Oracle10g数据泵的导入导出
oracle使用数据泵导出和导入

使用数据泵导出和导入几乎所有DBA都熟悉oracle的导出和导入实用程序,它们将数据装载进或卸载出数据库,在oracle database 10g和11g中,你必须使用更通用更强大的数据泵导出和导入(Data Pump Export and Import)实用程序导出和导入数据。
以前的导出和导入实用程序在oracle database 11g中仍然可以使用,但是Oracle强烈建议使用数据泵(Data Pump)技术,因为它提供了更多的高级特性。
例如,你可以中断导出/导入作业,然后恢复它们;可以重新启动已失败的导出和导入作业;可以重映射对象属性以修改对象;可以容易地从另一个会话中监控数据泵的作业,甚至可以在作业过程中修改其属性;使用并行技术很容易快速移动大量的数据;因为oracle提供了针对数据泵技术的API,所以可以容易地在PL/SQL 程序中包含导出/导入作业;可以使用更强大的可移植表空间特性来快速移植大量的数据,甚至可在不同操作系统平台之间移动。
与旧的导出和导入实用程序不同,数据泵程序有一组可以在命令行中使用的参数以及一组只能以交互方式使用的特殊命令,你可以通过在命令行中输入expdp help = y 或者impdp help = y快速获取所有数据泵参数及命令的概述。
一.数据泵技术的优点原有的导出和导入技术基于客户机,而数据泵技术基于服务器。
默认所有的转储,日志和其他文件都建立在服务器上。
以下是数据泵技术的主要优点:1.改进了性能2.重新启动作业的能力3.并行执行的能力4.关联运行作业的能力5.估算空间需求的能力6.操作的网格方式7.细粒度数据导入功能8.重映射能力二.数据泵导出和导入的用途1.将数据从开发环境转到测试环境或产品环境2.在不同的操作系统平台上的oracle数据库直接的传递数据3.在修改重要表之前进行备份4.备份数据库5.把数据库对象从一个表空间移动到另一个表空间6.在数据库直接移植表空间7.提取表或其他对象的DDL注意:数据库不建立完备的备份,因为在导出文件中没有灾难发生时的最新数据。
(Oracle管理)Oracle 数据泵导出和导入

(Oracle管理)Oracle 数据泵导出和导入Oracle10g数据导入导出简介Oracle10g引入了DATAPUMP提供的是一种基于服务器的数据提取和恢复的实用程序,DATAPUMP在体系结构和功能上与传统的EXPORT和IMPORT实用程序相比有了显著的提升。
DATAPUMP允许您停止和重启作业,查看运行的作业的状态,及对导入和导出的数据做限制。
注意:数据泵文件与传统的EXP/IMP数据转储文件是不兼容的。
以下是DATAPUMP的几个优点介绍:1.数据泵(DataPump)的所有工作都有数据库实例来完成,数据库可以并行来处理这些工作,不仅可以通过建立多个数据泵工作进程来读/写正在被导出/导入的数据,也可以建立并行I/O服务器以更快地读取或插入数据,从而,单进程瓶颈被彻底解决。
2.通过数据泵,以前通过EXP/IMP主要基于Client/Server的逻辑备份方式转换为服务器端的快速备份,数据泵主要工作在服务器端,可以通过并行方式快速装入或卸载数据,而且可以在运行过程中调整并行的程度,以加快或减少资源消耗。
3.数据泵通过新的API来建立和管理,这些新的工作主要由DBMS_DATAPUMP来完成。
新的导入/导出工具完全成为了一个客户端应用,通过IMPDP/EXPDP执行的命令实际上都是在调用Server端的API在执行操作,所以一旦一个任务被调度或执行,客户端就可以退出连接,任务会在server端继续执行,随后通过客户端实用程序从任何地方检查任务的状态和进行修改创建DIRECTORY按表空间导出:Expdpsystem/mingyue@HS2008dumpfile=tablespace_test.dmptablespaces=HS_HIS_DATA,HS_HIS_IDXlogfi le=tablespace_test.logdirectory=TEST_EXPDPjob_name=hs_hisjob6;导出整个数据库:expdpsystem/mingyue@HS2008dumpfile=full.dmpfull=ylogfile=full.logdirectory=TEST_EXPDPjob_name =hs_hisjob6;使用exclude,include导出数据Include导出用户中指定类型的指定对象仅导出hs_his用户下以HISFU开头的所有表包含与表相关的索引,备注等不包含过程等其它对象类型:expdphs_his/handsome@HS2008dumpfile=include_1.dmplogfile=include_1.logdirectory=TEST_EXPDP job_name=job_hisjob7include=TABLE:\"LIKE\'HISFU%\'\";导出hs_his用户下排除HISFU开头的所有表:expdpsystem/mingyue@HS2008schemas=hs_hisdumpfile=include_1.dmplogfile=include_1.logdirecto ry=TEST_EXPDPjob_name=job_hisjob7include=TABLE:\"NOTLIKE\'HISFU%\'\";仅导出hs_his用户下的所有存储过程:expdpsystem/mingyue@HS2008schemas=hs_hisdumpfile=include_1.dmplogfile=include_1.logdirectory= TEST_EXPDPjob_name=job_hisjob7include=PROCEDURE;Exclude导出用户中指定类型的指定对象导出hs_his用户下除出TABLE类型以外的所有对象,如果表不导出那么与表相关的索引,约束等与表有关联的对象类型也不会被导出:expdpsystem/mingyue@HS2008schemas=hs_hisdumpfile=exclude_1.dmplogfile=exclude_1.logdirect ory=TEST_EXPDPjob_name=job_hisjob7exclude=TABLE;导出hs_his用户下排除HISFU开头的所有表:expdphs_his/handsome@HS2008dumpfile=include_1.dmplogfile=include_1.logdirectory=TEST_EXPD Pjob_name=job_hisjob7exclude=TABLE:\"LIKE\'HISFU%\'\";导出hs_his用户下的所有对象,但是对于表类型只导出以HISFU开头的表:expdphs_his/handsome@HS2008dumpfile=include_1.dmplogfile=include_1.logdirectory=TEST_EXPD Pjob_name=job_hisjob7exclude=TABLE:\"NOTLIKE\'HISFU%\'\";注意:1.如果content=data_only那么导出时就不能使用exclude,include 2.LINUX及UNIX对于特殊字符都要加一个转义字符如’()等这些字符在参考连接:/edeed/blog/item/9e3b9e2fb2209c3b1f308915.html http:///hzfsai/blog/item/8f1c2d4c4cd346f7d62afcab.html。
数据泵导入导出详解

