Application of anomaly detection algorithms for detecting SYN flooding attacks
Anomaly Detection via Optimal Symbolic Observation of Physical Processes

Anomaly Detection via Optimal SymbolicObservation of Physical Processes∗Humberto E.Garcia and Tae-Sic YooSensor,Control,and Decision Systems GroupIdaho National LaboratoryIdaho Falls,ID83415-6180{humberto.garcia}@AbstractThe paper introduces a symbolic,discrete-event approach for online anomaly detection.The approach uses automata representations of the underlying physicalprocess to make anomaly occurrence determination.Automata may represent adiscrete-event formulation of the operation of the monitored system during bothnormal and abnormal conditions.Automata may also be constructed from gener-ated symbol sequences associated with parametric variations of equipment.Thiscollection of automata represents the symbolic behavior of the underlying physicalprocess and can be used as a pattern for anomaly detection.Within the possible be-havior,there is a special sub-behavior whose occurrence is required to detect.Thespecial behavior may be specified by the occurrence of special events representingdeviations of anomalous behaviors from the nominal behavior.These intermit-tent or non-persistent events or anomalies may occur repeatedly.An observationmask is then defined,characterizing the actual observation configuration availablefor collecting symbolic process data.The analysis task is to determine whetherthis observation configuration is capable of detecting the specified anomalies.Theassessment is accomplished by evaluating several observability notions,such asdetectability and diagnosability.To this end,polynomial-time,computationally-efficient verification algorithms have been developed.The synthesis of optimalobservation masks can also be conducted to suggest an appropriate observationconfiguration guaranteeing the detection of anomalies and to construct associatedmonitoring agents for performing the specified on-line condition monitoring task.The proposed discrete-event approach and supporting techniques for anomaly de-tection via optimal symbolic observation of physical processes are briefly presentedand illustrated with examples.1IntroductionCondition monitoring and anomaly detection are essential for the prevention of cascading failures but also for the assurance of acceptable operations dynamics and the improve-ment of process reliability,availability,performance,and cost.Anomaly detection is also a key element for strengthening nuclear non-proliferation objectives and for deploying∗This work was supported by the U.S.Department of Energy contract DE-AC07-05ID14517advanced proliferation detection measures such as nuclear operations accountability[2]. An anomaly can be defined as a deviation from a system nominal behavior.Three types of anomalies are considered here.First,anomalies may be associated with parametric or non-parametric changes evolving in system components.Lubricant viscosity changes, bearing damages,and structural fatigues are examples in this category.Second,anoma-lies may be associated with violations executed during operations that are opposite to demanded operability specifications.For example,a specification may be to avoid start-ing a given pump when its associated down-stream valve is closed.If a command is sent to start the pump when its valve is closed,this condition needs to be monitored and reported(and possibly aborted).Third,anomalies may be associated with the occur-rence of special events or behaviors.One relevantfield is failure analysis,in which special events are identified as faults.Other examples of special behaviors include(permanent) failures,execution of critical events,reaching unstable states,or more generally meeting formal specifications defining anomalies or special behaviors.To detect anomalies(including the three types mentioned above),it is needed not only a set of sensors(i.e.,a sensor configuration)to retrieve process data but also an observer to integrate and analyze the collected process information.Thus,optimizing sensor configurations and rigorously synthesizing their corresponding observers are important design goals in on-line condition monitoring.One relevantfield is failure analysis,in which special events are identified as faults.Recently,significant attention has been given to anomaly detection and fault analysis;see for example[1-10]and their references.The definition of diagnosability based on failure-event specifications wasfirst introduced in [8].Variations to the initial definition in[8]have been proposed recently.Failure states are introduced in[10]and the notion of diagnosability is accordingly redefined.The issue of diagnosing repeatedly and the associated notion of[1,∞]-diagnosability arefirst introduced in[5],along with a polynomial algorithm for checking it.To improve the complexity of previously-reported algorithms,which severely restricts their applicability, methods and an associated tool have been developed that utilizes the approach introduced in[9]for checking[1,∞]-diagnosability with the reduced complexity.Recently,techniques in symbolic time series analysis[7]have been proposed to reformulate the problem of anomaly detection from a time series setup to a discrete event framework,upon which the above developed algorithms can be utilized.This transformation allows to deal with complex processes and information systems in a more efficient manner by abstracting monitored systems/signals into simpler and rigorous mathematical representations.This paper builds upon the above efforts to introduce a rigorous methodology for opti-mizing sensor configurations and synthesizing associated observers meeting given system property requirements regarding on-line condition monitoring.Applications include su-pervisory observation and event/anomaly detection.2Problem StatementIn anomaly detection applications,the objective is to detect abnormal conditions occur-ring within the monitored system by analyzing observable process data.To this end, models are often constructed to characterize normal and abnormal behaviors.A model may represent the possible and unacceptable operational dynamics of a monitored pro-cess.Finite state machine(FSM)representations of system components(e.g.,tanks, valves,and pumps)can be formulated and composed to describe relevant operations of the integrated system(e.g.,a nuclear fuel reprocessing installation).For example,opera-tions models may define the expected changes on the state of a tank based on the states of associated valves and pumps.Operation models may also represent entityflow descrip-tions defined for a given routing network regarding possible and special item transfers (e.g.,violations or critical movements).Models may also be generated from symbolic string generations characterizing variations on representative parameters associated with process signals.In this case,time series data from a signal may be symbolized into discrete symbolic strings.This symbolization may be accomplished using wavelet trans-form,for example.In particular,coefficients of the wavelet transform of the time-domain signal are utilized for symbol generation instead of directly using the time series data[7]. Variations in the monitored signal is thus detected as variations of its associated wavelet coefficients.From the symbol sequences,a FSM model can then be constructed.Meth-ods have been proposed for encoding the underlying process dynamics from observed time series data and for constructing FSM models from symbolic sequences.Within the scope of this paper,the mentioned models are formulated as discrete event systems (DES)in order to describe their dynamics at a higher level of abstraction,reduce compu-tational complexity,and benefit from a developed mathematical framework suitable for computing optimal sensor configurations and synthesizing their corresponding observers.In either symbolic time series analysis or event/specification violation detection,the objective is to detect whether a special event or an operability specification violation has occurred by recording and analyzing observable events.System behavior is often divided into two mutually exclusive components,namely,the special behavior of interest(needed to be detected)and the ordinary behavior(which does not need to be reported).To accomplish the task of online anomaly detection,two design elements must be addressed. Thefirst element is the identification of the observational information required by an ob-server to determine whether a special event or an operability specification violation has occurred.The second element is the construction of the associated observer algorithm that automatically integrates and analyzes collected data to assess system condition.To improve information management and cost,the design goal is to construct a monitoring observer with a detection capability that relies on not only current measurements but also on recorded knowledge built from past observations.It is then important to rig-orously assess whether the monitored DES is intrinsically observable for a given sensor configuration and special behavior of interest.Otherwise,the task is to identify opti-mized observation configurations that meet given observability property requirements. The related cost functional may be based on different design criteria,such as costs and implementation difficulties of considered sensor technologies.3Proposed Anomaly Detection ApproachA methodology and associated tool have been developed to identify optimal sensor con-figurations and associated observers for detecting anomalies.The developed framework requiresfirst formal descriptions of the given monitored DES,(observability)property requirements,and observational constraints as shown in Fig. 1.Property requirements may include meeting detectability(e.g.,[8])or/and supervisory observability(e.g.,[6]) objectives,for example.Given these descriptions,optimized observational configura-tions and associated algorithms for data integration and analysis can be systematically computed that meet the specified property requirements.To formalize the monitored process,a DES model G must be constructed defining how system states change due to event occurrences.Other design elements are requested by the developed framework ac-Figure1:Flow chart of developed sensor optimization frameworkcording to the optimization task at hand.For example,in the case of designing observers for determining whether given operability specifications are being met during operations, one element must be specified,namely,the set of operability specifications S that should be preserved at all times(the intrinsic observability property P here is supervisory ob-servability).Similarly,in the case of designing sensor configurations for event detection applications,two elements must be specified,namely,the set of anomalies or special events S requiring detection and the intrinsic observability property P(i.e.,detectability or diagnosability)regarding S.To formalize observational constraints,a cost functional C should be included indicating the costs associated with observation devices.Given G, S,P,and C,the design task is to compute an observational configuration or observation mask M that guarantees P of S with respect to G,while optimizing C.This mask M defines an underlying observational configuration required to assure the observability of anomalies or the detection of operability violations.After a suitable observation mask M has been computed,the implementation task is to construct an observer O that will guarantee P of S by observing G via the observation mask M.The use of the proposed methodology in computing optimized sensor configurations for anomaly detection can be summarized as follows.For verification,the developed technology assesses whether a given observation configuration assures the observability of special behaviors within possible system behaviors(Fig.2.(a)).For design,the methodology identifies,for each event,which attributes need to be observed and suggests an optimal observation con-figuration meeting the specified on-line condition monitoring requirements(Fig.2.(b)).(a)Verification(b)DesignFigure2:Use of developed framework for event detection applications4Observability in Anomaly Detection4.1PreliminaryDenote by G the FSM model of the monitored system considered,with G={X,Σ,δ,x0}, where X is afinite set of states,Σis afinite set of event labels,δ:X×Σ→X is a partial transition function,and x0∈X is the initial state of the system.The symbol denotes the silent event or the empty trace.This model G accounts for both the ordinary(non-special)and special behavior of the monitored system,for example.To model observational limitations,an observation mask function M:Σ→∆∪{ }is introduced,where∆is the set of observed symbols.4.2DefinitionsLet S denote the set of either operability specifications,which should be met,or special events,which should be detected.In the case of event detection,special events can occur repeatedly,so they need to be detected repeatedly.It is assumed that events in S are not fully-observable because otherwise they could be detected/diagnosed trivially.Under supervisory observability,the interest is in signaling the occurrence of viola-tions to operability specifications.Under detectability,the interest is in signaling the occurrence of special events,but without explicitly indicating which event exactly has occurred.Diagnosability is a refined case of detectability,where the interest often is in exact event identification.The developed mathematical framework can be used to evalu-ate different system properties.To illustrate,let’s assume we are interested in the event detectability property termed[1,∞]-diagnosability(defined next)of a given monitored system.The proposed methodology then utilizes the polynomial algorithm described in [9]for checking this notion.Other notions can also be checked,including the observability of a given system regarding operability specifications,for example.Definition1(Uniformly bounded delay)[1,∞]-Diagnosability[5,9]A symbolic string(or language L)generated by a monitored system G is said to be uni-formly[1,∞]-diagnosable with respect to a mask function M and a special-event partitionΠs on S if the following holds:(∃n d∈N)(∀i∈Πs)(∀s∈L)(∀t∈L/s)[|t|≥n d⇒D∞] where N is the set of non-negative integers and the condition D∞is given by:D∞:(∀w∈M−1M(st)∩L)[N iw ≥N is].The above definition assumes the following necessary notation.For allΣsi∈Πs and atrace s∈L,let N is denote the number of events in s that belongs to the special eventtypeΣsi(or i for simplicity).The post-language L/s is the set of possible suffixes of a trace s;i.e.,L/s:={t∈(Σ)∗:st∈L}.4.3Optimal Sensor ConfigurationsThe problem of selection of an optimal mask function is studied in[4].Assuming a mask-monotonicity property,it introduces two algorithms for computing an optimal mask func-tion.However,these algorithms assume that a sensor set supporting the mask function can be always found,which may not be true in practice.Given the above considerations, the developed framework utilizes instead the algorithm introduced in[1].This algorithm searches the sensor set space rather than the mask function space.The computed sen-sor set induces a mask function naturally.Thus,it does not suffer from the issue of realization of the mask function.4.4Implementing Symbolic ObservationThe design task leads into a twofold objective:i)to compute objective-driven sensor con-figurations that optimize given information costs,and ii)to construct formal observers that guarantee the detectability of special events,specification violations,or anomalies, in general.The key design issue is then the management of sensor deployments.After computing an acceptable M that guarantees the desired property requirement(e.g.,su-pervisory observability,detectability,or diagnosability)using the optimization algorithm of Fig.1,an associated observer O is constructed.In event detection applications,for example,the observer algorithm will integrate and analyze observed event information (or measurements)and report the occurrences of special events.In supervisory control applications,the observer estimates system state and determines whether events executed by the monitored system violate given operability specifications.To implement the observer,either an offline or an online design approach may be used for its construction.Under an offline design approach,the deterministic automa-ton representation of the observer is a priori constructed,task that may be of a high computational complexity.To overcome computational complexity,an online approach may be used instead,as proposed in[5].Further improving[5]regarding computational complexity,the developed framework utilizes an improved version of the algorithm re-ported in[9].The proposed mathematical construction of observers can thus guarantee the fulfilment of given observability requirements regarding the detection of anomalies. 5Illustrative ApplicationsTo illustrate the notion of anomaly detection via optimal symbolic observation of physical processes,an application in specification violation detection and another in event detec-tion are briefly introduced next.Due to page limitation,no application of the proposed approach to symbolic time series analysis is discussed.5.1Specification Violation DetectionConsider the monitored system illustrated in Fig.3.This system consists of a pump, a tank,two valves,and interconnecting pipes.The monitored system may represent a portion of a nuclear fuel reprocessing facility,for example.The basic operation of this system is as follows.With Valve1open and Valve2close,the pump starts and operates in order tofill the tank by pumping afluid from an up-stream reservoir(not shown). When the tank is full,the pump should stop,Valve1should close,and Valve2should open until the tank is emptied;the cycle then repeats.Assume that there is the need to monitor the system and detect the possible violation of three operability specifications. In particular,Spec.1delineates that the pump should not start when Valve1is closed; Spec.2delineates that Valve1should not be closed when the pump is running;and Spec.3delineates the basic system operation described earlier.The synthesis task is to compute an optimized sensor configuration and associated observer to conduct this anomaly detection.To this end,DES models of each component(i.e.,pump,tank,valve 1,valve2)and their interactions are constructed.FSMs of the concerned specifications are also formulated.The developed framework then automatically determines minimal sets of events(and associated observers)that need to be observed to achieve the desired on-line condition monitoring task.For example,using the proposed methodology,it was determined that Valve2does not need to be observed(hence no sensor for Valve 2is needed)in order for the monitoring system to make a determination on whether a specification violation has occurred.Figure3:Monitored system under specification violation detection5.2Event/Anomaly DetectionConsider the monitored system illustrated in Fig.4(a).This system consists of one input port,I1,four internal stations,S i,i=1,2,3,and4,and two output ports,O1and O2.This system may represent a nuclear reprocessing facility or a nuclear power plant site,for example.Two authorized routes,(1)or(2),are identified in Fig.4(a).Under route(1),an item should enter the monitored system through the input port I1,move sequentially to locations S1and S3,and move either to location S2or S4;if it goes to S2, then an item may either exit through the output port O2or continue to location S4;if at location S4,it should exit through the output port O1.Under route(2),an item shouldenter the monitored system through the input port I1,move sequentially to locations S1, S2,and S3;it may then exit through the output port O2or continue to location S4,from which it should exit through the output port O2.Besides the normal(non-special)item(a)Monitored System(b)Ad-hoc Sensor Placement SolutionFigure4:Monitored system and ad-hoc sensor placement solution movements shown,assume that the two item transfer anomalies labeled with an S(for special)in Fig.4(a)(i.e.,1S and2S)are also possible.The design objective is to identify observation configurations(i.e.,set of sensors and locations)M that provide sufficient tracking information to an observer O for detecting the occurrence of any anomaly defined in S.For comparison,Fig.4(b)illustrates a sensor configuration that would allow an observer to immediately detect any anomaly after its occurrence.Three sensor types are shown for retrieving item movement data.“Circle,”“square,”and“triangular”sensors provide current item locations,previous item locations,and item types,respectively.This configuration may result from conducting an ad hoc design,without a rigorous analysis of the anomaly detection problem at hand.It is desired to determine whether there are other(objective-driven)sensor configurations with reduced information requirement and optimal information management.To this end,the possible-behavior model G of the system illustrated in Fig.4(a)is constructed.The monitoring goal P regarding the set of special events S is also specified.Finally,an information cost C criterion is formulated.The developed framework is then invoked to compute an observation mask M that optimizes C and meets P.Figs.5illustrate optimized sensor configurations and the reduction in the observational requirement M that may be obtained when selecting detectability rather than diagnosability of S as the observability goal P.The imposed cost objective C is to reduce information requirements and preferably exclude sensors that communicate item previous locations(i.e.,avoid using square sensors).Figs.6 show the effect of sensor reliability on required sensor configurations for meeting a given detection confidence requirement.In particular,Figs.6suggest that as the reliability of circle sensors(implemented as motion sensors,for example)decreases,more sensors may be required to meet the specified observability requirements.While the monitored system used in this example corresponds to an itemflow process,the DES model G used could have also been a high level representation of any other physical process.Numerous simulations were conducted with different M and corresponding O for given P and C,under both event and specification violation detection applications.Asguaranteed by the mathematical setting of the developed framework,the observer was always capable to meet the given observability requirements.(a)Diagnosability(b)DetectabilityFigure5:Optimized Sensor Placements:Case of reliable sensors(a)Sensor reliability≥60%(b)40%≤Sensor reliability≤60%Figure6:Optimized Sensor Placements:Case of unreliable sensors6ConclusionAn approach to anomaly detection via optimal symbolic observation of physical pro-cesses was presented.Symbolic,discrete-event reformulation of the problem of anomaly detection is suggested to deal with system complexities and utilize a rigorous framework where optimal sensor configurations and associated observers for on-line condition mon-itoring can be synthesized.The proposed methodology can thus be used to answer the question of how to optimally instrument a given monitored system.This design and im-plementation approach opens the possibility for information management optimization to reduce costs,decrease intrusiveness,and enhance automation,for example.Further-more,it provides rich analysis capability(enabling optimization,sensitivity,what-if,andvulnerability analysis),guarantees mathematical consistency and intended monitoring performance,yields a systematic method to deal with system complexity,and enables portability of condition monitoring.Briefly mentioned here,future research involves the extension of the proposed approach into the symbolic time series analysis paradigm. References[1]H.E.Garcia and T.Yoo,“Model-based detection of routing events in discreteflownetworks,”Automatica,41:583-594,2005.[2]H.E.Garcia and T.Yoo,“Option:a software package to design and implementoptimized safeguards sensor configurations,”In Proc.45th INMM Annual Meeting, Orlando,FL,Jul18-22,2004.[3]H.E.Garcia and T.Yoo,“A methodology for detecting routing events in discreteflownetworks,”In Proc.2004American Control Conf.,2004.[4]S.Jiang,R.Kumar,and H.E.Garcia,“Optimal sensor selection for discrete eventsystems with partial observation,”IEEE Trans.Autom.Control,48(3):369-381,2003.[5]S.Jiang,R.Kumar,and H.E.Garcia,“Diagnosis of repeated/intermittent failures indiscrete event systems,”IEEE Trans.Robotics and Automation,19(2):310-323,2003.[6]F.Lin and W.M.Wonham,“On observability of discrete-event systems,”InformationSciences,44(3):173-198,1988.[7]A.Ray,“Symbolic dynamic analysis of complex systems for anomaly detection,”Signal Processing,84:1115-1130,2004.[8]M.Sampath,R.Sengupta,K.Sinnamohideen,fortune,and D.Teneketzis,“Di-agnosability of discrete event systems,”IEEE Trans.Autom.Control,40(9):1555-1575,1995.[9]T.Yoo and H.E.Garcia,“Event diagnosis of discrete event systems with uniformlyand nonuniformly bounded diagnosis delays,”In Proc.2004American Control Conf., 2004.[10]S.H.Zad,“Fault diagnosis in discrete event and hybrid systems,”Ph.D.thesis,University of Toronto,1999.。
Anomaly Detection

Andrew Ng
Aircraft engines motivating example 10000 good (normal) engines 20 flawed engines (anomalous)
Training set: 6000 good engines CV: 2000 good engines ( ), 10 anomalous ( Test: 2000 good engines ( ), 10 anomalous ( ) )
• Monitoring machines in a data center
Andrew Ng
Anomaly detection
Choosing what features to use
Machine Learning
Non-gaussian features
Error analysis for anomaly detection Want large for normal examples . small for anomalous examples . Most common problem: is comparable (say, both large) for normal and anomalous examples
:
Anomaly if
Andrew Ng
Anomaly detection example
Andrew Ng
Anomaly detection
Developing and evaluating an anomaly detection system
Machine Learning
The importance of real-number evaluation When developing a learning algorithm (choosing features, etc.), making decisions is much easier if we have a way of evaluating our learning algorithm. Assume we have some labeled data, of anomalous and nonanomalous examples. ( if normal, if anomalous). Training set: anomalous) Cross validation set: Test set: (assume normal examples/not
参考文献——精选推荐

