点阵字库应用原理
点阵的原理和应用笔记 (2)

点阵的原理和应用笔记1. 点阵的概念点阵是一种由一系列点组成的二维图形或图像。
每个点都可以表示一个像素,通过控制每个点的亮度和颜色来形成图像或字符。
点阵技术是计算机图形和显示领域的基础,广泛应用于屏幕、打印机、LED显示屏等设备。
2. 点阵的原理点阵的原理是通过将图像或字符分解为小块(点),每个点都可以控制其位置、亮度和颜色。
根据点阵的排列方式和控制方法的不同,可以实现不同的点阵显示效果。
2.1 点阵排列方式常见的点阵排列方式包括:矩阵排列、旋转排列、旋转矩阵排列等。
其中,矩阵排列是最常见的方式,即将点按照一定的行列关系排列。
2.2 点的控制方法控制点亮度和颜色的方法有两种:模拟控制和数字控制。
2.2.1 模拟控制模拟控制是通过改变电流的大小来控制点的亮度。
一般来说,电流越大,点的亮度越高。
模拟控制可以实现连续变化的亮度效果。
2.2.2 数字控制数字控制是通过控制点的开关状态(通/断)来实现点的亮灭。
每个点对应一个开关,通过打开或关闭开关来实现点的状态控制。
数字控制可以实现较高的精确度和稳定性。
3. 点阵的应用3.1 点阵显示屏点阵显示屏是最常见的点阵应用之一。
它由许多点组成,可以显示文本、图像等内容。
点阵显示屏广泛应用于计算机显示器、手机屏幕、电子表格等设备中。
3.2 点阵打印机点阵打印机是一种通过控制点的墨水或油墨喷射来形成图像或字符的打印设备。
它可以打印出较高的分辨率和灰度效果,适用于打印各种类型的文件。
3.3 点阵车牌识别点阵车牌识别是一种通过识别车牌上的点阵字符来实现车辆识别的技术。
通过点阵字符的排列和颜色特征,可以准确地识别出车牌上的文字和数字,用于交通监控、停车场管理等领域。
3.4 LED点阵广告牌LED点阵广告牌是一种通过控制LED点的亮灭来显示文字、图像和动画的广告设备。
它具有高亮度、长寿命和多功能等特点,被广泛应用于室内外广告、商场展示等场所。
3.5 点阵图形处理点阵图形处理是一种通过对图像的每个点进行操作来实现图像处理的技术。
点阵字库的数字编码原理

点阵字库的数字编码原理
点阵字库的数字编码原理是数字显示技术中的关键概念。
点阵字库是用来存储和显示数字、字母和符号的数据集合。
在数字编码原理中,每个字符被表示为一系列由像素组成的点阵。
数字编码原理的核心概念是将每个字符分解为一个矩阵或网格,并将每个像素点表示为一个二进制数字。
每个像素点的状态可以是开启或关闭,分别对应为1或0。
这种二进制表示方法可以有效地存储和传输字体信息。
在点阵字库中,每个字符都被分配一个特定的编码,通常是一个唯一的数字或字符。
这些编码可以通过查找表或算法来确定,并存储在字库中。
当需要显示特定的字符时,计算机系统会通过访问相应的编码位置来获取正确的点阵数据,然后将其发送到显示设备上。
数字编码原理的好处是可以实现多种不同的字体和字符样式。
通过简单地修改和替换点阵数据,我们可以实现不同大小和风格的字符显示。
这种灵活性使点阵字库适用于各种应用,例如计算机、电子设备和显示技术等。
总之,点阵字库的数字编码原理是通过将字符分解为二进制表示的像素点阵来实现数字显示。
这种方法提供了灵活性和多样性,使我们能够创建不同样式和风格的字符显示。
点阵汉字的原理及应用

点阵汉字的原理及应用1. 点阵汉字的概述点阵汉字是通过一系列的点阵来表示汉字的一种方法。
每个点阵都代表了一个汉字的一个笔画或者一个组件。
通过将这些点阵组合在一起,我们可以呈现出完整的汉字。
2. 点阵汉字的原理点阵汉字的原理可以分为两个步骤:字形生成和显示。
2.1 字形生成字形生成是指根据汉字的笔画顺序和结构,在点阵上绘制出每个笔画的轮廓。
这可以通过以下步骤完成: 1. 根据汉字的笔画顺序确定每个笔画的起始点和结束点。
2. 根据笔画的形状,确定每个笔画的拐角和曲线。
3. 将每个笔画的拐角和曲线连接起来,形成字形的轮廓。
4. 将字形的轮廓转化为点阵,每个点表示一个像素。
2.2 显示显示是指将生成的点阵汉字在显示设备上呈现出来。
这可以通过以下步骤完成:1. 将点阵汉字发送给显示设备。
2. 在显示设备上按照点阵的位置和颜色信息,点亮对应的像素。
3. 重复上述步骤,直到所有点阵汉字都被显示出来。
3. 点阵汉字的应用点阵汉字广泛应用于各种显示设备和软件中,以下是几个常见的应用领域:3.1 数码产品在数码产品中,点阵汉字常用于显示屏、小型计算器、电子手表等设备的界面上。
通过点阵汉字,用户可以方便地查看和输入文字信息。
3.2 广告牌和标志在广告牌和标志中,点阵汉字可以用于显示商店名称、产品标语等信息。
通过使用点阵汉字,可以将文字信息以更加醒目和吸引人的方式展示出来。
3.3 字符识别在字符识别领域,点阵汉字可以用于机器视觉系统中的文字识别。
通过将图像中的文字转化为点阵汉字,可以方便地对文字进行处理和识别。
3.4 手写输入在智能手机和平板电脑等设备中,点阵汉字可用于手写输入法。
用户可以通过手指在设备屏幕上划出汉字的笔画,系统会自动将笔画转化为点阵汉字,从而实现输入汉字的功能。
3.5 打印和排版在打印和排版领域,点阵汉字可用于生成高质量的印刷品。
通过将文字转化为点阵汉字,可以保证文字在不同尺寸和分辨率的输出设备上都能显示清晰和精确。
点阵字库的原理

汉字点阵数据在字库文件中的偏移= ((区码-1) * 94 +位码) *一个点阵字模占用的字节数
在寻址以后,即可读取汉字的点阵数据到缓冲区进行显示了.以下是实现代码:
/*输出一个汉字的函数*/
void _draw_hz(char hz[2], FILE *fp, int x, int y, int w, int h, int color)
在明白了以上所讲的以后,我们可以写出一个显示一个任意大小的点阵字模的函数,这个函数的功能是输出一个宽度为w,高度为h的字模到屏幕的(x,y)坐标出,文字的颜色为color,文字的点阵数据为pdata所指:
/*输出字模的函数*/
void _draw_model(char *pdata, int w, int h, int x, int y, int color)
| | | | | | | | | | | | | | | | |
可以看出这是一个"汉"字的点阵,当然文本的方式效果不是很好.根据上面的原则,我们可以写出这个点阵的点阵数据:0x40,0x08,0x37,0xfc,0x10,0x08,…,当然写这个确实很麻烦所以我不再继续下去.我这样做,也只是为了向你说明,在点阵字库中,每一个点阵的数据就是按照这种方式存放的.
在实际应用中,同一个字符有多种字体(如宋体、楷体等),每种字体又有多种大小型号,因此字库的存储空间十分庞大.为了减少存储空间,一般采用压缩技术.
矢量字符记录字符的笔画信息而不是整个位图,具有存储空间小,美观、变换方便等优点.例如:在AutoCAD中使用图形实体-形(Shape)-来定义矢量字符,其中,采用了直线和圆弧作为基本的笔画来对矢量字符进行描述.对于字符的旋转、放大、缩小等几何变换,点阵字符需要对其位图中的每个象素进行变换,而矢量字符则只需要对其几何图素进行变换就可以了,例如:对直线笔画的两个端点进行变换,对圆弧的起点、终点、半径和圆心进行变换等等.
点阵字库生成的原理

