Linux攻略系统性能监测参数获取的方法
linux 运维监控指标

linux 运维监控指标
以下是一些常见的Linux 运维监控指标:
1. 系统性能指标:
- CPU 使用率:包括用户空间、内核空间和空闲时间的百分比。
- 内存使用情况:可用内存、已用内存和缓存的大小。
- 磁盘I/O:磁盘读取和写入的速度、IOPS(每秒I/O 操作数)和磁盘使用率。
- 网络带宽:网络输入和输出的带宽使用情况。
2. 进程和服务:
- 进程状态:检查运行中的进程及其资源使用情况。
- 服务状态:监控关键服务的运行状态,如Web 服务器、数据库等。
3. 系统日志:
- 查看系统日志以检测错误、警告和异常情况。
4. 文件系统:
- 监控文件系统的容量使用情况,包括空闲空间和文件数量。
5. 网络连接:
- 监控网络连接数、活动连接和异常的网络活动。
6. 性能计数器:
- 收集和分析性能计数器,如CPU 缓存命中率、页面错误等。
7. 硬件健康:
- 监控硬件传感器数据,如温度、风扇速度和硬盘健康状况。
这些指标可以通过命令行工具(如top、iostat、df、sar 等)、系统监控工具(如Nagios、Zabbix、Prometheus 等)或云监控服务来收集和监控。
根据实际需求,你可以选择适合的工具和指标来确保系统的稳定性和性能。
如何在Linux终端中进行进程调试和性能分析

如何在Linux终端中进行进程调试和性能分析在Linux系统中,终端是我们进行各种操作的主要界面之一。
除了常规的输入输出外,终端还提供了一些强大的工具和命令,用于进程调试和性能分析。
本文将介绍在Linux终端中如何进行进程调试和性能分析的方法和技巧。
一、进程调试1. 使用GDB调试器GDB(GNU Debugger)是一个功能强大的命令行调试器,支持多种编程语言(如C、C++等)。
使用GDB可以在终端中对正在运行的进程进行调试。
首先,确保你已经安装了GDB。
可以通过在终端中输入以下命令来检查GDB的安装情况:```gdb --version```如果显示了GDB的版本信息,则表示已经安装成功。
如果没有安装,可以使用以下命令来安装GDB:```sudo apt-get install gdb```接下来,我们需要编译并生成可调试的程序。
在编译时,需要添加`-g`选项,以便生成调试信息。
例如:```gcc -g my_program.c -o my_program```生成可调试的程序后,可以使用以下命令来在终端中启动GDB调试器,并加载可执行文件:```gdb my_program```此时,GDB会进入调试模式,可以使用各种调试命令来控制程序的执行。
例如,可以使用`run`命令来运行程序,使用`break`命令设置断点,使用`step`命令逐行执行程序等。
在调试过程中,可以使用`print`命令来打印变量的值,使用`backtrace`命令来查看函数调用栈等。
2. 使用strace工具strace是一个用于跟踪、分析系统调用的命令行工具。
通过strace,可以在终端中实时查看正在运行的进程所发起的系统调用和信号。
使用以下命令来安装strace:```sudo apt-get install strace```安装完成后,可以使用以下命令来启动strace,并跟踪指定进程的系统调用信息:```strace -p PID```其中,PID是要跟踪的进程的进程ID。
Linux环境下PowerPC-NC运行性能参数的获取

软件 技术 与数 攮库 ・ }
文章编号tl o 48 o6o_oo一3 文献标识码;A o 一32(o)_04_l o 2 2
中 圈分类号: P1 T31
Liu n x环 境 下 P we P NC 运 行 性 o r C. 能参数 的获取
孙立扛 ,朱 利 ,魏恒义
( 安交通 大学软件学 院,西安 7 0 4 ) 西 10 9
本手段 ,它包括数据采集和数据分析两个步骤 。选择合 适、 高效 的数据采集 方法不仅能够提高获取数据的精度 ,而且节 省被测试 系统 的资源 ,尽可能小地影响被测系统。
linux下查看内存频率,内核函数,cpu频率

linux下查看内存频率,内核函数,cpu频率查看CPU:cat /proc/cpuinfo# 总核数 = 物理CPU个数 X 每颗物理CPU的核数# 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数# 查看物理CPU个数cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l# 查看每个物理CPU中core的个数(即核数)cat /proc/cpuinfo| grep "cpu cores"| uniq# 查看逻辑CPU的个数cat /proc/cpuinfo| grep "processor"| wc -l# 查看CPU信息(型号)cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -cprocessor :系统中逻辑处理核的编号。
对于单核处理器,则课认为是其CPU编号,对于多核处理器则可以是物理核、或者使⽤超线程技术虚拟的逻辑核vendor_id :CPU制造商cpu family :CPU产品系列代号model :CPU属于其系列中的哪⼀代的代号model name:CPU属于的名字及其编号、标称主频stepping :CPU属于制作更新版本cpu MHz :CPU的实际使⽤主频cache size :CPU⼆级缓存⼤⼩physical id :单个CPU的标号siblings :单个CPU逻辑物理核数core id :当前物理核在其所处CPU中的编号,这个编号不⼀定连续cpu cores :该逻辑核所处CPU的物理核数apicid :⽤来区分不同逻辑核的编号,系统中每个逻辑核的此编号必然不同,此编号不⼀定连续fpu :是否具有浮点运算单元(Floating Point Unit)fpu_exception :是否⽀持浮点计算异常cpuid level :执⾏cpuid指令前,eax寄存器中的值,根据不同的值cpuid指令会返回不同的内容wp :表明当前CPU是否在内核态⽀持对⽤户空间的写保护(Write Protection)flags :当前CPU⽀持的功能bogomips :在系统内核启动时粗略测算的CPU速度(Million Instructions Per Second)clflush size :每次刷新缓存的⼤⼩单位cache_alignment :缓存地址对齐单位address sizes :可访问地址空间位数power management :对能源管理的⽀持,有以下⼏个可选⽀持功能: ts: temperature sensor fid: frequency id control vid: voltage id control ttp: thermal trip tm: stc: 100mhzsteps: hwpstate:查看内存:sudo cat /proc/meminfo这个命令只能看当前内存⼤⼩,已⽤空间等等。
Linux命令行中的系统监控和报警技巧