数据泵技术是Oracle Database 10g 中的新技术,它比原来导入/导出(imp,exp)技术快15-45倍。
速度的提高源于使用了并行技术来读写导出转储文件。
expdp使用使用EXPDP工具时,其转储文件只能被存放在DIRECTORY对象对应的OS目录中,而不能直接指定转储文件所在的OS目录。
因此使用EXPDP工具时,,必须首先建立DIRECTORY对象,并且需要为数据库用户授予使用DIRECTORY对象权限。
首先得建DIRECTORY:SQL> conn /as sysdbaSQL> CREATE OR REPLACE DIRECTORY dir_dump AS '/u01/backup/';SQL> GRANT read,write ON DIRECTORY dir_dump TO public;1) 导出scott整个schema--默认导出登陆账号的schema$ expdpscott/tiger@db_esuiteparfile=/orahome/expdp.parexpdp.par内容:DIRECTORY=dir_dumpDUMPFILE=scott_full.dmpLOGFILE=scott_full.log--其他账号登陆, 在参数中指定schemas$ expdp system/oracle@db_esuiteparfile=/orahome/expdp.parexpdp.par内容:DIRECTORY=dir_dumpDUMPFILE=scott_full.dmpLOGFILE=scott_full.logSCHEMAS=SCOTT2) 导出scott下的dept,emp表$ expdpscott/tiger@db_esuiteparfile=/orahome/expdp.par expdp.par内容:DIRECTORY=dir_dumpDUMPFILE=scott.dmpLOGFILE=scott.logTABLES=DEPT,EMP3) 导出scott下除emp之外的表$ expdpscott/tiger@db_esuiteparfile=/orahome/expdp.par expdp.par内容:DIRECTORY=dir_dumpDUMPFILE=scott.dmpLOGFILE=scott.logEXCLUDE=TABLE:"='EMP'"4) 导出scott下的存储过程$ expdpscott/tiger@db_esuiteparfile=/orahome/expdp.par expdp.par内容:DIRECTORY=dir_dumpDUMPFILE=scott.dmpLOGFILE=scott.logINCLUDE=PROCEDURE5) 导出scott下以'E'开头的表$ expdpscott/tiger@db_esuiteparfile=/orahome/expdp.parexpdp.par内容:DIRECTORY=dir_dumpDUMPFILE=scott.dmpLOGFILE=scott.logINCLUDE=TABLE:"LIKE 'E%'" //可以改成NOT LIKE,就导出不以E开头的表6) 带QUERY导出$ expdpscott/tiger@db_esuiteparfile=/orahome/expdp.parexpdp.par内容:DIRECTORY=dir_dumpDUMPFILE=scott.dmpLOGFILE=scott.logTABLES=EMP,DEPTQUERY=EMP:"whereempno>=8000"QUERY=DEPT:"wheredeptno>=10 and deptno<=40"注: 处理这样带查询的多表导出, 如果多表之间有外健关联, 可能需要注意查询条件所筛选的数据是否符合这样的外健约束, 比如EMP中有一栏位是deptno, 是关联dept中的主键, 如果"whereempno>=8000"中得出的deptno=50的话, 那么, 你的dept的条件"wheredeptno>=10 and deptno<=40"就不包含deptno=50的数据, 那么在导入的时候就会出现错误.expdp选项1. ATTACH该选项用于在客户会话与已存在导出作用之间建立关联.语法如下:ATTACH=[schema_name.]job_nameschema_name用于指定方案名,job_name用于指定导出作业名.注意,如果使用ATTACH选项,在命令行除了连接字符串和ATTACH选项外,不能指定任何其他选项,示例如下:expdpscott/tiger ATTACH=scott.export_job2. CONTENT该选项用于指定要导出的内容.默认值为ALL.语法如下:CONTENT={ALL | DATA_ONLY |METADATA_ONLY}当设置CONTENT为ALL 时,将导出对象定义及其所有数据; 为DATA_ONLY时,只导出对象数据; 为METADATA_ONLY时,只导出对象定义,示例如下:expdpscott/tiger DIRECTORY=dump DUMPFILE=a.dumpCONTENT=METADATA_ONLY3. DIRECTORY指定转储文件和日志文件所在的目录.语法如下:DIRECTORY=directory_objectdirectory_object用于指定目录对象名称.需要注意,目录对象是使用CREATE DIRECTORY语句建立的对象,而不是OS 目录,示例如下:expdpscott/tiger DIRECTORY=dump DUMPFILE=a.dump建立目录:CREATE DIRECTORY dump as 'd:dump';查询创建了那些子目录:SELECT * FROM dba_directories;4. DUMPFILE用于指定转储文件的名称,默认名称为expdat.dmp.语法如下:DUMPFILE=[directory_object:]file_name[,….]directory_object用于指定目录对象名,file_name用于指定转储文件名.需要注意,如果不指定directory_object,导出工具会自动使用DIRECTORY选项指定的目录对象,示例如下:expdpscott/tiger DIRECTORY=dump1 DUMPFILE=dump2:a.dmp5. ESTIMATE指定估算被导出表所占用磁盘空间的方法.默认值是BLOCKS.语法如下:EXTIMATE={BLOCKS | STATISTICS}设置为BLOCKS时,oracle会按照目标对象所占用的数据块个数乘以数据块尺寸估算对象占用的空间,设置为STATISTICS时,根据最近统计值估算对象占用空间,示例如下:expdpscott/tiger TABLES=emp ESTIMATE=STATISTICSDIRECTORY=dumpDUMPFILE=a.dump一般情况下, 当用默认值(blocks)时, 日志中估计的文件大小会比实际expdp出来的文件大, 用statistics时会跟实际大小差不多.6. EXTIMATE_ONLY指定是否只估算导出作业所占用的磁盘空间,默认值为N.语法如下:EXTIMATE_ONLY={Y | N}设置为Y时,导出作用只估算对象所占用的磁盘空间,而不会执行导出作业,为N时,不仅估算对象所占用的磁盘空间,还会执行导出操作,示例如下:expdpscott/tiger ESTIMATE_ONLY=y NOLOGFILE=y7. EXCLUDE该选项用于指定执行操作时要排除的对象类型或相关对象.语法如下:EXCLUDE=object_type[:name_clause][,….]object_type用于指定要排除的对象类型,name_clause用于指定要排除的具体对象.EXCLUDE和INCLUDE不能同时使用,示例如下:expdpscott/tiger DIRECTORY=dump DUMPFILE=a.dup EXCLUDE=VIEW在EXPDP的帮助文件中, 可以看到存在EXCLUDE和INCLUDE参数, 这两个参数文档中介绍的命令格式存在问题, 正确用法是:EXCLUDE=OBJECT_TYPE[:name_clause][,...]INCLUDE=OBJECT_TYPE[:name_clause][,...]示例:Expdp<other_parameters> schema=scottexclude=sequence,table:"in('EMP','DEPT')"impdp<other_parameters> schema=scott include = function,package, procedure, table:"='EMP'"有了这些还不够, 由于命令中包含了多个特殊字符, 在不同的操作系统下需要通过转义字符才能使上面的命令顺利执行,如:EXCLUDE=TABLE:"IN('BIGTALE')"8. FILESIZE指定导出文件的最大尺寸,默认为0(表示文件尺寸没有限制).9. FLASHBACK_SCN指定导出特定SCN时刻的表数据.语法如下:FLASHBACK_SCN=scn_valuescn_value用于标识SCN值.FLASHBACK_SCN和FLASHBACK_TIME不能同时使用,示例如下:expdpscott/tiger DIRECTORY=dump DUMPFILE=a.dmpFLASHBACK_SCN=35852310. FLASHBACK_TIME指定导出特定时间点的表数据.语法如下:FLASHBACK_TIME="TO_TIMESTAMP(time_value)"示例如下:expdpscott/tiger DIRECTORY=dump DUMPFILE=a.dmp FLASHBACK_TIME ="TO_TIMESTAMP('25-08-200414:35:00','DD-MM-YYYY HH24:MI:SS')"11. FULL指定数据库模式导出,默认为N.语法如下:FULL={Y | N}为Y时,标识执行数据库导出.12. HELP指定是否显示EXPDP命令行选项的帮助信息,默认为N.当设置为Y时,会显示导出选项的帮助信息,示例如下:expdp help=y13. INCLUDE指定导出时要包含的对象类型及相关对象.语法如下:INCLUDE=object_type[:name_clause][,… ]示例如下:expdpscott/tiger DIRECTORY=dump DUMPFILE=a.dmp INCLUDE=trigger1.1.2 expdp选项14. JOB_NAME指定要导出作用的名称,默认为SYS_XXX.语法如下:JOB_NAME=jobname_string示例如下:expdpscott/tiger DIRECTORY=dump DUMPFILE=a.dmpINCLUDE=triggerJOB_NAME=exp_trigger后面想临时停止expdp任务时可以按Ctrl+C组合键,退出当前交互模式,退出之后导出操作不会停止,这不同于Oracle以前的EXP. 以前的EXP,如果退出交互式模式,就会出错终止导出任务. 在Oracle10g中,由于EXPDP是数据库内部定义的任务,已经与客户端无关. 退出交互之后,会进入export的命令行模式,此时支持status等查看命令:Export> status如果想停止改任务,可以发出stop_job命令:Export>stop_job如果有命令行提示: "是否确实要停止此作业([Y]/N):" 或"Are you sure you wish to stop this job ([yes]/no):", 回答应是yes或者no, 回答是YES以后会退出当前的export界面.接下来可以通过命令行再次连接到这个任务:expdp test/test@acf attach=expfull通过start_job命令重新启动导出:Export>start_jobExport> status15. LOGFILE指定导出日志文件文件的名称,默认名称为export.log.语法如下:LOGFILE=[directory_object:]file_namedirectory_object用于指定目录对象名称,file_name用于指定导出日志文件名.如果不指定directory_object.导出作用会自动使用DIRECTORY的相应选项值,示例如下:expdpscott/tiger DIRECTORY=dump DUMPFILE=a.dmp logfile=a.log16. NETWORK_LINK指定数据库链名,如果要将远程数据库对象导出到本地例程的转储文件中,必须设置该选项.expdp中使用连接字符串和network_link的区别:expdp属于服务端工具,而exp属于客户端工具,expdp生成的文件默认是存放在服务端的,而exp生成的文件是存放在客户端.expdp username/password@connect_string //对于使用这种格式来说,directory使用源数据库创建的,生成的文件存放在服务端。
oracle10g安装以及数据库导入步骤
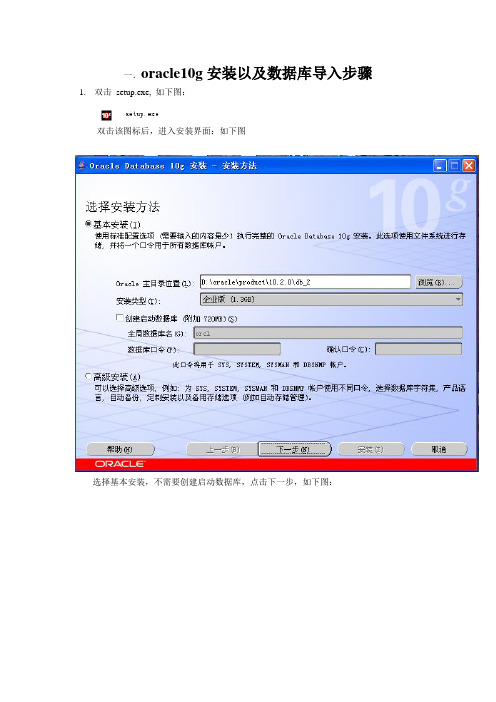
一.oracle10g安装以及数据库导入步骤1.双击setup.exe, 如下图:双击该图标后,进入安装界面:如下图选择基本安装,不需要创建启动数据库,点击下一步,如下图:进度条走完进入下一步操作界面,如下图:继续点击下一步按钮,进入下一操作界面,如下图:点击安装,即可安装好:如下图安装完毕后,退出即可。
2.创建数据库选择开始菜单——所有程序——Oracle —OraDb10g_home1——配置与移植工具——Database Configuration Assistant:如下图弹出数据库配置界面,如下图:点击下一步,弹出界面如下图:点击下一步,如图:点击下一步,如图:录入全局数据库名后,点击下一步:使用默认的设置,点击下一步:录入口令,点击下一步,如图:按默认的设置,点击下一步:按默认的设置,点击下一步:按默认的设置,点击下一步,继续点击下一步:按默认的设置,点击下一步:点击下一步:点击完成,即可完成数据库的创建。
数据库名为yy2010.3.新建监听器选择开始菜单——所有程序——Oracle —OraDb10g_home1——配置与移植工具——Net Configuration Assistant,如下图:弹出监听器配置界面如下图:选择监听程序配置,点击下一步:选择添加,点击下一步:录入监听程序名称,点击下一步:点击下一步:点击下一步:点击下一步,完成配置。
4.命名方法配置:选择开始菜单——所有程序——Oracle —OraDb10g_home1——配置与移植工具——Net Configuration Assistant,如下图:选择本地Net服务命名配置,点击下一步:点击下一步:录入服务名(在此填写数据库名称),点击下一步:点击下一步:点击下一步:点击下一步:完成配置5.安装oracle10g 客户端6.安装plsql7.用SYS 登录yy2010 ,创建用户create user yy identified by yy ;授权:grant connect,resource,dba to yy;8.导入数据库(1)先创建表空间,用yy 登录plsql,打开命令窗口,执行创建表空间的sql语句。
oracle数据泵应用及常见问题

