算法导论上机报告
计算方法上机实验报告

《计算方法》上机实验报告班级:XXXXXX小组成员:XXXXXXXXXXXXXXXXXXXXXXXXXXXX任课教师:XXX二〇一八年五月二十五日前言通过进行多次得上机实验,我们结合课本上得内容以及老师对我们得指导,能够较为熟练地掌握Newton迭代法、Jacobi迭代法、Gauss-Seidel 迭代法、Newton 插值法、Lagrange 插值法与Gauss 求积公式等六种算法得原理与使用方法,并参考课本例题进行了MATLAB程序得编写。
以下为本次上机实验报告,按照实验内容共分为六部分.实验一:一、实验名称及题目:Newton迭代法例2、7(P38):应用Newton迭代法求在附近得数值解,并使其满足、二、解题思路:设就是得根,选取作为初始近似值,过点做曲线得切线,得方程为,求出与轴交点得横坐标,称为得一次近似值,过点做曲线得切线,求该切线与轴得横坐标称为得二次近似值,重复以上过程,得得近似值序列,把称为得次近似值,这种求解方法就就是牛顿迭代法。
三、Matlab程序代码:function newton_iteration(x0,tol)syms z %定义自变量formatlong%定义精度f=z*z*z-z-1;f1=diff(f);%求导y=subs(f,z,x0);y1=subs(f1,z,x0);%向函数中代值x1=x0-y/y1; k=1;whileabs(x1—x0)〉=tolx0=x1;y=subs(f,z,x0);y1=subs(f1,z,x0);x1=x0-y/y1;k=k+1;endx=double(x1)K四、运行结果:实验二:一、实验名称及题目:Jacobi迭代法例3、7(P74):试利用Jacobi迭代公式求解方程组要求数值解为方程组得精确解、二、解题思路:首先将方程组中得系数矩阵分解成三部分,即:,为对角阵,为下三角矩阵,为上三角矩阵。
之后确定迭代格式,,(, 即迭代次数),称为迭代矩阵。
上机实验报告(精选11篇)

上机实验报告篇1用户名se××××学号姓名学院①实验名称:②实验目的:③算法描述(可用文字描述,也可用流程图):④源代码:(.c的文件)⑤用户屏幕(即程序运行时出现在机器上的画面):2.对c文件的要求:程序应具有以下特点:a可读性:有注释。
b交互性:有输入提示。
c结构化程序设计风格:分层缩进、隔行书写。
3.上交时间:12月26日下午1点-6点,工程设计中心三楼教学组。
请注意:过时不候哟!四、实验报告内容0.顺序表的插入。
1.顺序表的删除。
2.带头结点的单链表的\'插入。
3.带头结点的单链表的删除。
注意:1.每个人只需在实验报告中完成上述4个项目中的一个,具体安排为:将自己的序号对4求余,得到的数即为应完成的项目的序号。
例如:序号为85的同学,85%4=1,即在实验报告中应完成顺序表的删除。
2.实验报告中的源代码应是通过编译链接即可运行的。
3.提交到个人空间中的内容应是上机实验中的全部内容。
上机实验报告篇2一、《软件技术基础》上机实验内容1.顺序表的建立、插入、删除。
2.带头结点的单链表的建立(用尾插法)、插入、删除。
二、提交到个人10m硬盘空间的内容及截止时间1.分别建立二个文件夹,取名为顺序表和单链表。
2.在这二个文件夹中,分别存放上述二个实验的相关文件。
每个文件夹中应有三个文件(.c文件、.obj文件和.exe文件)。
3. 截止时间:12月28日(18周周日)晚上关机时为止,届时服务器将关闭。
三、实验报告要求及上交时间(用a4纸打印)1.格式:《计算机软件技术基础》上机实验报告用户名se××××学号姓名学院①实验名称:②实验目的:③算法描述(可用文字描述,也可用流程图):④源代码:(.c的文件)⑤用户屏幕(即程序运行时出现在机器上的画面):2.对c文件的要求:程序应具有以下特点:a 可读性:有注释。
b 交互性:有输入提示。
计算导论实验报告

一、实验目的1. 理解计算机科学的基本概念,掌握计算的基本原理。
2. 掌握算法设计的基本方法,提高算法分析能力。
3. 熟悉计算机编程语言,能够编写简单的计算程序。
二、实验内容1. 计算导论基础知识2. 算法设计与分析3. 计算机编程实现三、实验步骤1. 计算导论基础知识(1)学习计算机科学的基本概念,如计算机系统组成、信息处理过程、数据结构等。
(2)掌握计算机编程语言的基本语法和常用数据类型。
2. 算法设计与分析(1)学习算法设计的基本方法,如分治法、贪心法、动态规划等。
(2)掌握算法的时间复杂度和空间复杂度的分析方法。
(3)针对实际问题,设计合适的算法,并进行优化。
3. 计算机编程实现(1)选择一种编程语言(如Python、Java、C++等)进行编程。
(2)根据实验要求,编写计算程序,实现算法。
(3)调试程序,确保程序正确运行。
四、实验结果与分析1. 计算导论基础知识(1)掌握了计算机科学的基本概念,如计算机系统组成、信息处理过程、数据结构等。
(2)了解了计算机编程语言的基本语法和常用数据类型。
2. 算法设计与分析(1)学会了分治法、贪心法、动态规划等算法设计方法。
(2)能够分析算法的时间复杂度和空间复杂度。
(3)针对实际问题,设计并实现了高效的算法。
3. 计算机编程实现(1)掌握了编程语言的基本语法和常用数据类型。
(2)能够编写简单的计算程序,实现算法。
(3)通过调试程序,确保程序正确运行。
五、实验心得1. 通过本次实验,我对计算机科学的基本概念有了更深入的了解,认识到计算机科学在现代社会的重要性。
2. 在算法设计与分析方面,我学会了如何根据实际问题设计合适的算法,并分析算法的效率。
3. 在编程实现方面,我提高了自己的编程能力,学会了如何将算法转化为程序,并通过调试程序解决实际问题。
4. 本次实验让我体会到理论与实践相结合的重要性,只有将所学知识应用于实际,才能真正掌握。
六、实验建议1. 在实验过程中,应注重基础知识的学习,为后续实验打下坚实基础。
算法上机实验报告

