编译原理第8章
编译原理:第八章 符号表

合肥工业大学 计算机与信息学院软件所
表 0.1 符号名表 SNT NAME INFORMATION M 形式参数,整 型,值参数 N 形式参数,整 型,值参数 K 整型,变量
表 0.2 常数表 CT 值 (VALUE) (1) 1 (2) 4
表 0.3 入口名表 ENT NAME INFORMATION (1) INCWAP 二目子程序, 入口四元式:1
ax→
数组下限 数组上限 数组元素的体积 数组本身的体积 当元素为数组时,它指向 数组元素类型 数组的下标类型 该元素数组信息在atab表 中的位置,其他情况为0
合肥工业大学 计算机与信息学院软件所
type a=array[1..10, 1..10] of integer;
name kind typ ref
合肥工业大学 计算机与信息学院软件所
PL 语言编译程序的符号表
1. 表格的定义 名字表(nametab) 程序体表(btab) 层次显示表(display) 数组信息表(atab) 中间代码表(code)
合肥工业大学 计算机与信息学院软件所
1) 名字表(nametab) 名字表nametab:登记程序中出现的各种名 字及其属性
lastpar last psize vsize 0 1
bx→
指向本程序体中最后一个形式参在 本程序体所有局部数据所 指向本程序体中最后一个名字在 本程序体所有形参所需体积、包 nametab 中的位置 需空间大小 nametab 中的位置 括连接数据所占空间
清华大学编译原理第二版课后习答案

Lw.《编译原理》课后习题答案第一章第1章引论第1题解释下列术语:(1)编译程序(2)源程序(3)目标程序(4)编译程序的前端(5)后端(6)遍答案:(1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2)源程序:源语言编写的程序称为源程序。
(3)目标程序:目标语言书写的程序称为目标程序。
(4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第2题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含8个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
盛威网()专业的计算机学习网站1《编译原理》课后习题答案第一章目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
表格管理程序:负责建立、填写和查找等一系列表格工作。
编译原理课后习题答案+清华大学出版社第二版

用以引用非局部(包围它的过程)变量时,寻找该变量的地址。 DL: 动态链,指向调用该过程前正在运行过程的数据段基地址,用以过程执行结束释放
数据空间时,恢复调用该过程前运行栈的状态。 RA: 返回地址,记录调用该过程时目标程序的断点,即调用过程指令的下一条指令的地
编译程序大致有哪几种开发技术?
答案:
(1)自编译:用某一高级语言书写其本身的编译程序。 (2)交叉编译:A 机器上的编译程序能产生 B 机器上的目标代码。 (3)自展:首先确定一个非常简单的核心语言 L0,用机器语言或汇编语言书写出它的编
译程序 T0,再把语言 L0 扩充到 L1,此时 L0⊂ L1 ,并用 L0 编写 L1 的编译程序 T1,再把语 言 L1 扩充为 L2,有 L1 ⊂ L2 ,并用 L1 编写 L2 的编译程序 T2,……,如此逐步扩展下 去, 好似滚雪球一样,直到我们所要求的编译程序。 (4)移植:将 A 机器上的某高级语言的编译程序搬到 B 机器上运行。
(main).
答案: 程序执行到赋值语句 b∶=10 时运行栈的布局示意图为:
1
《编译原理》课后习题答案第二章
第 3题 写出题 2 中当程序编译到 r 的过程体时的名字表 table 的内 容。
name
kind
level/val
adr
size
答案:
题 2 中当程序编译到 r 的过程体时的名字表 table 的内容为:
盛威网()专业的计算机学习网站
2
《编译原理》课后习题答案第一章
合实现方案,即先把源程序翻译成较容易解释执行的某种中间代码程序,然后集中解释执行 中间代码程序,最后得到运行结果。
编译原理第三版课后习题答案

编译原理第三版课后习题答案编译原理是计算机科学中的一门重要课程,它研究的是如何将高级程序语言转换为机器语言的过程。
而《编译原理》第三版是目前被广泛采用的教材之一。
在学习过程中,课后习题是巩固知识、提高能力的重要环节。
本文将为读者提供《编译原理》第三版课后习题的答案,希望能够帮助读者更好地理解和掌握这门课程。
第一章:引论习题1.1:编译器和解释器有什么区别?答案:编译器将整个源程序转换为目标代码,然后一次性执行目标代码;而解释器则逐行解释源程序,并即时执行。
习题1.2:编译器的主要任务是什么?答案:编译器的主要任务是将高级程序语言转换为目标代码,包括词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等过程。
第二章:词法分析习题2.1:什么是词法分析?答案:词法分析是将源程序中的字符序列划分为有意义的词素(token)序列的过程。
习题2.2:请给出识别下列词素的正则表达式:(1)整数:[0-9]+(2)浮点数:[0-9]+\.[0-9]+(3)标识符:[a-zA-Z_][a-zA-Z_0-9]*第三章:语法分析习题3.1:什么是语法分析?答案:语法分析是将词法分析得到的词素序列转换为语法树的过程。
习题3.2:请给出下列文法的FIRST集和FOLLOW集:S -> aAbA -> cA | ε答案:FIRST(S) = {a}FIRST(A) = {c, ε}FOLLOW(S) = {$}FOLLOW(A) = {b}第四章:语义分析习题4.1:什么是语义分析?答案:语义分析是对源程序进行静态和动态语义检查的过程。
习题4.2:请给出下列文法的语义动作:S -> if E then S1 else S2答案:1. 计算E的值2. 如果E的值为真,则执行S1;否则执行S2。
第五章:中间代码生成习题5.1:什么是中间代码?答案:中间代码是一种介于源代码和目标代码之间的表示形式,它将源代码转换为一种更容易进行优化和转换的形式。
编译原理及其习题解答(武汉大学出版社)课件chap1

6
1.1 程序的翻译
1.1.2 翻译程序 所谓翻译程序,是指这样一种程
序,它能将用甲语言(源语言)编写 的程序翻译成与之等价的用乙语言 (目标语言)书写的程序。
程序的翻译通常有两种方式:一是 “编译”方式,二是“解释”方式。
(2) (* ,
id3 t1
(3) (+ ,
id2 t2
(4) (= ,
t3 -
t1 ) t2 ) t3 ) id1 )
29
1.2 编译程序的工作过程
1.2.4 代码优化
依据程序的等价变换规则,尽量压缩目标 程序运行所需的时间和所占的存储空间,以提 高目标程序的质量。
30
代码优化
id1= id2 + id3 * 60
3
第一章 引 论
本节内容: 程序的翻译 编译程序的工作过程 编译程序的结构 编译程序的组织方式 编译程序的构造
4
编译程序在计算机系统中的位置
分类
– 软件 – 系统软件 – 语言处理系统
编译系 统 操作系统
裸机
5
1.1 程序的翻译
1.1.1 程序设计语言 机器语言 001110010010 汇编语言 add R1 2 高级语言 begin x:=9+2 end
行分为两大阶段:编译阶段和运行阶段。 ·如果目标程序是汇编语言程序, 则源程序的执
行分为三大阶段:编译阶段、汇编阶段和运行 阶段。 编译方式下,生成了目标代码,且可多次执行。
9
1.1 程序的翻译
4.关于编译程序的几点说明
编译原理(清华大学-第2版)课后习题答案

