weka分类与回归
weka分类、聚类和关联分析概述

weka分类、聚类和关联分析概述数据挖掘算法概述数据挖掘算法我们总的来说有这么四大类算法:1.分类算法a)决策树b)神经网络c)SVMd)贝叶斯e)etc2.聚类算法3.关联分析4.回归这三类算法weka总都有实现,而且算法种类很多,仅有小部分算法是我知道的,大量的算法不清楚是怎样工作的。
具体的算法我们可以去看他的源码。
回归:什么叫回归?这个很简单,我们手上有一系列的二维数对,我们可以把数据在一个坐标轴上画出来,如果我们发现这个数对的大致轨迹是一条直线,我们可以用这条直线代表这些点的轨迹,拿到这条直线有什么用呢?第一个想法是可以进行预测,第二个用途是分析参数的重要程度,可以调整今后的策略。
回归的分类。
上段话只是简单的说了一下什么是回归,以及回归的用途。
我们使用回归最简单的就是一个自变量一个因变量这种叫做二元线性回归,当然就可以有多元线性回归。
如果我们把一次的指数增大为2,我们可以转换成多元线性回归,这里使用matlab就比较方便了。
即除了线性回归还有非线性回归。
分类:这个是我总的来说最擅长的一类算法,分类算法想法就是把两个物品分开,或称为分类。
总的过程有三部分:1.特征提取2.数据转换3.分类我们能看出来,分类算法很简单,只是最后一步,所以说难度在前两步,很多初学数据挖掘的人总会把重心放到第三步,但是其实最难的是前两步。
聚类:从名字上我们就可以看出来,什么叫聚类。
这个我用的比较少,没啥要说的,在工具使用上spass是比较好的工具。
关联分析:关联分析说白了就好像在数据库中的函数依赖,这个现在很多人正在这方面研究,当然没有那么狭隘的只是关联分析——购物篮分析。
这个百度一下可以发现很多关联分析的算法,这个可以看看书,估计暂时用不到。
Weka数据分类、回归挖掘工具

DMA数据分类公司Weka数据分类、回归挖掘工具WEKA的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),其源代码可从/ml/weka/得到。
2005年8月,在第11届ACM SIGKDD国际会议上,怀卡托大学的WEKA小组荣获了数据挖掘和知识探索领域的最高服务奖, WEKA 系统得到了广泛的认可,被誉为数据挖掘和机器学习历史上的里程碑,是现今最完备的数据挖掘工具之一。
作为一个大众化的数据挖掘工作平台, WEKA集成了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理、分类、回归、聚类、关联分析以及在新的交互式界面上的可视化等等。
通过其接口,可在其基础上实现自己的数据挖掘算法。
WEKA中的典型算法Bayes: 贝叶斯分类器BayesNet: 贝叶斯信念网络NaïveBayes: 朴素贝叶斯网络Functions: 人工神经网络和支持向量机MultilayerPerceptron: 多层前馈人工神经网络SMO: 支持向量机(采用顺序最优化学习方法)Lazy: 基于实例的分类器IB1: 1-最近邻分类器IBk: k-最近邻分类器Meta: 组合方法AdaBoostM1: AdaBoost M1方法Bagging: 袋装方法Rules: 基于规则的分类器JRip: 直接方法-Ripper算法Part: 间接方法-从J48产生的决策树抽取规则(不是C4.5规则算法)Trees: 决策树分类器Id3: ID3决策树学习算法(不支持连续属性)J48: C4.5决策树学习算法(第8版本)RandomForest: 基于决策树的组合方法。
weka实验总结

weka实验总结
Weka实验总结:
在数据挖掘和机器学习领域,Weka是一个广泛使用的开源软件工具,提供了
丰富的机器学习算法和数据预处理工具。
经过本次实验,我对Weka的功能和应用
有了更深入的了解。
首先,Weka提供了丰富的机器学习算法,包括分类、回归、聚类、关联规则等。
通过在实验中应用这些算法,我们可以通过输入数据来训练模型,然后利用模型对新数据进行预测和分类。
例如,在分类问题中,我们可以使用决策树算法来构建一个分类模型,然后利用该模型对未知数据进行分类。
其次,Weka还提供了数据预处理的功能,包括数据清洗、特征选择和特征变
换等。
在实验中我们可以使用Weka提供的数据预处理工具,对数据进行处理和准备。
例如,我们可以使用Weka中的缺失值处理工具来处理数据中的缺失值,在数
据清洗的过程中,我们还可以进行数据规范化、去除异常值等操作。
另外,Weka具有友好的用户界面,使得使用起来更加简单和直观。
无论是数
据导入、算法选择还是结果分析,Weka都提供了易于使用的界面。
这对于初学者
来说非常友好,也方便了快速上手和使用。
总之,Weka是一个功能强大且易于使用的数据挖掘和机器学习工具。
通过本
次实验,我发现Weka提供了丰富的算法和功能,能够满足不同实验和研究的需求。
我相信Weka将在我今后的学习和研究中发挥重要的作用。
基于Weka的数据分类分析实验报告