所有的汉字或者英文都是下面的原理,由左至右,每8个点占用一个字节,最后不足8个字节的占用一个字节,而且从最高位向最低位排列。
生成的字库说明:(以12×12例子)一个汉字占用字节数:12÷8=1····4也就是占用了2×12=24个字节。
编码排序A0A0→A0FE A1A0→A2FE依次排列。
以12×12字库的“我”为例:“我”的编码为CED2,所以在汉字排在CEH-AOH=2EH区的D2H-A0H=32H个。
所以在12×12字库的起始位置就是[{FE-A0}*2EH+32H]*24=104976开始的24个字节就是我的点阵模。
其他的类推即可。
英文点阵也是如此推理。
51单片机的13×14点阵缩码汉卡我们历时数载,开发成"51单片机13×14点阵缩码汉卡",适用于目前国内外应用最为广泛的MCSX-51及其兼容系列单片机.与此同时,还开发了13×14点阵汉字字模.13×14点阵字模,可完全与目前通用的16×16点阵汉字字模媲美,其在单片机和嵌入式系统的汉字显示应用中也具有明显的经济价值和实用意义.1.单片机目前的汉字显示信息交流的最主要方式之一即文字交流,但由于我国方块汉字数量繁多,构形迥异,使汉字显示一直是我国计算机普及的障碍.随着计算机技术的迅速发展,PC机的汉字显示已不成问题.但对于成本低、体积小、应用灵活且用量极为巨大的单片机而言,因其结构简单,硬件资源十分有限,其汉字显示仍面对着捉襟见肘,力不从心的窘境.目前单片机的汉字显示有三种基本方法.①采用标准字库法.即将国标汉字库固人ROM中,将单片机的硬件和软件进行特别扩展后以显示汉字.众所周知,即使是16×16点阵标准字库,也须占用200KB以上的单元内存,而就目前主流5l系列单片机而言,最大寻址范围仅64KB,即使程序区与数据区合起来也仅128KB内存.因此,若不加特别的扩展设计,不要说检字程序和用户空间,仅字库都装不下.这种方法虽然可以方便地使用现成标准字库,但却需占用大量的硬件和软件资源,增加很大一部分成本和设计难度,所以不经常使用.②字模直接固化法.即将所显示的汉字,依先后顺序将其字模一一从标准字库中提取后,重新固化,予以显示.此法虽为简捷,但只适于显示少量汉字,且字模的制取繁琐,软件的修改维护都很困难.③带索引小字库法.即将欲显示文件中的汉字字模,从标准字库中逐一提取固化,制成小型字库,并按其在小字库中的位置制成索引表,显示时从索引表查出其新的字模取码地址,取码显示.此方法虽比较灵活,可显示较多的汉字,但仍然局限于只能显示固定文件内容,且字模制取同样麻烦.一种较新的单片机"汉字动态编码与显示方案"(见《单片机与嵌入式系统应用》杂志2003年第1期和第9期),实际上也是一种动态的"小字库"法,只是字库的制取,索引的编写及文件的改码皆由PC机自动完成,免去了繁琐的人工处理.由上可见,目前单片机各种汉字显示方案均不理想.标准字库法,单片机不堪重负;而其它方法最大且又无法克服的缺点是,所显示文字皆有局限.显示内容也皆须专业人员设计而定,用户难于更改.这便极大地限制了单片机在各个领域的开拓和应用.究其原因,皆为单片机本身无汉卡,而这也正是我们致力于"51汉卡"开发的初衷.2.13×14点阵汉字字模为垫定"5l汉卡"的字型基础,首先开发成了l3×14点阵汉字字模.在目前通用的汉字字模中,最简单的是16×16点阵字模.在微型打字机中,也偶见有12×12点阵字模,但实用中不多见.字模点阵数直接决定着每一汉字所占单元内存值,能否在保证字模准确、美观的基础上,寻找一种较少的点阵字模呢?这便是我们最初的想法.于是我们经过反复选择比较,终于在国内首个推出了13×14点阵字模.此设计,一是基于我国汉字为方块字,故其行、列值需相近;二是汉字多有对称1生,故其列值宜奇不宜偶.设计实际表明,若行、列值很少,则难保证字模的准确性和美观性.?13×14点阵字模,是以我国现行简化字为准,并在此基础上设计而成.与目前通用的汉字16×l6点阵字模相比,其准确性和美观性并不逊色.然而其单字所占内存却由32个单元降至26个单元;另外使得每个单字显示由原来的256个像素降至l82个像素,使显示成本和空间均减少近三分之一.100×200点阵LED字屏,可显示16×l6点阵汉字72个,而l3×14点阵汉字便可显示l05个,且显示效果并无太大差异.这无疑对单片机和嵌入式系统汉字显示产品的开发和应用,具有明显的经济价值和实用意义.3.51单片机13×14点阵缩码汉卡"51汉卡"依据我国的汉字特点和单片机的快速构字功能,在13×14点阵字模基础上,以缩码形式开发而成单片机汉卡的开发,应以目前通用的主流单片机为研发对象,还应在囊括国标一、二级汉字及常用字符的前提下,使内存占用必须降至主流单片机可寻址范围内,且需留有足够的检字程序和用户应用空间.另外,字模设计必须准确、美观.字模提取速度也必须满足实用要求."51汉卡"的开发正是依据原则,并达到了以上各项要求.顾名思义,"51汉卡,即以MCS-51系列及其兼容单片机为研发对象.以51系列为代表的8位单片机,在过去、现在以及可以予见的将来,都将是嵌入式系统低端应用的主流机型.此乃业界专家的共识."51汉卡"囊括了"GB2312-80"国标字库的全部一、二级汉字,并增补汉字86个;同时包括了大、小英文字母、阿拉伯数字等160个常用字符和不到4KB的构字程序,却仅总共占用了不足66KB的内存.每字平均约占9.8个单元,相对于16×16点阵每字占32单兀内存而言,尚不到其三分之一.这对于具有相互独立的64KB程序区和64KB数据区的51系列单片机而言,若适当配置内存,可为检字程序和用户留出90%以上的程序空间及相当数量的数据空间,对于一般用户的应用,都将绰绰有余.另外,为使"51汉卡''更便于使用和进一步节省内存,在上述基础上又开发成一套简化版本,删去了部分较偏僻的二级汉字.简化版本包括约5580个汉字,共占用内存58KB.实际上,按有关权威部门的统计,一般文本99%的文字是由2400个字写成的,因此使用简化版本,并配以简单的造字程序,一般亦可满足我们的使用要求."51汉卡"所用字模,即我们开发的完全可与16×16点阵字模媲美的I3×14点阵汉字字模.字模提取速度是我们最为关心的问题之一.经测试及实际使用表明,"51汉卡''的提模速度完全可满足单片机汉字显示的实用要求.我们使用INTEL公司MCS-51经典系列87C51单片机在24MHz频率下测试,平均字模提取速度为2.1ms/字.因人的视觉暂留时间为0.1s,无论理论还是实际使用都表明,50字字模提取并显示,并无迟滞和待机之感.即使在1?2MHz频率下,20字取模,即点即出,在一般拼音检字和少量汉字显示中,完全可满足使用要求.随着单片机技术的迅速发展,目前,INTEL公司、Atmel 公司、philips公司、我国台湾华邦等公司生产的MCS-51兼容单片机时钟频率可达33MHz,增强型可达40MHz,以至达60MHz;现市售的"ST C89LE"系列单片机,最高频率可达90MHz.这些芯片都完全能与MCS-51芯片兼容,对于更高需求的场合,更新升级也十分简便.另外,在单片机和嵌入式系统中,文字显示速度要求并不高,只要满足换屏时的视觉要求即可.其汉字显示字数,一般也不太多.如用LCD显示屏,128×64点阵,才显示32个字;192×64点阵才显48个字;即使使用l3×14点阵字模,满屏也才56个汉字.4."51汉卡"设计依据及说明"51汉卡"设计依据是,我国汉字虽然数量繁多,字型各异,但其中复合结构者占大部分,并素有"偏旁取义,正字取音"之说.如"寸"字与不同偏旁可组成"村"、"付"、"讨"、"守"、"过"等字.因此"51汉卡"除单结构字基本以全码设计外,复台结构字多用相应的单体字及其偏旁,以结构代码写成.利用单片机快速的单元积木式构字程序,便可迅速生成字模代码.这既保证了提码速度,又节省了大量的汉卡内存.有关"51汉卡"的几点说明如下:①凡汉字库中简、繁体字都有的用简体.如"後"以"后"代,"馀"以"余"代等;②《新华字典》未收入字,多未收入,如"酏"、"鼽"等字,但"婧"、"弪"等字仍收入;③对于多体字,一般以常用字代,如"摺"以"折"代,"镟"以"旋,代等,但"吒"不以"咤"代,"雠"不以"仇"代等;④对通常已由其它字取代的字,都以这些字代替,如"岽"以"东"代,"肛''以"船"代等;⑤二级汉字中,不单独构成汉字的偏旁未收入;⑥依据名篇名著,生活用语等,增补汉字86个;⑦收编大、小写英文字母、阿拉伯数字、标点符号等各种常用字符160个.5."51单片机汉卡"应用举例利用"51单片机汉卡",将使51系列单片机的汉字显示轻而易举,并可大为降低成本、体积和设计开发的难度,为单片机在生产控制、信息通信、文化教育和日常生活等领域,特别是计算机终端和手持产品的开发提供极大的便利和支持.?我们现已初步开发成"51汉卡"的"区位码输入法"和"拼音输入法,检字程序,并利用"51汉卡"成功地开发了带有廉价单片机控制器的LED汉字显示屏.这不仅大幅度降低了成本费用.而且用户可以通过单片机控制器,随心所欲地改变显示内容.51硬件设计CPU--87C51、12MHz晶振.程序存储器一1片EPROM?27C512.数据存储器一1片EPROM?27C512;1片EEPROM28C64A;1片6116.控制器显示屏一LCD?HY一19264B(深圳秋田视佳实业有限公司).LED屏选240×16点阵.本系统用标准小键盘检字,一次可予选4000字;控制器LCD满屏显示l3×14点阵汉字56个;LED屏满屏显示汉字19个.地址分配及用途如表l所列.5.2程序设计框图程序设计流程如图1所示.本系统采用12MHz晶振,若LCD取满屏56字,换屏时有约0.1s 的延时,这对人的实际视觉并无大影响.标准点阵汉字字库芯片1 概述GT23L24M1W是一款内含24X24点阵的汉字库芯片,支持GB18030国标汉字(含有国家信标委合法授权)及ASCII字符.排列格式为横置横排.用户通过字符内码,利用本手册提供的方法计算出该字符点阵在芯片中的地址,可从该地址连续读出字符点阵信息.1.1 芯片特点●数据总线: SPI 串行总线接口PLII 精简地址并行总线接口●点阵排列方式:字节横置横排访问速度:SPI 时钟频率:20MHz(max.)PLII 访问速度:130ns(max.) @3.3V●工作电压:2.7V~3.6V●电流:工作电流:12mA待机电流:10uA●封装:SO20W●尺寸(SO20W):12.80mmX10.30mm●工作温度:-20℃~85℃(SPI 模式下);-10℃~85℃(PLII 模式下)2.2 SPI 接口引脚描述串行数据输出(SO):该信号用来把数据从芯片串行输出,数据在时钟的下降沿移出.串行数据输入(SI):该信号用来把数据从串行输入芯片,数据在时钟的上升沿移入.串行时钟输入(SCLK):数据在时钟上升沿移入,在下降沿移出.片选输入(CS#):所有串行数据传输开始于CE#下降沿,CE#在传输期间必须保持为低电平,在两条指令之间保持为高电平.总线挂起输入(HOLD#):2.3 SPI 接口与主机接口电路示意图SPI 与主机接口电路连接可以参考下图(#HOLD管脚建议接2K 电阻3.3V 拉高).若是采用系统电压为5V的,则需要进行电平转换匹配连接GT23 芯片,可以参考下图(#HOLD 管脚建议接2K 电阻3.3V 拉高).2.4 PLII 接口引脚描述2.5 PLII 接口与主机接口电路示意图SPI/PLII_SEL(管脚内部有100K 上拉电阻)接地,字库芯片选择PLII 接口模式,与主机接口电路连接可以参考下图.2.6 PLII 总线接口寻址说明在PLII 总线模式下,芯片内部有3个地址寄存器,主机需要把要读取数据的地址写入这3个地址寄存器,然后再从数据寄存器中读出数据.主机每读一次数据寄存器,芯片内部的地址寄存器会自动增一,从而使主机只写一次首地址,就可以连续读取数据.3 字库调用方法3.1 汉字点阵排列格式每个汉字在芯片中是以汉字点阵字模的形式存储的,每个点用一个二进制位表示,存1的点,当显示时可以在屏幕上显示亮点,存0的点,则在屏幕上不显示.点阵排列格式为横置横排:即一个字节的高位表示左面的点,低位表示右面的点(如果用户按word mode读取点阵数据,请注意高低字节的顺序),排满一行的点后再排下一行.这样把点阵信息用来直接在显示器上按上述规则显示,则将出现对应的汉字.3.1.1 24X24点汉字排列格式24X24 点汉字的信息需要72个字节(BYTE 0 – BYTE 71)来表示.该24X24 点汉字的点阵数据是横置横排的,其具体排列结构如下图:命名规则:最大字符集及字数S:GB2312 6,763汉字M:GB18030 27,484汉字T:GB12345 6,866汉字BIG5 5,401 / 13,060汉字U:Unicode V3.0 27,484汉字。
点阵的名词解释

