Grid-based Knowledge Discovery Services for High Throughput Informatics
地理信息科学专业英语

专业术语英译汉affine 仿射band 波段cartography 制图学clip 剪切digitizer 数字化仪DLG 数字线划图dpi 每英寸点数edgematching 边缘匹配equator 赤道equiarea 等积geoid 大地水准面geospatial 地理空间GPS 全球定位系统Habitat 栖息地Interface 接口Item 项目Latitude 纬度legend 图例longitude 经度median 中值meridian 子午线metadata 元数据neatline 图廓线Object-Based 基于对象的parcel 宗地photogrammetry 摄影测量precipitation 降水量range 范围raster 栅格resample 重采样resolution 分辨率RMS 均方根scanner 扫描仪siting 选址TIGER 拓扑统一地理编码topology 拓扑tuple 数组UTM 通用横轴墨卡托投影vector 矢量专业术语汉译英保护区protected area比例尺Scale bar标准差Standard deviation标准图幅Standard picture frame单精度Single precision地理空间数据Geospatial data点缓冲区Point buffer动态分段Dynamic segmentation度量标准Metrics多项式变换Polynomial transformation高程基准Elevation base跟踪算法Tracking algorithm规则格网Rules grid过渡带Transition zone基于位置服务Based on location service 畸形线Malformation line几何变换Geometric transformation检验图Inspection chart解析几何Analytic geometry空间要素Space element平面坐标系统Planar coordinate system曲流河Meandering river人口普查地段Census Lot上四分位数The upper quartile矢量数据模型Vector data model数据可视化data visualization数据探查Data exploration双精度Double precision水文要素Hydrological elements泰森多边型Tyson Polygons统一建模语言Unified Modeling Language投影坐标系统Projection coordinate system 线缓冲区Line buffer遥感数据Remote sensing data用材林Timber forest晕渲法Halo rendering method指北针Compass属性表Property sheet最短路径分析Shortest path analysis最小二乘法Least squares method翻译例子如下。
管理学英语词汇

管理学英语词汇(1)目标mission/ objective集体目标group objective内部环境internal environment外部环境external environment计划planning组织organizing人事staffing领导leading控制controlling步骤process原理principle方法technique经理manager总经理general manager行政人员administrator主管人员supervisor企业enterprise商业business产业industry公司company效果effectiveness效率efficiency企业家entrepreneur权利power职权authority职责responsibility科学管理scientific management 现代经营管理modern operational management行为科学behavior science生产率productivity激励motivate 动机motive法律law法规regulation经济体系economic system管理职能managerial function产品product管理学必备英语词汇服务service利润profit满意satisfaction归属affiliation尊敬esteem自我实现self-actualization人力投入human input盈余surplus收入income成本cost资本货物capital goods机器machinery设备equipment建筑building存货inventory(2)经验法the empirical approach人际行为法the interpersonal behavior approach集体行为法the group behavior approach 协作社会系统法the cooperative social systems approach社会技术系统法the social—technical systems approach决策理论法the decision theory approach 数学法the mathematical approach系统法the systems approach随机制宜法the contingency approach 管理任务法the managerial roles approach经营法the operational approach人际关系human relation心理学psychology态度attitude压力pressure冲突conflict招聘recruit鉴定appraisal选拔select培训train报酬compensation授权delegation of authority协调coordinate业绩performance考绩制度merit system管理学必备英语词汇表现behavior下级subordinate偏差deviation检验记录inspection record误工记录record of labor—hours lost 销售量sales volume产品质量quality of products先进技术advanced technology顾客服务customer service策略strategy结构structure(3)领先性primacy普遍性pervasiveness忧虑fear 忿恨resentment士气morale解雇layoff批发wholesale零售retail程序procedure规则rule规划program预算budget共同作用synergy大型联合企业conglomerate资源resource购买acquisition增长目标growth goal专利产品proprietary product竞争对手rival晋升promotion管理决策managerial decision商业道德business ethics有竞争力的价格competitive price 供货商supplier小贩vendor利益冲突conflict of interests派生政策derivative policy开支帐户expense account批准程序approval procedure病假sick leave休假vacation工时labor-hour机时machine—hour资本支出capital outlay现金流量cash flow工资率wage rate税收率tax rate股息dividend现金状况cash position资金短缺capital shortage总预算overall budget资产负债表balance sheet可行性feasibility投入原则the commitment principle 投资回报return on investment生产能力capacity to produce实际工作者practitioner最终结果end result业绩performance个人利益personal interest福利welfare市场占有率market share创新innovation生产率productivity利润率profitability社会责任public responsibility董事会board of director组织规模size of the organization组织文化organizational culture目标管理management by objectives 评价工具appraisal tool激励方法motivational techniques控制手段control device个人价值personal worth优势strength弱点weakness机会opportunity威胁threat个人责任personal responsibility顾问counselor定量目标quantitative objective 定性目标qualitative objective可考核目标verifiable objective优先priority工资表payroll(4)策略strategy政策policy灵活性discretion多种经营diversification评估assessment一致性consistency应变策略consistency strategy公共关系public relation价值value抱负aspiration偏见prejudice审查review批准approval主要决定major decision分公司总经理division general manager 资产组合距阵portfolio matrix明星star问号question mark现金牛cash cow赖狗dog采购procurement人口因素demographic factor地理因素geographic factor公司形象company image产品系列product line合资企业joint venture破产政策liquidation strategy紧缩政策retrenchment strategy战术tactics(5)追随followership个性individuality性格personality安全safety自主权latitude悲观的pessimistic静止的static乐观的optimistic动态的dynamic灵活的flexible抵制resistance敌对antagonism折中eclectic(6)激励motivation潜意识subconscious地位status情感affection欲望desire压力pressure满足satisfaction自我实现的需要needs forself-actualization尊敬的需要esteem needs归属的需要affiliation needs安全的需要security needs生理的需要physiological needs 维持maintenance保健hygiene激励因素motivator概率probability强化理论reinforcement theory 反馈feedback奖金bonus股票期权stock option劳资纠纷labor dispute缺勤率absenteeism人员流动turnover奖励reward(7)特许经营franchise热诚zeal信心confidence鼓舞inspire要素ingredient忠诚loyalty奉献devotion作风style品质trait适应性adaptability进取性aggressiveness热情enthusiasm毅力persistence人际交往能力interpersonal skills 行政管理能力administrative ability 智力intelligence专制式领导autocratic leader民主式领导democratic leader自由放任式领导free-rein leader管理方格图the managerial grid工作效率work efficiency服从obedience领导行为leader behavior支持型领导supportive leadership 参与型领导participative leadership 指导型领导instrumental leadership成就取向型领导achievement—oriented leadership汉语新难词英译保险业the insurance industry保证重点指出ensure funding for priority areas补发拖欠的养老金clear up pension payments in arrears不良贷款non—performing loan层层转包和违法分包multi—level contracting and illegal subcontracting城乡信用社credit cooperative in both urban and rural areas城镇居民最低生活保障 a minimum standard of living for city residents城镇职工医疗保障制度the system of medical insurance for urban workers出口信贷export credit贷款质量loan quality贷款质量五级分类办法the five—category assets classification for bank loans防范和化解金融风险take precautions against and reduce financial risks防洪工程flood—prevention project非法外汇交易illegal foreign exchange transaction非贸易收汇foreign exchange earnings through nontrade channels非银行金融机构non-bank financial institutions费改税transform administrative fees into taxes跟踪审计follow—up auditing 工程监理制度the monitoring system for projects国有资产安全the safety of state—owned assets过度开垦excess reclamation合同管理制度the contract system for governing projects积极的财政政策pro-active fiscal policy 基本生活费basic allowance解除劳动关系sever labor relation金融监管责任制the responsibility system for financial supervision经济安全economic security靠扩大财政赤字搞建设to increase the deficit to spend more on development扩大国内需求the expansion of domestic demand拉动经济增长fuel economic growth粮食仓库grain depot粮食收购企业grain collection and storage enterprise粮食收购资金实行封闭运行closed operation of grain purchase funds粮食销售市场grain sales market劣质工程shoddy engineering乱收费、乱摊派、乱罚款arbitrary charges, fund—raising, quotas and fines骗汇、逃汇、套汇obtain foreign currency under false pretenses,not turn over foreign owed to the government and illegal arbitrage融资渠道financing channels商业信贷原则the principles for commercial credit社会保险机构social security institution失业保险金unemployment insurance benefits偷税、骗税、逃税、抗税tax evasion, tax fraud and refusal to pay taxes外汇收支foreign exchange revenue and spending安居工程housing project for low-income urban residents信息化information—based;informationization智力密集型concentration of brain power; Knowledge-intensive外资企业overseas-funded enterprises 下岗职工laid-off workers分流reposition of redundant personnel 三角债chain debts素质教育education for all—round development豆腐渣工程jerry—built projects社会治安情况law-and—order situation 民族国家nation state“**" "independence of T aiwan”台湾当局Taiwan authorities台湾同胞Taiwan compatriots台湾是中国领土不可分割的一部分.Taiwan is an inalienable part of the Chinese territory。
降水预报格点化技术在洪水预报业务中的应用

