.9464.2770 Middle East +971-4-8871766 Other Countries +1-403-248-9226www.g a info@g a Conveniently manage your detectorsData storage and analysis has never been so simple. With the same look and feel as Fleet Manager, Fleet Manager II allows users to download information directly from BW instruments or the MicroDock II. With improved functionality, users can: • Automatically create accurate and user-friendly reports • Easily sort, format and graph data as well as view history • Archive and share data easily, including databases• Download and manage calibration and bump check records aswell as datalogged information onto any PCOther enhancements include: • Improved data transfer and download speed• Easily schedule routine automatic imports of test results • Calibration Certifi cates and bump test receipts are available at the press of a button• Produce reports in PDF format or Microsoft Excel• Flexible settings allow users to select the devices applicable to them • Full user’s manual embedded in the Help menu and onthe installation CDles directly from:Download datalogged fiGasAlert Extreme (use the IR DataLink)• GasAlertMicroClip (use the USB Connectivity Kit) • GasAlertClip Extreme 2 and 3 • GasAlertMicro (use the MMC Reader)• GasAlertMicro 5 / PID / IR (use the MMC Reader)• • MicroDock II • MicroDock IIDownload information quickly anddirectly from BW’s MicroDock II testand calibration system.The MMC reader , IR DataLink and IR Connectivity Kit download information directly from BW instruments to Fleet Manager II. Download a datalogged fi le from a GasAlertMicro 5 in less than aminute.6231-2-EN© 2007 Honeywell International Ltd. All Rights Reserved.。
若串s='software',其子串的数目是( )

若串s='software',其子串的数目是( ).
若串s='software',其子串的数目是(37 ).
串中任意个连续的字符组成的子序列称为该串的子串
对于一个字符串变量,例如"adereegfbw",它的子串就是像"ader"这样可以从中找到的连续的字符串。
字符串"adereegfbw"本身也属于它本身最长的子串。
ab的子串:a、b、ab和一个空子串共4个即(2+1+1)个,abc的子串:a、b、c、ab、bc 、abc和一个空子串共(3+2+1+1)个,所以若字符串的长度为n,则子串的个数就是[n*(n+1)/2]+1个,"software"中非空子串的个数就是8+7+....+1=36个。
C语言是一门面向过程的计算机编程语言,与C++、Java等面向对象编程语言有所不同。
C语言的设计目标是提供一种能以简易的方式编译、处理低级存储器、仅产生少量的机器码以及不需要任何运行环境支持便能运行的编程语言。
C语言描述问题比汇编语言迅速,工作量小、可读性好,易于调试、修改和移植,而代码质量与汇编语言相当。
C语言一般只比汇编语言代码生成的目标程序效率低10%~20%。
因此,C 语言可以编写系统软件。
当前阶段,在编程领域中,C语言的运用非常之多,它兼顾了高级语言和汇编语言的优点,相较于其它编程语言具有较大优势。
计算机系
统设计以及应用程序编写是C语言应用的两大领域。
同时,C语言的普适较强,在许多计算机操作系统中都能够得到适用,且效率显著。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Host-Based Detection of Worms through Peer-to-Peer Cooperation David J.Malan and Michael D.SmithDivision of Engineering and Applied SciencesHarvard UniversityCambridge,Massachusetts,USA{malan,smith}@ABSTRACTWe propose a host-based,runtime defense against worms that achieves negligible risk of false positives through peer-to-peer cooperation.We view correlation among otherwise independent peers’behavior as anomalous behavior,indi-cation of a fast-spreading worm.We detect correlation by exploiting worms’temporal consistency,similarity(low tem-poral variance)in worms’invocations of system calls.We evaluate our ideas on Windows XP with Service Pack2us-ing traces of nine variants of worms and twenty-five non-worms,including ten commercial applications andfifteen processes native to the platform.Wefind that two peers, upon exchanging snapshots of their internal behavior,de-fined with frequency distributions of system calls,can de-cide that they are,more likely than not,executing a worm between76%and97%of the time.More importantly,we find that the probability that peers might err,judging a non-worm a worm,is negligible.Categories and Subject DescriptorsD.4.6[OPERATING SYSTEMS]:Security and Protec-tion—Invasive softwareGeneral TermsAlgorithms,Experimentation,Measurement,SecurityKeywordsnative API,P2P,peer-to-peer,system calls,system services, temporal consistency,Win32,Windows,worms1.INTRODUCTIONThe fastest of worms do not allow time for human inter-vention[16,23,33,34,37].Necessary is an automated defense, thefirst step toward which is detection itself.But detection must be both accurate and rapid.Defenses as high in false Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on thefirst page.To copy otherwise,to republish,to post on servers or to redistribute to lists,requires prior specific permission and/or a fee.WORM’05,November11,2005,Fairfax,Virginia,USA.Copyright2005ACM1-59593-229-1/05/0011...