点阵的名词解释一、简介点阵,指的是一组排列在规则的矩形或方形网格中的小点。
这些小点经过特定的排列和组合,形成了形状各异的图像或文字。
点阵技术广泛应用于打印、显示、图像处理等领域,是现代信息技术不可或缺的重要组成部分。
二、点阵显示技术点阵显示技术是一种基于像素的显示方式,将图像或文字进行划分,每个像素点的状态控制图像的呈现。
在点阵显示屏中,每个像素点通常由三个小点(红、绿、蓝)组成,通过调节这些小点的亮度和色彩,可以实现千变万化的图像效果。
点阵显示屏广泛应用于计算机显示器、电视屏幕、手机屏幕等设备中。
随着技术的发展,点阵显示分辨率不断提高,像素越来越小,显示效果也越来越细腻。
这使得我们能够享受到更清晰、更逼真的视觉体验。
三、点阵字库点阵字库是一种特殊的字库,用于存储和呈现文本信息。
它将每个字符划分为一个个小的点阵图案,通过控制这些点阵的亮暗来显示文字。
点阵字库通常包含了各种字符的点阵图案,如汉字、英文字母、数字等。
点阵字库在打印、显示等领域发挥着重要作用。
通过点阵字库,我们可以方便地将文字信息转化为点阵图案,并进行显示、打印等处理。
此外,点阵字库还可以提供字体大小、粗细、形状等方面的调整,使得文本信息的呈现更加灵活多样。
四、点阵印刷技术点阵印刷技术是一种基于点阵的印刷方式,通过控制墨水或颜料从小孔中流出,形成图案或文字。
点阵印刷技术广泛应用于报纸、书籍、海报、宣传单等印刷品的制作中。
点阵印刷技术的原理是利用墨水或颜料在印刷版上形成一系列小点,通过这些小点的排列和组合,再将印刷版与纸张接触,将图案或文字转移至纸张上。
相比于其他印刷技术,点阵印刷技术成本低、效果好,因此被广泛应用于大批量印刷生产中。
五、点阵图像处理点阵图像处理是一种基于点阵的图像处理技术,通过对像素点的调整和处理,改变图像的亮度、色彩、对比度等特征。
点阵图像处理可以实现图像的增强、滤波、编码等多种操作,广泛应用于图像处理软件、相机、手机等设备中。
点阵字库的原理与应用

点阵字库的原理与应用1. 点阵字库的定义点阵字库是一种用来表示字符、数字和符号的编码系统。
它将每个字符、数字和符号映射成一个矩阵,其中的每个元素都表示一个像素点。
通过控制这些像素点的亮暗,我们可以在屏幕上显示出各种字符、数字和符号。
2. 点阵字库的原理点阵字库的原理是将每个字符表示成一个矩阵,其中的每个元素都表示一个像素点。
这些像素点可以通过不同的显示方式来呈现出不同的字符效果。
例如,一个常见的5x7点阵字库可以表示出128个字符。
每个字符由5行7列的像素矩阵组成,其中的每个元素可以是亮或暗。
通过控制这些像素的状态,我们可以显示出各种字符。
3. 点阵字库的应用点阵字库广泛应用于各种显示设备和系统中,例如计算机、手机、LED显示屏等。
它可以用来显示各种文字和图形,提供丰富的显示效果。
以下是点阵字库的一些常见应用:•计算机显示:在计算机上,点阵字库被用来显示各种字符、数字和符号。
它可以显示出不同的字体和大小,提供更好的可读性和用户体验。
•手机显示:点阵字库也被广泛用于手机屏幕上,用来显示各种文字和图标。
手机屏幕的分辨率越高,点阵字库所能呈现的效果就越清晰和细腻。
•LED显示屏:在LED显示屏上,点阵字库可以用来显示各种文字和图形,并且可以通过控制像素的亮暗和颜色来呈现出更丰富的效果。
•打印机:打印机也使用点阵字库来打印出文字和图形,通过控制打印头上的针或墨滴,将点阵字库中的信息转化为实际的印刷图案。
4. 点阵字库的优缺点使用点阵字库有以下优点:•灵活性:点阵字库可以根据需要显示不同的字体、大小和样式,从而满足用户的不同需求。
•可读性:因为点阵字库是基于像素的,所以能够提供较高的显示清晰度和可读性。
•节省存储空间:由于点阵字库是基于矩阵的存储方式,它可以有效地节省存储空间,使得系统更加高效。
然而,点阵字库也有一些缺点:•分辨率限制:点阵字库的显示效果受到分辨率的限制,低分辨率的显示设备可能无法呈现出更精细的字体和图形。
汉字点阵字库原理详解+例程

汉字点阵字库原理一、汉字编码1. 区位码在国标GD2312—80 中规定,所有的国标汉字及符号分配在一个94 行、94 列的方阵中,方阵的每一行称为一个“区”,编号为01 区到94 区,每一列称为一个“位”,编号为01 位到94位,方阵中的每一个汉字和符号所在的区号和位号组合在一起形成的四个阿拉伯数字就是它们的“区位码”。
区位码的前两位是它的区号,后两位是它的位号。
用区位码就可以唯一地确定一个汉字或符号,反过来说,任何一个汉字或符号也都对应着一个唯一的区位码。
汉字“母”字的区位码是3624,表明它在方阵的36 区24 位,问号“?”的区位码为0331,则它在03区3l位。
一级汉字16-55区二级汉字56-87区三级汉字1-9区空闲未用10-15区2. 机内码汉字机内码,又称“汉字ASCII码”,简称“内码”,汉字的机内码是指在计算机中表示一个汉字的编码。
机内码与区位码稍有区别。
如上所述,汉字区位码的区码和位码的取值均在1~94 之间,如直接用区位码作为机内码,就会与基本ASCII码混淆。
为了避免机内码与基本ASCII码的冲突,需要避开基本ASCII码中的控制码(00H~1FH),还需与基本ASCII码中的字符相区别。
为了实现这两点,可以先在区码和位码分别加上20H,在此基础上再加80H(此处“H”表示前两位数字为十六进制数)。
经过这些处理,用机内码表示一个汉字需要占两个字节,分别称为高位字节和低位字节,这两位字节的机内码按如下规则表示:高位字节= 区码+ 20H + 80H(或区码+ A0H)低位字节= 位码+ 20H + 80H(或位码+ AOH)由于汉字的区码与位码的取值范围的十六进制数均为01H~5EH(即十进制的01~94),所以汉字的高位字节与低位字节的取值范围则为A1H~FEH(即十进制的161~254)。
例如,汉字“啊”的区位码为1601,区码和位码分别用十六进制表示即为1001H,它的机内码的高位字节为B0H,低位字节为A1H,机内码就是B0A1H。
点阵显示原理

汉字显示屏广泛应用与汽车报站器,广告屏等。
本文介绍一种实用的汉字显示屏的制作,考虑到电路元件的易购性,没有使用8*8的点阵发光管模块,而是直接使用了256个高量度发光管,组成了16行16列的发光点阵。
同时为了降低制作难度,仅作了一个字的轮流显示,实际使用时可根据这个原理自行扩充显示的字数。
1汉字显示的原理:我们以UCDOS中文宋体字库为例,每一个字由16行16列的点阵组成显示。
即国标汉字库中的每一个字均由256点阵来表示。
我们可以把每一个点理解为一个像素,而把每一个字的字形理解为一幅图像。
事实上这个汉字屏不仅可以显示汉字,也可以显示在256像素范围内的任何图形。
用8位的AT89C51单片机控制,由于单片机的总线为8位,一个字需要拆分为2个部分。
一般我们把它拆分为上部和下部,上部由8*16点阵组成,下部也由8*16点阵组成。
在本例中单片机首先显示的是左上角的第一列的上半部分,即第0列的p00---p07口。
方向为p00到p07 ,显示汉字“大”时,p05点亮,由上往下排列,为p0.0 灭,p0.1 灭, p0.2 灭p0.3 灭, p0.4 灭, p0.5 亮,p0.6 灭,p0.7 灭。
即二进制00000100,转换为16进制为 04h.。
上半部第一列完成后,继续扫描下半部的第一列,为了接线的方便,我们仍设计成由上往下扫描,即从p27向p20方向扫描,从上图可以看到,这一列全部为不亮,即为00000000,16进制则为00h。
然后单片机转向上半部第二列,仍为p05点亮,为00000100,即16进制04h. 这一列完成后继续进行下半部分的扫描,p21点亮,为二进制00000010,即16进制02h. 依照这个方法,继续进行下面的扫描,一共扫描32个8位,可以得出汉字“大” 的扫描代码为:04H,00H,04H,02H,04H,02H,04H,04H 04H,08H,04H,30H,05H,0C0H,0FEH,00H05H,80H,04H,60H,04H,10H,04H,08H 04H,04H,0CH,06H,04H,04H,00H,00H 由这个原理可以看出,无论显示何种字体或图像,都可以用这个方法来分析出它的扫描代码从而显示在屏幕上。
点阵系统的工作原理和应用

点阵系统的工作原理和应用1. 点阵系统概述•点阵系统是一种将图像或文字信息以点阵矩阵的形式显示的设备。
它通常由一组LED或LCD等光源组成,用来显示图像、文字或图案。
2. 点阵系统的工作原理•点阵系统的工作原理是通过控制光源的开关来显示图像或文字。
下面是一个简单的点阵系统的工作原理:1.接收控制信号:点阵系统一般会通过接口接收控制信号,比如从计算机、单片机或其他控制器。
2.解析控制信号:点阵系统会解析控制信号以确定需要显示的图像或文字。
3.控制光源:点阵系统会根据解析的控制信号控制光源的开关状态。
每个光源对应一个像素,通过开关控制,可以实现不同亮度和颜色的显示效果。
4.显示图像或文字:通过控制光源的开关状态,点阵系统可以将图像或文字显示在点阵矩阵上。
3. 点阵系统的应用•点阵系统广泛应用于各个领域,以下列举了一些常见的应用场景:–数字时钟:点阵系统可以用来显示数字时钟,通过将数字的每个部分转化为对应的点阵,实现时、分、秒的显示。
–温度显示:点阵系统可以用来显示温度信息,将温度数值转化为对应的点阵,直观地显示当前温度。
–电子表格:点阵系统可以用来显示电子表格,以方便用户查看和编辑表格中的数据。
–游戏机:点阵系统可以用来显示游戏界面和游戏中的图像,提供更好的游戏体验。
–车载显示:点阵系统可以用来显示车辆的行驶信息和导航指示,提高行车安全性。
–信息显示:点阵系统可以用来显示公共场所的信息,比如车站、机场等的到站信息和航班信息。
–广告屏:点阵系统可以用来显示广告内容,吸引人们的注意和关注。
4. 点阵系统的优势和不足•点阵系统的优势:–显示效果好:点阵系统可以通过控制光源的开关状态来实现多种显示效果,可以显示丰富的图像和文字。
–易于控制:点阵系统可以通过接口接收控制信号,只要控制信号正确,可以实现快速、准确的显示。
–可靠性高:点阵系统通常采用固态光源,寿命长,不易出现故障。
•点阵系统的不足:–分辨率限制:点阵系统的分辨率通常是固定的,不易扩展。
点阵字库的原理及与矢量字库的差别

