importexcel
excel 中python用法

一、介绍Excel是一款广泛使用的电子表格软件,Python是一种流行的编程语言。
结合Excel和Python的使用可以提高数据处理的效率和灵活性。
本文将介绍在Excel中使用Python的方法和技巧。
二、Python插件安装1. 打开Excel并进入“文件”菜单。
2. 选择“选项”。
3. 在选项对话框中,选择“加载项”。
4. 点击“Excel加载项”下的“转到”按钮。
5. 在“添加-Ins”对话框中,点击“浏览”。
6. 找到并选择Python插件的安装文件,点击“打开”。
7. 完成安装并重启Excel。
三、使用Python进行数据处理1. 在Excel中新建一个工作表。
2. 在需要进行数据处理的单元格输入Python函数,例如“=Py.COUNTIF(A1:A10,">5")”。
3. 按下Enter键,Excel会调用Python插件执行该函数,并在单元格中显示结果。
四、Python函数示例1. 使用Python的COUNTIF函数统计大于5的数据个数。
2. 使用Python的SUM函数计算数据的总和。
3. 使用Python的AVERAGE函数计算数据的平均值。
4. 使用Python的IF函数进行条件判断。
5. 使用Python的VLOOKUP函数进行数据查找。
五、Python脚本执行1. 在Excel中打开一个工作表。
2. 点击“开发人员”选项卡。
3. 选择“插入”下的“ActiveX 控件”。
4. 在工作表中插入一个按钮控件,右键点击该按钮并选择“属性”。
5. 在“单击”事件中绑定Python脚本文件。
6. 点击按钮执行Python脚本,实现自定义的数据处理逻辑。
六、Python图表生成1. 在Excel中选择需要生成图表的数据范围。
2. 点击“插入”选项卡中的“插入统计图表”按钮。
3. 在弹出的对话框中选择“Python图表”。
4. 根据需要选择图表类型和样式,点击确定生成图表。
importExcel运用注解实现EXCEL导入poi类
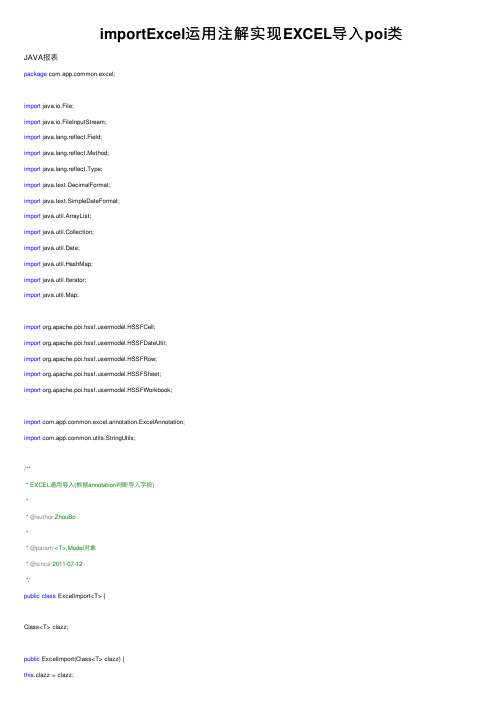
importExcel运⽤注解实现EXCEL导⼊poi类JAVA报表package mon.excel;import java.io.File;import java.io.FileInputStream;import ng.reflect.Field;import ng.reflect.Method;import ng.reflect.Type;import java.text.DecimalFormat;import java.text.SimpleDateFormat;import java.util.ArrayList;import java.util.Collection;import java.util.Date;import java.util.HashMap;import java.util.Iterator;import java.util.Map;import ermodel.HSSFCell;import ermodel.HSSFDateUtil;import ermodel.HSSFRow;import ermodel.HSSFSheet;import ermodel.HSSFWorkbook;import mon.excel.annotation.ExcelAnnotation;import mon.utils.StringUtils;/*** EXCEL通⽤导⼊(根据annotation判断导⼊字段)** @author ZhouBo** @param <T>,Model对象* @since 2011-07-12*/public class ExcelImport<T> {Class<T> clazz;public ExcelImport(Class<T> clazz) {this.clazz = clazz;}@SuppressWarnings("unchecked")public Collection<T> importExcel(File file, String... pattern) {Collection<T> dist = new ArrayList();try {/*** 类反射得到调⽤⽅法*/// 得到⽬标⽬标类的所有的字段列表Field filed[] = clazz.getDeclaredFields();// 将所有标有Annotation的字段,也就是允许导⼊数据的字段,放⼊到⼀个map中Map fieldmap = new HashMap();// 循环读取所有字段for (int i = 0; i < filed.length; i++) {Field f = filed[i];// 得到单个字段上的AnnotationExcelAnnotation exa = f.getAnnotation(ExcelAnnotation.class);// 如果标识了Annotationd的话if (exa != null) {// 构造设置了Annotation的字段的Setter⽅法String fieldname = f.getName();String setMethodName = "set"+ fieldname.substring(0, 1).toUpperCase()+ fieldname.substring(1);// 构造调⽤的method,Method setMethod = clazz.getMethod(setMethodName,new Class[] { f.getType() });// 将这个method以Annotaion的名字为key来存⼊。
easypoi importexcelbysax实例

easypoi importexcelbysax实例如何使用easypoi的importexcelbysax方法进行Excel数据导入。
easypoi是一个方便易用的Java库,可以用于操作Excel文件。
它提供了多种方法来读取和写入Excel数据,其中之一是importexcelbysax方法。
这种方法通过使用SAX解析器来读取大型Excel文件,可以大大减少内存消耗,并提高导入速度。
首先,我们需要在项目中引入easypoi的依赖。
可以在pom.xml文件中添加如下代码:<dependency><groupId>cn.afterturn</groupId><artifactId>easypoi-base</artifactId><version>3.2.2</version></dependency>接下来,我们需要定义一个实体类,用于存储Excel中的数据。
假设我们的Excel文件有两列:姓名和年龄。
我们可以创建一个Person类,如下所示:javapublic class Person {private String name;private int age;getters and setters}然后,我们可以创建一个处理Excel数据的类。
在这个类中,我们将使用importexcelbysax方法来读取Excel文件并将其转换为Person对象的列表。
代码如下:javaimport cn.afterturn.easypoi.excel.entity.result.ExcelImportResult; import cn.afterturn.easypoi.excel.imports.sax.SaxReadExcel;import java.io.FileInputStream;import java.io.InputStream;import java.util.List;public class ExcelImporter {public List<Person> importExcel(String filePath) throws Exception {InputStream inputStream = new FileInputStream(filePath);SaxReadExcel saxReadExcel = newSaxReadExcel(inputStream, 1, new PersonHandler());ExcelImportResult<Person> result = saxReadExcel.read();return result.getList();}}在上述代码中,我们首先创建了一个FileInputStream对象,用于读取Excel文件。
easypoi一行代码搞定excel导入导出

easypoi⼀⾏代码搞定excel导⼊导出开发中经常会遇到excel的处理,导⼊导出解析等等,java中⽐较流⾏的⽤poi,但是每次都要写⼤段⼯具类来搞定这事⼉,此处推荐⼀个别⼈造好的轮⼦【easypoi】,下⾯介绍下“轮⼦”的使⽤。
pom不再需要其他jar <dependency><groupId>cn.afterturn</groupId><artifactId>easypoi-base</artifactId><version>3.0.3</version></dependency><dependency><groupId>cn.afterturn</groupId><artifactId>easypoi-web</artifactId><version>3.0.3</version></dependency><dependency><groupId>cn.afterturn</groupId><artifactId>easypoi-annotation</artifactId><version>3.0.3</version></dependency>此处注意必须要有空构造函数,否则会报错“对象创建错误”关于注解@Excel,其他还有@ExcelCollection,@ExcelEntity ,@ExcelIgnore,@ExcelTarget等,此处我们⽤不到,可以去官⽅查看更多属性类型类型说明name String null列名needMerge boolean fasle纵向合并单元格orderNum String"0"列的排序,⽀持name_idreplace String[]{}值得替换导出是{a_id,b_id} 导⼊反过来savePath String"upload"导⼊⽂件保存路径type int1导出类型 1 是⽂本 2 是图⽚,3 是函数,10 是数字默认是⽂本width double10列宽height double10列⾼,后期打算统⼀使⽤@ExcelTarget的height,这个会被废弃,注意isStatistics boolean fasle⾃动统计数据,在追加⼀⾏统计,把所有数据都和输出这个处理会吞没异常,请注意这⼀点isHyperlink boolean false超链接,如果是需要实现接⼝返回对象isImportField boolean true校验字段,看看这个字段是不是导⼊的Excel中有,如果没有说明是错误的Excel,读取失败,⽀持name_id exportFormat String""导出的时间格式,以这个是否为空来判断是否需要格式化⽇期importFormat String""导⼊的时间格式,以这个是否为空来判断是否需要格式化⽇期format String""时间格式,相当于同时设置了exportFormat 和 importFormatdatabaseFormat String"yyyyMMddHHmmss"导出时间设置,如果字段是Date类型则不需要设置数据库如果是string 