dbf文件结构
编写EXCEL文件转DBF文件要知的资料

编写EXCEL文件转DBF文件要知的资料自从微软自EXCEL2007开始取消了另存为DBF文件功能之后。
我只好用国产WPSOFFICE中的ET把EXCEL文件转换成DBF文件了。
而其他软件都是收费的,所谓在线转换工具更就是个笑话。
不过ET的转换也不完美,偶然会碰到情况,不知为何只能转换前几列数据的情况。
这时要先把EXCEL表格先另存为CSV文件,然后再读入CSV文件再另成为DBF文件。
而且,用ET打开DBF文件编辑,若是增加新纪录后保存,往往DBF文件中记录个数是不变的,造成后面的纪录自动丢失。
因此我尝试自己写程序来转换,发现光从网上找到的DBF文件头结构资料是不够的,经过参考ET转换出来的DBF文件,发现若要正确转换成DBF文件,还有几个分隔符和某些格式需要注意。
(一)首先是前32字节的DBF文件头资料,这部分及第(二)部分基本上是从网上复制来的资料,参考(https:///weixin_30896657/article/details/95757196)1.表头记录的结构:字节偏移说明0 文件类型0x02 FoxBASE0x03 FoxBASE+/dBASE III PLUS,无备注0x30 Visual FoxPro0x43 dBASE IV SQL 表文件,无备注0x63 dBASE IV SQL 系统文件,无备注0x83 FoxBASE+/dBASE III PLUS,有备注0x8B dBASE IV 有备注0xCB dBASE IV SQL 表文件,有备注0xF5 FoxPro 2.x(或更早版本)有备注0xFB FoxBASE1 - 3 最近一次更新的时间(YYMMDD)其中第1字节是年份,其值+1900就是建立的年份,第2字节的值是月份,第3字节的值是日期4 - 7 文件中的记录数目第4字节的值是总记录数/256后的余数,一般第5字节的值*256 + 第4字节的值为记录总数目。
8 - 9 第一个数据记录的位置第8字节的值是位置/256后的余数,一般第9字节的值*256 + 第8字节的值为记录在DBF文件中开始的位置。
DBF文件结构中文说明

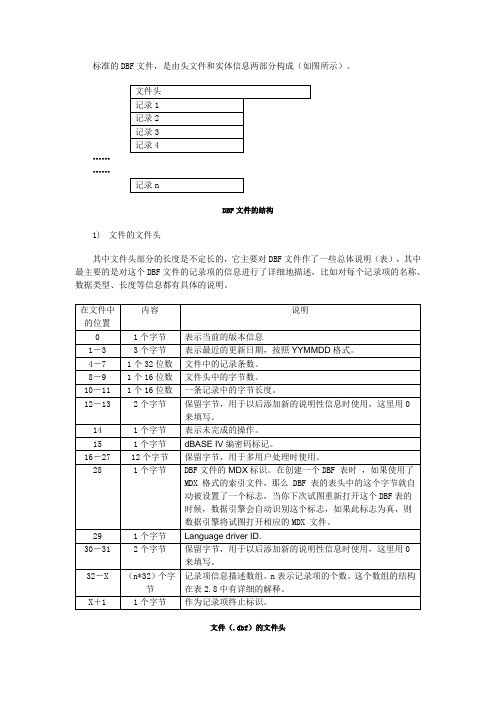
标准的DBF文件,是由头文件和实体信息两部分构成(如图所示)。
1)文件的文件头其中文件头部分的长度是不定长的,它主要对DBF文件作了一些总体说明(表),其中最主要的是对这个DBF文件的记录项的信息进行了详细地描述,比如对每个记录项的名称、数据类型、长度等信息都有具体的说明。
2)文件的实体信息实体信息部分就是一条条记录,每条记录都是由若干个记录项构成,因此只要依次循环读取每条记录就可以了。
3)一个读取dbf文件的例子假设要读取一个名为soil的dbf文件(存储了土地利用信息),它含有8个记录项, 记录项信息如表所示:2、行情文件格式 说明:(1)、表文件由头记录及数据记录组成。
头记录定义该表的结构及与表相关的其他信息。
数据 记录紧接在头记录之后,包含字段中实际的文本。
记录的长度等于所有字段定义的长度之和 (以 字节为单位)。
(2) 、头记录以终止符(OxOD )结束,数据记录以终止符( (3) 、表文件中存储整数时低位字节在前。
(4) 、数据记录从删除标记字节开始。
如果删除标记字节为 未被删除,如果该字节为星号 (0x2A ),则表示该记录被删除。
名的各字段的数据。
(5)、数据记录都是用 ASCII 码形式存放的,所以只要读岀文件头和字段类型描述区的内容, 就可以直接读取 dbf 文件中的每条记录。
0x1A )结束。
ASCII 空格(0x20),则表示该记录 在删除标记之后是字段记录中所命32 - n 字段子记录字段的数目决定了字段子记录的数目。
字段记录结构(32字节)F面是读取这个dbf文件的代码:void On ReadDbf(CStri ng Dbf)fread(&RecordByteNum, sizeof(short), 1,m_Dbf);FILE* m_Dbf;〃****Dbf 文件指针II 打开dbf 文件if((m_Dbf(Dbf,"rb"))==NULL) {return;} int i,j;//////**** 读取dbf 文件的文件头 开始BYTE versio n; fread(&versio n,1,1,m_Dbf); BYTE date[3]; for(i=0;i<3;i++) {fread(date+i,}fread(&HeaderByteNum, sizeof(short), 1,m_Dbf);short RecordByteNumint RecordNum; fread(&RecordNum, short HeaderByteNum;//****** sizeof( int),1, i_Dbf);1, 1,m_Dbf);short Reservedl;1,m_Dbf); Dbf);_Dbf);m_Dbf); fread(&Reserved1,BYTE Flag4s;fread(&F lag4s,BYTE En crypteFlag;fread(&EncrypteFlag,sizeof(short), 1,m_Dbf);sizeof(BYTE),sizeof(BYTE), 1,m_for(i=0;i<3;i++){fread(&Unu sed,}BYTE MDXFlag;fread(&MDXFIag, sizeof(BYTE), 1,mBYTE LDriID;fread(&LDrilD,short Reserved2;fread(&Reserved2, sizeof(short), 1,m_Dbf);BYTE n ame[11];sizeof( in t), 1,mi_Dbf);sizeof(BYTE), 1, BYTE fieldType;int Reserved3; fread(&decimalCou nt,sizeof(BYTE), 1,m_Dbf); IIReserved4——2 bytesBYTE fieldLength; BYTE decimalCou nt; short Reserved4; BYTE workID; short Reserved5[5]; BYTE mDXFIag1; int fieldsco unt;fieldscount = (HeaderByteNum - 32) / 32;II 读取记录项信息-共有8个记录项 for(i=0;i<HeaderByteNum;i++) {IIFieldName ——11 fread( name, IIFieldType ——1 fread( &fieldType, IIReserved3——4 Reserved3fread(&Reserved3, sizeof(i nt), 1,m_Dbf);IIFieldLe ngth--1bytesfread( &fieldLe ngth,sizeof(BYTE), 1,m_Dbf); IIDecimalCou nt-1bytesbytes 11, 1,m_Dbf);bytessizeof(BYTE), 1,m_Dbf);bytes =0;fread(&Reserved4, sizeof(short), 1,m_Dbf);//WorkID ----- 1 bytesfread(&worklD, sizeof(BYTE ),1,m_Dbf);〃Reserved5----10 bytesfor(j=0;j<5;j++){fread(Reserved5+j,sizeof(short),1,m_Dbf);}〃MDXFIag1-----1 bytesfread(&mDXFIag1, sizeof(BYTE),1,m_Dbf);}BYTE termi nator;fread(&termi nator, sizeof(BYTE), 1,m_Dbf);//读取dbf文件头结束double Area,Perimeter,Ce ntroid_y,Ce ntroid_x;int Soils_,Soils_id;CStri ng Soil_code,suit;BYTE deleteFlag;char media[31];//读取dbf文件记录开始fread(&Reserved4, sizeof(short), 1,m_Dbf); for(i=0;i<RecordNum;i++)fread(&deleteFlag,sizeof(BYTE), 1,m_Dbf);1,m_Dbf);// 读取 Area double for(j=0;j<31;j++)fread(media+j, sizeof(char),1,m_Dbf);Area =atof(media);// 读取 Perimeter double for(j=0;j<31;j++)fread(media+j, sizeof(char),Perimeter =atof(media); // 读取 soils_ int for(j=0;j<31;j++)strcpy(media+j,"");for(j=0;j<11;j++)fread(media+j, sizeof(char),Soils_=atoi(media);// 读取 Soils_id int for(j=0;j<31;j++)strcpy(media+j,"");for(j=0;j<11;j++)fread(media+j, sizeof(char),1,m_Dbf);1,m_Dbf);Soils_id =atoi(media);// 读取soil_code stringfor(j=0;j<31;j++)strcpy(media+j,"");for(j=0;j<3;j++)fread(media+j, sizeof(char), 1,m_Dbf);Soil_code =media;// 读取suit stringfor(j=0;j<31;j++)strcpy(media+j,"");for(j=0;j<1;j++)fread(media+j, sizeof(char), 1,m_Dbf);suit =media;// 读取Centroid_y doublefor(j=0;j<31;j++)strcpy(media+j,"");for(j=0;j<31;j++)fread(media+j, sizeof(char), 1,m_Dbf);Cen troid_y =atof(media);// 读取Centroid_x double for(j=0;j<31;j++)strcpy(media+j,"");for(j=0;j<31;j++)fread(media+j, sizeof(char),Cen troid_x =atof(media);}II读取dbf文件记录结束。
.DBF数据库文件结构形式及其利用

