实例6 IF()和REPT()函数创建文本直方图
【Excel】玩转Excel函数,REPT函数10种应用

【Excel】玩转Excel函数,REPT函数10种应⽤⼀、REPT函数基本定义=REPT('重复显⽰的⽂本',重复的次数)例如=rept('#',5),回车显⽰: #####⼆、实际应⽤实例01制作横向条形图对以下表格进⾏数据可视化,⽤数据条长短表⽰数据⼤⼩。
在c3单元格⾥输⼊公式:=REPT('|',B2/10)注意:除以⼀定系数可以调节合适的长度;然后设置单元格格式:设置 playbill 字体,灰⾊,就得到了灰⾊⽆缝隙的单元格⾥的数据条!最终效果如下图:如果把'|'换成'/',看看效果:02 纵向数据条再来看嵌⼊在表格⾥的纵向条形图,如果⽤图表中的柱形图来呈现费时费⼒。
我们还是通过REPT函数来实现⼀下这个效果:1、在C16单元格输⼊公式=REPT('|',C16/10),同理,d17单元格公式为=REPT('|',-D17/10)2、设置单元格对齐⽅式为底端对齐:3、设置单元格字体类型为playbill,对齐⽅向为90度:4、修改对应的字体颜⾊即可。
03 漏⽃图漏⽃图常⽤来反映⼀个业务流程中各环节数据衰减变化的过程。
当我们⽤图表来做漏⽃图的时候,需要使⽤辅助序列占位的技巧,⽽⽤ REPT 函数做,只需要对单元格实现居中对齐!以此类推,我们还可以实现⽢特图、瀑布图、蝴蝶图等….04 圆点百分⽐图在REPT函数中换个字符,可得到其他类型的图表,⽐如堆积圆点百分⽐图表。
⽅法为:1、淡⾊圆点:输⼊公式:=REPT(CHAR(41457),100),char(41457)得到的是圆点字符;单元格对齐⽅式为底端对齐、左对齐;2、深⾊圆点:在B9单元格中输⼊公式:=REPT(CHAR(41457),B6*100),字体颜⾊为深⾊,单元格对齐为顶端对齐,左对齐;4、拍照,然后对照⽚翻转后放置在淡⾊之上即可。
质量分析中用REPT函数创建文本柱状图

在质量分析中用REPT函数创建文本柱状图关键词:REPT函数文本柱状图一、REPT函数REPT函数的含义:一次性输入多个重复的相同文本。
REPT函数的语法格式:=REPT(text,number_times)。
第一个参数text表示重复出现的文本第一个参数number_times表示文本重复出现的次数二、REPT函数与柱状图REPT函数可以用于文本的重复输入。
在A1单元格输入:=REPT("★",ROW()),公式向下复制到A9单元格(图一)。
ROW()表示返归单元格行号,公式在A1单元格,ROW()返回1,公式在A2单元格,ROW()返回2……。
图一图二图三图四图一中的★改成|,就变成了图二样式。
(竖线|的输入方法:Shift+\)图一中的★改成n,就变成了图三样式。
图一中的★改成g,就变成了图四样式。
下面,改变图二、图三、图四的字体,奇迹出现了。
改变图二字体为Arial字体和Marlett字体, 产生图五、图六。
图五图六改变图三字体为Wingdings字体和Impact字体, 产生图七、图八。
图七图八改变图四字体为Mt Extra字体和Webdings字体, 产生图九、图十。
图九图十图五、图六、图七、图八、图九,与EXCEL中的柱状图有些相像,图十简直就是柱状图,只不过是由纯文本组成的柱状图,有人叫它为伪图表。
三、质量分析中的文本柱状图图十一是某学校某年级某次考试的总分均分数据,下面根据该数据创建文本柱状图。
图十一在F1:F14填充1、2、3……14。
在E3单元格输入:=REPT("g",IF(B2>$B$16,B2-$B$16,0)),公式向下复制到E15单元格。
在G3单元格输入:=REPT("g",IF(B2<$B$16,$B$16-B2,0)) ,公式向下复制到G15单元格。
E3:E15和G3:G15区域的字体分别设为Webdings字体(图十二)。
大学r语言考试题及答案

大学r语言考试题及答案一、选择题(每题2分,共20分)1. R语言是一种()。
A. 编程语言B. 数据分析工具C. 操作系统D. 网页浏览器答案:A2. 在R语言中,用于生成随机数的函数是()。
A. seq()B. rep()C. sample()D. random()答案:C3. 下列哪个函数可以用来计算R语言中的向量元素的总和?()A. sum()B. mean()C. median()D. max()答案:A4. R语言中,用于创建数据框(data frame)的函数是()。
A. data.frame()B. matrix()C. list()D. vector()答案:A5. 在R语言中,如何引用一个名为“x”的变量的第一个元素?()A. x[1]B. x(1)C. x{1}D. x->1答案:A6. R语言中,用于绘制直方图的函数是()。
A. plot()B. hist()C. bar()D. pie()答案:B7. 下列哪个选项是R语言中的数据类型?()A. 数字(numeric)B. 文本(text)C. 日期(date)D. 所有选项都是答案:D8. 在R语言中,如何将一个向量反向?()A. rev()B. reverse()C. flip()D. invert()答案:A9. R语言中,用于执行逻辑“与”操作的函数是()。
A. &B. &&C. &D. and()答案:A10. 下列哪个命令可以用来安装R语言的包?()A. install.packages()B. load.packages()C. get.packages()D. fetch.packages()答案:A二、简答题(每题5分,共30分)11. 简述R语言中向量和矩阵的区别。
答:R语言中的向量是一维的数据结构,可以包含相同类型的数据元素。
矩阵是二维的,由行和列组成,且矩阵中的所有元素必须是相同类型的。
Excel操作文本的公式

操作文本的公式一个单元格中可以容纳32000个字符。
如何确定单元格中的字符数,可以使用LEN()函数。
例如,使用“=LEN(A1)”可以返回A1单元格中文本的长度。
Excel可以区分数字和文本。
如果要强制数字被当做文本,可以使用下面的方法:⏹对单元格应用文本数字格式。
使用“开始”选项卡的“数字”组中的“数字格式”下拉列表,然后选择“文本”。
⏹在数字单元格前面加一个单引号。
单引号不会显示,但单元格的内容会被当做文本。
把单元格格式化为为本,如果输入的是数字,还是可以对单元格执行某些计算的操作。
例如,A1单元格包含一个前面带单引号的值,下面的公式将显示A1单元格的值加1后的值:=A1 + 1但是使用函数的时候,却会把A1单元格当成了0。
文本函数Excel有一个可以用来处理文本的工作表函数分类。
可以通过“公式”选项卡上的“函数库”组中的“文本”来访问所需的函数。
大多数文本函数并不只局限于处理文本。
这些函数也可以处理含有数值的单元格。
确定单元格是否包含文本可以通过一个公式来确认一个特定的单元格包含的数据类型。
例如,可以使用IF函数,只有当单元格包含文本时才返回结果。
确定是否包含文本可以使用ISTEXT()函数。
ISTEXT函数并不在“文本”函数类别中,而是在“函数库”的“其他函数”中。
ISTEXT()接受一个参数,如果参数包含文本,则返回True,反之,返回False。
例如下面的公式:=ISTEXT(A1)使用字符编码在屏幕上显示的每个字符都有一个相关的编码号。
对于Windows系统,Excel使用标准的ANSI字符集。
ANSI字符集由从1~255的255个字符组成。
在处理字符编码时可以使用的两个函数是CODE和CHAR。
这些函数和其他函数一起使用时就非常有用。
CODE函数Excel的CODE函数返回参数的字符编码。
下面的公式将返回大写字母A的字符编码65:=CODE(“A”)如果CODE函数的参数多于一个字符,函数也只返回第一个字符的编码。
r语言试题库

R语言试题库
一、选择题
R语言中用于向量下标的运算符是( )。
A. %
B. #
C. $
D. ^
答案:C
以下哪个不是R语言中的数据结构?
