class_prediction
chatglm2推理代码详解

chatglm2推理代码详解【最新版】目录1.ChatGLM2 推理代码的基本概念2.ChatGLM2 推理代码的运作原理3.ChatGLM2 推理代码的实际应用正文ChatGLM2 推理代码详解ChatGLM2 是一款基于深度学习技术的对话生成模型,其推理代码对于理解其运作原理至关重要。
在本文中,我们将详细解析 ChatGLM2 推理代码的基本概念、运作原理以及实际应用。
一、ChatGLM2 推理代码的基本概念ChatGLM2 推理代码主要包括两个部分:前向推理和后向推理。
前向推理是指根据输入的文本序列,通过模型生成对应的输出序列;后向推理则是指根据模型输出的序列,推测输入的文本序列。
在这两个过程中,模型会根据输入的文本序列和模型参数,计算出每个单词的概率分布,然后根据概率分布生成对应的输出序列。
二、ChatGLM2 推理代码的运作原理ChatGLM2 推理代码的运作原理主要基于深度学习技术中的自注意力机制。
该机制通过计算输入序列中每个单词与其他单词之间的相关性,来捕捉输入序列中的长距离依赖关系。
在模型训练过程中,ChatGLM2 会通过最大化似然估计,学习到输入序列和输出序列之间的对应关系,从而实现对话生成。
三、ChatGLM2 推理代码的实际应用ChatGLM2 推理代码在实际应用中主要表现为对话生成能力。
通过对输入的文本序列进行分析和推理,模型可以生成与输入序列相关的自然语言输出。
这种对话生成能力在很多场景中都有广泛的应用,例如智能客服、智能对话系统等。
综上所述,ChatGLM2 推理代码是理解其运作原理的重要组成部分。
通过对输入序列和模型参数的计算和分析,模型可以实现自然语言的生成和对话。
数据挖掘导论第4课数据分类和预测

II.
Issues Regarding Classification and Prediction (1): Data Preparation
Data cleaning Preprocess data in order to reduce noise and handle missing values Relevance analysis (feature selection) Remove the irrelevant or redundant attributes Data transformation Generalize and/or normalize data
I.
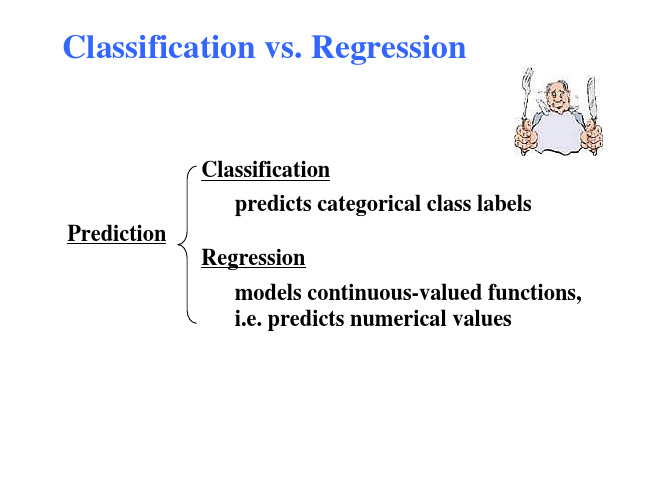
Classification vs. Prediction
Classification predicts categorical class labels (discrete or nominal) classifies data (constructs a model) based on the training set and the values (class labels) in a classifying attribute and uses it in classifying new data Prediction models continuous-valued functions, i.e., predicts unknown or missing values Typical applications Credit approval Target marketing Medical diagnosis Fraud detection
Issues regarding classification and prediction (2): Evaluating classification methods
python predict函数用法 -回复

