ch04_relational_model
9 Entity-Relationship Modeling(对应书第12章)

11
2.2 Relationship Types 联系类型
Examine examples of individual occurrences of the Has relationship using a semantic net. 用语义网来观察Has联 系的每个单独实例
The ’ ●’ symbol represents the entity and the ’ ● ’ symbol represents the relationship.
¾ Sometimes called atomic attribute. 原子属性
¾ 如:Staff实体的salary属性
Composite Attribute 组合属性
¾ Attribute composed of multiple components, each with an independent existence. 由多个 部分组成的属性,每个部分可独立存在
Relationship occurrence 联系的实例出现
Uniquely identifiable association, which includes one occurrence from each participating entity type. 一个可唯一标识的关 联,涉及参与该联系的每个实体类型的一个实 例
18
四川大学计算机(软件)学院 龚勋
Ch4 数据库建模(实体-联系模型)

如果在图中再增加一个元组 (a1, b1, c2, d1),ABC 还 成立吗?
图5-4 满足函数依赖ABC的一个关系实例
函数依赖说明
对于函数依赖,需做如下说明:
函数依赖不是指关系模式r(R)的某个或某些 关系实例满足的约束条件,而是指关系模式 r(R)的所有关系实例均要满足的约束条件。 函数依赖是语义范畴的概念,只能根据数据 的语义来确定函数依赖,是不能够被证明的 。
解决方法
模式分解导致的问题
将一个关系模式分解为较小关系模式集可 解决冗余问题。但由此可能产生两个新的 问题:
什么样的关系模式需要进一步分解为较
小的关系模式集?
根据范式要求决定(后面讨论)
是否所有的模式分解都是有益的?
模式分解问题举例
[例5.2] 设一关系模式STU (studentNo, studentName, sex, birthday, native, classNo),其中 studentNo为主码。
部分依赖:
{studentNo, courseNo}
传递函数依赖
定义5.4 在关系模式r(R)中,R,R, ,R。若,,,则必存在函数 依赖,并称是传递函数依赖,简称传 递依赖。 与部分依赖一样,传递依赖也可能会导致数据 冗余及产生各种异常。
本章重点:
本章难点:
内容概要
5.1 问题提出 5.2 函数依赖定义 5.3 函数依赖理论 5.4 范式 5.5 模式分解算法 5.6 数据库模式求精 本章小结
目
录
5.1 5.2
问题提出
函数依赖定义 函数依赖理论 范式 模式分解算法 数据库模式求精
关于特征(CT04)中使用函数进行“允许的值”检查以及“允许的值”HELP

业务说明:拉链产品中“颜色”有很多特征,比如“码庄左牙颜色”、“码庄左芯线的颜色”、“电镀颜色”等,我们可以看看SAP 对于这个检查功能模块的说明(在“功能”处按F1):检查值的功能模块在此字段中,可以输入功能模块的名称来检查用户输入的特征值。
功能模块可以在任何函数组中创建。
下列限制应用于:∙功能模块必须使用标准化界面。
∙功能模块名称不能多于27个字符。
这允许为进一功能模块推导名称:用于特征值指定屏幕上的可能的条目,及复制语言相关特征值描述:o可能条目的功能模块<值检查的功能模块> + 后缀"_F4"o语言相关特征值描述的功能模块<值检查的功能模块> + 后缀"_DC"值检查的功能模块的界面可能的条目的功能模块的界面功能模块也必须让您使用可能的条目按钮显示和选择值。
可以使用函数组SHL3 中的功能模块来显示可能的条目,如HELP_VALUES_GET_WITH_TABLE_EXT。
在功能模块文档中描述内容。
语言相关特征值描述的功能模块的界面若在用于检查值的功能模块之后使用此功能模块,值的语言相关描述复制到特征值指定屏幕上。
注释请注意源代码必须是基于预定义界面的。
若源代码不是基于这些界面的,源代码可能以程序崩溃而终止。
也请注意功能模块不能考虑因为继承或目标相关性的允许值上的任何限制,因为功能只能读取已经保存到数据库表中的数据。
功能不能读取当前用户输入。
按照这个我们在系统分别创建了:1)检查函数:ZDM_CH001_CHECK01FUNCTION zdm_ch001_check01.*"----------------------------------------------------------------------*"*"Local interface:*" IMPORTING*" REFERENCE(CHARACT_NO) LIKE CABN-ATINN*" REFERENCE(CHARACT) LIKE CABN-ATNAM*" REFERENCE(VALUE) LIKE CAWN-ATWRT*" EXPORTING*" VALUE(VALUE_EX) LIKE CAWN-ATWRT*" EXCEPTIONS*" NOT_FOUND*"----------------------------------------------------------------------DATA: lv_colpro LIKE cuov_01-atwrt,lv_colpro1 LIKE cuov_01-atwrt,lv_colpro2 LIKE cuov_01-atwrt,lv_varnam LIKE cuov_01-varnam,lv_memid1 LIKE cuov_01-atwrt,lv_mid(30). "MEMORY IDCLEAR: lv_colpro ,lv_colpro1,lv_colpro2.CASE charact.WHEN 'Z3EPZ2C003'.lv_varnam = 'Z3EPZ2C002'.WHEN 'Z3EPZ2C005'.lv_varnam = 'Z3EPZ2C004'.WHEN 'Z3EPZ2C007'.lv_varnam = 'Z3EPZ2C006'.WHEN 'Z3EPZ2C009'.lv_varnam = 'Z3EPZ2C008'.WHEN 'Z3EPZ3C003'.lv_varnam = 'Z3EPZ3C002'.WHEN 'Z3EPZ3C005'.lv_varnam = 'Z3EPZ3C004'.WHEN 'Z3EPZ3C007'.lv_varnam = 'Z3EPZ3C006'.WHEN 'Z3EPZ3C009'.lv_varnam = 'Z3EPZ3C008'.WHEN 'Z3EPZ4C003'.lv_varnam = 'Z3EPZ4C002'.WHEN 'Z3EPZ4C005'.lv_varnam = 'Z3EPZ4C004'.WHEN 'Z3EPZ4C007'.lv_varnam = 'Z3EPZ4C006'.WHEN 'Z3EPZ4C009'.lv_varnam = 'Z3EPZ4C008'.WHEN 'Z3EPZ5C003'.lv_varnam = 'Z3EPZ5C002'.WHEN 'Z3EPZ5C005'.lv_varnam = 'Z3EPZ5C004'.WHEN 'Z3EPZ5C007'.lv_varnam = 'Z3EPZ5C006'.WHEN 'Z3EPZ5C009'.lv_varnam = 'Z3EPZ5C008'.WHEN 'Z3EPZ6C003'.lv_varnam = 'Z3EPZ6C002'.WHEN 'Z3EPZ6C005'.lv_varnam = 'Z3EPZ6C004'.WHEN 'Z3EPZ6C007'.lv_varnam = 'Z3EPZ6C006'.WHEN 'Z3EPZ6C009'.lv_varnam = 'Z3EPZ6C008'.WHEN 'Z3S2ZCC003'.lv_varnam = 'Z3S2ZCC002'.WHEN 'Z3S2ZCC005'.lv_varnam = 'Z3S2ZCC004'.WHEN 'Z3S2ZCC007'.lv_varnam = 'Z3S2ZCC006'.WHEN 'Z3S2ZCC009'.lv_varnam = 'Z3S2ZCC008'.WHEN 'Z3SLZCC003'.lv_varnam = 'Z3SLZCC002'.WHEN 'Z3SLZCC005'.lv_varnam = 'Z3SLZCC004'.WHEN 'Z3SLZCC007'.lv_varnam = 'Z3SLZCC006'.WHEN 'Z3SLZCC009'.lv_varnam = 'Z3SLZCC008'.WHEN 'Z3BDZCC003'.lv_varnam = 'Z3BDZCC002'.WHEN 'Z3TBZCC003'.lv_varnam = 'Z3TBZCC002'.WHEN 'Z3CLZCC003'.lv_varnam = 'Z3CLZCC002'.WHEN 'Z3CVZCC003'.lv_varnam = 'Z3CVZCC002'.WHEN 'Z3SCZCC003'.lv_varnam = 'Z3SCZCC002'.WHEN 'Z3TSZCC003'.lv_varnam = 'Z3TSZCC002'.WHEN 'Z3BSZCC003'.lv_varnam = 'Z3BSZCC002'.WHEN 'Z3BXZCC003'.lv_varnam = 'Z3BXZCC002'.WHEN 'Z3PNZCC003'.lv_varnam = 'Z3PNZCC002'.WHEN OTHERS.lv_varnam = space.ENDCASE.IF NOT lv_varnam IS INITIAL.CONCATENATE 'ZID_' lv_varnam INTO lv_mid.IMPORT lv_colpro FROM MEMORY ID lv_mid.IF NOT lv_colpro IS INITIAL.CONCATENATE '%' lv_colpro '%' INTO lv_colpro. lv_colpro1 = space.lv_colpro2 = space.ELSE.lv_colpro = space.lv_colpro1 = space.lv_colpro2 = space.ENDIF.ELSE.CASE charact.WHEN 'Z3EPZ1C002' OR 'Z3EPZ1C003' OR 'Z3EPZ1C004' OR 'Z3EPZ1C00 5' OR "码庄颜色,Z1是成品码庄颜色 ZC是DC类码庄颜色'Z3EPZ1C005' OR 'Z3EPZ1C006' OR 'Z3EPZ1C007' OR 'Z3EPZ1C00 8' OR'Z3EPZ1C009' OR 'Z3EPZ1C010' OR 'Z3EPZ1C011' OR 'Z3EPZ1C01 2' OR'Z3DCZCC002' OR 'Z3DCZCC003' OR 'Z3DCZCC004' OR 'Z3DCZCC00 5' OR'Z3DCZCC006' OR 'Z3DCZCC007' OR 'Z3DCZCC008' OR 'Z3DCZCC00 9' OR'Z3DCZCC010' OR 'Z3DCZCC011' OR 'Z3DCZCC012' OR 'Z3DTZCC00 2'.lv_colpro = '%D%'.lv_colpro1 = '%T%'.lv_colpro2 = space.WHEN 'Z3EPZ2C010' OR 'Z3EPZ3C010' OR 'Z3EPZ4C010' OR 'Z3EPZ5C01 0' OR'Z3S2ZCC010' . "胶片颜色lv_colpro = '%D%'.lv_colpro1 = '%F%'.lv_colpro2 = space.WHEN OTHERS.lv_colpro = '%'.lv_colpro1 = '%'.lv_colpro2 = '%'.ENDCASE.IMPORT lv_memid1 FROM MEMORY ID 'ZMEMID_C001'.IF charact = 'Z3EPZ1C004' OR charact = 'Z3EPZ1C005' OR charact = 'Z3E PZ1C004' OR charact = 'Z3EPZ1C005'.IF lv_memid1+0(1) = 'I' OR lv_memid1+0(1) = 'P' OR lv_memid1+ 0(1) = 'A' .lv_colpro = '%D%'.lv_colpro1 = '%T%'.lv_colpro2 = '%M%'.ELSEIF lv_memid1+0(1) = 'M' OR lv_memid1+0(1) = 'Y' OR lv_memid1+0(1) = 'U' OR lv_memid1+0(1) = 'Q'.lv_colpro = '%L%'.lv_colpro1 = space.lv_colpro2 = space.ELSEIF lv_memid1+0(1) = 'D' OR lv_memid1+0(1) = 'X'. lv_colpro = '%I%'.lv_colpro1 = '%N%'.lv_colpro2 = space.ENDIF.ENDIF.ENDIF.* get the values for the input helpIF sy-tcode = 'CU50'.SELECT SINGLE yscod INTO value_exFROM ztdm_ch001WHERE yscod = valueAND ( gystr LIKE lv_colproOR gystr LIKE lv_colpro1OR gystr LIKE lv_colpro2 ).ELSE.SELECT SINGLE yscod INTO value_exFROM ztdm_ch001WHERE yscod = value.ENDIF.IF sy-subrc <> 0.ENDIF.ENDFUNCTION.1)帮助函数:ZDM_CH001_CHECK01_F4。
simulink中model reference的用法 -回复

