编译原理与实践第三章答案
清华版编译原理课后答案——第三章参考答案

第三章1、L(G[S])={ abc }2、L(G[N])={ n位整数或空字符串| n>0 }3、G[E]:E—>E+D | E-D | DD—>0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 94、L(G[Z])={ a n b n | n>0 }5、(1) 考虑不包括“0”的情况G[S]:S—>0S | ABC | 2 | 4| 6 | 8A—>1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9B—>AB | 0B | εC—>0 | 2 | 4 | 6 | 8考虑包括“0”的情况:G[S]:S—>AB | CB—>AB | CA—>0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9C—>0 | 2 | 4 | 6 | 8(2)方法1:G[S]:S—> ABC | 2 | 4 | 6 | 8A—>1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9B—>AB | 0B | εC—>0 | 2 | 4 | 6 | 8方法2:G[S]:S—>AB | CB—> AB | 0B | C | 0A—> 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9C—>2 | 4 | 6 | 86、设<表达式>为E,<项>为T,<因子>为F,注:推导过程不能省略,以下均为最左推导(1) E => T => F => i(4) E => E+T => T+T => T*F+T => F*F+T => i*F+T => i*i+T => i*i+F => i*i+i(6) E => E+T => T+T => F+T => i+T => i+T*F => i+F*F => i+i*F => i+i*I7、<表达式><表达式>*<表达式><表达式>+<表达式>i i i<表达式><表达式>+<表达式>i <表达式>*<表达式>i i8、是有二义性的,因为句子abc 有两棵语法树(或称有两个最左推导或有两个最右推导)最左推导1:S => Ac => abc最左推导2:S => aB => abc9、(1)(2) 该文法描述了变量a 和运算符+、*组成的逆波兰表达式10、(1) 该文法描述了各种成对圆括号的语法结构(2) 是有二义性的,因为该文法的句子()()存在两种不同的最左推导:最左推导1:S => S(S)S => (S)S => ()S => ()S(S)S => ()(S)S => ()()S => ()()最左推导2:S => S(S)S => S(S)S(S)S => (S)S(S)S => ()S(S)S => ()(S)S => ()()S => ()()11、(1) 因为从文法的开始符E 出发可推导出E+T*F ,推导过程如下:E => E+T => E+T*F ,所以E+T*F 是句型。
编译原理答案

《编译原理》课后习题答案第一章第 1 章引论第 1 题解释下列术语:(1)编译程序(2)源程序(3)目标程序(4)编译程序的前端(5)后端(6)遍答案:(1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2)源程序:源语言编写的程序称为源程序。
(3)目标程序:目标语言书写的程序称为目标程序。
(4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第 2 题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含 8 个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
盛威网()专业的计算机学习网站1《编译原理》课后习题答案第一章目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
编译原理第二版第三章课后答案

第三章作业第三章作业答案P47 练习1、文法G=({A,B,S},{a,b,c},P,S),其中P为:S->Ac|aB A->ab B->bc写出L(G [S])的全部元素。
S=>Ac=>abc或S=>aB=>abc所以L(G[S])={abc}2、文法G[N]为:N->D|NDD->0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?【解】N=>ND=>NDD.... =>NDDDD...D=>D......DG[N]的语言是V+。
V={0,1,2,3,4,5,6,7,8,9}或:解: N ND n-1D n{0,1,3,4,5,6,7,8,9}+∴L(G[N])= {0,1,3,4,5,6,7,8,9}+5.写一文法,使其语言是偶正数的集合。
要求:(1)允许0打头(2)不允许0打头【解】(1)允许0开头的偶正整数集合的文法E->NT|G|SFMT->NT|GN->D|1|3|5|7|9D->0|GG->2|4|6|8S->NS|εF->1|3|5|7|9|GM->M0|0(2)不允许0开头的偶正整数集合的文法E->NT|DT->FT|GN->D|1|3|5|7|9D->2|4|6|8F->N|0G->D|09.考虑下面上下文无关文法:S→SS*|SS+|a(1) 表明通过此文法如何生成串aa+a*,并为该串构造推导树。
(2) 该文法生成的语言是什么?【解】(1) S=>SS*=>SS+S*aa+a*该串的推导树如下:(2) 该文法生成的语言是只含+、*的算术表达式的逆波兰表示。
