英语wh_疑问构式的双突显_ffg_语义认知模型研究_曾国才
汉英“wh-不定词”功能等值性的新构语义图研究

问代词 “ 非疑问用法” 和英语 “ 不定代词”的跨语 言 比较 是 认 识 这 种 共 性 价 值 的 重 要 方 向 。汉 语 疑 问 句 的 生 成 语 法 研 究 曾对 语 言 共 性 研 究 产 生 了重 要 影 响 【(3o随着 汉 语语 法 化 研 究 的发 展 , 1P6 】1) 汉语 特殊 疑问句 、 特别是疑 问代 词 的 “ 非疑 问用
法 ”再 度 成 为 热 点 。H ppl ah关 于 世 界 语 言 a sem t ( 汉 语 )“ 定 代 词 ”功 能类 型学 和语 法 化 研 究 含 不 开 辟 了 疑 问 系 统跨 语 言 共 性研 究 的 新 路 , 中确 其 立 的 语 义 图 对 于 汉 语 疑 问代 词 “ 疑 问用 非 法 ”以至 汉 语 疑 问系 统难 题 提 供 了新 的 理论 和认 识 契 机 。汉 语 界 关 于 疑 问 代 词 “ 疑 问 用 法 ”的 非 早期研究 表明 , 中外 学 者 的认 识 其 实 多有 相 通 之 处 , 谓 殊 途 同归 。汉 英 研 究 传 统 的殊 途 主要 因 可 中西 语 言形 态 差 异 形 成 , 人 类 语 言 功 能 的等 值 而
于学界关于 “ 意义 ”s s ( 当于 cnet nl f ne 相 e ) ovn oa i m ai s 和 “ enn ) 使用 意义”ue ( 当于 cn x a g ( ’相 s) ot t l e u m ai s 用法松散 , enn ) g 他主张用更一般的 “ 功能” 概 念来概括。[这样 , 5 多义性实际上就是多功能性 , 可用 语 义 图 和概 念 空 间来 刻 画 。不 过 ,w 一不 定 “h
研究 集 中体现 了功 能类 型 学 的基 本语 言观 念 和研
高中英语写作技巧 Wh法

高中英语写作技巧Wh法Wh法:叙述一个事件,最简单的文章结构便是使用wh- 问句。
事情发生在什么人身上(Who)、何时发生(When)、在何处发生(Where)、发生了什么(What)、为何发生(Why)、如何发生(How)、结局是什么(What)、你的感觉又是如何(How)等。
其中,当然以What 和How 的问题作为你文章的重心。
但其他的问题会让你的文章更具体,也就更生动。
如主题句为:Not all picnics are enjoyable.,针对主题问自己几个以Who 、Where、What、When 、Why、How开始的问题,来思考段落发展的方向。
可列出(范例) Not all picnics are enjoyable. Last Sunday, my family and I went on a picnic at Wu-lai. The weather was fine when we set 1_____ in Taipei in the morning. But as we were waiting for the bus, it became cloudy. Since it was Sunday and there were a lot of people at the bus terminal, we had to wait for an hour 2_____ we could finally get on a bus. The ride on the bus was 3___ no means enjoyable, either, because the bus was packed 4____ people and we got no seats. For almost an hour, we stood on the crowded bus, not 5_______(have) a chance to watch the scenery along the way. When we arrived at Wu-lai, we all had to sit for a while to rest our aching feet. 6_____(Feel) refreshed again, we happily took the cable car and reached the mountain-top recreational park. 7______ 8____ our disappointment, however, as we found a perfect spot 9____ our picnic, it started to rain. It was not long 10______ it began to rain cats and dogs. We had no choice but 11_____(take) shelter indoors with a lot of other tourists, not 12_____(know) when we could actually started picnicking. The rain did not stop 13_____ four-thirty in the afternoon; of course, our picnic was ruined. On our way home, we couldn’t help 14_______(think) that perhaps we would 15________(be) better off if we 16_________(stay) home.以”………, something embarrassing happened to me.”为主题句,写成一篇文章。
基于顺应-关联模式的英语WH-对话构式分析

