Bootstrapping a semantic wiki application for learning mathematics
前端开发中的UI库和组件库推荐

前端开发中的UI库和组件库推荐前端开发是一门非常有挑战性和广泛应用的技术,它涉及到网站和应用程序的用户界面设计和开发。
UI(用户界面)的设计对于用户体验的重要性不言而喻,而在开发过程中,使用UI库和组件库能够提高效率和质量。
本文将推荐一些在前端开发中广受欢迎的UI库和组件库。
1. BootstrapBootstrap是一款开源的前端开发框架,它提供了一套用于网页和应用程序开发的HTML、CSS和JS工具。
Bootstrap具有响应式设计和移动优先的开发理念,能够帮助开发者快速构建美观且具有良好用户体验的界面。
它包含了丰富的组件和布局选项,能够满足不同项目的需求。
2. Ant DesignAnt Design是由蚂蚁金服推出的一款基于React开发的UI库。
它提供了一系列高质量、美观的React组件,通过这些组件能够快速搭建出现代化的Web界面。
Ant Design注重用户体验和界面一致性,提供了丰富的文档和示例,方便开发者学习和使用。
3. Material-UIMaterial-UI是一个实现了Google Material Design风格的React组件库。
它基于React框架,提供了各种符合Material Design规范的UI组件和模板,能够构建漂亮的Web界面。
Material-UI支持自定义主题和样式,使得开发者可以根据自己的设计需求调整界面风格。
4. Elemental UIElemental UI是一个轻量级的React组件库,它提供了一些精简、易于使用的UI组件,适用于构建简洁、高效的Web界面。
Elemental UI的组件经过精心设计,注重性能和可访问性,同时还提供了一套灵活的样式主题选项。
5. Vue MaterialVue Material是一个基于Vue.js的Material Design风格的组件库。
与Material-UI类似,Vue Material提供了一套符合Material Design规范的高质量组件,可以快速构建现代化的Web界面。
心理语言学名词解释_注释版

名词解释1. Mutual exclusivity bias相互排斥倾向A cognitive constraint in which children assume that an object is ordinarily not given two different names.2. Motherese 母式语言A form of adult-to-child speech characterized by relatively simple utterances,concrete referents指示物, exaggerated intonation patterns夸张的语调模式, and a high proportion of directive utterances指示话语.3. Critical period hypothesis临界期假设The view that there is a period early in life in which we are especially prepared to acquire a language.4. Language bioprogram hypothesis语言生物程序假设The hypothesis that children whose environmental exposure to language is limited use a backup linguistic system.5. Pidgin混杂语An auxiliary辅助的language that is created when speakers of mutually unintelligible 无法理解的languages are in close contact.6. Language transfer 语言迁移In second-language acquisition, the process in which the first language influences the acquisition of a subsequent后来的language.7. Overregularization规则泛化When a child a pplies a linguisitic rule to cases that ar e exceptions to the rule--for example, saying goed instead of went.8. Holophrase 表句词单词句A one-word utterance used by a child to express more than the meaning attributed to the word by adults.9. Idiomorph ?A sound or sound sequence音序used consistently by a child to refer to someone or something even though it is not the sound sequence conventionally used in the language for that purpose.10. Coalescence合并A phonological音位学的,音韵学的process in which phonemes音位,音素(the smallest unit of significant sound in a language)from different syllables音节are combined into a single syllable.11. Reduction减少cluster reduction音群删略A phonological process in child language in which one or more phonemes are deleted. Also called cluster reduction音群删略because consonant clusters辅音群,两个或两个以上的辅音连在一起are often reduced, such as saying take for steak.12. Assimilation 同化A phonological process in which one speech sound replaced by another that is similar sounds elsewhere in the utterance.13. Common ground共识The shared understanding of those involved in the conversation.14.Semantic bootstrapping语义引导She spent years bootstrapping herself through university.她靠自己多年奋斗念完大学The process of using semantics to acquire syntax.15. Accommodation顺应A phonological process in which elements that are shifted or deleted are adapted to their error-induced environments.20. Psycholinguistics心理语言学The study of the comprehension, production, and acquisition of language.21. Aphasia失语症A language or speech disorder caused by brain damage.A mental condition in which people are unable to remember simple words or communicate.22. Behaviorism行为主义The doctrine that states that the proper concern of psychology should be the objective study of behavior rather than the study of the mind.23. Distinctive features显著特征The specification详述of the differences between speech sounds in terms of individual contrasts.24. Observational adequacy观察充分性The extent to which a grammar can distinguish betw een acceptable and unacceptable strings of words.The grammar must specify what is and what is not acceptable sequence in the language.语法能对原始的语言材料做出正确的选择25.Descriptive adequacy描写充分性The grammar must specify the relationships between various sequences in the language. The extent to which a grammar can provide a structural description of a sentence.语法不仅应该能解释原始的语言材料,而且要正确解释说话人和听话人内在的语言能力。
前端开发中常用的UI框架推荐

前端开发中常用的UI框架推荐随着互联网的迅猛发展,前端开发在Web应用程序中的重要性日益突出。
而UI框架作为前端开发的重要组成部分,为开发人员提供了丰富的界面元素和交互效果,极大地提升了开发效率和用户体验。
本文将为大家推荐几款常用的前端UI框架。
1. BootstrapBootstrap是目前最受欢迎的前端UI框架之一。
它由Twitter开发并开源,提供了丰富的CSS样式和JavaScript插件,可以快速构建响应式网站和Web应用程序。
Bootstrap具有简洁易用的特点,提供了大量的预定义样式和布局组件,使开发者可以快速搭建页面,并且兼容各种主流浏览器。
2. Material-UIMaterial-UI是一个基于Google Material Design风格的前端UI框架。
它提供了一套美观、直观的界面元素和交互效果,使开发者可以轻松构建现代化的Web应用程序。
Material-UI具有丰富的组件库,包括按钮、表单、导航栏等,同时还提供了自定义主题和样式的功能,可以满足不同项目的需求。
3. Ant DesignAnt Design是由蚂蚁金服开发的一款企业级UI设计语言和React组件库。
它提供了一套完整的设计规范和丰富的组件库,可以帮助开发者构建高质量的Web界面。
Ant Design具有优雅简洁的设计风格,同时支持响应式布局和国际化,适用于各种类型的项目。
4. Semantic UISemantic UI是一个语义化的前端UI框架,它强调代码的可读性和可维护性。
Semantic UI提供了一套直观的命名规范和易于理解的语义化标签,使开发者可以更加方便地编写和维护代码。
同时,Semantic UI还提供了丰富的样式和组件,可以快速构建美观的界面。
5. Element UIElement UI是一款基于Vue.js的前端UI框架,它提供了一套美观、易用的界面元素和交互效果。
Element UI具有丰富的组件库,包括表格、表单、弹窗等,同时还提供了自定义主题和样式的功能。
bootstrap 法