$5.00.positives as they are low in overhead are perhaps just as bad as no defenses at all:both put systems’usability at risk. We propose a host-based,runtime defense against worms that leverages peer-to-peer(P2P)cooperation to lower its risk of false positives.We claim that,by exchanging snap-shots of their internal behavior alone(regardless of network traffic),peers can detect actions so correlated in time as to be more likely those of a fast-spreading worm than not. Common today are defenses based on automated recog-nizance of signatures,sequences of bytes indicating some worm’s presence in memory or network traffic.Such defenses are fast,and specificity of signatures renders false positives unlikely.But the protections are limited:systems are safe from only those worms for which researchers have had time to craft signatures,and signature-based defenses can be de-feated by metamorphic or polymorphic worms[13,36]. Behavior-based defenses,which monitor systems for anomalous(e.g.,yet unseen)behavior,are an alternative, perhaps less susceptible to defeat by mere transformations of text,insofar as they judge the effect of code more than they do its appearance.But this resilience comes at a cost: accuracy or rapidity.Faced with some anomalous action, behavior-based defenses must either block that action,po-tentially impeding desired behavior,or wait for the user’s judgement.Such defenses can be defeated by users them-selves,annoyed or confounded by too many false positives or prompts.Through P2P cooperation can we obviate the need for such manual intervention and still lower our risk of false positives.Worms stand out among other processes not so much for their novelty but for their simplicity and periodic-ity:their design is to spread,their execution thus cyclical. Granted,even the most innocuous of applications can evince cyclical behavior reminiscent of attacking worms.But less likely are we to see such behavior in near lockstep on mul-tiple hosts,unless triggered by some threat.1Through P2P cooperation,then,can we lower our risk of false positives by requiring that individual hosts no longer decide a worm’s presence but a cooperative instead.We focus in this paper on precisely this problem of col-laborative detection with few false positives.Wefind that we can detect worms by leveraging collaborative analysis of 1To allow for coordinated behavior in distributed applica-tions(e.g.,Entropia[2]),it would suffice to maintain whitelists.Such applications often provide protections in their virtual machines against ill-behaved and malicious grid pro-grams.peers’runtime behavior while reducing the collective’s risk of false positives.Specifically,wefind that two peers,upon exchanging snapshots of their internal behavior,can decide that they are,more likely than not,both executing the same worm between76%and97%of the time.Moreover,wefind that,while certain non-worms can exhibit sufficiently cycli-cal behavior as to be potentially mistaken by peers for worms themselves,such mistakes can be avoided.Finally,wefind that two peers are unlikely to mistake a non-worm executing on one for a worm executing on the other.In the section that follows,we motivate our inquiry into the viability of collaborative detection by expounding on our proposal for a host-based,runtime defense leveraging P2P cooperation.In Section3,we describe the methodology with which we explore the matter,and,in Section4,we present results on the efficacy of our approach.In Section5,we discuss threats to P2P cooperation.Finally,in Sections6 and7,respectively,we explore related work and conclude.2.TEMPORAL CONSISTENCY Conventional host-and behavior-based defenses dictate that hosts evaluate some current action vis-`a-vis prior ac-tions;a host’s behavior is deemed anomalous if it differs from that host’s prior behavior.We offer an alternative def-inition of anomalous behavior.We propose that a host eval-uate some current action vis-`a-vis its peers’current actions;a host’s behavior is deemed anomalous if it correlates all too well with other,otherwise independent,hosts’behavior.We argue that anomalous behavior,induced by some worm,can be detected because of temporal consistency,similarity(low temporal variance)in invocations of system calls.We exploit the reality that worms’behavior tends toward simplicity and periodicity.Of course,non-worms’behavior, on occasion,can resemble that of worms’,as we discuss in Section4.But so relatively few are a worms’actions,more likely are we to detect them in lockstep on multiple peers than those of larger,more complicated applications with more code paths.Through P2P cooperation,then,can we harness the power of combinatorics to lower our risk of false positives.Specifically,we propose a network of peers(Figure1),each running software designed to take snapshots of processes’calls into kernel space.On some schedule do peers exchange the relative frequencies of these calls during some window of time(Figure2).If the cooperativefinds too many simi-larities among snapshots,a worm is assumed present and a response initiated.Out of this vision comes a number of