《河南水利与南水北调》2023年第10期防汛抗旱降水预报格点化技术在洪水预报业务中的应用王鹏1,张亮2(1.华北水利水电大学,河南郑州450045;2.河南河长学院,河南郑州450045)摘要:降水预报的时空分布特征是水文情报预报工作的重要参考依据,开展降水预报格点化技术在洪水预报中的精细化应用,能有效提高预报精度。
文章简要介绍了降水预报格点化研究工作的系统设计和技术功能,通过对降水预报产品进行格点化插值计算和时空权重分配提取,按照洪水预报数据库入库规则对雨量信息格点处理保存,实现将降水预报格点数据应用于洪水预报系统的目的,并向业务平台提供降水预报图层服务,丰富格点化技术应用功能。
关键词:格点化;雨量;权重;降水预报中图分类号:P339文献标识码:A文章编号:1673-8853(2023)10-0019-02Application of Grid Technology of Precipitation Forecast in Flood Forecast BusinessWANG Peng1,ZHANG Liang2(1.North China University of Water Resources and Electric Power,Zhengzhou450045,China;2.Henan Hechang University,Zhengzhou450045,China)Abstract:The spatiotemporal distribution characteristics of precipitation forecast are important reference basis for hydrological information forecast.The refined application of grid-based precipitation forecast technology in flood forecast can effectively improve the forecast accuracy.This paper briefly introduces the system design and technical functions of the research on grid-based precipitation forecast.Through grid interpolation calculation and space-time weight allocation and extraction of precipitation forecast products,the grid-based precipitation information is processed and saved according to the warehousing rules of flood forecast database.This achieves the purpose of applying grid-basedprecipitation forecast data to flood forecast system,and the precipitation forecast layer service is provided to the business platform to enrich the grid-based technology application functions.Key words:gridding;rainfall volume;weight;precipitation forecast1系统概述1.1研究背景格点化降水可有效表征一定范围内的面雨量,在洪水预报作业中具有基础参考作用。
CSR 培训 MR

MRs 最低要求
Requirement Area Business practices 商业行为 The Supplier and Production unit should be Transparent in their reporting报告透明 The Supplier/Production Unit should not use Undeclared Unit不得使用未经申报的外发单 位
Chemical Hazards化学危害物
Facility/Production Unit should have a maintained/updated chemical inventory list. Chemical Inventory list is a list of all chemical substances kept or used in the facility. The content of chemical inventory should include the chemical commercial name, identification numbers (CAS no.) , hazard information, amount of storage or amount of consumption and storage location. 定期更新 完整的化学品清单 Facility/Production Unit should have documented chemical purchasing procedures to prevent the purchase of Restricted/Banned substances化学品采购政策确保不采购限制或禁用化 学品 Facility/Production Unit should not use H&M banned organic solvents in any production processes
波特的价值链模型 中英

Chapter 6 Strategic Information System: Information Technology’s Application for Enterprise Strategy.波特的价值链模型(Porter’s Value-Chain Model)企业的产品利润系基企业一连串的加值活动(Value-Add Activities)所产生,而企业的加值活动分为主要活动(Primary Activities)与支持活动(SupportActivities)。
主要活动系为与产品与服务有直接关联的活动,而支持活动则包含支持主要活动,但与产品与服务无直接关联的所有措施(包含管理与支持的活动)。
主要活动分为「进货后勤(Inbound Logistic)」、「生产制造(Operation)」、「出货后勤(Outbound Logistic)」、「营销销售(Sale and Marketing)」、「售后服务(Service)」五大项,主掌产品与服务的生产过程。
支持活动则涵盖了整个主要活动的范畴,如采购管理(Procurement)、科技开发(Technology Development)、人力资源管理(Human Resource Management)、财务会计管理(FinancialManagement)、企业的基础设施(Enterprise Infrastructure)等。
策略推力模型(Strategic Thrust Model)五个策略攻击的领域:✧差异化(Differentiation)-企业选择一种或数种对顾客有价值的需求,以自身优势的能力,单独满足这些需求,让其他对手在顾客认知上产生差异。
✧成本(Cost)-提供相当利益给顾客,但价格较低,竞争优势以降低成本为主要手段。
✧创新(Innovation)-开发新产品、服务或创新作业流程。
✧成长(Growth)-利用营业额、规模、市场、产品范围的扩大与提升来创造及维持其优势。
一种基于栅格网的无路网路径规划方法

2022 年 3 月
江苏科技信息
Jiangsu Science & Technology Information
No. 7
March,2022
一种基于栅格网的无路网路径规划方法
倪冰洁
( 江苏省测绘研究所,江苏 南京 210013)
摘要:路径规划功能在现代各类导航软件中得到广泛的应用和推广,但在军事背景下,特种车辆行驶
暂行条例施行细则[ J] . 中国税务,1988(11) :15 - 17.
( 编辑 姚 鑫)
Research on information management of labor remuneration in scientific research institutions
格,从而为后续计算最短通行时间做基础。 根据正方
做准备。 以地理栅格内所占权重面积最大的地形为
形的地理信息栅格,计算通行时间可以考虑两种方
主,各类地形的权重系数各不相同,划分原理如图 3
式,分别为对角线、对边线,如图 4 所示。
所示。
2. 2 通行模型
路径规划结果与所乘用的交通工具有着直接关
系,交通工具所具备的能力与通行速度直接决定了路
( 上接第 48 页)
[11] 毛爱燕. 事业单位劳务报酬涉税处理探析[ J] .
行政事业资产与财务,2020(17) :56 - 57.
[12] 龚乐. 新形势下高校科研劳务费信息化管理思考
[ J] . 新会计,2019(9) :47 - 48.
找各类地址,提供驾车、骑行、步行等各类出行方式的
策与支持等基本功能。 其中数据部分包含了大量的
路径规划能力,以及实时导航功能。 然而商用导航软
外文翻译--关于万维网新时代的学报英文版