Oracle数据泵应用及常见问题1、Oracle数据泵简介Oracle数据泵(Data Pump)是Oracle10G引进的新技术,在10g之前,传统的导出和导入分别使用EXP工具和IMP工具,从10g开始,不仅保留了原有的EXP和IMP工具,还提供了数据泵导出导入工具EXPDP和IMPDP。
经相关测试,Oracle数据泵方式进行数据导入导出要比以前的IMP/EXP快10倍左右,给大数据量的数据库导入导出提供了方便。
数据泵方式与IMP/EXP的主要区别在于EXP和IMP是客户段工具程序,它们既可以在可以客户端使用,也可以在服务端使用。
而EXPDP和IMPDP是服务端的工具程序,他们只能在ORACLE服务端使用,不能在客户端使用;IMP只适用于EXP导出文件,不适用于EXPDP 导出文件;IMPDP只适用于EXPDP导出文件,而不适用于EXP导出文件。
2、Oracle数据泵命令及主要参数a)EXPDP/IMPDP使用前准备运行命令前必须建立工作目录并赋权限,然后执行命令,具体步骤如下:a1在数据库所在机器上建立工作目录,如:d:\dp。
a2用数据库DBA用户SYS登录数据库,执行语句如下语句:create directory dump_dir as ' d:\dp ';grant read, write on directory dump_dir to db_user;(此处dump_dir 是第上面语句中工作目录名称,非实际目录名称,db_user是数据库用户名)。
a3运行EXPDP命令。
b)EXPDP主要参数a1DIRECTORY:导出数据的目录(目录是上面的设定的目录dump_dir)a2DUMPFILE:导出的文件名。
a3VERSION:以哪个版本导出数据,如果在不同的版本间导出导入数据,这个参数非常有用,例如将Oracle11G数据导入到Oracle10G(10.2.0.1.0)的数据库中,参数应写为VERSION=10.2.0.1.0,否则无法导入到低版本的数据库中。
数据泵

