15-1 文档数据库
Access 2016数据库基础与应用教学课件项目1数据库和表的创建

1.1.3 任务实现
6
1.创建数据库 启动Access 2016程序,自 动弹出“空白数据库”对话 框,单击“创建”按钮,即 可创建一个空白的数据库文 件,并自动命名为 “Database1.accdb”, 如图1-2所示。
1.1.3 任务实现
7
2.保存数据库
(1)单击“文件”选项卡,选择 “另存为”选项,在“文件类型”列 表中选择“数据库另存为”选项,如 图1-3所示。在右侧的“数据库另存 为”列表中选择相应的文件类型,这 里选择“Access 数据库(*.accbd)” 选项,单击“另存为”按钮。
1
2
3
4
实体完整性。
值域完整性。
参照完整性。 用户自定义完整性。
1.1.4 必备知识
45
4.数据库设计步骤
概念结构设计
需求分析
01
02
03 逻辑结构设计
数据库维护
物理结构设计
06
05
04
数据库实施
1.1.4 必备知识
46
5.数据库包含对象
表。图1-20所示为 一个表对象。
窗体。图1-21所示 为一个窗体对象。
1.1.4 必备知识
34
(2)Access数据库的用途。
①进行数据分析。
②能够开发软件。
③使用表格模板。
1.1.4 必备知识
35
3.关系型数据库基础
(1)关系型数据库的基本概念。关系型数据 库是指按照关系模型建立的数据库。
关系型数据库中的所有数据均组织成一个一个的二维表, 这些表之间的联系也用二维表表示。
和连接等。
1.1.4 必备知识
39
①传统的关系运算。传统的关系运算又称为逻辑运算,两个结构相同的关系 通过这样的运算可以得到一个结构相同的新关系。例如,两个关系进行交运 算,得到一个新的关系,如图1-15所示。
计算机一级14年选择题

1-1 美国科学家香农是(A )的创始人。
A、信息论B、概率论C、控制论D、存储程序原理1-2(A)是关于信息科学的错误叙述。
A、信息科学是以维纳创立的控制论为理论基础B、信息科学的主要目标是扩展人类的信息功能C、信息科学是以信息为主要研究对象D、信息科学的基础和核心是信息和控制1-3 信息论的创始人是(D )。
A、维纳B、图灵C、冯·诺依曼D、香农1-4 信息素养的三个层面不包括(A )。
A、技术素养B、信息意识C、文化素养D、信息技能1-5 (C )是对信息技术的错误描述。
A、信息技术的发展方向之一是智能化B、信息技术中的通信技术是传递信息的技术C、信息技术中不含控制技术D、信息技术中处于基础和核心位置的技术是计算机技术2-1第二代计算机的主要元件采用(A )。
A、晶体管B、中、小规模集成电路C、电子管D、大规模和超大规模集成电路2-2机器人是计算机在(C )方面的应用。
A、数据处理B、科学计算C、人工智能D、实时控制2-3 计算机的CPU性能指标主要有(D )。
A、所配备的语言、操作系统和外部设备B、机器的价格、光盘驱动器的速度C、外存容量、显示器的分辨率和打印机的配置D、字长、内存容量、运算速度2-4下列叙述中,正确的是(C )。
A、内存属于硬盘的一个存储区域B、关机时微机ROM中的数据会丢失C、计算机系统是由主机系统和软件系统组成D、运算器的主要功能是实现算术运算和逻辑运算2-5 冯·诺依曼提出的计算机工作原理是(B )。
A、存储器只保存程序指令B、存储程序,顺序控制C、计算机硬件由主机和I/O设备组成D、计算机中的数据和指令可以采用十进制或二进制3-1 将二进制数00101011和10011010进行“与”运算的结果是(D )。
A、10111011B、10110001C、11111111D、000010103-2用48×48点阵表示一个汉字的字形,所需的存储容量为(D )字节。
《数据库原理与应用》模拟题1与答案

模拟题_1_答案一、判断共10题(共计10分)第1题(1.0分)使用报表向导创建报表"可以在报表中排序和分组记录,但只能选择4个字段作为排序和分组依据"的说法是不正确的.答案:Y第2题(1.0分)将一个基表或查询作为新建窗体的数据源,"单击工具栏上的"属性"按钮,在"数据"选项卡中的" 记录源"属性下拉列表中选择一个表或查询"的操作是正确的.答案:Y第3题(1.0分)"文本框"可以作为绑定或未绑定控件来使用.答案:Y第4题(1.0分)SQL仅能创建"选择查询".答案:N第5题(1.0分)文本框是属于容器型控件.答案:N第6题(1.0分)在Access2000中,定义字段属性的默认值是指不得使字段为空.答案:N第7题(1.0分)绑定型控件与未绑定型控件之间的区别是未绑定控件可以放置在窗体任意位置,而绑定控件只能放置在窗体的固定位置.答案:N第8题(1.0分)"报表页眉"的内容是报表中不可缺少的关键内容.答案:N第9题(1.0分)Access中的"数据访问页"对象可以使用浏览器来访问Internet上的Web页.答案:Y第10题(1.0分)在SQL查询中使用WHILE子句指出的是"查询目标".答案:N二、单项选择共60题(共计60分)第1题(1.0分)数据库是()。
A:以—定的组织结构保存在辅助存储器中的数据的集合B:一些数据的集合.C:辅助存储器上的一个文件.D:磁盘上的一个数据文件.答案:A第2题(1.0分)Access数据库的类型是()。
A:层次数据库B:网状数据库C:关系数据库D:面向对象数据库答案:C第3题(1.0分)Access在同一时间,可打开()个数据库。
A:1B:2C:3D:4答案:A第4题(1.0分)将表中的字段定义为(),其作用使字段中的每一个记录都必须是惟一的以便于索引. A:索引B:主键C:必填字段D:有效性规则答案:B第5题(1.0分)内部计算函数"Min"的意思是求所在字段内所有的值的().A:和B:平均值C:最小值答案:C第6题(1.0分)将信息系99年以前参加工作的教师的职称改为副教授合适的查询为()。
实验一 ACCESS数据库及表的操作
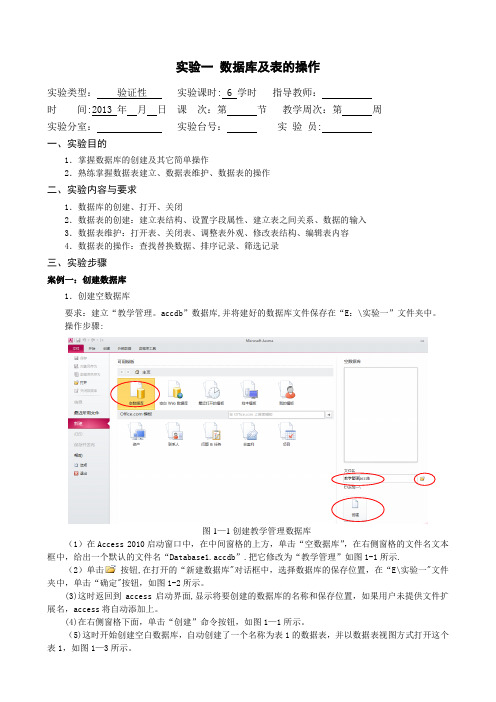
实验一数据库及表的操作实验类型:验证性实验课时: 6 学时指导教师:时间:2013 年月日课次:第节教学周次:第周实验分室:实验台号:实验员:一、实验目的1.掌握数据库的创建及其它简单操作2.熟练掌握数据表建立、数据表维护、数据表的操作二、实验内容与要求1.数据库的创建、打开、关闭2.数据表的创建:建立表结构、设置字段属性、建立表之间关系、数据的输入3.数据表维护:打开表、关闭表、调整表外观、修改表结构、编辑表内容4.数据表的操作:查找替换数据、排序记录、筛选记录三、实验步骤案例一:创建数据库1.创建空数据库要求:建立“教学管理。
accdb”数据库,并将建好的数据库文件保存在“E:\实验一”文件夹中。
操作步骤:图1—1创建教学管理数据库(1)在Access 2010启动窗口中,在中间窗格的上方,单击“空数据库”,在右侧窗格的文件名文本框中,给出一个默认的文件名“Database1.accdb”.把它修改为“教学管理”如图1-1所示.(2)单击按钮,在打开的“新建数据库"对话框中,选择数据库的保存位置,在“E\实验一"文件夹中,单击“确定"按钮,如图1-2所示。
(3)这时返回到access启动界面,显示将要创建的数据库的名称和保存位置,如果用户未提供文件扩展名,access将自动添加上。
(4)在右侧窗格下面,单击“创建”命令按钮,如图1—1所示。
(5)这时开始创建空白数据库,自动创建了一个名称为表1的数据表,并以数据表视图方式打开这个表1,如图1—3所示。
图1-2“文件新建数据库”对话框(6)这时光标将位于“添加新字段”列中的第一个空单元格中,现在就可以输入添加数据,或者从另一数据源粘贴数据。
图1-3表1的数据表视图2.使用模板创建Web数据库要求:利用模板创建“联系人Web数据库。
accdb”数据库,保存在“E:\实验一”文件夹中.操作步骤:(1)启动Access.(2)在启动窗口中的模板类别窗格中,双击样本模板,打开“可用模板”窗格,可以看到Access提供的12个可用模板分成两组.一组是Web数据库模板,另一组是传统数据库模板——罗斯文数据库。
第一章Web技术概述