11.令文法G[E]为:E→T|E+T|E-TT→F|T*F|T/FF→(E)|i证明E+T*F是它的一个句型,指出这个句型的所有短语、直接短语和句柄。
编译原理第三章练习题答案

编译原理第三章练习题答案编译原理第三章练习题答案编译原理是计算机科学中的重要学科,它研究的是如何将高级语言代码转化为机器语言的过程。
在编译原理的学习过程中,练习题是不可或缺的一部分,通过完成练习题可以更好地理解和掌握编译原理的知识。
本文将为大家提供编译原理第三章练习题的答案,希望对大家的学习有所帮助。
1. 什么是语法分析?语法分析是编译器中的一个重要模块,它的主要任务是根据给定的语法规则,对输入的源代码进行分析和解释。
语法分析器会根据语法规则构建一个语法树,用于表示源代码的结构和含义。
常用的语法分析方法有递归下降法、LL(1)分析法和LR分析法等。
2. 什么是LL(1)文法?LL(1)文法是一种特殊的上下文无关文法,它具有以下两个特点:(1) 对于任何一个句子,最左推导和最右推导是唯一的。
(2) 在预测分析过程中,只需要向前看一个输入符号就可以确定所采用的产生式。
LL(1)文法是一种常用的文法形式,它适用于递归下降法和LL(1)分析法。
3. 什么是FIRST集合和FOLLOW集合?FIRST集合是指对于一个文法符号,它能够推导出的终结符号的集合。
FOLLOW 集合是指在一个句型中,某个非终结符号的后继终结符号的集合。
计算FIRST集合和FOLLOW集合可以帮助我们进行语法分析,特别是LL(1)分析。
4. 什么是递归下降语法分析法?递归下降语法分析法是一种基于产生式的自顶向下的语法分析方法。
它的基本思想是从文法的开始符号开始,递归地根据产生式进行分析,直到推导出输入符号串或发现错误。
递归下降语法分析法的实现比较简单,但对于某些文法可能会出现回溯现象,影响分析效率。
5. 什么是LR分析法?LR分析法是一种自底向上的语法分析方法,它的基本思想是从输入符号串开始,逐步构建语法树,直到推导出文法的开始符号。
LR分析法具有较好的分析效率和广泛的适用性,常用的LR分析方法有LR(0)、SLR(1)、LR(1)和LALR(1)等。
蒋立源编译原理第三版第三章习题与答案(修改后)
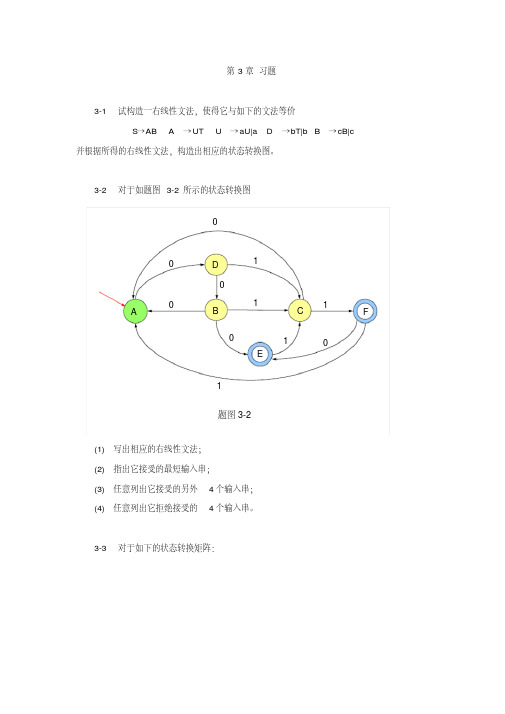
3-1 试构造一右线性文法,使得它与如下的文法等价 S→AB A → UT U → aU|a D →bT|b B → cB|c
并根据所得的右线性文法,构造出相应的状态转换图。
3-2 对于如题图 3-2 所示的状态转换图 0
0 0 A
D
1
0 1
B
C1
F
0
1
0
E
1 题图 3-2
(1) 写出相应的右线性文法; (2) 指出它接受的最短输入串; (3) 任意列出它接受的另外 4 个输入串; (4) 任意列出它拒绝接受的 4 个输入串。
但
{1}
b=
故 1 和 2 可区分,于是便得到下一分划
π1: {1}, {2}, {3}
此时子集已全部分裂,故最小化的过程宣告结束, M′即为状态数最小的 DFA。
(3) 将 NFA M确定化后得 DFA M′,其状态转换矩阵如答案图 3-4-(3) 之 (a) 所示, 给各状态重新命名,即令:
[S]=1, [A]=2, [S,B]=3 且由于 3 的组成中含有 M的终态 B,故 3 为 DFAM′的终态。于是,所构造之 DFAM′的 状态转换矩阵和状态转换图如答案图 3-4-(3) 之(b) 及(c) 所示。
π0:{1,2}, {3}
( ⅱ) 为得到下一分划,考察子集 {1,2} 。因为
{2} b ={3}
但
{1}
b=
故 1 和 2 可区分,于是便得到下一分划
π1: {1}, {2}, {3}
此时子集已全部分裂,故最小化的过程宣告结束, M′即为状态数最小的 DFA。
(4) 将 NFA M确定化后得 DFA M′,其状态转换矩阵如答案图 3-4-(4) 之 (a) 所示, 给各状态重新命名,即令:
编译原理教程-课后习题答案第三章语法分析ppt课件

a. LALR文法 b. LR(0)文法
c. LR(1)文法 d. SLR(1)文法
第三章 语法分析
(8) 同心集合并有能够产生新的 冲突。
a. 归约
b. “移进〞/“移进〞
c.“移进〞/“归约〞 〞
d. “归约〞/“归约
【解答】 (1) c (2) a (3) c (5) b (6) b (7) d (8) d
#⋖ (⋖,⋖ (⋖a⋗)⋗)⋗# 因此,素短语为a。
第三章 语法分析
3.8 下述文法描画了C言语整数变量的声明语句: G[D]: D→TL T→int|long|short L→id|L,id
(1) 改造上述文法,使其接受一样的输入序列, 但文法是右递归的;
(2) 分别用上述文法G[D]和改造后的文法G[D′] 为输入序列int a,b,c构造分析树。
第三章 语法分析
(2) 为了构造字母表Σ={a,b}上同时只需奇数个a 和奇数个b的一切串集合的正规式,我们画出如图3-3 所示的DFA,即由开场符S出发,经过奇数个a到达形状 A,或经过奇数个b到达形状B;而由形状A出发,经过 奇数个b到达形状C(终态);同样,由形状B出发经过奇 数个a到达终态C。
第三章 语法分析
第三章 语法分析
3.1 完成以下选择题:
(1) 文法G:S→xSx|y所识别的言语是 。
a. xyx
b. (xyx)*
c. xnyxn(n≥0)
d. x*yx*
(2) 假设文法G是无二义的,那么它的任何句子α 。
a. 最左推导和最右推导对应的语法树必定一样
b. 最左推导和最右推导对应的语法树能够不同 c. 最左推导和最右推导必定一样
