应用数理统计课后习题参考答案
应用数理统计吴翊李永乐第一章数理统计的基本概念课后习题答案

第一章 数理统计的基本概念课后习题参考答案1.1 设对总体X 得到一个容量为10的子样值:4.5,2.0,1.0,1.5,3.4,4.5,6.5,5.0,3.5,4.0,试分别计算子样均值X -和子样方差2S 的值。
解:12,n X X X 为总体X 的样本,根据 121()n XX X X n=+++ 求得X=3.59;根据2211()ni i S X X n ==-∑ 求得2S =2.5929。
1.2 设总体X 的分布函数为()x F ,密度函数为()x f ,n X X X ,,,21 为X 的子样,求最大顺序统计量()n X 及最小顺序统计量()1X 的分布函数及密度函数。
解:将总体X 中的样本按照从小到大的顺序排列成()()()n X X X ≤≤≤ 21 1.3 设总体X 服从正态分布N(12,4),今抽取容量为5的子样521,,,X X X ,试问:(1)子样的平均值X 大于13的概率为多少?(2)子样的极小值(最小顺序统计量)小于10的概率为多少? (3) 子样的极大值(最大顺序统计量)大于15的概率为多少? 解:(1)()()1314.08686.0112.1n /-X 15/41213n /-X P -113X P -113X P =-=⎪⎪⎭⎫ ⎝⎛≤-=⎪⎪⎭⎫⎝⎛-≤=≤=>σμσμP(2) ()()()5785.08412.011-X P -121210-X P -110P -110P 551i 51i 51min =-=⎪⎭⎫ ⎝⎛≤=⎪⎭⎫ ⎝⎛->=>=<∏∏∏===i i i i X X σμσμ(3) ()()()2923.093315.015.1-X P -121215-X P -115P -115P 551i 51i 51max =-=⎪⎭⎫ ⎝⎛≤=⎪⎭⎫⎝⎛->=≤=>∏∏∏===i i i i X X σμσμ1.4 试证:(1)22211()()()n niii i x a x x n x a ==-=-+-∑∑ 对任一实数a 成立。
清华大学杨虎应用数理统计后习题的参考答案.doc

清华大学杨虎应用数理统计后习题的参考答案练习1:设定总体的样本量,并写出以下4种情况下样本的联合概率分布。
2);3);4)溶液总体的样本是,1)对于总体,其中:2)就整体而言,其中:3)对于整个4)对于整个2为了研究玻璃产品在集装箱运输过程中的损坏,我们随机选取了XXXX年的人类身高来获取数据(单位: Cm),如下所示:组的下限165 167 169 171 173 175 177组的上限167 169 171 173 175 177 179人3 10 21 23 22 11 5尝试绘制原点高度的直方图,无论它是否近似遵循正态分布密度函数的图形。
为了求解图1.2中的数据直方图,它近似遵循平均值为172、方差为5.64的正态分布。
那是。
4假设总体x的方差为4,平均值为。
现在取容量为100的样本,并尝试确定常数k,以满足。
解因子k更大。
根据中心极限定理: 那么:查找表:,5从总体中抽取容量为36的样本,并计算样本平均值介于50.8和53.8之间的概率。
解决方案6从总体中抽取两个容量分别为10和15的独立样本,并计算它们的平均值之差的绝对值大于0.3的概率。
解决方案6假设两个独立的样本是:并且,相应的样本均值为:还有。
从这个问题的含义来看:并且相互独立;,7集是种群的样本,试确定C,使。
那么,溶液和每个样品是相互独立的,有:那么:检查卡方分位数表:如果c/4=18.31,则c=73.24.8假设总体X具有连续分布函数,是总体X的样本,并定义随机变量:尝试确定统计数据的分布。
该溶液由已知条件获得:其中。
因为它们相互独立,所以它们也相互独立。
根据二项式分布的可加性,有。
9设定为来自群体X的样本,并尝试找出答案。
假设人口的分布是:1) 2) 3) 4)解决方案1) 2) 3) 4) 10从人群中抽取样本,找出总数。
解和因为,所以:11组来自正常人群,定义:能够做某事。
,则集合12是整个总体的样本,这是样本平均值。
应用数理统计课后答案

(2)检验线性回归效果的显著性( 0.05 ); (3)求回归系数 b 的区间估计(置信度为1 0.95 );
(4)求 x0 225kg 时,0 的预测值及预测区间(置信度为1 0.95 )。
(参考数据:)
5-5. 解:解:(1)计算得
求未知参数 a、b 的估计值,并求回归方程的残差平方和。
5-14.
解:两边对 y
b
ae x
取对数,有: ln y
ln a
ln
y
,
A
ln a
,
t
1 x
,
得 z A bt
将数据整理如下表:
xi
0.05 0.06 0.07 0.10 0.14 0.20 0.25 0.31 0.38 0.43 0.47
xi2 518600 ,
x
1 12
xi 205 ,
y
1 12
yi 72.6 ,
xi yi 182943 ,
yi2 64572 .84 ,
所以 lxx xi2 nx 2 518600 12 2052 14300
lxy xi yi nxy 182943 12 205 72.6 4347
(参考数据:)
6-2. 解:检验问题 H0 :1 2 3
工厂
寿命
Ti
Ti
2
或 i
n
i
S
2 i
甲
40 48 38 42 45 (1600 2304 1444 1764 2025
213
45369 42.6
63.2
应用数理统计,施雨,课后答案,

习题11.1 解:由题意95.01=⎭⎬⎫⎩⎨⎧<--u x p 可得:95.0=⎪⎪⎭⎪⎪⎬⎫⎪⎪⎩⎪⎪⎨⎧<-σσn n u x p而()1,0~N u x n σ⎪⎭⎫ ⎝⎛-- 这可通过查N(0,1)分布表,975.0)95.01(2195.0=-+=⎪⎪⎭⎪⎪⎬⎫⎪⎪⎩⎪⎪⎨⎧<--σσn n u x p 那么96.1=σn∴2296.1σ=n1.2 解:(1)至800小时,没有一个元件失效,则说明所有元件的寿命>800小时。
{}2.10015.08000015.00800|e 0015.0800--∞+-=∞+-==>⎰e e dx x p x x 那么有6个元件,则所求的概率()2.762.1--==e e p(2)至300小时,所有元件失效,则说明所有元件的寿命<3000小时{}5.4300000015.030000015.001|e 0015.03000----=-==<⎰e e dx x p x 那么有6个元件,则所求的概率()65.41--=e p1.3解: (1) 123{(,,)|0,1,2,,1,2,3}k x x x x k χ===因为~()i X P λ,所以 112233{,,}P X x X x X x ≤≤≤112233{}{}{}P X x P X x P X x =≤≤≤1233123!!!x x x e x x x ++-λλ=其中,0,1,2,,1,2,3k x k ==(2) 123{(,,)|0;1,2,3}k x x x x k χ=≥=因为~()i X Exp λ,其概率密度为,0()0,0x e x f x x -λ⎧λ≥=⎨ <⎩所以, 123(,,)3123(,,)x x x f x x x e-λ=λ,其中0;1,2,3k x k ≥=(3) 123{(,,)|;1,2,3}k x x x a x b k χ=≤≤=因为~(,)i X U a b ,其概率密度为1,()0,|a x b f x b a x a x b⎧≤≤⎪=-⎨⎪ <>⎩所以,12331(,,)()f x x x b a =-,其中;1,2,3k a x b k ≤≤= (4) 123{(,,)|;1,2,3}k x x x x k χ=-∞<<+∞= 因为~(,1)i X N μ,其概率密度为(2(),()x f x x 2-μ)-=-∞<<+∞所以,311(2123321(,,)(2)k k x f x x x e π2=--μ)∑=,其中;1,2,3k x k -∞<<+∞=1.4解:由题意可得:()⎪⎩⎪⎨⎧∞<<=--,其它00,21)(i 2ln i i 22i x e x x f u x σσπ则∏==ni x f x x f 1i n i )(),...(=⎪⎪⎩⎪⎪⎨⎧=∞<<∏=∑--=,其它0,...1,0,1n )2()(ln 212n 12i 2i x x e i n i i u x ni σπσ1.5证: 令21()()nii F a Xa ==-∑则'1()2()nii F a Xa ==--∑,''()20F a n => 令'1()2()0ni i F a X a ==--=∑,则可解得11ni i a X X n ===∑由于这是唯一解,又因为''()20F a n =>,因此,当11ni i a X X n ===∑时,()F a 取得最小值1.6证: (1)等式左边11((nnii i i XX X X 22==-μ)=-+-μ)∑∑111(2()()(n n n i i i i i X X X X X X 22====-)+-μ-+-μ)∑∑∑21(()ni i X X n X 2==-)+-μ∑左边=右边,所以得证. (2) 等式左边22111(2nn ni iii i i XX X X X nX 2===-)=-+∑∑∑ 22212nii XnX nX ==-+∑221ni i X nX ==-∑左边=右边,所以得证.1.7证:(1)∑=-=ni i n x n x 11∑+=-++=11111n i i n x n x 那么)(11_1_n n n x x n x -+++=∑∑=+=•+-++ni i n n i i x n n x n x n 111111111 =111111+=+++∑n n i i x n x n =∑=+ni i x n 111=_1+n x ∴原命题得证(2)21221-=-=∑n n i i nx x n s211122111-++=+-+=∑n n i i n x x n s那么⎥⎦⎤⎢⎣⎡-+++-+212)(111n n n x x n s n n =∑=+n i i x n 1211--+21n x n n +212)1(++n x n n --++nn x x n n 12)1(2+22)1(-+n x n n=∑=+n i i x n 1211--+222)1(n x n n +2111++n x n -212)1(1++n x n --++n n x x n n 12)1(2=∑=+n i i x n 1211-(111++n x n +-+n x n n 1)2由(1)可得:111++n x n +-+n x n n 1=-+1n x则上式=∑=+n i i x n 1211-21-+n x =21+n s∴原命题得证1.10解: 因为2222111111,()n n n i i i i i i X X S X X X X n n n =====-=-∑∑∑所以 (1) 二项分布(,)B m p11()()()ni i i E X E X E X mp n ====∑21111(1)()()()n ni i i i mp p D X D X D X n n n ==-===∑∑222211111()(())()()(1)n n i i i i n E S E X X E X E X mp p n n n==-=-=-=-∑∑(2) 泊松分布()P λ()E X =λ, ()D X n λ=, 21()n E S n-=λ(3) 均匀分布(,)U a b()2b a E X +=, 2)()12b a D X n (-=, 221()()12n E S b a n-=-(4) 指数分布()Exp λ 1()E X =λ, 1()D X n 2=λ, 21()n E S n 2-=λ (5) 正态分布2(,)N σμ ()E X =μ, 21()D X n σ=, 221()n E S nσ-=1.11解:(1)是统计量(2)不是统计量,因为u未知 (3)统计量 (4)统计量(5)统计量,顺序统计量 (6)统计量 (7)统计量(8)不是统计量,因为u未知 1.14.解: 因为i X 独立同分布,并且~(,i X a Γλ),11ni i X X n ==∑所以1~(,nii Xna =Γλ)∑;令1nii Y X ==∑,则1X Y n =,由求解随机变量函数的概率密度公式可得 1()(),0)nana nx X f x nx e n x na --λλ=>Γ(1.15 解:(1))(m x 的概率密度为: [][])()(1)()!()!1(!)(1)(x f x F x F m n m n x f m n m m ------=又F(x)=2x 且f(x)=2x ,0<x<1则有x x x m n m n x f m n m m 2)1()!()!1(!)(2)1(2)(------=,0<x<1(2) )(1x 与)(n x 的联合概率密度为: [][])()()(1)()()11(!),(011))(1(y f x f y F x F y F n n y x f n n ----=--=y x x y n n n 22))(1(222⋅⋅---=222)()1(4---n x y xy n n 0<x<y<1对于其他x,y ,有0),())(1(=y x f n1.19证:现在要求Y=)X 1/(X m nm n +的概率密度。
《应用数理统计》习题解答