参考⽂献[1] Meng W., Wei J., Luo X., et al. Separation of β-agonists in pork on a weak cation exchange column by HPLC with fluorescence detection. Analytical Methods,2012, 4(4): 1163.[2] 聂建荣, 朱铭⽴, 连槿, 等. ⾼效液相⾊谱-串联质谱法检测动物尿液中的15 种β-受体激动剂. ⾊谱,2010, 28(8): 759-764.[3] Traynor I., Crooks S., Bowers J., et al. Detection of multi-β-agonist residues in liver matrix by use of a surface plasma resonance biosensor. Analytica Chimica Acta,2003, 483(1): 187-191. [4] Kuiper H., Noordam M., van Dooren-Flipsen M., et al. Illegal use of beta-adrenergic agonists: European Community. Journal of Animal Science,1998, 76(1): 195-207.[5] Watkins L., Jones D., Mowrey D., et al. The effect of various levels of ractopamine hydrochloride on the performance and carcass characteristics of finishing swine. Journal of Animal Science,1990, 68(11): 3588-3595.[6] Parr M. K., Opfermann G., Sch?nzer W. Analytical methods for the detection of clenbuterol. Bioanalysis,2009, 1(2): 437-450.[7] López-Mu?oz F., Alamo C., Rubio G., et al. Half a century since the clinical introduction of chlorpromazine and the birth of modern psychopharmacology. Prog Neuropsychopharmacol Biol Psychiatry,2004, 28(1): 205-208.[8] Goodman L., Gilman A. The pharmacological basis of therapeutics, 7th edn Macmillan. New York,1980: 1054-1105.[9] 王春燕. ⽑细管电泳—电化学发光检测吩噻嗪类药物的研究. 长春理⼯⼤学, 2006.[10] 孙雷, 张骊, 徐倩, et al. 超⾼效液相⾊谱-串联质谱法检测猪⾁和猪肾中残留的10 种镇静剂类药物. ⾊谱,2010, 28(1): 38-42.[11] 顾华兵, 谢洁, 彭涛, et al. 鸡⾁组织中氯丙嗪残留的HPLC-MS/MS 检测⽅法的建⽴. 中国家禽,2014, 36(15): 33-36.[12] Mitchell G., Dunnavan G. Illegal use of beta-adrenergic agonists in the United States. Journal of Animal Science,1998, 76(1): 208-211.[13] Directive C. Council Directive 96/23/EC of 29 April 1996 on measures to monitor certain substances and residues thereof in live animals and animal products and repealing Directives 85/358/EEC and 86/469/EEC and Decisions89/187/EEC and 91/664/EEC. Official Journal L125,1996, 23(5): 10-32.[14] 农业部, 卫⽣部. 禁⽌在饲料和动物饮⽤⽔中使⽤的药物品种⽬录[Z] 农业部公告[2002] 176 号. 2002.[15] Damasceno L., Ventura R., Cardoso J., et al. Diagnostic evidence for the presence of β-agonists using two consecutive derivatization procedures and gas chromatography–mass spectrometric analysis. Journal of Chromatography B,2002,780(1): 61-71.[16] 王培龙. β-受体激动剂及其检测技术研究. 农产品质量与安全,2014, 1): 44-52.[17] Wang L.-Q., Zeng Z.-L., Su Y.-J., et al. Matrix effects in analysis of β-agonists with LC-MS/MS: influence of analyte concentration, sample source, and SPE type. Journal of Agricultural and Food Chemistry,2012, 60(25): 6359-6363.[18] Shao B., Jia X., Zhang J., et al. Multi-residual analysis of 16 β-agonists in pig liver, kidney and muscle by ultra performance liquid chromatography tandem mass spectrometry. Food Chemistry,2009, 114(3): 1115-1121.[19] Josefsson M., Sabanovic A. Sample preparation on polymeric solid phase extraction sorbents for liquid chromatographic-tandem mass spectrometric analysis of human whole blood--a study on a number of beta-agonists and beta-antagonists. Journal of Chromatography A 2006, 1120(1-2):1-12.[20] Zhang Z., Yan H., Cui F., et al. Analysis of Multiple β-Agonist and β-Blocker Residues in Porcine Muscle Using Improved QuEChERS Method and UHPLC-LTQ Orbitrap Mass Spectrometry. Food Analytical Methods,2015: 1-10. [21] Wang P., Liu X., Su X., et al. Sensitive detection of β-agonists in pork tissue with novel molecularly imprinted polymer extraction followed liquid chromatography coupled tandem mass spectrometry detection. Food chemistry,2015, 184(72-79.[22] Li T., Cao J., Li Z., et al. Broad screening and identification of beta-agonists in feed and animal body fluid and tissues using ultra-high performance liquid chromatography-quadrupole-orbitrap high resolution mass spectrometry combined with spectra library search. Food Chem,2016, 192(188-196.[23] Xiong L., Gao Y.-Q., Li W.-H., et al. A method for multiple identification of four β2-Agonists in goat muscle and beefmuscle meats using LC-MS/MS based on deproteinization by adjusting pH and SPE for sample cleanup. Food Science and Biotechnology,2015, 24(5): 1629-1635.[24] Zhang Y., Zhang Z., Sun Y., et al. Development of an Analytical Method for the Determination of β2-Agonist Residues in Animal Tissues by High-Performance Liquid Chromatography with On-line Electrogenerated [Cu (HIO6) 2] 5--Luminol Chemiluminescence Detection. Journal of Agricultural and Food chemistry,2007, 55(13): 4949-4956.[25] Liu W., Zhang L., Wei Z., et al. Analysis of beta-agonists and beta-blockers in urine using hollow fibre-protected liquid-phase microextraction with in situ derivatization followed by gas chromatography/mass spectrometry. Journal of Chromatography A 2009, 1216(28): 5340-5346. [26] Caban M., Mioduszewska K., Stepnowski P., et al. Dimethyl(3,3,3-trifluoropropyl)silyldiethylamine--a new silylating agent for the derivatization of beta-blockers and beta-agonists in environmental samples. Analytica Chimica Acta,2013, 782(75-88.[27] Caban M., Stepnowski P., Kwiatkowski M., et al. Comparison of the Usefulness of SPE Cartridges for the Determination of β-Blockers and β-Agonists (Basic Drugs) in Environmental Aqueous Samples. Journal of Chemistry,2015, 2015([28] Zhang Y., Wang F., Fang L., et al. Rapid determination of ractopamine residues in edible animal products by enzyme-linked immunosorbent assay: development and investigation of matrix effects. J Biomed Biotechnol,2009, 2009(579175.[29] Roda A., Manetta A. C., Piazza F., et al. A rapid and sensitive 384-microtiter wells format chemiluminescent enzyme immunoassay for clenbuterol. Talanta,2000, 52(2): 311-318.[30] Bacigalupo M., Meroni G., Secundo F., et al. Antibodies conjugated with new highly luminescent Eu 3+ and Tb 3+ chelates as markers for time resolved immunoassays. Application to simultaneous determination of clenbuterol and free cortisol in horse urine. Talanta,2009, 80(2): 954-958.[31] He Y., Li X., Tong P., et al. An online field-amplification sample stacking method for the determination of β 2-agonists in human urine by CE-ESI/MS. Talanta,2013, 104(97-102.[32] Li Y., Niu W., Lu J. Sensitive determination of phenothiazines in pharmaceutical preparation and biological fluid by flow injection chemiluminescence method using luminol–KMnO 4 system. Talanta,2007, 71(3): 1124-1129.[33] Saar E., Beyer J., Gerostamoulos D., et al. The analysis of antipsychotic drugs in humanmatrices using LC‐MS (/MS). Drug testing and analysis,2012, 4(6): 376-394.[34] Mallet E., Bounoure F., Skiba M., et al. Pharmacokinetic study of metopimazine by oral route in children. Pharmacol Res Perspect,2015, 3(3): e00130.[35] Thakkar R., Saravaia H., Shah A. Determination of Antipsychotic Drugs Known for Narcotic Action by Ultra Performance Liquid Chromatography. Analytical Chemistry Letters,2015, 5(1): 1-11.[36] Kumazawa T., Hasegawa C., Uchigasaki S., et al. Quantitative determination of phenothiazine derivatives in human plasma using monolithic silica solid-phase extraction tips and gas chromatography–mass spectrometry. Journal of Chromatography A,2011, 1218(18): 2521-2527.[37] Flieger J., Swieboda R. Application of chaotropic effect in reversed-phase liquid chromatography of structurally related phenothiazine and thioxanthene derivatives. J Chromatogr A,2008, 1192(2): 218-224.[38] Tu Y. Y., Hsieh M. M., Chang S. Y. Sensitive detection of piperazinyl phenothiazine drugs by field‐amplified sample stacking in capillary electrophoresis with dispersive liquid–liquid microextraction. Electrophoresis,2015, 36(21-22): 2828-2836.[39] Geiser L., Veuthey J. L. Nonaqueous capillary electrophoresis in pharmaceutical analysis. Electrophoresis,2007, 28(1‐2): 45-57.[40] Lara F. J., García‐Campa?a A. M., Gámiz‐Gracia L., et al. Determination of phenothiazines in pharmaceutical formulations and human urine using capillary electrophoresis with chemiluminescence detection. Electrophoresis,2006,27(12): 2348-2359.[41] Lee H. B., Sarafin K., Peart T. E. Determination of beta-blockers and beta2-agonists in sewage by solid-phase extraction and liquid chromatography-tandem mass spectrometry. J Chromatogr A,2007, 1148(2): 158-167.[42] Meng W., Wei J., Luo X., et al. Separation of β-agonists in pork on a weak cation exchange column by HPLC with fluorescence detection. Analytical Methods,2012, 4(4): 1163-1167. [43] Yang F., Liu Z., Lin Y., et al. Development an UHPLC-MS/MS Method for Detection of β-Agonist Residues in Milk. Food Analytical Methods,2011, 5(1): 138-147.[44] Quintana M., Blanco M., Lacal J., et al. Analysis of promazines in bovine livers by high performance liquid chromatography with ultraviolet and fluorimetric detection. Talanta,2003, 59(2): 417-422.[45] Tanaka E., Nakamura T., Terada M., et al. Simple and simultaneous determination for 12 phenothiazines in human serum by reversed-phase high-performance liquid chromatography. J Chromatogr B Analyt Technol Biomed Life Sci,2007, 854(1-2): 116-120.[46] Kumazawa T., Hasegawa C., Uchigasaki S., et al. Quantitative determination of phenothiazine derivatives in human plasma using monolithic silica solid-phase extraction tips and gas chromatography-mass spectrometry. J ChromatogrA,2011, 1218(18): 2521-2527.[47] Qian J. X., Chen Z. G. A novel electromagnetic induction detector with a coaxial coil for capillary electrophoresis. Chinese Chemical Letters,2012, 23(2): 201-204.[48] Baciu T., Botello I., Borrull F., et al. Capillary electrophoresis and related techniques in the determination of drugs of abuse and their metabolites. TrAC Trends in Analytical Chemistry,2015, 74(89-108.[49] Sirichai S., Khanatharana P. Rapid analysis of clenbuterol, salbutamol, procaterol, and fenoterol in pharmaceuticals and human urine by capillary electrophoresis. Talanta,2008, 76(5):1194-1198.[50] Toussaint B., Palmer M., Chiap P., et al. On‐line coupling of partial filling‐capillary zone electrophoresis with mass spectrometry for the separation of clenbuterol enantiomers. Electrophoresis,2001, 22(7): 1363-1372.[51] Redman E. A., Mellors J. S., Starkey J. A., et al. Characterization of Intact Antibody Drug Conjugate Variants using Microfluidic CE-MS. Analytical chemistry,2016.[52] Ji X., He Z., Ai X., et al. Determination of clenbuterol by capillary electrophoresis immunoassay with chemiluminescence detection. Talanta,2006, 70(2): 353-357.[53] Li L., Du H., Yu H., et al. Application of ionic liquid as additive in determination of three beta-agonists by capillary electrophoresis with amperometric detection. Electrophoresis,2013, 34(2): 277-283.[54] 张维冰. ⽑细管电⾊谱理论基础. 北京:科学出版社,2006.[55] Anurukvorakun O., Suntornsuk W., Suntornsuk L. Factorial design applied to a non-aqueous capillary electrophoresis method for the separation of beta-agonists. J Chromatogr A,2006, 1134(1-2): 326-332.[56] Shi Y., Huang Y., Duan J., et al. Field-amplified on-line sample stacking for separation and determination of cimaterol, clenbuterol and salbutamol using capillary electrophoresis. J Chromatogr A,2006, 1125(1): 124-128.[57] Chevolleau S., Tulliez J. Optimization of the separation of β-agonists by capillary electrophoresis on untreated and C 18 bonded silica capillaries. Journal of Chromatography A,1995, 715(2): 345-354.[58] Wang W., Zhang Y., Wang J., et al. Determination of beta-agonists in pig feed, pig urine and pig liver using capillary electrophoresis with electrochemical detection. Meat Sci,2010, 85(2): 302-305.[59] Lin C. E., Liao W. S., Chen K. H., et al. Influence of pH on electrophoretic behavior of phenothiazines and determination of pKa values by capillary zone electrophoresis. Electrophoresis,2003, 24(18): 3154-3159.[60] Muijselaar P., Claessens H., Cramers C. Determination of structurally related phenothiazines by capillary zone electrophoresis and micellar electrokinetic chromatography. Journal of Chromatography A,1996, 735(1): 395-402.[61] Wang R., Lu X., Xin H., et al. Separation of phenothiazines in aqueous and non-aqueous capillary electrophoresis. Chromatographia,2000, 51(1-2): 29-36.[62] Chen K.-H., Lin C.-E., Liao W.-S., et al. Separation and migration behavior of structurally related phenothiazines in cyclodextrin-modified capillary zone electrophoresis. Journal of Chromatography A,2002, 979(1): 399-408.[63] Lara F. J., Garcia-Campana A. M., Ales-Barrero F., et al. Development and validation of a capillary electrophoresis method for the determination of phenothiazines in human urine in the low nanogram per milliliter concentration range using field-amplified sample injection. Electrophoresis,2005, 26(12): 2418-2429.[64] Lara F. J., Garcia-Campana A. M., Gamiz-Gracia L., et al. Determination of phenothiazines in pharmaceutical formulations and human urine using capillary electrophoresis with chemiluminescence detection. Electrophoresis,2006,27(12): 2348-2359.[65] Yu P. L., Tu Y. Y., Hsieh M. M. Combination of poly(diallyldimethylammonium chloride) and hydroxypropyl-gamma-cyclodextrin for high-speed enantioseparation of phenothiazines bycapillary electrophoresis. Talanta,2015, 131(330-334.[66] Kakiuchi T. Mutual solubility of hydrophobic ionic liquids and water in liquid-liquid two-phase systems for analytical chemistry. Analytical Sciences,2008, 24(10): 1221-1230.[67] 陈志涛. 基于离⼦液体相互作⽤⽑细管电泳新⽅法. 万⽅数据资源系统, 2011.[68] Liu J.-f., Jiang G.-b., J?nsson J. ?. Application of ionic liquids in analytical chemistry. TrAC Trends in Analytical Chemistry,2005, 24(1): 20-27.[69] YauáLi S. F. Electrophoresis of DNA in ionic liquid coated capillary. Analyst,2003, 128(1): 37-41.[70] Kaljurand M. Ionic liquids as electrolytes for nonaqueous capillary electrophoresis. Electrophoresis,2002, 23(426-430.[71] Xu Y., Gao Y., Li T., et al. Highly Efficient Electrochemiluminescence of Functionalized Tris (2, 2′‐bipyridyl) ruthenium (II) and Selective Concentration Enrichment of Its Coreactants. Advanced Functional Materials,2007, 17(6): 1003-1009.[72] Pandey S. Analytical applications of room-temperature ionic liquids: a review of recent efforts. Anal Chim Acta,2006, 556(1): 38-45.[73] Koel M. Ionic Liquids in Chemical Analysis. Critical Reviews in Analytical Chemistry,2005, 35(3): 177-192.[74] Yanes E. G., Gratz S. R., Baldwin M. J., et al. Capillary electrophoretic application of 1-alkyl-3-methylimidazolium-based ionic liquids. Analytical chemistry,2001, 73(16): 3838-3844.[75] Qi S., Cui S., Chen X., et al. Rapid and sensitive determination of anthraquinones in Chinese herb using 1-butyl-3-methylimidazolium-based ionic liquid with β-cyclodextrin as modifier in capillary zone electrophoresis. Journal of Chromatography A,2004, 1059(1-2): 191-198.[76] Jiang T.-F., Gu Y.-L., Liang B., et al. Dynamically coating the capillary with 1-alkyl-3-methylimidazolium-based ionic liquids for separation of basic proteins by capillary electrophoresis. Analytica Chimica Acta,2003, 479(2): 249-254.[77] Jiang T. F., Wang Y. H., Lv Z. H. Dynamic coating of a capillary with room-temperature ionic liquids for the separation of amino acids and acid drugs by capillary electrophoresis. Journal of Analytical Chemistry,2006, 61(11): 1108-1112.[78] Qi S., Cui S., Cheng Y., et al. Rapid separation and determination of aconitine alkaloids in traditional Chinese herbs by capillary electrophoresis using 1-butyl-3-methylimidazoium-based ionic liquid as running electrolyte. Biomed Chromatogr,2006, 20(3): 294-300.[79] Wu X., Wei W., Su Q., et al. Simultaneous separation of basic and acidic proteins using 1-butyl-3-methylimidazolium-based ion liquid as dynamic coating and background electrolyte in capillary electrophoresis. Electrophoresis,2008, 29(11): 2356-2362.[80] Guo X. F., Chen H. Y., Zhou X. H., et al. N-methyl-2-pyrrolidonium methyl sulfonate acidic ionic liquid as a new dynamic coating for separation of basic proteins by capillary electrophoresis. Electrophoresis,2013, 34(24): 3287-3292.[81] Mo H., Zhu L., Xu W. Use of 1-alkyl-3-methylimidazolium-based ionic liquids as background electrolytes in capillary electrophoresis for the analysis of inorganic anions. J Sep Sci,2008, 31(13): 2470-2475.[82] Yu L., Qin W., Li S. F. Y. Ionic liquids as additives for separation of benzoic acid and chlorophenoxy acid herbicides by capillary electrophoresis. Analytica Chimica Acta,2005, 547(2): 165-171.[83] Marszall M. P., Markuszewski M. J., Kaliszan R. Separation of nicotinic acid and itsstructural isomers using 1-ethyl-3-methylimidazolium ionic liquid as a buffer additive by capillary electrophoresis. J Pharm Biomed Anal,2006, 41(1): 329-332.[84] Gao Y., Xu Y., Han B., et al. Sensitive determination of verticine and verticinone in Bulbus Fritillariae by ionic liquid assisted capillary electrophoresis-electrochemiluminescence system. Talanta,2009, 80(2): 448-453.[85] Li J., Han H., Wang Q., et al. Polymeric ionic liquid as a dynamic coating additive for separation of basic proteins by capillary electrophoresis. Anal Chim Acta,2010, 674(2): 243-248.[86] Su H. L., Kao W. C., Lin K. W., et al. 1-Butyl-3-methylimidazolium-based ionic liquids and an anionic surfactant: excellentbackground electrolyte modifiers for the analysis of benzodiazepines through capillary electrophoresis. J ChromatogrA,2010, 1217(17): 2973-2979.[87] Huang L., Lin J. M., Yu L., et al. Improved simultaneous enantioseparation of beta-agonists in CE using beta-CD and ionic liquids. Electrophoresis,2009, 30(6): 1030-1036.[88] Laamanen P. L., Busi S., Lahtinen M., et al. A new ionic liquid dimethyldinonylammonium bromide as a flow modifier for the simultaneous determination of eight carboxylates by capillary electrophoresis. J Chromatogr A,2005, 1095(1-2): 164-171.[89] Yue M.-E., Shi Y.-P. Application of 1-alkyl-3-methylimidazolium-based ionic liquids in separation of bioactive flavonoids by capillary zone electrophoresis. Journal of Separation Science,2006, 29(2): 272-276.[90] Liu C.-Y., Ho Y.-W., Pai Y.-F. Preparation and evaluation of an imidazole-coated capillary column for the electrophoretic separation of aromatic acids. Journal of Chromatography A,2000, 897(1): 383-392.[91] Qin W., Li S. F. An ionic liquid coating for determination of sildenafil and UK‐103,320 in human serum by capillary zone electrophoresis‐ion trap mass spectrometry. Electrophoresis,2002, 23(24): 4110-4116.[92] Qin W., Li S. F. Y. Determination of ammonium and metal ions by capillary electrophoresis–potential gradient detection using ionic liquid as background electrolyte and covalent coating reagent. Journal of Chromatography A,2004, 1048(2): 253-256.[93] Borissova M., Vaher M., Koel M., et al. Capillary zone electrophoresis on chemically bonded imidazolium based salts. J Chromatogr A,2007, 1160(1-2): 320-325.[94] Vaher M., Koel M., Kaljurand M. Non-aqueous capillary electrophoresis in acetonitrile using lonic-liquid buffer electrolytes. Chromatographia,2000, 53(1): S302-S306.[95] Vaher M., Koel M., Kaljurand M. Ionic liquids as electrolytes for nonaqueous capillary electrophoresis. Electrophoresis,2002, 23(3): 426.[96] Vaher M., Koel M. Separation of polyphenolic compounds extracted from plant matrices using capillary electrophoresis. Journal of Chromatography A,2003, 990(1-2): 225-230.[97] Francois Y., Varenne A., Juillerat E., et al. Nonaqueous capillary electrophoretic behavior of 2-aryl propionic acids in the presence of an achiral ionic liquid. A chemometric approach. J Chromatogr A,2007, 1138(1-2): 268-275.[98] Lamoree M., Reinhoud N., Tjaden U., et al. On‐capillary isotachophoresis for loadability enhancement in capillary zone electrophoresis/mass spectrometry of β‐agonists. Biological mass spectrometry,1994, 23(6): 339-345.[99] Huang P., Jin X., Chen Y., et al. Use of a mixed-mode packing and voltage tuning for peptide mixture separation in pressurized capillary electrochromatography with an ion trap storage/reflectron time-of-flight mass spectrometer detector. Analytical chemistry,1999, 71(9):1786-1791.[100] Le D. C., Morin C. J., Beljean M., et al. Electrophoretic separations of twelve phenothiazines and N-demethyl derivatives by using capillary zone electrophoresis and micellar electrokinetic chromatography with non ionic surfactant. Journal of Chromatography A,2005, 1063(1-2): 235-240.。
异常检测方法简介Anomaly Detection A Tutorial