编译原理(清华⼤学-第2版)课后习题答案第三章N=>D=> {0,1,2,3,4,5,6,7,8,9}N=>ND=>NDDL={a |a(0|1|3..|9)n且 n>=1}(0|1|3..|9)n且 n>=1{ab,}a nb n n>=1第6题.(1) <表达式> => <项> => <因⼦> => i(2) <表达式> => <项> => <因⼦> => (<表达式>) => (<项>)=> (<因⼦>)=>(i)(3) <表达式> => <项> => <项>*<因⼦> => <因⼦>*<因⼦> =i*i(4) <表达式> => <表达式> + <项> => <项>+<项> => <项>*<因⼦>+<项>=> <因⼦>*<因⼦>+<项> => <因⼦>*<因⼦>+<因⼦> = i*i+i (5) <表达式> => <表达式>+<项>=><项>+<项> => <因⼦>+<项>=i+<项> => i+<因⼦> => i+(<表达式>) => i+(<表达式>+<项>)=> i+(<因⼦>+<因⼦>)=> i+(i+i)(6) <表达式> => <表达式>+<项> => <项>+<项> => <因⼦>+<项> => i+<项> => i+<项>*<因⼦> => i+<因⼦>*<因⼦> = i+i*i第7题第9题语法树ss s* s s+aa a推导: S=>SS*=>SS+S*=>aa+a*11. 推导:E=>E+T=>E+T*F语法树:E+T*短语: T*F E+T*F直接短语: T*F句柄: T*F12.短语:直接短语:句柄:13.(1)最左推导:S => ABS => aBS =>aSBBS => aBBS=> abBS => abbS => abbAa => abbaa 最右推导:S => ABS => ABAa => ABaa => ASBBaa => ASBbaa => ASbbaa => Abbaa => a1b1b2a2a3 (2) ⽂法:S → ABSS → AaS →εA → aB → b(3) 短语:a1 , b1 , b2, a2 , , bb , aa , abbaa,直接短语: a1 , b1 , b2, a2 , ,句柄:a114 (1)S → ABA → aAb | εB → aBb | ε(2)S → 1S0S → AA → 0A1 |ε第四章1. 1. 构造下列正规式相应的DFA (1)1(0|1)*101NFA(2) 1(1010*|1(010)*1)*0NFA(3)NFA(4)NFA2.解:构造DFA 矩阵表⽰b其中0 表⽰初态,*表⽰终态⽤0,1,2,3,4,5分别代替{X} {Z} {X,Z} {Y} {X,Y} {X,Y,Z} 得DFA状态图为:3.解:构造DFA矩阵表⽰构造DFA的矩阵表⽰其中表⽰初态,*表⽰终态替换后的矩阵4.(1)解构造状态转换矩阵:{2,3} {0,1}{2,3}a={0,3}{2},{3},{0,1}{0,1}a={1,1} {0,1}b={2,2}(2)解:⾸先把M的状态分为两组:终态组{0},和⾮终态组{1,2,3,4,5} 此时G=( {0},{1,2,3,4,5} ) {1,2,3,4,5}a={1,3,0,5} {1,2,3,4,5}b={4,3,2,5}由于{4}a={0} {1,2,3,5}a={1,3,5}因此应将{1,2,3,4,5}划分为{4},{1,2,3,5}G=({0}{4}{1,2,3,5}){1,2,3,5}a={1,3,5}{1,2,3,5}b={4,3,2}因为{1,5}b={4} {23}b={2,3}所以应将{1,2,3,5}划分为{1,5}{2,3}G=({0}{1,5}{2,3}{4}){1,5}a={1,5} {1,5}b={4} 所以{1,5} 不⽤再划分{2,3}a={1,3} {2,3}b={3,2}因为 {2}a={1} {3}a={3} 所以{2,3}应划分为{2}{3}所以化简后为G=( {0},{2},{3},{4},{1,5})7.去除多余产⽣式后,构造NFA如下G={(0,1,3,4,6),(2,5)} {0,1,3,4,6}a={1,3}{0,1,3,4,6}b={2,3,4,5,6}所以将{0,1,3,4,6}划分为 {0,4,6}{1,3} G={(0,4,6),(1,3),(2,5)}{0,4,6}b={3,6,4} 所以划分为{0},{4,6} G={(0),(4,6),(1,3),(2,5)}不能再划分,分别⽤ 0,4,1,2代表各状态,构造DFA 状态转换图如下;b8.代⼊得S = 0(1S|1)| 1(0S|0) = 01(S|ε) | 10(S|ε) = (01|10)(S|ε)= (01|10)S | (01|10)= (01|10)*(01|10)构造NFA由NFA可得正规式为(01|10)*(01|10)=(01|10)+9.状态转换函数不是全函数,增加死状态8,G={(1,2,3,4,5,8),(6,7)}(1,2,3,4,5,8)a=(3,4,8) (3,4)应分出(1,2,3,4,5,8)b=(2,6,7,8)(1,2,3,4,5,8)c=(3,8)(1,2,3,4,5,8)d=(3,8)所以应将(1,2,3,4,5,8)分为(1,2,5,8), (3,4)G={(1,2,5,8),(3,4),(6,7)}(1,2,5,8)a=(3,4,8) 8应分出(1,2,5,8)b=(2,8)(1,2,5,8)c=(8)(1,2,5,8)d=(8)G={(1,2,5),(8),(3,4),(6,7)}(1,2,5)a=(3,4,8) 5应分出G={(1,2), (3,4),5, (6,7) ,(8) }去掉死状态8,最终结果为 (1,2) (3,4) 5,(6,7) 以1,3,5,6代替,最简DFA为b正规式:b*a(da|c)*bb*第五章1.S->a | ^ |( T )(a,(a,a))S => ( T ) => ( T , S ) => ( S , S ) => ( a , S) => ( a, ( T )) =>(a , ( T , S ) ) => (a , ( S , S )) => (a , ( a , a ) ) S=>(T) => (T,S) => (S,S) => ( ( T ) , S ) => ( ( T , S ) , S ) => ( ( T , S , S ) , S ) => ( ( S , S , S ) , S )=> ( ( ( T ) , S , S ) , S ) => ( ( ( T , S ) , S , S ) , S ) =>( ( ( S , S ) , S , S ) , S ) => ( ( ( a , S ) , S , S ) , S ) => ( ( ( a , a ) , S , S ) , S ) => ( ( ( a , a ) , ^ , S ) , S ) => ( ( ( a , a ) , ^ , ( T ) ) , S )=> ( ( ( a , a ) , ^ , ( S ) ) , S ) => ( ( ( a , a ) , ^ , ( a ) ) , S ) => ( ( ( a , a ) , ^ , ( a ) ) , a )S->a | ^ |( T )T -> T , ST -> S消除直接左递归:S->a | ^ |( T )T -> S T’T’ -> , S T’ | ξSELECT ( S->a) = {a}SELECT ( S->^) = {^}SELECT ( S->( T ) ) = { ( }SELECT ( T -> S T’) = { a , ^ , ( }SELECT ( T’ -> , S T’ ) = { , }SELECT ( T’ ->ξ) = FOLLOW ( T’ ) = FOLLOW ( T ) = { )}构造预测分析表分析符号串( a , a )#分析栈剩余输⼊串所⽤产⽣式#S ( a , a) # S -> ( T )# ) T ( ( a , a) # ( 匹配# ) T a , a ) # T -> S T’# ) T’ S a , a ) # S -> a# ) T’ a a , a ) # a 匹配# ) T’,a) # T’ -> , S T’# ) T’ S , , a ) # , 匹配# ) T’ S a ) # S->a# ) T’ a a ) # a匹配# ) T’) # T’ ->ξ# ) ) # )匹配# # 接受2.E->TE’E’->+E E’->ξT->FT’T’->T T’->ξF->PF’F’->*F’F’->ξP->(E) P->a P->b P->∧SELECT(E->TE’)=FIRST(TE’)=FIRST(T)= {(,a,b,^)SELECT(E’->+E)={+}SELECT(E’->ε)=FOLLOW(E’)= {#,)}SELECT(T->FT’)=FIRST(F)= {(,a,b,^}SELECT(T’ —>T)=FIRST(T)= {(,a,b,^)SELECT(T’->ε)=FOLLOW(T’)= {+,#,)}SELECT(F ->P F’)=FIRST(F)= {(,a,b,^}SELECT(F’->*F’)={*}SELECT(F’->ε)=FOLLOW(F’)= {(,a,b,^,+,#,)}3. S->MH S->a H->Lso H->ξK->dML K->ξL->eHf M->K M->bLM FIRST ( S ) =FIRST(MH)= FIRST ( M ) ∪FIRST ( H ) ∪{ξ}∪{a}= {a, d , b , e ,ξ} FIRST( H ) = FIRST ( L ) ∪{ξ}= { e , ξ}FIRST( K ) = { d , ξ}FIRST( M ) = FIRST ( K ) ∪{ b } = { d , b ,ξ}FOLLOW ( S ) = { # , o }FOLLOW ( H ) = FOLLOW ( S ) ∪{ f } = { f , # , o }FOLLOW ( K ) = FOLLOW ( M ) = { e , # , o }FOLLOW ( L ) ={ FIRST ( S ) –{ξ} } ∪{o} ∪FOLLOW ( K )∪{ FIRST ( M ) –{ξ} } ∪FOLLOW ( M )= {a, d , b , e , # , o }FOLLOW ( M ) ={ FIRST ( H ) –{ξ} } ∪FOLLOW ( S )∪{ FIRST ( L ) –{ξ} } = { e , # , o }SELECT ( S-> M H) = ( FIRST ( M H) –{ξ} ) ∪FOLLOW ( S )= ( FIRST( M ) ∪FIRST ( H ) –{ξ} ) ∪FOLLOW ( S )= { d , b , e , # , o }SELECT ( S-> a ) = { a }SELECT ( H->L S o ) = FIRST(L S o) = { e }SELECT ( H ->ξ) = FOLLOW ( H ) = { f , # , o }SELECT ( K->ξ) = FOLLOW ( K ) = { e , # , o }SELECT ( L-> e H f ) = { e }SELECT ( M->K ) = ( FIRST( K ) –{ξ} ) ∪FOLLOW ( M ) = {d,e , # , o }SELECT ( M -> b L M )= { b }4 . ⽂法含有左公因式,变为S->C $ { b, a }C-> b A { b }C-> a B { a }A -> b A A { b }A-> a A’ { a }A’-> ξ{ $ , a, b }A’-> C { a , b }B->a B B { a }B -> b B’ { b }B’->ξ{ $ , a , b }B’-> C { a, b }5. <程序> --- S <语句表>――A <语句>――B <⽆条件语句>――C <条件语句>――D <如果语句>――E <如果⼦句> --FS->begin A end S->begin A end { begin }A-> B A-> B A’ { a , if }A-> A ; B A’-> ; B A’ { ; }A’->ξ{ end }B-> C B-> C { a } B-> D B-> D { if }C-> a C-> a { a }D-> E D-> E D’ { if }D-> E else B D’-> else B { else }D’->ξ{; , end } E-> FC E-> FC { if }F-> if b then F-> if b then { if }⾮终结符是否为空S-否A-否A’-是B-否C-否D-否D’-是E-否F-否FIRST(S) = { begin }FIRST(A) = FIRST(B) ∪FIRST(A’) ∪{ξ} = {a , if , ; , ξ} FIRST(A’) ={ ; , ξ}FIRST(B) = FIRST(C) ∪FIRST(D) ={ a , if }FIRST(C) = {a}FIRST(D) = FIRST(E)= { if }FIRSR(D’) = {else , ξ}FIRST(E) = FIRST(F) = { if }FIRST(F) = { if }FOLLOW(S) = {# }FOLLOW(A) = {end}FOLLOW(A’) = { end }FOLLOW(B) = {; , end }FOLLOW (C) = {; , end , else }FOLLOW(D) = {; , end }FOLLOW( D’ ) = { ; , end }FOLLOW(E) = { else , ; end }FOLLOW(F) = { a }S A A’ B C D D’ E F if then else begin end a b ;6. 1.(1) S -> A | B(2) A -> aA|a(3)B -> bB |b提取(2),(3)左公因⼦(1) S -> A | B(2) A -> aA’(3) A’-> A|ξ(4) B -> bB’(5) B’-> B |ξ2.(1) S->AB(2) A->Ba|ξ(3) B->Db|D(4) D-> d|ξ提取(3)左公因⼦(1) S->AB(2) A->Ba|ξ(3) B->DB’(4) B’->b|ξ(5) D-> d|ξ3.(1) S->aAaB | bAbB(2) A-> S| db(3) B->bB|a4(1)S->i|(E)(2)E->E+S|E-S|S提取(2)左公因⼦(1)S->i|(E)(2)E->SE’(3)E’->+SE’|-SE’ |ξ5(1)S->SaA | bB(2)A->aB|c(3)B->Bb|d消除(1)(3)直接左递归(1)S->bBS’(2)S’->aAS’|ξ(3)A->aB | c(4) B -> dB’(5)B’->bB’|ξ6.(1) M->MaH | H(2) H->b(M) | (M) |b消除(1)直接左递归,提取(2)左公因⼦(1)M-> HM’(2)M’-> aHM’ |ξ(3)H->bH’ | ( M )(4)H’->(M) |ξ7. (1)1)A->baB4)B->a将1)、2)式代⼊3)式1)A->baB2)A->ξ3)B->baBbb4)B->bb5)B->a提取3)、4)式左公因⼦1)A->baB2)A->ξ3)B->bB’4)B’->aBbb | b5)B->a(3)1)S->Aa2)S->b3)A->SB4)B->ab将3)式代⼊1)式1)S->SBa2)S->b3)A->SB4)B->ab消除1)式直接左递归1)S->bS’2)S’->BaS’ |ξ3)S->b4)A->SB5)B->ab删除多余产⽣式4)1)S->bS’(5)1)S->Ab2)S->Ba3)A->aA4)A->a5)B->a提取3)4)左公因⼦1)S->Ab4)A’-> A |ξ5)B->a将3)代⼊1)5)代⼊21)S->aA’b2)S->aa3)A->aA’4)A’-> A |ξ5)B->a提取1)2)左公因⼦1)S-> aS’2)S’->A’b | a3)A->aA’4)A’-> A |ξ5)B->a删除多余产⽣式5)1)S-> aS’2)S’->A’b | a3)A->aA’4)A’-> A |ξA A’S’S将3)代⼊4)1)S-> aS’2)S’->A’b | a3)A->aA ’4)A’-> aA’ |ξ3)S’->a4)S’->b5)A->aA ’6)A’-> aA’ |ξ对2)3)提取左公因⼦1)S->aS’2)S’->aS’’3)S’’->A’b|ξ4)S’->b5)A->aA ’6)A’-> aA’ |ξ删除多余产⽣式5)1)S->aS’2)S’->aS’’3)S’’->A’b|ξ4)S’->b第六章1S → a | ∧ | ( T )T → T , S | S解:(1) 增加辅助产⽣式 S’→#S#求 FIRSTVT集FIRSTVT(S’)= {#}FIRSTVT(S)= {a ∧ ( }= { a ∧ ( } FIRSTVT (T) = {,} ∪ FIRSTVT( S ) = { , a ∧ ( }求 LASTVT集LASTVT(S’)= { # }LASTVT(S)= { a ∧ )}LASTVT (T) = { , a ∧ )}(2)因为任意两终结符之间⾄多只有⼀种优先关系成⽴,所以是算符优先⽂法(3)a ∧( ) , #F 1 1 1 1 1 1g 1 1 1 1 1 1f 2 2 1 3 2 1g 2 2 2 1 2 1f 3 3 1 3 3 1g 4 4 4 1 2 1f 3 3 1 3 3 1g 4 4 4 1 2 1(4)栈优先关系当前符号剩余输⼊串移进或规约#<·( a,a)# 移进#( <· a ,a)# 移进#(T <·, a)# 移进#(T,<· a )# 移进#(T,a ·> ) # 规约#(T,T ·> ) # 规约#(T =·) # 移进#(T) ·> #规约#T =·#接受4.扩展后的⽂法S’→#S# S→S;G S→G G→G(T) G→H H→a H→(S)T→T+S T→S(1)FIRSTVT(S)={;}∪FIRSTVT(G) = {; , a , ( }FIRSTVT(G)={ ( }∪FIRSTVT(H) = {a , ( }FIRSTCT(H)={a , ( }FIRSTVT(T) = {+} ∪FIRSTVT(S) = {+ , ; , a , ( }LASTVT(S) = {;} ∪LASTVT(G) = { ; , a , )}LASTVT(G) = { )} ∪LASTVT(H) = { a , )}LASTVT(H) = {a, )}LASTVT(T) = {+ } ∪LASTVT(S) = {+ , ; , a , ) }构造算符优先关系表因为任意两终结符之间⾄多只有⼀种优先关系成⽴,所以是算符优先⽂法(2)句型a(T+S);H;(S)的短语有:a(T+S);H;(S) a(T+S);H a(T+S) a T+S (S) H直接短语有: a T+S H (S)句柄: a素短语:a T+S (S)最左素短语:a(3)(4)不能⽤最右推导推导出上⾯的两个句⼦。
编译原理习题