A. 向量
B. 矩阵
C. 数据框
D. 字符串
答案:D
R语言中用于逻辑运算的运算符是( )。
A. <
B. >
C. =
D. ==
答案:D
在R语言中,以下哪个函数用于计算向量的平均值?
A. sum
B. mean
C. median
D. mode
答案:B
二、填空题
R语言中,函数用于生成随机数。
答案:random() 或 rnorm() 或 runif() 等。
R语言中,函数用于读取数据文件。
答案:read.table() 或 read.csv() 等。
R语言中,函数用于绘制散点图。
答案:plot() 或 scatter()。
R语言中,函数用于计算一组数据的标准差。
答案:sd()。
三、简答题
简述R语言中常见的几个数据类型。
答案:数值型、字符型、逻辑型和复数型等。
简述R语言中条件语句的结构。
答案:if语句、if-else语句和switch语句等。
一文读懂如何用stata绘制直方图

一文读懂如何用stata绘制直方图
展开全文
来源:由计量经济学服务中心编辑整理,转载请注明来源
直方图是用矩形的面积(即长度和宽度)来表示频数分布的图形,在平面直角坐标系中,一般用纵轴表示频数或频率,用横轴表示数据的分组。
通过该种图形,用户可以较为直观地了解数据的整体情况,如分布类型、中心位置、分散程度等。
在Stata中绘制直方图的最基本命令语句为:
histogram varname [if] [in] [weight] [, [continuous_opts | discrete_opts] options]
其中varname是将要绘制图形的变量,if是条件语句,in是范围语句,weight是权重语句。
操作1:
为变量mpg绘制直方图,不进行任何设定
sysuse 'auto.dta', clear
histogram mpg
结果为:
操作2:
为变量volume绘制直方图,不进行任何设定sysuse sp500
histogram volume
histogram volume, frequency
添加标题、脚注等命令如下:。
如何用Excel中的rept函数创造效果

如何用Excel中的rept函数创造效果在Excel中,REPT函数是一个强大的函数,可以帮助我们创造一些有趣或实用的效果。
本文将介绍如何使用REPT函数来实现不同的效果,以及一些注意事项。
一、REPT函数简介REPT函数是Excel中的一个文本函数,用于将指定的文本重复多次。
该函数的语法如下:REPT(text, number_of_times)其中,text为要重复的文本,number_of_times为重复的次数。
二、使用REPT函数创造效果1. 创建重复字符串通过REPT函数,我们可以轻松地将一个字符串重复多次。
例如,我们要创建一个包含10个“Hello”的字符串,可以使用以下公式:=REPT("Hello", 10)2. 制作填充字符有时候,我们需要使用一些特殊符号来填充单元格,以达到一些美观或分隔的效果。
REPT函数可以帮助我们实现这一目标。
例如,我们要在一行中填充30个“-”,可以使用以下公式:=REPT("-", 30)3. 生成序列号有时候,我们需要生成一系列的序列号,而不是手动输入每个数字。
REPT函数可以帮助我们生成指定范围的序列号。
例如,我们要生成从1到10的序列号,可以使用以下公式:=REPT(ROW(A1)&",", 10)4. 制作简单图表通过将文本重复多次并使用空格作为分隔符,我们可以制作简单的柱状图或进度条。
例如,我们要制作一个柱状图,表示一个任务的完成情况,可以使用以下公式:=REPT("|", 30)&REPT(" ", 70)三、注意事项在使用REPT函数时,有几个注意事项需要注意:1. 文本长度限制:REPT函数所生成的文本长度是有限制的,根据不同版本的Excel而有所不同。
在Excel 2016及更高版本中,文本长度限制是32767个字符。
excel中rept函数

excel中rept函数REPT函数是Excel中的一个文本函数,用于将指定的文本重复指定的次数。
其语法如下:REPT函数的使用方法如下:首先,在一个单元格内输入一个文本,作为需要重复的文本。
然后,在另一个单元格内输入REPT函数,并将需要重复的文本作为第一个参数,将需要重复的次数作为第二个参数。
按下回车键后,就可以得到重复指定次数的文本。
下面是一些REPT函数的示例:示例1:=text("Hello",5)这个示例将会得到"HelloHelloHelloHelloHello"。
示例2:=text("Excel is great!",3)这个示例将会得到"Excel is great!Excel is great!Excel is great!"。
示例3:=REPT("abc",4)这个示例将会得到"abcabcabcabc"。
REPT函数还可以与其他函数一起使用,以实现更复杂的功能。
下面是一些REPT函数与其他函数组合使用的示例:示例4:=CONCATENATE(REPT("a",3),REPT("b",2))这个示例将会得到"aaabbb"。
在这个示例中,我们使用了CONCATENATE函数将两个REPT函数的结果拼接在一起。
示例5:=LEFT(REPT("Excel ",5),20)这个示例将会得到"Excel Excel Excel Ex"。
在这个示例中,我们使用了LEFT函数来截取REPT函数的结果的前20个字符。
示例6:通过上面的示例,我们可以看到REPT函数的灵活性和多用途性。
它可以用于字符串的处理、模板的生成等多种情况下。
总结:REPT函数是Excel中的一个文本函数,用于将指定的文本重复指定的次数。
频率分布直方图绘制指南

频率分布直方图绘制指南频率分布直方图是一种用于可视化数据分布的常见工具。
它能够展示数据集中的值在给定范围内的频率分布情况,帮助我们更好地理解数据的分布特征和趋势。
本文将介绍频率分布直方图的基本概念和绘制方法,帮助你快速掌握绘制直方图的技巧。
什么是频率分布直方图频率分布直方图是一种用矩形条表示数据集中每个值的频率的图表。
它将数据范围划分成若干等距区间,统计每个区间内的数据值数量,并将数量显示为相应的矩形高度。
通过直方图,我们可以观察到数据的分布形状、集中程度和异常值等信息。
绘制频率分布直方图的步骤绘制频率分布直方图的过程通常包括以下步骤:1.确定数据集的范围:首先,需要确定你要绘制直方图的数据集的范围是多少。
根据数据的实际情况,选择一个适当的数据范围确保直方图可以清晰地展示数据的分布情况。
2.将数据划分成区间:通过将数据划分成区间,可以更好地展示数据的分布情况。
根据数据的范围和数量,合理选择区间的数量和等距划分方式。
3.计算每个区间内的频率:统计每个区间内的数据值数量,得到每个区间的频率。
频率可以通过计算每个区间内的数据数量除以总数据量得到。
4.绘制直方图:使用柱状图绘制直方图,即将每个区间的频率作为柱状图的高度,区间的起点作为柱状图的横坐标。
5.添加轴标签和标题:为了提高图表的可读性,添加合适的轴标签和标题,包括横轴标题、纵轴标题和整个图表的标题。
示例假设我们有一个学生年龄数据集,包含了100个学生的年龄信息。