类型,这个需要设置这个数据库格式,⽤以转换时间格式输出numFormat String""数字格式化,参数是Pattern,使⽤的对象是DecimalFormatimageType int1导出类型 1 从file读取 2 是从数据库中读取默认是⽂件同样导⼊也是⼀样的suffix String""⽂字后缀,如% 90 变成90%isWrap boolean true是否换⾏即⽀持\nmergeRely int[]{}合并单元格依赖关系,⽐如第⼆列合并是基于第⼀列则{1}就可以了mergeVertical boolean fasle纵向合并内容相同的单元格实体类:import cn.afterturn.easypoi.excel.annotation.Excel;import java.util.Date;public class Person {@Excel(name = "姓名", orderNum = "0")private String name;@Excel(name = "性别", replace = {"男_1", "⼥_2"}, orderNum = "1")private String sex;@Excel(name = "⽣⽇", exportFormat = "yyyy-MM-dd", orderNum = "2")private Date birthday;public Person(String name, String sex, Date birthday) { = name;this.sex = sex;this.birthday = birthday;}public String getName() {return name;}public void setName(String name) { = name;}public String getSex() {return sex;}public void setSex(String sex) {this.sex = sex;}public Date getBirthday() {return birthday;}public void setBirthday(Date birthday) {this.birthday = birthday;}}public static void exportExcel(List<?> list, String title, String sheetName, Class<?> pojoClass,String fileName,boolean isCreateHeader, HttpServletResponse response){ ExportParams exportParams = new ExportParams(title, sheetName);exportParams.setCreateHeadRows(isCreateHeader);defaultExport(list, pojoClass, fileName, response, exportParams);}public static void exportExcel(List<?> list, String title, String sheetName, Class<?> pojoClass,String fileName, HttpServletResponse response){defaultExport(list, pojoClass, fileName, response, new ExportParams(title, sheetName));}public static void exportExcel(List<Map<String, Object>> list, String fileName, HttpServletResponse response){defaultExport(list, fileName, response);}private static void defaultExport(List<?> list, Class<?> pojoClass, String fileName, HttpServletResponse response, ExportParams exportParams) {Workbook workbook = ExcelExportUtil.exportExcel(exportParams,pojoClass,list);if (workbook != null);downLoadExcel(fileName, response, workbook);}private static void downLoadExcel(String fileName, HttpServletResponse response, Workbook workbook) {try {response.setCharacterEncoding("UTF-8");response.setHeader("content-Type", "application/vnd.ms-excel");response.setHeader("Content-Disposition","attachment;filename=" + URLEncoder.encode(fileName, "UTF-8"));workbook.write(response.getOutputStream());} catch (IOException e) {throw new NormalException(e.getMessage());}}private static void defaultExport(List<Map<String, Object>> list, String fileName, HttpServletResponse response) {Workbook workbook = ExcelExportUtil.exportExcel(list, ExcelType.HSSF);if (workbook != null);downLoadExcel(fileName, response, workbook);}public static <T> List<T> importExcel(String filePath,Integer titleRows,Integer headerRows, Class<T> pojoClass){if (StringUtils.isBlank(filePath)){return null;}ImportParams params = new ImportParams();params.setTitleRows(titleRows);params.setHeadRows(headerRows);List<T> list = null;try {list = ExcelImportUtil.importExcel(new File(filePath), pojoClass, params);}catch (NoSuchElementException e){throw new NormalException("模板不能为空");} catch (Exception e) {e.printStackTrace();throw new NormalException(e.getMessage());}return list;}public static <T> List<T> importExcel(MultipartFile file, Integer titleRows, Integer headerRows, Class<T> pojoClass){if (file == null){return null;}ImportParams params = new ImportParams();params.setTitleRows(titleRows);params.setHeadRows(headerRows);List<T> list = null;try {list = ExcelImportUtil.importExcel(file.getInputStream(), pojoClass, params);}catch (NoSuchElementException e){throw new NormalException("excel⽂件不能为空");} catch (Exception e) {throw new NormalException(e.getMessage());}return list;}对的,没看错,这就可以导出导⼊了,看起来代码挺多,其实是提供了多个导⼊导出⽅法⽽已导出实现类,使⽤@ExcelTarget注解与@Excel注解:import cn.afterturn.easypoi.excel.ExcelExportUtil;import cn.afterturn.easypoi.excel.ExcelImportUtil;import cn.afterturn.easypoi.excel.annotation.Excel;import cn.afterturn.easypoi.excel.entity.ExportParams;import cn.afterturn.easypoi.excel.entity.ImportParams;import cn.afterturn.easypoi.excel.entity.enmus.ExcelType;import com.fasterxml.jackson.annotation.JsonFormat;import com.jn.ssr.superrescue.annotation.Translate;import com.jn.ssr.superrescue.cache.DictCache;import ng.StringUtils;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import ermodel.Workbook;import org.springframework.web.multipart.MultipartFile;import javax.servlet.http.HttpServletResponse;import java.io.File;import ng.reflect.Field;import ng.reflect.InvocationHandler;import ng.reflect.Proxy;import .URLEncoder;import java.util.*;import java.util.stream.Collectors;public class FileUtil {private static Logger log = LogManager.getLogger(FileUtil.class);public static final int BIG_DATA_EXPORT_MIN = 50000;public static final int BIG_DATA_EXPORT_MAX = 2000000;//excel处理注解set集合public static HashSet<String> transClassSet = new HashSet();public static void exportExcel(List<?> list, String title, String sheetName, Class<?