ForeSpider教程之如何爬取位置不固定的图片
Python网络爬虫定向爬取与智能化抓取技巧

Python网络爬虫定向爬取与智能化抓取技巧网络爬虫是一种自动获取互联网上信息的程序,而Python作为一门强大的编程语言,提供了丰富的库和工具来实现网络爬虫的功能。
本文将介绍Python网络爬虫的定向爬取和智能化抓取技巧。
一、定向爬取定向爬取是指针对特定的网站或特定的内容进行爬取,而不是对整个互联网进行全面抓取。
Python提供了许多库,如requests、BeautifulSoup等,可以帮助我们实现定向爬取。
1. 确定爬取目标在进行定向爬取之前,我们首先需要确定爬取的目标。
这包括确定要爬取的网站、页面和需要获取的信息。
通过分析网站的结构和页面的内容,我们可以确定需要使用的爬取策略和技术手段。
2. 发送HTTP请求使用Python的requests库,我们可以发送HTTP请求来获取网页的内容。
通过设置相应的请求头和参数,我们可以模拟浏览器的行为,绕过网站的反爬机制。
3. 解析网页内容获取网页内容后,我们需要解析其中的信息。
使用BeautifulSoup库可以方便地处理和解析HTML和XML等类型的网页内容。
通过标签选择器、属性选择器和文本选择器等方法,我们可以定位和提取我们所需的信息。
4. 存储数据爬取到的数据需要进行存储,以供后续分析和使用。
我们可以将数据存储到数据库中,如MySQL、MongoDB等,或者存储到本地文件中,如CSV、Excel等格式。
二、智能化抓取智能化抓取是指根据网站的内容和结构,通过智能化的算法和机制来进行数据抓取。
Python提供了一些强大的库和工具,如Scrapy、Selenium等,可以实现智能化抓取的功能。
1. 使用Scrapy框架Scrapy是一个功能强大的Python爬虫框架,它提供了高度可定制化和可扩展的架构,适用于各种网站和爬取任务。
通过编写Scrapy的Spider和Item Pipeline,我们可以定义爬取的规则和流程,实现自动化抓取。
2. 动态网页的抓取一些网站使用了动态网页技术,其内容是通过JavaScript动态加载的,无法通过普通的HTML解析方式获取到。
Python网络爬虫中的地理信息数据抓取与分析

Python网络爬虫中的地理信息数据抓取与分析地理信息数据在当今社会中的重要性不断增加,随着互联网的发展,获取地理信息数据的需求也越来越迫切。
Python作为一种简单、易学的编程语言,被广泛应用于网络爬虫的开发与数据分析。
本文将介绍如何利用Python网络爬虫技术来抓取地理信息数据并进行分析。
一、地理信息数据的抓取要进行地理信息数据的抓取,我们首先需要明确目标网站。
以某个城市的房地产信息为例,我们可以选择国内的房产网站,如链家网、安居客等。
接下来,我们需要分析目标网站的页面结构,确定我们需要抓取的数据所在的位置。
通常,我们可以使用网页解析库(如BeautifulSoup、Scrapy等)来提取网页中的数据。
在进行抓取之前,我们需要了解目标网站是否允许爬虫访问。
有些网站会设置反爬虫机制,对爬虫进行限制。
为了避免被封禁,我们可以设置爬虫的访问频率,模拟浏览器行为,或者通过使用代理IP来进行访问。
针对地理信息数据的抓取,我们可以考虑以下几个方面:1. 获取地理位置信息:通过爬取目标网站上的地图信息或者地址信息,获取地理位置的经纬度坐标。
可以使用地理编码库(如geopy、百度地图API等)来实现坐标的获取。
2. 抓取空气质量数据:通过爬取气象网站或者相关政府机构的网站,获取空气质量数据。
可以使用网络爬虫库(如requests、Scrapy等)发送HTTP请求获取数据,并使用正则表达式或者XPath来提取所需信息。
3. 抓取地理相关的新闻和热点:通过爬取新闻网站或者社交媒体平台,获取与地理相关的新闻和热点话题。
可以使用第三方API(如新浪微博API、知乎API等)来获取对应的数据。
二、地理信息数据的分析抓取到地理信息数据后,我们可以对其进行进一步的分析。
Python提供了丰富的数据分析库(如Pandas、Numpy、Matplotlib等),可以帮助我们进行数据处理、可视化和统计分析。
1. 数据清洗与处理:在进行数据分析之前,我们需要对数据进行清洗和处理,以确保数据的质量和可用性。
网站数据爬取方法

网站数据爬取方法随着互联网的蓬勃发展,许多网站上的数据对于研究、分析和商业用途等方面都具有重要的价值。
网站数据爬取就是指通过自动化的方式,从网站上抓取所需的数据并保存到本地或其他目标位置。
以下是一些常用的网站数据爬取方法。
1. 使用Python的Requests库:Python是一种功能强大的编程语言,具有丰富的第三方库。
其中,Requests库是一个非常常用的库,用于发送HTTP请求,并获取网页的HTML内容。
通过对HTML内容进行解析,可以获取所需的数据。
2. 使用Python的Scrapy框架:Scrapy是一个基于Python的高级爬虫框架,可以帮助开发者编写可扩展、高效的网站爬取程序。
通过定义爬虫规则和提取规则,可以自动化地爬取网站上的数据。
3. 使用Selenium库:有些网站使用了JavaScript来加载数据或者实现页面交互。
对于这类网站,使用传统的爬虫库可能无法获取到完整的数据。
这时可以使用Selenium库,它可以模拟人为在浏览器中操作,从而实现完整的页面加载和数据获取。
4.使用API:许多网站为了方便开发者获取数据,提供了开放的API接口。
通过使用API,可以直接获取到所需的数据,无需进行页面解析和模拟操作。
5. 使用网页解析工具:对于一些简单的网页,可以使用网页解析工具进行数据提取。
例如,使用XPath或CSS选择器对HTML内容进行解析,提取所需的数据。
6.使用代理IP:一些网站为了保护自身的数据安全,采取了反爬虫措施,例如设置访问速度限制或者封锁IP地址。
为了避免被封禁,可以使用代理IP进行爬取,轮流使用多个IP地址,降低被封禁的风险。
7.使用分布式爬虫:当需要爬取大量的网站数据时,使用单机爬虫可能效率较低。
这时,可以使用分布式爬虫,将任务分发给多台机器,同时进行爬取,从而提高爬取效率。
8.设置合理的爬取策略:为了避免对网站服务器造成过大的负担,并且避免触发反爬虫机制,需要设置合理的爬取策略。
Python爬虫之网页图片抓取的方法

