编译原理第第7和第8章作业
编译原理 第7章习题解答

第七章习题解答7.1 给定文法:S→(A)A→ABBA→BB→bB→c①构造它的基本LR(0)项目集;②构造它的LR(0)项目集规范族;③构造识别该文法活前缀的DFA;④该文法是SLR文法吗?若是,构造它的SLR分析表。
7.2 给定文法:E→EE+E→EE*E→a①构造它的LR(0)项目集规范族;②它是SLR(1)文法吗?若是,构造它的SLR(1)分析表;③它是LR(1)文法吗?若是,构造它的LR(1)分析表;④它是LALR(1)文法吗?若是,构造它的LALR分析表。
7.3 给出一个非LR(0)文法。
7.4 给出一个SLR(1)文法,但它不是LR(0)文法,构造它的SLR分析表。
7.5 给出一个LR(1)文法,但它不是LALR(1)文法,构造它的规范LR(1)分析表。
7.6 给定二义性文法:① E→E+E② E→E*E③ E→(E)④ E→id用所述的无二义性规则和(或)另加一些无二义性规则,例如,给算符*、+施加某种结合规则。
①构造它的LR(0)项目集规范族及识别活前缀的DFA;②构造它的LR分析表。
习题参考答案7.1 解:文法的基本LR(0)项目集为S→.(A) S→(.A) S→(A.) S→(A).A→.ABB A→A.BB A→AB.B A→ABB.A→.B A→B. B→.b B→b.B→.c B→c.构造该文法的识别活前缀的DFSA如下图所示:I文法的识别活前缀的DFSA该文法的LR(0)项目集规范族={I0,I1,I2,I3,I4,I5,I6,I7,I8}因为在构造出来的识别活前缀的DFA中,每一个状态对应的项目集都不含有移进-归约、归约-归约冲突,所以该文法是LR(0)文法,当然也是SLR文法。
因为 FOLLOW(S)={#}FOLLOW(A)=FIRST{)}∪FIRST(BB)={),b,c}FOLLOW(B)=FIRST(B)∪FOLLOW(A)={b,c,)}其对应的SLR(1)分析表如下表所示。
编译原理第8章作业及习题参考答案
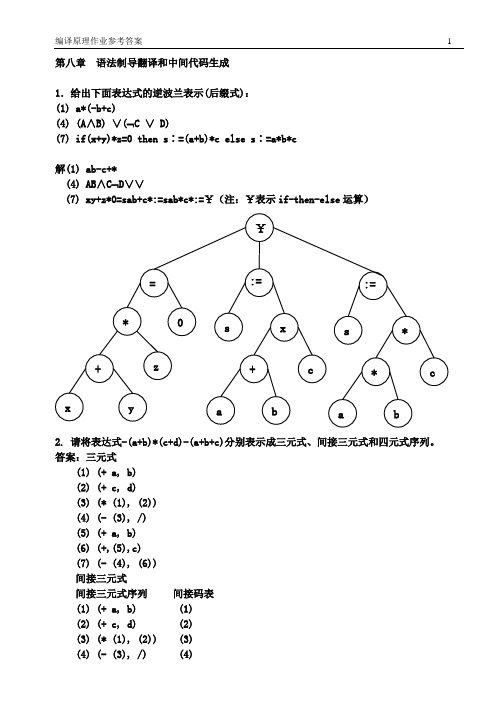
第八章 语法制导翻译和中间代码生成1.给出下面表达式的逆波兰表示(后缀式): (1) a*(-b+c)(4) (A ∧B) ∨(⌝C ∨ D)(7) if(x+y)*z=0 then s ∶=(a+b)*c else s ∶=a*b*c解(1) ab-c+*(4) AB ∧C ⌝D ∨∨(7) xy+z*0=sab+c*:=sab*c*:=¥(注:¥表示if-then-else 运算)2. 请将表达式-(a+b)*(c+d)-(a+b+c)分别表示成三元式、间接三元式和四元式序列。
答案:三元式(1) (+ a, b) (2) (+ c, d)(3) (* (1), (2)) (4) (- (3), /) (5) (+ a, b)(6) (+,(5),c) (7) (- (4), (6)) 间接三元式间接三元式序列 间接码表 (1) (+ a, b) (1) (2) (+ c, d) (2) (3) (* (1), (2)) (3) (4) (- (3), /) (4)¥= :=*:=+ xyzs +cxa bs* c*a b(5) (- (4), (1)) (1)(6) (- (4), (5)) (5)(6)四元式(1) (+, a, b, t1) (2) (+, c, d, t2) (3) (*, t1, t2, t3) (4) (-, t3, /, t4)(5) (+, a, b, t5) (6) (+, t5, c, t6) (6) (-, t4, t6, t7)3. 采用语法制导翻译思想,表达式E 的"值"的描述如下: 产生式 语义动作(0) S ′→E {print E.VAL}(1) E →E1+E2 {E.VAL ∶=E1.VAL+E2.VAL} (2) E →E1*E2 {E.VAL ∶=E1.VAL*E2.VAL} (3) E →(E1) {E.VAL ∶=E1.VAL} (4) E →n {E.VAL ∶=n.LEXVAL}如果采用LR 分析法,给出表达式(5 * 4 + 8) * 2的语法树并在各结点注明语义值VAL 。
编译原理一些习题答案