河北 张永义
1994-09-16
一个文件在磁盘上的储存包括三部分:目录区、文件分配表、数据区。对于FOXBASE的核心部分.DBF文件也不例外,在前两点上同于其它类型文件,(目录区的形式和含义见表一),这里着重数据区的分析。 .DBF文件在数据区的结构又可分为三部分;文件头描述区,字段结构描述区(形式和含义见表二)和数据描述区。当新建库未录入数据时,无第三区和文件结束标志1AH,有记录时,此区总长度=字段宽度总和×记录个数,文件尾1AH标志在最后一个字节,数据按字段顺序和宽度排列,每条记录间用20H隔断。当ZAP后,原1AH标志不变,新1AH标志写在记录起始偏移字节处,数据不删除Байду номын сангаас但遇写盘操作时,将会被覆盖。 了解文件结构后,我们可以使用NORTON、PCTOOLS、DEBUG等工具按照本文中的一些方法对其加以利用,达到满足某些特殊要求的目的。例如:抓住目录区的文件长、文件分配表的簇号分配链、文件头的记录个数值、数据推述区的1AH标志位置这四要素,就可以做到误作ZAP后的手工数据恢复;又因能直接对字段名及其类型改写,得以确保万条记录的安全转换。目录项适当修改后,整个文件就被隐形加密,还可以采用位移法把目录项中的起始簇号、文件长、文件头中的记录个数、数据描述区的1A标志转移到DOS保留区,以自己掌握的密码形式存放。(河北 张永义)
vf常用命令
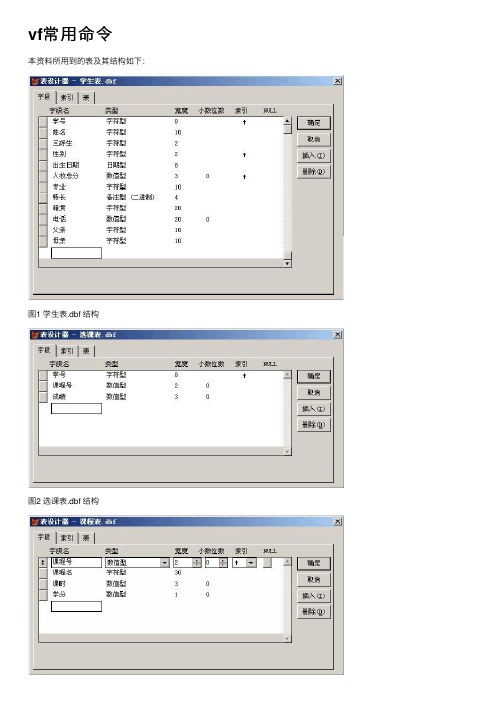
vf常⽤命令本资料所⽤到的表及其结构如下:图1 学⽣表.dbf 结构图2 选课表.dbf 结构图3 课程表.dbf 结构1本资料所⽤到的表及其结构如下:图1 学⽣表.dbf 结构图2 选课表.dbf 结构图3 课程表.dbf 结构21、设置⼯作⽬录:set default to命令格式:set default to <⽬录名>命令功能:设置vfp系统默认的⼯作⽬录(⽂件夹),以后存取⽂件均以该⽂件夹作为默认⽂件夹。
实例1:set defa to d:\data练习:打开vfp,然后观察此时的默认⼯作⽬录;再在D盘新建⼀⽂件夹:test,并设置该⽂件夹为vfp的默认⼯作⽬录。
2、赋值语句:Store 、=Store格式:Stroe <表达式> to <内存变量名表>功能:将表达式的值赋给内存变量名表中的变量。
实例1:store 100 to a1, a2 , b, c, num=格式:<变量名>=<表达式>功能:注意:表达式与变量名顺序不能写反了。
3、输出命令:? 、??命令格式1:?<表达式列表>命令格式2:??<表达式列表>4、定义数组命令:dimension、declare命令格式:dimension/declare <数组名1>[<下标上界1>[,<下标上界2]…]命令功能:定义⼀维数组或⼆维数组,每⼀维的下标⼀般从1 开始。
实例1:Dimension A(20),B(3,2)B(1,1)=10B(1,2)=20B(2,2)=30B(6)=40B(1,1), B(1,2), B(2,2), B(3,2)实例2:Dimension sz1(20),sz2(3,2)Store 10 to sz1store “警察学院”to sz2(1,1)sz2(3,2)=.F.sz(2,1)=3.14159如果数组元素没有赋值,则默认值为.F.历史考题:语句DIME TM(3,5)定义的数组元素的个数是()(15)练习:定义⼀个4 ⾏5 列的⼆维数组,数组名为Arr1,给元素赋值(第⼀个元素值为10,第四个元素值为20,第七个元素值为”hello”,最后⼀个元素值为888)。
dbf是什么文件-

dbf是什么文件?篇一:dbf文件结构---- 中dbf 文件结构---- dbf 文件由文件头和文件记录组成,其中文件头又由数据库说明和字段说明组成。
数据库说明由32 个字节组成,各字节含义见表一:字节含义数据库文件标志有无备注型字段(03H 无)1-3最后一次修改日期4-7文件记录数8-9文件头长度10-11记录长度12-31未用---- 表一---- 字段说明由若干个32 字节组成,每32 字节说明一个字段,各字节含义见表二:字节含义0-10字段名11字段类型12-15该字段在文件首记录中的地址16字段长度17小数位数18-31未用---- 表二---- 文件记录以ASCII 形式存储,每条记录以空格(20H)开头,该空格用来作删除标志用。
---- 3. 建立对应Foxpro 的Oracle 表的SQL 语句---- Foxpro 和Oracle 对应的数据类型的描述见表三:FoxproOracleCharacter(n)char(n) varchar2(n)Number(n,m)number(n-1,m) m0number(n,m) m=0Float(n,m)Logicalchar(1)DATEDATE---- 三---- 注:---- * 不考虑完整性约束,同时对于TABLESPACE 及STORAGE 存储参数取缺省值。
---- * 对于数字型字段,n 表示数字的宽度,在Foxpro 中包含小数点位置,而在Oracle 中不包含。
---- * 对于Foxpro logical 型字段类型,由于Oracle 中没有相应的逻辑型变量,故将其转换为字符类型。
---- * 暂且不考虑memo、general、picture 字段的转换。
---- 4. SQL*Loader 控制文件的建立---- 控制文件为SQL*Loader 的核心文件,与Foxpro 字段对应关系为表四: Foxpro 数据类型---- 控制文件语句对应的格式Character(n)CHARNumber(n,m)Float(n,m)DECIMAL EXTERNAL NULLIF = BLANKS (m0)INTEGER EXTERNAL NULLIF = BLANKS ( m=0)LogicalCHARDATEDATE “YYYYMMDD” NULLIF = BLANKS---- 四---- 以下是用Borland C++ 在中文Windows 95 下编制的产生CREATE TABLE SQL 语句和产生SQL*Loader 数据文件、控制文件的源程序。
DBF文件格式详细说明及程序设计