Python爬⾍之⽹页图⽚抓取的⽅法⼀、引⼊这段时间⼀直在学习Python的东西,以前就听说Python爬⾍多厉害,正好现在学到这⾥,跟着⼩甲鱼的Python视频写了⼀个爬⾍程序,能实现简单的⽹页图⽚下载。
⼆、代码__author__ = "JentZhang"import urllib.requestimport osimport randomimport redef url_open(url):'''打开⽹页:param url::return:'''req = urllib.request.Request(url)req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36')# 应⽤代理'''proxyies = ["111.155.116.237:8123","101.236.23.202:8866","122.114.31.177:808"]proxy = random.choice(proxyies)proxy_support = urllib.request.ProxyHandler({"http": proxy})opener = urllib.request.build_opener(proxy_support)urllib.request.install_opener(opener)'''response = urllib.request.urlopen(url)html = response.read()return htmldef save_img(folder, img_addrs):'''保存图⽚:param folder: 要保存的⽂件夹:param img_addrs: 图⽚地址(列表):return:'''# 创建⽂件夹⽤来存放图⽚if not os.path.exists(folder):os.mkdir(folder)os.chdir(folder)for each in img_addrs:filename = each.split('/')[-1]try:with open(filename, 'wb') as f:img = url_open("http:" + each)f.write(img)except urllib.error.HTTPError as e:# print(e.reason)passprint('完毕!')def find_imgs(url):'''获取全部的图⽚链接:param url: 连接地址:return: 图⽚地址的列表'''html = url_open(url).decode("utf-8")img_addrs = re.findall(r'src="(.+?\.gif)', html)return img_addrsdef get_page(url):'''获取当前⼀共有多少页的图⽚:param url: ⽹页地址:return:'''html = url_open(url).decode('utf-8')a = html.find("current-comment-page") + 23b = html.find("]</span>", a)return html[a:b]def download_mm(url="/ooxx/", folder="OOXX", pages=1):'''主程序(下载图⽚):param folder:默认存放的⽂件夹:param pages: 下载的页数:return:'''page_num = int(get_page(url))for i in range(pages):page_num -= ipage_url = url + "page-" + str(page_num) + "#comments"img_addrs = find_imgs(page_url)save_img(folder, img_addrs)if __name__ == "__main__":download_mm()三、总结由于代码中访问的⽹址已经运⽤了反爬⾍的算法。
python爬虫爬取图片的简单代码