2214243.(1)[||]0.140(2)[||]0.144(,4),(,),(0,)[||]20.1800255(3){||0.1}2(10.9521.9615372tnE a D nnE aN a N a t a NnnE t t dtnP t Pnξξξξξξπ-+∞-==≤⇒=-≤=-==≤==≤=≤=Φ-≥=⇒≥⎰《应用数理统计》参考答案习题一0.51.(,0.5)(,){||0.1}0.9972.97442N a N anP a Pnξξξξ⇒-<=<==⇒=2242.(,4)(,)100||(1)(||)()0.90,0.330.20.2(2):P(||)N a N aa UP a U P Uaξξξξσξεε⇒--<=<==-≥≤挈比学夫不等式(5)(5)125515(3){15}1{15}1{15,15,,15}1215121[{}]221[1(1.5)]0.292P P P P ξξξξξξ>=-≤=-≤≤≤--=->=--Φ=1121212111()(1){}{,,,}{1,1,,1}()()(1)(1)k n n nn m nm n m n m ni i P k pq P M m P m m m P m m m pqpq q q ξξξξξξξ----======≤≤≤-≤-≤-≤-=-=---∑∑4.5. 6. 13.0)25(1}8.012138.012{}13{)54,12(~)1()4,12(~=Φ-=->-=>ξξξξP P N N (1)(1)1255511515(2){10}1{10}1{10,10,,10}1[{10}]1[1{10}]1210121[1{}]221[11(1)]0.579P P P P P P ξξξξξξξξ<=-≥=->>>=->=--≤--=--≤=--+Φ=6(1)0.001567.2800~(0.0015)(1){800}[{800}][0.0015]x E P P e dx e ξξξ∞-->=>==⎰6(6)30000.00156 4.56(2){3000}[{3000}][0.0015](1)x P P e dx e ξξ--<=<==-⎰1212(2){}{,,,}{1,1,,1}n n nn P K k P k k k P k k k ξξξξξξ==≥≥≥-≥+≥+≥+7.8.均值的和(差)等于和的均值,方差的和差都等于方差的和9.由中心极限定理:10.11.22222(1)(1)(1)()222~()()()[()](,)it itit n e n n e n e it i t t tn it it n n nn p t e t t ee n e e e N n λξλλξξλλλλλξλϕϕϕλξλ---+--∴=∴======∴12121233~(20,3),~(20,),~(20,)10151~(0,)2{||0.3}1220.67N N N N P P ξξξξξξξξξ-∴->=->=-Φ=2(),(),E a D ξξσ==121(0,1)(0,1)~(,)n n i i i ni i na a n N N N a n nξξσξσξ==--∴∴=∑∑∑22222222,(),()()(),(),(),(,)k k k k k k k k k k k k k kk k E a E a D E E a a a a E A a D A n a a A N a nξξξξξ===-=--∴==-∴22121212222(),()(),()0,()()()2,()()()2,i i E E a D D E D D D E E D ξξξξσξξξξξξσξξξξξξσ====∴-=-=+=∴-=-+-=13.14.15.16.2212221221,(),(),()()0,()()()(1),11[()](1)1niii ii i iniiniiE a E a D DnE D D DnDn D nDES n Dn nE ES Dn n nσξξξσξξξξξξξσξξξξξξξ=======∴-=-=+--===--==--∑∑∑222222222424222(1),11()(1)()2(1)21 ()2(1)() nsnns nE n Es On nns nD n Ds On n n χσσσσσσσ--=-⇒==+-=-⇒==+112323''' '2(121)(1)()()()()5231()(121)23023021AD E E E EA E E A AVar Aξξξξξξηξηηηηηξξξξξ⎛⎫⎪-+=-==⎪⎪⎝⎭=--=--⎛⎫⎛⎫⎪⎪==--=⎪⎪⎪⎪⎝⎭⎝⎭11223''''110(2)(,)111()()()()5231()(121)23023021BE E E EB E E B BVar Bξηηηξξξηηηηξξξξξ⎛⎫⎛⎫ ⎪===⎪ ⎪⎝⎭ ⎪⎝⎭∑=--=--⎛⎫⎛⎫⎪⎪==--=⎪⎪⎪⎪⎝⎭⎝⎭11222211()2822121(2)||2241128116xx xxe dx dxπ⎛⎫⎛⎫- ⎪⎪∞∞⎝⎭⎝⎭-∞-∞-=∑-⎛⎫⎛⎫∑==⎪ ⎪-⎝⎭⎝⎭⎰⎰17.18.21.22.()11223'122'111110(,),211151,1101221111111100130111100310110N A A AAA Aξηξηξηηθθ⎛⎫⎛⎫⎛⎫ ⎪⎪ ⎪ ⎪⎝⎭⎝⎭ ⎪⎝⎭∑⎛⎫⎛⎫⎛⎫⎪==⎪ ⎪⎪⎝⎭⎝⎭⎪⎝⎭⎛⎫⎛⎫⎛⎫⎛⎫⎪⎪∑=-=⎪ ⎪⎪⎪⎝⎭⎝⎭⎪⎪⎝⎭⎝⎭‘=,由引理1.2.3,则-的联合分布为--11223''12111111~(,),1011111432111111121301111210.2N A A AA Aξηξξηξηθρρρρρρρρρηη⎛⎫⎛⎫⎛⎫ ⎪⎪ ⎪ ⎪-⎝⎭⎝⎭ ⎪⎝⎭∴∑⎛⎫⎛⎫+--⎛⎫⎛⎫⎪⎪∑=-=⎪ ⎪⎪⎪---⎝⎭⎝⎭⎪⎪-⎝⎭⎝⎭∴--=⇒=-==A,--时与独立2''44''22'''''' 44224(0,)(,)()()2()()()()()cov(,)(,)()() ()()2()()()2()nN IE A B tr A tr B tr ABE A E B tr A tr BA B E A B E A E Btr A tr B tr AB tr A tr B tr AB ζσζζζζσσζζζζσσζζζζζζζζζζζζσσσσσ=+=∴=-=+-=()11112222121122,1,1,0822177,122477yay y Qyba babθθθθθθθ--⎛⎫⎛⎫--=⎪⎪-⎝⎭⎝⎭⇒===-=⎛⎫⎪⎛⎫⎛⎫∴=∑== ⎪⎪ ⎪⎪⎝⎭⎝⎭⎪⎝⎭23.24.又 则令 则与 独立,则 与独立,且26.则2212221~(,),~(0,),~(1),(0,1)/(1)n n N a N n n ns n N T t n σξξξσξξχσξξ++----=-'11111(,,),(,,)111(,,),()11n n n ij n n n n i i i ia a B D nn n ξξθξσσσσδσσ⨯======-∑∑'2,0,D D D BD ===221(,)(,)1()n ni i nnB N a N I ηξθσσ===∑,i i i aξγσ-=2'11,()()()ni i i a D n ηγζγγξθξθσ=-==-=--∑∑B nηξ=ξηζ)1(~2-n χζ11(,)22U ξθθ-+(1)()121111221111()2201()121()()[1()]1[]21()()[()][]2(,)(1)()()[()()](1)[]n x n n n n n n n x f x other F x dx x f x nf x F x n x f x nf x F x n x f x y n n f x f y F y F x n n y x ξξθξξθθθθθ-------⎧-<<+⎪=⎨⎪⎩==-+∴=-=⋅⋅-+==⋅+-=--=⋅-⋅-⎰27.33.2222122222212222(0,),1()||2 ()()()()22(1)iyniniiY a NE d Y dynaD dE d E d Ennn nσξσσξσσσπσσσππ-∞-∞===-==-=-=-=⋅-=-∑⎰∑2222122122210.3(0,0.3),(0,)1010()(9)0.310()100.18{}0.30.3{(2}0.01iniiniiniN NPPξξξξχξξξ===--⨯<=<=∑∑∑222(2)(0,1),(1)0.3(9){0.9}0.9932nsN ntP Psnξχσξξξ--<=<=12121222221221212(3)(0,0.18),(0,0.18)(0,1),(0,1)0.18(1),()(1)0.18{()40}0.9N NN NPξξξξχχξξξξ+-+-+<=-224132244(4)~(1),~(0,0.12),10.73 {10.73}{}0.95NP Pξχξξξξ-<=<=34.《应用数理统计》参考答案2211222212222211(1)(0,),(0,)(1),()(1)11,()()(2)nn miii i n nniii nn mi i i i n N n N m n m m a b n m a b n m ξσξσξξχχσσσξξχ+==+=+==+--==++-∑∑∑∑∑∑222211112(2)(),(0,)(0,1),/(),n mni ii n i nniii i i m N n N t m c m n ξχξσσξξσσ+=+===∴=∑∑∑∑∑2222221121221(3)(),()()/(1,1),/nn mi i i i n ni i n mi i n n m n mF n m d nm ξξχχσσξσξσ+==+=+=+--∴=∑∑∑∑1. 由矩估计法2. (1) 由矩估计法(2)(3)(4)(5)818226212266174.00281610(74.002)88610 6.85710181ii i i a X x S x n S S n σ=-=--⎧===⎪⎪⎨⎪==⨯=-⎪⎩∴==⨯⨯=⨯--∑∑11'1202()33A x EX x dx θαξθθαξθθξ==-====∴=⎰111'101(1)2211A EX x x dx θαξθαθξθξθξ==+==+==+-∴=-⎰1211211122222221212222222121112()2x x n i i e xdx e x dx A X n A S S S θθθθθθαθθξθαθθξθξθξθθξθξθ--+∞--+∞==⋅=+==⋅===+∴=+==-+⎧=-⎪∴⎨=⎪⎩⎰∑⎰111(1)122Ni N NA x N NN ξξ=+===⋅⇒=∑11102()1A dx ξξθξ===⇒=-⎰2∞3.4.2()2{0},(){0}{}()0.7,110.7,0.525x aA X AP A P dxa aP a pp aξξξ--=<=<=--=<=Φ-=≈∴≈=-⎰设表示出现的次数,(1)11111(1)()ln()[ln ln(1)ln]ln()1[ln ln]ln ln0 ln lnniiniin ni ii iniiL c xL c xLc x n c xnnx n cθθθθθθθθθθθθθ-+=======+-+∂=+-=+-=∂=-∏∑∑∑∑1111221(2)()ln()[ln1)ln]ln()]0(ln)niniiniiniiLL xLxnxθθθθθ======+∂=+=∂=∑∑∑11()()()()11(3)()ln()lnln()11,,,,()0,0,11,()()nnin nn nnn nnnLL nL nLother otherL Lθθθθθθθθξξθξθθθθθξθξθξ====-∂=-=∂⎧⎧≤≤⎪⎪==⎨⎨⎪⎪⎩⎩≤≤=∏11()()()()11(3)()ln()lnln()11,,,,()0,0,11,()()nnin nn nnn nnnLL nL nLother otherL Lθθθθθθθθξξθξθθθθθξθξθξ====-∂=-=∂⎧⎧≤≤⎪⎪==⎨⎨⎪⎪⎩⎩≤≤=∏5.221()212212241(5)()()ln()[ln]22()2()ln()[022in xiniini iiLxLx xLθθθθθθθθθθθθθξθ--====-=-----∂==∂=∑∑(1)11(1)11(1)(1)(6)()ln()[ln ln(1)ln]ln()(),,,()()nc ciiniinc ci niL c xL c c c xL ncL c xL Lθθθθθθθθθθθξξθξθξ-+==-+===--+∂=-=∂=≤≤⇒=∏∑∏不能解出,所以由22111(7)()1)(1)ln()[2ln(2)ln(1)ln(1)]2ln()22]01inxiini iiniiL xL x xx nL nθθθθθθθθθθθξ-====--=+--+--∂=-=⇒=∂-∏∑∑(~(,0)11nUξθ∏6.7.所以不唯一。
应用数理统计课后习题参考答案