要绘制学生年龄分布的直方图,我们可以按照以下步骤进行:1.确定数据集的范围:观察数据集,确定数据集中最小和最大的年龄值。
假设最小年龄为18岁,最大年龄为22岁。
2.将数据划分成区间:根据数据范围和数量,选择合适的区间数量和划分方式。
这里我们选择5个区间,并采用等宽划分方式。
即,每个区间的宽度为(22 - 18)/5 = 0.8岁。
3.计算每个区间内的频率:统计数据集中落入每个区间内的年龄数量。
matplotlib 选择题

一、matplotlib 的作用Matplotlib 是 Python 中常用的绘图库,它可以帮助用户快速、高效地创建各种类型的图表和可视化效果。
Matplotlib 提供了丰富的绘图功能和灵活的参数设置,使得用户可以根据自己的需求自定义图表样式,控制图表的各个细节。
二、matplotlib 的基本用法1. 导入 matplotlib 库在使用 matplotlib 之前,首先需要导入该库,通常采用以下语句进行导入:```pythonimport matplotlib.pyplot as plt```2. 创建图表在 matplotlib 中,图表是通过 Figure 对象来管理的。
用户可以使用plt.figure() 函数创建一个新的 Figure 对象,然后在该对象上绘制各种图表。
```pythonfig = plt.figure()```3. 绘制图表在创建了 Figure 对象之后,可以使用各种函数来在图表上进行绘制。
可以使用 plt.plot() 函数绘制折线图,使用 plt.scatter() 函数绘制散点图,使用 plt.bar() 函数绘制柱状图等。
```pythonplt.plot(x, y)plt.scatter(x, y)plt.bar(x, y)```4. 显示图表使用 plt.show() 函数显示所绘制的图表。
```pythonplt.show()三、matplotlib 常用图表类型及参数介绍1. 折线图折线图是一种常用的图表类型,可以用于展示数据随时间变化的趋势。
在绘制折线图时,可以通过设置线条颜色、样式、宽度等参数来控制折线的外观。
2. 散点图散点图常用于展示两组数据之间的相关性或分布情况。
用户可以通过设置散点的颜色、大小、形状等参数来增强图表的表现力。
3. 柱状图柱状图可以直观地比较不同类别之间的数据差异。
在绘制柱状图时,可以设置柱体的颜色、宽度、间距等参数,以及坐标轴的刻度、标签等内容。
教你利用Python玩转histogram直方图的五种方法

教你利⽤Python玩转histogram直⽅图的五种⽅法直⽅图直⽅图是⼀个可以快速展⽰数据概率分布的⼯具,直观易于理解,并深受数据爱好者的喜爱。
⼤家平时可能见到最多就是matplotlib,seaborn 等⾼级封装的库包,类似以下这样的绘图。
本篇博主将要总结⼀下使⽤Python绘制直⽅图的所有⽅法,⼤致可分为三⼤类(详细划分是五类,参照⽂末总结):纯Python实现直⽅图,不使⽤任何第三⽅库使⽤Numpy来创建直⽅图总结数据使⽤matplotlib,pandas,seaborn绘制直⽅图下⾯,我们来逐⼀介绍每种⽅法的来龙去脉。
纯Python实现histogram当准备⽤纯Python来绘制直⽅图的时候,最简单的想法就是将每个值出现的次数以报告形式展⽰。
这种情况下,使⽤字典来完成这个任务是⾮常合适的,我们看看下⾯代码是如何实现的。
>>> a = (0, 1, 1, 1, 2, 3, 7, 7, 23)>>> def count_elements(seq) -> dict:... """Tally elements from `seq`."""... hist = {}... for i in seq:... hist[i] = hist.get(i, 0) + 1... return hist>>> counted = count_elements(a)>>> counted{0: 1, 1: 3, 2: 1, 3: 1, 7: 2, 23: 1}我们看到,count_elements() 返回了⼀个字典,字典⾥出现的键为⽬标列表⾥⾯的所有唯⼀数值,⽽值为所有数值出现的频率次数。
hist[i] = hist.get(i, 0) + 1实现了每个数值次数的累积,每次加⼀。
EXCEL图表制作rept函数 以及甘特图制作

EXCEL图表制作rept函数——in-cell bar 图之终结篇⏹REPT函数功能按照给定的次数重复显示文本,可以通过函数REPT来不断地重复显示某一文本字符串,对单元格进行填充。
⏹REPT函数语法REPT(text, number_times)▲Text:必需。
需要重复显示的文本。
▲Number_times:必需。
用于指定文本重复次数的正数。
注解:●如果number_times为0,则REPT返回""(空文本)。
●如果number_times不是整数,则将被截尾取整。
●REPT函数的结果不能大于32,767个字符,否则,REPT将返回错误值#VALUE!。
示例:如果将示例复制到一个空白工作表中,可能会更容易理解该示例。
⏹用REPT函数模拟表格中的条形图在财经类杂志报刊上,经常可以看到带有bar图的表格,使表格更直观,也不需要增加大的空间。
在excel2007中提供了此功能,但2003中没有。
不过,用rept函数可以方便的模拟。
用rept做简易条形图确实非常巧妙和方便,特别是数据行数比较多时。
即使2007的数据条也不见得比它好,因为2007的数据条不是按比例的。
如图,在数据列的右边填入如下公式:=REPT("|",100*D5/$D$22),每行的重复次数是它占总数的百分比,设置字体颜色,就是一个很好的bar图啦。
注意,模拟列的字体不要用中文,否则很难看了。
这样甚至比做图还方便,特别是在分析一组数据时,用图表来模拟,都没有这样方便。
下边,总结一下用rept做图的多种情形。
一般单元格条图之前的日志已说明做法,=REPT("|",E2),Arial字体,不再细述。
在宋体字下,竖线会显得很疏散,不象图表。
可使用Arial字体,则可使竖线更紧凑。
建议使用8磅大小。
有热心网友指出,如果rept Webdings字体的"g"字符,可出现完全连接的方块字符。
一个函数实现基因内具有多种突变类型的热图的绘制

⼀个函数实现基因内具有多种突变类型的热图的绘制版权声明:本⽂为博主原创⽂章,转载请注明出处 我们平常多见的基因突变热图是⼀个基因⼀个格⼦,⼀种突变类型,但实际上在同⼀个病⼈中,同⼀个基因往往具有多种突变类型,因此传统的热图绘制⼯具并不能满⾜我们绘图的需要。
应研究需要,本⼈⾃⼰写了⼀个热图绘制函数,内部调⽤image 进⾏热图的绘制, barplot进⾏直⽅图绘制,⽤data.table进⾏数据处理。
对于⼀个基因内多种突变类型如何表现出来的问题,这个函数先采⽤image将初步的热图绘制出来,再使⽤points,以⽅块形式将第⼆种突变,第三种突变依次添加,在添加的同时⽅块位置稍为移动并且伴随着⼤⼩的略微缩⼩,以实现更好的显⽰效果,最多能在⼀个热图格⼦上表⽰四种突变。