Web Semantics:Science,on the World Wide Web 1(2003)1–5EditorialA new journal for a new era of the World Wide WebWe are delighted to welcome you to the first issue of the Journal of Web Semantics.With your help we aim to make this journal the premier publication for a new era of computing:one in which machine-readable semantics enable an intelligently capable Web.The “Semantic Web”is the most well known version of this new vision,and,despite its relative youth,has al-ready promoted a flurry of action.From exciting new research to the deployment of industrial standards;from academic experimental prototypes to commer-cial endeavours:we are at the centre of a maelstrom of activity.The languages needed to define the Semantic Web;the architectural components and tools needed to build and maintain it;the content necessary to use it;and the applications that will exploit it –all these activities are happening at once and yet are interdepen-dent.This makes the Semantic Web an exciting place.First,a few questions:•What are “Web Semantics”,what technologies do we need to deliver semantics to the Web and how might they be used by Web-based applications?•Given the wide range and relative maturity of ac-tivities in the community,how will this journal provide the breadth and depth needed,and how will it itself become part of the Semantic Web?•How does this first issue reflect the ambitions of the Semantic Web and set the tone for the Journal of Web Semantics?Now,a few answers.1.Science,services and agents on the World Wide WebThe urge to find,collect,store and share information has always been with mankind.The Web has madethis easier than ever.It has revolutionized the way we seek information.It has brought democracy to publi-cation.It has speeded up the dissemination of facts,as well as fictions,to a global community.It offers a ubiquitous interface to databases and document man-agement systems and a universal connective fabric for intranets as well as the Internet.The good news is that if you need a piece of in-formation it is sure to be available to you somewhere.The problem is how to find it and how to integrate different pieces in a meaningful way.Document man-agement systems and search engines do not provide answers—they offer more or less relevant documents to be interpreted by the human reader.A query to a database only provides exact answers and cannot sug-gest results beyond its current content.To search for and link information,a person or some specific application must interpret the content of these information resources.To make the contents of documents and the links between them gener-ally machine -interpretable,to make the contents of databases interpretable on a conceptual level,we must associate with web resources metadata that conveys their semantics —hence the Semantic Web [1].The Semantic Web does not replace the Web;it offers an integrating descriptive fabric alongside the web for search engines,information brokers and ultimately ‘intelligent’agents.No one technology holds the monopoly of Web Semantics.For example:•Underpinning metadata with precise and shared se-mantics requires ontologies to provide a consensual,shared conceptualization of a domain based on a consensus building process (see [2]and Dill et al.in this issue).1570-8268/$–see front matter ©2003Elsevier B.V .All rights reserved.doi:10.1016/j.websem.2003.09.0022Editorial/Web Semantics:Science,Services and Agents on the World Wide Web1(2003)1–5•Ontologies rely on formal knowledge representation languages that integrate aspects of formal languages with the requirements of the web.The Web On-tology Working Group of W3C,recently proposed OWL as the ontology language for the Semantic Web(see Horrocks et al.in this issue).•Web Services bring a computational element for accessing and executing software components and applications.Developments such as DAML-S[3] and The Web Service Modeling Framework[4]aim at integrating Semantic Web methods with Web Services,to enable automatic service discovery, configuration and execution(see Sycara et al.in this issue).•Agents benefit from the declarative framework; agent-based systems will evolve into effective sys-tems once more machine-interpretable content and intelligent services are available on the web[5].•Database view management,schema transforma-tion,schema integration,and query processing offer a plethora of experience in scaleable semantic technologies(see Melnik et al.in this issue).Com-bined with the strengths in transactions aspects and scalability,the database area will be an important contributor to the further development of Semantic Web applications[6].The web is not the only distributed computing infrastructure that can benefit from semantics.We are beginning to see the integration of semantic as-pects into Peer-to-Peer Systems and the Grid.Peer selection or message routing can be optimized by having more semantic information available about the services a peer offers or the information a peer is stor-ing(see Aberer et al.in this issue).The merging of Grid capabilities with Web Services(the Open Grid Service Architecture)and developments in Semantic Grids enable the dynamic formulation of“Virtual Organizations”of Grid resources and the integra-tion of data from different sources in a semantically consistent way[7,8].Many application areas and industry sectors al-ready benefit,or will come to do so,from the new semantic infrastructure that evolves.e-Commerce, or Enterprise Application Integration,gain a new level offlexibility for running business-to-business applications or networked enterprises.e-Science,ex-ploiting semantic grid technologies,will allow new ways of cooperation among scientists and thus enable a new level of synergy between researchers working in different institutions and locations[9].New gen-eration knowledge management solutions in which knowledge management is an effortless part of day to day activities,and where appropriate knowledge is automatically delivered to the right people at the right time at the right granularity via a range of user devices,is another promising application area.The web and web-based applications will reach a new level of functionality only if web contents and Web Services are characterized in a way that delivers as much semantics as is needed to meet the application needs.2.Structure and contents of the journalNo one discipline holds the monopoly of Web Se-mantics.Distributed computing,data and knowledge management,artificial intelligence,digital libraries, language design and implementation,architecture, natural language processing—all play their role.It is the confluence of these technologies that is the key,and so it is the key for the Journal of Web Se-mantics.We plan to bring together the best research from all disciplines aimed at capturing and exploiting semantics in distributed information management. The research is driven by applications and exposed through demonstrators;experimental prototypes are running alongside commercial developments;funda-mental research is working in consort with standards activities in W3C and other bodies.The journal will reflect all these streams of activity and their interaction to give a window on the whole of the state of the art. We aim to cover a dynamic and vibrant new area, and target an audience that needs to know the latest innovations while they are fresh.We plan to achieve this without sacrificing quality by providing a mix of traditional research papers as well as high-quality letters and short articles that present important results with the shortest possible publication delays. Thus,the range of papers will reflect the diversity of activity,and maturity:Papers,Short or Long:These are traditional re-search papers describing novel research,large-scale experiments,or exciting systems of relevance to the journal’s readership.We have no specific paper limit;Editorial/Web Semantics:Science,Services and Agents on the World Wide Web1(2003)1–53we particularly encourage short papers on less mature but exciting innovations.Letters:Letters are one to two page notifications(of the kind found in Scientific publications like Science) focusing on a specific result or important innovation, theoretical or practical.Letters will be an important way for exciting results to get into refereed publication in the shortest possible time.Demonstrations:Demonstration papers are short papers describing a freely available demonstration, accompanied by a pointer to a site where the demon-stration runs,or from which it can be downloaded. Reviewers will check the quality of the demonstra-tion,and that the paper presents enough information to understand what it does and that it actually works. Our web site gives details of licensing arrangements. Ontologies:Ontology papers are expected to describe the development of a publicly available on-tology,what is in it,and why it is important.The ontology should be published in a standard language or that the details of its representation should be pub-lished and available to our readers.We will review the quality of the write-up,and the modeling quality of the ontology itself.You can help us make this journal relevant to your needs.If you have something you think belongs in the journal,but it does not easilyfit into one of these categories,contact one of the Editors-in-Chief.3.Practicing what we preachWe expect this journal to have a strong web presence where we practice what we preach.Thus we plan to use web technologies in a number of different ways: Rapid publication mixing e-journal and print jour-nal models.Final submissions will be posted on our web site immediately after acceptance.After typeset-ting they will appear in traditional print form,and on Elsevier’s web site and in their electronic archives—a major resource available in thousands of libraries around the world.Metadata mark-up using Dublin Core will be cre-ated for you,and you will have the opportunity to add any other metadata you wish using tools devel-oped by the community.Our paper repository will be displayable not just as text,but also as bibtex entries (and other formats as they become standard).We aim to make the journal site a sand-box for the commu-nity.Searching andfiltering papers,using Semantic Web technologies,for generating custom pages containing the papers by a particular author or on a particular topic.Demonstrations and ontologies published in the journal will be made available linking back the authors’site and archiving a copy of the submission. Hence the most up to date version is visible,but the version at submission time is available.Our goal is to make this one of the most readable journals on your shelves and a repository of important resources on the web.4.This issueOurfirst issue purposely attempts to reflect the di-versity and range of research shaping Web Semantics, with representatives of most of our paper styles:five long research papers,each viewing the web in a differ-ent way,and two short papers describing an ontology and a demonstrator application.Knowledge representation is a major topic of Web Semantics.The challenge is to view the web as a huge knowledge base.In“From SHIQ and RDF to OWL: The Making of a Web Ontology Language”Horrocks et al.introduce the OWL Web Ontology Language, a formal language for representing ontologies in the Semantic Web,recently announced by W3C as a candidate recommendation.OWL offers the features culled from the results of knowledge representation research,and was designed on top of RDF.The paper describes how OWL was born,what research issues have been solved,and what remains.Agent technology facilitates the use of Web Seman-tics,and Web Services are facilitated by the use of Web Semantics.The challenge is to view the web as a huge service-based multi-agent system.Sycara et al. in“Automated Discovery,Interaction and Composi-tion of Semantic Web Services”propose DAML-S for describing Semantic Web Services,which combines the web services architecture with Semantic Web. DAML-S provides an abstract description of Web Services,and can support matching and interaction among web services.The paper describes the imple-mentation of the DAML-S/UDDI Matchmaker and4Editorial/Web Semantics:Science,Services and Agents on the World Wide Web1(2003)1–5the DAML-S Virtual Machine to actually prototype Semantic Web Services.Database technology is another stream of Web Semantics.Sergey Melnik et al.develop a generic model management system called Rondo in“Devel-oping Metadata-Intensive applications with Rondo”. The challenge is to view the web as the integration of a huge number of online applications,services, and databases.These systems are tied together using mediators,mappings,database views,and transforma-tion scripts.Model management reduces the amount of programming needed for integrating applications. The paper introduces high-level operators to manip-ulate models and mappings between models,such as change propagation,view reuse,and reintegration. Semantic annotation is the key to create the seman-tic content of the Semantic Web.“A case for automated large-scale semantic annotation”by Dill et al.rises to the challenge to automatically create a huge volume of tagged web contents from existing web pages.The paper describes Seeker,a platform for large-scale text analysis,and SemTag,an application written on the platform that performs the automated semantic tag-ging of large corpora.Approximately264million web pages are tagged,generating around434million dis-ambiguated semantic annotations.Aberer et al.’s“Start making sense:The Chatty Web approach for global semantic agreements”de-scribes a step towards self-learning networks of peers establishing semantic operability automatically.The challenge is to harness the huge network of inter-connected data sources,and to come to negotiated agreements on semantics.Participating data sources incrementally develop global agreement in an evo-lutionary and completely decentralized process that solely relies on pair-wise,local interactions.The authors’claim their approach applies to any sys-tem which provides a communication infrastructure (websites or databases,decentralized systems,P2P systems)and offers the opportunity to study semantic interoperability as a global phenomenon in a network of information sharing parties.Ontology is a key to realizing semantic contents. Golbeck et al.have developed an ontology based on the National Cancer Institute’s Thesaurus.The need for a comprehensive terminology arose because terms were often locally developed within various sections of the Institute.To make the knowledge in the The-saurus more useful and accessible,the National Cancer Institute and the University of Maryland have worked together to produce an OWL ontology from the The-saurus.Tools are needed to accelerate the advance of Web Semantics.R.Guha and Rob McCool report on TAP, an experimental system for identifying and research-ing different technical issues such as scalable query languages,sharing vocabularies,bootstrapping knowl-edge bases,automated extraction of RDF from text, etc.TAP has been used to create large-scale semantic annotation as described by Dill and colleagues. Future issues will include papers on Semantic Grid, Natural Language Processing,Digital Library and more to greatly advance Web Semantics.We are at a key point in the Web’s journey.This journal plans to not only chart it’s path but hopefully influence it—this is only possible if it serves you and you contribute to it.We look forward to your papers and your engagement as we strive to make the Journal of Web Semantics the cypher for a new community. We would like to thank all the authors and the paper reviewers for their efforts in starting up this journal, Elsevier for their support in the creation and running of the journal,and Karon Mee and Simon Harper for running the Editorial office.References[1]T.Berners-Lee,J.Hendler,ssila,The Semantic Web,Scientific American,May2001.[2]S.Staab,R.Studer(Eds.),Handbook on Ontologies,Springer-Verlag,Berlin,2003.[3]The DAML Services Coalition:DAML-S:Semantic Markupfor Web Services./services/daml-s/0.9/.[4]D.Fensel,Ch.Bussler,The web service modeling frameworkWSMF,merce Res.Appl.1(2)(2002)113–137.[5]J.Hendler,Agents and the semantic web,IEEE Intell.Syst.16(2(March–April))(2001)30–37.[6]A.Sheth,R.Meersmann,Amicalola Report:Database andInformation Systems Research Challenges and Opportunities in Semantic Web and Enterprises.SIGMOD Record31,4 December2002.[7]C.Goble,D.De Roure,The grid:an application of the semanticweb,SIGMOD Rec.31(4)(2002)65–70.[8]C.Kesselmann,The Grid,grid services and the semanticweb:technologies and opportunities,in:Proceedings of the1st International Semantic Web Conference(ISWC’02),Sardinia, LNCS2342,Springer-Verlag,Berlin,July2002.[9]J.Hendler,Science and the semantic web,Science(24January)(2003)299.Editorial/Web Semantics:Science,Services and Agents on the World Wide Web1(2003)1–55Stefan Decker Digital Enterprise Research Institute,IrelandCarole Goble∗Department of Computer Science University of Manchester,Oxford RoadManchester M139PL,UK∗Corresponding author E-mail address:*************(C.Goble)Jim Hendler University of Maryland,USAToru IshidaKyoto University,JapanRudi Studer University of Karlsruhe,Germany。
网格计算

MDS (Monitoring and discovery Service)
GRAM (Grid Resource Allocation Manager)
GridFTP
Secure data transfer.
28
Globus Toolkit: Recent History
GT2 (2.4 released in 2002)
26
Grid Computing Software Infrastructure
Globus Project
Open source software toolkit developed for grid computing. Roots in I-way experiment. Work started in 1996.
Web Services和Grid技 术融合的产物
遵循Web Service标准,扩 展它
20
OGSA服务
Resource allocation Authentication & authorization are applied to all requests Create Service Service factory Grid Service Handle Service requestor (e.g. user application) Service discovery
GRAM, MDS, GridFTP, GSI.
GT3 (3.2 released mid-2004): redesign
OGSA (Open Grid Service Architecture)/OGSI (Open Grid Services Infrastructure) based. Introduced “Grid services” as an extension of web services. OGSI now abandoned.
Grid Computing