点阵字库的原理及与⽮量字库的差别点阵字库的原理及与⽮量字库的差别点阵字库的⽣产原理所有的汉字或者英⽂都是下⾯的原理,由左⾄右,每8个点占⽤⼀个字节,最后不⾜8个字节的占⽤⼀个字节,⽽且从最⾼位向最低位排列。
⽣成的字库说明:(以12×12例⼦)⼀个汉字占⽤字节数:12÷8=1····4也就是占⽤了2×12=24个字节。
编码排序A0A0→A0FE A1A0→A2FE依次排列。
以12×12字库的“我”为例:“我”的编码为CED2,所以在汉字排在CEH-AOH=2EH区的D2H-A0H=32H个。
所以在12×12字库的起始位置就是[{FE-A0}*2EH+32H]*24=104976开始的24个字节就是我的点阵模。
其他的类推即可。
英⽂点阵也是如此推理。
在DOS程序中使⽤点阵字库的⽅法⾸先需要理解的是点阵字库是⼀个数据⽂件,在这个数据⽂件⾥⾯保存了所有⽂字的点阵数据。
⾄于什么是点阵,我想我不讲⼤家都知道的,使⽤过"⽂曲星"之类的电⼦辞典吧,那个的液晶显⽰器上⾯显⽰的汉⼦就能够明显的看出"点阵"的痕迹。
在PC 机上也是如此,⽂字也是由点阵来组成了,不同的是,PC机显⽰器的显⽰分辨率更⾼,⾼到了我们⾁眼⽆法区分的地步,因此"点阵"的痕迹也就不那么明显了。
点阵、矩阵、位图这三个概念在本质上是有联系的,从某种程度上来讲,这三个就是同义词。
点阵从本质上讲就是单⾊位图,他使⽤⼀个⽐特来表⽰⼀个点,如果这个⽐特为0,表⽰某个位置没有点,如果为1表⽰某个位置有点。
矩阵和位图有着密不可分的联系,矩阵其实是位图的数学抽象,是⼀个⼆维的阵列。
位图就是这种⼆维的阵列,这个阵列中的(x,y)位置上的数据代表的就是对原始图形进⾏采样量化后的颜⾊值。
但是,另⼀⽅⾯,我们要⾯对的问题是,计算机中数据的存放都是⼀维的,线性的。
点阵字库的显示原理

其他的类推即可。
英文点阵也是如此推理。
当然也存在着不规则的点阵,这里说的不规则,指的是点阵的宽度不是8的倍数,比如 12*12
的点阵,那么这样的点阵数据又是如何存放的呢?其实也很简单,每一行的前面8个点存放在一个字节里面,每一行的剩下的4点就使用一个字节来存放,也就是说
剩下的4个点将占用一个字节的高4位,而这个字节的低4位没有使用,全部都默认的为零.这样做当然显得有点浪费,不过却能够便于我们进行存放和寻址.对于
2、16*16点阵字库
对于16*16的矩阵来说,它所需要的位数共是16*16=256个位,每个字节为8位,因此,每个汉字都需要用256/8=32个字节来表示。
即每两个字节代表一行的16个点,共需要16行,显示汉字时,只需一次性读取32个字节,并将每两个字节为一行打印出来,即可形成一个汉字。
dos所用字库,文件头结构很简单,如默认的8*16英文字库,文件头长度为4,跳过这四个字节就是字模数据;也有没有文件头的,从第一个字节开始就是字模数据。
点阵字库结构
1、点阵字库存储
在汉字的点阵字库中,每个字节的每个位都代表一个汉字的一个点,每个汉字都是由一个矩形的点阵组成,0代表没有,1代表有点,将0和1分别用不同颜色画出,就形成了一个汉字,常用的点阵矩阵有12*12,
点阵结构如下图所示:
第一字节 第二字节
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
点阵字库应用原理

点阵字库[浏览次数:492次]点阵字库是把每一个汉字都分成16X16或24X24个点,然后用每个点的虚实来表示汉字的轮廓,常用来作为显示字库使用,这类点阵字库汉字最大的缺点是不能放大,一旦放大后就会发现文字边缘的锯齿。
目录点阵字库的显示原理点阵字库与字符字模点阵字库结构汉字点阵获取在DOS程序中使用点阵字库的方法点阵字库和矢量字库的差别如何使用Windows的系统字库生成点阵字库标准点阵字库芯片点阵字库的显示原理* 所有的汉字或者英文都是下面的原理,由左至右,每8个点占用一个字节,最后不足8个字节的占用一个字节,而且从最高位向最低位排列。
生成的字库说明:(以12 X12例子)一个汉字占用字节数:12- 8=1 • -4也就是占用了2X 12= 24个字节。
编码排序AOAO T AOFE A1A0 宀A2FE依次排列。
以12X 12字库的我”为例:我”的编码为CED2,所以在汉字排在CEH-AOH=2EH 区的D2H -A0H=32H 个。
所以在12 X12字库的起始位置就是[{FE-A0}*2EH+32H]*24= 10 4976开始的24个字节就是我的点阵模。
其他的类推即可。
英文点阵也是如此推理。
点阵字库与字符字模« 在dos终端模式下是不可以显示中文汉字的,只能显示英文。
汉字与英文的区别是:1.汉字字库中,任何字符均用2个字节编码,即区码和位码,在英文字库中,所有字符均用单字节编码。
2.16点阵汉字字库(16*16)用32个字节存储一个字符的字模,16点阵英文字库(8*16)用16个字节存储单个字符的字模。
在DOS终端模式下用的是16点阵英文字库,如果要让DOS终端中显示中文,可以改写终端模式下的16点阵英文字库,使其显示的不是原有的英文字符,而是汉字字符,当然也可以加入自造点阵图形图像。
原理为:我们输入AB,正常显示的是AB,但如果改变AB的字模,用汉字的字模代替,这样输入AB字符,并不显示AB,而是显示一个汉字。
点阵字体的原理

点阵字体的原理点阵字体(bitmap font)是一种常见的计算机字体,它的原理是使用一个二维的矩阵(也称为位图)来描述每个字符的图形外形。
每个字符被表示成一系列的点阵,这些点阵可以被储存在一个字形(glyph)存储器中,用于在文本编辑器、图像处理软件、游戏等应用程序中进行显示。
点阵字体最早出现于20世纪50年代早期的打印机技术中,之后逐步用于计算机屏幕显示、字形设计和打印等领域。
点阵字体最大的优点是易于实现和存储。
一旦某个字形的点阵矩阵被编码并储存下来,即可在任何时候被快速地绘制出来,这种方式也确保了字体在不同平台和设备上的一致性。
点阵字体的矩阵中,每个点被称为像素(pixel),是计算机图像中的最小单位。
像素的颜色和亮度可以用数值来表示,通常是8位或16位无符号整数。
一个字符的像素矩阵可以由黑色(表示字符的前景)和白色(表示背景)组成,也可以使用灰度和其他颜色。
点阵字体的最基本组成部分是字形定义文件,也叫做字形数据文件(glyph data file)。
这个文件中包含了每个字符的像素点阵信息、字符的尺寸、位置、偏移量和字母间距等信息。
字形定义文件通常以一种类似于位图的格式保存,可以使用各种编辑器和工具进行创建、修改和转换。
在计算机上渲染点阵字体时,首先要确定每个字符的大小和位置。
大小通常由像素数目来表示,可以选择在字形数据文件中设置或者在应用程序中动态调整。
然后,需要将二维像素矩阵转换为要渲染的实际屏幕像素大小。
这个过程被称为缩放(scaling)或者拉伸(stretching),可以使用一些算法来实现,如Nearest Neighbor、Bilinear等。
另外,点阵字体的渲染还受到一些其他的因素的影响,例如字体平滑度、抗锯齿算法的选择、颜色混合模式和输出设备的分辨率等。
如果字体被放大或缩小时,它会变得模糊或失真,因此需要选取合适的抗锯齿算法或者增加字体的分辨率。
总体来说,点阵字体以其易用性、易传播性、体积小等优点而广泛应用于计算机领域。
点阵字库的原理及与矢量字库的差别

点阵字库的原理及与矢量字库的差别点阵字库的生产原理所有的汉字或者英文都是下面的原理,由左至右,每8个点占用一个字节,最后不足8个字节的占用一个字节,而且从最高位向最低位排列。
生成的字库说明:(以12×12例子)一个汉字占用字节数:12÷8=1····4也就是占用了2×12=24个字节。
编码排序A0A0→A0FE A1A0→A2FE依次排列。
以12×12字库的“我”为例:“我”的编码为CED2,所以在汉字排在CEH-AOH=2EH区的D2H-A0H=32H个。
所以在12×12字库的起始位置就是[{FE-A0}*2EH+32H]*24=104976开始的24个字节就是我的点阵模。
其他的类推即可。
英文点阵也是如此推理。
在DOS程序中使用点阵字库的方法首先需要理解的是点阵字库是一个数据文件,在这个数据文件里面保存了所有文字的点阵数据。
至于什么是点阵,我想我不讲大家都知道的,使用过"文曲星"之类的电子辞典吧,那个的液晶显示器上面显示的汉子就能够明显的看出"点阵"的痕迹。
在PC 机上也是如此,文字也是由点阵来组成了,不同的是,PC机显示器的显示分辨率更高,高到了我们肉眼无法区分的地步,因此"点阵"的痕迹也就不那么明显了。
点阵、矩阵、位图这三个概念在本质上是有联系的,从某种程度上来讲,这三个就是同义词。
点阵从本质上讲就是单色位图,他使用一个比特来表示一个点,如果这个比特为0,表示某个位置没有点,如果为1表示某个位置有点。
矩阵和位图有着密不可分的联系,矩阵其实是位图的数学抽象,是一个二维的阵列。
位图就是这种二维的阵列,这个阵列中的(x,y)位置上的数据代表的就是对原始图形进行采样量化后的颜色值。
但是,另一方面,我们要面对的问题是,计算机中数据的存放都是一维的,线性的。
点阵的原理和应用解析