基于Weka的数据分类分析实验报告1 实验目的使用数据挖掘中的分类算法,对数据集进行分类训练并测试。
应用不同的分类算法,比较他们之间的不同。
与此同时了解Weka平台的基本功能与使用方法。
2 实验环境2.1 Weka介绍Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。
Weka使用Java 写成的,并且限制在GNU通用公共证书的条件下发布。
它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。
Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。
图1 Weka主界面Weka系统包括处理标准数据挖掘问题的所有方法:回归、分类、聚类、关联规则以及属性选择。
分析要进行处理的数据是重要的一个环节,Weka提供了很多用于数据可视化和与处理的工具。
输入数据可以有两种形式,第一种是以ARFF格式为代表的文件;另一种是直接读取数据库表。
使用Weka的方式主要有三种:第一种是将学习方案应用于某个数据集,然后分析其输出,从而更多地了解这些数据;第二种是使用已经学习到的模型对新实例进预测;第三种是使用多种学习器,然后根据其性能表现选择其中一种来进行预测。
用户使用交互式界面菜单中选择一种学习方法,大部分学习方案都带有可调节的参数,用户可通过属性列表或对象编辑器修改参数,然后通过同一个评估模块对学习方案的性能进行评估。
2.2 数据和数据集根据应用的不同,数据挖掘的对象可以是各种各样的数据,这些数据可以是各种形式的存储,如数据库、数据仓库、数据文件、流数据、多媒体、网页,等等。
即可以集中存储在数据存储库中,也可以分布在世界各地的网络服务器上。
大部分数据集都以数据库表和数据文件的形式存在,Weka支持读取数据库表和多种格式的数据文件,其中,使用最多的是一种称为ARFF格式的文件。
ARFF格式是一种Weka专用的文件格式,Weka的正式文档中说明AREF代表Attribute-Relation File Format(属性-关系文件格式)。
weka数据预处理标准化方法说明

weka数据预处理标准化方法说明Weka(Waikato Environment for Knowledge Analysis)是一套用于数据挖掘和机器学习的开源软件工具集,提供了丰富的功能,包括数据预处理、分类、回归、聚类等。
在Weka中,数据预处理是一个关键的步骤,其中标准化是一个常用的技术,有助于提高机器学习算法的性能。
下面是在Weka中进行数据标准化的一般步骤和方法说明:1. 打开Weka:启动Weka图形用户界面(GUI)或使用命令行界面。
2. 加载数据:选择“Explorer”选项卡,然后点击“Open file”按钮加载您的数据集。
3. 选择过滤器(Filter):在“Preprocess”选项卡中,选择“Filter”子选项卡,然后点击“Choose”按钮选择一个过滤器。
4. 选择标准化过滤器:在弹出的对话框中,找到并选择标准化过滤器。
常见的标准化过滤器包括:- Normalize:这个过滤器将数据标准化为给定的范围,通常是0到1。
- Standardize:使用这个过滤器可以将数据标准化为零均值和单位方差。
- AttributeRange:允许您手动指定每个属性的范围,以进行标准化。
5. 设置标准化选项:选择标准化过滤器后,您可能需要配置一些选项,例如范围、均值和方差等,具体取决于选择的过滤器。
6. 应用过滤器:配置完成后,点击“Apply”按钮,将标准化过滤器应用于数据。
7. 保存处理后的数据:如果需要,您可以将标准化后的数据保存到文件中。
8. 查看结果:在数据预处理完成后,您可以切换到“Classify”选项卡,选择一个分类器,并使用标准化后的数据进行模型训练和测试。
记住,具体的步骤和选项可能会因Weka版本的不同而有所差异,因此建议查阅Weka文档或在线资源以获取更具体的信息。
此外,标准化的适用性取决于您的数据和机器学习任务,因此在应用标准化之前,最好先了解您的数据的分布和特征。
weka分类与回归

weka分类与回归1.背景知识WEKA把分类(Classification)和回归(Regression)都放在“Classify”选项卡中,这是有原因的。
在这两个任务中,都有一个目标属性(输出变量)。
我们希望根据一个样本(WEKA中称作实例)的一组特征(输入变量),对目标进行预测。
为了实现这一目的,我们需要有一个训练数据集,这个数据集中每个实例的输入和输出都是已知的。
观察训练集中的实例,可以建立起预测的模型。
有了这个模型,我们就可以新的输出未知的实例进行预测了。
衡量模型的好坏就在于预测的准确程度。
在WEKA中,待预测的目标(输出)被称作Class属性,这应该是来自分类任务的“类”。
一般的,若Class 属性是分类型时我们的任务才叫分类,Class属性是数值型时我们的任务叫回归。
2.选择算法这一节中,我们使用C4.5决策树算法对bank-data建立起分类模型。
我们来看原来的“bank-data.csv”文件。
“ID”属性肯定是不需要的。
由于C4.5算法可以处理数值型的属性,我们不用像前面用关联规则那样把每个变量都离散化成分类型。
尽管如此,我们还是把“Children”属性转换成分类型的两个值“YES”和“NO”。
另外,我们的训练集仅取原来数据集实例的一半;而从另外一半中抽出若干条作为待预测的实例,它们的“pep”属性都设为缺失值。
经过了这些处理的训练集数据在这里下载;待预测集数据在这里下载。
我们用“Explorer”打开训练集“bank.arff”,观察一下它是不是按照前面的要求处理好了。
切换到“C lassify”选项卡,点击“Choose”按钮后可以看到很多分类或者回归的算法分门别类的列在一个树型框里。
3.5版的WEKA中,树型框下方有一个“Filter...”按钮,点击可以根据数据集的特性过滤掉不合适的算法。
我们数据集的输入属性中有“Binary”型(即只有两个类的分类型)和数值型的属性,而Class变量是“Binary”的;于是我们勾选“Binary attributes”“Numeric attributes”和“Binary class”。
weka学习笔记

Weka 学习笔记一、数据格式:以“%”开始的行是注释。
除去注释后,整个ARFF文件可以分为两个部分。
第一部分给出了头信息(Head information),包括了对关系的声明和对属性的声明。
第二部分给出了数据信息(Data information),即数据集中给出的数据。
从“@data”标记开始,后面的就是数据信息了。
1、关系声明:@relation <relation-name>在ARFF文件的第一个有效行来定义。
<relation-name>是一个字符串。
如果这个字符串包含空格,它必须加上引号(指英文标点的单引号或双引号)。
2、属性声明: @attribute <attribute-name> <datatype>声明语句的顺序按照该项属性在数据部分的位置来排。
最后一个声明的属性被称作class属性,在分类或回归任务中,它是默认的目标变量。
<attribute-name>是必须以字母开头的字符串。
和关系名称一样,如果这个字符串包含空格,它必须加上引号。
WEKA支持的<datatype>有四种,分别是:numeric数值型、<nominal-specification>分类型、string字符串型、date [<date-format>日期型。
(1)数值属性:数值型属性可以是整数或者实数,但WEKA把它们都当作实数看待。
(2)分类属性:分类属性由<nominal-specification>列出一系列可能的类别名称并放在花括号中:{<nominal-name1>, <nominal-name2>, <nominal-name3>, ...} 。
例如如下的属性声明说明“outlook”属性有三种类别:“sunny”,“ overcast”和“rainy”:@attribute outlook {sunny, overcast, rainy}如果类别名称带有空格,仍需要将之放入引号中。
Weka–分类