能否不画出语法树,而直接由定义(即在句型中)寻觅满足某 个产生式的候选式这样一个最左子串(即句柄)呢?例如,对句型 aAaBcbbdcc,我们可以由左至右扫描找到第一个子串AaB,它恰好 是满足A→AaB右部的子串;与树(a)对照,AaB确实是该句型的句 柄。能否这一方法一直正确呢?我们继续检查句型aAcbBdcc,由 左至右找到第一个子串c,这是满足A→C右部的子串,但由树(b) 可知,c不是该句型的句柄。由此可知,画出对应句型的语法树然 后寻觅最左直接短语是确定句柄的好方法。
c++程序设计原理与实践第三章课后答案

“std_lib_facilities.h”这个头文件是《c++程序设计原理与实践》一直用到的头文件,要将此头文件放在你的文件目录中,下面我给出这个头文件://// This is a standard library support code to the chapters of the book// "Programming -- Principles and Practice Using C++" by Bjarne Stroustrup//#ifndef STD_LIB_FACILITIES_GUARD#define STD_LIB_FACILITIES_GUARD 1#include <iostream>using namespace std;//------------------------------------------------------------------------------// The call to keep_window_open() is needed on some Windows machines to prevent// them from closing the window before you have a chance to read the output.inline void keep_window_open(){cin.get();}//------------------------------------------------------------------------------#endif // STD_LIB_FACILITIES_GUARD将上述代码拷贝到记事本中,把后缀.txt改为.h,放在你的根目录即可引用。
第三章对象,类型和值第6 题#include"std_lib_facilities.h"int main(){int a;int b;int c;int t;cout<<"请您输入三个数:\n";cin>>a>>b>>c;if(a>b)//如果a大于b,将a,b交换.{t=a;a=b;b=t;}if(a>c){t=a;a=c;c=t;}if(b>c){t=b;b=c;c=t;}cout<<a<<","<<b<<","<<c<<endl;}下面是vc6.0的运行结果:第7题#include <iostream>#include<string>using namespace std;//------------------------------------------------------------------------------int main(){cout << "请您输入三个字符串:\n";string first;string second;string third;string space;cin >> first >> second>>third; // 读入三个字符串。
编译原理第三章答案

第3 章文法和语言第1 题文法G=({A,B,S},{a,b,c},P,S)其中P 为:S→Ac|aBA→abB→bc写出L(G[S])的全部元素。
答案:L(G[S])={abc}第2 题文法G[N]为:N→D|NDD→0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?答案: G[N]的语言是V+。
V={0,1,2,3,4,5,6,7,8,9}N=>ND=>NDD.... =>NDDDD...D=>D......D或者:允许0 开头的非负整数?第3题为只包含数字、加号和减号的表达式,例如9-2+5,3-1,7等构造一个文法。
答案:G[S]:S->S+D|S-D|DD->0|1|2|3|4|5|6|7|8|9第4 题已知文法G[Z]:Z→aZb|ab写出L(G[Z])的全部元素。
答案:Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbbL(G[Z])={anbn|n>=1}第5 题写一文法,使其语言是偶正整数的集合。
要求:(1) 允许0 打头;(2)不允许0 打头。
答案:(1)允许0 开头的偶正整数集合的文法E→NT|DT→NT|DN→D|1|3|5|7|9D→0|2|4|6|8(2)不允许0 开头的偶正整数集合的文法E→NT|DT→FT|GN→D|1|3|5|7|9D→2|4|6|8F→N|0G→D|0第6 题已知文法G:<表达式>::=<项>|<表达式>+<项> <项>::=<因子>|<项>*<因子><因子>::=(<表达式>)|i试给出下述表达式的推导及语法树。
(5)i+(i+i)(6)i+i*i答案:(5) <表达式>=><表达式>+<项>=><表达式>+<因子>=><表达式>+(<表达式>)=><表达式>+(<表达式>+<项>)=><表达式>+(<表达式>+<因子>)=><表达式>+(<表达式>+i)=><表达式>+(<项>+i)=><表达式>+(<因子>+i)=><表达式>+(i+i)=><项>+(i+i)=><因子>+(i+i)=>i+(i+i)(6) <表达式>=><表达式>+<项>=><表达式>+<项>*<因子> =><表达式>+<项>*i=><表达式>+<因子>*i =><表达式>+i*i=><项>+i*i=><因子>+i*i=>i+i*i<表达式><表达式> + <项><因子><表达式><表达式> + <项><因子>i<项><因子>i<项><因子>i()<表达式><表达式> + <项><项> * <因子><因子> i<项><因子>ii第7 题证明下述文法G[〈表达式〉]是二义的。