DBF文件格式详细说明及程序设计三峡大学水利与环境学院肖泽云1 DBF文件格式说明DBF文件是一种以二进制进行存储的表格数据文件,其文件内部有着严格的格式要求,具体由文件头和记录项组成。
其中文件头中包括字段的相关信息。
DBF注意,在表格记录数据中每行数据具体占多长字节,这个由文件头中定义的字段数目以及字段长度来决定,如果该文件一共只有两个字段,其中第一个字段为数值,其长度为4,第二个字段为字符串,长度为50,则每一行数据占的字节长度为4+50=54,在读取数据时也是读取前4个为第一个字段对应的值,读取第5-54个为第二个字段对应的值。
另外,为便于理解表格与下面内容的关系,特说明字段即是指表格中的列,记录指表格中的行数据,DBF按行数据方式来存储,即在文件头中定义了列数、列的名称、列的数据类型、列长度等等,然后在后面的记录数据中插入每行数据。
每个字段定义格式如下表,每个字段定义都用32个字节来完成:2 DBF文件数据结构实例分析下面以一个具体实例来分析DBF数据结构:该表格数据为:列1 列21 22 43 64 85 106 127 148 169 1810 20用UltraEdit打开该dbf文件,其内容如下:现在先分解一下,找出文件头,并分析一下文件头的内容。
首先看第一个字节,值为03,这个是16进制的数据,第一个字节表示数据库类型,值03即0x03,对应FoxBASE+/Dbase III plus,。
然后看第4个字节到第7个字节,这一段表示文件中的记录条数,即表格的行数,其Byte值为0A 00 00 00,转换成Int32即为10,即表格的行数为10。
关于Byte数组转换成数值类型,其代码如下:/// <summary>/// 将字节组转换成为整型/// </summary>/// <param name="tempBytes">字节数组</param>/// <returns></returns>public static Int32 ConvertBytesToInt32(byte[] tempBytes){Int32 result = System.BitConverter.ToInt32(tempBytes, 0); return result;}接着看第8个和第9字节,其值为61 00,转换成Int16其值即为97,意思就是说文件头所占字节长度为97,所以文件头的范围就是下面红色框内:蓝色框为左边红色框对应的值,这个仅供参考。
通达信目录文件结构及说明