函数如下,需要安装并加载data.table 1.10.4,加载RColorBrewermy_heatmap <- function(vr, pal = c("#F2F2F2",colorRampPalette(c("blue", "white", "red"))(5)[c(1,2)],"#F2F2F2",colorRampPalette(c("blue", "white", "red"))(5)[c(4,5)],brewer.pal(n = 8, name ="Accent")[c(1,4,6,8,2,3,5,7)],"#E31A1C","#6A3D9A"),typ {if((length(pal) - length(type)) !=1 ){stop("Pal must be one longer than type, because first one pal is col for no mutation")}if(!is.null(sub_gene)){pal_dt <- data.table(pal, type=c("NoMut",type))vr <- vr[Gene %in% sub_gene,]type <- pal_dt[type %in% unique(vr$Type),type]pal <- c(pal[1],pal_dt[type, on="type"][,pal])}else{pal_dt <- data.table(pal, type=c("NoMut",type))type <- pal_dt[type %in% unique(vr$Type),type]pal <- c(pal[1],pal_dt[type, on="type"][,pal])}dt <- unique(vr[,.(Gene,Type,Patient)])dt$Type <- factor(dt$Type, levels = type)if(order_gene){gene <- dt[!Type %in% order_omit,.(N=length(unique(Patient))),by=Gene][order(N),Gene]}else{gene <- unique(dt[!Type %in% order_omit, Gene])}dt$Gene <- factor(dt$Gene, levels = gene)if(order_patient){patient <- data.table(table(vr[!Type %in% order_omit,]$Patient))[order(-N),V1]}else{patient <- unique(dt[!Type %in% order_omit, Patient])}dt$Patient <- factor(dt$Patient, levels = c(patient, setdiff(unique(dt$Patient),patient)))setkey(dt, "Type")n <- length(unique(dt$Type))dt$Gene_Patients <- paste(dt$Gene, dt$Patient)dt_inf <- dt[,.N,by=.(Gene, Patient)]max_mut_num <- max(dt_inf$N)dt[,Mut_num:=seq_len(.N),by=.(Patient,Gene)]#main plotdt1 <- copy(dt)dt1[Mut_num !=1, Type:=NA]dc <- data.frame(dcast(dt1, Patient ~ Gene, value.var = "Type", fun.aggregate = function(x)(x[!is.na(x)][1])))rownames(dc)<- dc[,1]data_matrix<-data.matrix(dc[,-1])data_matrix[is.na(data_matrix)] <- 0pal=palbreaks<-seq(-1,10,1)if(!hist_plot & is.null(annotation_col)){layout(matrix(data=c(1,2), nrow=1, ncol=2), widths=c(8,2), heights=c(1,1))par(mar=heatmap_mar, oma=heatmap_oma, mex=heatmap_mex)}else if(hist_plot & is.null(annotation_col)){layout(matrix(c(2,4,1,3),2,2,byrow=TRUE), widths=c(heatmap_width,1),heights=c(1,heatmap_height), TRUE)par(mar=heatmap_mar)}else if(hist_plot & !is.null(annotation_col)){if(is.null(anno_height)){anno_height <- 0.02 * ncol(annotation_col)}layout(matrix(data=c(3,5,2,5,1,4), nrow=3, ncol=2, byrow=TRUE), widths=c(heatmap_width,1), heights=c(1, anno_height, heatmap_height))par(mar=heatmap_mar, oma=heatmap_oma, mex=heatmap_mex)}else if(!hist_plot & !is.null(annotation_col)){if(is.null(anno_height)){anno_height <- 0.02 * ncol(annotation_col)}layout(matrix(data=c(2,4,1,3), nrow=2, ncol=2, byrow=TRUE), widths=c(8,2), heights=c(anno_height,1))par(mar=heatmap_mar, oma=heatmap_oma, mex=heatmap_mex)}image(x=1:nrow(data_matrix),y=1:ncol(data_matrix),z=data_matrix,xlab="",ylab="",breaks=breaks,col=pal[1:11],axes=FALSE)#sub plotadd_plot <- function(dt, i){dt1 <- copy(dt)dt1[Mut_num != i, Type:=NA]dc <- data.frame(dcast(dt1, Patient ~ Gene, value.var = "Type", fun.aggregate = function(x){ifelse(length(x) >1,x[!is.na(x)][1],factor(NA))}))rownames(dc)<- dc[,1]data_matrix <- data.matrix(dc[,-1])xy <- which(data_matrix !