However, when they do occur, their consequences can be quite dramatic and quite often in a negative sense
“Mining needle in a haystack. So much hay and so little time”
Aspects of Anomaly Detection Problem
• • • • • Nature of input data Availability of supervision Type of anomaly: point, contextual, structural Output of anomaly detection Evaluation of anomaly detection techniques
Introduction
We are drowning in the deluge of data that are being collected world-wide, while starving for knowledge at the same time* Anomalous events occur relatively infrequently
Data Labels
• Supervised Anomaly Detection
– Labels available for both normal data and anomalies – Similar to rare class mining
• Semi-supervised Anomaly Detection
Accuracy is not sufficient metric for evaluation
Modbus TCP功能代码流量异常检测方法:基于CUSUM算法说明书

4th National Conference on Electrical, Electronics and Computer Engineering (NCEECE 2015)Anomaly Detection Approach based on Function Code Traffic by UsingCUSUM AlgorithmMing Wan a*, Wenli Shang b, Peng Zeng cShenyang Institute of Automation, Chinese Academy of Sciences, Shenyang, ChinaKey Laboratory of Networked Control System, Chinese Academy of Sciences, Shenyang, Chinaa**************,b**************,c*********Keywords: Anomaly detection; Modbus/TCP; Function code traffic; Cumulative sum;Abstract. There is an increasing consensus that it is necessary to resolve the security issues in today’s industrial control system. From this point, this paper proposes an anomaly detection approach based on function code traffic to detect abnormal Modbus/TCP communication behaviors efficiently. Furthermore, this approach analyzes the Modbus/TCP communication packets in depth, and obtains the function code in each packet. According to the function code traffic change, this approach uses the Cumulative Sum (CUSUM) algorithm for change point detection, and generates an alarm. Our simulation results show that, the proposed approach is very available and effective to provide the security for industrial control system. Besides, we also discuss some advantages and drawbacks when using this approach.IntroductionNowadays, industrial control system has become an important part in many critical infrastructures, for example power, water, oil, gas, transportation, et al. With the development of modern networking, computing and control technologies, the deep integration of industrialization and informationization has been regarded as the inevitable tendency by both academia and industry. Especially, the “Industry 4.0” revolution, defined by Germany, further emphasizes the essential role of the networking technology [1]. However, the incoming networking technology has broken the original closure in industrial control system, and has brought some security problems into industrial control system [2]. Although there are various kinds of security methods in regular IT system, the traditional security methods cannot be applied directly to networked control system [3].There are two general approaches for improving the security in industrial control system. One is the communication control or access control approach, and its typical application is industrial firewall [4]. However, due to the manual rule setting and the real-time performance, this approach has been used to a limited extent. Secondly, the intrusion detection approach in industrial control system [5,6] is effective to identify network attacks, and it can give an alarm when suffering a great destruction. As a bypass approach to monitor the abnormal behaviors, intrusion detection technology has been attracting great interests of industry and researchers. Furthermore, intrusion detection can be into two categories: misuse detection and anomaly detection, and the proposed approach in this paper falls into the latter category.Anomaly detection technology in industrial control system can be divided into three categories [7,8]: statistics-based approach, knowledge-based approach, and machine learning-based approach. By supervising the industrial communication behaviors, these three categories of approaches can detect attacks, alarm and carry out the defensive measures before suffering from kinds of attacks. In the statistics-based approaches, Reference [9] uses the sequential detection model to realize the aberrant communication behaviors in control system. References [10] and [11] use the CUSUM algorithm to implement the communication traffic statistics in industrial control system, and explore the abnormal change point. However, the above statistical analysis only aims at the common industrial communication traffic, and cannot analyze the communication packets in depth according to the industrial communication protocol specification. In this paper, we propose an anomalyapproach based on function code traffic. In accordance with the Modbus/TCP protocol specification, this approach analyzes the Modbus/TCP communication packets in depth, and utilizes the function code traffic to detect abnormal Modbus/TCP communication behaviors. According to the function code traffic change, this approach uses the Cumulative Sum (CUSUM) algorithm for change point detection, and generates an alarm.Modbus/TCP and Vulnerability AnalysisModbus/TCP, regarded as an application layer protocol, is an open industrial communication protocol, and uses a typical master-slave communication mode. Namely, one Modbus master sends a request message to one Modbus slave, and the Modbus slave responds this message in accordanceAs shown in Fig. 1, the Modbus/TCP packet format mainly consists of three parts: MBAP (Modbus Application Protocol) header, Modbus function code and data. Wherein, MBAP header is a special header which is used to identify Modbus application data unit. Function code is a flag field to perform various operations, and is used to inform the slave to operate the corresponding function. The data domain can be regards as the parameters of function code, and indicates the specific data to perform one operation.The vulnerabilities of this protocol are increasingly exposed in recent years [12,13], and can be concluded as follows: firstly, Modbus/TCP lacks the authentication, and any Modbus master can use an illegal IP address and one function code to establish a Modbus session; secondly, Modbus/TCP does not consider the authorization, and any Modbus master can perform any operation by using some invalid function codes; finally, Modbus/TCP is short of the integrity detection, and the communication data may be tampered. For example, the function code can be changed to another illegal function code by one attacker.Anomaly Detection Approach based on Function Code TrafficIt is highly necessary to study on the anomaly detection approach in industrial control system. However, the industrial communication traffic is high-dimensional, and it hard to detect the abnormal communication behaviors. Therefore, we use the function code traffic to execute the anomaly detection, because the function code traffic is simple and single dimensional, and can indirectly reflect the industrial communication behaviors. In our approach, we first capture the industrial communication packets, and extract the Modbus/TCP communication packets. After that, we analyze these Modbus/TCP packets in depth, and get the function code in each packet. From this base, we perform a statistical analysis to form the function code traffic in each specified time interval. Finally, according to the function code traffic, we use the CUSUM algorithm to detect the change point. When one change point appears, the corresponding alarm will be generated. The CUSUM algorithm can be described as follows [14]:Assume the time sequence 1x , 2x ,…,1v x − are independent identically distributed variables withthe Gaussian distribution (0,1)N , and the time sequence v x , 1v x +,…, n x are independent identicallydistributed variables with the Gaussian distribution (,1)N δ, where v (v n <) is an unknown changepoint and the value i x represents the number of function codes in the th i time interval. Suppose thereis no change point, namely v =∞, the statistical value of the log-likelihood ratio is:11max ()2n n i v n i v Z x δ≤<+=−∑ (1) Eq. (1) describes the most ordinary CUSUM statistical value. Suppose h (0h >) is a chosen threshold which may be determined empirically through experiments. If i Z h ≤, 1,2,...,i n =, the former 1n − values are under normal conditions; if n Z h >, anomaly happens and an alarm should begenerated. Similarly, the foregoing judgment also can be understood that if an existing number r satisfies 0(1)2r n i i x r h δ−=−+>∑, where 01r n ≤≤−, then the anomaly happens and an alarm should begenerated.The aforementioned equation illustrates the basic CUSUM algorithm. However, the prerequisite is that we have assumed that {n x } are independent Gaussian random variables. Of course, this is nottrue for network traffic measurements owning to seasonality, trends and time correlations [16]. Therefore, in order to remove such non-stationary behaviors, the work in [15] further improves the basic CUSUM algorithm, and n Z can be calculated by:111120[()]20n n n n n n Z Z x Z αµαµµσ+−−−− =+−− = (2) where α is an amplitude percentage parameter, which intuitively corresponds to the most probable percentage of increase of the mean rate after a change has happened. 2σ is the variance of σ. Meanwhile, the mean n µ can be calculated by using an exponentially weighted moving average(EWMA) of previous measurements:1(1)nn n x µβµβ−=+− (3) where β is the EWMA factor. Thus, the conditions to generate an alarm can be summarized as follow:1, if ;()0, otherwise.n n Z h f Z > =(4) In Eq. (4), 1 indicates that the anomaly in the detected sequence {n x } is identified and an alarm isgenerated. By contrast, 0 indicates that the detected sequence {n x } is normal.However, a disadvantage or flaw exists in the CUSUM algorithm [17]. That is, when the anomaly or attack is over, CUSUM still continues generating the false alarms for a long time. Resulting from accumulation effect of the CUSUM algorithm, the increased amount to n Z caused by the attacktraffic is much greater than the decreasing amount provided by the normal traffic. In order to resolve this issue, our approach uses the following formula to revoke an alarm.2()0, if and v i n n i f Z Z h x ϕµ−=≥< (5)where ϕ is an amplitude and 1ϕ>. Assume an anomalous behavior happens at time v , and i x is the detected mapping request traffic in the th i time interval, i v > . 2v i µ− is the traffic mean of theformer 2v i − time intervals, which can be calculated by Eq. (3). The main idea of Eq. (5) is that when the traffic i x is less than the traffic mean 2v i µ− and n Z h ≥, the alarm will be revoked. In addition, inorder to revoke an alarm more accurately, the condition 2v i i x ϕµ−< can be improved as:201{}i j v i j k j x θϕµ+−−=≥<∑ (6)where θ is a positive integer and 1k θ>>. Eq. (6) describes that when the number satisfies the condition 2v i i x ϕµ−< is larger than θ, the alarm will be revoked. At the same time, after revoking thealarm, we also reset n Z between 0 and h .Performance Evaluations In the simulation experiment, we build a small SCADA system, whose communication is based on Modbus/TCP. As shown in Fig. 2, the whole technological process can be simply depicted as follows: when the valve switches A and B are respectively turned on, materials A and B successively flow into the container through the valve switches A and B to produce material C. When material C in the container reaches the level upper point, the valve switches A and B are turned off, and then the valve switch C is turned on. When material C in the container exhausts and reaches the level lower point, the valve switch C is turned off. Besides, the above-described technological process is repeatedly performed every 5 minutes.Fig.2 Simulation experiment topologyIn order to detect the abnormal communication behaviors, we deploy a monitoring computer on industrial switch to capture the communication packets between the supervisory control layer and the control unit layer. Furthermore, we carry out two experiments: one is under normal condition, and the other is under abnormal condition. Under normal condition, we run the simulation for 120 minutes. Fig. 3(a) shows the communication traffic captured by the monitoring computer per 1 minute, and Fig. 3(b) shows the corresponding function code traffic. From these two figures we can see that, the communication traffic is complex and changed, but the function code traffic varies periodically and can reflect every technological process. Under abnormal condition, we perform two attacks at 30th minute and at 80th minute respectively. Here, the attacker sends 50 Modbus/TCP packets whose function code is to write a coil at 30th minute, and sends the same 30 packets at 80th minute. Besides, we apply our anomaly detection approach to the corresponding function code traffic. Fig. 4(a) plots the communication traffic after the attacks. From this figure we can conclude that the attack traffic is hidden into the normal communication traffic, and we cannot identify the attack behaviors only from the communication traffic. Similarly, Fig. 4(b) plots the alarm points in the function code traffic after the attacks. From this figure we find that the proposed approach can detect the abnormal behaviors and generate alarms when the attacks happen. To sum up the above arguments, our approach is available and effective to identify and diagnose some network anomalies in industrial control system. In other words, compared with the anomaly detection using the communication traffic, our approach is more advantage.Fig.4 Under normal conditionConclusionThis paper aims to propose an anomaly detection approach based on function code traffic, and the basic idea behind the proposed approach is very simple. That is, identifying and detecting the anomalous communication behaviors in industrial control system by judging the function code traffic anomaly. In this paper, we first analyze Modbus/TCP protocol and its vulnerabilities, and then we present the detailed design of our approach, including the CUSUM algorithm. At last, we evaluate our approach in detail by simulation experiment. We show that, our approach is very available and effective to provide the security for industrial control system. Besides, we also discuss some drawbacks of our approach for our future research.AcknowledgementsThis work is supported by the National Natural Science Foundation of China (Grant No. 61501447) and Independent project of Key Laboratory of Networked Control System Chinese Academy of Sciences: Research on abnormal behavior modeling, online intrusion detection and self-learning method in industrial control network.References[1] H. Kagermann, W. Wahlster, J. Helbig, Recommendations for implementing the strategic initiative INDUSTRIE 4.0, Final Report, http://www.plattform-i40.de/finalreport2013, 2013.[2] B. Genge, C. Siaterlis, I. N. Fovino, et al., A cyber-physical experimentation environment for the security analysis of networked industrial control systems, Computer and Electrical Engineering, 38(5) (2012) 1146-1161.[3] C. Shao, L. G. Zhong, An information security solution scheme of industrial control system based on trusted computing, Information and Control, 44(5) (2015) 628-633.[4] S. S. Zhang, W. L. Shang, M. Wan, et al., Security defense module of Modbus TCP communication based on region/enclave rules, Computer Engineering and Design, 35(11) (2014) 3701-3707.[5] A. Carcano, A. Coletta, M. Guglielmi, et al., A multidimensional critical state analysis for detecting intrusions in SCADA systems, IEEE Transactions on Industrial Informatics, 7(2) (2011) 179-186.[6] A. Anoop, M. S. Sreeja, New genetic algorithm based intrusion detection system for SCADA, International Journal of Electronics Communication and Computer Engineering, , 2(2) (2013) 171-175.[7] S. M. Papa, V. S. S. Nair, A behavioral intrusion detection system for SCADA systems, Southern Methodist University, 2013.[8] B. Zhu, S. Sastry, SCADA-specific intrusion detection/prevention systems: a survey and taxonomy, The 1st Workshop on Secure Control Systems (SCS), 2010.[9] A. A. Cardenas, S. Amin, Z. S. Lin, Attacks against process control systems: risk assessment, detection, and response, The 6th ACM Symposium on Information, Computer and Communications Security, Hong Kong, 2011, pp.355-366.[10] Y. G. Zhang, H. Zhao, L. N. Wang, A non-parametric CUSUM intrusion detection method based on industrial control model, Journal of Southeast University(Natual Science Edition), A01 (2012) 55-59.[11] M. Wei, K. Kim, Intrusion detection scheme using traffic prediction for wireless industrial networks, Journal of Communications and Networks, 14(3) (2012) 310-318.[12] N. Goldenberg, A. Wool, Accurate modeling of Modbus/TCP for intrusion detection in SCADA systems, International Journal of Critical Infrastructure Protection, 6(2) (2013) 63-75.[13] T. H. Kobayashi, A. B. Batista, A. M. Brito, et al., Using a packet manipulation tool for security analysis of industrial network protocols, IEEE Conference on Emerging Technologies and Factory Automation. Patras, 2007, pp.744-747.[14] M. Wan, H. K. Zhang, T. Y. Wu, et al., Anomaly detection and response approach based on mapping requests, Security and Communication Networks, 7 (2014) 2277-2292.[15] V. A. Siris, F. Papagalou, Application of anomaly detection algorithms for detecting SYN flooding attacks, 2004 IEEE Global Telecommunications Conference GLOBECOM’04, Dallas, 2004, pp.2050-2054.[16] J. L. Hellerstein, F. Zhang, P. Shahabuddin, A statistical approach to predictive detection, International Journal of Computer and Telecommunications Networking, 35(1) (2001) 77-95. [17] H. H. Takada, U. Hofmann, Application and analyses of cumulative sum to detect highly distributed denial of service attacks using different attack traffic patterns, /dissemination/newsletter7.pdf, 2004.。
基于多分辨率网格的异常检测方法

基于多分辨率网格的异常检测方法刘文芬1,穆晓东1,黄月华1,21.桂林电子科技大学广西密码学与信息安全重点实验室,广西桂林5410042.桂林航天工业学院计算机科学与工程学院,广西桂林541004摘要:作为一种重要的数据挖掘手段,异常检测在数据分析领域有着广泛的应用。
然而现有的异常检测算法针对不同的数据,往往需要调整不同的参数才能达到相应的检测效果,在面对大型数据时,现有算法检测的时间效率也不尽如人意。
基于网格的异常检测技术,可以很好地解决低维数据异常检测的时间效率问题,然而检测精度严重依赖于网格的划分尺度和密度阈值参数,该参数鲁棒性较差,不能很好地推广到不同类型数据集上。
基于上述问题,提出了一种基于多分辨率网格的异常检测方法,该方法引入一个鲁棒性较好的子矩阵划分参数,将高维数据划分到多个低维的子空间,使异常检测算法在子空间上进行,从而保证了高维数据的适用性;通过从稀疏到密集的多分辨率网格划分,综合权衡了数据点在不同尺度网格下的局部异常因子,最终输出全局异常值的得分排序。
实验结果表明,新引入的子矩阵划分参数具有较好的鲁棒性,该方法能较好地适应高维数据,并在多个公开数据集上都能得到良好的检测效果,为解决高维数据异常检测的相关问题提供了一种高效的解决方案。
关键词:异常检测;多分辨率网格;高维数据;子空间;数据挖掘文献标志码:A中图分类号:TP311.13doi:10.3778/j.issn.1002-8331.1908-0188刘文芬,穆晓东,黄月华.基于多分辨率网格的异常检测方法.计算机工程与应用,2020,56(17):78-85.LIU Wenfen,MU Xiaodong,HUANG Yuehua.Anomaly detection method based on multi-resolution puter Engi-neering and Applications,2020,56(17):78-85.Anomaly Detection Method Based on Multi-resolution GridLIU Wenfen1,MU Xiaodong1,HUANG Yuehua1,21.Guangxi Key Laboratory of Cryptography and Information Security,Guilin University of Electronic Technology,Guilin, Guangxi541004,China2.College of Computer Science and Engineering,Guilin University of Aerospace Technology,Guilin,Guangxi541004,ChinaAbstract:As an important means of data mining,anomaly detection is widely used in the field of data analysis.However, existing anomaly detection algorithms often need to adjust different parameters for different data to achieve the corre-sponding detection effect.In the face of big data,the detection time efficiency of existing algorithms is not satisfactory. The anomaly detection technology based on grid can well solve the problem of time efficiency of low-dimensional data anomaly detection.However,the detection accuracy depends heavily on the grid partition scale and density threshold parameters,which have poor robustness and cannot be well extended to different types of data sets.Based on the above problems,the proposed method firstly introduces a submatrix partition parameter with good robustness,divides high-dimensional data into several low-dimensional subspaces,and makes the anomaly detection algorithm carry out on the⦾大数据与云计算⦾基金项目:国家自然科学基金(No.61862011);广西自然科学基金(No.2018GXNSFAA138116);广西密码学与信息安全重点实验室研究课题(No.GCIS201704);桂林电子科技大学硕士研究生创新项目(No.2019YCXS052)。
AnomalyDetectionTutorial

1.Keep the Anomaly Detection Method at RXD and use the default RXDsettings.2.Change the Mean Calculation Method to Local from the drop-down list.Withthis method,the mean spectrum will be derived from a localized kernel around the pixel.3.Enable the Preview check box.A Preview Window appears.As you move thePreview Window around,areas that are identified as anomalies in the original image display as white areas.The current settings highlight the anomaly in the upper-right corner of the Image window,though there is a lot of visible noise in the Preview Window.4.Keep the Preview Window open and change the Anomaly Detection Methodsetting to UTD.UTD and RXD work identically,but instead of using a sample vector from the data,as with RXD,UTD uses the unit vector.UTD extractsbackground signatures as anomalies and provides a good estimate of the imagebackground.Check the result in the Preview Window.5.Continue to keep the Preview Window open.This time,change the AnomalyDetection Method setting to RXD-UTD,which is a hybrid of the previous two methods you tried.The best condition to use RXD-UTD in is when the anomalies have an energy level that is comparable to,or less than,that of thebackground.In those cases,using UTD by itself does not detect the anomalies, but using RXD-UTD enhances them.Check the result in the Preview Window.6.Keep the detection method at RXD-UTD,but change the Mean CalculationMethod to Global from the drop-down list.With this method setting,the mean spectrum will be derived from the entire dataset.Check the results in the Preview Window.7.Finally,return the Anomaly Detection Method to RXD and leave the MeanCalculation Method at Global from the drop-down list.Check the results in the Preview Window.8.The preview of these settings appears to highlight anomalous areas more whilefiltering out more of the noise.You will use these settings to proceed.9.Click Next to go to the Anomaly Thresholding panel,10.Enter0.15in the Anomaly Detection Threshold field and press the Enterkey.11.View the results in the Preview Window.3.In the Additional Export tab,enable the check boxes for the remaining exports:l Export Anomaly Detection Statistics saves statistics on the thresholding image.The output area units are in square meters.l Export Unthresholded Anomaly Detection Image saves the unthresholded anomaly detection image to an ENVI raster.e the default paths and filenames.5.Click Finish.ENVI creates the output,opens the layers in the Image window,and saves the files to the directory you specified.6.Finally,compare the original image to the anomaly detection image.In theLayer Manager,right-click on the Vector Layer and select Remove.7.Open a Portal and move the Portal to the upper-right in the Image window tothe area where an anomaly appears.8.Adjust the Transparency so you can see both images in the Portal.9.Select File>Exit to exit ENVI.Copyright Notice:ENVI is a registered trademark of Exelis Inc.。
第十三讲 异常检测(Anomaly detection)

