Python按一列拆分Excel表格
使用python操作excel

使⽤python操作excel使⽤python操作excelpython操作excel主要⽤到xlrd和xlwt这两个库,即xlrd是读excel,xlwt是写excel的库。
安装xlrd模块#pip install xlrd使⽤介绍常⽤单元格中的数据类型 empty(空的) string(text) number date boolean error blank(空⽩表格) empty为0,string为1,number为2,date为3,boolean为4, error为5(左边为类型,右边为类型对应的值)导⼊模块import xlrd打开Excel⽂件读取数据data = xlrd.open_workbook(filename[, logfile, file_contents, ...])#⽂件名以及路径,如果路径或者⽂件名有中⽂给前⾯加⼀个r标识原⽣字符。
#filename:需操作的⽂件名(包括⽂件路径和⽂件名称);若filename不存在,则报错FileNotFoundError;若filename存在,则返回值为xlrd.book.Book对象。
常⽤的函数 excel中最重要的⽅法就是book和sheet的操作# (1)获取book中⼀个⼯作表names = data.sheet_names()#返回book中所有⼯作表的名字table = data.sheets()[0]#获取所有sheet的对象,以列表形式显⽰。
可以通过索引顺序获取,table = data.sheet_by_index(sheet_indx))#通过索引顺序获取,若sheetx超出索引范围,则报错IndexError;若sheetx在索引范围内,则返回值为xlrd.sheet.Sheet对象table = data.sheet_by_name(sheet_name)#通过名称获取,若sheet_name不存在,则报错xlrd.biffh.XLRDError;若sheet_name存在,则返回值为xlrd.sheet.Sheet对象以上三个函数都会返回⼀个xlrd.sheet.Sheet()对象data.sheet_loaded(sheet_name or indx)# 检查某个sheet是否导⼊完毕,返回值为bool类型,若返回值为True表⽰已导⼊;若返回值为False表⽰未导⼊# (2)⾏的操作nrows = table.nrows#获取该sheet中的有效⾏数table.row(rowx)#获取sheet中第rowx+1⾏单元,返回值为列表;列表每个值内容为:单元类型:单元数据table.row_slice(rowx[, start_colx=0, end_colx=None])#以切⽚⽅式获取sheet中第rowx+1⾏从start_colx列到end_colx列的单元,返回值为列表;列表每个值内容为:单元类型:单元数据table.row_types(rowx, start_colx=0, end_colx=None)#获取sheet中第rowx+1⾏从start_colx列到end_colx列的单元类型,返回值为array.array类型。
拆分工作表的代码

拆分工作表(或将工作表拆分为多个工作表)的代码具体取决于您使用的编程语言和工作表处理库。
以下是一个示例,演示如何使用Python和openpyxl库将一个工作表拆分为多个工作表。
在这个示例中,我们假设您要按行数拆分工作表。
```pythonimport openpyxl# 打开工作簿workbook = openpyxl.load_workbook('your_workbook.xlsx')# 选择要拆分的工作表source_sheet = workbook['Sheet1'] # 将'Sheet1' 替换为您要拆分的工作表名称# 指定每个子工作表的行数chunk_size = 100 # 每个子工作表包含的行数# 计算总行数total_rows = source_sheet.max_row# 计算需要创建的子工作表数量num_chunks = (total_rows - 1) // chunk_size + 1# 创建和复制子工作表for i in range(num_chunks):start_row = i * chunk_size + 2 # 从第2行开始,因为通常第1行是标题end_row = min((i + 1) * chunk_size + 1, total_rows) # 最后一行可能不足chunk_size 行# 创建新的子工作表new_sheet = workbook.create_sheet(title=f'SubSheet{i+1}')# 复制数据for row in source_sheet.iter_rows(min_row=start_row, max_row=end_row, values_only=True):new_sheet.append(row)# 删除原始工作表(如果需要)# workbook.remove(source_sheet)# 保存工作簿workbook.save('split_workbook.xlsx')```在上面的示例中,我们首先打开工作簿,然后选择要拆分的工作表。
python excel分列 制定分隔符 案例

一、引言随着信息技术的发展,数据处理已经成为各行各业中不可或缺的一部分。
在日常工作中,我们经常会遇到需要将数据进行分列分隔的情况,而Excel作为一款常用的数据处理工具,也提供了多种方法来实现这一目的。
本文将主要介绍如何利用Python来对Excel中的数据进行分列,并制定分隔符的方法,并结合实际案例进行说明。
二、Python处理Excel分列的方法1. 使用pandas库Pandas是一款功能强大的数据分析工具,在处理Excel数据时十分实用。
通过pandas库,我们可以很容易地对Excel中的数据进行分列和制定分隔符。
我们需要利用pandas的read_excel方法将Excel文件中的数据读取为DataFrame格式。
接下来,可以使用DataFrame的str.split方法将数据按照指定的分隔符进行分列。
再将处理后的数据保存到新的Excel文件中。
2. 使用openpyxl库Openpyxl是一款专门用于读写Excel文件的Python库,通过它,我们也可以很方便地对Excel数据进行分列。
我们需要使用openpyxl的load_workbook方法打开Excel文件,并定位到我们需要进行操作的工作表。
可以通过遍历工作表中的每一行数据,使用split方法按照指定的分隔符进行分列处理。
再将处理后的数据保存到新的Excel文件中。
三、案例分析为了更好地理解Python处理Excel分列并制定分隔符的方法,我们将以一份包含学生成绩信息的Excel文件为例进行说明。
该Excel文件中包含学生尊称和各科成绩,而每个学生的成绩都是用逗号分隔的。
我们希望将每个学生的成绩分列开,并且重新使用冒号作为分隔符。
1. 使用pandas库我们使用pandas库的read_excel方法将Excel文件中的数据读取为DataFrame格式。
```pythonimport pandas as pddf = pd.read_excel('学生成绩.xlsx')```可以使用DataFrame的str.split方法将数据按照逗号进行分列。
python处理excel文件(xls和xlsx)

python处理excel⽂件(xls和xlsx)⼀、xlrd和xlwt使⽤之前需要先安装,windows上如果直接在cmd中运⾏python则需要先执⾏pip3 install xlrd和pip3 install xlwt,如果使⽤pycharm则需要在项⽬的解释器中安装这两个模块,File-Settings-Project:layout-Project Interpreter,点击右侧界⾯的+号,然后搜索xlrd和xlwt,然后点击Install Package进⾏安装。
