Information Storage and Retrieval(信息存储与检索)_probability_model
清华大学-信息检索-第2章

28
2.3 检索系统与检索方法
2.3.2 检索方法 1. 常用法
常用法是利用检索工具查找信息的一种方法, 因为这种方法是目前查找信息中最常使用的,故亦 称常用法。 (1) 顺查法 (2) 倒查法 (3) 抽查法
29
2.3 检索系统与检索方法
(1) 顺查法
是指按年代由远及近的顺序进行查找的方法, 如检索“电视文化”这一课题,首先要弄清起始时 间,即“电视文化”产生的时间是哪一年,然后从 这一年开始查起,一直查到当前“电视文化”方面 的相关信息为止和查准率都较高,但是检 索整个课题较费时费力。
1) 手工检索 手工检索简称“手检”,是指人们通过手工 的方式检索信息,其使用的检索工具主要是书本 型、卡片式的信息系统,即目录、索引、文摘和 各类工具书。检索过程是由人工以手工的方式完 成的。 2) 计算机检索 计算机检索简称“机捡”,是指人们利用数 据库、计算机软件技术、计算机网络及通信系统 进行的信息检索,其检索过程是在人机的协同作 用下完成的。
11
2.1 信息检索概念及类型
3) 数据型信息检索
数据型信息检索是一种确定性检索,是以 数值或图表形式表示的数据为检索对象的信息检 索,又称“数值检索”。检索系统中存储的是大 量的数据,这些数据既包括物质的各种参数、电 话号码、银行账号、观测数据、统计数据等数字 数据,也包括图表、图谱、市场行情、化学分子 式、物质的各种特性等非数字数据。
22
2.2 检索途径与检索语言
(2)主题语言 主题“是一组具有共性事物的总称,用以表达 文献所论述和研究的具体对象和问题”,即文献的 “中心内容”。每种文献都包含着若干主题,研究 或阐述一个或多个问题。主题词就是表达主题概念 的词汇。
23
文献检索复习资料

第一章网络信息概述一. 基本概念1信息狭义:信号和消息广义:是物质的存在方式和运动方式的体现,是物质的一种客观存在,它反映了物质客体及其相互作用、相互联系过程中表现出来的种种状态与特征。
2 知识按照表述方法可以分为两类:显性知识和隐性知识显性知识,又称可编码的知识,是记录于一定物质载体上的知识,可以看得见,摸得着的,可以通过正常的语言方式传播的知识。
以文字、语言、图像的形式保存下来,如专利、商标、计划、软件设计报告等等。
显性知识是可以编码和表述的,有载体的。
隐性知识又可称为不可编码的知识,是存储在人们大脑里的经历、经验、技巧、体会、感悟、智能等尚未公开的秘密知识,就是你看不见、摸不着,只可意会不可言传,难以直接交流和表达出来的知识。
隐性知识的特点是不易被认识到、不易衡量其价值、不易被其他人所理解和掌握3文献是记录有知识的一切载体。
精确描述:凡是用文字、图形、代码、符号、音频、视频等方式记载在一定载体上的每一件记录,均称为“文献”。
构成文献要素有三,知识、记录与载体方式。
4情报是人们在一定时间内为一定目的而传递的有使用价值的知识或信息。
钱学森:“情报是激活了的知识”情报是对特定的人而言的,对需要它的人而言是情报,对不需要的人而言它只是信息与知识。
知识与信息转化为情报必须经过传递、只有将特定的知识与信息传递到特定需要的人那里,它们才能成为情报。
传递是情报的一个基本特征。
二. 网络信息的特性1 性质客观性寄附性传递性共享性衍生性时效性2 特点数量大来源广语种多多媒体传播快跨国界内容杂更新快三. 网络信息的资源1 知识信息网站教育和科技部门网站,如:学校、科研单位、学术团体、政府部门等。
2 文献信息网站出版和收藏文献网站。
有数字图书馆,如:超星、书生之家等;数字平台,如:中国知网、万方、维普等。
四. 网络信息的检索主要信息网站种类:政府网站(.gov)免费教育机构(.edu)科研部门(.ac)商业网站(.com)收费社会组织(.org)互联网络(.net)五.图书馆印刷型文献:图书、期刊、工具书、报纸电子型文献:随书光盘、电子期刊数据库、电子图书及其他数据库1. 按文献内容性质划分(不同加工深度)零次文献(Zeroth Litterature) 是指非正式出版或非正式渠道交流的文献,未公开于社会,只为个人或某一团体所用。
信息检索名词解释