实验名称:排序算法性能比较实验目的:1. 理解常见的排序算法及其原理。
2. 分析不同排序算法的时间复杂度和空间复杂度。
3. 通过实际编程实现排序算法,并进行性能比较。
实验环境:1. 操作系统:Windows 102. 编程语言:Python3.83. 开发环境:PyCharm实验内容:1. 实现冒泡排序、选择排序、插入排序、快速排序、归并排序和堆排序算法。
2. 对随机生成的数据集进行排序,比较不同算法的执行时间和稳定性。
3. 分析不同排序算法在不同数据规模下的性能差异。
实验步骤:1. 实现冒泡排序算法。
2. 实现选择排序算法。
3. 实现插入排序算法。
4. 实现快速排序算法。
5. 实现归并排序算法。
6. 实现堆排序算法。
7. 生成不同规模的数据集,对每个数据集使用上述算法进行排序。
8. 记录每个算法的执行时间,并进行比较。
9. 分析不同排序算法在不同数据规模下的性能差异。
实验结果与分析:一、冒泡排序冒泡排序是一种简单的排序算法,它重复地遍历要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。
遍历数列的工作是重复地进行,直到没有再需要交换,也就是说该数列已经排序完成。
冒泡排序的时间复杂度为O(n^2),空间复杂度为O(1)。
在数据规模较小的情况下,冒泡排序的性能较好。
二、选择排序选择排序是一种简单直观的排序算法。
它的工作原理是:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
以此类推,直到所有元素均排序完毕。
选择排序的时间复杂度为O(n^2),空间复杂度为O(1)。
在选择排序中,元素的移动次数较少,因此在某些情况下,选择排序的性能可能优于冒泡排序。
三、插入排序插入排序是一种简单直观的排序算法。
它的工作原理是:通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
插入排序的时间复杂度为O(n^2),空间复杂度为O(1)。
算法设计与分析上机实习报告

算法设计与分析上机实习报告姓名:学号:指导老师:1.分治法求解棋盘覆盖问题●问题描述:在一个2k×2k 个方格组成的棋盘中,恰有一个方格与其它方格不同,称该方格为一特殊方格,且称该棋盘为一特殊棋盘。
在棋盘覆盖问题中,要用图示的4种不同形态的L型骨牌覆盖给定的特殊棋盘上除特殊方格以外的所有方格,且任何2个L型骨牌不得重叠覆盖。
●算法思想:将棋盘分割为4个2k-1×2k-1的子棋盘。
对无特殊方格的3个子棋盘,在靠近中心的位置上各添一个特殊方格,转化为特殊棋盘。
对四个已成特殊子棋盘的棋盘进行同样处理●算法:#include<iostream>#define max 1000using namespace std;int Board[max][max];//最大数组int tile=1;//骨牌号码void ChessBoard(int tr,int tc,int dr,int dc,int size)//tr长,tc宽, dr,dc特殊方格位置,size大小{if(size == 1){return ;}int t =tile++,//L骨牌号码s=size/2;//左上角if(dr<tr+s && dc<tc+s)//方格在棋盘中{ChessBoard(tr,tc,dr,dc,s);}else//方格不在棋盘中{Board[tr+s-1][tc+s-1] =t;//在这部分中的右下角ChessBoard(tr,tc,tr+s-1,tc+s-1,s);}//右上角if(dr<tr+s && dc>=tc+s)//方格在棋盘中{ChessBoard(tr,tc+s,dr,dc,s);}else//方格不在棋盘中{Board[tr+s-1][tc+s]=t;ChessBoard(tr,tc+s,tr+s-1,tc+s,s);}//左下角if(dr>=tr+s && dc<tc+s)//方格在棋盘中{ChessBoard(tr+s,tc,dr,dc,s);}else//方格不在棋盘中{Board[tr+s][tc+s-1]=t;ChessBoard(tr+s,tc,tr+s,tc+s-1,s);}//右下角if(dr>=tr+s && dc>=tc+s)//方格在棋盘中{ChessBoard(tr+s,tc+s,dr,dc,s);}else//方格不在棋盘中{Board[tr+s][tc+s]=t;ChessBoard(tr+s,tc+s,tr+s,tc+s,s);}}int main(){for(int i=0;i<max;i++){for(int j=0;j<max;j++){Board[i][j]=0;}}int n,a,b;cin>>n;cin>>a>>b;a--;b--;//Board[0][0]=0;tile=1;//设置数目为1/*for(int i=0;i<n;i++){for(int j=0;j<n;j++){printf("%3d",Board[i][j]);}cout<<endl;}cout<<endl;*/ChessBoard(0,0,a,b,n);//初始骨牌在左上角,//tr长,tc宽, dr,dc特殊方格位置,size大小for(int i=0;i<n;i++){for(int j=0;j<n;j++){printf("%3d",Board[i][j]);}cout<<endl;}cout<<endl;return 0;}测试数据8*8的棋盘,特殊棋子在(2,2)上,结果为:2. 修改3.1节的算法,找出计算n 个矩阵之积的最少乘法数,并完成添括号过程。
西安电子科技大学算法上机报告

西安电子科技大学(2018年度)算法分析实验报告实验名称:渗透实验班级:1603012*名:**学号:***********实验一:渗透问题(Percolation)一、实验题目使用合并-查找(union-find)数据结构,编写程序通过蒙特卡罗模拟(Monte Carlo simulation)来估计渗透阈值的值。
给定由随机分布的绝缘材料和金属材料构成的组合系统:金属材料占多大比例才能使组合系统成为电导体?给定一个表面有水的多孔渗水地形(或下面有油),水将在什么条件下能够通过底部排出(或油渗透到表面)?科学家们已经定义了一个称为渗透(percolation)的抽象过程来模拟这种情况。
模型:我们使用N×N网格点来模型一个渗透系统。
每个格点或是open格点或是blocked格点。
一个full site是一个open格点,它可以通过一连串的邻近(左,右,上,下)open格点连通到顶行的一个open格点。
如果在底行中有一个full site格点,则称系统是渗透的。
(对于绝缘/金属材料的例子,open格点对应于金属材料,渗透系统有一条从顶行到底行的金属路径,且full sites格点导电。
对于多孔物质示例,open格点对应于空格,水可能流过,从而渗透系统使水充满open格点,自顶向下流动。
)问题:在一个著名的科学问题中,研究人员对以下问题感兴趣:如果将格点以空置概率p 独立地设置为open格点(因此以概率1-p被设置为blocked格点),系统渗透的概率是多少?当p = 0时,系统不会渗出; 当p=1时,系统渗透。
下图显示了20×20随机网格和100×100随机网格的格点空置概率p与渗滤概率。
当N足够大时,存在阈值p*,使得当p <p*,随机N⨯N网格几乎不会渗透,并且当p> p*时,随机N⨯N网格几乎总是渗透。
尚未得出用于确定渗滤阈值p*的数学解。
你的任务是编写一个计算机程序来估计p*。
中国科技大学算法导论_第一次实验报告