python predict函数用法-回复Predict函数是Python中常用的函数之一,它用于预测未知数据的结果。
在机器学习和数据分析领域,predict函数被广泛应用于各种领域,例如分类、回归、聚类等。
本文将详细介绍predict函数的用法,包括使用步骤、参数解释以及示例代码等。
一、predict函数的基本介绍在Python中,predict函数通常是机器学习模型类的一个成员函数,用于根据已经训练好的模型预测未知数据的结果。
常见的机器学习模型包括线性回归、逻辑回归、支持向量机、决策树、随机森林等。
这些模型都提供了predict函数,用于对新的数据进行预测。
二、predict函数的使用步骤使用predict函数进行预测通常包括以下步骤:1. 导入所需的库和模型类:首先,需要导入所需的库和机器学习模型类。
例如,如果想使用线性回归模型进行预测,可以导入sklearn库中的LinearRegression类。
2. 加载训练好的模型:使用模型类的构造函数创建一个模型对象,并从磁盘上加载已经训练好的模型。
可以使用pickle或者joblib库中的函数进行模型的保存和加载。
3. 准备待预测的数据:将待预测的数据按照模型要求的格式进行准备。
通常需要进行数据预处理,例如特征缩放、特征选择和特征转换等。
4. 调用predict函数进行预测:使用加载的模型对象调用predict函数,传入待预测的数据,得到预测结果。
5. 处理预测结果:根据实际需求,对预测结果进行后续处理。
例如,可以将预测结果转换为分类标签或者进行概率计算。
三、predict函数的参数解释predict函数通常有以下常用参数:1. X:待预测的数据集,类型通常是数组或矩阵。
每一行代表一个样本,每一列代表一个特征。
2. 返回值:预测结果,类型通常是数组或矩阵。
每个元素代表一个样本的预测结果。
四、predict函数的示例代码下面以线性回归模型为例,展示predict函数的具体用法:pythonfrom sklearn.linear_model import LinearRegressionimport numpy as np# 加载训练好的模型model = LinearRegression()model.load('linear_model.pkl')# 准备待预测的数据X_test = np.array([[1, 2], [3, 4], [5, 6]])# 调用predict函数进行预测y_pred = model.predict(X_test)# 处理预测结果print(y_pred)以上示例代码中,首先导入了LinearRegression类和numpy库。
python中predict函数参数

python中predict函数参数摘要:1.介绍Python 中的predict 函数2.详述predict 函数的参数3.总结predict 函数的使用方法及注意事项正文:一、Python 中的predict 函数在Python 中,predict 函数是一种常见的机器学习函数,主要用于对模型进行预测。
通过使用训练好的模型,我们可以对新的数据进行预测,以获取相应的结果。
predict 函数广泛应用于各种机器学习领域,例如回归、分类、聚类等。
二、predict 函数的参数predict 函数在Python 中主要有以下几个参数:1.model:模型对象。
这是predict 函数最重要的参数,也是必须的参数。
model 对象通常是我们通过训练得到的机器学习模型,例如线性回归模型、支持向量机模型等。
2.X:输入数据。
X 是predict 函数的另一个重要参数,它是一个数组或者列表,用于存储我们需要预测的新数据。
X 的形状通常是(n_samples,n_features),其中n_samples 表示样本数量,n_features 表示特征数量。
3.return_dict:返回字典。
这是一个可选参数,默认值为False。
如果设置为True,那么predict 函数会返回一个字典,其中包含了每个样本的预测结果以及对应的概率。
如果设置为False,那么predict 函数只会返回每个样本的预测结果。
4.verbose:打印详细信息。
这也是一个可选参数,默认值为False。
如果设置为True,那么predict 函数会在执行过程中打印出一些详细的信息,例如每个样本的预测结果、模型的参数等。
三、总结predict 函数是Python 中机器学习领域中常用的一个函数,它主要用于对模型进行预测。
在使用predict 函数时,我们需要注意以下几个参数:model(模型对象)、X(输入数据)、return_dict(返回字典)和verbose (打印详细信息)。
mmsegmentation二分类