> pojoClass, String fileName, boolean isCreateHeader, HttpServletResponse response) { ExportParams exportParams = new ExportParams(title, sheetName);exportParams.setCreateHeadRows(isCreateHeader);defaultExport(list, pojoClass, fileName, response, title, sheetName);}/*** 导出函数** @param list 导出集合* @param title 标题* @param sheetName sheet名* @param pojoClass 映射实体* @param fileName ⽂件名* @param response httpresponce* size如果过⼤需采⽤poi SXSSF*/public static void exportExcel(List<?> list, String title, String sheetName, Class<?> pojoClass, String fileName, HttpServletResponse response) {//判断该类是否已经处理过excel注解long startTime = System.currentTimeMillis();if (!transClassSet.contains(String.valueOf(pojoClass))) {initProperties(pojoClass);transClassSet.add(String.valueOf(pojoClass));}defaultExport(list, pojoClass, fileName, response, title, sheetName);("此⽂件[{}]导出耗时:{}ms", fileName, (System.currentTimeMillis() - startTime));}public static void exportExcel(List<Map<String, Object>> list, String fileName, HttpServletResponse response) {defaultExport(list, fileName, response);}private static void defaultExport(List<?> list, Class<?> pojoClass, String fileName, HttpServletResponse response, String title, String sheetName) {Workbook workbook = null;ExportParams exportParams = new ExportParams(title, sheetName);if (list != null && list.size() > BIG_DATA_EXPORT_MAX) {sizeBeyondError(response);return;} else if (list != null && list.size() > BIG_DATA_EXPORT_MIN) {("⽂件过⼤采⽤⼤⽂件导出:" + list.size());for (int i = 0; i < (list.size() / BIG_DATA_EXPORT_MIN + 1) && list.size() > 0; i++) {("当前切⽚:" + i * BIG_DATA_EXPORT_MIN + "-" + (i + 1) * BIG_DATA_EXPORT_MIN);List<?> update = list.stream().skip(i * BIG_DATA_EXPORT_MIN).limit(BIG_DATA_EXPORT_MIN).collect(Collectors.toList());exportParams.setCreateHeadRows(true);exportParams.setMaxNum(BIG_DATA_EXPORT_MIN * 2 + 2);workbook = ExcelExportUtil.exportBigExcel(exportParams, pojoClass, update);}ExcelExportUtil.closeExportBigExcel();workbook = ExcelExportUtil.exportExcel(new ExportParams(title, sheetName), pojoClass, list);}if (workbook == null) return;downLoadExcel(fileName, response, workbook);}private static void downLoadExcel(String fileName, HttpServletResponse response, Workbook workbook) { try {response.setCharacterEncoding("UTF-8");response.setHeader("content-Type", "application/vnd.ms-excel");response.setHeader("Content-Disposition","attachment;filename=" + URLEncoder.encode(fileName, "UTF-8"));// workbooks.forEach(e -> e.write(response.getOutputStream()));workbook.write(response.getOutputStream());} catch (Exception e) {e.printStackTrace();response.setCharacterEncoding("UTF-8");response.setContentType("application/json");try {response.getWriter().println("{\"code\":597,\"message\":\"export error!\",\"data\":\"\"}");response.getWriter().flush();} catch (Exception e1) {e1.printStackTrace();} finally {closeIo(response);}}}/*** ⽂件过⼤,不允许导出** @param response*/private static void sizeBeyondError(HttpServletResponse response) {response.setCharacterEncoding("UTF-8");response.setContentType("application/json");try {response.getWriter().println("{\"code\":599,\"message\":\"⽂件过⼤!\",\"data\":\"\"}");response.getWriter().flush();} catch (Exception e1) {e1.printStackTrace();} finally {closeIo(response);}}private static void defaultExport(List<Map<String, Object>> list, String fileName, HttpServletResponseresponse) {Workbook workbook = ExcelExportUtil.exportExcel(list, ExcelType.HSSF);if (workbook != null) ;downLoadExcel(fileName, response, workbook);}public static <T> List<T> importExcel(String filePath, Integer titleRows, Integer headerRows, Class<T> pojoClass) { if (StringUtils.isBlank(filePath)) {return null;}ImportParams params = new ImportParams();params.setTitleRows(titleRows);params.setHeadRows(headerRows);List<T> list = null;try {list = ExcelImportUtil.importExcel(new File(filePath), pojoClass, params);} catch (NoSuchElementException e) {e.printStackTrace();System.out.println("模版为空");} catch (Exception e) {e.printStackTrace();}return list;}public static <T> List<T> importExcel(MultipartFile file, Integer titleRows, Integer headerRows, Class<T> pojoClass) { if (file == null) {return null;}ImportParams params = new ImportParams();params.setTitleRows(titleRows);params.setHeadRows(headerRows);List<T> list = null;try {list = ExcelImportUtil.importExcel(file.getInputStream(), pojoClass, params);} catch (NoSuchElementException e) {e.printStackTrace();System.out.println("⽂件为空");} catch (Exception e) {e.printStackTrace();}}/*** 代理初始化该类的注解** @param cl*/public synchronized static void initProperties(Class cl) {try {Field[] fields = cl.getDeclaredFields();for (Field field : fields) {if (field.isAnnotationPresent(Excel.class)) {field.setAccessible(true);Excel excel = field.getAnnotation(Excel.class);InvocationHandler h = Proxy.getInvocationHandler(excel);Field hField = h.getClass().getDeclaredField("memberValues");// 因为这个字段事 private final 修饰,所以要打开权限hField.setAccessible(true);// 获取 memberValuesMap memberValues = (Map) hField.get(h);//判断是否有转义注解,将字典添加到excel replace属性中if (field.isAnnotationPresent(Translate.class)) {Translate translate = field.getAnnotation(Translate.class);String dicName = translate.dicName();Map dicMap = DictCache.getProperties(dicName);if (dicMap == null) {continue;}String[] replace = new String[dicMap.size()];List<String> replaceList = new ArrayList<>();dicMap.forEach((key, val) -> {replaceList.add(val + "_" + key);});for (int i = 0; i < dicMap.size(); i++) {replace[i] = replaceList.get(i);}memberValues.put("replace", replace);}//json格式化与JsonFormat统⼀,⽬前暂⽤于时间if (field.isAnnotationPresent(JsonFormat.class)) {JsonFormat jsonFormat = field.getAnnotation(JsonFormat.class);if (StringUtils.isNotEmpty(jsonFormat.pattern())) {memberValues.put("format", jsonFormat.pattern());}}}}} catch (Exception e) {e.printStackTrace();}}/*** 关闭writer** @param response*/private static void closeIo(HttpServletResponse response) {try {if (response.getWriter() != null) {response.getWriter().close();}} catch (Exception e) {e.printStackTrace();}}}使⽤VUE前端数据导出实现类:import excel from '../../../utils/export'var exportExcel = {};exportExcel.exportData=function (params) {var str = '&';for(key in params){str+= key+'='+params[key]+'&';}//alert(nodePath+'/export?token='+er+str);console.log(nodePath+'/export?token='+er+str);window.location.href = nodePath+'/export?token='+er+str; }module.exports = exportExcel;在VUE页⾯中的导出:exportExcel(){console.log(22222);let param = {url: '/automaticCar/export',params:JSON.stringify(this.ruleForm)excel.exportData(param);},@RequestMapping("export")public void export(HttpServletResponse response){//模拟从数据库获取需要导出的数据List<Person> personList = new ArrayList<>();Person person1 = new Person("路飞","1",new Date());Person person2 = new Person("娜美","2", DateUtils.addDate(new Date(),3));Person person3 = new Person("索隆","1", DateUtils.addDate(new Date(),10));Person person4 = new Person("⼩狸猫","1", DateUtils.addDate(new Date(),-10));personList.add(person1);personList.add(person2);personList.add(person3);personList.add(person4);//导出操作FileUtil.exportExcel(personList,"花名册","草帽⼀伙",Person.class,"海贼王.xls",response);}@RequestMapping("importExcel")public void importExcel(){String filePath = "F:\\海贼王.xls";//解析excel,List<Person> personList = FileUtil.importExcel(filePath,1,1,Person.class);//也可以使⽤MultipartFile,使⽤ FileUtil.importExcel(MultipartFile file, Integer titleRows, Integer headerRows, Class<T> pojoClass)导⼊ System.out.println("导⼊数据⼀共【"+personList.size()+"】⾏");//TODO 保存数据库}导出结果导出结果测试导⼊导出结果再添加⼀⾏,执⾏,输出导⼊数据⾏数。
importexcel用法

importexcel用法可以使用"import openpyxl"模块来导入Excel文件。
使用openpyxl打开Excel文件:```pythonfrom openpyxl import load_workbook# 打开Excel文件wb = load_workbook('example.xlsx')# 选择工作表sheet = wb['Sheet1']# 读取单元格数据cell_value = sheet['A1'].value# 修改单元格数据sheet['A1'] = 'Hello, World!'# 保存修改后的Excel文件wb.save('example.xlsx')```使用openpyxl创建新的Excel文件:```pythonfrom openpyxl import Workbook# 创建一个新的工作簿wb = Workbook()# 选择默认的工作表sheet = wb.active# 设置单元格数据sheet['A1'] = 'Hello, World!'# 保存工作簿为Excel文件wb.save('example.xlsx')```使用openpyxl读取Excel文件中的数据:```pythonfrom openpyxl import load_workbook# 打开Excel文件wb = load_workbook('example.xlsx')# 选择工作表sheet = wb['Sheet1']# 获取所有的行数据rows = sheet.iter_rows()# 遍历每行数据for row in rows:# 读取每个单元格数据for cell in row:print(cell.value)```使用openpyxl写入Excel文件中的数据:```pythonfrom openpyxl import Workbook# 创建一个新的工作簿wb = Workbook()# 选择默认的工作表sheet = wb.active# 写入数据sheet['A1'] = 'Hello,'sheet['B1'] = 'World!'# 保存工作簿为Excel文件wb.save('example.xlsx')```。
使用python操作excel

使⽤python操作excel使⽤python操作excelpython操作excel主要⽤到xlrd和xlwt这两个库,即xlrd是读excel,xlwt是写excel的库。
安装xlrd模块#pip install xlrd使⽤介绍常⽤单元格中的数据类型 empty(空的) string(text) number date boolean error blank(空⽩表格) empty为0,string为1,number为2,date为3,boolean为4, error为5(左边为类型,右边为类型对应的值)导⼊模块import xlrd打开Excel⽂件读取数据data = xlrd.open_workbook(filename[, logfile, file_contents, ...])#⽂件名以及路径,如果路径或者⽂件名有中⽂给前⾯加⼀个r标识原⽣字符。
#filename:需操作的⽂件名(包括⽂件路径和⽂件名称);若filename不存在,则报错FileNotFoundError;若filename存在,则返回值为xlrd.book.Book对象。
常⽤的函数 excel中最重要的⽅法就是book和sheet的操作# (1)获取book中⼀个⼯作表names = data.sheet_names()#返回book中所有⼯作表的名字table = data.sheets()[0]#获取所有sheet的对象,以列表形式显⽰。
可以通过索引顺序获取,table = data.sheet_by_index(sheet_indx))#通过索引顺序获取,若sheetx超出索引范围,则报错IndexError;若sheetx在索引范围内,则返回值为xlrd.sheet.Sheet对象table = data.sheet_by_name(sheet_name)#通过名称获取,若sheet_name不存在,则报错xlrd.biffh.XLRDError;若sheet_name存在,则返回值为xlrd.sheet.Sheet对象以上三个函数都会返回⼀个xlrd.sheet.Sheet()对象data.sheet_loaded(sheet_name or indx)# 检查某个sheet是否导⼊完毕,返回值为bool类型,若返回值为True表⽰已导⼊;若返回值为False表⽰未导⼊# (2)⾏的操作nrows = table.nrows#获取该sheet中的有效⾏数table.row(rowx)#获取sheet中第rowx+1⾏单元,返回值为列表;列表每个值内容为:单元类型:单元数据table.row_slice(rowx[, start_colx=0, end_colx=None])#以切⽚⽅式获取sheet中第rowx+1⾏从start_colx列到end_colx列的单元,返回值为列表;列表每个值内容为:单元类型:单元数据table.row_types(rowx, start_colx=0, end_colx=None)#获取sheet中第rowx+1⾏从start_colx列到end_colx列的单元类型,返回值为array.array类型。
stata 循环提取excel

stata 循环提取excel使用Stata循环提取Excel标题的方法在数据分析的过程中,我们经常会需要从Excel表格中提取数据进行分析。
而Excel表格的标题通常是我们需要的数据的关键标识。
使用Stata软件可以方便地实现这一功能。