习题五1试检验不同日期生产的钢锭的平均重量有无显著差异?(α=0.05) 解 根据问题,因素A 表示日期,试验指标为钢锭重量,水平为5.假设样本观测值(1,2,3,4)ij y j =来源于正态总体2~(,),1,2,...,5i i Y N i μσ= .检验的问题:01251:,:i H H μμμμ===L 不全相等 .计算结果:表5.1 单因素方差分析表注释: 当=0.001表示非常显著,标记为 ‘***’,类似地,= 0.01,0.05,分别标记为 ‘**’ ,‘*’ .查表0.95(4,15) 3.06F =,因为0.953.9496(4,15)F F =>,或p = 0.02199<0.05, 所以拒绝0H ,认为不同日期生产的钢锭的平均重量有显著差异.2 考察四种不同催化剂对某一化工产品的得率的影响,在四种不同催化剂下分别做试验 试检验在四种不同催化剂下平均得率有无显著差异?(α=0.05)解根据问题,设因素A 表示催化剂,试验指标为化工产品的得率,水平为4 .假设样本观测值(1,2,...,)ij i y j n =来源于正态总体2~(,),1,2,...,5i i Y N i μσ= .其中样本容量不等,i n 分别取值为6,5,3,4 .检验的问题:012341:,:i H H μμμμμ===不全相等 .计算结果:表5.2 单因素方差分析表查表0.95(3,14) 3.34F =,因为0.952.4264(3,14)F F =<,或p = 0.1089 > 0.05,所以接受0H ,认为在四种不同催化剂下平均得率无显著差异 .3 试验某种钢的冲击值(kg ×m/cm2),影响该指标的因素有两个,一是含铜量A ,另试检验含铜量和试验温度是否会对钢的冲击值产生显著差异?(α=0.05) 解 根据问题,这是一个双因素无重复试验的问题,不考虑交互作用.设因素,A B 分别表示为含铜量和温度,试验指标为钢的冲击力,水平为12.假设样本观测值(1,2,3,1,2,3,4)ij yi j ==来源于正态总体2~(,),1,2,3,ij ij Y N i μσ=1,2,3,4j = .记i α⋅为对应于i A 的主效应;记j β⋅为对应于j B 的主效应;检验的问题:(1)10:i H α⋅全部等于零,11:i H α⋅不全等于零;(2)20:j H β⋅全部等于零,21:j H β⋅不全等于零; 计算结果:表5.3 双因素无重复试验的方差分析表查表0.95(2,6) 5.143F =,0.95(3,6) 4.757F =,显然计算值,A B F F 分别大于查表值,或p = 0.0005,0.0009 均显著小于0.05,所以拒绝1020,H H ,认为含铜量和试验温度都会对钢的冲击值产生显著影响作用.设每个工人在每台机器上的日产量都服从正态分布且方差相同 .试检验:(α=0.05)1) 操作工之间的差异是否显著? 2) 机器之间的差异是否显著?3) 它们的交互作用是否显著?解 根据问题,这是一个双因素等重复(3次)试验的问题,要考虑交互作用.设因素,A B 分别表示为机器和操作,试验指标为日产量,水平为12. 假设样本观测值(1,2,3,1,2,3,4)ijk y i j ==来源于正态总体2~(,),1,2,3,ij ij Y N i μσ= 1,2,3,4j =,1,2,3k = .记i α⋅为对应于i A 的主效应;记j β⋅为对应于j B 的主效应;记ij γ为对应于交互作用A B ⨯的主效应; 检验的问题:(1)10:i H α⋅全部等于零,11:i H α⋅不全等于零; (2)20:j H β⋅全部等于零,21:j H β⋅不全等于零; (3)30:ij H γ全部等于零,31:ij H γ不全等于零;计算结果:表5.4 双因素无重复试验的方差分析表查表0.95(3,24) 3.01F =,0.95(2,24) 3.4F =,0.95(6,24) 2.51F =,计算值 3.01,A F <3.4, 2.51B A B F F ⨯>>,或0.05A p >>,而,B A B p p ⨯均显著小于0.05,所以拒绝2030,H H ,接受10H ,认为操作工之间的差异显著,机器之间的差异不显著,它们之间的交互作用显著 . 5 某轴承厂为了提高轴承圈退火的质量,制定因素水平分级如下表所示因素 上升温度℃ 保温时间(h)出炉温度℃水平1 800 6 400 水平28208500试填好正交试验结果分析表并对试验结果进行直观分析和方差分析 .解 根据题意,这是一个3因素2水平的试验问题 .试验指标为硬度的合格率 .应选择正交表44(2)L 来安排试验,随机生成正交试验表如下:方差来源 自由度 平方和 均方 F 值 P 值 因素A 因素B 相互效应A ×B误差 总和3 2 6 24 352.750 27.167 73.5 41.333 144.750.917 13.583 12.250 1.7220.5323 7.8871 7.11290.6645 0.00233** 0.00192**由此可见第三号试验条件为:上升温度800℃、保温时间6h 、出炉温度500℃ . 直观分析需要计算K 值,计算结果如下:直观分析 由计算的K 值知,因素A 、B 、C 的极差分别为70,40,40,因此主次关系为A B C >=,B ,C 相当 .由于试验指标为硬度的合格率,应该是越大越好,所以各确定因素的水平分别是121,,A B C ,即最佳的水平组合是121A B C ,即最佳搭配为:上升温度800℃、保温时间8h 、出炉温度400℃.采用方差分析法,计算得下表:表5.7 方差分析表方差来源平方和 自由度 均方差 F 值 A 1225 1 1225 1 B 400 1 400 0.33 C 400 1 400 0.33 误差 1225 1 1225 总和32504如果显著性检验水平取0.1α=,则查表得0.9(1,1)39.9F =,显然计算的F 值1,0.33A B C F F F ===均小于查表值,所以认为三个因素对结果影响都显著 .6问应选用哪张正交表安排试验,并写出第8号试验的条件;如果9组试验结果为(单位:kg/100m 2):62.925,57.075,51.6,55.05,58.05,56.55,63.225,50.7,54.45,试对该正交试验结果进行直观分析和方差分析.解 该问题属于3因素3水平的试验问题,试验指标为水稻产量 .根据题意应选择正交表49(3)L 来安排试验,随机生成正交表如下:由表可知,第8号试验的条件:品种(A 3)珍珠矮11号,插值密度(B 2)3.75棵/100m 2,施肥量(C 1)0.75kg/100m 2纯氨; 直观分析需要计算K 值,计算结果如下:同上题进行直观分析,得出K 值的大小关系为:111312212223333132,,K K K K K K K K K >>>>>>由直观分析看出:本例较好的水平搭配是:113A B C 采用方差分析法,计算得下表:表5.10 方差分析表方差来源平方和自由度 均方差F 值A 1.759 2 0.879 0.0223B 65.861 2 32.931 0.8361C 6.660 2 3.330 0.0845 误差78.776 239.388 39.3880.9(2,2)9F =,所以认为三个因素对结果影响都不显著.7 在阿魏酸的合成工艺考察中,为了提高产量,选取了原料配比A ,吡啶量B 和反应时间C 三个因素,它们各取了7个水平如下:原料配比A :1.0,1.4,1.8,2.2,2.6,3.0,3.4 吡啶量B :10,13,16,19,22,25,28 反应时间C :0.5,1.0,1.5,2.0,2.5,3.0,3.5试选用合适的均匀设计表安排试验,并写出第7号试验的条件;如果7组试验的结果(收率)为:0.33,0.336,0.294,0.476,0.209,0.451,0.482,试对该均匀试验结果进行直观分析并通过回归分析发现可能更好的工艺条件.解 根据题意选择均匀设计表47(7)U 来安排试验,有3个因素,根据使用表,实验安排如:表5.11 试验安排表6 6 5 4 0.4517 7 7 7 0.482 所以第7号实验的条件为:原配料比3.4,吡啶量28ml,反应时间3.5h.通过直观分析,最好的实验条件是:原配料比3.4,吡啶量28ml,反应时间3.5h. 通过回归分析,最合适的实验条件是:原配料比2.6,吡啶量16ml,反应时间0.5h.习题六1 从某中学高二女生中随机选取8名,测得其升高、体重如下:1 2 3 4 5 6 78身高(cm)160 159 160 157 169 162 165 154体重(kg)49 46 53 41 49 50 48 43在绝对距离下,试用最短距离法和离差平方和法对其进行聚类分析.解由R软件,用最短距离(左)和差离平方和法(右)对题目进行聚类分析如下图6.1,表6.1和表6.2:最短距离法离差平方和法图6.1 聚类树形图表6.1 聚类附表(最短距离法)步骤聚类合并系数首次出现的阶段类别下一步组1 组2 组1 组21 1 6 5.000 0 0 22 1 2 10.000 1 0 43 4 8 13.000 0 0 74 1 7 13.000 2 0 55 1 3 13.000 4 0 66 1 5 17.000 5 0 7表6.2 聚类附表(离差平方和法)2 已知五个变量的距离矩阵为03674012340444401592343331).;2);3)036034022020401000⎛⎫⎛⎫⎛⎫⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭试用最短距离法和最长距离法对这些变量进行聚类,并画出聚类图和二分树.解 针对距离矩阵1),采用两种方法计算如下. ①最短距离法的聚类步骤如下:12345036740159036020w w w w w ⎛⎫ ⎪⎪ ⎪ ⎪⎪⎪⎝⎭a )将()236,1w w f h =合并为一类,,{}11456,,,,H w w w h =距离矩阵如下0743023060⎛⎫ ⎪⎪ ⎪ ⎪⎝⎭{}()457457),,,2b w w h w w f h ==合并为一类,{}2167,,,H w h h =距离矩阵如下:034030⎛⎫ ⎪⎪ ⎪⎝⎭{}()()1681689),,3,3c w h h w h f h f h ===合并为一类,最后,,聚类图和树状图如图6.2:图6.2 聚类图(左)与树状图(右)②最长距离法与最短距离法类似,步骤如下: a )()236,1w w f h =合并为一类,{}11456,,,,H w w w h =距离矩阵如下0746025090⎛⎫ ⎪⎪ ⎪ ⎪⎝⎭ {}(){}4574572167),,,2,,,b w w h w w f h H w h h ===合并为一类,距离矩阵如下:067090⎛⎫⎪⎪ ⎪⎝⎭{}()()1681689),,69c w h h w h f h f h ===合并为一类,最后,,,聚类图和树状图如图6.3:图6.3 聚类图(左)与树状图(右)(2)针对距离矩阵2)012340234034040⎛⎫ ⎪⎪ ⎪ ⎪⎪⎪⎝⎭①最短距离法的聚类步骤如下 a )()216,1w w f h =合并为一类,{}13456,,,,0342043040H w w w h =⎛⎫⎪⎪ ⎪ ⎪⎝⎭距离矩阵如下{}()367367),,,2b w h h w h f h ==合并为一类,{}24567,,,,H w w h h =聚类矩阵如下:043040⎛⎫⎪⎪ ⎪⎝⎭{}(){}()4784789879),,3,,4c w h h w h f h h w h f h ====合并为一类,最后,,聚类图和树状图如图6.4:图6.4 聚类图(左)与树状图(右)②由于本题数据的特殊性,最长距离法与最短距离法结果相同(略). (3)044440333022010⎛⎫ ⎪⎪ ⎪ ⎪⎪⎪⎝⎭最短距离法的聚类步骤如下a ) ()456,1w w f h =合并为一类,{}11236,,,,H w w w h =距离矩阵如下0444033020⎛⎫ ⎪⎪ ⎪ ⎪⎝⎭{}(){}36736724567),,,2,,,,b w h h w h f h H w w h h ===合并为一类,距离矩阵如下:044030⎛⎫⎪⎪ ⎪⎝⎭{}(){}()4784789879),,3,,4c w h h w h f h h w h f h ====合并为一类,最后,,,聚类图和树状图如图6.5:图6.5 聚类图(左)与树状图(右)由于本题数据的特殊性,最长距离法与最短距离法结果相同(略).3 在一项关于作物对土壤营养的反应的研究中,要测定土壤的总磷量和总氮量(占干物质重的百分比),今对10份土样测得数据如下:总氮量(%)0.120.63 1.19 2.30 1.29 0.73 0.52 0.33 0.61 0.470.66在绝对距离下,试用重心法对其进行聚类分析.解由R软件得到重心法聚类分析的结果如图6.6与表6.3:图6.6 聚类树形图表6.3 聚类过程记录表步骤聚类合并系数首次出现的阶段类别下一步组1 组2 组1 组21 1 8 .001 0 0 22 1 10 .002 1 0 43 6 9 .005 0 0 64 15 .010 2 0 75 2 4 .010 0 0 86 67 .027 3 0 77 1 6 .048 4 6 88 1 2 .459 7 5 99 1 3 2.572 8 0 04 1975年Dagnelie收集了11年的气象数据资料如下表变量年序x1x2x3x4其中:x 1—前一年11月12日的降水量;x 2—7月均温;x 3—7月降雨量;x 4—月日辐射,试对这四个气象因子进行主成分分析. 解 由R 软件分析得到如下表6.4,6.5:表6.4 各主成分的重要性:主成分1 主成分2 主成分3 主成分4 标准差 1.6103349 0.9890848 0.53407741 0.37854199 方差贡献率 0.6482947 0.2445722 0.07130967 0.03582351 累积贡献率0.64829470.89286680.964176491.00000000表6.5 因子荷载:主成分1 主成分2 主成分3 主成分4 X1 0.291 0.871 0.332 -0.214 X2 -0.506 0.425 -0.742 -0.111 X3 0.577 0.136 -0.418 0.688 X4-0.5710.2050.4040.685由于前两个主成分对应的累积贡献率已经达到89.287,因此选取主成分的数目为2.5 对某初中12岁的女生进行体检,测量其身高x 1、体重x 2、胸围x 3和坐高x 4,共测得58个样本,并算得1234(,,,)x x x x x ='的样本协方差为19.9410.5023.566.5919.7120.958.637.97 3.937.55S ⎛⎫ ⎪⎪= ⎪ ⎪ ⎪⎝⎭ 试进行样本主成分分析.解 首先计算样本的相关系数矩阵:10.484410.32240.887210.70330.59760.31251⎛⎫ ⎪ ⎪ ⎪ ⎪⎝⎭设相关系数矩阵的特征值和特征向量分别为d 和v 阵,计算得到0.0546000 0 0.312600= 000.96470 000 2.6681d ⎛⎫ ⎪ ⎪ ⎪ ⎪⎝⎭即四个特征值依次为:2.6681,0.9647,0.3126,0.0546,前两个主成分的累计贡献率为:90.8471%,因此提取主成分为2.四个特征根相应的特征向量为0.06000.70600.5333 0.4620 0.7317 0.17430.34040.5642=0.60570.19320.60400.48060.30690.65870.48460.4870v -⎛⎫ ⎪-⎪ ⎪--- ⎪-⎝⎭ 因此,两个主成分的表达式为:112340.060.73170.60570.3069z x x x x =+-- 212340.7060.17430.19320.6587z x x x x =-+-+6 比较因子分析和主成分分析模型的异同,阐明两者的关系. 解(1)提取公因子的方法主要有主成分法和公因子法.若采取主成分法,则主成分分析和因子分析基本等价,该法从解释变量的变异的角度出发,尽量使变量的方差能被主成分解释;而公因子法主要从解释变量的相关性角度,尽量使变量的相关程度能被公因子解释,当因子分析目的重在确定结构时则用到该法.(2)主成分分析和因子分析都是在多个原始变量中通过他们之间的内部相关性来获得新的变量,达到既减少分析指标个数,又能概括原始指标主要信息的目的.但他们各有其特点:主成分分析是将n 个原始变量提取m 个支配原始变量的公因子,和1个特殊因子,各因子之间可以相关或不相关.(3)统用降维的方法,但差异也很明显:主成分分析把方差划分为不同的正交成分,而因子分析则把方差化分为不同的起因因子;因子分析中的特征值的计算只能从相关系数矩阵出发,且必须把主成分划分为因子.(4)因子分析提取的公因子比主成分分析提取的主成分更具有可解释性.(5)两者分析的实质及重点不同.主成分的数学模型为Y AX =,因子分析的数学模型为X AF ε=+.因而可知主成分分析是实际上是线性变换,无假设检验,而因子分析是统计模型,某些因子模型是可以得到假设检验的;主成分分析主要综合原始数据的信息,而因子分析重在解释原始变量之间的关系.(6)SPSS 数据的实现:两者都通过“analyzedata reduction Factor ···”过程实现,但主成分分析主要使用“descriptires ”,“extraction ”,“stores ”对话框,而因子分析处使用这些外,还可使用“rotaction ”对话框进行因子旋转.7 试对第4题的变量作因子分析,并将结果和上面的结果进行比较. 解 用SPSS 分析,计算结果如下表6.6-6.8:表6.6 反应压缩比情况表 提取方法: 主成分法计算的相关系数矩阵的特征值和方差贡献率:表6.7 方差解释度提取方法: 主成分法表6.8 主成分矩阵8 为研究某一树种的叶片形态,选取50片叶测量其长度x 1(mm )和宽度x 2(mm ),按样本数据求得其平均值和协方差矩阵为:129048134,92,4845x x S ⎛⎫=== ⎪⎝⎭求出相关系数阵R ,并由R 出发作因子分析;解1)求相关系数矩阵:904810.7303,48900.73031S R ⎛⎫⎛⎫== ⎪ ⎪⎝⎭⎝⎭ 2)用R 软件求R 的特征根及其相应的特征向量,软件输出结果如下:$values[1] 2.99393809 0.07273809 $vectors[,1] [,2] [1,] 0.7071068 -0.7071068 [2,] 0.7071068 0.7071068122.9939,0.0727,λλ∴==12(),()0.7071,0.7071-0.7071,0.7071T Tηη==3) 求载荷矩阵A :1.22350.19071.22350.1907A -⎛⎫= ⎪⎝⎭4)22121.5333, 1.5333,h h == 0.98810.154*0.98810.154A -⎛⎫= ⎪⎝⎭12121,1,0.3043,0.3043u u v v ===-=,222222000011112,0,()0.9074,20i i iii i i i i i A u B v C u v D u v =========-===∑∑∑∑9 1981年,生物学家Grogan 和Wirth 对两种蠓虫Af 和Apf 根据其触角长度x 1和翼长x 2进行了分类,分类的数据资料如下:Af 1 2 3 4 5 6 7 8 x 1 1.24 1.36 1.38 1.38 1.38 1.40 1.48 1.54 x 2 1.27 1.74 1.64 1.82 1.90 1.70 1.82 1.82 Apf 1 2 3 4 5 6 x 1 1.14 1.18 1.20 1.26 1.28 1.30 x 2 1.78 1.96 1.86 2.00 2.00 1.96 (1)试建立Af 和Apf 的Fisher 判别模型;(2)对样本(1.24,1.80),(1.28,1.84),(1.40,2.04)进行判别分类. 解 (1)建立Fisher 判别模型991122121111(,)(1.42,1.75),(,)(1.23,1.93)99T TT T i i i i i i x x y y μμ======∑∑120.08480.1490.01980.0218,0.1490.39120.02180.039A A ⎛⎫⎛⎫== ⎪ ⎪⎝⎭⎝⎭12120.0080.0130.0130.0332A A n n ⎛⎫+== ⎪+-⎝⎭∑()120.19,0.18Tμμ-=-,()()121 1.325,1.842T μμ+= 1345.05135.42135.4283.33--⎛⎫= ⎪-⎝⎭∑, 带入Fisher 判别函数 ()12345.05135.42[(,)(1.325,1.84)]0.19,0.18135.4283.33Tx x -⎛⎫-- ⎪-⎝⎭1291.301741.336944.534x x =--(2)把三个样本(1.24,1.80),(1.28,1.84),(1.4,2.04)带入模型,得到结果:三个样本均属于Apf 类.10 在两个玉米品种之间进行判别:137玉米G 1和甜玉米G 2,选取的两个变量是:x 1—玉米果穗长;x 2—玉米果穗直径,两个类的样本容量为n 1=n 2=40,实际算得两个类的样本均值和样本协方差为:121218.5625.348.120 4.4589.661 3.720,,,5.98 4.12 4.458 4.350 3.720 3.410x x S S ⎛⎫⎛⎫⎛⎫⎛⎫==== ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭⎝⎭试建立G 1,G 2的Bayes 类线性判别函数.解 因为已知两类的样本均值和样本协方差为:12(18.56,5.98),(25.34,4.12)T T x x ==,128.120 4.4589.661 3.720,4.458 4.350 3.720 3.410S S ⎛⎫⎛⎫== ⎪ ⎪⎝⎭⎝⎭可计算得到修正的公共协方差矩阵和逆矩阵12120.2280.1450.1450.0992A A n n ⎛⎫+== ⎪+-⎝⎭∑,15.6393.738.25147.38--⎛⎫= ⎪-⎝⎭∑()()()121216.78,1.86,21.95,5.052TTμμμμ-=-+= 带入Fisher 判别函数()112121(())()2T W x x μμμμ-=-+-∑ ()()12 5.6393.73[(,)21.95,5.05] 6.78,1.868.25147.38Tx x -⎛⎫=-- ⎪-⎝⎭1274.396.951141.29x x =-+-。
西安交通大学——应用数理统计课后答案_