第三章词法分析练习3.1给出一个正则表达式和自动机,使之表示满足下面条件的0、1序列:1)只包含两个1。
2)不包含连续的1。
3)包含偶数个1。
3.2写出下面符号串集的正则表达式:1){a,b,c}a偶数出现2){a,b,c}不包含子串baa3)二进制数,大于1010014)二进制数,4的倍数5)偶数个0奇数个1的0/1串3.3构造识别下列正则表达式定义的NFA:1)(a|(b)+2)(a*|(b*)*3)(a|(bc)*d*4)((0|1)*(2|3)*)|00115)(a|b)*abb(a|b)*3.4为下列正则表达式构造极化的DFA:1)(a|b)*a(a|b)2)(a|b)*a(a|b)(a|b)3.5利用自动机原理构造模式匹配程序,即构造一个程序,使它能识别给定a/b串是不是a i b j a k b m类串:,其中i和j是大于等于0的整数,而k和m是大于0的整数。
3.5将下面不确定自动机NFA转换为确定自动机DFA:3.6将下面不确定自动机NFA转换为确定自动机DFA:3.7试将下面不确定自动机NFA转换为确定自动机DFA:3.8试写出下面确定自动机DFA的正则表达式:3.9设置一个名字表NameL和整数表ConstL,当遇到标识符时,将其字符串送入名字表NameL,并把其名字表地址作为标识符的Value值。
整常数情形也一样,不要求翻译成二进制数。
要求在NameL表和ConstL表中没有相同元素。
试用C语言写一个针对上述单词集的词法分析器。
单词class valuebegin BeginSymbend EndSymbvar VarSymbinteger IntSymbif IfSymbthen ThenSymbelse ElseSymb;SemiSymb:ColonSymb:=AssigSymb<LittleSymb<=LittEquiSymb标识符IdentSymb名字表地址整常数ConstSymb常数表地址3.10实数的语法定义如下面所述:<实数>::=<整数部分><小数部分><指数部分><整数部分>::=<数字>|<整数部分><数字><小数部分>::=ε|.<整数部分><指数部分>::=ε|e<指数符号><整数部分><指数符号>::=ε|+|-试写出实数的非确定自动机。
(完整版)编译原理课后答案(第三版蒋立源康慕宁编)

