基于SQL技术的频繁模式的发掘
基于SQL的频繁模式挖掘的研究与实现

的知识 发现功能 , 难于嵌 人大型应用 ; 数据挖掘 引擎 与数据库 系
统 是 松 散 耦 合 , .miisi H. a n a称 其 为 “ 件 挖 掘 系 T I e nk 和 l M ni l 文
统 ” :
给定事 务数据 库 T B和最 小支持 度 阈值 mn sp 频繁模 D i— u ,
含 A当且仅当 A T时包 含 k个项的模式称 为 k模式 模式 A 一
1 引 言
数据挖掘技 术的研究与应用至今为止 已经取得 了很 大的成
果 , 同 时 也 面 临 着 一 些 问题 , 如 : 据 挖 掘 系统 仅 提 供 孤 立 但 例 数
的支持 度计 数是指事 务集 中包含该 模式 的事 务数 , 如果模 式 A
R E RC A MP E ES A H ND I L ME A I QL B E R QUE T P T E N MI I G NT T ON OF S AS D F E N A T R NN
L uj ’ Z a gJ in ’ J n igu i ie G i hn i a g i gQ ny e x a
Ab t a t s r c F e u n a tr n n sa k y p o lm n ma y d t n n p l ain T i p p rt k sa h g e o ma c P g o t lo r q e t t n mi i g i e r b e i n aa mi ig a pi t . h s a e a e ih p r r n e F — w h ag — p e c o f r
rh r xm l,sst l i R B oeF ・e n ie eu n pt rs rm ib N I Q n r l P / Q r a i i m f a pe ue be n D MSt s r Pt eadm ns rq et a e o t yA S LadO a e L S Lpo mmn t oe a ot r f tn f S c r g g t h o g ,i st e i dpoe ue lm n ti S Lbsdf q et at nn t d e nl y g e h d tl r d rst i e eths Q ae r un pt r mii me o . c o v e ae c o mp e e n g h Ke w r s y od Fe un pt r nn S L F -e F -rwh rq et at mii e n g Q Pt e Pgo t - r -
基于SQL Server 2005的数据挖掘系统优势分析

基于SQLServer2005的数据挖掘系统优势分析[摘要]本文介绍了数据挖掘软件及工具的发展历史,提出基于SQL Server 2005的数据挖掘系统,阐述了SQL Server 2005平台的功能优势。
[关键词]SQL Server 2005;数据挖掘;数据仓库数据挖掘(Data Mining,DM))是从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程,是统计学、数据库技术和人工智能技术的综合。
数据挖掘的工具和软件已广泛应用于银行金融、零售与批发、制造、保险、公共设施、政府、教育、远程通讯、软件开发、运输等领域。
随着数据挖掘应用日渐广泛,人们发现有些工具只有精通数据挖掘算法的专家才能熟练使用,如果对算法不了解,难以得出好的模型,所以迫切需要一类使用简单而又具有针对性、功能良好的数据挖掘软件。
因此,本文结合数据挖掘软件的发展,提出一种基于SQL Server 2005的纵向数据挖掘解决方案,并阐述了SQL Server 2005平台的功能优势。
1 数据挖掘软件及其开发工具的发展状况及趋势1. 1数据挖掘软件的发展状况及趋势在对数据挖掘技术和数据挖掘软件的探索和开发过程中,很多学者提出了自己独特的观点,Robert Grossman认为,数据挖掘软件的发展将经历4个时代[1]:第一代数据挖掘软件。
支持一个或少数几个数据挖掘算法,挖掘向量数据,数据一般一次性调进内存进行处理。
如果数据足够大,并且频繁变化,这就需要利用数据库或者数据仓库技术进行管理,第一代系统显然不能满足需求。
第二代数据挖掘软件。
与数据库管理系统集成、支持数据库和数据仓库,和它们具有高性能的接口具有高的可扩展性。
能够挖掘大数据集以及更复杂的数据集,通过支持数据挖掘模式和数据挖掘查询语言增加系统的灵活性。
虽然注重模型的生成,但如何与预测模型系统集成导致了第三代数据挖掘系统的开发。
基于SQL Server2005的数据挖掘系统优势分析

保险、 公共设施 、 政府、 教育 、 远程通讯 、 软件开发、 运输等领 域。随着数据挖掘应用 日渐广泛 . 人们发现有些工具只有 精通数据挖掘算法的专家才能熟练使用 . 如果对算法不了 解. 难以得 出好的模 型. 所以迫切需要一类使用简单 而又 具有针对性 、 功能 良好的数据挖掘软件 。因此, 本文结合数
持数 据挖 掘模 式 和数据 挖 掘查 询语 言 增加 系 统 的灵 活 性 。 商开始提供称之为“ 工具集” 的数据挖掘软件。此类工具集 虽然注重模 型的生成 . 但如何与预测模型 系统集成导致了 的特 点是 提 供 多种数 据 挖掘 算法 ,非 面 向特 定 的应 用 , 是
第三代数据挖掘系统的开发 。 通用的算法集合. 以称为横 向的数据挖掘工具 。 可 第三代数据挖掘软件 。 与预测模型系统之间能够无缝 12 3纵 向的数据挖掘解决方案(9 9 .. 1 9 年开始) 集成 . 使得 由数据挖掘软件产生的模型的变化 能够及时反 随着横向的数据挖掘工具 的使用 日渐广泛 . 人们发现
四代软件能够挖掘嵌入式系统 、 移动系统和普遍存在计算 设备产生 的各种类型的数据。 12 数 据 挖掘工 具 的发展 状况 及趋 势 .