对于excel来说,整个excel⽂件称为⼯作簿,⼯作簿中的每个页称为⼯作表,⼯作表⼜由单元格组成。
对于xlrd和xlwt,⾏数和列数从0开始,单元格的⾏和列也从0开始,例如sheet.row_values(2)表⽰第三⾏的内容,sheet.cell(1,2).value表⽰第⼆⾏第三列单元格的内容。
1.xlrd模块读取excel⽂件使⽤xlrd模块之前需要先导⼊import xlrd,xlrd模块既可读取xls⽂件也可读取xlsx⽂件。
获取⼯作簿对象:book = xlrd.open_workbook('excel⽂件名称')获取所有⼯作表名称:names = book.sheet_names(),结果为列表根据索引获取⼯作表对象:sheet = book.sheet_by_index(i)根据名称获取⼯作表对象:sheet = book.sheet_by_name('⼯作表名称')获取⼯作表⾏数:rows = sheet.nrows获取⼯作表列数:cols = sheet.ncols获取⼯作表某⼀⾏的内容:row = sheet.row_values(i) ,结果为列表【sheet.row(i),列表】获取⼯作表某⼀列的内容:col = sheet.col_values(i) 结果为列表【sheet.col(i),列表】获取⼯作表某⼀单元格的内容:cell = sheet.cell_value(m,n)、 sheet.cell(m,n).value、sheet.row(m)[n].value,sheet.col(n)[m].value,结果为字符串或数值【sheet.cell(0,0),xlrd.sheet.Cell对象】⽰例:假设在py执⾏⽂件同层⽬录下有⼀fruit.xls⽂件,有三个sheet页Sheet1、Sheet2、Sheet3,其中Sheet1内容如下:import xlrdbook = xlrd.open_workbook('fruit.xls')print('sheet页名称:',book.sheet_names())sheet = book.sheet_by_index(0)rows = sheet.nrowscols = sheet.ncolsprint('该⼯作表有%d⾏,%d列.'%(rows,cols))print('第三⾏内容为:',sheet.row_values(2))print('第⼆列内容为%s,数据类型为%s.'%(sheet.col_values(1),type(sheet.col_values(1))))print('第⼆列内容为%s,数据类型为%s.'%(sheet.col(1),type(sheet.col(1))))print('第⼆⾏第⼆列的单元格内容为:',sheet.cell_value(1,1))print('第三⾏第⼆列的单元格内容为:',sheet.cell(2,1).value)print('第五⾏第三列的单元格内容为:',sheet.row(4)[2].value)print('第五⾏第三列的单元格内容为%s,数据类型为%s'%(sheet.col(2)[4].value,type(sheet.col(2)[4].value)))print('第五⾏第三列的单元格内容为%s,数据类型为%s'%(sheet.col(2)[4],type(sheet.col(2)[4])))# 执⾏结果# sheet页名称: ['Sheet1', 'Sheet2', 'Sheet3']# 该⼯作表有5⾏,3列.# 第三⾏内容为: ['梨', 3.5, 130.0]# 第⼆列内容为['单价/元', 8.0, 3.5, 4.5, 3.8],数据类型为<class 'list'>.# 第⼆列内容为[text:'单价/元', number:8.0, number:3.5, number:4.5, number:3.8],数据类型为<class 'list'>.# 第⼆⾏第⼆列的单元格内容为: 8.0# 第三⾏第⼆列的单元格内容为: 3.5# 第五⾏第三列的单元格内容为: 300.0# 第五⾏第三列的单元格内容为300.0,数据类型为<class 'float'># 第五⾏第三列的单元格内容为number:300.0,数据类型为<class 'xlrd.sheet.Cell'>xlrd读取excel⽰例可以看出通过sheet.row(i)、sheet.col(i)也可获取⾏或列的内容,并且结果也是⼀个列表,但是列表中的每⼀项类似字典的键值对,形式为数据类型:值。
Python处理Excel效率高十倍(下篇)通篇硬干货,再也不用加班啦

Python处理Excel效率高十倍(下篇)通篇硬干货,再也不用加班啦《用Python处理Excel表格》下篇来啦!身为工作党或学生党的你,平日里肯定少不了与Excel表格打交道的机会。
当你用Excel处理较多数据时,还在使用最原始的人工操作吗?现在教你如何用Python处理Excel,从此处理表格再也不加班,时间缩短数十倍!上篇我们进行了一些事前准备,目的是用Python提取Excel表中的数据。
而这一篇便是在获取数据的基础上,对Excel表格的实操处理。
操作创建新的excel第9行代码用来指定创建的excel的活动表的名字:·不写第9行,默认创建sheet·写了第9行,创建指定名字的sheet表import osimport openpyxlpath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.Workbook()sheet = workbook.activesheet.title = '1号sheet'workbook.save('1.xlsx') 修改单元格、excel另存为第9行代码,通过给单元格重新赋值,来修改单元格的值第9行代码的另一种写法sheet['B1'].value = 'age'第10行代码,保存时如果使用原来的(第7行)名字,就直接保存;如果使用了别的名字,就会另存为一个新文件import osimport openpyxlpath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表sheet['A1'] = 'name'workbook.save('test.xlsx')添加数据插入有效数据使用append()方法,在原来数据的后面,按行插入数据import osimport openpyxlpath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print('当前活动表是:' + str(sheet))data = [ ['素子',23], ['巴特',24], ['塔奇克马',2]]for row in data: sheet.append(row) # 使用append 插入数据workbook.save('test.xlsx')插入空行空列·insert_rows(idx=数字编号, amount=要插入的行数),插入的行数是在idx行数的下方插入·insert_cols(idx=数字编号, amount=要插入的列数),插入的位置是在idx列数的左侧插入import osimport openpyxlpath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print('当前活动表是:' + str(sheet))sheet.insert_rows(idx=3, amount=2)sheet.insert_cols(idx=2,amount=1)workbook.save('test.xlsx')删除行、列·delete_rows(idx=数字编号, amount=要删除的行数)·delete_cols(idx=数字编号, amount=要删除的列数)import