hadoop2.2集群配置
Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu_CentOS

Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS本教程讲述如何配置Hadoop 集群,默认读者已经掌握了Hadoop 的单机伪分布式配置,否则请先查看Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置。
本教程由厦门大学数据库实验室出品,转载请注明。
本教程适合于原生Hadoop 2,包括Hadoop 2.6.0, Hadoop 2.7.1 等版本,主要参考了官方安装教程,步骤详细,辅以适当说明,保证按照步骤来,都能顺利安装并运行Hadoop。
另外有Hadoop安装配置简略版方便有基础的读者快速完成安装。
为了方便新手入门,我们准备了两篇不同系统的Hadoop 伪分布式配置教程。
但其他Hadoop 教程我们将不再区分,可同时适用于Ubuntu 和CentOS/RedHat 系统。
例如本教程以Ubuntu 系统为主要演示环境,但对Ubuntu/CentOS 的不同配置之处、CentOS 6.x 与CentOS 7 的操作区别等都会尽量给出注明。
环境本教程使用Ubuntu 14.04 64位作为系统环境,基于原生Hadoop 2,在Hadoop 2.6.0 (stable)版本下验证通过,可适合任何Hadoop 2.x.y 版本,例如Hadoop 2.7.1,Hadoop 2.4.1 等。
本教程简单的使用两个节点作为集群环境: 一个作为Master 节点,局域网IP 为192.168.1.121;另一个作为Slave 节点,局域网IP 为192.168.1.122。
准备工作Hadoop 集群的安装配置大致为如下流程:1.选定一台机器作为Master2.在Master 节点上配置hadoop 用户、安装SSH server、安装Java 环境3.在Master 节点上安装Hadoop,并完成配置4.在其他Slave 节点上配置hadoop 用户、安装SSH server、安装Java 环境5.将Master 节点上的/usr/local/hadoop 目录复制到其他Slave 节点上6.在Master 节点上开启Hadoop配置hadoop 用户、安装SSH server、安装Java 环境、安装Hadoop 等过程已经在Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置中有详细介绍,请前往查看,不再重复叙述。
Hadoop集群配置与数据处理入门

Hadoop集群配置与数据处理入门1. 引言Hadoop是一个开源的分布式计算框架,被广泛应用于大规模数据处理和存储。
在本文中,我们将介绍Hadoop集群的配置和数据处理的基本概念与入门知识。
2. Hadoop集群配置2.1 硬件要求架设Hadoop集群需要一定的硬件资源支持。
通常,集群中包含主节点和若干个从节点。
主节点负责整个集群的管理,而从节点负责执行具体的计算任务。
在硬件要求方面,主节点需要具备较高的计算能力和存储空间。
从节点需要具备较低的计算能力和存储空间,但数量较多。
此外,网络带宽也是一个关键因素。
较高的网络带宽可以加快数据的传输速度,提升集群的效率。
2.2 软件要求Hadoop运行在Java虚拟机上,所以首先需要确保每台主机都安装了适当版本的Java。
其次,需要安装Hadoop分发版本,如Apache Hadoop或Cloudera等。
针对集群管理,可以选择安装Hadoop的主节点管理工具,如Apache Ambari或Cloudera Manager。
这些工具可以帮助用户轻松管理集群的配置和状态。
2.3 配置文件Hadoop集群部署需要配置多个文件。
其中,最重要的是核心配置文件core-site.xml、hdfs-site.xml和yarn-site.xml。
core-site.xml配置Hadoop的核心参数,如文件系统和输入输出配置等;hdfs-site.xml用于配置Hadoop分布式文件系统;yarn-site.xml配置Hadoop资源管理器和任务调度器相关的参数。
3. 数据处理入门3.1 数据存储与处理Hadoop的核心之一是分布式文件系统(HDFS),它是Hadoop集群的文件系统,能够在集群中存储海量数据。
用户可以通过Hadoop的命令行工具或API进行文件的读取、写入和删除操作。
3.2 数据处理模型MapReduce是Hadoop的编程模型。
它将大规模的数据集拆分成小的数据块,并分配给集群中的多个计算节点进行并行处理。
Hadoop集群配置详细

Linux系统配置
7安装JDK 将JDK文件解压,放到/usr/java目录下 cd /home/dhx/software/jdk mkdir /usr/java mv jdk1.6.0_45.zip /usr/java/
cd /usr/java
unzip jdk1.6.0_45.zip
从当前用户切换root用户的命令如下: 编辑主机名列表的命令
从当前用户切换root用户的命令如下:
Linux系统配置
操作步骤需要在HadoopMaster和HadoopSlave节点
上分别完整操作,都是用root用户。 从当前用户切换root用户的命令如下:
su root
从当前用户切换root用户的命令如下:
Linux系统配置
1拷贝软件包和数据包 mv ~/Desktop/software ~/
环境变量文件中,只需要配置JDK的路径
gedit conf/hadoop-env.sh
从当前用户切换root用户的命令如下: 编辑主机名列表的命令
Hadoop配置部署
3配置核心组件core-site.xml
gedit conf/core-site.xml
<configuration> <property> <name></name> /*2.0后用 fs.defaultFS代替*/ <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/dhx/hadoopdata</value> </property> </configuration>
集群的配置步骤