一、概述mmsegmentation是一个基于PyTorch的语义分割库,提供了一系列强大的模型和训练、测试工具。
在语义分割任务中,模型需要将图像中的每个像素分配给特定的类别,这对于图像理解和实时场景分析非常重要。
而mmsegmentation提供了丰富的功能和工具,使得用户可以方便地进行语义分割任务的实验和研究工作。
二、mmsegmentation的特点和优势1. 多种模型支持:mmsegmentation支持多种经典的语义分割模型,包括FCN、PSPNet、DeepLabV3等,用户可以根据具体任务选择合适的模型进行训练和测试。
2. 多样化的数据增强:mmsegmentation集成了丰富的数据增强方法,包括随机裁剪、随机翻转、色彩抖动等,可以有效提升模型的鲁棒性和泛化能力。
3. 灵活的训练配置:用户可以通过简单的配置文件实现对模型、数据集、训练参数等的灵活管理,同时支持分布式训练,使得训练过程更加高效。
4. 强大的可视化工具:mmsegmentation提供了丰富的可视化工具,包括TensorBoard等,可以直观地展现模型的训练过程和结果。
5. 兼容性好:mmsegmentation兼容了大部分的语义分割数据集,并且提供了方便的数据集处理工具,用户可以快速地搭建自己的数据处理流程。
三、使用mmsegmentation进行二分类的实践在实际应用中,二分类是一种常见的语义分割任务,常见的场景包括道路和非道路的分割、人像和背景的分割等。
接下来,我们将以道路和非道路的分割任务为例,介绍如何使用mmsegmentation进行二分类任务的实践。
1. 数据准备我们需要准备道路和非道路的标注数据集,可以使用开源数据集,也可以自行收集和标注数据。
对于道路和非道路的分割任务,可以采集无人机或者卫星图像,并对图像进行标注,标注方法可以是像素级标注、矢量标注等。
2. 模型选择根据实际情况和要求,我们选择合适的模型进行训练和测试。
贝叶斯决策理论(英文)--非常经典!
What is Bayesian classification?
Bayesian classification is based on Bayes theorem
Bayesian classifiers have exhibited high accuracy and fast speed when applied to large databases
贝叶斯决策理论英文非常经典
Classification vs. Regression
Classification predicts categorical class labels Prediction Regression models continuous-valued functions, i.e. predicts numerical values
Two step process of prediction (I)
Step 1: Construct a model to describe a training set
• the set of tuples used for model construction is called training set • the set of tuples can be called as a sample (a tuple can also be called as a sample) • a tuple is usually called an example (usually with the label) or an instance (usually without the label) • the attribute to be predicted is called label Training algorithm
mmsegmentation中解决类别不平衡的损失函数

mmsegmentation中解决类别不平衡的损失函数在mmsegmentation中,可以使用Dice Loss(SoftDiceLoss)来解决类别不平衡的问题。
Dice Loss是一种基于交叉熵的损失函数。
对于每个像素点,它首先计算预测分割结果和真实分割标签之间的交叉熵损失,然后再计算预测的前景和背景之间的Dice系数,将交叉熵损失和Dice系数进行加权求和,得到最终的损失函数。
Dice Loss的计算公式如下:$\text{DiceLoss}(p, t) = 1 - \frac{2 \cdot \sum_{i=0}^{N-1} p_i \cdot t_i}{\sum_{i=0}^{N-1} p_i^2 + \sum_{i=0}^{N-1} t_i^2}$ 其中,$p$表示预测的概率图,在mmsegmentation中一般会经过Softmax函数得到,$t$表示真实的分割标签。
由于Dice Loss是通过计算Dice系数来量化前景的重要性,因此对于类别不平衡的问题,Dice Loss可以自动调整不同类别之间的权重,将更多的关注放在少数类别上,从而缓解类别不平衡问题。
在mmsegmentation中,可以通过在配置文件中的loss项设置损失函数为DiceLoss来使用Dice Loss。
例如:```pythonloss=dict(type='DiceLoss',loss_weight=1.0,class_weight=[1, 2] # 设置前景类别的权重为2,背景类别的权重为1,可以根据具体情况进行调整)```需要注意的是,mmsegmentation还提供了其他的损失函数,如CrossEntropyLoss、LovaszLoss等,可以根据具体场景选择合适的损失函数来解决类别不平衡的问题。
transformerclassifier()参数