osimport openpyxlpath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print('当前活动表是:' + str(sheet))sheet.delete_rows(idx=10) # 删除第10行sheet.delete_cols(idx=1, amount=2) # 删除第1列,及往右共2列workbook.save('test.xlsx')移动指定区间的单元格(move_range)move_range(“数据区域”,rows=,cols=):正整数为向下或向右、负整数为向左或向上import osimport openpyxlpath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print('当前活动表是:' + str(sheet))sheet.move_range('D11:F12',rows=0,cols=-3) # 移动D11到F12构成的矩形格子workbook.save('test.xlsx')字母列号与数字列号之间的转换核心代码from openpyxl.utils import get_column_letter, column_index_from_string# 根据列的数字返回字母print(get_column_letter(2)) # B# 根据字母返回列的数字print(column_index_from_string('D')) # 4举个例子:import osimport openpyxlfrom openpyxl.utils import get_column_letter, column_index_from_stringpath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('2.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print('当前活动表是:' + str(sheet))# 根据列的数字返回字母print(get_column_letter(2)) # B# 根据字母返回列的数字print(column_index_from_string('D')) # 4字体样式查看字体样式import osimport openpyxlimport openpyxl.stylespath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print('当前活动表是:'+str(sheet))cell = sheet['A1']font = cell.fontprint('当前单元格的字体样式是')print(, font.size, font.bold, font.italic, font.color)'''当前活动表是:<Worksheet '1号sheet'>当前单元格的字体样式是等线11.0 False False <openpyxl.styles.colors.Color object>Parameters:rgb=None, indexed=None, auto=None, theme=1, tint=0.0, type='theme'''' 修改字体样式openpyxl.styles.Font(name=字体名称,size=字体大小,bold=是否加粗,italic=是否斜体,color=字体颜色)其中,字体颜色中的color是RGB的16进制表示import osimport openpyxlimport openpyxl.stylespath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print(sheet)cell = sheet['A1']cell.font = openpyxl.styles.Font(name='微软雅黑', size=20, bold=True, italic=True, color='FF0000')workbook.save('test.xlsx')再者,可以使用for循环,修改多行多列的数据,在这里介绍了获取的方法import osimport openpyxlimport openpyxl.stylespath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print(sheet)cell = sheet['A']for i in cell: i.font = openpyxl.styles.Font(name='微软雅黑', size=20, bold=True, italic=True, color='FF0000')workbook.save('test.xlsx')设置对齐格式Alignment(horizontal=水平对齐模式,vertical=垂直对齐模式,text_rotation=旋转角度,wrap_text=是否自动换行)水平对齐:'distributed’,'justif y’,'center’,'left’,'centerContinuous’,'right,'general’垂直对齐:'bottom’,'distributed’,'justify’,'center’,'top’import osimport openpyxl.stylespath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print('当前活动表是:' + str(sheet))cell = sheet['A1']alignment = openpyxl.styles.Alignment(horizontal='center', vertical='center', text_rotation=0, wrap_text=True)cell.alignment = alignmentworkbook.save('test.xlsx')当然,你仍旧可以调用for循环来实现对多行多列的操作import osimport openpyxl.stylespath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print('当前活动表是:' + str(sheet))cell = sheet['A']alignment = openpyxl.styles.Alignment(horizontal='center', vertical='center',text_rotation=0, wrap_text=True)for i in cell: i.alignment = alignment workbook.save('test.xlsx')设置行高列宽设置行列的宽高:·row_dimensions[行编号].height = 行高·column_dimensions[列编号].width = 列宽import osimport openpyxlimport openpyxl.stylespath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print('当前活动表是:' + str(sheet))# 设置第1行的高度sheet.row_dimensions[1].height = 50# 设置B列的卷度sheet.column_dimensions['B'].width = 