习题11.1 解:由题意95.01=⎭⎬⎫⎩⎨⎧<--u x p 可得:95.0=⎪⎪⎭⎪⎪⎬⎫⎪⎪⎩⎪⎪⎨⎧<-σσn n u x p而()1,0~N u x n σ⎪⎭⎫ ⎝⎛-- 这可通过查N(0,1)分布表,975.0)95.01(2195.0=-+=⎪⎪⎭⎪⎪⎬⎫⎪⎪⎩⎪⎪⎨⎧<--σn n u x p 那么96.1=σn∴2296.1σ=n1.2 解:(1)至800小时,没有一个元件失效,则说明所有元件的寿命>800小时。
{}2.10015.08000015.00800|e 0015.0800--∞+-=∞+-==>⎰e e dx x p x x那么有6个元件,则所求的概率()2.762.1--==e ep(2)至300小时,所有元件失效,则说明所有元件的寿命<3000小时{}5.4300000015.030000015.001|e 0015.03000----=-==<⎰e e dx x p x 那么有6个元件,则所求的概率()65.41--=ep1.3解: (1) 123{(,,)|0,1,2,,1,2,3}k x x x x k χ===因为~()i X P λ,所以 112233{,,}P X x X x X x ≤≤≤112233{}{}{}P X x P X x P X x =≤≤≤1233123!!!x x x e x x x ++-λλ=其中,0,1,2,,1,2,3k x k == (2) 123{(,,)|0;1,2,3}k x x x x k χ=≥=因为~()i X Exp λ,其概率密度为,0()0,0x e x f x x -λ⎧λ≥=⎨ <⎩所以, 123(,,)3123(,,)x x x f x x x e-λ=λ,其中0;1,2,3k x k ≥=(3) 123{(,,)|;1,2,3}k x x x a x b k χ=≤≤=因为~(,)i X U a b ,其概率密度为1,()0,|a x b f x b a x a x b⎧≤≤⎪=-⎨⎪ <>⎩所以,12331(,,)()f x x x b a =-,其中;1,2,3k a x b k ≤≤= (4) 123{(,,)|;1,2,3}k x x x x k χ=-∞<<+∞= 因为~(,1)i X N μ,其概率密度为(2(),()x f x x 2-μ)-=-∞<<+∞所以,311(2123321(,,)(2)k k x f x x x e π2=--μ)∑=,其中;1,2,3k x k -∞<<+∞=1.4解:由题意可得:()⎪⎩⎪⎨⎧∞<<=--,其它00,21)(i 2ln i i 2i x e x x f u x σσπ则∏==ni x f x x f 1i n i )(),...(=⎪⎪⎩⎪⎪⎨⎧=∞<<∏=∑--=,其它0,...1,0,1n )2()(ln 212n 12i 2i x x e i n i i u x ni σπσ1.5证: 令21()()nii F a Xa ==-∑则'1()2()nii F a Xa ==--∑,''()20F a n => 令'1()2()0ni i F a X a ==--=∑,则可解得11ni i a X X n ===∑由于这是唯一解,又因为''()20F a n =>,因此,当11ni i a X X n ===∑时,()F a 取得最小值1.6证: (1)等式左边11((nnii i i XX X X 22==-μ)=-+-μ)∑∑111(2()()(n n n i i i i i X X X X X X 22====-)+-μ-+-μ)∑∑∑21(()ni i X X n X 2==-)+-μ∑左边=右边,所以得证. (2) 等式左边22111(2nn ni iii i i XX X X X nX 2===-)=-+∑∑∑ 22212nii Xn X n X ==-+∑221ni i X nX ==-∑左边=右边,所以得证.1.7证:(1)∑=-=ni i n x n x 11∑+=-++=11111n i i n x n x 那么)(11_1_n n n x x n x -+++=∑∑=+=∙+-++ni i n n i i x n n x n x n 111111111 =111111+=+++∑n n i i x n x n =∑=+ni i x n 111=_1+n x ∴原命题得证(2)21221-=-=∑n n i i nx x n s211122111-++=+-+=∑n n i i n x x n s那么⎥⎦⎤⎢⎣⎡-+++-+212)(111n n n x x n s n n =∑=+n i i x n 1211--+21n x n n +212)1(++n x n n --++nn x x n n 12)1(2+22)1(-+n x n n=∑=+n i i x n 1211--+222)1(n x n n +2111++n x n -212)1(1++n x n --++n n x x n n 12)1(2=∑+=+11211n i i x n -(111++n x n +-+n x n n 1)2由(1)可得:111++n x n +-+n x n n 1=-+1n x则上式=∑=+n i i x n 1211-21-+n x =21+n s∴原命题得证1.10解: 因为2222111111,()n n n i i i i i i X X S X X X X n n n =====-=-∑∑∑所以 (1) 二项分布(,)B m p11()()()ni i i E X E X E X mp n ====∑21111(1)()()()n ni i i i mp p D X D X D X n n n ==-===∑∑222211111()(())()()(1)n n i i i i n E S E X X E X E X mp p n n n==-=-=-=-∑∑(2) 泊松分布()P λ()E X =λ, ()D X n λ=, 21()n E S n-=λ(3) 均匀分布(,)U a b()2b a E X +=, 2)()12b a D X n (-=, 221()()12n E S b a n-=-(4) 指数分布()Exp λ 1()E X =λ, 1()D X n 2=λ, 21()n E S n 2-=λ (5) 正态分布2(,)N σμ ()E X =μ, 21()D X n σ=, 221()n E S nσ-=1.11解:(1)是统计量(2)不是统计量,因为u未知 (3)统计量 (4)统计量(5)统计量,顺序统计量 (6)统计量 (7)统计量(8)不是统计量,因为u未知 1.14.解: 因为i X 独立同分布,并且~(,i X a Γλ),11ni i X X n ==∑所以1~(,nii Xna =Γλ)∑;令1nii Y X ==∑,则1X Y n =,由求解随机变量函数的概率密度公式可得 1()(),0)nana nx X f x nx e n x na --λλ=>Γ(1.15 解:(1))(m x 的概率密度为: [][])()(1)()!()!1(!)(1)(x f x F x F m n m n x f m n m m ------=又F(x)=2x 且f(x)=2x ,0<x<1则有x x x m n m n x f m n m m 2)1()!()!1(!)(2)1(2)(------=,0<x<1(2) )(1x 与)(n x 的联合概率密度为: [][])()()(1)()()11(!),(011))(1(y f x f y F x F y F n n y x f n n ----=--=y x x y n n n 22))(1(222⋅⋅---=222)()1(4---n x y xy n n 0<x<y<1对于其他x,y ,有0),())(1(=y x f n1.19证:现在要求Y=)X 1/(X m nm n +的概率密度。
《应用数理统计》第五章方差分析课后作业参考答案

第五章 方差分析课后习题参考答案5.1 下面给出了小白鼠在接种三种不同菌型伤寒杆菌后的存活日数:设小白鼠存活日数服从方差相等的正态分布,试问三种菌型的平均存活日数有无显著差异?(01.0=α)解:(1)手工计算解答过程 提出原假设:()3,2,10:0==i H i μ记167.2081211112=⎪⎪⎭⎫ ⎝⎛-=∑∑∑∑====r i n j ij ri n j ij T i iX n X S467.7011211211=⎪⎪⎭⎫ ⎝⎛-⎪⎪⎭⎫ ⎝⎛=∑∑∑∑====r i n j ij ri n j ij iA ii X n X n S7.137=-=A T e S S S当H成立时,()()()r n r F r n S r S F e A ----=,1~/1/本题中r=3经过计算,得方差分析表如下:查表得()()35.327,2,195.01==---F r n r F α且F=6.909>3.35,在95%的置信度下,拒绝原假设,认为不同菌型伤寒杆菌对小白鼠的存活日数有显著影响。
(2)软件计算解答过程组建效应检验Dependent Var iable: 存活日数a70.429235.215 6.903.004137.73727 5.101208.16729方差来源菌型误差总和平方和自由度均值F 值P 值R Squared = .338 (Adjusted R Squared = .289)a.从上表可以看出,菌种不同这个因素的检验统计量F 的观测值为6.903,对应的检验概率p 值为0.004,小于0.05,拒绝原假设,认为菌种之间的差异对小白鼠存活日数有显著影响。
5.2 现有某种型号的电池三批,他们分别是甲、乙、丙三个工厂生产的,为评论其质量,各随机抽取6只电池进行寿命试验,数据如下表所示:工厂 寿命(小时) 甲 40 48 38 42 45 乙 26 34 30 28 32 丙39 40 43 50 50试在显著水平0.05α=下,检验电池的平均寿命有无显著性差异?并求121323,μμμμμμ---及的95%置信区间。
应用数理统计课后习题参考答案

