LIST_ENTRY结构图详解
Linux内核中的算法和数据结构

Linux内核中的算法和数据结构算法和数据结构纷繁复杂,但是对于Linux Kernel开发⼈员来说重点了解Linux内核中使⽤到的算法和数据结构很有必要。
在⼀个国外问答平台的Theoretical Computer Science⼦板有⼀篇讨论实际使⽤中的算法和数据结构,Vijay D做出了详细的解答,其中有⼀部分是Basic Data Structures and Algorithms in the Linux Kernel对Linux内核中使⽤到的算法和数据结构做出的归纳整理。
详情参考。
下⾯就以Vijay D的回答作为蓝本进⾏学习总结。
测试⽅法准备由于需要在内核中进⾏代码测试验证,完整编译安装内核⽐较耗时耗⼒。
准备采⽤module形式来验证。
Makefileobj-m:=linked-list.oKERNELBUILD:=/lib/modules/$(shell uname -r)/builddefault:make -C ${KERNELBUILD} M=$(shell pwd) modulesclean:rm -rf *.o *.cmd *.ko *.mod.c .tmp_versionslinked-list.c#include <linux/module.h>#include <linux/init.h>#include <linux/list.h>int linked_list_init(void){printk("%s\n", __func__);return 0;}void linked_list_exit(void){printk("%s\n", __func__);}module_init(linked_list_init);module_exit(linked_list_exit);MODULE_AUTHOR("Arnold Lu");MODULE_LICENSE("GPL");MODULE_DESCRIPTION("Linked list test");安装modulesudo insmod linked-list.ko查找安装情况lsmod | grep linked-list执⾏log<4>[621267.946711] linked_list_init<4>[621397.154534] linked_list_exit删除modulesudo rmmod linked-list链表、双向链表、⽆锁链表, , .有⼀篇关于内核链表《》值得参考。
linux 内核list使用

linux 内核list使用
在Linux内核中,list是一种常用的数据结构,用于实现链表。
它在内核中被广泛使用,包括进程管理、文件系统、网络等多个方面。
在内核中使用list时,有几个常见的操作和用法需要注意:
1. 初始化list,在使用list之前,需要先对其进行初始化。
可以使用宏INIT_LIST_HEAD来初始化一个空的list。
2. 添加元素到list,使用list_add、list_add_tail等函数
可以将新元素添加到list中。
这些函数会在指定位置插入新元素,
并更新相关指针。
3. 遍历list,可以使用list_for_each、
list_for_each_entry等宏来遍历list中的元素。
这些宏会帮助我
们遍历整个list,并执行指定的操作。
4. 删除元素,使用list_del和list_del_init函数可以从
list中删除指定的元素。
需要注意的是,在删除元素之后,需要手
动释放相关资源,以避免内存泄漏。
除了上述基本操作外,list还支持一些高级操作,如合并两个list、反转list等。
在编写内核代码时,合理地使用list可以提高代码的可读性和性能。
总的来说,Linux内核中的list是一种非常灵活和强大的数据结构,合理地使用它可以帮助我们更好地管理和组织数据。
在实际编程中,需要根据具体的需求和场景来选择合适的list操作,以达到最佳的效果。
list_for_each_entry_safe用法

list_for_each_entry_safe用法list_for_each_entry_safe是Linux内核中提供的一个用于遍历链表元素的宏,它与list_for_each_entry宏完全相同,只是list_for_each_entry_safe允许在遍历期间修改链表。
一般在Linux中,创建链表和栈的宏有以下两种:(1)list_add()、list_del()宏;(2)list_for_each_entry()、list_for_each_entry_safe宏 list_for_each_entry()宏的定义如下:#define list_for_each_entry(pos, head, member)ttttfor (pos = list_entry((head)->next, typeof(*pos), member);tt &pos->member != (head); tttttt pos = list_entry(pos->member.next, typeof(*pos), member))先,需要注意上面宏定义中涉及到的list_entry()函数,该函数的作用是从一个链表1成员(list_head类型)中取得链表1所属的数据结构,list_entry函数的定义为/** container_of - cast a member of a structure out to the containing structure* @ptr:tthe pointer to the member.* @type:tthe type of the container struct this is embedded in.* @member:tthe name of the member within the struct.**/#define container_of(ptr, type, member) ({ttttconst typeof( ((type *)0)->member ) *__mptr = (ptr);t t(type *)( (char *)__mptr - offsetof(type,member) );})list_entry的第一个参数是指向struct list_head的指针,第二个参数是包含list_head的数据结构的类型,第三个参数是list_head在数据结构中的成员名称。
Dll 模块隐藏技术