python爬⾍爬取图⽚的简单代码Python是很好的爬⾍⼯具不⽤再说了,它可以满⾜我们爬取⽹络内容的需求,那最简单的爬取⽹络上的图⽚,可以通过很简单的⽅法实现。
只需导⼊正则表达式模块,并利⽤spider原理通过使⽤定义函数的⽅法可以轻松的实现爬取图⽚的需求。
1、spider原理spider就是定义爬取的动作及分析⽹站的地⽅。
以初始的URL**初始化Request**,并设置回调函数。
当该request**下载完毕并返回时,将⽣成**response ,并作为参数传给该回调函数。
2、实现python爬⾍爬取图⽚第⼀步:导⼊正则表达式模块import re # 导⼊正则表达式模块import requests # python HTTP客户端编写爬⾍和测试服务器经常⽤到的模块import random # 随机⽣成⼀个数,范围[0,1]第⼆步:使⽤定义函数的⽅法爬取图⽚def spiderPic(html, keyword):print('正在查找 ' + keyword + ' 对应的图⽚,下载中,请稍后......')for addr in re.findall('"objURL":"(.*?)"', html, re.S): # 查找URLprint('正在爬取URL地址:' + str(addr)[0:30] + '...')# 爬取的地址长度超过30时,⽤'...'代替后⾯的内容try:pics = requests.get(addr, timeout=100) # 请求URL时间(最⼤10秒)except requests.exceptions.ConnectionError:print('您当前请求的URL地址出现错误')continuefq = open('H:\\img\\' + (keyword + '_' + str(random.randrange(0, 1000, 4)) + '.jpg'), 'wb')# 下载图⽚,并保存和命名fq.write(pics.content)fq.close()到此这篇关于python爬⾍爬取图⽚的简单代码的⽂章就介绍到这了,更多相关python爬⾍怎么爬取图⽚内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
Python爬虫学习总结-爬取某素材网图片
Python爬⾍学习总结-爬取某素材⽹图⽚ Python爬⾍学习总结-爬取某素材⽹图⽚最近在学习python爬⾍,完成了⼀个简单的爬取某素材⽹站的功能,记录操作实现的过程,增加对爬⾍的使⽤和了解。
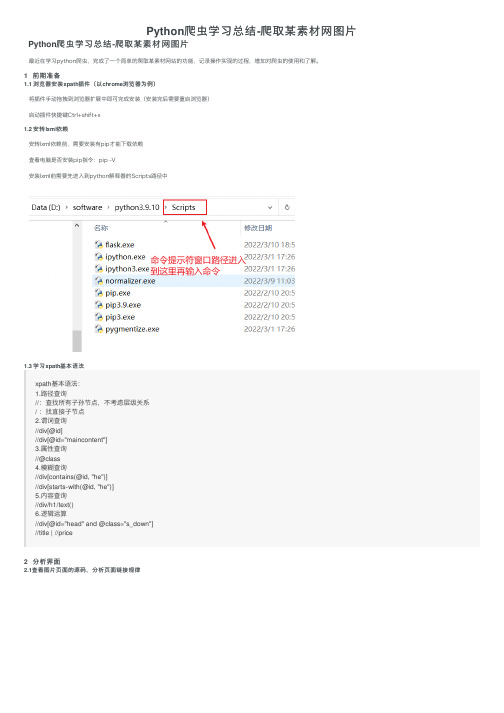
1 前期准备1.1 浏览器安装xpath插件(以chrome浏览器为例)将插件⼿动拖拽到浏览器扩展中即可完成安装(安装完后需要重启浏览器)启动插件快捷键Ctrl+shift+x1.2 安转lxml依赖安转lxml依赖前,需要安装有pip才能下载依赖查看电脑是否安装pip指令:pip -V安装lxml前需要先进⼊到python解释器的Scripts路径中1.3 学习xpath基本语法xpath基本语法:1.路径查询//:查找所有⼦孙节点,不考虑层级关系/ :找直接⼦节点2.谓词查询//div[@id]//div[@id="maincontent"]3.属性查询//@class4.模糊查询//div[contains(@id, "he")]//div[starts‐with(@id, "he")]5.内容查询//div/h1/text()6.逻辑运算//div[@id="head" and @class="s_down"]//title | //price2 分析界⾯2.1查看图⽚页⾯的源码,分析页⾯链接规律打开有侧边栏的风景图⽚(以风景图⽚为例,分析⽹页源码)通过分析⽹址可以得到每页⽹址的规律,接下来分析图⽚地址如何获取到2.2 分析如何获取图⽚下载地址⾸先在第⼀页通过F12打开开发者⼯具,找到图⽚在源代码中位置: 通过分析源码可以看到图⽚的下载地址和图⽚的名字,接下来通过xpath解析,获取到图⽚名字和图⽚地址2.3 xpath解析获取图⽚地址和名字调⽤xpath插件得到图⽚名字://div[@id="container"]//img/@alt图⽚下载地址://div[@id="container"]//img/@src2注意:由于该界⾯图⽚的加载⽅式是懒加载,⼀开始获取到的图⽚下载地址才是真正的下载地址也就是src2标签前⾯的⼯作准备好了,接下来就是书写代码3 代码实现3.1 导⼊对应库import urllib.requestfrom lxml import etree3.2 函数书写请求对象的定制def create_request(page,url):# 对不同页⾯采⽤不同策略if (page==1):url_end = urlelse:#切割字符串url_temp = url[:-5]url_end = url_temp+'_'+str(page)+'.html'# 如果没有输⼊url就使⽤默认的urlif(url==''):url_end = 'https:///tupian/fengjingtupian.html'# 请求伪装headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39' }# 请求对象的定制request = urllib.request.Request(url = url_end,headers=headers)# 返回伪装后的请求头return request获取⽹页源码def get_content(request):# 发送请求获取响应数据response = urllib.request.urlopen(request)# 将响应数据保存到contentcontent = response.read().decode('utf8')# 返回响应数据return content下载图⽚到本地def down_load(content):# 下载图⽚#urllib.request.urlretrieve('图⽚名称','⽂件名字')# 解析⽹页tree = etree.HTML(content)# 获取图⽚姓名返回的是列表img_name = tree.xpath('//div[@id="container"]//a/img/@alt')img_add = tree.xpath('//div[@id="container"]//a/img/@src2')# 循环下载图⽚for i in range(len(img_name)):# 挨个获取下载的图⽚名字和地址name = img_name[i]add = img_add[i]# 对图⽚下载地址进⾏定制url = 'https:'+add# 下载到本地下载图⽚到当前代码同⼀⽂件夹的imgs⽂件夹中需要先在该代码⽂件夹下创建imgs⽂件夹urllib.request.urlretrieve(url=url,filename='./imgs/'+name+'.jpg')主函数if __name__ == '__main__':print('该程序为采集站长素材图⽚')url = input("请输⼊站长素材图⽚第⼀页的地址(内置默认为风景图⽚)")start_page = int(input('请输⼊起始页码'))end_page = int(input('请输⼊结束页码'))for page in range(start_page,end_page+1):#请求对象的定制request = create_request(page,url)# 获取⽹页的源码content = get_content(request)# 下载down_load(content)完整代码# 1.请求对象的定制# 2.获取⽹页源码# 3.下载# 需求:下载前⼗页的图⽚# 第⼀页:https:///tupian/touxiangtupian.html# 第⼆页:https:///tupian/touxiangtupian_2.html# 第三页:https:///tupian/touxiangtupian_3.html# 第n页:https:///tupian/touxiangtupian_page.htmlimport urllib.requestfrom lxml import etree# 站长素材图⽚爬取下载器def create_request(page,url):# 对不同页⾯采⽤不同策略if (page==1):url_end = urlelse:#切割字符串url_temp = url[:-5]url_end = url_temp+'_'+str(page)+'.html'# 如果没有输⼊url就使⽤默认的urlif(url==''):url_end = 'https:///tupian/fengjingtupian.html'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39' }request = urllib.request.Request(url = url_end,headers=headers)return requestdef get_content(request):response = urllib.request.urlopen(request)content = response.read().decode('utf8')return contentdef down_load(content):# 下载图⽚#urllib.request.urlretrieve('图⽚名称','⽂件名字')tree = etree.HTML(content)# 获取图⽚姓名返回的是列表img_name = tree.xpath('//div[@id="container"]//a/img/@alt')img_add = tree.xpath('//div[@id="container"]//a/img/@src2')for i in range(len(img_name)):name = img_name[i]add = img_add[i]# 对图⽚下载地址进⾏定制url = 'https:'+add# 下载到本地urllib.request.urlretrieve(url=url,filename='./imgs/'+name+'.jpg')if __name__ == '__main__':print('该程序为采集站长素材图⽚')url = input("请输⼊站长素材图⽚第⼀页的地址(内置默认为风景图⽚)")start_page = int(input('请输⼊起始页码'))end_page = int(input('请输⼊结束页码'))for page in range(start_page,end_page+1):#请求对象的定制request = create_request(page,url)# 获取⽹页的源码content = get_content(request)# 下载down_load(content)4 运⾏结果总结此次案例是基于尚硅⾕的python视频学习后的总结,感兴趣的可以去看全套视频,⼈们总说兴趣是最好的⽼师,⾃从接触爬⾍后我觉得python⼗分有趣,这也是我学习的动⼒,通过对⼀次案例的简单总结,回顾已经学习的知识,并不断学习新知识,是记录也是分享。
爬虫——爬取百度贴吧每个帖子里面的图片