编译原理(第三版)第3章课后练习及参考答案中石大版

第3章练习P47作业布置:P47 4 ,9,11,14(1)4、已知文法G[Z]:(1)Z::=aZb (2)Z::=ab写出L(G[Z])的全部元素解:L(G[Z])={a n b n,n>=1}9、考虑下面的上下文无关文法:S→SS* | SS+ | a(1)表明通过此文法如何生成串aa+a*,并为该串构造语法树(2)该文法生成的语言是什么?解:(1)推导过程见语法树。
语法树如下(2)该文法生成的语言为用递归逆波兰式表示的运算式。
逆波兰式是将运算对象写在前面,把运算符写在后面。
11、G[E]:E→T|E+T|E-TT→F|T*F|T/FF → (E)|i证明E+T*F 是它的一个句型,指出这个句型的所有短语、直接短语和句柄。
解:可为E+T*F 构造一棵语法树(见下图),所以它是句型。
从语法树中容易看出,E+T*F 的短语有:T*F 是句型E+T*F 的相对于T 的短语,也是相对于规则T →T*F 的直接短语。
E+T*F 是句型E+T*F 的相对于E 的短语。
句型E+T*F 的句柄(最左直接短语)是T*F 。
14、给出生成下述语言的上下文无关文法:(1){a n b n a m b m |n,m>=0}(2){1n 0m 1m 0n |n,m>=0}(3){WaW r |W 属于{0|a}*,W r 表示W 的逆}解:(1)所求文法为G[S]=({S,A},{a,b},P,S),其中P 为:S →AA A →aAb|ε (2)所求文法为G[S]=({S,A},{0,1},P,S),其中P 为: S →1S0|AA →0A1|ε(3)W 属于{0|a}*是指W 可以的取值为{ε,0,a,00,a0,aa0,00aa,a0a0,…}E E + T T * F如果W=aa0a00,则W r=00a0aa。
所求文法为G[S]=({S,P,Q},{0,a},P,S),其中P为:S 0S0|aSa|a。
蒋立源编译原理第三版第三章习题与答案(修改后)
[S] [A] [S,B]
ab
[A]
[S,B]
2
[A]
初态 : [S] 终态 : [S,B] (a) 确定化后的状态矩阵
ab
1
2
3
3
2
初态 : 1 终态 : 3 (b) 改名后的状态矩阵
a
1
2
b 3
a (c) DFA M ′的状态转换图
答案图 3-4-(3)
现将 DFA M′最小化:
( ⅰ) 初始分划由两个子集组成,即
3-3 对于如下的状态转换矩阵:
ab
S
AS
AAB
B
BB
ab S
ABA B
AB BB
( ⅰ ) 初态 : S 终态 : B
( ⅲ ) 初态 : S 终态 : B
ab
S
AB
A
CA
BBC
C
CC
ab S
ACB BBC
C
AS CC
( ⅱ ) 初态 : S 终态 : A,C
( ⅳ ) 初态 : S 终态 : C
答案图 3-3
a, b C
(2) 相应的 3 型文法为:
( ⅰ ) S →aA|bS
A→aA|bB| b
B→ aB|bB|a|b
( ⅱ) S →aA|bB| a源自A→bA|aC| a|bB→aB|bC| b
C→ aC|bC|a|b
( ⅲ) S →aA|bB| b A→aB|bA| a
B→aB| bB|a|b
**
(2) b|a(aa b) b
NFA。
3-8 构造与正规式 (a|b) *(aa|bb)(a|b) * 相应的 DFA。
第 3 章 习题答案
编译原理教程-课后习题答案第三章语法分析

c. 最左推导和最右推导必定相同
d. 可能存在两个不同的最左推导,但它们对应的语法树 相同
第三章 语法分析
(3) 采用自上而下分析,必须 。
a. 消除左递归
b. 消除右递归
c. 消除回溯
d. 提取公共左因子
(4) 设a、b、c是文法的终结符,且满足优先关系 ab和bc,则 。
a. 必有ac
b. 必有ca
第三章 语法分析 表3-1 预测分析表
A A′ B B′
能否不画出语法树,而直接由定义(即在句型中)寻 找满足某个产生式的候选式这样一个最左子串(即句柄) 呢?例如,对句型aAaBcbbdcc,我们可以由左至右扫描 找到第一个子串AaB,它恰好是满足A→AaB右部的子串; 与树(a)对照,AaB的确是该句型的句柄。是否这一方法 始终正确呢?我们继续检查句型aAcbBdcc,由左至右找 到第一个子串c,这是满足A→C右部的子串,但由树(b) 可知,c不是该句型的句柄。由此可知,画出对应句型 的语法树然后寻找最左直接短语是确定句柄的好方法。
c. 必有ba
d. a~c都不一定成立
第三章 语法分析
(5) 在规范归约中,用 来刻画可归约串。
a. 直接短语
b. 句柄
c. 最左素短语 d. 素短语
(6) 若a为终结符,则A→α ·aβ 为 项目。
a. 归约
b. 移进
c. 接受
d. 待约
(7) 若项目集Ik含有A→α · ,则在状态k时,仅 当 面 临 的 输 入 符 号 a∈FOLLOW(A) 时 , 才 采 取
第三章 语法分析
因此,文法G[S]为二义文法(对句子abbb也可画出 两棵不同语法树)。
3.4 已知文法G[S]为S→SaS|ε ,试证明文法G[S] 为二义文法。
习题参考答案-编译原理及实践教程(第3版)-黄贤英-清华大学出版社

附录部分习题参考答案第1章习题1. 解释下列术语。
翻译程序,编译程序,解释程序,源程序,目标程序,遍,前端,后端解答:略!2. 高级语言程序有哪两种执行方式?阐述其主要异同点。
描述编译方式执行程序的过程。