problems:how best to detect similarities,how best to exchange snapshots,and how best to respond.We address in this work thefirst of these challenges:the problem of detection.We assume,for the purposes of this inquiry,that communication among peers is not only instantaneous and infinite but also cen-tralized at some node.We bound,through experimenta-tion with both worms and non-worms,the probabilities with which peers might detect and mistake worms.We leave,for subsequent work,relaxation of these assumptions,focusing now on whether peers might detect worms at all with few false positives.We recognize that execution of some worm within a net-work of hosts might not be perfectly synchronized,as hosts might not have become infected at the same moment in time. We must therefore tolerate some difference in timing,even Figure1:Our vision of collaborative detection offast-spreading worms using P2P networks.On someschedule,peers exchange snapshots of their internalbehavior;too many similarities suggest anomalousbehavior,a worm’spresence.Figure2:Hypothetical trace of a process’s invoca-tion over time of three system calls,each of which isplotted as a separate line.Point(i,j)indicates j in-vocations of some system call around time i.Shadedare two samples,representative of snapshots thatmight be exchanged by two peers.The more peersthat exchange snapshots similar to these,the morecorrelated is their behavior,and the more likely arethey infected by some worm.though hosts are to exchange snapshots of their behavior onsome schedule.We offer two effective measures of similarity,both of whichare tolerant of offsets in timing.Neither measure expectsperfect matches in peers’sequences of system calls,lest itbe too sensitive to slight variance in worms’execution and torandomization along code paths by the stealthiest of worms.2.1Measuring Similarity with Edit Distance Ourfirst measure of similarity treats snapshots of hosts’behavior as ordered sets of system calls,enumerated accord-ing to their frequencies of execution during some window oftime.Each such set is of the form S=(s0,s1,...,s n−1), where each s i is a unique token representing some systemcall,and the relative frequency of s i within the snapshot isgreater than or equal to that of s j,for i<j.A process issaid to be temporally consistent if a majority of snapshotsof its execution over time are similar.We judge the similarity of two snapshots by way of theedit distance between them,which we define here as the number of insertions,deletions,and substitutions required to transform one set of tokens into the other.Inasmuch as this distance,d ,is thus bounded by the larger of |S 1|and |S 2|,for two snapshots,S 1and S 2,we define the percentageof similarity between the snapshots as 1−dmax(|S 1|,|S 2|).If 1−dmax(|S 1|,|S 2|)≥0.5for a majority of pairs of snapshots over time,the process to which those snapshots pertain is said to be temporally consistent.In that it considers invocations of system calls in the ag-gregate,this measure finds similarity where mere pattern matching (to which edit distance is conventionally applied)might fail.But it is particularly sensitive to fluctuations in system calls’order (as might be induced by branches in a worm’s call graph).2.2Measuring Similarity with IntersectionOur second measure of similarity treats snapshots of hosts’behavior as unordered sets of system calls invoked during some window of time.Each such set is again of the form S =(s 0,s 1,...,s n −1),where each s i is a unique token representing some system call,but no ordering is imposed on the set.A process is still said to be temporally consistent if a majority of snapshots of its execution over time are similar.But we judge the similarity of two snapshots,S 1and S 2,by way of S 1∩S 2.We define the percentage of similarity be-tween two snapshots as |S 1∩S 2|max(|S 1|,|S 2|).If |S 1∩S 2|max(|S 1|,|S 2|)≥0.5for a majority of pairs of snapshots over time,the process to which the snapshots pertain is said to be temporally con-sistent.Blind as this version is to order,it allows for the emergence of patterns despite slight differences in execution.3.METHODOLOGYWe target Windows XP with Service Pack 2(WinXP SP2)for our proposed defense,as the platform offers a richness of available worms (important in any behavioral study)and is a perpetual recipient of innovative attacks.We look,as have others before us [5,10,21,31,32],albeit on Linux and UNIX,to system calls as a proxy for hosts’behavior.And we deploy our two measures of similarity to quantify the probability that snapshots of calls into kernel space do,in fact,belong to the same executable.As our approach to detection does not require synchro-nization among peers,we