Dll模块隐藏技术学习各种外挂制作技术,马上去百度搜索"魔鬼作坊"点击第一个站进入、快速成为做挂达人。
如果你细细读完这篇文章,你会学到一下内容:1.PEB,TEB,LDR_DATA_TABLE_ENTRY等数据结构2.自己覆盖掉自己执行过的一段代码3.调试这个Dll你会发现DLL_PROCESS_ATTACH中的代码在OD首次停下即加载停止时已经执行完了!多么美妙啊!哈哈,OD不会发现你执行了什么4.本例最后附件有个ASM的控制台程序,用SDK编写,你可以学到用汇编写一个基本的控制台程序的格式5.最后那个控制台源码还包含完整的CreateRemoteThread注入进程的写法本文主要讲的是怎样隐藏一个dll模块,这里说的隐藏是指,dll被加载后怎样使它用一般的工具无法检测出来。
为什么要这么做呢?1.远程线程中的应用(1)大家都知道,远程线程注入主要有两种一种是直接copy母体中预注入的代码到目标进程地址空间(WriteProcessMemory),然后启动注入的代码(CreateRemoteThread),这种远程线程一旦成功实现,那么它只出现在目标进程的内存中,并没有对应的磁盘文件,堪称进程隐藏中的高招,可是缺点就是,你必须要在注入代码中对所有直接寻址的指令进行修正,这可是个力气活,用汇编写起来很烦。
(2)另一种更为常用的方法是注入一个dll文件到目标进程,这种方法的实现可以是以一个消息Hook为由进行注入,或者仍然使用CreateRemoteThread,这种方法的优点是Dll文件自带重定位表,也就是说你不必再为修正直接寻址指令而烦恼了!,dll自己会重定位!~~~嗯,真是不错的方法---可是我们说它不如上面说的方法牛。
为什么?因为它的致命伤就是可以用进程管理工具看见被加载的dll文件名、文件路径。
这真是太不爽了,因为只要用户看看模块列表很容易发现可疑模块!,再依据名字,找到路径,定位文件---dll文件就这样暴露了.这样也就不是很完美的隐藏进程。
线性表的链式存储结构

线性表的链式存储结构
线性表的链式存储结构是指用一组任意的存储单 元(可以连续,也可以不连续)存储线性表中的数据 元素。为了反映数据元素之间的逻辑关系,对于每个 数据元素不仅要表示它的具体内容,还要附加一个表 示它的直接后继元素存储位置的信息。假设有一个线 性表(a,b,c,d),可用下图2所示的形式存储:
27
p
s
图 2-9
28
完整的算法:
int DuListInsert(DuLinkList *L,int i,EntryType e)
if (L.head->next==NULL) return TRUE; else return FALSE; }
12
6. 通过e返回链表L中第i个数据元素的内容 void GetElem(LinkList L,int i,EntryType *e) {
LNode *p; int j; //j为计数器,记载所经过的结点数目 if (i<1||i>ListLength(L)) exit ERROR; //检测i值的合理性 for (p=L.head,j=0; j!=i;p=p->next,j++); //找到第i个结点 *e=p->data; //将第i个结点的内容赋给e指针所指向的存储单元中 }
10
4. 求链表L的长度
int ListLength(LinkList L)
{
LNode *p;
int len;
for(p=L.head, len=0;p->next==NULL; p=p->next,len++);
return(len);
循环条件表达式 重复执行的语句
kernel_list