爬⾍——爬取百度贴吧每个帖⼦⾥⾯的图⽚现在我们⽤正则来做⼀个简单的爬⾍,我们尝试爬取某个百度贴吧⾥⾯的所有帖⼦,并且将这个帖⼦⾥⾸页每个楼层发布的图⽚下载到本地。
分析:以美⼥吧为例 ……可以发现,url地址中pn及其前⾯的部分是相同的,改变的只是pn后⾯的值不难发现,每页中共有50个帖⼦,所有pn的值是以每页50的值递增。
则第page页的pn值为:(page - 1) * 50⽽kw=%E7%BE%8E%E5%A5%B3为urllib.parse.urlencode{"kw":"美⼥"}#!/usr/bin/python3# -*- coding:utf-8 -*-__author__ = 'mayi'"""⽤正则做⼀个简单的爬⾍:尝试爬取某个贴吧⾥的所有帖⼦,并且将帖⼦⾥每层楼发布的图⽚下载到本地。
例:美⼥吧(https:///f? + kw=%E7%BE%8E%E5%A5%B3 + &pn=50)https:///f?kw=%E7%BE%8E%E5%A5%B3&pn=50其中:kw=%E7%BE%8E%E5%A5%B3为urllib.parse.urlencode({"kw":"美⼥"})pn为值从0开始,每页为50个帖⼦,故:第⼀页,pn的值为:0第⼆页,pn的值为:50第三页,pn的值为:100……"""import osimport reimport urllib.request# ⼀个爬⾍类class Spider(object):"""⼀个爬⾍类"""# 初始化def __init__(self, name):"""类的初始化:param name: 百度贴吧名:return:"""# User-Agent头self.header = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36'}keyword = urllib.parse.urlencode({"kw":name})self.url = "https:///f?" + keyword + "&pn="self.run()# 获取帖⼦的最后⼀页def getLastPage(self, url):"""获取url帖⼦的尾页的pn值:param url: url地址:return: pn值"""html = self.loadPage(url)html = html.decode("utf-8")# 利⽤正则匹配尾页的pn值pattern = pile(r'<a href=.*?pn=(\d+).*?>尾页</a>')try:pn = pattern.findall(html)[0]pn = int(pn)except:pn = 1return pn# 爬⾍开始⼯作def run(self):"""爬⾍开始⼯作:return:"""start_page = 1end_page = self.getLastPage(self.url) // 50 + 1print("该吧共" + str(end_page) + "页")for page in range(start_page, end_page + 1):# 计算pn的值pn = (page - 1) * 50# 拼接成完整的url地址full_url = self.url + str(pn)# 调⽤loadPage()函数,下载full_url的页⾯内容html = self.loadPage(full_url)# 调⽤screenPage()函数,筛选下载的页⾯内容item_list = self.screenPage(html)print("正在下载第" + str(page) + "页,共" + str(len(item_list)) + "个帖⼦")# 调⽤loadImage()函数,下载帖⼦⾥⾸页的图⽚self.loadImage(item_list)# 下载⽹页内容def loadPage(self, url):"""下载url的页⾯内容:param url: 需下载页码的url地址:return: 页⾯内容"""# url 连同 headers,⼀起构造Request请求,这个请求将附带 chrome 浏览器的User-Agent request = urllib.request.Request(url, headers = self.header)# 向服务器发送这个请求response = urllib.request.urlopen(request)# 获取⽹页内容:byteshtml = response.read()return html# 筛选内容def screenPage(self, html):"""筛选内容:筛选出每层楼帖⼦的链接:param html: 页⾯内容:return: 需下载的图⽚链接地址"""# 转码:bytes转utf-8html = html.decode("utf-8")# 利⽤正则匹配每层楼帖⼦的链接pattern = pile(r'<a href="(/p/\d+).*?>.*?</a>', re.S)item_list = pattern.findall(html)return item_list# 下载帖⼦⾥⾸页⾥⾯的图⽚def loadImage(self, item_list):"""下载帖⼦⾥⾸页⾥⾯的图⽚:param item_list: 需下载图⽚的帖⼦的ID列表:return: None"""for id in item_list:# 根据id拼接帖⼦链接link = "https://" + idstart_page = 1end_page = self.getLastPage(link)print("正在下载帖⼦:" + link + " 中图⽚")image_no = 0for page in range(start_page, end_page + 1):# 拼接完整链接full_link = link + "?pn=" + str(page)# 获取需下载图⽚的帖⼦的页⾯内容html = self.loadPage(full_link)# 转码:bytes转utf-8html = html.decode("utf-8")# 利⽤正则匹配帖⼦中的图⽚链接pattern = pile(r'<img class="BDE_Image".*?src="(.*?)".*?>', re.S)# 图⽚链接列表image_list = pattern.findall(html)for image in image_list:image_no = image_no + 1self.writeImage(image, id[3:], image_no)print("帖⼦:" + full_link + " 共下载" + str(len(image_list)) + "个图⽚")# 向本地磁盘中存储图⽚def writeImage(self, url, id, image_no):"""向本地磁盘中存储图⽚:param url: 图⽚url:param id: 帖⼦id:本地⽂件夹:param image_no: 图⽚序号:return:"""# 判断是否存在对应的⽂件夹if not os.path.exists("image/" + id):# 若不存在,则创建os.makedirs("image/" + id)# 图⽚⽂件名:id + "_" + 5位图⽚序号image_no = str(image_no)file_name = "image/" + id + "/" + id + "_" + "0" * (6 - len(image_no)) + image_no + ".jpg" # 以wb⽅式打开⽂件file = open(file_name, "wb")# 获取图⽚名为名为images = self.loadPage(url)# 写⼊图⽚file.write(images)# 关闭⽂件file.close()# 主函数if __name__ == '__main__':# 要爬取的百度贴吧名name = input("请输⼊您要爬取的百度贴吧名:")# 创建⼀个爬⾍对象mySpider = Spider(name)。
Python网络爬虫实践爬取地理位置数据

Python网络爬虫实践爬取地理位置数据网络爬虫是一种自动化程序,可以在互联网上收集和提取数据。
Python是一种广泛使用的编程语言,在网络爬虫开发中,它具有便捷的库和工具,能够帮助开发者快速地实现爬取数据的需求。
本文将介绍如何使用Python网络爬虫实践爬取地理位置数据。
一、概述地理位置数据是指记录了地理坐标、位置信息等内容的数据。
在许多应用场景中,如地图软件、导航系统、天气预报等,都需要使用地理位置数据。
而互联网上存在大量的地理位置数据,通过网络爬虫可以帮助我们获取这些数据,并进行进一步的分析和应用。
二、爬取目标网站选择在进行网络爬虫实践时,首先需要选择合适的目标网站。
对于地理位置数据的爬取,我们可以选择包含相应信息的网站,如地图网站、位置服务网站等。
在选择目标网站时,需要考虑网站的数据质量、数据量、访问限制等因素。
三、分析目标网站结构在爬取地理位置数据之前,我们需要先了解目标网站的结构。
通过查看网站的源代码,可以获取网站页面的HTML结构。
在这个过程中,可以使用浏览器的开发者工具来查看网页元素、网络请求等信息。
四、使用Python爬虫库Python拥有丰富的网络爬虫库,如BeautifulSoup、Scrapy、Requests等,这些库可以帮助我们进行网页解析、HTTP请求、数据提取等操作。
在选择使用的爬虫库时,可以根据自己的实际需求和熟悉程度来进行选择。
五、编写爬虫代码在获取目标网站的结构和选择好爬虫库之后,可以开始编写爬虫代码了。
首先,需要进行HTTP请求,获取网页的HTML代码。
然后,使用爬虫库对HTML代码进行解析,提取需要的地理位置数据。
最后,可以将爬取的数据保存到本地文件或数据库中,以备后续的分析和应用。
六、数据处理和分析爬取到地理位置数据后,可以进行进一步的数据处理和分析。
可以使用Python的数据处理库,如Pandas、NumPy等,对数据进行清洗、整理、转换等操作。
根据具体的需求,还可以进行数据可视化、统计分析、机器学习等工作,来挖掘数据的潜在价值。
ultimascraper 使用方法

