基于完备回溯树的语义Web服务自动组合
《人工智能》测试题答案

《人工智能》测试题答案测试题——人工智能原理一、填空题1.人工智能作为一门学科,它研究的对象是______,而研究的近期目标是____________ _______;远期目标是___________________。
2.人工智能应用的主要领域有_________,_________,_________,_________,_______和__________。
3.知识表示的方法主要有_________,_________,_________,_________和________。
4.产生式系统由三个部分所组成,即___________,___________和___________。
5.用归结反演方法进行定理证明时,可采取的归结策略有___________、___________、_________、_________、_________和_________。
6.宽度优先搜索对应的数据结构是___________________;深度优先搜索是________________。
7.不确定知识处理的基本方法有__________、__________、__________和__________。
8.AI研究的主要途径有三大学派,它们是________学派、________学派和________学派。
9.专家系统的瓶颈是________________________;它来自于两个阶段,第一阶段是,第二阶段是。
10.确定因子法中函数MB是描述________________________、而函数MD是描述________________________。
11.人工智能研究的主要领域有_________、_________、_________、_________、_______和__________。
12.一阶谓词逻辑可以使用的连接词有______、_______、_______和_______。
第10章知识图谱

5
2 语义网络
优点
①结构性:以节点和弧形式把事物属性 以及事物间的语义联想显式地表示出来。 ②联想性:作为人类联想记忆模型提出。 ③自然性:直观地把事物的属性及其语 义联系表示出来,便于理解,自然语言 与语义网络的转换比较容易实现。
84 语义Web源自奠基人Tim Berners-Lee 2016年图灵奖得 主万维网、语义网 之父,提出语义 Web
Web1.0
Web1.0,是以编辑为 特征,网站提供给用 户的内容是网站编辑 进行编辑处理后提供 的,用户阅读网站提 供的内容。这个过程 是网站到用户的单向 行 为 , web1.0 时 代 的 代表站点为新浪,搜 狐,网易三大门户, 强调的是文档互连。
作用
为真实世界的各个场 景直观地建模,运用 “图”这种基础性、通用 性的“语言”,“高保真” 地表达这个多姿多彩 世界的各种关系,并 且非常直观、自然、 直接和高效,不需要 中间过程的转换和处 理。
术语
①实体: 具有可区别 性且独立存在的某种 事物。 ②类别:主要指集合、 类别、对象类型、事 物的种类。 ③属性、属性值:实 体具有的性质及其取 值。 ④关系:不同实体之 间的某种联系,
11
10.2 知识图谱基本原理
10.2.1 10.2.2 10.2.3 10.2.4 10.2.5
认知智能是人工智能的高级目标 知识图谱概念 知识图谱模型 知识图谱特点 知识图谱分类
1 认知智能是人工智能的高级目标
13
2 知识图谱概念
定义
知识图谱用节点和关系 所组成的图谱。
语义网中的本体构建与推理研究

语义网中的本体构建与推理研究随着互联网技术的不断发展,人们在网络上获取信息变得越来越容易,然而,这些信息往往是海量的、杂乱无章的,并不便于机器自动处理。
因此,我们需要一种能够理解信息含义的方式,来帮助我们更好地处理这些信息。
这就是语义网的基本思想。
语义网(Semantic Web)的核心是充分地使用信息的语义,通过构建本体(Ontology)、推理等手段来实现Web资源的高效利用和共享。
本体是语义网的基石本体是语义网中的核心概念。
顾名思义,本体就是用于描述实体及其关联关系的模型。
它是对某一领域中实体、概念、属性和关系等的描述,以及这些描述之间的约束、规则等。
本体的目的是消除不同人、不同组织、不同机器对同一概念的不同解释,为不同使用者提供一个一致的、标准的基础。
因此,本体的构建关系到语义网的推广和应用。
本体构建的方法本体构建的方法可以大致分为三大类:手工构建法、半自动化构建和自动化构建。
手工构建是最早出现的一种本体构建方式。
其优点在于可以高度抽象地描述概念,缺点在于速度慢、成本高。
半自动化构建则是在手工构建的基础上,在人工干预的情况下涉及到自动化工具,优点在于缩短了构建时间。
自动化构建是一种基于机器学习的方法,具有时间成本低、可扩展性好等优点。
本体推理的方法本体推理是指通过基于本体知识的逻辑推断,从本体中出发,再结合外部实例数据,推导出新的知识或结论,从而完善和扩展本体的过程。
本体推理的方法可以大致分为逻辑推理和规则推理。
逻辑推理是利用逻辑形式化地表示本体知识,然后进行逻辑推理的过程。
逻辑推理需要对本体进行形式化表示,从而使推理结果是形式化规则所允许的。
规则推理是指利用基于规则或规则表示的推理方法,利用规则的强特定性来完成推理任务。
本体构建和推理的应用完善的本体和推理技术可以帮助我们更好地利用和共享网络信息。
下面分别介绍几个应用。
1. 语义搜索语义搜索可以从网络数据中精确提取用户所需信息。
在语义搜索中,可以利用本体中的概念间关系,由搜索关键词推断出更适合用户需求的结果,从而不必对搜索结果进行手工筛选。
基于动态描述逻辑的语义Web服务组合