点阵的原理和应用解析1. 什么是点阵点阵(Dot Matrix),也称为像素点阵,是由一个个像素组成的图像或文字显示方式。
每个像素代表图像的最小单元,通过不同的排列组合,可以显示出各种图形、字母、数字等内容。
点阵通常使用方形或者圆形的像素来构成图像。
2. 点阵的原理点阵的原理是基于电子显示技术,它通常通过控制每个像素的亮度和颜色来实现图像或文字的显示。
点阵通常由行和列组成,每个像素都有一个对应的行和列地址。
通过控制行和列的信号,可以选择并点亮相应的像素,从而显示出所需的图像。
以下是点阵显示的基本原理: - 点阵由多行多列的像素组成,每个像素都有一个控制信号 - 控制信号根据所要显示的图像或文字的需求,选择并点亮相应的像素- 控制信号通常通过驱动电路进行处理和控制,以控制像素的亮度和颜色3. 点阵的应用点阵技术在许多领域都有广泛的应用,下面列举几个典型的应用场景:3.1 数字显示器点阵在数字显示器中扮演着重要的角色。
例如,七段显示器就是一种常见的数字显示器,它通过点阵的方式来显示数字0-9以及一些字母。
每个数字或字母都由一组点阵组成,通过控制每个像素的亮暗,可以显示出所需的数字或字母。
3.2 字符型液晶屏字符型液晶屏也是基于点阵技术实现的。
字符型液晶屏通常由若干个行和列的像素组成,每个像素代表一个字符或者一个图标。
通过控制每个像素的亮度和颜色,可以显示出所需的字符或者图标。
3.3 点阵显示屏点阵显示屏是点阵技术最常见的应用之一。
它可以用于室内和室外的广告牌、LED显示屏、显示面板等。
通过点阵的方式,可以实现高亮度、高清晰度的图像和视频显示。
3.4 点阵字库点阵字库是将文字字符转化为点阵形式的文本库。
通过设计和存储各种大小和样式的点阵,可以实现需要的文字显示效果。
点阵字库广泛应用于打印机、电子标签、嵌入式系统等领域。
3.5 LED灯光显示LED灯光显示也是点阵技术的一种应用形式。
通过控制每个LED的亮度和颜色,可以实现各种图案、图像和文字的显示效果。
点阵字模原理与读取

点阵字模原理与读取点阵字模原理与读取一、字模生成原理汉字的点阵字模是从点阵字库文件中提取出来的。
例如常用的16×16点阵HZK16文件,12×12点阵HZK12文件等等,这些文件包括了GB 2312字符集中的所有汉字。
现在只要弄清汉字点阵在字库文件中的格式,就可以按照自己的意愿去显示汉字了。
下面以HZK16文件为例,分析取得汉字点阵字模的方法。
HZK16文件是按照GB 2312-80标准,也就是通常所说的国标码或区位码的标准排列的。
国标码分为 94 个区(Section),每个区 94 个位(Position),所以也称为区位码。
其中01~09 区为符号、数字区,16~87 区为汉字区。
而 10~15 区、88~94 区是空白区域。
如何取得汉字的区位码呢?在计算机处理汉字和ASCII字符时,使每个ASCII字符占用1个字节,而一个汉字占用两个字节,其值称为汉字的内码。
其中第一个字节的值为区号加上32(20H),第二个字节的值为位号加上32(20H)。
为了与ASCII字符区别开,表示汉字的两个字节的最高位都是1,也就是两个字节的值都又加上了128(80H)。
这样,通过汉字的内码,就可以计算出汉字的区位码。
具体算式如下:qh=c1-32-128=c1-160 wh=c2-32-128=c2-160或qh=c1-0xa0 wh=c2-0xa0qh,wh为汉字的区号和位号,c1,c2为汉字的第一字节和第二字节。
根据区号和位号可以得到汉字字模在文件中的位置:location=(94*(qh-1)+(wh-1))*一个点阵字模的字节数。
那么一个点阵字模究竟占用多少字节数呢?我们来分析一下汉字字模的具体排列方式。
例如下图中显示的“汉”字,使用16×16点阵。
字模中每一点使用一个二进制位(Bit)表示,如果是1,则说明此处有点,若是0,则说明没有。
这样,一个16×16点阵的汉字总共需要16*16/8=32个字节表示。
点阵汉字的原理及应用
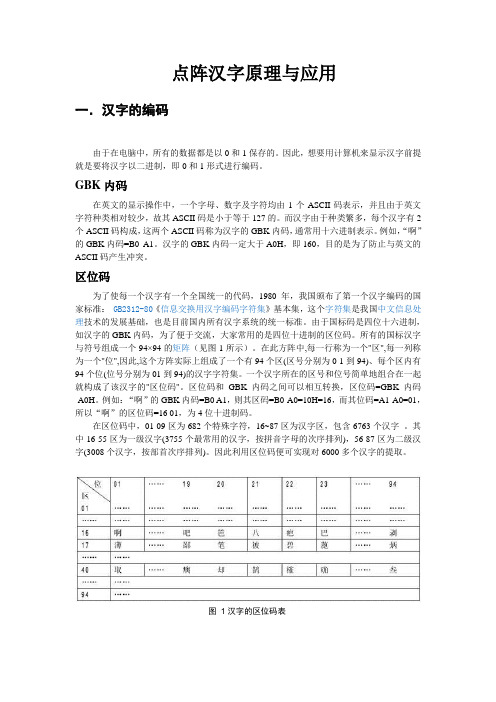
点阵汉字原理与应用一.汉字的编码由于在电脑中,所有的数据都是以0和1保存的。
因此,想要用计算机来显示汉字前提就是要将汉字以二进制,即0和1形式进行编码。
GBK内码在英文的显示操作中,一个字母、数字及字符均由1个ASCII码表示,并且由于英文字符种类相对较少,故其ASCII码是小于等于127的。
而汉字由于种类繁多,每个汉字有2个ASCII码构成,这两个ASCII码称为汉字的GBK内码,通常用十六进制表示。
例如,“啊”的GBK内码=B0 A1。
汉字的GBK内码一定大于A0H,即160,目的是为了防止与英文的ASCII码产生冲突。
区位码为了使每一个汉字有一个全国统一的代码,1980年,我国颁布了第一个汉字编码的国家标准:GB2312-80《信息交换用汉字编码字符集》基本集,这个字符集是我国中文信息处理技术的发展基础,也是目前国内所有汉字系统的统一标准。
由于国标码是四位十六进制,如汉字的GBK内码,为了便于交流,大家常用的是四位十进制的区位码。
所有的国标汉字与符号组成一个94×94的矩阵(见图1所示)。
在此方阵中,每一行称为一个"区",每一列称为一个"位",因此,这个方阵实际上组成了一个有94个区(区号分别为0 1到94)、每个区内有94个位(位号分别为01到94)的汉字字符集。
一个汉字所在的区号和位号简单地组合在一起就构成了该汉字的"区位码"。
区位码和GBK内码之间可以相互转换,区位码=GBK内码-A0H。
例如:“啊”的GBK内码=B0 A1,则其区码=B0-A0=10H=16,而其位码=A1-A0=01,所以“啊”的区位码=16 01,为4位十进制码。
在区位码中,01-09区为682个特殊字符,16~87区为汉字区,包含6763个汉字。
其中16-55区为一级汉字(3755个最常用的汉字,按拼音字母的次序排列),56-87区为二级汉字(3008个汉字,按部首次序排列)。
计算机汉字显示原理(点阵字)

for(int row=0;row<16;row++)
{
for(int c=0;c<8;c++)
if((FontModule[row*2]&cmp_w[c])!=0)
putpixel(c+x,row+y,15);
for(c=0;c<8;c++)
if((FontModule[row*2+1]&cmp_w[c])!=0)
0x35,0x04, 0x51,0xFC, 0x50,0x40, 0x17,0xFE,
0x10,0x90, 0x11,0x08, 0x16,0x06, 0x00,0x00
};
代码如下:
unsigned char cmp_w[8]={128,64,32,16,8,4,2,1};
void FontDisplay(int x, int y, unsigned char * FontModule)
因此,汉字在汉字库中的具体位置计算公式为:94*(区号-1)+位号-1。
减1是因为数组是以0为开始而区号位号是以1为开始的。
这仅为以汉字为单位该汉字在汉字库中的位置,那么,如何得到以字节为单位得到该汉字在汉字库中的位置呢?
只需乘上一个汉字字模占用的字节数即可,
即:(94*(区号-1)+位号-1)*一个汉字字模占用字节数,而按每种汉字库的汉字大小不同又会得到不同的结果。
0x06,0x0C,0xDC, 0x06,0x7F,0xF0, 0x06,0xCC,0xC0, 0x1F,0xF0,0x70,
0x06,0x3F,0xF0, 0x07,0x30,0x70, 0x0F,0xBF,0xF0, 0x0E,0xF0,0x70,
点阵字库和矢量字库