集群的配置步骤一、搭建集群环境的准备工作在开始配置集群之前,我们需要先进行一些准备工作。
首先,确保所有服务器都已经正确连接到网络,并且能够相互通信。
其次,确保每台服务器上已经安装了操作系统,并且操作系统版本一致。
最后,确保每台服务器上已经安装了必要的软件和工具,例如SSH、Java等。
二、创建集群的主节点1.选择一台服务器作为集群的主节点,将其IP地址记录下来。
2.登录到主节点服务器上,安装并配置集群管理软件,例如Hadoop、Kubernetes等。
3.根据集群管理软件的要求,配置主节点的相关参数,例如集群名称、端口号等。
4.启动集群管理软件,确保主节点能够正常运行。
三、添加集群的工作节点1.选择一台或多台服务器作为集群的工作节点,将其IP地址记录下来。
2.登录到工作节点服务器上,安装并配置集群管理软件,确保与主节点的版本一致。
3.根据集群管理软件的要求,配置工作节点的相关参数,例如主节点的IP地址、端口号等。
4.启动集群管理软件,确保工作节点能够正常连接到主节点。
四、测试集群的连接和通信1.在主节点服务器上,使用集群管理软件提供的命令行工具,测试与工作节点的连接和通信。
例如,可以使用Hadoop的hdfs命令测试与工作节点的文件系统的连接。
2.确保主节点能够正确访问工作节点的资源,并且能够将任务分配给工作节点进行处理。
五、配置集群的资源管理1.根据集群管理软件的要求,配置集群的资源管理策略。
例如,可以设置工作节点的CPU和内存的分配比例,以及任务的调度算法等。
2.确保集群能够合理分配资源,并且能够根据需要动态调整资源的分配。
六、监控和管理集群1.安装并配置集群的监控和管理工具,例如Ganglia、Zabbix等。
2.确保监控和管理工具能够正常运行,并能够及时发现和处理集群中的故障和问题。
3.定期对集群进行巡检和维护,确保集群的稳定和可靠性。
七、优化集群的性能1.根据实际情况,对集群的各项参数进行调优,以提高集群的性能和效率。
hadoop集群部署之双虚拟机版

1、采用一台机器开两个虚拟机的方式构成两台电脑的环境,用root登录。
分别查看其IP地址:输入# ifconfig,可得主机IP:192.168.1.99;分机为:192.168.1.100。
2、在两台机器上的/etc/hosts均添加相应的主机名和IP地址:这里主机名命名为shenghao,分机名命名为slave:保存后重启网络:3、两台机器上均创立hadoop用户(注意是用root登陆)# useradd hadoop# passwd hadoop输入111111做为密码登录hadoop用户:注意,登录用户名为hadoop,而不是自己命名的shenghao。
4、ssh的配置进入centos的“系统→管理→服务器设置→服务,查看sshd服务是否运行。
在所有的机器上生成密码对:# ssh-keygen -t rsa这时hadoop目录下生成一个.ssh的文件夹,可以通过# ls .ssh/来查看里面产生的私钥和公钥:id_rsa和id_rsa.pub。
更改.ssh的读写权限:# chmod 755 .ssh在namenode上(即主机上)进入.ssh,将id_rsa.pub直接复制为authorized_keys(namenode的公钥):# cp id_rsa.pub authorized_keys更改authorized_keys的读写权限:# chmod 644 authorized_keys 【这个不必须,但保险起见,推荐使用】然后上传到datanode上(即分机上):# scp authorized_keys hadoop@slave:/home/hadoop/.ssh# cd .. 退出.ssh文件夹这样shenghao就可以免密码登录slave了:然后输入exit就可以退出去。
然后在datanode上(即分机上):将datanode上之前产生的公钥id_rsa.pub复制到namenode上的.ssh目录中,并重命名为slave.id_rsa.pub,这是为了区分从各个datanode上传过来的公钥,这里就一个datanode,简单标记下就可。
尚硅谷大数据技术之 Hadoop(生产调优手册)说明书

尚硅谷大数据技术之Hadoop(生产调优手册)(作者:尚硅谷大数据研发部)版本:V3.3第1章HDFS—核心参数1.1 NameNode内存生产配置1)NameNode内存计算每个文件块大概占用150byte,一台服务器128G内存为例,能存储多少文件块呢?128 * 1024 * 1024 * 1024 / 150Byte ≈9.1亿G MB KB Byte2)Hadoop2.x系列,配置NameNode内存NameNode内存默认2000m,如果服务器内存4G,NameNode内存可以配置3g。
在hadoop-env.sh文件中配置如下。
HADOOP_NAMENODE_OPTS=-Xmx3072m3)Hadoop3.x系列,配置NameNode内存(1)hadoop-env.sh中描述Hadoop的内存是动态分配的# The maximum amount of heap to use (Java -Xmx). If no unit # is provided, it will be converted to MB. Daemons will# prefer any Xmx setting in their respective _OPT variable.# There is no default; the JVM will autoscale based upon machine # memory size.# export HADOOP_HEAPSIZE_MAX=# The minimum amount of heap to use (Java -Xms). If no unit # is provided, it will be converted to MB. Daemons will# prefer any Xms setting in their respective _OPT variable.# There is no default; the JVM will autoscale based upon machine # memory size.# export HADOOP_HEAPSIZE_MIN=HADOOP_NAMENODE_OPTS=-Xmx102400m(2)查看NameNode占用内存[atguigu@hadoop102 ~]$ jps3088 NodeManager2611 NameNode3271 JobHistoryServer2744 DataNode3579 Jps[atguigu@hadoop102 ~]$ jmap -heap 2611Heap Configuration:MaxHeapSize = 1031798784 (984.0MB)(3)查看DataNode占用内存[atguigu@hadoop102 ~]$ jmap -heap 2744Heap Configuration:MaxHeapSize = 1031798784 (984.0MB)查看发现hadoop102上的NameNode和DataNode占用内存都是自动分配的,且相等。
Hadoop平台搭建与应用(第2版)(微课版)项目2 Hive环境搭建与基本操作