基于顺应-关联模式的英语WH-对话构式分析刘姗,李健雪(江南大学外国语学院,江苏无锡214122)摘要:英语特殊疑问句是以WH-疑问词开头,在句法上形成了:WH-word+auxiliary+remainder?的WH-疑问构式,答话者根据问句所提供的事件域范围来提供具体信息,一问一答在构式语法视角下可看作对话构式。
在顺应—关联模式下,文章从交际双方的视角,通过分析问话者和答话者话语的生成、理解、交际双方的认知期待,对该构式进行研究,将顺应—关联模式与构式的承继性、对话构式的临时构式特征相结合,从语用与认知角度揭示了该构式的认知机制,并为构式语法提供了一个新的研究视角。
关键词:WH-对话构式;顺应-关联;承继性;临时构式特征;认知语用中图分类号:H0文献标识码:A文章编号:1009-5039(2019)15-0234-031背景英语中的问句主要有特殊疑问句、一般疑问句、选择疑问句以及反义疑问句。
而特殊疑问句是以WH-疑问词开头,它是该类构式的核心要素,其后接疑问助动词或情态助动词,再加其他成分,在句法上形成了“Wh-word+auxiliary+remain⁃der”的WH-特殊疑问句结构,而答话者根据问话人给出的信息范围来向其提供相应的具体信息,从而构成了一对对话,一问一答形成了一个话轮。
针对不同的问句,答话者会根据不同的场合、不同的心绪而给予相应的回答,使得对话传递出不同的意义。
根据Adele E.Goldberg(2006)对构式的定义,特殊疑问句及其回答可视为一个Wh-对话构式。
对话句法学作为当前认知语言学的最前沿课题之一,已将构式研究拓展到句法层面(Geert Brône&Elisabeth Zima,2014;曾国才,2015)。
目前,较为常见的几个英语构式,如there构式、双及物构式、致使——移动构式、动结构式等,在国内外备受关注,但是对WH-对话构式的研究相对来说比较少。
基于深度学习的教材德目教育文本分类方法
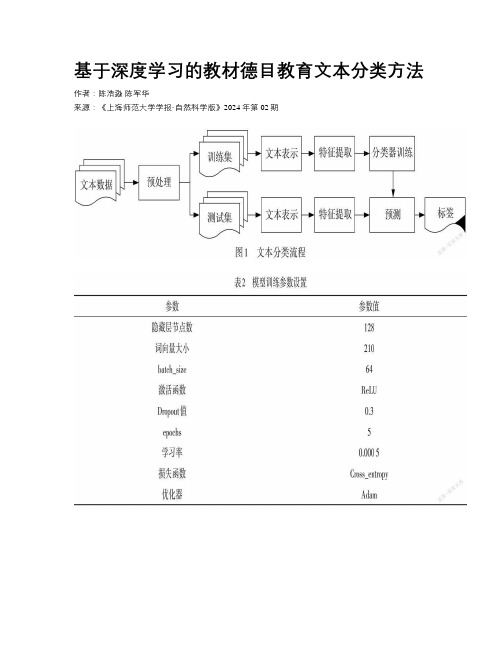
基于深度学习的教材德目教育文本分类方法作者:陈浩淼陈军华来源:《上海师范大学学报·自然科学版》2024年第02期Abstract:The classification of moral education texts in Shanghai primary and secondary school textbooks was studied and an IoMET_BBA(Indicators of moral education target based on BERT,BiLSTM and attention)model was proposed based on bidirectional encoder representations from transformer(BERT)pre-training model,bidirectional long short-term memory (BiLSTM)network,and attention mechanism. Firstly,data augmentation was performed using synthetic minority oversampling technique(SMOTE)and exploratory data analysis (EDA). Secondly,BERT was used to generate semantic vectors with rich contextual information. Thirdly,BiLSTM was adopted to extract features,and attention mechanism was combined to obtain word weight information. Finally,classification was performed through a fully connected layer. The comparative experimental results indicated that F1measurement value of IoMET_BBA reached 86.14%,which was higher than other models and could accurately evaluate the moral education texts of textbooks.Key words:moral education index;chinese text classification;bidirectional encoder representations from transformer(BERT)model;bidirectional long short-term memory (BiLSTM)network;attention mechanism德目教育是指将道德或品格的条目通过一定方式传授给学生的教育活动[1]. 德目教育的目标是帮助个体形成正确的道德判断,培养个人的道德观念、价值观和道德行为,进而推动整个社会形成道德共识.近年来,国内对德目教育的研究已经有了很多成熟的理论与实践模式,但对于教材文本的德目指标评估大部分是依靠人工完成的,结论较为主观,且效率较低[2].文本分类是自然语言处理(NLP)领域中的一项关键任务,它把文本数据归入不同的预先定义类别,在数字化图书馆、新闻推荐、社交网络等领域起到重要的作用. JOACHIMS[3]首次采用支持向量机方法将文本转化成向量,将文本分类任务转变成多个二元分类任务. KIM[4]提出了基于卷积神经网络(CNN)的TextCNN方法,在多个任务中取得了良好的效果. 徐军等[5]运用朴素贝叶斯和最大熵等算法,实现了中文新闻和评论文本的自动分类. 冯多等[6]提出了基于CNN的中文微博情感分类模型,并运用于社交场景.由于教材文本数据具有稀疏性,使用传统的分类算法进行建模时很难考虑上下文和顺序信息,并且数据集不平衡,不同指标的文本条数差异较大. 之前的相关研究[7-8]主要基于静态词向量(GloVe,Word2Vec)与CNN进行建模,所获得的词向量表示与上下文无关,也不能解决一词多义问题,且CNN只能提取局部空间特征,无法捕捉长距离的位置信息. 本文作者采用深度学习方法,对教材短文本数据进行分类,首先采用合成少数类过采样技术(SMOTE)和easy data augmentation(EDA)技术获得更平衡、更充分的文本数据集,提出基于深度学习的教材德目教育文本分类模型(IoMET_BBA),使用基于转换器的双向编码表征(BERT)预训练模型来生成富含语境信息的语义向量,然后使用双向长短期记忆网络(BiLSTM)和注意力机制来进一步进行特征提取,充分考虑上下文和位置信息,从而提高分类任务的准确性. 实验证明:相比于传统模型,IoMET_BBA模型的准确率与F1值提升明显,可高效准确地完成大规模的教材德目教育文本分类任务.1 相关技术1.1 深度学习分类模型文本分类需要使用已标注的训练数据来构建分类模型. 常见的文本分类流程如图1所示. 在进行文本分类之前,通常需要对原始数据进行预处理,包括分词、去除停用词、词干提取等.文本分类可以使用多种算法进行建模. 传统的机器学习分类模型,如朴素贝叶斯[9]、Kmeans[10]、支持向量机[3]、决策树[11]等,通常需要依靠人工来获取样本特征,忽略了文本数据的上下文信息和自然顺序. 近年来,基于神经网络的深度学习方法成为研究的热点. 这种方法主要包含两个关键任务:通过构建词向量来表示文本、使用一定的模型来提取特征并进行分类.计算机不能理解人类的语言,因此在NLP任务中,首先要将单词或词语表示成向量. 独热编码将词转化为长向量,向量维度与词数量相同,每个向量中某一维度的值是1,其余值都是0. 独热编码虽然简单,但不能体现出词与词之间的关系,并且当词量过大时,会出现维度灾难及向量十分稀疏的情况. 分布式的表示方法则可以将词表示为固定长度、稠密、互相存在语义关系的向量,这类方法也称为词嵌入. MIKOLOV等[12]提出了Word2Vec框架,包含Skip-Gram和Cbow算法,分别用单词来预测上下文和用上下文来预测单词. PENNINGTON 等[13]提出的GloVe方法,同时考虑到了局部信息和全局统计信息,根据词与词之间的共现矩阵来表示词向量.深度学习方法已经成为文本分类的主流方法. KIM等[4]使用包含卷积结构的CNN来分类文本,将文本映射成向量,并将向量输入到模型,通过卷积层提取特征、池化层对特征采样,但CNN没有时序性,忽略了局部信息之间的依赖关系. 循环神经网络(RNN)则从左到右浏览每个词向量,保留每个词的数据,可以为模型提供整个文本的上下文信息,但RNN计算速度较慢,且存在梯度消失等问题. 作为RNN的一种变体,长短期记忆网络(LSTM)通过过滤无效信息,有效缓解了梯度消失问题,更好地捕获长距离的依赖关系. 而BiLSTM由一个前向的LSTM和一个后向的LSTM组成,能够捕获双向语义依赖.1.2 BERT预训练模型同一个词在不同环境中可能蕴含不同的意义,而使用Word2Vec,GloVe等方法获得的詞向量都是静态的,即这类模型对于同一个词的表示始终相同,因此无法准确应对一词多义的情况. 为了解决这一问题,基于语言模型的动态词向量表示方法应运而生.预训练语言模型在大规模未标注数据上进行预训练,通过微调的方式在特定任务上进行训练.DEVLIN 等[14]提出了BERT模型,它拥有极强的泛化能力和稳健性,在多类NLP问题中表现优异.BERT模型本质是一种语言表示模型,通过在大规模无标注语料上的自监督学习,为词学习到良好的特征表示,并且可以通过微调,适应不同任务的需求. BERT模型采用多层双向Transformer结构,在建模时,Transformer结构使用了自注意力机制,取代传统深度学习中的CNN和RNN,有效地解决了长距离依赖问题,并通过并行计算提高计算效率. 通过计算每一个单词与句中其他单词之间的关联程度来调整其权重. BERT模型的结构如图2所示.文本分类是自然语言处理(NLP)领域中的一项关键任务,它把文本数据归入不同的预先定义类别,在数字化图书馆、新闻推荐、社交网络等领域起到重要的作用. JOACHIMS[3]首次采用支持向量机方法将文本转化成向量,将文本分类任务转变成多个二元分类任务. KIM[4]提出了基于卷积神经网络(CNN)的TextCNN方法,在多个任务中取得了良好的效果. 徐军等[5]运用朴素贝叶斯和最大熵等算法,实现了中文新闻和评论文本的自动分类. 冯多等[6]提出了基于CNN的中文微博情感分类模型,并运用于社交场景.由于教材文本数据具有稀疏性,使用传统的分类算法进行建模时很难考虑上下文和顺序信息,并且数据集不平衡,不同指标的文本条数差异较大. 之前的相关研究[7-8]主要基于静态词向量(GloVe,Word2Vec)与CNN进行建模,所获得的词向量表示与上下文无关,也不能解决一词多义问题,且CNN只能提取局部空间特征,无法捕捉长距离的位置信息. 本文作者采用深度学习方法,对教材短文本数据进行分类,首先采用合成少数类过采样技术(SMOTE)和easy data augmentation(EDA)技术获得更平衡、更充分的文本数据集,提出基于深度学习的教材德目教育文本分类模型(IoMET_BBA),使用基于转换器的双向编码表征(BERT)预训练模型来生成富含语境信息的语义向量,然后使用双向长短期记忆网络(BiLSTM)和注意力机制来进一步进行特征提取,充分考虑上下文和位置信息,从而提高分类任务的准确性. 实验证明:相比于传统模型,IoMET_BBA模型的准确率与F1值提升明显,可高效准确地完成大规模的教材德目教育文本分类任务.1 相关技术1.1 深度学习分类模型文本分类需要使用已标注的训练数据来构建分类模型. 常见的文本分类流程如图1所示. 在进行文本分类之前,通常需要对原始数据进行预处理,包括分词、去除停用词、词干提取等.文本分类可以使用多种算法进行建模. 传统的机器学习分类模型,如朴素贝叶斯[9]、Kmeans[10]、支持向量机[3]、决策树[11]等,通常需要依靠人工来获取样本特征,忽略了文本数据的上下文信息和自然顺序. 近年来,基于神经网络的深度学习方法成为研究的热点. 这种方法主要包含两个关键任务:通过构建词向量来表示文本、使用一定的模型来提取特征并进行分类.计算机不能理解人类的语言,因此在NLP任务中,首先要将单词或词语表示成向量. 独热编码将词转化为长向量,向量维度与词数量相同,每个向量中某一维度的值是1,其余值都是0. 独热编码虽然简单,但不能体现出词与词之间的关系,并且当词量过大时,会出现维度灾难及向量十分稀疏的情况. 分布式的表示方法则可以将词表示为固定长度、稠密、互相存在语义关系的向量,这类方法也称为词嵌入. MIKOLOV等[12]提出了Word2Vec框架,包含Skip-Gram和Cbow算法,分别用单词来预测上下文和用上下文来预测单词. PENNINGTON 等[13]提出的GloVe方法,同时考虑到了局部信息和全局统计信息,根据词与词之间的共现矩阵来表示词向量.深度学习方法已经成为文本分类的主流方法. KIM等[4]使用包含卷积结构的CNN来分类文本,将文本映射成向量,并将向量输入到模型,通过卷积层提取特征、池化层对特征采样,但CNN没有时序性,忽略了局部信息之间的依赖关系. 循环神经网络(RNN)则从左到右浏览每个詞向量,保留每个词的数据,可以为模型提供整个文本的上下文信息,但RNN计算速度较慢,且存在梯度消失等问题. 作为RNN的一种变体,长短期记忆网络(LSTM)通过过滤无效信息,有效缓解了梯度消失问题,更好地捕获长距离的依赖关系. 而BiLSTM由一个前向的LSTM和一个后向的LSTM组成,能够捕获双向语义依赖.1.2 BERT预训练模型同一个词在不同环境中可能蕴含不同的意义,而使用Word2Vec,GloVe等方法获得的词向量都是静态的,即这类模型对于同一个词的表示始终相同,因此无法准确应对一词多义的情况. 为了解决这一问题,基于语言模型的动态词向量表示方法应运而生.预训练语言模型在大规模未标注数据上进行预训练,通过微调的方式在特定任务上进行训练.DEVLIN 等[14]提出了BERT模型,它拥有极强的泛化能力和稳健性,在多类NLP问题中表现优异.BERT模型本质是一种语言表示模型,通过在大规模无标注语料上的自监督学习,为词学习到良好的特征表示,并且可以通过微调,适应不同任务的需求. BERT模型采用多层双向Transformer结构,在建模时,Transformer结构使用了自注意力机制,取代传统深度学习中的CNN和RNN,有效地解决了长距离依赖问题,并通过并行计算提高计算效率. 通过计算每一个单词与句中其他单词之间的关联程度来调整其权重. BERT模型的结构如图2所示.文本分类是自然语言处理(NLP)领域中的一项关键任务,它把文本数据归入不同的预先定义类别,在数字化图书馆、新闻推荐、社交网络等领域起到重要的作用. JOACHIMS[3]首次采用支持向量机方法将文本转化成向量,将文本分类任务转变成多个二元分类任务. KIM[4]提出了基于卷积神经网络(CNN)的TextCNN方法,在多个任务中取得了良好的效果. 徐军等[5]运用朴素贝叶斯和最大熵等算法,实现了中文新闻和评论文本的自动分类. 冯多等[6]提出了基于CNN的中文微博情感分類模型,并运用于社交场景.由于教材文本数据具有稀疏性,使用传统的分类算法进行建模时很难考虑上下文和顺序信息,并且数据集不平衡,不同指标的文本条数差异较大. 之前的相关研究[7-8]主要基于静态词向量(GloVe,Word2Vec)与CNN进行建模,所获得的词向量表示与上下文无关,也不能解决一词多义问题,且CNN只能提取局部空间特征,无法捕捉长距离的位置信息. 本文作者采用深度学习方法,对教材短文本数据进行分类,首先采用合成少数类过采样技术(SMOTE)和easy data augmentation(EDA)技术获得更平衡、更充分的文本数据集,提出基于深度学习的教材德目教育文本分类模型(IoMET_BBA),使用基于转换器的双向编码表征(BERT)预训练模型来生成富含语境信息的语义向量,然后使用双向长短期记忆网络(BiLSTM)和注意力机制来进一步进行特征提取,充分考虑上下文和位置信息,从而提高分类任务的准确性. 实验证明:相比于传统模型,IoMET_BBA模型的准确率与F1值提升明显,可高效准确地完成大规模的教材德目教育文本分类任务.1 相关技术1.1 深度学习分类模型文本分类需要使用已标注的训练数据来构建分类模型. 常见的文本分类流程如图1所示. 在进行文本分类之前,通常需要对原始数据进行预处理,包括分词、去除停用词、词干提取等.文本分类可以使用多种算法进行建模. 传统的机器学习分类模型,如朴素贝叶斯[9]、Kmeans[10]、支持向量机[3]、决策树[11]等,通常需要依靠人工来获取样本特征,忽略了文本数据的上下文信息和自然顺序. 近年来,基于神经网络的深度学习方法成为研究的热点. 这种方法主要包含两个关键任务:通过构建词向量来表示文本、使用一定的模型来提取特征并进行分类.计算机不能理解人类的语言,因此在NLP任务中,首先要将单词或词语表示成向量. 独热编码将词转化为长向量,向量维度与词数量相同,每个向量中某一维度的值是1,其余值都是0. 独热编码虽然简单,但不能体现出词与词之间的关系,并且当词量过大时,会出现维度灾难及向量十分稀疏的情况. 分布式的表示方法则可以将词表示为固定长度、稠密、互相存在语义关系的向量,这类方法也称为词嵌入. MIKOLOV等[12]提出了Word2Vec框架,包含Skip-Gram和Cbow算法,分别用单词来预测上下文和用上下文来预测单词. PENNINGTON 等[13]提出的GloVe方法,同时考虑到了局部信息和全局统计信息,根据词与词之间的共现矩阵来表示词向量.深度学习方法已经成为文本分类的主流方法. KIM等[4]使用包含卷积结构的CNN来分类文本,将文本映射成向量,并将向量输入到模型,通过卷积层提取特征、池化层对特征采样,但CNN没有时序性,忽略了局部信息之间的依赖关系. 循环神经网络(RNN)则从左到右浏览每个词向量,保留每个词的数据,可以为模型提供整个文本的上下文信息,但RNN计算速度较慢,且存在梯度消失等问题. 作为RNN的一种变体,长短期记忆网络(LSTM)通过过滤无效信息,有效缓解了梯度消失问题,更好地捕获长距离的依赖关系. 而BiLSTM由一个前向的LSTM和一个后向的LSTM组成,能够捕获双向语义依赖.1.2 BERT预训练模型同一个词在不同环境中可能蕴含不同的意义,而使用Word2Vec,GloVe等方法获得的词向量都是静态的,即这类模型对于同一个词的表示始终相同,因此无法准确应对一词多义的情况. 为了解决这一问题,基于语言模型的动态词向量表示方法应运而生.预训练语言模型在大规模未标注数据上进行预训练,通过微调的方式在特定任务上进行训练.DEVLIN 等[14]提出了BERT模型,它拥有极强的泛化能力和稳健性,在多类NLP问题中表现优异.BERT模型本质是一种语言表示模型,通过在大规模无标注语料上的自监督学习,为词学习到良好的特征表示,并且可以通过微调,适应不同任务的需求. BERT模型采用多层双向Transformer结构,在建模时,Transformer结构使用了自注意力机制,取代传统深度学习中的CNN和RNN,有效地解决了长距离依赖问题,并通过并行计算提高计算效率. 通过计算每一个单词与句中其他单词之间的关联程度来调整其权重. BERT模型的结构如图2所示.文本分类是自然语言处理(NLP)领域中的一项关键任务,它把文本数据归入不同的预先定义类别,在数字化图书馆、新闻推荐、社交网络等领域起到重要的作用. JOACHIMS[3]首次采用支持向量機方法将文本转化成向量,将文本分类任务转变成多个二元分类任务. KIM[4]提出了基于卷积神经网络(CNN)的TextCNN方法,在多个任务中取得了良好的效果. 徐军等[5]运用朴素贝叶斯和最大熵等算法,实现了中文新闻和评论文本的自动分类. 冯多等[6]提出了基于CNN的中文微博情感分类模型,并运用于社交场景.由于教材文本数据具有稀疏性,使用传统的分类算法进行建模时很难考虑上下文和顺序信息,并且数据集不平衡,不同指标的文本条数差异较大. 之前的相关研究[7-8]主要基于静态词向量(GloVe,Word2Vec)与CNN进行建模,所获得的词向量表示与上下文无关,也不能解决一词多义问题,且CNN只能提取局部空间特征,无法捕捉长距离的位置信息. 本文作者采用深度学习方法,对教材短文本数据进行分类,首先采用合成少数类过采样技术(SMOTE)和easy data augmentation(EDA)技术获得更平衡、更充分的文本数据集,提出基于深度学习的教材德目教育文本分类模型(IoMET_BBA),使用基于转换器的双向编码表征(BERT)预训练模型来生成富含语境信息的语义向量,然后使用双向长短期记忆网络(BiLSTM)和注意力机制来进一步进行特征提取,充分考虑上下文和位置信息,从而提高分类任务的准确性. 实验证明:相比于传统模型,IoMET_BBA模型的准确率与F1值提升明显,可高效准确地完成大规模的教材德目教育文本分类任务.1 相关技术1.1 深度学习分类模型文本分类需要使用已标注的训练数据来构建分类模型. 常见的文本分类流程如图1所示. 在进行文本分类之前,通常需要对原始数据进行预处理,包括分词、去除停用词、词干提取等.文本分类可以使用多种算法进行建模. 传统的机器学习分类模型,如朴素贝叶斯[9]、Kmeans[10]、支持向量机[3]、决策树[11]等,通常需要依靠人工来获取样本特征,忽略了文本数据的上下文信息和自然顺序. 近年来,基于神经网络的深度学习方法成为研究的热点. 这种方法主要包含两个关键任务:通过构建词向量来表示文本、使用一定的模型来提取特征并进行分类.计算机不能理解人类的语言,因此在NLP任务中,首先要将单词或词语表示成向量. 独热编码将词转化为长向量,向量维度与词数量相同,每个向量中某一维度的值是1,其余值都是0. 独热编码虽然简单,但不能体现出词与词之间的关系,并且当词量过大时,会出现维度灾难及向量十分稀疏的情况. 分布式的表示方法则可以将词表示为固定长度、稠密、互相存在语义关系的向量,这类方法也称为词嵌入. MIKOLOV等[12]提出了Word2Vec框架,包含Skip-Gram和Cbow算法,分别用单词来预测上下文和用上下文来预测单词. PENNINGTON 等[13]提出的GloVe方法,同时考虑到了局部信息和全局统计信息,根据词与词之间的共现矩阵来表示词向量.深度学习方法已经成为文本分类的主流方法. KIM等[4]使用包含卷积结构的CNN来分类文本,将文本映射成向量,并将向量输入到模型,通过卷积层提取特征、池化层对特征采样,但CNN没有时序性,忽略了局部信息之间的依赖关系. 循环神经网络(RNN)则从左到右浏览每个词向量,保留每个词的数据,可以为模型提供整个文本的上下文信息,但RNN计算速度较慢,且存在梯度消失等问题. 作为RNN的一种变体,长短期记忆网络(LSTM)通过过滤无效信息,有效缓解了梯度消失问题,更好地捕获长距离的依赖关系. 而BiLSTM由一个前向的LSTM和一个后向的LSTM组成,能够捕获双向语义依赖.1.2 BERT预训练模型同一个词在不同环境中可能蕴含不同的意义,而使用Word2Vec,GloVe等方法获得的词向量都是静态的,即这类模型对于同一个词的表示始终相同,因此无法准确应对一词多义的情况. 为了解决这一问题,基于语言模型的动态词向量表示方法应运而生.预训练语言模型在大规模未标注数据上进行预训练,通过微调的方式在特定任务上进行训练.DEVLIN 等[14]提出了BERT模型,它拥有极强的泛化能力和稳健性,在多类NLP问题中表现优异.BERT模型本质是一种语言表示模型,通过在大规模无标注语料上的自监督学习,为词学习到良好的特征表示,并且可以通过微调,适应不同任务的需求. BERT模型采用多层双向Transformer结构,在建模时,Transformer结构使用了自注意力机制,取代传统深度学习中的CNN和RNN,有效地解决了长距离依赖问题,并通过并行计算提高计算效率. 通过计算每一个单词与句中其他单词之间的关联程度来调整其权重. BERT模型的结构如图2所示.文本分类是自然语言处理(NLP)领域中的一项关键任务,它把文本数据归入不同的预先定义类别,在数字化图书馆、新闻推荐、社交网络等领域起到重要的作用. JOACHIMS[3]首次采用支持向量机方法将文本转化成向量,将文本分类任务转变成多个二元分类任务. KIM[4]提出了基于卷积神经网络(CNN)的TextCNN方法,在多个任务中取得了良好的效果. 徐军等[5]运用朴素贝叶斯和最大熵等算法,实现了中文新闻和评论文本的自动分类. 冯多等[6]提出了基于CNN的中文微博情感分类模型,并运用于社交场景.由于教材文本数据具有稀疏性,使用传统的分类算法进行建模时很难考虑上下文和顺序信息,并且数据集不平衡,不同指标的文本条数差异较大. 之前的相关研究[7-8]主要基于静态词向量(GloVe,Word2Vec)与CNN进行建模,所获得的词向量表示与上下文无关,也不能解决一词多义问题,且CNN只能提取局部空间特征,无法捕捉长距离的位置信息. 本文作者采用深度学习方法,对教材短文本数据进行分类,首先采用合成少数类过采样技术(SMOTE)和easy data augmentation(EDA)技术获得更平衡、更充分的文本数据集,提出基于深度学习的教材德目教育文本分类模型(IoMET_BBA),使用基于转换器的双向编码表征(BERT)预训练模型来生成富含语境信息的语义向量,然后使用双向长短期记忆网络(BiLSTM)和注意力机制来进一步进行特征提取,充分考虑上下文和位置信息,从而提高分类任务的准确性. 实验证明:相比于传统模型,IoMET_BBA模型的准确率与F1值提升明显,可高效准确地完成大规模的教材德目教育文本分类任务.1 相关技术1.1 深度学习分类模型文本分类需要使用已标注的训练数据来构建分类模型. 常见的文本分类流程如图1所示. 在进行文本分类之前,通常需要对原始数据进行预处理,包括分词、去除停用词、词干提取等.文本分类可以使用多种算法进行建模. 传统的机器学习分类模型,如朴素贝叶斯[9]、Kmeans[10]、支持向量機[3]、决策树[11]等,通常需要依靠人工来获取样本特征,忽略了文本数据的上下文信息和自然顺序. 近年来,基于神经网络的深度学习方法成为研究的热点. 这种方法主要包含两个关键任务:通过构建词向量来表示文本、使用一定的模型来提取特征并进行分类.计算机不能理解人类的语言,因此在NLP任务中,首先要将单词或词语表示成向量. 独热编码将词转化为长向量,向量维度与词数量相同,每个向量中某一维度的值是1,其余值都是0. 独热编码虽然简单,但不能体现出词与词之间的关系,并且当词量过大时,会出现维度灾难及向量十分稀疏的情况. 分布式的表示方法则可以将词表示为固定长度、稠密、互相存在语义关系的向量,这类方法也称为词嵌入. MIKOLOV等[12]提出了Word2Vec框架,包含Skip-Gram和Cbow算法,分别用单词来预测上下文和用上下文来预测单词. PENNINGTON 等[13]提出的GloVe方法,同时考虑到了局部信息和全局统计信息,根据词与词之间的共现矩阵来表示词向量.深度学习方法已经成为文本分类的主流方法. KIM等[4]使用包含卷积结构的CNN来分类文本,将文本映射成向量,并将向量输入到模型,通过卷积层提取特征、池化层对特征采样,但CNN没有时序性,忽略了局部信息之间的依赖关系. 循环神经网络(RNN)则从左到右浏览每个词向量,保留每个词的数据,可以为模型提供整个文本的上下文信息,但RNN计算速度较慢,且存在梯度消失等问题. 作为RNN的一种变体,长短期记忆网络(LSTM)通过过滤无效信息,有效缓解了梯度消失问题,更好地捕获长距离的依赖关系. 而BiLSTM由一个前向的LSTM和一个后向的LSTM组成,能够捕获双向语义依赖.1.2 BERT预训练模型。
语料库语言学研究的新进展——《语料库语言学研究中的三角验证方