快速排序实验报告SA14225010一、题目当输入数据已经“几乎”有序时,插入排序速度很快。
在实际应用中,我们可以利用这一特点来提高快速排序的速度。
当对一个长度小于k的子数组调用快速排序时,让它不做任何排序就返回。
当上层的快速排序调用返回后,对整个数组运行插入排序来完成排序过程。
试证明:这一排序算法的期望时间复杂度为O (nk+nlg(n/k))。
分别从理论和实践的角度说明我们应该如何选择k?二、算法思想当输入数据已经“几乎”有序时,插入排序速度很快。
当对一个长度小于k的子数组调用快速排序时,让它不做任何排序就返回。
当上层的快速排序调用返回后,对整个数组运行插入排序来完成排序过程。
累加k的值,计算出当k为不同值时算法运行的时间,来算出当k大约为什么值时运行的时间最短,并与传统的快速排序算法的运行时间进行比较。
三、实验结果输入100个不同的整数值,选取不同的k的值,观察所用时间四、实验分析理论上看,k的值选取为20到25较好;但是,从实际上来看,当k为50左右时间为39毫秒,最少,但不同的时刻运行后的时间都不相同,而且不同的输入时刻的运行时间也不相同,当数据较大时候,对k 的值的选取有会有所不同,同时不同性能的机器对测试结果也不同,所以对于k值的选取没有固定的数值。
#include<iostream>#include<sys/timeb.h>using namespace std;#define M 40void swap(int * a,int * b){int tem;tem=*a;*a=*b;*b=tem;}int partition(int v[],const int low,const int high){int i,pivotpos,pivot;pivotpos=low;pivot=v[low];for(i=low+1;i<=high;++i){if(v[i]<pivot){pivotpos++;if(pivotpos!=i)swap(v[i],v[pivotpos]);}}v[low]=v[pivotpos];v[pivotpos]=pivot;//cout<<"the partition function is called\n";return pivotpos;}/*void QuickSort(int a[], const int low,const int high) {int item;if(low<high){item=partition(a,low,high);QuickSort(a,low,item-1);QuickSort(a,item+1,high);}}*/void QuickSort(int a[], const int low,const int high) {int item;if(high-low<=M)return;if(low<high){item=partition(a,low,high);QuickSort(a,low,item-1);QuickSort(a,item+1,high);}// cout<<"the QuickSort is called"<<endl;}void InsertSort(int a[],const int low,const int high){int i,j;int tem;for(i=1;i<high+1;++i){tem=a[i];j=i-1;while(j>=0&&tem<a[j]){a[j+1]=a[j];j--;}a[j+1]=tem;}//cout<<"the InsertSort is called"<<endl;}void HybridSort(int a[],const int low,const int high){QuickSort(a,low,high);InsertSort(a,low,high);cout<<"the HybidSort is called"<<endl;}int main(){int i,a[100];//int *a=NULL;long int t;struct timeb t1,t2;/*cout<<"please input the number of the element:"<<endl;cin>>n;a = (int*)malloc(n*sizeof(int));cout<<"please input every element:"<<endl;*/for( i=0; i<100; i++){a[i]=i+10;}//QuickSort(a,0,n-1);ftime(&t1);HybridSort(a,0,99);cout<<" after sorted quickly,the result is"<<endl;for(i=0; i<100; i++){cout<<a[i]<<" ";if(i%10==0)cout<<endl;}cout<<endl;ftime(&t2);t=(t2.time-t1.time)*1000+(litm); /* 计算时间差 */ printf("k=%d 用时%ld毫秒\n",M,t);//cout<<"the memory of array a is free"<<endl;//free(a);cout<<"\n"<<endl;return 0;}。
西安交通大学算法上机实验报告

《计算机算法设计与分析》上机实验报告姓名:班级:学号:日期:2016年12月23日算法实现题3-14 最少费用购物问题★问题描述:商店中每种商品都有标价。
例如,一朵花的价格是2元,一个花瓶的价格是5元。
为了吸引顾客,商店提供了一组优惠商品价。
优惠商品是把一种或多种商品分成一组,并降价销售。
例如,3朵花的价格不是6元而是5元。
2个花瓶加1朵花的优惠价格是10元。
试设计一个算法,计算出某一顾客所购商品应付的最少费用。
★算法设计:对于给定欲购商品的价格和数量,以及优惠价格,计算所购商品应付的最少费用。
★数据输入:由文件input.txt提供欲购商品数据。
文件的第1行中有1个整数B(0≤B≤5),表示所购商品种类数。
在接下来的B行中,每行有3个数C,K和P。
C表示商品的编码(每种商品有唯一编码),1≤C≤999;K表示购买该种商品总数,1≤K≤5;P是该种商品的正常单价(每件商品的价格),1≤P≤999。
请注意,一次最多可购买5*5=25件商品。
由文件offer.txt提供优惠商品价数据。
文件的第1行中有1个整数S(0≤S≤99),表示共有S种优惠商品组合。
接下来的S行,每行的第1个数描述优惠商品组合中商品的种类数j。
接着是j个数字对(C,K),其中C是商品编码,1≤C≤999;K表示该种商品在此组合中的数量,1≤K≤5。
每行最后一个数字P (1≤P≤9999)表示此商品组合的优惠价。
★结果输出:将计算出的所购商品应付的最少费用输出到文件output.txt。
输入文件示例输出文件示例Input.txt offer.txt output.txt2 2 147 3 2 1 7 3 58 2 5 2 7 1 8 2 10解:设cost(a,b,c,d,e)表示购买商品组合(a,b,c,d,e)需要的最少费用。
A[k],B[k],C[k],D[k],E[k]表示第k种优惠方案的商品组合。
offer (m)是第m种优惠方案的价格。
算法与程序设计上机报告
程序代码如下:
#include<stdio.h>
int A[1024]; //A[1024]是全程数组,其中存放待分类的元素
void interchange(int i,int j) //将A[i]与A[j]换位
{ int t;
t=A[i];
A[i]=A[j];
A[j]=t;
}
int partition(int m,int p) //用划分元素A[m]划分集合A(m:p-1),并返回划分元素定位后的位置
printf("input M:");
scanf("%d",&M); //输入背包容量
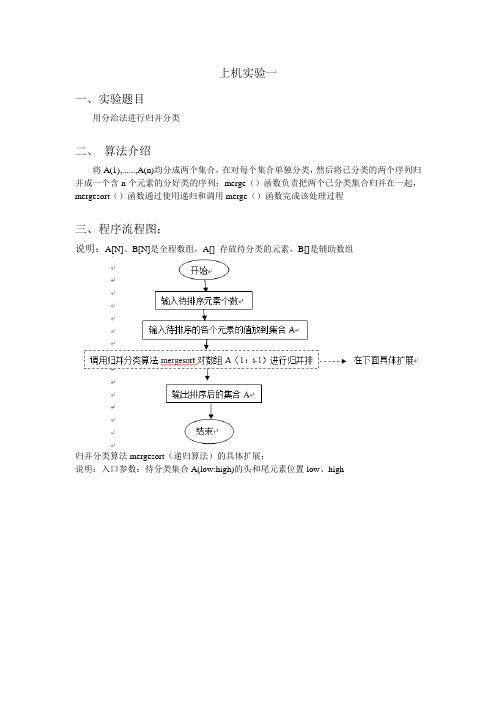
三、程序流程图
说明:A[1024]是全程数组,其中存放待分类的元素
快速分类算法quicksort(递归算法)的具体扩展如下:
说明:入口参数:集合A(p:q)的p、q
partition函数的具体扩展如下:
说明:入口参数:集合A(m:q)的头m和尾后一个位置q
出口参数:划分元素A[m]在集合A排序后的集合中的位置
四、源程序及实验结果程序代源自如下:#include<stdio.h>
int n; //n用于存放物品的数目
float A[1024]; //数组A[]存放待分类元素(在本问题中是指物品的单位容量增量)
float X[1024]; //数组X[]存放解向量,即各个物品在背包中的存放情况,0=<X[i]<=1
return p;
}
void quicksort(int p,int q) //快速分类(本算法为递归算法)
/*将全局数组A(1:n)中的元素A[p],.....,A[q]按递增的方式分类,认为A[n+1]已被定义,且不小于A(p:q)的所有元素,即A[n+1]为正无穷大(在主函数令正无穷大为1000)
c语言算法与程序设计的上机报告