Hadoop平台搭建与应用教案教学过程教学提示项目2 Hive环境搭建与基本操作任务2.1 Hive的安装与配置Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,将类SQL语句转换为MapReduce任务,如图2-1所示,并执行此任务。
图2-1 将类SQL语句转换为MapReduce任务1.Hive数据结构Hive中所有的数据都存储在HDFS中,Hive中包含以下数据结构。
(1)Table:Hive中的Table和数据库中的Table在概念上是类似的,每一个Table在Hive中都有一个相应的目录存储数据。
(2)Partition(可选):在Hive中,表中的一个Partition对应于表中的一个目录,所有的Partition的数据都存储在对应的目录中。
(3)Bucket(可选):Bucket对指定列计算Hash,Partition根据某个列的Hash值散列到不同的Bucket中,目的是进行并行处理,每一个Bucket对应一个文件。
2.Hive架构Hive架构如图2-2所示。
Hadoop和MapReduce是Hive架构的基础。
用户接口主要有CLI客户端、HiveServer客户端、HWI客户端和HUE客户端(开源的Apache Hadoop UI系统),其中最常用的是CLI客户端。
在CLI客户端启动时,会同时启动一个Hive副本。
在Windows中,可通过JDBC连接HiveServer的图形界面工具,包括SQuirrel SQLClient、Oracle SQL Developer及DbVisualizer。
HWI通过浏览器访问Hive,通过Web控制台与Hadoop集群进行交互来分析及处理数据。
MetaStore用于存储和管理Hive的元数据,使用关系数据库来保存元数据信息(MySQL、Derby等),Hive中的元数据包括表的名称、表的列和分区及其属性、表的属性(是否为外部表等)、表的数据所在目录等。
Hadoop集群配置心得(低配置集群+自动同步配置)

Hadoop集群配置⼼得(低配置集群+⾃动同步配置)本⽂为本⼈原创,⾸发到炼数成⾦。
情况是这样的,我没有⼀个⾮常强劲的电脑来搞出⼀个性能⾮常NB的服务器集群,相信很多⼈也跟我差不多,所以现在把我的低配置集群经验拿出来写⼀下好了。
我的配备:1)五六年前的赛扬单核处理器2G内存笔记本 2)公司给配的ThinkpadT420,i5双核处理器4G内存(可⽤内存只有3.4G,是因为装的是32位系统的缘故吧。
)就算是⽤公司配置的电脑,做出来三台1G内存的虚拟机也显然是不现实的。
企业笔记本运⾏的软件多啊,什么都不做空余内存也才不到3G。
所以呢,我的想法就是:⽤我⾃⼰的笔记本(简称PC1)做Master节点,⽤来跑Jobtracker,Namenode 和SecondaryNamenode;⽤公司的笔记本跑两个虚拟机(简称VM1和VM2),⽤来做Slave节点,跑Tasktracker和Datanode。
这么做的话,就需要让PC1,VM1和VM2处于同⼀个⽹段⾥,保证他们之间可以互相连通。
⽹络环境:我的两台电脑都是通过⼀个⽆线路由上⽹。
构建跟外部的电脑同⼀⽹段的虚拟机配置过程:准备⼯作:构建⼀个集群,⾸先前提条件是每台服务器都要有⼀个固定的IP地址,然后才可能进⾏后续的操作。
所以呢,先把我的两台笔记本电脑全部设置成固定IP(注意,如果像我⼀样使⽤⽆线路由上⽹,那就要把⽆线⽹卡的IP设置成固定IP)。
⽤来做Master节点的PC1:192.168.33.150,⽤来跑虚拟机的宿主笔记本:192.168.33.157。
⽬标:VM1和VM2的IP地址分别设置成192.168.33.151和152。
步骤:1)新建VM1虚拟机。
2)打开VM1的⽹卡设置界⾯,连接⽅式选Bridge。
(桥接)关于桥接的具体信息,可以百度⼀下。
我们需要知道的,就是⽤桥接的⽅式,可以让虚拟机通过本机的⽹关来上⽹,所以就可以跟本机处于同⼀个⽹段,互相之间可以进⾏通信。
ubuntu下hadoop配置指南