话语 分析 、 多维 度分析 、主题词分析 等) ,解决 研 究问题均为关于四个英语变体和三个领域间的
2 .内容概述 该书共十二章 ,可分为五个部分。第一部分
与其他三个进行比较 ,并用对数似然率检验 ,从
而得出每一个子语料库 的主题词表。研 究发现 ,
为第一章 ,介绍 了该论文集的背景信息和结构 ;
中图分类号 :H 0
1 . 引言
文献标识码 :A 文章编号 :2 0 9 5 - 4 8 9 1 ( 2 0 1 7 ) 0 3 - 0 0 9 3 - 0 4 了基 于语料库的方法 ;第四部分为第十章到第 十
一
基于语料库 的语 言学研究 日益成为语言学研 究的活跃 领域。语料库语 言学研究方法众多 ,且 各有所长 。采用多种研 究方法互证 ,可以将因研 究者的个人知识 背景导致的研究缺陷最小定 性和定 量研
究 ;第五部分 为最后一章 ,对 比了各个研究所取 得的发现和结论 ,并对相互矛盾的结论作出了可 能的解释。 第一部分即第一章 。P a d B a k e r  ̄ D J e s s e E g b e r r 介绍 了该论文集的 目的和组织架构 。该论文集包 含十项研究 ,研究所用的语料是 “ 网络问答语料
库 ,综 合运用 多种 研究方 法 ( 包括基于语 料库的
相 同的研 究问题 ,旨在对 比语料库语言学研 究中
的不 同方法 。
系、政治与政府等三个领域 。这十项研 究涉及的 语 言使 用差 异。 第 二部 分包括 第二 章到 第五章 。T o n y
Mc E n e r y 采取 了主题词分析法 ,以研究四个英语 变体的相似和差异。他分别将其中一个子语料库
息性表 达维度 ,发现 “ 网络 问答语料 库”总体 上 类标注 分析 ,作者发现英国和美国英语都 较少使 具有 交互性和 非正式性特征 此发现与第三章 中 用强义务性情态动词 {  ̄ D c a n , m u s t , s h o u l d 等) :而 B e t h a n y G r a y 的发现具有一致性 。具体 地说 ,英 印 度和 菲律 宾 英 语 则 较 多使 用 强 义 务 性 情 态
构式语法理论