bootstrap 法随着社会不断发展,不同领域的研究者越来越倾向于探索所有可能的研究方向,以便更好地理解特定领域的机制和规律。
与此同时,新的统计学方法也随之诞生,其中最著名的便是Bootstrap 法。
本文旨在介绍Bootstrap法及其机制,并讨论它为研究发展带来的重要影响。
Bootstrap法源自统计学中的重计,其最初的概念由Bradley Efron在1979年提出,被用于假设检验和统计模型的估计。
这一方法利用bootstrap样本(也称为重抽样),通过对原始数据集进行重新抽样,以模拟实际研究问题所需的各种概率分布中的抽样分布。
它可以解决统计学中常见的问题,比如估计总体参数(比如平均值和标准偏差)时,其与传统的抽样方法相比具有较高的精确性和准确性。
基于Bootstrap法,研究者只需从一个给定的数据集中进行抽样,即可根据抽样结果得到不同的结论和模型使他们更容易地探索潜在的研究机会,并从更多的细节中提炼有价值的信息。
此外,此方法还可以用于无组织数据的非参数分析,这非常适合那些具有异质性的复杂数据。
Bootstrap法的另一个有点在于,它可以被用于研究可能存在的相关性,而不必完全依赖于复杂的数学统计学模型,同时可以检验统计学模型的可靠性。
此外,它还可以帮助研究者更好地理解特定领域中的关键问题,这有助于改善他们的研究工作。
此外,Bootstrap法还具有良好的统计学和机器学习方面的性能,可以用于估计参数估计,实现统计技巧,快速抽取数据,结果拟合等。
这些统计分析技术有助于让研究者更好地解读数据并找出结论,从而加深其对特定领域的理解。
自Bootstrap法诞生以来,它已经成为学术界经常使用的机器学习及统计分析工具之一,其用途涉及众多不同的研究领域,如药物研发,数据挖掘,机器学习,生物学,医学,计算机科学等。
这一方法的出现,为研究领域的发展带来了无尽的可能性,让研究人员更容易地得出有价值的结论。
总之,Bootstrap法是一种十分有用的统计学方法,能够更好地估计总体参数、研究相关性,且具有良好的机器学习和统计学性能。
bootstrap方面的文献

bootstrap方面的文献标题:Bootstrap:构建现代化网页设计的利器引言:在当今互联网时代,网页设计已成为企业推广、品牌塑造甚至个人展示的重要方式。
然而,要创建一个现代化、响应式的网页设计并不容易。
本文将介绍Bootstrap,这一强大的前端开发框架,它可以帮助开发人员快速搭建美观、灵活、易于维护的网页设计。
1. Bootstrap的概述Bootstrap是一个开源的前端开发框架,它提供了丰富的CSS和JavaScript组件,以及响应式的网格系统。
它的目标是让开发人员能够快速构建现代化的网页设计,而无需从头开始编写大量的代码。
Bootstrap的设计原则包括易用性、可定制性和响应式布局,使得它成为了众多网页设计师的首选工具。
2. Bootstrap的特点2.1 响应式布局:Bootstrap的网格系统能够根据设备的屏幕大小自动调整布局,使得网页在不同设备上都能够良好地展示。
这使得开发人员可以轻松创建适应手机、平板电脑和桌面电脑等多种终端的网页设计。
2.2 CSS组件:Bootstrap提供了丰富的CSS组件,例如按钮、导航、表单等,这些组件具有现代化的样式和交互效果,可以帮助开发人员快速构建功能丰富的网页设计。
2.3 JavaScript插件:除了CSS组件,Bootstrap还提供了众多的JavaScript插件,例如弹出框、轮播图、标签页等,这些插件能够增强网页的交互性和用户体验,使得网页更具吸引力。
3. Bootstrap的应用场景由于Bootstrap具有易用性和定制性,它被广泛应用于各种网页设计项目中。
以下是一些常见的应用场景:3.1 网页开发:无论是企业官网、电子商务网站还是个人博客,Bootstrap都能够提供丰富的组件和布局选项,帮助开发人员快速构建各种类型的网页设计。
3.2 响应式设计:随着移动设备的普及,响应式设计已成为网页设计的重要趋势。
Bootstrap的响应式网格系统和组件能够帮助开发人员轻松实现适应不同屏幕大小的网页设计。
bootstrap面试题

bootstrap面试题Bootstrap是一种流行的前端开发框架,被广泛应用于网页设计和开发中。
今天,我们将为大家整理一些常见的Bootstrap面试题,帮助大家更好地了解和掌握这个框架。
第一部分:基础知识回顾1. 什么是Bootstrap?它有哪些特点和优势?Bootstrap是一个基于HTML、CSS和JavaScript的开源框架,用于开发响应式、移动设备优先的网站和应用程序。
它的特点和优势包括:易于上手、跨浏览器兼容、快速开发、预置了丰富的样式和组件等。
2. Bootstrap的网格系统是什么?它是如何工作的?Bootstrap的网格系统是一种用于创建响应式布局的强大工具。
它将页面划分为12列,并在不同屏幕宽度下自动适应布局。
通过使用预定义的CSS类,可以将元素放置在不同列和行中,从而实现自适应布局。
3. Bootstrap中的栅格类是如何使用的?栅格类是Bootstrap中用于实现网格布局的CSS类。
通过为元素添加`.col-*-*`类,可以指定元素在不同屏幕宽度下的占比和布局。
其中,第一个`*`代表屏幕尺寸(如`xs`、`sm`、`md`、`lg`),第二个`*`代表占比(1-12),第三个`*`代表偏移量。
4. 什么是响应式设计?Bootstrap是如何实现响应式设计的?响应式设计是一种能够根据用户的设备尺寸和屏幕宽度自动适应布局的设计方式。
Bootstrap通过使用弹性网格系统、媒体查询、栅格类等技术来实现响应式设计。
用户访问网页时,页面会根据设备尺寸进行自动调整,以提供更好的用户体验。
第二部分:应用实践1. 如何在项目中引入Bootstrap?可以通过以下两种方式引入Bootstrap:- 下载Bootstrap的CSS和JavaScript文件,并在项目中引入相关文件。
- 使用Bootstrap的CDN(内容分发网络)链接,直接在HTML文件中引入CDN链接。
2. Bootstrap中的按钮样式有哪些?如何使用它们?Bootstrap提供了多种按钮样式,包括默认按钮、主要按钮、成功按钮、信息按钮、警告按钮、危险按钮等。
Bootstrapping算法