第2章形式语言基础2.2 设有文法G[N]: N -> D | NDD -> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9(1)G[N]定义的语言是什么?(2)给出句子0123和268的最左推导和最右推导。
解答:(1)L(G[N])={(0|1|2|3|4|5|6|7|8|9)+} 或L(G[N])={α| α为可带前导0的正整数}(2)0123的最左推导:N ⇒ ND ⇒ NDD ⇒ NDDD ⇒ DDDD ⇒ 0DDD ⇒ 01DD ⇒ 012D ⇒ 0123 0123的最右推导:N ⇒ ND ⇒ N3 ⇒ ND3 ⇒ N23 ⇒ ND23 ⇒ N123 ⇒ D123 ⇒ 0123268的最左推导:N ⇒ ND ⇒ NDD ⇒ DDD ⇒ 2DDD ⇒ 26D ⇒ 268268的最右推导:N ⇒ ND ⇒ N8 ⇒ ND8 ⇒ N68 ⇒ D68 ⇒ 2682.4 写一个文法,使其语言是奇数的集合,且每个奇数不以0开头。
解答:首先分析题意,本题是希望构造一个文法,由它产生的句子是奇数,并且不以0开头,也就是说它的每个句子都是以1、3、5、7、9中的某个数结尾。
如果数字只有一位,则1、3、5、7、9就满足要求,如果有多位,则要求第1位不能是0,而中间有多少位,每位是什么数字(必须是数字)则没什么要求,因此,我们可以把这个文法分3部分来完成。
分别用3个非终结符来产生句子的第1位、中间部分和最后一位。
引入几个非终结符,其中,一个用作产生句子的开头,可以是1-9之间的数,不包括0,一个用来产生句子的结尾,为奇数,另一个则用来产生以非0整数开头后面跟任意多个数字的数字串,进行分解之后,这个文法就很好写了。
N -> 1 | 3 | 5 | 7 | 9 | BNB -> 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | B02.7 下面文法生成的语言是什么?G1:S->ABA->aA| εB->bc|bBc G2:S->aA|a A->aS解答:B ⇒ bcB ⇒ bBc⇒ bbccB ⇒ bBc⇒ bbBcc ⇒ bbbccc……A ⇒εA ⇒ aA ⇒ aA ⇒ aA ⇒ aaA ⇒ aa……∴S ⇒ AB ⇒ a m b n c n , 其中m≥0,n≥1即L(G1)={ a m b n c n | m≥0,n≥1} S ⇒ aS ⇒ aA ⇒ aaS ⇒ aaaS ⇒ aA ⇒ aaS ⇒ aaaA ⇒aaaaS ⇒ aaaaa ……∴S ⇒ a2n+1 , 其中n≥0即L(G2)={ a2n+1 | n≥0}2.11 已知文法G[S]: S->(AS)|(b)A->(SaA)|(a)请找出符号串(a)和(A((SaA)(b)))的短语、简单短语和句柄。
编译原理作业集-第七章

第七章语义分析和中间代码产生本章要点1. 中间语言,各种常见中间语言形式;2. 说明语句、赋值语句、布尔表达式、控制语句等的翻译;3. 过程调用的处理;4. 类型检查;本章目标掌握和理解中间语言,各种常见中间语言形式;各种语句到中间语言的翻译;以及类型检查等内容。
本章重点1.中间代码的几种形式,它们之间的相互转换:四元式、三元式、逆波兰表示;3.赋值语句、算术表达式、布尔表达式的翻译及其中间代码格式;4.各种控制流语句的翻译及其中间代码格式;5.过程调用的中间代码格式;6.类型检查;本章难点1. 各种语句的翻译;2. 类型系统和类型检查;作业题一、单项选择题:1. 布尔表达式计算时可以采用某种优化措施,比如A and B用if-then-else可解释为_______。
a. if A then true else B;b. if A then B else false;c. if A then false else true;d. if A then true else false;2. 为了便于优化处理,三地址代码可以表示成________。
a. 三元式b. 四元式c. 后缀式d. 间接三元式3. 使用三元式是为了________:a. 便于代码优化处理b. 避免把临时变量填入符号表c. 节省存储代码的空间d. 提高访问代码的速度4. 表达式-a+b*(-c+d)的逆波兰式是________。
a. ab+-cd+-*;b. a-b+c-d+*;c. a-b+c-d+*;d. a-bc-d+*+;5. 赋值语句x:=-(a+b)/(c-d)-(a+b*c)的逆波兰式表示是_______。
a. xab+cd-/-bc*a+-:=;a. xab+/cd-bc*a+--:=;a. xab+-cd-/abc*+-:=;a. xab+cd-/abc*+--:=;6. 在一棵语法树中结点的继承属性和综合属性之间的相互依赖关系可以由________来描述。
编译原理清华大学出版社第7章习题重点题解答