目前 在整 个 数据 挖 掘技 术 的发展 过程 中 . 挖掘 工 数据
具一 共经 历 了 3 阶段 : 个 据挖 掘软 件 的发 展 .提 出一 种 基 于 S LSre 0 Q evr 0 5的纵 12 1独立的数据挖掘软件 (9 5 2 .. 19 年以前) 向数 据挖 掘解决 方案 . 阐述 了 S LSre 0 并 Q vr 0 5平 台 的功 e 2 独立 的数 据 挖掘 软 件对应 第 一代 系统 . 出现在 数 据挖 能优 势 。 掘技 术 发展 早期 . 究人 员 开发 出一 种新 型 的数 据 挖 掘算 研
使用标准SQL实现多维关联规则的挖掘

M iigM ut i n in l scainRue i tn ad S nn l dme so a o it lsw t Sa d r QL i As o h
CHENG i . Ln Yn ig
( n u u l eui r e i a ol e Hfi 30 1 C i ) A h i bi Scr yPo s o l lg , e 0 3 , hn P c t f sn C e e2 a
多维 关联规 则挖 掘 的相 关 问题 , 并给 出了一种 实现 算 法。 . 关 键词 : 据挖 掘 ; 数 多维 关联规 则 ;Q S L语 言 中图分 类号 : T 3 1 P 1 文献标 识 码 : B 文章 编 号 :6 2— 7 6(0 7) 1— 16— 3 17 9 0 2 0 0 0 0 0
Ab t a t Aso ito ul sa mp ra tmo li aa mi n s r c : s c ain r e i n i o tn de n d t nig.Th sp p rdic s e he p o lmsa o t i a e s u s st r b e b u
维普资讯 htBiblioteka p://第 十 二 卷 第 一 期 安 徽 电气 工 程 职 业 技 术 学 院 学 报 V 11 . o 1 0.2 N . J R LO N I L C R C NGNE R N R E SO A E H Q O ,E OU NA FA HU E T IALE I E I G P OF SI N LT C NIUEC I GE E L
m n gm ldmes n l soit nrls i tn adS La dpo ssa p rahb sdo Q . ii ut i ni a sc i ue t s d r Q n rp e la po c ae nS L n i o a ao wh a o l Ke o d :a nn ; ut i ni a asca o ue ;Q n ug yw rs d t miig m ld a i me s n l oi i rl S Ll gae o s tn s a
构建基于Microsoft SQL的数据挖掘解决方案

【 ( 伊 蒙(n o, H) 据 仓 库 ( 书 第 四版 ) 】 志 海 2 美) 】 [i n n W. . 数 原 【. M 王
等 . . 京: 械 工业 出版 社 。0 6 译 北 机 20 .
摘
603 ; 10 9
603 ) 10 9
要 : 析 了Mi ot 司  ̄S LS r r 0 5 数 据 挖 掘 功 能 和 优 势 , 出 了数 据 挖 掘 解 决 方 案 , 快 速 实现 纵 向 的 分 c f ms  ̄ J Q ev 0  ̄ e2 提 可
数 据 挖掘 。
关 键 词 : 据 挖 掘 ;Q e e 0 5 V ae 虚 拟 化 ; 拟 机 数 S LSr r 0 ; Mw r ; v 2 虚
参考文献 :
利 用分析服务创建数据库 ,Q e e 0 5 S LSr r 0 为数据挖掘提 v 2 供 了 多维数据 集 ( u e 和数 据集 ( a st, 于数据 挖 掘的 C b) D t e)用 a
【 安淑 芝. 据仓 库与数 据挖掘f 北京 : 华 大学 出版社, 1 】 数 M】 清
32 设 计 OL 模 型 . AP
S LSre 0 5为数据挖掘解 决方案提供 了强大 的设计 Q evr 0 2 和开发平 台, 为企业级的数据挖掘系统的设计和实现带来极 大
的便利。充分利用S L e e20 提供 的功能, Q r r 05 S v 结合具体 的应
用, 以快速实现纵 向的数据挖掘解决方案 。 可
大多数数据挖掘项 目的主要 目标是使用挖掘模 型来创建 预测 。数据挖掘对查 找和描述特定多维数据集 中的隐藏模式 非常有用 , 因为多维数据集 中的数据增长很快 , 以手动查找 所
基于SQLServer2000的数据仓库和数据挖掘

2004年第25卷第5期华 北 工 学 院 学 报V o l.25 N o.5 2004 (总第97期)JOURNAL OF NORTH CH I NA I NSTI TUTE OF TECHNOLOG Y(Sum N o.97)文章编号:100625431(2004)0520322203基于SQL Server2000的数据仓库和数据挖掘Ξ刘爽英,张 静(华北工学院计算机科学与技术系,山西太原030051)摘 要: M icro soft在SQL Server2000中第一次包含了数据挖掘功能.其数据挖掘解决方案基于OL E DB规范,为数据挖掘提出了一种新的类SQL语言,便于开发者更好地建立数据挖掘的应用.利用SQL Server2000去创建数据仓库,对关联规则数据挖掘经典算法A p ri o ri进行改进和测试,在算法效率上得到明显提高.