解答:略!3. 在你所使用的C语言编译器中,观察程序1.1经过预处理、编译、汇编、链接四个过程生成的中间结果。
解答:略!4. 编译程序有哪些主要构成成分?各自的主要功能是什么?解答:略!5. 编译程序的构造需要掌握哪些原理和技术?编译程序构造工具的作用是什么?解答:略!6. 复习C语言,其字母表中有哪些符号?有哪些关键字、运算符和界符?标识符、整数和实数的构成规则是怎样的?各种语句和表达式的结构是什么样的?解答:略!7.编译技术可应用在哪些领域?解答:略!8. 你能解释在Java编译器中,输入某个符号后会提示一些单词、某些单词会变为不同的颜色是如何实现的吗?你能解释在Code Blocks中在输入{后,会自动添加},输入do 会自动添加while()是为什么吗?解答:略!第2章习题1. 判断题,对下面的陈述,正确的在陈述后的括号内画√,否则画×。
(1) 有穷自动机识别的语言是正规语言。
()(2) 若r1和r2是Σ上的正则表达式,则r1|r2也是。
()(3) 设M是一个NFA,并且L(M)={x,y,z},则M的状态数至少为4个。
()(4) 令Σ={a,b},则所有以b开头的字构成的正规集的正则表达式为b*(a|b)*。
()(5) 对任何一个NFA M,都存在一个DFA M',使得L(M')=L(M)。
()1解答:略!2.从供选择的答案中,选出应填入下面叙述中?内的最确切的解答。
有穷自动机可用五元组(Q,V T,δ,q0,Q f)来描述,设有一有穷自动机M定义如下:V T={0,1},Q={q0,q1,q2},Q f={q2},δ的定义为:δ (q0,0)=q1δ (q1,0)=q2δ (q2,1)=q2δ (q2,0)=q2M是一个 A 有穷状态自动机,它所对应的状态转换图为 B ,它所能接受的语言可以用正则表达式表示为 C 。
编译原理第3章习题解答
第3章习题解答1.构造正规式1(0|1)*101相应的D FA.[答案]先构造NFA确定化============================================================== 2.将下图确定化:[答案]E、Z为F。
转化为DFA:================================================================ 3.把下图最小化:[答案](1)初始分划得Π0:终态组{0},非终态组{1,2,3,4,5}对非终态组进行审查:{1,2,3,4,5}a {0,1,3,5}而{0,1,3,5}既不属于{0},也不属于{1,2,3,4,5} ∵{4} a {0},所以得新分划 (2)Π1:{0},{4},{1,2,3,5} 对{1,2,3,5}进行审查: ∵{1,5} b {4}{2,3} b {1,2,3,5},故得新分划 (3)Π2:{0},{4},{1, 5},{2,3} {1, 5} a {1, 5}{2,3} a {1,3},故状态2和状态3不等价,得新分划 (3)Π3:{0},{2},{3},{4},{1, 5} 这是最后分划了 (4)最小DFA :======================================= 4.构造一个D F A ,它接收Σ={0,1}上所有满足如下条件的字符串:每个1都有0直接跟在右边。
并给出该语言的正规式和正规文法。
[答案]按题意相应的正规表达式是0*(100*)*0* 构造相应的D F A ,首先构造N F A 为用子集法确定化可最小化,终态组为G 1={C, D},非终态组为G 2={S, A, B} 对于G2分析:f(S,0)=A, f(A,0)=A, 后继状态均属于G2 而f(B,0)=C, 后继状态属于G 1 将G2分割成G 21={S ,A}, G22={B}经检查DFA最小状态集有三个,可用S、B、D表示。
蒋立源编译原理 第三版 第三章 习题与答案(修改后)
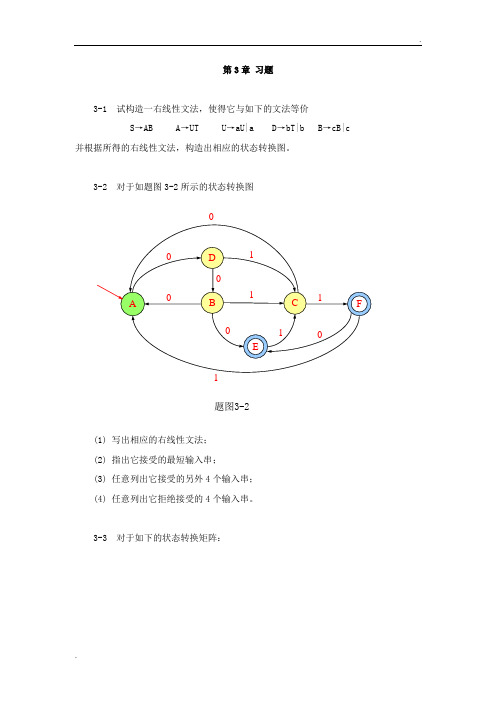
第3章习题3-1 试构造一右线性文法,使得它与如下的文法等价S→AB A→UT U→aU|a D→bT|b B→cB|c 并根据所得的右线性文法,构造出相应的状态转换图。
3-2 对于如题图3-2所示的状态转换图(1) 写出相应的右线性文法;(2) 指出它接受的最短输入串;(3) 任意列出它接受的另外4个输入串;(4) 任意列出它拒绝接受的4个输入串。
3-3 对于如下的状态转换矩阵:(1) 分别画出相应的状态转换图;(2) 写出相应的3型文法;(3) 用自然语言描述它们所识别的输入串的特征。
3-4 将如下的NFA确定化和最小化:3-5 将如题图3-5所示的具有ε动作的NFA确定化。
题图3-5 具有ε动作的NFA3-6 设有文法G[S]:S→aA A→aA|bB B→bB|cC|c C→cC|c 试用正规式描述它所产生的语言。
3-7 分别构造与如下正规式相应的NFA。
(1) ((0* |1)(1* 0))*(2) b|a(aa*b)*b3-8 构造与正规式(a|b)*(aa|bb)(a|b)*相应的DFA。
第3章习题答案3-1 解:根据文法知其产生的语言是:L[G]={a m b n c i| m,n,i≧1}可以构造与原文法等价的右线性文法:S→aA A→aA|bB B→bB|cC|c C→cC|c 其状态转换图如下:3-2 解:(1) 其对应的右线性文法是G[A]:A →0D B→0A|1C C→0A|1F|1D→0B|1C E→0B|1C F→1A|0E|0(2) 最短输入串为011(3) 任意接受的四个输入串为:0110,0011,000011,00110(4) 任意拒绝接受的输入串为:0111,1011,1100,10013-3 解:(1) 相应的状态转换图为:(2) 相应的3型文法为:(ⅰ) S→aA|bS A→aA|bB|b B→aB|bB|a|b(ⅱ) S→aA|bB|a A→bA|aC|a|b B→aB|bC|b C→aC|bC|a|b(ⅲ) S→aA|bB|b A→aB|bA|a B→aB|bB|a|b(ⅳ) S→bS|aA A→aC|bB|a B→aB|bC|b C→aC|bC|a|b(3) 用自然语言描述的输入串的特征为:(ⅰ) 以任意个(包括0个)b开头,中间有任意个(大于1)a,跟一个b,还可以有一个由a,b组成的任意字符串。