编译原理课后答案(第三版蒋立源康慕宁编)第一章习题解答1解:源程序是指以某种程序设计语言所编写的程序。
目标程序是指编译程序(或解释程序)将源程序处理加工而得的另一种语言(目标语言)的程序。
翻译程序是将某种语言翻译成另一种语言的程序的统称。
编译程序与解释程序均为翻译程序,但二者工作方法不同。
解释程序的特点是并不先将高级语言程序全部翻译成机器代码,而是每读入一条高级语言程序语句,就用解释程序将其翻译成一段机器指令并执行之,然后再读入下一条语句继续进行解释、执行,如此反复。
即边解释边执行,翻译所得的指令序列并不保存。
编译程序的特点是先将高级语言程序翻译成机器语言程序,将其保存到指定的空间中,在用户需要时再执行之。
即先翻译、后执行。
2解:一般说来,编译程序主要由词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、代码优化程序、目标代码生成程序、信息表管理程序、错误检查处理程序组成。
3解:C语言的关键字有:auto break case char const continue default do double else enum extern float for goto if int long register return short signed sizeof static struct switch typedef union unsigned void volatile while。
上述关键字在C语言中均为保留字。
4解:C语言中括号有三种:{},[],()。
其中,{}用于语句括号;[]用于数组;()用于函数(定义与调用)及表达式运算(改变运算顺序)。
C语言中无END关键字。
逗号在C语言中被视为分隔符和运算符,作为优先级最低的运算符,运算结果为逗号表达式最右侧子表达式的值(如:(a,b,c,d)的值为d)。
5略第二章习题解答1.(1)答:26*26=676(2)答:26*10=260(3)答:{a,b,c,...,z,a0,a1,...,a9,aa,...,az,...,zz,a00,a01,...,zzz},共26+26*36+26*36*36=34658个2.构造产生下列语言的文法(1){anbn|n≥0}解:对应文法为G(S) = ({S},{a,b},{ S→ε| aSb },S)(2){anbmcp|n,m,p≥0}解:对应文法为G(S) = ({S,X,Y},{a,b,c},{S→aS|X,X→bX|Y,Y→cY|ε},S)(3){an # bn|n≥0}∪{cn # dn|n≥0}解:对应文法为G(S) = ({S,X,Y},{a,b,c,d,#}, {S→X, S→Y,X→aXb|#,Y→cYd|# },S)(4){w#wr# | w?{0,1}*,wr是w的逆序排列}解:G(S) = ({S,W,R},{0,1,#}, {S→W#, W→0W0|1W1|# },S)(5)任何不是以0打头的所有奇整数所组成的集合解:G(S) = ({S,A,B,I,J},{-,0,1,2,3,4,5,6,7,8,9},{S→J|IBJ,B→0B|IB|e, I→J|2|4|6|8, Jà1|3|5|7|9}, S)(6)所有偶数个0和偶数个1所组成的符号串集合解:对应文法为S→0A|1B|e,A→0S|1C B→0C|1S C→1A|0B3.描述语言特点(1)S→10S0S→aAA→bAA→a解:本文法构成的语言集为:L(G)={(10)nabma0n|n, m≥0}。
编译原理课后习题答案(陈火旺+第三版)

编译原理课后习题答案(陈火旺+第三版)第二章P36-6(1)L G ()1是0~9组成的数字串(2) 最左推导:N ND NDD NDDD DDDD DDD DD D N ND DD D N ND NDD DDD DD D ⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒0010120127334556568最右推导:N ND N ND N ND N D N ND N D N ND N ND N D ⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒77272712712701274434886868568P36-7G(S)O N O D N S O AO A AD N→→→→→1357924680|||||||||||P36-8文法:E T E T E T TF T F T F F E i→+-→→|||*|/()|最左推导:E E T T TF T i T i T F i F F i i F i i i E T T F F F i F i E i E T i T T i F T i i T i i F i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+********()*()*()*()*()*()*()最右推导:E E T E TF E T i E F i E i i T i i F i i i i i E T F T F F F E F E T F E F F E i F T i F F i F i i i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+⇒+**********()*()*()*()*()*()*()*()语法树:/********************************EE FTE +T F F T +iiiEEFTE-T F F T -iiiEEFT+T F FTiii*i+i+ii-i-ii+i*i*****************/P36-9句子iiiei 有两个语法树: S iSeS iSei iiSei iiiei S iS iiSeS iiSei iiiei ⇒⇒⇒⇒⇒⇒⇒⇒P36-10/**************)(|)(|S T T TS S →→***************/1 ε ε 1 0 11 确定化:1 1111 1 最小化:{,,,,,},{}{,,,,,}{,,}{,,,,,}{,,,}{,,,,},{},{}{,,,,}{,,}{,,,},{},{},{}{,,,}{,012345601234513501234512460123456012341350123456012310100==== 3012312401234560110112233234012345610101}{,,,}{,,}{,},{,}{},{},{}{,}{}{,}{,}{,}{}{,}{}{},{},{,},{},{},{}=====0 1111 1P64–8(1) 01)0|1(*(2))5|0(|)5|0()9|8|7|6|5|4|3|2|1|0)(9|8|7|6|5|4|3|2|1(*(3)******)110|0(01|)110|0(10P64–12(a)aa确定化:给状态编号:aaa b b ba0 1最小化:{,},{,}{,}{}{,}{}{,}{,}{,}{}{,},{},{}012301101223032330123a ba b ====aabb ab (b)b baa baa baa a已经确定化了,进行最小化最小化:{{,}, {,,,}}012345011012423451305234523452410243535353524012435011012424{,}{}{,}{,}{,,,}{,,,}{,,,}{,,,}{,}{,}{,}{,}{,}{,}{,}{,}{{,},{,},{,}}{,}{}{,}{,}{,}a b a b a b a b a b a =============={,}{,}{,}{,}{,}{,}{,}10243535353524 b a baa baP64–14(1) 00 (2):(|)*0100 1 ε确定化:给状态编号:1 0110 最小化:{,},{,}{,}{}{,}{}{,}{,}{,}{}{,},{},{}0123011012231323301230101====1 11第四章P81–1(1) 按照T,S 的顺序消除左递归ε|,)(||^)(T S T T S T T a S S G '→''→→'递归子程序: procedure S; beginif sym='a' or sym='^' then abvance else if sym='(' then beginadvance;T;if sym=')' then advance;else error;endelse errorend;procedure T;beginS;'Tend;procedure 'T;beginif sym=','then beginadvance;S;'Tendend;其中:sym:是输入串指针IP所指的符号advance:是把IP调至下一个输入符号error:是出错诊察程序(2)FIRST(S)={a,^,(} FIRST(T)={a,^,(} FIRST('T )={,,ε} FOLLOW(S)={),,,#} FOLLOW(T)={)} FOLLOW('T )={)} 预测分析表是LL(1)文法P81–2文法:|^||)(|*||b a E P F F F P F T T T F T E E E T E →'→''→→''→+→''→εεε(1)FIRST(E)={(,a,b,^} FIRST(E')={+,ε}FIRST(T)={(,a,b,^} FIRST(T')={(,a,b,^,ε} FIRST(F)={(,a,b,^} FIRST(F')={*,ε} FIRST(P)={(,a,b,^} FOLLOW(E)={#,)} FOLLOW(E')={#,)} FOLLOW(T)={+,),#} FOLLOW(T')={+,),#} FOLLOW(F)={(,a,b,^,+,),#} FOLLOW(F')={(,a,b,^,+,),#} FOLLOW(P)={*,(,a,b,^,+,),#} (2)考虑下列产生式:'→+'→'→'→E E T T F F P E a b||*|()|^||εεεFIRST(+E)∩FIRST(ε)={+}∩{ε}=φ FIRST(+E)∩FOLLOW(E')={+}∩{#,)}=φ FIRST(T)∩FIRST(ε)={(,a,b,^}∩{ε}=φ FIRST(T)∩FOLLOW(T')={(,a,b,^}∩{+,),#}=φFIRST(*F')∩FIRST(ε)={*}∩{ε}=φFIRST(*F')∩FOLLOW(F')={*}∩{(,a,b,^,+,),#}=φFIRST((E))∩FIRST(a) ∩FIRST(b) ∩FIRST(^)=φ所以,该文法式LL(1)文法.(3)(4)procedure E;beginif sym='(' or sym='a' or sym='b' or sym='^'then begin T; E' endelse errorendprocedure E';beginif sym='+'then begin advance; E endelse if sym<>')' and sym<>'#' then errorendprocedure T;beginif sym='(' or sym='a' or sym='b' or sym='^'then begin F; T' endelse errorendprocedure T';beginif sym='(' or sym='a' or sym='b' or sym='^'then Telse if sym='*' then errorendprocedure F;beginif sym='(' or sym='a' or sym='b' or sym='^'then begin P; F' endelse errorendprocedure F';beginif sym='*'then begin advance; F' endendprocedure P;beginif sym='a' or sym='b' or sym='^'then advanceelse if sym='(' thenbeginadvance; E;if sym=')' then advanceelse errorendelse error end;P81–3/***************(1) 是,满足三个条件。
《编译原理》教学大纲