transformerclassifier()参数一、参数介绍1. 文本数据 (text_data):用于分类的文本数据,需要通过预处理转换为数字表示的输入数据。
2. 标签数据 (label_data):文本数据对应的分类标签,需要通过预处理转换为数字表示的输出数据。
3. 预训练模型 (pretrained_model):预训练的 Transformer 模型,可以是 BERT、RoBERTa、XLNet 等。
4. 词汇表大小 (vocab_size):文本数据的词汇表大小,对应预训练模型的词汇表。
5. 最大序列长度 (max_seq_length):输入文本数据的最大序列长度,需要保持一致。
6. 隐藏单元数 (hidden_units):Transformer 模型的隐藏单元数,影响模型的表示能力。
7. 分类器层 (num_classes):分类问题的类别数,用于输出层的调整。
8. 学习率 (learning_rate):优化器的学习率,用于更新模型参数。
9. 训练批次大小 (batch_size):每个训练批次中的样本数量,影响模型训练的效率。
10. 训练周期数 (num_epochs):完整数据集训练的周期数,用于模型的迭代更新。
11. 训练验证比例 (validation_split):训练数据和验证数据的划分比例。
12. 设备 (device):模型运行的硬件设备,可以选择 GPU 或 CPU 运行。
二、实现原理Transformer 模型是一种基于自注意力机制的深度学习模型,适用于序列数据处理任务。
其核心思想是通过自注意力机制实现输入序列中每个元素的上下文关系计算,从而捕捉序列中的语义关系和依赖关系。
transformerclassifier() 函数基于 Transformer 模型实现文本分类任务,主要包括以下步骤:1. 数据预处理:将输入文本数据和标签数据转换为数字表示的输入数据和输出数据,保证数据格式的统一性和可处理性。
python中predict函数参数

python中predict函数参数一、引言在Python中,predict函数是机器学习中常见的一种函数,用于对模型进行预测。
本文将对predict函数的参数进行详细解析,帮助读者更好地理解和使用该函数。
二、predict函数概述1.函数定义predict函数是scikit-learn库中Model类的一个方法,用于对模型进行预测。
其定义如下:```pythondef predict(self, X, batch_size=None, verbose=0, num_threads=1, epochs=100, shuffle=True, callbacks=None):```2.函数用途predict函数的主要用途是对训练好的模型进行预测,可以用于分类、回归等任务。
三、predict函数主要参数1.X_test:测试数据,用于模型预测。
可以是ndarray、Pandas DataFrame或NumPy数组。
2.y_test:真实标签,用于评估模型的预测结果。
可以是ndarray、Pandas DataFrame或NumPy数组。
3.batch_size:批量大小,用于控制预测过程中每次处理的数据量。
默认值为None,表示不使用批量预测。
4.verbose:输出信息,用于控制预测过程中的日志输出。
默认值为0,表示不输出日志信息。
5.num_threads:线程数量,用于控制预测过程中的多线程数量。
默认值为1,表示使用单线程预测。
6.epochs:训练轮数,用于控制预测过程中的迭代次数。
默认值为100,表示进行100次预测。
7.shuffle:随机打乱数据,用于控制预测过程中数据的重排序。
默认值为True,表示打乱数据。
8.callbacks:回调函数,用于在预测过程中执行自定义操作。
可以是一个或多个回调函数组成的列表。
四、实例演示1.加载数据集这里以Iris数据集为例,首先导入所需的库和数据集:```pythonfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_scoreiris = load_iris()X = iris.datay = iris.target```2.划分训练集和测试集将数据集划分为训练集和测试集:```pythonX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)```3.训练模型创建一个Logistic回归模型并进行训练:```pythonmodel = LogisticRegression(max_iter=1000)model.fit(X_train, y_train)```4.使用predict函数进行预测对模型进行预测:```pythony_pred = model.predict(X_test)```5.分析预测结果计算预测准确率:```pythonaccuracy = accuracy_score(y_test, y_pred)print("预测准确率:", accuracy)```五、总结与展望本文详细介绍了Python中predict函数的参数及其用法,通过实例演示了如何使用predict函数进行模型预测。
Unit 2 Looking into the future : Using language

hence nevertheless on the one hand....on the other hand for example moreover also personally of course
…oppose the idea of... …some advances in technology is unnecessary and could even be dangerous We should cease accepting... ... live happily in the absence of new technology …is better ... rather than living in large polluted cities ... changes the way we live, ... a scary prospect
完成下面的表格,梳理第一段的脉络,以及其中各方对无人驾驶汽车的态度和看法。
Should we fight driverless cars?
Side
Attitud Options e
Various people
Yes
The family of the Yes decreased
The car company No
... provide people with many benefits …save many lives advocate ... …make it possible for... …make ... much easier ...have benefited a lot from ... help get into the best shape of my life ... look on the positive side of change and accept it rather than resist it
python predict函数用法