一种新的语法研究方法论——构式语法(construction grammar)理论构式语法的思想最早是由格语法的创始者Fillmore (1990)提出来的,后经 Adele E. Goldberg(1995)和 Paul Kay (1995)等学者的研究而越见深入,其中以Goldberg的研究成果最引人注意,她是一位年轻的女性学者,也是认知语言学的泰斗LAKOFF的高徒,现为普林斯顿大学的语言学教授。
她的博士论文是《A Construction:Grammar Approach to Argument Structure》,后经整理在美国出版,现在成为构式语法理论的代表性著作。
本书今年三月已由北大出版社出版,译者吴海波,书的中文译名是《构式:论元结构的构式语法研究》。
构式语法的基本观点是:假设C 是一个独立的构式,当且仅当 C 是一个形式(Fi)和意义(Si)的对应体,而无论是形式或意义的某些特征,都不能完全从C这个构式的组成成分或另外的先前已有的构式推知。
Goldberg所说的构式范围比较广,不仅包括一般所说的句式,也包括成语、复合词、语素等。
从句式这个平面说,按 Goldberg的构式语法理论,句式有独立的语义,因此一个句子的意义,并不能只根据组成句子的词语的意义、词语之间的结构关系或另外的先前已有的句式所能推知,句式本身也表示独立的意义,并将影响句子的意思。
举例说明。
现汉中有一类表示存在义的句式(存现句):NP1+V+着+NP2,如(A)台上坐着主席团。
(B)墙上挂着一幅画。
这种句式有三个特点:1、主语和宾语的置位。
2、B类句式的施事者的隐藏。
3、按说句法成分的语义角色不同,所造成的语法意义有差异,但A类句式的宾语角色是施事,而B类句式的宾语角色是受事,但是两种句式的语法意义一致,怎么解释这种现象?针对这三个问题,生成语法学有三种理论解释:一是“句式变异说”,二是“动词变异说”,即由一元变为二元,三是“轻动词说”。
英汉双宾结构构式研究熊学亮复旦大学外文学院