1S → a | ∧ | ( T )T → T , S | S解:(1) 增加辅助产生式 S’→#S#求 FIRSTVT集FIRSTVT(S’)= {#}FIRSTVT(S)= {a ∧ ( }FIRSTVT (T) = {,} ∪ FIRSTVT( S ) = { , a ∧ ( }求 LASTVT集LASTVT(S’)= { # }LASTVT(S)= { a ∧ )}LASTVT (T) = { , a ∧ )}(2)算符优先关系表a ∧( ) , #a ·> ·> ·> ∧·> ·> ·> ( <·<·<·=·<·) ·> ·> ·>, <·<·<··> ·># <·<·<·=·因为任意两终结符之间至多只有一种优先关系成立,所以是算符优先文法(3)a ∧( ) ,F 1 1 1 11 1g 1 1 1 11 1f 2 2 1 3 2g 2 2 2 1 2f 3 3 1 3 3g 4 4 4 1 2f 3 3 1 3 3g 4 4 4 1 2(4)栈优先关系当前符号剩余输入串移进或规约#<·( a,a)#移进#( <· a,a)# 移进# (a ·> , a)# #(T <·, a)# #(T,<· a )# #(T,a ·> ) # #(T,T ·> ) # #(T =·) # #(T) ·> ##T =·#4.扩展后的文法S’→#S# S→S;G S→G G→G(T)G→H H→a H→(S)T→T+S T→S(1)FIRSTVT(S)={;}∪FIRSTVT(G) = {; , a , ( } FIRSTVT(G)={ ( }∪FIRSTVT(H) = {a , ( } FIRSTCT(H)={a , ( }FIRSTVT(T) = {+} ∪FIRSTVT(S) = {+ , ; , a , ( }LASTVT(S) = {;} ∪LASTVT(G) = { ; , a , )}LASTVT(G) = { )} ∪LASTVT(H) = { a , )}LASTVT(H) = {a, )}LASTVT(T) = {+ } ∪LASTVT(S) = {+ , ; , a , ) }构造算符优先关系表; ( ) a + # ;·> <··> <··> ·> ( <·<·=·<·<·) ·> ·> ·> ·> ·> a ·> ·> ·> ·> ·> + <·<··> <··># <·<·<·=·因为任意两终结符之间至多只有一种优先关系成立,所以是算符优先文法(2)句型a(T+S);H;(S)的短语有:a(T+S);H;(S) a(T+S);H a(T+S) a T+S (S) H直接短语有: a T+S H (S)句柄: a素短语:a T+S (S)最左素短语:a(3)分析a;(a+a)栈优先关系当前符号剩余输入串移进或规约##a #T #T;#T;(<··><·<·<·a;;(a;(a+a)#(a+a)#(a+a)#a+a)#+a)#移进规约移进移进移进#T;(T #T;(T +#T;(T +a#T;(T +T#T;(T #T;(T)#T;T #T <·<··>·>=··>·>=·+a)))###a)#)####移进移进规约规约移进规约规约接受分析a;(a+a)栈优先关系当前符号剩余输入串移进或规约##(#(a #(T #(T+<·<··><·<·(a++aa+a)#+a)#a)#移进移进规约移进移进#(T+T #(T#(T)#T ·>=··>=·))##)####规约移进规约接受(4)不能用最右推导推导出上面的两个句子。
编译原理(第2版)课后习题答案详解

第1 章引论第1 题解释下列术语:(1)编译程序(2)源程序(3)目标程序(4)编译程序的前端(5)后端(6)遍答案:(1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2)源程序:源语言编写的程序称为源程序。
(3)目标程序:目标语言书写的程序称为目标程序。
(4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第2 题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含8 个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
表格管理程序:负责建立、填写和查找等一系列表格工作。
表格的作用是记录源程序的各类信息和编译各阶段的进展情况,编译的每个阶段所需信息多数都从表格中读取,产生的中间结果都记录在相应的表格中。
《编译原理》习题解答:

《编译原理》习题解答:第一次作业:P14 2、何谓源程序、目标程序、翻译程序、汇编程序、编译程序和解释程序?它们之间可能有何种关系?答:被翻译的程序称为源程序;翻译出来的程序称为目标程序或目标代码;将汇编语言和高级语言编写的程序翻译成等价的机器语言,实现此功能的程序称为翻译程序;把汇编语言写的源程序翻译成机器语言的目标程序称为汇编程序;解释程序不是直接将高级语言的源程序翻译成目标程序后再执行,而是一个个语句读入源程序,即边解释边执行;编译程序是将高级语言写的源程序翻译成目标语言的程序。
关系:汇编程序、解释程序和编译程序都是翻译程序,具体见P4 图 1.3。
P14 3、编译程序是由哪些部分组成?试述各部分的功能?答:编译程序主要由8个部分组成:(1)词法分析程序;(2)语法分析程序;(3)语义分析程序;(4)中间代码生成;(5)代码优化程序;(6)目标代码生成程序;(7)错误检查和处理程序;(8)信息表管理程序。
具体功能见P7-9。
P14 4、语法分析和语义分析有什么不同?试举例说明。
答:语法分析是将单词流分析如何组成句子而句子又如何组成程序,看句子乃至程序是否符合语法规则,例如:对变量x:= y 符合语法规则就通过。
语义分析是对语句意义进行检查,如赋值语句中x与y类型要一致,否则语法分析正确,语义分析则错误。
P15 5、编译程序分遍由哪些因素决定?答:计算机存储容量大小;编译程序功能强弱;源语言繁简;目标程序优化程度;设计和实现编译程序时使用工具的先进程度以及参加人员多少和素质等等。
补充:1、为什么要对单词进行内部编码?其原则是什么?对标识符是如何进行内部编码的?答:内部编码从“源字符串”中识别单词并确定单词的类型和值;原则:长度统一,即刻画了单词本身,也刻画了它所具有的属性,以供其它部分分析使用。
对于标识符编码,先判断出该单词是标识符,然后在类别编码中写入相关信息,以表示为标识符,再根据具体标识符的含义编码该单词的值。
编译原理第七章例题