《编译原理》教学大纲一、课程概述编译原理是计算机科学与技术专业的一门重要课程,也是软件工程领域的基础课程之一、本课程通过对编译器的原理和实现技术的学习,使学生掌握编译器的设计和实现方法,培养学生独立解决实际问题的能力。
二、教学目标1.理解编译器的基本原理和工作流程;2.掌握常见编译器的构建方法和技术;3.能够设计和实现简单的编译器;4.培养分析和解决实际问题的能力。
三、教学内容和教学进度1.第一章:引论1.1编译器的定义和分类1.2编译器的基本工作流程2.第二章:词法分析2.1编译器的基本结构2.2词法单元的定义和识别方法2.3正则表达式和有限自动机3.第三章:语法分析3.1语法分析的基本概念3.2语法规则的定义和表示方法3.3自顶向下的语法分析方法3.4自底向上的语法分析方法4.第四章:语义分析4.1语义分析的基本概念4.2属性文法和语法制导翻译4.3语义动作和符号表管理5.第五章:中间代码生成5.1中间代码的定义和表示方法5.2基本块和控制流图5.3三地址码的生成方法6.第六章:优化6.1优化的基本概念和原则6.2常见的优化技术和方法6.3编译器的优化策略7.第七章:目标代码生成7.1目标代码生成的基本原理7.2目标代码的表示方法和存储管理7.3基本块的划分和目标代码生成算法8.第八章:附加主题8.1解释器和编译器的比较8.2面向对象语言的编译8.3并行编译和动态编译四、教学方法1.理论教学与实践相结合,注重教学案例的分析和实践;2.引导学生主动探索,注重培养学生的自主学习能力;3.激发学生的兴趣,鼓励学生提问和讨论。
五、考核方式1.平时成绩:包括课堂测验、作业和实验报告等;2.期末考试:闭卷笔试,主要考查学生对编译原理的理论知识和实践能力的掌握程度。
六、参考教材1.《编译原理与技术》(第2版),龙书,机械工业出版社,2024年2.《现代编译原理-C语言描述》(第2版),谢路云,电子工业出版社,2024年七、参考资源1. 实验环境:Dev-C++、gcc、llvm等2.相关网站:编译原理教学网站、编译器开源项目等八、教学团队本课程由计算机科学与技术学院的相关教师负责教学,具体安排详见教务处发布的教学计划。
编译原理课后题答案【清华大学出版社】ch8

如果题目是 S::=L.L | L L::=LB | B B::=0 | 1 则写成: S`::=S {print(S.val);} S::=L1.L2 { S.val:=L1.val+L2.val/2L2.length ;} S::= L { S.val:=L.val; } L::=L1B { L.val:=L1.val*2+B.val; L.length:=L1.length+1; } L::=B { L.val:=B.val; L.length:=1;} B::=0 { B.val:=0; } B::=1 { B.val:=1;}
如采用 LR 分析方法,给出表达式(5*4+8)*2 的语法树并在各结点注明语义值 VAL。
答案:
计算机咨询网()陪着您
5
缄默TH浩的小屋
《编译原理》课后习题答案第八章
采用语法制导翻译思想,表达式 E 的“值”的描述如下:
产生式
语义动作
(0) S′→E
{print E.VAL}
四元式:
100 (+, a, b, t1) 101 (+, c, d, t2) 102 (*, t1, t2, t3) 103 (-, t3, /, t4) 104 (+, a, b, t5) 105 (+, t5, c, t6) 106 (-, t4, t6, t7)
树形:
计算机咨询网()陪着您
计算机咨询网()陪着您
6
缄默TH浩的小屋
《编译原理》课后习题答案第八章
第5题
令 S.val 为下面的文法由 S 生成的二进制数的值(如,对于输入 101.101,S.val=5.625); SÆL.L | L LÆLB | B BÆ0 | 1
编译原理教案