ubuntu下hadoop配置指南目录1.实验目的2.实验内容(hadoop伪分布式与分布式集群环境配置)3.运行wordcount词频统计程序一 . 实验目的通过学习和使用开源的Apache Hadoop工具,亲身实践云计算环境下对海量数据的处理,理解并掌握分布式的编程模式MapReduce,并能够运用MapReduce编程模式完成特定的分布式应用程序设计,用于处理实际的海量数据问题。
二 . 实验内容1.实验环境搭建1.1. 前期准备操作系统:Linux Ubuntu 10.04Java开发环境:需要JDK 6及以上,Ubuntu 10.04默认安装的OpenJDK可直接使用。
不过我使用的是sun的jdk,从官方网站上下载,具体可以参考博客:ubuntu下安装JDK 并配置java环境Hadoop开发包:试过了hadoop的各种版本,包括0.20.1,0.20.203.0和0.21.0,三个版本都可以配置成功,但是只有0.20.1这个版本的eclipse插件是可用的,其他版本的eclipse插件都出现各种问题,因此当前使用版本为hadoop-0.20.1Eclipse:与hadoop-0.20.1的eclipse插件兼容的只有一些低版本的eclipse,这里使用eclipse-3.5.2。
1.2. 在单节点(伪分布式)环境下运行Hadoop(1)添加hadoop用户并赋予sudo权限(可选)为hadoop应用添加一个单独的用户,这样可以把安装过程和同一台机器上的其他软件分离开来,使得逻辑更加清晰。
可以参考博客:Ubuntu-10.10如何给用户添加sudo权限。
(2)配置SSH无论是在单机环境还是多机环境中,Hadoop均采用SSH来访问各个节点的信息。
在单机环境中,需要配置SSH 来使用户hadoop 能够访问localhost 的信息。
首先需要安装openssh-server。
[sql]view plaincopyprint?1. s udo apt-get install openssh-server其次是配置SSH使得Hadoop应用能够实现无密码登录:[sql]view plaincopyprint?1. s u - hadoop2. s sh-keygen -trsa -P ""3. c p ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys第一条命令将当前用户切换为hadoop(如果当前用户就是hadoop,则无需输入),第二条命令将生成一个公钥和私钥对(即id_dsa和id_dsa.pub两个文件,位于~/.ssh文件夹下),第三条命令使得hadoop用户能够无需输入密码通过SSH访问localhost。
hadoop2.2安装
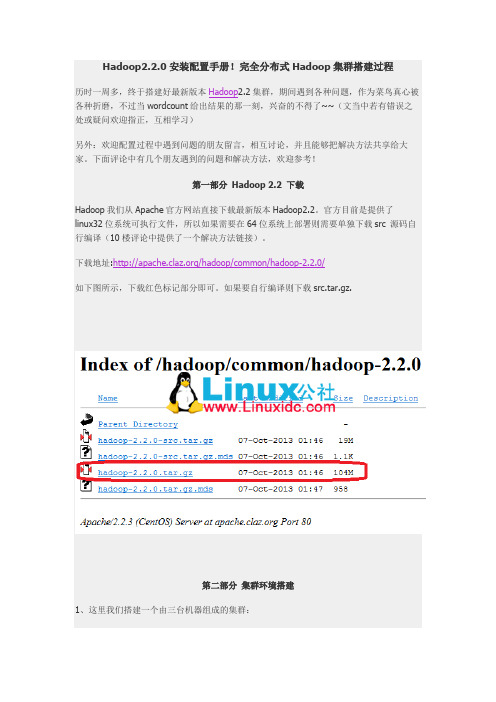
Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程历时一周多,终于搭建好最新版本Hadoop2.2集群,期间遇到各种问题,作为菜鸟真心被各种折磨,不过当wordcount给出结果的那一刻,兴奋的不得了~~(文当中若有错误之处或疑问欢迎指正,互相学习)另外:欢迎配置过程中遇到问题的朋友留言,相互讨论,并且能够把解决方法共享给大家。
下面评论中有几个朋友遇到的问题和解决方法,欢迎参考!第一部分Hadoop 2.2 下载Hadoop我们从Apache官方网站直接下载最新版本Hadoop2.2。
官方目前是提供了linux32位系统可执行文件,所以如果需要在64位系统上部署则需要单独下载src 源码自行编译(10楼评论中提供了一个解决方法链接)。
下载地址:/hadoop/common/hadoop-2.2.0/如下图所示,下载红色标记部分即可。
如果要自行编译则下载src.tar.gz.第二部分集群环境搭建1、这里我们搭建一个由三台机器组成的集群:192.168.0.1 hduser/passwd cloud001 nn/snn/rm CentOS6 64bit192.168.0.2 hduser/passwd cloud002 dn/nm Ubuntu13.04 32bit192.168.0.3 hduser/passwd cloud003 dn/nm Ubuntu13.0432bit1.1 上面各列分别为IP、user/passwd、hostname、在cluster中充当的角色(namenode, secondary namenode, datanode , resourcemanager, nodemanager)1.2 Hostname可以在/etc/hostname中修改(ubuntu是在这个路径下,RedHat稍有不同)1.3 这里我们为每台机器新建了一个账户hduser.这里需要给每个账户分配sudo的权限。
大数据--Hadoop集群环境搭建

⼤数据--Hadoop集群环境搭建⾸先我们来认识⼀下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式⽂件系统。
它其实是将⼀个⼤⽂件分成若⼲块保存在不同服务器的多个节点中。
通过联⽹让⽤户感觉像是在本地⼀样查看⽂件,为了降低⽂件丢失造成的错误,它会为每个⼩⽂件复制多个副本(默认为三个),以此来实现多机器上的多⽤户分享⽂件和存储空间。
Hadoop主要包含三个模块:HDFS模块:HDFS负责⼤数据的存储,通过将⼤⽂件分块后进⾏分布式存储⽅式,突破了服务器硬盘⼤⼩的限制,解决了单台机器⽆法存储⼤⽂件的问题,HDFS是个相对独⽴的模块,可以为YARN提供服务,也可以为HBase等其他模块提供服务。
YARN模块:YARN是⼀个通⽤的资源协同和任务调度框架,是为了解决Hadoop中MapReduce⾥NameNode负载太⼤和其他问题⽽创建的⼀个框架。
YARN是个通⽤框架,不⽌可以运⾏MapReduce,还可以运⾏Spark、Storm等其他计算框架。
MapReduce模块:MapReduce是⼀个计算框架,它给出了⼀种数据处理的⽅式,即通过Map阶段、Reduce阶段来分布式地流式处理数据。
它只适⽤于⼤数据的离线处理,对实时性要求很⾼的应⽤不适⽤。
多相关信息可以参考博客:。
本节将会介绍Hadoop集群的配置,⽬标主机我们可以选择虚拟机中的多台主机或者多台阿⾥云服务器。
注意:以下所有操作都是在root⽤户下执⾏的,因此基本不会出现权限错误问题。
⼀、Vmware安装VMware虚拟机有三种⽹络模式,分别是Bridged(桥接模式)、NAT(⽹络地址转换模式)、Host-only(主机模式):桥接:选择桥接模式的话虚拟机和宿主机在⽹络上就是平级的关系,相当于连接在同⼀交换机上;NAT:NAT模式就是虚拟机要联⽹得先通过宿主机才能和外⾯进⾏通信;仅主机:虚拟机与宿主机直接连起来。
Hadoop实验集群搭建手册