1、Bootstrapping方法简介
Bootstrapping算法又叫自扩展技术,它是一种被广泛用于知识获取的机器学习技术。
它是一种循序渐进的学习方法,只需要很小数量的种子,以此为基础,通过一次次的训练,把种子进行有效的扩充,最终达到需要的数据信息规模。
2、Bootstrapping算法的主要步骤
(1) 建立初始种子集;
(2) 根据种子集,在抽取一定窗口大小的上下文模式,建立候选模式
集;
(3) 利用模式匹配识别样例,构成候选实体名集合。
将步骤(2)所得的
模式分别与原模式进行匹配,识别出样例,构成候选集合。
(4) 利用一定的标准评价和选择模式和样例,分别计算和样例的信息
熵增益,然后进行排序,选择满足一定要求的模式加入最终可用模式集,选择满足一定条件的样例加入种子集。
(5) 重复步骤(2)-(4),直到满足一定的迭代次数或者不再有新的样例
被识别。
3 相关概念
(1)上下文模式
它是指文本中表达关系和事件信息的重复出现的特定语言表达形式,可以按照特定的规则通过模式匹配,触发抽取特定信息。
上下文模式是由项级成的有有序序列,每个项对应于一个词或者词组的集合。
(2)模式匹配
模式匹配是指系统将输入的句子同有效模式进行匹配,根据匹配成功的模式,得到相应的解释。
(3)样例
样例是在Bootstrapping迭代过程中,经过模式匹配后,抽取出来的词语。
哈工大知识图谱(KnowledgeGraph)课程概述
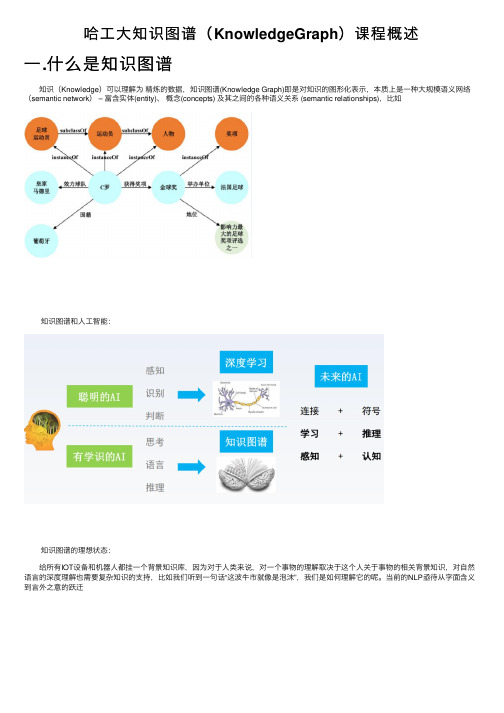
1.知 识 图 谱 中 的 概 念
实体 (entity):现实世界中可区分、可识别的事物或概念。 ➢ 客观对象:人物、地点、机构 ➢ 抽象事件:电影、奖项、赛事 关系 (relation):实体和实体之间的语义关联。 事实 (fact):陈述两个实体之间关系的断言,通常表示为 (head entity, relation, tail entity) 三元组形式。
四 .实体识别
1.信 息 抽 取
概念:从自然语言文本中抽取指定类型的实体、关系、事件等事实信息, 并形成结构化数据输出的文本处理技术
主要任务:实体识别与抽取,关系抽取,时间抽取,实体消歧
2.命 名 实 体 识 别 ( Named Entity Recognition, 简 称 NER)
定义:狭义地讲,命名实体指现实世界中具体或抽象的实体 , 如人(张三)、机构(哈尔滨工业大学)、地点等,通常用唯一的标志符(专 有名称)表示。
Ontology(本体):通过对概念的严格定义和概念与概念之间的关系来确定概念的精确含义,表示共同认可的、可共享的知识,对于 ontology来说,author,creator和writer是同一个 概念,而doctor在大学和医院分别表示的是两个概念。因 此在语义网中,ontology具有非常 重要的地位,是解决语义层次上Web信息共享和交换的基础。简单理解就是某个领域关于自身和相关关系的描述
2.知 识 图 谱 的 特 性
知识图谱不太专注于对知识框架的定义,而专注于如何以工程的方式,从文本中自动抽取或依靠众包的方式获取并 组建广泛的、具有平铺结 构的知识实例,最后再要求使用 它的方式具有容错、模糊匹配等机制。 知识图谱的真正魅力在于其图结构,可以在知识图谱上运行搜索、 随机游走、网络流等大规模图算法,使知识图谱与图论、概率图等碰撞出火花。
bootstrap试题及答案

bootstrap试题及答案1. 什么是Bootstrap?- A. 一种前端开发框架- B. 一种后端开发框架- C. 一种数据库管理系统- D. 一种操作系统答案:A2. Bootstrap是由哪个公司开发的?- A. Google- B. Facebook- C. Twitter- D. Microsoft答案:C3. Bootstrap的默认栅格系统有多少个列?- A. 12- B. 16- C. 24- D. 48答案:A4. 在Bootstrap中,哪个类用于创建一个容器?- A. `.container`- B. `.row`- C. `.col`- D. `.grid`答案:A5. 如何在Bootstrap中创建一个响应式导航栏?- A. 使用`.navbar`类- B. 使用`.nav`类- C. 使用`.navbar-nav`类- D. 使用`.navbar-responsive`类答案:A6. Bootstrap的哪个组件用于创建模态框?- A. `.modal`- B. `.dropdown`- C. `.alert`- D. `.tooltip`答案:A7. 在Bootstrap中,如何实现一个按钮的悬停效果? - A. 添加`.hover`类- B. 添加`.active`类- C. 使用CSS的`:hover`伪类- D. 使用JavaScript监听鼠标事件答案:C8. Bootstrap的哪个版本开始引入了Flexbox布局? - A. Bootstrap 3- B. Bootstrap 4- C. Bootstrap 5- D. Bootstrap 6答案:B9. 如何在Bootstrap中创建一个带有图标的按钮? - A. 使用`.btn-icon`类- B. 使用`.icon`类- C. 使用`.glyphicon`类- D. 使用`.fas`类答案:D10. Bootstrap的哪个组件用于创建折叠面板? - A. `.panel`- B. `.collapse`- C. `.card`- D. `.tab`答案:B。
语言心理学名词解释附答案