关键词: 数据仓库;数据挖掘;挖掘模型;测试中图分类号: T P311 文献标识码:ABuild i ng Data W arehouse and Data M i n i ng w ith SQ L Server2000L I U Shuang2ying,ZHAN G J ing(D ep t.of Computer Science and T echno logy,N o rth Ch ina Institute of T echno logy,T aiyuan030051,Ch ina) Abstract:M icro soft SQL Server2000includes data m in ing functi on fo r the first ti m e.T he data m in ing so lu ti on is based on OL E DB sp ecificati on,p resenging a new SQL2like language fo r data m in ing.It can help database develop ers to bu ild data m in ing app licati on.T he research is discu ssed in detail based on A p ri o ri.A n efficien t m ethod is pu t fo r w ard fo r bu ilding data w arehou se and data m in ing app licati on u s2 ing SQL Server2000.Key words:data w arehou se;data m in ing;m in ing m odel;test0 引 言数据挖掘是数据库和人工智能领域最前沿、最活跃的研究方向之一,数据挖掘是一个数据驱动的过程[1],目的是发掘以前没有被发现或是容易被忽略的有意义的数据模式,是管理层作出决策的依据.数据挖掘的一个显著特点是它依靠计算机而不是人力来做那些用来建立预测模型的复杂的数学运算.大量原始数据的分析需要深层次的归纳推理,这部分工作是由计算机来完成的.推理过程结束之后,计算机再按照某种格式输出相应分析结果,供决策者分析决策.数据仓库作为一种高效的解决数据收集和使用的技术,正在越来越多地应用到传统的数据库技术领域,数据挖掘则在数据库和数据仓库的支持下进行高效率的知识挖掘工作[2,3].1 数据仓库设计数据挖掘的物理结构描述了客户应用程序与数据挖掘模型的相互作用,结构的选择是根据数据源的大小和对该数据挖掘模型发布的预测查询频率来选择的.根据应用特点,可使用两层体系结构或三层体Ξ收稿日期:2003212231 基金项目:2003年院自然科学基金资助项目 作者简介:刘爽英(1972-),女,讲师,硕士.主要从事计算机应用研究.系结构方案.两层体系结构的物理结构不太复杂,能够在合理高效的服务器上挖掘数百万的记录.服务器中一并存放着数据挖掘引擎和数据仓库,在本地运行所有处理过程.通过一个OL E DB 连接,客户机可以简单调用引擎执行所有必要的数据挖掘处理,并在需要时接受预测结果集.当数据挖掘任务进一步增加,客户机选用挖掘结果需求量增大时,可选用三层体系结构.这个结构总体上需要一个专用的高性能服务器在中间层来用作数据挖掘引擎,数据仓库被置于后端,中间层负责挖掘其数据.中间层从后端载入数据并进行挖掘,挖掘结果被传到客户机.在众多的数据仓库产品中,选择SQL server 2000[4]作为数据仓库的支撑平台.主要原因如下:首先,SQL server 2000既可以方便地接受各种形式的数据,也可以方便地输出各种形式的数据.其二,SQL server 2000的A nalysis Services 具有简易的使用性能及其良好的发展势头.第三,SQL server 2000的A nalysis Services 中提供了灵活的对象编程接口,这为进一步开发智能决策支持系统提供了可能.由于SQL server 2000的A nalysis Services 是一个管理多维记录集的服务器,可按照A nalysis Ser 2vices 中的各种向导建立数据仓库的维度和多维记录集.通过数据仓库或关系数据库,在A nalysis Ser 2vices 的支持下可以进一步进行各种数据挖掘.2 数据挖掘方法2.1 OL E DB 用于数据挖掘数据挖掘模型是OL E DB fo r DM 中提出的一个概念.一个数据挖掘模型就是一个容器,在某种程度上可以看成是由各种不同数据类型的列构成的一个关系表,实际上它并不存储原始数据,而是存储数据挖掘算法在关系表中发现的模式.为了建立一个数据挖掘模型,OL E DB fo r DM 可采用SQL 中创建表的语法,例如CR EA T E 语句.2.1.1 数据挖掘模型测试当一个数据挖掘模型建立之后,它只是一个空的容器.在测试阶段,数据挖掘算法分析输入的事件和挖掘模型已经发现的模式.根据针对数据挖掘的OL E DB ,测试数据可以来源于任何表格数据源,只要它存在于OL E DB 的驱动器上.它不需要用户从关系数据源中导出数据到任何特殊的中间存储形式.这就极大地简化了数据挖掘过程.可采用SQL 中数据插入句法,例如I N SER T I N TO 语句.Open row set 命令可以从一个OL E DB 数据源中访问远程数据.SQL Server 2000为SQL Server A ccess 和O racle 装备了OL E DB 驱动器.测试过程需要花费一些时间.在测试完成之后,数据挖掘算法将发现隐藏在数据挖掘模型中的模式,用户可以浏览挖掘模型来查看发现的模式,或用测试过的挖掘模型来进行预测任务.2.1.2 数据挖掘预测预测是数据挖掘的一个重要任务.它需要一个测试过的数据挖掘模型和一系列的新事件.预测的结果是一个新记录集,它包括预测的列的值以及其它输入的列的值.整个过程与关系连接非常相似,但它不是连接两个表,而是连接数据挖掘模型和输入表.可以采用SQL 中查询表的语法,例如:SEL ECT ...FROM A JO I N BON <条件>其中A 表示测试过的数据挖掘模型;B 表示新的数据表;<条件>是两个表的公共属性,进行等值连接或自然连接.从以上分析可知,OL E DB 与标准SQL 紧密结合,可以快速,准确地进行查询处理,而SQL Server 2000是创建数据,建立数据挖掘的一种有效方案.323(总第97期)基于SQL Server 2000的数据仓库和数据挖掘(刘爽英等)423华北工学院学报2004年第5期2.2 利用SQL Server2000进行数据挖掘在基于数据挖掘的OL E DB的使用中,从不同数据挖掘ISV中来的不同的数据挖掘算法可以很容易地嵌入到用户的应用中去.这些数据挖掘算法的软件包提供了两个数据挖掘算法:M icro soft的决策树和M icro soft的集群.数据挖掘提供者是分析服务2000的一部分(在SQL Server7.0中叫OLA P服务).和M icro soft的OLA P服务相似,SQL Server2000中的数据挖掘组件也主要是针对DBA的.A nalysis Services由OLA P和数据挖掘两部分组成,是数据分析的重要技术.在A nalysis Services中存在一些数据挖掘工具,这些工具包括模型建立向导,模型编辑器,模型内容浏览器以及D T S预测任务. SQL server2000包含了两种数据挖掘算法:即决策树和聚类算法.