要实现上述目的就得使用另外一个宏list_entry(): #define list_entry(ptr, type, member) \ ((type*)((char*)(ptr)-(unsigned long)(&((type*)0)-> member))) 其中ptr为list_head结构体指针,type为你所定义的结构体 类型,member是结构体中list_head结构体成员变量的名. type的作用是为了强制转换,即宏中两次用到(type *) 指针ptr指向结构体type中的成员member;通过指针ptr, 返回应用
到这里我们已经理解了内核中双向链表如何实现的,但是我 们如果仅仅到此为止,而没有在我们的程序中应用它,那不 免有些可惜。所以经过改造后的list. h(见源程序),让我们 可以在平时的编程中方便这种结构。程序example2.c(见源 代码example2.c)使用了上述改造后的list. h来实现一系列操 作。
例如前面的例子就可以按如下方式定义: struct my_list{ void *mydata; struct list_head list; }; 几点说明: a) list字段,隐藏了链表的指针特性,但正是它,把我们要 链接的数据组织成了链表。 b) struct list_head可以位于结构的任何位置 c) 可以给struct list_head起任何名字。 d) 在一个结构中可以有多个list
为了方便大家阅读,我把上面的结构体写成这样 ( (type*) ( (char*)(ptr) (unsigned long) (&((type*)0)->member) ) ) 这个表达式最终的结果就是type 型的地址, ((size_t) &(type *)0)->member)把0地址转化为type结构的 指针,然后获取该结构中member成员的指针,并将其强制转 换为size_t类型。于是,由于结构从0地址开始定义,因此,这 样求出member的成员地址,实际上就是它在结构中的偏移量. 然后ptr减去这个偏移量就得到了所要的结构体指针。
Linux内核分析及编程
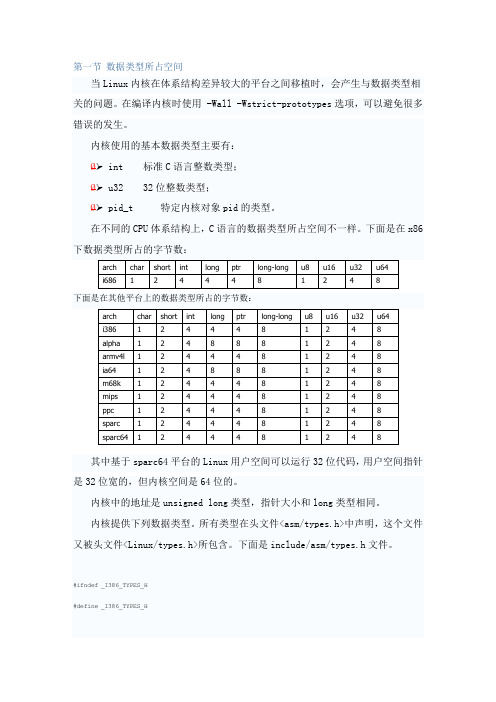
其中基于sparc64平台的Linux用户空间可以运行32位代码,用户空间指针是32位宽的,但内核空间是64位的。
内核中的地址是unsigned long类型,指针大小和long类型相同。
内核提供下列数据类型。
所有类型在头文件<asm/types.h>中声明,这个文件又被头文件<Linux/types.h>所包含。
下面是include/asm/types.h文件。
#ifndef _I386_TYPES_H#define _I386_TYPES_H#ifndef __ASSEMBLY__typedef unsigned short umode_t;// 下面__xx类型不会损害POSIX 名字空间,在头文件使用它们,可以输出给用户空间typedef __signed__ char __s8;typedef unsigned char __u8;typedef __signed__ short __s16;typedef unsigned short __u16;typedef __signed__ int __s32;typedef unsigned int __u32;#if defined(__GNUC__) && !defined(__STRICT_ANSI__)typedef __signed__ long long __s64;typedef unsigned long long __u64;#endif#endif /* __ASSEMBLY__ *///下面的类型只用在内核中,否则会产生名字空间崩溃#ifdef __KERNEL__#define BITS_PER_LONG 32#ifndef __ASSEMBLY__#include <Linux/config.h>typedef signed char s8;typedef unsigned char u8;typedef signed short s16;typedef unsigned short u16;typedef signed int s32;typedef unsigned int u32;typedef signed long long s64;typedef unsigned long long u64;/* DMA addresses come in generic and 64-bit flavours. */ #ifdef CONFIG_HIGHMEM64Gtypedef u64 dma_addr_t;#elsetypedef u32 dma_addr_t;#endiftypedef u64 dma64_addr_t;#ifdef CONFIG_LBDtypedef u64 sector_t;#define HAVE_SECTOR_T#endiftypedef unsigned short kmem_bufctl_t;#endif /* __ASSEMBLY__ */#endif /* __KERNEL__ */#endif下面是Linux/types.h的部分定义。
【转载】64位Windows内核虚拟地址空间布局(基于X64CPU)