are able to evaluate our proposal’s viability with traces of hosts’behavior;we do not require the experimental overhead of an actual network of peers.With such traces,we simulate snapshots’instantaneous exchange between pairs of peers and compute the probabilities with which those peers can decide that they are,more likely than not,both executing the same worm.As part of this work,we have implemented Wormboy 1.0,software with which to gather these traces.And we have traced the behavior of WinXP SP2’s fastest worms and commonest non-worms.We elaborate here on our choice of system calls (Section 3.1),our implementation of Worm-boy (Section 3.2),and our experimentation on WinXP SP2(Section 3.3).And we frame our inquiry into the efficacy of collaborative detection as a set research questions (Sec-tion 3.4).3.1A Proxy for Hosts’BehaviorTo the extent that they circumscribe kernel space,restrict-ing execution’s passage from Ring-3to Ring-0,system calls enable summarization of code into low-level,but still seman-tically cogent,building blocks.Other summaries might be useful,particularly bytes received or even sent.But,covered in literature as is the behavior of worms’network traffic al-ready [12,18,29],we focus instead for temporal consistency on worms’utilization of WinXP SP2’s native API ,the near-est equivalent of Linux’s and UNIX’s system calls.This native API comprises 284functions,known also as system services ,implemented in kernel space by NTOSKRL.EXE and exposed with stubs in user space by NTDLL.DLL ,against which most higher-level Win32APIs are linked.When called to invoke a system service,a stub in NTDLL.DLL invokes SharedUserData!SystemCallStub after moving into register EAX the service’s service ID and into register EDX a pointer to the call’s arguments.To trap from user-to kernel-mode,SharedUserData!SystemCallStub then executes Intel’s SYSENTER instruction (for the Pentium II and newer)or AMD’s SYSCALL instruction (for the K7or newer).2Control is ultimately passed to _KiSystemService ,which dispatches control to the appro-priate service by indexing into _KeServiceDescriptorTable for the service’s address and number of parameters using the value in EAX .[3,7–9,20,24]3.2Wormboy 1.0To capture the behavior of WinXP SP2with respect to its system services,we have implemented Wormboy 1.0,a kernel-mode driver that inserts hooks into _KeServiceDescriptorTable before and after all but two system services.3,4Inspired by Strace for NT [26],as well as by work by Nebbett [17]and Dabak et al.[3],Wormboy not only captures a call’s service ID and input parameters,but also its output parameters and return value,along with a caller’s name,process ID,thread ID,and mode.Though Wormboy will ultimately serve as the core of a real-time de-fense,the driver,for now,captures all such data to disk,timestamping and sequencing each entry per trace,so that we might experiment offline with different approaches to de-tection.A link to Wormboy’s source code is offered at this paper’s end.2On older CPUs,SharedUserData!SystemCallStub exe-cutes a slower INT 2e instruction.3By default,_KeServiceDescriptorTable is read-only,so Wormboy first disables the WP bit in regis-ter CR0[22,30].Alternatively,protection of kernel memory itself could be relaxed,albeit dangerously,by creating registry key HKEY LOCAL MACHINE \SYSTEM \CurrentControlSet \Control \Session Manager \Memory Management \EnforceWriteProtection with a DWORD value of 0x0[26].4WinXP SP2appears to make certain assumptions about system services NtContinue and NtRaiseException ,whereby it attempts to manipulate the stack frame based on register EBP [25];inasmuch as our hooks insert a frame of their own,we do not hook these services to avoid system crashes.WormsNon-WormsCommercial Applications WinXP SP2ProcessesI-Worm/Bagle.Q Adobe Photoshop7.0.1alg.exeI-Worm/Bagle.S Microsoft Access XP SP2csrss.exe I-Worm/Jobaka.A Microsoft Excel XP SP2defrag.exe I-Worm/Mydoom.D Microsoft Outlook XP SP2dfrgntfs.exe I-Worm/Mydoom.F Microsoft Powerpoint XP SP2explorer.exe I-Worm/Sasser.B Microsoft Word XP SP2helpsvc.exe I-Worm/Sasser.D Network Benchmark Client1.0.3lsass.exe Worm/Lovesan.A Nullsoft Winamp5.094msmsgs.exe Worm/Lovesan.H Windows Media Encoder9.0services.exeWinZip8.1spoolsv.exesvchost.exewmiprvse.exewinlogon.exewscntfy.exewuauclt.exe Table1:Worms and non-worms whose traces we analyzed.3.3Traces of Worms and Non-WormsTo validate our claim of collaborative detection’s efficacy, we look to some of WinXP SP2’s fastest worms and com-monest non-worms to date.We base our results,put forth in Section4,on traces of nine variants of worms and twenty-five non-worms,including ten commercial applications and fifteen processes native to