一、EXPDP和IMPDP介绍
1.数据泵导出(Data Dump Export)
数据泵导出的是Oracle Database 10g新增的功能功能,它使用实用工具EXPDP将数据库对象的元数据(对象结构)或数据导出到
1、以sys登录,建目录并将该目录的读写权利授予SCOTT
connect sys/orcl123 as sysdba
create directory dump_dir as 'd:\dump';
grant read,write on directory dump_dir to scott;
impdp scott/tiger directory=dump_dir dumpfile=tab.dmp tables=dept,emp
(2) 将DEPT,EMP表导入到system方案中。
impdp system/orcl123 directory=dump_dir dumpfile=tab.dmp tables=scott.dept,scott.emp remap_schema=scott:sy库是指将存放在转蓄文件中所有的数据库对象及其相关数据装载到数据库中,导入数据库是使用FULL选项来完成的。
注意:导出转蓄文件需要具有DBA角色或是EXP_FULL_DATABASE角色,导入转蓄文件是需要具有DBA角色或是IMP_FULL_DATABASE角
色。
二、使用EXPDP导出数据
EXPDP是服务器端的工具,该工具只能在Oracle服务器端使用,而不能在Oracle客户端使用。数据泵导出包括导出表、导出方案、导出表空间、导出数据库等4种模式。
oracle的导出命令

oracle的导出命令资料来⾃百度搜索,测试全库备份正常导出。
常⽤的oracle数据库备份(导⼊/导出)有两种,分别是exp/imp和expd/impd,前者是Orace早期版本带有的导⼊导出⼯具,后者是Oracle10g后出现的,下⾯进⾏分别介绍!1.exp/imp三种导⼊导出类型Oracle⽀持三种导⼊导出类型分别是表⽅式(T⽅式),⽤户⽅式(U⽅式),全库⽅式(Full⽅式)A: 表⽅式(T⽅式)备份(exp)某个⽤户模式下指定的对象(表),exp guwei/ai123456@10.21.19.63/orcl rows=y indexes=n compress=n buffer=50000000 file=exp_table.dmplog=exp_table.log tables=USER_INFO,POLICY_INFO恢复(imp)备份数据中的指定表,imp yuwen/ai123456@10.21.13.14/orcl fromuser=guwei touser=yuwen rows=y indexes=n commit=y buffer=50000000 ignore=nfile=exp_table.dmp log=exp_table.log tables=USER_INFO,POLICY_INFOB:⽤户⽅式(U⽅式)备份(exp)某个⽤户模式下的所有对象,exp jnth/thpassword@oracle owner=guwei rows=y indexes=n compress=n buffer=50000000 file=exp_table.dmp log=exp_table.log恢复(imp)备份数据的全部内容,imp yuwen/ai123456@10.21.13.14/orcl fromuser=guwei touser=yuwen rows=y indexes=n commit=y buffer=50000000 ignore=nfile=exp_table.dmp log=exp_table.log恢复(imp)备份数据中的指定表,imp yuwen/ai123456@10.21.13.14/orcl fromuser=guwei touser=yuwen rows=y indexes=n commit=y buffer=50000000 ignore=nfile=exp_table.dmp log=exp_table.log tables=USER_INFO,POLICY_INFOC:全库⽅式(Full⽅式)备份(exp)完整的数据库,exp system/systempassword@oracle rows=y indexes=n compress=n buffer=50000000 full=y file=exp_table.dmp log=exp_table.log导⼊(imp)完整数据库,imp system/systempassword@oracle rows=y indexes=n commit=y buffer=50000000 ignore=y full=y file=exp_table.dmp log=exp_table.log 导出导⼊的优缺点优点:简单易⾏;可靠性⾼;不影响数据库的正常运⾏。
董镇军—Oracle 数据泵的运用

Oracle数据泵导出导入数据董镇军北京北科博研科技有限公司oracle数据泵是oracle提供的更新、更快、更灵活的数据导入、导出工具。
Oracle的数据泵导入导出功能比原有的导入导出工具(exp/imp)功能强很多,特别是大数量的数据导入导出时,速度一般的数据导入导出速度提高很多。
1、连接Oracle数据库C:\Users>sqlplus请输入用户名:输入口令:连接到:Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 - ProductionWith the Partitioning, OLAP and Data Mining options2、创建一个操作目录SQL> create directory dump_dir as 'e:\testDir';目录已创建。
**注意同时需要使用操作系统命令在硬盘上创建这个物理目录。
3、使用以下命令创建一个导出文件目录scott用户操作dump_dir目录的权限,SQL>grant read,write on directory dump_dir to gwpj;授权成功。
4、使用命令expdp导出数据(可以按照用户模式导出、按照表、按照表空间导出和全库导出)C:\>expdp zcxxfw/zcxxfw directory=dump_dir dumpfile=20090517scotttab.dmp ----------------------------------------------------------------------------------------Export: Release 10.2.0.3.0 - Production on 星期一, 14 10月, 2013 19:23:43 Copyright (c) 2003, 2005, Oracle. All rights reserved.连接到: Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 - Production With the Partitioning, OLAP and Data Mining options启动"ZCXXFW"."SYS_EXPORT_SCHEMA_01": zcxxfw/******** directory=dump_dir dumpfile=20131014.dmp正在使用 BLOCKS 方法进行估计...处理对象类型 SCHEMA_EXPORT/TABLE/TABLE_DATA使用 BLOCKS 方法的总估计: 32.81 MB处理对象类型 SCHEMA_EXPORT/USER处理对象类型 SCHEMA_EXPORT/SYSTEM_GRANT处理对象类型 SCHEMA_EXPORT/ROLE_GRANT处理对象类型 SCHEMA_EXPORT/DEFAULT_ROLE处理对象类型 SCHEMA_EXPORT/PRE_SCHEMA/PROCACT_SCHEMA处理对象类型 SCHEMA_EXPORT/TABLE/TABLE处理对象类型 SCHEMA_EXPORT/TABLE/INDEX/INDEX处理对象类型 SCHEMA_EXPORT/TABLE/CONSTRAINT/CONSTRAINT处理对象类型 SCHEMA_EXPORT/TABLE/INDEX/STATISTICS/INDEX_STATISTICS处理对象类型 SCHEMA_EXPORT/TABLE/COMMENT处理对象类型 SCHEMA_EXPORT/TABLE/CONSTRAINT/REF_CONSTRAINT处理对象类型 SCHEMA_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS. . 导出了 "ZCXXFW"."XX_APPLOG" 7.151 MB 52402 行. . 导出了 "ZCXXFW"."XX_BOOK" 819.8 KB 3398 行已成功加载/卸载了主表 "ZCXXFW"."SYS_EXPORT_SCHEMA_01"*************************************************************************** ***ZCXXFW.SYS_EXPORT_SCHEMA_01 的转储文件集为:E:\TESTDIR\20131014.DMP作业 "ZCXXFW"."SYS_EXPORT_SCHEMA_01" 已于 19:24:26 成功完成---------------------------------------------------------------------------------------------5、导入命令C:\Users\dzj>impdp zcxxfw/zcxxfw directory=dump_dir dumpfile=20131014.DMP ---------------------------------------------------------------------------------Import: Release 10.2.0.3.0 - Production on 星期一, 14 10月, 2013 19:34:22 Copyright (c) 2003, 2005, Oracle. All rights reserved.连接到: Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 - Production With the Partitioning, OLAP and Data Mining options已成功加载/卸载了主表 "ZCXXFW"."SYS_IMPORT_FULL_01"启动"ZCXXFW"."SYS_IMPORT_FULL_01": zcxxfw/******** directory=dump_dir dumpfile=20131014.DMP处理对象类型 SCHEMA_EXPORT/USERORA-31684: 对象类型 USER:"ZCXXFW" 已存在处理对象类型 SCHEMA_EXPORT/SYSTEM_GRANT处理对象类型 SCHEMA_EXPORT/ROLE_GRANT处理对象类型 SCHEMA_EXPORT/DEFAULT_ROLE处理对象类型 SCHEMA_EXPORT/PRE_SCHEMA/PROCACT_SCHEMA处理对象类型 SCHEMA_EXPORT/TABLE/TABLEORA-39151: 表 "ZCXXFW"."XX_NOTICE" 已存在。
【Oracle】EXPDP和IMPDP数据泵进行导出导入的方法