UltimaScraper使用方法一、简介UltimaScraper是一款功能强大的网页数据爬取工具,能够帮助用户轻松快捷地获取网页上的所需数据。
它具有友好的用户界面和丰富的功能,可以满足用户不同的数据爬取需求,是一款非常实用的工具。
二、下载与安装1. 用户可以在UltimaScraper冠方全球信息站上下载安装包,根据系统版本选择合适的安装文件。
2. 下载完成后,双击安装包进行安装,按照提示进行操作,即可完成安装。
三、使用方法1. 打开UltimaScraper软件,进入主界面。
2. 在主界面的URL输入框中输入要爬取数据的网页信息。
3. 点击“开始”按钮,软件将开始获取网页上的数据。
4. 用户可以根据需求,设置数据提取规则,包括字段名称、数据类型、提取方式等。
5. 在设置完成后,点击“确定”按钮,软件将根据设置的规则进行数据提取并显示在界面上。
6. 用户可以选择将提取的数据保存为CSV、Excel等格式,也可以通过API接口连接到其他应用程序。
四、注意事项1. 在使用UltimaScraper时,需要保证网络畅通,否则可能影响数据的获取。
2. 用户在设置数据提取规则时,需要确保规则的准确性,以免获取到错误的数据。
五、结语UltimaScraper是一款强大而实用的网页数据爬取工具,它为用户提供了方便快捷的数据获取方式,能够满足用户不同的数据爬取需求。
希望以上介绍能够帮助用户更好地了解UltimaScraper,从而更好地使用该软件。
六、高级功能除了基本的网页数据爬取功能外,UltimaScraper还具有一些高级功能,帮助用户更加灵活地进行数据操作和提取。
1. 自动化任务UltimaScraper支持设置自动化任务,用户可以通过定时任务或者事件触发来执行数据爬取操作。
这样可以节省用户的时间和精力,也可以保证数据的及时更新和准确性。
用户可以根据实际需求,设置不同的触发条件和执行时间,使数据爬取操作更加智能化。
爬虫提取数据的方法

爬虫提取数据的方法
爬虫提取数据的方法有:HTML解析、XPath或CSS选择器、API调用、正则表达式、数据库查询以及AJAX动态加载数据。
1.HTML解析:爬虫通常会下载网页的HTML源代码,然后使用HTML解析库(例如Beautiful Soup、PyQuery等)来提取所需的数据。
这些库允许您通过标签、类、属性等方式来定位和提取数据。
2.XPath或CSS选择器:XPath和CSS选择器是用于在HTML文档中定位和提取数据的强大工具。
XPath是一种用于选择HTML元素的语言,而CSS选择器是一种常用的用于选择样式表中的元素的语言。
您可以使用XPath和CSS 选择器来提取特定元素及其属性。
3.API调用:许多网站提供API(应用程序编程接口),允许开发者通过API 访问和获取数据。
使用爬虫时,您可以直接调用这些API获取数据,而无需解析HTML。
4.正则表达式:正则表达式是一种强大的文本处理工具,可以用于从HTML 源代码或文本中提取特定的模式数据。
通过编写适当的正则表达式,您可以捕获和提取所需的数据。
5.数据库查询:有些网站将其数据存储在数据库中。
爬虫可以模拟数据库查询语言(如SQL),直接向数据库发送查询请求并提取结果。
6.AJAX动态加载数据:某些网页使用AJAX技术动态加载数据。
在这种情况下,您可能需要使用模拟浏览器行为的工具(如Selenium)来处理JavaScript 渲染,并提取通过AJAX请求加载的数据。
波爬操作手法

波爬操作手法波爬操作手法是目前互联网数据采集的主要方法。
它可以自动获取网页上的信息,并将其转化成结构化的数据。
在大数据时代,波爬技术被广泛应用于市场调研、商业竞争、舆情分析等领域。
本文将介绍波爬的主要流程及操作手法,并给出一些实用的技巧和注意事项,以帮助广大数据爱好者更好地使用波爬。
1. 网站分析在使用波爬前,我们需要对目标网站进行分析。
包括网站的结构、页面类型、需求数据的位置等。
尽可能了解目标网站的特点,有助于优化波爬效果。
2. 网络请求波爬的第一步是发起网络请求。
通常我们会使用Python的requests库来实现。
需要注意的是,在发起请求时需设置参数,如User-Agent、Cookie等,以模拟浏览器行为,与网站建立更好的连接。
3. 解析HTML请求成功响应后,我们需要解析网页的HTML代码,这通常由Python上的BeautifulSoup库来实现。
它可以快速而准确地定位目标数据的位置,为后面的数据采集提供基础。
4. 数据提取数据提取是波爬的核心部分。
通过定位HTML中的标签、属性、文本,可以针对需求数据进行数据抽取。
一般使用XPath、CSS Selector 语法来完成。
同时,为了避免数据错误或漏抓,我们需要尽可能使用多种提取方法。
5. 存储与处理采集到的数据通常需要进行存储和处理。
我们可以使用Python中的csv、json库来存储。
也可以使用pandas来进行处理和分析。
此外,我们还需要注意数据的清洗、去重等问题。
6. 反爬对策在进行波爬时,我们常常会遇到反爬技术的阻碍。
比如验证码、动态加载、限速等。
这些问题通常可以通过模拟浏览器、动态代理、分布式爬虫等方式来解决。
7. 波爬法律注意事项最后,使用波爬技术的朋友们,需要注意一些法律问题。
比如使用波爬爬取他人数据可能会涉及侵权、网络安全等问题,应当遵守相关法律法规。
总之,波爬技术是一项非常有用且广泛应用的方法。
通过深入了解波爬技术,学习并应用波爬,可以更好地获取互联网上的信息资源,为我们的研究和生活带来更多的帮助。
python爬取数据的方法