WinXP SP2(Table1).5For each worm,we have traced its live activity forfif-teen minutes,more than enough for its recurrent behavior to surface.For each commercial application save one,we have traced its execution under PC Magazine’s WebBench5.0[14] or PC World’s WorldBench5[19]benchmarking suites.6For each native process,we have traced its execution during twenty-four hours of user-free intervention.Of course,none of these traces,save those of the worms, may be representative of normal activity,if such can even be said to exist.But,insofar as these traces have been gathered in environments as deterministic as possible,we argue that they actually allow us to estimate lower bounds on peers’ability to detect or mistake worms;it’s hard to imagine programs more cyclical(and thus worm-like)than those executing repeated tests or taking no input.3.4Research QuestionsTo detect novel worms by leveraging collaborative analysis of peers’runtime behavior,we must demonstrate that worms tend to stand out in traces of system behavior based on calls to system services.Given two or more samples from those very same traces(i.e.,snapshots of behavior),distinguishing an attacking worm from an otherwise benevolent application reduces to the following three questions,each irrespective of our timing of samples.5We call the worms by their names according to AVG Free Edition7.0.322[6].6We traced Nullsoft Winamp5.094as it played an MP3of James Horner’s19-minute“Titanic Suite,”encoded at160 kbps.1.How likely is a worm to look like itself?The more sim-ilar a worm’s execution during some window of time to its execution during any other,the more capable should peers be to correlate actions.Moreover,the more similar a worm with respect to itself,the less it should matter when peers sample their behavior.We thus inquire as to whether worms are temporally con-sistent.2.How likely is a non-worm to look like itself?The moresimilar a non-worm’s execution during some window of time to its execution during any other,the more likely might peers be to think it a worm.We thus inquire as to whether non-worms are temporally consistent.3.How likely is a non-worm to look like a worm?Themore similar a non-worm’s execution to that of a worm, the more likely might peers be to mistake the benign for the malevolent.We thus inquire as to whether worms manifest similarities with non-worms.4.RESULTSWe present in this section our results for the research ques-tions of Section3.4.4.1How likely is a worm to look like itself?A worm is remarkably likely to look like itself,though it depends on the measure of similarity.Wefind that,while edit distance allows us to notice with near certainty(at least95%)the similarity,with respect to themselves,of I-Worm/Sasser.D,Worm/Lovesan.A,and Worm/Lovesan.H, using a window size of15seconds,the metric proves less effective on other variants(Table2),even for windows as wide as30seconds.Bagle’s variants,in particular,appear resistant to classification as temporally consistent using the metric,with no more than14%of possible pairs of snap-shots resembling each other.The disparity,though signifi-cant,is not surprising,if we consider the traces themselves.51530I-Worm/Bagle.Q14%11%10%I-Worm/Bagle.S14%11%11%I-Worm/Jobaka.A59%50%69%I-Worm/Mydoom.D92%81%73%I-Worm/Mydoom.F17%31%41%I-Worm/Sasser.B60%54%72%I-Worm/Sasser.D95%97%93%Worm/Lovesan.A99%98%93%Worm/Lovesan.H47%95%93%Table2:Probability with which two peers,upon ex-changing snapshots of their internal behavior,can decide using edit distance alone that they are,more likely than not,both executing the same worm dur-ing some window of time,for window sizes of5,15, and30seconds.In other words,percentages of all possible pairs of samples from some worm for which1−dmax(|S1|,|S2|)≥0.5,where S1and S2are snap-shots,treated as ordered sets,and d is the edit dis-tance between them.For instance,whereas Worm/Lovesan.A(Figure3)mani-fests an obvious,nearly constant,pattern,I-Worm/Bagle.Q (Figure4)boasts a less obvious pattern,clouded by over-lapping frequencies.With less precise measures,though,we canfilter such noise.If we consider only calls’intersection but not relative frequencies,we notice more trends.We now notice with near certainty(97%),using a window size of15seconds,every one of our worms save Bagle;but now even Bagle appears temporally consistent(Table3).Still worthy of note,though not unexpected,is Worm/Lovesan.H,which resists detection,no matter our metric,using a window size of5seconds.Such narrow win-dows simply fail to capture this worm’s periodicity(Fig-ure5);wider windows do capture its periodicity(Figure6).4.2How likely is a non-worm to look like it-self?A non-worm is not nearly as likely to resemble itself as is