语 义 We b服 务 自动 组 合 方 法 . 首先 , 在 将 OW L — S表 示 的语 义 We b服 务 建 模 为 动 作 的 基 础 上 , 将 语 义 We b服 务 组
摘 要
应用合适的形式系统对语义 We b 服务建模 是实现语义 we b服务 自动组合 的前提 ; 形 式系统 的表达 能力
和计 算 性 能 决 定 了语 义 W e b 服 务 组 合 的准 确 度 和求 解 效 率 . 动态描述逻辑 D DL( X) 将 动态 逻 辑 、 描 述 逻 辑 以 及 构
T P 1 8
∞
2
中图法分类号
史 D O I 号
忠
1 0 . 3 7 2 4 / S P . J . 1 0 1 6 . 2 0 1 3 . 0 2 ቤተ መጻሕፍቲ ባይዱ 6 8
S e ma nt i c We b S e r v i c e Co m po s i t i o n Ba s e d o n Dy n a mi c De s c r i pt i o n Lo g i c s
mo de l t he s e s e r vi c e s wi t h s u i t a bl e f o r ma l s y s t e ms ; b ot h t h e a c c ur a c y a nd t he e f f i c i e nc y o f t he c omp os i t i o n a r e d e t e r mi n e d by t he e x pr e s s i ve p o we r a n d t he c o mp ut i n g pr o pe r t y o f t he f o r ma l s y s t e m a do pt e d. The dy na mi c d e s c r i p t i o n l o gi c D DL ( X) i s a c ombi n a t i on of d yn a mi c l o gi c s, d e s c r i pt i o n l o g i c s a nd a c t i o n f o r ma l i s ms c on s t r u c t e d ov e r d e s c r i p t i o n l o g i c s ;i t pr o v i d e s a ne w t o ol
一种基于OWL-S的语义Web服务自动组合方法

一种基于OWL-S的语义Web服务自动组合方法
徐德智;汤益华
【期刊名称】《计算机应用研究》
【年(卷),期】2010(027)010
【摘要】提出了一种基于OWL-S的语义Web服务自动组合的方法.该方法充分利用OWL-S的顶层本体结构,基于最小满意度阈值,从网络上获取满足要求的Web 原子服务并将其存储在两个DAG图中;然后基于该图生成Web服务组合候选集;最后从该候选集中随机选取最终的Web服务组合.该方法在保证Web服务组合质量的前提下,实现了根据服务请求对Web服务的自动化组合.
【总页数】4页(P3767-3770)
【作者】徐德智;汤益华
【作者单位】中南大学,信息科学与工程学院,长沙,410083;中南大学,信息科学与工程学院,长沙,410083
【正文语种】中文
【中图分类】TP301.2
【相关文献】
1.基于语义关系图的Web服务自动组合方法 [J], 冯建周;孔令富;王晓寰
2.一种基于与或图的语义Web服务自动组合方法研究 [J], 卢锦运;张为群
3.一种QoS最优的语义Web服务自动组合方法 [J], 邓水光;黄龙涛;吴斌;尹健伟;李革新
4.一种基于OWL-S领域本体的Web服务语义标注方法研究 [J], 李建新;柯钢;杨
怀德
5.基于Petri网的语义Web服务自动组合方法 [J], 祁方民;
因版权原因,仅展示原文概要,查看原文内容请购买。
语义网搜索引擎设计与实现

语义网搜索引擎设计与实现语义网搜索引擎是一种基于Web语义这种机器可读的语言进行搜索的搜索引擎。
与传统的搜索引擎不同,语义网搜索引擎更加侧重于语义的理解和表达,可以实现更加精准、智能的搜索结果。
本文将从设计和实现两个方面来探讨语义网搜索引擎的相关问题。
一、设计语义网搜索引擎1. 语义理解的重要性语义网搜索引擎的设计首先需要考虑如何对语义进行理解。
语义理解是指通过自然语言的表达和上下文信息来解析语义的过程。
语义理解是非常重要的,因为语义网的本质在于构建机器可读的语言,其目的就是帮助机器能够自动理解这种语言。
2. 元数据的应用语义网搜索中的元数据是指与Web内容相关的信息,包括作者、摘要、关键词、主题等等。
元数据可以在语义网中为内容增加附加信息,从而提供更加深入、详细的搜索结果,帮助用户更好地找到自己想要的信息。
因此,在语义网搜索引擎设计过程中,需要对元数据的应用进行深入探讨,以提高搜索结果的准确性和可用性。
3. 计算机语言的使用语义网采用的是一种基于计算机语言的形式化语言,该语言可以轻松地为数据附加元数据,表达数据之间的关系,从而实现数据的自动分析和推理。
因此,语义网搜索引擎设计需要涉及计算机语言的使用,帮助机器能够更好地理解和理解语言,提高搜索结果的准确性和可用性。
二、实现语义网搜索引擎1. 知识表示和推理知识表述是语义网搜索引擎的核心,它建立在基于Web的知识库上。
知识库是指包含了一些基本概念、实体、属性和关系的数据库,这些概念可以用来描述语义网中的各种内容。
推理是指通过推理算法对知识库中的数据进行分析,推出更加深入、具体的信息,从而实现更加智能、准确的搜索结果。
2. Web服务技术的应用Web服务是一种为Web应用程序和机器之间提供通信机制的技术。
Web服务可以使不同的应用程序之间可以互操作,实现信息的共享和交换。
在语义网搜索引擎实现过程中,Web服务技术可以帮助搜索引擎更好地处理搜索请求,组织和查询知识库中的数据,从而提高搜索结果的准确性和可用性。
语义网介绍及体系结构分析