1)信息检索(information retrieval) 是指将信息按一定的方式组织和存储起来,并根据信息用户的需要找出有关信息的过程。
所以,它的全称又叫信息存储与检索(information storage and retrieval), 这是广义的信息检索。
狭义的信息检索则仅指该过程的后一步,即从信息集合中找出所需要信息的过程。
相当于我们所说的信息查询(information search)。
2)零次文献:也叫灰色文献,未经公开发表或未交流于社会的文献。
如私人笔记,设计草图、实验记录、文章草稿、会议记录、书信文书、以及档案等。
其主要特点是内容新颖,但不成熟,不公开交流,难以获得。
3)一次文献(Primary Document): 以著者本人的研究或研制成果为依据而创作或撰写的文献,习惯上称做原始文献。
如期刊论文、科技报告、专利说明书、会议论文、学位论文等。
体现创作性。
其主要特点是内容新颖丰富,叙述具体详尽,参考价值大,但数量庞大、分散。
4)二次文献(Secondary Document):就是检索工具。
是将大量分散的无组织的一次文献经浓缩,整序的加工整理,编辑成目录、题录、文摘、索引等检索工具或数据库。
如文摘,目录、索引等。
它有存贮、检索、报道的功能。
体现高度的浓缩性。
其主要功能是检索、通报、控制一次文献,帮助人们在较少时间内获得较多的文献信息。
二次文献具有汇集性、工具性、综合性、交流性等特点。
5)三次文献(Tertiary Document):在一、二次文献的基础上,经过综合分析而编写出来的文献,如专题述评、动态综述、学科年度总结,进展报告以及数据手册、百科全书等参考工具书。
三次文献是情报研究的产物和成果。
具有很强的的综合性。
总之,一次文献(创造性),二次文献(有序化),三次文献(高度浓缩,提炼,再创造)。
6)以上四个级别的文献中,零次文献由于没有进入出版、发行和流通这些渠道,收集利用十分困难,一般不作为我们利用的文献类型。
文献信息检索作业

信息检索大作业一、名词解释1、信息检索信息检索最普通的理解就是信息查找。
它是将信息按一定的方式组织起来,并根据信息用户的需求查找出有关的信息的过程和技术。
信息检索又叫做信息存储与检索(information storage and retrieval)。
信息检索可以分为事实检索、数据检索、文献检索。
2、文献检索文献检索实在检索工具或文献数据库中查找含有情报用户特定需要内容的文献的方法和过程。
它是信息检索的信息检索中最重要的部分。
因此可以将信息检索和文献检索看做是同义词。
3、特种文献特种文献是一种不以书刊形式出版的文献,一般不公开发行,它包括专利文献、会议资料、科技报告、技术标淮、学位论文、政府出版物、产品样本及其说明书等。
其特点是内容涉及面广、种类多、数量大、报道快、参考价值高。
4、检索语言信息检索语言是根据信息检索的需要而创造的专门供信息标引和信息检索使用的一种人工语言。
检索语言是人与检索系统进行对话的基础。
5、专利的“国际三性”三性是指专利的新颖性、创造性、实用性。
新颖性是指专利申请的发明或者实用新型不属于现有技术,是前所未有的。
创造性是指同申请日以前的技术相比,该发明有突出的实质性特点和显著进步,该实用新型有实质性特点和进步。
实用性是指该发明或者实用新型能够制造或者使用,并且能够产生积极效果。
6、计算机检索计算机检索就是通过计算机进行的文献信息检索。
计算机检索包括光盘数据库检索、网络数据库检索和互联网信息检索。
7、数据库从信息的角度来说,数据的集合,指将大量的信息按照一定的方式组织并存储起来所形成的数据集合。
8、布尔逻辑算符布尔逻辑算符是在信息检索过程中为了提高检索效率而用来组合检索词,进行检索语言或者检索代码的组配,规定检索词之间的逻辑关系的算符。
布尔逻辑算符包括逻辑与(and *)、逻辑和(or +)、逻辑非(not -)。
二、简答1.信息、知识、情报和文献之间的关系。
信息是物质存在方式及其运动规律、特点的外在表现。
文件检索的方法及案例
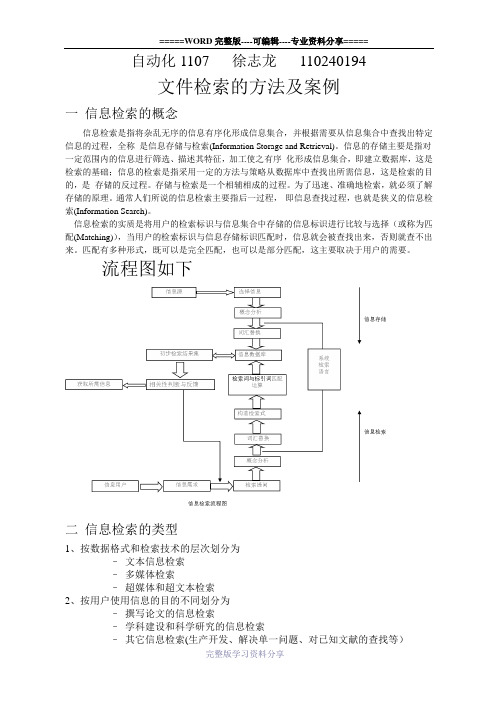