Weka–分类1. weka简单介绍1) weka是新西兰怀卡托⼤学WEKA⼩组⽤JAVA开发的机器学习/数据挖掘开源软件。
2)相关资源链接3)主要特点集数据预处理、学习算法(分类、回归、聚类、关联分析)和评估⽅法等为⼀体的综合性数据挖掘⼯具具有交互式可视化界⾯提供算法学习⽐較环境通过其接⼝。
可实现⾃⼰的数据挖掘算法2. 数据集(.arff⽂件)数据集的呈现形式如上图所看到的,其表现为⼀个⼆维表,当中:表格⾥⼀⾏称作⼀个实例(Instance),相当于统计学中的⼀个样本,或者数据库中的⼀条记录表格⾥⼀列称作⼀个属性(Attribute)。
相当于统计学中的⼀个变量,或者数据库中的⼀个字段数据集的存储格式如上图所看到的。
是⼀种ASCII⽂本⽂件,整个ARFF⽂件能够分为两个部分:第⼀部分给出了头信息(Headinformation)。
包含了对关系的声明和对属性的声明第⼆部分给出了数据信息(Datainformation)。
即数据集中给出的数据。
从”@data”标记開始。
后⾯即为数据信息注:当中凝视部分以”%”開始。
凝视部分weka将忽略这些⾏;假设关系名。
属性名,数据的字符串包括空格,它必须加上引號;最后⼀个声明的属性被称作class属性,在分类或回归任务中它是默认的⽬标变量。
3. 数据类型1)Weka⽀持四种数据类型,分别为:numeric 数值型数值型能够是整数(integer)或者实数(real),weka将它们都当作实数看待。
nominal 标称型标称属性由⼀系列的类别名称放在花括号⾥。
string 字符串型字符串属性能够包括随意的⽂本。
date⽇期和时间型⽇期和时间属性统⼀⽤”date”类型表⽰,默认的字符串是ISO-8601所给的⽇期时间组合格式:“yyyy-MM-dd HH:mm:ss” timestamp DATE“yyyy-MM-dd HH:mm:ss”@DATA “2015-06-23 20:05:40”2)稀疏数据当数据集中含有⼤量的0值时。
WEKA中文详细教程

Weka可以将分析结果导出为多种格式,如CSV、ARFF、LaTeX等,用户可以通过“文件”菜单 选择“导出数据”来导出数据。
数据清理
缺失值处理
Weka提供了多种方法来处理缺失值, 如删除含有缺失值的实例、填充缺失 值等。
异常值检测
Weka提供了多种异常值检测方法, 如基于距离的异常值检测、基于密度 的异常值检测等。
Weka中文详细教程
目录
• Weka简介 • 数据预处理 • 分类算法 • 关联规则挖掘 • 回归分析 • 聚类分析 • 特征选择与降维 • 模型评估与优化
01
Weka简介
Weka是什么
01 Weka是一款开源的数据挖掘软件,全称是 "Waikato Environment for Knowledge Analysis",由新西兰怀卡托大学开发。
解释性强等优点。
使用Weka进行决策树 分类时,需要设置合 适的参数,如剪枝策 略、停止条件等,以 获得最佳分类效果。
决策树分类结果易于 理解和解释,能够为 决策提供有力支持。
贝叶斯分类器
贝叶斯分类器是一种 基于概率的分类算法, 通过计算不同类别的 概率来进行分类。
Weka中的朴素贝叶斯 分类器是一种基于贝 叶斯定理的简单分类 器,适用于特征之间 相互独立的场景。
08
模型评估与优化
交叉验证
01
交叉验证是一种评估机器学习模型性能的常用方法,通过将数据集分成多个子 集,然后使用其中的一部分子集训练模型,其余子集用于测试模型。
02
常见的交叉验证方法包括k-折交叉验证和留出交叉验证。在k-折交叉验证中, 数据集被分成k个大小相近的子集,每次使用其中的k-1个子集训练模型,剩余 一个子集用于测试。
weka的4种检验方法

weka的4种检验方法Weka是一款强大的机器学习软件,它提供了多种方法用于数据预处理、分类、回归、聚类和关联规则挖掘等任务。
在数据挖掘过程中,为了评估模型的性能和选择最佳的特征子集,我们需要使用各种检验方法。
在本文中,我将介绍Weka 中的四种主要的检验方法:交叉验证、自助法、留一法和训练集/测试集划分。
1. 交叉验证(Cross-Validation)交叉验证是一种常用的检验方法,它将数据集划分为训练集和测试集。
首先,将数据集划分为k个大小相等的子集,称为折(fold)。
然后,依次选取其中一个折作为测试集,剩下的k-1个折作为训练集。
重复这个过程k次,每次都使用不同的折作为测试集,最后得到k个模型的性能评估结果。
最常用的交叉验证方法是k折交叉验证。
在Weka中,使用交叉验证方法可以通过点击“Classify”->“More options...”->“Cross-validation”的选项来设置。
可以选择评估方法(Evaluation method)和折的数量。
Weka会自动进行数据划分和建模,并给出每个模型的性能评估结果。
2. 自助法(Bootstrap)自助法是一种通过有放回重抽样的方式来进行模型评估的方法。
它的基本思想是从原始数据集中有放回地抽取样本来构建新的训练集,然后使用该训练集训练模型,并将原始数据集中未被选中的样本作为测试集进行性能评估。
这个过程重复n次,得到n个模型的性能评估结果。
在Weka中,使用自助法可以通过点击“Classify”->“More options...”->“Bootstrap”的选项来设置。
可以选择自助示例的数量,并进行建模和性能评估。
3. 留一法(Leave-One-Out)留一法是一种特殊的交叉验证方法,即将每个样本作为一个测试集,其他样本作为训练集进行建模和性能评估。
对于含有n个样本的数据集,它将生成n个模型的性能评估结果。
Java用 WEKA 进行机器学习、数据挖掘(第一部分:简介和回归)