=0, arr.ind = T)#apply(xy, 1, function(x)points(x[1], x[2],pch=15, cex=2.5 -0.5*i, col=pal[data_matrix[x[1],x[2]]+1]))apply(xy, 1, function(x)points(x[1]-0.6+i*0.25, x[2],pch=15, cex=1.2 - i*0.08, col=pal[data_matrix[x[1],x[2]]+1]))}ploti <- data.frame(i=2:max_mut_num)apply(ploti, 1, function(i){print(add_plot(dt, i))})text(x=1:nrow(data_matrix)+0.1, y=par("usr")[1] - xlab_adj,srt = 90, adj = 0.5, labels = rownames(data_matrix),xpd = TRUE, cex=col_text_cex)axis(2,at=1:ncol(data_matrix),labels=colnames(data_matrix),col="white",las=1, b=0.1, cex.axis=row_text_cex)abline(h=c(1:ncol(data_matrix))+0.5,v=c(1:nrow(data_matrix))+0.5,col="white",lwd=2,xpd=F)#add annotation plotif(!is.null(annotation_col)){change_factor <- function(x){as.numeric(factor(x, labels = 1:length(levels(x))))} #change infomation to numericcolname_tmp <- colnames(annotation_col)annotation_col_mt <- as.matrix(apply(annotation_col, 2, change_factor))rownames(annotation_col_mt) <- rownames(annotation_col)colnames(annotation_col_mt) <- colname_tmpannotation_col_mt <- annotation_col_mt[rownames(data_matrix),]## change infomation numric to unique numbercumsum <- 0if(!is.null(dim(annotation_col_mt))){#if more than one column, cummulate info numericfor(i in 1:ncol(as.data.frame(annotation_col_mt))){annotation_col_mt[,i] <- cumsum + annotation_col_mt[,i]cumsum <- max(annotation_col_mt[,i])}}## get color according to infomationget_color <- function(anno){return(annotation_colors[[anno]][levels(annotation_col[,anno])])}palAnn <- NULLif(is.null(dim(annotation_col_mt))){rowname_tmp <- rownames(annotation_col_mt)annotation_col_mt <- as.matrix(annotation_col_mt, nrow=1)rownames(annotation_col_mt) <- rowname_tmpcolnames(annotation_col_mt) <- colname_tmpfor(anno in colnames(annotation_col_mt)){palAnn <- c(palAnn, get_color(anno))}par(mar=c(0,heatmap_mar[2], 0, heatmap_mar[4]))image(x=1:nrow(annotation_col_mt), y=1:ncol(annotation_col_mt), z= annotation_col_mt, col=palAnn, xlab="",ylab="",axes=FALSE)axis(2,at=1:ncol(annotation_col_mt),labels=colnames(annotation_col_mt),col="white",las=1, b=0.1, cex.axis=row_text_cex)abline(h=c(1:ncol(annotation_col_mt))+0.5,v=c(1:nrow(annotation_col_mt))+0.5,col="white",lwd=2,xpd=F)}if(hist_plot){#histpar(mar=c(0,2+0.5,3,heatmap_mar[4]-0.9))patient_dt <- dt[,.N,by=.(Patient,Type)]mt <- data.frame(dcast(patient_dt, Type ~ Patient, value.var = "N"))data_matrix <- data.matrix(mt[,-1])rownames(data_matrix) <- mt[,1]tryCatch(data_matrix <- data_matrix[setdiff(type, order_omit), patient], error = function(e){print("type argument or your patient name format(include "-" and so on )")})data_matrix[is.na(data_matrix)] <- 0omit_idx <- NULLfor(i in order_omit){omit_idx <- c(omit_idx,1+which(type == i))}barplot(data_matrix, col=pal[-c(1,omit_idx)],space=0,border = "white",axes=T,xlab="",ann=F, xaxt="n")par(mar=c( heatmap_mar[1]-2 , 0.8, heatmap_mar[3]+2.2, 3),las=1)gene_dt <- dt[,.N,by=.