自动化1107 徐志龙110240194文件检索的方法及案例一信息检索的概念信息检索是指将杂乱无序的信息有序化形成信息集合,并根据需要从信息集合中查找出特定信息的过程,全称是信息存储与检索(Information Storage and Retrieval)。
信息的存储主要是指对一定范围内的信息进行筛选、描述其特征,加工使之有序化形成信息集合,即建立数据库,这是检索的基础;信息的检索是指采用一定的方法与策略从数据库中查找出所需信息,这是检索的目的,是存储的反过程。
存储与检索是一个相辅相成的过程。
为了迅速、准确地检索,就必须了解存储的原理。
通常人们所说的信息检索主要指后一过程,即信息查找过程,也就是狭义的信息检索(Information Search)。
信息检索的实质是将用户的检索标识与信息集合中存储的信息标识进行比较与选择(或称为匹配(Matching)),当用户的检索标识与信息存储标识匹配时,信息就会被查找出来,否则就查不出来。
匹配有多种形式,既可以是完全匹配,也可以是部分匹配,这主要取决于用户的需要。
流程图如下二信息检索的类型1、按数据格式和检索技术的层次划分为–文本信息检索–多媒体检索–超媒体和超文本检索2、按用户使用信息的目的不同划分为–撰写论文的信息检索–学科建设和科学研究的信息检索–其它信息检索(生产开发、解决单一问题、对已知文献的查找等)3、按信息检索的技术手段划分:–手工检索-计算机检索4、依据信息类型划分-事实与数值型信息检索、图书信息检索、期刊信息检索、专利信息检索、商标信息检索、学位论文检索、标准信息检索、科技报告信息检索等。
案例:事实与数值型信息检索举例如下:检索国家统计局公布的(2002年1——2季度)牧业产值(按现行价格计算)是3728.7亿元。
用《中国大百科全书(简明本)》或者其他工具检索园艺术语“蔷薇科”,中国有53属1000余种。
5、依据检索界面划分-初级检索-高级检索三具体的检索方法(一) 文献检索(Document Retrieval)–文献检索是以文献为检索对象,从已存贮的文献数据库中查找出特定文献的过程。
网络信息的检索与利用~

第一章1.信息检索(information retrieval)是指将新鲜一定的方式组织和存储起来,并根据信息用户的需要找出有关信息的过程.全称又叫信息存储于检索(information storage and retrieval).狭义的信息检索则仅指从信息集合中找出所需信息的过程.信息检索的分类:A根据检索手段的不同,可分为:手工检索、光盘检索、联机检索和网络检索。
(网络检索式信息检索的发展方向,因而本书以网络检索为主)。
B根据检索对象形式的不同,可分为:①文献信息检索:是以文献(包括题录、文摘和全文)为检索对象的检索。
②数值型信息检索:是以数值或数据为对象的一种检索,包括文献中的某一数据、公式、图表,以及某一物质的化学分子式等,数据检索分为数值型和费数值型。
③事实型信息检索:是以某一客观事实为检索对象,查找某一事物发生的时间地点及过程的检索,其检索结果主要是客观事实或为说明事实而提供的相关资料。
2.检索语言是把信息的存储与检索联系起来,把标引人员与用户联系起来,以便取得共同理解,实现交流的语言. 目前使用的检索语言包括:人工语言(分为主题语言和分类语言)和自然语言(可以为那些不懂人工语言的网络用户提供极大的便利).3.数据库是“至少由一个文档组成,并能满足某一特定目的或某一特定数据处理系统需要的一种数据集合”. (通俗)数据库就是在计算机存储设备上按一定方式存储的相互关联的数据集合。
数据库是计算机技术与信息检索技术相结合的产物,是现代重要的信息资源,也是信息检索的重要资料来源.根据载体不同可分为:联机数据库(online database),光盘数据库(CD-ROM database)和网络数据库(networked database).根据内容与功能可划分为:指南数据库(directory database),交易(执行)数据库(transactional database),全文数据库(full text database),书目数据库(bibliographic database),字(词)典数据库(dictionary database),数值数据库(numeric database)与统计数据库(statistical database)和图像数据库(image database).4.