通达信目录文件结构及说明vipdoc:下载或缓存的历史数据目录diary:投资日志目录RemoteSH:缓存的上海F10RemoteSZ:缓存的深圳F10Ycinfo:缓存的公告消息安装目录下的SZ.*,SH.*是缓存的盘中数据文件T0002:个人信息目录,内有公式和自选股,个人设置等信息T0002\blocknew:该文件夹保存自定义板块的信息T0002\mark.dat:该文件保存标记文字的信息T0002\PriCS.dat 、 PriGS.dat 这两个文件是自定义指标模板的信息Advhq.dat 星空图相关个性化数据Block.cfg 板块设置文件cbset.dat 筹码分析个性化数据colwarn3.dat 行情栏目和预警个性化数据colwarnTj.dat 条件预警个性化数据CoolInfo.Txt 系统备忘录Line.dat 画线工具数据MyFavZX.dat 资讯收藏夹数据newmodem.ini 交易客户端个性化数据padinfo.dat 定制版面个性化数据PriCS.dat,PriGS.dat,PriText.dat 公式相关数据recentsearch.dat 最近资讯搜索数据Scheme.dat 配色方案tmptdx.css 临时网页CSS文件user.ini 全局个性化数据userfx.dat K线图个性化数据[blocknew] 板块目录[cache] 系统数据高速缓存[zst_cache] 分时图数据高速缓存[coolinfo] 系统备忘录目录[Invest] 个人理财数据目录SUPERSTK下的文件:SYS.DTA 存放系统提供的公式;USERDATA下的文件:AUTOBLK.CFG:自动板块设定;SELF.DTA 存放用户自编的公式;BLOCK文件夹下的文件:*.IBK 板块指数定义;*.BLK 板块定义;*.EBK 条件选股结果;SELF 文件夹下的文件:*.WSV 保存页面文件;ALERT.DAT 历史预警纪录;EXTDATA.INF 扩展数据定义;*.CEP 保存组合条件选股条件;TEMPCMPD.CEP测试附加条件;*.INV 用户个人投资纪录;*.TPT 保存指标模板;SELF年月日.DTA 每日自动公式备份文件;TEST 文件夹下的文件:*.TST 存放系统测试结果;*.OPT 存放参数优化的结果; PARAM参数指引文件夹:*.PRM 存放参数指引的结果;TABLE文件夹下的文件:*.ESS数据表文件;*.ESD数据表文件(带数据保存); SelfData文件夹下的文件:*.str字符串数据;*.oth 与股票无关序列值数据; Pattern 文件夹下的文件:*.PIN 模式匹配设计;*.PWT模式匹**法;SpotAna文件夹下的文件:*.SPT 定位分析结果;Relate文件夹下的文件:*.RTL相关分析结果;Posible文件夹下的文件:*.PSB预测分布设计;DATA件夹下的文件:DAY.DAT 日线数据;EXTDAY.DAT 扩展数据;MIN.DAT 5分钟线数据;REPORT.DAT 当天的分笔成交数据;STKINFO.DAT 代码表/即时行情数据/财务数据/除权数据;*.PRP 历史回忆数据,一天一个文件;NEWS文件夹下的文件:*.TXT 财经报道、上交所公告、深交所公告通达信自选股:T0002\\blocknew\\ZXG.blk通达信软件系统目录结构,来自内部资料,仅供研究学习,不得用于商业用途,特此声明一、通达信软件系统目录结构┌ y xhj 运行环境目录,存放当日行情数据├ vip8 分析系统执行程序和系统配置库├ block 系统板块公用存盘文件├ doc 通达信文档│┌ fzline 分钟tdx 通达信┤├ lday 日线│┌ sz 深圳┼ lwek 周线││└ lmon 月线││┌ fzline 分钟线││├ lday 日线└ vipdoc 历史数据┼ sh 上海┼ lwek 周线│└ lmon 月线├ sav6 v6版工作站信息│┌ fzline 分钟线│├ lday 日线├ qh 期货┼ lwek 周线│└ lmon 月线├ tick 历史成交明细└ sav 跨越2000工作站信息:若没有购买配套产品,以上有些目录可能不存在。
DBF文件结构中文说明
标准的DBF文件,是由头文件和实体信息两部分构成(如图所示)。
…………DBF文件的结构1)文件的文件头其中文件头部分的长度是不定长的,它主要对DBF文件作了一些总体说明(表),其中最主要的是对这个DBF文件的记录项的信息进行了详细地描述,比如对每个记录项的名称、数据类型、长度等信息都有具体的说明。
文件(.dbf)的文件头记录项信息描述表2.9 dbf文件中的数据类型2)文件的实体信息实体信息部分就是一条条记录,每条记录都是由若干个记录项构成,因此只要依次循环读取每条记录就可以了。
3)一个读取dbf文件的例子假设要读取一个名为soil的dbf文件(存储了土地利用信息),它含有8个记录项,记录项信息如表所示:dbf文件中的数据类型32 - n字段子记录字段的数目决定了字段子记录的数目。
n+1 头记录终止符(0x0D),n+2 到n+264 此范围内的263 个字节包含后链信息(相关数据库(.dbc) 的相对路径)。
如果第一个字节为0x00,则该文件不与数据库关联。
因此数据库文件本身总是包含0x00。
数据记录从除标记字节开始。
如果此字节为ASCII 空格(0x20),该记录没有删除标记,如果第一字节为星号(0x2A),该记录有删除标记。
在标记之后是字段记录中所命名各字段中的数据下面是读取这个dbf文件的代码:void OnReadDbf(CString DbfFileName){FILE* m_DbfFile_fp; //****Dbf文件指针//打开dbf文件if((m_DbfFile_fp=fopen(DbfFileName,"rb"))==NULL){return;}int i,j;//////****读取dbf文件的文件头开始BYTE version;fread(&version, 1, 1,m_DbfFile_fp);BYTE date[3];for(i=0;i<3;i++){fread(date+i, 1, 1,m_DbfFile_fp);}int RecordNum; //******fread(&RecordNum, sizeof(int), 1,m_DbfFile_ fp);short HeaderByteNum;fread(&HeaderByteNum, sizeof(short), 1,m_DbfFile_fp);short RecordByteNumfread(&RecordByteNum, sizeof(short), 1,m_DbfFile_fp);short Reserved1;fread(&Reserved1, sizeof(short), 1,m_DbfFile_fp);BYTE Flag4s;fread(&Flag4s, sizeof(BYTE), 1,m_DbfFile_fp);BYTE EncrypteFlag;fread(&EncrypteFlag, sizeof(BYTE), 1,m_ DbfFile_fp);for(i=0;i<3;i++){fread(&Unused, sizeof(int), 1,m _DbfFile_fp);}BYTE MDXFlag;fread(&MDXFlag, sizeof(BYTE), 1,m_DbfFile_fp);BYTE LDriID;fread(&LDriID, sizeof(BYTE), 1, m_DbfFile_fp);short Reserved2;fread(&Reserved2, sizeof(short), 1,m_DbfFile_fp);BYTE name[11];BYTE fieldType;int Reserved3;BYTE fieldLength;BYTE decimalCount;short Reserved4;BYTE workID;short Reserved5[5];BYTE mDXFlag1;int fieldscount;fieldscount = (HeaderByteNum - 32) / 32;//读取记录项信息-共有8个记录项for(i=0;i< HeaderByteNum;i++){//FieldName----11 bytesfread(name, 11, 1,m_DbfFile_fp);//FieldType----1 bytesfread(&fieldType, sizeof(BYTE), 1,m_DbfFile_fp);//Reserved3----4 bytesReserved3 =0;fread(&Reserved3,sizeof(int), 1,m_DbfFile_fp);//FieldLength--1 bytesfread(&fieldLength,sizeof(BYTE),1,m_DbfFile_fp);//DecimalCount-1 bytesfread(&decimalCount,sizeof(BYTE),1,m_DbfFile_fp);//Reserved4----2 bytesReserved4 =0;fread(&Reserved4,sizeof(short), 1,m_DbfFile_fp);//WorkID-------1 bytesfread(&workID, sizeof(BYTE ), 1,m_DbfFile_fp);//Reserved5----10 bytesfor(j=0;j<5;j++){fread(Reserved5+j,sizeof(short), 1,m_DbfFile_fp);}//MDXFlag1-----1 bytesfread(&mDXFlag1, sizeof(BYTE),1,m_DbfFile_fp);}BYTE terminator;fread(&terminator, sizeof(BYTE),1,m_DbfFile_fp);//读取dbf文件头结束double Area,Perimeter,Centroid_y,Centroid_x;int Soils_,Soils_id;CString Soil_code,suit;BYTE deleteFlag;char media[31];//读取dbf文件记录开始for(i=0;i<RecordNum;i++){fread(&deleteFlag, sizeof(BYTE),1,m_DbfFile_fp);//读取 Area doublefor(j=0;j<31;j++)fread(media+j, sizeof(char), 1,m_DbfFile_fp);Area =atof(media);//读取 Perimeter doublefor(j=0;j<31;j++)fread(media+j, sizeof(char), 1,m_DbfFile_fp);Perimeter =atof(media);//读取 soils_ intfor(j=0;j<31;j++)strcpy(media+j,"");for(j=0;j<11;j++)fread(media+j, sizeof(char), 1,m_DbfFile_fp);Soils_ =atoi(media);//读取 Soils_id intfor(j=0;j<31;j++)strcpy(media+j,"");for(j=0;j<11;j++)fread(media+j, sizeof(char), 1,m_DbfFile_fp);Soils_id =atoi(media);//读取 soil_code stringfor(j=0;j<31;j++)strcpy(media+j,"");for(j=0;j<3;j++)fread(media+j, sizeof(char), 1,m_DbfFile_fp);Soil_code =media;//读取 suit stringfor(j=0;j<31;j++)strcpy(media+j,"");for(j=0;j<1;j++)fread(media+j, sizeof(char), 1,m_DbfFile_fp);suit =media;//读取 Centroid_y doublefor(j=0;j<31;j++)strcpy(media+j,"");for(j=0;j<31;j++)。
dbf是什么文件?

转载请保留出处,谢谢支持!
不锈钢橱柜 /
为编辑和搜索的一些附加功能的便携式DBF表查看器。 2.sdbf(dbf文件查看器)dbf文件查看器是一款用户友好且直 观的应用程序,可以轻松地
打开和读取DBF文件,以及对其进行编辑或创建新的DBF 文件。dbf文件查看器能方便用户使用,旨在为您提供打 开和使用数据库文件,而无需在您的系
统上安装任何其他程序的手段。若要使用该应用程序, 没有必要安装它,由于其可移植性功能。只是,可以解 压缩存档和启动Sdbf。它的接口是很基本的不
dbf是什么文件?DBF文件是一种数据库格式文件, Foxbase,Dbase,VisualFoxPro等数据库处理系统会运用到 DB数据库。作为一个在商 业应用中的结构化数据存储标准格式,DBF格式文件得以 广泛的应用于各类企业及事业单位用于数
据交换。dbf文件怎么打开?1.DBFViewerPlus,DBF表查看器, 查看和编辑DBF文件。可以搜索和筛选的字段值。DBF查 看器加是同
起眼,但是可以管理,成功地完成其工作。 3.DatabaseBrowser数据库浏览器是数据库资料查询浏览 的工具软件,可以查询数据库数据内容,
也可以查询数据库的结构信息,包括数据库信息,表结 构、索引、主键的信息,并且可以查询数据库查询及视 图信息。4.直接用EXCEL打开5.用ACC
ESS打开。ACCESS数据库-MicrosoftAccess是一种关系式数 据库,关系式数据库由一系列表组成,表又由一系列行 和列组成。
文书档目录数据交换格式与著录细则