【Oracle】EXPDP和IMPDP数据泵进⾏导出导⼊的⽅法⼀、expdp/impdp和exp/imp客户端⼯具1、exp和imp是客户端⼯具程序,它们既可以在客户端使⽤,也可以在服务端使⽤。
服务端⼯具2、expdp和impdp是服务端的⼯具程序,他们只能在oracle服务端使⽤,不能在客户端使⽤。
注意:3、imp只适⽤于exp导出的⽂件,不适⽤于expdp导出⽂件;impdp只适⽤于expdp导出的⽂件,⽽不适⽤于exp导出⽂件。
4、对于10g以上的服务器,使⽤exp通常不能导出0⾏数据的空表,⽽此时必须使⽤expdp导出。
⼆、expdp导出步骤(1)创建导出逻辑⽬录⽤sys管理员登录sqlplus[oracle@shdb02 ~]$ export ORACLE_SID=fp2[oracle@shdb02 ~]$ echo $ORACLE_SIDfp2[oracle@shdb02 ~]$ sqlplusSQL*Plus: Release 11.2.0.4.0 Production on Sat Mar 19 21:53:42 2022Copyright (c) 1982, 2013, Oracle. All rights reserved.Enter user-name: sys as sysdbaEnter password:**********Connected to:Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit ProductionWith the Partitioning, Real Application Clusters, Automatic Storage Management, OLAP,Data Mining and Real Application Testing optionsSQL>如果提⽰:Connected to an idle instance. //这个就是错误的信息。
用imp_exp命令_导入导出Oracle数据

准备启用约束条件...
成功终止导入,但出现警告。
附录二:
Oracle 不允许直接改变表的拥有者, 利用Export/Import可以达到这一目的.
先建立import9.par,
2、commit
指定在每次数组插入完成后是否提交数据,默认为N
3、compile
指定在导入包,过程,函数时是否要进行编译,默认为Y
4、constraints
指定是否要导入表的约束,默认为Y
5、datafiles
指定要搬移到数据库的数据文件列表
6、destroy
指定是否要覆盖已存在的数据文件,默认为N。如果存在同名文件,则导入失败
8、object_consistent
指定是否要基于对象级设置只读事务导出,默认为N
9、owner
指定用户导出模式。exp system/manager owner=scott file=a.dmp log=a.log
10、query
指定where条件字句,导出表的部分数据,当使用直接导出方式不能指定该选项
DROP ANY VIEW,EXP_FULL_DATABASE,IMP_FULL_DATABASE,
DBA,CONNECT,RESOURCE,CREATE SESSION TO 用户名字
第五, 运行-cmd-进入dmp文件所在的目录,
imp userid=system/manager full=y file=*.dmp
13、rows
指定是否导出表行数据,默认值为Y。
exp scott/tiger tables=emp file=a.dmp rows=N
Oracle 10G 的数据迁移方案

第二种方法是使用数据泵,它对表空间是否为只读没有要求。当只需要移动指定的表而不是整个表空间时,这种方法很有用。
最后一种方法是拖出表空间,该方法把可移动表空间方法的所有步骤组合成一步操作。用这种方法复制数据非常简单,但要想调整每个具体步骤以便进行性能优化时,它为数据库管理员提供的灵活性太少。
这条命令使用数据泵导入工具将通过数据库链接srcdb(在以前的章节中已讨论过)检索到的数据加载到表中。但是,由于网络带宽通常是受到限制的,因此这种方法可能比使用导出/传输/导入周期方法要慢一些。
如果只需将特定的表或表集合进行转移,那么Lora可以在expdp命令中使用TABLES=子句来只下载特定的表或表集合。
拖出表空间
作为第三种选择,Lora建议使用Oracle数据库10g中的新工具,它简化了可移动表空间的移动方法,因此只涉及执行一个打包过程。在这种方法中,用户利用所提供的DBMS_STREAMS_TABLESPACE_ADM包从源系统中"拖?quot;表空间。这个包使用数据泵转移表空间并将数据文件转换成目标系统的格式。它还自动执行任何所需的字节顺序变换。
会议结束
针对Acme的数据仓库/数据集市体系结构,Lora提出了几种移动数据的可选方法。
第一种可选方法是使用可移动表空间,它能移动完整的表空间集合(不仅包括表,还包括索引、物化视图和其他对象)。通常它还是这三种方法中最快的一种。但是,它的一个主要缺点是对指定的表空间必须在复制文件时设置为只读。
conversion_extension => 'linux'
);
END;
该操作在后台完成了许多步骤:设置源表空间为只读;用数据泵导出工具进行一次表空间的元数据转储;用DBMS_FILE_TRANSFER包移动数据文件和转储的文件;把源表空间恢复到其最初的读写状态;使用数据泵导入工具将表空间插入到本地数据库中。由于源数据库运行在Linux上,而目标数据库运行在Solaris上,因此这一操作首先复制原始数据文件(Linux的文件格式),然后将它转换到目标平台上(Solaris)的文件格式。复制过程保持最初被转移的文件,而创建一个新文件用于转换。新文件与最初的文件同名,但具有CONVERSION_EXTENSION参数指定的linux扩展名。在目标数据库中创建的表空间为只读表空间。
PLSQL导入导出Oracle数据库方法

PLSQL导入导出Oracle数据库方法在Oracle数据库中,我们可以使用PL/SQL来导入和导出数据。
下面是一些常用的方法:1. 使用SQL*Loader工具导入数据:SQL*Loader是Oracle提供的一个强大的数据导入工具。
通过创建一个控制文件和数据文件,可以将数据从外部文件导入到Oracle表中。
以下是一个简单的示例:```sqlLOADDATAINFILE 'data.txt'INTO TABLE empFIELDSTERMINATEDBY','```2. 使用Oracle Data Pump导入导出数据:Oracle Data Pump是Oracle 10g之后引入的一种高效的导入导出工具。
它提供了更快的数据加载和卸载速度,并且可以在导入导出过程中进行并行操作。
以下是一个简单的示例:```sql--导出数据EXPORT SCHEMA scott DIRECTORY=data_pump_dirDUMPFILE=scott.dmp--导入数据IMPORT SCHEMA scott DIRECTORY=data_pump_dirDUMPFILE=scott.dmp```3.使用PL/SQL脚本导入导出数据:我们可以使用PL/SQL脚本编写自定义的导入导出逻辑。
以下是一个简单的示例:```sql--导出数据DECLAREfile_handle UTL_FILE.FILE_TYPE;emp_rec emp%ROWTYPE;BEGINfile_handle := UTL_FILE.FOPEN('DATA_DIR', 'emp_data.txt', 'W');FOR emp_rec IN (SELECT * FROM emp) LOOPUTL_FILE.PUT_LINE(file_handle, emp_rec.empno , ',' ,emp_rec.ename , ',' , emp_rec.job);ENDLOOP;UTL_FILE.FCLOSE(file_handle);END;--导入数据DECLAREfile_handle UTL_FILE.FILE_TYPE;line_text VARCHAR2(200);BEGINfile_handle := UTL_FILE.FOPEN('DATA_DIR', 'emp_data.txt', 'R');LOOPUTL_FILE.GET_LINE(file_handle, line_text);--解析并插入数据ENDLOOP;UTL_FILE.FCLOSE(file_handle);END;```这是一些常用的PL/SQL导入导出Oracle数据库的方法。
数据泵导入导出步骤(从sqlplus登录到导入过程)