决策树被广泛应用于分类任务,不像分类算法中的其它算法,如最近邻居法、神经网络法、基于统计的回归算法等.决策树能够处理多维数据,并且发现的规则很容易被理解.聚类分类算法是一个最大期望算法的可伸缩实现,从重要数据源构造适当的统计模型,并且产生包含离散和连续值的聚类数据库.SQL Server2000数据挖掘模型是基于OL E DB fo r DM规范,使用灵活.任何数据库开发者都能够利用数据挖掘功能开发应用程序,它的数据挖掘语言非常类似于SQL,数据挖掘供应者是一个开放系统,因为它是一个OL E DB的部件,来自于其它数据挖掘公司的算法,能够嵌入到同样的平台上,数据挖掘服务能够通过D SO(D ecisi on Suppo rt O b ject)或ADO包含在任何用户程序系统中.在建立应用之前,首要任务就是建立一个数据挖掘模型和训练这个模型.实现这个任务有多种方法,最容易的一种方法就是利用A nalysis Services的数据模型向导,这个向导将产生数据挖掘模型和训练查询,并通过OL E DB fo r DM接口向数据挖掘供应者发送这个查询.另外一种方法是自行编写一些程序,例如利用面向对象编程技术编写一些VB或V C程序,通过D SO或ADO把它与数据挖掘供应者连接起来,然后就向这个供应者发布这个文本查询,就像一个数据库开发者处理数据库查询一样.A nal2 ysis Services已扩展了D SO模型从而能够支持数据挖掘,所以可以通过D SO连接数据挖掘供应者.通过D SO对象相连的方法与通过简单的ADO相连方法比较起来有许多优越性.例如,使用这个模型有较好的安全控制、远程数据服务及挖掘模型的仓库支持;但是使用D SO编程需要更多的编码工作并且开发者需要描述每个列对象和挖掘模型对象的属性.3 结 论作者在院自然科学基金资助项目《基于图论的关联规则数据挖掘与标准查询语言应用分析》中采用SQL server2000数据库,利用面向对象编程技术编写VB程序,通过ADO连接数据库,对关联规则数据挖掘经典算法A p ri o ri进行改进,在算法效率上得到明显提高.有了A nalysis Services of SQL Server2000,数据挖掘不再是统计专家们的保留领域,数据挖掘算法的复杂性对用户是隐藏的,每一个数据库的开发者都能够建立和训练数据挖掘模型并把这些优点嵌入到他们用户的应用系统中去.数据挖掘将很快会成为被普通采用的知识发现技术.参考文献:[1] A graw al R,I m ielinsk i T,Sw am iA.M ining associati on rules betw een sets of item s in large databases[M].P roceed2ings of1993A C M S IG M OD Internati onal Conference on M anagem ent of D ata.W ash ington,DC,1993.207-216.[2] 范明,孟小峰.数据挖掘概念与技术[M].北京:机械工业出版社,2001.[3] 刘爽英,贺利坚.企业数据仓库设计方法研究[J].华北工学院学报,2001,(6):461-463.[4] 郑阿奇.SQL Server2000实用教程.北京:电子工业出版社,2002.。
SWRL数据集中频繁模式发现

据 集上 的数据挖 掘 过程 必须 充分考 虑数据 的语 义特征 。 已有 的 关于这 种类 型数据 的候 选频繁模 式 生成 方法可 能产 生大量 无意 义的模 式 , 重 了模 式评价 过程 的计 算 负担 。 对这 一缺 陷提 出 了基 于 加 针 向下求精规 则和相 容谓 词 的候 选频繁 模 式生成 方法 , 同时定 义 了谓 词数 量 约束 , 而避 免产 生过 多 从
1 S WRL数 据 集 中 的频 繁 模 式 发 现
假设 指 定 : 某种 模 式 语 言 以; 数 据 集 合 , ① ② . ;
③ 出现在 r 中的一个 一元 谓词 ky 1 ④ 频繁 阈值 t e ̄ ; 。
频 繁模式 的发现在 于 找到 C A且 口 fr ≥ t ∈ ( ,) 的
Q — q ) CKy ) 口1口2 … , ( 一 ( , , ,
式 中 , K 是 一 个 一 元 谓 词 ky 1 它 是 出 现 在 Ce y e ̄, S L 中的任 意概 念 , 示 用户 在 频繁模 式 发现 中 WR 表 所关注 的概念 。 是 P中唯 一的受 C 约束 的变量 , (≤i 1 < ) 数据集 中 出现 的概 念 ( 是 一元谓 词) 或
袁 柳 ,李战 怀 ,陈世 亮
( 北 工 业 大 学 计 算 机 学 院 , 西 西 安 70 7 ) 西 陕 1 0 2
摘
要: 用S 使 WRI(e n i We l L n u g ) S ma t bRue a g a e 描述 的数据 蕴含 了更 多的语 义信 息 ,WR c S L数
的非频繁 模式 和 冗余 模 式 。实验证 明该 方法 可提 高频繁模 式 生成 的效 率 。 关 键 词 : 义 We , WRL,频繁模 式 ,向下 求精规 则 语 b S
fpgrowth算法sql代码

fpgrowth算法是一种常用的频繁模式挖掘算法,它能够快速有效地发现数据集中的频繁模式和关联规则。
而在实际应用中,我们常常需要将该算法应用到SQL数据库中,以便更好地对数据进行分析和挖掘。
本文将介绍fpgrowth算法的原理和SQL代码实现,以帮助读者更好地理解和应用该算法。
一、fpgrowth算法原理fpgrowth算法是一种基于频繁模式树(FP-tree)结构的频繁模式挖掘算法。
它通过两次遍历数据集,首先构建FP树,然后通过递归方式挖掘FP树中的频繁模式。
具体步骤如下:1. 构建FP树(1) 遍历数据集,统计每个项的频数,然后根据频数降序排序得到频繁1项集;(2) 再次遍历数据集,根据频繁1项集和频数构建FP树,每个项在FP树上对应一条路径。
2. 挖掘频繁模式(1) 从FP树的底部开始,递归向上回溯每个项的前缀路径,得到条件模式基;(2) 对于每个条件模式基,构建条件FP树,然后递归挖掘得到频繁模式。
二、fpgrowth算法SQL代码实现在SQL数据库中,我们可以通过使用递归查询和临时表来实现fpgrowth算法。
下面是一个简单的示例,假设我们有一个名为transaction_table的交易表,表中包含了交易ID和对应的商品项集。