20workbook.save('test.xlsx')设置所有单元格(显示的结果是设置所有,有数据的单元格的)from openpyxl import load_workbookfrom openpyxl.utils import get_column_letterimport osos.chdir(r'C:\Users\asuka\Desktop')workbook = load_workbook('1.xlsx')print(workbook.sheetnames) # 打印所有的sheet表ws = workbook[workbook.sheetnames[0]] # 选中最左侧的sheet表width = 2.0 # 设置宽度height = width * (2.2862 / 0.3612) # 设置高度print('row:', ws.max_row, 'column:', ws.max_column) # 打印行数,列数for i in range(1, ws.max_row + 1): ws.row_dimensions[i].height = heightfor i in range(1, ws.max_column + 1): ws.column_dimensions[get_column_letter(i)].width = widthworkbook.save('test.xlsx')合并、拆分单元格合并单元格有下面两种方法,需要注意的是,如果要合并的格子中有数据,即便python没有报错,Excel打开的时候也会报错。
python处理excel实例

python处理excel实例Python是一种功能强大的编程语言,可以用来处理各种数据类型,包括Excel文件。
Python处理Excel文件的能力极强,可以进行数据提取、数据处理、数据分析等多方面操作。
下面是一个Python处理Excel文件的实例:1. 导入所需的库```pythonimport openpyxl```2. 读取Excel文件```pythonwb = openpyxl.load_workbook('example.xlsx')```这个代码块会打开名为example.xlsx的Excel文件,并将其存储在变量wb中。
3. 选择工作表```pythonsheet = wb['Sheet1']```这个代码块会选择名为Sheet1的工作表,并将其存储在变量sheet中。
4. 读取单元格数据cell_value = sheet['A1'].value```这个代码块会读取A1单元格的数据,并将其存储在变量cell_value中。
5. 读取行数据```pythonrow_values = []for row in sheet.iter_rows(min_row=2, max_col=3):row_values.append([cell.value for cell in row])```这个代码块会读取工作表中第2行到最后一行、第1列到第3列的数据,并将其存储在列表row_values中。
6. 读取列数据```pythoncolumn_values = []for column in sheet.iter_cols(min_row=2, max_row=4):column_values.append([cell.value for cell in column]) ```这个代码块会读取工作表中第2列到第4列、第1行到最后一行的数据,并将其存储在列表column_values中。
excel批量拆分工作表vba代码

Excel批量拆分工作表VBA 代码===================本代码将帮助您将一个包含多个工作表的Excel 文件拆分成多个单独的工作簿,每个工作簿包含原始工作表中的一个工作表。
以下是代码的详细步骤:1. 打开源文件和目标文件夹--------------------首先,您需要打开源文件和目标文件夹。
您可以使用`Workbooks.Open` 方法打开源文件,并使用`FSO` (文件系统对象)来访问目标文件夹。
```vba' 打开源文件Workbooks.Open "C:\path\to\source\file.xlsx"' 获取目标文件夹路径Dim targetFolder As StringtargetFolder = "C:\path\to\target\folder"2. 遍历源文件中的每个工作表----------------------接下来,您需要遍历源文件中的每个工作表。
您可以使用`Workbook.Sheets` 属性来获取所有工作表,并使用`For Each` 循环遍历每个工作表。
```vba' 遍历每个工作表Dim sheet As WorksheetFor Each sheet In ActiveWorkbook.Sheets```3. 将每个工作表中的数据复制到目标文件夹中的新建工作表中--------------------------------------------------------在遍历每个工作表后,您需要将当前工作表中的数据复制到目标文件夹中的新建工作表中。
您可以使用`Worksheet.Copy` 方法复制工作表,并将其保存到目标文件夹中。
```vba' 复制当前工作表并将其保存到目标文件夹中Dim targetWorkbook As WorkbookSet targetWorkbook = ActiveWorkbook.Sheets().Copy(After:=Sheets(Sheets.Cou nt))targetWorkbook.SaveAs targetFolder & "\" & & ".xlsx"```4. 根据需求对数据进行格式化和排版--------------------------您可以在复制工作表后对其进行格式化和排版。
用Kutools插件快速拆分Excel工作表,新手必学技能

用Kutools插件快速拆分Excel工作表,新手必学技能
在日常办公中,我们经常需要将一个Excel工作表拆分成独立的工作表,有可能还需要将这些工作表保存为单独的Excel文件。
对于Excel新手朋友来说,大部分都是筛选、复制、粘贴来完成,相对比较麻烦。
今天教大家使用一款Excel插件Kutools进行快速拆分,一键搞定!
单表拆分成多表
如下图所示,安装Kutools插件之后,切换到【KUTOOLS PLUS】菜单,选择【工作表】【分割数据】,然后选择【指定列】【班级】,即可按照班级将此工作表拆分成不同的工作表。
拆分完之后会自动新建一个工作簿,包含拆分之后的所有工作表,如下图所示。
多表拆分为多个单表文件
紧接着上一步,在【KUTOOLS PLUS】菜单中选择【工作簿】【分割工作簿】,点击【分割】,选择拆分后文件的保存位置,点击【确定】即可。
拆分之后的工作簿如下图所示。
是不是特别简单呢?你学会了吗?。
使用Python处理excel表格(openpyxl)教程

使⽤Python处理excel表格(openpyxl)教程现在有个⼩任务,需要处理excel中的数据。
其实就是简单的筛选,excel玩的不熟练,⽽且需要处理的表有70多个,于是想着写个脚本处理⼀下吧。
python中的openpyxl包可以轻松实现读写excel⽂件,下⾯简单介绍⼀下过程。
1.安装openpyxl通过pip或者easy_install均可安装openpyxl。
openpyxl官⽹:https:///en/latest/安装命令:pip install openpyxl (在线安装)或者 easy_install openpyxl 即可。
2.使⽤openpyxl读xlsx加载workbook,注意,openpyxl只⽀持xlsx格式,⽼版的xls格式需要其他⽅法去加载。