• 虽然句式作为语言的基本思维单位,其意义和形
式在组构上有其独立性,即既不是其内部构件的简单
组合,也不从语言体系中的其它相关结构直接派生, 但这并不等于说句式就成了语言或语法的“清单元素”
(eat、drink) 两种现象。看来 (10a) 应属于第一种情
况。因此,动词和句式的关系,可能是用更具体的动
词结构 (如致使移动) 来表达更一般的事件结构 (如转
移)。
a
14
• 动词和句式的互动一般有下面几种情况:
• a. 句式规定框架,动词指定其中显突部分,故是转喻性的,即动词和
句式共同产生“致使”(因果) 关系义,用“结果”代“过程”形成转喻义。
a
7
• She topamased him something→give (60%) • Word Frequency Book 用 5 百万字的语料,
发现中英语的一些基本常用动词的使用频率
• 是呈 • give 3366 < tell 3715 < take 4089 < get
5700 > make 8333
语双宾结构中,参与角色 (P-role) 和论元 (A-role) 的运行相异,互动后产生构式义。
•
P-role
A-role
• Sem CAUSE-RECEIVE <agt rec pat>
•
│R
│ ↓ │ ←fusion
• R: PRED
<
>
•
│
│ ││
英语教学中wh问句树形结构图解析法

英语教学中wh问句树形结构图解析法
英语教学中的wh问句树形结构图解析法是一种近年来逐渐兴起
的英语教学方法,它充分利用了树形结构图的力量,将复杂的问题结构分解成若干个有层次的子问题,以便学生们更容易理解。
首先,这种方法能够帮助学生们更准确、更有条理地学习英语。
它能够把一个复杂的问题,比如一句英文句子,分解成若干子问题,这样学生们能够一层层地剖析每一个问题,而不会受到复杂性的困扰。
其次,它能够有效地帮助学生们学习更大型的语言文本,比如关于某一个话题的长文本。
它能够把一篇文章分解成一个个子问题,比如事实、原因、结果等等,从而使学生们更加清晰地看清文章的结构,从而更好地理解文章的内容。
此外,这种方法还可以有效地运用到实际教学中。
在课堂上,教师可以让学生们用树形结构图来分解复杂的句子,从而帮助他们更好地理解句子的内容。
此外,教师还可以使用树形结构图来帮助学生们分析长文本的结构,以便更好地理解文章的内容。
最后,这种方法也可以在写作教学中得到应用。
学生们可以先用树形结构图分解出文章的框架,从而有效地把握文章的主要思路,细化文章的想法,最终写出一篇高质量的文章。
综上所述,英语教学中的wh问句树形结构图解析法是一种新兴
的教学方法,它能够有效地帮助学生们理解英语,并且逐渐被运用到实际教学中,有着许多优点。
未来,它可能会得到更多的应用,并帮助更多的学生提高他们的英语水平。
语言加工视角下wh- 双子句习得不对称性研究综述