本文将介绍如何使用Stata循环提取Excel表格的标题,并给出相应的代码示例。
我们需要安装Stata的Excel插件。
在Stata命令窗口中输入以下命令:```statassc install importexcel```这样就成功安装了importexcel插件,我们可以使用它来进行Excel数据的导入和操作。
接下来,我们需要使用importexcel插件中的`excel describe`命令来获取Excel表格的结构信息,包括标题和数据。
```stataexcel describe using "文件路径\文件名.xlsx", sheet("工作表名")```其中,`文件路径\文件名.xlsx`表示要导入的Excel文件的路径和文件名,`工作表名`表示要导入的工作表的名称。
执行完上述命令后,Stata会在结果窗口中显示Excel表格的结构信息,包括列名和数据类型。
我们可以通过观察结果窗口中的信息来确定标题所在的行数。
接下来,我们可以使用Stata的循环功能来提取Excel表格的标题。
首先,我们需要使用`egen`命令创建一个新的变量,用于存储提取到的标题。
```stataegen titles = group(1) if _n == 1```上述命令将在数据集中创建一个名为`titles`的新变量,并将第一行的值设置为1,其余行的值设置为缺失值。
然后,我们可以使用循环结构来逐行遍历数据集,并将标题的值赋给`titles`变量。
```stataquietly forval i = 2/`_N' {replace titles = titles[_n-1] if titles[_n] == .}```上述代码中,`_N`表示数据集的总行数,`_n`表示当前行号。
ImportExceltoDOORS
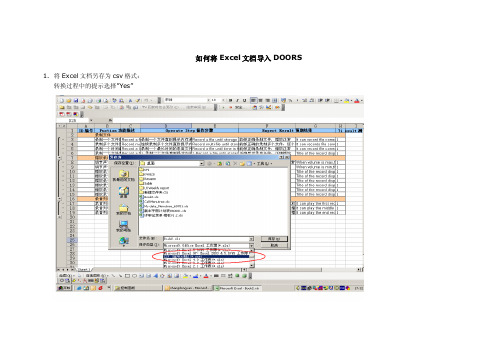
如何将Excel文档导入DOORS1.将Excel文档另存为csv格式:转换过程中的提示选择”Yes”2.对转换完成的csv格式文档进行整理,去掉第一列空列(DOORS中对对象有自动编号功能)和标题栏:3.登陆DOORS,进入TD-BB项目Test case文件夹4. 在Test case文件夹内,点击鼠标右软键,选择“New Formal Module…”,进入步骤5,New Formal Module编辑界面:5. 在New Formal Module编辑界面,编辑Module name、Description(可选)和对象编号前缀(Prefix)(可选):6. 步骤5中点击OK,Formal Module新建完成:7. 双击对应Formal Module进入对象编辑界面:8. 点击“Edit Attributes…”进入Step9 Columns&Attributes界面(注:csv文档一列对应DOORS中一个属性列):9. 在Columns&Attributes界面,点击“New”,进入Step10,New Attributes编辑界面:10. 在New Attributes编辑界面,编辑属性列显示名称(按照Step2 csv文档对应每列对应Title,从第二列Title开始添加,第一列将显示在该Formal Module带两个小点的列中,如Step11所述)11. 全部属性列标题添加完成后,选到Columns&Attributes编辑界面的Columns table,编辑csv文档第一列Title,显示在Formal module带两个小点的列中,这一列为Module的主列,所有链接都建立在这一列的对象上:12.全部属性列标题编辑完成界面如下图所示:13.选择”View Save as…’’进入保存视图界面(注:只有保存新视图后,对所有属性列的编辑才会被保存下来,否则只保存带两个小点的属性列内容)14. 在”Save as”新视图编辑界面,钩选Default “For module“(必选,使该视图成为进入该Formal module的默认视图)选择“Public”(必选,设置视图的访问权限),编辑视图名称,点击“OK“后视图保存成功,之后的修改在选择保存后将直接保存到该视图中:15.准备工作已经完成,下面开始导入工作:选择“File→ Import→ Spreadsheet”,进入Step16 Import Spreadsheet界面16.Import Spreadsheet界面:选择“From list”,编辑“Attributes to import”(从Existing attributes中选择,然后点击“Add”添加)注:第一个为Doors中的主列(带两个小点的列),属性为“Object Text”,后续各列按照csv文档第二列以后对应的Title添加17. 在Import file位置选择Step2中的csv文档;开“Advance”,Encoding选择936 简体中文;点击“Import”进入Step1818. 确认属性列,选择“Select”开始导入19. 导入完成界面:点击保存按钮保存变更20. 编辑对象间的层级结构:鼠标左键点住某个对象,将其拖拽到目标对象下,松开鼠标,出现如图菜单,选择“Move”,可根据需要将所选对象移到目标对象之后或下一级21. 调整完层级结构后:22. 为新建视图修改、添加用户访问权限:选择”View Manage Views…”,进入Step2323. 修改、添加访问权限:可以通过”Add”从用户列表中选择,也可以钩选“Inherent from parent”继承项目访问权限。
python excel解析

python excel解析Python是一门强大的编程语言,它可以与多种文件格式交互,包括Microsoft Excel。
利用Python语言,我们可以读取、处理和创建Excel文件,以及从Excel文件中提取有用的信息。
在Python中,我们可以使用第三方库——openpyxl来操作Excel文件。
openpyxl可以读取和写入Excel文件中的数据、格式和图表,也可以创建新的Excel文件。
下面是一些openpyxl库所支持的操作:1. 读取Excel文件要读取Excel文件,我们需要使用openpyxl库中的load_workbook 函数。
load_workbook函数将Excel文件作为输入,并返回一个Workbook对象,该对象包含Excel文件中的所有工作表。
2. 读取工作表一旦我们加载了Excel文件,我们就可以通过名字或索引访问其中的工作表。
我们可以使用Worksheet对象中的cell函数读取单元格中的数据,或使用iter_rows函数读取整个工作表中的行。
3. 写入Excel文件要写入Excel文件,我们需要使用Workbook对象的create_sheet函数创建新的工作表。
我们可以使用Worksheet对象中的cell函数写入单元格中的数据,或使用append函数向工作表中添加新行。
4. 格式化Excel文件我们可以使用openpyxl库中的各种函数和属性来格式化Excel文件。
例如,我们可以设置列宽、行高、单元格字体、颜色和边框等。
5. 创建图表使用openpyxl库,我们可以创建各种类型的图表,例如线图、柱状图、饼图等。
我们可以使用Chart对象中的各种函数和属性来设置图表的大小、数据系列、颜色等。
总之,利用Python和openpyxl库可以轻松地操作Excel文件。
无论是读取数据、处理数据还是创建新的Excel文件,Python都可以成为您的得力助手。
excelimportexport could not find zip member

ExcelImportExport是一个用于在Java应用程序中导入和导出Excel 文件的库。
然而,有时候在使用这个库时,可能会遇到一个错误:“ExcelImportExport could not find zip member”。
这个错误通常发生在尝试导入或导出ZIP文件时。
要解决这个问题,首先需要确保你的ZIP文件中包含一个有效的Excel文件。
你可以使用任何ZIP压缩工具来检查ZIP文件中的内容。
如果ZIP文件中没有有效的Excel文件,那么你需要将正确的Excel文件添加到ZIP文件中,然后再尝试导入或导出。
如果你确定ZIP文件中包含一个有效的Excel文件,但仍然遇到这个错误,那么可能是由于ExcelImportExport库的版本不兼容导致的。
你可以尝试更新ExcelImportExport库到最新版本,或者查看官方文档以获取更多关于兼容性的信息。
此外,还可以尝试使用其他Java库来处理ZIP文件和Excel文件。
例如,Apache POI是一个非常流行的Java库,用于处理Microsoft Office 格式的文件,包括Excel。
你可以使用Apache POI来读取和写入Excel 文件,而不需要使用ExcelImportExport库。
总之,“ExcelImportExport could not find zip member”这个错误通常是由于ZIP文件中缺少有效的Excel文件或版本不兼容导致的。
通过检查ZIP文件中的内容、更新ExcelImportExport库或使用其他Java 库,可以解决这个问题。
excelimportexport could not find zip member

excelimportexport could not find zip member【最新版】目录1.引言:介绍 Excel 导入导出功能及问题背景2.问题分析:解释“无法找到 ZIP 成员”错误3.解决方案:提供解决此问题的方法4.结论:总结并强调注意事项正文一、引言Excel 是一款广泛应用的电子表格软件,其数据导入导出功能为广大用户提供了极大的便利。
然而,在使用过程中,部分用户可能会遇到“excelimportexport could not find zip member”的问题,导致文件无法正常导入或导出。
本文将针对这一问题进行详细解答。
二、问题分析“excelimportexport could not find zip member”错误信息通常表示在导入或导出过程中,Excel 无法找到 ZIP 文件中的成员。
这可能是由于 ZIP 文件损坏、文件路径错误或 Excel 版本问题等原因造成的。
三、解决方案1.检查 ZIP 文件是否损坏:如果 ZIP 文件损坏,可能导致导入或导出失败。
您可以使用其他 ZIP 文件进行测试,或使用文件修复工具修复损坏的 ZIP 文件。
2.确保文件路径正确:请检查 ZIP 文件的路径是否正确,以及文件是否被移动或删除。
如果文件路径不正确,请修正并重新尝试导入或导出。
3.更新 Excel 版本:部分旧版本 Excel 可能存在兼容性问题,导致导入或导出失败。
您可以尝试升级 Excel 至最新版本,以解决此问题。
4.尝试其他导入或导出方式:如果您仍然遇到问题,可以尝试使用其他方式导入或导出数据,例如使用 CSV 或 XLSX 格式。
四、结论在使用 Excel 导入导出功能时,可能会遇到“excelimportexport could not find zip member”的问题。
通过检查 ZIP 文件是否损坏、确保文件路径正确、更新 Excel 版本以及尝试其他导入或导出方式,您可以有效解决这一问题。
excelutil importexcel 科学计数法改数字

在Excel中,如果数字太大或太小,它可能会以科学计数法的形式显示。
例如,数字1234567890可能显示为1.23E+09。
如果你希望将这些科学计数法的数字转换为其实际的数值,你可以使用Excel的某些功能或使用其他工具来实现。
以下是一些方法:使用Excel的内置功能:选择包含科学计数法的单元格。