wb = load_workbook(filename = r'tj.xlsx')获取每个sheet的名称sheetnames = wb.get_sheet_names()获得第⼀个sheetws = wb.get_sheet_by_name(sheetnames[0])获取⼀个单元格的数据c = ws['A4']或者c = ws.cell('A4')或者d = ws.cell(row = 4, column = 2)⼀次获取多个单元格的数据cell_range = ws['A1':'C2']或者tuple(ws.iter_rows('A1:C2'))或者1. for row in ws.iter_rows('A1:C2'):2. for cell in row:3. <span style='white-space:pre'> </span>print cell或者1. data_dic = []2.3. for rx in range(0,ws.get_highest_row()):4.5. temp_list = []6. money = ws.cell(row = rx,column = 1).value7. kind = ws.cell(row = rx,column = 2).value8.9. temp_list = [money , kind]10. #print temp_list11.12. data_dic.append(temp_list)13.14. for l in data_dic:15. print l[0],l[1]3.写⼊xlsx⽐如数据存在上边定义的data_dic中1. out_filename = r'result.xlsx'2.3. outwb = Workbook()4.5. ew = ExcelWriter(workbook = outwb)6.7. ws = outwb.worksheets[0]8.9. ws.title = 'res'9. ws.title = 'res'10.11. i=112. for data_l in data_dic:13. for x in range(0,len(data_l)):14. #col = get_column_letter(x)15. ws.cell(column = x+1 , row = i , value = '%s' % data_l[x])16. i+=117.18. ew.save(filename = out_filename)再增加⼀个sheet写内容1. ws2 = outwb.create_sheet(title = 's2')2.3. for data_l in data_dic:4. for x in range(0,len(data_l)):5. ws2.cell(column = x+1 , row = i , value = '%s' % data_l[x])6. i+=17.8. ew.save(filename = out_filename)4.中⽂编码问题表格中的值,openpyxl会⾃动转换为不同的类型,有些表格中会有中⽂出现,就需要进⾏相应的转码。
自动按列分组拆分excel工作表

自动按列分组拆分excel工作表可以将一个excel工作表按照指定列分组拆分成多个工作表,甚至可以将已经拆分的多个工作表再次拆分成单独的excel文件;略懂一些编程语言的可以将代码改编,以达到批量拆分多个工作表,或者批量合并多个excel文件、工作表,有了vbs的支持,只要你想的到就能做的到拷贝代码时请注意自动换行格式;自动拆分工作表自动创建文件夹自动保存单独的excel文件至文件夹自动过滤空行,如果存在大量集中的空行请尽量删除空行,因为大量空行会影响运行效率使用方法:打开待拆分的excel文档,按ALT+F11进入vba模式,鼠标选插入---模块,在右侧新建的模块内将准备好的代码粘贴进去,然后按F5,直接运行;此时会让你选择标题行和待分组的列标题;选完确定开始自动拆分,此时鼠标会不停闪动,根据文档大小,运行一段时间,并不是死机,一般会有几分钟时间,如果你的文档有上万行那会更久;你只需关注文档所在目录是否已经自动创建文件夹并创建excel文件;‘vbs代码开始Sub CFGZBDim myRange As VariantDim myArrayDim titleRange As RangeDim title As StringDim ShName As StringDim columnNum As IntegermyRange = prompt:="请选择标题行:", Type:=8myArray = myRangeSet titleRange = prompt:="请选择拆分的表头,必须是第一行,且为一个单元格,如:姓名", Type:=8title =columnNum =ShName == False= FalseDim i&, Myr&, Arr, num&Dim d, kFor i = To 1 Step -1If <> ShName ThenSheetsi.DeleteEnd IfNext iSet d = CreateObject""Myr = WorksheetsShName. Arr = WorksheetsShName.RangeCells2, columnNum, CellsMyr, columnNumFor i = 1 To UBoundArrdArri, 1 = ""Nextk =For i = 0 To UBoundkIf ki <> "" ThenSet conn = CreateObject"""provider= properties=excel ;data source=" &Sql = "select from " & ShName & "$ where " & title & " = '" & ki & "'" after:=SheetsWith ActiveSheet.Name = kiFor num = 1 To UBoundmyArray.Cells1, num = myArraynum, 1Next num.Range"A2".CopyFromRecordset SqlEnd WithSheets1.SelectSheets1.Paste:=xlPasteFormats, Operation:=xlNone, _SkipBlanks:=False, Transpose:=False= FalseEnd IfNext iSet conn = Nothing= True= True‘拆分至工作表完毕,开始拆分至单独文件,如无需拆分至文件,请将以下代码删除,保留最后一行End Sub结束语Dim sht As WorksheetDim MyBook As WorkbookSet MyBook = ActiveWorkbookSet fso = CreateObject""& "\" & ShNameFor Each sht InIf <> ShName ThenFilename:= & "\" & ShName & "\" & , FileFormat:=xlNormalEnd IfNextMsgBox "文件已经被分拆完毕"End Sub‘vbs代码结束。
python表格处理方法

Python中处理表格数据的方法有很多,以下是其中一些常用的方法:
1.Pandas库:Pandas是Python中一个强大的数据处理库,它可以轻松地读写和处理表格数据。
使用Pandas,您可以方便地对表格进行各种操作,例如筛选、排序、分组聚合等。
2.Numpy库:Numpy是Python中用于数值计算的库,它也可以用来处理表格数据。
通过Numpy,您可以方便地读写CSV文件、Excel文件等格式的表格数据。
3.Openpyxl库:如果您需要处理Excel表格数据,可以使用Openpyxl库。