1.Mutual exclusivity bias It is a cognitive constraint which refers to the fact that a child who knows the name of a particular object will then generally reject applying a second name to that object.2. Motherese Adult-to-child language, which has been called motherese, differ in a number of ways from adult-to-adult language. In general, speech to children learning language is shorter, more concrete, more directive, and more intonationally exaggerated than adult-directed speech.3. Critical period hypothesis The view that there is a period early in life in which we are especially prepared to acquire a language is referred to as the critical period hypothesis. Many investigators who favor the critical period hypothesis suggest that there are neurological changes in the brain that leave a learner less able to acquire a language, although the nature of these supposed changes is not well understood. Most commonly, these changes are assumed to occur near puberty.nguage bioprogram hypothesis On version of how innate processes operate in child language has been called the Language bioprogram hypothesis by Bickerton. Bickerton’s claim, in brief, is that we, as children, have an innate grammar that is available biological if our language input is insufficient to acquire the language of our community. It is something like a linguistic backup system.5. Pidgin A pidgin is “an auxiliary language that arises when speakers of several mutually unintelligible languages are in close contact〞. Typically this occurs when workers from diverse countries are brought in as cheap labor in an agricultural community. Immigrant workers come to speak a simpler form of the dominant language of the area —just enough to get by.6. Language transfer In second-language acquisition, the process in which the first language influences the acquisition of a subsequent language.7. Overregularization An overregularization is the child’s use of a regular morpheme in a word that is irregular, such as the past-tense morpheme in breaked and goed. There are two theories about how children acquire overregularizations: the rule-and-memory model and the parallel distributed processing model.8.Holophrase A holophrase has been defined as a single-word utterance that is used by a child to express more than the meaning usually attributed to that single word by adults.9.Idiomorph A sound or sound sequence used consistently by a child to refer to someone or something, objects or events in their environment even though it is not the sound sequence conventionally used in the language for that purpose.10. Coalescence Coalescence occurs when phonemes from different syllables are combined into a single syllable.11. Reduction A phonological process in child language in which one or more phonemes are deleted. Also called cluster reduction because consonant clusters are often reduced, such as saying take for steak.12. Assimilation Assimilation is a phonological process. Assimilation occurs when children change one sound to make it similar to another sound in the same word, such as saying nance for dance or fweet for sweet. In the latter case, the f is articulated closer to the front of the mouth than s, making it more similar to the bilabial w.13. Common ground Common ground refers to the shared understanding of those involved in the conversation. For knowledge to qualify as common ground, person A must know a given information X, and person B must know X, and A must know that B knows, and B knows that A knows, and so on. That is, both parties are aware that they share the information.14.Semantic bootstrapping The process of using semantics to acquire syntax. (Ultimately children must graspcategories that are defined in syntactic terms, and there has been much debate concerning how they do this. One suggestion is that they use their knowledge of semantic relations to learn syntactic relations. This process is known as semantic bootstrapping )15. Accommodation A phonological process in which elements that are shifted or deleted are adapted to their error-induced environments.16. Incremental processing The notion that we are planning one portion of our utterance as we articulate another portion.17. Speech errors =slip of tongue Speech errors refer to faults made by speakers during the production of sounds, words and sentences. Both native and non-native speakers of a language make mistakes when speaking. There are eight types of speech errors: exchange, substitution, addition, deletion, anticipation, perseveration, blend, and shift.18. Assemblage errors The correct choice or word has been made, but the utterance has been faultily assembled. Eg. writtening threat letters---writing threatening letters19. Selection errors A wrong item (or items) is chosen, where something has gone wrong with the selection process. Eg. tooth hache---tooth paste20.Psycholinguistics Psycholinguistics is the study of how individuals comprehend, produce, and acquire language.The psychological study of language is called psycholinguistics. The study of psycholinguistics is part of the field of cognitive science.It deals with the mental processes that are involved in language use. Psycholinguistics stresses the knowledge of language and the cognitive processes involved in ordinary language use. Psycholinguists are also interested in the social rules involved in language use and the brain mechanisms associated with language. Contemporary interest in psycholinguistics began in the 1950s, although important precursors existed earlier in the 20th century.21.Aphasia A language disorder produced by brain damage is called an aphasia.we begin by examining some of the more common types of aphasia. One type is Broca’s Aphasia. The disorder Broca’s aphasia,also known as expressive aphasia, was discovered by and named after the French surgeon Paul Broca. The second type is Wernicke’s Aphasia.It results from damage to a region in the left temporal lobe near the auditory cortex.A third major type of aphasia is conduction aphasia, which is a disturbance of repetition, and other aphasias.22. BehaviorismBy the 1920s, behaviorism took over the mainstream of experimental psychology. Behaviorist favored the study of objective behavior, often in laboratory animals, as opposed to the study of mental processes. Moreover, behaviorists had a strong commitment to the role of experience in shaping behavior. Emphasis was placed on the role of environmental contingencies (such as reinforcement and punish-ment) and on models present in the immediate environment.23. Distinctive features A distinctive feature is a characteristic of a speech sound whose presence or absence distinguishes the sound from other sounds.24. Observational adequacy First, the grammar must specify what is and what is not an acceptable sequence in the language. This criterion, referred to as observational adequacy, applies at several levels of language. A grammar is observationally adequate if it generates all of the acceptable sequences in a language and none of the unacceptable sequences.25. Descriptive adequacy The second criterion is that the grammar must specify the relationships between various sequences in the language, a criterion known as descriptive adequacy. It is not enough for the grammar to mark a sequence as permissible; it must also explain how it relates to other sentences that are similar in meaning, oppositein meaning and so on.26. Explanatory adequacy The extent to which a grammar can explain the facts of language acquisition. See also descriptive adequacy and observational adequacy. The third criterion is called explanatory adequacy. That children choose one particular grammar implies that certain innate language constraints enable the child to deduce the correct grammar. This level of adequacy involves the ability to explain the role of linguistic universals in language acquisition.27. Transformational-generative grammar T ransformational grammar discusses a historically significant theory of grammar. Transformational grammar assumes that sentences have a deep structure and a surface structure. The deep structure is derived by a series of phrase-structure rules, and the surface structure is derived from the deep structure by a series of transformational rules.28. Psychological reality A grammar or theory of language that takes psychological or processing considerations into account.29. Core grammar Core grammar is the grammar that rules the essence of the syntax of a language (principle and parameters). It is an innate ability.30. Working memory Working memory has been defined as referring to “the temporary storage of information that is being processed in any range of cognitive tasks〞(Baddeley, 1986, p. 34). Working memory is measured in several ways. The most simple is a memory span test (or simple span test) in which participants are given a series of items (words, letters, numbers, and so forth) and asked to recall the items in the order presented. Sometimes they are asked to recall them in backward order.31.Memory span :it is the number of items that can be reliably recalled in the correct order. This simple test not only is a common method in psychological experiments but also is included in most commonly used intelligence tests.32.Episodic memory The division of permanent memory in which personally experienced information is stored.It dealt with personally experienced facts33.Semantic memory It dealt with general facts.Semantic memory refers to our organized knowledge of words, concepts, symbols, and objects. It includes such broad classes of information as motor skills (typing, swimming, bicycling), general knowledge (grammar, arithmetic), spatial knowledge (the typical layout of a house), and social skills (how to begin and end conversations, rules for self-confidence).34.Parallel processing If two or more of the processes take place simultaneously, it is called parallel processing.35.Categorical perception Categorical perception refers to a failure to discriminate speech sounds any better than you can identify them. This may be illustrated with an experimental example. On a speech spectrometer, it is possible to identify the difference between the voiced sound [ba] and the voiceless sound [pa] as due to the time between when the sound is released at the lips and when the vocal cords begin vibrating. It suggests that categorical perception is a reflection of the phonetic level of processing in which a phonetic identity is imposed and all other acoustic features are lost (thus leading to especially poor performance on within-category discrimination).36.Semantic network A semantic network is an interconnected web of concepts connected by various relations. In the hierarchical model, we store our knowledge of words in the form of a semantic network, with some words represented at higher nodes in the network than others. Although the hierarchical network model can explain some results, it is too rigid to capture all of our tacit knowledge of the lexicon.37.Typicality effect The fact that it takes longer to verify a statement of the form An A is a B when A is no t typical or characteristic of B. This has generally been called the typicality effect: Items that are more typical of a given subordinate take less time to verify than atypical items in true statements; the opposite is true for false statements.38.Logogen : Morton (1969) proposed one of the earliest activation models. In Morton’s model, eac h word (or morpheme) in the lexicon is represented as a logogen, which specifies the word’s various attributes (semantic, orthographic, phonological, and so on).The logogen is activated in either of two ways: by sensory input or by contextual information. Consider first the sensory route. As orthographic or phonological features of the input stimulus are detected, they are matched to the logogen. The logogen functions as a scoreboard or counter; when the counter rises above a predesignated threshold, the item is recognized.39.Cohort Model A model of auditory word recognition in which listeners are assumed to develop a group of candidates, a word initial cohort, and then determine which member of that cohort corresponds to the presented word. Marslen-Wilson (1987,1990) and colleagues noticed several aspects of spoken word recognition that needed to be accounted for in a model of lexical access. First, listeners recognize words very rapidly, perhaps within 200 to 250 milliseconds of the beginning of the word. Second, listeners are sensitive to the recognition point of a word- the point at which the word diverges from other possible words.40.Semantic priming Semantic priming occurs when a word presented earlier activates another, semantically related word. The priming task consists of two phases. The priming task consists of two phases. In the first phase, a priming stimulus is presented. Often no response tothe prime is required or recorded; in any event, the response to the prime itselfis of little interest. In the second phase, a second stimulus (the target) is presented, the participant makes some response to it, and the time taken to make this response is recorded. An experimental procedure in which oneword is presented in advance of another, target word, which reduces the time needed to retrieve or activate the target word.41.Parsing Parsing is the process of assigning elements of surface structure to linguistic categories. Because of limitations in processing resources, we begin to parse sentences as we see or hear each word in a sentence.A first step in the process of understanding a sentence is to assign elements of its surface structure to linguistic categories, The result of parsing is an internal representation of the linguistic relationships within a sentence, usually in the form of a tree structure or phrase marker.42.Minimal attachment strategy A principle used in parsing. It states that we prefer attaching new items into the phrase marker being constructed using the fewest syntactic nodes consistent with the rules of the language43.Coherence The degree to which different parts of a text are connected to one another. Coherence exits at both local and global levels of discourse.44.Anaphoric reference A form of reference cohesion in which one linguistic expression refers back to prior information in discourse.In all of these examples, cohesion consists of relating some current expression to one encountered earlier. This is called anaphoric reference. When we use an expression to refer back to something previously mentioned in discourse, the referring expression is called an anaphor, and the previous referent is called an antecedent.45. Schema A schema (plural: schemata) is a structure in semantic memory that specifies the general or expected arrangement of a body of information. The notion of a schema is not new in psychology. it is generally associated with the early work on story recall by Bartlett(1932).. An alternative perspective on cognitive development, one that challenges the notion of invariance, has been described by the Swiss scholar Jean Piaget,Piaget (1952) claimed that children’s thinking processes are qualitatively different from those of adults. Adults do not merely think faster or more accurately than children, but in a different way. Piaget referred to the concepts that we use to organize our experience as schemata.。
bootstrap自举法

