实验二 编译 词法分析器的构造
编译原理实验报告

编译原理实验报告一、实验目的本次编译原理实验的主要目的是通过实践加深对编译原理中词法分析、语法分析、语义分析和代码生成等关键环节的理解,并提高实际动手能力和问题解决能力。
二、实验环境本次实验使用的编程语言为 C/C++,开发工具为 Visual Studio 2019,操作系统为 Windows 10。
三、实验内容(一)词法分析器的设计与实现词法分析是编译过程的第一个阶段,其任务是从输入的源程序中识别出一个个具有独立意义的单词符号。
在本次实验中,我们使用有限自动机的理论来设计词法分析器。
首先,我们定义了单词的种类,包括关键字、标识符、常量、运算符和分隔符等。
然后,根据这些定义,构建了相应的状态转换图,并将其转换为程序代码。
在实现过程中,我们使用了字符扫描和状态转移的方法,逐步读取输入的字符,判断其所属的单词类型,并将其输出。
(二)语法分析器的设计与实现语法分析是编译过程的核心环节之一,其任务是在词法分析的基础上,根据给定的语法规则,判断输入的单词序列是否构成一个合法的句子。
在本次实验中,我们采用了自顶向下的递归下降分析法来实现语法分析器。
首先,我们根据给定的语法规则,编写了相应的递归函数。
每个函数对应一种语法结构,通过对输入单词的判断和递归调用,来确定语法的正确性。
在实现过程中,我们遇到了一些语法歧义的问题,通过仔细分析语法规则和调整函数的实现逻辑,最终解决了这些问题。
(三)语义分析与中间代码生成语义分析的任务是对语法分析所产生的语法树进行语义检查,并生成中间代码。
在本次实验中,我们使用了四元式作为中间代码的表示形式。
在语义分析过程中,我们检查了变量的定义和使用是否合法,类型是否匹配等问题。
同时,根据语法树的结构,生成相应的四元式中间代码。
(四)代码优化代码优化的目的是提高生成代码的质量和效率。
在本次实验中,我们实现了一些基本的代码优化算法,如常量折叠、公共子表达式消除等。
通过对中间代码进行分析和转换,减少了代码的冗余和计算量,提高了代码的执行效率。
C语言词法分析器构造实验报告
C语言词法分析器构造实验报告02计算机(2)2002374203 冯绍欣一、题目要求:完成一个C语言的词法分析器的构造。
此词法分析器能识别附值语句、循环语句、条件语句、并能处理注释。
二、设计方案:这个词法分析器分析的主要关键字有:main, int, float, char, if, else, for, while, do, switch, case, break; default。
选择要分析的c文件,首先对其去掉注释和与空格处理,再根据字符的不同类型分析。
1、全局数据结构:字符数组set[ ]:存放从文件中读到的所有字符;str[ ]:存放经过注释处理和预空格处理的字符;strtoken[ ]:存放当前分析的字符;结构体KEYTABLE:存放关键字及其标号;全局字符变量ch:当前读入字符;全局整型变量sr, to:数组str, strtoken 的指针。
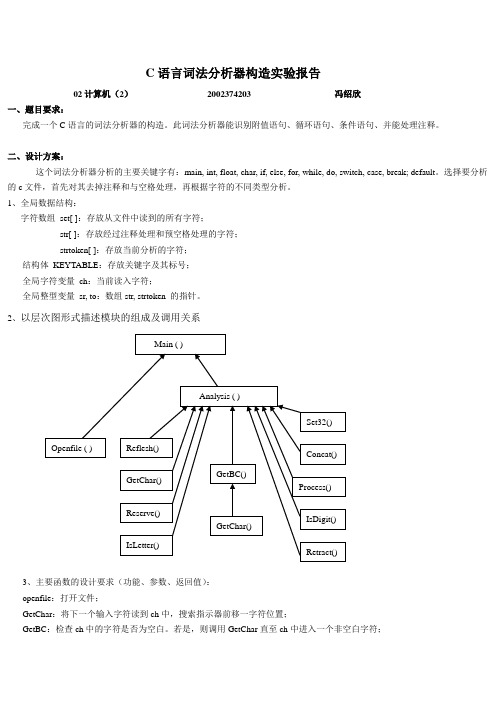
2、以层次图形式描述模块的组成及调用关系3、主要函数的设计要求(功能、参数、返回值):openfile:打开文件;GetChar:将下一个输入字符读到ch中,搜索指示器前移一字符位置;GetBC:检查ch中的字符是否为空白。
若是,则调用GetChar直至ch中进入一个非空白字符;Concat:将ch中的字符连接到strtoken之后;IsLetter 和IsDigit:布尔函数过程,分别判断ch中的字符是否为字母和数字;Reserve:整型函数过程,对strtoken中的字符串查找关键字表,若是关键字则返回编码,否则返回-1;Retract:将搜索指示器回调一个字符位置,将ch置为空白字符;reflesh:刷新,把strtoken数组置为空;prearrange1:将注释部分置为空格;prearrange2:预处理空格,去掉多余空格;analysis:词法分析;main:主函数。
4、状态转换图:字符a包括:= , & , | , + , --字符b包括:-- , < , > , | , *字符c包括:, , : , ( , ) , { , } , [ , ] , ! ,# , % , ” , / , * , + , -- , > , <, .三、源代码如下:#include <stdio.h>#include <string.h>char set[1000],str[500],strtoken[20];char sign[50][10],constant[50][10];char ch;int sr,to,id=0,st=0;typedef struct keytable /*放置关键字*/{char name[20];int kind;}KEYTABLE;KEYTABLE keyword[]={ /*设置关键字*/{"main",0},{"int",1},{"float",2},{"char",3},{"if",4},{"else",5},{"for",6},{"while",7},{"do",8},{"switch",9},{"case",10},{"break",11},{"default",12},};openfile() /*打开文件*/{FILE *fp;char a,filename[10];int n=0;printf("Input the filename:");gets(filename);if((fp=fopen(filename,"r"))==NULL){printf("cannot open file.\n");exit(0);}elsewhile(!feof(fp)) /*文件不结束,则循环*/{a=getc(fp); /*getc函数带回一个字符,赋给a*/set[n]=a; /*文件的每一个字符都放入set[]数组中*/n++;}fclose(fp); /*关闭文件*/set[n-1]='\0';printf("\n\n-------------------Source Code--------------------------\n\n");puts(set);printf("\n--------------------------------------------------------\n");}reflesh() /*清空strtoken数组*/{to=0; /*全局变量to是strtoken的指示器*/strcpy(strtoken," ");}prearrange1() /*预处理程序1*/{int i,a,b,n=0;do{if(set[n]=='/' && set[n+1]=='*'){a=n; /*记录第一个注释符的位置*/while(!(set[n]=='*' && set[n+1]=='/'))n++;b=n+1; /*记录第二个注释符的位置*/for(i=a;i<=b;i++) /**/set[i]=' '; /*把注释的内容换成空格,等待第二步预处理*/ }n++;}while(set[n]!='\0');}prearrange2() /*预处理程序2*/{int j=0;sr=0; /*全局变量sr是str[]的指示器*/do{if(set[j]==' ' || set[j]=='\n'){while(set[j]==' ' || set[j]=='\n') /*扫描到有连续的空格或换行符*/j++;str[sr]=' '; /*用一个空格代替扫描到的连续空格和换行符放入str[]*/sr++;}else{str[sr]=set[j]; /*若当前字符不为空格或换行符就直接放入str[]*/sr++;j++;}}while(set[j]!='\0');str[sr]='\0';}char GetChar() /*把字符读入全局变量ch中,指示器sr前移*/{ch=str[sr];sr++;return(str[sr-1]);}void GetBC() /*开始读入符号,直至第一个不为空格*/{while(ch==' '){ch=GetChar();}}Concat() /*把ch中的字符放入strtoken[]*/{strtoken[to]=ch;to++; /*全局变量to是strtoken的指示器*/strtoken[to]='\0';}int IsLetter() /*判断是否为字母*/{if((ch>=65 && ch<=90)||(ch>=97 && ch<=122))return(1);else return(0);}int IsDigit() /*判断是否为数字*/{if(ch>=48 && ch<=57)return(1);else return(0);}int Reserve() /*对strtoken中的字符串查找保留字表,若是则返回它的编码,否则返回-1*/ {int i,k=0;for(i=0;i<=20;i++){if(strcmp(strtoken,keyword[i].name)==0){ k=1;return(keyword[i].kind);}}if(k!=1)return(-1);}void Retract() /*指示器sr回调一个字符位置,把ch置为空*/{sr--;}int InsertId(){int i,k;for(i=0;i<id;i++){k=strcmp(strtoken,sign[i]);if(k==0)return(i);}strcpy(sign[id],strtoken); /*插入标识符*/id++;return(id-1);}int InsertConst(){int i,k;for(i=0;i<st;i++){k=strcmp(strtoken,constant[i]);if(k==0)return(i);}strcpy(constant[st],strtoken); /*插入常数*/st++;return(st-1);}void analysis(){int value;reflesh(); /*清空strtoken数组*/prearrange1(); /*预处理,使注释内容换成单个空格,放回set[]中*/prearrange2(); /*预处理,使set[]中连续的空格置换成单个空格,并把set[]的内容放到str[]中*/GetChar();GetBC(); /*读取第一个字符*/while(ch!='\0') /*当不等于结束符,继续执行*/{if(IsLetter()){while(IsLetter() || IsDigit()) /*若第一个是字符,继续读取,直到出现空格*/{Concat();GetChar();}Retract(); /*指示器sr回调一个字符位置,把ch置为空*/value=Reserve(); /*对strtoken中的字符串查找保留字表,若是则返回它的编码,否则返回-1*/ if(value==-1) /*如果返回值是-1,那就是变量,把它输出*/{InsertId(); /*插入标识符*/printf("\n%s",strtoken);getch();}else /*否则就是关键字,也输出*/{printf("\n%s",strtoken);getch();}reflesh();}else if(IsDigit()){while(IsDigit()) /*否则,若第一个是数字,继续读取,知道出现空格*/{Concat();GetChar();}Retract();InsertConst(); /*插入常数*/printf("\n%s",strtoken);getch();reflesh();}elseswitch(ch) /*否则,若是下面的符号,就直接把它输出*/{case ',':case ';':case '(':case ')':case '{':case '}':case '[':case ']':case '!':case '#':case '%':case '"':case '/':case '*':Concat();printf("\n'%s'",strtoken);getch();reflesh();break;default:if(ch=='=' || ch=='&' || ch=='|' || ch=='+' || ch=='-') /*如果是这些符号,继续读取下一个*/ {Concat(); /*判断是否为==,&&,||,++,--的情况*/GetChar();if(ch==strtoken[0])Concat();elseRetract();printf("\n'%s'",strtoken);getch();reflesh();break;}else if(ch=='+' || ch=='-' || ch=='<' || ch=='>' || ch=='!' || ch=='*'){Concat(); /*判断是否为+=,-=,<=,>=,!=,*=的情况*/GetChar();if(ch=='=')Concat();elseRetract();printf("\n'%s'",strtoken);getch();reflesh();break;}else{printf("Error!");getch();break;}}GetChar();GetBC();}}main(){clrscr();openfile();analysis();printf(“analysis is over!”);}五、测试结果:1、分析文件test1.c中的程序:Input the filename:test.c*****************Original Code************************/* HELLO.C -- Hello, world */#include "stdio.h"#include "conio.h"main(){printf("Hello, world\n");getch();}*****************************************************'#'include'"'stdio'.'h'"''#'include'"'conio'.'h'"'main'('')''{'printf'(''"'Hello','worldError!n'"'')'';'getch'('')'';''}'Analysis is over!六、实验总结:这个程序主要参考书上关于词法分析器的设计。
编译原理词法分析实验报告