Java用WEKA 进行机器学习、数据挖掘(第一部分:简介和回归)简介什么是数据挖掘?您会不时地问自己这个问题,因为这个主题越来越得到技术界的关注。
您可能听说过像Google 和Yahoo! 这样的公司都在生成有关其所有用户的数十亿的数据点,您不禁疑惑,“它们要所有这些信息干什么?”您可能还会惊奇地发现Walmart是最为先进的进行数据挖掘并将结果应用于业务的公司之一。
现在世界上几乎所有的公司都在使用数据挖掘,并且目前尚未使用数据挖掘的公司在不久的将来就会发现自己处于极大的劣势。
那么,您如何能让您和您的公司跟上数据挖掘的大潮呢?我们希望能够回答您所有关于数据挖掘的初级问题。
我们也希望将一种免费的开源软件Waikato Environment for Knowledge Analysis (WEKA) 介绍给您,您可以使用该软件来挖掘数据并将您对您用户、客户和业务的认知转变为有用的信息以提高收入。
您会发现要想出色地完成挖掘数据的任务并不像您想象地那么困难。
此外,本文还会介绍数据挖掘的第一种技术:回归,意思是根据现有的数据预测未来数据的值。
它可能是挖掘数据最为简单的一种方式,您甚至以前曾经用您喜爱的某个流行的电子数据表软件进行过这种初级的数据挖掘(虽然WEKA 可以做更为复杂的计算)。
本系列后续的文章将会涉及挖掘数据的其他方法,包括群集、最近的邻居以及分类树。
(如果您还不太知道这些术语是何意思,没关系。
我们将在这个系列一一介绍。
)回页首什么是数据挖掘?数据挖掘,就其核心而言,是指将大量数据转变为有实际意义的模式和规则。
并且,它还可以分为两种类型:直接的和间接的。
在直接的数据挖掘中,您会尝试预测一个特定的数据点—比如,以给定的一个房子的售价来预测邻近地区内的其他房子的售价。
在间接的数据挖掘中,您会尝试创建数据组或找到现有数据内的模式—比如,创建“中产阶级妇女”的人群。
实际上,每次的美国人口统计都是在进行数据挖掘,政府想要收集每个国民的数据并将它转变为有用信息。
Weka分类