CLEMENTINE 12----ANOMALYANOMALY异常检测一种探索性的方法,常用于发现资料中的离群值或其他异常现象不须包含异常现象的训练资料集做为起点,其目的主要在寻找实质上与其他物件不同的异常值,该技术本身不受异常值的影响通过判断离同组其他记录的距离远近来判断异常点,离组中点越远的记录越有可能是异常的异常检测主要寻找在实质与其他物件不同的异常值,该技术本身不受异常值来源的影响。
STEP-1 MODELING—使训练资料格式化;—若不处理缺失值,则在任意变数上有缺失值的样本将被剔除;—处理缺失值:连续变数以均值替代缺失值,分类变数把缺失值看成一个有效组;—two-step群集,用于确定每个样本所在的类,根据输入变数的相似性;—对于连续变数,计算每类的平均值和标准差;对于分类变数,计算每类的次数分布表。
STEP-2 SCORING对每个样本计算variable deviation index(VDI):度量每个样本点到其类标准(c l u s t e r n o r m)的距离.对连续变数则类标准为样本平均值,分类变数则为众数。
计算每个样本的Group Deviation Index (GDI),即对数似然对所有样本按异常指数排序,异常指数越大越有可能是异常点。
一般认为,异常指数小于1或小于1.5,则不是异常点;异常指数大于2,则为异常点。
对每个异常样本,按其V D I 降幂排序,对应的前k 个变数是该样本被视为异常值的主要原因。
STEP-3 REASONINGANOMALY NODE&ANOMALY FIELDSANOMALY FIELDSANOMALYNODEU s e c u s t o ms e t t i n g:I n p u t s:用以建模之变数训练资料集中异常点占的比例(P e r c e n t a g e o f m o s t a n o m a l o u s r e c o r d s i nt h e t r a i n i n g d a t a):注意这个比例是为了确定临界值,实际异常点比例可能未必与指定值相等,而是因数据而异训练集中异常点的数目(N u m b e r o f m o s ta n o m a l o u s r e c o r d s i nt h e t r a i n i n g d a t a);同样,指定的异常点数目也是为了确定临界值,实际的异常点个数因数据而异。
异常侦测集群AnomalyDetectionclustering

類神經網路分析 (Neural Network Analysis) : 利用類神經網路具有學習能力的特性, 經由適當入侵資料與正常資料的訓練 後,使其具有辨識異常行為發生的能 力,目前已廣泛使用在信用卡詐欺偵 測中。
Anomaly Detection的優點及缺點
異常偵測的優點:
異常偵測主要的優點是不需要針對每一個攻擊徵兆建立資料庫,並提出解 決方法,所以在資料庫的成長速度較慢,且在資料比對執行速度會比誤用 偵測速度要來的快。 異常偵測主要利用學習的技術來學習使用者行為,僅需要取出某個正常使 用者的資料模型便可以進行比對,所以節省了資料定義與輸入的時間。
異常偵測集群 Anomaly Detection clustering
Anomaly Detection的崛起
根據美國電腦網路危機處理暨協調中心報告指出,在過 去的幾年內攻擊事件正以指數方式增加,而目前最常用 於入侵偵測的方式是不當行為偵測(misuse detection), 但此方法是利用先前已知的事件建立各種攻擊模式,再 比對找出異於正常行為的行為模式。 然而缺點是必須時常更新特徵資料庫或偵測系統,倘若 現行攻擊行為不存在於攻擊模式資料中,將無法偵測此 行為。 因為如此的限制,使得近來結合Data Mining方法於異常 偵測(anomaly detection)受到廣大的矚目與研究。
資料集群演算與標稱概念圖
集群演算法本身是非監督式學習方法(unsupervised learning), 因此無法得知每一個集群得本身所含的資訊或其所代表的意義, 如下圖之資料集群演算與標稱概念圖所示,集群演算結果仍然 無法判斷測試資料的行為模式。 有鑑於此,系統的建立仍須利用標記技術(labeling technique), 標稱每一個集群為正常或攻擊模式,而這一組具標稱的集群變 成為我們實驗中異常偵測系統的核心,因此我們可以利用這些 具有標稱的集群作測試資料的比對並預測其行為模式。
Anomaly Detection A Survey(综述)

A modified version of this technical report will appear in ACM Computing Surveys,September2009. Anomaly Detection:A SurveyVARUN CHANDOLAUniversity of MinnesotaARINDAM BANERJEEUniversity of MinnesotaandVIPIN KUMARUniversity of MinnesotaAnomaly detection is an important problem that has been researched within diverse research areas and application domains.Many anomaly detection techniques have been specifically developed for certain application domains,while others are more generic.This survey tries to provide a structured and comprehensive overview of the research on anomaly detection.We have grouped existing techniques into different categories based on the underlying approach adopted by each technique.For each category we have identified key assumptions,which are used by the techniques to differentiate between normal and anomalous behavior.When applying a given technique to a particular domain,these assumptions can be used as guidelines to assess the effectiveness of the technique in that domain.For each category,we provide a basic anomaly detection technique,and then show how the different existing techniques in that category are variants of the basic tech-nique.This template provides an easier and succinct understanding of the techniques belonging to each category.Further,for each category,we identify the advantages and disadvantages of the techniques in that category.We also provide a discussion on the computational complexity of the techniques since it is an important issue in real application domains.We hope that this survey will provide a better understanding of the different directions in which research has been done on this topic,and how techniques developed in one area can be applied in domains for which they were not intended to begin with.Categories and Subject Descriptors:H.2.8[Database Management]:Database Applications—Data MiningGeneral Terms:AlgorithmsAdditional Key Words and Phrases:Anomaly Detection,Outlier Detection1.INTRODUCTIONAnomaly detection refers to the problem offinding patterns in data that do not conform to expected behavior.These non-conforming patterns are often referred to as anomalies,outliers,discordant observations,exceptions,aberrations,surprises, peculiarities or contaminants in different application domains.Of these,anomalies and outliers are two terms used most commonly in the context of anomaly detection; sometimes interchangeably.Anomaly detectionfinds extensive use in a wide variety of applications such as fraud detection for credit cards,insurance or health care, intrusion detection for cyber-security,fault detection in safety critical systems,and military surveillance for enemy activities.The importance of anomaly detection is due to the fact that anomalies in data translate to significant(and often critical)actionable information in a wide variety of application domains.For example,an anomalous traffic pattern in a computerTo Appear in ACM Computing Surveys,092009,Pages1–72.2·Chandola,Banerjee and Kumarnetwork could mean that a hacked computer is sending out sensitive data to an unauthorized destination[Kumar2005].An anomalous MRI image may indicate presence of malignant tumors[Spence et al.2001].Anomalies in credit card trans-action data could indicate credit card or identity theft[Aleskerov et al.1997]or anomalous readings from a space craft sensor could signify a fault in some compo-nent of the space craft[Fujimaki et al.2005].Detecting outliers or anomalies in data has been studied in the statistics commu-nity as early as the19th century[Edgeworth1887].Over time,a variety of anomaly detection techniques have been developed in several research communities.Many of these techniques have been specifically developed for certain application domains, while others are more generic.This survey tries to provide a structured and comprehensive overview of the research on anomaly detection.We hope that it facilitates a better understanding of the different directions in which research has been done on this topic,and how techniques developed in one area can be applied in domains for which they were not intended to begin with.1.1What are anomalies?Anomalies are patterns in data that do not conform to a well defined notion of normal behavior.Figure1illustrates anomalies in a simple2-dimensional data set. The data has two normal regions,N1and N2,since most observations lie in these two regions.Points that are sufficiently far away from the regions,e.g.,points o1 and o2,and points in region O3,are anomalies.Fig.1.A simple example of anomalies in a2-dimensional data set. Anomalies might be induced in the data for a variety of reasons,such as malicious activity,e.g.,credit card fraud,cyber-intrusion,terrorist activity or breakdown of a system,but all of the reasons have a common characteristic that they are interesting to the analyst.The“interestingness”or real life relevance of anomalies is a key feature of anomaly detection.Anomaly detection is related to,but distinct from noise removal[Teng et al. 1990]and noise accommodation[Rousseeuw and Leroy1987],both of which deal To Appear in ACM Computing Surveys,092009.Anomaly Detection:A Survey·3 with unwanted noise in the data.Noise can be defined as a phenomenon in data which is not of interest to the analyst,but acts as a hindrance to data analysis. Noise removal is driven by the need to remove the unwanted objects before any data analysis is performed on the data.Noise accommodation refers to immunizing a statistical model estimation against anomalous observations[Huber1974]. Another topic related to anomaly detection is novelty detection[Markou and Singh2003a;2003b;Saunders and Gero2000]which aims at detecting previously unobserved(emergent,novel)patterns in the data,e.g.,a new topic of discussion in a news group.The distinction between novel patterns and anomalies is that the novel patterns are typically incorporated into the normal model after being detected.It should be noted that solutions for above mentioned related problems are often used for anomaly detection and vice-versa,and hence are discussed in this review as well.1.2ChallengesAt an abstract level,an anomaly is defined as a pattern that does not conform to expected normal behavior.A straightforward anomaly detection approach,there-fore,is to define a region representing normal behavior and declare any observation in the data which does not belong to this normal region as an anomaly.But several factors make this apparently simple approach very challenging:—Defining a normal region which encompasses every possible normal behavior is very difficult.In addition,the boundary between normal and anomalous behavior is often not precise.Thus an anomalous observation which lies close to the boundary can actually be normal,and vice-versa.—When anomalies are the result of malicious actions,the malicious adversaries often adapt themselves to make the anomalous observations appear like normal, thereby making the task of defining normal behavior more difficult.—In many domains normal behavior keeps evolving and a current notion of normal behavior might not be sufficiently representative in the future.—The exact notion of an anomaly is different for different application domains.For example,in the medical domain a small deviation from normal(e.g.,fluctuations in body temperature)might be an anomaly,while similar deviation in the stock market domain(e.g.,fluctuations in the value of a stock)might be considered as normal.Thus applying a technique developed in one domain to another is not straightforward.—Availability of labeled data for training/validation of models used by anomaly detection techniques is usually a major issue.—Often the data contains noise which tends to be similar to the actual anomalies and hence is difficult to distinguish and remove.Due to the above challenges,the anomaly detection problem,in its most general form,is not easy to solve.In fact,most of the existing anomaly detection techniques solve a specific formulation of the problem.The formulation is induced by various factors such as nature of the data,availability of labeled data,type of anomalies to be detected,etc.Often,these factors are determined by the application domain inTo Appear in ACM Computing Surveys,092009.4·Chandola,Banerjee and Kumarwhich the anomalies need to be detected.Researchers have adopted concepts from diverse disciplines such as statistics ,machine learning ,data mining ,information theory ,spectral theory ,and have applied them to specific problem formulations.Figure 2shows the above mentioned key components associated with any anomaly detection technique.Anomaly DetectionTechniqueApplication DomainsMedical InformaticsIntrusion Detection...Fault/Damage DetectionFraud DetectionResearch AreasInformation TheoryMachine LearningSpectral TheoryStatisticsData Mining...Problem CharacteristicsLabels Anomaly Type Nature of Data OutputFig.2.Key components associated with an anomaly detection technique.1.3Related WorkAnomaly detection has been the topic of a number of surveys and review articles,as well as books.Hodge and Austin [2004]provide an extensive survey of anomaly detection techniques developed in machine learning and statistical domains.A broad review of anomaly detection techniques for numeric as well as symbolic data is presented by Agyemang et al.[2006].An extensive review of novelty detection techniques using neural networks and statistical approaches has been presented in Markou and Singh [2003a]and Markou and Singh [2003b],respectively.Patcha and Park [2007]and Snyder [2001]present a survey of anomaly detection techniques To Appear in ACM Computing Surveys,092009.Anomaly Detection:A Survey·5 used specifically for cyber-intrusion detection.A substantial amount of research on outlier detection has been done in statistics and has been reviewed in several books [Rousseeuw and Leroy1987;Barnett and Lewis1994;Hawkins1980]as well as other survey articles[Beckman and Cook1983;Bakar et al.2006].Table I shows the set of techniques and application domains covered by our survey and the various related survey articles mentioned above.12345678TechniquesClassification Based√√√√√Clustering Based√√√√Nearest Neighbor Based√√√√√Statistical√√√√√√√Information Theoretic√Spectral√ApplicationsCyber-Intrusion Detection√√Fraud Detection√Medical Anomaly Detection√Industrial Damage Detection√Image Processing√Textual Anomaly Detection√Sensor Networks√Table parison of our survey to other related survey articles.1-Our survey2-Hodge and Austin[2004],3-Agyemang et al.[2006],4-Markou and Singh[2003a],5-Markou and Singh [2003b],6-Patcha and Park[2007],7-Beckman and Cook[1983],8-Bakar et al[2006]1.4Our ContributionsThis survey is an attempt to provide a structured and a broad overview of extensive research on anomaly detection techniques spanning multiple research areas and application domains.Most of the existing surveys on anomaly detection either focus on a particular application domain or on a single research area.[Agyemang et al.2006]and[Hodge and Austin2004]are two related works that group anomaly detection into multiple categories and discuss techniques under each category.This survey builds upon these two works by significantly expanding the discussion in several directions. We add two more categories of anomaly detection techniques,viz.,information theoretic and spectral techniques,to the four categories discussed in[Agyemang et al.2006]and[Hodge and Austin2004].For each of the six categories,we not only discuss the techniques,but also identify unique assumptions regarding the nature of anomalies made by the techniques in that category.These assumptions are critical for determining when the techniques in that category would be able to detect anomalies,and when they would fail.For each category,we provide a basic anomaly detection technique,and then show how the different existing techniques in that category are variants of the basic technique.This template provides an easier and succinct understanding of the techniques belonging to each category.Further, for each category we identify the advantages and disadvantages of the techniques in that category.We also provide a discussion on the computational complexity of the techniques since it is an important issue in real application domains.To Appear in ACM Computing Surveys,092009.6·Chandola,Banerjee and KumarWhile some of the existing surveys mention the different applications of anomaly detection,we provide a detailed discussion of the application domains where anomaly detection techniques have been used.For each domain we discuss the notion of an anomaly,the different aspects of the anomaly detection problem,and the challenges faced by the anomaly detection techniques.We also provide a list of techniques that have been applied in each application domain.The existing surveys discuss anomaly detection techniques that detect the sim-plest form of anomalies.We distinguish the simple anomalies from complex anoma-lies.The discussion of applications of anomaly detection reveals that for most ap-plication domains,the interesting anomalies are complex in nature,while most of the algorithmic research has focussed on simple anomalies.1.5OrganizationThis survey is organized into three parts and its structure closely follows Figure 2.In Section2we identify the various aspects that determine the formulation of the problem and highlight the richness and complexity associated with anomaly detection.We distinguish simple anomalies from complex anomalies and define two types of complex anomalies,viz.,contextual and collective anomalies.In Section 3we briefly describe the different application domains where anomaly detection has been applied.In subsequent sections we provide a categorization of anomaly detection techniques based on the research area which they belong to.Majority of the techniques can be categorized into classification based(Section4),nearest neighbor based(Section5),clustering based(Section6),and statistical techniques (Section7).Some techniques belong to research areas such as information theory (Section8),and spectral theory(Section9).For each category of techniques we also discuss their computational complexity for training and testing phases.In Section 10we discuss various contextual anomaly detection techniques.We discuss various collective anomaly detection techniques in Section11.We present some discussion on the limitations and relative performance of various existing techniques in Section 12.Section13contains concluding remarks.2.DIFFERENT ASPECTS OF AN ANOMALY DETECTION PROBLEMThis section identifies and discusses the different aspects of anomaly detection.As mentioned earlier,a specific formulation of the problem is determined by several different factors such as the nature of the input data,the availability(or unavailabil-ity)of labels as well as the constraints and requirements induced by the application domain.This section brings forth the richness in the problem domain and justifies the need for the broad spectrum of anomaly detection techniques.2.1Nature of Input DataA key aspect of any anomaly detection technique is the nature of the input data. Input is generally a collection of data instances(also referred as object,record,point, vector,pattern,event,case,sample,observation,entity)[Tan et al.2005,Chapter 2].Each data instance can be described using a set of attributes(also referred to as variable,characteristic,feature,field,dimension).The attributes can be of different types such as binary,categorical or continuous.Each data instance might consist of only one attribute(univariate)or multiple attributes(multivariate).In To Appear in ACM Computing Surveys,092009.Anomaly Detection:A Survey·7 the case of multivariate data instances,all attributes might be of same type or might be a mixture of different data types.The nature of attributes determine the applicability of anomaly detection tech-niques.For example,for statistical techniques different statistical models have to be used for continuous and categorical data.Similarly,for nearest neighbor based techniques,the nature of attributes would determine the distance measure to be used.Often,instead of the actual data,the pairwise distance between instances might be provided in the form of a distance(or similarity)matrix.In such cases, techniques that require original data instances are not applicable,e.g.,many sta-tistical and classification based techniques.Input data can also be categorized based on the relationship present among data instances[Tan et al.2005].Most of the existing anomaly detection techniques deal with record data(or point data),in which no relationship is assumed among the data instances.In general,data instances can be related to each other.Some examples are sequence data,spatial data,and graph data.In sequence data,the data instances are linearly ordered,e.g.,time-series data,genome sequences,protein sequences.In spatial data,each data instance is related to its neighboring instances,e.g.,vehicular traffic data,ecological data.When the spatial data has a temporal(sequential) component it is referred to as spatio-temporal data,e.g.,climate data.In graph data,data instances are represented as vertices in a graph and are connected to other vertices with ter in this section we will discuss situations where such relationship among data instances become relevant for anomaly detection. 2.2Type of AnomalyAn important aspect of an anomaly detection technique is the nature of the desired anomaly.Anomalies can be classified into following three categories:2.2.1Point Anomalies.If an individual data instance can be considered as anomalous with respect to the rest of data,then the instance is termed as a point anomaly.This is the simplest type of anomaly and is the focus of majority of research on anomaly detection.For example,in Figure1,points o1and o2as well as points in region O3lie outside the boundary of the normal regions,and hence are point anomalies since they are different from normal data points.As a real life example,consider credit card fraud detection.Let the data set correspond to an individual’s credit card transactions.For the sake of simplicity, let us assume that the data is defined using only one feature:amount spent.A transaction for which the amount spent is very high compared to the normal range of expenditure for that person will be a point anomaly.2.2.2Contextual Anomalies.If a data instance is anomalous in a specific con-text(but not otherwise),then it is termed as a contextual anomaly(also referred to as conditional anomaly[Song et al.2007]).The notion of a context is induced by the structure in the data set and has to be specified as a part of the problem formulation.Each data instance is defined using following two sets of attributes:To Appear in ACM Computing Surveys,092009.8·Chandola,Banerjee and Kumar(1)Contextual attributes.The contextual attributes are used to determine thecontext(or neighborhood)for that instance.For example,in spatial data sets, the longitude and latitude of a location are the contextual attributes.In time-series data,time is a contextual attribute which determines the position of an instance on the entire sequence.(2)Behavioral attributes.The behavioral attributes define the non-contextual char-acteristics of an instance.For example,in a spatial data set describing the average rainfall of the entire world,the amount of rainfall at any location is a behavioral attribute.The anomalous behavior is determined using the values for the behavioral attributes within a specific context.A data instance might be a contextual anomaly in a given context,but an identical data instance(in terms of behavioral attributes)could be considered normal in a different context.This property is key in identifying contextual and behavioral attributes for a contextual anomaly detection technique.TimeFig.3.Contextual anomaly t2in a temperature time series.Note that the temperature at time t1is same as that at time t2but occurs in a different context and hence is not considered as an anomaly.Contextual anomalies have been most commonly explored in time-series data [Weigend et al.1995;Salvador and Chan2003]and spatial data[Kou et al.2006; Shekhar et al.2001].Figure3shows one such example for a temperature time series which shows the monthly temperature of an area over last few years.A temperature of35F might be normal during the winter(at time t1)at that place,but the same value during summer(at time t2)would be an anomaly.A similar example can be found in the credit card fraud detection domain.A contextual attribute in credit card domain can be the time of purchase.Suppose an individual usually has a weekly shopping bill of$100except during the Christmas week,when it reaches$1000.A new purchase of$1000in a week in July will be considered a contextual anomaly,since it does not conform to the normal behavior of the individual in the context of time(even though the same amount spent during Christmas week will be considered normal).The choice of applying a contextual anomaly detection technique is determined by the meaningfulness of the contextual anomalies in the target application domain. To Appear in ACM Computing Surveys,092009.Anomaly Detection:A Survey·9 Another key factor is the availability of contextual attributes.In several cases defining a context is straightforward,and hence applying a contextual anomaly detection technique makes sense.In other cases,defining a context is not easy, making it difficult to apply such techniques.2.2.3Collective Anomalies.If a collection of related data instances is anomalous with respect to the entire data set,it is termed as a collective anomaly.The indi-vidual data instances in a collective anomaly may not be anomalies by themselves, but their occurrence together as a collection is anomalous.Figure4illustrates an example which shows a human electrocardiogram output[Goldberger et al.2000]. The highlighted region denotes an anomaly because the same low value exists for an abnormally long time(corresponding to an Atrial Premature Contraction).Note that that low value by itself is not an anomaly.Fig.4.Collective anomaly corresponding to an Atrial Premature Contraction in an human elec-trocardiogram output.As an another illustrative example,consider a sequence of actions occurring in a computer as shown below:...http-web,buffer-overflow,http-web,http-web,smtp-mail,ftp,http-web,ssh,smtp-mail,http-web,ssh,buffer-overflow,ftp,http-web,ftp,smtp-mail,http-web...The highlighted sequence of events(buffer-overflow,ssh,ftp)correspond to a typical web based attack by a remote machine followed by copying of data from the host computer to remote destination via ftp.It should be noted that this collection of events is an anomaly but the individual events are not anomalies when they occur in other locations in the sequence.Collective anomalies have been explored for sequence data[Forrest et al.1999; Sun et al.2006],graph data[Noble and Cook2003],and spatial data[Shekhar et al. 2001].To Appear in ACM Computing Surveys,092009.10·Chandola,Banerjee and KumarIt should be noted that while point anomalies can occur in any data set,collective anomalies can occur only in data sets in which data instances are related.In contrast,occurrence of contextual anomalies depends on the availability of context attributes in the data.A point anomaly or a collective anomaly can also be a contextual anomaly if analyzed with respect to a context.Thus a point anomaly detection problem or collective anomaly detection problem can be transformed toa contextual anomaly detection problem by incorporating the context information.2.3Data LabelsThe labels associated with a data instance denote if that instance is normal or anomalous1.It should be noted that obtaining labeled data which is accurate as well as representative of all types of behaviors,is often prohibitively expensive. Labeling is often done manually by a human expert and hence requires substantial effort to obtain the labeled training data set.Typically,getting a labeled set of anomalous data instances which cover all possible type of anomalous behavior is more difficult than getting labels for normal behavior.Moreover,the anomalous behavior is often dynamic in nature,e.g.,new types of anomalies might arise,for which there is no labeled training data.In certain cases,such as air traffic safety, anomalous instances would translate to catastrophic events,and hence will be very rare.Based on the extent to which the labels are available,anomaly detection tech-niques can operate in one of the following three modes:2.3.1Supervised anomaly detection.Techniques trained in supervised mode as-sume the availability of a training data set which has labeled instances for normal as well as anomaly class.Typical approach in such cases is to build a predictive model for normal vs.anomaly classes.Any unseen data instance is compared against the model to determine which class it belongs to.There are two major is-sues that arise in supervised anomaly detection.First,the anomalous instances are far fewer compared to the normal instances in the training data.Issues that arise due to imbalanced class distributions have been addressed in the data mining and machine learning literature[Joshi et al.2001;2002;Chawla et al.2004;Phua et al. 2004;Weiss and Hirsh1998;Vilalta and Ma2002].Second,obtaining accurate and representative labels,especially for the anomaly class is usually challenging.A number of techniques have been proposed that inject artificial anomalies in a normal data set to obtain a labeled training data set[Theiler and Cai2003;Abe et al.2006;Steinwart et al.2005].Other than these two issues,the supervised anomaly detection problem is similar to building predictive models.Hence we will not address this category of techniques in this survey.2.3.2Semi-Supervised anomaly detection.Techniques that operate in a semi-supervised mode,assume that the training data has labeled instances for only the normal class.Since they do not require labels for the anomaly class,they are more widely applicable than supervised techniques.For example,in space craft fault detection[Fujimaki et al.2005],an anomaly scenario would signify an accident, which is not easy to model.The typical approach used in such techniques is to 1Also referred to as normal and anomalous classes.To Appear in ACM Computing Surveys,092009.Anomaly Detection:A Survey·11 build a model for the class corresponding to normal behavior,and use the model to identify anomalies in the test data.A limited set of anomaly detection techniques exist that assume availability of only the anomaly instances for training[Dasgupta and Nino2000;Dasgupta and Majumdar2002;Forrest et al.1996].Such techniques are not commonly used, primarily because it is difficult to obtain a training data set which covers every possible anomalous behavior that can occur in the data.2.3.3Unsupervised anomaly detection.Techniques that operate in unsupervised mode do not require training data,and thus are most widely applicable.The techniques in this category make the implicit assumption that normal instances are far more frequent than anomalies in the test data.If this assumption is not true then such techniques suffer from high false alarm rate.Many semi-supervised techniques can be adapted to operate in an unsupervised mode by using a sample of the unlabeled data set as training data.Such adaptation assumes that the test data contains very few anomalies and the model learnt during training is robust to these few anomalies.2.4Output of Anomaly DetectionAn important aspect for any anomaly detection technique is the manner in which the anomalies are reported.Typically,the outputs produced by anomaly detection techniques are one of the following two types:2.4.1Scores.Scoring techniques assign an anomaly score to each instance in the test data depending on the degree to which that instance is considered an anomaly. Thus the output of such techniques is a ranked list of anomalies.An analyst may choose to either analyze top few anomalies or use a cut-offthreshold to select the anomalies.2.4.2Labels.Techniques in this category assign a label(normal or anomalous) to each test instance.Scoring based anomaly detection techniques allow the analyst to use a domain-specific threshold to select the most relevant anomalies.Techniques that provide binary labels to the test instances do not directly allow the analysts to make such a choice,though this can be controlled indirectly through parameter choices within each technique.3.APPLICATIONS OF ANOMALY DETECTIONIn this section we discuss several applications of anomaly detection.For each ap-plication domain we discuss the following four aspects:—The notion of anomaly.—Nature of the data.—Challenges associated with detecting anomalies.—Existing anomaly detection techniques.To Appear in ACM Computing Surveys,092009.。
A Hardware-Based Clustering Approach for Anomaly Detection