这个库可以读取、写入Excel文件,并且支持对单元格进行各种操作,例如设置单元格格式、计算公式等。
4.XlsxWriter库:XlsxWriter是一个用于将数据写入Excel文件的Python库。
使用XlsxWriter,您可以轻松地将数据写入Excel文件,并且可以设置单元格格式、插入图像等。
5.CSV模块:CSV模块是Python中用于读写CSV文件的模块。
通过CSV模块,您可以方便地读写CSV文件,并且可以对数据进行各种操作,例如筛选、排序等。
以上是一些常用的Python表格处理方法,具体使用哪种方法取决于您的需求和数据格式。
按列拆分工作表

按列拆分工作表1. 介绍在处理Excel文件时,有时候我们需要对工作表进行拆分,将一个大的工作表拆分为多个小的工作表,以便于数据分析和处理。
按列拆分工作表是一种常见的需求,它可以将一个包含多个列的工作表,按照某一列的数值进行拆分,生成多个新的工作表。
本文将介绍如何使用Python的pandas库来实现按列拆分工作表的功能。
我们将通过一个具体的示例来说明这个过程。
2. 示例假设我们有一个包含学生信息的工作表,其中包含姓名、年龄、性别和成绩四列。
我们希望按照性别将这个工作表拆分为两个工作表,一个包含男生的信息,另一个包含女生的信息。
首先,我们需要导入pandas库,并读取Excel文件中的工作表数据:import pandas as pd# 读取Excel文件data = pd.read_excel('students.xlsx')接下来,我们可以使用pandas的groupby函数来按照性别进行分组,并将每个分组保存为一个新的工作表:# 按照性别进行分组groups = data.groupby('性别')# 遍历每个分组for group_name, group_data in groups:# 创建新的工作表new_sheet = pd.DataFrame(group_data)# 保存为Excel文件new_sheet.to_excel(f'{group_name}.xlsx', index=False)在上述代码中,我们使用groupby函数将数据按照性别进行分组,然后使用for循环遍历每个分组。
对于每个分组,我们将其保存为一个新的工作表,并以性别作为文件名。
最后,我们可以将上述代码整合为一个函数,方便以后的重复使用:import pandas as pddef split_sheet_by_column(file_path, column_name):# 读取Excel文件data = pd.read_excel(file_path)# 按照指定列进行分组groups = data.groupby(column_name)# 遍历每个分组for group_name, group_data in groups:# 创建新的工作表new_sheet = pd.DataFrame(group_data)# 保存为Excel文件new_sheet.to_excel(f'{group_name}.xlsx', index=False)3. 总结按列拆分工作表是一种常见的需求,通过使用Python的pandas库,我们可以很方便地实现这个功能。
根据excel表格中的某一列内容,使用python将其拆分成多个excel表格
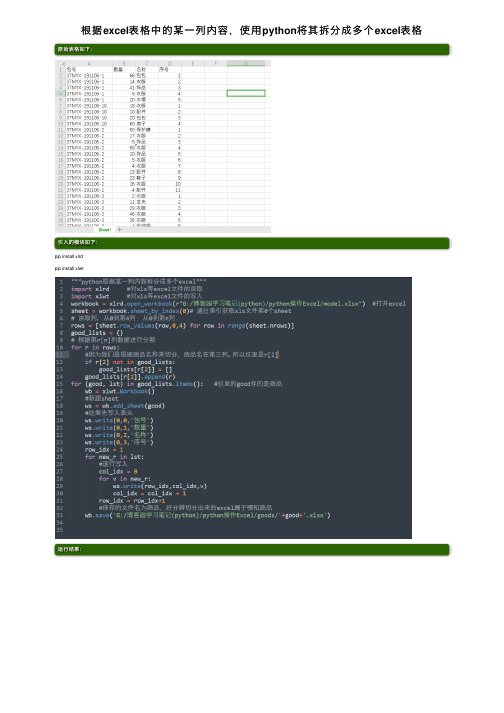
根据excel表格中的某⼀列内容,使⽤python将其拆分成多个excel表格原始表格如下:引⼊的模块如下:pip install xlrdpip install xlwt运⾏结果:打开表格检查:源码如下:"""python根据某⼀列内容拆分成多个excel"""import xlrd #对xls等excel⽂件的读取import xlwt #对xls等excel⽂件的写⼊workbook = xlrd.open_workbook(r"G:/博客园学习笔记(python)/python操作Excel/model.xlsx") #打开excel sheet = workbook.sheet_by_index(0)# 通过索引获取xls⽂件第0个sheet# 读取列,从0到第4列从0到第n列rows = [sheet.row_values(row,0,4) for row in range(sheet.nrows)]good_lists = {}# 根据第r[n]列数据进⾏分割for r in rows:#因为我们是根据商品名称来切分,商品名在第三列。
所以这⾥是r[2]if r[2] not in good_lists:good_lists[r[2]] = []good_lists[r[2]].append(r)for (good, lst) in good_lists.items(): #这⾥的good存的是商品wb = xlwt.Workbook()#新建sheetws = wb.add_sheet(good)#这⾥先写⼊表头ws.write(0,0,'包号')ws.write(0,1,'数量')ws.write(0,2,'名称')ws.write(0,3,'序号')row_idx = 1for new_r in lst:#逐⾏写⼊col_idx = 0for v in new_r:ws.write(row_idx,col_idx,v)col_idx = col_idx + 1row_idx = row_idx+1#保存的⽂件名为商品,好分辨切分出来的excel属于哪和商品wb.save('G:/博客园学习笔记(python)/python操作Excel/goods/'+good+'.xlsx') View Code。
python使用openpyxlexcel合并拆分单元格

python使⽤openpyxlexcel合并拆分单元格再次编辑中,这次是在使⽤删除列的时候发现,合并单元格会出现漏删除情况,才想到⽤拆分单元格,没想到unmerge_cells(),worksheet.merged_cells返回的合并单元格对象居然不能迭代,函数参数也变了,居然可以直接上参数;;openpyxl=Version: 2.5.9;列: worksheet.delete_cols(2, 1) 表⽰第⼆列开始,删除⼀列,⾏ worksheet.delete_rows(2, 1)worksheet.unmerge_cells(start_row=1, start_column=7, end_row=2, end_column=7)表⽰第⼀⾏开始,第⼆⾏结束,低7列开始第七列结束,就是把G1:G2合并的单元格给拆分了,下⾯的是合并单元格就不多说了worksheet.merge_cells(start_row=1, start_column=2, end_row=2, end_column=2)使⽤ openpyxl 库拆分已经合并的单元格;主要是使⽤了:worksheet.merged_cells获取已经合并单元格的信息;再使⽤worksheet.unmerge_cells()拆分单元格;import openpyxlworkbook = openpyxl.load_workbook(path) #加载已经存在的excel# workbook = openpyxl.Workbook(path)name_list = workbook.sheetnames# worksheet = workbook.get_sheet_by_name(name_list[0]) #最新版本已经不能使⽤这种⽅法worksheet = workbook[name_list[0]]m_list = worksheet.merged_cells #合并单元格的位置信息,可迭代对象(单个是⼀个'openpyxl.worksheet.cell_range.CellRange'对象),print后就是excel坐标信息cr = []for m_area in m_list:# 合并单元格的起始⾏坐标、终⽌⾏坐标。