bootstrap自举法什么是bootstrap自举法?Bootstrap自举法,也被称为自助法或自发采样法,是一种统计推断方法。
它主要用于解决样本容量有限的情况下,对总体参数进行推断的问题。
Bootstrap自举法通过重采样来创建一个虚拟的总体数据集,并基于这些虚拟数据集进行统计推断。
为什么需要bootstrap自举法?在实际问题中,我们经常面临样本容量有限的情况。
传统统计方法要求样本满足一些假设,如独立同分布和总体分布的已知性。
然而,在实际生活中,这些假设并不总能得到满足。
因此,bootstrap自举法应运而生,它不依赖于这些假设,而是利用样本自身的信息来进行推断,从而使得推断结果更加鲁棒可靠。
利用bootstrap自举法进行统计推断的步骤如下:第一步,从已有的样本中进行有放回的重复抽样,生成虚拟的样本数据集。
重复抽样的次数可以选取很大的数目,通常建议抽样次数为1000次以上。
第二步,对于每个虚拟样本数据集,用该样本数据计算所要估计的参数。
例如,如果我们想要估计总体均值,就计算每个虚拟样本数据集的均值。
第三步,将得到的参数估计值进行总结。
常见的总结方法包括计算估计值的正负标准误、置信区间、偏差等。
第四步,根据总结结果对总体参数进行推断。
可以使用估计值的置信区间来判断总体参数是否在某个范围内,也可以根据估计值的偏差来判断总体参数与某个值是否有显著差异。
以一个实例来说明:假设我们的问题是估计某个城市居民的平均收入,但我们只有100 个样本数据。
直接使用这些样本进行推断显然是不准确的。
这时,我们可以利用bootstrap 自助法来解决。
首先,我们从这100个样本中进行重复抽样,生成1000个虚拟样本数据集。
每个虚拟样本数据集由有放回抽样得到,样本容量为100。
接下来,对于每个虚拟样本数据集,我们计算其平均收入。
然后,对这1000个平均收入值进行总结统计。
例如,我们可以计算平均收入的标准误,从而得到估计值的置信区间。
bootstrap面试题

bootstrap面试题Bootstrap是一种流行的前端框架,广泛应用于网页设计和开发中。
在面试过程中,针对Bootstrap的问题经常被提出来评估一个候选人的前端技术水平和经验。
本文将介绍一些常见的Bootstrap面试题,并给出相应的答案和讨论。
1. 什么是Bootstrap?请描述一下Bootstrap的特点和优势。
Bootstrap是Twitter公司开发的一个开源的前端框架,用于构建响应式、移动设备优先的网页设计和开发。
它使用HTML、CSS和JavaScript的结合,提供了一系列的现成组件和样式,可以快速构建美观、规范的网页。
Bootstrap的特点和优势如下:- 响应式设计:Bootstrap可以根据设备的屏幕大小自动调整布局和样式,确保网页在各种设备上都能良好显示。
- 移动设备优先:Bootstrap在设计上优先考虑了移动设备的使用体验,使得在手机、平板等移动设备上的浏览效果更好。
- 组件丰富:Bootstrap提供了丰富的组件,包括导航、按钮、表单、模态框等等,大大简化了页面的构建过程。
- 样式定制:Bootstrap提供了易于定制的样式和主题,可以根据具体需求进行个性化的调整和设计。
- 跨浏览器兼容:Bootstrap经过了广泛的测试和优化,可以在主流的浏览器上稳定运行和兼容。
2. Bootstrap中的栅格系统是什么?请解释一下栅格系统的原理和使用方法。
栅格系统是Bootstrap的核心组成部分,用来实现响应式布局。
栅格系统将网页水平分为12列,并使用CSS样式将不同的元素放置在这些列中。
栅格系统可以根据屏幕大小自动调整列的宽度和排列方式,实现适应不同设备的布局。
栅格系统的原理如下:- 通过.container容器和.row行来定义栅格布局,每行由多个.col列组成。
- 栅格布局中的列总宽度为12,每个列可以占用1到12个单位列宽。
- 通过设置.col类的col-xs-*、col-sm-*、col-md-*和col-lg-*属性来定义不同屏幕尺寸下的列宽。
前端开发中常用的控件库

前端开发中常用的控件库在前端开发中,控件库是一个非常重要的工具,它可以帮助开发者快速构建和定制各种界面和场景。
控件库可以提供包括表单、按钮、图标、轮播图等各种UI元素,大大降低开发成本和时间,并且可以让开发者专注于业务部分的逻辑。
本文将主要介绍几个在前端开发中常用的控件库。
一、Ant DesignAnt Design,是一款设计语言和React UI组件库,是一个由阿里巴巴前端团队Andrewzhang开发的开源项目。
Antd由于它的Word文档、良好的设计以及包含了非常多的常用组件而成为了广大开发者喜欢使用的前端组件库,同时也是最受欢迎的前端UI框架之一,它包含了丰富的React组件和内置的设计基础,遵循 Ant Design 的设计规范,帮助开发者构建出现代化和优雅的网站和应用。
二、ElementElement是基于Vue2.0开发的组件库,由饿了么的前端团队负责开发和维护,它提供了非常多的基础组件,包括表单、按钮、导航、布局、表格、搜索、弹出框等,支持响应式布局和主题定制,非常适合开发管理型后台系统。
同时,Element还有针对移动端的Mint UI组件,并且有丰富的文档和社区支持,可以帮助开发者更快速地完成项目。
三、BootstrapBootstrap是最流行的HTML、CSS和JS框架之一。
由Twitter 前端团队开发,可用于开发具有响应式布局的网站和应用程序。
Bootstrap包含了许多预先设计好的组件和工具,包括用于网格系统、响应式设计、表单、按钮、导航和布局的类库。
Bootstrap的栅格系统非常好用,可以方便地快速搭建页面,而且有很多优秀的第三方插件,所以也是许多开发者的首选。
四、Semantic UISemantic UI是一个现代化的UI组件库,基于CSS标准和语义化原则开发,提供了非常美观、易于使用且可扩展的组件。
Semantic UI 支持多个主题,更重要的是,Semantic UI为界面中的每个元素提供了标签,这些标签代表着功能,而不是仅是简单的展示。
非参数统计中的Bootstrap方法详解(五)

在统计学中,Bootstrap方法是一种用于估计统计量的非参数统计方法。
它的提出和发展为统计学领域带来了重大的影响,成为了一种常用的统计分析工具。
本文将详细介绍Bootstrap方法的原理、应用和相关概念,以及在实际问题中的应用。
Bootstrap方法最早由Bradley Efron于1979年提出,它的核心思想是通过对样本数据的重抽样,来估计总体的分布以及统计量的性质。
这种方法的优势在于不需要对总体分布做出假设,尤其适用于小样本情况下的统计推断。
通过不断地重抽样和计算得到的统计量,可以得到统计量的抽样分布,从而对总体分布和统计量进行估计和推断。
在Bootstrap方法中,首先需要从原始样本中进行有放回的重抽样,得到和原始样本大小相同的重抽样集合。
然后利用这些重抽样数据集合来估计统计量,例如均值、方差等。
通过重复这一过程,可以得到大量的估计值,从而得到统计量的抽样分布。
最终可以利用这些抽样分布对总体分布的性质进行估计,以及对统计量的置信区间和假设检验进行推断。
Bootstrap方法在实际应用中有着广泛的应用。
例如在金融领域,利用Bootstrap方法可以对股票收益率的分布进行估计,从而对风险进行评估。
在医学研究中,Bootstrap方法可以用来对患者的生存时间进行推断。
在工程领域,Bootstrap方法可以用来对数据的不确定性进行分析。
总之,Bootstrap方法在各个领域都有着重要的应用价值,成为了一种强大的统计分析工具。
除了介绍Bootstrap方法的原理和应用,我们还需要了解一些相关的概念。
首先是自助样本(bootstrap sample),即通过有放回的重抽样得到的新样本。
其次是统计量(statistic),即对样本数据进行运算得到的数值,例如样本均值、样本方差等。
另外还有抽样分布(sampling distribution),即统计量在不同抽样情况下的分布。
了解这些相关概念,对深入理解Bootstrap方法的原理与应用至关重要。
bootstrap 算法