福建省地方标准DB35/T161-2002 文书档目录数据交换格式与著录细则2002-01-25发布 2002-03-01实施福建省质量技术监督局发布前言本标准是建设我省档案信息资源库的基础之一。
为了规范我省文书档案目录数据库,特制定本标准。
本标准对文书档案目录数据库分为案卷和文件两个层次,但案卷级有所省略,并要求案卷级和文件级一体化著录,这既考虑到传统档案,又兼顾到今后立卷改革的方向。
本标准是根据GB/T 3792.1—1983《文献著录总则》、DA/T18—1999《档案著录规则》的原则,结合我省建国后文书档案的特点制定的。
本标准基本上遵循了DA/T18—1999规定的档案著录项目和著录格式。
本标准具有以下特点:规定了文书档案案卷级和文件级目录数据库的基本结构、著录项目与交换格式;对著录规则和著录格式进行必要的细化;规定了档案著录与计算机档案目录数据库之间的联系;规定了文书档案案卷级目录数据库与文件级目录数据库之间的联系。
本标准在编写格式上采用GB/T1.1—2000《标准化工作导则第1部分:标准的结构和编写规则》。
本标准从2002年3月1日开始实施。
本标准由福建省档案局提出。
本标准由福建省质量技术监督局批准。
本标准由福建省档案局负责起草。
本标准主要起草人:刘虹黄建峰。
文书档案目录数据交换格式与著录细则1 范围本标准规定了《文书档案目录数据交换格式与著录细则》的定义、数据交换格式、数据交换要求、著录细则等内容。
本标准适用于建国后文书档案案卷级和文件级目录数据库的建库和传递,亦可作为编制相关档案管理软件、档案的全文数据库和多媒体数据库的目录管理系统以及建立其他专门档案目录数据库的参考。
2 规范性引用文件下列文件中的条款通过本标准的引用而成为本标准的条款。
凡是注日期的引用文件,其随后所有的修改单(不包括勘误的内容)或修订版均不适用于本标准,然而,鼓励根据本标准达成协议的各方研究是否可使用这些文件的最新版本。
shp格式结构

shp格式结构Shp格式(Shapefile)是一种常用的地理信息系统(GIS)数据格式,它由多个文件组成,包含了矢量地理数据的几何形状、属性信息和空间参考信息。
本文将详细介绍Shp格式的结构,包括主文件、索引文件和属性文件,并阐述其在GIS数据处理中的重要性和应用。
1. 主文件(.shp文件)Shp格式的主文件包含了矢量地理数据的几何形状信息,采用二进制格式存储。
它由一系列记录组成,每个记录对应一个地理对象(如点、线或面)。
每个地理对象的几何形状由类型编码和相关坐标点数据组成。
常见的几何类型包括点(Point)、线(Polyline)和面(Polygon)。
主文件还包含空间参考信息,如地理坐标系、投影坐标系和地理范围。
这些信息对于准确地定位和叠加分析至关重要。
2. 索引文件(.shx文件)Shp格式的索引文件用于快速访问和查询地理对象,它与主文件一一对应。
索引文件采用二进制格式存储,每个记录包含了主文件中对应地理对象的偏移量和长度信息。
通过索引文件,可以快速找到并读取特定地理对象的几何形状和属性信息,提高了数据查询和分析的效率。
3. 属性文件(.dbf文件)Shp格式的属性文件存储了地理对象的相关属性信息,采用dBASE文件格式。
属性文件由表格形式组成,每个列对应一个属性字段,每个行对应一个地理对象。
属性字段可以包含数字、文本、日期等不同类型的数据。
属性文件的字段结构定义了每个属性字段的名称、数据类型和长度。
通过属性文件,我们可以获取与地理对象相关的属性数据,如名称、面积、人口等,进而进行统计分析和空间查询。
Shp格式结构的重要性和应用Shp格式结构的合理设计和组织对于GIS数据的存储、管理和分析具有重要意义。
下面介绍其重要性和应用领域。
1. 数据交换和共享:Shp格式是一种通用的GIS数据格式,被多个GIS软件支持,并广泛应用于数据交换和共享。
通过将地理数据转换为Shp格式,用户可以方便地在不同的GIS平台和工具中进行数据共享和协作。
dbf是什么文件

dbf是什么文件什么是dbf文件DBF(dBase File)是一种常见的数据库文件格式,它最早是由Ashton-Tate公司于1983年开发的。
DBF文件主要用于存储结构化数据,适用于各种数据库应用程序,特别是在早期的数据库系统中广泛使用。
DBF文件通常包含了表格中的字段和记录,可以用于存储和组织大量数据。
dbf文件的结构DBF文件采用二进制格式存储数据,它的结构通常由文件头、字段描述头和数据记录组成。
文件头文件头是DBF文件的第一个部分,它包含了文件的元数据信息,比如文件版本号、记录数量和字段数量等。
文件头的长度为32个字节,其中包含了以下字段:•文件类型(1字节):用于标识文件的类型,通常为’0x03’,表示为dBASE III格式的文件。
•最后的更新日期(3字节):以YYMMDD的形式表示的日期,是文件最后一次被修改的时间。
•记录数量(4字节):用于记录文件中记录的数量。
•字段首行的长度(2字节):用于记录字段描述头的长度。
•一个记录的长度(2字节):用于记录每个记录的长度。
字段描述头字段描述头紧随文件头,用于描述数据表中的各个字段。
每个字段描述头的长度为32个字节,其中包含了以下字段信息:•字段名(11字节):用于记录字段的名称。
•字段类型(1字节):用于记录字段的数据类型,例如字符、日期等。
•字段长度(4字节):用于记录字段的长度,即字段可以存储的最大字符数或数字的位数。
•字段精度(1字节):用于记录字段的精度,即小数位数。
•保留字节(14字节):用于保留字段描述头的空间以备将来使用。
数据记录数据记录是DBF文件中实际存储数据的部分,它包含了表格中的各行记录。
每条记录的长度由文件头中的。
arcgis dbase格式

arcgis dbase格式ArcGIS dbf格式是一种常见的数据库格式,常用于存储空间数据和相关属性数据。
本文将逐步解释ArcGIS dbf格式的细节和用法,以帮助读者更好地了解并使用这种格式。
第一步:基本介绍ArcGIS dbf格式是dBase数据库文件格式的一种变体,在ArcGIS软件中被广泛使用。
它可以存储表格数据,包括空间数据和相关的属性数据。
dbf 文件是基于二进制编码的文本文件,其数据以表格形式进行组织。
每个表格行代表一个记录,每个记录包含一个或多个字段。
第二步:字段和记录在ArcGIS dbf格式中,字段是表格的列,每个字段有一个唯一的名称和数据类型。
常见的数据类型包括字符型、数值型、日期型和逻辑型。
字段的数据类型决定了字段所能存储的值的类型。
记录是表格的行,每个记录对应一个数据实体。
字段和记录是ArcGIS dbf格式中最基本的数据单位。
第三步:数据结构ArcGIS dbf格式使用Header部分来描述表格的结构。
Header部分包含字段定义和属性信息。
字段定义包括字段名称、字段数据类型和字段长度。
属性信息包括记录的总数、记录长度和数据文件的最后修改日期等。
Header部分的结构可以用十六进制编码查看和编辑。
第四步:数据内容数据内容是ArcGIS dbf格式中存储的实际数据。
每个字段的值都以特定的格式存储,如日期型以YYYYMMDD的格式存储,字符型以ASCII编码存储等。
当前记录的字段值按照字段在表格中的定义顺序排列。
每个字段值以特定的字节长度存储,长度取决于字段的数据类型和长度定义。
第五步:数据操作使用ArcGIS软件可以对dbf文件进行多种数据操作,如数据查询、添加记录、修改记录和删除记录等。
数据查询可以根据字段值或属性条件进行,以筛选出满足条件的记录。
添加记录可以在表格末尾添加新的记录并填写字段值。
修改记录可以对已存在的记录进行字段值的更新。
删除记录可以将满足条件的记录标记为删除状态。
dbf 文件列宽处理