分类器介绍1.BayesWEKA的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),WEKA作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。
Weka中典型分类算法:Bayes,knn,支持向量机,神经网络,决策树等训练测试20ng数据集(NB分类器)分类结果:=== Run information ===Scheme:weka.classifiers.bayes.NaiveBayesRelation:E__ProgramFiles_Weka-3-6_20ng-weka.filters.unsupervised.attribute.StringToWordVector-R1-W1000-prune-rate-1.0-N0-stemme rweka.core.stemmers.NullStemmer-M1-tokenizerweka.core.tokenizers.WordTokenizer -delimiters " \r\n\t.,;:\'\"()?!"Instances: 19997Attributes: 4856[list of attributes omitted]Test mode:split 60.0% train, remainder testTime taken to build model: 58.77 seconds=== Evaluation on test split ====== Summary ===Correctly Classified Instances 7080 88.5111 %Incorrectly Classified Instances 919 11.4889 %Kappa statistic 0.8791Mean absolute error 0.0116Root mean squared error 0.1037Relative absolute error 12.1997 %Root relative squared error 47.5812 %Total Number of Instances 7999=== Detailed Accuracy By Class ===TP Rate FP Rate Precision Recall F-Measure ROC Area Class0.82 0.012 0.775 0.82 0.797 0.982 alt.atheism0.915 0.011 0.828 0.915 0.87 0.987 comp.graphics0.942 0.001 0.977 0.942 0.959 0.994 comp.os.ms-windows.misc0.966 0.003 0.937 0.966 0.951 0.997 comp.sys.ibm.pc.hardware0.953 0.001 0.99 0.953 0.971 0.999 comp.sys.mac.hardware0.907 0.001 0.98 0.907 0.942 0.99 comp.windows.x0.913 0.023 0.683 0.913 0.782 0.985 misc.forsale0.902 0.003 0.944 0.902 0.923 0.99 rec.autos0.909 0.001 0.978 0.909 0.942 0.996 rec.motorcycles0.938 0.001 0.986 0.938 0.962 0.999 rec.sport.baseball0.949 0.001 0.98 0.949 0.964 0.999 rec.sport.hockey0.935 0.005 0.913 0.935 0.924 0.996 sci.crypt0.884 0.006 0.886 0.884 0.885 0.993 sci.electronics0.841 0.002 0.959 0.841 0.896 0.993 sci.med0.906 0.003 0.942 0.906 0.923 0.983 sci.space0.992 0.001 0.972 0.992 0.982 1 soc.religion.christian0.885 0.007 0.868 0.885 0.876 0.993 talk.politics.guns0.842 0.008 0.846 0.842 0.844 0.99 talk.politics.mideast0.777 0.022 0.642 0.777 0.703 0.973 talk.politics.misc0.529 0.009 0.747 0.529 0.619 0.964 talk.religion.miscWeighted Avg. 0.885 0.006 0.892 0.885 0.886 0.99=== Confusion Matrix ===a b c d e f g h i j k l m n o p q r s t <-- classified as314 4 0 0 0 0 3 2 2 0 0 0 2 1 0 4 0 6 4 41 | a = alt.atheism1 400 5 3 0 6 8 0 0 0 0 62 2 0 0 03 1 0 | b = comp.graphics0 1 387 10 0 0 4 0 0 0 0 3 0 0 0 0 0 0 6 0 | c = comp.os.ms-windows.misc0 2 1 369 1 0 4 0 0 0 0 2 1 0 0 0 0 0 2 0 | d = comp.sys.ibm.pc.hardware0 4 0 3 384 0 5 0 0 0 0 1 0 1 0 0 0 0 5 0 | e = comp.sys.mac.hardware1 202 1 0 350 0 0 0 0 0 2 0 1 1 0 0 7 1 0 | f = comp.windows.x0 3 1 4 2 0 369 9 0 0 0 3 2 1 0 0 0 0 10 0 | g = misc.forsale0 2 0 0 0 0 18 369 2 0 0 0 1 1 0 0 3 2 11 0 | h = rec.autos1 0 0 0 0 0 15 6 358 0 0 1 0 02 0 0 1 10 0 | i = rec.motorcycles1 0 0 0 0 0 12 0 1 364 7 0 0 0 0 0 0 1 2 0 | j = rec.sport.baseball 0 0 0 0 0 0 12 0 0 5 393 0 0 0 0 0 0 04 0 | k = rec.sport.hockey0 11 0 0 0 1 7 0 0 0 0 388 5 0 2 0 0 1 0 0 | l = sci.crypt0 1 0 4 1 0 7 2 0 0 0 13 342 6 6 0 0 0 5 0 | m = sci.electronics1 16 0 0 0 0 14 0 0 0 12 20 3493 0 0 54 0 | n = sci.med0 7 0 0 0 0 5 0 0 0 0 2 7 1 338 0 0 6 7 0 | o = sci.space0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 379 0 1 0 0 | p = soc.religion.christian0 2 0 0 0 0 9 0 2 0 0 1 1 1 1 0 368 7 19 5 | q = talk.politics.guns 0 7 0 0 0 0 21 3 1 0 0 0 1 0 1 0 4 347 25 2 | r = talk.politics.mideast 0 0 0 0 0 0 9 0 0 0 0 1 0 0 3 0 31 18 299 24 | s = talk.politics.misc 86 2 0 0 0 0 17 0 0 0 0 0 2 0 2 7 18 5 51 213 | t = talk.religion.misca实际Y 实际N判定Y 314 91判定N 65 75292.libsvmTest:svm-train wv_trainSvm-predict wv_test wv_train.model wv_test.outResult:Accurate = 92% (736/800) (classification)class1_predict:464class1_total:400class1_correct:400class2_predict:336class2_total:400class2_correct:336class1:Precision=86.21%Recall=100.00%class2:Precision=100.00%Recall=84.00%3.TSVMTransduction options (see [Joachims, 1999c], [Joachims, 2002a]):-p [0..1] - fraction of unlabeled examples to be classifiedinto the positive class (default is the ratio ofpositive and negative examples in the trainingReading model...OK. (369 support vectors read)Classifying test examples..100..200..300..400..500..600..doneRuntime (without IO) in cpu-seconds: 0.00Accuracy on test set: 96.00% (576 correct, 24 incorrect, 600 total)Precision/recall on test set: 95.70%/96.33%4.kNN=== Run information ====== Run information ===Scheme:zy.IBk -K 3 -W 0 -A "weka.core.neighboursearch.LinearNNSearch -A \"weka.core.EuclideanDistance -R first-last\""Relation: supermarketInstances: 4627Attributes: 217[list of attributes omitted]Test mode:split 60.0% train, remainder test=== Classifier model (full training set) ===IB1 instance-based classifierusing 3 nearest neighbour(s) for classificationTime taken to build model: 0.02 seconds=== Evaluation on test split ====== Summary ===Correctly Classified Instances 688 37.1691 %Incorrectly Classified Instances 1163 62.8309 %Kappa statistic -0.0008Mean absolute error 0.6112Root mean squared error 0.7694Relative absolute error 131.9609 %Root relative squared error 159.2962 %Total Number of Instances 1851=== Detailed Accuracy By Class ===TP Rate FP Rate Precision Recall F-Measure ROC Area Class 0.008 0.009 0.6 0.008 0.015 0.526 low 0.991 0.992 0.37 0.991 0.539 0.526 high Weighted Avg. 0.372 0.373 0.515 0.372 0.209 0.526=== Confusion Matrix ===a b <-- classified as9 1157 | a = low6 679 | b = high。
Java用 WEKA 进行机器学习、数据挖掘(第二部分:分类和群集)