检索词是用户或检索人员给出的字,词,字符或短语,用于查找含有它们的记录.检索式也称检索提问表达式,是要求系统执行的检索语句.检索策略是就一个问题检索一个或多个数据库所输入的全部检索式的集合,是为满足信息需求所制定的一系列检索式.5.查全率(recall ratio)与查准率(precision ratio)是检索质量的两个重要的评价指标.查全率是指检出文献中合乎需要的文献数量占数据库中存在的合乎该需要的所有文献的比例.查准率是指检出文献中合乎需要的文献数量占文献全部数量的比例.6.布尔逻辑检索的主要运算符是:①逻辑”与”,用AND(或*)表示.②逻辑”或”,用OR(或+)表示.③逻辑”非”,用NOT(AND NOT,BUT NOT)(或-)表示.7.邻近检索:又称位置算符检索,文献记录中词语的相对次序或位置不同,所表达的意思可能不同,而同样一个检索表达式中词语的相对次序不同,其表达的检索意图也不一样.位置算符检索是用一些特定的算符来表达检索词与检索词之间的关系,并且可以不依赖叙词表而直接使用, ,BDS拥有的国内信息库主要有:中国国防科技信息、中国军工报、网上新闻库、国防科技成果综合推广库、现代军事、中国工程院士学术报告、国防科技简讯、国内成果交流库、国防科技报告中文馆藏库、国防科技中文文摘库、中国经济信息库、中国科技期刊题录库、中国专利文摘库。
文献检索作业(二)

文献检索作业(二)名词解释(10分)信息检索:信息检索最普通的理解就是信息查找。
它是将信息按一定的方式组织起来,并根据信息用户的需求查找出有关的信息的过程和技术。
信息检索又叫做信息存储与检索(information storage and retrieval)。
信息检索可以分为事实检索、数据检索、文献检索。
会议论文:会议文献是指在各种专业会议上发表的论文和报告,属于一次文献。
学术性强、内容新颖、能够反映出一门学科、一个专业的研究水平和最新成果,对及时了解学科研究水平和发展动态有重要参考价值分类法:分类法就是将事物分门别类的方法,这里特指文献分类法,(documentaryclas-sification)简称“分类法”,又称“系统主题法”。
①即“分类组织法”。
②(classification scheme,classi-fication system)将代表各种概念的类目用号码来标识,并以学科属性为主加以系统排列的组织、检索文献的体系。
是按分类途径排检文献的基本工具和重要依据。
索引:又称通检、引得。
将图书、报刊中的篇目、词句、主题、人名、地名、书名、事件及其他事物名称,分别摘录出来,注明出处,按照一定的方法加以编排,供人查考的检索工具。
附在一书之后,或以书、刊的形式单独编辑成册。
文献检索的基本原理:文献检索包括存储和检索两个过程。
存储过程就是对文献进行标引,形成文献特征标识,为检索提供有规律的检索途径的过程。
检索过程就是按照词表(或分类表)及组配原则形成检索提问标识,按照存储所提供的检索途径,查获与检索提问标识相符合的文献特征标识的过程。
填空题(20分)1、世界著名的三大检索工具是《科学引文索引》(sci)、《科学技术会议录索引》(ISTP) 、《工程索引》(Ei)。
2、专利的主要类型有发明专利、实用新型专利、外观设计专利。
专利的基本特点新颖性、实用性、创造性。
3、依据文献传递知识、信息的质和量的不同以及加工层次的不同,人们将文献分为四个等级,它们是零次文献、一次文献、二次文献、三次文献。
信息检索原理

4.1
主题语言
标题词语言
Heading
主 题 语 言
关键词语言
单元词语言 叙词语言
Keyword
Uniterm
Descriptor
标题词语言
是最早使用的一种主题语言,它以规范 化的自然语义作为标识,来表达信息涉及的 主题概念,并将全部标识按字母顺序排列。
例子:一篇文章用“微型计算机”这个术语来叙述研究对象
另一篇文章用“微型电脑” 来叙述 虽然表示的概念都相同,但我们使用的时候只能用” 微 型计算机“作为标题词。
实际上是:
“主标题词”,根据主题词表决定
关键词语言
直接选用文献中的自然语言作基本词汇, 并将那些能够揭示文献题名或主要意旨的关 键性自然语词作为关键词进行标引的一种检 索语言.