在菜单中选择“数据”或“格式单元格”。
在“数字”标签中选择适当的数字格式。
例如,你可以选择“常规”格式来去除科学计数法。
使用VBA宏:如果你经常需要处理这个问题,你可以创建一个VBA宏来自动转换科学计数法的单元格。
以下是一个简单的示例:vbaSub ConvertScientificNotation()Dim rng As RangeDim cell As RangeSet rng = Selection ' 或者你可以选择其他范围,例如ActiveSheet.Range("A1:A100")For Each cell In rngIf IsNumeric(cell.Value) ThenIf cell.Value <> cell.Value Then ' 检查是否为空值或文本cell.Value = CDbl(cell.Value) ' 将科学计数法转换为数字End IfEnd IfNext cellEnd Sub要运行此宏,请按Alt + F11打开VBA编辑器,插入一个新的模块,然后将代码复制粘贴到该模块中。
之后,你可以通过按F5或选择“运行” -> “运行子/用户窗体”来运行这个宏。
3. 使用外部工具或库:有一些第三方工具或库,如Apache POI (Java库),可以用于处理Excel文件并转换科学计数法为正常数字。
如果你经常处理大量的Excel数据或复杂的任务,这可能是一个值得考虑的选项。
4. 手动调整:对于较小的数据量,你也可以手动调整每个单元格,选择“常规”格式或直接双击单元格来手动输入数字。
importexcelmore方法

对于importexcelmore方法这个主题,我将会按照你的要求进行全面的评估,并撰写一篇有价值的文章。
在文章中,我会遵循从简到繁、由浅入深的方式来探讨这个主题,以便你能更深入地理解。
第一部分:介绍importexcelmore方法在现代的数据处理中,Excel表格是一种非常常见的数据存储和处理方式。
在Python编程中,使用pandas库的read_excel方法可以轻松地读取Excel文件中的数据。
然而,当处理大型、复杂的Excel文件时,read_excel方法可能无法满足需求,这时就需要用到importexcelmore方法。
importexcelmore方法是一种更高级的数据导入方法,可以处理更复杂的Excel文件,包括大数据量的文件、多个工作表、特殊格式等。
第二部分:深入探讨importexcelmore方法的实现importexcelmore方法可以通过调用openpyxl库或者xlrd库来实现。
这两个库都是Python中常用的Excel文件处理库,可以帮助我们读取Excel文件的内容,并进行各种操作。
在使用importexcelmore方法时,我们可以指定要读取的Excel文件路径,以及需要处理的工作表名称或索引。
在处理大型文件时,我们还可以设置chunksize参数,实现分块读取,从而提高效率和降低内存占用。
第三部分:共享个人观点和理解个人而言,我认为importexcelmore方法的出现给我们在Python中处理Excel文件提供了更多灵活性和便利性。
通过对比read_excel和importexcelmore方法的使用,我们可以清晰地看到importexcelmore方法在处理复杂Excel文件时的优势。
尤其是在处理大数据量的Excel文件时,importexcelmore方法可以大大提高处理效率,减少内存占用,从而让我们更好地应对实际工作中的挑战。
第四部分:总结和回顾通过本文对importexcelmore方法的介绍和探讨,相信你已经对这个主题有了更深入的理解。
jeecg 中iexceldatahandler的使用 -回复

jeecg 中iexceldatahandler的使用-回复"jeecg 中iexceldatahandler的使用"jeecg 是一款使用Java 开发的快速开发平台,它为开发者提供了许多便捷的工具和功能来简化开发过程。
其中一个非常重要的功能就是iexceldatahandler,它是用来处理Excel 数据的接口。
在本文中,我们将逐步介绍jeecg 中iexceldatahandler 的使用,并提供对应的步骤。
第一步:了解iexceldatahandler 接口iexceldatahandler 接口是jeecg 提供的一个用于处理Excel 数据的接口。
开发者可以通过实现该接口,并重写其中的方法来实现对Excel 数据的特定处理。
该接口定义了以下方法:- importExcel 方法:用于将Excel 数据导入到系统中。
在该方法中,开发者可以根据需要进行数据的处理、验证和导入操作。
- exportExcel 方法:用于将系统中的数据导出到Excel 文件中。
在该方法中,开发者可以根据需要选择特定的数据源,并进行一些额外的数据处理。
第二步:准备工作在开始使用iexceldatahandler 接口之前,我们需要进行一些准备工作。
首先,我们需要在jeecg 的配置文件中进行相应的配置。
具体来说,我们需要在配置文件中指定iexceldatahandler 接口的实现类。
例如,可以将其配置为:jeecg-config.propertiesexcel.data.handler=com.your.package.path.YourExcelDataHandlerI mpl这里的"YourExcelDataHandlerImpl" 是你自己实现的iexceldatahandler 接口的具体实现类的路径。
第三步:实现iexceldatahandler 接口在开始实现自己的iexceldatahandler 接口之前,我们需要先导入jeecg 相关的依赖包,并创建一个新的Java 类,命名为YourExcelDataHandlerImpl。
importexcel用法

importexcel用法在现代社会中,电子表格已经成为了人们工作和生活中不可或缺的工具之一。
而在电子表格软件中,importexcel函数的使用更是为我们处理大量数据提供了便利。
本文将介绍importexcel函数的用法,帮助读者更好地利用这一功能。
首先,我们需要了解importexcel函数的基本语法。
importexcel函数的语法如下:importexcel(filename, sheetname, range)其中,filename表示要导入的Excel文件的路径;sheetname表示要导入的工作表的名称;range表示要导入的数据范围。
接下来,我们将通过一个实例来演示importexcel函数的使用。
假设我们有一个名为data.xlsx的Excel文件,其中包含了一个名为Sheet1的工作表,我们想要导入该工作表中的A1到C10的数据。
首先,我们需要在电子表格软件中打开一个新的工作表,假设该工作表为Sheet2。
然后,在Sheet2的A1单元格中输入以下公式:=importexcel("data.xlsx", "Sheet1", "A1:C10")按下回车键后,我们就可以看到Sheet2中导入了data.xlsx文件中Sheet1工作表中A1到C10的数据。
除了导入整个数据范围,我们还可以根据需要选择导入特定的列或行。
例如,如果我们只想导入data.xlsx文件中Sheet1工作表中的第一列数据,我们可以在Sheet2的A1单元格中输入以下公式:=importexcel("data.xlsx", "Sheet1", "A1:A10")同样地,如果我们只想导入data.xlsx文件中Sheet1工作表中的第一行数据,我们可以在Sheet2的A1单元格中输入以下公式:=importexcel("data.xlsx", "Sheet1", "A1:C1")通过这种方式,我们可以根据实际需求,灵活地导入所需的数据。
excelimportexport could not find zip member

excelimportexport could not find zip member摘要:1.问题描述:Excel导入导出功能无法找到Zip成员2.可能原因a.Zip文件损坏或不完整b.操作系统或Excel版本不兼容c.文件路径或权限设置问题3.解决方法a.检查并修复Zip文件b.更新操作系统或Excel版本c.检查文件路径和权限设置4.预防措施a.确保Zip文件完整且未损坏b.使用兼容的操作系统和Excel版本c.定期备份文件并检查权限设置正文:在日常工作和生活中,我们经常需要使用Excel进行数据导入和导出。
然而,有时候可能会遇到一些问题,例如无法找到Zip成员。
本文将分析可能的原因并提出相应的解决方法。
首先,我们来了解一下问题描述。
在尝试使用Excel导入导出功能时,系统提示“无法找到Zip成员”。
这表明Excel无法识别或访问Zip文件中的数据。
接下来,我们来探讨可能的原因。
首先,Zip文件可能已损坏或不完整。
这可能是由于下载失败、传输中断或其他原因导致的。
为了解决这个问题,可以尝试使用其他软件打开Zip文件,检查其中的数据是否正常。
如果Zip文件损坏,可以尝试修复它,或者重新下载完整的文件。
其次,问题可能是由于操作系统或Excel版本不兼容导致的。
请检查您的操作系统和Excel版本是否支持Zip文件导入导出功能。
如果兼容性存在问题,可以考虑升级操作系统或Excel版本,以获得更好的兼容性。
最后,文件路径或权限设置问题也可能导致这个问题。
请检查Zip文件是否位于正确的路径下,并确保您具有访问和操作该文件的权限。
如果需要,可以尝试更改文件路径和权限设置。
为了预防类似问题的发生,我们还可以采取一些预防措施。
首先,确保Zip文件完整且未损坏,以避免在导入导出过程中出现问题。
其次,使用兼容的操作系统和Excel版本,以确保功能正常运行。
最后,定期备份文件并检查权限设置,以便在出现问题时可以快速找到解决方法。
easypoi 分批解析

easypoi 分批解析easypoi是一款基于POI的JavaExcel解析工具库,它简化了Java程序中对Excel文档的读取、写入和样式设置的操作。
通过使用easypoi,开发者可以快速、高效地处理Excel文件,减少开发时间和工作量。
在使用easypoi时,可以将Excel文档分批解析,以逐步读取和处理大量的数据。
这种分批解析的方式能够有效地减少内存的占用,提高程序的性能。
为了实现分批解析,easypoi提供了一些相关的API和常用方法。
下面是一些常用的解析Excel文件的方法:1. ExcelImportUtil.importExcelMore:该方法可以用于分批读取Excel文件中的内容,并将读取的数据进行返回。
通过指定读取的sheetIndex(sheet的索引)、startRow(开始读取的行号)和rows(每批次读取的行数),可以实现分批读取。
2. ExcelImportUtil.importExcelMoreParams:该方法类似于importExcelMore,但是提供了更多的参数,可以指定需要读取的列、忽略某些列以及进行一些数据格式的转换。
3. ExcelImportUtil.importExcelBySax:该方法使用Sax方式解析Excel文件,可以有效地减少内存的占用。
通过传入一个实现了IReadHandler接口的对象,可以在解析过程中对数据进行操作并返回。
使用easypoi进行Excel文件的分批解析需要注意一些事项。
首先,需要合理地设置每次读取的行数,避免一次性读取过多的数据导致内存溢出。
其次,需要处理好分批读取的数据与后续操作之间的逻辑关系,确保数据的连贯性和准确性。