(Gene,Type)]mt <- data.frame(dcast(gene_dt, Type ~ Gene, value.var = "N"))data_matrix <- data.matrix(mt[,-1])rownames(data_matrix) <- mt[,1]gene <- gsub("ATM,", "ATM.", gene)tryCatch(data_matrix <- data_matrix[setdiff(type, order_omit), gene], error = function(e){print("type argument or check your gene name format(please not include "-" and so on)")})data_matrix[is.na(data_matrix)] <- 0barplot(data_matrix, col=pal[-c(1,omit_idx)],space=0,border = "white",axes=T,xlab="", ann=F, horiz = T, yaxt="n")}#add legendpar(mar=legend_mar)plot(3, 8, axes=F, ann=F, type="n")if(is.null(annotation_col)){ploti <- data.frame(i=1:length(type))}else{#add annotation legendploti <- data.frame(i=1:(length(type) + max(annotation_col_mt)))pal <- c("NULL", palAnn, pal[-1])anno_label <- NULLfor (anno in colnames(annotation_col)){anno_label <- c(anno_label, levels(annotation_col[[anno]]))}type <- c(anno_label,type)}if(!hist_plot){tmp <- apply(ploti, 1, function(i){print(points(2, 10+(length(type)-i)*legend_dist, pch=15, cex=2, col=pal[i+1]))})tmp <- apply(ploti, 1, function(i){print(text(3, 10+(length(type)-i)*legend_dist, labels = type[i],pch=15, cex=1, col="black"))})}if(hist_plot){tmp <- apply(ploti, 1, function(i){print(points(2, 5+(length(type)-i)*legend_dist, pch=15, cex=0.9, col=pal[i+1]))})tmp <- apply(ploti, 1, function(i){print(text(2.8, 5+(length(type)-i)*legend_dist, labels = type[i],pch=15, cex=0.9, col="black"))})}}描述: 绘制⼀个基因可以同时显⽰多种突变类型的热图,输⼊三列的data table数据框,列名分别是Gene,Type和 Patient,输出热图,还可以在热图上⽅和右⽅添加突变的直⽅图。
Excel函数(13)–用rept函数制作图表
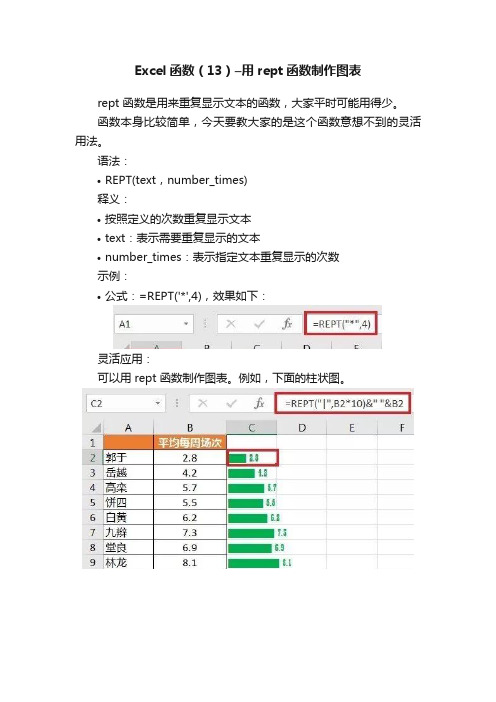
Excel函数(13)–用rept函数制作图表rept 函数是用来重复显示文本的函数,大家平时可能用得少。
函数本身比较简单,今天要教大家的是这个函数意想不到的灵活用法。
语法:•REPT(text,number_times)释义:•按照定义的次数重复显示文本•text:表示需要重复显示的文本•number_times:表示指定文本重复显示的次数示例:•公式:=REPT('*',4),效果如下:灵活应用:可以用 rept 函数制作图表。
例如,下面的柱状图。
解决方案:1. 下表是原数据,每对组合平均每周小剧场的演出次数,需要用柱状图显示。
2. 在 C2 单元格输入以下公式 --> 向下拖动公式 --> 将 C 列的字体改成“Playbill”,并改成自己喜欢的颜色:=REPT('|',B2*10)公式释义:•按照 B2*10 的次数显示符号“|”•*10 是为了让柱状图的落差效果看起来更明显一些•字体“Playbill” 会让“|”连在一起,呈现柱状效果3. 如果需要在柱状图上加上数据值,可以输入以下公式:=REPT('|',B2*10)&' '&B2公式释义:•&:连接符•' ':空格•B2:调用 B2 单元格的值4. 如果要垂直方向显示柱状图,可以按以下步骤操作:将原数据表转成横向排列--> 在表格上方的单元格输入同样的rept 公式 --> 右键单击 B7 单元格 --> 选择“Format Cells”--> 将字体方向调整为 90 度 --> 确定:=REPT('|',B7*10)5. 向右拖动公式,图表就制作完成了。
R语言绘制直方图实例讲解

R语⾔绘制直⽅图实例讲解直⽅图表⽰被存储到范围中的变量的值的频率。
直⽅图类似于条形图,但不同之处在于将值分组为连续范围。
直⽅图中的每个柱表⽰该范围中存在的值的数量的⾼度。
R语⾔使⽤hist()函数创建直⽅图。
此函数使⽤向量作为输⼊,并使⽤⼀些更多的参数来绘制直⽅图。
语法使⽤R语⾔创建直⽅图的基本语法是hist(v,main,xlab,xlim,ylim,breaks,col,border)以下是所使⽤的参数的描述v是包含直⽅图中使⽤的数值的向量。
main表⽰图表的标题。
col⽤于设置条的颜⾊。
border⽤于设置每个条的边框颜⾊。
xlab⽤于给出x轴的描述。
xlim⽤于指定x轴上的值的范围。
ylim⽤于指定y轴上的值的范围。
break⽤于提及每个条的宽度。
例使⽤输⼊vector,label,col和边界参数创建⼀个简单的直⽅图。
下⾯给出的脚本将创建并保存当前R语⾔⼯作⽬录中的直⽅图。
# Create data for the graph.v <- c(9,13,21,8,36,22,12,41,31,33,19)# Give the chart file a name.png(file = "histogram.png")# Create the histogram.hist(v,xlab = "Weight",col = "yellow",border = "blue")# Save the file.dev.off()当我们执⾏上⾯的代码,它产⽣以下结果X和Y值的范围要指定X轴和Y轴允许的值的范围,我们可以使⽤ xlim 和 ylim 参数。
每个条的宽度可以通过使⽤间隔来确定。
# Create data for the graph.v <- c(9,13,21,8,36,22,12,41,31,33,19)# Give the chart file a name.png(file = "histogram_lim_breaks.png")# Create the histogram.hist(v,xlab = "Weight",col = "green",border = "red", xlim = c(0,40), ylim = c(0,5),breaks = 5)# Save the file.dev.off()当我们执⾏上⾯的代码,它产⽣以下结果以上就是R语⾔绘制直⽅图实例讲解的详细内容,更多关于R语⾔直⽅图的资料请关注其它相关⽂章!。
R语言绘制频率直方图的案例