dbf 文件列宽处理1.引言1.1 概述概述DBF文件是一种常见的数据库文件格式,被广泛用于存储各种数据。
然而,在处理DBF文件时,我们经常会遇到列宽不匹配的问题。
列宽不匹配指的是DBF文件中某些列的宽度不足以容纳其内容,导致数据被截断或者显示不全的情况。
DBF文件的列宽处理是指对这些列宽不匹配的问题进行修复和调整的操作。
它可以确保数据在显示和处理过程中能够完整地展示,避免丢失或截断数据的情况发生。
在实际应用中,列宽不匹配问题常常会给数据的整理和分析带来一定的困扰。
如果不对这些问题进行处理,可能会导致数据的准确性受到影响,甚至影响后续的数据处理工作。
本文将重点讨论DBF文件列宽处理的方法和策略。
我们将介绍列宽不匹配的原因,探讨不同的解决方案,并提出一些建议和技巧,以便读者在实际应用中能够更好地处理列宽不匹配问题。
接下来的章节将依次介绍DBF文件的基本概念和列宽问题,总结列宽处理的方法和策略,并给出对DBF文件列宽处理的建议。
通过阅读本文,读者将能够深入了解和掌握DBF文件列宽处理的相关知识,提升数据处理的质量和效率。
1.2 文章结构文章结构部分的内容可以按照以下方式撰写:文章结构:本文分为引言、正文和结论三个部分。
引言部分主要对文章的背景和研究目的进行说明。
首先,介绍了DBF 文件的基本概念以及其在数据存储和管理中的重要性。
随后,指出了DBF 文件列宽的问题在实际应用中可能引发的一些挑战和困惑。
最后,明确了本文的研究目的,即探讨和提出对DBF文件列宽进行处理的解决方案和建议。
正文部分围绕DBF文件列宽的问题展开讨论。
首先,详细介绍了DBF 文件的基本概念,包括其文件结构、字段定义等。
随后,重点阐述了DBF 文件列宽可能存在的一些限制和不足,例如存储空间浪费、数据截断等。
接着,探讨了目前常见的处理DBF文件列宽的方法和技巧,如手动调整、批量处理工具等。
此外,还分析了不同处理方法的优缺点,并指出了可能需要注意的问题和改进空间。
dbf是什么文件怎么打开

dbf是什么文件怎么打开一些用户在工作的过程中,可能会碰到后缀名为dbf的文件,正常双击是无法打开的,那么这是什么文件呢?怎么打开。
下面给大家推荐一些软件来打开dbf文件,具体请看下文。
dbf是什么文件?dbf文件是一种数据库格式文件,Foxbase,Dbase,Visual FoxPro等数据库处理系统会运用到dbf格式文件,dbf格式数据库是常用的桌面型数据库。
作为一个在商业应用中的结构化数据存储标准格式,dbf格式文件得以广泛的应用于各类企业及事业单位用于数据交换。
dbf文件怎么打开?1、使用Excel办公软件直接调出dbf文件。
具体而言,在打开文件时,通过选择打开的文件格式即可顺利打开dbf文件,非常简便!2、使用Access办公软件直接调出dbf文件。
具体而言,在打开文件时,通过选择打开的文件格式即可顺利打开dbf文件,如图所示:打开数据库文件。
3、使用DBFViewerPlus直接调出dbf文件。
DBFViewerPlus是一个用于 Windows 下的 DBF 数据库文件管理器,直接打开dbf文件即可。
4、使用VFP打开dbf文件。
具体而言,选中所需的dbf文件,将其拖动到软件操作界面中command命令窗口,待鼠标图片变成圆圈后才可放开,文件即被打开;否则,软件没有响应。
5、使用《DataBaseBrowser数据库浏览器》打开dbf文件。
它是一种可视化数据库浏览管理软件,能够用最简单、直观的方式创建、编辑、处理DBF数据库文件。
补充:MySQL 数据库常用命令create database name; 创建数据库use databasename; 进入数据库drop database name 直接删除数据库,不提醒show tables; 显示表describe tablename; 查看表的结构select 中加上distinct去除重复字段mysqladmin drop databasename 删除数据库前,有提示。
shp系列(六)——利用C++进行Dbf文件的写(创建)