Hadoop实验集群搭建手册目录1.目的: (4)2.集群构成: (4)2.1.集群构成图: (4)2.2.集群构成明细: (5)3.Hadoop安装前的准备: (5)3.1.安装JDK (5)3.2.修改/etc/hosts文件 (6)3.3.增加Hadoop集群专有用户 (7)3.4.安装和配置SSH (7)4.安装和配置Hadoop集群 (8)4.1.在NameNode节点安装Hadoop (8)4.2.修改search用户环境设置文件 (9)4.3.在NameNode节点配置Hadoop (10)4.3.1配置hadoop-env.sh文件 (10)4.3.2配置core-site.xml文件. (11)4.3.3配置mapred-site.xml文件 (11)4.3.4配置hdfs-site.xml文件 (12)4.3.5配置yarn-site.xml文件 (13)4.3.6配置主、从节点列表文件 (14)4.4.远程复制Hadoop到集群其他节点 (14)5.启动Hadoop集群 (14)5.1.系统格式化 (14)5.2.启动集群 (15)5.2.1启动HDFS分布式文件系统 (15)5.2.2启动YARN资源管理器 (15)5.2.3验证集群运行状况 (15)6.Hadoop集群动态扩展 (17)6.1.Hosts和Slaves文件中增加新增节点信息 (18)6.2.配置新增节点的SSH (18)6.3.远程复制Hadoop到新增节点 (19)6.4.在新增节点上单独启动Hadoop (19)1.目的:本手册旨在熟悉Hadoop2.X集群的安装与配置过程。
通过本手册的内容,使用户可以搭建一个拥有三个节点的Hadoop集群。
2.集群构成:2.1.集群构成图:Secondary NameNode 192.168.82.109:50090DataNodeDataNode 192.168.82.1072.2.集群构成明细:该集群一共有三个安装了64位CentOS6.6系统的服务器节点。
Hadoop集群配置(最全面总结)

Hadoop集群配置(最全⾯总结)通常,集群⾥的⼀台机器被指定为 NameNode,另⼀台不同的机器被指定为JobTracker。
这些机器是masters。
余下的机器即作为DataNode也作为TaskTracker。
这些机器是slaves\1 先决条件1. 确保在你集群中的每个节点上都安装了所有软件:sun-JDK ,ssh,Hadoop2. Java TM1.5.x,必须安装,建议选择Sun公司发⾏的Java版本。
3. ssh 必须安装并且保证 sshd⼀直运⾏,以便⽤Hadoop 脚本管理远端Hadoop守护进程。
2 实验环境搭建2.1 准备⼯作操作系统:Ubuntu部署:Vmvare在vmvare安装好⼀台Ubuntu虚拟机后,可以导出或者克隆出另外两台虚拟机。
说明:保证虚拟机的ip和主机的ip在同⼀个ip段,这样⼏个虚拟机和主机之间可以相互通信。
为了保证虚拟机的ip和主机的ip在同⼀个ip段,虚拟机连接设置为桥连。
准备机器:⼀台master,若⼲台slave,配置每台机器的/etc/hosts保证各台机器之间通过机器名可以互访,例如:10.64.56.76 node1(master)10.64.56.77 node2 (slave1)10.64.56.78 node3 (slave2)主机信息:机器名 IP地址作⽤Node110.64.56.76NameNode、JobTrackerNode210.64.56.77DataNode、TaskTrackerNode310.64.56.78DataNode、TaskTracker为保证环境⼀致先安装好JDK和ssh:2.2 安装JDK#安装JDK$ sudo apt-get install sun-java6-jdk1.2.3这个安装,java执⾏⽂件⾃动添加到/usr/bin/⽬录。
验证 shell命令:java -version 看是否与你的版本号⼀致。
《hadoop学习》关于hdfs中的core-site.xml,hdfs-site.xml。。。

《hadoop学习》关于hdfs中的core-site.xml,hdfs-site.xml。
配置hadoop,主要是配置core-site.xml,hdfs-site.xml,mapred-site.xml三个配置⽂件,默认下来,这些配置⽂件都是空的,所以很难知道这些配置⽂件有哪些配置可以⽣效,上⽹找的配置可能因为各个hadoop版本不同,导致⽆法⽣效。
浏览更多的配置,有两个⽅法:1.选择相应版本的hadoop,下载解压后,搜索*.xml,找到core-default.xml,hdfs-default.xml,mapred-default.xml,这些就是默认配置,可以参考这些配置的说明和key,配置hadoop集群。
2.浏览apache官⽹,三个配置⽂件链接如下:这⾥是浏览hadoop当前版本号的默认配置⽂件,其他版本号,要另外去官⽹找。
其中第⼀个⽅法找到默认的配置是最好的,因为每个属性都有说明,可以直接使⽤。
另外,core-site.xml是全局配置,hdfs-site.xml和mapred-site.xml分别是hdfs和mapred的局部配置。
2 常⽤的端⼝配置2.1 HDFS端⼝参数描述默认配置⽂件例⼦值 namenode namenode RPC交互端⼝8020core-site.xml hdfs://master:8020/dfs.http.address NameNode web管理端⼝50070hdfs- site.xml0.0.0.0:50070dfs.datanode.address datanode 控制端⼝50010hdfs -site.xml0.0.0.0:50010dfs.datanode.ipc.address datanode的RPC服务器地址和端⼝50020hdfs-site.xml0.0.0.0:50020dfs.datanode.http.address datanode的HTTP服务器和端⼝50075hdfs-site.xml0.0.0.0:500752.2 MR端⼝参数描述默认配置⽂件例⼦值mapred.job.tracker job-tracker交互端⼝8021mapred-site.xml hdfs://master:8021/job tracker的web管理端⼝50030mapred-site.xml0.0.0.0:50030mapred.task.tracker.http.address task-tracker的HTTP端⼝50060mapred-site.xml0.0.0.0:500602.3 其它端⼝参数描述默认配置⽂件例⼦值dfs.secondary.http.address secondary NameNode web管理端⼝50090hdfs-site.xml0.0.0.0:500903 三个缺省配置参考⽂件说明3.1 core-default.html序号参数名参数值参数说明1hadoop.tmp.dir /tmp/hadoop-${} 临时⽬录设定2hadoop.native.lib true 使⽤本地hadoop库标识。
hadoop的安装与配置实验原理