编译原理第七章例题1.写出下列表达式的三地址形式的中间表示。
(1)5+6 ? (a + b);(2)?A∨( B ∧ (C ∨ D));(3)for j:=1 to 10 do a[j + j]:=0;(4)if x > y then x:=10 else x:= x + y;答:⑴100: t1:=a+b101: t2:=6*t1102: t3:=5+t2⑵100: if A goto 102101: goto T102: if B goto 104103: goto F104: if C goto T105: goto 106106: if D goto T107: goto F⑶100: j:=1101: if j>10 goto NEXT102: i:=j+j103: a[i]:=0104: goto 101⑷100: if x>y goto 102101: goto 104102: x:=10103: goto 105104: x:=x+y105:2.将语句if A V B>0 then while C>0 do C:=C+D翻译成四元式。
答:100 (jnz,A,-,104)101 (j,-,-,102)102 (j>,B,0,104)103 (j,-,-,109)104 (j>,C,0,106)105 (j,-,-,109)106 (+,C,D,T1)107 (:=,T1,-,C)108 (j,-,-,104)1093.试将下述程序段翻译成三地址形式的中间代码表示。
while ( a+b<="" a="b" bdsfid="102" or="" p=""> while ( a<5 AND b<10 ){ a=a+1;b=b+1;}答:三地址代码如下:100: t:=a+b101: if t<="" bdsfid="110" goto="" p="">102: goto 103103: if a=b goto 105104: goto 112105: if a<5 goto 107106: goto 100107: if b<10 goto 109108: goto 100109: a:=a+1110: b:=b+1111: goto 105112:4.While a>0 ∨b<0doBeginX:=X+1;if a>0 then a:=a-1else b:=b+1End;翻译成四元式序列。
编译原理第7章答案
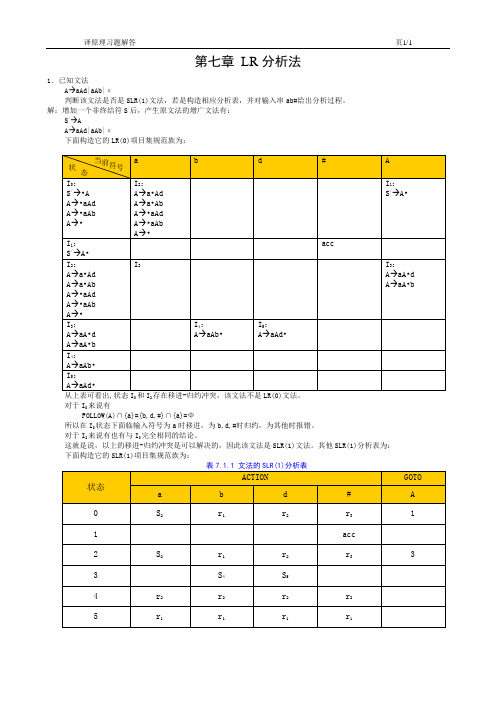
第七章LR分析法1.已知文法A→aAd|aAb|ε判断该文法是否是SLR(1)文法,若是构造相应分析表,并对输入串ab#给出分析过程。
解:增加一个非终结符S/后,产生原文法的增广文法有:S/→AA→aAd|aAb|ε下面构造它的LR(0)项目集规范族为:02对于I0来说有FOLLOW(A)∩{a}={b,d,#}∩{a}=Φ所以在I0状态下面临输入符号为a时移进,为b,d,#时归约,为其他时报错。
对于I2来说有也有与I0完全相同的结论。
这就是说,以上的移进-归约冲突是可以解决的,因此该文法是SLR(1)文法。
其他SLR(1)分析表为:下面构造它的SLR(1)项目集规范族为:15S→a|^|(T)T→T,S|S(1)构造它的LR(0),LALR(1),LR(1)分析表。
(2)给出对输入符号串(a#和(a,a#的分析过程。
(3)说明(1)中三种分析表发现错误的时刻和输入串的出错位置有何区别。
解:(1)加入非终结符S/,方法的增广文法为:S/→SS→aS→^S→(T)T→T,ST→S下面构造它的LR(0)项目集规范族为:表7.15.1 文法的LR(0)分析表17.若包含条件语句的语句文法可缩写为:S→iSeS|iS|S;S|a其中:i代表if,e代表else,a代表某一语句。
若规定:(1)else与其左边最近的if结合(2);服从左结合试给出文法中i,e,; 的优先关系,然后构造出无二义性的LR分析表,并对输入串iiaea#给出分析过程。
解:加入S/→S产生式构造出增广文法如下:[0] S/→S[1] S→iSeS[2] S→iS[3] S→S;S[4] S→a由习惯可知,定义文法中i,e,;,a4个算符的优先关系为:a>e>i>;。
并且i与;的结合方向均为自左至右。
由上述状态项目集可见:a.状态I1存在移进-归约冲突,由于FOLLOW(S/)∩{;}={#}∩{;}=Φ,所以面临#号时应acc,面临;号时应移进。
编译原理课后答案——第七章_目标代码生成