1、首先建立目录:create directory 目录名称as '数据库服务器上的一个目录',如:create directory 别名as 'd:\服务器目录名';将导入或导出的文件放在这个目录下2、导出及导入以SID=orcl,导出dmp的账号为test,导入dmp的账号为test为例。
若将数据从sfz中导出:expdp test/test@orcl directory=别名dumpfile=导出文件名导入到test中:impdp test/test@orcl directory=别名dumpfile=导出文件名.dmp导入到处用户名不一样时,做个映射,一样时,不用写remap_schema=test:test111g版本导出,导入到10g具体如下:导出脚本(11G):expdp test109/test109@orcl directory=expdp dumpfile=test10930bak.dmp logfile=mydb.log filesize=200m full=y version=10.2.0.1.0version号一定要哈导入脚本(10G):impdp shl1017/shl1017 directory=expdpdumpfile=TEST10930BAK.dmp version=10.2.0.1.0 REMAP_SCHEMA=test109:shl1017各参数对应的数据你根据自己的修改下2015-11-24下午数据泵方式导入zh.dmp过程:1、建立目录(expnc_dir为别名)create directory expnc_dir as 'E:\ncdatabak';2、导入数据impdp system/oracle@orcl directory=expnc_dir dumpfile=zh.dmp;3、根据错误日志文件(E:\ncdatabak目录下),建立用户、临时空间、用户空间a、删除用户及空间(再次导入的时候使用)drop user zh cascade;DROP TABLESPACE EAS_D_ZH_STANDARD INCLUDING CONTENTS AND DATAFILES;DROP TABLESPACE temp_zh INCLUDING CONTENTS AND DATAFILES;b、建立空间create tablespace EAS_D_ZH_STANDARDlogging datafile 'D:\app\Administrator\oradata\orcl\EAS_D_ZH_STANDARD.dbf'size 5gautoextend onnext 100m maxsize UNLIMITEDextent management local;c、建临时空间create temporary tablespace temp_zhtempfile 'D:\app\Administrator\oradata\orcl\temp_zh.dbf'size 100mautoextend onnext 32m maxsize UNLIMITEDextent management local;d、修改自动增长的太小alter database datafile 'D:\app\Administrator\oradata\orcl\EAS_D_ZH_STANDARD.dbf' autoextend on next 100m maxsize UNLIMITED;e、建用户create user zh identified by zhdefault tablespace EAS_D_ZH_STANDARDtemporary tablespace temp_zh;f、授权grant dba,connect,resource to zhg、导入数据impdpzh/zh directory=expnc_dir dumpfile=ZH.dmpremap_schema=zh:zhremap_tablespace=EAS_D_ZH_STANDARD:EAS_D_ZH_STANDARD(注意不带;)或impdp zh/zh@orcl directory=expnc_dir dumpfile=zh.dmp;注意:a、temp表空间不能自动扩展,所以建了一个有自动扩展的空间temp_zhb、出错的时候需要删除用户、表空间、临时空间再重新建立、再导入Oracle命令(一):Oracle登录命令()1、运行SQLPLUS工具C:\Users\wd-pc>sqlplus2、直接进入SQLPLUS命令提示符C:\Users\wd-pc>sqlplus /nolog3、以OS身份连接C:\Users\wd-pc>sqlplus / as sysdba 或SQL>connect / as sysdba4、普通用户登录C:\Users\wd-pc>sqlplus scott/123456 或SQL>connect scott/123456 或SQL>connect scott/123456@servername5、以管理员登录C:\Users\wd-pc>sqlplus sys/123456 as sysdba或SQL>connect sys/123456 as sysdba6、切换用户SQL>conn hr/123456注:conn同connect7、退出exitOracle数据导入导出imp/exp sp2-0734:未知的命令开头'imp 忽略了剩余行默认分类sp2-0734:未知的命令开头'imp 忽略了剩余行默认分类应该是在cmd的dos命令提示符下执行,而不是在sqlplus里面。
impdp与imp导出的文件格式

impdp(导入数据泵)和imp(导入工具)是Oracle 数据库中用于导入数据的工具。
它们支持不同的导入文件格式,具体如下:
impdp 导入数据泵工具:
impdp 是Oracle 10g 及更高版本引入的高级数据导入工具。
impdp 使用.dmp 文件格式进行导入,这是一种二进制导出文件格式,其中包含了数据库对象、数据和元数据信息。
.dmp 文件是由expdp(数据泵导出)工具创建的。
imp 导入工具:
imp 是Oracle 数据库早期版本(9i及之前)使用的传统数据导入工具。
imp 支持.dmp 文件格式,这与impdp 使用的.dmp 文件格式不同,因为它们在文件结构上有差异。
imp 也支持使用文本文件(通常以.sql 或.dat 文件扩展名保存)导入数据。
这些文本文件包含SQL 语句或平面文本数据。
需要注意的是,虽然imp 仍然存在于Oracle 数据库中,但它已经不再是Oracle 推荐的数据导入方法。
impdp 提供更强大的功能和性能,因此在现代Oracle 数据库环境中,通常建议使用impdp 进行数据导入。
无论你选择使用impdp 还是imp,在进行数据导入之前,都需要确保导出的数据文件与相应的导入工具兼容,并且包含了所需的数据库对象、数据和元数据。
数据泵工具导出的步骤

数据泵工具导出的步骤:1、创建DIRECTORYcreate directory dir_dp as 'D:\oracle\dir_dp';2、授权Grant read,write on directory dir_dp to lttfm;--查看目录及权限SELECT privilege, directory_name, DIRECTORY_PATH FROM user_tab_privs t, all_directories dWHERE t.table_name(+) = d.directory_name ORDER BY 2, 1;3、执行导出expdp lttfm/lttfm@fgisdb schemas=lttfm directory=dir_dp dumpfile =expdp_test1.dmp logfile=expdp_test1.log;连接到: Oracle Database 10g Enterprise Edition Release 10.2.0.1 With the Partitioning, OLAP and Data Mining options启动"LTTFM"."SYS_EXPORT_SCHEMA_01": lttfm/********@fgisdb schory=dir_dp dumpfile =expdp_test1.dmp logfile=expdp_test1.log; */ 备注:1、directory=dir_dp必须放在前面,如果将其放置最后,会提示ORA-39002: 操作无效ORA-39070: 无法打开日志文件。
ORA-39087: 目录名DA TA_PUMP_DIR; 无效2、在导出过程中,DATA DUMP 创建并使用了一个名为SYS_EXPORT_SCHEMA_01的对象,此对象就是DATA DUMP 导出过程中所用的JOB名字,如果在执行这个命令时如果没有指定导出的JOB名字那么就会产生一个默认的JOB名字,如果在导出过程中指定JOB名字就为以指定名字出现如下改成:expdp lttfm/lttfm@fgisdb schemas=lttfm directory=dir_dp dumpfile =expdp_test1.dmp logfile=expdp_test1.log,job_name=my_job1;3、导出语句后面不要有分号,否则如上的导出语句中的job 表名为‘my_job1;’,而不是my_job1。
impdp详解

3.导出表空间
Expdp system/manager DIRECTORY=dump_dir DUMPFILE=tablespace.dmp
TABLESPACES=user01,user02
4,导出数据库
Expdp system/manager DIRECTORY=dump_dir DUMPFILE=full.dmp FULL=Y
4.REUSE_DATAFILES
16. NETWORK_LINK
指定数据库链名,如果要将远程数据库对象导出到本地例程的转储文件中,必须设置该选项.
17. NOLOGFILE
该选项用于指定禁止生成导出日志文件,默认值为N.
18. PARALLEL
指定执行导出操作的并行进程个数,默认值为1
19. PARFILE
指定导出参数文件的名称
GRANT READ, WIRTE ON DIRECTORY dump_dir TO scott;
1,导出表
Expdp scott/tiger DIRECTORY=dump_dir DUMPFILE=tab.dmp TABLES=dept,emp
2,导出方案
Expdp scott/tiger DIRECTORY=dump_dir DUMPFILE=schema.dmp
调用EXPDP
使用EXPDP工具时,其转储文件只能被存放在DIRECTORY对象对应的OS目录中,而不能直接指定转储文件所在的OS目录.因此,使用EXPDP工具时,必须首先建立DIRECTORY对象.并且需要为数据库用户授予使用DIRECTORY对象权限.
CREATE DIRECTORY dump dir AS ‘D:DUMP’;
Oracle数据泵方式导入导出