这种语言是目前使用最广泛的一种。非图书馆学专业 从这种方法入手最简洁和易懂。
信息存储:
通过多种形式记录、排序、存储信息的过程
信息检索:
从以任何方式组成的信息集合中,查找特定用 户在特定时间和条件下所需信息的过程
ቤተ መጻሕፍቲ ባይዱ
授权 文献著者 文献标引者
信息集
信 息 的 存 储
检索语言
信 息 的 检 索 信息检索者
信息用户
结果集
第2节 信息检索方法与途径
1. 信息检索的一般方法 工具法(常用法): 顺查法、倒查法、抽查法 追溯法(引文法) 综合法
关键词语言例子
国际联机检索概论 关键词:国际联机检索
国际联机
联机 检索
数字信号处理及MATLAB实现 关键词:数字信号 信息处理 粮食储蓄中机械通风保粮方法 关键词:粮食储藏 机械通风 技术措施 经济效益
信息检索-检索基本知识
19.6.22
排列举例:
1. H1、H12、H、H134、H2、H219、H0、 H-44、 H 2-44 2. TP311.1、F0、G624、F2、O-44、I2457 、 TN912、TP319、
F 181、O13-43 、O-62 3. I247.5/J3、 I247.5/G5、F0/L21、FO/L12
1:H、H-44、H0、H1、H12、H134、H2、H 2-44、H219、 2:F0、F 181、F2、G624、I2457 、O-44、O-62、O13-
43、 TN912、TP311.1、 TP319 3:F0/L12、F0/L21、 I247.5/G5、 I247.5/J3
19.6.22
《科图法》
早,只好用倒查法,新兴学科,起始年代不远,可 用顺查法,波浪发展的学科,可选择发展高峰,用 循环法
19.6.22
检索语言
信息检索要克服的三个语言障碍: ★自然语言障碍 ★学科专业语言障碍 ★检索语言障碍
19.6.22
又称文献存储和检索语言,是根据文献信 息存储与检索的需要而创制的一种人工语言, 是汇集、组织、存储、检索文献信息的工具和 手段。
19.6.22
★00 马列、毛泽东思想 ★10 哲学 ★20 社会科学
21 历史、历史学 … 48 艺术 49 无神论、宗教学 ★50 自然科学 51 数学 … 54 化学 65 农业科学 71 技术科学 ★90 综合性图书
以字符构建主题语言:
1.关键词:直接从文献信息的标题、摘要或内 容本身抽取出来的用于揭示信息主题内容的自 由词。
磁盘式
19.6.22
19.6.22
第三章文献信息检索的基本知识

第三章文献信息检索基本知识随着信息技术的发展,互联网的应用得到广泛普及,信息环境发生了相当大的变化,应用现代化技术手段获取各种信息、知识成为高等院校师生与广大科技工作者的一种必备知识和技能。
为此,首先就必须了解文献信息检索的基本知识。
第一节信息检索的基本原理一、信息检索的概念信息检索(Information Retrieval)全称为“信息存储与检索”(Information Storage and Retrieval),其概念有广义和狭义之分。
广义上认为,信息检索包括文献信息的存储和检索两个方面,即一个完整的信息检索系统由信息存储子系统和信息检索子系统两部分组成。
信息存储子系统:首先对一定数量的信息进行筛选,把能够描述文献信息的外部特征和内部特征进行加工、整理,使之有序化,形成信息特征标识集合,然后将之存储在某种载体上,编制成为检索工具或建立一个数据库。
信息检索子系统:根据信息用户的特定需求,对用户需求进行主题分析,利用一定的检索方法和检索技术,对存储子系统中的特征标识进行比对,把需要的文献线索或知识信息从系统中查找出来的过程,即信息检索。
这就是通常人们所说的信息检索过程,也就是狭义上的信息检索。
信息存储与信息检索是意义不同却又相互联系、相互依存、不可分割的两个过程。
信息存储是为了检索,信息检索又必须先有信息存储。
如果没有存储,检索就无法实现;没有检索,信息存储也就变得没有意义。
所以说存储是检索的前提和基础,检索是存储的目的。
信息检索系统的工作原理如图3-1所示。
图3-1 信息检索系统的工作原理二、 信息检索的类型信息检索可以按不同的划分标准划分为不同的类型。
(一)、 根据检索内容划分根据检索信息内容不同可划分为文献信息检索、事实信息检索和数据信息检索。
1、文献信息检索(document retrieval ):是以文献(包括目录、索引、文摘等二次文献或全文)为检索对象,查找有关文献的出处和收藏处等信息,都属于文献信息检索范畴。
留美学子的美好记忆——怀念李华伟馆长

形,开始了中国现代化建设的探索。
中国图书馆现代化可追溯到20世纪70年代早期。
1973年初,以北京图书馆(现国家图书馆)馆长刘季平为团长的中国图书馆访美考察团与计算机访美考察团,同时赴美访问考察。
回国后,刘季平馆长向中央领导部门汇报,同时向图书馆界介绍美国图书馆现代化情况。
随着北京图书馆新馆建设,开始引进图书馆自动化系统,相关业务部门做相应改革。
1974年全国实施“748工程”,各行各业开始进行计算机的研发与应用。