bootstrap 算法Bootstrap算法是一种常用的机器学习算法,用于解决分类和回归问题。
它是一种基于决策树的集成学习方法,通过组合多个弱分类器来构建一个强分类器。
在本文中,我将介绍Bootstrap算法的原理、应用和优缺点。
让我们了解一下Bootstrap算法的原理。
Bootstrap算法的核心思想是通过自助采样和集成学习来提高模型的准确性。
自助采样是指从训练集中有放回地随机采样,得到与原始训练集大小相等的新训练集。
通过反复进行自助采样,可以得到多个不同的训练集,然后在每个训练集上训练一个弱分类器。
最后,通过投票或取平均值的方式来得到最终的分类结果。
Bootstrap算法的应用非常广泛。
它可以用于解决二分类、多分类和回归问题。
在二分类问题中,可以使用Bootstrap算法来构建一个强分类器,从而提高分类的准确性。
在多分类问题中,可以使用多个弱分类器进行集成,从而得到更好的分类结果。
在回归问题中,可以使用Bootstrap算法来构建一个强回归模型,从而提高预测的准确性。
虽然Bootstrap算法在实际应用中取得了很好的效果,但它也存在一些缺点。
首先,由于自助采样的随机性,有些样本在训练集中可能会出现多次,而有些样本可能会被遗漏。
这可能导致模型的方差增大,造成过拟合的问题。
其次,Bootstrap算法在构建弱分类器时可能会受到噪声样本的影响,从而降低分类的准确性。
此外,Bootstrap算法的计算复杂度较高,需要进行多次自助采样和训练,对计算资源的要求较高。
为了克服Bootstrap算法的缺点,研究人员提出了一些改进的方法。
例如,可以通过自适应权重调整的方式来降低噪声样本的影响。
另外,可以使用自适应增强方法来减少模型的方差,提高分类的准确性。
此外,还可以使用并行计算的方式来加速Bootstrap算法的训练过程,提高算法的效率。
总结起来,Bootstrap算法是一种常用的机器学习算法,通过自助采样和集成学习来提高模型的准确性。
Bootstrapping

Bootstrapping转⾃:Bootstrapping从字⾯意思翻译是拔靴法,从其内容翻译⼜叫⾃助法,是⼀种再抽样的统计⽅法。
⾃助法的名称来源于英⽂短语“to pull oneself up by one’s bootstrap”,表⽰完成⼀件不能⾃然完成的事情。
1977年美国Standford⼤学统计学教授Efron提出了⼀种新的增⼴样本的统计⽅法,就是Bootstrap⽅法,为解决⼩⼦样试验评估问题提供了很好的思路。
Bootstrapping算法,指的就是利⽤有限的样本资料经由多次,重新建⽴起⾜以代表母体的新样本。
bootstrapping的运⽤基于很多统计学假设,因此假设的成⽴与否影响采样的准确性。
统计学中,bootstrapping可以指依赖于重置随机抽样的⼀切试验。
bootstrapping可以⽤于计算样本估计的准确性。
对于⼀个采样,我们只能计算出某个(例如)的⼀个取值,⽆法知道均值统计量的分布情况。
但是通过(⾃举法)我们可以模拟出均值统计量的近似分布。
有了分布很多事情就可以做了(⽐如说有你推出的结果来进⽽推测实际总体的情况)。
bootstrapping⽅法的实现很简单,假设抽取的样本⼤⼩为n:在原样本中有放回的抽样,抽取n次。
每抽⼀次形成⼀个新的样本,重复操作,形成很多新样本,通过这些样本就可以计算出样本的⼀个分布。
新样本的数量通常是1000-10000。
如果计算成本很⼩,或者对精度要求⽐较⾼,就增加新样本的数量。
优点:简单易于操作。
缺点:bootstrapping的运⽤基于很多统计学假设,因此假设的成⽴与否会影响采样的准确性。
1、⾃助法的基本思路:如果不知道总体分布,那么,对总体分布的最好猜测便是由数据提供的分布。
⾃助法的要点是:①假定观察值便是总体;②由这⼀假定的总体抽取样本,即再抽样。
由原始数据经过再抽样所获得的与原始数据集含量相等的样本称为再抽样样本(resamples)或⾃助样本(bootstrapsamples)。
bootstrap方法

bootstrap方法Bootstrap方法。
Bootstrap方法是一种统计学上的重要技术,它可以用来估计统计量的抽样分布,计算置信区间和假设检验的p值。
Bootstrap方法的基本思想是通过对原始数据的重抽样来模拟总体分布,从而进行统计推断。
本文将介绍Bootstrap方法的基本原理、应用领域以及实际操作步骤。
Bootstrap方法的基本原理是利用样本数据来模拟总体分布,通过对原始数据的重抽样来构建多个虚拟样本,进而估计统计量的抽样分布。
在实际应用中,我们通常会进行大量的重抽样,比如重复抽取1000次或更多次,以获得统计量的抽样分布。
通过这种方法,我们可以获得统计量的置信区间,评估参数的不确定性,以及进行假设检验。
Bootstrap方法在实际应用中有着广泛的应用领域,比如金融、医学、生态学、工程等领域。
在金融领域,Bootstrap方法常常用于风险管理和金融衍生品定价;在医学领域,Bootstrap方法可以用于估计参数的置信区间和进行假设检验;在生态学领域,Bootstrap方法可以用于估计物种丰富度和多样性指数;在工程领域,Bootstrap方法可以用于估计工程参数的不确定性。
实际操作Bootstrap方法时,首先需要从原始数据中进行重抽样,构建多个虚拟样本。
然后针对每个虚拟样本计算统计量的值,比如均值、中位数、方差等。
通过对这些统计量的分布进行分析,我们可以得到统计量的抽样分布,从而获得置信区间和假设检验的p值。
总之,Bootstrap方法是一种强大的统计学技术,它可以在不知道总体分布的情况下进行统计推断,适用于各种领域的数据分析和统计推断。
通过对原始数据的重抽样,Bootstrap方法可以帮助我们更准确地估计参数的不确定性,评估统计量的置信区间,以及进行假设检验。
因此,掌握Bootstrap方法对于数据分析和统计推断是非常重要的。
bootstrap检验原理 例子

概述bootstrap检验是一种统计学中常用的方法,用于估计参数的置信区间、检验假设以及进行其他统计推断。
本文将介绍bootstrap检验的基本原理,并通过具体的例子来说明其应用。
一、bootstrap检验的基本原理1. 什么是bootstrap检验Bootstrap检验是一种非参数统计方法,它通过重采样的方法来估计参数的置信区间,并进行假设检验。
相比于传统的方法,bootstrap 检验不需要对数据进行严格的分布假设,因此更加灵活和有效。
2. bootstrap检验的步骤(1)重采样我们需要从原始样本中进行重采样,这意味着我们从原始样本中有放回地抽取相同大小的样本。
重复该过程多次,得到多个重采样样本。
(2)参数估计对于每个重采样样本,我们都可以估计参数的值,例如均值、方差等。
通过对这些参数值的分布进行分析,我们可以得到参数的置信区间。
(3)假设检验bootstrap检验也可以用于进行假设检验。
我们可以根据重采样样本得到的分布,判断原始样本是否来自某个特定的分布,从而进行统计推断。
二、bootstrap检验的应用示例下面我们将通过一个具体的例子来说明bootstrap检验的应用。
假设我们有一个包含100个观测值的样本,我们希望通过bootstrap检验来估计样本均值的置信区间,并进行假设检验。
1. 参数估计我们从原始样本中进行重采样,假设我们进行1000次重采样。
对于每个重采样样本,我们都计算均值。
通过对这1000个均值的分布进行分析,我们可以得到样本均值的置信区间。
2. 假设检验我们也可以用bootstrap检验来进行假设检验。
假设我们想要检验样本均值是否大于0。
我们可以通过重采样样本得到的分布,来计算P 值,从而判断原始样本的均值是否大于0。
结论通过以上例子,我们可以看到bootstrap检验的灵活性和有效性。
它不仅可以用于估计参数的置信区间,还可以用于进行假设检验,从而进行统计推断。
bootstrap检验在实际的统计分析中具有重要的应用价值。
自举法(Bootstrapping)