第七章 目标代码生成
7.1 对下列四元式序列生成目标代码: T=A-B S=C+D
W=E-F
U=W/T V=U*S 其中,V是基本块出口的活跃变量,R0和R1是可用寄存 器。
第七章 目标代码生成 【解答】 简单代码生成算法依次对四元式进行翻译。
我们以四元式T=a+b为例来说明其翻译过程。 汇编语言的加法指令代码形式为 ADD R, X 其中,ADD为加法指令;R为第一操作数,第一操作数必 须为寄存器类型;X为第二操作数,它可以是寄存器类型,也 可以是内存型的变量。ADD R,X指令的含意是:将第一操作数 R与第二操作数相加后,再将累加结果存放到第一操作数所在 的寄存器中。要完整地翻译出四元式T=a+b,则可能需要下面 三条汇编指令:
第七章 目标代码生成 此外,如果必须使用第一条指令,即第一操作数 不在寄存器而是在内存中,且此时所有可用寄存器都 已分配完毕,这时就要根据寄存器中所有变量的待用 信息(也即引用点)来决定淘汰哪一个寄存器留给当前 的四元式使用。寄存器的淘汰策略如下: (1) 如果某寄存器中的变量已无后续引用点且该 变量是非活跃的,则可直接将该寄存器作为空闲寄存 器使用。 (2) 如果所有寄存器中的变量在基本块内仍有引 用点且都是活跃的,则将引用点最远的变量所占用寄 存器中的值存放到内存与该变量对应的单元中,然后 再将此寄存器分配给当前的指令使用。
第七章 目标代码生成 因此,本题所给四元式序列生成的目标代码如下: MOV R0, A SUB R0, C MOV R1, C ADD R1, D /*R1=S*/ /*R0=T*/
MOV S, R1 的值送内存单元S*/
MOV R1, E SUB R1, F SUB R1, R0 MUL R1, S
编译原理王生原课后习题第七章

编译原理模拟试卷一、选择题(每题1分,共5分)1.在编译过程中,词法分析的主要任务是什么?A.构建语法树B.将源程序分解为单词序列C.语义分析D.代码2.下列哪个不属于编译器的组成部分?A.词法分析器B.语法分析器C.代码器D.数据库管理系统3.在编译器中,中间代码的作用是什么?A.提高编译速度B.方便目标代码C.提高程序的可读性4.下列哪种语言通常被用作编译器的实现语言?A.PythonB.JavaC.C++5.在编译原理中,形式语言的主要作用是什么?A.描述程序设计语言的语法B.描述程序的语义C.描述程序的数据结构D.描述程序的算法二、判断题(每题1分,共5分)1.编译器的主要任务是将源程序转换为目标代码。
(正确/错误)2.语法分析器负责检查源程序中的语法错误。
(正确/错误)3.语义分析是在语法分析之后进行的。
(正确/错误)4.中间代码是一种与机器无关的代码。
(正确/错误)5.代码优化不会影响程序的正确性。
(正确/错误)三、填空题(每题1分,共5分)1.编译器包括____、____、____、____等组成部分。
2.在编译过程中,____负责将源程序分解为单词序列。
3.语法分析器的主要任务是构建____。
4.语义分析器负责检查____。
5.代码器负责____。
四、简答题(每题2分,共10分)1.简述编译器的工作流程。
2.解释什么是词法分析。
3.什么是语法分析?它的主要任务是什么?4.什么是语义分析?它的主要作用是什么?5.简述中间代码的作用。
五、应用题(每题2分,共10分)1.给出一个简单的C语言程序,请描述它通过编译器的过程。
2.什么是编译器的优化?请给出一个例子。
3.解释什么是编译器的错误处理。
4.什么是编译器的调试信息?它的作用是什么?5.请解释编译器的前端和后端。
六、分析题(每题5分,共10分)1.分析并解释编译器中的词法分析、语法分析和语义分析之间的关系。
2.分析并解释编译器中的中间代码和目标代码之间的关系。
编译原理习题答案,1-8章龙书第二版7.8章

第七章
习题7.2.6 :C语言函数f的定义如下:
Int f(int x, *py, **ppz){
**ppz +=1;*py +=2;x +=3; return x+*py+**ppz;
}
变量a是一个指向b的指针;变量b是一个指向c的指针,而c是一个当前值为4的整数变量。
如果我们调用f(c,b,a),返回值是什么?
答:x是传值,而b和c是传地址方式;由函数定义可以得到:b=&c,a=&b, 而**a=**a+1=c+1=5 => c=5; *b=*b+2=c+2=7 =>c=7,**a=7;c=c+3=4+3=7
所以调用f(c,b,a)返回值是7+7+ 7=21
练习7.3.2:假设我们使用显示表来实现下图中的函数。
请给出对fib0(1)的第一次调用即将返回时的显示表。
同时指明那时在栈中的各种活动记录中保存的显示表条目
答:结果如下
第八章
练习8.2.1:假设所有的变量都存放在内存中,为下面的三地址语句生成代码:
5)下面的两个语句序列
X=b*c
Y=a+X
答:生成的代码如下
练习8.5.1:为下面的基本块构造构造DAG
d=b*c
e=a+b
b=b*c
a=e-d
答:DAG如下
练习8.6.1:为下面的每个C语言赋值语句生成三地址代码1)x=a+b*c
答:生成的三地址代码如下。
编译原理第八章习题答案