Linux命令行中的系统监控和报警技巧Linux作为一种稳定可靠的操作系统,在服务器和大型计算机系统中被广泛使用。
对于管理员来说,有效监控系统的健康状况,并在出现问题时迅速报警是非常重要的。
本文将介绍一些在Linux命令行下实现系统监控和报警的技巧,帮助管理员更好地管理和维护系统。
1. 基础系统监控指标为了及时发现系统性能问题,我们首先需要了解一些基础的系统监控指标。
下面是一些常用的命令行工具,可以获取这些指标的信息:1.1 top:显示当前系统中运行的进程列表和系统资源的使用情况,如CPU、内存和磁盘等。
1.2 mpstat:查看系统的CPU使用情况,包括每个核心的负载和闲置时间。
1.3 free:用于显示系统内存的使用情况。
1.4 df:查看磁盘使用情况和可用空间。
1.5 iostat:用于监控系统磁盘和I/O设备的使用情况。
通过使用这些命令,管理员可以定期检查系统的运行状态,及时发现资源瓶颈和异常情况。
2. 高级系统监控技巧除了基础的系统监控指标外,Linux还提供了一些高级的监控技巧,帮助管理员更全面地了解系统的运行情况。
2.1 sar:System Activity Reporter(系统活动报告器)是一个强大的系统性能监控工具,可以收集CPU、内存、磁盘、网络和I/O等方面的数据,并生成报告供管理员分析。
使用sar命令,管理员可以查看历史数据,分析系统的使用模式和趋势,并根据需要调整系统配置。
2.2 vmstat:用于监控系统的虚拟内存、进程、CPU利用率和I/O等信息。
通过使用vmstat命令,管理员能够快速了解系统的性能状况,实时监控系统的各项参数。
2.3 netstat:用于监控网络连接和网络统计信息。
管理员可以使用netstat命令查看当前连接到系统的网络服务和端口,以及网络流量的情况。
除了上述命令外,还有一些其他的工具和技术可以用于系统监控,如nmap、iftop、htop等。
如何在Linux系统中查看系统硬件信息

如何在Linux系统中查看系统硬件信息在使用Linux系统时,了解计算机的硬件信息对于优化性能、故障排除和系统管理都非常重要。
幸运的是,在Linux中,我们可以使用一些命令和工具来查看系统的硬件信息。
本文将介绍在Linux系统中查看系统硬件信息的几种常用方法。
1. 使用lshw命令lshw是Linux硬件检测工具,它可以提供完整的硬件信息。
要使用lshw命令,请按照以下步骤操作:打开终端窗口,输入以下命令并按下回车键:```sudo lshw```系统可能会要求你输入管理员密码以获得root访问权限。
一旦通过验证,lshw将会列出所有系统硬件的详细信息,包括处理器、内存、磁盘、显卡等。
你可以根据需要滚动查看或使用管道将结果输出到文件中。
2. 使用dmidecode命令dmidecode是一个命令行工具,用于从BIOS中读取硬件信息。
要使用dmidecode命令,请按照以下步骤操作:打开终端窗口,输入以下命令并按下回车键:sudo dmidecode```dmidecode将显示系统的各种硬件组件的详细信息,包括处理器、内存、磁盘、主板、BIOS等。
通过阅读该命令的输出,你可以了解系统的硬件规格和配置信息。
3. 使用lspci命令lspci是一个用于列出PCI设备信息的命令。
要使用lspci命令,请按照以下步骤操作:打开终端窗口,输入以下命令并按下回车键:```lspci```lspci命令将列出所有PCI设备的信息,包括网络适配器、声卡、显卡、USB控制器等。
你可以根据需要滚动查看或使用管道将结果输出到文件中。
4. 使用lsblk命令lsblk命令可以用来显示系统中所有块设备的信息,包括硬盘、分区和挂载点。
要使用lsblk命令,请按照以下步骤操作:打开终端窗口,输入以下命令并按下回车键:lsblk```lsblk命令将显示系统中所有块设备的树形结构,包括设备名称、大小、挂载点等。
通过阅读该命令的输出,你可以了解系统中存储设备的配置情况。
Linux命令高级技巧使用sar命令收集和分析系统性能数据