【转载】64位Windows内核虚拟地址空间布局(基于X64CPU)对于原⽂中,较难理解或者论述过于简单的部分,则添加了译注;译注来⾃于内核调试器验证的结果,以及 WRK 源码中的逻辑,还有《深⼊解析 Windows 操作系统》⼀书中的译⽂。
本⽂档解释 X64 版本的 Windows 7 与 Server 2008 R2 上,内核虚拟地址空间的细节。
调试器扩展命令 !CMKD.kvas 应⽤这⼀理论来显⽰X64 虚拟地址空间,并且将⼀个给定的地址映射到其中⼀个地址范围。
内核虚拟地址布局X64 CPU 仅⽀持 64 位虚拟地址中的 48 位,这 48 位虚拟地址被运⾏在该 CPU 上的软件使⽤。
对于⽤户模式地址,64 位虚拟地址中的⾼16 位总是被设置为 0x0;对于内核模式地址,总是设置为 0xF。
这有效地将 X64 地址空间分开成2部分——⽤户模式地址的范围:0x00000000`00000000~0x0000FFFF`FFFFFFFF;内核模式地址的范围:0xFFFF0000`00000000~0xFFFFFFFF`FFFFFFFF。
此内核虚拟地址范围总计为 256 TB,⽤于 Windows 上可访问的全部内核虚拟地址空间。
然后,Windows 静态划分此空间成多个固定⼤⼩的虚拟地址范围(VA),每个范围被赋予特定⽤途。
每个范围的起始和结束地址如下表所⽰:因此,为了简化处理器芯⽚架构以及避免⾮必要的开销——尤其是地址翻译⽅⾯(后⾯会讨论)—— 当前 AMD 和 Intel 的 x64 处理器仅实现了 16 EB 虚拟地址空间中的 256 TB。
换⾔之,⼀个 64 位的虚拟地址中,仅有低 48 位被实现(使⽤)。
然⽽,虚拟地址仍旧是 64 位宽,在寄存器中,或存储在内存中,它们都占⽤ 8 字节。
虚拟地址中的⾼ 16 位(⽐特位 48~63)需要被设置成与最⾼的“实现位”(也就是⽐特位 47)相同的值,这是通过⼀种类似于⼆进制补码运算的符号扩展来完成的。
WindowsXp句柄表结构

Windows Xp句柄表结构Windows Xp句柄表结构2010-07-06 06:13底层知识转载并学习之--前奏ExpLookupHandleTableEntry表的小介绍句柄这东西到了底层还真烦琐。
HANDLE本来就是个void类型的4字节,保存指向object的指针.于是就有了HANDLE_TABLE、HANDLE_TABLE_ENTRY、OBJECT_HEADER、EXHANDLE琢磨着这个EXHANDLE,它里面的Index保存着3层表索引。
通过它,也就是EXHANDLE。
Value的后30位可以找到进程ID指向的object关于这个3层表,"JIURL玩玩Win2k进程线程篇HANDLE_TABLE"一文中也有比较详细的介绍,可惜是W2K滴,HANDLE_TABLE在XP中发生了变化,不过其中的第一个参数保存的内容仍然是指向HANDLE_TABLE_ENTRY,不过是要经过索引偏移后才能得到.开始还准备用Windbg探索下这个3层表,发现困难重重---准备搞下QQ进程中的HANDLE_TABLE,一张图接着一张图后,到TableCode 这里卡住了。
不晓得具体怎么偏移才能继续搜索到下一层的表了。
就是这点破东西害的偶看WRK看了2天多。
还是木有完全理解。
哎,等以后脑子清醒了再看吧。
标记之:这个破函数偶现在是看不明白了。
糊涂的很,关键还是对这个3层表没有理解正确。
里面一会儿求余、一会儿整除的,搞糊涂了。
要是哪位牛牛能给偶解释下就好了。
PHANDLE_TABLE_ENTRY ExpLookupHandleTableEntry(IN PHANDLE_TABLE HandleTable,IN EXHANDLE tHandle){//一大堆局部变量ULONG_PTR i,j,k;ULONG_PTR CapturedTable;ULONG TableLevel;PHANDLE_TABLE_ENTRYEntry=NULL;EXHANDLE Handle;PUCHAR TableLevel1;PUCHAR TableLevel2;PUCHAR TableLevel3;ULONG_PTR MaxHandle;PAGED_CODE();Handle=tHandle;Handle.TagBits=0;MaxHandle=*(volatileULONG*)&HandleTable-NextHandleNeedingPool;//判断当前句柄是否有效if(Handle.Value=MaxHandle){return NULL;}////得到当前的索引等级--即CapturedTable的最后2位//而(CapturedTable-TableLevel)便是这个3层表的起始地址。
list类函数

list类函数List类函数是编程中常用的一种数据结构,它可以存储多个元素,并且可以根据需要进行增删改查操作。
在本文中,我将介绍几个常用的List类函数,并详细解释它们的功能和用法。
一、append函数append函数用于在List的末尾添加一个元素。
例如,如果我们有一个List存储了几个数字,我们可以使用append函数在List末尾添加一个新的数字。
二、insert函数insert函数用于在List的指定位置插入一个元素。
该函数接受两个参数,第一个参数是要插入的位置,第二个参数是要插入的元素。
三、remove函数remove函数用于从List中删除指定的元素。
该函数接受一个参数,即要删除的元素。
如果List中有多个相同的元素,remove函数只会删除第一个匹配的元素。
四、pop函数pop函数用于从List中删除指定索引位置的元素,并返回被删除的元素。
该函数接受一个参数,即要删除的元素的索引位置。
如果不指定索引位置,默认删除最后一个元素。
五、sort函数sort函数用于对List中的元素进行排序。
该函数可以接受多个参数,用于指定排序的方式。
默认情况下,sort函数按照元素的大小进行升序排序。
六、reverse函数reverse函数用于将List中的元素逆序排列。
该函数不接受任何参数。
七、index函数index函数用于返回List中指定元素的索引位置。
该函数接受一个参数,即要查找的元素。
如果List中有多个相同的元素,index函数只会返回第一个匹配的元素的索引位置。
八、count函数count函数用于返回List中指定元素的个数。
该函数接受一个参数,即要统计的元素。
九、len函数len函数用于返回List中元素的个数。
该函数不接受任何参数。
以上就是几个常用的List类函数的介绍,它们在编程中非常有用,能够帮助我们更方便地对List进行操作和处理。
当然,除了这些函数之外,还有很多其他的List类函数可以使用,需要根据实际的需求选择适合的函数。
Entry控件的使用方法