simulink中model reference的用法-回复Simulink中的Model Reference是一个非常强大且常用的功能,它允许用户在一个模型中嵌入另一个模型,从而使得系统的设计和开发更加模块化、可维护和可扩展。
在本文中,我们将逐步介绍Simulink中Model Reference的用法,并提供实例来帮助读者更好地理解。
Model Reference的概念和作用Model Reference是指在一个主模型中嵌入一个或多个子模型的设计方法。
在Simulink中,主模型通常被称为父模型或顶层模型,子模型则是在顶层模型中使用的模块化组件。
Model Reference的好处主要有以下几个方面:1. 模块化开发:通过使用Model Reference,用户可以将复杂系统分解为更小、更易于管理的模块,使得系统的开发和维护变得更加简单和高效。
2. 可重用性:子模型可以重复使用,减少系统设计中的重复劳动,并提高代码的可维护性和可扩展性。
3. 团队协作:不同的团队成员可以独立开发和测试不同的子模型,从而提高团队的并行开发能力和协同工作效率。
Model Reference的使用步骤下面将介绍在Simulink中使用Model Reference的具体步骤。
步骤一:创建子模型在使用Model Reference之前,首先需要创建子模型。
可以将子模型定义为独立的模型文件,也可以在主模型中创建子系统,并将其转换为子模型。
子模型可以包含各种Simulink模块和功能,例如信号处理算法、控制逻辑和状态机等。
确保子模型在单独的命名空间中工作,以避免可能的变量名称冲突。
步骤二:在主模型中添加Model Reference Block一旦子模型创建完成,下一步是在主模型中添加Model Reference Block。
这可以通过在Simulink库浏览器中找到Model Reference Block,然后将其拖放到主模型中完成。
使用Include构建面向对象的Abaqus分析