编译原理-第3章 词法分析--习题答案

第3章词法分析习题答案1.判断下面的陈述是否正确。
(1)有穷自动机接受的语言是正规语言。
(√)(2)若r1和r2是Σ上的正规式,则r1|r2也是Σ上的正规式。
(√)(3)设M是一个NFA,并且L(M)={x,y,z},则M的状态数至少为4个。
(× )(4)设Σ={a,b},则Σ上所有以b为首的符号串构成的正规集的正规式为b*(a|b)*。
(× )(5)对任何一个NFA M,都存在一个DFA M',使得L(M')=L(M)。
(√)(6)对一个右线性文法G,必存在一个左线性文法G',使得L(G)=L(G'),反之亦然。
(√) (7)一个DFA,可以通过多条路识别一个符号串。
(× )(8)一个NFA,可以通过多条路识别一个符号串。
(√)(9)如果一个有穷自动机可以接受空符号串,则它的状态图一定含有 边。
(× )(10)DFA具有翻译单词的能力。
(× )2.指与出正规式匹配的串.(1)(ab|b)*c 与后面的那些串匹配?ababbc abab c babc aaabc(2)ab*c*(a|b)c 与后面的那些串匹配? acac acbbc abbcac abc acc(3)(a|b)a*(ba)* 与后面的那些串匹配? ba bba aa baa ababa答案(1) ababbc c babc(2) acac abbcac abc(3) ba bba aa baa ababa3. 为下边所描述的串写正规式,字母表是{0, 1}.(1)以01 结尾的所有串(2)只包含一个0的所有串(3) 包含偶数个1但不含0的所有串(4)包含偶数个1且含任意数目0的所有串(5)包含01子串的所有串(6)不包含01子串的所有串答案注意 正规式不唯一(1)(0|1)*01(2)1*01*(3)(11)*(4)(0*10*10*)*(5)(0|1)*01(0|1)*(6)1*0*4.请描述下面正规式定义的串. 字母表{x, y}.(1) x(x|y)*x(2)x*(yx)*x*(3) (x|y)*(xx|yy) (x|y)*答案(1)必须以 x 开头和x结尾的串(2)每个 y 至少有一个 x 跟在后边的串 (3)所有含两个相继的x或两个相继的y的串5.处于/* 和 */之间的串构成注解,注解中间没有*/。
编译原理教程课后习题答案——第三章

第三章语法分析3.1 完成下列选择题:(1) 文法G:S→xSx|y所识别的语言是。
a. xyxb. (xyx)*c. xnyxn(n≥0)d. x*yx*(2) 如果文法G是无二义的,则它的任何句子α。
a. 最左推导和最右推导对应的语法树必定相同b. 最左推导和最右推导对应的语法树可能不同c. 最左推导和最右推导必定相同d. 可能存在两个不同的最左推导,但它们对应的语法树相同(3) 采用自上而下分析,必须。
a. 消除左递 a. 必有ac归b. 消除右递归c. 消除回溯d. 提取公共左因子(4) 设a、b、c是文法的终结符,且满足优先关系a b和bc,则。
b. 必有cac. 必有bad. a~c都不一定成立(5) 在规范归约中,用来刻画可归约串。
a. 直接短语b. 句柄c. 最左素短语d. 素短语(6) 若a为终结符,则A→α·aβ为项目。
a. 归约b. 移进c. 接受d. 待约(7) 若项目集Ik含有A→α·,则在状态k时,仅当面临的输入符号a∈FOLLOW(A)时,才采取“A→α·”动作的一定是。
a. LALR文法b. LR(0)文法c. LR(1)文法d. SLR(1)文法(8) 同心集合并有可能产生新的冲突。
a. 归约b. “移进”/“移进”c.“移进”/“归约”d. “归约”/“归约”【解答】(1) c (2) a (3) c (4) d (5) b (6) b (7) d (8) d3.2 令文法G[N]为G[N]: N→D|NDD→0|1|2|3|4|5|6|7|8|9(1) G[N]的语言L(G[N])是什么?(2) 给出句子0127、34和568的最左推导和最右推导。
【解答】(1) G[N]的语言L(G[N])是非负整数。
(2) 最左推导:NNDNDDN DDDDDD D0DDD01DD012D0127NNDDD3D34NNDNDDD DD5DD56D568最右推导:NNDN7ND7N27ND27N127D1270127NNDN4D434NNDN8ND8N68D685683.3 已知文法G[S]为S→aSb|Sb|b,试证明文法G[S]为二义文法。
编译原理第3章课后习题答案

consonant -> [b-df-hj-np-tv-z] ctnvowels->(consonant*)(((a+)(consonant*))+)(((e+)(consonant*))+)
(((i+)(consonant*))+)(((o+)(consonant*))+)(((u+)(consonant*))+)