c语言算法与程序设计的上机报告
C语言程序设计上机实践报告,在这之前,我们已经对c语言这门课程学习了差不多一个学期,对其有了一定的了解,但是也仅仅是停留在了解的范围,对里面的好多东西还是很陌生的,在运用起来的时候还是感到很棘手,毕竟,万事开头难嘛。
由于时间的关系,我们的这次实践课程老师并没有给我们详细的介绍,只是给我们简单的介绍了几个比较重要的实际操作。
对于程序设计语言的学习目的,可以概括为学习语法规定、掌握程序设计方法、提高程序开发能力。
这些都必须通过充分的实际上机操作才能完成。
学习c程序设计语言除了课堂讲授以外,必须保证有一定的上机时间。
因为学时所限,课程不能安排过多的统一上机实验,所以我们学生都很有效地利用课程上机实验的机会,尽快掌握用c语言开发程序的能力,为今后的继续学习打下一个良好的基础。
为此,我们结合课堂讲授的内容和进度,安排了多周的上机实验。
试验一:简单的C语言程序操作体会:运算符的种类可以分为算术运算符、关系运算符和逻辑运算符。
(整除)对int型、float型和double型变量都适用(取余数)运算符只适用开int型运算,不允许对浮点数)float或double)操作,对浮点型数进行操作会引起编绎错误。
算法上机实验报告

算法上机实验报告课程实验报告课程名称:算法设计与分析专业班级:信息安全1303学号:U201315182姓名:刘⽴鹏指导教师:王多强报告⽇期:2015-6-16计算机科学与技术学院⽬录⽬录 (2)实验⼀最近点对问题 (1)1.1实验内容与要求 (1)1.2算法设计 (1)1.3 实验结果与分析 (2)1.4编程技术与⽅法 (3)1.5 源程序及注释 (3)实验⼆⼤整数乘法 (8)2.1实验内容与要求 (8)2.2算法设计 (9)2.3 实验结果与分析 (12)2.4编程技术与⽅法 (12)2.5 源程序及注释 (12)实验三单源点 (14)3.1实验内容与要求 (14)3.2算法设计 (14)3.3 实验结果与分析 (14)3.4编程技术与⽅法 (16)3.5 源程序及注释 (16)实验四最优⼆分检索树 (19)4.1实验内容与要求 (19)4.2算法设计 (19)4.3实验结果与分析 (20)六、参考书⽬ (27)实验⼀最近点对问题1.1 实验内容与要求已知平⾯上分布着点集P 中的n 个点p 1,p 2,...p n ,点i 的坐标记为(x i ,y i ),1≤i≤n 。
两点之间的距离取其欧式距离,记为22)()(),(j i j i j i y y x x p p d -+-=问题:找出⼀对距离最近的点。
注:允许两个点位于同⼀个位置,此时两点之间的距离为0 要求:⽤分治法实现最近点对的问题。
1.2 算法设计(1)⾸先将所有的点按照x 坐标排序。
排序过程需要O(nlogn)的时间,不会从整体上增加时间复杂度的数量级。
(2)划分:由于点已经按x 坐标排序,所以空间上可以“想象” 画⼀条垂线,作为分割线,将平⾯上的点集分成左、右两半P L 和P R 。
如下图所⽰:d Ld CdR分割线P L P R记, d L:P L中的最近点对距离;d R:P R中的最近点对距离;d C:跨越分割线的最近点对距离。
计算方法与实习上机报告

计算方法与实习——上机报告学院:电子工程学院学号:姓名:刘波2015.1.4计算方法与实习上机报告习题一:1 舍入误差及稳定性一、实验目的(1)通过上机编程,复习巩固以前所学程序设计语言及上机操作指令;(2)通过上机计算,了解舍入误差所引起的数值不稳定性二、实验内容1、用两种不同的顺序计算1000021n n -=∑,分析其误差的变化 2、已知连分数()101223//(.../)n n a f b b a b a a b =++++,利用下面的算法计算f : 11,i n n i i i a d b d b d ++==+(1,2,...,0)i n n =-- 0f d = 写一程序,读入011,,,...,,,...,,n n n b b b a a 计算并打印f 3、给出一个有效的算法和一个无效的算法计算积分1041nn x y dx x =+⎰ (0,1,...,10)n = 4、设2211N N j S j ==-∑,已知其精确值为1311221N N ⎛⎫-- ⎪+⎝⎭ (1)编制按从大到小的顺序计算N S 的程序 (2)编制按从小到大的顺序计算N S 的程序(3)按两种顺序分别计算10001000030000,,,S S S 并指出有效位数三、实验步骤、程序设计、实验结果及分析1、用两种不同的顺序计算1000021n n -=∑,分析其误差的变化 (1)实验步骤:分别从1~10000和从10000~1两种顺序进行计算,应包含的头文件有stdio.h 和math.h(2)程序设计:a.顺序计算#include<stdio.h>#include<math.h>void main(){double sum=0;int n=1;while(1){sum=sum+(1/pow(n,2));if(n%1000==0)printf("sun[%d]=%-30f",n,sum);if(n>=10000)break;n++;}printf("sum[%d]=%f\n",n,sum);}b.逆序计算#include<stdio.h>#include<math.h>void main(){double sum=0;int n=10000;while(n!=0){sum=sum+(1/pow(n,2));if(n%200==0)printf("sum[%d]=%-10f",n,sum);if(n<1)break;n--;}printf("sum[%d]=%f\n",n,sum);}(3)实验结果及分析:程序运行结果:a.顺序计算b.逆序计算结果分析:两种不同顺序计算结果是一样的,顺序计算误差从一开始就很小,而逆序计算误差最开始十分大,后来结果正确。
《算法设计与分析》上机实验报告(2)