Linux命令高级技巧使用sar命令收集和分析系统性能数据Linux系统的性能监控和调优对于系统管理员和开发人员来说是非常重要的。
sar命令是一个常用的性能分析工具,可以帮助我们收集和分析系统性能数据。
本文将介绍如何使用sar命令来收集和分析系统性能数据的高级技巧。
一、sar命令简介sar命令是System Activity Reporter的缩写,可以收集系统的性能数据,包括CPU使用率、内存使用率、网络流量、磁盘IO等。
sar命令能够以不同的时间间隔收集数据,并将其存储在日志文件中,以供后续分析和报告。
二、sar命令的安装与基本用法sar命令通常是通过安装sysstat软件包来获取的。
在大多数Linux发行版中,可以使用以下命令来安装sysstat:```sudo apt-get install sysstat # Ubuntu/Debiansudo yum install sysstat # CentOS/RHEL```安装完成后,我们可以使用sar命令来收集系统性能数据。
以下是sar命令的一些常用选项:- -u: 收集CPU使用率数据- -r: 收集内存使用率数据- -n DEV: 收集网络流量数据,DEV为具体的网络设备名称- -b: 收集磁盘IO数据- -q: 收集系统负载数据例如,要收集CPU使用率数据,可以使用以下命令:```sar -u 1 10 # 每隔1秒收集一次,一共收集10次```三、sar命令的输出与格式说明sar命令的输出通常是以文本形式呈现的,包含了一系列的性能数据。
以下是一个示例输出:```12:00:01 CPU %user %nice %system %iowait %steal %idle12:00:02 all 0.30 0.00 0.20 0.00 0.00 99.5012:00:03 all 0.40 0.00 0.20 0.00 0.00 99.40...```输出中的各列含义如下:- 时间戳(Time): 记录数据采集时的时间- CPU: 表示该行数据对应的是整个系统或特定CPU核心的数据- %user: 用户态CPU使用率- %nice: 以较低优先级运行的进程(如nice命令调整优先级)的CPU使用率- %system: 内核态CPU使用率- %iowait: 等待IO完成的CPU使用率- %steal: 被其他虚拟机偷取的CPU使用率- %idle: CPU空闲率四、sar命令的高级使用技巧1. 收集过去的系统性能数据sar命令可以指定一个日志文件作为输入来分析过去的系统性能数据。
linux系统常用监控指标

linux系统常用监控指标Linux系统常用监控指标Linux系统中,监控指标是评估系统性能和健康状况的重要依据。
通过监控指标,可以及时发现问题并及时采取措施,保证系统的稳定和高效运行。
本文将介绍Linux系统常用的监控指标。
一、CPU使用率CPU使用率是衡量系统负载的重要指标之一。
通过监控CPU使用率可以了解系统的运行状况,判断是否存在CPU资源瓶颈。
通常使用top命令或者sar命令来查看CPU使用率。
二、内存使用情况内存是系统性能的关键因素之一,合理的内存使用可以提升系统的运行效率。
通过监控内存使用情况,可以了解系统内存的分配和使用情况,判断是否存在内存不足的情况。
常用的命令有free和top 命令。
三、磁盘I/O磁盘I/O是指计算机与硬盘之间的数据传输,磁盘I/O的性能直接影响系统的整体性能。
通过监控磁盘I/O指标,可以了解磁盘的读写速度和响应时间,判断是否存在磁盘I/O瓶颈。
常用的命令有iostat和sar命令。
四、网络流量网络流量是指数据在网络中的传输情况,网络流量的监控可以帮助我们了解网络的负载情况,判断是否存在网络瓶颈。
通过监控网络流量指标,可以了解网络的带宽使用情况,常用的命令有netstat 和iftop命令。
五、进程状态进程是系统中正在运行的程序的实例,进程的状态可以反映系统的运行情况。
通过监控进程状态指标,可以了解系统中各个进程的运行情况,判断是否存在进程过多或者进程阻塞的情况。
常用的命令有ps和top命令。
六、系统负载系统负载是指系统中正在运行的进程数目,系统负载的大小可以反映系统的工作负荷。
通过监控系统负载指标,可以了解系统的繁忙程度,判断是否存在系统负载过高的情况。
常用的命令有uptime 和top命令。
七、文件打开数文件打开数是指系统中打开的文件数量,文件打开数的过高可能会导致系统资源的浪费。
通过监控文件打开数指标,可以了解系统中打开文件的情况,判断是否存在文件句柄泄漏或者文件描述符不足的情况。
linux查看cpu信息