语义网介绍及体系结构分析作者:暂无来源:《声屏世界》 2015年第13期张海亮随着网络的迅猛发展,网页上的信息成指数增长,网页已经成为最主要的信息交流渠道。
由于HTML本身的局限性而导致网页上缺乏足够的语义信息,难以实现WEB信息的自动化处理,因此WWW、HTTP和HTML的创始人Tim Berners-Lee在一般万维网的基础上提出了语义网的概念,从而大大改进了人类思维和机器思维之间的差异,提高了机器自动处理网络上信息的能力。
语义网是对未来网络的一个设想,现在与WEB 3.0这一概念结合在一起,是3.0网络时代的特征之一。
简单地说,语义网是一种智能网络,它不但能够理解词语和概念,而且还能够理解它们之间的逻辑关系,可以使交流变得更有效率和价值。
语义网和人工智能中的语义网络是两个不同的概念,所以它采用的方法与自然语言处理不同。
它对现有的WEB进行了语义扩展,从而使其上面的信息能够被计算机理解和处理,从功能上看它将是一个能够“理解”人类信息的智能网络。
在其体系结构中,第一层是Unicode(统一编码)和URI,它是整个语义网的基础。
Unicode是处理资源的编码,URI负责标识资源;第二层是XML+名空间+XML模式,用于表示数据的内容和结构;第三层是RDF和RDF模式,用于描述资源及其类型;第四层是本体词汇,用于描述各种资源之间的联系;第五层是逻辑,在前面四层的基础上进行逻辑推理操作;第六层是验证,根据逻辑陈述进行验证以得出结论;第七层是信任,在用户间建立信任关系。
其中,第二、三、四层是一个语义网的关键层,用于表示WEB信息的语义,也是现在语义网研究的热点所在。
可扩展标记语言XML让每个人都能创建自己的信息标签,来对网页或页面的部分文字进行注释。
资源描述框架RDF的基本结构是对象、属性和值所组成的三元组,也就相当于一个句子中的主语,动词和宾语。
这些三元组可以用XML语法来表示。
用这种结构描述并由机器处理大量数据,是非常自然的方法。
语义Web服务通信协议分层模型设计