点阵字库的生产原理(转)2011-05-17 15:31:45| 分类:其他技术| 标签:|字号大中小订阅点阵字库的生产原理所有的汉字或者英文都是下面的原理,由左至右,每8个点占用一个字节,最后不足8个字节的占用一个字节,而且从最高位向最低位排列。
生成的字库说明:(以12×12例子)一个汉字占用字节数:12÷8=1····4也就是占用了2×12=24个字节。
编码排序A0A0→A0FE A1A0→A2FE依次排列。
以12×12字库的“我”为例:“我”的编码为CED2,所以在汉字排在CEH-AOH=2EH区的D2H-A0H=32H个。
所以在12×12字库的起始位置就是[{FE-A0}*2EH+32H]*24=104976开始的24个字节就是我的点阵模。
其他的类推即可。
英文点阵也是如此推理。
在DOS程序中使用点阵字库的方法首先需要理解的是点阵字库是一个数据文件,在这个数据文件里面保存了所有文字的点阵数据.至于什么是点阵,我想我不讲大家都知道的,使用过"文曲星"之类的电子辞典吧,那个的液晶显示器上面显示的汉子就能够明显的看出"点阵"的痕迹.在 PC 机上也是如此,文字也是由点阵来组成了,不同的是,PC机显示器的显示分辨率更高,高到了我们肉眼无法区分的地步,因此"点阵"的痕迹也就不那么明显了.点阵、矩阵、位图这三个概念在本质上是有联系的,从某种程度上来讲,这三个就是同义词.点阵从本质上讲就是单色位图,他使用一个比特来表示一个点,如果这个比特为0,表示某个位置没有点,如果为1表示某个位置有点.矩阵和位图有着密不可分的联系,矩阵其实是位图的数学抽象,是一个二维的阵列.位图就是这种二维的阵列,这个阵列中的 (x,y) 位置上的数据代表的就是对原始图形进行采样量化后的颜色值.但是,另一方面,我们要面对的问题是,计算机中数据的存放都是一维的,线性的.因此,我们需要将二维的数据线性化到一维里面去.通常的做法就是将二维数据按行顺序的存放,这样就线性化到了一维.那么点阵字的数据存放细节到底是怎么样的呢.其实也十分的简单,举个例子最能说明问题.比如说 16*16 的点阵,也就是说每一行有16个点,由于一个点使用一个比特来表示,如果这个比特的值为1,则表示这个位置有点,如果这个比特的值为0,则表示这个位置没有点,那么一行也就需要16个比特,而8个比特就是一个字节,也就是说,这个点阵中,一行的数据需要两个字节来存放.第一行的前八个点的数据存放在点阵数据的第一个字节里面,第一行的后面八个点的数据存放在点阵数据的第二个字节里面,第二行的前八个点的数据存放在点阵数据的第三个字节里面,…,然后后面的就以此类推了.这样我们可以计算出存放一个点阵总共需要32个字节.看看下面这个图形化的例子:| |1| | | | | | | | | | |1| | | || | |1|1| |1|1|1|1|1|1|1|1|1| | || | | |1| | | | | | | | |1| | | ||1| | | | | |1| | | | | |1| | | || |1|1| | | |1| | | | | |1| | | || | |1| | | |1| | | | |1| | | | || | | | |1| | |1| | | |1| | | | || | | |1| | | |1| | |1| | | | | || | |1| | | | | |1| |1| | | | | ||1|1|1| | | | | | |1| | | | | | || | |1| | | | | |1| |1| | | | | || | |1| | | | |1| | | |1| | | | || | |1| | | |1| | | | | |1| | | || | |1| | |1| | | | | | |1|1|1| || | | | |1| | | | | | | | |1| | || | | | | | | | | | | | | | | | |可以看出这是一个"汉"字的点阵,当然文本的方式效果不是很好.根据上面的原则,我们可以写出这个点阵的点阵数据:0x40,0x08,0x37,0xfc,0x10,0x08,…, 当然写这个确实很麻烦所以我不再继续下去.我这样做,也只是为了向你说明,在点阵字库中,每一个点阵的数据就是按照这种方式存放的.当然也存在着不规则的点阵,这里说的不规则,指的是点阵的宽度不是8的倍数,比如12*12 的点阵,那么这样的点阵数据又是如何存放的呢?其实也很简单,每一行的前面8个点存放在一个字节里面,每一行的剩下的4点就使用一个字节来存放,也就是说剩下的4个点将占用一个字节的高4位,而这个字节的低4位没有使用,全部都默认的为零.这样做当然显得有点浪费,不过却能够便于我们进行存放和寻址.对于其他不规则的点阵,也是按照这个原则进行处理的.这样我们可以得出一个 m*n 的点阵所占用的字节数为 (m+7)/8*n.在明白了以上所讲的以后,我们可以写出一个显示一个任意大小的点阵字模的函数,这个函数的功能是输出一个宽度为w,高度为h的字模到屏幕的 (x,y) 坐标出,文字的颜色为color,文字的点阵数据为 pdata 所指:/*输出字模的函数*/void _draw_model(char *pdata, int w, int h, int x, int y, int color){int i; /* 控制行 */int j; /* 控制一行中的8个点 */int k; /* 一行中的第几个"8个点"了 */int nc; /* 到点阵数据的第几个字节了 */int cols; /* 控制列 */BYTE static mask[8]={128, 64, 32, 16, 8, 4, 2, 1}; /* 位屏蔽字 */w = (w + 7) / 8 * 8; /* 重新计算w */nc = 0;for (i=0; i<h; i++){cols = 0;for (k=0; k<w/8; k++){for (j=0; j<8; j++){if (pdata[nc]&mask[j])putpixel(x+cols, y+i, color);cols++;}nc++;}}}代码很简单,不用怎么讲解就能看懂,代码可能不是最优化的,但是应该是最易读懂的.其中的 putpixel 函数,使用的是TC提供的 Graphics 中的画点函数.使用这个函数就可以完成点阵任意大小的点阵字模的输出.接下来的问题就是如何在汉子库中寻址某个汉子的点阵数据了.要解决这个问题,首先需要了解汉字在计算机中是如何表示的.在计算机中英文可以使用 ASCII 码来表示,而汉字使用的是扩展 ASCII 码,并且使用两个扩展 ASCII 码来表示一个汉字.一个 ASCII 码使用一个字节表示,所谓扩展 ASCII 码,也就是 ASCII 码的最高位是1的 ASCII 码,简单的说就是码值大于等于 128 的 ASCII 码.一个汉字由两个扩展 ASCII 码组成,第一个扩展ASCII 码用来存放区码,第二个扩展 ASCII 码用来存放位码.在 GB2312-80 标准中,将所有的汉字分为94个区,每个区有94个位可以存放94个汉字,形成了人们常说的区位码,这样总共就有 94*94=8836 个汉字.在点阵字库中,汉字点阵数据就是按照这个区位的顺序来存放的,也就是最先存放的是第一个区的汉字点阵数据,在每一个区中有是按照位的顺序来存放的.在汉字的内码中,汉字区位码的存放实在扩展 ASCII 基础上存放的,并且将区码和位码都加上了32,然后存放在两个扩展 ASCII 码中.具体的说就是:第一个扩展ASCII码 = 128+32 + 汉字区码第二个扩展ASCII吗 = 128+32 + 汉字位码如果用char hz[2]来表示一个汉字,那么我可以计算出这个汉字的区位码为:区码 = hz[0] - 128 - 32 = hz[0] - 160位码 = hz[1] - 128 - 32 = hz[1] - 160.这样,我们可以根据区位码在文件中进行殉职了,寻址公式如下:汉字点阵数据在字库文件中的偏移 = ((区码-1) * 94 + 位码) * 一个点阵字模占用的字节数在寻址以后,即可读取汉字的点阵数据到缓冲区进行显示了.以下是实现代码:/* 输出一个汉字的函数 */void _draw_hz(char hz[2], FILE *fp, int x, int y, int w, int h, int color){char f ON tbuf[128]; /* 足够大的缓冲区,也可以动态分配 */int ch0 = (BYTE)hz[0]-0xA0; /* 区码 */int ch1 = (BYTE)hz[1]-0xA0; /* 位码 *//* 计算偏移 */long offset = (long)pf->_hz_buf_size * ((ch0 - 1) * 94 + ch1 - 1);fseek(fp, offset, SEEK_SET); /* 进行寻址 */ fread(fontbuf, 1, (w + 7) / 8 * h, fp); /* 读入点阵数据 */ _draw_model(fontbuf, w, h, x, y, color); /* 绘制字模 */}以上介绍完了中文点阵字库的原理,当然还有英文点阵字库了.英文点阵字库中单个点阵字模数据的存放方式与中文是一模一样的,也就是对我们所写的 _draw_model 函数同样可以使用到英文字库中.唯一不同的是对点阵字库的寻址上.英文使用的就是 ASCII 码,其码值是0到127,寻址公式为:英文点阵数据在英文点阵字库中的偏移 = 英文的ASCII码 * 一个英文字模占用的字节数可以看到,区分中英文的关键就是,一个字符是 ASCII 码还是扩展 ASCII 码,如果是ASCII 码,其范围是0到127,这样是使用的英文字库,如果是扩展 ASCII 码,则与其后的另一个扩展 ASCII 码组成汉字内码,使用中文字库进行显示.只要正确区分 ASCII 码的类型并进行分别的处理,也就能实现中英文字符串的混合输出了.点阵字库和矢量字库的差别我们都只知道,各种字符在电脑屏幕上都是以一些点来表示的,因此也叫点阵.最早的字库就是直接把这些点存储起来,就是点阵字库.常见的汉字点阵字库有 16x16, 24x24 等.点阵字库也有很多种,主要区别在于其中存储编码的方式不同.点阵字库的最大缺点就是它是固定分辨率的,也就是每种字库都有固定的大小尺寸,在原始尺寸下使用,效果很好,但如果将其放大或缩小使用,效果就很糟糕了,就会出现我们通常说的锯齿现象.因为需要的字体大小组合有无数种,我们也不可能为每种大小都定义一个点阵字库.于是就出现了矢量字库.矢量字库矢量字库是把每个字符的笔划分解成各种直线和曲线,然后记下这些直线和曲线的参数,在显示的时候,再根据具体的尺寸大小,画出这些线条,就还原了原来的字符.它的好处就是可以随意放大缩小而不失真.而且所需存储量和字符大小无关.矢量字库有很多种,区别在于他们采用的不同数学模型来描述组成字符的线条.常见的矢量字库有 Type1字库和Truetype字库.在点阵字库中,每个字符由一个位图表示(如图2.5所示),并把它用一个称为字符掩膜的矩阵来表示,其中的每个元素都是一位二进制数,如果该位为1表示字符的笔画经过此位,该像素置为字符颜色;如果该位为0,表示字符的笔画不经过此位,该像素置为背景颜色.点阵字符的显示分为两步:首先从字库中将它的位图检索出来,然后将检索到的位图写到帧缓冲器中.在实际应用中,同一个字符有多种字体(如宋体、楷体等),每种字体又有多种大小型号,因此字库的存储空间十分庞大.