linux查看cpu信息Linux查看CPU信息在Linux系统中,我们可以通过一些命令和工具来查看CPU相关的信息。
本文将介绍一些常用的方法来获取CPU信息,包括CPU型号、核心数、频率等。
1. /proc/cpuinfo文件在Linux系统中,/proc目录是一个虚拟文件系统,里面包含了许多与系统硬件相关的文件。
其中,/proc/cpuinfo文件包含了CPU的详细信息。
我们可以使用cat命令来查看该文件的内容。
打开终端,输入以下命令:```cat /proc/cpuinfo```执行命令后,你将看到一系列关于CPU的信息。
包括CPU型号、频率、核心数等。
该命令会将系统中所有的CPU信息列出来,如果你的系统有多颗CPU,可能会看到多段输出。
2. lscpu命令lscpu是一个用于显示CPU架构信息的命令行工具。
它可以提供更为详细的CPU信息,包括架构、核心数、线程数等。
在终端输入以下命令来安装lscpu:```sudo apt-get install lscpu```安装完成后,输入以下命令来查看CPU信息:```lscpu```执行命令后,你将看到更为清晰明了的CPU信息,包括架构、CPU型号、核心数、线程数等。
3. dmidecode命令dmidecode是一个用于获取系统硬件信息的命令行工具。
它可以显示关于主板、内存、BIOS等各个硬件组件的详细信息,其中也包括了CPU信息。
在终端输入以下命令来安装dmidecode:```sudo apt-get install dmidecode```安装完成后,输入以下命令来查看CPU信息:```sudo dmidecode -t processor```执行命令后,你将看到关于CPU的详细信息,包括制造商、型号、核心数、线程数等。
4. top命令top是一个用于实时查看系统资源使用情况的命令行工具。
它可以显示当前CPU的使用情况,并提供一些有关CPU的基本信息。
统信操作系统基本参数获取

统信操作系统基本参数获取
统信操作系统是一种基于Linux的操作系统,它具有许多基本参数可以通过命令行或者图形界面来获取。
以下是一些常见的基本参数获取方法:
1. 系统版本信息,可以通过命令 `cat /etc/issue` 或者
`cat /etc/-release` 来获取系统的版本信息,这会显示操作系统的发行版本和版本号。
2. 内核版本,通过命令 `uname -r` 可以获取当前系统的内核版本号。
3. CPU 信息,可以使用命令 `cat /proc/cpuinfo` 来获取CPU的详细信息,包括型号、核心数、频率等。
4. 内存信息,通过命令 `free -h` 可以查看系统的内存使用情况,包括总内存、已使用内存、空闲内存等。
5. 磁盘空间,使用命令 `df -h` 可以查看系统中各个挂载点的磁盘空间使用情况,包括总空间、已用空间、剩余空间等。
6. 网络信息,可以通过命令 `ifconfig` 或者 `ip addr` 来获取系统的网络接口信息,包括IP地址、子网掩码、MAC地址等。
7. 运行进程,通过命令 `ps aux` 可以查看系统中正在运行的进程列表,包括进程的PID、占用CPU和内存的情况等。
以上是一些常见的获取统信操作系统基本参数的方法,你可以根据具体的需求选择合适的命令来获取相应的信息。
希望以上信息能够满足你的需求。
Linux系统性能测试与评估方法

Linux系统性能测试与评估方法Linux操作系统作为开源的操作系统,被广泛应用于服务器领域。
保证Linux系统的性能稳定和高效是非常重要的,而系统性能测试与评估是实现这一目标的关键步骤。
本文将介绍Linux系统性能测试与评估的方法。
一、性能测试的目的和原则性能测试的目的是通过采用一系列规定的测试方法和工具来检测目标系统在不同压力下的性能表现。
性能测试的原则包括:1.全面性:测试应该覆盖目标系统的各个方面,包括CPU、内存、磁盘IO、网络等。
2.可重复性:测试过程应该是可重复的,即相同条件下的测试应该得到相同的结果。
3.可扩展性:测试应该能够模拟现实生产环境下的负载情况,能够适应未来硬件和软件的升级。
二、性能测试的方法1.基准测试基准测试是通过对系统进行一系列测试,以获取系统在正常负载下的性能参数作为基准值。
可以选择常用的基准测试工具,如UnixBench、SPEC等,通过运行这些工具来获取基准值。
2.压力测试压力测试是通过模拟真实负载对系统进行测试,以评估系统在高负载下的性能表现。
可以选择工具如Apache Bench、JMeter等,通过模拟高并发请求来测试系统的性能。
3.负载测试负载测试是通过增加系统的负载,评估系统在高负载下的性能表现。
可以选择工具如Sysbench、DD等,可以对CPU、内存、磁盘IO等进行负载测试。
三、性能评估的方法1.监控工具监控工具可以实时监测系统的各项性能指标,如CPU利用率、内存利用率、磁盘IO等。
可以选择工具如top、vmstat、sar等来进行监控。
2.日志分析通过分析系统的日志文件,可以获取系统在不同时间段的性能信息。
可以选择工具如logwatch、Syslog等进行日志分析,以便对系统性能进行评估。
3.报告和分析根据测试结果和监控数据,生成报告,并进行分析。
在报告中可以包括测试环境、测试过程、测试结果等信息,并给出相应的改进建议。
四、案例分析以某公司的Web服务器为例,进行性能测试和评估。
Linux命令高级技巧使用perf进行系统性能分析