13.通道(Tunnel):是作为两个连接中继的中介程序。一旦激活,通道 便被认为不属于HTTP通讯,尽管通道可能是被一个HTTP请求初始化的。 当被中继的连接两端关闭时,通道便消失。当一个门户(Portal)必须存 在或中介(Intermediary)不能解释中继的通讯时通道被经常使用。
14.缓存(Cache):反应信息的局域存储。
Internet(Inter Network)译为“因特网”, 也称国际互 联网,简称互联网。因特网是一个把世界范围内的众多计算 机、人、数据库、软件和文件连接在一起的,通过一个共同 的通信协议(TCP/IP协议)相互会话的网络。
14
Web技术基础
Internet主要技术: ·采用标准协议——TCP/IP协议,使网上各种不同的 计算机进行通信 ·通过路由器将不同网络互连 ·建立在TCP/IP协议基础之上的WWW浏览服务 ·应用DNS域名解析系统完成计算机和用户之间的地 址解析工作
网络病毒、保密、黑客(Huckman)
16
路由器 路由器
R
校园网子网
校园网
R
路由器 路由器
电子商务网站
R R
路由器
路由器
Internet
具有上网功能的手机 PDA掌上电脑 卫星接收系统
路由器
路由器
ISP网络
R R
路由器
路由器
企业子网
路由器
路由器
R
企业网
R
个人电脑
17
WWW的核心-HTTP
HTTP协议简介
20
10.源服务器(Originserver):是一个给定资源可以在其上驻留或被创 建的服务器。
11.代理(Proxy):一个中间程序,它可以充当一个服务器,也可以充当 一个客户机,为其它客户机建立请求。请求是通过可能的翻译在内部或 经过传递到其它的服务器中。一个代理在发送请求信息之前,必须解释 并且如果可能重写它。
第一部分 数据库系统概述答案

填空1.Sql语言特点:1简单易学2非过程化语言3面向集合的语言4多种使用方式2.数据库模型:层次数据模型, 网状数据模型, 关系数据模型, 面向对象数据模型.3.数据库体系结构:模式外模式内模式映像4.Sql语言的分类:据定义语言(简称DDL,用于定义、修改、删除数据库的表结构、视图、索引等);数据操纵语言(简称DML,用于对数据库中的数据进行查询和更新等操作);数据控制语言(简称DCL用于设置数据库用户的各种操作权限)事务处理语言(用于数据库中的数据完整性).5.触发器的组成:触发器名, 触发器的触发事件, 触发器执行的操作6.触发器的作用:对数据库中相关的表进行级联修改; 撤销或回滚违反引用完整性的操作,防止非法修改数据; 完成比检查约束更为复杂的约束操作; 比较表修改前后数据之间的差别并根据这些差别进行相应的操作; 对一个表的不同操作可调用不同的触发器,对一个表的相同操作也可调用不同的触发器.1.数据库设计的一般步骤:需求分析设计阶段, 概念设计阶段逻辑设计阶段, 物理设计阶段, 数据库实施阶段, 数据库运行和维护阶段.2.大数据特征:数据体量巨大, 处理速度快, 数据类型繁多,价值密度低.3.NoSQL数据库分类:键值存储数据库, 列存储数据库, 文档型数据库图形数据库.4.函数依赖:设有关系模式R(A1,A2,…,An)的子集X、Y。
如果对于具体关系r的任何两个元组u和v,只要u[X]=v[X],就有u[Y]=v[Y],则称X函数决定Y,或Y函数依赖X,记为X→Y。
5.函数依赖集F的闭包F+:所有被F逻辑蕴含的函数依赖所组成的依赖集合称为F的闭包。
6. 1NF:在一个关系模式R中,如果R的每一个属性的值域中的值都是不可再分的最小数据单位,则称R为第一范式,记为1NF。
7. 2NF:如果一个关系模式R属于1NF,并且它的每一个非主属性都完全依赖于它的每一个候选键,则称R为第二范式,记为2NF。
数据库系统的设计方法(1)

设计步骤是:首先要将现实世界中的数据及应用情况用 数据流程图和数据字典表示,并详细描述其中的数据操作要求 (即操作对象、方法、频度和实时性要求),进而得出系统的层 次结构、功能模块结构和数据库的子模式。
3. 数据库的物理模式设计
要求:根据库结构的动态特性(即数据库应用处理要求), 在选定的DBMS环境下,把数据库的逻辑结构模型加以物理实现,从 而得出数据库的存储模式和存取方法。
内容:数据库的结构特性设计、行为特性设计和物理模式 设计。在数据库系统设计过程中,数据库结构特性的设计起着关键 作用,行为特性设计起着辅助作用,两者结合起来,相互参照,同 步进行,才能较好地达到设计目标。
1. 数据库的结构特性设计 数据库的结构特性是指数据库的逻辑结构特征。数据库的
结构特性设计又称为数据库的静态结构设计。 设计过程是:先将现实世界中的事物、事物间的联系用E-R
程。数据库设计过程是结构设计和行为设计分离设计、相互参照、 反复探寻的过程。
● 3.1.3 数据库设计的基本方法
手工试凑法。使用手工试凑法设计数据库与设计人员的 经验和水平有直接关系
新奥尔良(New Orleans)方法。是规范设计法中的一种, 它将数据库设计分为4个阶段:需求分析、概念设计、逻辑设计和 物理设计。其后,经过改进,认为数据库设计应分6个阶段进行: 需求分析、概念结构设计、逻辑结构设计、物理结构设计、数据 库实施和数据库运行与维护。
在概念结构的设计过程中,设计者要对用户需求进行综合、 归纳和抽象,形成一个独立于具体计算机和DBMS的概念模型。 3.逻辑结构设计阶段
数据逻辑结构设计的主要任务是将概念结构转换为某个 DBMS所支持的数据模型,并将其性能进行优化。
4.数据库物理结构设计阶段 主要任务是为逻辑数据模型选取一个最适合应用环境的物
2011第二章 电子图书的检索(1)