使用Include构建面向对象的Abaqus分析作者:王永冠卜继玲姜其斌李心来源:《计算机辅助工程》2013年第05期摘要:简要阐述面向对象的基本概念和思想,介绍利用Abaqus中的Include功能构建面向对象分析任务的思路.以铁路行业典型单组件产品与多组件装配体产品分析为例,具体描述面向对象分析任务的结构和构建方法.展示以面向对象分析为核心思想的Include构建分析任务的优越性.关键词:面向对象;抗侧滚扭杆; Abaqus; Include中图分类号: TB115.1文献标志码: B引言产品概念设计阶段经常会出现多种结构方案优选的情况.此时需要采用CAE方法来进行比选.尽管产品的功能目的一致,但其结构存在一定的差异,因此在进行有限元分析时,需要重复进行大量的分析模型前处理工作.特别是对于复杂产品结构,由于其中含有大量不同形式的受力结构件(如抗侧滚扭杆的连杆、橡胶球头、橡胶套筒、扭杆和支座等),往往零件的更换会使整个产品重新进行分析前处理工作.建立这类结构件有限元模型时不同的模型简化处理方式往往导致差别较大的分析结果,导致CAE分析过程效率低,分析结果可靠性差.[1]本文介绍的利用Include功能构建面向对象的分析任务,可以为结构设计分析工作提供一种简单、快速的建模分析工作思路.1面向对象方法长期以来,人们一直在设法争取使问题空间与求解空间在结构上尽可能一致,也就是说,使分析、设计和研究系统的方法学与人们认识客观世界的过程尽可能一致,这也正是面向对象方法学的出发点和追求的原则.面向对象的方法认为,客观世界由许多各种各样的对象组成,每个对象都有自己的内部状态和运动规律,不同对象之间的相互作用和联系构成各种不同的系统,这与人们认识世界的自然思维方式是一致的.面向对象的方法是一种在分析和设计阶段独立于程序设计语言的概念化过程,它是一种程序设计技术,更重要地,它是一种新的思维方式,是一种完全不同于传统功能设计的方法.面向对象分析、面向对象设计和面向对象程序设计是面向对象方法学提供的3种主要技术手段.面向对象分析基于对象思想描述问题域和系统任务,而面向对象设计则是面向对象分析的扩充,主要是增加各种实现软件系统所必需的组成部分,从面向对象分析到面向对象设计是一个逐步扩充模型的过程.面向对象的分析设计遵循抽象、封装性、多态性和继承性的原则.[26]2Include介绍Abaqus中的Include功能提供一种简单、快速地构建有限元分析任务的思路.Include将一个或多个外部文件作为数据块引入计算文件中,形成一个总的文件用于计算.Include不但可以在inp文件中引入外部文件数据,也能在CAE中实现外部数据文件的引入,比如材料编辑器就可以读入外部ASCII文件.通过它,可以指定任意外部数据文件成为分析工作的一部分,这些外部数据文件可以是模型、历史输出、注释或其他参考.当程序执行工作文件遇到Include 时,无论它在哪里,都转向执行外部数据文件,当外部文件执行完后,又继续处理原来的工作文件.这种功能的核心就是在主分析中的外部文件或数据块指针,这具备构建面向对象思想的分析基础.3构建面向对象分析使用inp文件可以方便地描述模型参数、控制分析过程.文献[7]详细地介绍inp文件的结构和创建.可以认为一个inp任务主要由4种数据对象构成:有限元模型对象(节点、单元集和单元属性)、材料属性对象或对象属性、初始边界对象(包括约束条件)、一个或多个载荷步对象(包括边界条件、接触条件、计算控制参数集和结果输出等众多对象属性).无论对象还是对象属性都可以由单独的外部文件描述,而Include可以将这些独立外部对象文件组成一个完整的分析工作,可视Include为在主工作分析文件中这些单独对象文件的指针.图1可简单示意各对象与主工作文件的关系.每一个框图都是一个对象或对象属性,每一个对象或属性数据都可以作为一个外部文件,用Include引入.图 1完整的面向对象分析文件构成示意在产品设计初期阶段,结构设计工程师的工作是通过计算遴选多个方案,比较、确定产品结构和材料.因此,对于一个既定产品结构分析工作,只有模型结构和材料是变化的,而边界条件、载荷、接触、控制参数和输出量等都是确定的,因此能将整个分析工作分隔成几个特定功能或对象模块.在特定的分析中,仅变动其中个别对象,而其他对象始终不变.由此可见,Include提供一种面向对象的构建分析工作的思路,而按这种思路建立的多个ASCII文件集合即是Abaqus面向对象分析任务.使用ASCII文件来封装上述的对象或对象属性而非编译后的程序.这使得改动工作变得非常容易且迅速.改动工作不仅指特定类型产品分析任务的改进,也指修改已有任务、建立新类型产品分析任务的工作.在Abaqus执行文件inp内,载荷、约束、接触和材料属性赋值等都通过节点、单元或面的集合名称确定.inp文件按特定名称指定的节点、单元和面等执行相关计算分析,因此可方便地进行对象属性确认.综上所述,把一个由特定结构组成的产品的inp工作执行文件按功能和特性分为几个不同对象内容,每次具体计算只改动需变化的一两个文件就能形成完整的执行文件inp的创建,可节省大量的重复劳动.这就是本文面向对象分析任务的构建思路.由于整个面向对象分析都由inp文件集合构成,因此基于面向对象的任务文件执行基本不受Abaqus版本的限制.下面以2个铁路行业典型产品来说明Include面向对象分析任务的创建思路.3.1胶垫板结构分析以单个组件产品为例,介绍Include面向对象分析在快速分析中的应用.胶垫板是轨道扣件系统的一个重要部件.对于无碴轨道,胶垫板起减振和隔振作用,决定轨道的弹性性能,具体结构类型介绍参见参考文献[8].某胶垫板产品的原型结构见图2.产品施加集中力于工装上端板,工装下端板固定,简化为1/4模型(见图2).对于分析任务,本案例只调整胶垫板结构以满足强度和刚度的要求.因此,只有胶垫板模型对象FEA_MODEL.inp不断变化,其他工装模型、边界条件、载荷条件、接触设置、材料参数和结果输出设置等对象或属性则一律不变.很明显,由于主分析文件只包含工装模型、材料参数以及其他引入文件命令(见图4),因此它是不变的.载荷步对象包括载荷(位移和力)、计算参数和结果输出等属性定义,见图5.这部分都可由集合名称定义,故当针对某一特定结构产品时,这个文件也是不变的.初始条件及约束对象与载荷步一样,其内容也是固定不变的,见图6.因此,对于分析产品调整,整个分析任务中只有FEA_MODEL模型对象需要改动.如图7所示,胶垫板产品模型的节点、单元,节点集和单元集等信息都存在于FEA_MODEL模型对象里.直接在Command中执行Main_FE_JOB.inp即可计算.本次案例计算结果的应力云图和刚度曲线见图8.结果不理想,需要调整结构.有2种不同结构的胶垫板可以尝试计算,见图9.以后的工作只需使用不同结构产品的模型对象FEA_MODEL.inp,其他完全不用处理.具体细节不再赘述.这里有2个关键细节需要注意:一是不能改动节点集、单元集的名称,因为接触、加载、材料赋值和结果输出等定义全部依赖于集合的名称;二是要注意胶垫板产品模型的节点、单元序号的范围,不能与主文件中工装的相关序号冲突.图 8原型胶垫板有限元计算结果(a)(b)图 9其他2种不同结构的胶垫板设计3.2抗侧滚扭杆系统分析上例为单组件产品,而本案例为由多组件装配而成的产品结构分析,情况更为复杂,使用Include构建面向对象分析任务的优势更大.抗侧滚扭杆能使车辆具有良好的垂向振动性能和抗侧滚性能[9].某型抗侧滚扭杆产品包括吊杆、吊杆上球铰(球铰又包含芯轴、外套与胶层)、吊杆下球铰、摆臂、支座和扭杆等13个组件.支座固定约束;垂向载荷施加于吊杆上球铰芯轴,模型及加载示意见图10.抗侧滚扭杆各组件相互组装关系和有限元模型构建详见参考文献[10].。
RelationalModel

Jennifer Widom
The Relational Model
Database set value of named relations (or ) in Schema structural description of relations database Schema NULL – special –= structural description for “unknown” of relations ortables “undefined” in database Each relation has a set of named attributes (or columns) Instance actual contents at given point in time Instance –= actual contents at given point in time Each tuple (or row) has a value for each attribute Each attribute has a type (or domain)
Jennifer Widom
The Relational Model
Database set of named relations (or tablesin ) in Schema structural description of relations database Schema –= structural description of relations database Each relation has a set of named attributes (or columns) Instance actual contents at given point in time Instance –= actual contents at given point in time Each tuple (or row) has a value for each attribute Each attribute has a type (or domain)
超声波清洗机清洗假牙