Entry控件的使用方法Entry控件是tkinter库中的一个基本控件,用于接受用户输入的单行文本字符串。
以下是Entry控件的使用方法:1.导入tkinter库:pythonimport tkinter as tk2.创建Entry控件:pythonentry = tk.Entry(master)其中,master参数指定Entry控件的父控件,通常是一个tkinter窗口或框架。
3.设置Entry控件的属性:Entry控件有许多可选属性,可以通过在创建控件时传递关键字参数来设置。
例如,可以设置输入框的背景颜色、边框大小、光标形状、字体属性等。
pythonentry = tk.Entry(master, bg='white', bd=2, cursor='arrow', font=('Arial', 12))4.将Entry控件添加到父控件中:使用grid()或pack()方法将Entry控件添加到父控件中。
pythonentry.grid(row=0, column=0)或者pythonentry.pack()5.获取Entry控件中的文本:可以使用get()方法获取Entry控件中的文本内容。
pythontext = entry.get()6.示例代码:下面是一个简单的示例代码,演示了如何创建和使用Entry控件。
pythonimport tkinter as tkdef show_entry_text():text = entry.get()label.config(text=text)root = ()root.title("Entry控件示例")label = bel(root, text="")label.grid(row=0, column=0)entry = tk.Entry(root, bg='lightblue', bd=2, cursor='arrow', font=('Arial', 12))entry.grid(row=1, column=0)button = tk.Button(root, text="显示文本", command=show_entry_text)button.grid(row=2, column=0)root.mainloop()在上面的示例中,创建了一个带有Entry控件和按钮的窗口。
易语言list列表解析

易语言list列表解析
易语言是一种中文编程语言,旨在让编程变得更加容易和直观。
在易语言中,你可以使用类似于其他编程语言的语法和结构来编写程序。
对于易语言中的列表(list)解析,你可以使用类似于其他编程语言的迭代
器来遍历列表中的元素。
以下是一个简单的示例,展示了如何在易语言中解析一个列表:
```easy_language
易语言`易语言`list 列表名 = 创建列表(数据类型)
// 添加元素到列表中
列表名.添加("元素1")
列表名.添加("元素2")
列表名.添加("元素3")
// 遍历列表中的元素
遍历索引, 元素
输出("索引:" + 索引 + ",元素:" + 元素)
遍历结束`
```
在上面的示例中,我们首先创建了一个名为“列表名”的列表,并使用`添
加`方法向其中添加了三个元素。
然后,我们使用`遍历`循环来遍历列表中的元素,并使用`输出`函数将索引和元素打印出来。
请注意,上述示例中的语法和函数可能会根据易语言的版本和具体实现有所不同。
因此,你可能需要根据你所使用的易语言版本和文档进行适当的调整。
list_for_each与list_entry详解

list_for_each与list_for_each_entry详解一、list_for_each1.list_for_each原型#define list_for_each(pos, head) \for (pos = (head)->next, prefetch(pos->next); pos != (head); \pos = pos->next, prefetch(pos->next))它实际上是一个for 循环,利用传入的pos 作为循环变量,从表头head开始,逐项向后(next方向)移动pos ,直至又回到head (prefetch() 可以不考虑,用于预取以提高遍历速度)。
注意:此宏必要把list_head放在数据结构第一项成员,至此,它的地址也就是结构变量的地址。
2.使用方法(以访问当前进程的子进程为例):struct list_head {struct list_head *next, *prev;};在struct task_struct 中有如下定义:struct list_head children;所以struct task_struct *task;struct list_head *list;list_for_each(list,¤t->chilidren) {task = list_entry(list, struct task_struct, sibling);/*task指向当前的某个子进程*/}其中用到了函数list_entry():这个函数的作用在图1中表示就是可以通过已知的指向member子项的指针,获得整个结构体的指针(地址)#define list_entry(ptr, type, member) \container_of(ptr, type, member)二、list_for_each_entry:在Linux内核源码中,经常要对链表进行操作,其中一个很重要的宏是list_for_each_entry:意思大体如下:假设只有两个结点,则第一个member代表head,list_for_each_entry的作用就是循环遍历每一个pos中的member子项。
ucore文件系统详解