词法分析器实验报告一、实验目的选择一种编程语言实现简单的词法分析程序,设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求待分析的简单的词法(1)关键字:begin if then while do end所有的关键字都是小写。
(2)运算符和界符:= + - * / < <= <> > >= = ; ( ) #(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:ID = letter (letter | digit)*NUM = digit digit*(4)空格有空白、制表符和换行符组成。
空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
各种单词符号对应的种别码:表各种单词符号对应的种别码词法分析程序的功能:输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……三、词法分析程序的算法思想:算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
主程序示意图:主程序示意图如图3-1所示。
其中初始包括以下两个方面:⑴关键字表的初值。
关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。
如能查到匹配的单词,则该单词为关键字,否则为一般标识符。
关键字表为一个字符串数组,其描述如下:Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,};是图3-1(2)程序中需要用到的主要变量为syn,token和sum扫描子程序的算法思想:首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn 用来存放单词符号的种别码。
编译原理实验二LL(1)语法分析实验报告

专题3_LL(1)语法分析设计原理与实现李若森 13281132 计科1301一、理论传授语法分析的设计方法和实现原理;LL(1) 分析表的构造;LL(1)分析过程;LL(1)分析器的构造。
二、目标任务实验项目实现LL(1)分析中控制程序(表驱动程序);完成以下描述算术表达式的 LL(1)文法的LL(1)分析程序。
G[E]:E→TE’E’→ATE’|εT→FT’T’→MFT’|εF→(E)|iA→+|-M→*|/设计说明终结符号i为用户定义的简单变量,即标识符的定义。
加减乘除即运算符。
设计要求(1)输入串应是词法分析的输出二元式序列,即某算术表达式“专题 1”的输出结果,输出为输入串是否为该文法定义的算术表达式的判断结果;(2)LL(1)分析程序应能发现输入串出错;(3)设计两个测试用例(尽可能完备,正确和出错),并给出测试结果。
任务分析重点解决LL(1)表的构造和LL(1)分析器的实现。
三、实现过程实现LL(1)分析器a)将#号放在输入串S的尾部b)S中字符顺序入栈c)反复执行c),任何时候按栈顶Xm和输入ai依据分析表,执行下述三个动作之一。
构造LL(1)分析表构造LL(1)分析表需要得到文法G[E]的FIRST集和FOLLOW集。
构造FIRST(α)构造FOLLOW(A)构造LL(1)分析表算法根据上述算法可得G[E]的LL(1)分析表,如表3-1所示:表3-1 LL(1)分析表主要数据结构pair<int, string>:用pair<int, string>来存储单个二元组。
该对照表由专题1定义。
map<string, int>:存储离散化后的终结符和非终结符。
vector<string>[][]:存储LL(1)分析表函数定义init:void init();功能:初始化LL(1)分析表,关键字及识别码对照表,离散化(非)终结符传入参数:(无)传出参数:(无)返回值:(无)Parse:bool Parse( const vector<PIS> &vec, int &ncol );功能:进行该行的语法分析传入参数:vec:该行二元式序列传出参数:emsg:出错信息epos:出错标识符首字符所在位置返回值:是否成功解析。
基于LEX的C语言词法分析器

实验二C-语言的词法分析器(基于Lex)1. 课程设计目标自动构造C-语言的的词法分析器,要求能够掌握编译原理的基本理论,,理解编译程序的基本结构,掌握编译各阶段的基本理论和技术,掌握编译程序设计的基本理论和步骤.,增强编写和调试高级语言源程序的能力,掌握词法分析的基本概念和实现方法,熟悉C-语言的各种Token。
2. 分析与设计基于Parser Genarator的词法分析器构造方法Lex输入文件由3个部分组成:定义集(definition),规则集(rule)和辅助程序集(auxiliary routine)或用户程序集(user routine)。
这三个部分由位于新一行第一列的双百分号分开,因此,Lex输入文件的格式如下{definitions}%%{rules}%%{auxiliary routines}而且第一部分用“%{”和“%}”括起来。
第一和第三个部分为C语言的代码和函数定义,第二个部分为一些规则。
定义正则表达式如下ID = letter letter*NUM = digit digit*Letter = a|…|z|A|…|ZDig it = 0|…|9Keyword = else|if|int|return|void|whileSpecial symbol = +|-|*|/|<|<=|>|>=|==|!=|=|;|,|(|)|[|]|{|}|/*|*/White space = “ ”Enter = \n在lex中的构造letter [A-Za-z]digit [0-9]id ({letter}|[_])({letter}|{digit}|[_])*error_id ({digit})+({letter})+num {digit}+whitespace [ \t]+enter [\n]+在Lex中的规则定义构造定义识别保留字规则"int"|"else"|"return"|"void"|"if"|"while"{Upper(yytext,yyleng);printf("%d 行",lineno);printf("%s reserved word\n",yytext);}//保留字定义识别数字规则{num}{printf("%d 行",lineno);printf("%s NUM\n",yytext);}//数字定义识别专用符号规则","|";"|"("|")"|"{"|"}"|"*"|"/"|"+"|"-"|">"|"<"|">="|"<="|"=="|"!="|"="|"/*"|"*/" {printf("%d 行",lineno);printf("%s special symbol\n",yytext);}//特殊符号定义识别标识符规则{id}{printf("%d 行",lineno);printf("%s ID\n",yytext);}//标识符定义识别错误的字符串规则当开头为数字的后面为字母的字符串时,是错误的标识符。
词法分析器的实验报告