Java用WEKA 进行机器学习、数据挖掘(第二部分:分类和群集)简介在用WEKA 进行数据挖掘,第 1 部分:简介和回归,我介绍了数据挖掘的概念以及免费的开源软件Waikato Environment for Knowledge Analysis(WEKA),利用它可以挖掘数据来获得趋势和模式。
我还谈到了第一种数据挖掘的方法—回归—使用它可以根据一组给定的输入值预测数字值。
这种分析方法非常容易进行,而且也是功能最不强大的一种数据挖掘方法,但是通过它,读者对WEKA 有了很好的了解,并且它还提供了一个很好的例子,展示了原始数据是如何转换为有意义的信息的。
在本文中,我将带您亲历另外两种数据挖掘的方法,这二者要比回归模型稍微复杂一些,但功能则更为强大。
如果回归模型只能为特定输入提供一个数值输出,那么这两种模型则允许您对数据做不同的解析。
正如我在第 1 部分中所说的,数据挖掘的核心就是将正确的模型应用于数据。
即便有了有关客户的最佳数据(无论这意味着什么),但是如果没有将正确的模型应用于数据,那么这些数据也没有任何意义。
不妨从另一个角度考虑这件事情:如果您只使用能生成数值输出的回归模型,那么Amazon 如何能告知您“购买了X 产品的客户还购买了Y 产品”?这里没有数值型的函数能够告诉您这类信息。
所以让我们来深入研究可用在数据中的其他两个模型。
在本文中,我会反复提及称为“最近邻”的数据挖掘方法,但我不会过多地对其进行剖析,详细的介绍会在第 3 部分给出。
不过,我在本文中的比较和描述部分将它包括进来以使讨论更为完整。
回页首分类vs. 群集vs. 最近邻在我深入探讨每种方法的细节并通过WEKA 使用它们之前,我想我们应该先理解每个模型—每个模型适合哪种类型的数据以及每个模型试图实现的目标。
我们还会将我们已有的模型—回归模型—也包括在我们的讨论之中,以便您可以看到这三种新模型与我们已经了解的这个模型的对比。
我将通过实际的例子展示每个模型的使用以及各自的不同点。
数据挖掘weka实现步骤
实际操作:
再选算法和修改属性
结论:
另外i还可以实现:分类与回归:(建议:再网上找几张图,借一个图,做简单的解释)
回归于分类:实现的是对未来的上网时间段(或者上网流量)预测分析
聚类分析:k-means算法;
实现把分散的点聚类到一起。从而实现上网时间段的集中百分比。
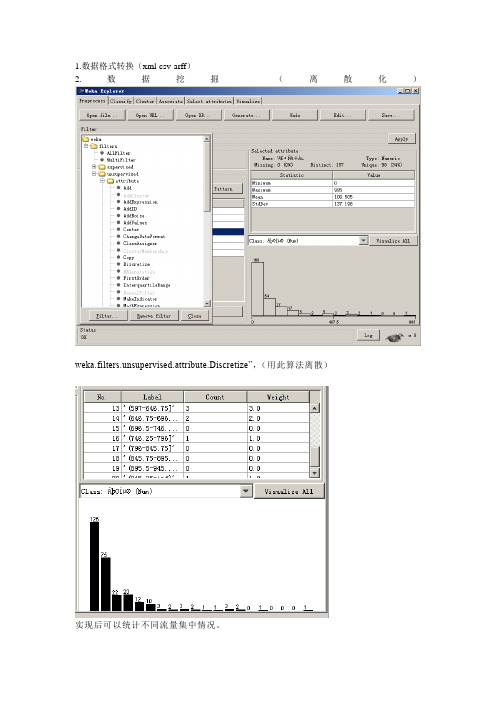
1.数据格式转换(xml-csv-arff)
2.数据挖掘(离散化)
weka.filters.unsupervised.attribute.Discretize”,(用此算法离散)
实现后可以统计不同流量集中情况。
3实现可视化步骤:
(需要修改数据(使数据只剩时间和流量:每个用1,2个数字表示))
4实现关联分析:(关ቤተ መጻሕፍቲ ባይዱ分析概念)
Weka数据挖掘软件使用指南

Weka数据挖掘软件使用指南Weka 数据挖掘软件使用指南1. Weka简介该软件是WEKA的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),它的源代码可通过得到。
Weka作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。
如果想自己实现数据挖掘算法的话,可以看一看Weka的接口文档。
在Weka中集成自己的算法甚至借鉴它的方法自己实现可视化工具并不是件很困难的事情。
2. Weka启动打开Weka主界面后会出现一个对话框,如图:主要使用右方的四个模块,说明如下:Explorer使用Weka探索数据的环境,包括获取关联项,分类预测,聚簇等;(本文主要总结这个部分的使用)Experimenter运行算法试验、管理算法方案之间的统计检验的环境;KnowledgeFlow这个环境本质上和Explorer所支持的功能是一样的,但是它有一个可以拖放的界面。
它有一个优势,就是支持增量学习;SimpleCLI提供了一个简单的命令行界面,从而可以在没有自带命令行的操作系统中直接执行Weka命令;(某些情况下使用命令行功能更好一些)3.主要操作说明点击进入Explorer模块开始数据探索环境:3.1主界面进入Explorer模式后的主界面如下:3.1.1标签栏主界面最左上角(标题栏下方)的是标签栏,分为五个部分,功能依次是:1. Preprocess. 选择和修改要处理的数据;2. Classify. 训练和测试关于分类或回归的学习方案;3. Cluster. 从数据中学习聚类;4. Associate.从数据中学习关联规则;5. Select attributes. 选择数据中最相关的属性;6. Visualize.查看数据的交互式二维图像。
3.1.2载入、编辑数据标签栏下方是载入数据栏,功能如下:1.Open file.打开一个对话框,允许你浏览本地文件系统上的数据文件(.dat);2.Open URL.请求一个存有数据的URL 地址;3.Open DB.从数据库中读取数据;4.Generate.从一些数据生成器中生成人造数据。
weka的贝叶斯分类

weka的贝叶斯分类
WEKA(Waikato Environment for Knowledge Analysis)是一款开源的、基于Java的平台,用于数据挖掘和数据分析。
在WEKA中,可以使用多种分类算法,其中包括贝叶斯分类器。
贝叶斯分类器基于贝叶斯定理,是一种基于概率的分类方法。
在WEKA中,可以使用朴素贝叶斯分类器,它是一种简化的贝叶斯分类器,假设特征之间相互独立。
朴素贝叶斯分类器在处理大量特征的数据集时非常有效,因为它可以大大减少计算复杂度。
要使用WEKA中的朴素贝叶斯分类器,可以按照以下步骤进行操作:
1. 打开WEKA软件并加载要分类的数据集。
2. 在“Classify”选项卡下选择“Naive Bayes”。
3. 如果数据集具有连续的特征值,可以选择“Gaussian”作为分布函数;如果特征值为离散的,可以选择“Multinomial”或“Bernoulli”。
4. 点击“Start”按钮开始进行分类。
通过以上步骤,就可以使用WEKA中的朴素贝叶斯分类器对数据进行分类。
weka操作介绍