Linux命令高级技巧使用perf进行系统性能分析Linux命令高级技巧:使用perf进行系统性能分析Linux操作系统是一款广泛使用的开源操作系统,性能优化是使用Linux系统的开发人员和系统管理员必须掌握的技能。
在Linux系统中,perf是一个重要的工具,可以用于系统性能分析和调优。
本文将介绍perf命令的基本用法和高级技巧,帮助读者更好地利用perf进行系统性能分析。
1. perf概述perf是Linux内核中的一款性能分析工具,可以收集系统的各种事件,并提供详细的性能分析报告。
它利用了Linux内核中的性能事件子系统,可以监测CPU的硬件性能计数器、trace用户态和内核态的函数调用、记录程序的事件等。
使用perf可以帮助开发人员和系统管理员了解系统的性能瓶颈,以及优化程序和系统的方法。
2. 安装perfperf是Linux内核的一部分,通常已经默认安装在大多数Linux发行版中。
可以通过以下命令检查perf是否已经安装:```$ perf --version```如果没有安装,可以使用包管理工具进行安装。
例如,使用apt-get命令安装perf:```$ sudo apt-get install linux-tools-common linux-tools-$(uname -r)```3. 基本用法perf命令的基本用法非常简单,可以通过perf [options] [command]的方式运行。
其中,options是一些参数配置,command是要执行的命令或程序。
以下是perf的一些常用命令行参数:- record:用于记录性能事件,并生成数据文件以供后续分析。
例如,记录CPU的硬件性能计数器事件:```$ perf record -e cycles,instructions -c 10000 command```- report:用于分析和展示从record阶段收集到的数据。
例如,生成性能分析报告:```$ perf report```- top:以类似top命令的方式展示系统当前的性能状况和占用资源最多的进程。
linux 获取cpu利用率的函数

linux 获取cpu利用率的函数摘要:1.Linux中获取CPU利用率的方法2.CPU利用率计算公式和步骤3.具体操作示例正文:在Linux系统中,获取CPU利用率的方法主要有两种:一种是通过/proc 文件系统获取,另一种是通过SNMP服务获取。
首先,我们来看通过/proc文件系统获取CPU利用率的方法。
在Linux系统中,/proc文件系统是一个虚拟的文件系统,它提供了关于系统中各个进程和系统资源的信息。
其中,我们可以通过查看/proc/stat文件来获取CPU的使用情况。
具体的查看方法如下:```bashcat /proc/stat```这个命令会显示CPU的使用情况,包括用户的模式(user)、低优先级的用户模式(nice)、系统内核模式(system)以及系统空闲的处理器时间(idle)。
通过这些信息,我们可以计算出CPU的利用率。
CPU利用率的计算公式如下:CPU利用率= (用户模式+ 系统模式+ 低优先级用户模式)/ 处理器核数* 100%接下来,我们来看如何通过SNMP服务获取CPU利用率。
SNMP (Simple Network Management Protocol)是一种用于管理和监控网络设备的协议。
在Linux系统中,我们可以安装SNMP服务,并通过HOST-RESOURCES-MIB库中的节点获取CPU利用率等信息。
具体的操作步骤如下:1.在Linux虚拟机上安装SNMP服务。
2.通过SNMP库中的hrProcessorLoad节点获取CPU负载值。
3.根据获取到的CPU负载值,计算CPU利用率。
CPU利用率的计算公式如下:CPU利用率= (CPU负载值之和/ 处理器的个数)* 100%以上就是如何在Linux系统中获取CPU利用率的方法和具体的操作步骤。
Linux终端命令之系统硬件信息查看

Linux终端命令之系统硬件信息查看在Linux操作系统中,终端命令提供了一种快速方便的方式来查看系统硬件信息。
通过使用合适的命令,我们可以获取关于CPU、内存、硬盘和网络等方面的详细信息。
本文将介绍几个常用的Linux终端命令,用于查看系统硬件信息。
1. 查看CPU信息首先,我们可以使用"cat /proc/cpuinfo"命令来查看CPU的详细信息。
该命令会输出关于每个CPU核心的信息,包括型号、频率和缓存等。
2. 查看内存信息要查看系统的内存信息,可以使用"cat /proc/meminfo"命令。
该命令可以显示可用内存、已用内存和缓存等信息。
3. 查看硬盘信息使用"df -h"命令可以查看硬盘的使用情况和可用空间。
该命令将列出每个文件系统的挂载点、容量和已用空间等信息。
若要查看更详细的硬盘信息,可以使用"sudo fdisk -l"命令。
该命令将显示所有磁盘分区的信息,包括分区类型和大小等。
4. 查看网络信息要查看网络接口的信息,可以使用"ifconfig"命令。
该命令将列出所有网络接口的配置信息,包括IP地址、MAC地址和网络状态等。
若要查看网络连接的详细信息,可以使用"netstat"命令。
例如,"netstat -tuln"命令可显示当前打开的所有TCP和UDP端口。
5. 查看其他硬件信息除了CPU、内存、硬盘和网络信息之外,我们还可以使用其他命令来查看其他硬件设备的信息。
例如,要查看显示设备信息,可以使用"lspci | grep VGA"命令。
另外,要查看声卡信息,可以使用"lspci | grep Audio"命令。
总结:通过使用以上的Linux终端命令,我们可以方便快捷地查看系统硬件信息。
从CPU到硬盘再到网络设备,这些命令可以帮助我们详细了解系统的硬件配置和性能情况。
Linux记录-linux系统常用监控指标