编译原理教案说明:一、参考书:1、陈意云、张昱:《编译原理》,高等教育出版社,2003年。
2、陈意云、张昱:《编译原理习题精选》,中国科技大学出版社,2003年。
3、吕映芝、张素琴、蒋维杜:《编译原理》,清华大学出版社,1998年第二版。
4、王生原、吕映芝、张素琴:《编译原理课程辅导》,清华大学出版社,2007年。
5、伍春香:《编译原理习题与解析》,清华大学出版社,2001年。
6、Andrew W.Appel:《现代编译原理—C语言描述》,人民邮电出版社,2005年。
7、Noam Nison等:《计算机系统要素》,电子工业出版社,2007年。
8、Randall Hyde:《编程卓越之道(第二卷)》,电子工业出版社,2007年。
二、教学目的:通过学习形式语言与自动机理论、词法分析、语法分析、语义分析、代码优化和生成等内容使学生掌握构造编译程序的基本原理和基本方法,并通过上机实习使学生进一步掌握开发应用程序的基本方法,为深入理解计算机系统、程序设计语言与开发大型应用程序打下良好的基础。
三、教学时数:课堂教学51学时,上机实验30学时。
四、授课内容:第一章编译程序概述第二章 PL/0编译程序的实现第三章文法和语言第四章词法分析第五章自顶向下语法分析方法第六章自底向上优先分析方法第七章 LR分析方法第八章语法制导翻译和中间代码生成第九章符号表第一○章目标程序运行时的存储组织第一一章代码优化第一二章代码生成第一章概述一、说明:1、教学目的与要求:了解编译程序的概念、结构以及工作流程。
2、主要内容:什么是编译程序、编译过程概述、编译程序的结构、编译阶段的组合、编译技术和软件工具以及实例分析。
3、教学重点:编译程序的结构以及每一阶段的任务。
4、教学难点:理解编译程序各模块的判错功能、编译方式和解释方式执行速度上的不同。
二、教学内容第一节编译程序1、机器语言:直接用计算机能够识别的二进制代码指令来编写程序的语言。
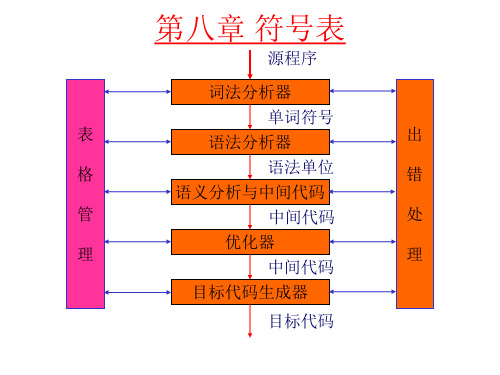
编译原理第八章 符号表
8.3 名字的作用范围(Fortran)
• Fortran 局部、全局
• 执行时过程(函数)不
Name
Information
嵌套,局部区域只有一
···
局
个现行段;
···
部 • 编译时,尽管查填符号
表过程只限于局部,但
考虑到地址分配的全局
性,需将每个程序段符
号表保存在外存中,采
• 定长方式 • 间接方式 (1)名字的间接存储 (2)信息的间接存储
Name ● ●
Information
如何组织
方式
6 S A MP L E 3 S U M
Name
Information ● ●
数组信息表 维数 首地址 维1
内情向量表
··· ···
以数组为例 维n
如何组织
• 对于名称:把所有标识符都存放在一个 独立的字符串数组,主栏只放一个指示 器和一个整数(名字的长度)
var f, g: real; procedure B3(y:real) const b=5; procedure B4 … end B4 end B3
end B2 end B1
8.3 名字的作用范围 (Pascal)
top
(14)…
B4 (13)…
0
h (12)… 13
sp b (11)…
12
y (10)…
最近使用优先查找 (链头)
较难
中 排序整理 折半查找
二叉树
较难
中 构造排序树,查找时 依子树次序逼近。
杂凑(哈希
难
表)
高 杂凑函数: 名称于位置的映射 基于计算的查找。
数据结构的知识
编译原理考试知识点复习

第一章:编译过程的六个阶段:词法分析,语法分析,语义分析,中间代码生成,代码优化,目标代码生成解释程序:把某种语言的源程序转换成等价的另一种语言程序——目标语言程序,然后再执行目标程序。
解释方式是接受某高级语言的一个语句输入,进行解释并控制计算机执行,马上得到这句的执行结果,然后再接受下一句。
编译程序:就是指这样一种程序,通过它能够将用高级语言编写的源程序转换成与之在逻辑上等价的低级语言形式的目标程序(机器语言程序或汇编语言程序)。
解释程序和编译程序的根本区别:是否生成目标代码第三章:Chomsky对文法中的规则施加不同限制,将文法和语言分为四大类:0型文法(PSG)◊ 0型语言或短语结构语言文法G的每个产生式α→β中:若α∈V*VNV*, β∈(VN∪VT)* ,则G是0型文法,即短语结构文法。
1型文法(CSG)◊ 1型语言或上下文有关语言在0型文法的基础上:若产生式集合中所有|α|≤|β|,除S→ε(空串)外,则G是1型文法,即:上下文有关文法另一种定义:文法G的每一个产生式具有下列形式:αAδ→αβδ,其中α、δ∈V*,A∈VN,β∈V+;2型文法(CFG)◊ 2型语言或上下文无关语言文法G的每个产生式A→α,若A∈VN ,α∈(VN∪VT)*,则G是2型法,即:上下文无关文法。
3型文法(RG)◊ 3型语言或正则(正规)语言若A、B∈VN,a∈VT或ε,右线性文法:若产生式为A→aB或A→a左线性文法:若产生式为A→Ba或A→a都是3型文法(即:正规文法)最左(最右)推导在推导的任何一步α⇒β,其中α、β是句型,都是对α中的最左(右)非终结符进行替换规范推导:即最右推导。
规范句型:由规范推导所得的句型。
句子的二义性(这里的二义性是指语法结构上的。
)文法G[S]的一个句子如果能找到两种不同的最左推导(或最右推导),或者存在两棵不同的语法树,则称这个句子是二义性的。
文法的二义性一个文法如果包含二义性的句子,则这个文法是二义文法,否则是无二义文法。
编译原理习题及答案(整理后)

编译原理习题及答案(整理后)第⼀章1、将编译程序分成若⼲个“遍”是为了。
b.使程序的结构更加清晰2、构造编译程序应掌握。
a.源程序b.⽬标语⾔c.编译⽅法3、变量应当。
c.既持有左值⼜持有右值4、编译程序绝⼤多数时间花在上。
d.管理表格5、不可能是⽬标代码。
d.中间代码6、使⽤可以定义⼀个程序的意义。
a.语义规则7、词法分析器的输⼊是。
b.源程序8、中间代码⽣成时所遵循的是- 。
c.语义规则9、编译程序是对。
d.⾼级语⾔的翻译10、语法分析应遵循。
c.构词规则⼆、多项选择题1、编译程序各阶段的⼯作都涉及到。
b.表格管理c.出错处理2、编译程序⼯作时,通常有阶段。
a.词法分析b.语法分析c.中间代码⽣成e.⽬标代码⽣成三、填空题1、解释程序和编译程序的区别在于是否⽣成⽬标程序。
2、编译过程通常可分为5个阶段,分别是词法分析、语法分析中间代码⽣成、代码优化和⽬标代码⽣成。
3、编译程序⼯作过程中,第⼀段输⼊是源程序,最后阶段的输出为标代码⽣成程序。
4、编译程序是指将源程序程序翻译成⽬标语⾔程序的程序。
⼀、单项选择题1、⽂法G:S→xSx|y所识别的语⾔是。
a. xyxb. (xyx)*c. x n yx n(n≥0)d. x*yx*2、⽂法G描述的语⾔L(G)是指。
a. L(G)={α|S+?α , α∈V T*}b. L(G)={α|S*?α, α∈V T*}c. L(G)={α|S*?α,α∈(V T∪V N*)}d. L(G)={α|S+?α, α∈(V T∪V N*)}3、有限状态⾃动机能识别。
a. 上下⽂⽆关⽂法b. 上下⽂有关⽂法c.正规⽂法d. 短语⽂法4、设G为算符优先⽂法,G的任意终结符对a、b有以下关系成⽴。
a. 若f(a)>g(b),则a>bb.若f(a)c. a~b都不⼀定成⽴d. a~b⼀定成⽴5、如果⽂法G是⽆⼆义的,则它的任何句⼦α。
a. 最左推导和最右推导对应的语法树必定相同b. 最左推导和最右推导对应的语法树可能不同c. 最左推导和最右推导必定相同d. 可能存在两个不同的最左推导,但它们对应的语法树相同6、由⽂法的开始符经0步或多步推导产⽣的⽂法符号序列是。
《编译原理》总复习-07级

《编译原理》总复习-07级第一章编译程序的概述(一)内容本章介绍编译程序在计算机科学中的地位和作用,介绍编译技术的发展历史,讲解编译程序、解释程序的基本概念,概述编译过程,介绍编译程序的逻辑结构和编译程序的组织形式等。
(二)本章重点编译(程序),解释(程序),编译程序的逻辑结构。
(三)本章难点编译程序的生成。
(四)本章考点全部基本概念。
编译程序的逻辑结构。
(五)学习指导引论部分主要是解释什么是编译程序以及编译的总体过程。
因此学习时要对以下几个点进行重点学习:翻译、编译、目标语言和源语言这几个概念的理解;编译的总体过程:词法分析,语法分析、语义分析与中间代码的生成、代码优化、目标代码的生成,以及伴随着整个过程的表格管理与出错处理。
第三章文法和语言课外训练(一)内容本章是编译原理课程的理论基础,主要介绍与课程相关的形式语言的基本概念,包括符号串的基本概念和术语、文法和语言的形式定义、推导与归约、句子和句型、语法分析树和二义性文法等定义、文法和语言的Chomsky分类。
(二)本章重点上下文无关文法,推导,句子和句型,文法生成的语言,语法分析树和二义性文法。
(三)本章难点上下文无关文法,语法分析树,文法的分类。
(四)本章考点上下文无关文法的定义。
符号串的推导。
语法分析树的构造。
(五)学习指导要构造编译程序,就要把源语言用某种方式进行定义和描述。
学习高级语言的语法描述是学习编译原理的基础。
上下文无关文法及语法树是本章学习的重点。
语法与语义的概念;程序的在逻辑上的层次结构;文法的定义,文法是一个四元组:终结符号集,非终结符号集,开始符号、产生式集;与文法相关的概念,字符,正则闭包,积(连接),或,空集,产生式,推导,直接推导,句子,句型,语言,最左推导,最右推导(规范推导);学会用文法来描述语言及通过文法能分析该文法所描述的语言;语法树及二义性的概念、能通过画语法树来分析一个文法描述的语言是否具有二义性;上下文无关文法的定义和正规文法的定义,能判断一个语言的文法是哪一类文法。
编译原理教程课后习题答案