第八章习题答案2、请将算术表达式翻-(a+b)*(c+d)+(a+b+c)翻译为:(1)四元式(2)三元式(3)间接三元式答:(2)三元式(3)间接三元式间接码表:三元式:4、修改图8.5中计算声明语句中的名字的类型及相对对峙的翻译方案,以允许在一个声明中可以同时声明多个变量名。
答:翻译方案如下:P->{ offset:= 0 } DD-> D;DD->LL->id,L1 {L.type = L1.type;L.width = L1.width;enter(id,name,L.type,offset;Offset:= offset +L.width}L->:T{ L.type = T.type;L.width = T.width;}T->integer { T.type = integer; T.width:= 4 }T->real { T.type= real; T.width:= 8 }T-> array[num] of T1 { T.type:= array(num.val, T1.type);T.width:= num.val X T1.width }T->^T1 {T.type:=pointer(T1.type); T.width : = 4 }7、利用8.11的翻译方案,将下面的赋值语句翻译成三地址代码:A[i,j] = B[i,j] + C[A[k,l]]+D[i+j]答:令:域宽为wA的维数为:da1,da2, 不变部分为na, B的维数为db1,db2, 不变部分nbC的维数为dc,不变部分ncD的维数为dd,不变部分nd,t1 := i*db1t1:= t1+jt2:= B-nbt3:=w*t1t4:=t2[t3]xb = t4;t1 := k*da1t1:= t1+lt2:= A-nat3:=w*t1t4:=t2[t3]xa = t4;t1:=xa;t2:=C-nc;t3:=w*t1t4:=t2[t3]xca:=t4t1:=i+j;t2:=D-nd;t3:=w*t1;t4:=t2[t3];xd=t4;t5:=xb+xca;t6:=t5+xd;t1 := i*da1t1:= t1+jt2:= A-nat3:=w*t1t2[t3]:=t6。
编译原理课后作业参考答案

第6章 属性文法和语法制导翻译7. 下列文法由开始符号S 产生一个二进制数,令综合属性val 给出该数的值:试设计求的属性文法,其中,已知B 的综合属性c, 给出由B 产生的二进位的结果值。
例如,输入时,=,其中第一个二进位的值是4,最后一个二进位的值是。
【答案】11. 设下列文法生成变量的类型说明:(1)构造一下翻译模式,把每个标识符的类型存入符号表;参考例。
【答案】第7章 语义分析和中间代码产生1. 给出下面表达式的逆波兰表示(后缀式):3. 请将表达式-(a+b)*(c+d)-(a+b+c)分别表示成三元式、间接三元式和四元式序列。
【答案】间接码表:(1)→(2)→(3)→(4)→(1)→(5)→(6)4. 按节所说的办法,写出下面赋值句A:=B*(-C+D) 的自下而上语法制导翻译过程。
给出所产生的三地址代码。
【答案】5. 按照7.3.2节所给的翻译模式,把下列赋值句翻译为三地址代码: A[i, j]:=B [i, j] + C[A [k, l]] + d [ i+j] 【答案】6. 按7.4.1和节的翻译办法,分别写出布尔式A or ( B and not (C or D) )的四元式序列。
【答案】用作数值计算时产生的四元式: 用作条件控制时产生的四元式:其中:右图中(1)和(8)为真出口,(4)(5)(7)为假出口。
7. 用7.5.1节的办法,把下面的语句翻译成四元式序列:While A<C and B<D do if A=1 then C:=C+1else while A ≦D do A:=A+2; 【答案】第9章 运行时存储空间组织4. 下面是一个Pascal 程序:当第二次( 递归地) 进入F 后,DISPLAY 的内容是什么当时整个运行栈的内容是什么 【答案】第1次进入F 后,运行栈的内容: 第2次进入F 后,运行栈的内容: 109 87 6 5 4 3 2 1 017 16 15 14 13 12 11 10 9 8 7第2次进入F 后,Display 内容为:5. 对如下的Pascal 程序,画出程序执行到(1)和(2)点时的运行栈。
编译原理第7章 习题与答案

第7章习题7-1 设有如下的三地址码(四元式)序列:read NI:=NJ:=2L1 : if I≤J goto L3L2 : I:=I-Jif I>J goto L2if I=0 goto L4J:=J+1I:=Ngoto L1L3 : Print ′YES′haltL4 : Print ′NO′halt试将它划分为基本块,并作控制流程图。
7-2 考虑如下的基本块:D:=B*CE:=A+BB:= B*CA:=E+D(1) 构造相应的DAG;(2) 对于所得的DAG,重建基本块,以得到更有效的四元式序列。
7-3 对于如下的两个基本块:(1) A:=B*CD:=B/CE:=A+DF:=2*EG:=B*CH:=G*GF:=H*GL:=FM:=L(2) B:=3D:=A+CE:=A*CF:=E+DG:=B*FH:=A+CI:=A*CJ:=H+IK:=B*5L:=K+JM:=L分别构造相应的DAG,并根据所得的DAG,重建经优化后的四元式序列。
在进行优化时,须分别考虑如下两种情况:(ⅰ)变量G、L、M在基本块出口之后被引用;(ⅱ)仅变量L在基本块出口之后被引用。
7-4 对于题图7-4所示的控制流程图:(1) 分别求出它们各个结点的必经结点集;(2) 分别求出它们的各个回边;(3) 找出各流程图的全部循环。
7-5 对于如下的程序:I:=1read J,KL: A:=K*IB:=J*IC:=A*Bwrite CI:=I+1if A<100 goto Lhalt试对其中的循环进行可能的优化。
第8章习题答案7-1 解:划分情况及控制流程如答案图7-1所示:答案图7-1 将四元式序列划分为基本块7-2 解:(1) 相应的DAG如答案图7-2所示。
答案图7-2 DAG(2) 优化后的代码为:D:=B*CE:=A+BB:=DA:=E+D7-3 解:(1) 相应的DAG如答案图7-3-(1)所示。
若只有G、L、M在出口之后被引用,则优化后的代码为:G:=B*CH:=G*GL:=H*GM:=L若只有L在出口之后被引用,则代码为:G:=B*CH:=G*GL:=H*G(2) 相应的DAG如答案图7-3-(2)所示。
编译原理 第七章 习题解答