1 2 3 4
6
7 5
8
1.区域1的几个选项卡是用来切换不同的 挖掘任务面板。assify(分类)
Cluster(聚类) Associate(关联分析) Select Attributes(选择属性)
Visualize(可视化)
2. 区域2是一些常用按钮。包括打开数据, 保存及编辑功能。我们可以在这里把 “bank-data.csv”,另存为“bank-data.arff”
WEKA 操作介绍
命令环境
算法实验环境
知识流环境
在KnowledgeFlow 窗口顶部有八个标签: DataSources--数据载入器 DataSinks--数据保存器 Filters--筛选器 Classifiers--分类器 Clusterers--聚类器 Associations—关联器 Evaluation—评估器 Visualization—可视化
Cluster
右击左侧栏result list,点“Visualize cluster assignments”。 弹出的窗口给出了各实例的散点图。
Associate 设置参数 car:如果设为真,则会挖掘类关联规则而不是全 局关联规则。 classindex: 类属性索引。如果设置为-1,最后的 属性被当做类属性。 delta: 以此数值为迭代递减单位。不断减小支持 度直至达到最小支持度或产生了满足数量要求的 规则。 lowerBoundMinSupport: 最小支持度下界。 metricType: 度量类型,设置对规则进行排序的 度量依据。可以是:置信度(类关联规则只能用 置信度挖掘),提升度(lift),平衡度(leverage), 确信度(conviction)。 minMtric :度量的最小值。 numRules: 要发现的规则数。 outputItemSets: 如果设置为真,会在结果中输 出项集。 removeAllMissingCols: 移除全部为缺失值的列。 significanceLevel :重要程度。重要性测试(仅用 于置信度)。 upperBoundMinSupport: 最小支持度上界。 从这 个值开始迭代减小最小支持度。 verbose: 如果设置为真,则算法会以冗余模式运 行。
weka总结