福州大学数学与计算机科学学院《计算机算法设计与分析》上机实验报告(2)4.根据计算最优值时得到的信息,构造最优解3.算法正确性证明对于矩阵连乘积的最优计算次序问题,设计算A[ i : j ],1<=i<=j<=n,所需的最少数乘次数为m[ i ][ j ],则原问题的最优值为m[ 1 ][ n]。
当i=j时,A[ i ; j ]=Ai,为单一矩阵,无需计算,因此m[ i ][ i ]=0。
当i < j时,可以利用最优子结构的性质来计算m[ i ][ j ]。
事实上,若计算A[ i : j ]的最优次序在Ak和Ak+1之间断开,i<=k<j,则m[ i ][ j ]=m[ i ][ k ]+m[k+1][ j ]+Pi-1*Pk*Pj。
其中Pi表示第i个矩阵的列数,也是第i-1个矩阵的行数,P0表示第一个矩阵的行数。
由于在计算时并不知道断开点k的位置,所以k还未定。
不过k的位置只有j-i个可能。
从而m[ i ][ j ]可以递归地定义为当i=j m[ i ][ j ] = 0当i<j m[ i ][ j ] = min{ m[ i ][ k ]+m[ k+1 ][ j ]+Pi-1*Pk*Pj }m[ i ][ j ]给出了最优值,即计算A[ i : j ]所需的最少数乘次数。
同时还确定了计算A[ i : j ]的最优次序中的断开位置k,也就是说,对于这个k有m[ i ][ j ]=m[ i [ k ]+m[ k+1 ][ j] + Pi-1*Pk*Pj若将对应于m[ i ][ j ]的断开位置k记为s[ i ][ j ],在计算最优值m[ i ][ j ]后,可以递归地有s[ i ][ j ]构造出相应的最优解。
根据计算m[ i ][ j ]的递归式,容易写一个递归算法计算m[ 1 ][ n ]。
但是简单地递归将好费指数计算时间。
在递归计算时,许多子问题被重复计算多次。
算法导论上机报告

算法导论上机报告班级: 1313012学号:姓名:黄帮振描述一个运行时间为θ(nlgn)的算法给定n个整数的集合S和另一个整数x该算法能确定S中是否存在两个其和刚好为x的元素。
一、算法分析1、运用归并排序算法归并排序运用的是分治思想,时间复杂度为θ(nlgn)能够满足题目要求的运行时间。
归并排序的分解部分是每次将数组划分两个部分,时间复杂度为θ(1)再对已经分解的两个部分再进行分解直到将数组分解成单个元素为止。
解决部分是递归求解排序子序列,合并部分是将已经排序的子序列进行合并得到所要的答案,时间复杂度为θ(lgn)。
2、在已经排好序的基础上,对其运用二分查找二分查找算法的时间复杂度为θ(lgn)在题目要求的范围内,二分查找的条件为待查的数组为有序序列。
算法的主要思想为设定两个数low指向最低元素high指向最高元素,然后比较数组中间的元素与待查元素进行比较。
如果待查元素小于中间元素,那么表明查找元素在数组的前半段,反之,如果待查元素大于中间元素,那么表明查找元素在数组的后半段。
实现优先队列排序算法,需要支持以下操作:INSERT(S,x):把元素x插入到集合S中MAXMUM(S):返回S中具有最大key的元素EXTRACT-MAX(S):去掉并返回S中的具有最大key的元素INCREASE-KEY(S,x,k):将元素x的关键字值增到k。
一、算法原理快速排序采用分治策略,时间复杂度为θ(nlgn),但是最坏情况下为θ(n2),并且快速排序算法属于原地排序,并不需要开辟空间。
快速排序复杂的步骤为其分解的步骤分解的过程数组A[p..r]被划分为两个子数组A[p..q-1]和A[q+1..r],使得A[p..q-1]中的每个元素都小于A[q],而A[q]也小于等于A[q+1..r]中的每个元素。
而在实现的过程总是选择将A[r]作为基准点进行划分A[p..r]数组。
二、伪代码QUICKSORT(A,p,r)1 if p < r2 q = PARTITION(A,p,q)3 QUICKSORT(A,p,q-1)4 QUICKSORT(A,q+1,r)PARTITION(A,p,r)1 x = A[r]2 i = p-13 for j = p to r-14 if A[j]?x5 i = i+16 exchange A[i] with A[j]7 exchange A[i+1] with A[r]8 return i + 1三、实验总结问题答案:当选取第一个或者最后一个为基准点时,当n个元素相同的时候为最坏情况比较次数为n*(n-1)/2;快速排序比较次数最少为θ(nlgn),,最大的比较次数为θ(n2)。
西电软院算法上机报告

算法上机报告学号:13121234姓名:陈恒实验一一、实验内容1.编写程序实现书上2.3.7:运行时间为nlgn的算法确定n个整数的集合中是否存在两个数的和刚好为x。
先对n个整数的集合进行排序。
使用快速排序,时间复杂度即是nlgn,然后计算两数之和,可以知道快速排序(从小到大)后第一个元素begin为最小,最后一个元素end最大。
所以用最小和最大相加和x比较,大于x即是end太大,小于x就是begin太小。
一直循环直到begin==end时还没有就不存在了。
2.实现优先级队列。
用堆排序和一个结构体实现即可。
Java实现用类代替结构体。
并未编写测试用例。
3.实现快速排序。
问题1就是快速排序。
最大数比较是有序的数组,例如123456789.最小的比较是每次partition都能分成恰好两半,例如132。
n个相同的数快排比较计算次数n*(n-1)/2.原理:每次分一半都要从头到尾(比较n-1次)比较一次,最后分到每组只有2个为止(即是分n/2次)。
4.找两个已排序不同数组之间第k大的数。
有a,b两个数组。
把 A ,B平均分为前后两个部分,前部分有 x 个元素,后部分有 n-x 个元素(比如,由于 A 是有序的,所以后一部分的所有元素大于前一部分)。
A[x] = A的后一部分的第一个元素)。
然后使用分枝-限界法和递归。
每次比较k和a.size/2+b.size/2以及a[x]于b[x]的大小。
进而缩小其中一个数组一半大小。
实验截图:第一个:题目1和3 第二个:题目4,优先级队列没有写主方法二、实验心得本次实验对排序几个关键算法进行了实现,还练习了别的几个问题。
本来算法是很简单的,但是由于数组下标的原因总是出现越界问题。
说明在具体编程的时候还缺乏思考,需要多加训练。
还有就是选择分支的时候需要写下来不然光去想是很难把情况完全列出来的。
实验二一、实验内容以动态规划算法解决以下几个问题动态规划思想是找到并求解问题的最优子结构,然后递归定义最优子结构,再用自底向上的方法去构建一张表,最后用查表找到解。
西安交通大学 计算方法上机报告