词法分析器的实验报告词法分析器的实验报告引言:词法分析器是编译原理中的重要组成部分,它负责将源代码中的字符序列转换为有意义的词法单元,为后续的语法分析提供基础。
本实验旨在设计和实现一个简单的词法分析器,并对其进行测试和评估。
实验设计:1. 词法规则设计:在开始实验之前,我们首先需要设计词法规则,即定义源代码中的合法词法单元。
例如,对于一门类C的语言,我们可以定义关键字(如if、while、int等)、标识符、运算符(如+、-、*等)、分隔符(如()、{}等)等。
2. 有限自动机(DFA)的设计:基于词法规则,我们可以设计一个有限自动机,用于识别和分析源代码中的词法单元。
有限自动机是一个状态转换图,其中每个状态代表一种词法单元,而边表示输入字符的转换关系。
3. 实现代码:根据有限自动机的设计,我们可以使用编程语言(如Python、C++等)实现词法分析器的代码。
代码的主要功能包括读取源代码文件、逐个字符进行词法分析、识别和输出词法单元。
实验过程:1. 词法规则设计:我们以一门简单的算术表达式语言为例,设计了以下词法规则:- 数字:由0-9组成的整数或浮点数。
- 运算符:包括+、-、*、/等。
- 分隔符:包括括号()和逗号,。
- 标识符:以字母开头,由字母和数字组成的字符串。
2. 有限自动机(DFA)的设计:我们基于词法规则,设计了一个简单的有限自动机。
该自动机包含以下状态:- 初始状态:用于读取和识别源代码中的字符。
- 数字状态:用于识别和输出数字。
- 运算符状态:用于识别和输出运算符。
- 分隔符状态:用于识别和输出分隔符。
- 标识符状态:用于识别和输出标识符。
3. 实现代码:我们使用Python编程语言实现了词法分析器的代码。
代码主要包括以下功能:- 读取源代码文件。
- 逐个字符进行词法分析,根据有限自动机的设计进行状态转换。
- 识别和输出词法单元。
实验结果:我们对几个测试样例进行了词法分析,并对结果进行了评估。
编译-词法分析器-语法分析器实验报告

一、目的编译技术是理论与实践并重的课程,而其实验课要综合运用一、二年级所学的多门课程的内容,用来完成一个小型编译程序。
从而巩固和加强对词法分析、语法分析、语义分析、代码生成和报错处理等理论的认识和理解;培养学生对完整系统的独立分析和设计的能力,进一步培养学生的独立编程能力。
二、任务及要求基本要求:1.词法分析器产生下述小语言的单词序列这个小语言的所有的单词符号,以及它们的种别编码和内部值如下表:单词符号种别编码助记符内码值DIMIFDO STOP END标识符常数(整)=+***,()1234567891011121314$DIM$IF$DO$STOP$END$ID$INT$ASSIGN$PLUS$STAR$POWER$COMMA$LPAR$RPAR------内部字符串标准二进形式------对于这个小语言,有几点重要的限制:首先,所有的关键字(如IF﹑WHILE等)都是“保留字”。
所谓的保留字的意思是,用户不得使用它们作为自己定义的标示符。
例如,下面的写法是绝对禁止的:IF(5)=x其次,由于把关键字作为保留字,故可以把关键字作为一类特殊标示符来处理。
也就是说,对于关键字不专设对应的转换图。
但把它们(及其种别编码)预先安排在一张表格中(此表叫作保留字表)。
当转换图识别出一个标识符时,就去查对这张表,确定它是否为一个关键字。
再次,如果关键字、标识符和常数之间没有确定的运算符或界符作间隔,则必须至少用一个空白符作间隔(此时,空白符不再是完全没有意义的了)。
例如,一个条件语句应写为IF i>0 i= 1;而绝对不要写成IFi>0 i=1;因为对于后者,我们的分析器将无条件地将IFI看成一个标识符。
这个小语言的单词符号的状态转换图,如下图:2.语法分析器能识别由加+ 减- 乘* 除/ 乘方^ 括号()操作数所组成的算术表达式,其文法如下:E→E+T|E-T|TT→T*F|T/F|FF→P^F|Pp→(E)|i使用的算法可以是:预测分析法;递归下降分析法;算符优先分析法;LR分析法等。
C语言词法分析器构造实验报告

编译原理C语言词法分析器构造学院:信工班级: 1 4 0学号: **********名:******师:**2014年 6 月12日一、实验题目:编译原理词法分析二、实验内容:2.1主程序设计考虑:主程序的说明部分为各种表格和变量安排空间(关键字和特殊符号表)。
id 和ci 数组分别存放标识符和常数;还有一些为造表填表设置的变量。
主程序的工作部分建议设计成便于调试的循环结构。
每个循环处理一个单词;调用词法分析过程;输出每个单词的内部码(种别编码,属性值)。
建议从文件中读取要分析的符号串。
2.2词法分析过程考虑该过程根据输入单词的第一个有效字符(有时还需读第二个字符),判断单词种别,产生种别编码。
对于标识符和常数,需分别与标识符表和常数表中已登记的元素相比较,如表中已有该元素,则记录其在表中的位置,如未出现过,将标识符按顺序填入数组id 中,将常数存入数组中ci 中,并记录其在表中的位置。
注:所有识别出的单词都用二元组表示。
第一个表示单词的种别编码。
例如:关键字的t=1;标识符的t=2;常数t=3;运算符t=4;界符t=5。
第二个为该单词在各自表中的指针或内部码值(常数表和标识符表是在编译过程中建立起来的。
其i 值是根据它们在源程序中出现的顺序确定的)。
将词法分析程序设计成独立一遍扫描源程序的结构。
其主流程图如下:图1 词法分析程序流程图三、程序源代码:#include "stdafx.h"#include<iostream>#include<string>#include<math.h>#include<fstream>using namespace std;//关键字结构体struct key{string key_word;int bm;string zjf;};//界符结构体struct JF{char jf_ch;int bm;string zjf; };//运算符结构体struct ysf{string ysf_w;int bm;string zjf;};//得到关键字字母表void fuc_K_table(key K_w[]){int i=0;ifstream infile("E:\\cffx\\key.txt",ios::in);if(!infile){cerr<<"open error!"<<endl;}for(i=0;i<12;i++){infile>>K_w[i].key_word ;infile>>K_w[i].bm ;infile>>K_w[i].zjf ; }infile.close ();}//得到界符字母表void fuc_JF_table(JF J_CHAR[]){int i=0;ifstream infile("E:\\cffx\\jf.txt",ios::in);if(!infile){cerr<<"open error!"<<endl; }for(i=0;i<9;i++){infile>>J_CHAR[i].jf_ch;infile>>J_CHAR[i].bm;infile>>J_CHAR[i].zjf; }infile.close ();}//得到运算符表void fuc_ysf_table(ysf YSF_W[]){int i=0;ifstream infile("E:\\cffx\\ysf.txt",ios::in);if(!infile){cerr<<"open error!"<<endl; }for(i=0;i<18;i++){infile>>YSF_W[i].ysf_w;infile>>YSF_W[i].bm; infile>>YSF_W[i].zjf; } infile.close ();}//查找是否为保留字int Reserve(string strToken,key K_w[]){int i=0;for(i=0;i<12;i++)if(strToken==K_w[i].key_word ) return K_w[i].bm;if(i>=12) return -1; }//查找是否为界符int Reservejf(char ch,JF J_CHAR[]){int i=0;for(i=0;i<9;i++)if(ch==J_CHAR[i].jf_ch ) return J_CHAR[i].bm;if(i>=9) return -1;}//查找是否为运算符int Reserveysf(string strToken,ysf YSF_W[]){int i=0;for(i=0;i<18;i++)if(strToken==YSF_W[i].ysf_w ) return YSF_W[i].bm;if(i>=18) return -1;}//将strToken中的常数插入常数表int InsertConst(string strToken,key K_w[]){int i=0,j=0,m=0;while(strToken[i]!='\0') i++;for(j=0;j<i;j++) m=10*m+((int)strToken[j]-48);return m;}//判断是否为字母bool IsLetter(char ch){if((ch>=97&&ch<=122)||( ch>=65&&ch<=90))return true; else return false;} //判断是否为数字bool IsDigit(char ch){if((ch>=48&&ch<=57))return true; else return false;}//判断是否为界符bool IsJF(char ch){switch(ch){case'{': case'}': case'[': case']':case'(': case')':case';': case',':case'"':return true;default:return false;}}//判断是否为运算符bool IsYSF(char ch){bool re=false;switch(ch){case'>': case'<': case'=': case'+': case'-': case'*':case'/': case'%': case'&': case'|': case'!':case'"':{re=true;break;} }return re; }//主函数int main(int argc, char* argv[]){key K_w[12]; JF J_CHAR[9];ysf YSF_W[18];fuc_K_table(K_w); fuc_JF_table(J_CHAR);fuc_ysf_table(YSF_W); int i=0;cout<<"关键字种别编码表:"<<endl;for(i=0;i<12;i++)cout<<K_w[i].key_word<<" "<<K_w[i].bm<<endl;cout<<"界符种别编码表:"<<endl;for(i=0;i<9;i++)cout<<J_CHAR[i].jf_ch<<" "<<J_CHAR[i].bm<<endl;cout<<"运算符种别编码表:"<<endl;for(i=0;i<18;i++)cout<<YSF_W[i].ysf_w<<" "<<YSF_W[i].bm<<endl;cout<<"常数的种别编码为:50"<<endl;cout<<"普通标识符的种别编码为:51"<<endl;FILE*fp;fp=fopen("E:\\cffx\\f1.txt","r");cout<<"词法分析器输出结果为:"<<endl;char ch; int digit=0;string strToken;if(fp==NULL){cout<<"error";exit(0);} else{while(ch!='#'){strToken="\0";ch=fgetc(fp);if(ch==' '||ch=='\t'||ch=='\n'){}elseif(IsLetter(ch)){while(IsLetter(ch)||IsDigit(ch)){strToken=strToken+ch;ch=fgetc(fp); }fseek(fp,-1L,SEEK_CUR);i=Reserve(strToken,K_w);if(i>-1)cout<<'('<<strToken<<','<<i<<')'<<endl;elsecout<<'('<<strToken<<",51)"<<endl; }elseif(IsDigit(ch)){while(IsDigit(ch)){strToken=strToken+ch;ch=fgetc(fp); }fseek(fp,-1L,SEEK_CUR);digit=InsertConst(strToken,K_w);cout<<'('<<digit<<",50"<<')'<<endl; }elseif(IsJF(ch)){int jfcount=Reservejf(ch,J_CHAR);cout<<'('<<ch<<','<<jfcount<<')'<<endl; }elseif(IsYSF(ch)){while(IsYSF(ch)){strToken=strToken+ch;ch=fgetc(fp); }fseek(fp,-1L,SEEK_CUR);i=Reserveysf(strToken,YSF_W);if(i>-1)cout<<'('<<strToken<<','<<i<<')'<<endl;elsecout<<"输入符号错误!"<<endl; }}fclose(fp);}return 0;}四、实验截图:F1中是数据为:实验结果为:五、实验总结:这个程序主要参考书上关于词法分析器的设计。
编译原理词法分析器