45
E、再回到家中打开超星阅读器,点击“注册” 登录”
---》“离线
F、输入用户名,并导入离线证书,点击确定。即可在家中阅 读学校下载的图书。
1、输入用户名 (与学校的用 户名一致)
2、导入离线 注册证书
点击
4.3.1 把PDG格式的电子图书转换成PDF格式
具体步骤:
1、下载 Pdffactory FRO软件并安装; 2、打开超星电子图书; 3、在打开界面右键点击打印,选择虚拟打 印机“Pdffactory FRO”; 4、弹出对话框,点击保存。
图书信息检索(二)
外文图书及其检索
联机馆藏目录检索系统:
1、美国国会图书馆联机目录数据库
2信息检索(二)
外文图书及其检索 1、美国国会图书馆(LC)联机目录数据库
网址: 拥有馆藏书目记录约1200万条,包括图书、期 刊、计算机文档、手稿、音乐、录音及视频资 料。
图书信息检索(二)
外文图书及其检索
5、字面检索:在所有检索途径中检索。
Apabi数字图书馆进入方法
书生之家数字图书馆
书生之家数字图书馆特点
50万种图书;2000年以后;
可在线阅读;
可在图书阅读界面,将电子图书转为PDF格式; 全文检索
书生之家进入方法
上机操作
• 请在读秀中查看该图书在本馆的索书号及收藏地点;并对其中 的50-80页进行文献传递 1、王宏亮编著,大学物理实验. 北京市:机械工业出版社,2010
建议在不知道具体的书名或作者时采用分类检索
11
3.2 快速检索
快速检索只有一个检索框, 可选择下面任一检索项:书 名、作者、主题词。
在检索框里输入 相应检索词
实验训练1在MySQL中创建数据库和表

单击“运行”出现对话框,如下图在图中单击“next”进行下一步的安装,如下图。
勾选协议,如下图。
单击“next”进行下一步的安装,选择“Typical”,如下图。
单击“install”进行安装,如下图。
这时会多弹出一个窗口,如下图。
在这个窗口中连续单击“next”,这个窗口消失,出现下图。
在上图中选中Launch the MySQL Instance Configuration Wizard复选框,单击“Finish”按钮,进行配置,显示如下图所示的对话框。
在上图中,单击“next”,如下图。
在上图中选择使用哪种配置方式在上图中,选中Detailed Configuration进行详细配置,单击Next按钮,下一界面选中Developer Machine(开发者机器)单选按钮,单击Next按钮;继续选中Multifunctional Database(多功能数据库),单击Next按钮;选择InnoDB表空间保存位置,如下图。
继续单击“Next”按钮;下一界面中选择服务器并发访问人数;如下图。
继续单击“Next”按钮,如下图。
设置端口号和服务器SQL模式(MySQL使用的默认端口是3306,在安装时,可以修改为其他的,如3307,但是一般情况下,不要修改默认的端口号,除非3306端口已经被占用);单击Next按钮,出现下图。
在上图中选中Manual Selected Default Character Set/Collation(设置默认字符集编码为utf8),单击Next按钮,出现下图。
在上图中选中Install As Windows Service和Include Bin Directory in Windows PATH复选框,针对Windows系统设置,选中后如下图。
单击Next按钮,打开下图所示的对话框;在图中输入数据库的密码“111”,(注意:在安装MySQL数据库时,一定要牢记在上述步骤中设置的默认用户root 的密码,这是我们在访问MySQL数据库时必须使用的)。
一份智能化系统集成工程量清单表

1
推荐品牌
联想、戴尔、惠普 微软 微软
联想、戴尔、惠普
4
决策支持管 理模块
将分散在系统中的各审核和反 审核功能集中在一个界面中, 方便操作。
套
1
按投诉单的状态(是否处理)
5
客户服务中 或房屋对投诉单进行查看,并 心管理模块 且还可按投诉类别、投诉时间
套
1
、投诉主题进行统计。
自定义保安值勤的班次、时段
服务器操作 系统
工作站
Windows Server 2012 64位
i5-7400 8G 1T 2G独显23.6英 寸
IBMS数据库 系统集成数据库
大数据平台
对组织内部外部的数据进行清 洗、分析、整合,可以洞察各 数据之间的相关性,经由对历 史数据和现在数据的准确分析
平台及高级管理模块 为实现页面连接、数据交换、
IBMS系统基 数据共享、数据备份、数据恢
础运行平台 复、控制联动提供框架集成基
础。 IBMS系统基 人员、权限、区域及各种信息
础配置平台 配置等
客户端套件
客户端应用软件,支持B/S与 C/S工作模式
报警等级管 理模块 报表打印模 块
报警等级管理及显示 根据要求进行报表打印 在地图上显示点属性设置、 图
(IOS)
现相关监控、查询等功能。
APP软件
通过手机端访问IBMS系统,实
(Android) 现相关监控、查询等功能。
前端用户UI 界面设计
定制
物业及设施管理系统软件
物业及设施 管理基础软 件
设备监控模
为实现页面连接、数据交换、 数据共享、数据备份、数据恢 复、控制联动提供框架集成基 础。 对系统设备的运行数据及状态
理工15_1信息检索与利用

+
02文献信息资源的类型和识别
+
文献信息出版类型识别 会议文献(conference、paper)
• 定义:会议文献是在各种学术、专题会议上发表的论文和报 告。会议文献多数以会议录的形式出现。是专业领域最新研 究成果报道的一种主要方式 。 • 【例】张玉心.重载货车高摩擦系数合成闸瓦的研制和应用 [A].见:中国铁道学会编译.国际重载运输协会制动专题讨论 会论文集[C].北京:中国铁道学会,1988.242.
– 内心的疑惑
• 查全率?查准率?时效性?可性度?
+
课程简介—关于教材
+
• • • •
书名:现代信息检索 主编:胡琳 出版社:科学出版社 出版时间:2012年8月
+
课程简介—授课方式
+
– 课堂理论和上机实践相结合 课堂理论
上机实践
50%
50%
+
课程简介—课程安排
+
周次 9 10 11 12 13 14 15 16
2、知识
– 人类社会实践的总结 – 其初级形态是经验和知识,高级形态是系统科学理论
+
01信息检索的定义和方式
+
信息、知识、文献概念
3、文献
– 用文字、图形、符号、声频、视频等技术手段记录人类知识的一种 载体 – 基本属性:知识性、记录性、物质性 – 功能:存贮知识、传递和交流信息
+
01信息检索的定义和方式
主题途径
专门项目途径
+
03信息检索—计算机检索基本知识
+
数据库概念
– 数据库(Database)是按照数据结构来组织、存储和管理数据的仓 库,产生于50年代。 – 数据库通常由文档、记录、字段三个自上而下的层次构成。
第1章-Visual-FoxPro基础精选全文