Java系列概論
資料庫入門程式
Java System Concepts and Database Programming
賈蓉生 胡大源 林金池 編著
第一篇
Java資料庫環境
ቤተ መጻሕፍቲ ባይዱ
• 本書在眾多資料庫中,選定Java/Access資料庫系 統,以實作方式表現資料庫之功能。Access應屬 最方便且功能不輸其他者,凡有Office的電腦,開 機即可使用,無需另添購軟體。Java是功能強大 的物件導向語言,本身即擁有網路功能,是多數 網路電玩採用的設計語言,也是多數大銀行建立 網路銀行的設計語言,本書使用Java剖析資料庫 之各項應用。
第二章
第一個Java資料庫應用
2-1 簡介
• 我們可以關聯代數(Relation Algebra) 輕易地解釋非 常困難的查詢邏輯、並藉SQL資料庫語言實作執行, 而Java却可流暢地驅動SQL執行各類查詢邏輯。 • 在尚未真正進入資料庫精髓之前,為了讓讀者先 觸摸Java與Access之關係,本章將片段基礎介紹: 建立資料庫、設定ODBC、建立資料表、輸入資料、 讀取資料。
2-2 建立Access資料庫
• 本書使用Java/Access系統,以Access2007為範例資 料庫(如要使用其他資料庫請自行按規定轉換),本 節以手動於目錄 C:\BookJavaVol_4\Program\ch02\02_2建立資料庫 Book.accdb。
2-3 設定ODBC
• 當資料庫建立完成後(如前節之Book.accdb),我們 可立即以手動方式建立資料表(Data Tables)、輸入 /讀取資料。但却無法藉由Win作業系統之應用程 式來建立資料表、輸入/讀取資料。 • • 如果要藉由Win作業系統之應用程式來建立資料表、 輸入/讀取資料,必頇先設定ODBC(Open Database Connectivity),用以連通Win作業系統與資料庫。
SPSS_PROCESS_templates
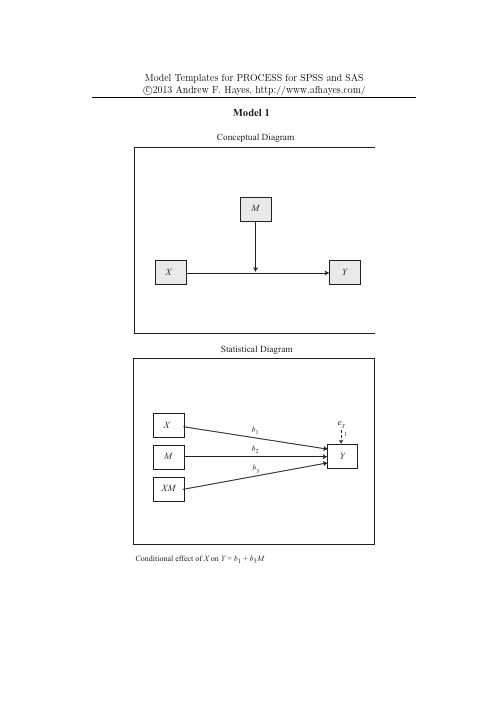
Model Templates for PROCESS for SPSS and SAS c⃝2013Andrew F.Hayes,/Model 1Conceptual DiagramStatistical DiagramConditional effect of X on Y = b1 + b3MModel Templates for PROCESS for SPSS and SAS c⃝2013Andrew F.Hayes,/Model 2Conceptual DiagramStatistical DiagramConditional effect of X on Y = b1 + b4M + b5WModel Templates for PROCESS for SPSS and SAS c⃝2013Andrew F.Hayes,/Model 3Conceptual DiagramStatistical DiagramConditional effect of X on Y = b1 + b4M + b5W+ b7MWModel Templates for PROCESS for SPSS and SAS c⃝2013Andrew F.Hayes,/Model 4Conceptual DiagramStatistical DiagramIndirect effect of X on Y through M i = a i b iDirect effect of X on Y = c'*Model 4 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SAS c⃝2013Andrew F.Hayes,/Model 5Conceptual DiagramStatistical DiagramIndirect effect of X on Y through M i = a i b iConditional direct effect of X on Y = c1'+ c3'W*Model 5 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SAS c⃝2013Andrew F.Hayes,/Model 6(2 mediators)Conceptual DiagramStatistical DiagramIndirect effect of X on Y through M i only = a i b iIndirect effect of X on Y through M1 and M2 in serial = a1d21 b2 Direct effect of X on Y = c'Model Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 6(3 mediators)Conceptual DiagramStatistical DiagramIndirect effect of X on Y through M i only = a i b iIndirect effect of X on Y through M1 and M2 in serial = a1 d21 b2Indirect effect of X on Y through M1 and M3 in serial = a1d31 b3Indirect effect of X on Y through M2 and M3 in serial = a2d32 b3Indirect effect of X on Y through M1, M2, and M3 in serial = a1 d21 d32 b3 Direct effect of X on Y = c'Model Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 6(4 mediators)Conceptual DiagramStatistical DiagramIndirect effect of X on Y through M i only = a i b iIndirect effect of X on Y through M1 and M2 in serial = a1 d21 b2Indirect effect of X on Y through M1 and M3 in serial = a1d31 b3Indirect effect of X on Y through M1 and M4 in serial = a1d41 b4Indirect effect of X on Y through M2 and M3 in serial = a2d32 b3Indirect effect of X on Y through M2 and M4 in serial = a2d42 b4Indirect effect of X on Y through M3 and M4 in serial = a3d43 b4Indirect effect of X on Y through M1, M2, and M3 in serial = a1 d21 d32 b3 Indirect effect of X on Y through M1, M2, and M4 in serial = a1 d21 d42 b4 Indirect effect of X on Y through M1, M3, and M4 in serial = a1 d31 d43 b4 Indirect effect of X on Y through M2, M3, and M4 in serial = a2 d32 d43 b4 Indirect effect of X on Y through M1, M2, M3, and M4 in serial = a1 d21 d32 d43 b4 Direct effect of X on Y = c'Model Templates for PROCESS for SPSS and SAS c⃝2013Andrew F.Hayes,/Model 7Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a3i W)b i Direct effect of X on Y = c'*Model 7 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SAS c⃝2013Andrew F.Hayes,/Model 8Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a3i W)b i Conditional direct effect of X on Y = c1'+ c3'W*Model 8 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SAS c⃝2013Andrew F.Hayes,/Model 9Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a4i W + a5i Z) b i Direct effect of X on Y = c'*Model 9 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SAS c⃝2013Andrew F.Hayes,/Model 10Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a4i W + a5i Z) b i Conditional direct effect of X on Y = c1'+ c4'W + c5'Z*Model 10 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 11Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a4i W + a5i Z + a7i WZ) b i Direct effect of X on Y = c'*Model 11 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 12Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a4i W + a5i Z + a7i WZ) b i Conditional direct effect of X on Y = c1'+ c4'W + c5'Z + c7'WZ*Model 12 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 13Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a4i W + a5i Z + a7i WZ) b i Conditional direct effect of X on Y = c1'+ c3'W*Model 13 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SAS c⃝2013Andrew F.Hayes,/Model 14Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = a i (b1i + b3i V) Direct effect of X on Y = c'*Model 14 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SAS c⃝2013Andrew F.Hayes,/Model 15Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = a i (b1i + b2i V) Conditional direct effect of X on Y = c1'+ c3'V*Model 15 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SAS c⃝2013Andrew F.Hayes,/Model 16Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = a i (b1i + b4i V + b5i Q) Direct effect of X on Y = c'*Model 16 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SAS c⃝2013Andrew F.Hayes,/Model 17Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = a i (b1i + b2i V + b3i Q) Conditional direct effect of X on Y = c1' + c4'V + c5'Q*Model 17 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SAS c ⃝2013Andrew F.Hayes,/Model 18Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = a i (b 1i + b 4i V + b 5i Q + b 7i VQ ) *Model 18 allows up to 10 mediators operating in parallelDirect effect of X on Y = c'Model Templates for PROCESS for SPSS and SAS c ⃝2013Andrew F.Hayes,/*Model 19 allows up to 10 mediators operating in parallelModel 19Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = a i (b 1i + b 2i V + b 3i Q + b 4i VQ ) Conditional direct effect of X on Y = c 1' + c 4'V + c 5'Q + c 7'VQModel Templates for PROCESS for SPSS and SAS c ⃝2013Andrew F.Hayes,/Model 20Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = a i (b 1i + b 3i V + b 4i Q + b 6i VQ ) *Model 20 allows up to 10 mediators operating in parallelConditional direct effect of X on Y = c 1' + c 3'VModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 21Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a3i W)(b1i + b3i V) Direct effect of X on Y = c'*Model 21 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 22Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a3i W)(b1i + b3i V) Conditional direct effect of X on Y = c1'+ c3'W*Model 22 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 23Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a4i W + a5i Z)(b1i + b3i V) Direct effect of X on Y = c'*Model 23 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 24Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a4i W + a5i Z)(b1i + b3i V) Conditional direct effect of X on Y = c1'+ c4'W+ c5'Z*Model 24 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 25Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a4i W + a5i Z + a7i WZ)(b1i + b3i V) Direct effect of X on Y = c'*Model 25 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 26Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a4i W + a5i Z + a7i WZ)(b1i + b3i V) Conditional direct effect of X on Y = c1'+ c4'W + c5'Z + c7'WZ*Model 26 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 27Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a4i W + a5i Z + a7i WZ)(b1i + b3i V) Conditional direct effect of X on Y = c1'+ c3'W*Model 27 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 28Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a3i W)(b1i + b2i V) Conditional direct effect of X on Y = c1'+ c3'V*Model 28 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 29Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a3i W)(b1i + b2i V) Conditional direct effect of X on Y = c1'+ c4'W + c5'V*Model 29 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SAS c ⃝2013Andrew F.Hayes,/Model 30Conceptual DiagramConditional indirect effect ofX on Y through M i = (a 1i + a 4i W + a 5i Z )(b 1i + b 2i V )*Model 30 allows up to 10 mediators operating in parallelConditional direct effect of X on Y = c 1' + c 3'VStatistical DiagramModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 31Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a4i W + a5i Z)(b1i + b2i V) Conditional direct effect of X on Y = c1'+ c4'W + c5'Z + c7'V*Model 31 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 32Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a4i W + a5i Z + a7i WZ)(b1i + b2i V) Conditional direct effect of X on Y = c1'+ c3'V*Model 32 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 33Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a4i W + a5i Z + a7i WZ)(b1i + b2iV) Conditional direct effect of X on Y = c1'+ c4'W + c5'Z + c7'WZ + c9'V*Model 33 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 34Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a4i W + a5i Z + a7i WZ)(b1i + b2i V) Conditional direct effect of X on Y = c1'+ c3'W + c5'V*Model 34 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 35Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a3i W)(b1i + b4i V + b5i Q) Direct effect of X on Y = c'*Model 35 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 36Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a3i W)(b1i + b2i V + b3i Q) Conditional direct effect of X on Y = c1' + c4'V + c5'Q*Model 36 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 37Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a3i W)(b1i + b4i V + b5i Q + b7i VQ) Direct effect of X on Y = c'*Model 37 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SAS c ⃝2013Andrew F.Hayes,/Model 38Conceptual DiagramConditional indirect effect of X on Y through M i = (a 1i + a 3i W )(b 1i + b 2i V + b 3i Q + b 4i VQ ) *Model 38 allows up to 10 mediators operating in parallelStatistical DiagramConditional direct effect of X on Y = c 1' + c 4'V + c 5'Q + c 7'VQModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 39Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a3i W)(b1i + b3i V + b4i Q + b6i VQ) Conditional direct effect of X on Y = c1' + c3'V*Model 39 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 40Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a3i W)(b1i + b4i V + b5i Q) Conditional direct effect of X on Y = c1' + c3'W*Model 40 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 41Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a3i W)(b1i + b2i V + b3i Q) Conditional direct effect of X on Y = c1' + c3'W + c6'V + c7'Q*Model 41 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 42Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a3i W)(b1i + b4i V + b5i Q + b7i VQ) Conditional direct effect of X on Y = c1' + c3'W*Model 42 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 43Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a3i W)(b1i + b2i V + b3i Q + b4i VQ) Conditional direct effect of X on Y = c1'+ c3'W + c6'V + c7'Q + c9'VQModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 44Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a3i W)(b1i + b3i V + b4i Q + b6i VQ) Conditional direct effect of X on Y = c1' + c3'W + c5'V*Model 44 allows up to 10 mediators operating in parallelModel Templates for PROCESS for SPSS and SAS c ⃝2013Andrew F.Hayes,/Model 45Conceptual DiagramConditional indirect ef fect of Xon Y through M i = (a 1i + a 4i W + a 5i Z )(b 1i + b 4i V + b 5i Q )Direct effect of X on Y = c'Statistical DiagramModel Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 46Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a4i W + a5i Z + a7i WZ)(b1i + b4i V + b5i Q) Direct effect of X on Y = c'Model Templates for PROCESS for SPSS and SASc⃝2013Andrew F.Hayes,/Model 47Conceptual DiagramStatistical DiagramConditional indirect effect of X on Y through M i = (a1i + a4i W + a5i Z)(b1i + b4i V + b5i Q + b7i VQ) Direct effect of X on Y = c'Model Templates for PROCESS for SPSS and SAS c ⃝2013Andrew F.Hayes,/Model 48Conceptual DiagramConditional indirect effect of X on Y through M i = (a 1i + a 4i W + a 5i Z + a 7i WZ ) . (b 1i + b 4i V + b 5i Q + b 7i VQ ) *Model 48 allows up to 10 mediators operating in parallelDirect effect of X on Y = c'Statistical Diagram。
relationaloperator模块的用法