编译原理词法分析器
编译原理词法分析器是编译器中的一个重要组成部分。
它负责将源代码分解成一个个词素(token)。
在进行词法分析过程中,我们需要定义各种词法规则,例如标识符的命名规则、关键字的集合、运算符的定义以及常量的表示方式等。
词法分析器通常使用有限自动机来实现。
有限自动机是一种能接受或拒绝某个输入序列的计算模型。
在词法分析器中,有限自动机可以方便地根据输入字符的不同状态进行相应的转移,直至得到一个完整的词法单元。
在编写词法分析器时,我们通常会先定义各个词法规则,然后将其转化为正则表达式或有限自动机的形式。
接下来,我们会根据这些规则生成一个词法分析器的状态转换图,并使用该图构建词法分析器的代码。
词法分析器的工作过程如下:输入源代码文本,逐个读取字符并根据当前状态进行状态转移。
如果当前字符能够完成一个词法单元的匹配,那么就将当前词法单元输出,并进入下一个状态。
如果当前字符不能完成一个词法单元的匹配,则继续读取下一个字符,直至完成一个词法单元的匹配或遇到非法字符。
通过词法分析器,我们可以将源代码文本转化为一系列的词法单元,例如关键字、标识符、运算符、常量等。
这些词法单元将作为编译器后续阶段的输入,用于进行语法分析和语义分析。
词法分析器是编译器的重要基础工具之一,它能够帮助我们更好地理解和处理源代码。
编译原理课程设计报告——词法分析器

精选课程设计任务书引言 (4)第一章概述 (5)1.1设计内容 (5)1.2设计要求 (5)第二章设计的基本原理 (6)2.1 (6)2.2 (6)第三章程序设计 (7)3.1 总体方案设计 (7)3.2 各模块设计 (8)第四章程序测试 (9)4.1一般测试4.2出错处理测试第五章结论 (10)参考文献 (10)附录程序清单 (11)引言《编译原理》是国内外各高等院校计算机科学技术类专业,特别是计算机软件专业的一门重要专业课程。
该课程系统地向学生介绍编译程序的结构、工作流程及编译程序各组成部分的设计原理和实现技术。
由于该课程理论性和实践性都比较强,内容较为抽象复杂,涉及到大量的软件设计算法,因此,一直是一门比较难学的课程。
为了使学生更好地理解和掌握编译技术的基本概念、基本原理和实现方法,实践环节非常重要,只有通过上机进行程序设计,才能使学生对比较抽象的教学内容产生具体的感性认识,增强学生综合分析问题、解决问题的能力,并对提高学生软件设计水平大有益处。
编译原理涉及词法分析,语法分析,语义分析及优化设计等各方面。
词法分析阶段是编译过程的第一个阶段,是编译的基础。
这个阶段的任务是从左到右一个字符一个字符地读入源程序,即对构成源程序的字符流进行扫描然后根据构词规则识别单词(也称单词符号或符号)。
词法分析程序实现这个任务。
词法分析程序可以使用 Lex 等工具自动生成。
从左到右逐个字符对构成源程序的字符串进行扫描,依据词法规则,识别出一个一个的标记(token ),把源程序变为等价的标记串序列。
执行词法分析的程序称为词法分析器,也称为扫描器。
词法分析是所有分析优化的基础,涉及的知识较少,如状态转换图等,易于实现。
本次课程设计,我的选题是词法分析, C++ 代码实现。
第一章概述1.1 设计内容对 C 语言的一个子集设计并实现一个简单的词法分析器,掌握利用状态转换图设计词法分析器的基本方法。
1.2设计要求利用该词法分析器完成对源程序字符串的词法分析。
编译原理 词法分析器 实验报告

词法分析器实验报告实验目的:设计、编制、调试一个词法分析子程序-识别单词,加深对词法分析原理的理解。
功能描述:该程序要实现的是一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。
并依次输出各个单词的内部编码及单词符号自身值。
(遇到错误时可显示“Error!”,然后跳过错误部分继续进行)设计思想:设计该词法分析器的过程中虽然没有实际将所有的状态转移表建立出来,但是所用的思想是根据状态转移表实现对单词的识别。
首先构造一个保留字表,然后,每输入一个字符就检测应该进入什么状态,并将该字符连接到d串后继续输入,如此循环,最后根据所在的接受状态以及保留字表识别单词。
①标识符及保留字:②number:③关系操作符:digitdigitdigitEdigitotherotherletter or④⑤算术运算符:(<=, 2) * (<>, 2)(<,2)(>=, 2)(>, 2)(:=,2)使用环境:Windows xp下的visual c++6.0 程序测试:input1 :int a,b;a=b+2;input2:while(a>=0)do7x=x+6.7E+23;end;input3:begin:x:=9if x>0 then x:=x+1;while a:=0 dob:=2*x/3,c:=a;end;output1: 3,int 3,a 5,,3,b 5,;3,a2,=3,b2,+4,2 5,; output2:1,while5,(3,a2,>=4,05,)1,doerror line 32,=3,x2,+4,6.7E+235,;1,end5,;output3:1,beginerror line 13,x2,:=4,91,if3,x2,>4,01,then3,x2,:=3,x2,+4,15,;1,while3,a2,:=4,01,do3,b2,:=4,22,*3,x2,/4,35,,3,c2,:=3,a5,;1,end5,;测试结果与预期结果一致源程序代码:#include<stdio.h>#include<string.h> void main(){int i=0,j,k=0,state=1,f=0,linenum=1;chara[11][10]={"const","var","call","begin","if","while","do","odd","e nd","then","procedure"};char b,d[40]={"\0"};freopen("input.txt","r",stdin);freopen("output.txt","w",stdout);b=getchar();while(b!=EOF)/*判断所输入字符是否为结束符*/{if(b==' '||b=='\n'||b=='\t')/*滤过空格、换行等分隔符号*/{ if(b='\n') linenum++;b=getchar();}else if((b>='a'&&b<='z')||(b>='A'&&b<='Z'))/*识别标识符以及保留字*/{d[i++]=b;b=getchar();while((b>='a'&&b<='z')||(b>='A'&&b<='Z')||(b>='0'&&b<='9')) {d[i++]=b;b=getchar();}for(j=0;j<11;j++)/*查询保留字表确定该单词是否是保留字*/{ if(strcmp(d,a[j])==0){ printf("1,%s\n",d);k=1;break;}}if(k==0)/*在保留字表中没有查到该单词,是标识符*/printf("3,%s\n",d);for(j=0;j<=i;j++)d[j]='\0';i=0;k=0;}else if(b>='0'&&b<='9')/*识别常数*/{ d[i++]=b;b=getchar();while(f!=1){switch (state) {case 1:if(b>='0'&&b<='9') {state=1;d[i++]=b;b=getchar();}else if(b=='.') { state=2;d[i++]=b;b=getchar();}else if(b=='E') { state=4;d[i++]=b;b=getchar();}else state=7;break;case 2:if(b>='0'&&b<='9') {state=3;d[i++]=b;b=getchar();}else state=8;break;case 3:if(b>='0'&&b<='9') {state=3;d[i++]=b;b=getchar();}else if(b=='E') { state=4;d[i++]=b;b=getchar();} else state=7;break;case 4:if(b=='+'||b=='-'){ state=5;d[i++]=b;b=getchar();}elseif(b>='0'&&b<='9'){ state=6;d[i++]=b;b=getchar();}else state=8;break;case 5:if(b>='0'&&b<='9'){ state=6;d[i++]=b;b=getchar();}else state=8;break;case 6:if(b>='0'&&b<='9'){ state=6;d[i++]=b;b=getchar();}else state=7;break;case 7: f=1;break;case 8: f=1;break;}}if(state==7&&(b<'a'||b>'z')&&(b<'A'||b>'Z'))printf("4,%s\n",d);else if(state==7&&(b>='a'&&b<='z')||(b>='A'&&b<='Z'))/*数字后接字母的出错控制*/{while((b>='a'&&b<='z')||(b>='A'&&b<='Z')){ d[i++]=b;b=getchar();}printf("error line %d\n",linenum);}else printf("error line %d\n",linenum);for(j=0;j<=i;j++)d[j]='\0';i=0;f=0;state=1;}else if(b=='<')/*识别'<'、'<='和'<>'*/{ d[i++]=b;b=getchar();if(b=='='||b=='>'){ d[i++]=b;b=getchar();printf("2,%s\n",d);for(j=0;j<=i;j++)d[j]='\0';i=0;}else{ printf("2,%s\n",d);for(j=0;j<=i;j++)d[j]='\0';i=0;}}else if(b=='>')/*识别'>'和'>='*/ { d[i++]=b;b=getchar();if(b=='='){ d[i++]=b;b=getchar();printf("2,%s\n",d);for(j=0;j<=i;j++)d[j]='\0';i=0;}else{ printf("2,%s\n",d);for(j=0;j<=i;j++)d[j]='\0';i=0;}}else if(b==':')/*识别':='*/{ d[i++]=b;b=getchar();if(b=='='){ d[i++]=b;b=getchar();printf("2,%s\n",d);}else printf("error line %d\n",linenum);for(j=0;j<=i;j++)d[j]='\0';i=0;}else if(b=='*'||b=='+'||b=='-'||b=='/'||b=='=')/*识别运算符*/{ printf("2,%c\n",b);b=getchar();}else if(b=='('||b==')'||b==','||b==';'||b=='.')/*识别分隔符*/{ printf("5,%c\n",b);b=getchar();}else{ printf("error line %d\n",linenum);b=getchar();}}}实验心得:此次实验让我了解了如何设计、编制并调试词法分析程序,并加深了我对词法分析器原理的理解;熟悉了直接构造词法分析器的方法和相关原理,并学会使用c 语言直接编写词法分析器;同时更熟练的掌握用c语言编写程序,实现一定的实际功能。
编译器构造与语法分析