hadoop的安装与配置实验原理主题:Hadoop的安装与配置实验原理导语:随着大数据时代的到来,数据的处理和分析变得越来越重要。
Hadoop作为目前最流行的分布式数据处理框架之一,为我们提供了一种高效、可扩展的方式来处理大规模的数据。
而要使用Hadoop进行数据处理,首先需要完成Hadoop的安装和配置。
本文将深入探讨Hadoop的安装与配置实验原理,并为读者提供具体的步骤和指导。
第一部分:Hadoop简介与原理概述1.1 Hadoop的定义与作用Hadoop是一个开源的分布式计算系统,它使用HDFS(Hadoop分布式文件系统)和MapReduce(分布式计算概念)来存储和处理大规模数据。
Hadoop的设计目标是能够在普通的硬件上高效地存储和处理大数据集。
1.2 Hadoop的原理与特点Hadoop的核心原理是基于分布式计算和分布式存储。
它通过将大数据集划分为多个小的数据块,并将这些数据块分布式存储在多个服务器上,实现了数据的高可靠性和高可扩展性。
Hadoop中的MapReduce编程模型可以将复杂的数据处理任务划分为多个简单的Map和Reduce步骤,以实现并行计算,提升数据处理效率。
第二部分:Hadoop的安装与配置步骤2.1 准备环境和工具在开始安装Hadoop之前,需要确保操作系统中已安装Java开发环境,并具备一台或多台服务器用于组成Hadoop集群。
还需要下载Hadoop的二进制文件以及相关配置文件。
2.2 安装Hadoop将下载好的Hadoop二进制文件解压到指定目录,然后在配置文件中设置Hadoop的各项参数,包括HDFS和MapReduce的配置。
配置项包括数据块大小、副本数、集群节点等。
2.3 配置Hadoop集群需要配置Hadoop的主从节点关系,包括指定主节点和从节点IP位置区域,并将相关信息写入配置文件中。
配置HDFS的相关参数,确保所有节点都能够访问和使用HDFS。
hadoop配置

硬件环境共有3台机器,均使用的linux系统,Java使用的是jdk1.6.0。
IP配置如下:hadoop1:192.168.0.97(NameNode)hadoop2:192.168.0.226(DataNode)hadoop3:192.168.0.100 (DataNode)这里有一点需要强调的就是,务必要确保每台机器的主机名和IP地址之间能正确解析。
一个很简单的测试办法就是ping一下主机名,比如在hadoop1上ping hadoop2,如果能ping通就OK!若不能正确解析,可以修改/etc/hosts文件,如果该台机器作Namenode用,则需要在hosts文件中加上集群中所有机器的IP地址及其对应的主机名;如果该台机器作Datanode用,则只需要在hosts文件中加上本机IP地址和Namenode 机器的IP地址。
以本文为例,hadoop1(NameNode)中的/etc/hosts文件看起来应该是这样的:127.0.0.1hadoop1localhost192.168.0.97hadoop1hadoop1192.168.0.226hadoop2hadoop2192.168.0.100hadoop3hadoop3hadoop2(DataNode)中的/etc/hosts文件看起来就应该是这样的:127.0.0.1hadoop2localhost192.168.0.97hadoop1hadoop1192.168.0.226hadoop2hadoop2hadoop3(DataNode)中的/etc/hosts文件看起来就应该是这样的:127.0.0.1hadoop3localhost192.168.0.97hadoop1hadoop1192.168.0.100hadoop3hadoop3对于Hadoop来说,在HDFS看来,节点分为Namenode和Datanode,其中Namenode只有一个,Datanode 可以是很多;在MapReduce看来,节点又分为Jobtracker和Tasktracker,其中Jobtracker只有一个,Tasktracker 可以是很多。
Hadoop集群搭建详细简明教程