PPDG ---技术方案
第二步(2000-2001年): Development of a generalized file-mover framework (supporting QoS) Implementation/generalization of the cataloging, resource broker and matchmaking services needed as foundations for both transparent write access and agent technology Implementation of transparent write access for files Implementation of limited support for „agents Implementation of distributed resource management for the Data Grid Major efforts on robustness and rapid problem diagnosis, both at the component level and at the architectural level
Grid Computing
关于GRID的基本概念 GRID技术产生的背景 GRID技术要点 GRID技术的发展现状 HEP领域中的GRID技术
GRID的基本概念
GRID技术代表一种机制,用于集成或共享地
理上分布的各种物理或逻辑资源(包括各类 CPU、存储系统、I/O设备、通信系统、文件、 数据库、程序等),使之成为一个有机的整体, 共同完成各种所需任务。它的主要应用包括了 分布式计算、高性能计算、协同工程、计算密 集型和数据密集型科学计算。
Infoblox 服务关键网络顶层架构与系统考虑说明书

DevOps Automation IPAM & DNS
DHCP Infra Rollout and Zero Trust Provisioning
Security Ecoystem Integration &DNS Secutity
automation is overlooked or considered to be ?mandatory?with no consideration of integration points, metadata discontinuity and functional requirements for infrastructure automation. Choosing a unified end to end DNS solution from core to edge and far edge across all network slices provides the most redundant, recoverable and reliable solution available.
Security Considerations
Restrict caching DNS service to "subscribers only" to avoid acting as an open resolver to the Internet. ACLs must be set appropriately to ensure only valid users or applications are accessing DNS infrastructure. Enabling RPZ, ADP, Threat Insight for Data Exfiltration, provides best in class DNS security. Protect the DNS server and all the underlying protocols required to deliver DNS services (UDP/TCP/NTP/OSPF/BGP etc.) against security threats. By enabling and tuning Infoblox Advanced DNS Protection ?Threat Protect?. Implement Role Based Access Control such that access rights are aligned with the tasks to be executed using a least permissions model. Discover unknown devices deployed in the network and provide those details to IPAM (IP Address Management) with Infoblox Discovery. Secure DNS service for GRX/IPX (Behavioral and Signature-based protection). Enabling "Threat Defense, Threat Protect and Threat Insight" for Reputation, Signature and Behavioral threat mitigation improves security posture & reduces overall attack surface exposed to the Internet and internally. Increase visibility into which devices are making requests to connect to
质保期服务承诺和维保方案说明

质保期服务承诺和维保方案说明一、售后服务承诺我们公司承诺提供优质的售后服务,包括工程回访与保修。
在工程交工验收后,我们将定期回访并记录工程竣工后的使用情况和质量情况,以便在以后的工作中加以改进。
如果工程出现质量问题,我们将在24小时内到位进行修理、维护直至工程合格,为业主提供满意的后期服务。
我们的“工程回访与保修小组”由公司工程部相关人员构成,由公司直接领导,负责在缺陷责任期内提供满意的后期服务。
合同规定缺陷责任期结束,并且修缮任务完成时,公司负责与业主签订工程移交手续,保证向业主交出优质的产品。
2、用户服务目的我们公司的企业宗旨是全方位、全过程为用户提供“至诚至信的完美服务、百分之百的用户满意的服务”。
我们致力于完善产品的质量和售后服务,创造优质、全方位的服务。
我们以一流的管理、一流的技术、一流的施工、一流的服务去实现我们对业主的承诺,创建用户完全满意的工程。
3、用户服务目标我们的用户服务目标是提供“至诚至信的完美服务、百分之百的用户满意的服务”。
在工程施工及管理的全过程中,我们致力于完成业主对项目明确的和潜在的服务需求,以达到工程预定的工程质量目标,实现对业主的承诺。
在工程竣工后,我们保证道路及附属工程的安全和使用功能,协助业主对道路及附属工程进行全面的维护。
4、用户服务工作的原则及标准我们的用户服务工作的原则是站在客户的立场上考虑问题、解决问题,把客户的需求和满意放到一切考虑因素之首,同时必须做到兼顾企业利益,使客户利益与企业利益相得益彰。
我们的标准是服务热情周到,信息交流畅通,反应快速准确,质量保证完善。
5、保修期限我们的工程保修期限将按照合同和国家规定执行。
6、用户服务的组织机构和管理体系我们的用户服务的组织机构是由优秀的管理人员组成的工程项目管理班子,按照项目管理手册和程序文件的要求进行项目施工管理。
我们严格按照公司的质量保证体系来运作,以全面质量管理为中心环节,出色地完成施工阶段的服务目标。
Discovery Studio官方教程(Help-Tutorials) 创建3D QASR模型

采用能量格点作为描述符构建PLS模型(3D-QSAR)教程介绍药物设计即试图发现能够同生物大分子靶标在形状(steric)和电荷(静电势)上互补的小分子。
与2D-QSAR相比,3D-QSAR方法更能间接反映配体小分子和蛋白大分子之间的非键相互作用特征,具有更加丰富的物理化学内涵,因此得到了迅速的发展和广泛的应用。
3D-QSAR模型时基于小分子的立体(steric)和静电(electrostatic)场构建的回归模型,可以用于预测未知配体小分子的活性及观察受体-配体间有利和不利的相互作用。
本教程利用能量格点作为描述符构建了一个偏最小二乘(PLS)模型。
该能量格点是通过两种用于测量静电势和立体效应的探针计算得到的。
本教程包括以下步骤:♦构建3D-QSAR模型♦观察分析结果♦基于3D-QSAR模型预测活性3D QSAR模型的构建在构建3D QSAR模型之前,需要对训练集分子进行叠合,叠合好坏决定了最终模型的可信度。
叠合方式一般有以下几种:♦如果配体分子都来源于晶体结构且都与同一靶标相结合,则可以直接使用晶体结合构象♦如果有配体小分子的药效团模型,则可将配体小分子匹配至药效团模型以实现对配体小分子的叠合♦可直接基于配体小分子的公共骨架进行叠合♦可将配体小分子公共骨架中的药效团特征元素加以提取,用于构建药效团模型,再通过配体药效团的匹配流程(Ligand Pharmacophore Mapping)进行小分子的叠合♦可基于立体场和静电场通过场匹配的方式进行小分子的叠合(Structure | Superimpose | Molecular Overlay…)1. 3D-QSAR的构建在文件浏览器(Files Explorer)中,展开Samples | Tutorials | QSAR,双击trainingset.sd。
在分子窗口中打开一个表格,共14行,即14个训练集分子,该分子事先已进行叠合。
在文件浏览器(Files Explorer)中,展开Samples | Tutorials | QSAR,双击testset.sd。
KDD Knowledge Discovery in Databases

KDD Knowledge Discovery in Databases百科名片知识发现知识发现(KDD:Knowledge Discovery in Databases)是从数据集中别出有效的、新颖的、潜在有用的,以及最终可理解的模式的非平凡过程。
知识发现将信息变为知识,从数据矿山中找到蕴藏的知识金块,将为知识创新和知识经济的发展作出贡献。
该术语于1989年出现,Fayyad定义为"KDD"是从数据集中识别出有效的、新颖的、潜在有用的,以及最终可理解的模式的非平凡过程”。
目录详细解释1.KDD基本过程(the process of the KDD)2.常用KDD过程模型 (KDD process model)编辑本段详细解释数据库知识发现(knowledge discovery in databases,KDD)的研究非常活跃。
在上面的定义中,涉及几个需要进一步解释的概念:“数据集”、“模式”、“过程”、“有效性”、“新颖性”、“潜在有用性”和“最终可理解性”。
数据集是一组事实 F(如关系数据库中的记录)。
模式是一个用语言L来表示的一个表达式E,它可用来描述数据集F的某个子集凡上作为一个模式要求它比对数据子集FE的枚举要简单(所用的描述信息量要少)。
过程在KDD中通常指多阶段的处理,涉及数据准备、模式搜索、知识评价以及反复的修改求精;该过程要求是非平凡的,意思是要有一定程度的智能性、自动性(仅仅给出所有数据的总和不能算作是一个发现过程)。
有效性是指发现的模式对于新的数据仍保持有一定的可信度。
新颖性要求发现的模式应该是新的。
潜在有用性是指发现的知识将来有实际效用,如用于决策支持系统里可提高经济效益。
最终可理解性要求发现的模式能被用户理解,目前它主要是体现在简洁性上。
有效性、新颖性、潜在有用性和最终可理解性综合在一起称为兴趣性。
由于知识发现是一门受到来自各种不同领域的研究者关注的交叉性学科,因此导致了很多不同的术语名称。
人力资源专业英汉对照翻译-英汉对照翻译