计算方法上机报告姓名:学号:班级:机械硕4002上课班级:02班说明:本次上机实验使用的编程语言是Matlab 语言,编译环境为MATLAB 7.11.0,运行平台为Windows 7。
1. 对以下和式计算:∑∞⎪⎭⎫ ⎝⎛+-+-+-+=0681581482184161n n n n S n,要求:① 若只需保留11个有效数字,该如何进行计算; ② 若要保留30个有效数字,则又将如何进行计算;(1) 算法思想1、根据精度要求估计所加的项数,可以使用后验误差估计,通项为: 142111416818485861681n n n a n n n n n ε⎛⎫=---<< ⎪+++++⎝⎭; 2、为了保证计算结果的准确性,写程序时,从后向前计算; 3、使用Matlab 时,可以使用以下函数控制位数: digits(位数)或vpa(变量,精度为数)(2)算法结构1. ;0=s⎪⎭⎫⎝⎛+-+-+-+=681581482184161n n n n t n; 2. for 0,1,2,,n i =⋅⋅⋅ if 10m t -≤end;3. for ,1,2,,0n i i i =--⋅⋅⋅;s s t =+(3)Matlab源程序clear; %清除工作空间变量clc; %清除命令窗口命令m=input('请输入有效数字的位数m='); %输入有效数字的位数s=0;for n=0:50t=(1/16^n)*(4/(8*n+1)-2/(8*n+4)-1/(8*n+5)-1/(8*n+6));if t<=10^(-m) %判断通项与精度的关系break;endend;fprintf('需要将n值加到n=%d\n',n-1); %需要将n值加到的数值for i=n-1:-1:0t=(1/16^i)*(4/(8*i+1)-2/(8*i+4)-1/(8*i+5)-1/(8*i+6));s=s+t; %求和运算ends=vpa(s,m) %控制s的精度(4)结果与分析当保留11位有效数字时,需要将n值加到n=7,s =3.1415926536;当保留30位有效数字时,需要将n值加到n=22,s =3.14159265358979323846264338328。
算法导论学习报告

算法设计与分析学习报告第一部分学习内容归纳“计算机算法是以一步接一步的方式来详细描述计算机如何将输入转化为所要求的输出的过程,或者说,算法是对计算机上执行的计算过程的具体描述。
”(参考文献:百度百科)《算法设计与分析》是一门面向设计,在计算机科学中处于核心地位的课程。
这门课程主要讲授了在计算机应用中经常遇到的问题和求解的方法,分治法、动态规划法、随机算法等设计算法的基本原理、技巧和算法复杂性的分析,以及计算理论简介。
第一部分“概论和数学准备”在简单了解了算法的基本概念和复杂性、研究步骤等几个重要知识点后,着重学习了算法的数学基础,包括生成函数、差方方程的求解等,主要适用于求解算法的时间复杂性。
“任何可以用计算机求解的问题所需要的计算时间都与其规模有关:问题的规模越小,解题所需的计算时间往往也越短,从而也就比较容易处理。
”(参考文献:《计算机算法设计与分析(第3版)》)而第二部分介绍的算法常用技术之首——分治法就运用了这样的思想。
分治法的要领在于Divide(子问题的划分)-Conquer(子问题的求解)-Combine(子问题解的组合)。
由于子问题和原问题是同类的,递归的思想在分治法中显得尤其重要,它们经常同时运用在算法设计中。
这部分内容从Select(求第k小元)算法,寻找最近点对算法和快速傅立叶变换FFT等实际应用中深化对分治法思想的理解,同时也强调了平衡思想的重要性。
第三部分“动态规划”与分治法类似,同样是把问题层层分解成规模越来越小的同类型的子问题。
但与分治法不同的是,分治法中的子问题通常是相互独立的,而动态规划法中的子问题很多都是重复的,因此通常采用递推的方法以避免重复计算。
然而,也不是所有的情况下都采用递推法,当有大量的子问题无需求解时,更好的方式是采用动态规划法的变形——备忘录方法。
通常需要用到动态规划法求解的问题都具有子问题的高度重复性和最优子结构性质两大特征,这也是我们分析问题和设计算法时的关键点。
《算法设计与分析》上机实验报告(5)