relationaloperator模块的用法1.概述r e la ti on al op er ato r模块是一个用于比较和操作关系的Py t ho n工具包。
它提供了一系列的运算符和函数,用于比较两个对象的关系,包括相等性、大小关系等。
本文将详细介绍re l at io na lo pe ra tor模块的用法和功能。
2.安装r e la ti on al op er ato r模块可以通过p ip包管理工具进行安装。
在命令行中执行以下命令即可安装re la ti ona l op er at or模块:p i pi ns ta ll re la tio n al op er at or安装完成后,即可在P yt ho n代码中引入r el at io na lo pe ra t or模块进行使用。
3.基本运算符r e la ti on al op er ato r模块提供了一些基本的运算符,用于比较两个对象的关系。
以下是常用的基本运算符:-`==`:检查两个对象是否相等。
-`!=`:检查两个对象是否不相等。
-`>`:检查一个对象是否大于另一个对象。
-`<`:检查一个对象是否小于另一个对象。
-`>=`:检查一个对象是否大于等于另一个对象。
-`<=`:检查一个对象是否小于等于另一个对象。
通过使用这些基本运算符,可以对不同类型的对象进行比较,如数字、字符串、列表等。
示例代码:x=5y=10i f x<y:p r in t("x小于y")e l se:p r in t("x大于或等于y")4.自定义对象的比较除了可以比较基本类型的对象外,re la ti o na lo pe ra to r模块还支持自定义对象的比较。
通过在自定义类中实现比较运算符的特殊方法,可以定义对象之间的比较规则。
常用的比较特殊方法包括:-`__eq__(s el f,oth e r)`:定义相等性比较的规则。
关系模型设计(范式)_图文