1.4 VFP项目管理器
1.项目的建立-菜单法 第一步: “文件”菜
单“新建”,启动 “新建”对话框,或单 击工具栏中的“新建” 图标,系统将弹出“新 建”对话框 选择“项目”选项。然 后单击“新建文件”按 钮
1.4 VFP项目管理器
第二步:在弹出的 “新建”对话模式 中确定存放项目文件 的路径,输入项目名 称(默认名称为“项 目1”),单击“保存” 按钮,即可建立一个 新项目。
浏览器 :IE4.0或更高版本 CPU:80486 66MHz以上 内存:16M以上 硬盘:典型安装85MB,最大安装90MB 其他:鼠标和光驱等
1.2 VFP 6.0的运行环境、安装、启动与退出
二、安装
将VFP6.0 安装盘CD-ROM放入光驱找到序列号 文件(若需要)找到setup.exe,双击安装安装过程 根据提示选择或选择下一步,直到完成。
1.2 VFP 6.0的运行环境、安装、启动与退出
三、启动
方法 一: “ 开 始” “ 所有 程序 ” “ Microsoft Visual FoxPro 6.0”
方法二:双击桌面上的快捷方式(如果有) 方法三:单击任务栏中的快捷方式(如果有)
1.2 VFP 6.0的运行环境、安装、启动与退出
学习一门新课首要解决的两个问题:
1.为什么要学习这门课? 2. 这门课能干什么?
?
什么是VFP?
DBMS OR(+) Programming Language
?
自己带有数据库的程序,并且同时添加了一组可以在数据上执行的命令 为数据处理而生
VFP能做什么?
信息系统 数据库系统 桌面信息系统
VFP发展历程
发展总过程:
DBase→Foxbase→Foxpro→Visual Foxpro (1)DBase阶段 Dbase: Ashton Tate公司(80年代初期) (2)FoxBase 和 FoxPro阶段 Foxbase :Fox公司(1986) Foxpro 1.0:Fox公司(1989)
实验1+MySQL数据库服务器配置

实验1 MySQL数据库服务器配置1.实验目的掌握MySQL的安装方法,练习MySQL数据库服务器的使用,理解MySQL服务器的组成,掌握MySQL服务器的配置方法。
2.实验内容【实验1-1】下载当前最新版本的MySQL,或者之前某个版本的MySQL,并在Windows上完成安装。
【实验1-2】安装完毕后,找到MySQL的配置文件;并查看初始化配置文件的内容。
【实验1-3】使用start和stop命令启动和关闭mysql数据库。
【实验1-4】连接到MySQL服务器,连接成功后是一个mysql>的提示。
【实验1-5】在MySQL数据库服务器端找到错误日志文件,并查看错误日志的内容。
【实验1-6】通过初始化配置文件,启用二进制日志、慢查询日志和通用查询日志。
【实验1-7】查看二进制日志、慢查询日志和通用查询日志的内容。
【实验1-8】关闭二进制日志、慢查询日志和通用查询日志。
【实验1-9】用CREATE DATABASE语句创建数据库,使用SHOW DATABASES命令查看显示所有数据库,可以看到新建的数据库名称。
【实验1-10】使用Workbench图形化管理工具创建数据库。
【实验1-11】使用SHOW STATUS命令查看系统状态参数;使用SHOW VARIABLES 命令查看服务器变量设置。
【实验1-12】使用命令“select @@basedir”和“select @@datadir”寻找到MySQL的安装目录和数据存放目录。
【实验1-13】使用SHOW ENGINES查看所有引擎,在配置文件中更改默认存储引擎default-storage-engine变量,改为MyISAM。
重启MySQL,查看默认存储引擎是否改变。
【实验1-14】创建一个数据表t_myisam(id int auto_increment, name varchar(30),primary key(id)),创建时显式指定存储引擎为MyISAM。
01.《大数据导论》第1章 数据与大数据时代

历年、各省、文理科、各专业分数线
3 of 38
1.1 从数据到大数据
2. 海量的数据的产生
智能终端拍照、拍 视频
</部分地区主要作物产量(万吨)>
JSON格式数据
{ "部分地区主要作物产量(万吨)":{ "北京":{ "小麦":18.7, "玉米":75.2 }, "河北":{ "稻谷":58.8, "玉米":1703.9, "小麦":1387.2 }, "广西":{ "稻谷":1156.2, "甘蔗":8104.3 } }
XML格式数据
<部分地区主要作物产量(万吨)> <地区 名称=“北京”> <小麦>18.7</小麦> <玉米>75.2</玉米> </地区> <地区 名称=“河北”> <稻谷>58.8</稻谷> <玉米>1703.9</玉米> <小麦>1387.2</小麦> </地区> <地区 名称=“广西”> <稻谷>1156.2</稻谷> <甘蔗>8104.3</甘蔗> </地区>
1. 数据思维的由来
(1)科学研究的三种方法及思维
南开大学22春“物联网工程”《大数据开发技术(一)》期末考试高频考点版(带答案)试卷号3

南开大学22春“物联网工程”《大数据开发技术(一)》期末考试高频考点版(带答案)一.综合考核(共50题)1.Google Fusion Tables是哪种可视化工具()A.信息图表B.地图工具C.时间线工具D.分析工具参考答案:B2.数据仓库、专家系统产生于大数据发展的成熟期。
()A.正确B.错误参考答案:B3.以下哪种不属于为大数据时代提供关键技术支撑的信息科技变化()。
A.网络宽带不断增加B.存储设备容量不断增加C.CPU处理能大幅提升D.存储设备尺寸不断减小参考答案:D4.Hbase中Zookeeper文件记录了()的位置A..META.表B.-ROOT-表C.RegionD.Master参考答案:B5.MongoDB将数据存储为一个()A.关系B.属性C.字段D.文档参考答案:D6.UMP系统的哪个功能实现了负载均衡()A.读写分离B.资源隔离C.资源调度D.可扩展参考答案:A7.静态数据采取()计算模式A.批量B.实时C.大数据D.动态参考答案:A8.行式数据库采用()存储模型。
A.NSMB.DSMC.HbaseD.MySQL参考答案:A9.数据产生方式的运营式系统阶段的数据产生方式是主动的。
()A.正确B.错误参考答案:B10.SQL中的table对应与MongoDB中的()参考答案:collection/集合11.HDFS中()记录了每个文件中各个块所在的数据节点的位置信息NodeB.SecondaryNameNodeC.DataNodeD.Block参考答案:A12.Hadoop启动所有进程的命令为()。
A.all-start.shB.all-start.C.start-all.shD.start-all.参考答案:C13.Hbase中性能监视的工具有()。
A.GangliaB.AmbariC.OpenTSDBD.Zookeeper参考答案:ABC14.以下哪些是数据可视化信息图表工具()A.大数据魔镜B.D3C.Google Chart APID.Google Fusion Tables参考答案:ABC15.HDFS集群中的数据节点一般是一个节点运行多个数据节点进程,负责处理文件系统客户端的读/写请求。
SAP Replication Server 15.7.1 SP200 异构复制指南说明书