A Hardware-Based Clustering Approach for Anomaly DetectionKhaled Labib and V. Rao VemuriDepartment of Applied Science, University of California, Davis, California, U.S.A.Email: {kmlabib, rvemuri}@AbstractSeveral clustering methods have been developed for clustering network traffic in order to detect traffic anomalies and possible intrusions. Many of these methods are typically implemented in software. As a result they suffer performance limitations while processing real time traffic. This study presents a hardware implementation of the k-means clustering algorithm that is used to cluster network traffic. The implementation uses the Verilog hardware description language to build a circuit to read packet information from system memory and produce the output cluster assignments in a 32-bit register. After reset is applied, the circuit uses a state-machine that represents the k-means algorithm to process IP packets for a fixed number of iterations and then generates an interrupt to indicate that it had finished processing the data. The implementation is synthesized into a Field Programmable Gate Array in order to study the number of gates required for the implementation. The maximum achievable clock cycle without applying timing constraints is 40 MHz. To compare the performance of this implementation with a software-based implementation, a C version of the k-means algorithm is compiled, run and profiled with similar parameters of the hardware-based implementation. The results show that the performance of the hardware-based implementation is approximately 300 times faster than a software-based implementation.1.IntroductionThe field of anomaly detection in computer network security is rich with many methods that are devised and implemented to enable the detection of anomalous traffic and possible intrusions. Anomaly detection attempts to identify anomalies in the network traffic that suggest a possibility of an attack or intrusion that is taking place. This is achieved by establishing what the normal traffic patterns look like for a given network, and flagging out any variations in traffic from this norm.At the core of most anomaly detection systems are a set of algorithms that attempt to cluster the input traffic data into a number of output clusters. This clustering process is needed to separate normal traffic from anomalous traffic, which in turn may include intrusive traffic. Several algorithms have been used including k-means [1], hierarchical clustering [2], Self-Organizing Maps [3] and Principal Component Analysis [4] as the core algorithms for anomaly detectors. However, these implementations suffer performance penalties as they are typically designed and implemented as software programs running on a host machine and clustering the packets as they arrive. There are several disadvantages to this software-based implementation. First, the performance of these software-based methods does not scale well to meet the requirements of real time processing. This performance limitation is true because of the limited processing power of the hosts running the software in terms of instructions per second (IPS) that can be executed by the Central Processing Units (CPU) in these hosts. When run as software programs, these algorithms are typically compiled from a high-level language to some object format that the host CPU executes. There is an upper limit on the number of IPS these CPUs can execute. Second, the processing of these algorithms places a burden on the host CPU running them, thereby hogging the host CPU bandwidth when processing other tasks. One implication of this fact is that it requires a dedicated host machine that serves as an anomaly detector node on every network segment in order not to burden others hosts running the main applications on that network segment which in turn increases the budget for building secure networks. Third, to meet the performance goals required for processing a large number of packets, the clock frequency for these CPUs must be increased, thereby increasing the cost of the systems and consuming more power as the frequency is increased. For example, performing full system monitoringincluding detailed behavior such as memory references made by all applications and the operating system including network monitoring can be performed with slowdowns of roughly 10X [5].To address some of the performance drawbacks of software-based clustering methods for network anomaly detection, this study presents a hardware-based clustering circuit based on the k-means clustering algorithm. The circuit is developed using synthesizable Verilog Hardware Description Language (HDL) [6]. The circuit can be viewed as a back-end hardware-assisting block that performs the clustering of network data once started and interrupts the host CPU when finished. Therefore it is designed to replace the functionality of a software-based k-means clustering algorithm by implementing the core function in hardware to attain much higher performance. This relieves the host CPU from performing the computational intensive task of clustering the data and allows it to handle other system tasks without hogging its bandwidth. The circuit consists of a clock and reset pins at the input and the cluster assignment and an interrupt pin at the output. The circuit is tested in a simulation environment by constructing a Verilog test bench that supplies the clock and reset. The circuit processes 32 packets at a time, and generates an output cluster assignment for each packet along with an interrupt. This generated interrupt indicates that the clustering process has finished and that the cluster assignments are ready to be read and further processed by the CPU.After testing the circuit functionality, it is synthesized using an FPGA (Field Programmable Gate Array) flow to create a physical implementation. When synthesized with no timing constraints, the maximum clock frequency of 40 MHz can be achieved. Higher clock frequencies are achievable by applying timing constraints during the synthesis process on the expense of more gates and therefore more die area.The rest of the paper is organized as follows: Section 2 presents related work in the field of anomaly detection using hardware accelerators. Section 3 presents the details of the circuit implementation in Verilog. Section 4 discusses the results obtained using the circuit in clustering test data and selected attack data from the 1998 DARPA intrusion detection data sets. Section 5 presents the synthesis results of the design in an FPGA flow. Section 6 compares the results obtained using this hardware implementation to a software implementation of the same algorithm in terms of performance. Finally, section 7 presents the conclusion and future work.2.Related WorkSoftware implementations of the k-means algorithm for anomaly detection exist in the literature [7]. However, there were no attempts to employ a hardware-based clustering algorithm for anomaly detection similar to the work reported in this study.Nevertheless, few hardware implementations of the k-means algorithm have been used in the area of video and image processing.Estlick et al [8] use algorithm level transforms to map the k-means algorithm into an FPGA and apply it to multi-spectral and hyper-spectral images having tens of hundreds of channels per pixel of data. They examine basically two algorithm level transforms. First, they studied using the Manhattan and Max distance measures that do not require multipliers. Second, they examined the effects of using single precision and truncated bit width in the algorithm. The algorithm is mapped to a reconfigurable hardware. Their implementation resulted in speedups by a factor of about 200 over a software implementation.Filho et al [9] implemented a parameterized k-means algorithm for clustering hyper-spectral images in a hardware/software co-design approach. Two models, a software and a hardware/software co-design ones, have been implemented. Although the hardware component operates in 40MHz, being 12.5 times lesser than the software operating frequency (PC), the co-design implementation was approximately 2 times faster than software one.While the above-cited works differ from this study primarily from an application point of view, there are other differences in terms of the hardware implementation details. The implementation done in this studydoes not use co-design methodologies. The work done by Estlick et al focuses on the efficiency of implementation of the algorithm for handling a large number of pixel data using the VHDL language. While this approach may be suitable for clustering large amounts of data and where optimal implementation is sought, the implementation presented in this study deals with much less data for clustering, thereby lending itself to a simpler design that synthesizes directly from Verilog HDL. In hardware/software co-design a portion of the algorithm is implemented in software while the remaining computational intensive portion of the algorithm is implemented in hardware. A co-design approach has its merits and demerits but it eventually places some computational burden on the host CPU. This unnecessary burden is avoided using the simple structured implementation in this study.3.Circuit ImplementationThe k-means algorithm is a well-structured algorithm and therefore is suitable for implementation as a hardware circuit. The basic algorithm can be summarized in the following steps:1)Take as input the number of clusters (k), the number of iterations to run and the input data set.In this study k = 2.2)Create the initial k cluster centers by choosing k data points (records) randomly from the dataset.3)Calculate the arithmetic mean of each cluster.4)Assign each record from the input data set to the nearest cluster using some distance measurelike Euclidean or Manhattan distance measure. This study uses Manhattan distance measurefor reasons explained below.5)When all records are assigned, re-calculate the arithmetic mean of each cluster. This newarithmetic mean is the center of a new cluster.6)Assign each record from the input data set to the nearest new cluster center.7)Repeat steps 4 to 6 six above until stable clusters are formed or for a fixed number ofiterations.The circuit block diagram in Figure 1 shows the main components of the circuit that implements the k-means algorithm. The circuit has two input signals namely: clk (input clock) and reset. The clk signal supplies a clock of 40 MHz and the reset signal resets all internal state machines and registers. The outputs of the circuit are a 32-bit bus carrying cluster assignments and an interrupt pin that can be used to interrupt a host CPU to indicate that the clustering process is finished and that the cluster assignments are valid. Each of the 32 input packets is assigned a value of either zero or one indicating one of the two clusters it can be assigned. In addition the circuit reads the 32-input packet header information from a [192x32] bit memory array.When the clock is running and after reset has been de-asserted, the main FSM (Finite State Machine) assigns the next state variable to one of the following values. This parameter declaration uses Verilog syntax where 3’b means a 3 bit binary value:parameter IDLE = 3'b000,3'b001,SELECT_CLUST_CENTERS=CALC_DIST_CENTER0 = 3'b010,CALC_DIST_CENTER1 = 3'b011,ASSIGN_ROW_TO_CLUST = 3'b100,CALC_NEW_CENTER = 3'b101,DUMMY = 3'b110,CALC_CENTER_AVG = 3'b111;Figure 1: Block Level Diagram of the k-means circuitThe structure of the main FSM is depicted in Figure 2 which shows the different states the FSM can be in. At reset, the current state is assigned to IDLE. On the following positive clock edge after reset is de-asserted, the next state assigned is SELECT_CLUST_CENTERS. In this state, two data points are selected to form the input data to form the initial cluster centers and the next state is assigned to CALC_DIST_CENTER0. In this state the distance between all input data points and first cluster center (center 0) is calculated. Since it is difficult to implement the square root function in hardware (needed in Euclidean distance calculations), the Manhattan distance measure is used instead. The Manhattan distance, also known as the L1-distance or City Block distance, is the distance between two points measured along axes at right angles. In a plane, the Manhattan distance between the point P1 with coordinates (x1, y1) and the point P2 at (x2, y2) is| x1 - x2 | + | y1 - y2 |Using the Manhattan distance yields less optimal clusters than the Euclidean distance but provides for a more efficient hardware circuit implementation. Theiler et al [10] examined the k-means method using Manhattan distance and Max distances as well as a linear combination of the two in a fixed-point hardware implementation. They could fit more distance-computation nodes on their chip, obtain a higher degree of parallelism and therefore faster performance but at the price of slightly less optimal clusters.The CALC_DIST_CENTER0 state takes 32 clock cycles before it advances to the next state. At each of the 32 clock cycles, the value of the row pointer of the input data array is advanced by one. The row pointer is incremented by one at each clock to point to the next row in the input memory array. Similar calculations are done when the FSM advances to state CALC_DIST_CENTER1.In state ASSIGN_ROW_TO_CLUST each row of the input data is assigned to one of the two clusters based on its distance to the center of the cluster. In state CALC_NEW_CENTER the new cluster centers are calculated based on the assignments of each input row to one of the two clusters. In this state the sum of the clusters is calculated by adding up the values of the components of rows belonging to each center. After the new centers are calculated, the state machine advances to the DUMMY state which, as its name reflects, provides no calculations but is added as a staging state to ensure that the values of the flip flops of the previous state are stable. In state CALC_CENTER_AVG the arithmetic mean of each cluster center is calculated by dividing the cluster sums obtained in state CALC_NEW_CENTER by the number of rows in each cluster. After calculating the new cluster centers, the state machine jumps back to state CALC_DIST_CENTER0 to re-calculate the distance of each input row to the new cluster centers. This process is repeated a number of times defined by the constant NUM_OF_ITERATIONS which is set to eight in this implementation. This value of eight reflects the typical default number of iterations in a software implementation of the algorithm. When the desired number of iterations is reached the circuit triggers an interrupt to indicate that the calculations are finished. In a full system implementation this interrupt would be directed to a host CPU that reads the clusters assignments output of the algorithm from a 32-bit register. Each of the 32 input packets would be assigned a value of either zero or one in this 32-bit register output. All packets that are similar would be clustered together in one of the two clusters.Figure 2: Main Finite State Machine structure for the design4.ResultsThe circuit described in Section 3 was tested using both synthetic test data and real network traffic data. The synthetic test data was used during the development phase of the circuit to create a simple test bench where the input data rows contain numbers that can easily be manipulated by the k-means implementationand later studied. After the algorithm was stable, real network traffic data was tested using attack data sets from the 1998 DARPA Intrusion Detection Evaluation data sets [11]. These data sets represent four attack types namely: Smurf, Neptune, IPsweep and Portsweep.Smurf attacks, also known as directed broadcast attacks, are a popular form of denial-of-service packet floods. Smurf attacks rely on directed broadcast to create a flood of traffic for a victim. The attacker sends a ping packet to the broadcast address for some network on the Internet that will accept and respond to directed broadcast messages, known as the Smurf amplifier. These are typically mis-configured hosts that allow the translation of broadcast Internet Protocol (IP) addresses to broadcast Medium Access Control (MAC) addresses. The attacker uses a spoofed source address of the victim. For Example, if there are 30 hosts connected to the Smurf amplifier, the attacker can cause 30 packets to be sent to the victim by sending a single packet to the Smurf amplifier [12].Neptune attacks can make memory resources too full for a victim by sending a TCP packet requesting to initiate a TCP session. This packet is part of a three-way handshake that is needed to establish a TCP connection between two hosts. The SYN flag on this packet is set to indicate that a new connection is to be established. This packet includes a spoofed source address, such that the victim is not able to finish the handshake but had allocated an amount of system memory for this connection. After sending many of these packets, the victim eventually runs out of memory resources.IPsweep and Portsweep, as their names suggest, sweep through IP addresses and port numbers for a victim network and host respectively looking for open ports that could potentially be used later in an attack.Most of the current inexpensive home and small-office routers in addition to high-end ones employ mechanisms to detect the selected attacks and a dozen other common attacks, many of which exist in the DARPA data sets. These attacks are becoming simple to detect using stateful packet inspection (SPI) techniques. The use of the selected attacks in this study is mainly to demonstrate the process of clustering for anomaly detection where the clustering engine attempts to explore the relationships within the multidimensional input packet data.A Verilog test bench is constructed to provide the clock, assertion and de-assertion of reset and to initialize the 144x32 bit array of input data.4.1.Input Data FormatThe following data format was used to create the input feature vectors representing data to be clustered. The same format was used for both synthetic test data and selected DARPA test data. To create the four sets of test data from the DARPA data sets, the data sets were preprocessed by extracting the IP packet header information to create feature vectors. The resulting feature vectors were used as input to the circuit implementing the k-means algorithm. The feature vector chosen has the following format:48 bit 12 bit 48 bit 12 bit 12 bit 12 bitSIPx SPort DIPx Dport Prot PlenWhere•SIP x = Source IP address nibble, where x = [1-4]. Four nibbles constitute the full source IP address •SPort = Source Port number•DIP x = Destination IP address nibble, where x = [1-4]. Four nibbles constitute the full destination IP address•DPort = Destination Port number•Prot = Protocol type: TCP, UDP or ICMP•PLen = Packet length in bytesThis format represents the IP packet header information. Each feature vector has 12 components. Each component is represented by 12-bits. Therefore, each input row is represented by a 144 bit value. A total of32 rows are processed at a time by the circuit. The IP source and destination addresses are broken down to their network and host addresses to enable the analysis of all types of network addresses.Figure 3 shows the output cluster assignments using the synthetic test data as input. The input data in this case consists of interleaved data where similar data rows appeared in every other row of the 32 input rows. It can be seen, using signal “cluster” in the figure, that the circuit clustered the output as 0x55555555 which is a 32-bit value with zeros and ones alternating in the sequence. This simply means that the first row was assigned to cluster one, the second row to cluster zero, the third row to cluster one, and so on.Figure 3: Signal Waveforms for Synthetic Input DataIn the above figure, the final cluster assignment is shown by the signal “cluster” (The third signal above the yellow marker on the left part of the figure). The final value of this signal when the interrupt was generated by signal “int” is 0x55555555 indicating the 32 cluster assignments of the input rows. Signals “c0match” and “c1match” indicate the number of input rows assignments to clusters zero and one respectively. The final values of these signals were both 16, indicating that both clusters zero and one had 16 members each, totaling to 32 input rows.Figure 4 shows output cluster assignment for the Smurf attack data. The 32 input rows for this data set consist of normal traffic for the first 20 rows after which the Smurf attack packets start for 12 additional rows.Figure 4: Signal Waveform for Smurf Attack DataIn the above figure, the final cluster assignment is shown by signal “cluster” with a value of 0xfff00000. This value represents the first 20 packets (rows) of normal traffic as being assigned to cluster zero, while the last 12 packets (rows) of Smurf attack traffic as being assigned to cluster one. In addition, the final values of signals “c0match” and “c1match” when the interrupt is generated are 20 and 12 respectively.The above results suggests that the circuit is able to cluster the input data correctly by applying both synthetic input data and real packet data extracted from the DARPA data sets.Similar results were obtained using Neptune and IPsweep data sets. The data sets have a similar structure as the Smurf data set where first 20 rows included normal traffic while the remaining 12 rows include tracesof each attack respectively. The results of using these sets are shown in Figure 5 and Figure 6.Figure 5: Signal Waveform for Neptune Attack DataFigure 6: Signal Waveform for IPsweep Attack DataFor the Portsweep data set, the results were slightly different. Even though similar format as previous data sets was used, the results indicate that the first 27 rows were assigned to one cluster while the remaining 5 rows were assigned to a different cluster. These results are shown in Figure 7.Figure 7: Signal Waveform for Portsweep Attack DataThe above Portsweep results can be explained by the small size of the input data set where the clustering process maybe impaired by the small number of observations. In a different experiment with the Portsweep data set the number of rows containing the attack data were increased to 16. In this case the algorithm was able to correctly classify the data. Another approach would be to increase the number of observations that the algorithm operates on from 32 observations to possibly 64. The primary disadvantage of such approach would be the drastic increase in the size of the design in terms of gate count, where the size of the design will roughly double.4.2.Circuit Execution TimeThe clk signal is a free running clock that is synchronously used in the design. Careful examination of Figure 4 reveals the time it took the algorithm to finish all iterations. The time is shown in nano-seconds in the top portion of the figure. When the interrupt is generated (white marker on the right) the time indicates that 11,800 nano-seconds have elapsed indicating the total time it took to finish the clustering process. 5.Design SynthesisThe circuit described in section 3 was synthesized using an FPGA synthesis flow to determine the details of the physical implementation and to ensure that the design is synthesizable.The Xilinx ISE (Integrated Synthesis Environment) was used to synthesize the design. In addition the Xilinx Project Navigator was used to load and control the synthesis parameters. The following data was obtained as part of the design synthesis process:Finite State Machines (FSMs) 1RAMs 232x32-bit single-port distributed RAM 2Registers 361-bit register 34144-bit register 2Counters 232-bit up counter 116-bit up counter 1Multiplexers 21-bit 32-to-1 multiplexer 1144-bit 32-to-1 multiplexer 1Adders/Subtractors 7012-bit adder 2414-bit subtractor 2414-bit adder 215-bit adder 416-bit adder 818-bit adder 217-bit adder 6Comparators 232-bit comparator lessequal 132-bit comparator greater 1Table 1 : Design Synthesis ResultsAs shown in Table 1, a FSM is synthesized which controls the different states described in section 3. The two 32 x 32 bit RAM represent the memory required to hold the distance of each row to each of the two cluster centers. The 34 1-bit registers hold the cluster assignment for each row. The two 144-bit registers each holds the cluster center values at any time during the process of clustering. The counters are used to hold incrementing row values since each row is processed in a single clock cycle. The multiplexers, adders and subtractors are used in calculating the Manhattan distance measures and the averages. Finally, the comparators are used to compare the distance values when assigning a cluster to each row.The total equivalent gate count for the design is 58,484 gates. To compare the size of this circuit to other components of a modern system-on-a-chip (SoC), a typical 32-bit Reduced Instruction Set Computer (RISC) CPU is roughly 800,000 gates, where a PCI controller is roughly 150,000 gates. A small component such as a Timer/Counter which features an interval timer, a pulse generator and a watch-dog timer is roughly 5000 gates. Therefore the size of the k-means design is relatively large given that it serves as a hardware-assist circuit. In addition, to configure the k-means design to process more than 32 packets at a time will cause the circuit to grow even bigger in terms of number of gates, making it expensive to manufacture for mass production.parison between Hardware and Software Implementations In order to compare the results obtained by the hardware implementation of the k-means algorithm to a software implementation in terms of performance, a software implementation was created, run and profiled. The basic k-means algorithm code in C was configured to process 32-packet data and was run on a Sun Ultra2 200MHZ machine running Solaris 5 operating system. A generic GCC compiler was used to compile the C code with a –gprof option to create a profile of the code. The number of iterations of the algorithm was set to NUM_OF_ITERATIONS to mimic that of the hardware implementation. Next the algorithm was run to process the input data and the following data was collected in the output profile:% Time CumulativeSecondsSelfSecondsSelfCallsTotalus/callus/call Name75.00 0.003 0.003 8 37.500 37.500 CalculateMidPoints 25.00 0.004 0.001 8 12.500 12.500 CalculateDistances0.00 0.004 0.0001 0.00 0.00 Initialize0.00 0.004 0.0001 0.00 4000.00Kmeans0.00 0.004 0.0001 0.00 4000.00MainTable 2 : Results of profiling the k-means implementation in CWhere:% Time: the percentage of the total running time of the program used by this function.Cumulative Seconds: a running sum of the number of seconds accounted for by this function and those listed above it.Self Seconds: the number of seconds accounted for by this function alone.Self Calls: the number of times this function was invoked, if this function is profiled, else blank.Total us/call: the average number of microseconds spent in this function and its descendents per call, if this function is profiled, else blank.us/call: the average number of microseconds spent in this function per call, if this function is profiled, else blank.Name: the name of the function.As shown in Table 2 above, the C implementation of the k-means algorithm spent most of the time in two functions, namely “calculateMidPoints” and “calculateDistances”. The total amount of time spent in both functions is 4000 microseconds. The hardware implementation of the same algorithms can process the same number of packets and iterations in a total of 11.8 microseconds at 40MHZ clock speed. The hardware implementation is over 300 times faster than the software implementation leading to a much greater performance when processing real time packets.7.Summary and Future WorkThis study presented a hardware-based implementation of the k-means algorithm that is used in network anomaly detection to cluster network packets. The circuit is designed to replace the functionality of a software-based k-means algorithm by implementing the core function in hardware to attain much higher performance. The circuit consists of a clock and reset pins at its input and a 32-bit cluster value and an interrupt pin at the output. A Finite State Machine controls the transition of the different states in the circuit. The circuit can process 32 packets at a time. The processing is initiated by asserting the reset signal and is completed by the assertion of an interrupt. The design is synthesized to run at a clock frequency of 40 MHZ at which it processes 32 packets in 11.8 microseconds. The performance of the design is compared with a software-based implementation of the k-means algorithm with similar parameters and was found to be over 300 times faster. Future work includes optimizing the implementation to yield a smaller die area and enhance its capability to process a larger number of packets at a time.8.References1.Shi Zhong, Taghi M. Khoshgoftaar, and Naeem Seliya. Evaluating Clustering Techniques forUnsupervised Network Intrusion Detection. International Journal of Reliability, Quality, and Safety Engineering, 2005.2.Khaled Labib, V. Rao Vemuri, "Application of Exploratory Multivariate Analysis for NetworkSecurity", CRC Press, 20053.Rhodes B., Mahaffey J., Cannady J., “Multiple Self-Organizing Maps for Intrusion Detection”.Proceedings of the NISSC 2000 conference, Baltimore M.D. 2000.4.Shah H., Undercoffer J., Joshi A., “Fuzzy Clustering for Intrusion Detection”. FUZZ-IEEE, 20035.David L. Oppenheimer and Margaret R. Martonosi., “Performance Signatures: A Mechanism forIntrusion Detection”. Proceedings of the 1997 IEEE Information Survivability Workshop, 1997.6.Samir Palnitkar, “Verilog HDL : A Guide to Digital Design and Synthesis”. Prentice Hall, 1996.7.Shi Zhong, Taghi M. Khoshgoftaar, and Naeem Seliya, “Evaluating Clustering Techniques forNetwork Intrusion Detection”. In 10th ISSAT Int. Conf. on Reliability and Quality Design, pp. 149-155. Las Vegas, Nevada, USA. August 2004.8.Mike Estlick, Miriam Leeser, James Theiler, John J. Szymanski, “Algorithmic Transformations in theImplementation of K-means Clustering on Reconfigurable Hardware”. International Symposium on Field Programmable Gate Arrays. Proceedings of the 2001 ACM/SIGDA ninth international symposium on Field programmable gate arrays.9.Abel Guilhermino da S. Filho, Alejandro C. Frery , Cristiano Coêlho de Araújo , Haglay Alice, JorgeCerqueira, Juliana A. Loureiro, Manoel Eusebio de Lima , Maria das Graças S. Oliveira , Michelle Matos Horta, “HYPERSPECTRAL IMAGES CLUSTERING ON RECONFIGURABLE HARDWARE USING THE K-MEANS ALGORITHM”. 16th Symposium on Integrated Circuits and Systems Design (SBCCI’03), September 08 - 11, 2003, São Paulo, Brazil.。
Application-level anomaly detection