python列表分割方法

在Python中,你可以使用多种方法来分割列表,根据你的需求选择最合适的方法。
以下是一些常见的列表分割方法:使用切片(Slice):使用切片操作可以轻松地分割列表。
切片的语法是list[start:stop:step],其中start表示开始的索引,stop表示结束的索引(不包括该索引的元素),step表示步长(默认为1)。
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]sublist = my_list[2:6] # 从索引2到索引5的元素(不包括索引6)使用循环:你可以使用循环遍历列表,并根据特定条件将元素分割成多个子列表。
这对于根据元素值或其他条件进行分组很有用。
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]sublists = []sublist = []for item in my_list:sublist.append(item)if item % 2 == 0: # 根据条件分割子列表sublists.append(sublist)sublist = []使用列表解析:列表解析是一种简洁的方式来创建一个新的列表,你可以根据特定条件将元素添加到新列表中,实现列表分割。
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]sublists = [my_list[i:i+4] for i in range(0, len(my_list), 4)] # 每4个元素分割成一个子列表使用itertools.groupby:如果你希望根据某些条件将列表分组,可以使用itertools.groupby函数。
这个函数需要一个可迭代对象和一个分组函数,它将返回一个包含分组键和分组迭代器的迭代器。
from itertools import groupbymy_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]groups = []for key, group in groupby(my_list, lambda x: x % 2 == 0):groups.append(list(group))这些方法中的选择取决于你的具体需求,你可以根据数据结构和条件来选择最合适的列表分割方法。
按列拆分工作表

按列拆分工作表摘要:一、工作表概述1.工作表的定义与作用2.常见的工作表类型二、按列拆分工作表的概念与原理1.按列拆分工作表的定义2.原理与实现方式三、按列拆分工作表的优势与适用场景1.优势a.提高数据处理效率b.便于数据分析和可视化c.简化数据筛选与查询2.适用场景a.数据量较大b.需要对数据进行分类汇总c.涉及到多维度的数据分析四、如何实现按列拆分工作表1.使用电子表格软件a.Microsoft Excelb.Google Sheets2.使用编程语言a.Pythonb.R五、按列拆分工作表的注意事项1.数据格式的规范2.处理大量数据的技巧3.数据安全与隐私保护正文:一、工作表概述工作表是电子表格软件中用于存储、处理和展示数据的基本单元。
它可以帮助用户对数据进行分类、筛选、排序、计算等操作,广泛应用于数据分析、报表制作、项目管理等领域。
常见的工作表类型包括:表格工作表、图表工作表、透视表等。
二、按列拆分工作表的概念与原理按列拆分工作表是一种将数据按照列进行拆分的工作表类型。
在这种工作表中,每一列数据都具有相同的属性,方便用户对数据进行分类汇总。
原理上,按列拆分工作表通过将数据按照列进行拆分,实现了数据的简化展示,提高了数据处理与分析的效率。
三、按列拆分工作表的优势与适用场景按列拆分工作表具有以下优势:1.提高数据处理效率:通过按列拆分,可以快速地对数据进行分类、筛选和查询,减少繁琐的数据处理步骤。
2.便于数据分析和可视化:按列拆分后的数据更易于进行可视化展示,方便用户发现数据之间的联系和规律。
3.简化数据筛选与查询:按列拆分工作表可以帮助用户快速定位所需数据,提高数据查询效率。
适用场景包括:1.数据量较大:当数据量较大时,按列拆分工作表可以提高数据处理的效率,降低计算机的负担。
2.需要对数据进行分类汇总:当用户需要对数据进行分类汇总时,按列拆分工作表可以清晰地展示各分类的数据情况。
3.涉及到多维度的数据分析:在多维度的数据分析中,按列拆分工作表可以帮助用户快速切换不同维度,进行深入的数据分析。
【Python】处理Excel中数据1(单元格中的数据拆分,拆分后数据作为新列追加)
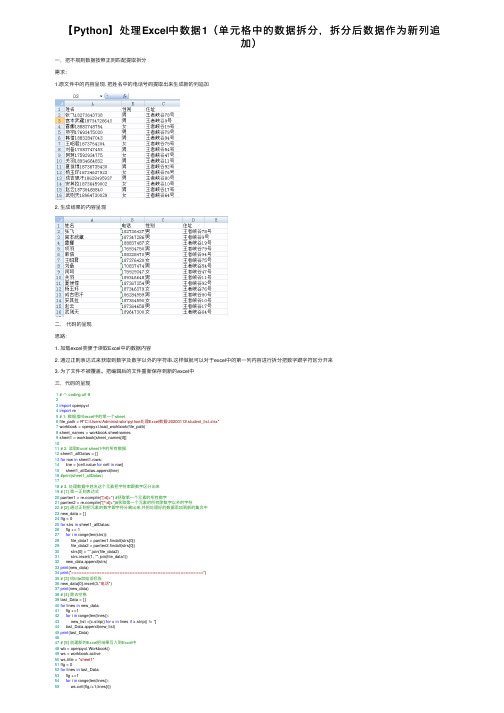
【Python】处理Excel中数据1(单元格中的数据拆分,拆分后数据作为新列追加)⼀,把不规则数据按照正则匹配提取拆分需求:1.原⽂件中的内容呈现. 把姓名中的电话号码提取出来⽣成新的列追加2. ⽣成结果的内容呈现⼆,代码的呈现思路:1. 加载excel类便于读取Excel中的数据内容2. 通过正则表达式来获取到数字及数字以外的字符串.这样做就可以对于excel中的第⼀列内容进⾏拆分把数字跟字符区分开来3. 为了⽂件不被覆盖。
把编辑后的⽂件重新保存到新的excel中三,代码的呈现1# -*- coding:utf-823import openpyxl4import re5# 1. 数据指向excel中的第⼀个sheet6 file_path = R"C:\Users\Administrator\python处理Excel数据\20200113\student_list.xlsx"7 workbook = openpyxl.load_workbook(file_path)8 sheet_names = workbook.sheetnames9 sheet1 = workbook[sheet_names[0]]1011# 2. 读取Excel sheet1中的所有数据12 sheet1_allDatas = []13for row in sheet1.rows:14 line = [cell.value for cell in row]15 sheet1_allDatas.append(line)16#print(sheet1_allDatas)1718# 3. 处理数据中姓名这个元素把字符串跟数字区分出来19# [1] 第⼀正则表达式20 parrten1 = pile("[\d]+") #获取第⼀个元素的所有数字21 parrten2 = pile("[^\d]+")#获取第⼀个元素的所有除数字以外的字符22# [2] 通过正则把元素的数字跟字符分离出来,并把处理好的数据添加到新的集合中23 new_data = []24 flg = 025for strs in sheet1_allDatas:26 flg += 127for i in range(len(strs)):28 file_data1 = parrten1.findall(strs[0])29 file_data2 = parrten2.findall(strs[0])30 strs[0] = "".join(file_data2)31 strs.insert(1, "".join(file_data1))32 new_data.append(strs)33print(new_data)34print("====================================================")35# [3] 给title加电话标签36 new_data[0].insert(3,"电话")37print(new_data)38# [4] 除去空格39 last_Data = []40for lines in new_data:41 flg +=142for i in range(len(lines)):43 new_list =[x.strip() for x in lines if x.strip() != '']44 last_Data.append(new_list)45print(last_Data)4647# [5] 创建新的Excel把结果写⼊到Excel中48 wb = openpyxl.Workbook()49 ws = workbook.active50 ws.title = "sheet1"51 flg = 052for lines in last_Data:53 flg +=154for i in range(len(lines)):55 ws.cell(flg,i+1,lines[i])56 workbook.save("C:\\Users\\Administrator\\python处理Excel数据\\20200113\\student_list2.xlsx")57print("⽂件保存成功!")