Weka总结引言Weka是一个免费、开源的数据挖掘和机器学习软件,于1997年首次发布。
它由新西兰怀卡托大学的机器学习小组开发,提供了一系列数据预处理、分类、回归、聚类和关联规则挖掘等功能。
本文将对Weka进行总结,并讨论其主要功能和优点。
主要功能1. 数据预处理Weka提供了各种数据预处理技术,用于数据的清洗、转换和集成。
最常用的预处理技术包括缺失值处理、离散化、属性选择和特征缩放等。
通过这些预处理技术,用户可以减少数据中的噪声和冗余信息,提高机器学习模型的性能。
2. 分类Weka支持多种分类算法,包括决策树、贝叶斯分类器、神经网络和支持向量机等。
用户可以根据自己的需求选择适当的算法进行分类任务。
Weka还提供了交叉验证和自动参数调整等功能,帮助用户评估和优化分类器的性能。
3. 回归除了分类,Weka还支持回归问题的解决。
用户可以使用线性回归、多项式回归和局部回归等算法,对给定的数据集进行回归分析。
Weka提供了模型评估和可视化工具,帮助用户理解回归模型和评估其预测性能。
4. 聚类Weka的聚类算法可用于将数据集中相似的样本归类到一起。
Weka支持K-means、DBSCAN、谱聚类和层次聚类等常用的聚类算法。
用户可以根据数据的特点选择适当的算法并解释聚类结果。
5. 关联规则挖掘关联规则挖掘是一种常见的数据挖掘任务,用于发现数据集中的频繁项集和关联规则。
通过Weka,用户可以使用Apriori和FP-growth等算法来挖掘数据中的关联规则。
Weka还提供了支持多种评估指标的工具,用于评估关联规则的质量和可信度。
优点1. 易于使用Weka的用户界面友好且易于使用。
它提供了直观的图形界面,使用户可以快速上手并进行各种数据挖掘任务。
此外,Weka还支持命令行操作,方便用户在脚本中使用和集成Weka的功能。
2. 强大的功能Weka提供了丰富的数据挖掘和机器学习功能,涵盖了数据预处理、分类、回归、聚类和关联规则挖掘等领域。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
weka分类与回归1.背景知识WEKA把分类(Classification)和回归(Regression)都放在“Classify”选项卡中,这是有原因的。
在这两个任务中,都有一个目标属性(输出变量)。
我们希望根据一个样本(WEKA中称作实例)的一组特征(输入变量),对目标进行预测。
为了实现这一目的,我们需要有一个训练数据集,这个数据集中每个实例的输入和输出都是已知的。
观察训练集中的实例,可以建立起预测的模型。
有了这个模型,我们就可以新的输出未知的实例进行预测了。
衡量模型的好坏就在于预测的准确程度。
在WEKA中,待预测的目标(输出)被称作Class属性,这应该是来自分类任务的“类”。
一般的,若Class 属性是分类型时我们的任务才叫分类,Class属性是数值型时我们的任务叫回归。
2.选择算法这一节中,我们使用C4.5决策树算法对bank-data建立起分类模型。
我们来看原来的“bank-data.csv”文件。
“ID”属性肯定是不需要的。
由于C4.5算法可以处理数值型的属性,我们不用像前面用关联规则那样把每个变量都离散化成分类型。
尽管如此,我们还是把“Children”属性转换成分类型的两个值“YES”和“NO”。
另外,我们的训练集仅取原来数据集实例的一半;而从另外一半中抽出若干条作为待预测的实例,它们的“pep”属性都设为缺失值。
经过了这些处理的训练集数据在这里下载;待预测集数据在这里下载。
我们用“Explorer”打开训练集“bank.arff”,观察一下它是不是按照前面的要求处理好了。
切换到“C lassify”选项卡,点击“Choose”按钮后可以看到很多分类或者回归的算法分门别类的列在一个树型框里。
3.5版的WEKA中,树型框下方有一个“Filter...”按钮,点击可以根据数据集的特性过滤掉不合适的算法。
我们数据集的输入属性中有“Binary”型(即只有两个类的分类型)和数值型的属性,而Class变量是“Binary”的;于是我们勾选“Binary attributes”“Numeric attributes”和“Binary class”。
点“OK”后回到树形图,可以发现一些算法名称变红了,说明它们不能用。
选择“trees”下的“J48”,这就是我们需要的C4.5算法,还好它没有变红。
点击“Choose”右边的文本框,弹出新窗口为该算法设置各种参数。
点“More”查看参数说明,点“Capa bilities”是查看算法适用范围。
这里我们把参数保持默认。
现在来看左中的“Test Option”。
我们没有专门设置检验数据集,为了保证生成的模型的准确性而不至于出现过拟合(overfitting)的现象,我们有必要采用10折交叉验证(10-fold cross validation)来选择和评估模型。
若不明白交叉验证的含义可以Google一下。
3.建模结果OK,选上“Cross-validation”并在“Folds”框填上“10”。
点“Start”按钮开始让算法生成决策树模型。
很快,用文本表示的一棵决策树,以及对这个决策树的误差分析等等结果出现在右边的“Classifier output”中。
同时左下的“Results list”出现了一个项目显示刚才的时间和算法名称。
如果换一个模型或者换个参数,重新“Start”一次,则“Results list”又会多出一项。
我们看到“J48”算法交叉验证的结果之一为Correctly Classified Instances 206 68.6667 %也就是说这个模型的准确度只有69%左右。
也许我们需要对原属性进行处理,或者修改算法的参数来提高准确度。
但这里我们不管它,继续用这个模型。
右键点击“Results list”刚才出现的那一项,弹出菜单中选择“Visualize tree”,新窗口里可以看到图形模式的决策树。
建议把这个新窗口最大化,然后点右键,选“Fit to screen”,可以把这个树看清楚些。
看完后截图或者关掉500)this.width=500" border=0>这里我们解释一下“Confusion Matrix”的含义。
=== Confusion Matrix ===a b <-- classified as74 64 | a = YES30 132 | b = NO这个矩阵是说,原本“pep”是“YES”的实例,有74个被正确的预测为“YES”,有64个错误的预测成了“NO”;原本“pep”是“NO”的实例,有30个被错误的预测为“YES”,有132个正确的预测成了“NO”。
74+64+30+132 = 300是实例总数,而(74+132)/300 = 0.68667正好是正确分类的实例所占比例。
这个矩阵对角线上的数字越大,说明预测得越好。
4.模型应用现在我们要用生成的模型对那些待预测的数据集进行预测了,注意待预测数据集和训练用数据集各个属性的设置必须是一致的。
WEKA中并没有直接提供把模型应用到带预测数据集上的方法,我们要采取间接的办法。
在“Test Opion”中选择“Supplied test set”,并且“Set”成“bank-new.arff”文件。
重新“Start”一次。
注意这次生成的模型没有通过交叉验证来选择,“Classifier output”给出的误差分析也没有多少意义。
这也是间接作预测带来的缺陷吧。
现在,右键点击“Result list”中刚产生的那一项,选择“Visualize classifier errors”。
我们不去管新窗口中的图有什么含义,点“Save”按钮,把结果保存成“bank-predicted.arff”。
这个ARFF文件中就有我们需要的预测结果。
在“Explorer”的“Preprocess”选项卡中打开这个新文件,可以看到多了两个属性“Instance_number”和“predictedpep”。
“Instance_number”是指一个实例在原“bank-new. arff”文件中的位置,“predictedpep”就是模型预测的结果。
点“Edit”按钮或者在“ArffViewer”模块中打开可以查看这个数据集的内容。
比如,我们对实例0的pep预测值为“YES”,对实例4的预测值为“NO”。
使用命令行(推荐)虽然使用图形界面查看结果和设置参数很方便,但是最直接最灵活的建模及应用的办法仍是使用命令行。
打开“Simple CLI”模块,像上面那样使用“J48”算法的命令格式为:java weka.classifiers.trees.J48 -C 0.25 -M 2 -t directory-path\bank.arff -d directory-path \ bank.model其中参数“ -C 0.25”和“-M 2”是和图形界面中所设的一样的。
“-t ”后面跟着的是训练数据集的完整路径(包括目录和文件名),“-d ”后面跟着的是保存模型的完整路径。
注意!这里我们可以把模型保存下来。
输入上述命令后,所得到树模型和误差分析会在“Simple CLI”上方显示,可以复制下来保存在文本文件里。
误差是把模型应用到训练集上给出的。
把这个模型应用到“bank-new.arff”所用命令的格式为:java weka.classifiers.trees.J48 -p 9 -l directory-path\bank.model -T directory-path \bank-ne w.arff其中“-p 9”说的是模型中的Class属性是第9个(也就是“pep”),“-l”后面是模型的完整路径,“-T”后面是待预测数据集的完整路径。
输入上述命令后,在“Simple CLI”上方会有这样一些结果:0 YES 0.75 ?1 NO 0.7272727272727273 ?2 YES 0.95 ?3 YES 0.8813559322033898 ?4 NO 0.8421052631578947 ?...这里的第一列就是我们提到过的“Instance_number”,第二列就是刚才的“predictedpep”,第四列则是“bank-new.arff”中原来的“pep”值(这里都是“?”缺失值)。
第三列对预测结果的置信度(confide nce )。
比如说对于实例0,我们有75%的把握说它的“pep”的值会是“YES”,对实例4我们有84.2%的把握说它的“pep”值会是“NO”。
我们看到,使用命令行至少有两个好处。
一个是可以把模型保存下来,这样有新的待预测数据出现时,不用每次重新建模,直接应用保存好的模型即可。
另一个是对预测结果给出了置信度,我们可以有选择的采纳预测结果,例如,只考虑那些置信度在85%以上的结果。
可惜,命令行仍不能保存交叉验证等方式选择过的模型,也不能将它们应用到待预测数据上。
要实现这一目的,须用到“KnowledgeFlow”模块的“ PredictionAppender”。
5.DM步骤1. 明确目标与理解资料;2. 获取相关技术与知识;3. 整合与查核资料;4. 去除错误或不一致及不完整的资料;5. 由数据选取样本先行试验;6. 研发模式(model)与型样(pattern);7. 实际Data Mining的分析工作;8. 测试与检核;9. 找出假设并提出解释;10. 持续应用于企业流程中。