Linux 操作系统安装
利用 vmware 安装 Linux 虚拟机,选择 CentOS 操作系统
搭建机器配置说明
本人机器是 thinkpadt410,i7 处理器,8G 内存,虚拟机配置为 2G 内存,大家可以 按照自己的机器做相应调整,但虚拟机内存至少要求 1G。
会出现虚拟机硬件清单,我们要修改的,主要关注“光驱”和“软驱”,如下图: 选择“软驱”,点击“remove”移除软驱:
选择光驱,选择 CentOS ISO 镜像,如下图: 最后点击“Close”,回到“硬件配置页面”,点击“Finsh”即可,如下图: 下图为创建all or upgrade an existing system”
执行 java –version 命令 会出现上图的现象。 从网站上下载 jdk1.6 包( jdk-6u21-linux-x64-rpm.bin )上传到虚拟机上 修改权限:chmod u+x jdk-6u21-linux-x64-rpm.bin 解压并安装: ./jdk-6u21-linux-x64-rpm.bin (默认安装在/usr/java 中) 配置环境变量:vi /etc/profile 在该 profile 文件中最后添加:
选择“Skip”跳过,如下图:
选择“English”,next,如下图: 键盘选择默认,next,如下图:
选择默认,next,如下图:
输入主机名称,选择“CongfigureNetwork” 网络配置,如下图:
选中 system eth0 网卡,点击 edit,如下图:
选择网卡开机自动连接,其他不用配置(默认采用 DHCP 的方式获取 IP 地址), 点击“Apply”,如下图:
标准hadoop集群配置