Python中的predict函数是机器学习和深度学习领域中一个十分重要的函数,它可以用来对数据进行预测或分类。
本文将就Python中的predict函数的用法进行详细介绍,帮助读者更好地了解和掌握这一函数的使用方法。
一、predict函数的基本介绍1. predict函数是机器学习和深度学习模型中常用的函数之一,它可以对输入的数据进行预测或分类。
2. 在Python中,predict函数通常是由各种机器学习框架或库提供的,在使用之前需要先安装相应的库,并导入需要的模块。
二、predict函数的使用方法1. 导入相关的库和模块在使用predict函数之前,首先需要导入相关的库和模块,例如在使用TensorFlow框架中的predict函数时,需要导入tensorflow库,并加载训练好的模型。
```pythonimport tensorflow as tfmodel = tf.keras.models.load_model('model.h5')```2. 准备输入数据在使用predict函数时,需要准备输入数据,通常是一个numpy数组或者Pandas DataFrame。
具体的数据格式需要根据模型的要求来进行转换和处理。
```pythonimport numpy as npdata = np.array([1, 2, 3, 4, 5])```3. 调用predict函数进行预测一旦准备好输入数据,就可以调用predict函数进行预测。
在调用predict函数时,可以传入单个数据样本或者批量数据样本,具体的参数设置需要根据模型的要求来进行调整。
```pythonresult = model.predict(data)```predict函数的返回结果通常是模型对输入数据的预测值或者分类结果,根据具体的需求,可以进一步对预测结果进行处理和分析,比如获取预测概率最大的类别。
```pythonpredicted_class = np.argmax(result)```三、predict函数的注意事项1. 输入数据的格式在使用predict函数时,需要特别注意输入数据的格式和维度要求,不同的模型对输入数据的要求可能不同,需要根据具体的情况来进行处理。
classifier.predict 用法

在机器学习中,`classifier.predict()` 是一个常用的方法,用于根据已经训练好的分类器模型对新的数据进行预测。
这个方法通常用于分类任务,例如预测一个样本属于哪个类别。
下面是`classifier.predict()` 方法的基本用法:```python# 导入必要的库from sklearn.ensemble import RandomForestClassifier# 创建一个分类器模型clf = RandomForestClassifier()# 准备数据X_test = [[0, 0], [1, 1]]# 使用训练好的模型进行预测y_pred = clf.predict(X_test)# 输出预测结果print(y_pred)```在这个例子中,我们使用了`RandomForestClassifier` 分类器,并对测试数据`X_test` 进行了预测。
`predict()` 方法返回一个数组`y_pred`,其中包含了模型对每个输入样本的预测结果。
在这个例子中,`y_pred` 应该是`[0, 1]`,表示第一个样本被预测为类别0,第二个样本被预测为类别1。
需要注意的是,为了使用`predict()` 方法,你需要先训练一个分类器模型。
通常,你可以使用`fit()` 方法来训练模型,如下所示:```python# 准备训练数据X_train = [[0, 0], [1, 1], [2, 2]]y_train = [0, 1, 2]# 训练模型clf.fit(X_train, y_train)```在这个例子中,我们使用训练数据`(X_train, y_train)` 来训练模型,并使用`fit()` 方法来拟合模型。
完成训练后,我们就可以使用`predict()` 方法对新的数据进行预测了。
predict()的用法和固定搭配

predict()的用法和固定搭配
predict()是机器学习中常用的函数,用于对给定数据进行预测
或分类。
它通常与训练好的模型结合使用,根据已知的模式和规律对
新的数据进行预测。
predict()的常见用法和固定搭配有以下几种:
1. 用于监督学习模型:对于监督学习模型,predict()函数用于
对新的输入数据进行分类或回归预测。
它接受特征向量作为输入,并
返回预测的类别标签或连续值。
例如,在分类问题中,可以使用
predict()函数来对新的样本进行分类。
2. 用于无监督学习模型:对于无监督学习模型,predict()函数
用于对新的输入数据进行聚类或异常检测。
它接受特征向量作为输入,并返回聚类标签或异常分数。
例如,在聚类问题中,可以使用
predict()函数将新的数据点分配给特定的聚类簇。
3. 用于时间序列预测模型:对于时间序列预测模型,predict()
函数用于根据过去的数据预测未来的值。
它接受历史数据作为输入,
并返回预测的未来值。
例如,在股票市场预测中,可以使用predict()函数根据历史价格预测未来几天或几周的股票价格。
总之,predict()函数的用法和固定搭配取决于具体的机器学习
模型和任务。
根据不同的模型和问题,predict()函数可以根据需要进
行参数配置和适当的数据预处理。
catboostclassifier predict