为了减少存储空间,一般采用压缩技术.矢量字符记录字符的笔画信息而不是整个位图,具有存储空间小,美观、变换方便等优点.例如:在AutoCAD中使用图形实体-形(Shape)-来定义矢量字符,其中,采用了直线和圆弧作为基本的笔画来对矢量字符进行描述. 对于字符的旋转、放大、缩小等几何变换,点阵字符需要对其位图中的每个象素进行变换,而矢量字符则只需要对其几何图素进行变换就可以了,例如:对直线笔画的两个端点进行变换,对圆弧的起点、终点、半径和圆心进行变换等等.矢量字符的显示也分为两步.首先从字库中将它的字符信息.然后取出端点坐标,对其进行适当的几何变换,再根据各端点的标志显示出字符.轮廓字形法是当今国际上最流行的一种字符表示方法,其压缩比大,且能保证字符质量.轮廓字形法采用直线、B样条/Bezier曲线的集合来描述一个字符的轮廓线.轮廓线构成一个或若干个封闭的平面区域.轮廓线定义加上一些指示横宽、竖宽、基点、基线等等控制信息就构成了字符的压缩数据.如何使用Windows的系统字库生成点阵字库?我的程序现在只能预览一个汉字的不同字体的点阵表达.界面很简单: 一个输出点阵大小的选择列表(8x8,16x16,24x24等),一个系统中已有的字体名称列表,一个预览按钮,一块画图显示区域.得到字体列表的方法:(作者称这一段是用来取回系统的字体,然后添加到下拉框中) //取字体名称列表的回调函数,使用前要声明一下该方法int CALLBACK MyEnumF ON tProc(ENUMLOGFONTEX* lpelf,NEWTEXTMETRICEX* lpntm,DWORD nFontType,long lParam){CFontPeekerDlg* pWnd=(CFontPeekerDlg*) lParam;if(pWnd){if( pWnd->m_combo_sfont.Find ST ring(0, lpelf->elfLogFont.lfFaceName) <0 )pWnd->m_combo_sfont.AddString(lpelf->elfLogFont.lfFaceName);return 1;}return 0;}//说明:CFontPeekerDlg 是我的dialog的类名, m_combo_sfont是列表名称下拉combobox关联的control变量//调用的地方 (******问题1:下面那个&lf怎么得到呢……){::EnumFontFamiliesEx((HDC) dc,&lf, (FONTENUMPROC)MyEnumFontProc,(LPARAM) this,0);m_combo_sfont.SetCurSel(0);}字体预览:如果点阵大小选择16,显示的时候就画出16x16个方格.自定义一个类CMyStatic继承自CStatic,用来画图.在CMyStatic的OnPaint()函数中计算并显示.取得字体:常用的方法:用CreateFont创建字体,把字TextOut再用GetPixel()取点存入数组. 缺点:必须把字TextOut出来,能在屏幕上看见,不爽.我的方法,用这个函数:GetGlyphOutline(),可以得到一个字的轮廓矢量或者位图.可以不用textout到屏幕,直接取得字模信息函数原型如下:DWORD GetGlyphOutline(HDC hdc, //画图设备句柄UINT uChar, //将要读取的字符/汉字 UINT uFormat, //返回数据的格式(字的外形轮廓还是字的位图) LPGLYPHMETR ICS lpgm, // GLYPHMETRICS结构地址,输出参数DWORD cbBuffer, //输出数据缓冲区的大小LPVOID lpvBuffer, //输出数据缓冲区的地址CO NS T MAT2 *lpmat2 //转置矩阵的地址);说明:uChar字符需要判断是否是汉字还是英文字符.中文占2个字节长度.lpgm是输出函数,调用GetGlyphOutline()是无须给lpgm 赋值.lpmat2如果不需要转置,将 eM11.value=1; eM22.value=1; 即可.cbBuffer缓冲区的大小,可以先通过调用GetGlyphOutline(……lpgm, 0, NULL, mat); 来取得,然后动态分配lpvBuffer,再一次调用GetGlyphOutline,将信息存到lpvBuffer. 使用完毕后再释放lpvBuffer.程序示例:(***问题2:用这段程序,我获取的字符点阵总都是一样的,不管什么字……)……前面部分省略……GLYPHMETRICS glyph;MAT2 m2;memset(&m2, 0, sizeof(MAT2));m2.eM11.value = 1;m2.eM22.value = 1;//取得buffer的大小DWORD cbBuf = dc.GetGlyphOutline( nChar, GGO_BITMAP, &glyph,0L, NULL, &m2);BYTE* pBuf=NULL;//返回GDI_ERROR表示失败.if( cbBuf != GDI_ERROR ){pBuf = new BYTE[cbBuf];//输出位图GGO_BITMAP 的信息.输出信息4字节(DWORD)对齐dc.GetGlyphOutline( nChar, GGO_BITMAP, &glyph, cbBuf, pBuf, &m2);}else{if(m_pFont!=NULL)delete m_pFont;return;}编程中遇到问题:一开始,GetGlyphOutline总是返回-1,getLastError显示是"无法完成的功能",后来发现是因为调用之前没有给hdc设置Font.后来能取得pBuf信息后,又开始郁闷,因为不太明白bitmap的结果是按什么排列的.后来跟踪汉字"一"来调试(这个字简单),注意到了 glyph.gmBlackBoxX 其实就是输出位图的宽度,glyph.gmBlackBoxY就是高度.如果gmBlackBoxX=15,glyph.gmBlackBoxY=2,表示输出的pBuf中有这些信息:位图有2行信息,每一行使用15 bit来存储信息.例如:我读取"一":glyph.gmBlackBoxX = 0x0e,glyph.gmBlackBoxY=0x2; pBuf长度cbBuf=8 字节pBuf信息: 00 08 00 00 ff fc 00 00字符宽度 0x0e=14 则第一行信息为: 0000 0000 0000 100 (只取到前14位)第二行根据4字节对齐的规则,从0xff开始 1111 1111 1111 110看出"一"字了吗?呵呵直到他的存储之后就可以动手解析输出的信息了.我定义了一个宏#define BIT(n) (1<<(n)) 用来比较每一个位信息时使用后来又遇到了一个问题,就是小头和大头的问题了.在我的机器上是little endian的形式,如果我用unsigned long *lptr = (unsigned long*)pBuf;//j from 0 to 15if( *lptr & BIT(j) ){//这时候如果想用j来表示写1的位数,就错了}因为从字节数组中转化成unsigned long型的时候,数值已经经过转化了,像上例中,实际上是0x0800 在同BIT(j)比较.不多说了,比较之前转化一下就可以了if( htonl(*lptr) & BIT(j) )Unicode中文点阵字库的生成与使用点阵字库包含两部分信息.首先是点阵字库文件头信息,它包含点阵字库文字的字号、多少位表示一个像素,英文字母与符号的size、起始和结束 unicode编码、在文件中的起始偏移,汉字的size、起始和结束unicode编码、在文件中的起始偏移.然后是真实的点阵数据,即一段段二进制串,每一串表示一个字母、符号或汉字的点阵信息.要生成点阵字库必须有文字图形的来源,我的方法是使用ttf字体.ttf字体的显示采用的是SDL_ttf库,这是开源图形库SDL的一个扩展库,它使用的是libfreetype以读取和绘制ttf字体.它提供了一个函数,通过传入一个Unicode编码便能输出相应的文字的带有alpha 通道的位图.那么我们可以扫描这个位图以得到相应文字的点阵信息. 由于带有alpha通道,我们可以在点阵信息中也加入权值,使得点阵字库也有反走样效果.我采用两位来表示一个点,这样会有三级灰度(还有一个表示透明).点阵字库的显示首先需要将文件头信息读取出来,然后根据unicode编码判断在哪个区间内,然后用unicode编码减去此区间的起始unicode编码,算出相对偏移,并加上此区间的文件起始偏移得到文件的绝对偏移,然后读出相应位数的数据,最后通过扫描这段二进制串,在屏幕的相应位置输出点阵字型.显示点阵字体需要频繁读取文件,因此最好做一个固定大小的缓存,采用LRU置换算法维护此缓存,以减少磁盘读取.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
点阵字库[浏览次数:492次]点阵字库是把每一个汉字都分成16×16或24×24个点,然后用每个点的虚实来表示汉字的轮廓,常用来作为显示字库使用,这类点阵字库汉字最大的缺点是不能放大,一旦放大后就会发现文字边缘的锯齿。
目录∙点阵字库的显示原理∙点阵字库与字符字模∙点阵字库结构∙汉字点阵获取∙在DOS程序中使用点阵字库的方法∙点阵字库和矢量字库的差别∙如何使用Windows的系统字库生成点阵字库∙标准点阵字库芯片点阵字库的显示原理∙所有的汉字或者英文都是下面的原理,由左至右,每8个点占用一个字节,最后不足8个字节的占用一个字节,而且从最高位向最低位排列。
生成的字库说明:(以12×12例子)一个汉字占用字节数:12÷8=1····4也就是占用了2×12=24个字节。
编码排序A0A0→A0FE A1A0→A2FE依次排列。
以12×12字库的“我”为例:“我”的编码为CED2,所以在汉字排在CEH-AOH=2EH区的D2H-A0H=32H个。
所以在12×12字库的起始位置就是[{FE-A0}*2EH+32H]*24=104976开始的24个字节就是我的点阵模。
其他的类推即可。
英文点阵也是如此推理。
点阵字库与字符字模∙在dos终端模式下是不可以显示中文汉字的,只能显示英文。
汉字与英文的区别是:1. 汉字字库中,任何字符均用2个字节编码,即区码和位码,在英文字库中,所有字符均用单字节编码。
2.16点阵汉字字库(16*16)用32个字节存储一个字符的字模,16点阵英文字库(8*16)用16个字节存储单个字符的字模。
在DOS终端模式下用的是16点阵英文字库,如果要让DOS终端中显示中文,可以改写终端模式下的16点阵英文字库,使其显示的不是原有的英文字符,而是汉字字符,当然也可以加入自造点阵图形图像。
原理为:我们输入AB,正常显示的是AB,但如果改变AB的字模,用汉字的字模代替,这样输入AB字符,并不显示AB,而是显示一个汉字。
将一个汉字从中间劈为两半,左面部分顶替A的字模,右面部分顶替B的字模。
dos所用字库,文件头结构很简单,如默认的8*16英文字库,文件头长度为4,跳过这四个字节就是字模数据;也有没有文件头的,从第一个字节开始就是字模数据。
点阵字库结构∙1、点阵字库存储在汉字的点阵字库中,每个字节的每个位都代表一个汉字的一个点,每个汉字都是由一个矩形的点阵组成,0代表没有,1代表有点,将0和1分别用不同颜色画出,就形成了一个汉字,常用的点阵矩阵有12*12, 14*14, 16*16三种字库。