```sql-- 创建临时表存储频繁1项集CREATE TEMPORARY TABLE frequent_item1 ASSELECT item, COUNT(*) AS countFROM transaction_tableGROUP BY itemHAVING count >= min_support;-- 构建FP树WITH RECURSIVE fp_tree(item, count, parent) AS (SELECT item, SUM(count) AS count, NULL AS parentFROM frequent_item1GROUP BY itemUNION ALLSELECT t.item, SUM(t.count), f.idFROM transaction_table tJOIN fp_tree f ON t.item = f.itemGROUP BY t.item, f.idSELECT * FROM fp_tree;```上述SQL代码中,我们首先创建一个临时表frequent_item1来存储频繁1项集,然后使用递归查询构建FP树。
数据分析知识:数据挖掘中的频繁模式挖掘

数据分析知识:数据挖掘中的频繁模式挖掘数据挖掘中的频繁模式挖掘数据挖掘是一个复杂的过程,需要从庞大的数据集中提取出有价值的信息,这些信息可以用于业务分析、决策支持、市场营销等方面。
而频繁模式挖掘,就是在大量数据中寻找频繁出现的组合,从而发现数据集中的一些结构、规律和特征,帮助人们更好地理解数据,作出可靠的决策。
本文将介绍频繁模式挖掘的概念、算法和应用,并探讨其在实践中的优势和不足之处。
一、频繁模式挖掘的概念频繁模式挖掘是数据挖掘中的一种技术,它通过数据集中的项集来寻找频繁出现的组合,从而发现数据集中的一些规律、结构和特征。
在频繁模式挖掘中,一个项集是指包含若干个属性(或特征)的集合,而频繁项集指在数据集中出现频率较高的项集。
举个例子,某超市的销售数据表格中,每一行代表一次购物,每一列代表某种商品,如果某些商品常常同时被购买,那么这些商品就组成了一个频繁项集。
对于频繁项集的挖掘,可以应用一些经典的算法,如Apriori算法、FP-growth算法等。
这些算法可以从数据集中提取出频繁项集,并进行支持度和置信度的计算,从而评估每个项集的重要性和关联性。
而支持度指项集在数据集中出现的概率,而置信度则是指在包含某项集的条件下,另一个项集出现的概率。
二、频繁模式挖掘的算法1、Apriori算法Apriori算法是频繁项集挖掘领域中的经典算法,它最早由R. Agrawal和R. Srikant于1994年提出。
该算法是基于Apriori原理的,即如果一个项集是频繁的,那么它的所有子集必须也是频繁的。
具体而言,Apriori算法的流程包括:(1)对数据集中的单个项进行扫描,统计每个项的出现次数,得到一个项集L1;(2)对于项集L1中的每一项,计算其支持度,只保留支持度大于等于设定阈值minsup的项,得到一个新的项集L2;(3)对于项集L2中的每两个项,判断它们是否能够组合成一个新的项集,如果满足条件,则进行计数,并得到一个新的项集L3;(4)重复第二步和第三步,直到无法生成新的项集为止。
浙江大学远程教育2014年数据挖掘离线作业

浙江大学远程教育学院《数据挖掘》课程作业姓名:学号:年级:学习中心:—————————————————————————————第一章引言一、填空题(1)数据库中的知识挖掘(KDD)包括以下七个步骤:数据清理、数据集成、数据选择、数据变换、数据挖掘、模式评估和知识表示(2)数据挖掘的性能问题主要包括:算法的效率、可扩展性和并行处理(3)当前的数据挖掘研究中,最主要的三个研究方向是:统计学、数据库技术和机器学习(4)孤立点是指:一些与数据的一般行为或模型不一致的孤立数据二、简答题(1)什么是数据挖掘?答:数据挖掘指的是从大量的数据中挖掘出那些令人感兴趣的、有用的、隐含的、先前未知的和可能有用的模式或知识。
(2)一个典型的数据挖掘系统应该包括哪些组成部分?答:一个典型的数据挖掘系统应该包括以下部分:数据库、数据仓库或其他信息库数据库或数据仓库服务器知识库数据挖掘引擎模式评估模块图形用户界面(3)Web挖掘包括哪些步骤?答:数据清理: (这个可能要占全过程60%的工作量)数据集成将数据存入数据仓库建立数据立方体选择用来进行数据挖掘的数据数据挖掘(选择适当的算法来找到感兴趣的模式)展现挖掘结果将模式或者知识应用或者存入知识库(4)请列举数据挖掘应用常见的数据源。
(或者说,我们都在什么样的数据上进行数据挖掘)答:常见的数据源包括关系数据库、数据仓库、事务数据库和高级数据库系统和信息库。
其中高级数据库系统和信息库包括:空间数据库、时间数据库和时间序列数据库、流数据、多媒体数据库、面向对象数据库和对象-关系数据库、异种数据库和遗产(legacy)数据库、文本数据库和万维网(WWW)等。
第二章认识数据一、填空题(1)两个文档向量d1和d2的值为:d1= (1, 0, 3, 0, 2),d2 = (3, 2, 0, 0, 1),则它们的余弦相似度为:5/13(2)数据离散度的常用度量包括极差、分位数、四分位数、百分位数四分位数极差和标准差(3)一种常用的确定离群点的简单方法是:出落在至少高于第三个四分位数或低于第一个四分位数1.5×IQR处的值。
基于SQL Serve构建数据挖掘解决方案

Management Console, MMC )和 管 企业 理 器 ((SQL Enterprise Manager ,SQLIEM)实
现, SQL/ EM 并不 直接与数据库引擎交互, 而 是与一个已经编译好的SQL 分布式管理对象 ((SQL Distributed Management Objects , SQL- DMO)的COM库通信。 数据转换服务 (Data Transformation Services DTS )在构建 数据仓 库以及数 转 据 移中 常有用, 支 都非 DTS 持双向 的任何OLE DB 或ODBC 数据源, 它提供了 脚本语言的程 序接口 DTS 已 和分析服务 , 经 集成在了 起, 一 这意味着可以从多 个分散的数据源中 导入数 据, 并在此过程中处理这些数据。 英语查询(English Quer )可 y 以使简 单的 英语问题转化为数据库语言, 也就是实实在在 的SQL 语句代码, 元数据服务(Met a Dat a Ser vices)经常用来存储有关数据来源的信息, 分析服务中也常利用元数据服务存储多个多
1 SQL Server 的基本结构 SQL Server 是一个庞大 而复杂的软 件