第七章习题答案1.拓广该文法:(0) S→A (1)A→aAd (2)A→aAb (3)A→ε构造LR(0)项目集规范族如下:由图可知,在项目集I0、I2中存在移进-归约冲突,该文法不是LR(0)文法。
在I0中,移进符号为a,而归约符号为Follow(A)={b,d,#},交集为空,可以解决冲突;在I2中,移进符号为a,而归约符号为Follow(A)={b,d,#},交集为空,可以解决冲突。
因此,该文法是SLR(1)文法。
输入串ab#的分析过程7.拓广该文法:(0) S’→S (1) S→A (2)A→Ab (3)A→bBa(4)B→aAc (5)B→a (6)B→aAb构造LR(0)项目集规范族如下:由图可知,在项目集I2、I6中存在移进-归约冲突,该文法不是LR(0)文法。
Follow(S’)={#}Follow(S)=Follow(S’)={#}Follow(A)=Follow(S)∪{b,c}={b,c,#}Follow(B)={a}在I2中,移进符号为b,归约符号为Follow(S)={#},交集为空,可以解决冲突;在I6中,移进符号为b,归约符号为Follow(B)={a},交集为空,可以解决冲突。
因此,该文法为SLR(1)文法。
8.拓广该文法:(0) S’→S (1) S→A$ (2)A→BaBb(3)A→DbDa (4)B→ε(5)D→ε构造LR(0)项目集规范族如下:由图可知,在项目集I0中存在归约-归约冲突,该文法不是LR(0)文法。
Follow(S’)={#}Follow(S)=Follow(S’)={#}Follow(A)= {$}Follow(B)={a,b}Follow(D)={a,b}在I 0中,归约项目B→·的归约符号集为Follow(B)={a,b},归约项目D→·的归约符号集为{a,b},交集不为空,因此,该文法不是SLR(1)文法。
构造LR(1)项目集规范族如下:由图可知,不存在任何冲突,该文法是LR(1)文法。
编译原理(第三版)第7章课后练习及参考答案中石大版

第7章练习P165作业布置:P1651、21.已知文法A→aAd | aAb |ε,判断该文法是否是SLR(1)文法,若是构造相应分析表,并对输入串ab#给出分析过程。
解:拓广文法为G',增加产生式S'→A若产生式排序为:0 S'→A 1 A→aAd 2 A→aAb 3 A→ε由产生式知:从在I0、I2中:A→•aAd和A→•aAb为移进项目,A→•为归约项目,存在移进-归约冲突,因此所给文法不是LR(0)文法。
在I0、I2中:Follow(A)∩{a}= {d, b, #}∩{a}=φ所以在I0状态下面临输入符号为a时移进,为{d, b, #}时归约,为其他时报错。
因此在I0、I2中的移进-归约冲突可以由Follow集解决,所以G是SLR(1)文法。
下面是文法的2、若有定义二进制数的文法如下:S→L.L|LL→LB|BB→0|1(1)试为该文法构造LR分析表,并说明属哪类LR分析表。
(2)给出输入串101.110的分析过程。
答:(1)拓广文法为G′,增加产生式S′→S,若产生式排序为:0 S' →S 1 S →L.L 2 S →L 3 L →LB4 L →B5 B →06 B →1从S'→状态项目集经过符号到达的状态0 S'→•S S 1 S→•L.L L 2 S→•L L 2 L→•LB L 2 L→•B B 3 B→•0 0 4 B→•1 1 51 S'→S•2 S→L•.L . 6 S→L•L→L•B B 7 B→•0 0 4 B→•1 1 53 L→B•4 B→0•5 B→1•6 S→L.•L L 8 L→•LB L 8 L→•B B 3 B→•0 0 4 B→•1 1 57 L→LB•8 S→L.L•L→L•B B 7 B→•0 0 4 B→•1 1 5在I2中:B→•0和B→•1为移进项目,S→L•为归约项目,存在移进-归约冲突,因此所给文法不是LR(0)文法。
编译原理(龙书)习题(5-6-7-8)章PPT课件