专利名称:Application-level anomaly detection发明人:Mauro Baluda,Paul C. Castro,MarcoPistoia,John J. Ponzo申请号:US14030337申请日:20130918公开号:US09141792B2公开日:20150922专利内容由知识产权出版社提供专利附图:摘要:An example includes intercepting one or more activities performed by an application on a computing device. The intercepting uses an instrumentation layerseparating the application from an operating system on the computing device. The oneor more activities are compared with one or more anomaly detection policies in a policy configuration file to detect or not detect presence of one or more anomalies. In response to the comparison detecting presence of one or more anomalies, indication(s) of the one or more anomalies are stored. Another example includes receiving indication(s) of anomaly(ies) experienced by an application on computing device(s) and analyzing the indication(s) of the anomaly(ies) to determine whether corrective action(s) should be issued. Responsive to a determination corrective action(s) should be issued based on the analyzing, the corrective action(s) are issued to the computing device(s). Methods, program products, and apparatus are disclosed.申请人:International Business Machines Corporation地址:Armonk NY US国籍:US代理机构:Harrington & Smith更多信息请下载全文后查看。
ANOMALY DETECTION METHOD, ANOMALY DETECTION PROGRA

专利名称:ANOMALY DETECTION METHOD,ANOMALY DETECTION PROGRAM, ANDINFORMATION PROCESSING DEVICE发明人:MATSUOKA, Kenta,KASAMA, Kouichirou 申请号:EP15897146.5申请日:20150630公开号:EP3319058A4公开日:20180627专利内容由知识产权出版社提供摘要:An information processing apparatus acquires data indicating a time when a monitored subject is detected to have assumed a predetermined posture, based on an output value from a sensor corresponding to the monitored subject. The information processing apparatus (100) references a storage unit (110) judges whether the time indicated by the acquired data is included in a time period when the monitored subject assumes the predetermined posture. When the time indicated by the acquired data is not included in the time period when the predetermined posture is assumed, the information processing apparatus (100) detects an abnormality of the monitored subject. On the other hand, when the time indicated by the acquired data is included in the time period when the predetermined posture is assumed, the information processing apparatus (100) does not detect an abnormality of the monitored subject.申请人:Fujitsu Limited地址:1-1, Kamikodanaka 4-chome Nakahara-ku Kawasaki-shi, Kanagawa 211-8588 JP 国籍:JP代理机构:Haseltine Lake LLP 更多信息请下载全文后查看。
System and method of anomaly detection
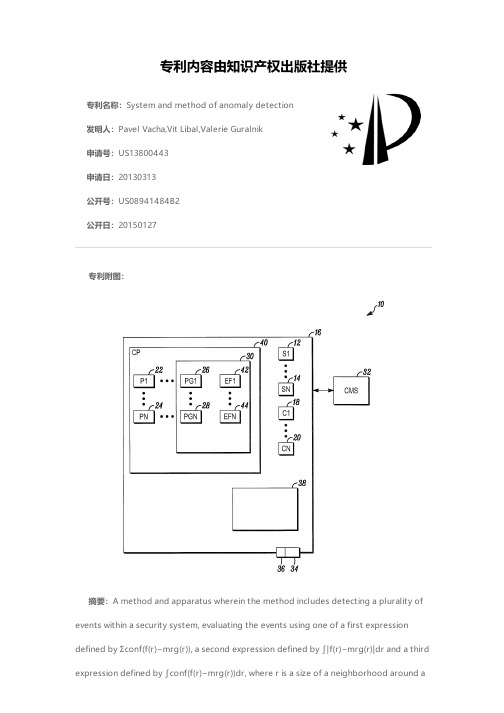
专利名称:System and method of anomaly detection发明人:Pavel Vacha,Vit Libal,Valerie Guralnik申请号:US13800443申请日:20130313公开号:US08941484B2公开日:20150127专利内容由知识产权出版社提供专利附图:摘要:A method and apparatus wherein the method includes detecting a plurality of events within a security system, evaluating the events using one of a first expressiondefined by Σconf(f(r)−mrg(r)), a second expression defined by ∫|f(r)−mrg(r)|dr and a third expression defined by ∫conf(f(r)−mrg(r))dr, where r is a size of a neighborhood around adata point, f(r) is a Local Correlation Integral (LOCI) of r, mrg(r) is a margin of r, R is a predetermined set of intervals of neighborhood sizes, Q is a predetermined discrete set of neighborhood sizes and conf(d) is a non-linear confidence function being 0 for near distance to the data point and quickly approaching 1 for larger distances, comparing a value of the evaluated expression with a threshold value and setting an alarm upon detecting that the value exceeds the threshold value.申请人:Honeywell International Inc.地址:Morristown NJ US国籍:US代理机构:Husch Blackwell LLP更多信息请下载全文后查看。
ANOMALY DIAGNOSIS METHOD AND ANOMALY DIAGNOSIS APP

专利名称:ANOMALY DIAGNOSIS METHOD ANDANOMALY DIAGNOSIS APPARATUS发明人:TATSUMI OBA申请号:US16136408申请日:20180920公开号:US20190095300A1公开日:20190328专利内容由知识产权出版社提供专利附图:摘要:There is provided an anomaly diagnosis method performed by an anomalydiagnosis apparatus that diagnosis to determine whether an observed value composed of values of variables representing a state of a monitoring target obtained by observing themonitoring target is anomalous. The anomaly diagnosis apparatus includes a processor and a memory. The memory stores an anomaly detection model generated by learning using observed values. The processor acquires group information indicating one or more groups each constituted by a combination of at least two mutually-related variables, acquires the observed value, determines whether the observed value is anomalous by employing the anomaly detection model read from the memory, and in a case where the observed value is determined to be anomalous, identifies a group causing an anomaly among the one or more groups in the observed value.申请人:Panasonic Intellectual Property Corporation of America地址:Torrance CA US国籍:US更多信息请下载全文后查看。
基于声学信号的异常检测算法研究

基于声学信号的异常检测算法研究一、异常检测算法的概述异常检测(algorithm anomaly detection)是指在大量数据中找出与众不同的数据记录,这些数据记录通常称为异常点,或者离群点。
异常检测算法是一种关键技术,在现代数据挖掘,机器学习和人工智能领域有着广泛的应用。
现实生活中,许多系统和应用程序都需要进行异常检测,例如:在工业生产中,如石油和煤气行业,机械制造业,异常检测有助于发现发动机、泵、加热器和其他设备故障;医学中,异常检测可以自动检测癌症病变,异常细胞和其他健康问题。
二、声学信号在异常检测中的应用声波(声学信号)在异常检测中的应用非常广泛,由于声音的性质,声音对于物体的物理和化学变化非常敏感,并且能够传播很远。
因此,声学信号可以用于许多领域的异常检测和监控。
例如,在机器设备故障监测和检测系统中,声音信号可以反映机器中的部件损坏和摩擦;在煤矿安全监测系统中,声音信号可以用于检测瓦斯爆炸和地质和动态问题。
此外,声音信号也可以用于医学和化学领域中异常检测。
三、常见的声学信号异常检测方法1. 时间序列方法时间序列是指将连续的数据按照时间先后顺序排列而形成的数据序列。
时间序列方法是将数据视为时间序列然后对其进行分析以检测异常点的方法。
在声学信号异常检测中,时间序列方法可以区分正常和异常的声音,可以用于诊断机器故障。
2. 谱分析方法谱分析是一种将信号按频率分解成一系列分量来显示其频谱特性的方法。
谱分析方法利用信号在频率域和时间域的相互转换来对声音进行探测和分类。
这种方法通常用于确定在各个频率范围内是否存在异常点,并用于识别矿井,工厂或医院中的异常声音。
3. 机器学习方法采用机器学习方法来检测声音的异常。
机器学习方法建立一个模型,这个模型可以对不同的声音进行分类,从而识别异常点。
四、基于声学信号的异常检测算法基于声学信号的异常检测算法的主要目标是从音频信号中检测出与众不同的声音。
在声学信号异常检测中,需要先对声音信号进行处理以去除噪声,并提取有效信息。
异常检测(AnomalyDetection)

异常检测(AnomalyDetection)github:本⽂算法均使⽤python3实现1. 异常检测1.1 异常检测是什么? 异常检测即为发现与⼤部分样本点不同的样本点,也就是离群点。
我们可通过下⾯这个例⼦进⾏理解,在飞机引擎制造商对制造好的飞机引擎进⾏测试时,选择了对飞机引擎运转时产⽣的热量以及震动强度进⾏测试,测试后的结果如下: 很明显我们能够看出,存在⼀个点(绿⾊),其热量较低时震动强度却很⾼,它在坐标轴中的分布明显偏离了其它的样本点。
因此我们可以认为这个样本点就是异常点即离群点。
1.2 异常检测的⽅法 异常检测不同于监督学习,其正样本(异常点)容量明显远⼩于负样本(正常点)的容量,因此我们并不能使⽤监督学习的⽅法来进⾏异常检测的判断。
对于异常检测主要有以下⼏种⽅法: (1)基于模型的技术:许多异常检测技术⾸先建⽴⼀个数据模型,异常是那些同模型不能完美拟合的对象。
例如,数据分布的模型可以通过估计概率分布的参数来创建。
在假设⼀个对象服从该分布的情况下所计算的值⼩于某个阈值,那么可以认为他是⼀个异常对象。
(2)基于邻近度的技术:通常可以在对象之间定义邻近性度量,异常对象是那些远离⼤部分其他对象的对象。
当数据能够以⼆维或者三维散布图呈现时,可以从视觉上检测出基于距离的离群点。
(3)基于密度的技术:对象的密度估计可以相对直接计算,特别是当对象之间存在邻近性度量。
低密度区域中的对象相对远离近邻,可能被看做为异常。
本⽂主要讨论基于模型的异常检测⽅法1.3 基于模型的异常检测基本步骤 (1)对样本集进⾏建模:P(x) ,即对x的分布概率进⾏建模 (2)对于待检测样本x test,若P(x test)<ϵ则样本为异常,若P(x test)>ϵ则样本为正常。
2. ⾼斯分布2.1 什么是⾼斯分布? ⾼斯分布即为正态分布。
是指对于样本x∈R,假设其服从均值µ ,⽅差σ2的⾼斯分布,可记为x∼N(µ,σ2) 。
ABSTRACT Anomaly Detection of Web-based Attacks