第一范式(1NF):数据库表中的字段 都是单一属性的,不可再分。
字段1
字段2
字段3
字段4
第一范式(1NF)
• 例如,如下的数据库表是符合第一范式的:
字段1 字段第2 一范式字(段13NF) 字段4
第二范式举例
• 假定选课关系表为SelectCourse(学号, 姓名, 年 龄, 课程名称, 成绩, 学分),关键字为组合关键字( 学号, 课程名称),因为存在如下决定关系: (学号, 课程名称) → (姓名, 年龄, 成绩, 学分)
这个数据库表不满足第二范式,因为存在如下决 定关系:
(课程名称) → (学分) (学号) → (姓名, 年龄)
关系模式规范化的作用
•
关系数据库的设计主要是关
系模式设计。关系模式设计的好
坏直接影响到数据库设计的成败
。将关系模式规范化,是设计较
好的关系模式的惟一途径。
•
关系模式的规范化主要是
由关系范式来完成的。
关系范式
所谓范式(Normal Form,NF)是指规 范化的关系模式。由规范化程度不同,就产 生了不同的范式。根据满足条件的不同,经 常称某一关系模式R为“第几范式”。
• 原则:遵从概念单一化 “一事一地”原则,即一个关系 模式描述一个实体或实体间的一种联系。
• 方法:将关系模式投影分解成两个或两个以上的关系模式 。
• 要求:分解后的关系模式集合应当与原关系模式“等价” ,即经过自然联接可以恢复原关系而不丢失信息,并保持 属性间合理的联系。
关键字段 → 非关键字段x → 非关键字段y
第01讲 体系结构

1 数据不保存在计算机内 2 数据由应用程序管理 3 数据面向程序,不共享 数据面向程序,
二:文件管理阶段
1 数据长期保存 2 数据共享性差 三 :数据库管理阶段 1 有利于实现数据共享 2 数据面向应用,而非面向程序 数据面向应用,
数据库发展历史
Model)是数据库系统中最早 Model)是数据库系统中最早 出现的一种模型,它用树型结 构来表示各类实体的类型和实 体之间的联系。在数据库中满 足下述两个条件的“ 足下述两个条件的“基本层次 联系” 联系”的集合称为层次模型: 有且只有一个结点无双亲结点, 这个结点就是根结点;‘ 这个结点就是根结点;‘其他 结点有且仅有一个双亲结点。
数据建模(概念数据模型中的相关术语) 数据建模(概念数据模型中的相关术语)
• 属性:描述实体的特性 属性: • 实体集:同一类实体的集合 实体集:
• 关系(Relation):实体之间存在的对应或连接关系 关系(Relation) – 一对一关系(1:1):表中的一行与相关表中的一行相 一对一关系(1:1):表中的一行与相关表中的一行相 关 – 一对多关系(1:n):表中的一行与相关表中的零行或 一对多关系(1:n):表中的一行与相关表中的零行或 多行相关;如班级和学生,一个 多行相关;如班级和学生,一个 班级,有多个学生 – 多对多关系(n:m):表中的多行与相关表中的零行或 多对多关系(n:m):表中的多行与相关表中的零行或 多行相关;例如学生与课程的关系就属于多对多 – 联系的实现:在关系数据库设计中,联系通常利用逻 辑键来实现。
• 第一代 非关系型数据库系统
上世纪60年代问世, 上世纪60年代问世,包括层次型和网状型 第二代 关系型数据库系统 上世纪70年代中期问世 上世纪70年代中期问世 第三代 对象-关系数据库系统 对象-
14 ER Model实体关系图

2-2 弱實體(Weak Entity )
【定義】 是指需要依賴其他實體而存在的實體。
【例如】教職員的眷屬或課程的上課教室 【表示圖形】雙同心長方形表示
3 屬性(Attribute)
【定義】用來描述實體的性質(Property)。 【例如】學號、姓名、性別是用來描述學生實體的性質。 【分類】
學生
1 參加 M
考試
注意:如果只針對一個學生情況時(1:M);但是,如果針對全班學生 時,則「學生」與「考試」的關係為(M:N)
3.多對一的關係(M:1)
3.多對一的關係(M:1):表示兩個實體之間的關係是多對一的關係。
A實體
M 關係 1
B實體
說明:一個B實體會對應到多個A實體。
【對應關係圖】
說明:B3實體對應到A3與A4兩個實體
6 衍生屬性(Derived attribute)
【定義】指可由其他屬性或欄位計算而得的屬性,即某一個屬性的值是 由其他屬性的值推演而得。
【例如】以實際的「年齡」表示,我們可以由目前的系統時間減去生日 屬性的值,便可換算出「年齡」屬性的值;因此,年齡屬性便 屬於衍生屬性。
【表示圖形】以「虛線橢圓形」方式表示,如下:
A實體
1 關係 M
B體。
【對應關係圖】
說明:A3實體對應B3與B4兩個實體
【舉例】假設每一位教授可以同時指導多位研究生,但每一位研究生只 能有一位指導教授,不可以有共同指導現象。
教授
1 指導 M
研究生
【對應關係圖】
說明:每一位教授可以指導多位研究生,但每一位研究生只能有一位指導教授。 例如:T3教授同時指導S3與S4兩位研究生。但S1~S4只能找一位教授指導。
应用回归分析(第三版)何晓群_刘文卿_课后习题答案_完整版

第二章 一元线性回归分析思考与练习参考答案2.1 一元线性回归有哪些基本假定?答: 假设1、解释变量X 是确定性变量,Y 是随机变量;假设2、随机误差项ε具有零均值、同方差和不序列相关性: E(εi )=0 i=1,2, …,n Var (εi )=σ2 i=1,2, …,n Cov(εi, εj )=0 i≠j i,j= 1,2, …,n假设3、随机误差项ε与解释变量X 之间不相关: Cov(X i , εi )=0 i=1,2, …,n假设4、ε服从零均值、同方差、零协方差的正态分布 εi ~N(0, σ2 ) i=1,2, …,n 2.2 考虑过原点的线性回归模型 Y i =β1X i +εi i=1,2, …,n误差εi (i=1,2, …,n)仍满足基本假定。
求β1的最小二乘估计 解:21112)ˆ()ˆ(ini i ni i i e X Y Y Y Q β∑∑==-=-=得:2.3 证明(2.27式),∑e i =0 ,∑e i X i =0 。
证明:∑∑+-=-=nii i ni X Y Y Y Q 121021))ˆˆ(()ˆ(ββ其中:即: ∑e i =0 ,∑e i X i =02.4回归方程E (Y )=β0+β1X 的参数β0,β1的最小二乘估计与最大似然估计在什么条件下等价?给出证明。
答:由于εi ~N(0, σ2 ) i=1,2, …,n所以Y i =β0 + β1X i + εi ~N (β0+β1X i , σ2 ) 最大似然函数:)()(ˆ1211∑∑===ni ini ii XY X β01ˆˆˆˆi ii i iY X e Y Y ββ=+=-0100ˆˆQQββ∂∂==∂∂使得Ln (L )最大的0ˆβ,1ˆβ就是β0,β1的最大似然估计值。
同时发现使得Ln (L )最大就是使得下式最小,∑∑+-=-=nii i ni X Y Y Y Q 121021))ˆˆ(()ˆ(ββ上式恰好就是最小二乘估计的目标函数相同。
ARELATIONALMODEL...