在实际应用中,easypoi的分批解析功能可以应用于很多场景。
例如,在对大量的数据进行统计分析时,可以使用easypoi分批解析Excel文件,逐步读取和处理数据,以减少内存的压力。
另外,在需要实时展示Excel数据的情况下,可以使用easypoi分批解析,将读取的数据逐步展示在前端页面,提升用户体验。
PHP导入Excel表格,读取Excel的内容到数组。
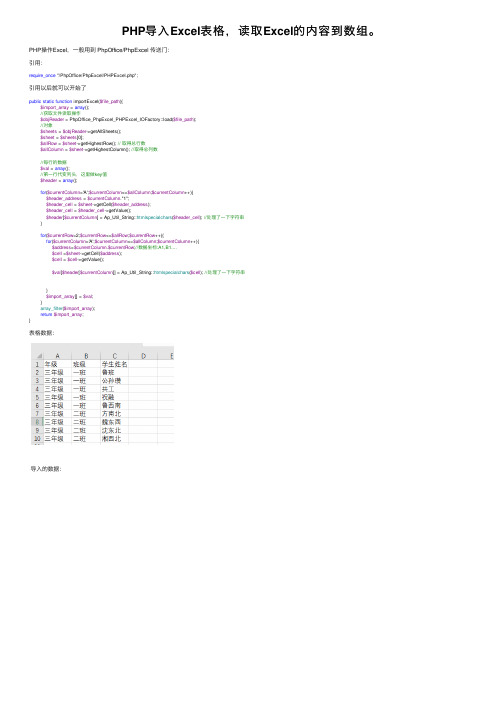
public static function importExcel($file_path){ $import_array = array(); //获取文件读取操作 $objReader = PhpOffice_PhpExcel_PHPExcel_IOFactory::load($file_path); //对象 $sheets = $objReader->getAllSheets(); $sheet = $sheets[0]; $allRow = $sheet->getHighestRow(); // 取得总行数 $allColumn = $sheet->getHighestColumn(); //取得总列数 //每行的数据 $val = array(); //第一行代变列头,这里做key值 $header = array(); for($currentColumn='A';$currentColumn<=$allColumn;$currentColumn++){ $header_address = $currentColumn."1"; $header_cell = $sheet->getCell($header_address); $header_cell = $header_cell->getValue(); $header[$currentColumn] = Ap_Util_String::htmlspecialchars($header_cell); //处理了一下字符串 } for($currentRow=2;$currentRow<=$allRow;$currentRow++){ for($currentColumn='A';$currentColumn<=$allColumn;$currentColumn++){ $address=$currentColumn.$currentRow;//数据坐标:A1,B1.... $cell =$sheet->getCell($address); $cell = $cell->getValue(); $val[$header[$currentColumn]] = Ap_Util_String::htmlspecialchars($cell); //处理了一下字符串
应用import过程步导入excel文件的问题

应用import过程步导入excel文件的问题
应用import过程步导入excel文件的问题格式例如:
procimport
datafile='C:\Users\Winkey1230\Desktop\data_mky\ adata.xlsx 'out=mky.basic replace;
sheet='sheet1';
textsize=12;
scantext=no;
run;
其中textsize=表示设定字符变量的长度
scantext默认为yes,他的作用是浏览字符变量的所用观测值,选择长度最大的作为该变量的长度(特别注意:若字符为中文时,长度即为中文字符的个数,实际上一个中文字符的长度应该为2;例如你需要导入观测值为“人生”的变量,scantext=yes,你只能导入”人“,sas中的变量长度为2;解决办法本人一般是将scantext设置为no,然后用textsize=option) 当scantext=yes而textsize=n时,字符变量的长度取较小的一个。
导入excel数据时,sas根据第一二个观测值的类型确定变量的类型,注意空格为字符变量的缺失值。
另外:用libname导入excel数据时需注意:
一定要指明engine为excel,而且导入的excel数据不能直接通过explorer查看例如:li bnamelibref excel …C:\user\dd.xls?; 引用其中的sheet比较特殊:libref.?sheet1$?n。
import excel的问题

我先前表达的问题可能不是很清楚,
因为我运行程序后会出现n个循环,我也很奇怪参数化后为再import excel,什么会按照excel表里的行数循环多次,却不能读取新的excel一行数据,所以我先是在程序访问datatable前加了这段话:
...
Dim n = 0
for i=1 to n
版主
状态 离线 首先,n不能等于零啊,呵呵,应该等于记录的条数。
其次,
QUOTE:
The imported table replaces all data in the existing run-time Data Table (including all data sheets).
希望从excel里面导入数据到datatable里,而实际上也是成功的。
只是这个时候参数化就没有从这个导入的datatable里循环读取值,而是每次都读第一行的值。
刚才手工加循环也不对,还是没有得到正确结果。
2005-11-17 10:04 #8 lovetest6
Set ExlSheet = Exlobj.Workbooks(1).Worksheets(1)
。。。。。。。。
Exlsheet.Cells(i, 3)="T"
Exlobj.Save
Exlobj.Workbooks.close
set fso=nothing
set Exlpath=nothing
DataTable("DbTable_source_testname","Global") = "select testname from DbTable where NAME='" & " variable1 & variable2 & "'"。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
package mon.excel;import mon.DataBase.DataAccess; //我们项目自己的访问数据库的东东import java.io.FileInputStream;import java.io.InputStream;import java.sql.SQLException;import java.sql.*;import java.io.*;import java.io.Serializable;import java.util.*;import javax.sql.RowSet;import jxl.Cell;import jxl.Sheet;import jxl.Workbook;import jxl.write.*;import java.text.DateFormat;import jxl.DateCell;import java.text.*;public class ImExExcel{private boolean flag=false;private ArrayList subdata = new ArrayList();public boolean download(String filename,String jhbh){Connection conn = null;PreparedStatement pStatement = null;ResultSet rs = null;JDBC_Pool dBean = new JDBC_Pool();String mysql;mysql = "select xh,qy,wdmc,zdlx,sfgw,tdsj,tzsj,tzsc,pdr,pdkh,jddw,jdr,jddh,dzsj,dzkh,fdkssj,bksfdsjh,tdyy,fdjssj, bjsfdsjh ,jkxsfydh,tdsc,fdsc,fdqr,fdxs,syfl,jsfy ,bz from DBF_RM_FaDian001 order by tzsj asc";try {conn = dBean.getConnection();pStatement = conn.prepareStatement(mysql);rs = pStatement.executeQuery();Workbook wb=Workbook.getWorkbook(new File("pengyue\\webmis\\template\\zscjh.xls"));WritableWorkbook book= Workbook.createWorkbook(new File("pengyue\\webmis\\download\\"+filename+".xls"),wb);WritableSheet sheet = book.getSheet("zscjh");jxl.write.WritableCellFormat wcfFC = new jxl.write.WritableCellFormat();wcfFC.setBorder(jxl.format.Border.ALL,jxl.format.BorderLineStyle.THIN);int i=4;jxl.write.DateFormat df = new jxl.write.DateFormat("yyyy-mm-dd hh:mm");jxl.write.WritableCellFormat wcfDF = new jxl.write.WritableCellFormat(df);wcfDF.setBorder(jxl.format.Border.ALL,jxl.format.BorderLineStyle.THIN);while(rs.next()) {sheet.addCell(new Label(2,i,rs.getString("xh"),wcfFC)); //序号sheet.addCell(new Label(3,i,rs.getString("qy"),wcfFC)); //区域sheet.addCell(new Label(4,i,rs.getString("wdmc"),wcfFC)); //以下为“表字段”网点名称sheet.addCell(new Label(5,i,rs.getString("zdlx"),wcfFC)); //站点类型sheet.addCell(new Label(6,i,rs.getString("sfgw"),wcfFC)); //是否固网sheet.addCell(new Label(7,i,rs.getString("tdsj"),wcfFC)); //停电时间sheet.addCell(new Label(8,i,rs.getString("tzsj"),wcfFC)); //通知时间sheet.addCell(new Label(9,i,rs.getString("tzsc"),wcfFC)); //通知时长sheet.addCell(new Label(10,i,rs.getString("pdr"),wcfFC)); //派单人sheet.addCell(new Label(11,i,rs.getString("pdkh"),wcfFC)); //派单考核sheet.addCell(new Label(10,i,rs.getString("jddw"),wcfFC)); //接单单位sheet.addCell(new