2021-03文艺生活LITERATURE LIFE说文解字语言加工视角下wh-双子句习得不对称性研究综述李莉刘红艳(怀化学院外国语学院,湖南怀化418008)摘要:从语言加工的视角来探讨wh-问句习得的各类不对称现象已成为二语习得研究的一个热点。
近年来心理语言学和语言习得领域对学习者如何在符合语法的wh-双子句进行语言加工做了大量的研究。
本文通过对wh-双子句习得不对称性研究进行文献综述,为语言加工该类结构的后续不对称性研究做铺垫。
关键词:wh-双子句;不对称;语言加工中图分类号:H319.3文献标识码:A文章编号:1005-5312(2021)09-0066-02DOI:10.12228/j.issn.1005-5312.2021.09.032一、前言大脑的语言加工处理机制即语言分析器和内在语法之间的相互作用是语言学和自然语言加工领域的热门研究课题。
早在一些研究者探讨毗邻原则及普遍语法可及性问题时便发现高级英语学习者,甚至英语本族语者在语法判断中对符合语法的主语和宾语wh-双子句(即含有两个分句的问句)如例(1)a-b的接受程度不同(Juffs2005)。
这两类wh-双子句在英语中都完全合法,故该现象不能解释为学习者语言能力的缺陷,因从语言加工的视角来探讨此类不对称习得已成为二语习得研究的一个热点。
(1)a.Whoi did Ellen believe ei met Mark?(主语问句)b.Whoi did Ellen believe Mark met ei?(宾语问句)二、主/宾不对称一语有关研究主要探讨英语儿童在习得wh-单子句(即含有一个分句的问句)如(2)a和(2)b的习得顺序(Yoshinaga, 1996)。
研究发现,即使英语儿童在习得了wh-单子句很长一段时间后,他们仍表现出对主语问句如(2)a的偏好。
(2)a.Who is hitting John?(主语wh-单子句)b.Who is John hitting?(宾语wh-单子句)二语习得中此类研究大都采用语法判断来探讨高级英语学习者对英语wh-双子句例(1)a-b的习得情况(Juffs2005),他们发现二语中主宾偏好与一语中的截然相反,受试者在语法判断中体现出对宾语提取句的偏好。
英语双宾语构式的语法语义微探

英语双宾语构式的语法语义微探曾望【摘要】英语双宾语结构是一种特殊的语法结构,是语言学家研究的热点.该构式所表达的核心语义是施事通过某种行为让客体向接受者成功传递,但还存在其他引申意义.从认知语言学的角度,借助一些实例来研究英语双宾语结构,发现该构式还可表达意欲传递、隐喻传递、否定传递等意义,具有语义的多义性.【期刊名称】《中南林业科技大学学报(社会科学版)》【年(卷),期】2014(008)006【总页数】3页(P154-156)【关键词】英语;双宾语结构;多义性【作者】曾望【作者单位】湖南涉外经济学院,湖南长沙410205【正文语种】中文【中图分类】H314“构式”一词近年来广受关注,简而言之就是指形式和意义的配对。
其形式有语音、文字和结构等,内容有语义、语用和话语等功能。
认知语言学家们把构式看成是音义结合的语言单位[2]。
Goldberg是构式语法的代表,她认为构式是形式和意义的结合体或“形式与功能的结合体”。
构式不仅是一个语法概念,而且还是意义和形式的匹配,即使具体词语缺席,构式也具有与形式相对应的意义和语用功能。
一直以来,双宾语构式都是语言学家研究的重点之一。
双宾语动词是指可以同时带两个宾语的动词,一个指人为间接宾语;另一个宾语指物,它是直接宾语。
某事件中所得某客体或损失某客体的人是间接宾语,而动作行为或事件所涉及的事或人是直接宾语,两个宾语分别跟谓语发生动宾关系[3]。
Goldberg认为英语中大部分双宾语构式表达“给予”类事件时,就是指事件中客体所有权右向的转移[1]。
而近年来又有很多学者认为双及物结构是一个构式,它的核心意义是“有意向的所有权转移”(Goldberg 1995,徐盛桓2001,张伯江1999,张宁1999)。
研究表明英语中大部分双宾语构式都是表达“给予”类事件, 语法意义是“物件或效果的传递”。
一般来说,在英语中要表示客体所有权向右向传递,是通过动词接两个宾语进行结构表述。
基于构式语法的英语话语标记语you know的研究

科技视界Science &TechnologyVisionScience &Technology Vision 科技视界1话语标记语话语标记语(discourse markers)是言语交际中说话者为使听话者更好地理解语句之间以及交际情景中各种因素之间的连贯关系,从而实现成功言语交际所采用的重要手段之一,从结构上看这些表达方式不仅限于单词,还包括短语或结构组合,它们体现的不只是形式上的特点与功能,应该被视为话语信息的一部分,其作用不是局部的,主要是从整体上对话语的构建与理解产生影响,具有动态的语用特征。
日常言语会话中存在很多类似you know、you see、see,say,listen,oh、I mean、that is to say、in the other words、well、however 等常见的言语表达形式,这些话语标记语近似于汉语中的“你知道”、“我的意思是”、“我想说的是”等插入语,其中you know 是一个使用频率颇高而且语用功能十分丰富的话语标记语。
2话语标记语“you know”“You know”是20世纪80年代以后最早对话语标记语进行研究的学者之一Ostman 研究的第一个话语标记语。
Ostman 认为此话语标记语可以帮助听话者理解说话者所隐含传递的各种态度和情感及与语境有关的必要信息。
作为一个常用的话语标记语,“you know”大致有四种语用功能:第一,信息提醒功能“you know”的信息提醒功能指的是言语交际中的说话人通过使用you know 这个话语标记语,突显其与听话人彼此之间共享的信息。
例1:A:Can you help me with my forthcoming interview?It is said you have much experience.B:No problem.You should make a good impression on the interveners,you know,your qualities are very important,including your physical appearance,energy,rate of speech,pitch and tone of voice,gestures,expression through the eyes.Others form an impression about you based on these.此例中,you know 显然是提醒对方应该知道的常识性信息。
英语WH-问答对话构式的语义分析(之二)

A Semantic Analysis of WH-Question-and-Answer
Dialogue Construction(Ⅱ)
作者: 王寅[1];曾国才[2]
作者机构: [1]四川外国语大学语言哲学研究中心,重庆400031;[2]上海交通大学外国语学院,上海200240
出版物刊名: 外语教学
页码: 1-6页
年卷期: 2016年 第2期
主题词: WH-问答构式;语义共振;疑问焦点;背景义域
摘要:"对话构式"亦已成为当今认知语言学最前沿研究课题之一。
本文基于心理学中的记忆原理和认知构式语法中的传承观建构了"语义共振(Semantic Resonance)"分析方法,以揭示"英语WH-问答对话构式"背后的认知机制。
问话者Q为答话者A给出一个语义图式,后者则为前者提供例示性信息,两者形成了图式—例示关系。
美国COCA语料表明A有多种方法例示Q形成两者间不同的语义共振类型:1)完全共振;2)冗余共振;3)局部共振;4)零位共振(包括:语气共振、否问共振、否己共振、复问共振、模糊共振、转移共振等);5)多元共振。
本文据此还对Grice的合作原则提出了点滴补充。
浅析英语双宾语中的语义凸显