一、EXPDP和IMPDP使用说明Oracle Database 10g引入了最新的数据泵(Data Pump)技术,数据泵导出导入(EXPDP和IMPDP)的作用1)实现逻辑备份和逻辑恢复.2)在数据库用户之间移动对象.3)在数据库之间移动对象4)实现表空间搬移.二、数据泵导出导入与传统导出导入的区别在10g之前,传统的导出和导入分别使用EXP工具和IMP工具,从10g开始,不仅保留了原有的EXP和IMP工具,还提供了数据泵导出导入工具EXPDP和IMPDP.使用EXPDP和IMPDP时应该注意的事项:1) EXP和IMP是客户端工具程序,它们既可以在可以客户端使用,也可以在服务端使用。
2) EXPDP和IMPDP是服务端的工具程序,他们只能在ORACLE服务端使用,不能在客户端使用。
3) IMP只适用于EXP导出文件,不适用于EXPDP导出文件;IMPDP只适用于EXPDP导出文件,而不适用于EXP导出文件。
数据泵导出包括导出表,导出方案,导出表空间,导出数据库4种方式.【pump特点】与原有的export和import使用程序相比,oracle的data pump工具的功能特点如下:1) 在导出或者导入作业中,能够控制用于此作业的并行线程的数量。
2) 支持在网络上进行导出导入,而不需要是使用转储文件集。
3) 如果作业失败或者停止,能够重新启动一个data pump作业。
并且能够挂起恢复导出导入作业。
4) 通过一个客户端程序能够连接或者脱离一个运行的作业。
5) 空间估算能力,而不需要实际执行导出。
6) 可以指定导出导入对象的数据库版本。
允许对导出导入对象进行版本控制,以便与低版本数据库兼容。
三、导入导出操作1.导出数据1.1在数据库服务端,用system用户通过sqlplus命令登录到oracle,sqlplus logis/logis@logis_local;1.2在oracle中创建目录,如下:CREATE DIRECTORY LOGIS_EXP_DIR AS 'd:\data';注意:d:\data 这个目录必须是磁盘上实际存在的,可以是其他目录名称和路径。
Oracle10g的数据迁移方案

Oracle10g的数据迁移方案数据迁移是将数据从一个存储系统迁移到另一个存储系统的过程。
在Oracle10g中,有许多不同的数据迁移方案可供选择,每个方案都有其优势和适用场景。
以下是一些常见的Oracle10g数据迁移方案。
1. 导出/导入(exp/imp):这是Oracle10g中最常见的数据迁移方法之一、它通过使用exp将数据从源数据库导出到一个文件中,然后使用imp将数据从该文件中导入到目标数据库中。
这种方法适用于小型数据库或需要频繁迁移的数据库,但不适用于大型数据库或需要迁移大量数据的情况。
2. 数据泵(expdp/impdp):数据泵是Oracle10g中引入的新特性,它提供了更高效和更灵活的数据迁移方法。
数据泵使用expdp将数据从源数据库以二进制格式导出到一个文件中,然后使用impdp将数据以二进制格式从该文件中导入到目标数据库中。
相对于导出/导入,数据泵具有更快的速度和更小的导出/导入文件大小。
3. SQL Loader:SQL Loader是Oracle10g中的另一种数据迁移工具,它可以将大量数据从平面文件导入到数据库中。
它通过读取一个控制文件和一个或多个数据文件来工作。
控制文件指定要导入的数据的格式和目标表,而数据文件包含实际的数据。
SQL Loader适用于需要从外部系统或文件导入数据的场景。
4.数据库链接:如果源数据库和目标数据库位于不同的服务器上,可以使用数据库链接来实现数据迁移。
数据库链接允许在一个数据库中对另一个数据库进行查询和操作。
通过在目标数据库上创建一个链接对象,然后使用该链接对象在源数据库上执行查询和操作,可以将数据从源数据库迁移到目标数据库。
5. Oracle数据同步/复制:如果需要实时数据同步或定期数据复制,可以考虑使用Oracle的数据同步或复制工具。
Oracle提供了许多数据同步和复制解决方案,如Oracle Streams和Oracle GoldenGate。
Data pump数据泵导入导出