人力资源专业英汉对照翻译|英汉对照翻译人力资源专业英汉对照翻译|英汉对照翻译Action learning:行动学习 Alternation ranking method:交替排序法 Annual bonus:年终分红 Application forms:工作申请表Appraisal interview:评价面试 Aptitudes :资质Arbitration :仲裁 Attendance incentive plan:参与式激励计划 Authority :职权BBehavior modeling:行为模拟 Behaviorally anchored rating scale (bars):行为锚定等级评价法 Benchmark job:基准职位 Benefits :福利Bias :个人偏见 Boycott :联合抵制Bumping/layoff procedures:工作替换/临时解雇程序Burnout :耗竭CCandidate-order error:候选人次序错误 Capital accumulation program:资本积累方案 Career anchors:职业锚 Career cycle:职业周期Career planning and development:职业规划与职业发展 Case study method:案例研究方法 Central tendency:居中趋势 Citations :传讯Civil Rights Act:民权法 Classes :类Classification (or grading) method:归类(或分级)法 Collective bargaining:集体谈判 Comparable worth:可比价值 Compensable factor:报酬因素Computerized forecast:计算机化预测 Content validity:内容效度Criterion validity:效标效度 Critical incident method:关键事件法 DDavis-Bacon Act (DBA):戴维斯―佩根法案 Day-to-day-collective bargaining:日常集体谈判 Decline stage:下降阶段 Deferred profit-sharing plan:延期利润分享计划 Defined benefit:固定福利 Defined contribution:固定缴款Department of Labor job analysis:劳工部工作分析法Discipline :纪律Dismissal :解雇;开除 Downsizing :精简EEarly retirement window:提前退休窗口 Economic strike:经济罢工Edgar Schein:艾德加•施恩 Employee compensation:职员报酬Employee orientation:雇员上岗引导Employee Retirement Income Security Act (ERISA) :雇员退休收入保障法案Employee services benefits:雇员服务福利Employee stock ownership plan (ESOP) :雇员持股计划Equal Pay Act:公平工资法 Establishment stage:确立阶段 Exit interviews:离职面谈 Expectancy chart:期望图表 Experimentation :实验 Exploration stage:探索阶段 FFact-finder :调查 Fair day"s work:公平日工作Fair Labor Standards Act:公平劳动标准法案Flexible benefits programs:弹性福利计划 Flex place:弹性工作地点 Flextime :弹性工作时间Forced distribution method:强制分布法 Four-day workweek:每周4天工作制 Frederick Taylor :弗雷德里克•泰罗 Functional control:职能控制Functional job analysis:功能性工作分析法General economic conditions:一般经济状况 Golden offerings:高龄给付 Good faith bargaining:真诚的谈判Grade description:等级说明书Grades :等级 Graphic rating scale:图尺度评价法Grid training:方格训练 Grievance :抱怨Grievance procedure:抱怨程序 Group life insurance:团体人寿保险Group pension plan:团体退休金计划 Growth stage:成长阶段Guarantee corporation:担保公司 Guaranteed fair treatment:有保证的公平对待 Guaranteed piecework plan:有保障的计件工资制 Gain sharing:收益分享HHalo effect:晕轮效应 Health maintenance organization (HMO) :健康维持组织 IIllegal bargaining:非法谈判项目 Impasse :僵持Implied authority:隐含职权 Incentive plan:激励计划Individual retirement account (IRA) :个人退休账户In-house development center:企业内部开发中心Insubordination :不服从 Insurance benefits:保险福利Interviews :谈话;面谈JJob analysis:工作分析 Job description:工作描述Job evaluation:职位评价 Job instruction training (JIT) :工作指导培训 Job posting:工作公告 Job rotation:工作轮换Job sharing:工作分组 Job specifications:工作说明书John Holland:约翰•霍兰德 Junior board:初级董事会Layoff :临时解雇 Leader attach training:领导者匹配训练Lifetime employment without guarantees:无保证终身解雇 Line manager:直线管理者 Local market conditions:地方劳动力市场 Lockout :闭厂MMaintenance stage:维持阶段 Management assessment center:管理评价中心 Management by objectives (MBO) :目标管理法Management game:管理竞赛 Management grid:管理方格训练Management process:管理过程 Mandatory bargaining:强制谈判项目Mediation :调解 Merit pay:绩效工资Merit raise:绩效加薪 Mid career crisis sub stage:中期职业危机阶段NNondirective interview:非定向面试OOccupational market conditions:职业市场状况Occupational orientation:职业性向 Occupational Safety and Health Act:职业安全与健康法案Occupational Safety and Health Administration (OSHA) :职业安全与健康管理局Occupational skills:职业技能 On-the-job training (OJT) :在职培训Open-door :敞开门户 Opinion survey:意见调查Organization development(OD) :组织发展Outplacement counseling:向外安置顾问 PPaired comparison method:配对比较法 Panel interview:小组面试Participant diary/logs:现场工人日记/日志 Pay grade:工资等级Pension benefits:退休金福利 Pension plans:退休金计划People-first values:" 以人为本" 的价值观Performance analysis:工作绩效分析 Performance Appraisal interview:工作绩效评价面谈Personnel (or human resource) management:人事(或人力资源)管理Personnel replacement charts:人事调配图Piecework :计件Plant Closing law:工厂关闭法 Point method/Policies :政策 Position Analysis Questionnaire (PAQ) :职位分析问卷 Position replacement cards:职位调配卡 Pregnancy discrimination act:怀孕歧视法案Profit-sharing plan利润分享计划 Programmed learning:程序化教学QQualifications inventories:资格数据库 Quality circle:质量圈RRanking method:排序法 Rate ranges:工资率系列Ratio analysis:比率分析 Reality shock:现实冲击Reliability :信度Retirement :退休 Retirement benefits:退休福利Retirement counseling:退休前咨询 Rings of defense:保护圈Role playing:角色扮演SSkip-level interview:越级谈话 Social security:社会保障Speak up! :讲出来! Special awards:特殊奖励Special management development techniques:特殊的管理开发技术Stabilization sub stage:稳定阶段 Staff (service) function:职能(服务)功能 Standard hour plan:标准工时工资 Stock option:股票期权Straight piecework:直接计件制 Strategic plan:战略规划Stress interview:压力面试 Strictness/leniency:偏紧/偏松Strikes :罢工 Structured interview:结构化面试Succession planning:接班计划 Supplement pay benefits:补充报酬福利Supplemental unemployment benefits:补充失业福利Salary surveys:薪资调查 Savings plan:储蓄计划Scallion plan:斯坎伦计划Scatter plot:散点分析 Scientific management:科学管理Self directed teams:自我指导工作小组 Self-actualization :自我实现Sensitivity training:敏感性训练 Serialized interview:系列化面试 Severance pay:离职金 Sick leave:病假Situational interview:情境面试 Survey feedback:调查反馈Sympathy strike:同情罢工System Ⅳ组织体系ⅣSystem I:组织体系ⅠTT ask analysis:任务分析 Team building:团队建设Team or group:班组 Termination :解雇;终止Termination at will:随意终止 Theory X:X 理论Theory Y:Y 理论 Third-party involvement:第三方介入Training :培训 Transactional analysis (TA) :人际关系心理分析 Trend analysis:趋势分析 Trial sub stage:尝试阶段UUnsafe conditions:不安全环境 Unclear performance standards:绩效评价标准不清 Unemployment insurance:失业保险 Unfair labor practice strike:不正当劳工活动罢工 Unsafe acts:不安全行为VValidity :效度 Value-based hiring:以价值观为基础的雇佣Vroom-Yetton leadership trainman:维罗姆-耶顿领导能力训练Variable compensation:可变报酬 Vestibule or simulated training:新雇员培训或模拟 Vesting :特别保护权 Voluntary bargaining:自愿谈判项目Voluntary pay cut:自愿减少工资方案WWage carve:工资曲线Work sampling technique:工作样本技术Work sharing:临时性工作分担Worker"s benefits:雇员福利 Voluntary time off:自愿减少时间 Work samples:工作样本 Worker involvement:雇员参与计划第 11 页共 11 页。
基于知识图谱的数字化电网标准信息系统设计与应用