编译器构造与语法分析在计算机科学中,编译器是一个重要的概念。
它是将高级编程语言翻译成计算机能够理解的低级语言的工具。
编译器的构造和语法分析是编译器设计中的两个关键步骤。
本文将介绍编译器的构造原理和语法分析算法。
一、编译器构造在编译器构造中,主要包括以下几个步骤:词法分析、语法分析、语义分析、中间代码生成和代码优化。
1. 词法分析词法分析是将源代码分割成一个个词法单元的过程。
词法单元包括关键字、标识符、运算符、常量和分隔符等。
词法分析器会从源代码中逐个读取字符,并根据预定的规则将其组合成具有特定含义的词法单元。
2. 语法分析语法分析是将词法分析的结果进行语法分析的过程。
语法分析器根据预定的文法规则,检查源代码是否符合语法规范。
常用的语法分析算法有自顶向下的递归下降分析和自底向上的LR分析等。
3. 语义分析语义分析是对源代码进行语义检查和语义处理的过程。
在语义分析阶段,编译器会根据预定的语义规则检查源代码中是否存在语义错误,并生成相应的语法树或符号表。
4. 中间代码生成中间代码生成是将源代码转换成中间代码的过程。
中间代码是介于源代码和目标代码之间的一种抽象表示形式,通常是一种类似于三地址码或虚拟机指令的形式。
5. 代码优化代码优化是对中间代码进行优化的过程。
通过对中间代码进行逻辑优化和算法优化,可以提高生成目标代码的效率和质量。
二、语法分析语法分析是编译器设计中的一个重要环节,它负责分析源代码的语法结构,并根据语法规则构建语法树。
常用的语法分析算法有自顶向下的递归下降分析和自底向上的LR分析。
1. 自顶向下的递归下降分析自顶向下的递归下降分析是一种简单直观的语法分析方法。
它从文法的起始符号开始,通过递归地调用子程序来逐步分析源代码,直到达到终结符号或非终结符号的底部。
2. 自底向上的LR分析自底向上的LR分析是一种自底向上的语法分析方法。
它从输入的末尾开始,逐步向前移动,以确定语法规则。
通过构建LR分析表和状态机,可以在线性时间内进行语法分析。
编译原理词法分析器实验报告

编译原理词法分析器实验报告1. 引言编译原理是计算机科学中的重要概念,它涉及将高级语言程序转换为计算机可执行的低级指令。
词法分析是编译过程中的第一个阶段,它负责将源代码分解为词法单元,为后续的语法分析做准备。
本实验旨在设计和实现一个基本的词法分析器,以了解词法分析的原理和实际应用。
2. 实验目标本实验的主要目标是实现一个基本的词法分析器,能够识别并提取源代码中的各种词法单元。
具体而言,我们将设计一个针对某种编程语言的词法分析器,能够识别关键字、标识符、算术运算符、括号、常量等。
3. 实验环境为了完成本实验,我们需要使用以下工具和环境:•一种编程语言,例如Python、Java或C++•一个文本编辑器,例如Visual Studio Code或Sublime Text•一个命令行终端4. 实验步骤4.1 定义词法规则首先,我们需要定义词法分析器的词法规则。
这些规则描述了编程语言中各种词法单元的模式。
例如,关键字可以被定义为由特定字符组成的字符串,标识符可以被定义为以字母开头并由字母和数字组成的字符串。
4.2 实现词法分析器接下来,我们将根据定义的词法规则,使用编程语言实现一个词法分析器。
在实现过程中,我们可以使用正则表达式来匹配和提取各种词法单元。
4.3 编写测试用例完成词法分析器的实现后,我们需要编写一些测试用例来验证其正确性。
测试用例应该包含各种可能的输入情况,以确保词法分析器能够正确地识别和提取词法单元。
4.4 运行测试用例最后,我们将使用编写的测试用例来运行词法分析器,并检查输出是否符合预期。
如果测试通过,说明词法分析器能够正常工作;否则,我们需要检查代码并进行调试。
5. 实验结果经过实验,我们成功地设计并实现了一个基本的词法分析器。
该词法分析器能够按照预定义的词法规则,正确地识别和提取源代码中的各种词法单元。
在运行测试用例时,词法分析器能够产生符合预期的输出,表明其具有良好的准确性和可靠性。
编译原理实验-词法分析器