应用数理统计课后习题参考答案1. 描述性统计问题1描述性统计是一种对数据进行整理、呈现和分析的方法。
它可以提供数据的基本特征,包括数据的中心趋势、离散程度和分布形状。
常见的描述性统计方法有:•平均数:用于衡量数据的中心趋势,是所有数据值的总和除以数据的个数。
•中位数:将数据按大小顺序排列,中间位置的数值即为中位数。
•众数:数据中出现次数最多的数值。
•范围:数据的最大值减去最小值。
•方差:用于衡量数据的离散程度,是每个数据与平均数之差的平方的平均值。
•标准差:方差的正平方根。
问题2对于给定数据集,以下是计算描述性统计的步骤:1.求出数据的个数。
2.计算数据的总和。
3.求出数据的平均数。
4.将数据按大小顺序排列。
5.求出数据的中位数。
6.找出数据中出现次数最多的数值,即众数。
7.计算数据的范围。
8.计算数据的方差。
9.计算数据的标准差。
2. 概率分布问题1概率分布是用来描述随机变量的分布规律的函数。
常见的概率分布包括:•二项分布:适用于具有两个可能结果的离散型随机变量,如投硬币的结果。
•泊松分布:适用于描述单位时间或单位空间内随机事件发生次数的离散型随机变量。
•正态分布:也称为高斯分布,是一种连续型概率分布,常用于描述自然界中许多现象的分布情况,如身高、体重等。
问题2对于给定的概率分布,以下是计算概率的步骤:1.对于离散型概率分布,计算每个可能结果的概率,并将其加总为1。
2.对于连续型概率分布,计算指定区间内的概率,可以使用积分来进行计算。
3.根据需要计算特定事件的概率,可以使用概率密度函数(PDF)或累积分布函数(CDF)来计算。
3. 统计推断问题1统计推断是一种利用样本数据对总体特征进行估计和推断的方法。
常见的统计推断方法有:•置信区间估计:对总体参数进行估计时,构造一个区间,使得真实值以一定概率包含在该区间内。
•假设检验:用于判断一个总体参数是否等于某个特定值。
•方差分析:用于比较两个或多个总体的均值是否有显著差异。
(完整版)清华大学_杨虎_应用数理统计课后习题参考答案

习题一1 设总体X 的样本容量5=n ,写出在下列4种情况下样本的联合概率分布. 1)),1(~p B X ; 2))(~λP X ; 3)],[~b a U X ; 4))1,(~μN X .解 设总体的样本为12345,,,,X X X X X , 1)对总体~(1,)X B p ,1122334455511155(1)(,,,,)()(1)(1)i inx x i i i i x x P X x X x X x X x X x P X x p p p p -==-========-=-∏∏其中:5115ii x x ==∑2)对总体~()X P λ11223344555115551(,,,,)()!!ixni i i i i xi i P X x X x X x X x X x P X x e x e x λλλλ-==-==========∏∏∏其中:5115ii x x ==∑3)对总体~(,)X U a b5511511,,1,...,5 (,,)()0i i i i a x b i f x x f x b a==⎧≤≤=⎪==-⎨⎪⎩∏∏,其他4)对总体~(,1) X N μ()()()25555/222151111 (,,)()=2exp 2i x i i i i i f x x f x x μπμ---===⎛⎫==-- ⎪⎝⎭∑∏2 为了研究玻璃产品在集装箱托运过程中的损坏情况,现随机抽取20个集装箱检查其产品损坏的件数,记录结果为:1,1,1,1,2,0,0,1,3,1,0,0,2,4,0,3,1,4,0,2,写出样本频率分布、经验分布函数并画出图形.解 设(=0,1,2,3,4)i i 代表各箱检查中抽到的产品损坏件数,由题意可统计出如下的样本频率分布表1.1:表 1.1 频率分布表i 0 1 2 3 4 个数6 7 3 2 2 iX f0.3 0.35 0.15 0.1 0.1经验分布函数的定义式为:()()()(1)10,(),,=1,2,,1,1,n k k k x x kF x x x x k n n x x +<⎧⎪⎪≤<-⎨⎪≥⎪⎩,据此得出样本分布函数:200,00.3,010.65,12()0.8,230.9,341,4x x x F x x x x <⎧⎪≤<⎪⎪≤<⎨≤<⎪⎪≤<⎪≥⎩图1.1 经验分布函数3 某地区测量了95位男性成年人身高,得数据(单位:cm)如下:组下限165 167 169 171 173 175 177 组上限167 169 171 173 175 177 179x()n F x人 数3 10 21 23 22 11 5试画出身高直方图,它是否近似服从某个正态分布密度函数的图形.解图1.2 数据直方图它近似服从均值为172,方差为5.64的正态分布,即(172,5.64)N .4 设总体X 的方差为4,均值为μ,现抽取容量为100的样本,试确定常数k ,使得满足9.0)(=<-k X P μ.解 ()- 54100X P X k P k μμ⎫-⎪<=<⎪⎭()()555 P k X k μ=-<-<因k 较大,由中心极限定理(0,1)4100X N : ()()()-55P X k k k μ<≈Φ-Φ-(5)(1(5))k k =Φ--Φ()2510.9k =Φ-=所以:()50.95k Φ=查表得:5 1.65k =,0.33k ∴=.5 从总体2~(52,6.3)X N 中抽取容量为36的样本,求样本均值落在50.8到53.8之间的概率.解 ()50.853.8 1.1429 1.7143X P X P ⎛⎫<<=-<< ⎪⎝⎭(0,1) 6.3X U N =()()50.853.8 1.1429 1.7143(1.7143)( 1.14290.9564(10.8729)0.8293P X P U ∴<<=-<<=Φ-Φ-=--=)6 从总体~(20,3)X N 中分别抽取容量为10与15的两个独立的样本,求它们的均值之差的绝对值大于0.3的概率.解 设两个独立的样本分别为:110,,X X 与115,,Y Y ,其对应的样本均值为:X 和Y .由题意知:X 和Y 相互独立,且: 3~(20,)10X N ,3~(20,)15Y N(0.3)1(0.3)P X Y P X Y ->=--≤1P =-~(0,0.5)~(0,1)(0.3)22(0.4243)0.6744X Y N X YN P X Y -->=-Φ=7 设110,,X X 是总体~(0,4)X N 的样本,试确定C ,使得1021()0.05ii P XC =>=∑.解 因~(0,4)i X N ,则~(0,1)2iX N ,且各样本相互独立,则有:10122~(10)2i i X χ=⎛⎫⎪⎝⎭∑所以:10102211()()144iii i CP X C P X ==>=>∑∑1021110.0544i i c P X =⎛⎫=-≤= ⎪⎝⎭∑102110.9544i i c P X =⎛⎫≤= ⎪⎝⎭∑查卡方分位数表:c/4=18.31,则c=73.24.8 设总体X 具有连续的分布函数()X F x ,1,,n X X 是来自总体X 的样本,且i EX μ=,定义随机变量:1,,1,2,,0,i i i X Y i n X μμ>==≤⎧⎨⎩试确定统计量∑=ni i Y 1的分布.解 由已知条件得:~(1,)i Y B p ,其中1()X p F μ=-.因为i X 互相独立,所以i Y 也互相独立,再根据二项分布的可加性,有1~(,)nii YB n p =∑,1()X p F μ=-.9 设1,,n X X 是来自总体X 的样本,试求2,,EX DX ES 。
应用数理统计课后习题参考答案

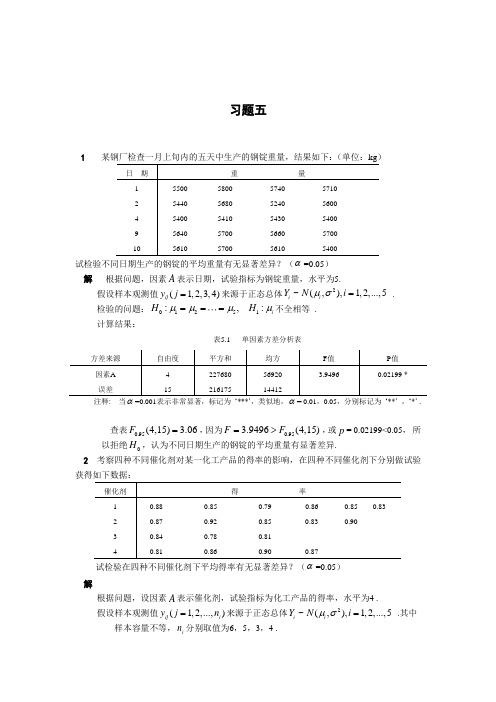
习题五1 某钢厂检查一月上旬内的五天中生产的钢锭重量,结果如下:(单位:k g)日期重旦量1 5500 5800 5740 57102 5440 5680 5240 56004 5400 5410 5430 54009 5640 5700 5660 570010 5610 5700 5610 5400试检验不同日期生产的钢锭的平均重量有无显著差异? ( =0.05)解根据问题,因素A表示日期,试验指标为钢锭重量,水平为 5.2假设样本观测值y j(j 123,4)来源于正态总体Y~N(i, ),i 1,2,...,5检验的问题:H。
:i 2 L 5, H i : i不全相等.计算结果:注释当=0.001表示非常显著,标记为*** '类似地,=0.01,0.05,分别标记为查表F0.95(4,15) 3.06,因为F 3.9496 F0.95(4,15),或p = 0.02199<0.05 ,所以拒绝H。
,认为不同日期生产的钢锭的平均重量有显著差异2 考察四种不同催化剂对某一化工产品的得率的影响,在四种不同催化剂下分别做试验解根据问题,设因素A表示催化剂,试验指标为化工产品的得率,水平为 4 .2假设样本观测值y j(j 1,2,..., nJ来源于正态总体Y~N(i, ), i 1,2,...,5 .其中样本容量不等,n分别取值为6,5,3,4 .日产量操作工查表 F O .95(3,14) 3.34,因为 F 2.4264 F °.95(3,14),或 p = 0.1089 > 0.05, 所以接受H 。
,认为在四种不同催化剂下平均得率无显著差异3试验某种钢的冲击值(kg Xm/cm2 ),影响该指标的因素有两个,一是含铜量 A ,另一个是温度试检验含铜量和试验温度是否会对钢的冲击值产生显著差异? ( =0.05 )解 根据问题,这是一个双因素无重复试验的问题,不考虑交互作用设因素A,B 分别表示为含铜量和温度,试验指标为钢的冲击力,水平为 12.2假设样本观测值y j (i 1,2,3, j 1,2,3,4)来源于正态总体 Y j ~N (j ,),i 1,2,3,j 1,2,3,4 .记i 为对应于A 的主效应;记 j 为对应于B j 的主效应;检验的问题:(1) H i 。
应用数理统计课后答案

1 n ˆ xi x n i 1 1 n 2 ˆ 2 ( xi x) 2 sn n i 1
则 , 2 的极大似然估计量:
1 n ˆ n X i X i 1 1 n 2 ˆ 2 ( X i X )2 Sn n i 1
1 e x, F (x) 0,
x 0, x 0.
(1) FY ( y) P{Y y} P{aX b y} P{ X
y b yb }(a 0) F ( ) a a
y b y b 当 0,即y b时,FY ( y ) 1 e a . a 当 y b 0,即y b时,F ( y ) 0. Y a
Xi
i 1
2
(t ) e i1
i ( eit 1)
2
根据特征函数的性质(5)得: X 1 X 2 ~ P(1 2 )
第二章 数理统计的基本概念
8.解:设 X 为样本,x 为样本的观测值。由于数据已经按照从小到大的顺序排列,
于是经验分布函数为:
0, 1 , 8 1 , 4 3 , 8 1 Fn ( x ) , 2 5 8 , 3, 4 7 , 8 1,
y
1 e y, FY ( y ) 0,
y 0, y 0.
14.证明:
Cov( , ) Cov(aX b, cY d ) acCov ( X , Y ) D( ) D(aX b) a 2 D( X )同理:D( ) c 2 D(Y )
由极大似然估计的不变性可知
ˆ Sn
应用数理统计,施雨,课后答案,