Dtran[I,b] =ε-closure(move(I,b))= ε-closure({5, 16})=G DFA D 的转换表 Dtran NFA 状态 {0,1,2,4,7} {1,2,3,4,6,7,8} {1,2,4,5,6,7} {1,2,4,5,6,7,9} {1,2,4,5,6,7,10,11,12,13,15} {1,2,3,4,6,7,8,12,13,14,15,17,18} {1,2,4,5,6,7, 12,13,15,16,17,18} {1,2,4,5,6,7, 9,12,13,15,16,17,18} {1,2,4,5,6,7, 10,11,12,13,15,16,17,18} 可得 DFA 的如下状态转换图: DFA 状态 A B C D E F G H I a B B B B F F F F F b C D C E G H G I G
编译原理第 2 版参考习题答案 (3 章) 第 3 章 词法分析 3.2.2 试描述下列正则表达式定义的语言 (1) a( a|b )*a 答: { aa, aaa, aba, aaaa, aaba, abaa, abba, ... },(按穷举法) 或以 a 开头和结尾,长度大于等于 2 的 a,b 串 (2) ( (ε|a)b*) )* 答: 由 a 和 b 组成的任意符号串 (自然语言描述)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
The exercises of Chapter Three3.2 Given the grammar A →AA|(A)|εa. Describe the language it generates;b. Show that it is ambiguous.[Solution]:a. Generates a string of balanced parenthesis, including the empty string.b. parse trees of ():3.3 Given the grammar exp → exp addop term | termaddop → + | -term → term mulop factor| factormulop → *factor → ( exp ) | numberWrite down leftmost derivations, parse trees, and abstract syntax trees for the following expression:a. 3+4*5-6b. 3*(4-5+6)c. 3-(4+5*6)[Solution]:a.The leftmost derivations for the expression3+4*5-6:Exp => exp addop term =>exp addop term addop term =>term addop term addop term=> factor addop term addop term=>3 addop term addop term => 3 + term addop term =>3+term mulop factor addop term =>3+factor mulop factor addop term A()εA AA AA ()εε=>3+4 mulop factor addop term => 3+4* factor addop term=>3+4*5 addop term => 3+4*5-term=> 3+4*5-factor=>3+4*5-63.5 Write a grammar for Boolean expressions that includes the constants true and false, the operators and, or and not, and parentheses. Be sure to give or a lower precedence than and and and a lower precedence that not and to allow repeated not’s, as in the Boolean expression not not true. Also be sre your grammar is not ambiguous.[solution]bex p→bexp or A | AA→ A and B | BB→ not B | CC→ (bexp) | true | falseEx: not not trueboolExp → A→ B→ not B→ not not B→ not not C→ not not true3.8 Given the following grammarstatement→if-stmt | other | εif-stmt→ if ( exp ) statement else-partelse-part→ else statement | εexp→ 0 | 1a. Draw a parse tree for the stringif(0) if (1) other else else otherb. what is the purpose of the two else’s?The two else’s allow the programmer to associate an else clause with the outmost else, when two if statements are nested and the first does not have an else clause.c. Is similar code permissible in C? Explain.The grammar in C looks like:if-stmt→if ( exp ) statement | if (exp) statement else statementthe way to override “dangling else” problem is to enclose the inner if statement in {}s. e.g. if (0) { if(1) other } else other.3.10 a. Translate the grammar of exercise 3.6 into EBNF.b. Draw syntax diagramms for the EBNF of part (a).