python爬取数据的方法Python是一种强大的编程语言,可以用来编写爬虫程序,从网页或其他数据源中抓取数据。
下面介绍一些常用的Python爬取数据的方法。
1. 使用Requests库:Requests是一个功能强大的库,可以发送HTTP请求,并获得响应数据。
可以使用GET或POST方法发送请求,并使用其提供的方法来处理返回的数据。
3. 使用Selenium库:Selenium是一个用于自动化浏览器操作的库,可以模拟用户在浏览器中的操作,并获取网页数据。
可以使用它来加载动态渲染的网页,并提取所需的数据。
4. 使用Scrapy框架:Scrapy是一个用于爬取网站的高级Python框架,它提供了一系列的工具和组件,使得开发爬虫程序更加方便。
可以使用它定义爬虫规则,从网页中提取数据,并进行数据处理和存储。
5. 使用API接口:许多网站提供了API接口,可以通过API获取数据。
可以使用Python的requests库来向API发送请求,并获取返回的数据,然后进行处理和存储。
7.使用代理IP:有些网站可能会限制同一个IP地址的访问频率,可以使用代理IP来轮流发送请求,以避免被封禁。
8. 数据存储:爬取的数据可以以文本文件、CSV文件、E某cel文件、数据库等形式进行存储。
可以使用Python的内置模块或第三方库来实现数据存储功能。
9. 使用多线程或多进程:为了提高爬取效率,可以使用多线程或多进程来并发爬取数据。
可以使用Python的内置模块threading或multiprocessing来实现多线程或多进程的功能。
10. 异常处理:在进行数据爬取时,可能会遇到一些异常情况,如网络异常、网页解析错误等。
可以使用Python的try-e某cept语句来捕获和处理异常,保证程序的稳定性。
以上是一些常用的Python爬取数据的方法,通过合理选择和组合这些方法,可以实现各种不同的数据爬取需求。
在实际应用中,还需要注意合法性和道德性,遵守相关的法律法规和网站的规则,确保合法、合规的数据爬取。
爬虫爬取数据的方式和方法

爬虫爬取数据的方式和方法爬虫是一种自动化的程序,用于从互联网上获取数据。
爬虫可以按照一定的规则和算法,自动地访问网页、抓取数据,并将数据存储在本地或数据库中。
以下是一些常见的爬虫爬取数据的方式和方法:1. 基于请求的爬虫这种爬虫通过向目标网站发送请求,获取网页的HTML代码,然后解析HTML代码获取需要的数据。
常见的库有requests、urllib等。
基于请求的爬虫比较简单,适用于小型网站,但对于大型网站、反爬机制严格的网站,这种方式很容易被限制或封禁。
2. 基于浏览器的爬虫这种爬虫使用浏览器自动化工具(如Selenium、Puppeteer等)模拟真实用户操作,打开网页、点击按钮、填写表单等,从而获取数据。
基于浏览器的爬虫能够更好地模拟真实用户行为,不易被目标网站检测到,但同时也更复杂、成本更高。
3. 基于网络爬虫库的爬虫这种爬虫使用一些专门的网络爬虫库(如BeautifulSoup、Scrapy 等)来解析HTML代码、提取数据。
这些库提供了丰富的功能和工具,可以方便地实现各种数据抓取需求。
基于网络爬虫库的爬虫比较灵活、功能强大,但也需要一定的技术基础和经验。
4. 多线程/多进程爬虫这种爬虫使用多线程或多进程技术,同时从多个目标网站抓取数据。
多线程/多进程爬虫能够显著提高数据抓取的效率和速度,但同时也需要处理线程/进程间的同步和通信问题。
常见的库有threading、multiprocessing等。
5. 分布式爬虫分布式爬虫是一种更为强大的数据抓取方式,它将数据抓取任务分散到多个计算机节点上,利用集群计算和分布式存储技术,实现大规模、高效的数据抓取。
常见的框架有Scrapy-Redis、Scrapy-Cluster 等。
分布式爬虫需要解决节点间的通信、任务分配、数据同步等问题,同时还需要考虑数据的安全性和隐私保护问题。
python爬虫之spider用法
python爬⾍之spider⽤法Spider类定义了如何爬取某个⽹站, 包括爬取的动作以及如何从⽹页内容中提取结构化的数据, 总的来说spider就是定义爬取的动作以及分析某个⽹页.⼯作流程分析 : 1. 以初始的URLRequest, 并设置回调函数, 当该requeset下载完毕并返回时, 将⽣成response, 并作为参数传递给回调函数. spider中初始的request是通过start_requests()来获取的. start_requests()获取start_urls中的URL, 并以parse以回调函数⽣成Request 2. 在回调函数内分析返回的⽹页内容, 可以返回item对象, 或者Dict,或者Request, 以及是⼀个包含三者的可迭代的容器, 返回的Request对象之后会经过Scrapy 处理, 下载相应的内容, 并调⽤设置的callback函数. 3. 在回调函数, 可以通过lxml, bs4, xpath, css等⽅法获取我们想要的内容⽣成item 4. 最后将item传送给pipeline处理源码分析 : 在spiders下写爬⾍的时候, 并没有写start_request来处理start_urls处理start_urls中的url, 这是因为在继承的scrapy.Spider中已经写过了 在上述源码中可以看出在⽗类⾥实现了start_requests⽅法, 通过make_requests_from_url做了Request请求 上图中, parse回调函数中的response就是⽗类中start_requests⽅法调⽤make_requests_from_url返回的结果, 并且在parse回调函数中可以继续返回Request,就像代码中yield request()并设置回调函数.spider内的⼀些常⽤属性 : 所有⾃⼰写的爬⾍都是继承于spider.Spider这个类 name: 定义爬⾍名字, 通过命令启动的额时候⽤的就是这个名字, 这个名字必须唯⼀ allowed_domains: 包含了spider允许爬取的域名列表. 当offsiteMiddleware启⽤时, 域名不在列表中URL不会被访问, 所以在爬⾍⽂件中, 每次⽣成Request请求时都会进⾏和这⾥的域名进⾏判断. start_urls: 其实的URL列表 这⾥会通过spider.Spider⽅法调⽤start_request循环请求这个列表中的每个地址 custom_settings: ⾃定义配置, 可以覆盖settings的配置, 主要⽤于当我们队怕重有特定需求设置的时候 设置的以字典的⽅式设置: custom_settings = {} from_crawler: ⼀个类⽅法, 可以通过crawler.settings.get()这种⽅式获取settings配置⽂件中的信息. 同时这个也可以在pipeline中使⽤ start_requests(): 此⽅法必须返回⼀个可迭代对象, 该对象包含了spider⽤于爬取的第⼀个Request请求 此⽅法是在被继承的⽗类中spider.Spider中写的, 默认是通过get请求, 如果需要修改最开始的这个请求, 可以重写这个⽅法, 如想通过post请求 make_requests_from_url(url): 此房也是在⽗类中start_requests调⽤的, 可以重写 parse(response): 默认的回调函数 负责处理response并返回处理的数据以及跟进的url 该⽅法以及其他的Request回调函数必须返回⼀个⽽包含Request或者item的可迭代对象.。
抓爬蚱的小技巧