ucore⽂件系统详解最近⼀直在mooc上学习清华⼤学的操作系统课程,也算是复习下基本概念和原理,为接下来的找⼯作做准备。
每次深⼊底层源码都让我深感操作系统实现的琐碎,即使像ucore这样简单的kernel也让我烦躁不已,⽂件系统相⽐于中断⼦系统、调度⼦系统、进程管理⼦系统等等,要复杂很多,因此被称为⽂件系统⽽不是⽂件⼦系统。
参看⽹络上的资料有时会增加我的困惑,很多⼈只是简单转载,很多细节描述的很模糊,实验环境也各不相同,最终很难深⼊理解⽂件系统的本质,参考源码我觉得有点像从三维世界进⼊到⼆维世界,⼀切变得清晰但是却需要消耗更多精⼒,我觉得这样做是值得的,因为如果不能深⼊⽽只是泛泛的理解,对于操作系统这样偏向于⼯程学的东西来说意义不⼤,本⽂的研究内容主要是根据清华⼤学陈渝副教授、向勇副教授在mooc上所讲,以及实验参考书的内容和我⾃⼰在系统上打的log验证过的,如果有读者发现错误还请批评指正。
本篇博客希望尽可能照顾到初学者,但是有些简单原理默认读者已经掌握,很多细节不会展开叙述,读者请⾃⾏Google或者参看Intel Development Manual,实验⽤的源码来⾃于清华⼤学教学操作系统,读者可在github上搜索ucore_os_lab。
附上ucore的实验参考书.综述最初实现⽂件系统是为了实现对磁盘数据的⾼效管理,使得⽤户可以⾼效、快速的读取磁盘上的数据内容。
其实我个⼈觉得⽂件系统就是操作系统内核和外设之间的⼀套输⼊输出协议,我们所采⽤的算法和索引结点的建⽴⽅式都是为了根据实际应⽤情况所设计的⼀套⾼效的协议。
在实现的过程中,我们还要将⽂件系统进⾏分层抽象,也就是实现我们的虚拟⽂件系统,虚拟⽂件系统有对上和对下两个⽅⾯,对上是为了向上层应⽤提供⼀套通⽤的访问接⼝,可以⽤相同的⽅式去访问磁盘上的⽂件(包括⽬录,后⾯会介绍)和外设;对下兼容不同的⽂件系统和外设。
虚拟⽂件系统的层次和依赖关系如下图所⽰:对照上⾯的层次我们再⼤致介绍⼀下⽂件系统的访问处理过程,加深对⽂件系统的总体理解。
python list 原理

python list 原理Python中的列表(list)是一种可变、有序、可重复的数据结构,用于存储多个元素。
列表的原理涉及到内存管理和数据结构的实现。
1. 数据存储原理列表在内存中以连续的方式存储数据。
当创建一个列表时,Python会分配一块连续的内存空间来存储列表的元素。
每个元素占据相同的内存大小,并按照顺序存储在连续的内存地址上。
列表使用一个指针来跟踪第一个元素的位置。
当添加或删除元素时,列表会在内存中重新分配空间,以保证元素的连续存储和顺序不变。
2. 动态数组的实现Python中的列表实际上是通过动态数组(Dynamic Array)来实现的。
动态数组是一种在数组基础上增加了自动扩容和缩容功能的数据结构。
Python的列表可以动态地增加和减少元素,而且无需手动处理内存空间。
当列表的元素数超过当前分配的空间时,Python会重新分配更大的空间,将原来的元素复制到新的空间中。
3. 列表方法的原理Python的列表提供了一系列的方法来对列表进行操作和管理。
这些方法的实现是基于动态数组的原理。
例如,添加元素的方法append()通过检查列表是否已达到分配的内存大小来决定是否需要重新分配更大的空间。
列表的方法pop()用于删除指定位置的元素,它会将后面的元素向前移动一位,以填补删除的空白。
4. 列表的迭代Python中的列表可以使用迭代器来实现。
迭代器是一种允许按照顺序遍历集合元素的对象。
列表的原理是通过实现__iter__()和__next__()两个函数来实现迭代器。
当使用for循环遍历列表时,后台会自动调用__iter__()函数获取迭代器对象,然后通过不断调用__next__()函数来获取列表的下一个元素。
5. 列表的切片Python中的列表支持切片操作,可以通过指定起始索引和结束索引来获取一个子列表。
切片操作的原理是通过指针和索引来确定子列表的起始和结束位置,然后通过复制元素来创建一个新的列表。
linux内核中的list详解