Data pump数据泵导入导出从oracle10g开始引入了data pump数据泵功能,它是一种基于服务器的数据提取和恢复的实用程序,与传统export和import使用程序相比其在功能和传输性能上有很大提升。
Data pump的所有工作通过数据库的实例来完成,可以通过建立多个Data pump工作进程来并行处理这些工作,提高导入导出性能;data pump工作在服务端,可以通过调整并行度来加快或减少资源消耗,同时可以快速装入或卸载数据。
使用data pump步骤如下:首先要为创建和读取的数据文件及日志文件创建一个目录,这个目录对应的是服务端的目录,同时,将要访问data pump文件的用户必须要拥有该目录的读写权限。
下面将创建一个名为BAK的目录,并授予system用户对此目录的读写权限。
同时需要在系统目录下创建相应的\u01\backup目录。
使用datapump导出方法有很多种,举两个常用例子:1)schema导出expdp [用户名]/[密码]@[主机字符窜] schemas=[用户名] directory=BAK dumpfile=xxx.dmp logfile=xxx.log2)数据库全库导出expdp [用户名]/[密码]@[主机字符窜] full=y directory=BAK dumpfile=xxx.dmp logfile=xxx.logdata pump导入1)schema导入impdp [用户名]/[密码]@[主机字符窜] schemas=[用户名] directory=BAK dumpfile=xxx.dmp logfile=xxx.log2)数据库全库导入impdp [用户名]/[密码]@[主机字符窜] full=y directory=BAK dumpfile=xxx.dmp logfile=xxx.log南京宝云教育。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
从故障中恢复
重启动任务的能力使你可以从某些类型的故障中恢复过来。例如, 清单 5 显示了一个用完了转储文件空间的导出任务的日志文件的结尾部分。然而,什么也没有丢失。该任务只是进入了一个空闲状态,当你连接到该任务并查看状态输出时就可以看到这一点。这个状态不显示任务空闲的原因。要确定这是因为转储文件的空间不够了,则你需要查看日志文件。
启动一个导出任务
你可以使用新的 expdp 实用程序来启动一个导出任务。因为参数与老的 exp 实用程序不同,所以你得熟悉这些新的参数。你可以在命令行中指定参数,但在本文中我使用了参数文件。我想导出我的整个模式( schema ),使用了以下参数:
DUMPFILE=gnis%U.dmp
仅导入那些与密歇根州相关的数据行
不导入原始的存储参数
一开始,我可以在我的导入参数文件中写出以下四行:
DUMPFILE=gnis%U.dmp
DIRECTORY=export_dumps
LOGFILE=gnis_import.log
JOB_NAME=gnis_import
DUMPFILE=export_dumps01:gnis%U.dmp,
export_dumps02:gnis%U.dmp
PARALLEL=2
注意,在这个并行导出任务中,目录名作为文件名的一部分来被指定。
检查状态
你可以随时连接到一个运行中的任务来检查其状态。要连接到一个导出任务,必须执行一条 expdp 命令,使用 ATTACH 参数来指定任务名称。 清单 2 显示了到 GNIS_EXPORT 任务的连接。当你连接到一个任务, expdp 显示该任务的相关信息和当前状态,并为你提供一个 EXPORT> 提示符。
我可以很轻松地完成该模式的改变,将来自 GNIS 模式的数据表重新映射到 MICHIGAN 模式:
REMAP_SCHEMA=gennick: michigan
我只需要关于密歇根州的数据行。为此,我可以使用 QUERY 参数来指定一个 WHERE 子句:
QUERY="WHERE gnis_state_abbr='MI'"
清单 1 显示了一个导出任务已被启动。该任务所做的第一件事是估计所需的磁盘空间大小。当估计值显示出来后,我按 ctrl-C 进入一个交互式的导出提示窗口,然后使用 EXIT_CLIENT 命令回到我操作系统的命令窗口。该导出任务仍然运行在服务器上。
注意,如果我要做并行导出并且将我的 I/O 分布在两个磁盘上,那么我可以对 DUMPFILE 参数值做出修改,并如下添加 PARALLEL 参数和值,如下所示:
DIRECTORY=export_dumps
LOGFILE=gnis_export.log
JOB_NAME=gnis_export
DUMPFILE 指定我将向其中写入被导出数据的文件。 %U 语法给出了一个增量计数器,得到文件名 gnis01.dmp 、 gnis02.dmp 等。 DIRECTORY 指定了我的目标目录。
Oracle10g:数据的导入导出
给数据泵加压
Oracle 数据库 10g 中的新的实用程序使其性能和多功能性达到了新的水平。
Oracle 数据库 10g 中增加的叫做 Oracle Data Pump (数据泵)的新的导入和导出特性,彻底改变了数据库用户已经习惯的过去几代 Oracle 数据库的客户 / 服务器工作方式。现在服务器可以运行导出和导入任务。你可以通过并行方式快速装入或卸载大量数据,而且你可以在运行过程中调整并行的程度。导出和导入任务现在可以重新启动,所以发生故障不一定意味着要从头开始。 API 是公诸于众的,并且易于使用;用 PL/SQL 建立一个导入和导出任务非常简单。一旦启动,这些任务就在后台运行,但你可以通过客户端实用程序从任何地方检查任务的状态和进行修改。
重新启动任务的功能是数据泵体系结构的一个重要特性。你可以随时停止和重启动一个数据泵任务,比如为在线用户释放资源。你还可以从文件系统的空间问题中轻松地恢复。如果一个 12 小时的导出任务在进行了 11 小时后因磁盘空间不够而失败,那么你再也不用从头开始重新启动该任务,重复前面 11 小时的工作。而是你可以连接到这个失败的任务,增加一个或多个新的转储( dump )文件,从失败的地方重新启动,这样只需一个小时你就可以完成任务了。这在你处理很大数据量时非常有用。
连接到因转储文件空间不够用了而停止的任务后,你可以在两个操作中选择其一:你可以使用 KILL_JOB 命令来中止该任务,或者增加一个和多个转储文件来继续该任务的运行。如果空间不够的问题是因为磁盘空间不足,则当然你要确保你增加的文件是在另一个有可用空间的磁盘上。你也许需要创建一个新的 Oracle 目录对象来指向这一新位置。
对文件系统的访问
由服务器处理所有的文件 I/O 对于远程执行导出和导入任务的数据库管理员来说非常有利。如今,用户可以很轻松地在类似 UNIX 的系统 ( 如 Linux) 上 telnet 或 ssh 到一个服务器,在命令行方式下初始化一个运行在服务器上的导出或导入任务。然而,在其他操作系统上就不那么容易, Windows 是最明显的例子。在推出数据泵之前,要从一个 Windows 系统下的 Oracle 数据库中导出大量数据,你很可能必须坐在服务器控制台前发出命令。通过 TCP/IP 连接导出数据只对小数据量是可行的。数据泵改变了这一切,因为即使你通过在你的客户端上运行该导出和导入实用程序来初始化一个导出或导入任务,该任务其实也运行在服务器上,所有的 I/O 也都发生在该服务器上。
你可以使用一个或多个 INCLUDE 参数列出你要导入的那些对象。
你可以使用 EX我只需要一个对象,明确包含该对象比起明确不包括其它对象要容易得多。我的 INCLUDE 参数值的第一部分是关键字 TABLE ,表明我要导入的对象是一个数据表(其它的可能是一个函数或一个过程)。 接下来是一个冒号,然后是一个 WHERE 子句的谓词。我明确希望数据表名为 GNIS ,所以这个谓词是 "= 'GNIS'" 。如果必要,则你可以写出多个详细的谓词。通过 INCLUDE 和 EXCLUDE 参数,你可以确切地指出以什么样的粒度导入或导出。我建议你仔细地阅读关于这两个参数的文档。它们的功能之强大和多功能性是我在本文中所无法描述的。
我的 LOGFILE 参数指定了日志文件的名字,这个文件是为每个导出任务默认创建的。 JOB_NAME 给任务指定了一个名字。我选择了一个易于记忆(和输入)的名字,因为我可能需要在后面才连接这个任务。要注意在指定任务名称时不要与你登录模式( schema )中的模式对象名称冲突。数据泵在你的登录模式中建立一个被称为任务主表的数据表,该表的名字与任务的名字相匹配。这个数据表跟踪该任务的状态,并最终被写入转储文件中,作为该文件所含内容的一个记录。
当你连接到了一个任务后,你可以随时执行 STATUS 命令查看当前状态,如 清单 3 所示。你还可以执行 CONTINUE_CLIENT 命令返回到显示任务进度的日志输出状态,该命令可以被缩写成如 清单 4 所示的 CONTINUE 。
你可以通过查询 DBA_DATAPUMP_JOBS 视图快速查看所有数据泵任务的状态。你不能获得 STATUS 命令所给出的详细信息,但你可以快速查看到哪些任务在执行、哪些处于空闲状态等。另一个需要了解的视图是 DBA_DATAPUMP_SESSIONS ,它列出了所有活跃的数据泵工作进程。
QUERY 在老的实用程序中也有,但只能用于导出操作。数据泵使 QUERY 也能用于导入操作,因为数据泵利用了 Oracle 较新的外部数据表功能。只要可能,数据泵会选择直接路径来导出或导入数据,包括从数据库数据文件中读取数据然后直接写到一个导出转储文件中,或读取转储文件然后直接写入数据库数据文件中。但是,当你指定了 QUERY 参数时,数据泵将使用一个外部数据表。对于一个导入任务,数据泵将使用 ORACLE_DATAPUMP 存取驱动程序建立一个外部数据表,并执行一条 INSERT...SELECT...FROM 语句。
出于安全性考虑,数据泵要求你通过 Oracle 的目录对象来指定其中存放着你要建立或读取的转储文件的目标目录。例如:
CREATE DIRECTORY export_dumps
AS 'c:\a';
GRANT read, write
ON DIRECTORY export_dumps
导入选定的数据
本文中的例子到目前为止显示的是对用户 GENNICK 拥有的所有对象进行模式( schema )数据库级别的导出。为了展示数据泵的一些新的功能,我要导入那些数据,而且为了使问题更有意思,我列出了以下要求:
仅导入 GNIS 数据表
将该数据表导入到 MICHIGAN 模式中
体系结构
在 Oracle 数据库 10g 之前(从 Oracle7 到 Oracle9I ),导入和导出实用程序都作为客户端程序运行,并且完成大量工作。导出的数据由数据库实例读出,通过连接传输到导出客户程序,然后写到磁盘上。所有数据在整个导出进程下通过单线程操作。今天的数据量比这个体系结构最初采用的时候要大得多,使得单一导出进程成了一个瓶颈,因为导出任务的性能受限于导出实用程序所能支持的吞吐量。
TO gennick;
我以 SYSTEM 身份登录到我的实验室数据库上,并执行以上语句来建立一个目录对象,这个目录对象指向了我磁盘上的一个临时目录,以用来存放导出的转储文件。 GRANT 语句为用户 gennick- 就是我 - 分配了访问该目录的权限。我给自己分配读 / 写权限,因为我将导出和导入数据。你可以为一个用户分配读权限,限制他只能导入数据。
清单 6 使用 ADD_FILES 命令为我的空闲任务增加两个文件。这两个文件位于不同的目录中,它们都不同于为该任务的第一个转储文件所指定的目录。我使用 START_JOB 命令来重新启动该任务,然后使用 CONTINUE 查看屏幕上滚动的其余日志输出。