⾃举法(Bootstrapping)
⾃举法是在1个容量为n的原始样本中重复抽取⼀系列容量也是n的随机样本,并保证每次抽样中每⼀样本观察值被抽取的概率都是1/n(复置抽样)。
这种⽅法可⽤来检查样本统计数θ的基本性质,估计θ的标准误和确定⼀定置信系数下θ的置信区间。
⾃助法(Bootstrap Method)是Efron(1979)於Annals of Statistics所发表的⼀个办法,是近代统计发展上极重要的⼀个⾥程碑,⽽在执⾏上常需借助於现代快速的电脑。
举例来说,当⽤样本平均来估算母群体期望值时,为对此⼀估算的误差有所了解,我们常⽤信赖区间(confidence interval)的办法来做推估,此时得对样本平均的sampling distribution有所了解。
在基本统计教本上,当样本所来⾃的母群体,可⽤常态分配描述时,其sampling distribution可或为常态分配或为t分配。
但当样本所来⾃的母群体,不宜⽤常态分配描述时,我们或⽤电脑模拟或⽤渐进分析的办法加以克服。
当对母群体的了解不够深时,渐进分析的办法是较有效的⽅法,故中央极限定理(Central Limit Theorem),Edgeworth Expansion (small sample theory)等办法及其可⾏性及限制等於⽂献中⼴被探讨,⼈们虽不全然喜欢这些办法,但也找不出更理性的⽅法来取代渐进分析的办法。
⽽⾃助法确是⼀个相当具说服⼒的⽅法,更提供了统计⼯作者另⼀个寻找sampling distribution 的办法,故在近年来於⽂献中⼴被探讨。
bootstrap tag 标签