shp系列(六)——利⽤C++进⾏Dbf⽂件的写(创建)上⼀篇介绍了shp⽂件的创建,接下来介绍dbf的创建。
推荐结合读取dbf的博客⼀起看!推荐结合读取dbf的博客⼀起看!推荐结合读取dbf的博客⼀起看!1.Dbf头⽂件的创建Dbf头⽂件的结构如下:记录项数组说明:字段类型说明:关于每项的具体含义参照读取dbf⽂件的解释,这⾥重点解释⼏项:HeaderByteNum指dbf头⽂件的字节数,数值不⽤除于2,具体为:从version到Reserved2(共32) + n个字段 * 每⼀个字段长度 32 + terminator。
RecordByteNum指每条记录的字节数,数值不⽤除于2,RecordByteNum根据记录的实际长度来写,具体为:∑每个字段的字节数(字段数量根据读取打开shp的字段数决定)。
例如我的例⼦中写了⼋个字段,则⼀条记录的实际长度为:1(deleteFlag) + 10 + 32 + 16 + 10 + 10 + 8 + 19 + 19 = 1 + 124 =125。
2.Dbf记录实体的创建记录实体就是每条记录,⼀个记录有多个字段,部分字段上存储必要的信息。
由于实际上每个shp⽂件的表的字段数可能不⼀样,并且每个字段的类型不固定,需要每次判定字段类型,然后根据不同类型设置来输出信息。
但是这费时费⼒,根据实际情况,简化⼀下,读取已知字段数和字段类型的DBF的信息,或者说,根据实际需要的字段数和字段类型来输出,牺牲普遍性来获取快速结果,以后修改也不困难。
3.创建Dbf的代码void WriteDbf(CString filename){//创建与Shp⽂件同名的指针int n = filename.ReverseFind('.');filename = filename.Left(n);filename = filename + ".dbf";FILE* m_DbfFile_fp;if ((m_DbfFile_fp = fopen(filename, "wb")) == NULL)return;//****创建dbf⽂件的⽂件头int i, j;BYTE version = 4;fwrite(&version, 1, 1, m_DbfFile_fp);CTime t = CTime::GetCurrentTime();int d = t.GetDay();int y = t.GetYear() % 2000;int m = t.GetMonth();BYTE date[3];date[0] = y;date[1] = m;date[2] = d;for (i = 0; i<3; i++) //记录时间fwrite(date + i, 1, 1, m_DbfFile_fp);int RecordNum = map->layer->objects.size(); //⽂件中的记录条数fwrite(&RecordNum, sizeof(int), 1, m_DbfFile_fp);short HeaderByteNum = 0; //⽂件头中的字节数,暂时写0,后⾯要返回来修改fwrite(&HeaderByteNum, sizeof(short), 1, m_DbfFile_fp);short RecordByteNum = 0; //⼀条记录中的字节长度,暂时写0,后⾯要返回来修改fwrite(&RecordByteNum, sizeof(short), 1, m_DbfFile_fp);short Reserved1 = 0;fwrite(&Reserved1, sizeof(short), 1, m_DbfFile_fp);BYTE Flag4s = 0;fwrite(&Flag4s, sizeof(BYTE), 1, m_DbfFile_fp);BYTE EncrypteFlag = 0;fwrite(&EncrypteFlag, sizeof(BYTE), 1, m_DbfFile_fp);int Unused[3] = { 0,0,0 };for (i = 0; i<3; i++)fwrite(Unused + i, sizeof(int), 1, m_DbfFile_fp);BYTE MDXFlag = 0;fwrite(&MDXFlag, sizeof(BYTE), 1, m_DbfFile_fp);BYTE LDriID = 0;fwrite(&LDriID, sizeof(BYTE), 1, m_DbfFile_fp);short Reserved2 = 0;fwrite(&Reserved2, sizeof(short), 1, m_DbfFile_fp);//****写记录项数组int fieldscount = fieldscount_final; //字段数量可以根据读取的shp⽂件确定for (i = 0; i< fieldscount; i++){RecordItem recordItem = recordItems[i]; //recordItems是⾃⼰设置的记录项数组(字段)的数组,//根据需求设定每个记录项数组(字段)的参数,以供调⽤//****name--------11 bytesfwrite(, 11, 1, m_DbfFile_fp);//****FieldType----1 bytesfwrite(&(recordItem.fieldType), sizeof(BYTE), 1, m_DbfFile_fp);//****Reserved3----4 bytesfwrite(&(recordItem.Reserved3), sizeof(int), 1, m_DbfFile_fp);//****FieldLength--1 bytesfwrite(&(recordItem.fieldLength), sizeof(BYTE), 1, m_DbfFile_fp);//****DecimalCount-1 bytesfwrite(&(recordItem.decimalCount), sizeof(BYTE), 1, m_DbfFile_fp);//****Reserved4----2 bytesfwrite(&(recordItem.Reserved4), sizeof(short), 1, m_DbfFile_fp);//****WorkID-------1 bytesfwrite(&(recordItem.workID), sizeof(BYTE), 1, m_DbfFile_fp);//****Reserved5----10 bytesfor (j = 0; j<5; j++)fwrite(recordItem.Reserved5 + j, sizeof(short), 1, m_DbfFile_fp);//****MDXFlag1-----1 bytesfwrite(&(recordItem.mDXFlag1), sizeof(BYTE), 1, m_DbfFile_fp);}BYTE terminator = 13; //头⽂件终⽌标识符fwrite(&terminator, sizeof(BYTE), 1, m_DbfFile_fp);fseek(m_DbfFile_fp, 8, SEEK_SET); //转到头⽂件字节数RecordByteNum,开始重写HeaderByteNum = 32 + 32 * fieldscount + 1; //从version到Reserved2(共32) + n个字段 * 每⼀个字段长度 32 + terminator fwrite(&HeaderByteNum, sizeof(short), 1, m_DbfFile_fp);RecordByteNum = 1 + 124; //RecordByteNum根据记录的实际长度来写,∑每个字段的长度// 1 + 10 + 32 + 16 + 10 + 10 + 8 + 19 + 19 = 1 + 124 =125fseek(m_DbfFile_fp, 10, SEEK_SET); //转移每条记录长度RecordByteNumfwrite(&RecordByteNum, sizeof(short), 1, m_DbfFile_fp);fseek(m_DbfFile_fp, 0, SEEK_END);//****写dbf⽂件头结束//****写每条记录BYTE deleteFlag;char media[40];for (i = 1; i <= RecordNum; i++){CGeoPolygon* polygon = (CGeoPolygon*)map->layer->objects[i - 1];deleteFlag = 32; //默认写32fwrite(&deleteFlag, sizeof(BYTE), 1, m_DbfFile_fp); //读取删除标记 1字节//****写 ObjectID intstringstream ss;ss << (i - 1);string str = ss.str();int length = str.length();memset(media, '\0', 40);for (int m = 0; m < 10 - length; m++)media[m] = ' ';for (int c = 10 - length; c < 10; c++)media[c] = str[c - 10 + length];//****写Dest stringmemset(media, '\0', 40);media[0] = '/';for (int c = 1; c <32; c++)media[c] = ' ';for (j = 0; j<32; j++)fwrite(media + j, sizeof(char), 1, m_DbfFile_fp); //--32 //****写Ec stringfor (j = 0; j<16; j++)fwrite(media + j, sizeof(char), 1, m_DbfFile_fp); //--16 //****写EcRm intss << -8888;str = ss.str();length = str.length();memset(media, '\0', 40);for (int m = 0; m < 10 - length; m++)media[m] = ' ';for (int c = 10 - length; c < 10; c++)media[c] = str[c - 10 + length];for (j = 0; j<10; j++)fwrite(media + j, sizeof(char), 1, m_DbfFile_fp); //--10 //****写Elevt intfor (j = 0; j<10; j++)fwrite(media + j, sizeof(char), 1, m_DbfFile_fp); //--10 //****写Cc intstr = polygon->objectAttribute;memset(media, '\0', 40);length = str.length();for (int c = 0; c < length; c++)media[c] = str[c];for (int c = length; c < 8; c++)media[c] = ' ';for (j = 0; j<8; j++)fwrite(media + j, sizeof(char), 1, m_DbfFile_fp); //--8 //****写shape_length doubleCString str1;double shape_length = polygon->getAllLength();str1.Format(_T("%.11e"), shape_length);memset(media, '\0', 40);media[0] = ' ';for (int c = 1; c < 16; c++)media[c] = str1[c - 1];if (str1.GetLength() == 18)for (int c = 16; c < 19; c++)media[c] = str1[c - 1];else {media[16] = '0';media[17] = str1[15];media[18] = str1[16];}//*(media + length ) = '\0';for (j = 0; j<19; j++)fwrite(media + j, sizeof(char), 1, m_DbfFile_fp); //--19 //****写shape_Area doubledouble shape_area = polygon->shapeArea;str1.Format(_T("%.11e"), shape_area);memset(media, '\0', 40);media[0] = ' ';for (int c = 1; c < 16; c++)media[c] = str1[c - 1];if (str1.GetLength() == 18)for (int c = 16; c < 19; c++)media[c] = str1[c - 1];else {media[16] = '0';media[17] = str1[15];media[18] = str1[16];}}//****写dbf⽂件记录结束fclose(m_DbfFile_fp);}下⼀篇将介绍Shx的创建。
dbc文件数据类型的解释

在数据库中,DBF(Database File)是一种表格文件格式,常见于基于文件的数据库系统,如 dBASE、FoxPro、Clipper 等。
DBF 文件通常包含表格的结构和数据,用于存储和管理数据。
在 DBF 文件中,每个字段(列)都有一个相应的数据类型,用于指定该字段中数据的类型。
以下是一些常见的 DBF 文件中的数据类型及其解释:
1.Character (C):存储字符串数据。
最大长度由字段定义确定。
2.Date (D):存储日期,格式为 YYYYMMDD。
3.Numeric (N):存储数字数据,包括整数和浮点数。
4.Logical (L):存储逻辑值(真或假)。
5.Memo (M):存储文本或二进制数据的指针。
通常用于存储较大的文本字段
或二进制数据,而不是直接在记录中存储。
6.Float (F):存储浮点数。
7.Double (O):存储双精度浮点数。
8.Timestamp (T):存储日期和时间信息。
9.Binary (B):存储二进制数据。
这些数据类型的选择取决于数据的性质。
例如,如果字段包含字符串,就选择Character 类型;如果包含日期,就选择 Date 类型。
在读取或处理 DBF 文件时,了解每个字段的数据类型是非常重要的,因为它决定了如何正确解释和处理数据。
请注意,不同的数据库系统可能支持不同的数据类型,上述列举的类型主要是针对经典的 dBASE 数据库格式。
在使用任何特定 DBF 文件之前,建议查看相应的文件文档或元数据以获取准确的数据类型信息。
剖析一个用C++写的行情交易系统