Label(11,i,rs.getString("jdr"),wcfFC)); //接单人sheet.addCell(new Label(11,i,rs.getString("jddh"),wcfFC)); //接单电话sheet.addCell(new Label(2,i,rs.getString("dzsj"),wcfFC)); //断站时间sheet.addCell(new Label(3,i,rs.getString("dzkh"),wcfFC)); //断站考核sheet.addCell(new Label(4,i,rs.getString("fdkssj"),wcfFC)); //发电开始时间sheet.addCell(new Label(5,i,rs.getString("bksfdsjh"),wcfFC)); //报开始发电手机号sheet.addCell(new Label(6,i,rs.getString("tdyy"),wcfFC)); //停电原因sheet.addCell(new Label(7,i,rs.getString("fdjssjj"),wcfFC)); //发电结束时间sheet.addCell(new Label(8,i,rs.getString("bjsfdsjh"),wcfFC)); //报结束发电手机号sheet.addCell(new Label(9,i,rs.getString("jkxsfydh"),wcfFC)); //监控下是否有倒换sheet.addCell(new Label(10,i,rs.getString("tdsc"),wcfFC)); //停电时长sheet.addCell(new Label(11,i,rs.getString("fdsc"),wcfFC)); //发电时长sheet.addCell(new Label(7,i,rs.getString("fdqr"),wcfFC)); //发电确认sheet.addCell(new Label(8,i,rs.getString("fdxs"),wcfFC)); //发电小时sheet.addCell(new Label(9,i,rs.getString("syfl"),wcfFC)); //适用费率sheet.addCell(new Label(10,i,rs.getString("jsfy"),wcfFC)); //结算费用sheet.addCell(new Label(11,i,rs.getString("bz"),wcfFC)); //备注// if(rs.getString("jddw")!=null)sheet.addCell(new jxl.write.DateTime(12, //i,DateFormat.getDateTimeInstance().parse(rs.getString("jddw")), wcfDF));// if(rs.getString("jdr")!=null)sheet.addCell(new jxl.write.DateTime(13, //i,DateFormat.getDateTimeInstance().parse(rs.getString("jdr")), wcfDF));// sheet.addCell(new Label(14,i,rs.getString("jddh"),wcfFC)); //备注i++;}book.write();book.close();rs.close();pStatement.close();return true;}catch(Exception e){e.printStackTrace();return false;}finally{try{if (rs!=null){rs.close();}if (pStatement!=null){pStatement.close();}if (conn!=null){conn.close();}}catch(SQLException sqle){conn = null;}}}public void upload(String filename){String flagstr;try{jxl.Workbook rwb = Workbook.getWorkbook(new File("pengyue\\webmis\\upload\\"+filename+".xls"));Sheet st = rwb.getSheet("表1.3发电记录201212");int i = 4; //其始列-1flagstr = st.getCell(0,0).getContents();if(flagstr.equals("zscjhbegin"))flag=true;while(st.getCell(2,i).getContents().length()!=0&&flag==true){dataZJHXM mydata = new dataZJHXM();for(int j=2;j<st.getColumns();j++){if(st.getCell(j,0).getContents().equals("xh"))mydata.xh = st.getCell(j,i).getContents();if(st.getCell(j,0).getContents().equals("qy"))mydata.qy =st.getCell(j,i).getContents();if(st.getCell(j,0).getContents().equals("wdmc"))mydata.wdmc = st.getCell(j,i).getContents();if(st.getCell(j,0).getContents().equals("zdlx"))mydata.zdlx = st.getCell(j,i).getContents();if(st.getCell(j,0).getContents().equals("sfgw"))mydata.sfgw = st.getCell(j,i).getContents();if(st.getCell(j,0).getContents().equals("tdsj"))mydata.tdsj = st.getCell(j,i).getContents();if(st.getCell(j,0).getContents().equals("tzsj"))mydata.tzsj = st.getCell(j,i).getContents();if(st.getCell(j,0).getContents().equals("tzsc"))mydata.tzsc = st.getCell(j,i).getContents();if(st.getCell(j,0).getContents().equals("pdr"))mydata.pdr = st.getCell(j,i).getContents();if(st.getCell(j,0).getContents().equals("pdkh"))mydata.pdkh = st.getCell(j,i).getContents();//时间处理if(st.getCell(j,0).getContents().equals("tdsj"))mydata.tdsj = FormateData(st.getCell(j,i));if(st.getCell(j,0).getContents().equals("dzsj"))mydata.dzsj = FormateData(st.getCell(j,i));if(st.getCell(j,0).getContents().equals("fdkssj"))mydata.fdkssj = FormateData(st.getCell(j,i));if(st.getCell(j,0).getContents().equals("fdjssj"))mydata.fdjssj = FormateData(st.getCell(j,i));if(st.getCell(j,0).getContents().equals("tzsj"))mydata.tzsj = st.getCell(j,i).getContents();}subdata.add(mydata);i++;}rwb.close();}catch(Exception e){e.printStackTrace();flag = false;}}//处理日期格式数据public String FormateData(Cell formatecell){try{java.util.Date mydate=null;DateCell datecll = (DateCell)formatecell;mydate =datecll.getDate();long time=(mydate.getTime()/1000)-60*60*8;mydate.setTime(time*1000);Calendar cal = Calendar.getInstance();SimpleDateFormat formatter = new SimpleDateFormat("yyyy-MM-dd HH:mm");return formatter.format(mydate);}catch(Exception e){e.printStackTrace();return null;}}public boolean getFlag(){return flag;}public ArrayList getData(){return subdata;}public static class dataZJHXM implements Serializable{public String xh;public String qy;public String wdmc;public String zdlx;public String sfgw;public String tdsj;public String tzsj;public String tzsc;public String pdr;public String pdkh;public String jddw;public String jdr;public String jddh;public String dzsj;public String dzkh;public String fdkssj;public String bksfdsjh;public String tdyy;public String fdjssj;public String bjsfdsjh;public String kxsfydh;public String tdsc;public String fdsc;public String fdqr;public String fdxs;public String syfl; public String jsfy ;public String bz;public dataZJHXM(){xh = "";qy = "";wdmc = "";zdlx = "";sfgw = "";tdsj = "";tzsj = "";tzsc = "";pdr = "";pdkh = "";jddw = "";jdr = "";jddh = "";dzsj=””;dzkh=””;fdkssj=””;bksfdsjh=””;tdyy=””;fdjssj=””;bjsfdsjh=””;bkxsfydh=””;tdsc=””;fdsc=””;fdqr=””;fdxs=””;syfl=””;jsfy=””;bz=””;}}}。