异构复制指南SAP Replication Server® 15.7.1SP200文档 ID: DC31034-01-1571200-01最后修订日期: 2014 年 4 月©2014 SAP股份公司或其关联公司版权所有,保留所有权利。
未经SAP股份公司明确许可,不得以任何形式或为任何目的复制或传播本文的任何内容。
本文包含的信息如有更改,恕不另行事先通知。
由SAP股份公司及其分销商营销的部分软件产品包含其它软件供应商的专有软件组件。
各国的产品规格可能不同。
上述资料由SAP股份公司及其关联公司(统称“SAP集团”)提供,仅供参考,不构成任何形式的陈述或保证,其中如若存在任何错误或疏漏,SAP集团概不负责。
与SAP集团产品和服务相关的保证仅限于该等产品和服务随附的保证声明(若有)中明确提出之保证。
本文中的任何信息均不构成额外保证。
SAP和本文提及的其它SAP产品和服务及其各自标识均为SAP股份公司在德国和其他国家的商标或注册商标。
如欲了解更多商标信息和声明,请访问:/corporate-en/legal/copyright/index.epx#trademark。
目录约定 (1)复制系统概述 (3)基本复制系统 (3)异构复制系统 (4)SAP 复制系统组件 (5)主数据服务器 (6)Replication Agent (6)Replication Server (7)Replication Server 系统数据库 (RSSD) (8)数据库网关 (9)ExpressConnect for Oracle (9)ExpressConnect for SAP HANA 数据库 (10)复制数据服务器 (10)非 ASE 复制 (11)主数据库 (11)复制数据库 (12)字符集 (12)异构复制限制 (13)存储过程复制 (13)所有者限定对象名 (13)大对象复制 (13)复制数据库的设置 (14)Replication Server 对加密列的支持 (14)预订实现 (15)Replication Server rs_dump 命令 (15)Replication Server rs_marker 命令 (15)Replication Server rs_dumptran 命令 (16)Replication Server rs_subcmp 实用程序 (16)动态 SQL (16)批量复制 (16)Replication Server rs_ticket 存储过程 (17)目录复制系统非 ASE 配置 (17)非 ASE 主数据库到 Adaptive Server 复制数据库 (17)ASE 服务器主数据库到非 ASE 服务器复制数据库 (17)非 ASE 主数据库到非 ASE 复制数据库 (18)非 ASE 到非 ASE 双向复制 (19)SAP 复制产品 (21)Replication Server (21)Replication Server 的工作方式 (21)“发布-预订”模型 (22)复制函数 (22)事务管理 (23)与其它系统组件的关系 (23)数据库连接 (26)DDL 用户的用途 (28)在表级复制带引号的标识符 (28)数据类型、数据类型定义和受限制的数据类型 (30)非 ASE 数据服务器的错误类 (30)非 ASE 数据服务器的函数字符串类 (30)对象发布和预订限制 (32)Replication Agent (32)Replication Agent 的工作方式 (33)DDL 用户处理 (35)非 ASE Replication Agent (35)Enterprise Connect Data Access (36)ECDA 的工作方式 (36)ECDA 数据库网关 (37)ECDA Option for ODBC (38)Mainframe Connect DirectConnect for z/OSOption (38)ExpressConnect for Oracle (38)ExpressConnect for SAP HANA 数据库 (39)IBM DB2 for z/OS 作为主数据服务器 (41)Replication Agent for DB2 UDB (41)目录复制侵扰和影响 (41)DB2 UDB 主数据库权限 (42)主数据服务器连接 (42)Replication Server 连接 (43)Replication Server 系统数据库连接 (43)DB2 UDB 主数据库配置 (43)DB2 for z/OS 中主表的复制定义 (44)DB2 for z/OS 主数据类型转换 (44)字符集 (45)实现 (45)IBM DB2 for Linux, UNIX, and Windows 作为主数据服务器 (47)Replication Agent for UDB (47)DB2 UDB 系统管理 (47)DB2 UDB 中的复制侵扰和影响 (47)DB2 UDB 主数据库权限和限制 (48)主数据服务器连接 (48)Replication Server 和 RSSD 连接 (48)Replication Agent 对象 (49)用于截断的 Java 过程 (49)获取复制对象的实际名称 (49)DB2 UDB 主数据库配置 (50)Java 运行环境 (50)rs_source_ds 和 rs_source_db 配置参数 (50)Filter_maint_userid 配置参数 (50)ltl_character_case 配置参数 (50)复制定义中的字符大小写和带引号的标识符配置 (51)以大写形式存储的对象名 (51)DB2 UDB 中的主表的复制定义 (51)DB2 UDB 主数据类型转换 (51)Microsoft SQL Server 作为主数据服务器 (53)Replication Agent for Microsoft SQL Server (53)sybfilter 驱动程序 (53)目录Microsoft SQL Server 系统管理 (53)Replication Agent 权限 (54)主数据服务器连接 (54)设置 CLASSP A TH 环境变量 (54)Replication Server 和 RSSD 连接 (55)Replication Agent 对象 (55)表、过程、标记和触发器对象 (55)Microsoft SQL Server 主数据库配置 (56)rs_source_ds 和 rs_source_db 配置参数 (56)Filter_maint_userid 配置参数 (56)ltl_character_case 配置参数 (56)Microsoft SQL Server 中主表的复制定义 (57)Microsoft SQL Server 主数据类型转换 (57)复制 Microsoft SQL Server 较大值数据类型 (57)Microsoft SQL Server 较大值数据类型的限制 (58)Microsoft SQL Server 较大值数据类型的部分更新 (58)Oracle 作为主数据服务器 (59)Replication Agent for Oracle (59)Oracle 中主表的复制定义 (59)Oracle 系统管理 (59)Oracle 中的复制侵扰和影响 (60)从 Oracle 到 SAP HANA 数据库的连续复制限制 (60)Oracle 主数据库权限 (60)主数据服务器连接 (60)Replication Server 和 RSSD 连接 (61)Replication Agent 对象 (61)Oracle 主数据库配置 (61)Java 运行环境 (62)所需的 JDBC 驱动程序 (62)rs_source_ds 和 rs_source_db 配置参数 (62)Filter_maint_userid 配置参数 (62)ltl_character_case 配置参数 (62)目录复制定义中的字符大小写和带引号的标识符配置 (63)Oracle 主数据类型转换 (63)自动存储管理 (63)实际应用程序集群 (63)SAP Business Suite 数据库作为主数据服务器 (65)SAP Business Suite 数据库复制 (65)聚簇表复制 (66)SAP Business Suite 数据库实现和复制方案 (66)方案 1 (67)方案 2 (69)IBM DB2 for z/OS 作为复制数据服务器 (73)DB2 UDB for z/OS 复制数据服务器环境 (73)DB2 UDB for z/OS 系统管理 (73)DB2 UDB for z/OS 中的复制侵扰和影响 (73)DB2 for z/OS 复制数据库权限 (74)DB2 UDB for z/OS 的复制数据库连接 (74)DB2 for z/OS 中的复制数据库限制 (75)DB2 for z/OS 复制数据库配置 (75)Replication Server 安装 (75)连接配置文件 (76)其它设置 (77)IBM DB2 for Linux, UNIX, and Windows 作为复制数据服务器 (79)DB2 UDB 复制数据服务器 (79)DB2 UDB 中的复制侵扰和影响 (79)DB2 UDB 复制数据库权限和限制 (80)DB2 UDB 复制数据库连接 (80)DB2 UDB 复制数据库配置 (80)Replication Server 安装 (81)连接配置文件 (81)其它设置 (82)IBM DB2 复制数据库的并行 DSI 线程 (83)外部提交控制 (84)目录内部提交控制 (84)事务序列化方法 (84)Microsoft SQL Server 作为复制数据服务器 (89)Microsoft SQL Server 复制数据服务器 (89)对 Microsoft SQL Server 的复制侵扰和影响 (89)对 Microsoft SQL Server 的复制数据库限制 (90)Microsoft SQL Server 复制数据库权限 (91)Microsoft SQL Server 的复制数据库连接性 (91)Microsoft SQL Server 复制数据库配置 (91)Replication Server 安装 (92)连接配置文件 (92)其它设置 (94)Microsoft SQL Server 复制数据库的并行 DSI 线程 (95)外部和内部提交控制 (95)事务序列化方法 (96)Oracle 作为复制数据服务器 (99)Oracle 复制数据服务器 (99)对 Oracle 的复制侵扰和影响 (99)Oracle 复制数据库权限 (100)Oracle 的复制数据库连接性 (100)Oracle 复制数据库配置 (100)Replication Server 安装 (101)连接配置文件 (101)其它设置 (103)Oracle 复制数据库的并行 DSI 线程 (105)外部和内部提交控制 (106)事务序列化方法 (106)SAP IQ 作为复制数据服务器 (109)实时装载解决方案 (109)RTL 编译和批量应用 (110)净更改数据库 (112)RTL 处理和限制 (112)SAP IQ 复制数据服务器 (114)对 SAP IQ 的复制侵扰和影响 (114)目录SAP IQ 的复制数据库连接性 (115)SAP IQ 复制数据库权限 (116)向维护用户 ID 授予权限 (116)SAP IQ 复制数据库配置 (117)Replication Server 安装 (117)启用 RTL (118)RTL 性能调优 (119)增强的重试机制 (122)内存消耗量控制 (122)到 SAP IQ 的多路径复制 (124)创建到 SAP IQ 的替代复制连接 (125)更改或删除替代复制 SAP IQ 连接 (126)显示复制连接信息 (126)复制装载分布 (127)设置分配模型 (127)具有参照约束的表 (128)复制定义创建和改变 (128)显示 RTL 信息 (129)Replication Server 中的系统表支持 (130)混合版本支持和向后兼容性 (130)复制到 SAP IQ 的方案 (131)创建 Interfaces 文件条目 (131)创建测试表 (131)创建到主数据库和复制数据库的连接 (132)启用 RTL (133)将表标记为准备复制测试 (133)创建复制定义和预订 (134)检验 RTL 是否在运行 (135)从 Staging 解决方案迁移到 RTL (135)准备从 staging 解决方案迁移 (136)迁移到实时装载解决方案 (136)迁移后清除 (137)Replication Server 与 SAP IQ InfoPrimer 集成 (138)目录使用 Replication Server 与 SAP IQ InfoPrimer 集成 (138)参数 (143)Replication Server 组件 (144)缺省数据类型转换 (145)不支持的功能 (145)SAP HANA 数据库作为复制数据服务器 (147)SAP HANA 数据库复制数据服务器 (147)对 SAP HANA 数据库的复制侵扰和影响 (147)以 Oracle RAW 和 LONG RAW 作为主键类型 (148)Oracle TIMESTAMP WITH TIME ZONE 数据类型映射 (148)从 Oracle 到 SAP HANA 数据库的连续复制限制 (148)标识列 (148)SAP HANA 数据库复制数据库权限 (148)异构复制环境中的 DDL 复制 (149)表复制定义消除 (149)复制不含唯一键的表中的 LOB 列 (150)ExpressConnect for SAP HANA 数据库和 SAP HANA数据库的复制数据库连接 (150)配置 ExpressConnect for SAP HANA 数据库 (151)ExpressConnect for SAP HANA 数据库许可证发放 (152)跟踪和调试 (152)字符集转换 (152)LOB 指针函数 (153)SAP HANA 数据库复制数据库配置 (153)Replication Server 安装 (153)连接配置文件 (154)其它设置 (156)复制定义中的字符大小写和带引号的标识符配置 (156)异构多路径复制 (159)目录并行事务流 (160)缺省和替代连接 (161)SAP IQ 的 Interfaces 文件要求 (161)专用路由 (161)创建专用路由 (162)管理专用路由的命令 (162)显示专用路由信息 (163)异构多路径复制方案 (164)从 Adaptive Server 到 SAP HANA 数据库的多路径复制 (164)从 Adaptive Server 到 Oracle 的多路径复制 (168)从 Adaptive Server 到 SAP IQ 的多路径复制 (172)从 Oracle 到 Adaptive Server 的多路径复制 (175)从 Oracle 到 SAP HANA 数据库的多路径复制..178从 Oracle 到 Oracle 的多路径复制 (183)从 Oracle 到 SAP IQ 的多路径复制 (186)Oracle 的异构热备份 (191)Oracle 热备份的工作方式 (191)热备份应用程序 (192)热备份要求和限制 (192)用于维护备用数据库的函数字符串 (193)Oracle 热备份应用程序的复制信息 (193)设置热备份数据库 (193)创建逻辑连接 (194)初始化活动数据库的 Replication Agent (195)向复制系统中添加活动数据库 (197)初始化备用数据库 (197)为备用数据库初始化 Replication Agent (197)创建到备用数据库的连接 (199)重新开始到活动数据库和备用数据库的连接 (200)重新开始活动数据库或备用数据库的 ReplicationAgent (200)切换活动数据库和备用数据库 (200)切换活动数据库和备用数据库之前 (201)目录内部切换步骤 (202)切换活动数据库和备用数据库之后 (202)热备份应用程序监控 (203)复制定义和预订 (203)热备份数据库的更多复制定义 (203)预订和热备份应用程序 (204)升级注意事项 (205)降级注意事项 (205)降级后重新开始复制 (205)Oracle 复制数据库重新同步 (207)产品兼容性 (207)配置数据库重新同步 (207)指示 Replication Server 跳过事务 (208)向 Replication Server 发送 Resync Database 标记 (208)获取数据库的转储 (209)向 Replication Server 发送 Dump Database 标记 (211)监控 DSI 线程信息 (211)将转储应用于要重新同步的数据库 (212)重新初始化复制数据库 (212)数据库重新同步方案 (216)直接从主数据库重新同步一个或多个复制数据库 (216)使用第三方转储实用程序重新同步 (218)通过相同转储重新同步主数据库和复制数据库 (219)数据类型转换和映射 (221)同构映射 (221)异构映射 (222)DB2 数据类型 (223)Adaptive Server 到 DB2 数据类型 (223)DB2 到 Adaptive Server 数据类型 (224)从 DB2 到 SAP HANA 数据库 (224)DB2 到 Microsoft SQL Server 数据类型 (226)目录DB2 到 Oracle 数据类型 (226)DB2 的 Replication Server 数据类型名 (227)Microsoft SQL Server 数据类型 (227)Adaptive Server 到 Microsoft SQL Server 数据类型 (228)Microsoft SQL Server 到 DB2 数据类型 (228)Microsoft SQL Server 到 SAP HANA 数据库 (229)Microsoft SQL Server 到 Oracle 数据类型 (231)Microsoft SQL Server 的 Replication Server 数据类型名 (231)Oracle 数据类型 (231)Adaptive Server 到 Oracle 数据类型 (232)Oracle 数据类型到 Adaptive Server 数据类型 (232)Oracle 到 DB2 数据类型 (233)Oracle 到 SAP HANA 数据库 (233)Oracle 数据类型到 Microsoft SQL Server 数据类型 (236)Oracle 的 Replication Server 数据类型名 (236)SAP HANA 数据库数据类型 (236)Adaptive Server 到 SAP HANA 数据库数据类型 (237)实现 (239)实现类型 (239)异构实现 (239)批量实现选项 (240)从主数据库卸载数据 (240)数据类型转换 (241)将数据装载到复制数据库中 (241)原子批量实现 (241)准备实现 (241)执行原子批量实现 (242)非原子批量实现 (243)准备实现 (244)执行非原子批量实现 (244)目录自动更正 (246)直接装载实现 (246)预订和直接装载实现 (248)从 Adaptive Server 到 SAP HANA 数据库的直接装载实现 (248)从非 Adaptive Server 数据库到 SAP HANA 数据库的直接装载实现 (249)直接装载实现配置参数 (251)异构数据库调和 (253)SAP rs_subcmp 实用程序 (253)SAP Replication Server Data Assurance 选件 (253)数据库比较应用程序 (254)排除异构复制系统的故障 (255)入站队列问题 (255)确定未更新入站队列的原因 (255)出站队列问题 (256)确定未更新出站队列的原因 (257)确定未更新复制数据库的原因 (257)HDS 问题和限制 (259)源值超出目标数据类型界限 (259)精确数值数据类型问题 (259)Microsoft SQL Server 中的数值转换和标识列 (261)排除特定错误 (261)rs_lastcommit fail 更新失败 (261)未发生预期的数据类型转换 (262)列值缺失 (263)日志传送语言的生成和跟踪 (264)Oracle 到 Oracle 复制的参考实现 (267)平台支持 (267)Oracle 参考实现组件 (267)验证参考环境的前提条件 (268)Oracle 的参考实现配置文件 (268)词汇表 (269)索引 (281)约定约定SAP®文档中使用以下样式和语法约定。
MongoDB面试题