剖析⼀个⽤C++写的⾏情交易系统最近hen ci hen ci⽤C++写完了⼀整套证券⾏情系统,但是不是服务沪深交易所的,是给⽂交所⽤的。
整个系统涵盖了从DBF⽂件解析开始到客户端展现这⼀整条逻辑。
想来⼀年多没有更新博客了,所以趁这个机会,把整个系统的架构和开发中遇到的问题写下来,权当总结和分享。
⾸先要说明的是,整个系统的架构都是以当前业务为出发点的,所以和⽬前⽹上看到的,⽐⽅说⼴发⾃研的系统是肯定有差别的,我们就没有合规⼀说。
另外,从⽤户规模和市场活跃程度来看,我们也⽆法和国内证券市场⽐较,所以和⽬前公开出来的系统结构相⽐也还是有差异的。
我们根据⾃⾝⼈⼒资源限制和当前业务⾓度考虑,⾸要⽬标是希望整体架构要简单,易于横向扩展。
因为⼀,⼈太少,平均下来,我就俩⼈;⼆,不懂业务,其中接⼿我服务端开发的还是应届毕业⽣。
这⾥先把系统结构图罗列⼀下:你会看到⾥⾯有很多让⼈意想不到的东西,⽐⽅说SQLite!容我后续慢慢来说!DBF⽂件解析⽬前沪深L1数据更新的频率是3秒。
⽂交所这边是1秒。
总得来说解析DBF⽂件没有太⼤的难度,就是要理解⽂件结构。
DBF⽂件结构其实也是开放的,随便查。
这个程序没有任何难度,不需要多线程,只有⼀个要求,就是解析⽂件越快越好。
关于DBF么,我就画⼀个结构图在这⾥好了。
⽅便⼤家查阅。
⾏情数据库程序⾸先来张图展⽰下⾏情数据库程序的结构。
从图上看,我们的⾏情程序分三⼤模块:1. 业务驱动对象2. Logger3. Config AgentLogger也就是⽇志。
我们这⾥是直接⽤了Linux⾃带的Syslog。
当然了回归到代码的话,是⼀个logger接⼝,然后在Linux上基于Syslog实现了这个logger接⼝。
为什么选⽤Syslog?⼀是我们没有那么多资源搞⼀个异步logger;⼆是以我们⽬前的压⼒来看,Syslog从各⽅⾯都满⾜我们的要求。
⽽且是独⽴的进程,万⼀发⽣不测,不影响我们⾏情正常运⾏,⽆⾮就是没有⽇志了。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
---- 2.Foxpro 中dbf 文件结构---- dbf 文件由文件头和文件记录组成,其中文件头又由数据库说明和字段说明组成。
数据库说明由32 个字节组成,各字节含义见表一:字节含义数据库文件标志有无备注型字段(03H 无)1-3最后一次修改日期4-7文件记录数8-9文件头长度10-11记录长度12-31未用---- 表一---- 字段说明由若干个32 字节组成,每32 字节说明一个字段,各字节含义见表二:字节含义0-10字段名11字段类型12-15该字段在文件首记录中的地址16字段长度17小数位数18-31未用---- 表二---- 文件记录以ASCII 形式存储,每条记录以空格(20H)开头,该空格用来作删除标志用。
---- 3. 建立对应Foxpro 的Oracle 表的SQL 语句---- Foxpro 和Oracle 对应的数据类型的描述见表三:FoxproOracleCharacter(n)char(n) varchar2(n)Number(n,m)number(n-1,m) m< >0number(n,m) m=0Float(n,m)Logicalchar(1)DATEDATE---- 三---- 【注】:---- * 不考虑完整性约束,同时对于TA BLESPACE 及STORA GE 存储参数取缺省值。
---- * 对于数字型字段,n 表示数字的宽度,在Foxpro 中包含小数点位置,而在Oracle 中不包含。
---- * 对于Foxpro logical 型字段类型,由于Oracle 中没有相应的逻辑型变量,故将其转换为字符类型。
---- * 暂且不考虑memo、general、picture 字段的转换。
---- 4. SQL*Loader 控制文件的建立---- 控制文件为SQL*Loader 的核心文件,与Foxpro 字段对应关系为表四:Foxpro 数据类型---- 控制文件语句对应的格式Character(n)CHARNumber(n,m)Float(n,m)DECIMAL EXTERNA L NULLIF < field > = BLANKS (m< >0)INTEGER EXTERNAL NULLIF < field > = BLANKS (m=0)LogicalCHARDATEDATE "YYYYMMDD" NULLIF < field > = BLA NKS---- 四---- 以下是用Borland C++ 5.0 在中文Windows 95 下编制的产生CREATE TA BLE SQL 语句和产生SQL*Loader 数据文件、控制文件的源程序load.cpp。
#include < stdio.h >#include < stdlib.h >#include < iostream.h >#include < fstream.h >#include < string.h >#include < math.h >#define MAX_ROW_LENGTH 1200#define MAX_FIELD_NUMBER 30typedef struct head // dbf头文件结构{ unsigned char mask ;unsigned char date[3] ;unsigned long record_num;unsigned short int head_length;unsigned short int field_length ;} HEA D ;typedef struct field // dbf字段结构{ unsigned char name[11];unsigned char type ;unsigned long add;unsigned char length;unsigned char dec ;} FIELD ;int main(int argc,char **argv){ char buf[MAX_ROW_LENGTH],dbf[40],*sqlload;unsigned int i,field_num;HEAD *dbfhead ;FIELD dbffield[MAX_FIELD_NUM BER];FILE *fout, *fp;if (argc!=2){ cout < < "Usage : load dbfile" < < endl ;return -1;}sqlload = new char(40);dbfhead = new HEA D;strcpy(buf,"");strcpy(dbf,argv[1]);strcat(dbf,".dbf");if ((fp=fopen(dbf,"rb")) == NULL){ cout < < "Cannot open file " < < dbf < < endl;return -1 ;}fseek(fp,0,SEEK_SET);fread(dbfhead,sizeof(HEAD),1,fp); // 读dbf头文件信息field_num = (dbfhead- >head_length-1)/32 -1 ; //字段个数for( i=0; i< field_num; i++){ fseek(fp,32*(i+1),SEEK_SET);fread(&dbffield[i],sizeof(FIELD),1,fp); // 读dbf结构信息}// 产生SQL*Loader 控制文件strcpy(sqlload,argv[1]);strcat(sqlload,".ctl");if ((fout=fopen(sqlload,"w")) == NULL){ cout < < "Cannot open file " < < sqlload < < endl;return -1 ;}fprintf(fout,"LOAD DATA\n");fprintf(fout,"INFILE '%s.txt'\n", argv[1]);fprintf(fout,"INTO TABLE %s (\n", argv[1]);for(i=0;i< field_num;++i){ fprintf(fout, "%11s POSITION(%d:%d)", dbffield[i].name, dbffield[i].add, dbffield[i].add + dbffield[i].length -1 ); switch (dbffield[i].type){ case 'C':case 'L': // 字符型/ 逻辑型fprintf(fout, " CHA R");break ;if (dbffield[i].dec == 0 ) //整数型fprintf(fout, "INTEGER EXTERNAL NULLIF %s = BLANKS", dbffield[i].name);else //实数型fprintf(fout, " DECIMAL EXTERNAL NULLIF %s =BLA NKS", dbffield[i].name );break;case 'D': //日期型fprintf(fout, " DATE 'YYYYMMDD' NULLIF %s = BLANKS", dbffield[i].name);break;default:break;}if(i< field_num -1)fprintf(fout, ",\n") ;}fprintf(fout, ")\n");fclose(fout);// 产生CREATE TA BEL. 的SQL 语句strcpy(sqlload,argv[1]);strcat(sqlload,".sql");if ((fout=fopen(sqlload,"w")) == NULL){ cout < < "Cannot open file " < < sqlload < < endl;return -1 ;}fprintf(fout, "create table %s (\n", argv[1]);for(i=0;i< field_num;i++){ fprintf(fout,"%11s",dbffield[i].name);switch (dbffield[i].type){ case 'C': //字符型fprintf(fout, " CHA R(%d)",dbffield[i].length);break;case 'L': //逻辑型fprintf(fout, " CHA R(1)");break;case 'N': //数字型if (dbffield[i].dec==0)fprintf(fout," NUMBER(%d)", dbffield[i].length) ;elsefprintf(fout, " NUMBER(%d,%d)",dbffield[i].length-1, dbffield[i].dec);case 'D': // 日期型fprintf(fout, " DATE");;break;default:break;}if (i< field_num - 1)fprintf(fout, ",\n");}fprintf(fout, ")\n");fclose(fout);// 产生SQL*Loader数据文件strcpy(sqlload,argv[1]);strcat(sqlload,".txt");if((fout=fopen(sqlload,"w")) == NULL){ cout < < "Cannot open file " < < sqlload < < endl; return -1 ;}fseek(fp,dbfhead- >head_length,SEEK_SET);for(i=0;i< dbfhead- >record_num;i++){ fread(buf,dbfhead- >field_length,1,fp);buf[dbfhead- >field_length] ='\0';fprintf(fout,"%s\n", buf+1); //skip记录首字节(删除标志) }fclose(fout);fclose(fp);delete sqlload;return 0 ;}。