习题11.1 解:由题意95.01=⎭⎬⎫⎩⎨⎧<--u x p 可得:95.0=⎪⎪⎭⎪⎪⎬⎫⎪⎪⎩⎪⎪⎨⎧<-σσn n u x p而()1,0~N u x n σ⎪⎭⎫ ⎝⎛-- 这可通过查N (0,1)分布表,975.0)95.01(2195.0=-+=⎪⎪⎭⎪⎪⎬⎫⎪⎪⎩⎪⎪⎨⎧<--σσn n u x p 那么96.1=σn∴2296.1σ=n1.2 解:(1)至800小时,没有一个元件失效,则说明所有元件的寿命>800小时。
{}2.10015.08000015.00800|e 0015.0800--∞+-=∞+-==>⎰e e dx x p x x 那么有6个元件,则所求的概率()2.762.1--==e e p(2)至300小时,所有元件失效,则说明所有元件的寿命<3000小时{}5.4300000015.030000015.001|e 0015.03000----=-==<⎰e e dx x p x 那么有6个元件,则所求的概率()65.41--=e p1。
3解: (1) 123{(,,)|0,1,2,,1,2,3}k x x x x k χ===因为~()i X P λ,所以 112233{,,}P X x X x X x ≤≤≤112233{}{}{}P X x P X x P X x =≤≤≤1233123!!!x x x e x x x ++-λλ=其中,0,1,2,,1,2,3k x k ==(2) 123{(,,)|0;1,2,3}k x x x x k χ=≥=因为~()i X Exp λ,其概率密度为,0()0,0x e x f x x -λ⎧λ≥=⎨ <⎩所以, 123(,,)3123(,,)x x x f x x x e-λ=λ,其中0;1,2,3k x k ≥=(3) 123{(,,)|;1,2,3}k x x x a x b k χ=≤≤=因为~(,)i X U a b ,其概率密度为1,()0,|a x b f x b a x a x b⎧≤≤⎪=-⎨⎪ <>⎩所以,12331(,,)()f x x x b a =-,其中;1,2,3k a x b k ≤≤= (4) 123{(,,)|;1,2,3}k x x x x k χ=-∞<<+∞= 因为~(,1)i X N μ,其概率密度为(2(),()x f x x 2-μ)-=-∞<<+∞所以,311(2123321(,,)(2)k k x f x x x e π2=--μ)∑=,其中;1,2,3k x k -∞<<+∞=1.4解:由题意可得:()⎪⎩⎪⎨⎧∞<<=--,其它00,21)(i 2ln i i 22i x e x x f u x σσπ则∏==ni x f x x f 1i n i )(),...(=⎪⎪⎩⎪⎪⎨⎧=∞<<∏=∑--=,其它0,...1,0,1n )2()(ln 212n 12i 2i x x e i n i i u x ni σπσ1.5证: 令21()()nii F a Xa ==-∑则'1()2()nii F a Xa ==--∑,''()20F a n => 令'1()2()0ni i F a X a ==--=∑,则可解得11ni i a X X n ===∑由于这是唯一解,又因为''()20F a n =>,因此,当11ni i a X X n ===∑时,()F a 取得最小值1.6证: (1)等式左边11((nnii i i XX X X 22==-μ)=-+-μ)∑∑111(2()()(n n n i i i i i X X X X X X 22====-)+-μ-+-μ)∑∑∑21(()ni i X X n X 2==-)+-μ∑左边=右边,所以得证。
清华大学 杨虎 应用数理统计课后习题参考答案

习题一1 设总体X 的样本容量5=n ,写出在下列4种情况下样本的联合概率分布. 1)),1(~p B X ; 2))(~λP X ; 3)],[~b a U X ; 4))1,(~μN X .解 设总体的样本为12345,,,,X X X X X , 1)对总体~(1,)X B p ,1122334455511155(1)(,,,,)()(1)(1)i inx x i i i i x x P X x X x X x X x X x P X x p p p p -==-========-=-∏∏其中:5115ii x x ==∑2)对总体~()X P λ11223344555115551(,,,,)()!!ixni i i i i xi i P X x X x X x X x X x P X x e x e x λλλλ-==-==========∏∏∏其中:5115ii x x ==∑3)对总体~(,)X U a b5511511,,1,...,5 (,,)()0i i i i a x b i f x x f x b a==⎧≤≤=⎪==-⎨⎪⎩∏∏,其他4)对总体~(,1) X N μ()()()25555/222151111 (,,)()=2exp 2i x i i i i i f x x f x x μπμ---===⎛⎫==-- ⎪⎝⎭∑∏2 为了研究玻璃产品在集装箱托运过程中的损坏情况,现随机抽取20个集装箱检查其产品损坏的件数,记录结果为:1,1,1,1,2,0,0,1,3,1,0,0,2,4,0,3,1,4,0,2,写出样本频率分布、经验分布函数并画出图形.解 设(=0,1,2,3,4)i i 代表各箱检查中抽到的产品损坏件数,由题意可统计出如下的样本频率分布表:经验分布函数的定义式为:()()()(1)10,(),,=1,2,,1,1,n k k k x x kF x x x x k n n x x +<⎧⎪⎪≤<-⎨⎪≥⎪⎩,据此得出样本分布函数:200,00.3,010.65,12()0.8,230.9,341,4x x x F x x x x <⎧⎪≤<⎪⎪≤<⎨≤<⎪⎪≤<⎪≥⎩图 经验分布函数3 某地区测量了95位男性成年人身高,得数据(单位:cm)如下:试画出身高直方图,它是否近似服从某个正态分布密度函数的图形.解图 数据直方图它近似服从均值为172,方差为的正态分布,即(172,5.64)N .4 设总体X 的方差为4,均值为μ,现抽取容量为100的样本,试确定常数k ,使得满足9.0)(=<-k X P μ.x()n F x解 ()- 5P X k P k μ⎫⎪<=<⎪⎭()()555 P k X k μ=-<-<因k 较大,由中心极限定理(0,1)X N : ()()()-55P X k k k μ<≈Φ-Φ-(5)(1(5))k k =Φ--Φ()2510.9k =Φ-=所以:()50.95k Φ=查表得:5 1.65k =,0.33k ∴=.5 从总体2~(52,6.3)X N 中抽取容量为36的样本,求样本均值落在到之间的概率.解 ()50.853.8 1.1429 1.7143X P X P ⎛⎫<<=-<< ⎪⎝⎭(0,1) 6.3X U N =()()50.853.8 1.1429 1.7143(1.7143)( 1.14290.9564(10.8729)0.8293P X P U ∴<<=-<<=Φ-Φ-=--=)6 从总体~(20,3)X N 中分别抽取容量为10与15的两个独立的样本,求它们的均值之差的绝对值大于的概率.解 设两个独立的样本分别为:110,,X X 与115,,Y Y ,其对应的样本均值为:X 和Y .由题意知:X 和Y 相互独立,且:3~(20,)10X N ,3~(20,)15Y N(0.3)1(0.3)P X Y P X Y ->=--≤1P =-~(0,0.5)~(0,1)(0.3)22(0.4243)0.6744X Y NX YNP X Y-->=-Φ=7 设110,,X X是总体~(0,4)X N的样本,试确定C,使得1021()0.05iiP X C=>=∑.解因~(0,4)iX N,则~(0,1)2iXN,且各样本相互独立,则有:10122~(10)2iiXχ=⎛⎫⎪⎝⎭∑所以:10102211()()144i ii iCP X C P X==>=>∑∑1021110.0544iicP X=⎛⎫=-≤=⎪⎝⎭∑102110.9544iicP X=⎛⎫≤=⎪⎝⎭∑查卡方分位数表:c/4=,则c=.8设总体X具有连续的分布函数()XF x,1,,nX X 是来自总体X的样本,且iEXμ=,定义随机变量:1,,1,2,,0,iiiXY i nXμμ>==≤⎧⎨⎩试确定统计量∑=niiY1的分布.解由已知条件得:~(1,)iY B p,其中1()Xp Fμ=-.因为iX互相独立,所以iY也互相独立,再根据二项分布的可加性,有1~(,)niiY B n p=∑,1()Xp Fμ=-.9 设1,,nX X是来自总体X的样本,试求2,,EX DX ES。
《应用数理统计》第三章假设检验课后作业参考答案