图书情报界承担了汉字信息处理、计算机检索语言的编制等项目。
20世纪70年代末,科技情报系统研发的二次文献数据库的建库技术进展很快。
20世纪70年代末,国外关心中国图书情报现代化的专家学者开始陆续到中国考察访问,介绍国外图书馆现代化情况,李博士是促进中美图书情报界交流最多的图书馆学专家。
他1982年第一次来华到昆明,首先是应中国科技情报研究所邀请,在科技情报中心管理培训班讲课,尔后陆续在福建等地介绍美国图书馆自动化和新技术应用。
除了来华交流,李博士还在美国组织和接待了近170位我国图书情报专业工作者。
拜读《李华伟文集》,深深感受到李博士始终以图书情报学的思维和理念,根据图书情报工作需要,介绍新技术作为工具的应用情况。
他提出,图书馆自动化中,“信息技术是信息存储、检索与传播的新工具和新的可能性”(The information technology—new tools and new possibilities for information storage,retrieval and dissemination)。
李博士的图书情报现代化理念值得认真领会。
他对图书情报专业人才培养亦有心得,认为在高等教育中,图书馆学、信息管理专业的培养目标,首先应该通过各种途径让学生详细、深入了解图书情报实际,在此基础上,根据专业领域,了解与本学科相关的信息技术、网络技术原理和发展,研究新技术在本学科的应用,建设以时代的历史使命为己任,应用新技术且具有各种功能的新型现代化图书馆。
信息检索课程感悟

《信息检索》课程感悟知识有两类:一类是我们通常所说的专业知识,另一类是我们怎样去查获所需要专业知识的知识。
塞繆尔.约翰逊《信息检索》这门课程同时具备上述两类知识的特征,学好《信息检索》能让我们成为一个具有信息素质能力的人。
作为一个具有信息素质能力的人,必须能够充分地认识到何时需要信息,并有能力去有效地发现、检索、评价和利用所需要的信息。
从根本上说,他们已经掌握了学习的方法、知道如何学习、因为他们知道知识是如何组织的,如何去发现和使用信息。
他们具有终身学习的能力,因为他们总是能够为任何任务和决策找到所需信息。
一、对于信息检索概念的认识穆尔斯(Calvin N. Mooers, 1919~1994) 在1948年提出此术语时,把它定义为一种“延时性通讯形式”。
其特点是:发信者在某一时刻发出信息,而接收者可以在晚一些时刻才收到该信息;发信者必须发出一切可能的信息,而接受者必须有某种检索装置以便从大量发送的信息中筛选出适合自己需要的信息。
信息检索的全称是信息存储与检索(information storage and retrieval),包含两个方面,存储的过程是信息的组织加工和记录的过程,即建立检索系统(编制检索工具)的过程——输入的过程;检索的过程是按一定方法从检索系统(检索工具)中查出信息用户需要的特定信息的过程——输出的过程。
二者是相辅相成的,存储是为了检索,而检索又必须先进行存储。
只有经过组织的有序信息集合才能提供检索,因此了解了一个信息系统(检索工具)的组织方式也就找到了检索该检索系统(检索工具)的根本方法。
二、对于信息检索方法的认识1. 布尔检索(1)逻辑“与”,用AND表示,检索式“A and B”表示文献中同时包含检索词A和检索词B的文献才是命中文献。
(2)逻辑“或”,用OR表示,检索式“A or B”表示包含检索词A的文献或者包含检索词B的文献或者同时包含检索词A和B的文献为命中文献。
药学文献检索

药学是连接健康科学和化学科学的医疗保健行业,它承担着确保药品的安全和有效使用的职责。
药学主要研究药物的来源、炮制、性状、作用、分析、鉴定、调配、生产、保管和寻找(包括合成)新药等。
主要任务是不断提供更有效的药物和提高药物质量,保证用药安全,使病患得以以伤害最小,效益最大的方式治疗或治愈疾病。
文献检索:文献检索的概念有狭义和广义之分。
广义的检索包括信息的存储和检索两个过程(Storage and Retrieval)。
信息存储是将大量无序的信息集中起来,根据信息源的外表特征和内容特征,经过整理、分类、浓缩、标引等处理,使其系统化、有序化,并按一定的技术要求建成一个具有检索功能的数据库或检索系统,供人们检索和利用。
而检索是指运用编制好的检索工具或检索系统,查找出满足用户要求的特定信息。
狭义的文献检索仅指文献的查找过程。
文摘:文摘是以简明扼要的文字摘述文献的主要内容和原始数据、向读者报道最新研究成果、传递文献的情报信息和查寻文献线索的一种工具。
文献:文献是记录有知识的一切物质载体。
根据对文献内容加工深度的不同,文献可分为一次文献、二次文献、三次文献、零次文献,根据文献的载体,文献可以分为文本型文献、图片型文献、音频文献、视频文献等。
第二章 参考工具书

药学信息检索
Information Storage and Retrieval
七.图谱(略)
八.丛书(略)
第二章 参考工具书
药学信息检索
Information Storage and Retrieval
本章完毕,谢谢!