[Solution]a. The original grammarlexp→atom|listatom→number|identifierlist→(lexp-seq)lexp-seq→lexp-seq lexp| lexpThe EBNF of the above grammar:lexp→atom|listatom→number|identifierlist→(lexp-seq)lexp-seq→lexp {lexp}b. The syntax diagramms for the above EBNF:3.12. Unary minuses can be added in several ways to the simple arithmetic expression grammar of Exercise 3.3. Revise the BNF for each of the cases that follow so that it satisfies the stated rule.a. At most one unary minus is allowed in each expression, and it must come at the beginning of an expression, so -2-3 is legal ( and evaluates to -5 ) and -2-(-3) is legal, but -2--3 is not.exp →exp addop term | termaddop →+ | -term → term mulop factor| factormulop →*factor →( exp) | (-exp) | number |b. At most one unary minus are allowed before a number or left parenthesis, so -2--3 is legal but --2 and -2---3 are not.exp →exp addop term | termaddop →+ | -term → term mulop factor| factormulop →*factor →( exp) | -(exp) | number | -numberc. Arbitrarily many unary minuses are allowed before numbers and left parentheses, so everything above is legal.3.19 In some languages ( Modula-2 and Ada are examples), a procedure declaration is expected to be terminated by syntax that includes the name of the procedure. For example, in Modular-2 a procedure is declared as follows:PROCEDURE P;BEGIN……END P;Note the use of the procedure name P alter the closing END. Can such a requirement be checked by a parser? Explain.[Answer]This requirement can not be handled as part of the grammar without making a new rule for each legal variable name, which makes it intractable for all practical purposes, even if variable names are restricted to a very short length. The parser will just check the structure, that an identifier follows the keyword PROCEDURE and an identifier also follows the keyword END, however checking that it is the same identifier is left for semantic analysis. See the discussion on pages 131-132 of your text.3.20 a. Write a regular expression that generate the same language as the following grammar:A→aA|B|εB→bB|Ab. Write a grammar that generates the same language as the following regularexpression:(a|c|ba|bc)*(b|ε)[Solution]a. The regular expression:(a|b)*b. The grammar:Step 1:A→BCB→aB|cB|baB|bcB|εC→b|εStep 2:A→Bb|BB→aB|cB|baB|bcB|ε。