linux内核中的list详解原因:file_operation 结构中的open函数定义如下:int (*open)(struct inode *inode, struct file* filp);inode中含有i_cdev属性,它描述的是字符设备。
在自己定义的字符设备中,一般会包含字符设备的指针,而open方法被调用时,通常需要获取特定的设备对象,这里就涉及到一个问题:如何通过结构中的某个变量获取结构本身的指针。
Linux 内核中提供了container_of宏(WDM中也定义了相似功能的宏)。
C99中定义了两个宏,typeof和offsetof,它们返回的是某个变量的类型和结构中某变量在结构中的偏移量。
可以预想的是,没有编译器的支持,container_of的宏是很难实现的(至少我还没有想出能够不用 typeof宏实现container_of的方法)。
优点:值得一提的是,offsetof宏的实现非常巧妙,它把0地址转化为TYPE结构的指针,然后获取该结构中MEMBER成员的指针,并将其强制类型转换为size_t类型。
于是,由于结构从0地址开始定义,因此,cast后的MEMBER成员地址,实际上就是它在结构中的偏移量。
这也显示出了C语言中指针的强大。
因为,在某个体系结构下实现的libc,结构中各个成员的偏移总是可以预见的,这比C#那种以托管的方式管理内存的自由度要大的多。
实现:container_of宏定义在include/linux/kernel.h中:offsetof宏定义在include/linux/stddef.h中:container_of宏,它的功能是得到包含某个结构成员的结构的指针:其实现如下:#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)#define container_of(ptr, type, member) ({ \const typeof( ((type *)0)->member ) *__mptr = (ptr); \(type *)( (char *)__mptr - offsetof(type,member) );})分析可知__mptr指向的是一个type结构里typeof(((type *)0)->member)类型member成员的指针,offsetof(type,member)是这个成员在结构中的偏移,单位是字节,所以为了计算type结构的起始地址,__mptr减去它自己的偏移。
--entry参数-概述说明以及解释

--entry参数-概述说明以及解释1.引言1.1 概述entry参数是指在编程中使用的一个关键参数,它在许多编程语言和框架中被广泛使用。
它通常用于指定程序的入口点或起始位置。
当一个程序被执行时,系统会从指定的entry点开始执行,并按照一定的顺序执行其他函数或模块。
在许多编程语言中,entry参数可以是一个函数名、方法名或特定的标识符。
它可以用来指定程序的主函数,也可以用来指定程序中的某个特定功能模块。
无论是使用哪种形式的entry参数,它都起到了指导程序执行流程的重要作用。
通过使用entry参数,程序员可以更加灵活地控制程序的执行流程。
例如,在一个大型的程序中,可能有多个函数或模块需要依次执行。
通过指定不同的entry参数,程序员可以选择执行不同的功能模块,从而实现不同的程序逻辑。
另外,entry参数还常用于编写可扩展的程序。
通过将entry参数抽象化或参数化,程序可以接受外部输入,并根据不同的输入值执行不同的操作。
这种方式可以使得程序的功能更加灵活,能够满足不同场景下的需求。
总之,entry参数是编程中一个非常重要的概念。
它可以指定程序的入口点或起始位置,并通过控制程序的执行流程,实现不同的程序逻辑和功能。
对于程序员来说,理解和掌握entry参数的使用方法,将有助于提高程序的可读性、可维护性和可扩展性。
1.2 文章结构文章结构是指文章的整体架构和组织方式。
一个良好的文章结构能够使读者更好地理解文章内容,并能够清晰地传达作者的观点和论证。
在本文中,文章的结构主要包括引言、正文和结论三个部分。
引言部分用来引入文章的主题,并向读者介绍文章要解决的问题和目的。
它包括概述、文章结构和目的三个方面。
概述部分主要对文章的主题进行简要的介绍,引起读者的兴趣,并提出问题或挑战。
文章结构部分是对整篇文章的组织和安排进行说明。
可以在这部分明确指出文章的章节和段落结构,以及各部分的内容概要。
目的部分用来明确文章撰写的目的和意义,指出文章要解决的问题和提供的观点或论证。
pcb钻孔机的操作技术及流程详解