编译原理教程课后习题答案【篇一:编译原理教程课后习题答案——第一章】完成下列选择题:(1) 构造编译程序应掌握a. 源程序b. 目标语言c. 编译方法d. 以上三项都是(2) 编译程序绝大多数时间花在上。
a. 出错处理b. 词法分析c. 目标代码生成d. 表格管理(3) 编译程序是对。
a. 汇编程序的翻译b. 高级语言程序的解释执行c. 机器语言的执行d. 高级语言的翻译【解答】(1) d (2) d(3) d1.2 计算机执行用高级语言编写的程序有哪些途径?它们之间的主要区别是什么?【解答】计算机执行用高级语言编写的程序主要有两种途径:解释和编译。
在解释方式下,翻译程序事先并不采用将高级语言程序全部翻译成机器代码程序,然后执行这个机器代码程序的方法,而是每读入一条源程序的语句,就将其解释(翻译)成对应其功能的机器代码语句串并执行,而所翻译的机器代码语句串在该语句执行后并不保留,最后再读入下一条源程序语句,并解释执行。
这种方法是按源程序中语句的动态执行顺序逐句解释(翻译)执行的,如果一语句处于一循环体中,则每次循环执行到该语句时,都要将其翻译成机器代码后再执行。
在编译方式下,高级语言程序的执行是分两步进行的:第一步首先将高级语言程序全部翻译成机器代码程序,第二步才是执行这个机器代码程序。
因此,编译对源程序的处理是先翻译,后执行。
从执行速度上看,编译型的高级语言比解释型的高级语言要快,但解释方式下的人机界面比编译型好,便于程序调试。
这两种途径的主要区别在于:解释方式下不生成目标代码程序,而编译方式下生成目标代码程序。
1.3 请画出编译程序的总框图。
如果你是一个编译程序的总设计师,设计编译程序时应当考虑哪些问题?【解答】编译程序总框图如图1-1所示。
作为一个编译程序的总设计师,首先要深刻理解被编译的源语言其语法及语义;其次,要充分掌握目标指令的功能及特点,如果目标语言是机器指令,还要搞清楚机器的硬件结构以及操作系统的功能;第三,对编译的方法及使用的软件工具也必须准确化。
陈火旺编译原理(第三版)课后习题答案