包。 它的核心是一 个强大的关系型数据库引 擎, 时还包含相关 同 的服务、工具及开发技术 等。 数据库引擎是整个数据库管理系 核 统的 心, 它的两个组件, 可以被其他应用程序通 过 调用OLE D B 接口 的方式来使用。SQL Server 的 管理通 软管 过微 理控制台 (Microsoft
将 据挖 算 外 于SQL Servt. 可 数 掘 法 挂 以 构建数据挖掘解决方案, 但是在这种方式下,
Cubes:用 存 立 体对 于 放 方 象; Shared Dimensions:存放可以用于所有
一种改进的基于SQL的频繁项集挖掘算法

12 A r r算 法的 S L实现[ . pi i o Q 2
Apir 算法 采用逐 层迭 代 的方法 , 先扫描源 数据 库 D, r i o 首 生成 频繁 1 集 L , 项 然后 连接 L 与 L 生成 候选 项集 C , 。再从 C :中找 出满 足最小 支持度 的频 繁 2项 集 L 。 : 依此 再连接 L 与 L 生成候 选 3 集 C , 。 。 项 。 并对 C 进行 剪枝 , 。 删除一 些非频 繁 的候选 3项集 , 得到满 足最小 支持 度 的频 繁 3 集 L 。 此循 环 , 到 项 依 直
[ 要 ] 数 据 挖 掘 中 的关 联 规 则 应 用 广 泛 , 而 频 繁项 集 的产 生 又 是 关联 规 则 挖 掘 最 重 要 的 一 步 。 讨 论 了关 摘
系数 据 库 中利 用 A r r 算 法 实 现 频 繁 项集 挖 掘 的 问题 , 并 借 助 Apir i 法 思 想 ,提 出 了一 种 改进 的 pi i o r i d算 oT 基 于’Q 的 频 繁 项 集 挖 掘 算 法 。试 验 证 明 ,在 事 务 数 据 量 和 支 持 度 变 化 的情 况 下 ,此 算 法 性 能 稳定 且 执 SL
集 的产生 ,但 当数 据事务 集较 大 时在 执行 效 率 上并 不 高 。笔 者 借 助 于 Apir i 法 的 思想 ,提 出 了 r i d算 oT
一
种基于 S L的改进算法 。试验证明,该算法相 比其他 S L实现的算法而言性能较好。 Q Q
1 关 系数 据 库 中 的频 繁 项 集 挖 掘
SQL Server 2008中运用数据挖掘模型

SQL Server 2008中运用数据挖掘模型日期:2009年4月9日为一个数据挖掘模型定型后,可以通过运用 SQL Server Management Studio 或 Business Intelligence Development Studio 中提供的自定义查看器来阅读此模型。
但是,如果您希望执行预测或者从模型中获取更深入的或更具体的信息,则必须依据此数据挖掘模型建立一个查询。
在以下情况下,查询可帮助您更好地理解和处理模型中的信息:执行单个预测和批预测。
了解有关模型发觉的模式的更多信息。
查看有关模型的特定模式或子集的细致信息或定型事例。
在挖掘模型中钻取到事例的细致信息。
提取有关全部或部分模型和数据的公式、准则或统计信息。
SQL Server Analysis Services 提供用于建立查询的图形设计界面,以及一种称为数据挖掘扩展插件 (DMX) 的查询语言,这种语言对于建立自定义预测和复杂查询很有用。
若要生成 DMX 预测查询,可以运用 SQL Server Management Studio 和 Business Intelligence Development Studio 中均提供的查询生成器。
SQL Server Management Studio 中还提供了一组 DMX 查询模板。
有关如何运用查询生成器的细致信息,请参阅运用预测查询生成器建立 DMX 预测查询。
有关如何运用 DMX 查询模板的细致信息,请参阅在 SQL Server Management Studio 中建立 DMX 查询或如何在 SQL Server Management Studio 中运用模板。
预测查询许多数据挖掘项目的主要目标是运用挖掘模型来执行预测。
例如,您可能要在十二月期间预测公司明年销售的产品数量,或者可能要预测在某个广告活动后潜在客户能不能会购买产品。
建立预测时,通常会提供一些新数据,并要求模型基于新数据生成一个预测。
基于SQL的大数据分析与挖掘系统设计与开发

基于SQL的大数据分析与挖掘系统设计与开发一、引言随着互联网和信息技术的快速发展,大数据已经成为当今社会中不可或缺的重要资源。
大数据分析与挖掘系统的设计与开发变得愈发重要,而基于SQL的系统在这一领域中扮演着至关重要的角色。
本文将探讨基于SQL的大数据分析与挖掘系统的设计与开发过程。
二、系统架构设计在设计基于SQL的大数据分析与挖掘系统时,首先需要考虑系统架构。
典型的架构包括数据采集模块、数据存储模块、数据处理模块、数据分析模块和用户界面模块。
其中,SQL作为结构化查询语言,被广泛应用于数据存储和处理模块中,能够高效地进行数据查询和操作。
三、数据采集与清洗数据采集是大数据分析的第一步,而数据清洗则是确保数据质量的关键环节。
在基于SQL的系统中,可以利用各种ETL工具(Extract-Transform-Load)来实现数据的抽取、转换和加载,保证数据的准确性和完整性。
四、数据存储与管理对于大规模的数据集,高效的存储和管理是至关重要的。
SQL数据库(如MySQL、PostgreSQL等)提供了强大的数据存储和管理功能,能够支持复杂的查询和事务处理,同时也具备较高的可靠性和稳定性。
五、数据处理与分析在基于SQL的大数据分析系统中,SQL语句可以帮助用户快速地进行数据处理和分析。
通过编写复杂的SQL查询语句,用户可以从海量数据中提取出所需信息,并进行统计、聚合、筛选等操作,为后续的挖掘和分析提供有力支持。
六、数据挖掘与建模数据挖掘是大数据分析中的重要环节,通过各种算法和技术从海量数据中发现隐藏的模式和规律。
在基于SQL的系统中,可以结合机器学习算法(如决策树、聚类分析等)来进行数据挖掘和建模,实现对数据更深层次的理解和利用。
七、可视化与报告最终阶段是将分析结果以直观形式呈现给用户。
通过可视化工具(如Tableau、Power BI等),用户可以生成各种图表、报表和仪表盘,直观地展示分析结果,并为决策提供参考依据。
基于SQL Server的数据挖掘步骤-以聚类分析为例
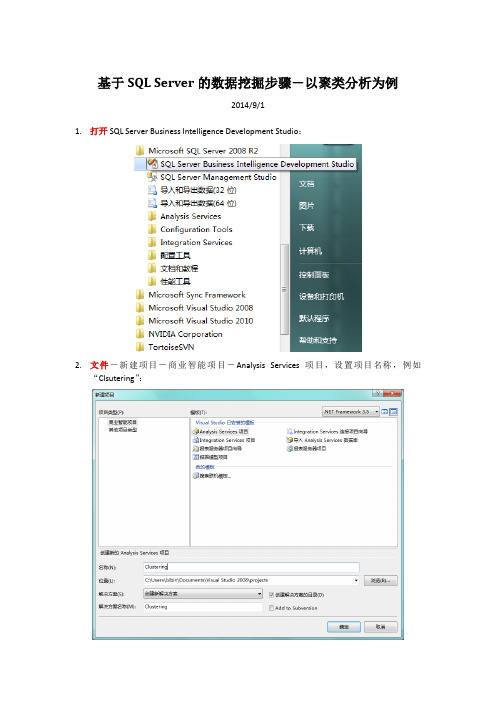