“A RELATIONAL MODEL OF DATA FOR LARGE SHARED DATA BANKS”Through the internet, I find more information about Edgar F. Codd. He is a mathematician and computer scientist who laid the theoretical foundation for relational databases--the standard method by which information is organized in and retrieved from computers. In 1981, he received the A. M. Turing Award, the highest honor in the computer science field for his fundamental and continuing contributions to the theory and practice of database management systems.This paper is concerned with the application of elementary relation theory to systems which provide shared access to large banks of formatted data. It is divided into two sections. In section 1, a relational model of data is proposed as a basis for protecting users of formatted data systems from the potentially disruptive changes in data representation caused by growth in the data bank and changes in traffic. A normal form for the time-varying collection of relationships is introduced. In Section 2, certain operationson relations are discussed and applied to the problems of redundancy and consistency in the user's model.Relational model provides a means of describing data with its natural structure only--that is, without superimposing any additional structure for machine representation purposes. Accordingly, it provides a basis for a high level data language which will yield maximal independence between programs on the one hand and machine representation and organization of data on the other.A further advantage of the relational view is that it forms a sound basis for treating derivability, redundancy, and consistency of relations. Finally, the relational view permits a clearer evaluation of the scope and logical limitations of present formatted data systems, and also the relative merits.If the user's relational model is set up in normal form, names of items of data in the data bank can take a simpler form than would otherwise be the case. A general name would take a form such asR (g).r.dwhere R is a relational name; g is a generation identifier (optional); r is a role name (optional); d is a domain name. Since g is needed only when several generations of a given relation exist, or are anticipated to exist, and r is needed only when the relation R has two or more domains named d, the simple form R.d will often be adequate.The operation of the relational data can use relational algebra or relational calculus to express. They are the basis of the actual relationship language and are equivalent to each other.The adoption of a relational model of data permits the development of a universal data sublanguage based on an applied predicate calculus. There are two forms: tuple relational calculus and domain relational calculus, which are tuples with relations as predicates and the domain variables.In the second section , it mainly talks about the redundancy and consistency. Firstly, Edgar F. Codd introduced a few additional operations about set. As we all know, traditional set operations include union, intersection, difference, product and so on. The operations discussed in this section are specially for relations. It play a key role in deriving relations from other relations.Permutation, projection, join, composition, restriction form a complete set of operations. And the other relational algebra operations can be a combination of these five operations to achieve. Thus we are now in a position to consider various applications of these operations on relations.Secondly, we can know something about redundancy. A set of relations is strongly redundant if it contains at least one relation that possesses a projection which is derivable from other projections of relations in the set.A collection of relations is weakly redundant if it contains a relation that has a projection which is not derivable from other members but is at all times a projection of some join of other projections of relations in the collection. Thirdly, Relational database can maintain the data consistency. Enabling data sharing, Relational database reduces an amount of duplicate data and data redundancy. Whenever the named set of relations is redundant in either sense, we shall associate with that set a collection of statements which define all of the redundancies which hold independent of time between the member relations. After writing the article” A Relational Model of Data for Large Shared Data Banks”, he continued to carefully develop series of papers. Dr. Codd built upon this space and in doing so has provided the impetus for widespread research into numerous related areas, including database languages, query subsystems, database semantics, locking and recovery, and inferential subsystems.Since the 1980s, almost all database management systems which computer makers launched have supported the relational model. Banks rely on relational database to track liquidity; retailers use them to monitor inventory levels; HR staff uses them to manage the accounts; libraries, hospitals and government agencies rely on them to store millions of records. Over 40 years passed, relational database has already been the basis for today’s businesses.When I am writing this review, there are still many puzzles in my mind. Although it is not difficult to know the meaning of each word, it is still not easy to well understand the meaning of the whole article after reading it several times. I know there are many things I have to learn. Just like one of my classmates said, "the adventure in the database begins." We may meet many challenges latter on. Just facing and beating them, we will get a further understand about the joy of learning and life.Source: /profiles/blogs/personal-review-of-a-relational-model-of-data-for-large-shared。
具有用户特征约束的多关系聚类

D I 1 . 7 ̄i n 10 .3 1 0 1 30 5 文章编 号:0 28 3 (0 12 . 140 文献标识码 : 中图分类号 : P l O :03 8 .s . 28 3 . 1. . 7 s 0 2 2 3 10 —3 l2 1) 30 2 .6 A T 3l
Байду номын сангаас
ct n .0 1 4 (3 :2 —2 . ai s2 1 . 7 2 ) 1 4 1 9 o
Ab t a t A o f c u trn l o i m s o u n d t t ef e c u trn i s f u e s n a t i a i n, u d n e f u e s sr c : l t o l se g ag rt i h f c s o aa i l. l se i g am o s r a d p ri p t s Th c o g i a c o s r
i c u t rn r c s r e l ce . e d o i a c r t e u t o l se n .o o v h r b e , e - n t i t M u t Re a n l se i g p o e s a e n g e td I la s t n c u a e r s l f c u tr gT s l e t e p o lm Us rCo sr n t i a l— l— i
S h o o mp tr S in e a d T c n l g Ch n i e st f M i ig a d T c n l g Xu h u Ja g u 2 1 , i a c o l f Co u e ce c n e h o o y, i a Un v ri o n n n e h o o y, z o , i n s 21 6 Ch n y 1
simulink转化为model reference -回复

simulink转化为model reference -回复如何将Simulink模型转化为Model Reference一、引言Simulink是MATLAB的一个重要工具箱,用于进行系统建模、仿真和模型基于代码的开发。
在构建复杂系统模型时,将模型拆分为多个模块并分别开发可以提高模型的可读性和可维护性。
而Model Reference是Simulink的一个功能,可以帮助用户将模型分解为可重用的组件,从而简化系统的设计和开发过程。
本文将详细介绍如何将Simulink模型转化为Model Reference,并给出具体的步骤和示例。
二、了解Model Reference在进行Simulink模型转化为Model Reference之前,首先需要了解Model Reference的基本概念和特性。
Model Reference是一种将大型模型分解为可重用的组件的方法,每个组件对应一个独立的Simulink模型。
这些组件可以将模型分离为更小的部分,便于集中精力进行开发和测试。
Model Reference具有以下特性:1. 可重用性:Model Reference可以作为模板,用于构建多个相似的模型。
2. 分层设计:通过将模型分解为多个模块,可以减少系统复杂性,提高可维护性。
3. 代码生成:Model Reference可以方便地生成可独立运行的代码,用于实际的部署和测试。
4. 仿真效率:Model Reference允许并行仿真,从而提高仿真效率。
三、将Simulink模型转化为Model Reference的步骤接下来,将介绍如何将Simulink模型转化为Model Reference的具体步骤。
步骤一:准备工作在将Simulink模型转化为Model Reference之前,需要完成一些准备工作:1. 组织好模型结构:确保模型的层次结构清晰,并且各个模块之间有良好的接口定义。
2. 确保模型可以正常运行:在进行模型转化之前,必须确保模型可以顺利运行,并且输出结果正确。
接纳承诺疗法在精神心理疾病中的应用与展望