第 42 卷第 3 期2023年 5 月Vol.42 No.3May 2023中南民族大学学报(自然科学版)Journal of South-Central Minzu University(Natural Science Edition)基于知识图谱的数字化电网标准信息系统设计与应用林正平1,涂亮1*,黄军凯2,吕黔苏2,王宏1(1 南方电网科学研究院广州510000;2 贵州电网有限责任公司电力科学研究院贵州550000)摘要知识图谱能有效地组织和管理互联网海量信息,并将客观世界中概念与实体关系以结构化的形式描述出来,而数据作为提升生产力的核心要素,通过企业内部业务数据与数字标准的深度融合,可将“标准”数据化和知识化.提出了一种基于知识图谱的数字化电网标准信息系统设计方案,对电网设备标准进行数字化、图谱化,并利用改进经验模态分解法信号分解模型,结果表明:能高效地把机器无法直接理解的线下技术文档转换为语义化的知识体系,为各类智能应用建设奠定基础.关键词知识图谱;数字标准;数字化;电网标准信息系统中图分类号O625.67;O643.3 文献标志码 A 文章编号1672-4321(2023)03-0394-08doi:10.20056/ki.ZNMDZK.20230315Design and application of digital grid standard information system basedon knowledge graphLIN Zhengping1,TU Liang1*,HUANG Junkai2,LV Qiansu2,WANG Hong1(1 China Southern Power Grid Research Institute, Guangzhou 510000, China; 2 Electric Power Research Institute,Guizhou Power Grid Co., LTD., Guizhou 550000, China)Abstract Knowledge graph can effectively organize and manage massive information on the Internet, and describe the relationship between concepts and entities in the objective world in a structured form. Data, as the core element to improve productivity, can be digitized and knowledge-based through the deep integration of enterprise internal business data and digital standards. A scheme of digital power grid standard information system based on knowledge atlas is put forward,digitize and map the power grid equipment standards,and use the improved empirical mode decomposition signal decomposition model to efficiently convert offline technical documents that cannot be directly understood by machines into semantic knowledge systems, laying the foundation for various intelligent application construction.Keywords knowledge graph; digital standard; digital; grid standard information system大数据时代数据和知识爆炸式增长,如何获取、管理、挖掘、识别海量数据并转化为解决问题的知识和能力,以支撑业务高质量发展是电网数字化转型的关键问题[1-5].面对复杂多变的大数据环境,由人工智能技术发展而来的知识图谱(Knowledge Graph, KG)这一新兴认知方法在电力领域获得了初步的应用,越来越多的研究者将知识图谱应用于电网调度[6-7]、电力设备运检[8]、电力营销等电力领域.文献[9-10]在图数据库的基础上构建电力知识图,对分散的数据源进行合并,并以结构化的形式描述电力系统中概念和实体之间的复杂关系.文献[11]采用自顶向下和收稿日期2022-08-28* 通信作者涂亮(1982-),男,高级工程师,研究方向:标准化管理、技术情报管理及行业知识挖掘分析研究,E-mail:189****************.基金项目南方电网公司数字标准关键技术研究与应用(一期)资助项目(GZKJXM20210015)第 3 期林正平,等:基于知识图谱的数字化电网标准信息系统设计与应用自底向上相结合的图谱构建方式,提出了一种基于知识图谱的配电网综合评价方法.在文献[12-13]中设计了一个基于知识图谱的油气勘探开发知识管理系统,并应用语义搜索进行智能预测.文献[14]在无人系统领域,通过知识图谱技术的抽取、融合及加工,构建了一个相互关联的知识体系;文献[15]面向配电网故障处置领域,提出一种利用知识图谱技术处理配电网故障的方法.由上述文献分析不难发现,当前电网在标准应用方面主要存在如下问题:(1)数据来源众多、质量不一,更新困难;(2)同一设备不同标准条款、指标存在冲突,难以发现;(3)企业标准应用反馈周期长不能及时修订;(4)标准利用手段单一效率低下,没有发挥应有价值.针对上述问题,本文在电网数字化转型及数字电网建设背景下,将标准的应用融入实际生产业务,发挥标准作用,以数据作为提升生产力的核心要素,释放数据资产的价值,促进以数字化为支撑的管理变革,将“标准”数据化和知识化,具有重要的应用价值.1 数字化电网标准信息的知识图谱构建方法1.1 标准数字化概述标准数字化是大势所趋.2022年政府工作报告提出要加快数字技术和实体经济的融合,这种融合表现在全方位多方面,其中就包含了电网标准化与数字技术融合的标准数字化转型[16-17].在IEC 研究基础上,标准数字化大致可分为5个阶段,如图1所示.目前,国际国内在标准数字化研究上主要聚焦于扩大标准检索的范围、丰富检索内容及提高标准加工的效率、保障标准数据的准确性上.在行业领域应用较为成熟,且与业务相融合从而提高生产组织效率,最突出显著的代表为航空制造领域.1.2 总体结构框架基于业界领先成熟的人工智能产品和技术,结合专家资源,以点带面,对主网设备标准文档进行数字化加工处理,形成数字化标准,支撑设备标准相关业务的高效开展.多渠道收集电力行业标准,应用数字标准治理工具,将标准数字化,构建数字标准知识库,实现标准数据结构化、碎片化、指标化、知识元化;通过统一的服务中台及智能服务平台,实现标准管理科学化、应需化;按照标准全生命周期管理要求及资产全生命周期管理要求,实现标准应用智能化、场景化,服务于南网实际业务管理需求.基于知识图谱的数字化电网标准信息系统设计结构如图2所示.1.3 方法实现技术路线整个项目以标准数字化转型即数字标准建设的现状和需求出发,首先进行顶层设计,然后进行数字化、碎片化和指标化的标准规范制定,同时进行核心关键技术的研究,包括标准文档数字化相关技术,数据加工标引技术以及智能化服务技术等,然后再进行工具集成和开发,实现数字化和知识元化的标准知识库,最后搭建智能化应用平台,面向业务应用提供场景化服务,其技术路线如图3所示.2 知识图谱构建方法的关键技术2.1 图谱构建知识图谱构建包括:实体识别、三元组抽取、实体消歧以及知识补全等过程,涉及的关键技术主要包括基于数据及语义智能辅助标注技术,以及知识抽取和识别技术.2.1.1 数据接入系统可支持如:数据库、API 、pdf 、excel 、word ,结构化和非/半结构化数据上传,数据接入示意图如图4所示.图1 标准数字化概述框图Fig.1 Block diagram of standard digitization overview395第 42 卷中南民族大学学报(自然科学版)2.1.2 知识定义Schema ,也称数据描述规范,用于描述、规范化数据的结构.定义一套完善的数据描述规范,是计算机理解知识的必要条件.平台预置了类目及其对应的属性信息,也可自定义添加各类目对应的字段属性信息,或从生产源数据库直连中选入数据快速生成Schema.知识定义示意图如图5所示.2.1.3 知识抽取基于schema 即开始进行文本的知识抽取, 知识抽取示意图如图6所示.2.2 数字化标准信息数据提取技术2.2.1 基于经验模态分解法的信号处理技术经验模态分解法(Empirical Mode Decomposition ,EMD )主要实现步骤如下:步骤1:利用原信号极值点x (t ),拟合原信号上下包络线u (t )和v (t ).步骤2:计算u (t )和v (t )平均值,在x (t )中去除平均值,得到新的信号值m 1(t).m 1(t )=x (t )-u (t )+v (t )2.(1)步骤3:根据IMF [18]分量特征条件判断m 1(t )是否满足.是,则将m 1(t )记为C 1(t ),否则将m 1(t )作为步骤1中的输入信号,继续执行上述步骤,直到满足条件.步骤4:在x (t )中剔除步骤3中得到的C 1(t ),并将此时的信号记作r 1(t).步骤5:此时,将r 1(t )作为原始信号,返回步骤1,循环执行,直到r n (t)单调.此时,x (t )为:x (t )=∑i =1nC i (t )+r n (t ) .(2)2.2.2 基于改进的经验模态分解法的信号处理技术EMD 在信号分解受主观性影响较大.为解决该问题,对IMF 分量选择提出一种自适应重构方法.实现过程如下:步骤1:将大小相等,方向相反的两个信号q i (t )和-q i (t)叠加在x (t )中,得新信号序列,即:ìíîx 1-i (t )=x (t )+a i ×q i (t )x 2-i (t )=x (t )-a i ×q i (t ),i =1,⋯,n ,(3)式中:a i 为叠加信号幅值,n 为叠加信号对数.步骤2:将x 1-i (t )、x 2-i (t)作为EMD 的原始信号进行分解,得到的IMF 分量,计为C 1-i (t )和C 2-i (t ),其平均值为:C 1(t )=12n ∑i =1n(C 1-i (t )+C 2-i (t )) .(4)步骤3:多个IMF 分量能量密度与周期之积为:P j =E j ×T j ,(5)式中:E j 、T j 分别是第j 个IMF 分量能量密度和平均周期.步骤4:判别系数RP j 为:RP j =|||||||||||P j -1j -1∑i =1j -1P i 1j -1∑i =1j -1P i||||||||||| ,(6)图2 基于知识图谱的数字化电网标准信息系统设计结构框图Fig.2 Block diagram of digital power grid standard information system design based on knowledge graph396第 3 期林正平,等:基于知识图谱的数字化电网标准信息系统设计与应用若RP j >1,剔除x (t )中的前j −1个IMF 分量,并再次对剔除IMF 分量的x (t )进行分解和重构.直到所有IMF 分量满足要求.3 数字化电网标准信息系统设计实现与应用3.1 数字标准服务平台设计整个数字标准服务平台都是部署在南网云环境,在软件上充分利用云平台提供的基础设施,基于南网云工具平台实现云化和微服务化,编撰工具本身所涉及的软件环境如表1所示.3.2 原型效果展示所开发出的原型界面如图7~10所示.3.3 预期性能指标数字标准服务平台性能直接影响用户体验和平台可用性,是平台设计开发的重要内容,根据项目招标要求,整个项目将从多个方面设计性能要求,即:首页的响应速度、标准比对的响应速度、指标检索的响应速度、检索速度、系统处理速度、吞吐图3 技术路线Fig.3 Technical route397第 42 卷中南民族大学学报(自然科学版)图4 数据接入示意图Fig. 4 Schematic diagram of data access图 5 知识定义示意图Fig. 5 Schematic diagram of knowledge definition图 6 知识抽取示意图Fig. 6 Schematic diagram of knowledge extraction398第 3 期林正平,等:基于知识图谱的数字化电网标准信息系统设计与应用量、响应速度、查全率等.达到各个指标性能要求所需要的设计和实现策略如表2所示.4 结论本文进行南网标准化工作全流程数字化转型,研究数字标准服务平台,全面服务技术创新和数字电网建设.目标:标准数据结构化、碎片化、指标化、知识元化,标准应用智能化、场景化.基于知识图谱技术研发数字标准智能化服务工具,实现公司标准知识的建模、抽取、积累等以及通用机器阅读理解算法与篇章等深度学习技术在专业领域文本的知表1 数字标准服务平台设计参数Tab. 1 Design parameters of digital standard service platform类别服务器操作系统数据库管理系统应用服务器中间件客户端操作系统客户端浏览器要求支持Windows 平台:Windows Server 2012或后续主流版本;支持Linux 平台:Linux2.6内核或后续主流版本支持KBase10或后续主流版本;支持Redis4.0或后续主流版本;支持MySQL 5或后续主流版本;注:为了支持对非结构化和半结构化数据的高效管理和检索,需要有非结构化数据库引擎及NXD 数据库引擎支持包括开源软件中间件,如Tomcat 8. 0或后续主流版本支持Windows7\10及后续主流版本支持Internet Explorer 11及后续主流版本;支持Google Chrome 32及后续主流版本;支持Mozilla Firefox 32及后续主流版本;Apple Safari 6及后续主流版本;图7 检索智能提示示意图Fig. 7 Schematic diagram of retrieval intelligent prompt图 8 标准检索支持字段示意图Fig. 8 Schematic diagram of the standard retrieval support fields399第 42 卷中南民族大学学报(自然科学版)表2 预期性能指标参数Tab. 2 Expected performance indicator parameters序号1 2 3 4 5 6 7 8 9 10指标首页响应速度标准比对的响应速度指标检索查全率检索速度系统处理速度吞吐量CPU占用率响应速度稳定性实现方案采用数据缓存、预加载和前端脚本交互的技术方案,提升用户编辑响应速度通过选定两个具有历史版本的标准进行,历史版本的章条比对响应速度指标数据的检索,可以通过指标名称和指标组进行查找关联,响应速度按关系型数据建立的索引可以完成99.9以上,对于全文索引的数据,可采用按字索引和按词索引多种方式,提高查全率按词做索引,并对常用词组合进行组合索引,提高检索效率.并对排序字段建立排序索引和排序词表数据入库时可采用多线程并发方式和批量索引方式,增加处理的速度系统的每一个后台处理环节都按可扩展模型设计,可以根据处理能力和压力动态地扩展均衡地使用各个CPU,并对长时间的大任务进行分解,每段任务之间根据系统繁忙程序适当地进行Sleep采用异步加载的方式,尽量使每个页面的打开速度降到最低对系统进行全面的运行监控,具有故障恢复功能达到性能小于2 s小于4 s小于2 s95%百万级数据毫秒响应达到50 M/s不高于30%≤3 s7 × 24 h服务图10 标准基本信息比较示意图Fig. 10 Comparison diagram of standard basic information图9 标准检索分组筛选示意图Fig. 9 Schematic diagram of standard retrieval group filtering400第 3 期林正平,等:基于知识图谱的数字化电网标准信息系统设计与应用识交互,提供标准知识搜索、知识推荐、知识问答、标准指标比对、电力标准体系执行情况评价、优化建议和知识运营服务等应用工具.参考文献[1]肖峻,王成山,周敏. 基于区间层次分析法的城市电网规划综合评判决策[J]. 中国电机工程学报, 2004,24(4): 50-57.[2]刘卓,尹忠东,詹惠瑜,等. 计及多种扰动源的有源配电网电能质量区间量化综合评估[J]. 现代电力,2021, 38(1): 24-31.[3]CHEN S,YAN H,RUAN W,et al. Research on collaborative regulation strategy of intelligent powerequipment group[C]//IEEE. International Conference onPower and Renewable Energy (ICPRE). Chengdu:IEEE,2017:612-616.[4]SHEN X, CAO M, LU Y, et al. Life cycle management system of power transmission and transformation equipmentbased on internet of things[C]//IEEE. China InternationalConference on Electricity Distribution (CICED). Xi’an:IEEE,2016:1-5.[5]ZHANG M,FANG J,WANG H B,et al. Life cycle management system of intelligent distribution roomcondition monitoring equipment[C]//IEEE. Intl Conf onWireless Communications and Smart Grid (ICWCSG).Qingdao:IEEE,2020: 230-235.[6]乔骥,王新迎,闵睿,等. 面向电网调度故障处理的知识图谱框架与关键技术初探[J]. 中国电机工程学报,2020,40(18): 5837−5948.[7]张虹,景欣,阮梦宇,等. 基于知识图谱的交直流大电网断面越限处置策略快速生成方法[J]. 现代电力,2021,38(4): 455-464.[8]张敏杰,徐宁,胡俊华,等. 面向变压器智能运检的知识图谱构建和智能问答技术研究[J]. 全球能源互联网, 2020, 3(6): 607-617.[9]TANG Y,LIU T,HE M,et al. Graph database based knowledge graph storage and query for power equipmentmanagement[C]//IEEE. 12th IEEE PES Asia-PacificPower and Energy Engineering Conf (APPEEC). Nanjing:IEEE,2020:1-5.[10]TANG Y,LIU T,LIU G,et al. Enhancement of power equipment management using knowledge graph[C]//IEEE. IEEE Innovative Smart Grid Technologies-Asia(ISGT Asia). Chengdu:IEEE,2019: 905-910.[11]朱晓荣,司羽,彭柏,等.基于知识图谱的配电网综合评价[J].现代电力,2021,38:1-14.[12]GUAN Q,ZHANG F,ZHANG E. Application prospect of knowledge graph technology in knowledge managementof oil and gas exploration and development[C]//IEEE.2nd International Conference on Artificial Intelligenceand Big Data (ICAIBD). Chengdu:IEEE,2019:161-166.[13]WU X P,TANG Y C,ZHOU C L,et al. An intelligent search engine based on knowledge graph for powerequipment management [C]//IEEE. The 5th InternationalConference on Energy, Electrical and Power Engineering.Chongqing:IEEE,2022:370-374.[14]喻凡坤,胡超芳,罗晓亮,等.无人系统故障知识图谱的构建方法及应用[J].计算机测量与控制.2020.28(10):66-71.[15]叶欣智,尚磊,董旭柱,等.面向配电网故障处置的知识图谱研究与应用[J]. 电网技术, 2022,46(10):3739-3749.[16]郭榕,杨群,刘绍翰,等. 电网故障处置知识图谱构建研究与应用[J]. 电网技术, 2021, 451(6): 1−9.[17]余建明,王小海,张越,等. 面向智能调控领域的知识图谱构建与应用[J]. 电力系统保护与控制, 2020,48(3): 29-35.[18]张佳,陈志英,陈丽安,等.基于改进集合模态分解的真空断路器分合闸线圈电流特征值提取[J]. 高压电器, 2020, 56(12):116-123.(责编&校对姚春娜)401。
擦亮“和为贵”品牌