MongoDB⾯试题1.什么是MongoDBMongoDB是⼀个⽂档数据库,提供好的性能,领先的⾮关系型数据库。
采⽤BSON存储⽂档数据。
BSON()是⼀种类json的⼀种⼆进制形式的存储格式,简称Binary JSON.相对于json多了date类型和⼆进制数组。
2.MongoDB的优势有哪些⾯向⽂档的存储:以 JSON 格式的⽂档保存数据。
任何属性都可以建⽴索引。
复制以及⾼可扩展性。
⾃动分⽚。
丰富的查询功能。
快速的即时更新。
3 什么是数据库 数据库可以看成是⼀个电⼦化的⽂件柜,⽤户可以对⽂件中的数据运⾏新增、检索、更新、删除等操作。
数据库是⼀个所有集合的容器,在⽂件系统中每⼀个数据库都有⼀个相关的物理⽂件。
4.什么是集合(表)集合就是⼀组 MongoDB ⽂档。
它相当于关系型数据库(RDBMS)中的表这种概念。
集合位于单独的⼀个数据库中。
⼀个集合内的多个⽂档可以有多个不同的字段。
⼀般来说,集合中的⽂档都有着相同或相关的⽬的。
5 什么是⽂档(记录) ⽂档由⼀组key value组成。
⽂档是动态模式,这意味着同⼀集合⾥的⽂档不需要有相同的字段和结构。
在关系型数据库中table中的每⼀条记录相当于MongoDB中的⼀个⽂6 MongoDB和关系型数据库术语对⽐图7.什么是⾮关系型数据库 ⾮关系型数据库的显著特点是不使⽤SQL作为查询语⾔,数据存储不需要特定的表格模式。
8 为什么⽤MOngoDB?架构简单没有复杂的连接深度查询能⼒,MongoDB⽀持动态查询。
容易调试容易扩展不需要转化/映射应⽤对象到数据库对象使⽤内部内存作为存储⼯作区,以便更快的存取数据。
9 在哪些场景使⽤MongoDB⼤数据内容管理系统移动端Apps数据管理10 MongoDB中的命名空间是什么意思?mongodb存储bson对象在丛集(collection)中.数据库名字和丛集名字以句点连结起来叫做名字空间(namespace). ⼀个集合命名空间⼜有多个数据域(extent),集合命名空间⾥存储着集合的元数据,⽐如集合名称,集合的第⼀个数据域和最后⼀个数据域的位置等等。
大数据技术概论期末复习题2023-11(附参考答案)(1)