R语⾔绘制频率直⽅图的案例频率直⽅图是数据统计中经常会⽤到的图形展⽰⽅式,同时在⽣物学分析中可以更好的展⽰表型性状的数据分布类型;R基础做图中的hist函数对单⼀数据的展⽰很⽅便,但是当遇到多组数据的时候就不如ggplot2绘制来的⽅便。
***1.基础做图hist函数hist(rnorm(200),col='blue',border='yellow',main='',xlab='')1.1 多图展⽰par(mfrow=c(2,3))for (i in 1:6) {hist(rnorm(200),border='yellow',col='blue',main='',xlab='')}2.ggplot2绘制构造⼀组正态分布的数据PH<-data.frame(rnorm(300,75,5))names(PH)<-c('PH')#显⽰数据head(PH)## PH## 1 72.64837## 2 67.10888## 3 89.34927## 4 75.70969## 6 82.85354加载ggplot2作图包并绘图library(ggplot2)library(gridExtra)p1<-ggplot(data=PH,aes(PH))geom_histogram(color='white',fill='gray60') #控制颜⾊ylab(label = 'total number') #修改Y轴标签2.1 修改柱⼦之间的距离p2<-ggplot(data=PH,aes(PH))geom_histogram(color='white',fill='gray60',binwidth = 3) 2.2 添加拟合曲线p3<-ggplot(data=PH,aes(PH,..density..))geom_histogram(color='white',fill='gray60',binwidth = 3) geom_line(stat='density')2.3 修改线条的粗细p4<-ggplot(data=PH,aes(PH,..density..))geom_histogram(color='white',fill='gray60',binwidth = 3) geom_line(stat='density',size=1.5)grid.arrange(p1,p2,p3,p4)2.4 绘制密度曲线p1<-ggplot(data=PH,aes(PH,..density..))geom_density(size=1.5)2.5 修改线条样式p2<-ggplot(data=PH,aes(PH,..density..))geom_density(size=1.5,linetype=2)p3<-ggplot(data=PH,aes(PH,..density..))geom_density(size=1.5,linetype=5)2.6 修改颜⾊p4<-ggplot(data=PH,aes(PH,..density..))geom_density(size=1.5,linetype=2,colour='red') grid.arrange(p1,p2,p3,p4)2.7 多组数据展⽰构造两组数据df<-data.frame(c(rnorm(200,5000,200),rnorm(200,5000,600)),rep(c('BJ','TJ'),each=200))names(df)<-c('salary','city')结果展⽰library(ggplot2)p1<-ggplot()geom_histogram(data=df,aes(salary,..density..,fill=city),color='white')p2<-ggplot()geom_histogram(data=df,aes(salary,..density..,fill=city),color='white',alpha=.5)p3<-ggplot()geom_density(data=df,aes(salary,..density..,color=city))p4<-ggplot()geom_histogram(data=df,aes(salary,..density..,fill=city),color='white') geom_density(data=df,aes(salary,..density..,color=city)) grid.arrange(p1,p2,p3,p4)补充:R语⾔在直⽅图上添加正太曲线与核密度曲线lines(x=横坐标向量,y=纵坐标向量),在已有图像上添加曲线hist(数值型向量,freq=TRUE/FALSE)freq取TRUE纵坐标为频数,否则为频率以上为个⼈经验,希望能给⼤家⼀个参考,也希望⼤家多多⽀持。
replot函数

replot函数1. 介绍在数据可视化中,绘图是一个重要的步骤。
Python语言中的Matplotlib库提供了强大的绘图功能,但有时候我们需要进行更加高级的绘图操作。
为了方便用户进行数据可视化,Matplotlib团队推出了一个名为replot的函数。
replot函数是Matplotlib库中的一个重要函数,它能够帮助用户快速绘制出各种类型的图表,同时还具备一些特殊的功能。
2. replot函数的基本用法replot函数的基本用法非常简单,只需要传入相应的参数即可。
一般来说,replot函数的参数主要包括数据、x轴和y轴的标签、图表的类型等。
下面是一个简单的示例代码:import matplotlib.pyplot as pltdata = [1, 2, 3, 4, 5]labels = ['A', 'B', 'C', 'D', 'E']plt.replot(data, labels, xlabel='x', ylabel='y', plot_type='bar')plt.show()在上述代码中,我们首先导入了Matplotlib库,并创建了一个data列表和一个labels列表作为数据。
然后,我们调用replot函数,并传入了相应的参数:数据data、标签labels、x轴标签和y轴标签以及图表类型。
最后,使用plt.show()函数显示图表。
3. replot函数的特殊功能除了基本的用法之外,replot函数还具备一些特殊的功能,下面将逐一介绍。
3.1 自动标注数据点在绘制散点图或者折线图时,我们经常会需要在图表上标注数据点的值。
replot 函数提供了自动标注数据点的功能,只需要在函数调用时添加一个参数即可。
下面是一个示例代码:import matplotlib.pyplot as pltx = [1, 2, 3, 4, 5]y = [1, 4, 9, 16, 25]plt.replot(x, y, xlabel='x', ylabel='y', plot_type='scatter', annotate=True) plt.show()在上述代码中,我们传入了一个新的参数annotate=True,它表示是否对数据点进行标注。
R语言入门:直方图histogram的绘制
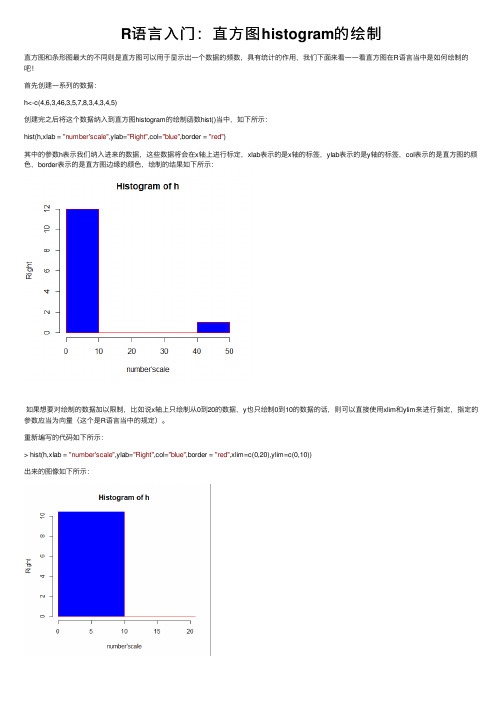
R语⾔⼊门:直⽅图histogram的绘制
直⽅图和条形图最⼤的不同则是直⽅图可以⽤于显⽰出⼀个数据的频数,具有统计的作⽤,我们下⾯来看⼀⼀看直⽅图在R语⾔当中是如何绘制的吧!