Linux记录-linux系统常⽤监控指标1.Linux运维基础采集项做运维,不怕出问题,怕的是出了问题,抓不到现场,两眼摸⿊。
所以,依靠强⼤的监控系统,收集尽可能多的指标,意义重⼤。
但哪些指标才是有意义的呢,本着从实践中来的思想,各位⼯程师在长期摸爬滚打中总结出来的经验最有价值。
在各位运维⼯程师长期的⼯作实践中,我们总结了在系统运维过程中,经常会参考的⼀些指标,主要包括以下⼏个类别:CPULoad内存磁盘IO⽹络相关内核参数ss 统计输出端⼝采集核⼼服务的进程存活信息采集关键业务进程资源消耗NTP offset采集DNS解析采集每个类别,具体的详细指标如下,这些指标,都是open-falcon的agent组件直接⽀持的。
falcon-agent每隔⼀定时间间隔(⽬前是60秒)会采集⼀次相关的指标,并汇报给server端。
2. CPU相关采集项计算⽅法:通过采集/proc/stat来得到,⼤家可以参考sar命令的统计输出来理解。
cpu.idle:Percentage of time that the CPU or CPUs were idle and the system did not have an outstanding disk I/O request.cpu.busy:与cpu.idle相对,他的值等于100减去cpu.idle。
cpu.guest:Percentage of time spent by the CPU or CPUs to run a virtual processor.cpu.iowait:Percentage of time that the CPU or CPUs were idle during which the system had an outstanding disk I/O request.cpu.irq:Percentage of time spent by the CPU or CPUs to service hardware interrupts.cpu.softirq:Percentage of time spent by the CPU or CPUs to service software interrupts.cpu.nice:Percentage of CPU utilization that occurred while executing at the user level with nice priority.cpu.steal:Percentage of time spent in involuntary wait by the virtual CPU or CPUs while the hypervisor was servicing another virtual processor.cpu.system:Percentage of CPU utilization that occurred while executing at the system level (kernel).er:Percentage of CPU utilization that occurred while executing at the user level (application).t:cpu核数。
Linux命令高级技巧使用vmstat命令查看内存与交换空间使用情况

Linux命令高级技巧使用vmstat命令查看内存与交换空间使用情况Linux命令高级技巧:使用vmstat命令查看内存与交换空间使用情况vmstat命令是Linux系统自带的一个工具,可以提供关于系统的虚拟内存、进程、CPU以及IO等方面的信息。
本文将详细介绍如何使用vmstat命令来查看系统的内存和交换空间的使用情况。
一、什么是vmstat命令vmstat是virtual memory statistics(虚拟内存统计)的缩写,它可以基于系统当前的状态提供多种信息。
vmstat命令提供了关于系统的综合性指标,可以用于监控性能问题、找出系统瓶颈,以及提供进一步的系统优化建议。
二、使用vmstat命令查看内存的使用情况1. 打开终端,并输入以下命令:```$ vmstat```2. vmstat命令会实时显示当前系统的内存使用情况。
输出的结果会包含以下几个参数解读:```procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st0 0 0 103180 80044 470400 0 0 0 0 0 0 0 0 100 0 0```参数解读:- procs:任务队列和进程使用情况;- memory:内存使用情况;- swap:交换空间使用情况;- io:I/O使用情况;- system:系统运行时间和CPU使用情况;- cpu:CPU使用情况。
在这里我们只关注memory和swap两个参数。
3. 查看内存使用情况- free:已经被内核释放的空闲内存;- buff:作为buffer缓存的内存;- cache:作为page cache缓存的内存。
这里一共有三个参数,free表示空闲内存,buff表示作为buffer缓存的内存,cache表示作为page cache缓存的内存。
kretprobe 获取函数参数