议本体模 型, 分层通信协议模 型可以有效的减 少通信过程 中数据丢 失的现 象, 增强通信 双方的互理 解性 , 更高效的完成数据传输. 中详细解释 了三层协议 的工作原理 , 文 并证 明 了通信 协议模型 的语
义性 .
关 键 词 : 体 ;通信 协 议 ;语 义 We 本 b服 务
中图分类号:T 33o ] [ P 9.4
语义 We 务通 信协 议 分层模 型 设计 b服
耿 丽 丽 余 雪 丽 ,
(. 1山西财 经 大学实 验教 学 中心 ,h i ta 太原 000 1 . 原理 工大学 计算 机与 软件学 院 ,山西 太原 306 2太 002) 304
摘
要: 随着语义 we 服务技术 的发展 , b 人们在互联 网环境 下实现通信过程语 义化进程得到 了极 大
程 中交 互 双 方 的语 义 理 解 , 进 语 义 W e 推 b服 务 发 展 . 1 通 信 协 议 模 型 的 分 层 设 计
型是首要的 , 是整个工作 的起始点 , 或者说先有模型 , 再有分析 , 后有实现. 要使计算机程序之间可以准确交换数据 , 首先就要有数 据所需 的传输 通道以及数据传输所要遵守 的规范 ,
所 以必 须 满 足 以下 条 件 :
() 1通信设备之 间必须有网络连接 , 并且保证可 以相互传输数据. () 2程序之间所要传输的数据必须遵循相互约定好 的语法格式 , 并且对所传输数据有 一致的语义理解度.
协议 的设计 更加容 易 、 灵活 , 各层 只需要 通过 接 口向其它 层提 供服 务和请 求服 务. 本 文借 鉴 网络 通信 协议 分层 的划分 原则 , 在语义 We b服 务通 信 协 议 的设 计 过程 中采用 分 层 的思 想 ,
WebFOCUS产品与其他工具比较
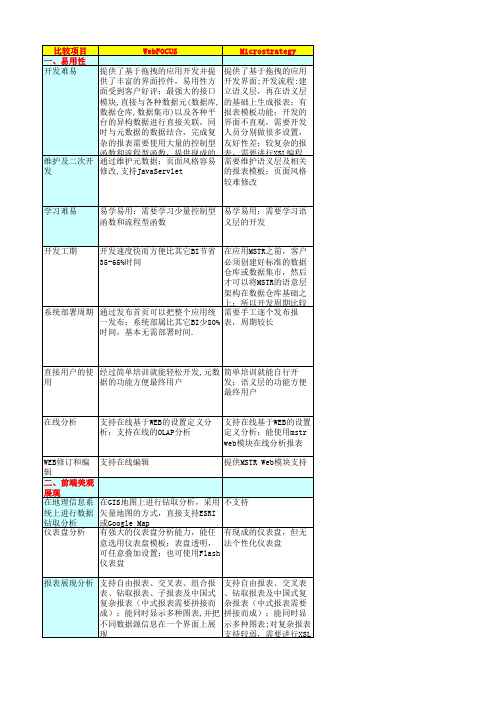
WEB修订和编 辑 二、前端美观 展现 在地理信息系 统上进行数据 钻取分析 仪表盘分析
在GIS地图上进行钻取分析,采 不支持 用矢量地图的方式,直接支持 ESRI或Google Map 有强大的仪表盘分析能力,能任 有现成的仪表盘,但无 意选用仪表盘模板;表盘透明, 法个性化仪表盘 可任意叠加设置;也可使用 Flash仪表盘 支持自由报表、交叉表 、钻取报表及中国式复 杂报表(中式报表需要 拼接而成);能同时显 示多种图表;对复杂报表 支持较弱,需要进行XSL
COGNOS 提供了基于拖拽的应用开发 界面;开发流程:使用 Framework Manager选择数 据源表和列,建立模型、查 询项、过滤项,最终生成数 据包发布到服务器,接着使 用ReportStudio在图形化界 面建立报表;有报表向导功 能;有报表模板功能;编写 需要维护Framework Manager开发的数据模型及 VB脚本语言 易学易用;需要学习VB脚本 语言 由于需要使用Framework Manager建立数据包后才能 建立报表,开发周期较长
BO 提供了基于拖拽的应用开发界面,类OFFICE 的开发操作,很多技术都成为行业标准;开 发流程是通过选取数据源的表建模,或者直 接连接语义层,再选用适当的字段在界面上 建立表格或者图形,整个过程都非常简单友 好,有层级的功能,能够通过类BASIC脚本编 写复杂的计算项及对报表的大部分属性进行 控制;提供了各种格式的报表向导;提供报 表模板功能,直接选取数据源套用模板就能 需要维护计算项及属性控制脚本;还需要维 护语义层,数据源更新需要重新刷新语义层, 若数据源发生变化需要在语义层中进行相应 修改,有些特殊字段需要在语义层中编写公 式,公式比较复杂,短时间内难以快速接受 易学易用;需要学习类BASIC脚本语言,表层 感觉使用比较简单,但是牵扯到相当多的细 节,例如展示数据行数的限制、报表服务器缓 存等设置方式需要对该产品有一定了解后才 具体开发工期视项目情况而定,由于BO属于产 品型,因此有些需求无法满足客户一些个性化 需求,而现今客户的需求名目繁多,有些需求 BO无法满足,导致客户对该产品的认可度下 降,若利用水晶报表进行复杂式报表的开发速 度较慢,水晶报表只是单纯的绘制表样的时间 可以逐个报表发布,也可以发布整个报表目 录,部署很快,但每张报表发布需要修改数据 源的用户名和密码,根据需要还必须对报表的 刷新机制进行定制,该产品占用资源比较大, 为保证系统能正常快速得运行需要建议客户 单独购买服务器,增加用户费用。 简单培训就能自行开发,语义层的功能很好 的解决了终端用户的数据源的辨识问题,使用 人员需要熟悉数据结构,语义层需要实施方技 术人员设置好才能快速交付客户,增加项目实 施工作量,水晶报表非专业人员无法迅速上手 通过层级的功能能够实现在线的预设分析钻 取,提供OLAP INTELLIGENCE模块在线进行 OLAP分析,数据响应时间长,第一次访问数据 源时间比较长,需要安装JAVA插件,仪表盘需 提供WEB INTELLIGENCE模块在线进行报表制 作修改 水晶报表内置地图,能够进行相关地图钻取, 但若需要添加其他类型的地图,例如山东省的 就比较复杂,必须按照其规定的地图格式来寻 仪表盘功能主要以静态展示为主,能通过层 级的功能能够实现预设分析钻取,功能相对 较弱,Dashboard能够实现动态仪表盘功能,并 且不仅限于仪表盘样式,支持切片分析、雷达 图等多种样式 支持自由报表、交叉表、组合报表、钻取报 表、子报表、运行合计及中国式复杂报表 (中式报表需要拼接而成);能同时显示多 种图表;报表功能在处理OLAP数据源时功能 较弱,能够利用水晶报表来进行智能分析报告 的制作。
【浙江省自然科学基金】_web services_期刊发文热词逐年推荐_20140813
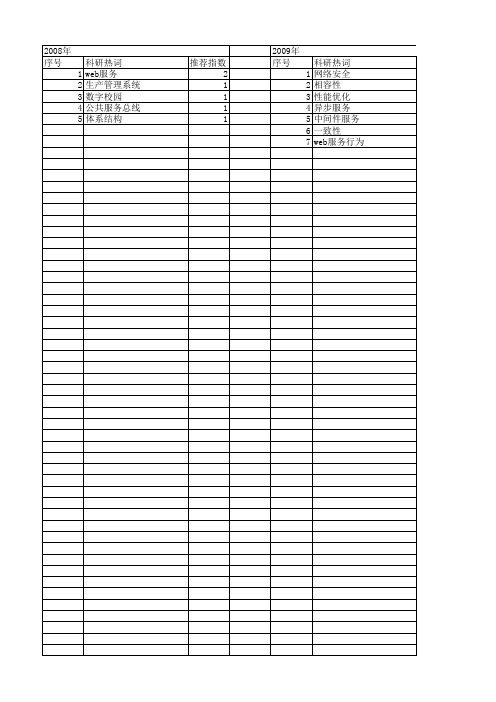
推荐指数 2 1 1 1 1
2009年 序号 1 2 3 4 5 6 7
科研热词 网络安全 相容性 性能优化 异步服务 中间件服务 一致性 web服务行为
推荐指数 1 1 1 1 1 1 1
推荐指数 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2014年 序号 1 2 3 4
2014年 科研热词 服务选择 服务质量 服务关联 web服务 推荐指数 1 1 1 1
2012年 序号 1 2 3 4
科研热词 移动终端 多源数据库 web service p2p
推荐指数 1 1 1 1
2013年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33
2010年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
科研热词 web服务 需求agent 网格gis 空间信息服务 移动网格 移动gis 潜在语义分析 本体 服务聚集 服务发现 服务agent 应用程序接口 嵌入式internet 关联行业 关联关键词 中介agent web应用服务 uip协议栈
科研热词 规划图 环境本体 web服务 逆向搜索 语义web服务 语义 自主web服务环境 组合模式 组合服务需求 竞争关系 社会网络 社交化 正向搜索 林权 本体 服务组合模式 服务发现 服务协同 服务匹配 广义随机petri网 向量空间 可达树 可达性分析 协作关系 信息采集 wordnet web服务自动组合 web服务组合 web服务器 qos petri网 pda lucene
语义层次网络在文书档案开放审核中的应用
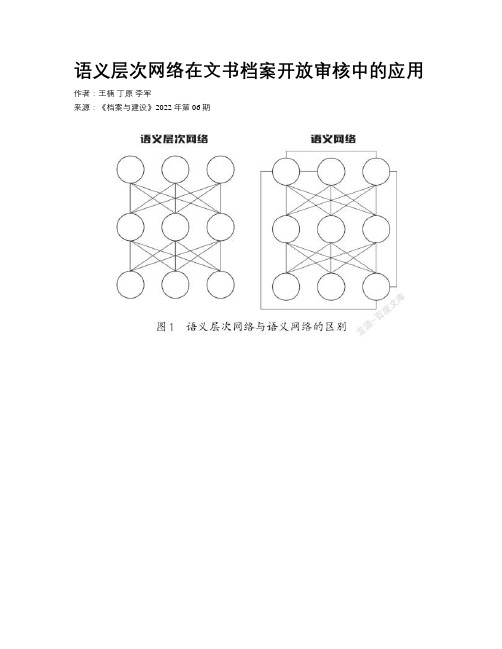
语义层次网络在文书档案开放审核中的应用作者:王楠丁原李军来源:《档案与建设》2022年第06期摘要:贯彻新《档案法》,加大档案开放力度,是《“十四五”全国档案事业发展规划》的主要任务之一。
文章采用语义工程技术,在构建语义层次网络的基础上,开发了档案智能开放审核系统。
选取江苏省档案馆4个全宗的11万余件档案,分别利用关键词过滤法和基于语义层次网络的语义分析法进行检测。
检测结果显示,基于语义层次网络的语义分析法较之关键词法,在精确率方面有显著提升,说明语义层次网络可以突破传统关键词技术只能匹配文书档案字面词义的局限,有效降低关键词技术带来的语义失真,从而减少开放审核中的误判、漏判和对不准的问题。
关键词:语义层次网络;档案开放审核;文书档案《“十四五”全国档案事业发展规划》明确将“加快推进档案开放”纳入“十四五”期间档案事业发展的主要任务,并进一步提出“新一代信息技术在档案工作中的应用更为广泛,信息化与档案事业各项工作深度融合,档案管理数字化、智能化水平得到提升,档案工作基本实现数字转型”的发展方向。
[1]2021年1月起正式施行的新《档案法》针对加大档案开放力度做了重要修订。
[2]采用智能化辅助手段提升档案开放审核工作效率,已是大势所趋。
一、研究背景1. 业内对档案开放审核的相关实践近年来,各地纷纷尝试利用信息化手段提升档案开放审核工作效率,如:青岛市档案馆编制敏感词库,通过软件对档案目录中的敏感词进行扫描;福建省档案馆利用类别特征词进行开放审核;上海市浦东新区档案馆借助人工智能技术对关键词进行审核;宁波市档案馆开发的馆藏资源管理系统可进行敏感词辅助鉴定提示。
[3]利用关键词方式辅助档案开放审核具有投入成本低、门槛低的优势,已成为当前业内主流。
2. 关键词技术存在的问题及解决之道利用关键词方式辅助档案开放审核,其有效程度严重依赖档案题名或全文中是否存在可供判断的关键词。
此方法的局限性在于关键词的词义必须和鉴定条件的语义完全对应。
多级分布式语义Web服务自动组合