catboostclassifier predict如何使用CatBoostClassifier进行预测CatBoost是一个开源的梯度提升库,可以用于分类、回归和排序任务。
它在处理高维数据、处理类别特征以及处理缺失数据方面非常强大和灵活。
CatBoostClassifier是CatBoost库中用于分类任务的分类器。
在本文中,我们将一步一步回答如何使用CatBoostClassifier进行预测。
第一步:准备数据在使用CatBoostClassifier进行预测之前,我们需要准备好相应的数据。
首先,我们需要将数据分为训练集和测试集。
训练集用于训练模型,测试集用于评估模型在新数据上的性能。
确保训练集和测试集的数据分布相似,这样才能更好地评估模型的泛化能力。
另外,CatBoostClassifier支持处理类别特征和缺失数据。
如果有类别特征,我们需要将其转换为数值特征,可以使用独热编码或者embedding 等方式。
如果有缺失数据,我们可以使用合适的方法进行填充,例如用均值、中位数或者众数进行填充。
第二步:安装CatBoost库使用CatBoostClassifier进行预测之前,我们需要安装CatBoost库。
可以使用PIP进行安装,运行以下命令:pip install catboost确保使用的是最新版本的CatBoost库,以获得最新的功能和修复的错误。
第三步:导入CatBoost库和数据安装CatBoost库后,我们需要在代码中导入相关库和数据。
首先,导入CatBoostClassifier类,并创建一个分类器实例。
pythonfrom catboost import CatBoostClassifier# 创建分类器对象model = CatBoostClassifier()接下来,导入训练数据和测试数据。
pythonimport pandas as pd# 导入训练数据train_data = pd.read_csv('train.csv')# 导入测试数据test_data = pd.read_csv('test.csv')确保训练数据和测试数据的特征和目标变量的列名一致,否则需要进行调整。
python的predict函数

python的predict函数Python的predict函数Python是一种高级编程语言,它的应用范围非常广泛,包括数据分析、机器学习、人工智能等领域。
在机器学习领域中,Python的predict函数是非常重要的一个函数,它可以用来预测模型的输出结果。
本文将从分类和回归两个方面来介绍Python的predict函数。
一、分类问题中的predict函数在分类问题中,predict函数的作用是预测一个样本属于哪一类。
在Python中,我们可以使用sklearn库中的分类器来实现分类问题的预测。
下面是一个简单的例子:```pythonfrom sklearn import datasetsfrom sklearn.model_selection import train_test_splitfrom sklearn.tree import DecisionTreeClassifier# 加载数据集iris = datasets.load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3,random_state=42)# 创建分类器clf = DecisionTreeClassifier()# 训练模型clf.fit(X_train, y_train)# 预测测试集y_pred = clf.predict(X_test)# 输出预测结果print(y_pred)```在上面的代码中,我们首先加载了鸢尾花数据集,然后将数据集划分为训练集和测试集。
接着,我们创建了一个决策树分类器,并使用训练集对其进行训练。
最后,我们使用predict函数对测试集进行预测,并输出预测结果。
二、回归问题中的predict函数在回归问题中,predict函数的作用是预测一个样本的输出值。
【统计学习】随机梯度下降法求解感知机模型