kretprobe 获取函数参数Kretprobe 获取函数参数Kretprobe是Linux内核提供的一个功能强大的跟踪工具,它可以用于在内核中插入钩子来监视系统调用、函数调用等事件。
在这篇文章中,我们将介绍如何使用Kretprobe来获取函数参数。
一、什么是Kretprobe?Kretprobe是内核提供的一个跟踪工具,它可以用于在函数返回时执行一些操作。
Kretprobe允许我们监视任何内核函数的返回值,并且可以访问该函数的所有参数和局部变量。
这使得我们能够非常方便地进行内核调试和性能分析。
二、如何使用Kretprobe获取函数参数?要使用Kretprobe获取函数参数,我们需要遵循以下步骤:1. 定义一个结构体来保存我们要监视的函数的参数和返回值。
2. 定义一个回调函数,在该回调函数中访问我们要监视的函数的参数和返回值,并将它们保存到先前定义的结构体中。
3. 使用kprobes_register()注册我们定义的回调函数。
4. 在需要监视的地方添加kprobes_probe()来触发回调函数。
下面是一个示例代码:```#include <linux/kernel.h>#include <linux/module.h>#include <linux/kprobes.h>struct my_data {int arg1;char *arg2;long ret;};static int my_callback(struct kretprobe_instance *ri, struct pt_regs *regs){struct my_data *data = (struct my_data *)ri->data;data->arg1 = regs->di;data->arg2 = (char *)regs->si;data->ret = regs->ax;return 0;}static struct kretprobe my_kretprobe = {.handler = my_callback,};static int __init my_init(void){int ret;my_kretprobe.kp.symbol_name = "my_function";ret = register_kretprobe(&my_kretprobe);if (ret < 0) {printk(KERN_INFO "Failed to register kretprobe\n");return ret;}printk(KERN_INFO "Registered kretprobe successfully\n");return 0;}static void __exit my_exit(void){unregister_kretprobe(&my_kretprobe);}module_init(my_init);module_exit(my_exit);```三、如何使用Kprobes_probe()触发回调函数?要使用Kprobes_probe()触发回调函数,我们需要遵循以下步骤:1. 定义一个结构体来保存我们要监视的函数的参数和返回值。
linux监控指标和命令
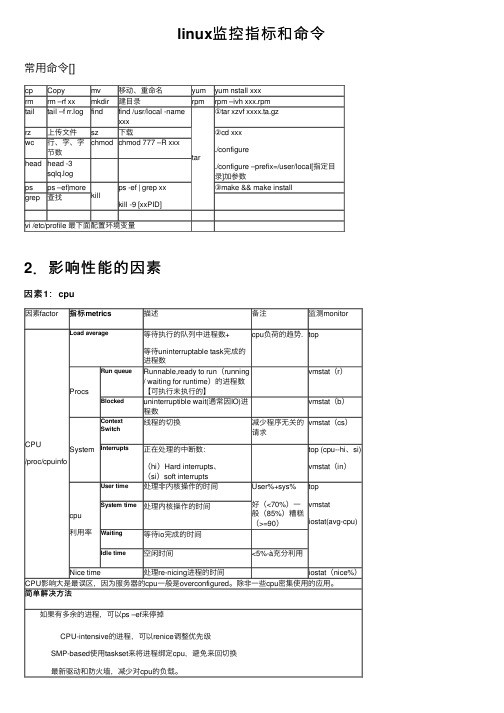
linux 监控指标和命令常⽤命令[]cp Copymv 移动、重命名yum yum nstall xxx rm rm –rf xx mkdir 建⽬录rpm rpm –ivh xxx.rpm tailtail –f rr.logfindfind /usr/local -name xxxtar①tar xzvf xxxx.ta.gz rz 上传⽂件sz 下载②cd xxx ./configure./configure –prefix=/user/local[指定⽬录]加参数wc ⾏、字、字节数chmod chmod 777 –R xxxhead head -3sqlq.logps ps –ef|morekill ps -ef | grep xxkill -9 [xxPID]③make && make install grep查找vi /etc/profile 最下⾯配置环境变量2.影响性能的因素因素1:cpu因素factor指标metrics描述备注监测monitorCPU /proc/cpuinfoLoad average等待执⾏的队列中进程数+等待uninterruptable task 完成的进程数cpu 负荷的趋势.topProcsRun queueRunnable,ready to run (running / waiting for runtime )的进程数【可执⾏未执⾏的】vmstat (r )Blocked uninterruptible wait(通常因IO)进程数vmstat (b )System Context Switch线程的切换减少程序⽆关的请求vmstat (cs )Interrupts正在处理的中断数:(hi )Hard interrupts 、(si )soft interruptstop (cpu--hi 、si)vmstat (in )cpu 利⽤率User time 处理⾮内核操作的时间User%+sys%好(<70%)⼀般(85%)糟糕(>=90)topvmstat iostat(avg-cpu) System time处理内核操作的时间Waiting 等待io 完成的时间Idle time空闲时间<5%-à充分利⽤Nice time 处理re-nicing 进程的时间 iostat (nice%)CPU 影响⼤是最误区,因为服务器的cpu ⼀般是overconfigured 。
linux查看系统性能

linux查看系统性能1. 查看内存和CPU信息cat /proc/cpuinfo cpu信息cat /proc/meminfo |grep MemTotal 内存信息查看物理cpu个数:cat /proc/cpuinfo | grep 'physical id' | sort | uniq | wc -l查看逻辑cpu个数:cat /proc/cpuinfo | grep 'processor' | wc -l查看单cpu是⼏核:cat /proc/cpuinfo | grep 'cores' |uniq查看cpu主频: cat /proc/cpuinfo | grep 'MHz'查看cpu是32位还是64位: getconf LONG_BITecho $HOSTTYPEuname -a2. 查看主机运⾏时间和Linux系统负载uptime[linux @ localhost]$ uptime10:19:04 up 257 days, 18:56, 12 users, load average: 2.10, 2.10,2.0910:19:04 //系统当前时间up 257 days, 18:56 //主机已运⾏时间,时间越⼤,说明你的机器越稳定。
12 user //⽤户连接数,是总连接数⽽不是⽤户数load average // 系统平均负载,统计最近1,5,15分钟的系统平均负载信息显⽰依次为:现在时间、系统已经运⾏了多长时间、⽬前有多少登陆⽤户、系统在过去的1分钟、5分钟和15分钟内的平均负载。
系统平均负载是指在特定时间间隔内运⾏队列中的平均进程数。
在0.00-1.00之间正常。
3. 实时监控CPUtoptop:实时显⽰系统中各个进程的资源占⽤情况,类似于windows的任务管理器。
第⼀⾏:15:39:48 当前系统时间up 293 days, 21:48 已经运⾏了293天21⼩时48分3 users 当前有3个⽤户登录load average: 0.01, 0.04, 0.09 分别为1分钟,5分钟,15分钟的系统负载。
Linux系统性能监测工具的Python脚本