pcb钻孔机的操作技术及流程详解制程目的单面或双面板的制作都是在下料之后直接进行非导通孔或导通孔的钻孔, 多层板则是在完成压板之后才去钻孔。
传统孔的种类除以导通与否简单的区分外,以功能的不同尚可分:零件孔,工具孔,通孔(Via),盲孔(Blind hole),埋孔(Buried hole)(后二者亦为via hole的一种).近年电子产品'轻.薄.短.小.快.'的发展趋势,使得钻孔技术一日千里,机钻,雷射烧孔,感光成孔等,不同设备技术应用于不同层次板子.本章仅就机钻部分加以介绍,其它新技术会在20章中有所讨论.流程上PIN→钻孔→检查上PIN作业钻孔作业时除了钻盲孔,或者非常高层次板孔位精准度要求很严,用单片钻之外,通常都以多片钻,意即每个stack两片或以上.至于几片一钻则视1.板子要求精度2.最小孔径3.总厚度4.总铜层数.来加以考虑. 因为多片一钻,所以钻之前先以pin将每片板子固定住,此动作由上pin机(pinning maching)执行之. 双面板很简单,大半用靠边方式,打孔上pin连续动作一次完成.多层板比较复杂,另须多层板专用上PIN机作业.. 钻孔钻孔机钻孔机的型式及配备功能种类非常多,以下List评估重点A. 轴数:和产量有直接关系B. 有效钻板尺寸C. 钻孔机台面:选择振动小,强度平整好的材质。
D. 轴承(Spindle)E. 钻盘:自动更换钻头及钻头数F. 压力脚G. X、Y及Z轴传动及尺寸:精准度,X、Y独立移动H. 集尘系统:搭配压力脚,排屑良好,且冷却钻头功能I. Step Drill的能力J. 断针侦测K. RUN OUT钻孔房环境设计A. 温湿度控制B. 干净的环境C. 地板承受之重量D. 绝缘接地的考虑E. 外界振动干扰物料介绍钻孔作业中会使用的物料有钻针(Drill Bit),垫板(Back-up board),盖板(Entry board)等.以下逐一介绍:图为钻孔作业中几种物料的示意图.钻针(Drill Bit), 或称钻头,其质量对钻孔的良窳有直接立即的影响, 以下将就其材料,外型构、及管理简述之。
$windows内核情景分析学习笔记_

$windows内核情景分析学习笔记_windows内核情景分析学习笔记6 分类:windows *****-10-19 11:*****人阅读评论(0)收藏举报1、用于数据存储的内存区间分类①全局数据所占空间。
由编译器在编译链接时就静态分配好的,与整个进程共存亡。
其分配和释放都是不可见、不可为的②局部数据所占的空间。
调用函数时自动从堆栈上动态分配的,其寿命取决于函数的作用域。
其分配和释放是隐含的。
③通过malloc一类函数动态分配的内存。
其会一直存在,直到通过free一类的函数加以释放(或进程终止运行)。
2、内核对用户空间的管理对于windows来说,其用户空间的虚存地址从0到0x7fffffff,范围是2GB,每个进程都有这么一个2GB的用户空间。
一般来说,真正使用的只有其中很小一部分。
所以,凡是不使用的虚存地址区间,就不需要物理映射。
事实上,只有当前正在受到访问的页面才必须映射到物理内存页面,暂时不受到访问的页面都可以映射到外设(硬盘)上的页面交换文件里,待到实际使用时,才倒换回物理内存页面中。
从原理上说,将一个空间中每一个已分配使用的区间作为节点,然后组成一个链表。
需要时从头扫描这个链表,就可以知道哪一些区间被使用了。
(实际应用中,是组成成一个AVL树) 每个进程的进程控制块中有个指针VadRoot,指向代表着这个用户空间的数据结构。
其中有一个指针,指向一颗AVL树,这颗树的节点就是已分配使用的区间信息。
其节点定义如下:[cpp]view plaincopyprint? 1 typedef struct _MEMORY_AREA 2 { 3 PVOID StartingAddress; 4 PVOID EndingAddress; 5 struct _MEMORY_AREA *Parent; 6 struct _MEMORY_AREA *LeftChild; 7 struct _MEMORY_AREA *RightChild; 8 ULONG Type; 9 ULONG Protect;10 ULONG Flags; 11 ***** DeleteInProgress; 12 ULONG PageOpCount;13 union 14 { 15 struct 16 { 17 ROS_*****_OBJECT* Section; 18 ULONG ViewOffset; 19 PMM_*****_***** Segment; 20 ***** WriteCopyView; 21 LIST_ENTRY RegionListHead; 22 } SectionData; 23 struct 24 { 25 LIST_ENTRY RegionListHead; 26 } VirtualMemoryData; 27 } Data; 28 } MEMORY_AREA, ******_AREA; 这颗以MEMORY_AREA数据结构为节点的AVL树,代表了用户空间。