W
图 1 MUDI CS框 架
S WU群 由若干 S WU组成 , A A 每一个 S WU A 是一 个带 有 U D 注 册 中心 的 A et其 部 署 在 D I g n, P P环境 中, 2 每个 S WU 仅仅 支持一 个特殊 的领 A
v e, i ) 如图 1 c 所示 , DIS框架分为两部分 : A MU C H
扩展 oWLS 立 we 服务本体 ( -4 A 建 b ) S s wu() — r A WL (wLSf WU) 并用其来描述 S WU 的功能 , oS , A 然后将 S WU A 的功能描述 注册 到 H A作为 H TN规划 的资源。 关键 词 : 语义 we b服务 ; 规划 ; AI 自动组合 中图分类号 : P 9 T 33 文献标识码 : A
务 自动组 合框 架 MU C ( tee Di r ue uo t o oio smat e ev  ̄) DIS MUll l s b t a t i C mps i e ni w bS ri 。在系统接收 到一 个 iv t i d ma c t n. c c
服务请求后 , 中心 A et A 首先用 F N规 划器 完成 第一阶段的规划 , 复杂问题划分成一组与领域 紧密相关 的 gn( ) H I T 将 子任 务 , 然后将这些子任务发送给相应 的带有 U D 注册 中心 的子 A etS WU) DI gn(A 进行 第二 阶段 规划 。本 文通过
Ma .0 6 v2 0
文章编号 :6 319 (0 6 0 —0 30 17 —5 X 2 0 )30 8 —3
多级 分 布 式 语 义 W e 务 自动 组 合 b服
谢春 芝
( 西华大学数学 与计算 机学 院, 四川 成都 6 0 3 ) 10 9
人工智能经典考试试题及答案20