基于SQL Server的数据挖掘步骤-以聚类分析为例2014/9/11.打开SQL Server Business Intelligence Development Studio:2.文件-新建项目-商业智能项目-Analysis Services项目,设置项目名称,例如“Clsutering”:3.新建数据源-数据源向导,下一步-服务器名称(本机请点击下拉选择ADMIN-PC,网络数据库请填写IP地址)-使用SQL Server身份验证(建议勾选“保存密码”)-连接到一个数据库(下拉选择待分析数据所在数据库)-测试连接,确定-下一步-点选“使用服务帐户”,下一步-数据源名称(默认即数据库名称),完成:4.新建数据源视图-数据源视图向导,下一步-双击上一步中新建的关系数据源如test-下一步-添加与分析相关的所有表,下一步-命名数据源视图,如MultiFactors:5.新建多维数据集-多维数据集向导,下一步-使用现有表,下一步-勾选与分析相关的表,下一步-勾选度量值(与分析相关的输入、输出)-自动创建维度,下一步-命名多维数据集,如MDD,完成:6.新建挖掘结构-数据挖掘向导,下一步-选择从现有关系数据库或数据仓库,下一步-选择挖掘结构,如聚类分析,下一步-选择前面建立的数据源视图,下一步-下一步-指定键列、输入列、待预测列,下一步-个别挖掘算法需要修改数据类型,如Discretized,下一步-将数据划分为训练集、测试集,默认测试集占30%,下一步-命名挖掘结构、模型,允许钻取,完成:7.设置算法参数-阅读每个参数的说明,进行相关设置:8.挖掘模型查看器-生成和部署项目,是-是-运行-关闭-关闭,等待数据挖掘结果分类关系图:9.挖掘模型预测-选择输入表-如建立单独查询,选择源、字段(待预测),输入输入列值,转到查询结果:。
SQL数据挖掘知识讲解

数据挖掘知识要点一.名词解释(4’*5=20’)1.数据仓库:是一种新的数据处理体系结构,是面向主题的、集成的、不可更新的(稳定性)、随时间不断变化(不同时间)的数据集合,为企业决策支持系统提供所需的集成信息。
2.孤立点:指数据库中包含的一些与数据的一般行为或模型不一致的异常数据。
3.OLAP:OLAP是在OLTP的基础上发展起来的,以数据仓库为基础的数据分析处理,是共享多维信息的快速分析,是被专门设计用于支持复杂的分析操作,侧重对分析人员和高层管理人员的决策支持。
4.粒度:指数据仓库的数据单位中保存数据细化或综合程度的级别。
粒度影响存放在数据仓库中的数据量的大小,同时影响数据仓库所能回答查询问题的细节程度。
5.数据规范化:指将数据按比例缩放(如更换大单位),使之落入一个特定的区域(如0-1)以提高数据挖掘效率的方法。
规范化的常用方法有:最大-最小规范化、零-均值规范化、小数定标规范化。
6.关联知识:是反映一个事件和其他事件之间依赖或相互关联的知识。
如果两项或多项属性之间存在关联,那么其中一项的属性值就可以依据其他属性值进行预测。
7.数据挖掘:从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。
8.OLTP:OLTP为联机事务处理的缩写,OLAP是联机分析处理的缩写。
前者是以数据库为基础的,面对的是操作人员和低层管理人员,对基本数据进行查询和增、删、改等处理。
9.ROLAP:是基于关系数据库存储方式的,在这种结构中,多维数据被映像成二维关系表,通常采用星型或雪花型架构,由一个事实表和多个维度表构成。
10.MOLAP:是基于类似于“超立方”块的OLAP存储结构,由许多经压缩的、类似于多维数组的对象构成,并带有高度压缩的索引及指针结构,通过直接偏移计算进行存取。
11.数据归约:缩小数据的取值范围,使其更适合于数据挖掘算法的需要,并且能够得到和原始数据相同的分析结果。
SQL Server中的数据挖掘工具

SQL Server中的数据挖掘工具一、实验目的1. 了解SQL Server 提供的数据挖掘模型;2. 掌握用决策树和聚集算法创建OLAP挖掘模型;3. 掌握用决策树和聚集算法创建关系挖掘模型;二、实验工具SQL Server 2000 Analysis Manager三、实验内容(一)用决策树创建OLAP挖掘模型——“客户模式”使用Microsoft 决策树创建OLAP 数据挖掘模型数据挖掘模型是一种包含运行特定数据挖掘任务所需的全部设置的模型。
为什么?数据挖掘对查找和描述特定多维数据集中的隐藏模式非常有用。
因为多维数据集中的数据增长很快,所以手动查找信息可能非常困难。
数据挖掘提供的算法允许自动模式查找及交互式分析。
管理员可以在Analysis Services 中设置将要训练数据的数据挖掘模型。
然后,用户可以使用ISV 客户端工具对受训数据运行高级分析。
方案:市场部想提高客户满意度和客户保有率。
于是实行了两个创造性的方法以达到这些目标。
对会员卡方案重新进行定义,以便更好地为客户提供服务并且使所提供的服务能够更加密切地满足客户的期望。
创办《每周赠券》杂志,将杂志送给客户群,以鼓励他们访问FoodMart 商店。
为了重新定义会员卡方案,市场部想分析当前销售事务并找出客户人口统计信息(婚姻状况、年收入、在家子女数等等)和所申请卡之间的模式。
然后根据这些信息和申请会员卡的客户的特征重新定义会员卡。
本节将创建一个数据挖掘模型以训练销售数据,并使用“Microsoft 决策树”算法在客户群中找出会员卡选择模式。
请将要挖掘的维度(事例维度)设置为客户,再将Member_Card 成员的属性设置为数据挖掘算法识别模式时要使用的信息。
然后选择人口统计特征列表,算法将从中确定模式:婚姻状况、年收入、在家子女数和教育程度。
下一步需要训练模型,以便能够浏览树视图并从中读取模式。
市场部将根据这些模式设计新的会员卡,使其适应申请各类会员卡的客户类型。
基于SQL的不产生候选集的频繁模式挖掘

基于SQL的不产生候选集的频繁模式挖掘
尚学群;沈均毅
【期刊名称】《计算机应用》
【年(卷),期】2004(024)001
【摘要】频繁模式挖掘是数据库挖掘中的一个十分重要的组成部分,然而以前的许多研究都是基于Apriori的产生候选集的测试迭代方法.这些方法普遍存在需要多次扫描数据库,对产生的大量候选集进行迭代测试的缺陷,尤其是对于挖掘长模式时这种缺陷就尤为突出.FP-growth方法采用分而治之的策略,只需对数据库进行二次扫描,而且避免了产生大量候选集的问题.文中的基于SQL的频繁模式挖掘方法既是在此基础上提出的,采用子查询及DBMS扩展技术(如用户定义函数等)对该方法进行了改进.