bootstrap tag 标签【原创实用版】目录1.概述 Bootstrap 标签2.Bootstrap 标签的分类3.Bootstrap 标签的使用方法4.Bootstrap 标签的优点5.结论正文一、概述 Bootstrap 标签Bootstrap 是一款流行的 HTML、CSS 和 JavaScript 框架,它为开发人员提供了一组易于使用的工具,使得开发网站变得更简单。
在 Bootstrap 中,标签(Tags)是一种非常重要的组件,它们可以帮助用户快速构建网页的结构。
二、Bootstrap 标签的分类Bootstrap 标签主要分为以下几类:1.输入框(Inputs):包括文本框、密码框、单选框、复选框等,用于用户输入信息。
2.按钮(Buttons):包括普通按钮、成功按钮、警告按钮、危险按钮等,用于提交表单或执行某些操作。
3.表单元素(Form Elements):包括表单域、表单标签、选项卡等,用于构建复杂的表单。
4.导航元素(Navigation):包括导航栏、导航按钮等,用于构建网站的导航结构。
5.媒体对象(Media Objects):包括图片、视频、音频等,用于展示多媒体内容。
6.进度条(Progress Bars):包括水平进度条、圆形进度条等,用于展示任务的进度。
三、Bootstrap 标签的使用方法要使用 Bootstrap 标签,首先需要在 HTML 文件中引入 Bootstrap 的 CSS 和 JavaScript 文件。
然后,可以使用相应的 Bootstrap 标签编写 HTML 代码。
Bootstrap 提供了大量的样式和类名,可以轻松地对标签进行样式定制。
例如,创建一个简单的表单可以使用以下代码:```html<form><div class="form-group"><label for="exampleInputEmail1">邮箱地址</label><input type="email" class="form-control"id="exampleInputEmail1" placeholder="请输入邮箱"></div><div class="form-group"><label for="exampleInputPassword1">密码</label><input type="password" class="form-control"id="exampleInputPassword1" placeholder="请输入密码"></div><button type="submit" class="btn btn-primary">提交</button> </form>```四、Bootstrap 标签的优点1.易于上手:Bootstrap 标签的使用方法非常简单,只需引入相应的 CSS 和JavaScript 文件,即可开始编写代码。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Bootstrapping a Semantic Wiki Applicationfor Learning MathematicsClaus Zinn∗1.MotivationThere is an enormous amount of math resources on the web: (a British site),http://www.mathe-online.at(Austrian),http://www.matheprisma. de(German),and the virtual community site ,to mention a few.Of course,our research group also created content,for instance,material for learning fractions,algebra, combinatorics,and statistics.Within the European project LeActiveMath,which aims at building an effective environment of technology-enhanced learning for mathematics(see www.leactivemath. org),we developed a significant amount of high quality teaching material in the math domain of differential calculus.The cost of authoring,however,has been high as our content providers were required to write content in a particular representation language,and to complement content with metadata along ontological and pedagogical dimensions.The extra effort,however,is not without reason as the resulting semantic-rich content is exploited by A ctiveMath components for personalised course generation,semantic search,and problem solving support.The rapid growth of math resources on the web,which is further pushed by wiki-based communities, is both a threat and an opportunity for intelligent math learning environments like A ctiveMath.On the one hand,the continuing development of wiki content will soon dwarf A ctiveMath’s carefully authored semantic-rich content;and this will make its intelligent learning services that exploit such limited but high-quality content less enticing to use.On the other hand,math learning environments like ours could potentially profit from the availability of math resources on the web.If such content were to be enriched with machine-readable annotations that describe it,and if we could harness the collaborative authoring process and encourage and guide wiki authors to continually provide content and metadata,then intelligent services could unleash their true potential,with immediate return and added value for authors and learners.In this paper,we describe se(ma)2wi,a semantic math wiki application that we bootstrapped with high-quality content plus metadata from the LeActiveMath project.We anticipate that the availability of se(ma)2wi,that is,the technical platform as well as the content resource,will help building and encouraging social communities to further make it grow,following,and potentially improving the blueprint of the original material.∗German Research Centre for Artificial Intelligence(DFKI),Stuhlsatzenhausweg3,66123Saarbr¨u cken,Germany, email:claus.zinn@dfki.de2.The ActiveMath Learning EnvironmentThe A ctiveMath system is an environment for technology-enhanced learning[4].It promotes the O MDoc representation language for writing mathematics.1This markup language extends O penMath and M athML,and allows authors to represent the meaning of mathematical formulae instead of their presentation or appearance.It has also markup for the document and theory level of mathematical documents,providing authors with labels to categorise mathematical items in terms of“definition”,“assertion”(“theorem”,“lemma”),and“proof”as well as(pedagogically motivated)categories such as“note”,“exercise”,and“motivation”.To inform the course generator of A ctiveMath there is also markup to label items in terms of“domain prerequisites”,“typical learning time”,“representation”,“field”,“learning context”,“competency level”,“abstractness”,and“trained competencies”.A ctiveMath authors use j EditOQMath,a purpose-built tool that supports the(template-based)cre-ation,editing,validation and management of O MDoc documents for their use in the A ctiveMath learning environment[2].The resulting semantic-rich content enables semantic search,which also uses fuzzy matching[3],informs the personalised selection of mathematical content(course gen-eration,given pedagogical strategies as well as individual user profiles and learner models)[5],pro-vides interactive exercises with feedback[1],allows learners to access external tools(function plotter, concept map tool,computer algebra systems),and facilitates the multi-format presentation of math content using standard web browsers and document viewers.To explore wiki technology and the potential to outsource content and metadata authoring to the wider community,we have built a semantic wiki with our semantic-rich content.3.Wiki TechnologyA website with wiki technology allows its visitors to view,add,remove,or otherwise edit and change (most of)its content with a standard web browser.The content is represented with a simple markup language;and it uses a subset of L A T E X for the authoring of math expressions.The high usability of the interface,the fact that changes take immediate effect,and the tools for discussing content and version control make a wiki an effective tool for collaborative authoring.The Wikipedia website has a very large user and author base and enormous content that increases by the day,thus testifying the success of wiki technology.Wikipedia’s coverage on math topics is also considerable.There are,for instance,a number of articles with category“Differential calculus”.2Yet, there are other wiki resources on differentiation.Wikibooks,the open-content textbooks collection, also features a book on calculus3,whereas Wikiversity,a community for the creation and use of free learning materials and activities,has a School of Mathematics that offers,for instance,an introductory course to differentiation4.There are several interesting observations:Wikipedia exploits categories to automatically generate a page that lists all articles with a given category;Wikibooks adds a new granularity to wiki articles, namely books;and Wikiversity introduces the notion of mass customisation offering different courses for different target audiences(e.g.,for pre-university and undergraduates).1See /omdoc.2See /wiki/Category:Differential_calculus.3See /wiki/Calculus.4See /wiki/Introduction_to_differentiation.The semantic annotation of this wiki math content is limited,however.Some articles have the cate-gory mark-up to link their page to an overall topic;but although pages are structured along explana-tions,definitions,proofs,and exercises,they are not labelled as such,and thus not open to machine interpretation.This is a pity since such annotations would facilitate the development and provision of intelligent services like semantic search(say,for all definitions within differential calculus),and personalised content selection and its presentation(say,the generation of additional examples or al-ternative proofs on request).4.Porting Semantic Rich Content to a Semantic WikiWefirst installed M ediaWiki5,the software used for Wikipedia and related sites,and extended it with “semantic”functions(attributes and binary relations)from the ontoworld community.6This included the installation of t exvc,a rendering engine for math formulae.To automate the import of articles, we also installed the python wikipedia bots package7,and adapted some of its scripts.⇓Figure1.XSLT conversion from O MDoc to wiki format5See .6See .7See /wiki/Interwiki_bot/Getting_started.The main task,however,has been the development and adaption of XSLT stylesheets that convert the XML-based O MDoc format into wiki-readable input.Thefirst set of stylesheets were written to identify the input format in terms of the high-level categories such as“definition”,“theorem”,and “proof”.For each such segment,which resulted into a separate se(ma)2wi article,we used a differ-ent set of stylesheets to translate its metadata into semantic relations and attributes,and to translate O penMath representations of math expressions into L A T E X.Fig.1shows O MDoc input(a definition) and wiki output fragments of this translation.Note that the wiki article preserves most of the semantic information,except,for the time being,those of math formulae.8The example transformation yieldsFigure2.se(ma)2wi screenshot(page on average slope)a wiki article on the definition“average slope”,which M ediaWiki renders with acceptable quality (see Fig.2).This page makes content references to the pages“straight line”,“secant”and“slope”. Below the content page,we see the metadata.The author’s annotations of“slope”and“secant”as domain prerequisite lead to the instantiation of the corresponding semantic attribute.Below,we see 8O MDoc segments that describe interactive elements were also not translated.semantic information that specifies that this article is an instance of“definition”,with several values for“learning context”,“field”,“typical learning time”,“representation”,and“abstractness”.When a learner clicks on any of the attached links,the semantic wiki gives a list of all definitions,or,for instance,a list of all articles with attribute“learning time:=00:01:00”.The available metadata thus offers effective navigational aids to browse through learning material.In total,1495wiki articles have been imported from over50O MDoc sourcefiles.The resulting wiki articles include121definitions,123theorems,35lemmas,208proofs,438exercises(but without interactive elements),74notes,47introductions,and405examples.5.Opportunities and RoadmapWe have imported all of the content that was authored within the LeActiveMath project into our semantic wiki.Before we start importing our other existing content,it is time for some reflection.We werefirst surprised by the benefits of Wiki technology.One gets a simple,effective,and widely accepted content authoring tool,which also includes facilities for page preview,version control,and discussion.Content storage,indexing and retrieval is provided under the hood;and the presentation of content,especially the rendering of math expressions is satisfactory,at least.M ediaWiki also delivers users and rights management;its semantic extension enables to search and organise wiki content via semantic relations.There is also editorial support via the wiki’s special pages,where one can access, for instance,“long pages”,“popular pages”,and“dead end pages”.In A ctiveMath,we had to implement those features ourselves,which,however,yielded more elabo-rated rendering options,a more sophisticated authoring environment,particularly for the provision of metadata,and more detailed semantic search facilities,to mention a few.We are currently exploring the roadmap of future A ctiveMath ing our expertise,we could either adopt and improve semantic wiki technology as a pure authoring environment,or we could go the whole way:port our intelligent services,such as the course generation for personalised content selection,to an improved semantic wiki platform.In any case,the authoring community will need to agree on common standards for authoring mathematical content.Here,our se(ma)2wi application, together with its semantic-rich content may serve as a technical vehicle and blueprint to promote ontological and pedagogical categories along the lines of the O MDoc standard. Acknowledgements.se(ma)2wi has been bootstrapped with content that has been developed by LeActiveMath project partners.The LeActiveMath project is funded under the6th Framework Pro-gramme of the European Community(contract IST-2003-507826).While A ctiveMath has an open source license for academic use,the LeActiveMath content providers chose the adopt the Creative Commons License9:users are allowed to freely copy,distribute,display, and perform the content,given that they give credit to the original author;do not exploit the content for commercial purposes;and do not alter,transform,or build upon this content.We are currently investigating to change to a license that is more open to collaborative authoring,in particular,with respect to editing existing content.9See /licenses/by-nc-nd/2.0/de/deed.en_GBReferences[1]G.Goguadze,A.Gonz´a lez Palomo,and E.Melis.Interactivity of exercises in ActiveMath.InC.K.Looi,D.Jonassen,and M.Ikeda,editors,Towards Sustainable and Scalable EducationalInnovations Informed by the Learning Sciences Sharing.Good Practices of Research Experimen-tation and Innovation,volume133of Frontiers in Artificial Intelligence and Applications.IOS Press,November2005.[2]P.Libbrecht and C.Gross.Experience report writing LeActiveMath calculus.In J.Borwein andW.Farmer,editors,Proceedings of Mathematical Knowledge Management2006,number4108 in LNAI.Springer Verlag,2006.[3]P.Libbrecht and E.Melis.Methods for access and retrieval of mathematical content in Active-Math.In N.Takayama,A.Iglesias,and J.Gutierrez,editors,Proceedings of ICMS-2006,number 4151in LNCS.Springer Verlag,2006.[4]E.Melis,G.Goguadze,M.Homik,P.Libbrecht,C.Ullrich,and S.Winterstein.Semantic-awarecomponents and services of ActiveMath.British Journal of Educational Technology,37(3),2006.[5]C.Ullrich.Tutorial planning:Adapting course generation to today’s needs.In M.Grandbastien,editor,Young Researcher Track Proceedings of12th International Conference on Artificial Intel-ligence in Education,pages155–160,Amsterdam,The Netherlands,2005.。