一、选择题(每题1分,共15分)1、AI的英文缩写是A)AutomaticIntelligence B)ArtificalIntelligenceC)AutomaticeInformation D)ArtificalInformation2、反演回结〔消解〕证实定理时,假设当前回结式是〔〕时,那么定理得证。
A)永真式B)包孕式〔subsumed〕C)空子句3、从事实动身,通过规那么库求得结论的产生式系统的推理方式是A)正向推理B)反向推理C)双向推理4、语义网络表达知识时,有向弧AKO链、ISA链是用来表达节点知识的〔〕。
A)无悖性B)可扩充性C)接着性5、(A→B)∧A=>B是A)附加律B)拒收律C)假言推理D)US6、命题是能够判定真假的A)祈使句B)疑咨询句C)感慨句D)陈述句7、仅个体变元被量化的谓词称为A)一阶谓词B)原子公式C)二阶谓词D)全称量词8、MGU是A)最一般合一B)最一般替换C)最一般谓词D)基替换9、1997年5月,著名的“人机大战〞,最终计算机以3.5比2.5的总比分将世界国际象棋棋王卡斯帕罗夫击败,这台计算机被称为〔〕A〕深蓝B〕IBM C〕深思D〕蓝天10、以下不在人工智能系统的知识包含的4个要素中A)事实B)规那么C)操纵和元知识D)关系11、谓词逻辑下,子句,C1=L∨C1‘,C2=¬L∨C2‘,假设σ是互补文字的〔最一般〕合一置换,那么其回结式C=〔〕A)C1’σ∨C2’σB)C1’∨C2’C)C1’σ∧C2’σD)C1’∧C2’12、或图通常称为A〕框架网络B)语义图C)博亦图D)状态图13、不属于人工智能的学派是A)符号主义B)时机主义C)行为主义D)连接主义。
14、人工智能的含义最早由一位科学家于1950年提出,同时同时提出一个机器智能的测试模型,请咨询那个科学家是15.要想让机器具有智能,必须让机器具有知识。
因此,在人工智能中有一个研究领域,要紧研究计算机如何自动猎取知识和技能,实现自我完善,这门研究分支学科喊〔〕。
一种基于OWL-S的语义Web服务自动组合方法

当前 , b服务 已经得 到了非 常广 泛的应 用。所谓 We We b 服务 , 是指一种 由 U I R 标志 的软件系统 , 它采用 X ML对应用接
口的定 义 和封 装 进 行 描 述 , 以被 其 他 的 We 可 b服 务 发 现 并 与
成服务 问题转换 为 H r 子句 的逻辑推理 问题 ; o n 然后 , 基于 P t e i f 网为该 H r 子句 集建模 , o n 基于 T 不变量技 术判定 是否存在 满 。
足用 户输 输 出请求 的合成 服务 ; 最后给 出了两种算法来 获
Au o tc s ma tc W e evc o o i o a e n OW L- tmai e n i b s r ie c mp st n b s d o i S
XU —hi TANG ・ a De z , Yihu
( oeeo nom t nSi c E g ̄e n ,Cnrl o t U iri ,C a gh 10 3, hn ) C lg fr ai c ne& n i n g et uh n esy h n sa40 8 C ia l fI o e aS v t
Ab ta t T i p p rp o o e u o t e n i e ev c o o i o a e n OWL S T e me h d to u l d a . s r c : hs a e rp s d a a tma i s ma t W b s r ie c mp s in b s d o c c t — . h t o o k f l a v n t g fte u p ro tlg e fOW L S t b an t e ao c s r ie a e n t e s r ie r q e ta d te mi i m ai a to a e o p e n oo is o h . o o t i h tmi e vc sb s d o e vc e u s n h n mu st f cin h s t r s od a d t e u h m n o t AGs h e h l n h n p tte it wo D .An e g n r td t ec n i ae i ms t r m h wo D d t n. e e a e a d d t t e o t e t AGsf m ih wo l h h e f o whc ud r g tt e We e i ec mp st n f al .C mp rn t e e i ig meh d , h to rp s d h d c n ie e es ma — e h b s r c o o i o n l v i i y o a gwi t x s n t o s t e meh d p o o e a o sd r d t e n i h h t h t t h e e vc s tg te i h f ce c it e c mp st n a d aS e l e h u o t e n i e e vc i 0 e W b s r ie o eh r w t t e ef in y o h o o i o n O r ai d t e a tmai s ma t W b s r ie c t h i i l z c c
一种基于认知模型检测的Web服务组合验证方法