Linux系统性能监测工具的Python脚本Linux系统是一种非常流行的操作系统,广泛应用于服务器、个人电脑以及嵌入式设备等。
用户通常会对Linux系统的性能进行监测和优化,以确保系统运行的稳定性和高效性。
为了简化性能监测的过程,我们可以借助Python编程语言来开发一些实用的脚本工具。
在本文中,我们将介绍一些用Python编写的Linux系统性能监测工具的示例脚本。
这些工具可以帮助我们收集和分析系统性能数据,以便我们更好地了解系统的运行状态。
一、系统负载监测脚本系统负载是指运行队列中的进程数,也可以理解为正在等待运行的进程数量。
系统负载越高,表示系统处理任务的能力越有限。
我们可以编写一个Python脚本来监测系统的负载情况。
```pythonimport osdef get_load_avg():load_avg = os.getloadavg()return load_avgif __name__ == "__main__":# 获取系统负载load_avg = get_load_avg()print("系统负载:", load_avg)```这段脚本使用了os模块的getloadavg()函数来获取系统负载信息,并打印出来。
我们可以使用cron定时任务来执行这个脚本,以便在特定时间间隔内收集系统的负载数据。
二、内存使用情况监测脚本内存是系统中非常重要的资源之一,合理地监测和管理内存的使用情况可以提升系统的性能。
下面是一个用于监测内存使用情况的Python脚本示例:```pythonimport psutildef get_memory_usage():memory = psutil.virtual_memory()return {"total": memory.total,"available": memory.available,"percent": memory.percent}if __name__ == "__main__":# 获取内存使用情况memory_usage = get_memory_usage()print("总内存:", memory_usage["total"])print("可用内存:", memory_usage["available"])print("内存占用率:", memory_usage["percent"])```这个脚本使用了psutil模块来获取系统的内存使用情况,并将结果以字典的形式返回。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Linux攻略系统性能监测参数获取的方法
目前的工程需要简单的监测一下Linux系统的:CPU负载、内存消耗情况、几个指定目录的磁盘空间、磁盘I/O、swap的情况还有就是网络流量。
Linux下的性能检测工具其实都有很多。
mrtg(http:
//people.ee.ethz.ch/~oetiker/webtools/mrtg/)就是一个很不错的选择。
不过用mrtg 就要装 sysstat、apache、snmp、perl之类的东西。
而且安装也要好几个步骤,似乎比较麻烦。
本来也想直接调用sar、vmstat之类的命令,parse一下结果就算了。
哪知道发现不同的版本的linux这些命令的结果也都是不一样。
既然要按版本 parse它们的结果,那还不如直接去系统里面获得算了。
于是研究了一下sysstat(http:
///projects/sysstat/)和gkrellm( )的源代码,找到监测性能的数据所在。
1、CPU
在文件"/proc/stat"里面就包含了CPU的信息。
每一个CPU的每一 tick用在什么地方都在这个文件里面记着。
后面的数字含义分别是: user、nice、sys、idle、iowait。
有些版本的kernel没有iowait这一项。
这些数值表示从开机到现在,CPU的每tick用在了哪里。
例如:
cpu0 256279030 0 11832528 1637168262
就是cpu0从开机到现在有 256279030 tick用在了user消耗,11832528用在了sys 消耗。
所以如果想计算单位时间(例如1s)里面CPU的负载,那只需要计算1秒前后数值的差除以每一秒的tick数量就可以了。
gkrellm就是这样实现的:((200 * (v2 - v1) / CPU_TICKS_PER_SECOND) + 1) /2
例如,第一次读取/proc/stat,user的值是256279030;一秒以后再读一次,值是256289030,那么CPU在这一秒的user消耗就是:((200 * (256289030 - 256279030) / CPU_TICKS_PER_SECOND) + 1) /2 = ((10000 * 200 / 1000000) + 1) / 2 = 1%了。
2、内存消耗
文件"/proc/meminfo"里面包含的就是内存的信息,还包括了swap的信息。
例如:
$ cat /proc/meminfo
total: used: free: shared: buffers: cached:
Mem: 1057009664 851668992 205340672 0 67616768 367820800
Swap: 2146787328 164429824 1982357504
MemTotal: 1032236 kB
MemFree: 200528 kB
MemShared: 0 kB
……
不过从gkrellm的源代码看,有些版本没有前面那两行统计的信息,只能够根据下面的Key: Value这种各式的数据收集。
3、磁盘空间
从gkrellm的源代码看,这个是一个很复杂的数据。
磁盘分区的数据有可能分布在:/proc/mounts、/proc/diskstats、 /proc/partitions等等。
而且如果想要检查某几个特定的路径,还需要通过mount、df等命令的帮助。
为了减少麻烦,这个数据我就直接用 statfs 函数直接获得了。
int statfs(const char *path, struct statfs *buf);
这个函数只需要输入需要检查的路径名称,就可以返回这个路径所在的分区的空间使用情况:
总空间:buf.f_bsize * buf.f_blocks
空余空间:buf.f_bsize * buf.f_bavail
4、磁盘I/O
磁盘I/O的数据也同样比较复杂,有些版本看/proc/diskstats,有些版本看
/proc/partitions,还有些版本至今我也不知道在那里看……不过可以看到数据的版本也像CPU那样,需要隔一段时间取值,两次取值的差就是流量。
5、网络流量
网络流量也是五花八门,不过基本上都可以在/proc/net/dev里面获得。
同样也是需要两次取值取其差作为流量值。