当代护士2021年4月第28卷第11期(中旬刊)•5•接纳承诺疗法在精神心理疾病中的应用与展望葛琳V郭佳1王红娟1摘要综述接纳承诺疗法在精神心理疾病领域中的应用,精神心理疾病包括焦虑症,抑郁症,物质依赖,心理弹性,创伤后应激障碍,精神分裂症以及双向情感障碍。
认为接纳承诺疗法作为一种心理治疗方式,可有效促进患者心理疾病的缓解和转归,同时提升患者的生活质量。
建议研究人员借鉴国外接纳承诺疗法治疗案例的经验,在国内开展接纳承诺疗法的临床实证研究,为有心理疾病的患者提供本土化的更加完善的接纳承诺疗法治疗。
关键词:接纳承诺疗法;精神心理疾病;应用接纳承诺疗法(acceptance and commitment therapy,ACT)是认知行为疗法“第三次浪潮”中最具有代表性的治疗方法之-[1],它强调接受和正念,注重在个人价值观指导下的行为策略改变,其目标是减少经验性回避,通过承认并接纳自己存在的问题和症状,让当事人构建与有效的价值方向一致的生活来达到治疗目的。
研究证实,ACT具有增进心理健康、减轻工作压力、改善生活质量、促进健康的行为方式等优势,在慢性疾病、心理疾病以及健康促进等方面具有积极的治疗效果,尤其在心理疾病治疗领域的应用较为广泛。
因此,本研究将对ACT在国内外心理疾病治疗领域的研究现状进行综述,以期为我国ACT的应用提供参考和指导。
1接纳承诺疗法的概述20世纪90年代初,ACT由美国内华达州大学心理学教授Steven C.Hayes及其同事所创立,以有关人类语言和认知的关系框架理论(relational frame theory,RFT)为理论基础,功能性语境主义哲学为哲学背景⑸。
ACT并不是直接改变当事人内在的体验(如,想法,信念,能力,记忆,感觉等),相反,它的主要目的是培养当事人的正念技能,以使这些内在的体验能够产生更大的行为适应来增加其心理灵活性,从而使当事人积极地接受并正视痛苦的存在,最终减轻痛苦对生活的干扰。
构造检索式例子

构造检索式例子1. 如何在Python中使用正则表达式进行模式匹配?正则表达式是一种强大的文本处理工具,它可以帮助我们在字符串中查找特定模式。
在Python中,我们可以使用re模块来实现正则表达式的功能。
首先,我们需要导入re模块,然后使用re.search()函数来进行模式匹配。
该函数接受两个参数,第一个参数是要匹配的模式,第二个参数是要搜索的字符串。
如果找到了匹配的模式,则返回一个匹配对象;如果没有找到,则返回None。
我们还可以使用re.findall()函数来查找字符串中所有匹配的模式,并返回一个包含所有匹配结果的列表。
此外,re模块还提供了许多其他函数和方法,可以帮助我们更灵活地使用正则表达式。
2. 如何在Python中实现列表的排序功能?在Python中,我们可以使用sort()函数来对列表进行排序。
sort()函数是列表对象的一个方法,它可以原地修改列表,使其按照指定的顺序进行排序。
默认情况下,sort()函数会按照升序对列表进行排序。
如果我们想要按照降序进行排序,可以通过传递reverse=True 参数来实现。
此外,sort()函数还可以接受一个可选的key参数,用于指定排序的依据。
key参数应该是一个函数,它接受一个列表的元素作为参数,并返回一个用于排序的关键字。
通过使用key参数,我们可以对复杂的数据结构进行排序,而不仅仅是对基本类型的元素进行排序。
3. 如何在Python中读写CSV文件?CSV文件是一种常用的数据存储格式,它可以用逗号或其他字符来分隔不同的数据字段。
在Python中,我们可以使用csv模块来读写CSV文件。
首先,我们需要导入csv模块,然后使用csv.reader()函数来读取CSV文件。
该函数接受一个文件对象作为参数,并返回一个迭代器,用于逐行读取CSV文件中的数据。
我们可以使用for循环来遍历迭代器,然后对每一行数据进行处理。
如果要写入CSV文件,我们可以使用csv.writer()函数来创建一个写入对象,然后使用writerow()方法来写入一行数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
three sets D1, D2, D3 with Cartesian Product D1 D2 D3; e.g.
D1 = {1, 3} D2 = {2, 4} D3 = {5, 6}
D1 D2 D3 = {(1,2,5), (1,2,6), (1,4,5), (1,4,6), (3,2,5), (3,2,6), (3,4,5), (3,4,6)}
Pearson Education © 2009
Chapter 1 - Objectives
Typical
functions of a DBMS. Major components of the DBMS environment. Personnel involved in the DBMS environment. History of the development of DBMSs. Advantages and disadvantages of DBMSs.
Pearson Education © 2009
3
Chapter 3 - Objectives
Components
of a DMBS Multi-user DBMS Architectures Web services Distributed DBMSs Data Warehousing Oracle Architecture
Chapter 1 - Objectives
Some
common uses of database systems. Characteristics of file-based systems. Problems with file-based approach. Meaning of the term database. Meaning of the term Database Management System (DBMS).
19
Chapter 4 - Objectives
Connection
between mathematical relations and relations in the relational model. How tables are used to represent data. Properties of database relations. Terminology of relational model. How to identify CK, PK, and FKs. Meaning of entity integrity and referential integrity. Purpose and advantages of views.
Pearson Education © 2009
10
Mattion
Consider
two sets, D1 & D2, where D1 = {2, 4} and D2 = {1, 3, 5}.
Cartesian
Product: D1 D2 – set of all ordered pairs, – first element is member of D1 and – second element is member of D2.
Pearson Education © 2009
9
Chapter 4 - Objectives
Connection
between mathematical relations and relations in the relational model. How tables are used to represent data. Properties of database relations. Terminology of relational model. How to identify CK, PK, and FKs. Meaning of entity integrity and referential integrity. Purpose and advantages of views.
Pearson Education © 2009
14
Chapter 4 - Objectives
Connection
between mathematical relations and relations in the relational model. How tables are used to represent data. Properties of database relations. Terminology of relational model. How to identify CK, PK, and FKs. Meaning of entity integrity and referential integrity. Purpose and advantages of views.
Pearson Education © 2009
Are these rows/records unique? Yes. But why? Does the order matter?
Why are the column names unique?
Does the order mater?
What values can “salary” have?
Pearson Education © 2009
Chapter 4 - Objectives
Connection
between mathematical relations and relations in the relational model. How tables are used to represent data. Properties of database relations. Terminology of relational model. How to identify CK, PK, and FKs. Meaning of entity integrity and referential integrity. Purpose and advantages of views.
D1 D2 = {(2, 1), (2, 3), (2, 5), (4, 1), (4, 3), (4, 5)}
R = {(2, 1), (4, 1)}
May
specify which pairs are in relation using some condition for selection; e.g. – second element is 1: R = {(x, y) | x D1, y D2, and y = 1}
Pearson Education © 2009
17
So…how does this apply to a database?
Relation
R is the mapping from attribute to domain (A1:d1, A2:d2,…An:dn)
{(branchNo: B005, street: 22 Deer Rd city: London, postcode: SW1 4EH)}
Let
Pearson Education © 2009
16
So…how does this apply to a database?
The
set {A1:D1, A2:D2,…An:Dn} is a relation schema
{branchNo: BranchNumbers, street: StreetNumbers, city: CityNames, postcode: Postcodes}
Any
subset of these ordered triples is a relation.
Pearson Education © 2009
13
Mathematical Definition of Relation
Cartesian product of n sets (D1, D2, . . ., Dn) is:
– first element is always twice the second: S = {(x, y) | x D1, y D2, and x = 2y} S = {(2, 1)}
Pearson Education © 2009
12
Mathematical Definition of Relation
select fname, lname, city from Staff Natural Join Branch where position = ‘Manager’
How do we “know” this query will return all records?
Chapter 4
The Relational Model
Pearson Education © 2009
Chapter 2 - Objectives
Three-Level ANSI-SPARC Architecture
Database Languages
Data models and Conceptual Modelling Functions of a DMBS
Pearson Education © 2009
15
So…how does this apply to a database?
A1, A2,…An, be attributes (columns) with domains (possible values) D1, D2,…Dn The set {A1:D1, A2:D2,…An:Dn} is a relation schema Relation R is the mapping from attribute to domain (A1:d1, A2:d2,…An:dn) We can think of a relation in the relational model as any subset of the Cartesian Product of the domains of the attributes