Anomaly Detection of Web-based AttacksChristopher Kruegel chris@Giovanni Vignavigna@ Reliable Software GroupUniversity of California,Santa Barbara Santa Barbara,CA93106ABSTRACTWeb-based vulnerabilities represent a substantial portion of the security exposures of computer networks.In order to de-tect known web-based attacks,misuse detection systems are equipped with a large number of signatures.Unfortunately,it is difficult to keep up with the daily disclosure of web-related vulnerabilities,and,in addition,vulnerabilities may be intro-duced by installation-specific web-based applications.There-fore,misuse detection systems should be complemented with anomaly detection systems.This paper presents an intrusion detection system that uses a number of different anomaly de-tection techniques to detect attacks against web servers and web-based applications.The system correlates the server-side programs referenced by client queries with the parameters contained in these queries.The application-specific charac-teristics of the parameters allow the system to perform fo-cused analysis and produce a reduced number of false posi-tives.The system derives automatically the parameter pro-files associated with web applications(e.g.,length and struc-ture of parameters)from the analyzed data.Therefore,it can be deployed in very different application environments without having to perform time-consuming tuning and con-figuration.Categories and Subject DescriptorsD.4.6[Operating Systems]:Security and ProtectionGeneral TermsSecurityKeywordsAnomaly Detection,World-Wide Web,Network Security 1.INTRODUCTIONWeb servers and web-based applications are popular at-tack targets.Web servers are usually accessible through cor-poratefirewalls,and web-based applications are often devel-Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on thefirst page.To copy otherwise,to republish,to post on servers or to redistribute to lists,requires prior specific permission and/or a fee.CCS’03,October27–31,2003,Washington,DC,USA.Copyright2003ACM1-58113-738-9/03/0010...$5.00.oped without following a sound security methodology.At-tacks that exploit web servers or server extensions(e.g.,pro-grams invoked through the Common Gateway Interface[7] and Active Server Pages[22])represent a substantial por-tion of the total number of vulnerabilities.For example,in the period between April2001and March2002,web-related vulnerabilities accounted for23%of the total number of vul-nerabilities disclosed[34].In addition,the large installation base makes both web applications and servers a privileged target for worm programs that exploit web-related vulnera-bilities to spread across networks[5].To detect web-based attacks,intrusion detection systems (IDSs)are configured with a number of signatures that sup-port the detection of known attacks.For example,at the time of writing,Snort2.0[28]devotes868of its1931signatures to detect web-related attacks.Unfortunately,it is hard to keep intrusion detection signature sets updated with respect to the large numbers of vulnerabilities discovered daily.In addition,vulnerabilities may be introduced by custom web-based applications developed in-house.Developing ad hoc signatures to detect attacks against these applications is a time-intensive and error-prone activity that requires substan-tial security expertise.To overcome these issues,misuse detection systems should be composed with anomaly detection systems,which sup-port the detection of new attacks.In addition,anomaly detection systems can be trained to detect attacks against custom-developed web-based applications.Unfortunately,to the best of our knowledge,there are no available anomaly de-tection systems tailored to detect attacks against web servers and web-based applications.This paper presents an anomaly detection system that de-tects web-based attacks using a number of different tech-niques.The anomaly detection system takes as input the web server logfiles which conform to the Common Log For-mat and produces an anomaly score for each web request. More precisely,the analysis techniques used by the tool take advantage of the particular structure of HTTP queries[11] that contain parameters.The parameters of the queries are compared with established profiles that are specific to the program or active document being referenced.This approach supports a more focused analysis with respect to generic anomaly detection techniques that do not take into account the specific program being invoked.This paper is structured as follows.Section2presents re-lated work on detection of web-based attacks and anomaly detection in general.Section3describes an abstract model for the data analyzed by our intrusion detection system.Sec-tion4presents the anomaly detection techniques used.Sec-tion5contains the experimental evaluation of the systemwith respect to real-world data and discusses the results ob-tained so far and the limitations of the approach.Finally, Section6draws conclusions and outlines future work.2.RELATED WORKAnomaly detection relies on models of the intended behav-ior of users and applications and interprets deviations from this‘normal’behavior as evidence of malicious activity[10, 17,13,19].This approach is complementary with respect to misuse detection,where a number of attack descriptions (usually in the form of signatures)are matched against the stream of audited events,looking for evidence that one of the modeled attacks is occurring[14,25,23].A basic assumption underlying anomaly detection is that attack patterns differ from normal behavior.In addition, anomaly detection assumes that this‘difference’can be ex-pressed quantitatively.Under these assumptions,many tech-niques have been proposed to analyze different data streams, such as data mining for network traffic[21],statistical analy-sis for audit records[16],and sequence analysis for operating system calls[12].Of particular relevance to the work described here are tech-niques that learn the detection parameters from the ana-lyzed data.For instance,the framework developed by Lee et al.[20]provides guidelines to extract features that are useful for building intrusion classification models.The approach uses labeled data to derive which is the best set of features to be used in intrusion detection.The approach described in this paper is similar to Lee’s because it relies on a set of selected features to perform both classification and link analysis on the data.On the other hand,the approach is different because it does not rely on the labeling of attacks in the training data in order to derive either the features or the threshold values used for detection. The learning process is purely based on past data,as,for example,in[18].3.DATA MODELOur anomaly detection approach analyzes HTTP requests as logged by most common web servers(for example,Apache [2]).More specifically,the analysis focuses on GET requests that use parameters to pass values to server-side programs or active documents.Neither header data of GET requests nor POST/HEAD requests are taken into account.Note,however, that it is straightforward to include the parameters of these requests.This is planned for future work.More formally,the input to the detection process consists of an ordered set U={u1,u2,...,u m}of URIs extracted from successful GET requests,that is,requests whose return code is greater or equal to200and less than300.A URI u i can be expressed as the composition of the path to the desired resource(path i),an optional path information component(pinfo i),and an optional query string(q).The query string is used to pass parameters to the referenced resource and it is identified by a leading‘?’character.A query string consists of an ordered list of n pairs of param-eters(or attributes)with their corresponding values.That is,q=(a1,v1),(a2,v2),...,(a n,v n)where a i∈A,the set of all attributes,and v i is a string.The set S q is defined as the subset{a j,...,a k}of attributes of query q.Figure1shows an example of an entry from a web server log and the cor-responding elements that are used in the analysis.For this example query q,S q={a1,a2}.The analysis process focuses on the association between programs,parameters,and their values.URIs that do not contain a query string are irrelevant,and,therefore,they are removed from U.In addition,the set of URIs U is partitioned into subsets U r according to the resource path.Therefore, each referred program r is assigned a set of corresponding queries U r.The anomaly detection algorithms are run on each set of queries U r,independently.This means that the modeling and the detection process are performed separately for each program r.In the following text,the term‘request’refers only to re-quests with queries.Also,the terms‘parameter’and‘at-tribute’of a query are used interchangeably.4.DETECTION MODELSThe anomaly detection process uses a number of different models to identify anomalous entries within a set of input requests U r associated with a program r.A model is a set of procedures used to evaluate a certain feature of a query attribute(e.g.,the string length of an attribute value)or a certain feature of the query as a whole(e.g.,the presence and absence of a particular attribute).Each model is associated with an attribute(or a set of attributes)of a program by means of a profile.Consider,for example,the string length model for the username attribute of a login program.In this case,the profile for the string length model captures the ‘normal’string length of the user name attribute of the login program.The task of a model is to assign a probability value to either a query or one of the query’s attributes.This proba-bility value reflects the probability of the occurrence of the given feature value with regards to an established profile. The assumption is that feature values with a sufficiently low probability(i.e.,abnormal values)indicate a potential at-tack.Based on the model outputs(i.e.,the probability values of the query and its individual attributes),a decision is made–that is,the query is either reported as a potential attack or as normal.This decision is reached by calculating an anomaly score individually for each query attribute and for the query as a whole.When one or more anomaly scores(either for the query or for one of its attributes)exceed the detection threshold determined during the training phase(see below), the whole query is marked as anomalous.This is necessary to prevent attackers from hiding a single malicious attribute in a query with many‘normal’attributes.The anomaly scores for a query and its attributes are de-rived from the probability values returned by the correspond-ing models that are associated with the query or one of the attributes.The anomaly score value is calculated using a weighted sum as shown in Equation1.In this equation,w m represents the weight associated with model m,while p m is its returned probability value.The probability p m is sub-tracted from1because a value close to zero indicates an anomalous event that should yield a high anomaly score.Anomaly Score=m∈Modelsw m∗(1−p m)(1)A model can operate in one of two modes,training or de-tection.The training phase is required to determine the char-acteristics of normal events(that is,the profile of a feature according to a specific model)and to establish anomaly score thresholds to distinguish between regular and anomalous in-169.229.60.105 − johndoe [6/Nov/2002:23:59:59 −0800 "GET /scripts/access.pl?user=johndoe&cred=admin" 200 2122path a = v a = v1122qFigure1:Sample Web Server Access Log Entryputs.This phase is divided into two steps.During thefirst step,the system creates profiles for each server-side program and its attributes.During the second step,suitable thresh-olds are established.This is done by evaluating queries and their attributes using the profiles created during the previ-ous step.For each program and its attributes,the highest anomaly score is stored and then,the threshold is set to a value that is a certain,adjustable percentage higher than this maximum.The default setting for this percentage(also used for our experiments)is10%.By modifying this value,the user can adjust the sensitivity of the system and perform a trade-offbetween the number of false positives and the ex-pected detection accuracy.The length of the training phase (i.e.,the number of queries and attributes that are utilized to establish the profiles and the thresholds)is determined by an adjustable parameter.Once the profiles have been created–that is,the models have learned the characteristics of normal events and suit-able thresholds have been derived–the system switches to detection mode.In this mode,anomaly scores are calculated and anomalous queries are reported.The following sections describe the algorithms that ana-lyze the features that are considered relevant for detecting malicious activity.For each algorithm,an explanation of the model creation process(i.e.,the learning phase)is included. In addition,the mechanism to derive a probability value p fora new input element(i.e.,the detection phase)is discussed.4.1Attribute LengthIn many cases,the length of a query attribute can be used to detect anomalous ually,parameters are either fixed-size tokens(such as session identifiers)or short strings derived from human input(such asfields in an HTML form). Therefore,the length of the parameter values does not vary much between requests associated with a certain program. The situation may look different when malicious input is passed to the program.For example,to overflow a buffer in a target application,it is necessary to ship the shell code and additional padding,depending on the length of the tar-get buffer.As a consequence,the attribute contains up to several hundred bytes.The goal of this model is to approximate the actual but unknown distribution of the parameter lengths and detect instances that significantly deviate from the observed normal behavior.Clearly,we cannot expect that the probability density function of the underlying real distribution will follow a smooth curve.We also have to assume that the distribution has a large variance.Nevertheless,the model should be able to identify significant deviations.4.1.1LearningWe approximate the mean˙µand the variance˙σ2of the real attribute length distribution by calculating the sample mean µand the sample varianceσ2for the lengths l1,l2,...,l n of the parameters processed during the learning phase(assum-ing that n queries with this attribute were processed).4.1.2DetectionGiven the estimated query attribute length distribution with parametersµandσ2as determined by the previous learning phase,it is the task of the detection phase to assess the regularity of a parameter with length l.The probability of l can be calculated using the Chebyshev inequality shown below.p(|x−µ|>t)<σ2t2(2) The Chebyshev inequality puts an upper bound on the probability that the difference between the value of a ran-dom variable x andµexceeds a certain threshold t,for an arbitrary distribution with varianceσ2and meanµ.This upper bound is strict and has the advantage that is does not assume a certain underlying distribution.We substitute the threshold t with the distance between the attribute length l and the meanµof the attribute length distribution(i.e., |l−µ|).This allows us to obtain an upper bound on the prob-ability that the length of the parameter deviates more from the mean than the current instance.The resulting probabil-ity value p(l)for an attribute with length l is calculated as shown below.p(|x−µ|>|l−µ|)<p(l)=σ2(l−µ)2(3)This is the value returned by the model when operating in detection mode.The Chebyshev inequality is independent of the underlying distribution and its computed bound is,in general,very weak.Applied to our model,this weak bound results in a high degree of tolerance to deviations of attribute lengths given an empirical mean and variance.Although such a property is undesirable in many situations,by using this technique only obvious outliers areflagged as suspicious, leading to a reduced number of false alarms.4.2Attribute Character DistributionThe attribute character distribution model captures the concept of a‘normal’or‘regular’query parameter by look-ing at its character distribution.The approach is based on the observation that attributes have a regular structure, are mostly human-readable,and almost always contain only printable characters.A large percentage of characters in such attributes are drawn from a small subset of the256possible8-bit values (mainly from letters,numbers,and a few special charac-ters).As in English text,the characters are not uniformly distributed,but occur with different frequencies.Obviously, it cannot be expected that the frequency distribution is iden-tical to a standard English text.Even the frequency of a cer-tain character(e.g.,the frequency of the letter‘e’)varies con-siderably between different attributes.Nevertheless,there are similarities between the character frequencies of query parameters.This becomes apparent when the relative fre-quencies of all possible256characters are sorted in descend-ing order.The algorithm is based only on the frequency values them-selves and does not rely on the distributions of particular characters.That is,it does not matter whether the character with the most occurrences is an‘a’or a‘/’.In the following, the sorted,relative character frequencies of an attribute are called its character distribution.For example,consider the parameter string‘passwd’with the corresponding ASCII values of‘11297115115119100’. The absolute frequency distribution is2for115and1for the four others.When these absolute counts are transformed into sorted,relative frequencies(i.e.,the character distribution), the resulting values are0.33,0.17,0.17,0.17,0.17followed by0occurring251times.For an attribute of a legitimate query,one can expect that the relative frequencies slowly decrease in value.In case of malicious input,however,the frequencies can drop extremely fast(because of a peak caused by a single character with a very high frequency)or nearly not at all(in case of random values).The character distribution of an attribute that is perfectly normal(i.e.,non-anomalous)is called the attribute’s ideal-ized character distribution(ICD).The idealized character distribution is a discrete distribution with:ICD:→with={n∈N|0≤n≤255},={p∈|0≤p≤1}and255i=0ICD(i)=1.0.The relative frequency of the character that occurs n-most often(0-most denoting the maximum)is given as ICD(n). When the character distribution of the sample parameter ‘passwd’is interpreted as the idealized character distribution, then ICD(0)=0.33and ICD(1)to ICD(4)are equal to0.17. In contrast to signature-based approaches,this model has the advantage that it cannot be evaded by some well-known attempts to hide malicious code inside a string.In fact, signature-based systems often contain rules that raise an alarm when long sequences of0x90bytes(the nop operation in Intel x86-based architectures)are detected in a packet. An intruder may substitute these sequences with instructions that have a similar behavior(e.g.,add rA,rA,0,which adds 0to the value in register A and stores the result back to A). By doing this,it is possible to prevent signature-based sys-tems from detecting the attack.Such sequences,nonetheless, cause a distortion of the attribute’s character distribution, and,therefore,the character distribution analysis still yields a high anomaly score.In addition,characters in malicious in-put are sometimes disguised by xor’ing them with constants or shifting them by afixed value(e.g.,using the ROT-13 code).In this case,the payload only contains a small rou-tine in clear text that has the task of decrypting and launch-ing the primary attack code.These evasion attempts do not change the resulting character distribution and the anomaly score of the analyzed query parameter is unaffected.4.2.1LearningThe idealized character distribution is determined during the training phase.For each observed query attribute,its character distribution is stored.The idealized character dis-tribution is then approximated by calculating the average of all stored character distributions.This is done by setting ICD(n)to the mean of the n th entry of the stored character distributions∀n:0≤n≤255.Because all individual char-acter distributions sum up to unity,their average will do so as well,and the idealized character distribution is well-defined.4.2.2DetectionGiven an idealized character distribution ICD,the task of the detection phase is to determine the probability that the character distribution of a query attribute is an actual sam-ple drawn from its ICD.This probability,or more precisely, the confidence in the hypothesis that the character distribu-tion is a sample from the idealized character distribution,is calculated by a statistical test.This test should yield a high confidence in the correctness of the hypothesis for normal(i.e.,non-anomalous)attributes while it should reject anomalous ones.The detection algo-rithm uses a variant of the Pearsonχ2-test as a‘goodness-of-fit’test[4].For the intended statistical calculations,it is not neces-sary to operate on all values of ICD directly.Instead,it is enough to consider a small number of intervals,or bins.For example,assume that the domain of ICD is divided into six segments as shown in Table1.Although the choice of six bins is somewhat arbitrary1,it has no significant impact on the results.Segment012345x-Values01-34-67-1112-1516-255Table1:Bins for theχ2-testThe expected relative frequency of characters in a segment can be easily determined by adding the values of ICD for the corresponding x-values.Because the relative frequencies are sorted in descending order,it can be expected that the values of ICD(x)are more significant for the anomaly score when x is small.This fact is clearly reflected in the division of ICD’s domain.When a new query attribute is analyzed,the number of occurrences of each character in the string is determined. Afterward,the values are sorted in descending order and combined according to Table1by aggregating values that belong to the same segment.Theχ2-test is then used to cal-culate the probability that the given sample has been drawn from the idealized character distribution.The standard test requires the following steps to be performed.1.Calculate the observed and expected frequencies-Theobserved values O i(one for each bin)are already given.The expected number of occurrences E i are calculated by multiplying the relative frequencies of each of the six bins as determined by the ICD times the length of the attribute(i.e.,the length of the string).pute theχ2-value asχ2=i<6i=0(O i−E i)2E i-note that i ranges over all six bins.3.Determine the degrees of freedom and obtain the sig-nificance-The degrees of freedom for theχ2-test are identical to the number of addends in the formula above minus one,which yieldsfive for the six bins used.The actual probability p that the sample is derived from the idealized character distribution(that is,its signif-icance)is read from a predefined table using theχ2-value as index.1The number six seems to have a particular relevance to the field of anomaly detection[32].The derived value p is used as the return value for this model.When the probability that the sample is drawn from the idealized character distribution increases,p increases as well.4.3Structural InferenceOften,the manifestation of an exploit is immediately vis-ible in query attributes as unusually long parameters or pa-rameters that contain repetitions of non-printable characters. Such anomalies are easily identifiable by the two mechanisms explained before.There are situations,however,when an attacker is able to craft her attack in a manner that makes its manifestation appear more regular.For example,non-printable characters can be replaced by groups of printable characters.In such situations,we need a more detailed model of the query at-tribute that contains the evidence of the attack.This model can be acquired by analyzing the parameter’s structure.For our purposes,the structure of a parameter is the regular grammar that describes all of its normal,legitimate values.4.3.1LearningWhen structural inference is applied to a query attribute, the resulting grammar must be able to produce at least all training examples.Unfortunately,there is no unique gram-mar that can be derived from a set of input elements.When no negative examples are given(i.e.,elements that should not be derivable from the grammar),it is always possible to create either a grammar that contains exactly the train-ing data or a grammar that allows production of arbitrary strings.Thefirst case is a form of over-simplification,as the resulting grammar is only able to derive the learned in-put without providing any level of abstraction.This means that no new information is deduced.The second case is a form of over-generalization because the grammar is capable of producing all possible strings,but there is no structural information left.The basic approach used for our structural inference is to generalize the grammar as long as it seems to be‘reasonable’and stop before too much structural information is lost.The notion of‘reasonable generalization’is specified with the help of Markov models and Bayesian probability.In afirst step,we consider the set of training items(i.e., query attributes stored during the training phase)as the out-put of a probabilistic grammar.A probabilistic grammar is a grammar that assigns probabilities to each of its productions. This means that some words are more likely to be produced than others,whichfits well with the evidence gathered from query parameters.Some values appear more often,and this is important information that should not be lost in the mod-eling step.A probabilistic regular grammar can be transformed into a non-deterministicfinite automaton(NF A).Each state S of the automaton has a set of n S possible output symbols o which are emitted with a probability of p S(o).Each transi-tion t is marked with a probability p(t)that characterizes the likelihood that the transition is taken.An automaton that has probabilities associated with its symbol emissions and its transitions can also be considered a Markov model.The output of the Markov model consists of all paths from its start state to its terminal state.A probability value can be assigned to each output word w(that is,a sequence of output symbols o1,o2,...,o k).This probability value(as shown in Equation4)is calculated as the sum of the probabilities of all distinct paths through the automaton that produce w.The probability of a single path is the product of the probabili-ties of the emitted symbols p Si(o i)and the taken transitions p(t i).The probabilities of all possible output words w sum up to1.p(w)=p(o1,o2,...,o k)=(4) (paths p f or w)(states∈p)p Si(o i)∗p(t i)Figure2:Markov Model ExampleFor example,consider the NF A in Figure2.To calculate the probability of the word‘ab’,one has to sum the probabil-ities of the two possible paths(one that follows the left arrow and one that follows the right one).The start state emits no symbol and has a probability of1.Following Equation4,the result isp(w)=(1.0∗0.3∗0.5∗0.2∗0.5∗0.4)+(1.0∗0.7∗1.0∗1.0∗1.0∗1.0)=0.706(5) The target of the structural inference process is tofind a NF A that has the highest likelihood for the given training elements.An excellent technique to derive a Markov model from empirical data is explained in[30].It uses the Bayesian theorem to state this goal asp(Model|T rainingData)=(6) p(T rainingData|Model)∗p(Model)p(T rainingData)The probability of the training data is considered a scal-ing factor in Equation6and it is subsequently ignored.As we are interested in maximizing the a posteriori probability (i.e.,the left-hand side of the equation),we have to maximize the product shown in the enumerator on the right-hand side of the equation.Thefirst term–the probability of the train-ing data given the model–can be calculated for a certain automaton(i.e.,for a certain model)by adding the probabil-ities calculated for each input training element as discussed above.The second term–the prior probability of the model –is not as straightforward.It has to reflect the fact that, in general,smaller models are preferred.The model proba-bility is calculated heuristically and takes into account the total number of states N as well as the number of transitions Strans and emissions S emit at each state S.This is。
Shift+Anomaly