擦亮“和为贵”品牌文/文平Polish “Invaluable Harmony” Brand打造“和为贵”体系打造“和为贵”社会治理服务品牌,济宁坚持以德为先,把“和为贵”的理念融入市域社会治理全过程各领域各环节。
秉承发扬孔子“和为贵”思想和无讼理念,济宁打造了市、县、乡、村“和为贵”体系,县(市、区)、乡镇(街道)全部建立“和为贵”社会治理服务中心,6500个村居全部建立“和为贵”调解室,筑牢了覆盖全市的基层社会治理服务阵地。
为化解群众提出的各类纠纷、信访诉求和投诉举报事项,济宁精准区分类型,分类导入程序,做到一站式受理、一揽子调处、全链条服务。
市级“和为贵”中心抓统筹、抓全盘;县级“和为贵”中心立足矛盾纠纷“终点站”,整合力量、集中服务;乡镇(街道)“和为贵”中心是“主战场”,让群众有问题进中心,专人快办解决;村(社区)“和为贵”调济宁聚力打造各级“和为贵”社会治理服务中心。
Jining pools efforts to build “Invaluable Harmony” social governance service centers at all levels.“礼之用,和为贵。
”这句出自《论语》的经典名句,体现了儒家的和谐思想。
作为儒家文化发源地,济宁大力弘扬与人为善、以和为贵的中华优秀传统文化,通过实施群众诉求办理、网格化服务管理、矛盾纠纷调处化解“三融合”,着力解决群众急难愁盼问题,推动群众诉求、矛盾纠纷源头治理,擦亮了“和为贵”社会治理服务品牌。
解室强化“前哨所”作用,矛盾纠纷随有随调、第一时间化解。
“群众遇到困难和烦心事,再也不用东奔西跑,直接到各级‘和为贵’中心反映‘要说法’,后续工作全部由中心分流、交办、督促、落实,让群众最多跑一地、最多跑一次。
”济宁市“和为贵”社会治理服务中心副主任、济宁市社会矛盾纠纷调处化解中心主任刘连营说。
为提升为民解难质效,济宁“和为贵”中心加快构建数字化、智能化社会治理服务信息系统,实现“一个中心管指挥、一个大脑管数据,一个场地抓化解、一个窗口抓服务”。
[华中科技大学副教授]李玉华[华中科技大学副教授]:李玉华[华中科技大学副教授]
![[华中科技大学副教授]李玉华[华中科技大学副教授]:李玉华[华中科技大学副教授]](https://img.taocdn.com/s3/m/be278a4a3a3567ec102de2bd960590c69ec3d8d2.png)
[华中科技大学副教授]李玉华[华中科技大学副教授]:李玉华[华中科技大学副教授]篇一: 李玉华[华中科技大学副教授]:李玉华[华中科技大学副教授]-人物简介,李李玉华,女,博士,副教授,华中科技大学计算机学院。
是国家863计划专家库评审专家,教育部专家系统库专家,曾参加2006、2007年863项目通讯评审。
曾任第一届全国全国WEB信息系统及其应用学术会议组织委员会委员。
作为项目负责人或主要完成人完成了国家“十五”科技攻关项目,“211工程”项目、国家自然科学基金、电子发展基金及其它合作研究项目等10多项科研项目。
现作为项目负责人主持国家自然科学基金项目一项。
在国际会议和中英文权威刊物上发表学术论文30余篇,多篇论文被EI、ISTP收录。
李玉华_李玉华[华中科技大学副教授] -人物简单介绍李玉华华中科技大学计算机学院副教授,博士,硕士、副博士导师。
1989年、1992年分别在哈尔滨理工大学仪器仪表系获学士、硕士学位,2006年在华中科技大学计算机学院获博士学位。
1992年5月至2002年8月在中国船舶重工集团公司第七一O所工作,先后任工程师、高级工程师,2002年9月考入华中科技大学计算机学院攻读博士学位,2003年7月起任华中科技大学计算机学院副教授。
现为中国计算机学会高级会员,是国家自然科学基金通信评审专家、国家863计划专家库评审专家。
作为项目负责人或主要完成人参与和完成了国家自然科学基金项目,国家863项目,国家“十五”科技攻关项目,“211工程”项目及其它合作研究项目等10余项,在国内外权威刊物发表论文30余篇,申请发明专利1项,获计算机软件著作权4项,获湖北省华中科技大学教学质量优秀奖二等奖等多项奖励。
主要研究方向为数据挖掘、社会网络、分布计算、金融工程等方面的研究工作。
李玉华_李玉华[华中科技大学副教授] -最新信息国家自然科学基金资助基于链接挖掘的动态金融网络分析技术研究李玉华_李玉华[华中科技大学副教授] -研究方向数据仓库、OLAP、数据挖掘、语义WEB和本体、人工智能、知识工程、金融工程李玉华_李玉华[华中科技大学副教授] -研究项目基于链接挖掘的动态金融网络分析技术研究,国家自然科学基金资助项目,2008-2010,项目负责人。
TCPUDP端口列表------6000到49151号端口
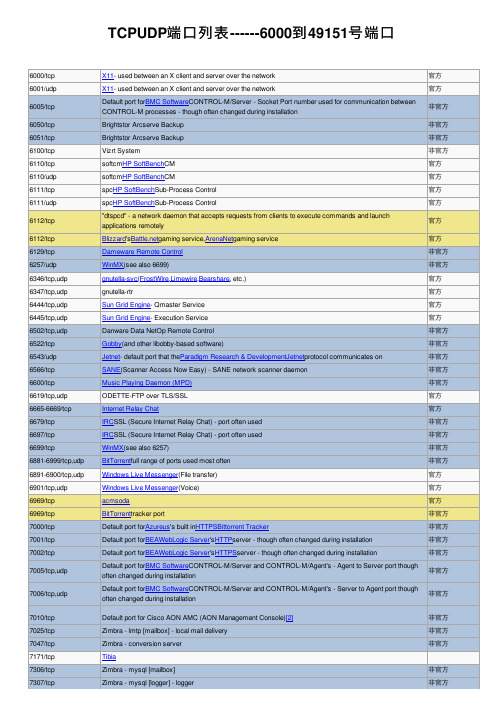
8294/tcp 8333 8400 8443/tcp 8500/tcp 8501/udp 8767/udp 8880 8881/tcp 8882/tcp 8888/tcp,udp 8888/tcp
8888/tcp 8888/tcp 9000/tcp 9000/tcp 9000/udp 9001 9001 9001/tcp 9009/tcp,udp 9043/tcp 9060/tcp 9100/tcp 9110/udp
6112/tcp 6129/tcp 6257/udp 6346/tcp,udp 6347/tcp,udp 6444/tcp,udp 6445/tcp,udp 6502/tcp,udp 6522/tcp 6543/udp 6566/tcp 6600/tcp 6619/tcp,udp 6665-6669/tcp 6679/tcp 6697/tcp 6699/tcp 6881-6999/tcp,udp 6891-6900/tcp,udp 6901/tcp,udp 6969/tcp 6969/tcp 7000/tcp 7001/tcp 7002/tcp
7005/tcp,udp
7006/tcp,udp
7010/tcp 7025/tcp 7047/tcp 7171/tcp 7306/tcp 7307/tcp
X11- used between an X client and server over the network X11- used between an X client and server over the network Default port forBMC SoftwareCONTROL-M/Server - Socket Port number used for communication between CONTROL-M processes - though often changed during installation Brightstor Arcserve Backup Brightstor Arcserve Backup Vizrt System softcmHP SoftBenchCM softcmHP SoftBenchCM spcHP SoftBenchSub-Process Control spcHP SoftBenchSub-Process Control "dtspcd" - a network daemon that accepts requests from clients to execute commands and launch applications remotely Blizzard'gaming service,ArenaNetgaming service Dameware Remote Control WinMX(see also 6699) gnutella-svc(FrostWire,Limewire,Bearshare, etc.) gnutella-rtr Sun Grid Engine- Qmaster Service Sun Grid Engine- Execution Service Danware Data NetOp Remote Control Gobby(and other libobby-based software) Jetnet- default port that theParadigm Research & DevelopmentJetnetprotocol communicates on SANE(Scanner Access Now Easy) - SANE network scanner daemon Music Playing Daemon (MPD) ODETTE-FTP over TLS/SSL Internet Relay Chat IRCSSL (Secure Internet Relay Chat) - port often used IRCSSL (Secure Internet Relay Chat) - port often used WinMX(see also 6257) BitTorrentfull range of ports used most often Windows Live Messenger(File transfer) Windows Live Messenger(Voice) acmsoda BitTorrenttracker port Default port forAzureus's built inHTTPSBittorrent Tracker Default port forBEAWebLogic Server'sHTTPserver - though often changed during installation Default port forBEAWebLogic Server'sHTTPSserver - though often changed during installation Default port forBMC SoftwareCONTROL-M/Server and CONTROL-M/Agent's - Agent to Server port though often changed during installation Default port forBMC SoftwareCONTROL-M/Server and CONTROL-M/Agent's - Server to Agent port though often changed during installation
ebscodiscoveryservice