如何利用爬虫技术抓取网页信息
一、选择目标网站
选择目标网站是进行网页抓取的第一步。
一般来说,选择目标网站的原则有两个:一是网站内容丰富,有价值的信息比较多;二是网站结构清晰,便于爬虫程序的编写。
在选择目标网站时,需要考虑以下几个方面:
1. 网站内容:选择一个内容丰富、有价值的网站可以提高抓取效率,减少无用信息的抓取。
2. 网站结构:选择一个结构清晰的网站可以更容易地编写爬虫程序,同时也可以避免抓取错误或无效信息。
3. 网站权限:有些网站需要登录才能访问,需要考虑是否拥有相应的权限,或者考虑使用代理 IP 等方式绕过限制。
二、编写爬虫程序
编写爬虫程序是进行网页抓取的关键步骤。
一般来说,编写爬虫程序需要掌握以下几个方面:
1. 网络协议:爬虫程序需要了解 HTTP 等网络协议,以便向目标网站发送请求并获取响应。
2. 网站结构:爬虫程序需要了解目标网站的结构,以便正确地抓取网页信息。
3. 数据库技术:爬虫程序需要将抓取到的信息存储到数据库中,以便后续处理和分析。
在编写爬虫程序时,需要考虑以下几个方面:
1. 爬取目标:确定要抓取哪些信息,例如标题、正文、图片等。
2. 爬取方式:确定要采用哪种方式进行爬取,例如定期抓取、触发式抓取等。
数据爬取和处理的步骤

数据爬取和处理的步骤一、数据爬取数据爬取是指从互联网上获取所需数据的过程。
下面是数据爬取的步骤:1. 确定爬取目标:确定需要爬取的网站或数据源,明确需要获取的数据类型和范围。
2. 分析网页结构:通过查看网页源代码,分析网页的结构和数据的存放位置,确定需要抓取的数据所在的标签或元素。
3. 编写爬虫程序:使用编程语言(如Python)编写爬虫程序,通过发送HTTP请求获取网页内容,并使用正则表达式或解析库(如BeautifulSoup)提取所需数据。
4. 处理反爬机制:一些网站采取了反爬机制,如设置验证码、限制访问频率等。
需要根据具体情况采取相应的措施,如使用代理IP、模拟登录等。
5. 数据存储:将爬取到的数据存储到数据库、本地文件或其他数据存储介质中,以便后续处理和分析。
二、数据处理数据处理是对爬取到的数据进行清洗、转换和整理的过程。
下面是数据处理的步骤:1. 数据清洗:对爬取到的原始数据进行清洗,去除重复数据、空值、异常值等,保证数据的准确性和一致性。
2. 数据转换:根据需求将数据进行转换,如将日期字段转换为特定格式、将文本字段进行分词等。
3. 数据整合:将多个数据源的数据进行整合,合并为一个数据集,便于后续分析和建模。
4. 数据分析:对数据进行统计分析、挖掘和可视化,发现数据中的规律、趋势和异常,提取有用的信息。
5. 数据建模:根据业务需求,使用机器学习、统计模型等方法对数据进行建模和预测,为决策提供支持。
6. 数据应用:将处理后的数据应用于实际业务场景,如推荐系统、风控模型等,实现数据的商业价值。
总结:数据爬取和处理是数据分析的重要环节,通过合理的爬取和处理步骤,可以获取到准确、完整的数据,为后续的数据分析和决策提供支持。
在实际操作中,需要根据具体情况选择合适的爬取和处理方法,并注意数据的质量和安全性。
同时,要遵守网站的规定和法律法规,避免对他人权益造成损害。
爬虫怎么解析不规则表格

爬虫怎么解析不规则表格
爬虫解析不规则表格通常需要使用到一些高级的网页抓取和分
析工具,例如 BeautifulSoup、Scrapy、Selenium 等。
以下是一些可能的方法:
1.使用 BeautifulSoup 进行解析:BeautifulSoup 是一个Python 库,可以用来解析 HTML 和 XML 文件。
它提供了许多方便的方法来查找和访问页面元素,包括表格元素。
通过遍历 HTML 文档,BeautifulSoup 可以找到所有的表格,并使用 find()、find_all()、children() 等方法获取表格中的数据。
2.使用 Scrapy 进行解析:Scrapy 是一个用于网页抓取的Python 框架,可以用来爬取复杂的网页结构。
Scrapy 使用类似于BeautifulSoup 的选择器来查找和访问页面元素,但它还提供了许多其他功能,例如设置请求头、处理 JavaScript、处理动态加载的页面等。
使用 Scrapy 可以更方便地解析复杂的网页结构。
3.使用 Selenium 进行解析:Selenium 是一个用于自动化网页操作的 Python 库,可以模拟用户操作来获取网页内容。
使用Selenium 可以直接操作网页元素,例如点击按钮、输入文本等,从
而获取动态加载的页面内容。
对于一些使用 JavaScript 生成的表格,使用 Selenium 可以更准确地获取数据。
需要注意的是,由于网页的结构可能非常复杂,因此在进行爬虫解析时需要仔细考虑页面的结构、CSS 选择器、JavaScript 代码等
因素,以确保能够准确地获取所需的数据。
爬取数据的方法

爬取数据的方法一、确定爬取目标在开始爬取数据之前,需要确定所要爬取的目标。
可以通过搜索引擎、社交媒体等渠道获取相关信息,并分析目标网站的页面结构和数据格式。
二、选择合适的爬虫框架爬虫框架是实现网络爬虫的重要工具,常用的有Scrapy、BeautifulSoup、Requests等。
选择合适的框架可以提高开发效率和代码可维护性。
三、编写爬虫程序1. 发送请求获取页面内容使用框架提供的网络请求方法,发送HTTP请求获取目标网站的HTML内容。
可以设置请求头部信息,模拟浏览器行为,避免被网站识别为机器人并被封禁。
2. 解析页面内容使用框架提供的解析HTML的方法,将HTML内容转换为可操作的Python对象。
可以使用XPath或CSS选择器等方式定位所需数据,并进行提取和清洗。
3. 存储数据将提取到的数据存储到本地文件或数据库中。
建议使用关系型数据库或NoSQL数据库进行存储,并设置合适的索引以提高查询效率。
四、处理反爬机制为了防止被网站识别为机器人并被封禁,需要采取一些措施处理反爬机制。
可以使用代理IP、设置请求头部信息、使用验证码识别等方式。
五、定期更新爬虫程序由于网站的页面结构和数据格式可能会发生变化,需要定期更新爬虫程序以适应变化。
同时也需要注意遵守网站的robots.txt协议,避免对网站造成不必要的负担。
六、注意法律风险在进行数据爬取时,需要注意相关法律法规,避免侵犯他人隐私和知识产权等问题。
如果涉及到敏感信息或商业机密,建议咨询相关专业人士并获得授权后再进行爬取。
七、总结数据爬取是一项复杂而又有趣的工作,需要具备一定的编程技能和分析能力。
通过选择合适的框架和采取合理的策略,可以高效地获取所需数据,并为后续分析和应用提供支持。
爬虫数据提取技巧有哪些