浅析英语双宾语中的语义凸显
刘向东
【期刊名称】《广东工业大学学报(社会科学版)》
【年(卷),期】2008(008)001
【摘要】文章首先回顾了不同语言学派对双宾语结构的研究,然后在对比不同学者对双宾结构定性的基础上,提出了应用认知语言的语义凸显理论可以为双宾语进行合理的定位.双宾语结构中的两个宾语的凸显度由双宾动词的语义框架决定,事实证明,两个宾语的凸显度具有强弱之分,而且这种强弱度是语义关系,而非句法关系.【总页数】3页(P69-70,90)
【作者】刘向东
【作者单位】四川外语学院研究生部,重庆,400031
【正文语种】中文
【中图分类】H313
【相关文献】
1.浅析语义场理论在服装英语词汇教学中的应用 [J], 蔡胜男
2.英语介词语义中折射出的认知凸显观方法表征--以介词
“into”“on”“over”“out”和“up”为例 [J], 周娟
3.浅析语义场理论在大学英语词汇教学中的应用 [J], 李丹
4.浅析英语无线电陆空通话中的语义理解失误 [J], 岳红梅
5.浅析语义场理论在军事英语教学词汇记忆中的应用 [J], 王学生;王磊
因版权原因,仅展示原文概要,查看原文内容请购买。
英语冠名构式_article_n_中冠词的认知语义和句法特征_曾国才

2014年1月第35卷第1期外语教学Foreign Language EducationJan.2014Vol.35No.1英语冠名构式(Article+N)中冠词的认知语义和句法特征曾国才(四川大学外国语学院四川成都610064)摘要:传统语法研究范式只归纳了冠词的句法使用环境。
认知语法认为语言是以使用为基础的模型;意义即概念化;语言的词汇、句法结构和语义是一个象征结构的连续统。
在认知语法框架下,冠词的语义功能主要表现在对与之搭配的名词性词语进行定位和量化。
冠词的句法结构和冠词的语义概念呈数量象似性特征。
冠词的语义概念是依存性的,体现在句法结构上即为冠词与名词的紧密共现关系。
冠名构式的构式义不是句法组合而来,而是冠词与名词整合的结果。
冠词的认知语法描写丰富了认知语法的理论应用。
对冠词的语义和句法结构描写可提高英语冠词的二语习得效率。
关键词:冠词;认知语法;名词性词语;构式中图分类号:H030文献标识码:A文章编号:1000-5544(2014)01-0012-05Abstract:Traditional paradigms of grammatical analysis of English articles merely summarize the use conditions of articles on the syntactic level.By contrast,the generalizations of the semantic and syntactic structures of English articles can be captured by a cognitive grammar approach,whose linguistic assumption is based on the usage-based language model.Cognitive grammar claims that meaning is conceptualization,and that lexicon,syntax and semantics form a continuum of symbolic structures.From the perspective of cognitive grammar,articles in Article+N constructions function as the grounding and quantification of the nominals.Syntactically,the increased morphological complexity of the article is an icon of the increased semantic content of the article.Since articles are conceptually dependent,they inherently co-occur with the nominals on the syntactical level.The meaning of Article+N is not the combination of an article and a nominal,but the conceptual integration of the article and the nominal.A cognitive grammar approach to English articles widens the application of cognitive grammar theory and is expec-ted to improve the acquisition of English articles.Key words:article;cognitive grammar;nominal;construction1.冠词的传统分析词类的分析是任何语法学派的基本任务。
英语WH-对话构式的焦点信息定位模型研究

英语WH-对话构式的焦点信息定位模型研究
曾国才
【期刊名称】《外国语文(四川外语学院学报)》
【年(卷),期】2017(033)001
【摘要】英语WH-问答对话的认知运作机理体现为疑问焦点信息在对话场景中的语义定位过程.本文基于认知语言学视角下的构式本位观和话语对话性特征,把该类对话视作一个构式单位,并构建基于事件域的图式一例示模型(Event-based Schema-Instance Model,简称ESI模型),同时本文从当代美国英语语料库(COCA)中收集到5,051个WH-问答对话作为封闭语料,以期用具体数据阐释该类对话构式的焦点语义由图式到例示的定位类型.
【总页数】7页(P60-66)
【作者】曾国才
【作者单位】上海交通大学外国语学院,上海200240
【正文语种】中文
【中图分类】H313
【相关文献】
1.基于顺应-关联模式的英语WH-对话构式分析 [J], 刘姗;李健雪
2.英语NP+VI构式的语义概念化研究——基于新自主/依存联结分析模型 [J], 王亚聪
3.英语NP+VI构式的语义概念化研究——基于新自主/依存联结分析模型 [J], 王亚聪
4.英语对比焦点重叠构式研究及其类型学研究启示 [J], 冯莉
5.基于顺应-关联模式的英语WH-对话构式分析 [J], 刘姗;李健雪
因版权原因,仅展示原文概要,查看原文内容请购买。
小学英语中Wh

论小学英语教学中Wh-问题的使用摘要:交际法语言教学是英语教学的主要趋势。
“Wh-问题”教学是小学英语教学主要的方法之一,它们包含着不同的内容和句子结构,教师可以通过用这些基本问题教新词汇和语法,Wh-questions在小学英语教学中使用较为普遍,同时学习Wh-开头的特殊疑问句正是通往语言交流的必要途径。
当然了,想让每个孩子勇敢地讲英语,并准确地使用它仍然是当今英语课堂教学的一大挑战。
关键词:英语教学 Wh-问题结构使用几年前,从小学 3 年级至 6 年级英语开始设为正规课程,在一些私人小学,更是提供了许多的英语班,同时也进行了几次英语教学改革,通过这些年的改革,英语教学取得了很快的进展,从以老师为中心,转为向更多学生为中心;从单纯的机械记忆的学习语言,转变为情境交流学习语言;从老师“满堂灌”教学转向更多的小组合作学习,这一切都需要使用语言来沟通,迫使每位学生能参与课堂活动并自由地用英语交流。
但是,英语教学在小学仍有一些新问题,比如在小学英语教学的目标是什么?用什么样的教学方法是最好的?我们对小学英语教学现状满意吗?等这些问题都有争议。
经过长期的英语学习和英语教学,我发现wh-问题几乎可以涵盖所有的英语语法和日常生活中相关的信息。
下面就以小学常用到的Wh-问题在教学中的使用作以下阐述。
首先,Wh-问题研究的是什么呢?Wh -问题在小学一般包括“干什么(what)”、“是谁(who)”、“什么时候(when)”、“在哪里(where)”、“为什么(why)”和“哪个(which)”的问题,他们是交际中通常使用的基本的疑问词,小学刚开始学英语以听、说为主,学生可以通过这些wh-问题和答案进行简单的交流,获取其中的语言信息。
因此,“Wh-问题”教学是小学英语教学主要的方法之一,它是一种自然、轻松学习语言的方法。
当然了,要了解wh-问题对孩子来说不是相当困难,但要准确使用它却是一大挑战。
让我们看一个句子:We study English atschool on Sunday.Who What todo Where when这句话,我们可以给出四个问题:1、谁在学校学英语?2、星期天我们在学校做些什么?3、星期天我们在哪里学英语?4、什么时候我们在学校学英语?这些疑问句包括“干什么”“在何处”“为什么”和“是谁”的问题。
双关何以为构式:词汇—构式语用学视角