单项选择题1.下列各项不属于数据的是()oA.文本B.图像C.视频D.印象2.下列各项不属于大数据特征的是()。
A.体量大B.种类多C真实性 D.数据生成慢3.数据异常值的处理方法不包括()。
A.极小值替换B删除 C.忽略 D.视为缺失值进行填补4.下列各项不能用于描述数据集中趋势的是()。
A.方差B.平均数C中位数 D.峰值5.下列各项不属于Hadoop的特点是()。
A存储迅速 B.成本高C计算能力强 D.灵活性强6.在工业网络实时监控系统中,需要连续不断地采集和处理数据。
以下()不属于这种计算模式。
A.在线处理B.实时处理C.流式计算D.批量计算7,下面不是研究数据方法的是()。
A统计学 B.机器学习C心理分析 D.数据挖掘8.下面不属于大数据的处理过程的是()。
A.数据获取B.数据清洗C数据分析 D.数据安全9.下面不属于大数据计算模式的类型的是()。
A.批量计算B.手动计算C流式计算 D.交互式计算10.下列各项属于合规数据的是()oA.非法收集隐私信息数据B.取得使用者同意的个人资料数据C泄露的隐私信息数据 D.垄断数据11.在Had∞p生态系统中,主要负责节点集群的任务调度和资源分配,将存储和计算资源分配给不同应用程序的组件是()oA.HDFSB-MapReduce C.YARN D.Storm12.下列属于图数据的主要特性的是()。
A数据驱动计算 B.不规则问题C高数据访问率 D.以上均是13.可以用来查看数值型变量的分布的可视化方法是()。
A箱线图 B.直方图C小提琴图 D.以上方法均可以14.如果只是研究两个数值变量之间的关系,最常见的可视化方法是()。
A直方图 B.散点图C.饼图 D.折线图15.下列各项不属于批处理系统的特点的是()oA.可以实现实时的分析报告或自动响应B.可以实现无缝扩展以处理峰值数据量或数据请求C.支持数据在不同系统之间进行交换D.支持作业执行状态的监控16.下列各项属于非结构化数据的是()oA.图像B.二维数据表CHTM1文档D.以上均是17.在大数据的处理流程中,()步骤是将数据转化为图形,以更直观的方式展示和表达。
数据管理与安全课件浙教版(2019)高中信息技术必修1(共20张PPT)