【统计学习】随机梯度下降法求解感知机模型1. 感知机学习模型感知机是⼀个⼆分类的线性分类问题,求解是使误分类点到超平⾯距离总和的损失函数最⼩化问题。
采⽤的是随机梯度下降法,⾸先任意选取⼀个超平⾯w0和b0,然后⽤梯度下降法不断地极⼩化⽬标损失函数,极⼩化过程中不是⼀次使所有误分类点的梯度下降,⽽是⼀次随机选取⼀个误分类点使其梯度下降。
假设误分类点集合M是固定的,那么损失函数L(w,b)的梯度:随机选取⼀个误分类点,对w和b进⾏更新:其中n是步长,⼜称为学习率(learning rate),这样通过迭代可以使损失函数L(w,b)不断减⼩,直到训练集中没有误分类点。
直观的解释:当⼀个实例点被误分类,即位于超平⾯的错误⼀侧时,则调整w和b的值,使分离超平⾯向该误分类点的⼀侧移动,以减少该误分类点与超平⾯间的距离,直⾄超平⾯越过该分类点使其正确分类[1]。
注意:当训练数据集线性可分时,这个迭代是收敛的,也就是经过有限次数的迭代是可以找到最优的超平⾯的[1]。
下⾯就详细讲解这个迭代的过程。
2.感知机算法的原始形式输⼊:训练数据集 T={(x1,y1),(x2,y2),...,(x n,y n)},其中x1∈R n,y i={+1,-1},i=1, 2, ..., n,学习率η(0 < η<= 1)输出:w, b;感知机模型 f(x) = sign(w·x + b)过程:1,选取初值w, b2,在训练集中取数据(x i,y i)3,若 y i(w·x i+ b) <= 0 即分类不正确,则:w= w + ηy i x ib= b + ηy i注:因为此时分类不对,所以y i= -14,转⾄步骤2,直到训练数据集中⽆误分类点3.感知机算法的对偶形式在原始形式中有公式:w= w + ηy i x ib= b + ηy i那么假设⼀共修改了n次,则w,b关于(x i(1),x i(2))的增量分别为:a i y i x i和 a i y i (a i= n iη)即:若η=1,则a i就是第i个点由于误分类⽽进⾏更新的次数,即a i = n i。
初中英语科三教学设计模板

教学设计模板(PWP模式—适于听说课、阅读课、写作课)Teaching Content:(阅读课)This is a reading material about 主题。
(听说课)This is a dialogue about 主题。
(写作课)This is a writing material about主题。
/ This is a letter (or invitation) that_writes to_.Teaching Objectives:Knowledge Objectives:(万能)①Students can understand and master the new words and phrases__.②Students can understand and master the sentence pattern__.(写作课)Students will know the structure/form of the writing.Ability Objectives:(万能)①Students can improve their听说读写abilities and grab the key information through 听说读写activities.②Students can express their opinion about主题by using the target language correctly and fluently.(阅读课)Students will be able to use different basic reading strategies correctly in their reading process.(写作课)Students can write a passage with the certain topic主题through imitation and practice.Emotional abilities:(万能)Students can cooperate with other group mates actively and complete the task together.Students will be more confident in learning English.(升华情感)Students can develop 具体行为。
gradientboostingclassifier分类

gradientboostingclassifier分类GradientBoostingClassifier是一种监督学习模型,用于解决分类问题。
它通过创建多个弱学习模型,使用反向传播算法(backpropagation algorithm)逐步对模型进行优化,从而实现对复杂数据集的准确分类。
在GradientBoostingClassifier模型中,每棵弱学习模型都是一棵决策树,它基于历史数据和当前决策点来进行分类。
当预测准确率较高时,它会不断增大权重值;当预测准确率较低时,它会降低权重值。
重复多次该过程,最终得到一个复杂的模型。
为了评估模型的性能,可以使用交叉验证(cross-validation)来确定模型的准确率、精确率、召回率和F1值等参数。
同时,还可以通过增大n_estimators来增加模型的复杂度,从而提高模型在训练集上的准确性。
不过,值得注意的是,如果模型过于复杂,可能会导致过拟合(overfitting)的问题,因此需要合理控制模型的复杂度。
总的来说,GradientBoostingClassifier是一种强大且常用的分类模型,广泛应用于各种领域,例如自然语言处理、计算机视觉等。
它在数据量较大的情况下也能表现出色。
通过对模型进行训练和优化,可以得到一个准确度较高的分类器。
python中predict函数参数