双关何以为构式:词汇—构式语用学视角
刘小红;侯国金
【期刊名称】《北京第二外国语学院学报》
【年(卷),期】2022(44)6
【摘要】本文在“词汇—构式语用学”框架下,把传统修辞学的“双关”当作“双关触发器”,而把真正的双关当作“双关构式”进行研究,以双关构式的音形义效为语用修辞参数,将双关构式分为3类:(1){X+同音同形异义异效词+X}双关构
式;(2){X+同/近音近形异义异效词+X}双关构式;(3){X+同/近音异形异义异效词+X}双关构式。
对于语效,除了前人指出的风趣幽默、新颖别致以及让人产生联想等修辞效果之外,本文还发现并阐述了双关构式表达说话者的情感态度、避实就婉、刻意曲解、缓解尴尬等语用功能,浅论了双关构式的语义—语用模糊性、传承性、网络性以及语用修辞性。
【总页数】15页(P148-162)
【作者】刘小红;侯国金
【作者单位】南京大学外国语学院;云南经济管理学院通识学院;华侨大学外国语学院
【正文语种】中文
【中图分类】H030
【相关文献】
1.基于Goldberg构式定义的构式与构式语法研究——兼谈现代汉语构式与构式语法研究思考
2.从构式语法到构式语用学
3.话题歧义句的词汇—构式语用学阐释
4.语法化、词汇化的认知构式语法研究——《构式化与构式调变》评介
5.既生“我的”,何生“的我”:“X的+人称代词”构式的词汇——构式语用学阐释
因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于认知语言学理论视角,Wh 构式的句法特征象 似人们对客观世界的识解过程和方式。认知语言学图 形—背景和认知识解突显理论是 Wh 构式形成的认知 基础。
认知语言学图形—背景理论( FG 理论) 首先由丹麦 心理学家 Rubin 于一个世纪前根据人面—花瓶幻觉图 ( 图 1: Face-vase illusion) 提出。
the researches concerning the Chinese interrogative constructions.
Key words: event; prominence; figure-ground; construction
1. 引言
英语中由 Wh 疑问词引导的问句具有固定的句法 表征,通常用于对不确定信息进行质询求证。英语中的 特殊疑问句通常由疑问词-Wh 语词( 包含 how) 置于句 首,表示情态或 时 间 的 助 词 紧 随 其 后,句 末 问 号 表 示 疑 问语气,即形成 Wh 词语 + 助词 + 其它词语 + ? 句式。 当前对 Wh 结构的动因研究主要基于转换生成语法理 论( Transformational Grammar,简称 TG) 框架进行。转换 生成语法倡导 语 言 的 模 块 论、自 治 论,从 形 式 化 的 角 度 提出语言天赋假说。转换生成语法认为 Wh 疑问句的 形成是 Wh 语词从右到左移位的结果。TG 理论视野下 的 Wh 句式研究焦点在于 Wh 移位的限制和条件 ( Lisa et al 2006: 2) 。转换生成语法在语言研究中仅考虑理想 人的话语状态,没有考虑语言在现实使用中人的认知机 制。转换生成语法对 Wh 句式的研究中完全排除人认
表 1. 英 语 句 子 的 存 在 中 心 结 构 ( Vョ = existential verb)
Anchor She We He
Existential Core Vョ is
weren’t has
Remainder never ever seldom
英语 的 存 在 中 心 结 构 ( Existential Core Structure )
模型可提高 Wh 构式的习得效率,并对汉语的特指疑问句研究有启示作用。
关键词: 事件; 突显; 图形—背景; 构式
中图分类号: H030
文献标识码: A
文章编号: 1673-9876( 2014) 02-0019-04
Abstract: Based on the linguistic assumption of cognitive embodiment,the formation of linguistic expression is grounded on
识客观世界时的认知加工过程。TG 的句法形式运算不 能合理解释人类语言中 Wh 句式的形成理据。
而 George Lakoff,Ronald W. Langacker,Adele E. Goldberg,William Croft 等学者引领的认知语言学和构 式研究则针对转换生成语法理论的不足,提出语言研究 以意义为中心的进路。认知语法理论认为意义即概念 化,意义等于识解的内容加识解的方式。认知语法强调 语法是语言规约单位有组织的清单; 语言表达式是由语 音单位和语义单位整合而成的象征单位; 语法的本质是 象征的( Langacker 2008: 5) 。Goldberg( 2006: 3) 认为一 个语法构式是形式和功能的规约化配对体。基于构式 语法理论视角,一个英语疑问句是由语音极和语义极整 合而成的象征单位( symbolic unit) ,即 Wh 疑问句构式。 认知语言学理论主张语言表达是基于人对客观世界的 体验认知结果。语言的表达具有理据性。表达式作为 “模型”,是语言表达主体在一定的心境和语境下对对象
3. Wh 构式的认知句法结构
根据 Langacker( 2009: 252) 的句法观,英语中的句子 都表征了一个存在中心结构( Existential Core) ,这个核 心句子结构由表定位的要素、表存在的要素和其他要素 构成。定位要素 + 存在要素 + 其他要素[Anchor + Existential verb + Remainder]可用表 1 表示:
摘 要: 语言研究的认知体验观认为,语言的形成是基于人与现实世界的互动体验。人们以事件为单位切分、理解和
表达客观世界。英语特殊疑问句在构式语法视角下是一种疑问构式( Wh-construction) 。Wh 构式是一个既定的事件单
位。在认知图形—背景和识解突显理论框架下,Wh 语词 + 助词 + 其它语词? 的句法动因是在 Wh 构式事件结构中,
Auxiliary + Remainder? is motivated on the fact that the profiled spatial-temporal relationship within the event frame of a given
Wh-construction is prominently projected from conceptual level to the syntactic level. The Wh-word and the auxiliary verb are
viewed as the Figure1 and Figure2 in the Figure-Ground alignment,whose Ground element in Wh-construction is the remainder
of the Wh-construction. The cognitive model of Double Figures in a Ground ( FFG) is an alternative way to construe the Eng-
the dynamic interaction of human beings with the real world. Events are the basic construal units for human beings to catego-
rize,conceptualize and linguistically express the objective world. From the perspective of construction grammar,English Wh-
·19·
的透视、认识、理解、再造的结果( 徐盛桓、何爱晶 2014: 1) 。Wh 构式的句法形成有人的认知参与。结合认知语 言学图形和背景联结 ( Figure-Ground alignment) 和认知 突显理论,英语特殊疑问句作为一种语法构式( Wh-construction) 是认知主体在概念识解中突显了 Wh 事件存在 的空间属性,和 Wh 事件存在的时间属性,心智突显的 结果进而被投射到了句法层面。未知信息( Wh 语词) 蕴 含的事件空间存在和助词指示的事件时间存在是整个 Wh 构式事件中被突显的双图形( Figure1,Figure2) ,构 式中的其余语词信息是事件背景信息。英语特殊疑问 句构式① 的双突显语义认知模型进一步论证了语言的理 据性和体验性。
Wh 语词表征的事件空间存在属性和助词表征的事件时间存在属性在认知主体的心智中受突显形成认知双图形( 图
形 1 和图形 2) ,进而投射到句法层面。Wh 构式中的其余语词信息是 Wh 构式的已知背景信息,从而形成 Wh 构式双
图形-背景( FFG) 认知突显模型。Wh 构式双突显认知模型反驳了转换生成语法的 Wh 句式移位观。Wh 双突显认知
lish Wh-constructions,being at a position against the view of Wh-movement assumed by transformational grammar. The FFG
semantic model is expected to improve the acquisition of Wh-constructions. And this semantic model will throw some light on
图 1. Face-vase illusion 图 1 表明: 人们在感知人面—花瓶图时,可以分别 识别出一个花瓶和两张人脸。人感知到花瓶是因为花 瓶在视觉上更加突出。而当人在感知到两张脸时,是由 于把黑色的花瓶形状当作了视觉背景,而 人 脸 更 加 突 出。在心理学上,人感知 到 的 更 加 突 出 的 事 体 是 图 形 ( Figure) ,而把识解图形的参照物视作是背景( Ground) , 从而形 成 图 形—背 景 联 结 ( Figure-Ground alignment ) 。 Leonard Talmy 把图形—背景理论成功应用于语言的认 知分析。Talmy ( 2000: 311) 认为表示图形的概念需要一 个定位 信 息,而 起 背 景 作 用 的 概 念 则 实 施 定 位 功 能。 Ronald W. Langacker 从认知功能的有效性和基本特征 来解释 Figure-Ground 结构,并以此为基础提出射体和界 标( Trajectory and Landmark) 、侧显( Profile) 概念,并进一 步提出认知突显理论。Langacker( 1987: 120) 认为图形 在一个场景中相对于其它要素( 即背景) 而言给人突出 印象,具有特别的显著度; 围绕这个中枢的认知实体,场 景和识解框架被建构起来。王寅 ( 2011: 423-440 ) 分析 了图形—背景的 分 离 性、转 换 性 等 结 构 属 性,概 括 了 图 形和背景之间的总体特征。 认知突显是识解语言表达式的一个重要理论。在 特定的识解事件中,受到突显的事体或关系汇聚了认知 主体最多的认知加工努力。认知识解的维度包括: 详略 ·20·