编译原理实验-词法分析器⼀、实验⽬的设计、编制、调试⼀个词法分析程序,对单词进⾏识别和编码,加深对词法分析原理的理解。
⼆、实验内容1.选定语⾔,编辑任意的源程序保存在⽂件中;2.对⽂件中的代码预处理,删除制表符、回车符、换⾏符、注释、多余的空格并将预处理后的代码保存在⽂件中;3.扫描处理后的源程序,分离各个单词符号,显⽰分离的单词类型。
三、实验思路对于实验内容1,选择编写c语⾔的源程序存放在code.txt中,设计⼀个c语⾔的词法分析器,主要包含三部分,⼀部分是预处理函数,第⼆部分是扫描判断单词类型的函数,第三部分是主函数,调⽤其它函数;对于实验内容2,主要实现在预处理函数processor()中,使⽤⽂档操作函数打开源程序⽂件(code.txt),去除两种类型(“//”,“/*…*/”)的注释、多余的空格合并为⼀个、换⾏符、回车符等,然后将处理后的保存在另⼀个新的⽂件(afterdel.txt)中,最后关闭⽂档。
对于实验内容3,打开处理后的⽂件,然后调⽤扫描函数,从⽂件⾥读取⼀个单词调⽤判断单词类型的函数与之前建⽴的符号表进⾏对⽐判断,最后格式化输出。
四、编码设计代码参考了两篇博主的,做了部分改动,添加了预处理函数等1 #include<iostream>2 #include<fstream>3 #include<cstdio>4 #include<cstring>5 #include<string>6 #include<cstdlib>78using namespace std;910int aa;// fseek的时候⽤来接着的11string word="";12string reserved_word[20];//保留13char buffer;//每次读进来的⼀个字符14int num=0;//每个单词中当前字符的位置15int line=1; //⾏数16int row=1; //列数,就是每⾏的第⼏个17bool flag; //⽂件是否结束了18int flag2;//单词的类型192021//预处理函数22int processor(){//预处理函数23 FILE *p;24int falg = 0,len,i=0,j=0;25char str[1000],str1[1000],c;26if((p=fopen("code.txt","rt"))==NULL){27 printf("⽆法打开要编译的源程序");28return0;29 }30else{31//fgets(str,1000,p);32while((c=getc(p))!=EOF){33 str[i++] = c;34 }35 fclose(p);36 str[i] = '\0';37for(i=0;i<strlen(str);i++){38if(str[i]=='/'&&str[i+1]=='/'){39while(str[i++]!='\n'){}40 }//单⾏注释41else if(str[i]=='/'&&str[i+1]=='*'){42while(!(str[i]=='*'&&str[i+1]=='/')){i++;}43 i+=2;44 }//多⾏注释45else if(str[i]==''&&str[i+1]==''){46while(str[i]==''){i++;}47 i--;48if(str1[j-1]!='')49 str1[j++]='';50 }//多个空格,去除空格51else if(str[i]=='\n') {52if(str1[j-1]!='')53 str1[j++]='';54 }//换⾏处理,55else if(str[i]==9){56while(str[i]==9){57 i++;58 }59if(str1[j-1]!='')60 str1[j++]='';61 i--;62 }//tab键处理63else str1[j++] = str[i];//其他字符处理64 }65 str1[j] = '\0';66if((p = fopen("afterdel.txt","w"))==NULL){ 67 printf("can not find it!");68return0;69 }70else{71if(fputs(str1,p)!=0){72 printf("预处理失败!");73 }74else printf("预处理成功!");75 }76 fclose(p);77 }78return0;79 }8081//设置保留字82void set_reserve()83 {84 reserved_word[1]="return";85 reserved_word[2]="def";86 reserved_word[3]="if";87 reserved_word[4]="else";88 reserved_word[5]="while";89 reserved_word[6]="return";90 reserved_word[7]="char";91 reserved_word[8]="for";92 reserved_word[9]="and";93 reserved_word[10]="or";94 reserved_word[11]="int";95 reserved_word[12]="bool";96 }9798//看这个字是不是字母99bool judge_word(char x)100 {101if(x>='a' && x<='z' || x>='A' && x<='Z' ){ 102return true;103 }104else return false;105 }106107//看这个字是不是数字108bool judge_number(char x)109 {110if(x>='0' && x<='9'){111return true;112 }113else return false;114 }115116//看这个字符是不是界符117bool judge_jiefu(char x)118 {119if(x=='('||x==')'||x==','||x==';'||x=='{'||x=='}'){ 120return true;121 }122else return false;123 }124125126//加减乘127bool judge_yunsuanfu1(char x)128 {129if(x=='+'||x=='-'||x=='*')130 {131return true;132 }133else return false;134 }135136//等于赋值,⼤于⼩于⼤于等于,⼩于等于,⼤于⼩于137bool judge_yunsuannfu2(char x)138 {139if(x=='='|| x=='>'||x=='<'||x=='&'||x=='||'){140return true;141 }142else return false;143 }144145146//这个最⼤的函数的总体作⽤是从⽂件⾥读⼀个单词147int scan(FILE *fp)148 {149 buffer=fgetc(fp);//读取⼀个字符150if(feof(fp)){//检测结束符151 flag=0;return0;152 }153else if(buffer=='')154 {155 row++;156return0;157 }158else if(buffer=='\n')159 {160 row=1;161return0;162 }163//如果是字母开头或'_' 看关键字还是普通单词164else if(judge_word(buffer) || buffer=='_')165 {166 word+=buffer;167 row++;168while((buffer=fgetc(fp)) && (judge_word(buffer) || judge_number(buffer) || buffer=='_'))169 {170 word+=buffer;171 row++;172 }173if(feof(fp)){174 flag=0;175return1;176 }177for(int i=1;i<=12;i++){178if(word==reserved_word[i]){179 aa=fseek(fp,-1,SEEK_CUR);//如果执⾏成功,stream将指向以fromwhere为基准,偏移offset(指针偏移量)个字节的位置,函数返回0。
《编译原理》科学实验指导说明书

《编译原理》实验指导书实验一词法分析器的设计一、实验目的和要求加深对状态转换图的实现及词法分析器的理解。
熟悉词法分析器的主要算法及实现过程。
要求学生掌握词法分析器的设计过程,并实现词法分析。
二、实验基本内容给出一个简单语言的词法规则,画出状态转换图,并依据状态转换图编制出词法分析程序,能从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。
并依次输出各个单Error”,然后跳过错误部分继续显示)词法规则如下:三、实验时间:上机三次。
第一次按照自己的思路设计一个程序。
第二、三次在理论课学习后修改程序,使得程序结构更加合理。
四、实验过程和指导:(一)准备:1.阅读课本有关章节(c/c++,数据结构),花一周时间明确语言的语法,写出基本算法以及采用的数据结构和要测试的程序例。
2.初步编制好程序。
3.准备好多组测试数据。
(二)上课上机:将源代码拷贝到机上调试,发现错误,再修改完善。
(三)程序要求:程序输入/输出示例:输入如下一段:main(){/*一个简单的c++程序*/int a,b; //定义变量a = 10;b = a + 20;}要求输出如右图。
要求:(1) 剔除注解符(2) 常数为无符号整数(可增加实型数,字符型数等)(四)练习该实验的目的和思路:程序开始变得复杂起来,可能是大家以前编过的程序中最复杂的,但相对于以后的程序来说还是简单的。
因此要认真把握这个过渡期的练习。
程序规模大概为200行及以上。
通过练习,掌握对字符进行灵活处理的方法。
(五)为了能设计好程序,注意以下事情:1.模块设计:将程序分成合理的多个模块(函数/类),每个模块(类)做具体的同一事情。
2.写出(画出)设计方案:模块关系简图、流程图、全局变量、函数接口等。
3.编程时注意编程风格:空行的使用、注释的使用、缩进的使用等。
4.程序设计语言不限,建议使用面向对象技术及可视化编程语言,如C++,VC,JA V A,VJ++等。
编译原理词法分析器

编译原理词法分析器
编译原理词法分析器是编译器的一个重要组成部分,负责将输入的源代码转换成一系列的词法单元,供后续的语法分析器进行进一步处理。
词法分析器的主要任务是按照预先定义的词法规则,识别出源代码中的各个合法的词法单元,并将其转化为内部表示形式。
在这个过程中,词法分析器需要读取输入字符流,并根据定义的词法规则进行模式匹配和转换。
一个基本的词法分析器通常由以下几个部分组成:
1. 字符扫描器(Scanner):负责从输入流中读取字符,并进行必要的预处理。
例如,过滤掉注释、空白字符等。
2. 词法规则(Lexical Rules):是定义词法单元的正则表达式或者有限自动机。
每个词法单元都有一个对应的识别规则。
3. 标记生成器(Token Generator):根据词法规则和字符扫描器的输出,生成符合内部表示形式的词法单元。
4. 符号表(Symbol Table):维护着程序中出现的所有标识符的符号表,包括标识符的名称和属性信息。
词法分析器的工作流程如下:
1. 初始化字符扫描器,读取第一个字符。
2. 逐个字符进行扫描和匹配,直到获取了一个完整的词法单元。
3. 根据匹配到的词法规则,生成对应的词法单元。
4. 如果需要记录标识符信息,将其添加到符号表中。
5. 返回步骤2,直到扫描完整个输入代码。
通过词法分析器的工作,我们能够将输入的源代码按照词法规则进行分割,将其转换为一系列的词法单元,为后续的语法分析器提供了处理的基础。
(完整)编译原理实验报告(词法分析器 语法分析器)