福州大学数学与计算机科学学院《算法设计与分析》上机实验报告(5)的长度小于当前最优路径长度,则将该顶点作为活结点插入到活结点优先队列中。
这个结点的扩展过程一直继续到活结点优先队列为空时为止。
3.剪枝策略在算法扩展结点的过程中,一旦发现一个结点的下界不小于当前找到的最短路长,则算法剪去以该结点为根的子树。
在算法中,利用结点间的控制关系进行剪枝。
从源顶点s 出发,2条不同路径到达图G的同一顶点。
由于两条路径的路长不同,因此可以将路长长的路径所对应的树中的结点为根的子树剪去。
4.单源最短路径问题程序代码1、MinHeap2.h1.#include <iostream>2.3.template<class Type>4.class Graph;5.6.template<class T>7.class MinHeap8.{9.template<class Type>10.friend class Graph;11.public:12. MinHeap(int maxheapsize = 10);13. ~MinHeap(){delete []heap;}14.15.int Size() const{return currentsize;}16. T Max(){if(currentsize) return heap[1];}17.18. MinHeap<T>& Insert(const T& x);19. MinHeap<T>& DeleteMin(T &x);20.21.void Initialize(T x[], int size, int ArraySize);22.void Deactivate();23.void output(T a[],int n);24.private:25.int currentsize, maxsize;26. T *heap;27.};28.29.template <class T>30.void MinHeap<T>::output(T a[],int n)31.{32.for(int i = 1; i <= n; i++)33. cout << a[i] << " ";34. cout << endl;35.}36.37.template <class T>38.MinHeap<T>::MinHeap(int maxheapsize)39.{40. maxsize = maxheapsize;41. heap = new T[maxsize + 1];42. currentsize = 0;43.}44.45.template<class T>46.MinHeap<T>& MinHeap<T>::Insert(const T& x)47.{48.if(currentsize == maxsize)49. {50.return *this;51. }52.int i = ++currentsize;53.while(i != 1 && x < heap[i/2])54. {55. heap[i] = heap[i/2];56. i /= 2;57. }59. heap[i] = x;60.return *this;61.}62.63.template<class T>64.MinHeap<T>& MinHeap<T>::DeleteMin(T& x)65.{66.if(currentsize == 0)67. {68. cout<<"Empty heap!"<<endl;69.return *this;70. }71.72. x = heap[1];73.74. T y = heap[currentsize--];75.int i = 1, ci = 2;76.while(ci <= currentsize)77. {78.if(ci < currentsize && heap[ci] > heap[ci + 1])79. {80. ci++;81. }82.83.if(y <= heap[ci])84. {85.break;86. }87. heap[i] = heap[ci];88. i = ci;89. ci *= 2;90. }91.92. heap[i] = y;93.return *this;94.}96.template<class T>97.void MinHeap<T>::Initialize(T x[], int size, int ArraySize)98.{99.delete []heap;100. heap = x;101. currentsize = size;102. maxsize = ArraySize;103.104.for(int i = currentsize / 2; i >= 1; i --)105. {106. T y = heap[i];107.int c = 2 * i;108.while(c <= currentsize)109. {110.if(c < currentsize && heap[c] > heap[c + 1])111. c++;112.if(y <= heap[c])113.break;114. heap[c / 2] = heap[c]; 115. c *= 2;116. }117. heap[c / 2] = y;118. }119.}120.121.template<class T>122.void MinHeap<T>::Deactivate()123.{124. heap = 0;125.}2、zuiduanlujing.cpp1.//单源最短路径问题分支限界法求解2.#include "stdafx.h"3.#include "MinHeap2.h"4.#include <iostream>5.#include <fstream>ing namespace std;7.8.ifstream fin("6d2.txt");9.10.template<class Type>11.class Graph12.{13.friend int main();14.public:15.void ShortesPaths(int);16.private:17.int n, //图G的顶点数18. *prev; //前驱顶点数组19. Type **c, //图G的领接矩阵20. *dist; //最短距离数组21.};22.23.template<class Type>24.class MinHeapNode25.{26.friend Graph<Type>;27.public:28. operator int ()const{return length;}29.private:30.int i; //顶点编号31. Type length; //当前路长32.};33.34.template<class Type>35.void Graph<Type>::ShortesPaths(int v)//单源最短路径问题的优先队列式分支限界法36.{37. MinHeap<MinHeapNode<Type>> H(1000);38. MinHeapNode<Type> E;39.40.//定义源为初始扩展节点41. E.i=v;42. E.length=0;43. dist[v]=0;44.45.while (true)//搜索问题的解空间46. {47.for (int j = 1; j <= n; j++)48.if ((c[E.i][j]!=0)&&(E.length+c[E.i][j]<dist[j])) {49.50.// 顶点i到顶点j可达,且满足控制约束51. dist[j]=E.length+c[E.i][j];52. prev[j]=E.i;53.54.// 加入活结点优先队列55. MinHeapNode<Type> N;56. N.i=j;57. N.length=dist[j];58. H.Insert(N);59. }`60.try61. {62. H.DeleteMin(E); // 取下一扩展结点63. }64.catch (int)65. {66.break;67. }68.if (H.currentsize==0)// 优先队列空69. {70.break;71. }73.}74.75.int main()76.{77.int n=11;78.int prev[12] = {0,0,0,0,0,0,0,0,0,0,0,0};79.80.int dist[12]={1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000,1000};81.82. cout<<"单源图的邻接矩阵如下:"<<endl;83.int **c = new int*[n+1];84.85.for(int i=1;i<=n;i++)86. {87. c[i]=new int[n+1];88.for(int j=1; j<=n; j++)89. {90. fin>>c[i][j];91. cout<<c[i][j]<<" ";92. }93. cout<<endl;94. }95.96.int v=1;97. Graph<int> G;98. G.n=n;99.100. G.c=c;101. G.dist=dist;102. G.prev=prev;103. G.ShortesPaths(v);104.105. cout<<"从S到T的最短路长是:"<<dist[11]<<endl;106.for (int i = 2; i <= n; i++)108. cout<<"prev("<<i<<")="<<prev[i]<<""<<endl;109. }110.111.for (int i = 2; i <= n; i++)112. {113. cout<<"从1到"<<i<<"的最短路长是:"<<dist[i]<<endl;114. }115.116.for(int i=1;i<=n;i++)117. {118.delete []c[i];119. }120.121.delete []c;122. c=0;123.return 0;124.}。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
算法导论上机报告班级: 1313012学号:姓名: 黄帮振描述一个运行时间为θ(nlgn)的算法给定n个整数的集合S与另一个整数x该算法能确定S中就是否存在两个其与刚好为x的元素。