第三章 假设检验课后作业参考答案3.1 某电器元件平均电阻值一直保持2.64Ω,今测得采用新工艺生产36个元件的平均电阻值为2.61Ω。
假设在正常条件下,电阻值服从正态分布,而且新工艺不改变电阻值的标准偏差。
已知改变工艺前的标准差为0.06Ω,问新工艺对产品的电阻值是否有显著影响?(01.0=α)解:(1)提出假设64.2:64.2:10≠=μμH H , (2)构造统计量36/06.064.261.2/u 00-=-=-=nX σμ(3)否定域⎭⎬⎫⎩⎨⎧>=⎭⎬⎫⎩⎨⎧>⋃⎭⎬⎫⎩⎨⎧<=--21212αααu u uu u u V (4)给定显著性水平01.0=α时,临界值575.2575.2212=-=-ααuu ,(5) 2αu u <,落入否定域,故拒绝原假设,认为新工艺对电阻值有显著性影响。
3.2 一种元件,要求其使用寿命不低于1000(小时),现在从一批这种元件中随机抽取25件,测得其寿命平均值为950(小时)。
已知这种元件寿命服从标准差100σ=(小时)的正态分布,试在显著水平0.05下确定这批元件是否合格。
解:{}01001:1000, H :1000X 950 100 n=25 10002.5V=u 0.05H x u αμμσμα-≥<====->=提出假设:构造统计量:此问题情形属于u 检验,故用统计量:此题中:代入上式得:拒绝域:本题中:0.950.950u 1.64u 0.0u H =>∴即,拒绝原假设认为在置信水平5下这批元件不合格。
3.3某厂生产的某种钢索的断裂强度服从正态分布()2,σμN ,其中()2/40cm kg =σ。
现从一批这种钢索的容量为9的一个子样测得断裂强度平均值为X ,与以往正常生产时的μ相比,X 较μ大20(2/cm kg )。
设总体方差不变,问在01.0=α下能否认为这批钢索质量显著提高? 解:(1)提出假设0100::μμμμ>=H H , (2)构造统计量5.13/4020/u 00==-=nX σμ (3)否定域{}α->=1u u V(4)给定显著性水平01.0=α时,临界值33.21=-αu(5) α-<1u u ,在否定域之外,故接受原假设,认为这批钢索质量没有显著提高。
清华大学 杨虎 应用数理统计课后习题参考答案3
习题五1试检验不同日期生产的钢锭的平均重量有无显著差异?(α=0.05) 解 根据问题,因素A 表示日期,试验指标为钢锭重量,水平为5.假设样本观测值(1,2,3,4)ij y j =来源于正态总体2~(,),1,2,...,5i i Y N i μσ= .检验的问题:01251:,:i H H μμμμ===不全相等 .计算结果:表5.1 单因素方差分析表注释: 当=0.001表示非常显著,标记为 ‘***’,类似地,= 0.01,0.05,分别标记为 ‘**’ ,‘*’ .查表0.95(4,15) 3.06F =,因为0.953.9496(4,15)F F =>,或p = 0.02199<0.05, 所以拒绝0H ,认为不同日期生产的钢锭的平均重量有显著差异.2 考察四种不同催化剂对某一化工产品的得率的影响,在四种不同催化剂下分别做试验 试检验在四种不同催化剂下平均得率有无显著差异?(α=0.05)解根据问题,设因素A 表示催化剂,试验指标为化工产品的得率,水平为4 .假设样本观测值(1,2,...,)ij i y j n =来源于正态总体2~(,),1,2,...,5i i Y N i μσ= .其中样本容量不等,i n 分别取值为6,5,3,4 .检验的问题:012341:,:i H H μμμμμ===不全相等 .计算结果:表5.2 单因素方差分析表查表0.95(3,14) 3.34F =,因为0.952.4264(3,14)F F =<,或p = 0.1089 > 0.05,所以接受0H ,认为在四种不同催化剂下平均得率无显著差异 .3 试验某种钢的冲击值(kg ×m/cm2),影响该指标的因素有两个,一是含铜量A ,另试检验含铜量和试验温度是否会对钢的冲击值产生显著差异?(α=0.05) 解 根据问题,这是一个双因素无重复试验的问题,不考虑交互作用.设因素,A B 分别表示为含铜量和温度,试验指标为钢的冲击力,水平为12.假设样本观测值(1,2,3,1,2,3,4)ij y ij ==来源于正态总体2~(,),1,2,3,ij ij Y N i μσ=1,2,3,4j = .记i α⋅为对应于i A 的主效应;记j β⋅为对应于j B 的主效应;检验的问题:(1)10:i H α⋅全部等于零,11:i H α⋅不全等于零;(2)20:j H β⋅全部等于零,21:j H β⋅不全等于零; 计算结果:表5.3 双因素无重复试验的方差分析表查表0.95(2,6) 5.143F =,0.95(3,6) 4.757F =,显然计算值,A B F F 分别大于查表值,或p = 0.0005,0.0009 均显著小于0.05,所以拒绝1020,H H ,认为含铜量和试验温度都会对钢的冲击值产生显著影响作用.设每个工人在每台机器上的日产量都服从正态分布且方差相同 .试检验:(α=0.05)1)操作工之间的差异是否显著? 2)机器之间的差异是否显著?3)它们的交互作用是否显著?解 根据问题,这是一个双因素等重复(3次)试验的问题,要考虑交互作用.设因素,A B 分别表示为机器和操作,试验指标为日产量,水平为12. 假设样本观测值(1,2,3,1,2,3,4)ijk y i j ==来源于正态总体2~(,),1,2,3,ij ij Y N i μσ= 1,2,3,4j =,1,2,3k = .记i α⋅为对应于i A 的主效应;记j β⋅为对应于j B 的主效应;记ij γ为对应于交互作用A B ⨯的主效应; 检验的问题:(1)10:i H α⋅全部等于零,11:i H α⋅不全等于零; (2)20:j H β⋅全部等于零,21:j H β⋅不全等于零; (3)30:ij H γ全部等于零,31:ij H γ不全等于零;计算结果:表5.4 双因素无重复试验的方差分析表查表0.95(3,24) 3.01F =,0.95(2,24) 3.4F =,0.95(6,24) 2.51F =,计算值 3.01,A F <3.4, 2.51B A B F F ⨯>>,或0.05A p >>,而,B A B p p ⨯均显著小于0.05,所以拒绝2030,H H ,接受10H ,认为操作工之间的差异显著,机器之间的差异不显著,它们之间的交互作用显著 . 5 某轴承厂为了提高轴承圈退火的质量,制定因素水平分级如下表所示因素 上升温度℃ 保温时间(h)出炉温度℃水平1 800 6 400 水平28208500试填好正交试验结果分析表并对试验结果进行直观分析和方差分析 .解 根据题意,这是一个3因素2水平的试验问题 .试验指标为硬度的合格率 .应选择正交表44(2)L 来安排试验,随机生成正交试验表如下:方差来源 自由度 平方和 均方 F 值 P 值 因素A 因素B 相互效应A ×B误差 总和3 2 6 24 352.750 27.167 73.5 41.333 144.750.917 13.583 12.250 1.7220.5323 7.8871 7.11290.6645 0.00233** 0.00192**由此可见第三号试验条件为:上升温度800℃、保温时间6h 、出炉温度500℃ . 直观分析需要计算K 值,计算结果如下:表5.6 计算表直观分析 由计算的K 值知,因素A 、B 、C 的极差分别为70,40,40,因此主次关系为A B C >=,B ,C 相当 .由于试验指标为硬度的合格率,应该是越大越好,所以各确定因素的水平分别是121,,A B C ,即最佳的水平组合是121A B C ,即最佳搭配为:上升温度800℃、保温时间8h 、出炉温度400℃.采用方差分析法,计算得下表:表5.7 方差分析表方差来源平方和 自由度均方差 F 值 A 1225 1 1225 1 B 400 1 400 0.33 C 400 1 400 0.33 误差 1225 1 1225 总和32504如果显著性检验水平取0.1α=,则查表得0.9(1,1)39.9F =,显然计算的F 值1,0.33A B C F F F ===均小于查表值,所以认为三个因素对结果影响都显著 .6问应选用哪张正交表安排试验,并写出第8号试验的条件;如果9组试验结果为(单位:kg/100m 2):62.925,57.075,51.6,55.05,58.05,56.55,63.225,50.7,54.45,试对该正交试验结果进行直观分析和方差分析.解 该问题属于3因素3水平的试验问题,试验指标为水稻产量 .根据题意应选择正交表49(3)L 来安排试验,随机生成正交表如下:由表可知,第8号试验的条件:品种(A 3)珍珠矮11号,插值密度(B 2)3.75棵/100m 2 ,施肥量(C 1)0.75kg/100m 2纯氨; 直观分析需要计算K 值,计算结果如下:表5.9 计算表同上题进行直观分析,得出K 值的大小关系为:111312212223333132,,K K K K K K K K K >>>>>>由直观分析看出:本例较好的水平搭配是:113A B C 采用方差分析法,计算得下表:表5.10 方差分析表方差来源平方和自由度 均方差F 值A 1.759 2 0.879 0.0223B 65.861 2 32.931 0.8361C 6.660 2 3.330 0.0845 误差78.776 239.388 39.3880.9(2,2)9F =,所以认为三个因素对结果影响都不显著.7 在阿魏酸的合成工艺考察中,为了提高产量,选取了原料配比A ,吡啶量B 和反应时间C 三个因素,它们各取了7个水平如下:原料配比A :1.0,1.4,1.8,2.2,2.6,3.0,3.4 吡啶量B :10,13,16,19,22,25,28 反应时间C :0.5,1.0,1.5,2.0,2.5,3.0,3.5试选用合适的均匀设计表安排试验,并写出第7号试验的条件;如果7组试验的结果(收率)为:0.33,0.336,0.294,0.476,0.209,0.451,0.482,试对该均匀试验结果进行直观分析并通过回归分析发现可能更好的工艺条件.解 根据题意选择均匀设计表47(7)U 来安排试验,有3个因素,根据使用表,实验安排如:表5.11 试验安排表6 6 5 4 0.4517 7 7 7 0.482 所以第7号实验的条件为:原配料比3.4,吡啶量28ml,反应时间3.5h.通过直观分析,最好的实验条件是:原配料比3.4,吡啶量28ml,反应时间3.5h. 通过回归分析,最合适的实验条件是:原配料比2.6,吡啶量16ml,反应时间0.5h.习题六1 从某中学高二女生中随机选取8名,测得其升高、体重如下:1 2 3 4 5 6 78身高(cm)160 159 160 157 169 162 165 154体重(kg)49 46 53 41 49 50 48 43在绝对距离下,试用最短距离法和离差平方和法对其进行聚类分析.解由R软件,用最短距离(左)和差离平方和法(右)对题目进行聚类分析如下图6.1,表6.1和表6.2:最短距离法离差平方和法图6.1 聚类树形图表6.1 聚类附表(最短距离法)步骤聚类合并系数首次出现的阶段类别下一步组1 组2 组1 组21 1 6 5.000 0 0 22 1 2 10.000 1 0 43 4 8 13.000 0 0 74 1 7 13.000 2 0 55 1 3 13.000 4 0 66 1 5 17.000 5 0 7表6.2 聚类附表(离差平方和法)2 已知五个变量的距离矩阵为03674012340444401592343331).;2);3)036034022020401000⎛⎫⎛⎫⎛⎫⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭试用最短距离法和最长距离法对这些变量进行聚类,并画出聚类图和二分树.解 针对距离矩阵1),采用两种方法计算如下. ①最短距离法的聚类步骤如下:12345036740159036020w w w w w ⎛⎫ ⎪⎪ ⎪ ⎪⎪⎪⎝⎭a )将()236,1w w f h =合并为一类,,{}11456,,,,H w w w h =距离矩阵如下0743023060⎛⎫ ⎪⎪ ⎪ ⎪⎝⎭{}()457457),,,2b w w h w w f h ==合并为一类,{}2167,,,H w h h =距离矩阵如下:034030⎛⎫ ⎪⎪ ⎪⎝⎭{}()()1681689),,3,3c w h h w h f h f h ===合并为一类,最后,,聚类图和树状图如图6.2:图6.2 聚类图(左)与树状图(右)②最长距离法与最短距离法类似,步骤如下: a )()236,1w w f h =合并为一类,{}11456,,,,H w w w h =距离矩阵如下0746025090⎛⎫ ⎪⎪ ⎪ ⎪⎝⎭ {}(){}4574572167),,,2,,,b w w h w w f h H w h h ===合并为一类,距离矩阵如下:067090⎛⎫⎪⎪ ⎪⎝⎭{}()()1681689),,69c w h h w h f h f h ===合并为一类,最后,,,聚类图和树状图如图6.3:图6.3 聚类图(左)与树状图(右)(2)针对距离矩阵2)012340234034040⎛⎫ ⎪⎪ ⎪ ⎪⎪⎪⎝⎭①最短距离法的聚类步骤如下 a )()216,1w w f h =合并为一类,{}13456,,,,0342043040H w w w h =⎛⎫⎪⎪ ⎪ ⎪⎝⎭距离矩阵如下{}()367367),,,2b w h h w h f h ==合并为一类,{}24567,,,,H w w h h =聚类矩阵如下:043040⎛⎫⎪⎪ ⎪⎝⎭{}(){}()4784789879),,3,,4c w h h w h f h h w h f h ====合并为一类,最后,,聚类图和树状图如图6.4:图6.4 聚类图(左)与树状图(右)②由于本题数据的特殊性,最长距离法与最短距离法结果相同(略). (3)044440333022010⎛⎫ ⎪⎪ ⎪ ⎪⎪⎪⎝⎭最短距离法的聚类步骤如下a ) ()456,1w w f h =合并为一类,{}11236,,,,H w w w h =距离矩阵如下0444033020⎛⎫ ⎪⎪ ⎪ ⎪⎝⎭{}(){}36736724567),,,2,,,,b w h h w h f h H w w h h ===合并为一类,距离矩阵如下:044030⎛⎫⎪⎪ ⎪⎝⎭{}(){}()4784789879),,3,,4c w h h w h f h h w h f h ====合并为一类,最后,,,聚类图和树状图如图6.5:图6.5 聚类图(左)与树状图(右)由于本题数据的特殊性,最长距离法与最短距离法结果相同(略).3 在一项关于作物对土壤营养的反应的研究中,要测定土壤的总磷量和总氮量(占干物质重的百分比),今对10份土样测得数据如下:总氮量(%)0.63 1.19 2.30 1.29 0.73 0.52 0.33 0.61 0.47 0.66在绝对距离下,试用重心法对其进行聚类分析.解由R软件得到重心法聚类分析的结果如图6.6与表6.3:图6.6 聚类树形图表6.3 聚类过程记录表步骤聚类合并系数首次出现的阶段类别下一步组 1 组 2 组 1 组 21 1 8 .001 0 0 22 1 10 .002 1 0 43 6 9 .005 0 0 64 15 .010 2 0 75 2 4 .010 0 0 86 67 .027 3 0 77 1 6 .048 4 6 88 1 2 .459 7 5 99 1 3 2.572 8 0 0 4 1975年Dagnelie收集了11年的气象数据资料如下表变量年序x1x2x3x4其中:x 1—前一年11月12日的降水量;x 2—7月均温;x 3—7月降雨量;x 4—月日辐射,试对这四个气象因子进行主成分分析. 解 由R 软件分析得到如下表6.4,6.5:表6.4 各主成分的重要性:主成分1 主成分2 主成分3 主成分4 标准差 1.6103349 0.9890848 0.53407741 0.37854199 方差贡献率 0.6482947 0.2445722 0.07130967 0.03582351 累积贡献率0.64829470.89286680.964176491.00000000表6.5 因子荷载:主成分1 主成分2 主成分3 主成分4 X1 0.291 0.871 0.332 -0.214 X2 -0.506 0.425 -0.742 -0.111 X3 0.577 0.136 -0.418 0.688 X4-0.5710.2050.4040.685由于前两个主成分对应的累积贡献率已经达到89.287,因此选取主成分的数目为2.5 对某初中12岁的女生进行体检,测量其身高x 1、体重x 2、胸围x 3和坐高x 4,共测得58个样本,并算得1234(,,,)x x x x x ='的样本协方差为19.9410.5023.566.5919.7120.958.637.97 3.937.55S ⎛⎫ ⎪⎪= ⎪ ⎪ ⎪⎝⎭ 试进行样本主成分分析.解 首先计算样本的相关系数矩阵:10.484410.32240.887210.70330.59760.31251⎛⎫ ⎪ ⎪ ⎪ ⎪⎝⎭设相关系数矩阵的特征值和特征向量分别为d 和v 阵,计算得到0.0546000 0 0.312600= 000.96470 000 2.6681d ⎛⎫ ⎪ ⎪ ⎪ ⎪⎝⎭即四个特征值依次为:2.6681,0.9647,0.3126,0.0546,前两个主成分的累计贡献率为:90.8471%,因此提取主成分为2.四个特征根相应的特征向量为0.06000.70600.5333 0.4620 0.7317 0.17430.34040.5642=0.60570.19320.60400.48060.30690.65870.48460.4870v -⎛⎫ ⎪-⎪ ⎪--- ⎪-⎝⎭ 因此,两个主成分的表达式为:112340.060.73170.60570.3069z x x x x =+-- 212340.7060.17430.19320.6587z x x x x =-+-+6 比较因子分析和主成分分析模型的异同,阐明两者的关系. 解(1)提取公因子的方法主要有主成分法和公因子法.若采取主成分法,则主成分分析和因子分析基本等价,该法从解释变量的变异的角度出发,尽量使变量的方差能被主成分解释;而公因子法主要从解释变量的相关性角度,尽量使变量的相关程度能被公因子解释,当因子分析目的重在确定结构时则用到该法.(2)主成分分析和因子分析都是在多个原始变量中通过他们之间的内部相关性来获得新的变量,达到既减少分析指标个数,又能概括原始指标主要信息的目的.但他们各有其特点:主成分分析是将n 个原始变量提取m 个支配原始变量的公因子,和1个特殊因子,各因子之间可以相关或不相关.(3)统用降维的方法,但差异也很明显:主成分分析把方差划分为不同的正交成分,而因子分析则把方差化分为不同的起因因子;因子分析中的特征值的计算只能从相关系数矩阵出发,且必须把主成分划分为因子.(4)因子分析提取的公因子比主成分分析提取的主成分更具有可解释性.(5)两者分析的实质及重点不同.主成分的数学模型为Y AX =,因子分析的数学模型为X AF ε=+.因而可知主成分分析是实际上是线性变换,无假设检验,而因子分析是统计模型,某些因子模型是可以得到假设检验的;主成分分析主要综合原始数据的信息,而因子分析重在解释原始变量之间的关系.(6)SPSS 数据的实现:两者都通过“analyze data reduction Factor···”过程实现,但主成分分析主要使用“descriptires ”,“extraction ”,“stores ”对话框,而因子分析处使用这些外,还可使用“rotaction ”对话框进行因子旋转.7 试对第4题的变量作因子分析,并将结果和上面的结果进行比较. 解 用SPSS 分析,计算结果如下表6.6-6.8:表6.6 反应压缩比情况表 提取方法: 主成分法计算的相关系数矩阵的特征值和方差贡献率:表6.7 方差解释度提取方法: 主成分法表6.8 主成分矩阵8 为研究某一树种的叶片形态,选取50片叶测量其长度x 1(mm )和宽度x 2(mm ),按样本数据求得其平均值和协方差矩阵为:129048134,92,4845x x S ⎛⎫=== ⎪⎝⎭求出相关系数阵R ,并由R 出发作因子分析;解1)求相关系数矩阵:904810.7303,48900.73031S R ⎛⎫⎛⎫== ⎪ ⎪⎝⎭⎝⎭ 2)用R 软件求R 的特征根及其相应的特征向量,软件输出结果如下:$values[1] 2.99393809 0.07273809 $vectors[,1] [,2] [1,] 0.7071068 -0.7071068 [2,] 0.7071068 0.7071068122.9939,0.0727,λλ∴==12(),()0.7071,0.7071-0.7071,0.7071T Tηη==3) 求载荷矩阵A :1.22350.19071.22350.1907A -⎛⎫= ⎪⎝⎭4)22121.5333, 1.5333,h h == 0.98810.154*0.98810.154A -⎛⎫= ⎪⎝⎭12121,1,0.3043,0.3043u u v v ===-=,222222000011112,0,()0.9074,20i i iii i i i i i A u B v C u v D u v =========-===∑∑∑∑9 1981年,生物学家Grogan 和Wirth 对两种蠓虫Af 和Apf 根据其触角长度x 1和翼长x 2进行了分类,分类的数据资料如下:Af 1 2 3 4 5 6 7 8 x 1 1.24 1.36 1.38 1.38 1.38 1.40 1.48 1.54 x 2 1.27 1.74 1.64 1.82 1.90 1.70 1.82 1.82 Apf 1 2 3 4 5 6 x 1 1.14 1.18 1.20 1.26 1.28 1.30 x 2 1.78 1.96 1.86 2.00 2.00 1.96 (1)试建立Af 和Apf 的Fisher 判别模型;(2)对样本(1.24,1.80),(1.28,1.84),(1.40,2.04)进行判别分类. 解 (1)建立Fisher 判别模型991122121111(,)(1.42,1.75),(,)(1.23,1.93)99T TT T i i i i i i x x y y μμ======∑∑120.08480.1490.01980.0218,0.1490.39120.02180.039A A ⎛⎫⎛⎫== ⎪ ⎪⎝⎭⎝⎭12120.0080.0130.0130.0332A A n n ⎛⎫+== ⎪+-⎝⎭∑()120.19,0.18Tμμ-=-,()()121 1.325,1.842T μμ+= 1345.05135.42135.4283.33--⎛⎫= ⎪-⎝⎭∑, 带入Fisher 判别函数 ()12345.05135.42[(,)(1.325,1.84)]0.19,0.18135.4283.33Tx x -⎛⎫-- ⎪-⎝⎭1291.301741.336944.534x x =--(2)把三个样本(1.24,1.80),(1.28,1.84),(1.4,2.04)带入模型,得到结果:三个样本均属于Apf 类.10 在两个玉米品种之间进行判别:137玉米G 1和甜玉米G 2,选取的两个变量是:x 1—玉米果穗长;x 2—玉米果穗直径,两个类的样本容量为n 1=n 2=40,实际算得两个类的样本均值和样本协方差为:121218.5625.348.120 4.4589.661 3.720,,,5.98 4.12 4.458 4.350 3.720 3.410x x S S ⎛⎫⎛⎫⎛⎫⎛⎫==== ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭⎝⎭试建立G 1,G 2的Bayes 类线性判别函数.解 因为已知两类的样本均值和样本协方差为:12(18.56,5.98),(25.34,4.12)T T x x ==,128.120 4.4589.661 3.720,4.458 4.350 3.720 3.410S S ⎛⎫⎛⎫== ⎪ ⎪⎝⎭⎝⎭可计算得到修正的公共协方差矩阵和逆矩阵12120.2280.1450.1450.0992A A n n ⎛⎫+== ⎪+-⎝⎭∑,15.6393.738.25147.38--⎛⎫= ⎪-⎝⎭∑()()()121216.78,1.86,21.95,5.052TTμμμμ-=-+= 带入Fisher 判别函数()112121(())()2T W x x μμμμ-=-+-∑ ()()12 5.6393.73[(,)21.95,5.05] 6.78,1.868.25147.38Tx x -⎛⎫=-- ⎪-⎝⎭1274.396.951141.29x x =-+-。
清华大学 杨虎 应用数理统计课后习题参考答案2