中国网民数量:7.51亿 半年增长率:2.7%
发布的网页数量:866亿页 年增速:~40%
注册微博用户数 : 2.9071亿
每日新发微 博数量: 1亿+条
手机网民:7.236亿 占网民总数:96.3%
网络直播用户:3.43亿 占网民总数:47.1%
月均网络交易: 16亿笔
大数据概念
图公司(SGI) 的一位科学家正式提出。2016年,数据科学家将大数 据正式定义为:大数据代表着信息量大、速度快、种类繁多的信息资产, 需要特定的技术和分析方法将其转化。为价值。也就是说,大数据之 “大”, 不仅指规模、速度和种类的特征,还意味着它超出以往常用的 数据采集、组织、 管理和加工等软件的处理能力,要求新型集成技术从 多元、复杂和巨量规模的数据集里洞察规律。
1. 大数据的特征可以用被总结为4V特征,以下哪个不属于大数据的
4V特征( )C
A.种类多(Variety) B.体量大(Volume) C.Venture(风险大) D.速度快(Velocity)
2. IBM副总裁Ditetrich曾说过“可以体用社交平台数据获得用户对 某个产品的评价,但往往上百条纪律中只有很小的一部分真正讨论
2 难点:影响数据安全的因素及防护手段。大数 据的思维。
数据管理 是利用计算机硬件和软件技术对数据进行有效收集、存储、处理
和应用的过程。
人工管理
文件管理
数据库管 理
计算机数据管理的三个阶段
计算机一般采用树形目录结构来管理文件,如图1.4.1所示。 在windows系统中,则采用了更为形象的文件夹来管理文件。 如图1.4.2所示。
Thanks
半结构化数据 半结构化数据,就是介 于结构化数据和非结构化数 据之间的数据,具有一定的 结构性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Mongodb 搭建与启动——副本集模式
1
基本架构
正常情况
1
Mongodb 搭建与启动——副本集模式
1
基本架构
主节点挂掉
1
特点:主节点挂掉后, 会从新竞选出新的主节 点。但是主节点压力可 能会很大。
Mongodb 搭建与启动——副本集模式
1
基本架构 特点:读写分 离,主节点负 责写,副节点 负责读,这样 主节点压力会 小很多。但是 交互平凡,节 点压力可能还 是会过大,无 法分担压力。
Mongodb 搭建与启动——主从模式
1
基本架构——单从节点
1
特点:采用双机备 份后主节点挂掉了 后从节点可以接替 主机继续服务。所 以这种模式比单节 点的高可用性要好 很多。但是这种模 式主节点挂了需要 手动切换。
Mongodb 搭建与启动——主从模式
1
基本架构——多从节点
1
特点:主节点挂 掉了后从节点可 以接替主机继续 服务。这种模式 可以起到分担压 力的作用。但是 这种模式主节点 挂了需要手动切 换。目前官方已 经不推荐使用这 种模式。
Infrastructure Cost Engineer Cost
Storage Cost Down, Dev Cost Up
Storage Cost per GB
$120,000 $100,000 $80,000 $60,000 $60,000 $40,000 $40,000 $20,000 $0 1985 2013 $20,000 $0 1985 2013 $100,000 $80,000
10
Schema design
RDBMS: join
11
Schema design
MongoDB: embed and link Embedding is the nesting of objects and arrays inside
a BSON document(prejoined). Links are references between documents(client-side follow-up query). "contains" relationships, one to many; duplication of data, many to many
Mongodb 基本操作——shell
集合创建、查看、删除 #创建集合 方法1: db.createCollection(name, options)
参数 Name Options 字段 capped 类型 String Document 类型 Boolean 描述 (可选)如果为true,则启用封顶集合。封顶集合是固定大小 的集合,会自动覆盖最早的条目,当它达到其最大大小。如果 指定true,则需要也指定尺寸参数。 (可选)如果为true,自动创建索引_id字段的默认值是false。 (可选)指定最大大小字节封顶集合。如果封顶如果是 true, 那么你还需要指定这个字段。 (可选)指定封顶集合允许在文件的最大数量。 描述 要创建的集合名称 (可选)指定有关内存大小和索引选项
Distributed Architecture
Replication /HA
Relational
MongoDB
Horizontal Scaling
We just can't get any faster than the way MongoDB handles our data.
Tony Tam CTO, Wordnik
8
• 技术特点
– – – – – – 面向集合存储,易存储对象类型的数据。 模式自由。 支持动态查询。 支持完全索引,包含内部对象。 支持复制和故障恢复。 使用高效的二进制数据存储,包括大型对象(如视频 等)。 – 自动处理碎片,以支持云计算层次的扩展性。 – 支持RUBY,PYTHON,JAVA,C++,PHP,C#等多 种语言。 – 文件存储格式为BSON(一种JSON的扩展)。
Agility
RDBMS MongoDB
{ _id : ObjectId("4c4ba5e5e8aabf3"), employee_name: "Dunham, Justin", department : "Marketing", title : "Product Manager, Web",
report_up: "Neray, Graha – CouchDB 构建在强大的 B+树储存引擎之上。 这种引擎负责对 CouchDB 中的数据进行排序 ,并提供一种能够在对数均摊时间内执行搜索 、插入和删除操作的机制。 – 数据库的结构独立于模式,依赖于使用视图创 建文档之间的任意关系,使用 Map/Reduce 计 算这些视图的结果 – 在 CouchDB 中没有锁机制,它使用的是多版 本并发性控制(Multiversion concurrency control,MVCC)
autoIndex Boolean ID size max number number
Mongodb 基本操作——shell
{name: “brendan”, aliases: [“el diablo”]}
name: “ben”, hat: ”yes”}
{name: “matt”, pizza: “DiGiorno”, height: 72, loc: [44.6, 71.3]}
MongoDB is easy to use
MySQL MongoDB
START TRANSACTION; INSERT INTO contacts VALUES (NULL, „joeblow‟); INSERT INTO contact_emails VALUES ( NULL, ”joe@”, LAST_INSERT_ID() ), ( NULL, “joseph@”, LAST_INSERT_ID() ); COMMIT;
23
MongoDB Architecture
Drivers & Ecosystem
Support for the most popular languages and frameworks
Java
Ruby
Python
Perl
MEAN Stack Morphia
Sharding and Replication
26
MongoDB Architecture
MongoDB Architecture
MongoDB Architecture
Defense in Depth Security Architecture
30
Mongodb 搭建与启动——单实例模式
1
基本架构
1
特点:这种配置只适合简易开发 时使用,生产使用不行,因为单 节点挂掉整个数据业务全挂
Document数据库
1
2
Document数据库特点及应用
应用场景:web应用等 优点:数据要求不严格,不需要预先定义结构 缺点:查询能力不高,缺乏统一的查询语法
3
• 可以通过 JavaScript Object Notation (JSON) API 访问 • “Couch” = “Cluster Of Unreliable Commodity Hardware” ,目标具有高度可伸缩性,提供了高可用性 和高可靠性,即使运行在容易出现故障的硬件上也是如此 • 特点
1
Mongodb 搭建与启动——分片(sharding)
1
分片简介 mongodb采用将集合进行拆分,然后将拆分的数据均摊到几 个片上的一种解决方案。
1
Mongodb 搭建与启动——副本集+分片集群
1
简易架构
Mongodb集群
Mongodb 基本操作
Mongodb客户端工具 1.Mongodb 自带JavaScript Shell工具:
pay_band: “C", benefits : [ { { type : type : "Health", "Dental", ] } plan : "PPO Plus" }, plan : "Standard" }
Optimize for Engineer Productivity
1985
2013
9
Data model: Using BSON (binary JSON), developers
can easily map to modern object-oriented languages without a complicated ORM layer. BSON is a binary format in which zero or more key/value pairs are stored as a single entity. lightweight, traversable, efficient
2.第三方图形化工具:MongVUE
Mongodb 基本操作
Mongodb 基本操作——shell
数据库创建、切换、查看、删除 #创建数据库 use DATABASE_NAME #查看当前数据库 >db DATABASE_NAME #查看所有数据库 >show dbs #删除数据库 >db.dropDatabase()
22
High Availability
Automated replication and failover
Multi-data center support
Improved operational simplicity (e.g., HW swaps)