一、算法分析1、运用归并排序算法归并排序运用的就是分治思想,时间复杂度为θ(nlgn)能够满足题目要求的运行时间。
归并排序的分解部分就是每次将数组划分两个部分,时间复杂度为θ(1)再对已经分解的两个部分再进行分解直到将数组分解成单个元素为止。
解决部分就是递归求解排序子序列,合并部分就是将已经排序的子序列进行合并得到所要的答案,时间复杂度为θ(lgn)。
2、在已经排好序的基础上,对其运用二分查找二分查找算法的时间复杂度为θ(lgn)在题目要求的范围内,二分查找的条件为待查的数组为有序序列。
算法的主要思想为设定两个数low指向最低元素high指向最高元素,然后比较数组中间的元素与待查元素进行比较。
如果待查元素小于中间元素,那么表明查找元素在数组的前半段,反之,如果待查元素大于中间元素,那么表明查找元素在实现优先队列排序算法,需要支持以下操作:INSERT(S,x):把元素x插入到集合S中MAXMUM(S):返回S中具有最大key的元素EXTRACT-MAX(S):去掉并返回S中的具有最大key的元素INCREASE-KEY(S,x,k):将元素x的关键字值增到k。
一、算法原理快速排序采用分治策略,时间复杂度为θ(nlgn),但就是最坏情况下为θ(n2),并且快速排序算法属于原地排序,并不需要开辟空间。
快速排序复杂的步骤为其分解的步骤分解的过程数组A[p、、r]被划分为两个子数组A[p、、q-1]与A[q+1、、r],使得A[p、、q-1]中的每个元素都小于A[q],而A[q]也小于等于A[q+1、、r]中的每个元素。
而在实现的过程总就是选择将A[r]作为基准点进行划分A[p、、r]数组。
二、伪代码QUICKSORT(A,p,r)1 if p < r2 q = PARTITION(A,p,q)3 QUICKSORT(A,p,q-1)4 QUICKSORT(A,q+1,r)PARTITION(A,p,r)1 x = A[r]2 i = p-13 for j = p to r-14 if A[j] x5 i = i+16 exchange A[i] with A[j]7 exchange A[i+1] with A[r]8 return i + 1三、实验总结问题答案:当选取第一个或者最后一个为基准点时,当n个元素相同的时候为最坏情况比较次数为n*(n-1)/2;快速排序比较次数最少为θ(nlgn),,最大的比较次数为θ(n2)。
运用分治的策略将两个已经排好序的序列中,找出第k大的元素且要求时间复杂度为θ(lgm+lgn),其中m与n分别为两个序列的长度。
一、算法原理1最优子结构为:如果最优的加括号的方式将其分解为Ai、、k与Ak+1、、j的乘积则分别对Ai、、k与Ak+1、、j加括号的方式也一定就是最优的。
2定义m[i,j]为计算矩阵Ai、、j所需标量乘法次数的最小值,对于i=j时,矩阵链乘只包含唯一的矩阵Ai,因此不需要做任何标量乘法运算,所以m[i,i]=0;当i<j时利用最优子结构来计算m[i,j]。
3矩阵链乘的递归式4在算法设计的时候需要m数组记录Ai、、j最小相乘次数,s数组记录构造最优解所需要的信息,其记录的k值指出了AiAi+1Aj的最优括号化方案的分割点应在AkAk+1之间。
5 矩阵链乘的时间复杂度为θ(n3)二、伪代码MATRIX-CHAIN-ORDER(p)1、n=p、length-12、Let m[1、、n,1、、n] and s[1、、n-1,2、、n] be new tables3、For i=1 to n4、 M[i,i]=05、for l=2 to n6、 For i=1 to n-l+17、 J=i+l-18、 M[i,j]=无穷9、 For k=i to j-110、 Q=m[i,k]+m[k+1,j]+p(i-1)*p(k)*p(j)11、 If q<m[i,j]12、 M[i,j]=q13、 S[i,j]=k一、算法原理1最优子结构:令X=<x1,x2,、、xm>与Y=<y1,y2,、、、,yn>为两个序列Z=<z1,z2,、、、,zk>为X与Y的任意LCS。
如果xm=yn,则zk=xm=yn且Zk-1就是Xm-1与Yn-1的一个LCS;如果xm≠yn,则zk≠xm意味着Z就是Xm-1与Y的一个LCS;如果xm ≠yn,则zk≠yn意味着Z就是X与Yn-1的一个LCS。
2定义一个b[i,j]指向表项对应计算c[i,j]时所选择的子问题最优解,过程返回表b与表c,c[m,n]保持X与Y的LCS长度。
3LCS的递归式为4LCS的时间复杂度为θ(m+n),b表的空间复杂度为θ(mn)。
二、伪代码LCS-LENGTH(X,Y)1.m=X、length2.n=Y、length3.Let b[1、、m,1、、n] and c[0、、m,0、、n] be new tables4.For i=1 to m5. c[i,0]=06.For j=0 to n7. c[0,j]=08.For i=1 to m9. For j=1 to n一、算法原理1最优子结构令X=<x1,x2,、、xm>与Y=<y1,y2,、、、,yn>为两个序列Z=<z1,z2,、、、,zk>为X与Y的任意最长公共子串。
如果xm=yn,则zk=xm=yn且Zk-1就是Xm-1与Yn-1的一个最长公共子串; 如果xm≠yn,则zk≠xm意味着Z就是Xm-1与Y的一个最长公共子串;如果xm≠yn,则zk≠yn意味着Z就是X与Yn-1的一个最长公共子串。
2定义L[i,j]为以x[i]与y[j]为结尾的相同子串的最大长度,记录着X与Y的最长公共子串的最大长度。
3最长公共子串的递归式4最长公共子串的时间复杂度为θ(mn),空间复杂度为θ(mn)。
二、伪代码getLCString(str1,tr2)len1 = str1、length;len2 = str2、length;maxLen = len1 > len2 ? len1 : len2;for j to maxLenif max[j] > 0Print j + 1for i = maxIndex[j] - max[j] + 1 to maxIndex[j]Print str1[i]三、实验总结要同上述的最长公共子序列进行对比区分她们的不同之处。
也要理解用动态规划求解时的相同之处与不同之处。
一、算法原理1 最优子结构:定义当所给整数全为负数的时候,最大子段与为0,则最大子段与为max{0,a[i]+a[i+1]、、、+a[j]},1≤i≤j≤n2 引入一个辅助数组b,动态规划的分解分为两步:(1)计算辅助数组的值;(2)计算辅助数组的最大值。
辅助数组b[j]用来记录以j为尾的子段以及集合中的最大子段与。
3 最大子段与的递归式一、算法原理1可以由图可知,图中的顶点讲图划分7个阶段,分别了解每个阶段可以有几种可供选择的点,引入f[k]表示状态k到终点状态的最短距离。
最优子结构为当前状态的f[k]由上个状态的f[k-1]与状态k-1到状态k的距离决定决策:当前状态应在前一个状态的基础上获得。
决策需要满足规划方程,规划方程f(k)表示状态k到终点状态的最短距离。
2多段图最短路径的递归式二、伪代码Shortestpathlet indexs [0、、W1[0]、length],isLabel [0、、W1[0]、length] be a new table i_count = -1distance = W1[start]index = startpresentShortest = 0indexs[++i_count] = index;isLabel[index] = true;while i_count<W1[0]、lengthmin = Integer、MAX_VALUE;for i = 0 to distance、lengthif !isLabel[i] and distance[i] != -1 and i != indexif distance[i] < minmin = distance[i]index = iif index == end一、算法原理10-1背包问题:选择n个元素中的若干个来形成最优解,假定为k个。
对于这k个元素a1, a2, 、、、ak来说,它们组成的物品组合必然满足总重量<=背包重量限制,而且它们的价值必然就是最大的。
假定ak就是我们按照前面顺序放入的最后一个物品,它的重量为wk,它的价值为vk。
前面k个元素构成了最优选择,把ak物品拿走,对应于k-1个物品来说,它们所涵盖的重量范围为0-(W-wk)。
假定W为背包允许承重的量,最终的价值就是V,剩下的物品所构成的价值为V-vk。
这剩下的k-1个元素构成了W-wk的最优解。
2分数背包问题:所选择的的贪心策略为按照选择单位重量价值最大的物品顺序进行挑选。
算法的步骤:设背包容量为C共有n个物品物品重量存放在数组W[n]中价值存放在数组V[n]中问题的解存放在数组X[n]中。
第一步,改变数组W与V的排列顺序使其按单位重量价值V[i]/W[i]降序排列,并将数组X[n]初始化为0;第二步初始化i=0,设计一个循环,循环终止条件为W[i]>C,循环体为将第i个物品放入背包,X[i]=1;C=C-W[i];i++最后一步将结果存入到X数组中X[i]=C/W[i]。
3 分数背包问题采用选择单位重量价值最大的物品顺序进行挑选,其算法的时间复杂度为θ(nlgn)。
4 背包问题的递归式:f[i][v]=max{f[i-1][v],f[i-1][v-c[i]]+w[i]}二、伪代码Knapsack01(v,w,weight)1.n=w、length2.let c[0、、n,0、、weight] be a new table3.For i=0 to n4. c[i,0]=05.For j=1 to weight6. c[0,j]=0Bellman-Ford算法通过对边进行松弛操作来渐近地降低从源点A到每个结点的最短路径的估计值,直到该估计值与实际的最短路径权重相同为止。
该算法返回TRUE值当且仅当输入图中不包含可以从源结点到达的权重为负值的环路。
Bellman-Ford算法的执行步骤:1、初始化:将除源点外的所有顶点的最短距离估计值d[v]←+∞, d[s]←0;2、迭代求解:反复对边集E中的每条边进行松弛操作,使得顶点集V中的每个顶点v的最短距离估计值逐步逼近其最短距离,运行|v|-1次;3、检验负权回路,判断边集E中的每一条边的两个端点就是否收敛。