Ab t a t I e e t y a s h o ma e iia i n o e e v c o p st n s g a u ly b - s r c n r c n e r ,t e f r 1v rfc t f W b s r i e c m o ii s i r d a l e o o c m i g a h tr s a c r a o n o e e r h a e .As a ma n t e m e h i u o o ma e i c to i s r a t c n q e f rf r lv rf a i n,mo e h c i g i i d l ek n c s a l o n to l v r o e t e s o to n ft a ii n l o t r e tt c n q e h tt e a n t b e t o n y o e c m h h r c mi g o r d to a fwa e t s e h i u s t a h y c n o s g n r t h o e e a e t e c mp e e s t o e t c s s u l o a t m a ie h e i c t n p o e s n t i a lt e ft s a e ,b t a s u o tz s t e v rf a i r c s .I h s p — i o p r h u h r r p s n mp e e ta p s e i mo e h c i g a p o c o h e i c to e ,t e a t o s p o o e a d i lm n n e it m c d l e k n p r a h f r t e v rf a i n c i o e e v c o o ii n y mo e i g t e a li g n y t ms fW b s r ie c mp sto sb d l h m s mu t a e ts s e .Afe n l z n h PEL n — t ra a y i g t e B
数据与知识工程

万维网(WWW)
根据所处理的数据对DM分类
关系数据库
事务数据库
面向对象数据库
对象关系数据库
数据仓库
空间数据库
时态数据库
流数据
异构数据库
历史数据库
文本数据库
多媒体数据库
WWW
……
根据挖掘的知识类型对DM分类
特征分析
区分
关联分析
分类
聚类
预测
离群点分析
演变分析
多种方法的集成
……
根据采用的技术对DM分类
–inconsistencies in terminology, outdated information.
Viewing information
–Impossible to define views on Web knowledge
4.语义web技术
Explicit Metadata
Ontologies
用户交互方面
数据挖掘查询语言
数据挖掘结果的表示和显示
多个抽象层的交互知识挖掘
应用和社会因素方面
特定域的数据挖掘&不可视的数据挖掘
数据安全,隐私保护
……
12.KDD发现目标
概念描述
关联分析
分类
聚类
离群点分析
趋势和演变分析
KDD中使用的方法
决策树方法
基于证据理论的方法
神经网络方法
遗传算法
基于粗糙集的方法
2.语义Web主要解决两个问题:
1)如何对Web资源进行表示,从而便于让agent进行处理(获取、存储、推理、查询等)。
2)如何重用Web页面、多媒体信息、数据库等遗留资源(legacy resource),以便实现从现有Web到语义Web的过渡。
echop方案

Echop方案概述Echop方案是一种基于人工智能和自然语言处理技术的自动问答系统。
该系统通过对用户提出的问题进行语义分析和知识图谱匹配,从而快速、准确地提供相关答案。
背景随着互联网的发展,人们对信息的获取需求也日益增长。
然而,大量的信息使得人们面临了信息过载的问题。
在这种情况下,开发一种高效的自动问答系统成为刻不容缓的任务。
Echop方案应运而生,旨在为用户提供高质量的问答服务,帮助他们快速解决问题。
原理Echop方案的核心原理是将用户输入的问题转化为计算机可理解的形式,并在知识图谱中进行匹配,寻找与问题相关的信息。
具体步骤如下:1.语义分析首先,对用户输入的问题进行语义分析,识别问题的关键词、实体以及问句类型。
通过自然语言处理技术,将问题转化为向量表示,以便与知识图谱中的内容进行比对。
2.知识抽取在知识图谱中,我们预先存储了大量结构化的知识和答案。
通过自动抽取和整理,将这些知识转化为知识图谱的形式,提供给系统使用。
3.知识匹配根据用户提出的问题,系统将问题的语义信息与知识图谱中的知识进行匹配。
通过计算问题表示向量与知识表示向量之间的相似度得分,找到与问题最相似的知识。
4.答案生成在确定了与问题最相关的知识之后,系统将从知识图谱中抽取相关信息,并生成最终的答案。
答案可以是一个简短的文字描述,也可以是一段文字、一张表格等。
5.答案展示最后,系统将生成的答案以易读的形式展示给用户。
用户可以通过查看答案,快速获取到所需的信息。
特点Echop方案具有以下几个特点:1.高效性由于采用了基于知识图谱的方式,Echop能够快速从大量的存储知识中找到与问题最相符的信息,并生成答案。
2.准确性通过语义分析和知识匹配,Echop能够准确理解用户问题的意图,提供与用户期望相符的答案。
3.可扩展性Echop的知识图谱可以根据需要进行更新和扩展。
用户可以根据自己的需求,将更多的知识和答案添加到系统中,从而提高系统的覆盖范围和准确性。
基于贪婪策略的局部优化服务组合方法