a worm to resemble itself.Of all our non-worms examined, only Nullsoft Winamp and alg.exe boasted traces for which more than90%of15-second snapshots resembled each other, no matter the metric.And only alg.exe boasted a trace for which more than90%of30-second snapshots resembled each other,no matter the metric.But alg.exe,during our twenty-four-hour run,made only 2295calls to system services,an average of no more than one per second.By contrast,even our“slowest”of worms, I-Worm/Jobaka.A,averaged sixty-four such calls per sec-ond.Insofar as processes averaging nearly zero calls per second do not likely belong to fast-spreading worms,we sim-ply require for temporal consistency that snapshots not be so empty.Nullsoft Winamp,by contrast,averaged896calls to sys-tem services per second,so its temporal consistency neces-sitates more intelligentfiltration.To discourage false posi-tives,whereby we classify non-worms as worms,we propose51530I-Worm/Bagle.Q80%76%81%I-Worm/Bagle.S82%76%73%I-Worm/Jobaka.A99%97%93%I-Worm/Mydoom.D99%97%93%I-Worm/Mydoom.F99%97%93%I-Worm/Sasser.B99%97%93%I-Worm/Sasser.D99%97%93%Worm/Lovesan.A99%97%93%Worm/Lovesan.H49%97%93%Table3:Probability with which two peers,upon ex-changing snapshots of their internal behavior,can decide using intersection alone that they are,more likely than not,both executing the same worm dur-ing some window of time,for window sizes of5,15, and30seconds.In other words,percentages of all possible pairs of samples from some worm for which |S1∩S2|max(|S1|,|S2|)≥0.5,where S1and S2are snapshots, treated as unordered sets.to ignore binaries for which we have ample history or read-only hashes(as we might for an application like Nullsoft Winamp,if installed and executed with consent),against which we might compare processes executing in memory.If a process’s behavior or text is as we expect,it is not likely a worm.Worms are by nature,after all,binaries foreign to a machine,suddenly installed without users’consent,for which we are unlikely to have history or hashes.In future work will we assess thisfilter’s efficacy.It is in this analysis of non-worms that the sensitivities of our measures of similarity become apparent.If we lower our threshold for detection,requiring only that50%(and not90%)of snapshots resemble each other,wefind that edit distance deems not only Nullsoft Winamp and alg.exe worms but seven other binaries as well.If we turn instead to intersection,as we did to catch Bagle,we realize that this metric’s power comes at a cost:eleven binaries besides Nullsoft Winamp and alg.exe are deemed worms.However,a higher threshold(90%)does avoid these false positives.4.3How likely is a non-worm to look like aworm?Through exhaustive comparison of every possible snap-shot from each worm against every possible snapshot from each non-worm,wefind that only one non-worm’s behav-ior resembles,more often than not,that of a worm:Net-work Benchmark Client is similar to I-Worm/Jobaka.A, I-Worm/Sasser.B,and I-Worm/Sasser.D,if intersection is our metric.But the resemblance is neither surprising nor troubling,as Network Benchmark Client is practically a worm itself,designed to forkfive threads,each of which induces stress on a server by initiating TCP sockets in rapid succession.5.THREATS TO P2P COOPERATION Threats to our proposed scheme for collaborative detec-tion include worms designed not to exhibit similarity in their invocations of system services,no matter our measure.Ran-306090120150180210240270300330360390420450480510540570600630660690720750780810840time (seconds)n u m b e r o f c a l l sFigure 3:Calls to system services by Worm/Lovesan.A per 30-second window of time.Point (i,j )indicates j calls to some service between times i and i +30.Both edit distance and intersection capture this worm’s pattern ofactivity.306090120150180210240270300330360390420450480510540570600630660690720750780810840time (seconds)n u m b e r o f c a l l sFigure 4:Calls to system services by I-Worm/Bagle.Q per 30-second window of time.Point (i,j )indicates j calls to some service between times i and i +30.For visual clarity,less frequently called system services are not pictured.Edit distance fails to capture this worm’s pattern of activity because of overlapping frequencies;intersection does capture the pattern.dom calls to system services by the stealthiest of worms could skew analysis of peers’behavior,particularly for our measure of similarity based on edit distance,insofar as the metric is sensitive to changes in order.However,to mitigate this threat,we could consider order but allow for transposi-tions,requiring only that the bubble-sort distance between two snapshots (the number of swaps that bubble sort would make to transform one