对本门课程有任何意见与建议,请发邮件至: zhangchengmin@
《英国药典》 British Pharmacopoeia 简称:BP 《英国处方集》 一部 《日本药局方》 13版 二部
第二章 参考工具书
药学信息检索
Information Storage and Retrieval
二.辞典、药典
联合化学词典ccd2004
The Combined Chemical Dictionary(综合化学词典)on CD-ROM 由CRC Press 公司 出版, 本数据库将该公司的五部大型经典化学词典即《有机化合物 词典》、《天然产物词典》、《药物词典》、《分析试剂词典》和 《无机及有机金属化合物词典》汇集成一体。每半年增补更新一次。 2002 年版包含近55 万个化合物的信息(有机化合物246,000 个; 天然产物177,000 个;药物及生理活性物质38,000 个;分析试剂 14,000 个;无机及金属有机化合物101,000 个;碳水化合物 20,000 个)。每条记录中包含如下内容:化学名和异名、结构式 和立体构型、CAS 登录号、分子式、分子量、危险品标识、化学物 质毒性作用登记号、危险性及毒性数据、来源及合成方法、用途、 物理性质、开发状况、主要衍生物、参考文献等, 文献后注明内容 属性, 提供菜单检索、文本检索、结构检索、快捷检索等多种途。
第二章 参考工具书
药学信息检索
图书馆学部分术语

藏书布局:将图书馆入藏的全部文献,按照一定的标准划分为相对独立又相互联系的若干部门,建立各种功能的书库,为每一部藏书确定合理的存放位置以便保存和利用。
藏书剔除:图书馆根据一定的原则和标准将长期滞留书库读者少用不用或无用的文献从藏书中分离出来,并按不同情况分别处理,是入藏的逆过程。
索书码索书码是识别一种图书的唯一标识,由分类号和书的种次号两部分组成,中间用“\”隔开。
磁带库磁带库是一种可将多台磁带机整合到一个封闭机构中的箱式磁带备份设备,它能够提供同样的基本自动备份和数据恢复功能,但同时具有更先进的技术特点。
数据压缩所谓数据压缩,就是以最少的数码表示信源所发的信号,减少容纳给定消息合或数据采集集合的信号空间。
范式理论:构造数据库必须遵循一定的规则。
在关系数据库中,这种规则就是范式。
范式是符合某一种级别的关系模式的集合。
关系数据库中的关系必须满足一定的要求,即满足不同的范式。
信息流:信息流的广义定义是指人们采用各种方式来实现信息交流,从面对面的直接交谈直到采用各种现代化的传递媒介,包括信息的收集、传递、处理、储存、检索、分析等渠道和过程。
信息流的狭义定义是从现代信息技术研究、发展、应用的角度看,指的是信息处理过程中信息在计算机系统和通信网络中的流动。
图书馆联盟:图书馆联盟(library consortia)图书馆联合的最新形式,为了实现资源共享,利益互惠的目的而组织起来的,受共同认可的协议和合同制约的图书馆联合体,它既可以理解为馆际合作,也可以理解为传统图书馆与数字和虚拟图书馆,纸型资源与电子资源的互补共存。
布拉德富定律:布拉德福定律是由英国著名文献学家B.C.Bradford于本世纪30年代率先提出的描述文献分散规律的经验定律。
其文字表述为:如果将科技期刊按其刊载某学科专业论文的数量多少,以递减顺序排列,那么可以把期刊分为专门面对这个学科的核心区、相关区和非相关区。
各个区的文章数量相等,此时核心区、相关区,非相关区期刊数量成1:n:n2(n的平方)的关系。
信息检索基本概念

图录类
检索工具书:包括书刊目录、文摘和索引。 ——仅能告诉读者从哪儿可以找到所需要的信息
核心文献、相关文献、边缘文献
核心文献——通常是指与本学科发展水平、发展动向密 切相关的一些文献。如核心期刊等。 相关文献——内容与学科的关系相对疏远一些的文献。 边缘文献——内容与学科的关系更疏远的文献。 布拉德福定律:核心文献、相关文献和边缘文献期刊 数量成1:n:n2的关系。(由英国著名文献学家 B.C.Bradford于本世纪30年代率先提出的描述文献分 散规律的经验定律)。
信息
文化
文化
信息
文化、知识与科学
文化——包括真善美三部分。其中“真”,与判断有关,有情 报和知识两种。 情报——有时效性和相对性,即不同的时刻不同的地方对不同 的人效果是不同的。 知识——逻辑上讲它们都是由全称判断组成的,即在一定条件 下对某类事物的判断,其特点是与时间地点和人物无关。因此 称知识是人们对客观规律的总结。 科学——用逻辑与实验严格建立起来的知识体系,且是一项社 会事业。 一般知识错误率很高,特别是原始知识(古代知识和各种 经验知识),因为它们都常常是人们自然归纳或错误理论产生 的。对复杂点的问题,往往自然归纳极易出错。没有逻辑理论 指导很难形成复杂的正确理论。
信息素养的内涵
(1)信息意识:指个体对信息的敏感度。也就是说能够认 识到信息的重要性,对信息由积极地内在需求; (2)信息知识:信息学中的基本概念、基本原理、方法学 等基本知识。像文献学知识、图书情报学知识、信息技术知 识和外语水平等等; (3)信息技能:储存信息、搜集信息、管理信息的一些技 术和能力,是信息检索的核心; (4)信息筛选与评价:对各种途径获得的信息进行选择, 再对选择出的信息作进一步的检查,确定他的层级; (5)信息道德与法律:指在获取、利用、加工和传播信息 的过程中必须遵守一定的社会公约和国家制定的相关法律法 规。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Probability of a relevant document
P(relevto 1.