第二章P36-6⑴L(G)是o~9组成的数字串⑵最左推导:N= ND= NDD= NDDD= DDDD= ODDD= 01DD= 012D= 0127N= ND= DD= 3D= 34N= ND= NDD= DDD= 5DD = 56D= 568最右推导:N= ND= N7= ND7= N27= ND 27= N127= D127= 0127N= ND= N 4= D4= 34N= ND= N8= ND8= N 68= D68= 568P36-7G(S)O > 1|3|5|7|9N > 2∣4∣6∣8∣OD > 0|NS > OlAoA—;AD |NP36-8文法:E τ T E +T|E —TT T F T* F|T/ FF > (E)|i最左推导:E= E T= T T= F T= i T= i T* F= i F*F = i i*F= i i*iE=T=T* F 二F * F 二i * F = i*( E)= i *( E T)二i *( T T)二i *( F T)=i*(i τ)= i*( i F)= i*( i i)最右推导:E= E T- E T*F= E T*i= E F*i= E i*i= T i*i= F i*i= i i*i E=T= F*T = F * F=F*( E)= F *( E T)= F *( E F)= F *( E i) =F*( T i)= F*( F i)= F*( i i)= i*(i i) ^语法树. /********************************P36-9句子iiiei 有两个语法树:S= iSeS= iSei = iiSei = iiiei S= iS= iiSeS= iiSei = iiieiP36-10/**************S > TS |T T > (S)∣()***************/P36-11/*************** L1:S > ACA — aAb |ab C — CC | ;L2:S > ABA —: aA| ;B — bBc|bcET F iEF FiET F ii i+i+ii-i-iii+i*i*************** **/L3:第三章习题参考答案P64 — 7确定化:01{X}φ{1,2,3}φφφ{1,2,3}{2,3}{2,3,4}{2,3}{2,3}{2,3,4}{2,3,4}{2,3,5}{2,3,4}{2,3,5}{2,3}{2,3,4,Y}{2,3,4,Y}{2,3,5}{2,3,4,}最小化:S > ABAr aAb| ;B > aBb|;L4:S > A| BA》0A1∣;B > 1B0| A***************/1(01)*1012 34{0,1,2,3,4,5},{6}{0,1,2,3,4,5}° ={135} {O,123,4,5}1={1,2,4Q{0,1,2,3,4},{ 5},{6}{ 0,1,2,3,4} 0√1,3,5}{0,1,23,{4},{ 5},{6}{0,1,23° ={1,3} {0,1,2,3}1={1,2,4}{0,1},{23{4},{ f},{6}{0,1}°={1} {0,1}1={1,2}{2,3}0={3 {231={4}{0},{1},{2,3},{ 4},{ 5},{ 6}P64- 8⑴(1∣0)*01⑵(1∣2∣3∣4∣5∣6∣7∣8∣9)(0∣1∣2∣3∣4∣5∣6∣7∣8∣9)*(0∣5)∣(0∣5 )⑶0*1(0∣10*1)* ∣1*0(0∣10*1)*P64- 12⑻φφφ给状态编号:a b012112203333 aaab bb2最小化:{0,1},{ 2,3}{0,1}a ={1} {0,1}b ={2}{2,3}a ={0,3} {2,3}b ={3}{0,1},{ 2},{ 3}已经确定化了,进行最小化最小化:{{O,1}, {2,3,4,5}}{0,1}a ={1} {0,叽={2,4}{2,3,4,5}a ={1, 3,0,5} {2,3,4,5}^ {2,3,4,5}{2,4}a ={1,0} {2,4}b ={3,5}{3,5}a ={3,5} {3,5}b ={2,4}{{0,1},{ 2,4},{ 3,5}}{0,1}a H1}{2,4}a ={1,0}{3,5}a ={3,5}01 {X,1,Y}{1,Y}{2}{0,1}b ={2,4}{2,4打={3,5{3,5}b ={2,4}最小化:{0,1},{2,3{0,1}o √1}{0,1}ι ={2} {2,3}o={1,3} {2,3}^{3} {0,1},{2},{3}P81- 1(1) 按照τ,s的顺序消除左递归G(S)S > a∣^∣仃)T > STTrST | ;递归子程序:ProCedUre S;beginif sym='a' or sym=' ^'the n abva nceelse if sym='('the n begi nadvance;T;if sym=')' the n adva nce; else error;endelse erroren d;PrOCedUre T;beginS; Ten d;PrOCedUre T ;beginif sym=','the n begi nadvance;S;Tenden d;其中:Sym:是输入串指针IP所指的符号 advance:是把IP调至下一个输入符号 error:是出错诊察程序⑵FlRST(S)={a,^,(}FIRST(T)={a,^,(}FIRST(T )={,, JFoLLoW(S)={),,,#}FoLLoW(T)={)}FOLLOW T )={)}预测分析表P81- 2文法:E > TEE^ E | ;T > FTT 》T I ;F -PFF > *F I;P > (E)∣a∣b∣^(1)FIRST(E)={(,a,b,^}FIRST(E')={+, ε }FIRST(T)={(,a,b,^}FIRST(T')={(,a,b,^, ε }FIRST(F)={(,a,b,^}FIRST(F')={*, ε }FIRST(P)={(,a,b,^}FoLLoW(E)={#,)}FoLLoW(E')={#,)}FOLLOW(T)={+,),#}FOLLOW(T')={+,),#}FOLLOW(F)={(,a,b,^,+,),*}FOLLOW(F')={(,a,b,^,+,),*}FOLLOW(P)={*,(,a,b,^,+,),*}⑵考虑下列产生式:E ,E| ;T J T| :F J *F | :P > (E)|A|a|bFIRST(+E) ∩ FIRST( ε )={+} ∩ { ε }= φFIRST(+E) ∩ FOLLOW(E')={+} ∩ {#,)}= φFIRST(T) ∩ FIRST( ε )={(,a,b,^} ∩ { ε }= φFIRST(T) ∩ FOLLOW(T')={(,a,b,^} ∩ {+,),#}= φFIRST(*F') ∩ FIRST( ε )={*} ∩ { ε }= φFIRST(*F') ∩ FOLLOW(F')={*} ∩ {(,a,b,^,+,),*}= φ FIRST((E)) ∩ FIRST(a) ∩ FIRST(b) ∩ FIRST(^)= φ 所以,该文法式LL(1)文法.⑶⑷ProCedUre E;beginif sym='(' or sym='a' or sym='b' or sym=' ^' the n beg in T; E' end else error endPrOCedUre E';beginif sym='+'the n beg in adva nce; E endelse if sym<>')' and sym<>'#' then error endPrOCedUre T;beginif sym='(' or sym='a' or sym='b' or sym=' ^' the n beg in F; T' end else error endPrOCedUre T';beginif sym='(' or sym='a' or sym='b' or sym=' ^' the n Telse if sym='*' then errorendPrOCedUre F;beginif sym='(' or sym='a' or sym='b' or sym=' ^' the n beg in P; F' end else error endPrOCedUre F';beginif sym='*'the n beg in adva nce; F' endendPrOCedUre P;beginif sym='a' or sym='b' or sym='^'the n adva nceelse if sym='(' the nbeginadvance; E;if sym=')' the n adva nceelse errorendelse erroren d;P81- 3/***************(1) 是,满足三个条件。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2
在程序的执行过程中,程序中数据的存取是通过对 应的存贮单元进行的。
在早期的计算机上,这个存贮管理工作是由程 序员自己来完成的。在程序执行以前,首先要将用机 器语言或汇编语言编写的程序输送到内存的某个指定 区域中,并预先给变量和数据分配相应的内存地址。
在有了高级语言之后,程序员不必直接和内存 地址打交道,程序中使用的存贮单元都由逻辑变量(标 识符)来表示,他们对应的内存地址都是由编译程序在 编译时或由其生成的目标程序运行时进行分配。程序 执行时,源程序中同样的名字可以指示目标机器中不 同的数据对象,本章即考察名字与数据对象的对应关 系。所以,对编译程序来说,存贮的组织及管理是一 个复杂而又十分重要的问题。 编译程序根据如何组织运行环境而生成目标代码。
• 简单变量: (以字节为单位)
– char:1,可以分配在任何地址。 – integer,short:2,对齐到2(即从能被2或4整除的
地址开始分配) – long : 4,对齐到4 – float: 4至16,对齐到相应字节数 – double(双精度型):8,对齐到8 – booleans: 1位,但常设为1个字节 • 指针:unsigned integers • 一维数组:一块连续的存储区 • 多维数组:一块连续的存储区,按行存放 • 结构(记录):把所有域(field)存放在一块存储区 • 对象:类的实例变量象结构的域一样存放在一块连续 的存储区,但方法(成员函数)不存在该对象里
即使在一个程序中每一个名字只被说明一次,同一个名 字在运行时刻仍可能代表不同的数据目标。 一个名字的说明是静态的概念,名字的联编是名字的说 明的动态副本。
7
•引进两个函数,environment(环境) state (状态) – environment把名字映射到一个存储单元上(Lvalue左-值)。 – state把存储单元映射到那里所存放的值上,即把 一个L-value(左-值)映射为一个 R-value(右-值)。如 下图所示。
environmen t
state
名字
存储单元
值
L-value
R-value
存储分配
程序运行
从名字到值的两个阶段映射
8
例如: PROGRAM swap; VAR x,y,t:real; BEGIN read(x,y); t:=x;x:=y;y:=t; END.
环境是:{(x,Mx),(y,My),(t,Mt)} Mx,My,Mz是x,y,z分配的存储地址。
3
本章内容
•序
•源语言中的一些问题
•存储组织—如何组织不同作用域变量的存储
•运行时刻存储分配策略—编译程序对目标程 序运行时的组织(设计运行环境和分配存储)
•非局部名字的访问
•参数传递
•符号表
4
序
源 计算环境 映射运行时的环境
程 序
计算
目标代码
源程序中的名字(常量,变量)目标 机存储空间。它受命于源程序的执行 语义。
6
名字与存储的绑定(数据空间的分配)P217
名字的联编(Bindings of Names),亦称汇集 • 是指把源程序中的数据名字映射到目标机存储单元的
过程。也称为数据空间的分配,称为名字x的一个联编。
• 标识符与数据目标的对应关系 –变量名 ── 数据存储单元地址 –过程名、函数名 ── 程序段入口地址
设x,y,z初值为5.1、2.3、0,则相应状态为 {(Mx,5.1)},{(My,2.3)},{(Mt,0)},执行程序 后:{(Mx,2.3)},{(My,5.1)}, {(Mt,5.1)} 总结:环境是由说明部分决定。
赋值语句仅能改变状态。
9
术语
静态:如果一个名字的性质通过说明语句或 隐或显规则而定义,则称这种性质是“静态 ”确定的。 动态:如果名字的性质只有在程序运行时才 能知道,则称这种性质为“动态”确定的。
– 字节数计算,通过类型计算空间需求 – 填写变量的地址(供引用)
– 动态绑定:运行时指定(具体地址/相对地
址),即名字的性质只有在程序运行时才能知 道。 • 如:参数、C++ 的引用变量
12
过程和函数的绑定
▪ 为过程指定程序代码段地址 ▪ 静态绑定:编译时指定相对地址,适用于
多数各种函数、过程。
第八章
目标程序运行时 的存储组织
1
•前面几章的讨论,主要集中在编译程序的前端,即研
究对源语言静态分析的各个阶段的原理、方法与技术
,上述分析过程主要取决于源语言的特性,对生成的
目标程序而言,能否正常运行,还与支持目标程序运
行时环境密切相关。
•运行时环境主要指的是目标计算机的寄存器及存储器
的结构,用来管理存储器并保存执行过程所需的信息
。即代码生成前如何安排目标机资源。因此,涉及到
与目标机、目标语言及操作系统相关的特性。
•编译程序必须组织与分配目标程序运行时的数据空间
。
•运行阶段的存储组织与分配是指编译程序在编译阶段
负责为源程序中出现的用户定义的变量与常量、临时
工作单元、过程或函数调用时需要的连接单元与返回
地址等组织好在运行阶段的存储空间。
5
•过程
一个过程定义就是一个说明,其最简单的形式
就是把一个标识符和一个语句联系起来。标识
符是过程的名字,语句是过程体。函数是指带
返回值的过程,可以作为过程来处理。
当过程名出现在可执行语句中时,这个过程便 在这一点被调用。过程调用的基本思想是执行 过程体,它也可以发生在表达式中。
过程定义中可以包含形式参数,与之相应的是实 在参数。我们可以把它们传递给被调用过程, 在过程体中用实参代替形参。
• 词法分析:在符号表建立过程的表项 • 过程体的语义分析
—构造目标代码,统计目标代码长度 —填写过程的入Байду номын сангаас地址(供引用) – 如:一般的函数、子例程
▪ 动态绑定:运行时指定
• 函数名作为形式参数。
13
静态概念 过程定义 名字说明 说明的作用域
动态对应 过程的活动 名字的绑定 绑定的生存期
14
数据表示(固定长度,直接或间接表示)
10
绑定的时机与策略
• 绑定的相关问题
–变量和过程的作用域,决定绑定的有效期
• 语言定义的标识符的生存期决定最终绑定 的时机
– 全局变量:全程有效——程序装入时 – 局部变量:分段有效——进入过程或分程序
时
11
变量名的绑定
– 静态绑定:编译时指定(相对地址), 即一
个名字的性质通过说明语句或隐或显规则而 定义,适用于多数各种变量名。 • 词法分析:在符号表建立变量的表项 • 说明语句的语义分析