编译原理实验报告实验一一、实验名称:词法分析器的设计二、实验目的:1,词法分析器能够识别简单语言的单词符号2,识别出并输出简单语言的基本字。
标示符。
无符号整数.运算符.和界符。
三、实验要求:给出一个简单语言单词符号的种别编码词法分析器四、实验原理:1、词法分析程序的算法思想算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号.2、程序流程图(1)主程序(2)扫描子程序3、各种单词符号对应的种别码五、实验内容:1、实验分析编写程序时,先定义几个全局变量a[]、token[](均为字符串数组),c,s( char型),i,j,k(int型),a[]用来存放输入的字符串,token[]另一个则用来帮助识别单词符号,s用来表示正在分析的字符.字符串输入之后,逐个分析输入字符,判断其是否‘#’,若是表示字符串输入分析完毕,结束分析程序,若否则通过int digit(char c)、int letter(char c)判断其是数字,字符还是算术符,分别为用以判断数字或字符的情况,算术符的判断可以在switch语句中进行,还要通过函数int lookup(char token[])来判断标识符和保留字。
2 实验词法分析器源程序:#include 〈stdio.h〉#include <math.h>#include <string。
h>int i,j,k;char c,s,a[20],token[20]={’0’};int letter(char s){if((s〉=97)&&(s〈=122)) return(1);else return(0);}int digit(char s){if((s〉=48)&&(s<=57)) return(1);else return(0);}void get(){s=a[i];i=i+1;}void retract(){i=i-1;}int lookup(char token[20]){if(strcmp(token,"while")==0) return(1);else if(strcmp(token,"if")==0) return(2);else if(strcmp(token,"else”)==0) return(3);else if(strcmp(token,"switch”)==0) return(4);else if(strcmp(token,"case")==0) return(5);else return(0);}void main(){printf(”please input string :\n");i=0;do{i=i+1;scanf("%c",&a[i]);}while(a[i]!=’#’);i=1;j=0;get();while(s!=’#'){ memset(token,0,20);switch(s){case 'a':case ’b':case ’c':case ’d':case ’e’:case ’f’:case 'g’:case ’h':case 'i':case ’j':case 'k’:case ’l':case 'm’:case 'n':case ’o':case ’p':case ’q’:case 'r’:case 's’:case 't’:case ’u’:case ’v’:case ’w’:case ’x':case ’y':case ’z’:while(letter(s)||digit(s)){token[j]=s;j=j+1;get();}retract();k=lookup(token);if(k==0)printf("(%d,%s)”,6,token);else printf("(%d,—)",k);break;case ’0':case ’1’:case ’2':case ’3':case '4’:case '5’:case ’6':case ’7’:case ’8’:case '9’:while(digit(s)){token[j]=s;j=j+1;get();}retract();printf(”%d,%s",7,token);break;case '+':printf(”(’+',NULL)”);break;case ’-':printf("(’-',null)");break;case ’*':printf(”('*’,null)");break;case '<':get();if(s=='=’) printf(”(relop,LE)”);else{retract();printf("(relop,LT)");}break;case ’=':get();if(s=='=’)printf("(relop,EQ)");else{retract();printf(”('=',null)”);}break;case ’;':printf(”(;,null)");break;case ' ’:break;default:printf("!\n”);}j=0;get();} }六:实验结果:实验二一、实验名称:语法分析器的设计二、实验目的:用C语言编写对一个算术表达式实现语法分析的语法分析程序,并以四元式的形式输出,以加深对语法语义分析原理的理解,掌握语法分析程序的实现方法和技术.三、实验原理:1、算术表达式语法分析程序的算法思想首先通过关系图法构造出终结符间的左右优先函数f(a),g(a)。
词法分析器的构造

实验报告(2015 / 2016学年第二学期)课程名称编译原理实验名称词法分析器的构造实验时间2016 年 4 月 29 日指导单位计算机软件教学中心指导教师学生姓名学院(系)wujun计算机学院、软件学院班级学号专业计算机科学与技术实验报告、实验环境(实验设备)硬件:计算机软件:Visual C ++6.0,'{') ,'int ') ,'a ') ,',') ,'b ') ,';') ,'a ') ,'=') ,'10') ,';') ,'b ') ,'=') ,'a ') ,'+') ,'20') ,';') ,'}')实验原理状态转换图(5 (1 (2 (5 (2 (5 (2 (4 (3 (5 (2 (4 (2 (4 (3 (5 (52、3、实验代码:实验代码:#i nclude <stri ng.h>#in elude <iostream.h>#in elude <fstream>#in clude<stdlib.h>#i nclude<stdio.h>#in clude<ctype.h>struct Char{ //创建一个结构用于存贮关键字char a[15];};typedef struct Char CH;//定义关键字CH keyWord[67]={"auto","break","case","cout","cin","char","const","continue","d efault", "do","double","else","e num","e ndl","extern","float","for","goto","if","mai n", "in clude","int","lo ng","register","return","short","sig ned","sizeof","static","string","struct","switch","typed ef","union","unsigned","void","stdio","whil e", "ci n"."cout"."catch","calss"."ctype"."stdlib"."fstream"."export"."iostream",cout<v"(2,'"vvwordvv"')"vve ndl; }else if(lsDigit(ch)){do{word[i++] = ch; ch = s[++j];}whil e(IsDigit(ch));j--;word[i] = '\0';cout<<"(3,'"<<word<<"')"<<e ndl;}else if(lsSeparator(ch)){word[0] = ch;cout<<"(5,'"<<word<<"')"<<e ndl;}else{word[0] = ch;if(word[0]=='+'||word[0]=='-'||word[0]=='>'||word[0]=='v'||word[0]=='&'||word[0]=='|'){ if(s[j+1]==word[0] || s[j+1]=='='){word[1] = s[++j]; cout<v"(4,'"vvwordvv"')"vve ndl;} elsecout<v"(4,'"vvwordvv"')"vve ndl;}else if(word[0]=='='||word[0]=='*'||word[0]=='/'||word[0]=='!'||word[0]=='%'||word[0]==z){ if (s[j+1] == '='){word[1] = s[++j]; cout<v"(4,'"vvwordvv"')"vve ndl;} elsecout<v"(4,'"vvwordvv"')"vve ndl;}else if (word[0] == '\\'){if (s[j+1] == 'n' ||s[j+1] == 't' || s[j+i]=='\\'||s[j+1]=='0'){ word[1] = s[++j];cout<v"(4,'"vvwordvv"')"vve ndl;} elsecout<v"(4,'"vvwordvv"')"vve ndl;―U输入代码:Please input you code 'ieoid wi th two^ T7): int mainO(int辺,b;//定义a・bd += 10.b - a十12.舛求b的值*/return 0;}??输出结果:系统经HfOl理后的输出(去掉注释和换行):int mainO { int a,b; a +- 10; b - a + 12; return 0; }. 系统经ii预处理冶的输岀〔去掉注释、换行、空格等):intminO {in坦b; a+=10 ; b-a +12 ! returnO !]词袪分析如下: (1,J int')(1,J mair?)(5,J C )(和门(5/ f )(1; int1〕⑵’『)⑸;)(2f' b') E ;)伦J a )(4,7匸)(3,' 10')⑸’:1、⑵'b1)(4,,J、(2/『)(4,1匸)<3,'挖)(1, ?return7)(3,' 0’ )(5/ r)(5, 丁)(2)测试二截图输入代码:Please input you code (end with two* ?'): do [ch = getchar(J ;s[i++] - ch;if(ch == 1\n |I ch== 3) for (int j =0; j < 4;j++) fputc (b, fp);fputc(ch, ip);用Ml e(s[i-l] != ??7| | s[i-2] != J输出结果:系统经过预处理后的输出(±4f注释和换行):,dn C ch = setcha.rO : s[i+*] = ch; if (ch == 1\n" | | ch==| \t* ) f cr L int j =U ;j € 4b j++) fputc (b^ fp) ; f putc (ch, fp); }wiiil日(s[iT] ! = ? 1 || s[i-2] I = ? ?;系统经过预处理后的输出(去掉注釋■换了亍、空梅等)=do 呂e tchar () ; s[i ■*-+■] -ch; if tch==,\n | |ch-=,\t?or (ini j=0; j<4; J-H-)fpoitc(b, fp): fputctch, fp):} flhile(s[i^l] \-r r \ |s[i-2]!=,,):词法分析如T:(1/dD1) (5/C)(2, ' eh J) 任,』)(2,11 get char?) (5/ (!) (5QJ (5/;5) Qd) (5「[') (2/iJ(4,1卄')(妇」) ⑵’山)(5,―)⑸’f )(2?T川)(5,…) 他’\n)(5,…)四、实验小结(包括问题和解决方法、心得体会、意见与建议等)在本实验中,我进一步学习了如何运用输入输出流,对文件进行读写操作。
词法分析程序的构造