⾸先创建⼀系列的数据:
h<-c(4,6,3,46,3,5,7,8,3,4,3,4,5)
创建完之后将这个数据纳⼊到直⽅图histogram的绘制函数hist()当中,如下所⽰:
hist(h,xlab = "number'scale",ylab="Right",col="blue",border = "red")
其中的参数h表⽰我们纳⼊进来的数据,这些数据将会在x轴上进⾏标定,xlab表⽰的是x轴的标签,ylab表⽰的是y轴的标签,col表⽰的是直⽅图的颜⾊,border表⽰的是直⽅图边缘的颜⾊,绘制的结果如下所⽰:
如果想要对绘制的数据加以限制,⽐如说x轴上只绘制从0到20的数据,y也只绘制0到10的数据的话,则可以直接使⽤xlim和ylim来进⾏指定,指定的参数应当为向量(这个是R语⾔当中的规定)。
重新编写的代码如下所⽰:
> hist(h,xlab = "number'scale",ylab="Right",col="blue",border = "red",xlim=c(0,20),ylim=c(0,10))
出来的图像如下所⽰:
这就是绘制直⽅图当中所有的内容了,它也是R语⾔当中绘图最简单的⼀个。
编写一个程序,打印输入中单词长度的直方图.垂直方向

(1):单词长度分布,我们这里的单词比较广,只要连着没有被空格 换行符 制表符分开就算.可能存在多个空格,多个空行,所以要判断当前状态是否在一个单词内.
在单词内遇到空格,说明是单词的边界,可以将单词的长度存入相应数组,并清空对单词长度的统计.
(2)打印垂直直方图, 循环分为y轴和x轴,我们先要知道y的最大值(某长度的单词数量最多的那个),从上向下打印
38
}
39
else{
40
++overflowWord;
41
}
42
wordLength = 0; //清除单词的长度,为统计下一个单词做准备.
43
}
44
}
45
else{
46
state = Word_IN;
47
++wordLength; //在单词内,单词长度+1
48
}
49 }
50 //调用函数
51 vertical(wordGraph,MaxWordLen);
请求出错错误代码503请尝试刷新页面重试
1.问题描述与分析
编写一个程序,打印输入中单词长度的直方图.垂直方向
描述:编写一个程序,打印输入中单词长度的直方图.水平方向的直方图比较容易绘制,垂直方向的直方图则比较困难.当然是选难的做了.
分析:本题目主要有两个要求(1):统计一段文本中单词的长度分布 (2)将单词长度的分布用直方图打印出来
84
}
85 }
86 printf("\n");
87 //打印各个单词长度的个数
88 for(j = 0;j < n; ++j){
R语言绘制直方图histogram(基础篇)

R语⾔绘制直⽅图histogram(基础篇)在上数据分析这门课时,⽼师要求使⽤R语⾔绘制直⽅图,以作业为例,带⼤家⾛⼀遍步骤要求:Copy and Paste Your R Output From the R Script (or the output of Excel)步骤:⾸先打开RStudio,输⼊以下代码,⽬的是导⼊数据v <- c(27, 27, 27, 28, 27, 25, 25, 28, 26, 28, 26, 28, 31, 30, 26, 26)其中v 是包含直⽅图中使⽤的数值的向量c() 是R语⾔中建⽴⼀个向量的函数然后使⽤ hist() 函数创建直⽅图使⽤R语⾔创建直⽅图的基本语法是hist(v, freq, main, xlab, ylab, xlim, ylim, breaks, col, border)其中v 是引⽤的上述向量freq 设置直⽅图y轴时表⽰频数还是概率密度,TRUE表⽰频数,FALSE表⽰概率密度,默认为TRUEmain 设置直⽅图的标题xlab, ylab 分别表⽰x轴和y轴的描述xlim, ylim 分别指定x轴和y轴上值的范围break ⽤于提及每个间隔 (interval) 的宽度border⽤于设置每个间隔边框的颜⾊col ⽤来设置每个间隔的颜⾊输⼊以下代码,构建直⽅图:hist (v, freq = TRUE, breaks = seq(24, 31.5, by = 1.5), main = "histogram", xlab = "units", ylab = "frequency", col = "yellow",border = "blue") 其中breaks 是是建议的分组组数,但R不⼀定会⽤(它不听话)如果要精准设置,可以使⽤以下⽅法:breaks = seq(1, 6, by = 1) #设置分组为(1,2) (2,3)...(5,6)就是从1到6,间隔为1此处 by = 可以舍去运⾏代码1v <- c(27,27,27,28,27,25,25,28,26,28,26,28,31,30,26,26)2hist (v, freq = TRUE, breaks = seq(24, 31.5, by = 1.5), main = "histogram", xlab = "units", ylab = "frequency", col = "yellow", border = "blue")得到结果图⾄于为什么x轴最右侧31.5取不到的原因,我个⼈猜测是因为这个绘图不能精确到⼩数点后⼀位,由于懒,也没有再细究,欢迎朋友们指正批评。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
■■ ■■■■ ■■■■■■■■■■■■■■■■■
■■ ■■■■■■■■■■ ■■■■■
�
差异率
3.67% -0.67% -5.71% 2.29% 4.29% 17.14% -14.40% -1.60% 2.00% 10.00% -7.00% 5.00%
未完成预测比例数
■
1月
■ 2月 ■■■■■■ 3月
4月 5月 6月 ■■■■■■■■■■■■■■ 7月 ■■ 8月 9月 10月 10月 ■■■■■■■ 11月 11月 12月 12月
2006年预测销量与实际销售完成比例分析
月份 预测销量 实际销量
1月 2月 3月 4月 5月 6月 7月 8月 9月 10月 11月 12月 知识点 1.rept()函数的应用 2.IF(),ROUND()函数的应用 函数说明 函数ROUND(number,num_digits)的功能是返回某个数字按指定位数取整后的数字.参数 number表示需要进行四舍五入的数字;num_digits表示指定的位数,如果为0,表示舍 入 到最接近的整数;如果大于0,表示舍入到指定的小数位;如果小于0,表示舍入到指定 的 整数位.此公式中,由于原数是百分数,因此先乘以100转换为数值,然后再四舍五入 300 300 350 350 350 350 500 500 500 500 600 600 311 298 330 358 365 410 428 492 510 550 558 630