Analytic Description and Suggested UsageName: Shift Anomaly DetectorDescription:A univariate anomaly detection algorithm that detects shift anomalies in data based on robust statistics. This analytic is especially effective where dimensions of data are not very high (typically less than 10 variables). For each univariate sample in time an anomaly score (0-1) is generated, where higher scores indicate higher chances of anomaly being present in data. All detected anomalies (based on individual tags) are then post-processed to identify a subset of Alerts where chances of anomaly are high based on all tags.Note: This version of the analytics implements a specific method for pre- and post-processing. In future versions users will be able to pick from different choices to suit a specific use case and combine with this anomaly detector through orchestration capability of the platform.Input DescriptionsAssumptions:1.No NaNs or missing data in any inputs. If missing data are encountered, anyinterplolation based imputation methods are not used, instead that tag isdisregarded for shift detection for the duration of missing data.2.Dimensions of data be at most 10 or less for effective statistical learning, elsethe amount of data required to learn meaningful patterns grows very large.This analytic is generic in that any number of inputs can be configured as long as above assumptions are valid for all input variables. Analysts can achieve the best performance by configuring all the relevant tags, which are expected to contain information from the anomalies present in the system. Some domain experience may come in handy in choosing appropriate tags, for instance in identifying key parameters where shift detection may be of interest from a physical process point of view.This particular implementation is for anomaly detection in wind turbines, the analytic is predefined to work with following 8 input variables. All 8 inputs must be mapped to corresponding tags in the current version. Future versions of this analytic will support handling missing data situations.OutputsThe shift anomaly detector analytic outputs post-processed alerts. Alerts outputs consist of following three elements in this version.1)Date: a vector of UTC UNIX epoch time stamps in milliseconds indicating thetime of detected alert.2)Score: A vector of scores in range 0-1 indicating the probability of anomaly ineach of the alerts generated.3)Sensor: ranked list of tags that contribute to generating high probabilityscores for any specific alert. A list of one or more tags is generated for eachalert generated.Tuning Analytics for a new Use Case or DeploymentThis analytic is parameterized by following constants. All constants are prepopulated with default values, however a user may modify these parameters to tune analytics performance. Below is a description of these parameters and how changing the value of these parameters is expected to affect analytic performance.1)"alpha": 0.001- Determines the level of significance in the statistical test for declaring ananomaly. Smaller the value of alpha more confident the system needs to be. Reducing the value of alpha parameter is expected to reduce the number of anomaly detection alerts.2)"MaxWindowSize":360 – An internal time-based parameter to specify the length of runningwindow (expressed in units specified by TimeGranularity) for computing statistics. Increasing thisparameter is likely to improve detection performance but also make it computationally slow.3)"practical_threshold": 0.04 – Its an internal threshold on sensors tags configured forthis analytic. Increasing this threshold is expected reduce the number of alerts generated, but canincrease missed detection rate on the other hand.4)"MaxTimeGapFactor":6000 – this time-based parameter is used to handle missing data. Ifmissing data duration spans longer than this parameter (expressed in units specified byTimeGranularity), the algorithm internally resets to start creating a new statistical model of nominal, as previous model based on last set of data are considered too far for meaningful statistical comparisons.5)"MinTimeGapFactor":1000 – This time-based internal parameter specifies minimumduration of missing data below which algorithm ignores that data are missing and proceeds withplanned statistical tests normally.6)"persistency":10 – This time-based parameter specifies the time for which a shiftphenomenon should persist to create an alert. This is to disregard temporary spike changes in data.7)"InitializationLengthAfterNodetection":20 – Internal time-based parameterto implement running statistical tests on incoming data. It is meant for providing flexibility in advanceapplication usage and is not recommended for change for most usage conditions.8)"InitializationLengthAfterDetection":15 - Internal time-based parameter toimplement running statistical tests on incoming data. It is meant for providing flexibility in advanceapplication usage and is not recommended for change for most usage conditions.9)“TimeGranularity”:1 min – specifies units that all other time-based parameters areexpressed in. E.g. MaxWindowSize = 360 with 1 min granularity specifies maximum length of runningwindow can be 360 minutes, or 6 hours for this application. This is currently fixed at 1 minute.Usage Example and Test DataFor purposes of illustration, the figure below shows input data tags configured for this analytic. These list of columns indicate the tags, which were found useful in detecting anomalies for this use case. In a more generalized setting any other tags may be mapped to this analytic for other use cases.Corresponding shift anomaly alerts generated from this algorithm are shown below for illustration. Since many alerts were generated in the six months time period between 03/03/15 and 09/02/15, only a subset are shown below:date:1425857400000,1426065000000,1426156800000,1426200600000,1426256400000,…score:0.0001230045355411491,0.00012868411901475105,0.00058093733074719245,0.00011662721688532329,0.00012681584597603232,…sensor:["gen_1_temp", "gen_2_temp", "temp_shaft_bearing"],["gen_1_temp", "gen_2_temp", "temp_shaft_bearing"],["bearing_a_temp", "gen_1_temp", "gen_2_temp"],["gen_1_temp", "gen_2_temp", “temp_shaft_bearing"],["bearing_a_temp", gen_1_temp", "gen_2_temp"],…。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Application of Anomaly Detection Algorithms for Detecting SYN Flooding AttacksVasilios A.Siris and Fotini PapagalouInstitute of Computer Science,Foundation for Research and Technology-Hellas(FORTH)P.O.Box1385,GR71110Heraklion,Crete,GreeceTel.+302810391726,fax:+302810391601,email:vsiris@ics.forth.grAbstract—We investigate statistical anomaly detection algo-rithms for detecting SYNflooding,which is the most common type of Denial of Service(DoS)attack.The two algorithms considered are an adaptive threshold algorithm and a partic-ular application of the cumulative sum(CUSUM)algorithm for change point detection.The performance is investigated in terms of the detection probability,the false alarm ratio,and the detection delay.Particular emphasis is on investigating the tradeoffs among these metrics and how they are affected by the parameters of the algorithm and the characteristics of the attacks.Such an investigation can provide guidelines to effectively tune the parameters of the detection algorithm to achieve specific performance requirements in terms of the above metrics.I.I NTRODUCTIONOver the past few years many sites on the Internet have been the target of denial of service(DoS)attacks,among which TCP SYNflooding is the most prevalent[1].Indeed,recent studies1have shown an increase of such attacks,which can result in disruption of services that costs from several millions to billions of dollars.The aim of denial of service attacks are to consume a large amount of resources,thus preventing legitimate users from receiving service with some minimum performance.TCP SYN flooding exploits TCP’s three-way handshake procedure,and specifically its limitation in maintaining half-open connections.A TCP connection starts with the client sending a SYN mes-sage to the server,indicating the client’s intention to establish a TCP connection.The server replies with a SYN/ACK message to acknowledge that it has received the initial SYN message, and at the same time reserves an entry in its connection table and buffer space.After this exchange,the TCP connection is considered to be half open.To complete the TCP connection establishment,the client must reply with an ACK message.In a TCP SYNflooding attack,an attacker,from a large number of compromised clients in the case of distributed DoS attacks, sends a very large number of SYN messages,withfictitious (spoofed)IP addresses,to a single server(victim).Although the server replies with SYN/ACK messages,these messages This work was supported in part by the EC funded project SCAMPI(IST-2001-32404).The authors are also with the Dept.of Computer Science,Univ.of Crete. 12002and2003CSI/FBI Cybercrime Survey Report.The2003report indicates that DoS attacks alone were responsible for a loss of$65million.are never acknowledged by the client.As a result,many half-open connections exist on the server,consuming its resources. This continues until the server has consumed all its resources, hence can no longer accept new TCP connection requests.In this paper we present and evaluate two anomaly detection algorithms for detecting TCP SYN attacks:an adaptive thresh-old algorithm and a particular application of the cumulative sum(CUSUM)algorithm for change point detection.Our focus is on investigating the tradeoffs between the detection probability,the false alarm ratio,and the detection delay,and how these tradeoffs are affected by the parameters of the detection algorithm and the characteristics of the attacks.Such an investigation can assist in tuning the parameters of the de-tection algorithm to satisfy specific performance requirements. Our results show that although simple and straightforward algorithms,such as the adaptive threshold algorithm,can exhibit good performance for high intensity attacks,their performance deteriorates for low intensity attacks.On the other hand,algorithms based on a strong theoretical foundation can exhibit robust performance over various attack types,and without necessarily being complex or costly to implement. Detection of low intensity attacks is particularly important since this would enable the early detection of attacks whose intensity slowly increases,and the detection of attacks close to the sources,either in routers or monitoring stations,thus facilitating the identification of compromised hosts that are participating in distributed DoS attacks[2].Next we present a brief overview of related work.The authors of[3]investigate predictive detection of anomalies for a web server,analysing time series measurements of the number of http operations per second.The proposed statistical model considers both seasonal and trend components,which are modelled using a Holt-Winters algorithm,and time correla-tions which are modelled using a second order autoregressive model.After removing the above non-stationarities from the time series measurements,anomalies are detected using a gen-eralized likelihood ratio(GLR)algorithm.A similar approach is used in[4],which considers measurements collected in MIB(Management Information Base)variables.The authors of[5]model the seasonal and trend components similar to [3].A problem is detected when the actual measured value deviates from the predicted value(estimated using a moving average procedure)by some number of standard deviations.The author of[6]considers a similar approach for modelling the seasonal and trend component,and detects an anomaly when the measured variable falls outside a confidence band, which is estimated from previous differences of the measured variable and its predicted value.The authors of[2]propose an approach for detecting SYN flooding attacks using a CUSUM-type algorithm,which is applied to the time series measurements of the difference of the number of SYN packets and the corresponding number of FIN packets in a time interval.Our work also considers a CUSUM-type algorithm,however the specific form,hence the corresponding equations,differ;moreover,we apply it to measurements of the number of SYN packets,while avoiding the need to explicitly take into account the seasonality and trend by considering an exponential weighted moving average for obtaining a recent estimate of the mean rate of SYN packets.Finally,the authors of[7]also consider a CUSUM-type algorithm,combined with aχ2goodness-to-fit test.In addition to the specific algorithms we investigate,our work differs from the above in that we emphasize on inves-tigating the performance of the detection algorithms in terms of three metrics:detection probability,false alarm ratio,and detection delay.Moreover,our experiments investigate how the tradeoff between these metrics is affected by the parameters of the detection algorithm and the characteristics of attacks. The rest of the paper is organized as follows.In Section II we present the two anomaly detection algorithms that we investigate.In Section III we present and discuss the results investigating the performance of the algorithms,in terms of detection probability,false alarm ratio,and detection delay, and how the performance is affected by the parameters of the algorithm and the characteristics of the attacks.Finally,in Section IV we present some concluding remarks and identify related ongoing work.II.A NOMALY DETECTION ALGORITHMSIn this section we present the two statistical anomaly detection algorithms that we apply for detecting SYNflooding attacks.Thefirst,which we will refer to as adaptive threshold algorithm,is a rather straightforward and simple algorithm that detects anomalies based on violations of a threshold that is adaptively set based on recent traffic measurements.The second is an application of the cumulative sum(CUSUM) algorithm,which is a widely used anomaly detection algorithm that has its foundations in change point detection theory.Our selection of these two algorithms is twofold:First,based on the numerical experiments presented in Section III,we wish to demonstrate that a simple and naive algorithm can exhibit satisfactory performance for some types of attacks,such as high intensity attacks,but can have very bad performance for other types of attacks,such as low intensity attacks. Second,we wish to demonstrate that algorithms based on a strong statistical foundation can exhibit robust performance over various attack types,without necessarily being complex or costly to implement.A.Adaptive threshold algorithmThis algorithm relies on testing whether the traffic mea-surement,number of SYN packets in our case,over a given interval exceeds a particular threshold.In order to account for seasonal(daily and weekly)variations and trends,the value of the threshold is set adaptively based on an estimate of the mean number of SYN packets.If x n is the number of SYN packets in the n-th time interval, and¯µn−1is the mean rate estimated from measurements prior to n,then the alarm condition isIf x n≥(α+1)¯µn−1then ALARM signalled at time n, whereα>0is a parameter that indicates the percentage above the mean value that we consider to be an indication of anomalous behaviour.The meanµn can be computed over some past time window or using an exponential weighted moving average(EWMA)of previous measurements¯µn=β¯µn−1+(1−β)x n,(1) whereβis the EWMA factor.Direct application of the above algorithm would yield a high number of false alarms(false positives).A simple modification that can improve its performance is to signal an alarm after a minimum number of consecutive violations of the threshold. Ifni=n−k+11{xi≥(α+1)¯µi−1}≥k then ALARM at time n,(2) where k>1is a parameter that indicates the number of consecutive intervals the threshold must be violated for an alarm to be raised.The tuning parameters of the above algorithm are the amplitude factorαfor computing the alarm threshold,the number of successive threshold violations k before signalling an alarm,the EWMA factorβ,and the length of the time interval over which traffic measurements(number of SYN packets)are taken.B.CUSUM(Cumulative SUM)algorithmThe CUSUM algorithm belongs to the family of change point detection algorithms that are based on hypothesis testing, and was developed for independent and identically distributed random variables{y i}.According to the approach,there are two hypothesisθ0andθ1,with probabilities pθand pθ1,where thefirst corresponds to the statistical distribution prior to a change and the second to the distribution after a change.The test for signalling a change is based on the log-likelihood ratio S n given byS n=ni=1s i,where s i=lnpθ1(y i)pθ(y i).The typical behaviour of the log-likelihood ratio S n includes a negative drift before a change and a positive drift after the change.Therefore,the relevant information for detecting achange lies in the difference between the value of the log-likelihood ratio and its current minimum value [8].Hence the alarm condition for the CUSUM algorithm isIf g n ≥h then ALARM signalled at time n ,(3)whereg n =S n −m nandm n =min 1≤j ≤nS j .(4)The parameter h is a threshold parameter.Assume that {y i }are independent Gaussian random vari-ables with known variance σ2,which we assume remains the same after the change,and µ0and µ1the mean before and after the change.After some calculations [8],(4)reduces tog n = g n −1+µ1−µ0σ2 y n −µ1+µ02 +.(5)Above we have assumed that {y n }are independent Gaussianrandom variables.Of course this is not true for network traffic measurements,such as the number of SYN packets,due to seasonality (weekly and daily variations),trends,and time correlations.Such non-stationary behaviour should be removed before applying the CUSUM algorithm.One approach for achieving this is proposed in [3],where seasonality and trend is removed using the Holt-Winters algorithm and time correlations are removed using an autoregressive algorithm.In addition to leading to complex and time-consuming calcula-tions,experiments we have conducted showed that the above approach,applied to the problem of detecting SYN flooding attacks,leads to minor gains compared to simpler approaches.For this reason we consider the following simple approach:We apply the CUSUM algorithm to ˜x n ,with˜x n =x n −¯µn −1,where x n is the number of SYN packets in the n -th time interval,and ¯µn is an estimate of the mean rate at time n ,which is computed using an exponential weighted moving average,as in (1).The mean value of ˜x n prior to a change is zero,hence the mean in (5)is µ0=0.A remaining issue that needs to be addressed is the value of µ1,i.e.the mean traffic rate after the change.This cannot be known beforehand,hence we approximate it with α¯µn ,were as in the adaptive threshold algorithm the average ¯µn is updated using an exponential weighted moving average,and αis an amplitude percentage parameter,which intuitively corresponds to the most probable percentage of increase of the mean rate after a change (attack)has occurred.Hence,(5)becomesg n = g n −1+α¯µn −12 x n −¯µn −1−α¯µn −1 +.(6)It is interesting to contrast the above approach with that in [2],where daily variations are addressed by dividing the difference of the number of SYN packets and the number of FIN packets in a time interval,with the average number of FIN packets,hence is based on detecting changes when the number of SYN packets exceeds the number of FIN packets.Our approach is more general,since it can be applied to attacks other than SYNflooding.Indeed,an interesting application would be to use the algorithm for early detection of QoS (such as maximum delay)violations;such an approach can be justified by the fact that a large number of QoS violations are due to anomalies (including DoS attacks),hence anomaly detection techniques can warn for potential QoS violations before they occur.The tuning parameters of the CUSUM algorithm are the amplitude percentage parameter α,the alarm threshold h ,the EWMA factor β,and the length of the time interval over which traffic measurements are taken.These parameters are identical to the ones for the adaptive threshold algorithm,except for h which is the alarm threshold in the CUSUM algorithm.III.P ERFORMANCE E VALUATIONIn this section we investigate the performance of the two algorithms presented in the previous section for detecting TCP SYN flooding attacks.The performance metrics considered include the detection probability,the false alarm rate,and the detection delay.Additional experiments investigating how different parameters of the detection algorithm and the char-acteristics of the attack affect the performance appear an the extended version of this paper [9].Our experiments used actual network traffic taken from the MIT Lincoln Laboratory 2.We used trace data taken during two days,with the trace from each day containing 11hours of collected packets (08.00-19.00).The first investigations that we present considered SYN packet measurements in 10second intervals.In some experiments,we also used a 14.5hour trace taken from the link connecting the University of Crete’s network to the Greek Research and Technology Network (GRNET).The attacks were generated synthetically;this allowed us to control the characteristics of the attacks,hence to investigate the performance of the detection algorithms for different attack types.The duration of one attack was normally distributed with mean 60time intervals (10minutes assuming 10second intervals)and variance 10time intervals.The inter-arrival time between consecutive attacks was exponentially distributed,with mean value 460time intervals (approximately 77minutes assuming 10second intervals);this results in approximately 8attacks in an 11hour period.The detection probability is the percentage of attacks for which an alarm was raised,and the false alarm ratio (FAR)is the percentage of alarms that did not correspond to an actual attack.Unless otherwise noted,the parameters we considered for the adaptive threshold algorithm were α=0.5,k =4,and β=0.98,and the parameters for the CUSUM algorithm were α=0.5,h =5,and β=0.98.A.High intensity attacksOur first experiment considered high intensity attacks,whose mean amplitude was 250%higher than the mean traffic rate,which was approximately 31.64SYN packets in one time interval;the length of the time interval was 10seconds.2DARPAintrusion detectionevaluation:/IST/ideval(a)Adaptive threshold (b)CUSUMFig.1.High intensity attacks.Both the adaptive threshold and the CUSUM algorithm have very good performance.Figures 1(a)and 1(b)show the results for the adaptive threshold and the CUSUM algorithm,respectively.The hori-zontal axis in these figures is the time interval,with 0and 4000corresponding approximately to 8:00and 19:00,respectively.In each figure,from top to bottom,we have the traffic trace with attacks,the original traffic trace without attacks,the attacks only,and finally the bottom graph shows the time intervals where an alarm was raised.The figures show that both the adaptive threshold and the CUSUM algorithm have excellent performance for high intensity attacks,since they both yielded a detection probability of 100%and a false alarm ratio (FAR)of 0%.The detection delay was very close:3.01and 2.75time intervals,respectively.B.Low intensity attacksNext we investigate the performance of the attack detection algorithms in the case of low intensity attacks,whose mean amplitude is 50%of the traffic’s actual mean rate.Detection of low intensity attacks is important for two reasons:First,early detection of DoS attacks with increasing intensity would enable defensive actions to be taken earlier.Second,detection of low intensity attacks would enable the detection of attacks close to the sources,since such a placement of detectors can facilitate the identification of stations that are participating in a distributed DoS attack.Figure 2(a)shows that for low intensity attacks the per-formance of the adaptive threshold algorithm has deteriorated significantly,giving a very high FAR equal to 32%.On the other hand,Figure 2(b)shows that the performance of the CUSUM algorithm remains close to its performance in the case of high intensity attacks,namely the FAR was less than 9%.Nevertheless,the detection delay of the CUSUM algorithm has increased to 10.25time intervals,from only 2.75time intervals in the case of high intensity attacks.Note that the detection probability for both algorithms was 100%.The difference in the performance of the adaptive threshold and the CUSUM algorithms lies in the way each maintains memory:the adaptive threshold algorithm has memory of whether the threshold was violated or not in the previous k −1time intervals.On the other hand,the CUSUM algorithm maintains finer information on the amount of data exceeding the amount expected based on some estimated mean rate,(6).1)Tradeoff between detection probability and false alarm ratio:The above results were for specific values of the param-(a)Adaptive threshold (b)CUSUMFig.2.Low intensity attacks.The performance of the adaptive threshold algorithm has deteriorated signifipared to its performance for high intensity attacks.On the other hand,the performance of the CUSUM algorithm remains very good.(a)Adaptive threshold (b)CUSUMFig.3.Detection probability and false alarm ratio for low intensity attacks.The CUSUM algorithm has better performance than the adaptive threshold algorithm (better performance corresponds to points towards the lower-right).eters of the two detection algorithms.Figures 3(a)and 3(b)show the tradeoff between the detection probability and the false alarm ratio (FAR)for different values of k for the adap-tive threshold algorithm (2),and h for the CUSUM algorithm (3).Each point in the graph corresponds to a different value of the tuning parameter,k or h ,in the interval [1,10].The data for each point was the average of 50runs.Observe that the CUSUM algorithm exhibits better performance,supporting our observation in the previous section.Figures 4(a)and 4(b)shows the performance of the CUSUM and of the algorithm in [2],for traces from the University of Crete (for which h obtains values in the interval [10,100]).The algorithm of [2]is given byg n =[g n −1+(X n −a )]+,where X n is the (#of SYN pkts -#of FIN pkts)/(average #FIN pkts).The graph in Figure 4(b)for the algorithm of [2]was obtained for an alarm threshold h =9,and for a in the interval [1,10].Observe that the CUSUM algorithm discussed in this paper has better performance than the algorithm in [2].Graphs such as those in Figures 3and 4can assist in tuning the parameters of the detection algorithm.Indeed,note that the alarm threshold h is different for different traces,and controls the sensitivity of the attack detection.2)Tradeoff between false alarm ratio and detection delay:Next we investigate the tradeoff between the false alarm ratio and the detection delay.Figures 5(a)and 5(b)show the results in the case of low intensity attacks for the adaptive threshold(a)CUSUM (b)algorithm in [2]Fig.4.False alarm ratio and detection probability for the CUSUMalgorithm proposed in this paper and the algorithm in [2].(a)Adaptive threshold (b)CUSUMFig.5.False alarm ratio and detection delay for the adaptive threshold and the CUSUM algorithms for low intensity attacks (better performance corresponds to points towards the lower-left).and the CUSUM algorithm,respectively.Each point in the graph corresponds to a different value of the tuning parameter,k or h .Note that in Figure 5(a),which is for the adaptive threshold algorithm,the values on the lower-left correspond to low detection delay,but have a small detection probability.3)Effect of the amplitude factor α:Figure 6(a)shows the effect of the amplitude factor αfor the CUSUM algorithm,when the threshold parameter h was adjusted in order to achieve a 100%detection probability.The graph was obtained by taking the average of 10runs,which yielded a 95%confidence interval of ±0.045.The figure shows that the performance of the CUSUM algorithm was indifferent to the factor α,for a large range of its values,approximately [0.1,1].4)Effect of the EWMA factor β:Figure 6(b)shows the effect of the EWMA factor βfor the CUSUM algorithm,when the threshold parameter h was adjusted in order to achieve a 100%detection probability.As before,the graph was obtained by takingthe average of 10runs,which yielded a 95%confidence interval of ±0.045.The figure shows that the best performance of the CUSUM algorithm was for values of βin the interval [0.95,0.99].IV.C ONCLUSIONSWe described and investigated two anomaly detection algo-rithms for detecting SYN flooding attacks,namely an adaptive threshold algorithm and an algorithm based on the CUSUM change point detection scheme.Our investigations considered the tradeoff between the attack detection probability,the false alarm ratio,and the detection delay,and how these are affected by the parameters of the anomaly detection algorithm.(a)Amplitude factor α(b)EWMA factor βFig.6.Effect of amplitude factor αand EWMA factor βfor the CUSUM algorithm.Our results illustrate that although a simple straightforward algorithm such as the adaptive threshold algorithm can have satisfactory performance for high intensity attacks,its per-formance deteriorates for low intensity attacks.On the other hand,an algorithm based on change point detection,such as the CUSUM algorithm,can exhibit robust performance over a range of different types of attacks,without being more complex.Ongoing work focuses on the application of the algorithms to an actual production network,for both the incoming and the outgoing traffic,the combination of the algorithms with defensive mechanisms,and the application of the algorithms for early detection of QoS,such as maximum delay,violations.R EFERENCES[1] D.Moore,G.V oelker,and S.Savage,“Inferring Internet denial of serviceactivity,”in Proc.of USENIX Security Symposium ,2001.[2]H.Wang,D.Zhang,and K.G.Shin,“Detecting SYN flooding attacks,”in Proc.of IEEE INFOCOM’02,2002.[3]J.Hellerstein,F.Zhang,and P.Shahabuddin,“A statistical approach topredictive detection,”Computer Networks ,vol.35,pp.77–95,2001.[4]M.Thottan and C.Ji,“Adaptive thresholding for proactive problemdetection,”in Proc.of IEEE Int’l Workshop on Syst.Manag.,1998.[5]P.Hoogenboom and J.Lepreau,“Computer system performance problemdetection using time series models,”in Proc.of USENIX Summer 1993Technical Conference ,June 1993.[6]J.Brutlag,“Aberrant behavior detection in time series for networkmonitoring,”in Proc.of LISA XIV ,December 2000.[7]R.B.Blazek,H.Kim,B.Rozovskii,and A.Tartakovsky,“A novelapproach to detection of denial-of-service attacks via adaptive sequential and batch sequential change-point detection methods,”in Proc.of IEEE Workshop on Syst.,Man,and rmat.Assurance ,June 2001.[8]M.Basseville and I.V .Nikiforov,Detection of Abrupt Changes:Theoryand Applications .Prentice Hall,1993.[9]V .A.Siris and F.Papagalou,“Application of anomaly detection algo-rithms for detecting SYN flooding attacks,”ICS-FORTH,Tech.Rep.No.330,December 2003.。