python中predict函数参数Python中的predict函数是机器学习和深度学习中常用的函数之一,用于对模型进行预测。
通过输入一组特征数据,该函数可以根据训练好的模型预测出相应的结果。
本文将详细介绍predict函数的使用方法和常见应用场景。
一、predict函数的基本用法predict函数通常是在完成模型的训练之后使用的。
它接受一个输入数据集作为参数,并返回对应的预测结果。
在使用predict函数时,我们需要首先导入相应的库,并加载训练好的模型。
以下是一个简单的示例代码:```pythonimport numpy as npfrom sklearn.linear_model import LinearRegression# 创建特征矩阵和目标向量X = np.array([[1, 2], [3, 4], [5, 6]])y = np.array([3, 5, 7])# 创建并训练线性回归模型model = LinearRegression()model.fit(X, y)# 使用predict函数进行预测new_X = np.array([[7, 8], [9, 10]])predictions = model.predict(new_X)print(predictions)```在上述代码中,我们首先导入了numpy和sklearn.linear_model库,并创建了一个特征矩阵X和目标向量y。
然后,我们使用LinearRegression()函数创建了一个线性回归模型,并使用fit()函数对模型进行训练。
最后,我们使用predict函数对新的特征矩阵new_X进行预测,并将结果打印出来。
二、predict函数的常见应用场景predict函数在机器学习和深度学习中有广泛的应用。
以下是一些常见的应用场景:1. 房价预测:通过输入房屋的各种特征(如面积、地理位置等),使用训练好的模型预测房价。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Agilent Technologies, Inc. 2005
sig_support@ | Main 866.744.7638
2
Fig 1: Each sample must be assigned to a class (ALL or AML in that example) in the Experiment Parameters window After saving the experiment parameter settings, make sure to set the class parameter (Leukemia) as continuous element in the Experiment Interpretation window. You may then proceed with the class prediction: 1. Go to Tools ⇒ select Class Prediction ⇒ select the K-Nearest Neighbors tab (see Fig. 2) 2. In the Class Prediction window, open the Experiments folder on the left-hand side of the window, and select the training set. Click on “Training Set >>” to assign training set. Do the same for test set and gene list. 3. Set appropriate prediction rules, such as the gene selection method, parameter to predict, number of predictor genes, number of neighbors (see details in following sections). Select Predict Test Set to start the prediction algorithm.
Agilent Technologies, Inc. 2005
sig_support@ | Main 866.744.7638
3
Number of Predictors: The number of best predictor genes that the algorithm will use for the prediction rule. Number of neighbors: K number of training samples that is nearest to the test sample, based on Euclidean distance of normalized expression intensity (K-nearest neighbor method). The number of neighbors should not exceed the number of samples or conditions in the smallest class. As a rule of thumb, set it to 2/3 of the number of samples in the smallest class. See details in section V. Decision cutoff for P-value ratio: A rule indicating how the algorithm should make a prediction for the test sample. A p-value ratio of 0.2 (equivalent to 1/5) indicates that the algorithm will make a prediction if the p value (probability that the test sample is predicted as belonging to one class by chance) of the first best class is at least 5 times smaller than the p-value of the next best class. If the actual p value ratio is less than the cutoff, a prediction will be made, if the ratio is higher, no prediction will be made. Setting the p value cutoff to 1 will force the algorithm to always make a prediction but may result in more prediction errors. Crossvalidate Training Set: This option tests how well the prediction rule – number of predictor genes, decision cutoff p value ratio, and number of neighbors – is at discriminating between classes in the training set. Predict Test Set: This option becomes enabled after a test set has been assigned in the Predict Parameter window. This will predict the test samples and generate a list of predictor genes.
Class Prediction: K-Nearest Neighbors
Contents at a glance
I. II. III. IV. Definition and Applications.................................................................................. 2 How do I access the Class Prediction tool? ........................................................ 2 How does the Class Prediction work?................................................................. 4 How does GeneSpring determine which genes are best discriminator/predictor?....................................................................................... 5 a. Prediction strength calculation ................................................................. 5 How does the algorithm predict test samples? ................................................... 7 a. Summary of the K-nearest algorithm........................................................ 7 b. Interpreting the Prediction Results window .............................................. 7 c. Figure illustrating prediction and k-nearest neighbors concepts .............. 9 What is the purpose of cross-validation and how does it work? .........................10 Most commonly asked questions about Class Predictor.....................................11
II. How to access the Class Prediction tool.
Before using the Class Prediction tool, you must assign class membership to every sample in your training set (set of samples with known class membership) by defining parameter values in the Change Parameter window. Samples belonging to the same class must be designated with the same parameter value. For example, all leukemia samples in our training set have been assigned as ALL or AML under the parameter Leukemia Type (as in data set published in Golub et al, 1999). Samples with unknown designation (N/A) should be removed from the experiment.