爬虫数据提取技巧有哪些在当今数字化的时代,数据成为了一种极其宝贵的资源。
而爬虫技术则为我们获取大量数据提供了可能。
然而,仅仅获取到数据还不够,如何有效地从海量的数据中提取出有价值的信息,才是关键所在。
下面就来详细探讨一下爬虫数据提取的一些实用技巧。
首先,明确数据提取的目标至关重要。
在开始爬虫和提取数据之前,必须清楚地知道自己需要什么样的数据。
是文本内容、图片、视频,还是特定格式的表格数据?确定好目标后,才能有的放矢地设计爬虫策略和提取方法。
对于网页结构的分析是数据提取的重要基础。
不同的网站有着各自独特的页面布局和代码结构。
我们需要通过查看网页的源代码,了解其HTML 标签的组织方式,找到包含我们所需数据的特定标签。
例如,文章的正文内容可能被包含在`<p>`标签中,标题可能在`<h1>`或`<h2>`标签里。
正则表达式是提取数据的强大工具之一。
它能够根据我们设定的规则,从杂乱的文本中准确地筛选出符合要求的部分。
比如,要提取网页中的所有邮箱地址,就可以使用相应的正则表达式来匹配。
但正则表达式的语法相对复杂,需要一定的学习和实践才能熟练掌握。
XPath 表达式在数据提取中也发挥着重要作用。
它是一种用于在XML 和 HTML 文档中定位节点的语言。
通过编写准确的 XPath 表达式,可以快速定位到我们想要的数据节点,从而实现高效提取。
另外,使用合适的编程语言和相关库也能大大提高数据提取的效率。
Python 语言因其丰富的库和简洁的语法,在爬虫领域应用广泛。
例如,`BeautifulSoup` 库能够方便地解析 HTML 和 XML 文档,`Scrapy` 框架则为构建复杂的爬虫系统提供了强大的支持。
在数据提取过程中,处理动态加载的页面是一个常见的挑战。
有些网页的数据并非在初始页面加载时就全部呈现,而是通过用户的交互动作(如滚动、点击等)或者 JavaScript 脚本的执行来动态获取。
爬虫定位元素的方法

爬虫定位元素的方法
在进行网络爬虫时,要定位网页上的元素是非常重要的一步。
这些元素可能是文本、图片、链接等。
但是,由于不同网站的结构和页面设计都不同,因此需要不同的方法来定位这些元素。
下面介绍几种常见的定位方法。
1.通过标签来定位元素
HTML文档中的每个元素都有标签,通过标签可以很容易地定位元素。
比如,可以通过“div”标签来定位页面上的某个区域,通过“a”标签来定位某个链接等。
使用Python的BeautifulSoup库可以很方便地通过标签来定位元素。
2.通过类名和ID来定位元素
除了标签,HTML文档中的元素还可以有类名和ID属性。
类名和ID属性可以在HTML文档中唯一地标识某个元素。
通过类名和ID 来定位元素是很常见的做法。
使用BeautifulSoup库可以通过类名和ID来定位元素。
3.通过XPath来定位元素
XPath是一种XML语言的查询语言,也可以用于HTML文档的查询。
XPath定位元素的方式更加灵活,可以通过元素的属性、位置等多种方式来定位元素。
使用Python的lxml库可以很方便地使用XPath来定位元素。
总之,定位网页上的元素是爬虫中非常重要的一步,需要通过合适的方法来定位元素,从而获取所需的信息。
以上介绍的几种方
法都是常见且实用的方法,可以根据具体情况选择合适的方法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
众所周知,对于新闻网站来说,图片位置是无法固定的,所以想要爬取到这些位置不固定的图片,需要一定的技术手段。
以某网站为例,任务入口地址为:/
一、对首页进行链接抽取。
抽取文章标题,使用地址过滤“包含”.shtml。
抽取到结果如下:
二、新建模板2,抽取图片链接及内容数据:
示例地址如下:/2016/0817/1810143.shtml
1.把图片链接抽取出来。
进行采集预览,查看图片的链接规律,通过地址过滤“排除”^jpg;^jpeg;^png;^bmp;^gif。
2.为图片设置唯一标志与正文相关联。
通过标题过滤脚本return MD5(URL.urlname)给模板2的主键赋值,因为新闻图片的不规则性,需要通过某个字段将内容与图片相关联,所以此处标题过滤还有个作用就是将整个网页内容传递到模板3,起到相关联的作用。
过滤好的图片链接如下:
3.设置字段,为了将爬取到的内容分类的放入数据库中。
取正文页的数据,配置如下表单:
4.给字段赋值,从而获得数据。
通过定位及脚本取值,取到如下数据:
由于新闻类网站文章的不规则性,所以某些字段是需要通过脚本取值实现的。
脚本取值字段包括:hkey、author、news_time、content、pub_web。
以下为字段脚本:
hkey:return MD5(URL.urlname);//返回本页链接地址,通过MD5方法加密。
author:
return "编辑" + DOM.GetTextAll(DOM.FindClass("font_gray")).Right("编辑");//在源码里找到包含作者标签的class,取出其中的文本,然后取右串“编辑”。
news_time:
return DOM.GetTextAll(DOM.FindClass("font_gray")).Left("来源");//在源码里找到包含新闻时间标签的class,取出其中的文本,然后取“来源”左侧的内容。
content:
return DOM.GetTextAll(DOM.FindClass("contxt"));//在源码里找到包含新闻
事件标签的class,取出其中的文本。
pub_web:
return DOM.GetTextAll(DOM.FindClass("font_gray")).Middle("来源:","");//源码里找到包含文章原出处标签的class,取出其中的文本,然后取”来源”和””中间的内容。
三.新建模板3,抽取图片。
取图片,配置如下表单:
需要注意的是003为新闻主键,即与模板二相对应的字段。
预览的结果图如下:
这样操作不仅可以使内容和图片一一对应,也便于之后的数据导出工作。
以上就是位置不固定的图片的抽取教程,大家学会了吗?。