0<= P <=1
The probability that a document is not relevant to the query is defined as:
Probability of a relevant document
[1] there are N documents in a DB [2] n of them (N) are relevant to a query( n<=N) in a DB [3] a document is randomly retrieved from the DB, therefore: The probability that a randomly retrieved document is relevant to the query is defined as:
P(rel | retrieved) > 0.5
Discrimination function
[5]. Discrimination function is defined as:
P(rel | retrieved) Dis(retrieved)=-------------------------P(not rel | retrieved)
Probability theory
P( Event ) is always smaller than or equal to 1.
0<= P <=1
The probability that an event does not happen is:
P(not event)=1-P(event)
Probability theory
Discrimination function
If event A is statistically independent from event B, it means that occurrence of event A(B) has no impact on event
B(A). In other words, Event A and event B
Example
P(H0|H1) = 0.6 P(H0|H2) = 0.07 P(H0|H3) = 0.001 What should be our guess about Joe's profession? Most likely, it is H1.
Statistical independence
P(not relevance)=1-P(relevance) P(not relevance)= 1-(n/N) P(not relevance)= (N-n)/N
Discrimination function
[1] A query can divide the database into two basic sets: the retrieved and the not retrieved. [2]. Since not all of documents retrieved are truly relevant, therefore, the probability of a retrieved document that is relevant or not relevant should be considered as:
Example
Let H0 = “Joe earns more than $70,000/year” H1 = “Joe is a doctor” H2 = “Joe is a college professor” H3 = “Joe works in food services” Suppose we do a survey and we find out (from observed/questionnaires, etc.--sampled doctors, college profs, food services folks for their salary $70,000/year) Hi is a hypothesis.
Probability retrieval model
The basic idea of probability retrieval model is that given a document and a query it should be possible to calculate the possibility that the document is relevance to a query. Probability retrieval model attempts to address the IR problem within a probabilistic framework.
P( rel | retrieved) and P(not rel | retrieved)
Discrimination function
[3] Ideally, a retrieval criteria should be set up to examine that the possibility that a retrieved document is relevant is larger than it is not relevant, that is:
Conditional probability The conditional probability of event A occurring given that event B has occurred is denoted by:
P(A|B)
It means that knowledge of B can affect the perception of the probability of A.
P(relevance)=n/N
Representation of Document
“Binary” Boolean presentation: documents are represented as binary vectors of terms :
D(x1, x2,… xj,…, xn) xj=1 if it is relevant, or 0 otherwise. Which is similar to the vector IR model. And finally all documents form a binary document-term matrix.
are statistically independent if an occurrence of either of them does not depend on the other.
Probability theory
The following equation is correct if event A is statistically independent from the event B
P(A*B)=P(A)*P(B)
Bayes theorem
P(B|A)*P(A) P(A|B)= ------------------P(B)
The theory allows us to invert conditional probability. Suppose event A and event B are statistically independent.
Documents are retrieved if and only if Dis(retrieved)>1
Discrimination function
[6]. Adjustment of the discrimination function If users want a more precision for the result, they can modify the two discrimination function. For example: P(rel|retrieved) > 3*P(not rel |retrieved) P(rel|retrieved) > 3*(1-P(rel |retrieved)) P(rel|retrieved) + 3*P(rel |retrieved)>3 P(rel|retrieved) > 0.75
Information Storage and Retrieval
540-671 Probability Model
What is the probability?
The occurrence likelihood of a specific event, which is expressed as a number between 1 and 0. An event with a probability of 1 can be considered a certainty. An event with a probability of 0 can be considered an impossibility.
What is the probability?
Summary: All possible events must be clearly defined. All events are mutually exclusive. Special event must be identified when you compute a probability. Probability ranges from 0 to 1. No negative! Possibility for all possible events is equal to 1. Theoretically speaking, all events considered should have even chances.