EBSCO DISCOVERY SERVICE EDS资源发现系统(Find+版本)帮助文档更新时间:2013 年 10 月 19日目录系统简介 (3)检索外文资源 (4)基本检索 (4)高级检索 (5)检索结果清单 (6)HTML 全文 (8)Fulltext with LinkSource (9)Tools 功能表 (9)文档导出 (10)A-to-Z 期刊导航 (11)期刊导航 (11)学科导航 (13)数据库期刊浏览 (14)参考引文检索 (14)检索馆藏目录 (15)基本检索 (15)书目详细信息 (16)检索 中文资源 (18)基本检索 (18)高级检索 (19)详细信息 (21)系统简介EDS资源发现系统(Find+版本)是美国EBSCO公司出品的EBSCO DISCOVERY SERVICE资源发现系统在中国大陆地区的本地化版本,系统在EDS外文资源发现的基础上,由南京大学数图技术实验室提供馆藏目录发现、中文发现、全文导航、学科发现、本地化技术支持和定制化服务;利用EDS系统包含的国外出版商授权提供的元数据和先进的多语种搜索技术,结合上述本地化功能和服务,搭建的国内领先的、适合中国地区图书馆用户的资源发现系统。
系统覆盖全球9万多家期刊和图书出版社的资源总量已达到7.5亿多条,覆盖的学术期刊超过17.7万种,其中全文资源近7千万,包含学科期刊、会议报告、学术论文、传记、音视频、评论、电子资源、新闻等几十种类型的学术资源。
学术资源的语言种类有近200种,非英语的出版社资源超过3000家。
中文资源总量也达到近2亿条,期刊论文篇目数据达到8000万,书目信息资源800万,电子书资源300万;图书超过1200万种,同时EDS/Find+平台也扩展了期刊导航、学科导航、数据库期刊浏览、期刊检索、参考引文检索等功能。
系统包含外文资源发现、中文资源发现、馆藏资源发现、全文导航四大模块,其中外文资源发现,是基于合法授权的内容极丰富的,部署于美国的元数据仓和外文检索技术来实现;中文资源发现采用不属于中国的元数据仓储和检索技术,内容涵盖所有主流中文数据库;馆藏目录发现在揭示OPAC信息的基础上,扩展提供封面、目录、简介、评论、图书馆导购等多种书目增值服务信息。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Grid-based Knowledge Discovery Services for High Throughput Informatics
M.Ghanem,Y.Guo,A.Rowe,P.Wendel
Imperial College of Science,Technology and Medicine
180Queen’s Gate,London
mmg,yg,asr99,pjw4@
Abstract
Discovery Net is an application layer for providing grid-based knowledge discovery services.These services allow scientists to create and manage complex knowledge discov-ery workflows that integrate data and analysis routines pro-vided as remote services.They also allow scientists to store, share and execute these workflows as well as publish them as new services.Discovery Net provides a higher level of abstraction of the Grid for knowledge discovery activities, thus separating the end-users from resource management issues already handled by existing and emerging standards.
1.Knowledge Discovery Services
Discovery Net provides the middleware for knowledge discovery services for a wide range of high throughput informatics applications including drug discovery,remote sensing and geo-hazard prediction.The data sets,and anal-ysis routines,used in such applications are increasingly be-coming available as remote services on the Internet.Exam-ples include gene and protein databases and DNA sequence similarity searches in the case of life sciences applications, and satellite images,map servers and spatial analysis rou-tines in the case of remote sensing applications.
Knowledge discovery procedures in all these applica-tions typically require the creation and management of com-plex,dynamic,multi-step workflows.At each step,data from various sources is integrated and fed into an analysis routine.Based on the output results,the analyst chooses which other data sets,and analysis components,can be in-tegrated in the workflow.
Discovery Net supports such activities by providing mechanisms and higher level services for representing,cre-ating and managing knowledge discovery procedures and for composing existing data services and data analysis ser-vices in a structured manner,allowing scientists to plan, store,document,verify,share and re-execute their work-flows as well as their output results.
Representing Knowledge Discovery Workflows: Knowledge Discovery Procedures(workflows)are defined using an XML-based language,DPML(Discovery Process Markup Language).DPML represents a workflow as a dataflow graph of nodes,each representing either a data analysis service or a data service.For each service,DPML records the service type,properties,parameters,and past parameter settings.This XML representation allows the workflows for discovery procedures to be easily stored, validated,shared and re-executed.
Discovery Net Components:The Discovery Net archi-tecture provides three types of servers:Knowledge Discov-ery Look-up and Registration Servers,Meta-Information Servers and Knowledge Servers.Knowledge Discovery Look-up and Registration Servers allow the publication and retrieval of data analysis services and provide a store of service descriptors including functionality and input/output types.Meta-Information Servers provide services for data type management including type checking and data com-position.Knowledge Servers provide services for ware-housing knowledge discovery workflows,generating re-ports from them and application generation services allow-ing users to deploy their own workflows as new services.
Discovery Net Prototype:The design and development of Discovery Net is funded under the UK government’s core programme for e-science.The data analysis compo-nents and visual programming environment used in the pro-totype implementation are based on the tools provided by the Kensington distributed data mining system[1].The lower-level grid-based resource management activities will be based on the emerging OGSA standard[2]. References
[1]J.Chattratichat,J.Darlington,Y.Guo,and S.Hedvall.An
Architecture for Distributed Enterprise Data Mining.Lecture Notes in Computer Science,1593:573–582,1999.
[2]I.Foster,C.kesselman,J.M.Nick,and S.Tuecke.The
Physiology of the Grid:An Open Grid Services Architec-ture for Distributed Systems Integration.Technical report, /research/papers/ogsa.pdf,2002.
Proceedings of the 11 th IEEE International Symposium on High Performance Distributed Computing HPDC-11 2002 (HPDC’02) 1082-8907/02 $17.00 © 2002
IEEE。