标准hadoop集群配置Hadoop是一个开源的分布式存储和计算框架,由Apache基金会开发。
它提供了一个可靠的、高性能的数据处理平台,可以在大规模的集群上进行数据存储和处理。
在实际应用中,搭建一个标准的Hadoop集群是非常重要的,本文将介绍如何进行标准的Hadoop集群配置。
1. 硬件要求。
在搭建Hadoop集群之前,首先需要考虑集群的硬件配置。
通常情况下,Hadoop集群包括主节点(NameNode、JobTracker)和从节点(DataNode、TaskTracker)。
对于主节点,建议配置至少16GB的内存和4核以上的CPU;对于从节点,建议配置至少8GB的内存和2核以上的CPU。
此外,建议使用至少3台服务器来搭建Hadoop集群,以确保高可用性和容错性。
2. 操作系统要求。
Hadoop可以在各种操作系统上运行,包括Linux、Windows和Mac OS。
然而,由于Hadoop是基于Java开发的,因此建议选择Linux作为Hadoop集群的操作系统。
在实际应用中,通常选择CentOS或者Ubuntu作为操作系统。
3. 网络配置。
在搭建Hadoop集群时,网络配置非常重要。
首先需要确保集群中的所有节点能够相互通信,建议使用静态IP地址来配置集群节点。
此外,还需要配置每台服务器的主机名和域名解析,以确保节点之间的通信畅通。
4. Hadoop安装和配置。
在硬件、操作系统和网络配置完成之后,接下来就是安装和配置Hadoop。
首先需要下载Hadoop的安装包,并解压到指定的目录。
然后,根据官方文档的指导,配置Hadoop的各项参数,包括HDFS、MapReduce、YARN等。
在配置完成后,需要对Hadoop集群进行测试,确保各项功能正常运行。
5. 高可用性和容错性配置。
为了确保Hadoop集群的高可用性和容错性,需要对Hadoop集群进行一些额外的配置。
例如,可以配置NameNode的热备份(Secondary NameNode)来确保NameNode的高可用性;可以配置JobTracker的热备份(JobTracker HA)来确保JobTracker的高可用性;可以配置DataNode和TaskTracker的故障转移(Failover)来确保从节点的容错性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop集群在linux下配置第一部分Hadoop 2.2 下载Hadoop我们从Apache官方网站直接下载最新版本Hadoop2.2。
下载地址:/hadoop/common/hadoop-2.2.0/如下图所示,下载红色标记部分即可。
第二部分集群环境搭建1、这里我们搭建一个由两台机器组成的集群:10.11.1.67 tan/123456 yang10.11.1.57 tan/123456 ubuntu1.1 上面各列分别为IP、user/passwd、hostname1.2 Hostname可以在/etc/hostname中修改1.3 这里我们为每台机器新建了一个账户tan.这里需要给每个账户分配sudo的权限。
(切换到root账户,修改/etc/sudoers文件,增加:tan ALL=(ALL) ALL )2、修改/etc/hosts 文件,增加两台机器的ip和hostname的映射关系10.11.1.67 yang10.11.1.57 ubuntu3、打通yang到ubuntu的SSH无密码登陆3.1 安装ssh一般系统是默认安装了ssh命令的。
如果没有,或者版本比较老,则可以重新安装:sudo apt-get install ssh3.2设置local无密码登陆安装完成后会在~目录(当前用户主目录,即这里的/home/tan)下产生一个隐藏文件夹.ssh(ls -a 可以查看隐藏文件)。
如果没有这个文件,自己新建即可(mkdir .ssh)。
具体步骤如下:1、进入.ssh文件夹2、 ssh-keygen -t rsa 之后一路回车(产生秘钥)3、把id_rsa.pub 追加到授权的key 里面去(cat id_rsa.pub >> authorized_keys)4、重启SSH 服务命令使其生效:service ssh restart此时已经可以进行ssh localhost的无密码登陆【注意】:以上操作在每台机器上面都要进行。
3.3设置远程无密码登陆这里只有yang是master,如果有多个namenode,或者rm的话则需要打通所有master 都其他剩余节点的免密码登陆。
(将yang的authorized_keys追加到ubuntu的authorized_keys)进入yang的.ssh目录scp authorized_keys tan@ubuntu:~/.ssh/ authorized_keys_from_yang进入ubuntu的.ssh目录cat authorized_keys_from_yang >> authorized_keys至此,可以在yang上面ssh tan@ubuntu进行无密码登陆了。
4、安装jdk注意:这里选择下载jdk并自行安装,而不是通过源直接安装(apt-get install)4.1、下载jdk(/technetwork/java/javase/downloads/index.html)4.1.1 对于32位的系统可以下载以下两个Linux x86版本(uname -a 查看系统版本)4.1.2 64位系统下载Linux x64版本(即x64.rpm和x64.tar.gz)4.2、安装jdk(这里以.tar.gz版本,32位系统为例)安装方法参/javase/7/docs/webnotes/install/linux/linux-jdk.html4.2.1 选择要安装java的位置,如/usr/目录下,新建文件夹java(mkdir java)4.2.2 将文件jdk-7u40-linux-i586.tar.gz移动到/usr/java4.2.3 解压:tar -zxvf jdk-7u40-linux-i586.tar.gz4.2.4 删除jdk-7u40-linux-i586.tar.gz(为了节省空间)至此,jkd安装完毕,下面配置环境变量4.3、打开/etc/profile(vim /etc/profile)在最后面添加如下内容:JAVA_HOME=/usr/java/jdk1.7.0_40(这里的版本号1.7.40要根据具体下载情况修改)CLASSPATH=.:$JAVA_HOME/lib.tools.jarPATH=$JAVA_HOME/bin:$PATHexport JAVA_HOME CLASSPATH PATH4.4、source /etc/profile4.5、验证是否安装成功:java–version【注意】每台机器执行相同操作,最后将java安装在相同路径下5、关闭每台机器的防火墙ufw disable (重启生效)第三部分Hadoop 2.2安装过程由于hadoop集群中每个机器上面的配置基本相同,所以我们先在namenode上面进行配置部署,然后再复制到其他节点。
所以这里的安装过程相当于在每台机器上面都要执行。
【注意】:master和slaves安装的hadoop路径要完全一样,用户和组也要完全一致1、解压文件将第一部分中下载的hadoop-2.2.tar.gz解压到/home/tan路径下。
然后为了节省空间,可删除此压缩文件,或将其存放于其他地方进行备份。
2、 hadoop配置过程配置之前,需要在cloud001本地文件系统创建以下文件夹:~/dfs/name~/dfs/data~/temp这里要涉及到的配置文件有7个:~/hadoop-2.2.0/etc/hadoop/hadoop-env.sh~/hadoop-2.2.0/etc/hadoop/yarn-env.sh~/hadoop-2.2.0/etc/hadoop/slaves~/hadoop-2.2.0/etc/hadoop/core-site.xml~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml~/hadoop-2.2.0/etc/hadoop/mapred-site.xml~/hadoop-2.2.0/etc/hadoop/yarn-site.xml以上文件默认不存在的,可以复制相应的template文件获得。
配置文件1:hadoop-env.sh修改JAVA_HOME值(export JAVA_HOME=/usr/java/jdk1.7.0_40)配置文件2:yarn-env.sh修改JAVA_HOME值(exportJAVA_HOME=/usr/java/jdk1.7.0_40)配置文件3:slaves (这个文件里面保存所有slave节点)写入以下内容:Ubuntu配置文件4:core-site.xml<configuration><property><name>fs.defaultFS</name><value>hdfs://yang:9000</value></property><property><name>io.file.buffer.size</name><value>131072</value><property><name>hadoop.tmp.dir</name><value>file:/home/hduser/tmp</value><description>Abase for other temporarydirectories.</description></property><property><name>hadoop.proxyuser.tan.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.tan.groups</name><value>*</value></property></configuration>配置文件5:hdfs-site.xml<configuration><property><name>node.secondary.http-address</name><value>yang:9001</value><property><name>.dir</name><value>file:/home/tan/dfs/name</value> </property><property><name>dfs.datanode.data.dir</name><value>file:/home/tan/dfs/data</value> </property><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.webhdfs.enabled</name><value>true</value></property></configuration>配置文件6:mapred-site.xml<configuration><property><name></name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>yang:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>yang:19888</value></property></configuration>配置文件7:yarn-site.xml<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value> </property><property><name>yarn.resourcemanager.address</name><value>yang:8032</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value> yang:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value> yang:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value> yang:8033</value></property><property><name>yarn.resourcemanager.webapp.address</name><value> yang:8088</value></property></configuration>3、复制到其他节点这里可以写一个shell脚本进行操作(有大量节点时比较方便)cp2slave.sh#!/bin/bashscp /home/tan/hadoop/etc/hadoop/slaves tan@ubuntu:~/hadoop/etc/ hadoop/slavesscp /home/tan/hadoop/etc/hadoop/core-site.xmltan@ubuntu:~/hadoop/etc/hadoop/core-site.xmlscp /home/tan/hadoop/etc/hadoop/hdfs-site.xmltan@ubuntu:~/hadoop/etc/hadoop/hdfs-site.xmlscp /home/tan/hadoop/etc/hadoop/mapred-site.xmltan@ubuntu:~/hadoop/etc/hadoop/mapred-site.xmlscp /home/tan/hadoop/etc/hadoop/yarn-site.xmltan@ubuntu:~/hadoop/etc/hadoop/yarn-site.xml4、启动验证4.1 启动hadoop进入安装目录:cd ~/hadoop/格式化namenode:./bin/hdfs namenode –format启动hdfs: ./sbin/start-dfs.sh此时在yang上面运行的进程有:namenode secondarynamenodeubuntu上面运行的进程有:datanode启动yarn: ./sbin/start-yarn.sh此时在yang上面运行的进程有:namenode secondarynamenode resourcemanager ubuntu上面运行的进程有:datanode nodemanaget查看集群状态:./bin/hdfs dfsadmin –report此时hadoop集群已全部配置完成!!!【注意】:而且所有的配置文件<name>和<value>节点处不要有空格,否则会报错!。