基于贪婪策略的局部优化服务组合方法黎辛晓;叶恒舟【摘要】Web service composition is the key technology to achieve the service-oriented computing. However, the research on composition approach with high efficiency is still a critical challenge for semantic, large scale web services. Unlike traditional graph based methods, an effective approach is proposed for automatic service composition which does not depend on service dependency graph and can support for inheritance and composition relationships between entities. Firstly, it marks out necessary and satisfied services, and then selects parts of them to generate a composition path directly. It can reduce the time and space overhead, avoid circulation and repetition search. To achieve the goal of local optimization, greedy strategy is used to mark satisfied services. Experimental results show that this approach has a good level of time complexity and can be applied to large-scale semantic service composition.%提出了一种不依赖于服务关系图、可支持实体之间继承与组合关系、高效的自动服务组合方法.该方法首先标记出必要的可满足服务,然后从中挑选出部分服务直接生成组合路径,从而减少时空开销,避免循环搜索与重复搜索.为达到局部优化的目标,标记可满足服务时运用了贪婪策略.仿真实验表明,该方法具有良好的时间复杂度,能够适用于大规模的语义服务组合.【期刊名称】《桂林理工大学学报》【年(卷),期】2012(032)002【总页数】5页(P271-275)【关键词】Web服务;服务组合;局部优化;贪婪算法【作者】黎辛晓;叶恒舟【作者单位】桂林理工大学信息科学与工程学院,广西桂林541004;桂林理工大学信息科学与工程学院,广西桂林541004【正文语种】中文【中图分类】TP311Web服务是基于现有互联网协议与公开标准的自包含、自描述、模块化的应用,可以提供一个灵活解决应用集成问题的方案[1]。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Absr c : Co a e o te ta to a y fc mp sn e e vc s s ma tc ba e y fc m p sng W e e i e ta t mp r d t h rdi n lwa s o o o i g W b s r ie , e n i— s d wa so o o i b s r c s i v at uomaial r r fe tv nd u o tc An p r a h ba e n o lt ba kwa d te t o p s s ma tc tc ly a e mo e ef cie a a t mai . a p o c s d o c mp ee c r r e o c m o e e ni W e b
提 出一 种 基 于 完备 回 溯 树 的 语 义 We 务 自动 组 合 方 法 ( B _ S C , 方 法 为 We b服 C T A WS ) 该 b服 务 引入 语 义 以 实现 对 象 间 的语 义转 化 并 将 搜 索空 间受 限 于 完 备 回 溯 树 中 , 加 快 We 服 务 组 合 效 率 的 同时提 高 了 We 务 组 合 的 成 功 率 。 在 b b服
K y w r s e ni We ev e ;sri s o oio ;C m lt B c w d T e C T e o d :smat b sri s e c mp s i c c v ec tn o p e ak a r e r e( B )
0 引言
传统 的 We b服务组合 方法有 : 于工 作流 的组合… 、 基 基 于 人 工 智 能 规 划 的 自动 服 务 组 合 、 于 中 问 件 的 服 务 组 基 合 和基于图搜索 的 自动服 务组合 。这些 方法存 在 的问 题 ” 有 :) 1 自动化程度 不高且效 率较 低 ; ) 2 方法 的复杂 度 较高, 不易实现 ;) 3 分析手段较为 固化 , 能适应需 求 的动 态 不 变 化 ;) 4 服务 关 系 图 的构 建 时 间开 销 很 大 。 为了解决 以上 问题 , 文献 [ ] 出一 种新 的基于 语义 的 5提 We b服务 自动组 合方法 , 将语 义引入 We b服务 , 在服务发 现 中应用本体推理 , 以实现服务 的 自动发现 、 合且具有较 高的 组 效率。但在 we b服务数 量大且关 系复 杂时 , 构建和遍历 服务 本体关 系图将耗费大量 时间 , 而影 响该 类方法 的实 际可用 从 性 。在传统 的 We b服务 组合方法 中 , 率较高 的是文献 [ ] 效 4 提出的基 于 回溯 树 的 we 务 自动组 合方法 , 该 方法 对 b服 但 We 务 的 定 义 缺 乏语 义 , 务 组 合 的 成 功 率 不 高 。 b服 服 本文提 出一种基 于完备 回溯树 的语 义 We b服务 自动 组 合 方 法 ( B — S C) 该 方 法 将 基 于 图 搜 索 与 基 于 语 义 C T A WS 。 We b的 自动 服务 组合 方 法 融 为一 体 , 用 本 体 来 标 注 We 利 b服 务的语义信 息, 过计算本体概念 间的语义相似度 , 通 为用户请 求 的每一个输出对象及时建立完备 回溯树 , 并在 回溯树的构建 过程 中选取最佳有效生成路径 , 最后将路径合成为可运行的流 程服 务 。该 方 法 为 We 务 引 入 语 义 , 将 搜 索 空 间 受 限 于 b服 并
关 键 词 : 义 We 服 务 ; 务 组 合 ; 语 b 服 完备 回 溯树
中图 分 类 号 : P 1 T 31
文 献 标 志 码 : A来自Aut m a i e a tc W e e v c s c m po ii n o tc s m n i b s r ie o s to b sd O o peeb c a e n c m l t a kwa d r e r te
维普资讯
第2 8卷 第 6期 20 0 8年 6 月
文 章 编 号 :0 1 9 8 (0 8 0 10 — 0 1 20 ) 6—12 0 4 7— 4
计 算机 应 用
Co mpu e p ia in trAp lc t s o
Vo. 8 No 6 12 .
LIRu - i g ZHOU u-o g in n , Zh r n
( oeefC m ue a dI om t nSi c,Suh e nvrt,C ogig4 0 1,C i ) C lg o p t n fr ai c ne otws U i sy hn qn 0 7 5 hn l o r n o e t ei a
sri s uo a cl a pooe.I nt nyaddtesm n c oWe e i s u a ohdas a e er pc e c tm t ayw s rpsd t o ol d e e at st v ea i l h i b sr c ,b tl a m l rsa h sae v e s l c
Jn 0 8 u e2 0
基 于 完 备 回溯 树 的 语 义 We b服 务 自动 组 合
李瑞 宁 , 荣 周竹
( 南大 学 计 算 机 与信 息科 学 学 院 , 庆 40 1 ) 西 重 07 5
(hur SU e u c) zoz@ W .d .n
摘
要 : 于语 义的 we 服 务 自动组合 方法具有较 高的效 率及 自动化程度 , 基 b 能更好地解决复杂的服务组 合 问题。