ordered set into the other)be within some bound.Our measure based on intersection is similarly vulnerable to adversarial randomness,as the stealthiest of worms might,on occasion,invoke all possible services in se-ries,simply to render any intersection with another peer’s snapshot negligible,thereby masking its presence on somehost.To mitigate this threat,though,we could simply re-quire that calls be present not necessarily in some order but at least in some proportion.Of course,the more peers in a network,the more likely we are to discover correlations,even in the face of randomness.There are only so many ways that fast-spreading worms might achieve malicious effects rapidly ,bounded by time as they are by their very definition.Just as future work will address how best to exchange snapshots and how best to respond to worms,once detected,it will also address additional threats,involving not only adversarial randomness but also matters of authentication,availability,efficiency,and integrity.895time (seconds)n u m b e r o f c a l l sFigure 5:Calls to system services by Worm/Lovesan.H per 5-second window of time.Point (i,j )indicates j calls to some service between times i and i +5.For visual clarity,less frequently called system services are not pictured;similarly are most x-axis labels omitted.5-second windows are not adequate to capture periodicity in this worm’sbehavior.020040060080010001200895time (seconds)n u m b e r o f c a l l sFigure 6:Calls to system services by Worm/Lovesan.H per 15-second window of time.Point (i,j )indicates j calls to some service between times i and i +15.For visual clarity,less frequently called system services are not pictured;similarly are most x-axis labels omitted.15-second windows are adequate to capture periodicity in this worm’s behavior.6.RELATED WORKInsofar as our own work aspires to generalize the problem of worms’discovery away from recognizance of pre-defined signatures toward detection of widespread and coordinated behavior,it falls within an area of research more generally focused on anomaly or intrusion detection,be it network-or host-based.Though a dearth of published work exists for Win32,a growing body of literature exists for Linux,UNIX,and TCP/IP alike.Of relevance to our own work is that of Somayaji et al.[31,32],whose Linux-based pH moni-tors processes’execution for unexpected sequences of system calls,though only with respect to a host’s own prior behav-ior.An outgrowth of the same is work by Hofmeyr [10,11],whose Sana Security,Inc.[27]provides “instant protection against a targeted,emerging attack class.”Similar are prod-ucts from Symantec Corporation [35]and McAfee,Inc.[15],the latter of which offers “zero-day protection against new attacks”by combining behavioral rules with signatures.Though more network-than host-based,worthy of note are Autograph [12]and Polygraph [18],signature-generation systems for novel and polymorphic worms,respectively.Also of interest are the methods for automated worm fingerprint-ing of Singh et al.[29]as well the network application ar-chitecture of Ellis et al.[4].Jung et al.,meanwhile,pro-pose sequential hypothesis testing for scanning worms’de-tection,while Schechter et al.[28]offer improvements on the same.Twycross and Williamson [38]propose that wormsbe throttled:instead of preventing such programs from en-tering a system,they seek to prevent them from leaving.Weaver et al.[39]similarly advance cooperative algorithms for worms’containment.In progress is work by Anderson and Li [1]on separating worm traffic from benign.7.CONCLUSIONHost-based detection of worms through P2P cooperation is possible with negligible risk of false positives,as we demon-strate through analysis on WinXP SP2of nine variants of worms and twenty-five non-worms.Our result follows from a definition of anomalous behavior as correlation among other-wise independent peers’behavior.For the set of worms and non-worms tested,we find that two peers,upon exchang-ing snapshots of their internal behavior,defined in terms of frequency distributions of calls to system services,can de-tect execution of some worm between 76%and 97%of the time because of worms’temporal consistency.More signif-icantly,the probability of false positives is negligible,and,in those rare cases in which non-worms manifest temporal consistency,simple filters eliminate the false positives.This paper focuses entirely on the problem of collabora-tive detection of worms.We will relax in subsequent work our assumptions that communication among peers is instan-taneous,the communication bandwidth infinite,and the de-tection centralized.We will also explore what constitutes an appropriate response for such a cooperative defense.。