四,重点解释1. print(sheet1_allDatas)打印出来的结果如下。
用Python对Excel数据进行分列处理

⽤Python对Excel数据进⾏分列处理split⽤法以下实例展⽰了 split() 函数的使⽤⽅法:#!/usr/bin/python3str = "this is string example....wow"print (str.split( )) # 以空格为分隔符print (str.split('i',1)) # 以 i 为分隔符print (str.split('w')) # 以 w 为分隔符以上实例输出结果如下:['this', 'is', 'string', 'example....wow']['th', 's is string example....wow']['this is string example....', 'o', '']pandas 分列pandas对⽂本列进⾏分列,⾮常简单:import pandas as pddf10 = pd.DataFrame({'姓名':['张三', '李四','王五'] ,"科⽬":['语⽂,100','语⽂,86','语⽂,96']})df10姓名科⽬0张三语⽂,1001李四语⽂,862王五语⽂,96res = df10["科⽬"].str.split(',',expand= True)res010语⽂1001语⽂862语⽂96df10[["科⽬",'分数']]=resdf10姓名科⽬分数0张三语⽂1001李四语⽂862王五语⽂96DataFrame.str.split() :对⽂本列分列,第⼀参数指定分隔符参数 expand ,表⽰是否扩展成列,若设置为 True ,则分割后的每个元素都成为单独⼀列出处:/maymay_/article/details/105361091。
按列拆分工作表

在Excel中,如果你想要按照列拆分工作表,你可以使用以下步骤:
1.打开Excel并导入数据:首先,打开你的Excel程序,并导入你想要拆分的表格数据。
2.选择要拆分的列:选择你想要拆分的那一列。
如果你想要按照多列拆分,你可以按住Ctrl
键并点击其他列的标题来选择多个列。
3.复制数据:在Excel的菜单栏上,点击“开始”->“复制”或直接使用快捷键Ctrl+C来复
制你选择的列。
4.创建新的工作表:在Excel的底部,你会看到一个工作表标签区域。
右键点击你想要插
入新工作表的位置,然后选择“插入”或“新建工作表”。
5.粘贴数据:在新建的工作表中,选择A1单元格,然后使用“粘贴”功能或按Ctrl+V将复
制的数据粘贴到新的工作表中。
6.重复上述步骤:对于每一列你想要拆分的数据,重复上述步骤,直到所有的列都被拆分
到不同的工作表中。
7.保存工作簿:完成所有拆分后,记得保存你的工作簿。
这样,你就成功地按照列拆分了工作表。
如果你有特定的要求或遇到问题,请随时告诉我,我会为你提供进一步的帮助。
表格按行拆分

表格按行拆分表格按行拆分教程介绍在处理表格数据时,我们经常遇到需要按行拆分表格的情况。
表格按行拆分可以将一行数据拆分成多行,从而更方便地进行数据分析和处理。
本文将介绍如何使用常见的工具和方法来实现表格按行拆分。
方法一:使用Excel进行表格按行拆分使用Excel是最常见和便捷的方法之一,以下是具体步骤: 1.打开Excel,将表格数据粘贴到一个新的工作表中。
2. 选中需要拆分的行数据。
3. 在Excel菜单中选择“数据”选项卡,并点击“文本到列”按钮。
4. 在打开的对话框中选择“固定宽度”,并点击“下一步”按钮。
5. 在下一步中,可以按需设置字段的宽度和数据格式。
6. 点击“完成”按钮,即可完成拆分。
方法二:使用Python编程进行表格按行拆分如果你熟悉Python编程语言,可以使用pandas库来实现表格按行拆分。
具体步骤如下:import pandas as pd# 读取表格数据data = _excel('your_')# 拆分行数据new_data = (data['your_column'].(', ').tolist())new_ = ['column_1', 'column_2', 'column_3'] # 可根据需要修改列名# 保存拆分后的数据new__excel('new_', index=False)方法三:使用Google Sheets进行表格按行拆分如果你喜欢在线协作,可以使用Google Sheets来进行表格按行拆分。
以下是具体步骤: 1. 打开Google Sheets,并创建一个新的工作表。
2. 将表格数据粘贴到工作表中。
3. 在一个空白单元格中,输入以下公式:=SPLIT(A1, ",")(假设要拆分的数据在A1单元格中)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Python按一列拆分Excel表格
开篇先感谢一下老公(这是他要求的),感谢他帮我写了这Python。
分享一拆表的代码。
把下表按B列店铺拆成分表,在总表后面加几个分表,分表按店铺命名。
做好的效果:VBA 的代码太长,Python很简洁,对比一下就可以看出来了。
我在百度上找了一个拆表的VBA代码,修改了一点,可以达到上面的效果。
VBA代码Python代码
import pandas as pdimport
xlsxwriterdata=pd.read_excel(r'C:\Users\Administrator\Desktop \hh\客户打款记录.xlsx',encode='gbk')area_list=list(set(data[u'
店铺
']))writer=pd.ExcelWriter(r'C:\Users\Administrator\Desktop\hh\拆好的
表.xlsx',engine='xlsxwriter')data.to_excel(writer,sheet_name='
总表',index=False)for j in area_list: df=data[data[u'店铺']==j] df.to_excel(writer,sheet_name=j,index=False)
比较一下VBA和Python,Python是不是很简洁?上面的英文很简单,能看懂英文的基本也能理解代码是什么意思。
安装Anaconda
我用的Python3,大家可以下载Anaconda然后安装,在Anaconda的官网下载。
Anaconda安装好后打开里面的Spyder,把代码复制进去,运行代码即可。
Python3也可以用其他的软件运行,看个人习惯。
我用Spyder的原因今天先分享代码,后面有空再解释上面的Python代码。