【总页数】4页(P92-95)
【作者】尚学群;沈均毅
【作者单位】西安交通大学,电子与信息工程学院,陕西,西安,710049;西安交通大学,电子与信息工程学院,陕西,西安,710049
【正文语种】中文
【中图分类】TP311.132
【相关文献】
1.基于SQL的频繁模式挖掘算法 [J], 张倩;王治和;景永霞
2.一种基于频繁模式有向无环图的数据流频繁模式挖掘算法 [J], 任家东;王倩;王蒙
3.基于SQL的频繁模式挖掘的研究与实现 [J], 李桂杰;张集祥;姜庆月
4.一种基于上三角频繁项集矩阵的频繁模式挖掘算法 [J], 王文正;王文平;许映秋;谈英姿
5.一种不产生候选集的最大频繁集快速挖掘算法 [J], 杨君锐;赵群礼
因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
技 术 的 方 法 , 速 实 现 把 数 据 库 D 分 成 一 组 短 模 式 快
则 X_> y 具 有 支 持 度 S - .
关 联规则 的 挖掘一 般 分 为 2步 : 找 出所 有 频 繁 ① 项 集 ; 由频 繁项 集 产 生强 关 联 规 则. 这 2个 步 骤 ② 在 中 , 2步 比较容 易 , 掘关联 规 则 的总 体 性能 由第 】 第 挖
收 稿 日 期 :0 8 0 — 0 20 ~ 6 4
作者简介 1 郑
斌 (9 7 ) 女 , 建 连 江 人 , 士 17一 , 福 硕
步确定 .
目前 已有 多 种 关 联 规 则 的 挖 掘算 法 ] 均 属 于 , 无 监督 学 习方 法 , Apir 算 法 、 样 算 法 、 I 算 如 r i o 抽 DC
法 等 ] Ap ir 算 法 是 一 种 经 典 算 法 , 算 法 大 . ro i 该
D n的过程 , 能够直 接得 到所 有频 繁 1 ~项 集 相 关 的条
关 键 词 : 关 联 规 则 ; FP—Gr wt 频繁 模 式 ; QI o h; S
中图分类号 : T 3 P
文献标识码 : A
F —Grwt P o h算法 是不 产生候 选 项 集 的关 联 规则 挖掘算 法 , 它把发 现 长模 式 的 问题 转 换 成递 归 的发 现 短模式 , 然后 连接 后缀 . 该算 法瓶 颈在 于需要 在 内存 中 建立 整个 数据 集 的 F P—t e 然 后搜 索 该树 获 取频 繁 r , e 1 一项 集 的条件库 , 当数 据 库很 大 时 , 算 法对 内存 空 该 间要求 较 高 , 索 过 程 花 费 时 间 也 很 长 , 空 效 率 不 搜 时
件库 , 然后 对 每个 条件 库 分别 构 造小 的条 件 F —te P re
幅度压 缩 了候选 集 的大 小 , 需要 多 次 扫 描 数据 库 并 但 产生大 量 的侯 选 集. 于是 人 们 相继 提 出 了一些 优 化 的
方 法 一 .
来得 到最终 所需 的频 繁模 式 , 而降低 算法 复杂 度 , 从 执 行速 度快且 占用 内存 空 间小 , 具有 良好 的伸缩性 . 并
时 也 包 含 y, 称 规 则 X一> y 在 事 务 集 D 成 立 , 具 则 并
模式 , P F —g o h算法 都 是 有效 的 , 且 其 挖 掘速 度 rwt 并 大 约 比 Ap ir算法 快一 个数 量级 . r i o
有 置信 度 c 如 果 D 中 s 的 的 性 能 分 析 表 明 : 于 挖 掘 长 的 和 短 的 频 繁 r wt 对
丁为 丁 ,的项 集 . 每个 事务 有 唯 一标 识 , 作 TI . 称 D
当 X T, 们 说 事 务 T 包 含 X ( 是 J中 的 某 些 项 我 X
集 ) 关联 规则是 形如 X=>y 的表 达式 , 中 X, C . 其 Y J且 XnY— j . 果 D 中 C 的事务 在 包 含 x 的 同 , 2 如 『
基于 S QL技 术 的频 繁模 式 的发 掘
郑 斌
( 建 省 经 济 管 理 干 部 学 院 , 州 30 0 ) 福 福 5 0 2
摘
要 : 分 析 了 频 繁 项 集 挖 掘算 法 F —g o h算 法 , 对 算 法 中 存 在 的效 率 瓶 颈 问题 , 出 了 一 个 改 进 的挖 掘算 法 . P r wt 针 提
2 F P—Gr wt o h算 法
F — G o h方 法 采 取 分 而 治 之 的 策 略 : 经 过 P r wt 在 第 1次 扫 描 之 后 , 数 据 库 中 的 频 繁 集 压 缩 进 一 颗 频 把
1 关 联 规 则 挖 掘 概 述
数 据 挖 掘 uiD t M iig 就 是 从 海 量 的 实 际 应 ( aa nn )
改进 后 的算 法 通 过 应 用 S 术 的 方 法 直 接 得 到 频 繁 1 QI技 一项 集 的 条件 模 式 基 , 而 减 少 了 F —go t 从 P rw h算 法 中构 造 F P
—
te 和 搜 索 的 开 销 . 析 结 果 表 明 , 进 的算 法 具有 比较 良好 的性 能. re 分 改
第 1 卷第 5 9 期 20 0 8年 l O月
中原 工学 院学 报
J OURNAI OF Z ONGYUAN H UNI VERS TY I OF TECHN0I ) GY (
VOI 1 No. .9 5 Oc ., 00 t 2 8
文 章 编 号 :6 1 9 6 2 0 )5 0 6 6 1 7 —6 0 ( 0 8 0 ~0 5 —0
f i,: … ~ 为一 项集 . D 为事 务集 , 个 事务 :{。 i, i} 设 每
和一个 长 度为 1的频 繁 集相 关 ; 最后 再 对 这 些 条件 库 分别进 行挖 掘. P G o h方 法 把 发 现 长 频 繁 模 式 F — r wt 的 问题转换 成递 归 发现 一 些 短模 式 , 使 用 最 不频 繁 它 的项作 为 后 缀 , 而 提 供 了 良 好 的选 择 性 . F 从 对 P—
用数 据 中提取 隐含在 其 中 , 人们 事先 不知道 的 , 是 又 但
是 潜 在 有 用 的 信 息 和 知 识 的 过 程 . 基 本 概 念 是 : 其 设
繁模 式树 ( P Tre , F e) 同时依 然保 留其 中 的关 联信 息 ;
—
随后再 将 F P— Tre 化 成 一 些 条 件 库 , 个 条 件 库 e分 每