词法分析程序的构造通达学院题专学班指指日II 词法分析程序的构造业生姓名级学号导教师导单位计算机学院计算机科学与技术系期专业课程设计目:词法分析程序的构造一、课题内容和要求通过状态转换图构造C或者PASCAL语言子集的词法分析程序。
原理解析:选取语言,例如选取了C语言,选取其中一个子集,例如包含了部分关键字main、float、if、for等等,特殊符号( 、的标识符变量以及部分常量等,采用《编译原理》词法分析中有穷自动机的思想构建出该语言子集的状态转换图,并编码实现。
基本要求:(1)将选取的语言子集编写一个简单程序,放在一个文本文件中;(2)要将一个个单词区分清楚并归类(例如for属于关键字)。
二、需求和思路分析本课题是用C++语言设计,选取的是C语言子集。
编写对简单语言进行词法分析的词法分析程序。
1、识别子集中的关键字、标识符、常数、运算符和分界符等。
2、对子集中的字符类型进行归类三、概要设计(1)状态转换图:(2)核心代码:1)定义:char cbuffer;char*keyword[14]={"if","else","for","while","do","float","return","break","con tinue","int","void","main","const","printf"}; //关键字char *border[8]={ "," , ";" , "{" , "}" , "(" , ")" ,":=","."}; //分隔符char *arithmetic[6]={"+" , "-" , "*" , "/" , "++" , "--"}; //运算符char *relation[7]={"" , ">=" , "==" ,"!="};char *lableconst[80];2)函数调用: search(char searchchar[],int wordtype)//查找类型alphaprocess(char buffer) //字符处理过程digitprocess(char buffer) //数字处理过程otherprocess(char buffer) //分隔符、运算符、逻辑运算符等main()//主函数3) 状态类型:状态转换图的形式:■每个状态对应一个带标号的case语句■转向边对应goto语句switch (wordtype){case 1:{ for (i=0;i{if (strcmp(keyword[i],searchchar)==0)return(i+1);}return(0);}case 2:{for (i=0;i{if (strcmp(border[i],searchchar)==0)return(i+1);}return(0);//关系运算符 //标识符}case 3:{for (i=0;i{if (strcmp(arithmetic[i],searchchar)==0) return(i+1);}return(0);}case 4:{for (i=0;i{if (strcmp(relation[i],searchchar)==0)return(i+1);}return(0);}case 5:{for (t=40;t{if (strcmp(searchchar,lableconst[t])==0)//判断该常数是否已出现过return(t+1);}lableconst[t-1]=(char *)malloc(sizeof(searchchar)); //为新的元素分配内存空间strcpy(lableconst[t-1],searchchar); //为数组赋值lableconst 指针数组名constnum++; //常数个数自加return(t);}case 6:{for (i=0;i{if (strcmp(searchchar,lableconst[i])==0) //判断标识符是否已出现过return(i+1);}lableconst[i-1]=(char *)malloc(sizeof(searchchar));strcpy(lableconst[i-1],searchchar);lableconstnum++; //标识符个数自加return(i);}5) 单字符判断if (otypetp=search(othertp,3)) //判断该运算符是否是由连续的两个字符组成的{coutfp.get(buffer);goto out;}else //单字符逻辑运算符{othertp[1]='\0';cout"goto out;}四、详细设计实验环境:visual C++6.0 win7系统源程序代码:#include#include#include#include#includeusing namespace std;ifstream fp("09002801.txt",ios::in);char cbuffer;char*keyword[14]={"if","else","for","while","do","float","return","break","continu e","int","void","main","const","printf"}; //关键字char *border[8]={ "," , ";" , "{" , "}" , "(" , ")" ,":=","."}; //分隔符char *arithmetic[6]={"+" , "-" , "*" , "/" , "++" , "--"}; //运算符char *relation[7]={"" , ">=" , "==" ,"!="}; //关系运算符 char*lableconst[80]; //标识符int constnum=40;int lableconstnum=0; //统计常数和标识符数量int row=1;int search(char searchchar[],int wordtype){int i=0,t=0;switch (wordtype){case 1:{ for (i=0;i{if (strcmp(keyword[i],searchchar)==0)return(i+1);}return(0);}case 2:{for (i=0;i{if (strcmp(border[i],searchchar)==0)return(i+1);}return(0);}case 3:{for (i=0;i{if (strcmp(arithmetic[i],searchchar)==0) return(i+1);}return(0);}case 4:{for (i=0;i{if (strcmp(relation[i],searchchar)==0)return(i+1);}return(0);}case 5:{for (t=40;t{if (strcmp(searchchar,lableconst[t])==0)//判断该常数是否已出现过return(t+1);}lableconst[t-1]=(char *)malloc(sizeof(searchchar)); //为新的元素分配内存空间strcpy(lableconst[t-1],searchchar); //为数组赋值lableconst指针数组名constnum++; //常数个数自加return(t);}case 6:{for (i=0;i{if (strcmp(searchchar,lableconst[i])==0) //判断标识符是否已出现过 return(i+1);}lableconst[i-1]=(char *)malloc(sizeof(searchchar));strcpy(lableconst[i-1],searchchar);lableconstnum++; //标识符个数自加return(i);}default:cout}}char alphaprocess(char buffer) //字符处理过程{int atype;int i=-1;char alphatp[20];while ((isalpha(buffer))||(isdigit(buffer)))//这两个函数分别是判字符和判数字函数位于ctype.h中 {alphatp[++i]=buffer;fp.get(buffer);}alphatp[i+1]='\0';//在末尾添加字符串结束标志if (atype=search(alphatp,1))coutelse{atype=search(alphatp,6); //标识符cout}return(buffer);}char digitprocess(char buffer) //数字处理过程{int i=-1;char digittp[20];int dtype;while ((isdigit(buffer))){digittp[++i]=buffer;fp.get(buffer);}digittp[i+1]='\0';dtype=search(digittp,5);coutreturn(buffer);}char otherprocess(char buffer) //分隔符、运算符、逻辑运算符等 {int i=-1;char othertp[20];int otype,otypetp;othertp[0]=buffer;othertp[1]='\0';if (otype=search(othertp,3)){fp.get(buffer);othertp[1]=buffer;othertp[2]='\0';if (otypetp=search(othertp,3)) //判断该运算符是否是由连续的两个字符组成的{coutgoto out;}else //单字符逻辑运算符{othertp[1]='\0';cout}}if (otype=search(othertp,4)) //关系运算符{fp.get(buffer);othertp[1]=buffer;othertp[2]='\0';if (otypetp=search(othertp,4)) //判断该关系运算符是否是由连续的两个字符组成的 {coutgoto out;}else //单字符逻辑运算符{othertp[1]='\0';cout}}if (buffer=='!') //"=="的判断{fp.get(buffer);if (buffer=='=')//coutfp.get(buffer);goto out;else{if (otype=search(othertp,2)) //分界符{coutfp.get(buffer);goto out;}}if ((buffer!='\n')&&(buffer!=' '))coutfp.get(buffer);out:return(buffer);}void main(){printf("=========================词法分析器==========================\n"); int i;for (i=0;i{lableconst[i]=" ";//用于保存标识符}if (!fp)coutelse{fp.get (cbuffer);while (!fp.eof()){if(cbuffer=='\n'){row++;fp.get(cbuffer);}else if (isalpha(cbuffer)){cbuffer=alphaprocess(cbuffer); }else if (isdigit(cbuffer))cbuffer=digitprocess(cbuffer); }elsecbuffer=otherprocess(cbuffer); }couti=0;while(i{cout}coutcoutgetchar();}}(3)程序流程图:五、测试数据及其结果分析若源程序中没有09002801.txt文档,则会出现如下提示:若文档中包含09002801.txt文档,文档代码为:运行后结果如下:六、调试过程中的问题在代码调试过程中,由于代码编写时将主函数main和文件打开的顺序颠倒,导致未写入源文档也会提示词法分析结束,实际上并未进行词法分析过程,应该提示文件打开错,返回检查。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验二词法分析器的构造
一、实验目的
掌握词法分析器的构造原理,掌握手工编程或LEX编程方法之一。
二、实验内容
编写一个词法分析器,能够将输入的源程序转换为单词序列输出。
三、实验指南
1.源语言定义见教材附录A.1,其中的终结符即词法分析需要得到的tokens。
(1)该语言的关键字:if while do break real true false int char bool float (其中,int、char、bool、float在产生式中为basic)
所有的关键字都是保留字,并且必须是小写。
(2)id和num的正则表达式定义;
(3)专用符号:+ - * / < <= > >= == != = ; , ( ) [ ] { } /* */
(4)空格由空白、换行符和制表符组成。
空格通常被忽略,除了它必须分开I D、N U M关键字。
(5)考虑注释。
注释由/*和*/包含。
注释可以放在任何空白出现的位置,且可以超过一行。
注释不能嵌套。
2.实现词法分析器的注意要点:
(1)关键字和标识符名的区别;
(2)数字的转换处理;
(3)“>=”和“>”这类单词的处理;
3.源程序测试示例
要求应自行准备多个源程序片段,运行并测试输出是否合符要求。
示例1:
源程序输入:
{
int i;
if ( i >= 0) i = i + 1;
}
输出token序列如下:
{,
int,
(id, i)
;,
if,
(,
(id, i)
>=,
(num, 0)
(id, i)
=,
(id, i)
+,
(num, 1)
示例2:
源程序片段:
{
int i; int j; float v; float x; float[100] a;
while ( true) {
do i = i + 1; while ( a[i] < v);
do j = j - 1; while ( a[j] > v);
if ( i >= j ) break;
x = a[i]; a[i] = a[j]; a[j] = x;
}
}
四、实验结果
五、实验小结
本次实验相对而言比较简单,最大的难点是不熟悉LEX程序的编写规则。
在编写过程中,一度对括号以及注释的处理出错,后来发现是忘了将括号用引号引起来,使得其语法规则错误。
关于注释的处理,后来查看了书本,知道了对* ?/ +等运算符字符表示它们自身的方法才得以解决。
编写过程中也因为一些低级错误而浪费了一点时间,主要还是因为程序编写太少的原因。
在对number和id 的定义以及main函数的书写大多是参考书本以及ppt的,在一定程度上降低了难度。