4
.
.
5
(2)设code 为综合属性,代表各非终结符 的代码属性
type为综合属性,代表各非终结符的类型属 性
inttoreal把整型值转换为相等的实型值
vtochar将数值转换为字符串
.
6
.
7
.
8
5.3.3 给出一个SDD对x*(3*x+x*x)这样的表达式求 微分。表达式中涉及运算符+和*,变量x和常 量。假设不进行任何简化,也就是说,比如 3*x将被翻译为3*1+0*x。
S1.code|| label(S1.next)|| B.code
.
21
S-->for ( S1; B; S2 ) S3
S1.next=newlabel() B.true=newlabel() begin=newlabel() B.fale=S.next S2.next =S1.next S3.next=begin S.code=S1.code||label(S1.next)||
不满足S属性定义,不满足L属性定义
1
.
5.2.4 这个文法生成了含“小数点”的二进制:
S L.L | L L LB | B B 0 |1
设计一个L属性的SDD来计算S.val,即输入串的十进制数值。 比如,串101.11应该被翻译为十进制数5.635。提示:使 用一个继承属性L.side来指明一个二进制位在小数点的哪 一边。
| { D .val 0;
D .b 0}
.
13
第6章 中间代码生成
6.1.1 为下面的表达式构造DAG ((x+y)-((x+y)*(x-y)))+((x+y)*(x-y))
编译原理清华大学出版社第8章习题重点题解答

1、已知文法:A → aAd|aAb|ξ判断该文法是否是SLR(1)文法,若是构造相应分析表,并对输入串 #ab# 给出分析过程。
解:(0) A’→ A(1)A → aAd(2) A → aAb(3) A →ξ构造该文法的活前缀DFA:由上图可知该文法是SLR(1)文法。
构造SLR(1)的分析表:3、考虑文法:S →AS|b A→SA|aFollow(A) = first(S) = {b}+first(A)= {a,b}(1)列出这个文法的所有LR(0)项目(2)按(1)列出的项目构造识别这个文法活前缀的NFA,把这个NFA确定化为DFA,说明这个DFA的所有状态全体构成这个文法的LR(0)规范族。
(3)这个文法是SLR的吗?若是,构造出它的SLR分析表。
(4)这个文法是LALR或LR(1)的吗?解:(0)S’→S (1)S→AS (2)S→b (3)A→SA (4)A→a(1)列出所有LR(0)项目:S’→·S S→·b A→·a S’→ S· S→b· A→a·S →·AS A→·SAS →A·S A→S·AS →AS· A→SA·(3)构造该文法的活前缀NFA:由上可知:I1 I3 I5 中存在着移进和归约冲突在I1中含项目:S’→ S·归约项 Follow(S’)={#}A →·a 移进项 Follow(S’)∩{a}=∮S →·b 移进项 Follow(S’)∩{b}=∮在I3中含项目:A →SA·归约项 Follow(A)={a,b}S →·b 移进项 Follow(A) ∩ {b}≠∮A →·a 移进项 Follow(A) ∩ {a}≠∮在I5中含项目:S →AS·归约项 Follow(S)={#,a,b}A →·a 移进项 Follow(S) ∩ {a}≠∮S →·b 移进项 Follow(S) ∩ {b }≠∮由此可知,I3、I5的移进与归约冲突不能解决,所以这个文法不是SLR (1)文法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第七章作业
练习7.2.5:在一个通过引用传递参数的语言中,有一个函数f(x,y)完成下面的计算:x=x+1;y=y+2;return x+y;
如果将a赋值为3,然后调用f(a,a),那么返回值是什么?
解:执行语句x=x+1,则a=a+1=4,
再执行语句y=y+2,则a=a+2=5,
最后返回x+y,则返回a+a=9。
练习7.2.6:C语言函数f的定义如下:
int f(int x,*py,**ppz) {
**ppz+=1;*py+=2;x+=3;return x+*py+**ppz;
}
变量a是一个指向b的指针;变量b是一个指向c的指针,而c是一个当前值为4的整数变量。
如果我们调用f(c,b,a),返回值是什么?
解:先执行语句**ppz+=1,则c=*b=**a=5,
再执行语句*py+=2,则*b=*b+2=7,c=*b=**a=7,
接着执行语句x+=3,则x=4,x=x+3=7,而c=*b=**a=7,
最后执行语句return x+*py+**ppz,则返回7+7+7=21。
练习7.3.2:假使我们使用显示表来实现下图中的函数。
请给出对fib0(1)的第一次调用即将返回时的显示表。
同时指明那时在栈中的各个活动记录中保存的显示表条目。
计算Fibonacci数的嵌套函数
解:
第八章练习
练习8.2.1:假设所有的变量都存放在内存中,为下面的三地址语句生成代码: 5)两个语句的序列 x=b*c y=a+x
解:生成的代码如下: LD R1, b LD R2, c
MUL R1, R1, R2 ST x, R1 LD R2, a
ADD R1, R2, R1 ST y, R1
练习8.2.6:确定下列指令序列的代价。
1)LD R0,y LD R1,z ADD R0,R0,R1 ST x,R0 解:2+2+1+2=7 2)LD R0,i MUL R0,R0,8 LD R1,a(R0) ST b,R1
main()
fib0(4) 保存的d[2] fib1(4) 保存的d[3] fib2(4) 保存的d[4] fib1(3) 保存的d[3] fib0(2) 保存的d[2] fib1(2) 保存的d[3] fib0(1) 保存的d[2]
d[1] d[2] d[3] d[4]
解:2+2+2+2=8
3)LD R0,c
LD R1,i
MUL R1,R1,8 ST a(R1),R0 解:2+2+2+2=8
4)LD R0,p
LD R1,0(R0) ST x,R1 解:2+2+2=6
5)LD R0,p
LD R1,x
ST 0(R0),R1 解:2+2+2=6
6)LD R0,x
LD R1,y SUB R0,R0,R1 BLTZ *R3,R0 解:2+2+1+1=6。