字库根据字节所表示点的不同有分为横向矩阵和纵向矩阵,目前多数的字库都是横向矩阵的存储方式(用得最多的应该是早期UCDOS字库),纵向矩阵一般是因为有某些液晶是采用纵向扫描显示法,为了提高显示速度,于是便把字库矩阵做成纵向,省得在显示时还要做矩阵转换。
我们接下去所描述的都是指横向矩阵字库。
2、16*16点阵字库对于16*16的矩阵来说,它所需要的位数共是16*16=256个位,每个字节为8位,因此,每个汉字都需要用256/8=32个字节来表示。
即每两个字节代表一行的16个点,共需要16行,显示汉字时,只需一次性读取32个字节,并将每两个字节为一行打印出来,即可形成一个汉字。
点阵结构如下图所示:第一字节第二字节0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 71234567891011121314153、14*14与12*12点阵字库对于14*14和12*12的字库,理论上计算,它们所需要的点阵分别为(14*14/8)=25, (12*12/8)=18个字节,但是,如果按这种方式来存储,那么取点阵和显示时,由于它们每一行都不是8的整位数,因此,就会涉到点阵的计算处理问题,会增加程序的复杂度,降低程序的效率。
为了解决这个问题,有些点阵字库会将14*14和12*12的字库按16*14和16*12来存储,即,每行还是按两个字节来存储,但是14*14的字库,每两个字节的最后两位是没有使用,12*12的字节,每两字节的最后4位是没有使用,这个根据不同的字库会有不同的处理方式,所以在使用字库时要注意这个问题,特别是14*14的字库。
汉字点阵获取1、利用区位码获取汉字汉字点阵字库是根据区位码的顺序进行存储的,因此,我们可以根据区位来获取一个字库的点阵,它的计算公式如下:点阵起始位置= ((区码- 1)*94 + (位码– 1)) * 汉字点阵字节数获取点阵起始位置后,我们就可以从这个位置开始,读取出一个汉字的点阵。
2、利用汉字机内码获取汉字前面我们己经讲过,汉字的区位码和机内码的关系如下:机内码高位字节= 区码+ 20H + 80H(或区码+ A0H)机内码低位字节= 位码+ 20H + 80H(或位码+ AOH)反过来说,我们也可以根据机内码来获得区位码:区码= 机内码高位字节- A0H位码= 机内码低位字节- AOH将这个公式与获取汉字点阵的公式进行合并计就可以得到汉字的点阵位置。
在DOS程序中使用点阵字库的方法首先需要理解的是点阵字库是一个数据文件,在这个数据文件里面保存了所有文字的点阵数据.至于什么是点阵,我想我不讲大家都知道的,使用过"文曲星"之类的电子辞典吧,那个的液晶显示器上面显示的汉子就能够明显的看出"点阵"的痕迹.在PC 机上也是如此,文字也是由点阵来组成了,不同的是,PC机显示器的显示分辨率更高,高到了我们肉眼无法区分的地步,因此"点阵"的痕迹也就不那么明显了。
点阵、矩阵、位图这三个概念在本质上是有联系的,从某种程度上来讲,这三个就是同义词.点阵从本质上讲就是单色位图,他使用一个比特来表示一个点,如果这个比特为0,表示某个位置没有点,如果为1表示某个位置有点.矩阵和位图有着密不可分的联系,矩阵其实是位图的数学抽象,是一个二维的阵列.位图就是这种二维的阵列,这个阵列中的(x,y) 位置上的数据代表的就是对原始图形进行采样量化后的颜色值.但是,另一方面,我们要面对的问题是,计算机中数据的存放都是一维的,线性的.因此,我们需要将二维的数据线性化到一维里面去.通常的做法就是将二维数据按行顺序的存放,这样就线性化到了一维。
那么点阵字的数据存放细节到底是怎么样的呢.其实也十分的简单,举个例子最能说明问题.比如说16*16 的点阵,也就是说每一行有16个点,由于一个点使用一个比特来表示,如果这个比特的值为1,则表示这个位置有点,如果这个比特的值为0,则表示这个位置没有点,那么一行也就需要16个比特,而8个比特就是一个字节,也就是说,这个点阵中,一行的数据需要两个字节来存放.第一行的前八个点的数据存放在点阵数据的第一个字节里面,第一行的后面八个点的数据存放在点阵数据的第二个字节里面,第二行的前八个点的数据存放在点阵数据的第三个字节里面,…,然后后面的就以此类推了.这样我们可以计算出存放一个点阵总共需要32个字节.看看下面这个图形化的例子:| |1| | | | | | | | | | |1| | | || | |1|1| |1|1|1|1|1|1|1|1|1| | || | | |1| | | | | | | | |1| | | ||1| | | | | |1| | | | | |1| | | || |1|1| | | |1| | | | | |1| | | || | |1| | | |1| | | | |1| | | | || | | | |1| | |1| | | |1| | | | || | | |1| | | |1| | |1| | | | | || | |1| | | | | |1| |1| | | | | ||1|1|1| | | | | | |1| | | | | | || | |1| | | | | |1| |1| | | | | || | |1| | | | |1| | | |1| | | | || | |1| | | |1| | | | | |1| | | || | |1| | |1| | | | | | |1|1|1| || | | | |1| | | | | | | | |1| | || | | | | | | | | | | | | | | | |可以看出这是一个"汉"字的点阵,当然文本的方式效果不是很好.根据上面的原则,我们可以写出这个点阵的点阵数据:0x40,0x08,0x37,0xfc,0x10,0x08,…,当然写这个确实很麻烦所以我不再继续下去.我这样做,也只是为了向你说明,在点阵字库中,每一个点阵的数据就是按照这种方式存放的.当然也存在着不规则的点阵,这里说的不规则,指的是点阵的宽度不是8的倍数,比如12*12 的点阵,那么这样的点阵数据又是如何存放的呢?其实也很简单,每一行的前面8个点存放在一个字节里面,每一行的剩下的4点就使用一个字节来存放,也就是说剩下的4个点将占用一个字节的高4位,而这个字节的低4位没有使用,全部都默认的为零.这样做当然显得有点浪费,不过却能够便于我们进行存放和寻址.对于其他不规则的点阵,也是按照这个原则进行处理的.这样我们可以得出一个m*n 的点阵所占用的字节数为(m+7)/8*n.在明白了以上所讲的以后,我们可以写出一个显示一个任意大小的点阵字模的函数,这个函数的功能是输出一个宽度为w,高度为h的字模到屏幕的(x,y) 坐标出,文字的颜色为color,文字的点阵数据为pdata 所指:/*输出字模的函数*/void _draw_model(char *pdata, int w, int h, int x, int y, int color) {int i; /* 控制行*/int j; /* 控制一行中的8个点*/int k; /* 一行中的第几个"8个点"了*/int nc; /* 到点阵数据的第几个字节了*/int cols; /* 控制列*/BYTE static mask[8]={128, 64, 32, 16, 8, 4, 2, 1}; /* 位屏蔽字*/ w = (w + 7) / 8 * 8; /* 重新计算w */nc = 0;for (i=0; i<h; i++){cols = 0;for (k=0; k<w/8; k++){for (j=0; j<8; j++){if (pdata[nc]&mask[j])putpixel(x+cols, y+i, color);cols++;}nc++;}}}代码很简单,不用怎么讲解就能看懂,代码可能不是最优化的,但是应该是最易读懂的.其中的putpixel 函数,使用的是TC提供的Graphics 中的画点函数.使用这个函数就可以完成点阵任意大小的点阵字模的输出.接下来的问题就是如何在汉子库中寻址某个汉子的点阵数据了.要解决这个问题,首先需要了解汉字在计算机中是如何表示的.在计算机中英文可以使用ASCII 码来表示,而汉字使用的是扩展ASCII 码,并且使用两个扩展ASCII 码来表示一个汉字.一个ASCII 码使用一个字节表示,所谓扩展ASCII 码,也就是ASCII 码的最高位是1的ASCII 码,简单的说就是码值大于等于128 的ASCII 码.一个汉字由两个扩展ASCII 码组成,第一个扩展ASCII 码用来存放区码,第二个扩展ASCII 码用来存放位码.在GB2312-80 标准中,将所有的汉字分为94个区,每个区有94个位可以存放94个汉字,形成了人们常说的区位码,这样总共就有94*94=8836 个汉字.在点阵字库中,汉字点阵数据就是按照这个区位的顺序来存放的,也就是最先存放的是第一个区的汉字点阵数据,在每一个区中有是按照位的顺序来存放的.在汉字的内码中,汉字区位码的存放实在扩展ASCII 基础上存放的,并且将区码和位码都加上了32,然后存放在两个扩展ASCII 码中.具体的说就是:第一个扩展ASCII码= 128+32 + 汉字区码第二个扩展ASCII吗= 128+32 + 汉字位码如果用char hz[2]来表示一个汉字,那么我可以计算出这个汉字的区位码为:区码= hz[0] - 128 - 32 = hz[0] - 160位码= hz[1] - 128 - 32 = hz[1] - 160.这样,我们可以根据区位码在文件中进行殉职了,寻址公式如下:汉字点阵数据在字库文件中的偏移= ((区码-1) * 94 + 位码) * 一个点阵字模占用的字节数在寻址以后,即可读取汉字的点阵数据到缓冲区进行显示了.以下是实现代码: /* 输出一个汉字的函数*/void _draw_hz(char hz[2], FILE *fp, int x, int y, int w, int h, int color){char ftbuf[128]; /* 足够大的缓冲区,也可以动态分配*/int ch0 = (BYTE)hz[0]-0xA0; /* 区码*/int ch1 = (BYTE)hz[1]-0xA0; /* 位码*//* 计算偏移*/long offset = (long)pf->_hz_buf_size * ((ch0 - 1) * 94 + ch1 - 1);fseek(fp, offset, SEEK_SET); /* 进行寻址*/fread(fontbuf, 1, (w + 7) / 8 * h, fp); /* 读入点阵数据*/_draw_model(fontbuf, w, h, x, y, color); /* 绘制字模*/}以上介绍完了中文点阵字库的原理,当然还有英文点阵字库了.英文点阵字库中单个点阵字模数据的存放方式与中文是一模一样的,也就是对我们所写的_draw_model 函数同样可以使用到英文字库中.唯一不同的是对点阵字库的寻址上.英文使用的就是ASCII 码,其码值是0到127,寻址公式为:英文点阵数据在英文点阵字库中的偏移= 英文的ASCII码* 一个英文字模占用的字节数可以看到,区分中英文的关键就是,一个字符是ASCII 码还是扩展ASCII 码,如果是ASCII 码,其范围是0到127,这样是使用的英文字库,如果是扩展ASCII 码,则与其后的另一个扩展ASCII 码组成汉字内码,使用中文字库进行显示.只要正确区分ASCII 码的类型并进行分别的处理,也就能实现中英文字符串的混合输出了。