习题三1 正常情况下,某炼铁炉的铁水含碳量2(4.55,0.108)X N .现在测试了5炉铁水,其含碳量分别为 4.28,4.40,4.42,4.35,4.37. 如果方差没有改变,问总体的均值有无显著变化?如果总体均值没有改变,问总体方差是否有显著变化(0.05α=)?解 由题意知 2~(4.55,0.108),5,0.05X N n α==,1/20.975 1.96u u α-==,设立统计原假设 0010:,:H H μμμμ=≠拒绝域为 {}00K x c μ=->,临界值1/2 1.960.108/0.0947c u α-==⋅=,由于 0 4.364 4.550.186x c μ-=-=>,所以拒绝0H ,总体的均值有显著性变化.设立统计原假设 22220010:,:H H σσσσ=≠由于0μμ=,所以当0.05α=时 22220.0250.97511()0.03694,(5)0.83,(5)12.83,n i i S X n μχχ==-===∑ 2210.02520.975(5)/50.166,(5)/5 2.567c c χχ====拒绝域为 {}222200201//K s c s c σσ=><或 由于220/ 3.167 2.567S σ=>,所以拒绝0H ,总体的方差有显著性变化.2 一种电子元件,要求其寿命不得低于1000h .现抽测25件,得其均值为x =950h .已知该种元件寿命2(100,)XN σ,问这批元件是否合格(0.05α=)?解 由题意知 2(100,)X N σ,设立统计原假设0010:,:,100.0.05.H H μμμμσα≥<==拒绝域为 {}00K x c μ=->临界值为 0.050.0532.9c u u =⋅=⋅=-由于 050x c μ-=-<,所以拒绝0H ,元件不合格.3 某食品厂用自动装罐机装罐头食品,每罐标准重量为500g,现从某天生产的罐头中随机抽测9罐,其重量分别为510,505,498,503,492,502,497,506,4α=)?95(g),假定罐头重量服从正态分布. 问 (1)机器工作是否正常(0.052)能否认为这批罐头重量的方差为5.52(0.05α=)?解 (1)设X 表示罐头的重量(单位:g). 由题意知2(,)X N μσ,μ已知设立统计原假设 0010:500,:H H μμμμ==≠,拒绝域 {}00K x c μ=->当0.05α=时,2500.89,34.5, 5.8737x s s ===临界值 1(1) 4.5149c t n α-=-⋅=,由于00.8889x c μ-=<,所以接受0H ,机器工作正常.(2)设X 表示罐头的重量(单位:g). 由题意知2(,)X N μσ,σ已知设立统计原假设 222220010: 5.5,:H H σσσσ==≠拒绝域为 {}{}222200102K s c s c σσ=<> 当α=0.05时,可得2220.0250.97512500.89,34.5,(5) 2.7,(5)19.02,0.3, 2.11x s c c χχ======由于22001.0138s K σ=∈,所以接受0H ,可以认为方差为25.5.4 某部门对当前市场的鸡蛋价格情况进行调查,抽查某市20个集市上鸡蛋的平均售价为3.399(元/500克),标准差为0.269(元/500克).已知往年的平均售价一直稳定在 3.25(元/500克)左右, 问该市当前的鸡蛋售价是否明显高于往年?(0.05α=)解 设X 表示市场鸡蛋的价格(单位:元/克),由题意知2(,)X N μσ设立统计原假设 0010: 3.25,:H H μμμμ==>, 拒绝域为 {}00K x c μ=->当α=0.05时,13.399,0.269,20,0.0992x n c ασμ-====⋅=临界值由于0 3.399 3.250.149.x c μ-=-=>所以拒绝0H ,当前的鸡蛋售价明显高于往年.5 已知某厂生产的维尼纶纤度2(,0.048)X N μ,某日抽测8根纤维,其纤度分别为 1.32,1.41,1.55,1.36,1.40,1.50,1.44,1.39,问这天生产的维尼纶纤度的方差2σ是否明显变大了(0.05α=)?解 由题意知 2(,0.048)X N μ,0.05α=设立统计原假设 2222220010:0.048,:0.048H H σσσσ==>=拒绝域为{}2200K s c σ=>, 当0.05α=时, 2220.950.951.4213,0.0055,(7)14.07,(7)7 2.0096x s c χχ=====由于220 2.3988s c σ=>,所以拒绝0H ,认为强度的方差明显变大.6 某种电子元件,要求平均寿命不得低于2000h ,标准差不得超过130h .现从一批该种元件中抽取25只,测得寿命均值1950h ,标准差148h s =.设元件寿命服从正态分布,试在显著水平 α=0.05下, 确定这批元件是否合格.解 设X 表示电子元件的平均寿命(单位:h ),由题意知2(,)XN μσ 设立统计原假设 0010:=2000H <H μμμμ≥,:拒绝域为 {}00K x c μ=-<当0.05α=时,1950,148,(1)50.64x s c t n α===-=-临界值由于 050x c μ-=->,所以接受0H ,即这批电子元件的寿命是合格的.7 设n X X X ,...,,21为来自总体(,4)X N μ的样本,已知对统计假01:1;: 2.5H H μμ== 的拒绝域为0K {}2>=X .1)当9=n 时,求犯两类错的概率α与β;2)证明:当n →∞时,α→0,β→0.解 (1)由题意知 {}010~(,4),:1;: 2.5,2,9.X N H H K X n μμμ===>=犯第一类错误的概率为 ()21 1.51(1.5)0.0668.X P X P αμ⎫=>==>==-Φ=⎪⎭犯第二类错误的概率为 ()2 2.50.75(0.75)1(0.75)0.2266.X P X P βμ⎫=≤==≤=-⎪⎭=Φ-=-Φ= (2)若0:1H μ=成立,则(1,4)X N}{}{00000()=11)n P H H P X c P X c nc αμμσ=≥+=-<+=-Φ否定成立 当n →∞时,0)1nc σΦ→,所以0()n n α→→∞同理 }{0010=<+=+c )/)()=0()n P X c n βμμμσΦ-→Φ-∞→∞8 设需要对某一正态总体,4()N μ的均值进行假设检验H 0:μ= 15,H 1:μ<15取检验水平α=0.05,试写出检验H 0的统计量和拒绝域.若要求当H 1中的μ=13时犯第二类错误的概率不超过β=0.05,估计所需的样本容量n .解 由题意知 (,4)X N μ,σ已知, 设立统计原假设 01:15,:15H H μμ=<则拒绝域为}{015K X c =-<,其中临界值0.05c μ=⋅=-犯第二类错误的概率1513130.05P X P Xβ⎛⎫⎛⎫=->==->≤⎪⎭⎝⎝即1.65)0.95Φ≥, 化简得23.311n≥≈.9 设nXXX,...,,21为来自总体X~2(,)Nμσ的样本,2σ为已知, 对假设:0011:;:H Hμμμμ==其中01μμ≠,试证明:22011212()()nαβσμμμμ--=+⋅-解(1)10>μμ当时,由题意知00110:;:;H Hμμμμμ==>犯第一,二类错误分别为,αβ,则有001(|)P X c c uααμμμ-=>+=⇒=011100(|))XP X c P uαβμμμμμ-=≤+==≤=⇒()()220 11111120010 u u u u n u u ββααβαβσμμμ------=-=⇒+==+-(2)10μμ≤当时由题意知00110:,:H Hμμμμμ==≤,犯第一,二类错误分别为,αβ,则有00(|)P X c c uααμμμ=<+=⇒=()()01100220 1111120010 (|))XP X c P uu u u u n u uαβααβαββμμμμμσμμ-----=≥+==≥+=⇒=⇒+==+-10设171,...,XX为总体2(0,)X N σ样本,对假设:2201:9,: 2.905H Hσσ==的拒绝域为}{24.93K s=<. 求犯第Ⅰ类错误的概率α和犯第Ⅱ类错的概率β.解由题意知2(0,)X N σ,222~().nsnχσ统计假设为2201:9,: 2.905H Hσσ==. 拒绝域为}{24.93K s=<则犯第一,二类错误的概率,αβ分别是()()22222221717417174497.3040.0259999171744 3.319120.48810.750.253.319 3.319s s P s P P s P s P ασβσ⎛⎫⎛⎫⨯⨯=<==<=<== ⎪ ⎪⎝⎭⎝⎭⎛⎫⨯=<==-<==-= ⎪⎝⎭ 11 设总体是密度函数是1,01(;)0,x x f x θθθ-<<=⎧⎨⎩其他统计假设 01:1,:2H H θθ==.现从总体中抽取样本21,X X ,拒绝域2134ΚX X =≤⎧⎫⎨⎬⎩⎭,求:两类错误的概率,αβ 解 由题意知 010213:1;:2,, 2.4H H K X n X θθ⎧⎫===≤=⎨⎬⎩⎭当12121,0,11(;1) 1.~(0,1),(,)0,x x f x X U f x x θ<<⎧===⎨⎩时,其他 此时 212121231431(,)0.250.75ln 0.75.4x x P X f x x dx dx X αθ≤⎛⎫=≤===+ ⎪⎝⎭⎰⎰当1212122,014,0,12(;2).(,)0,0,x x x x x x f x f x x θ<<<<⎧⎧===⎨⎨⎩⎩时,其他其他 此时 21212123143992(,)ln 0.75.4168x x P X f x x dx dx X βθ>⎛⎫=>===+ ⎪⎝⎭⎰⎰ 12 设总体2(,)XN μσ,根据假设检验的基本原理,对统计假设:00110:,:()()H Hμμμμμσ==>已知;0010:,:H H μμμμσ≥<(未知),试分析其拒绝域.解 由题意知 2(,)X N μσ,当00110:,:()H H μμμμμ==>成立时()01X P X c P αμμμ=->==>=-Φ {}1100,u c u K X c ααμ--===-> 所以拒绝域为 }{00K X c μ=->当0010:,:H H μμμμ≥<成立时00()()X P X c P X c P αμμμμ⎛⎛⎫⎫=-<≥≥-<=<=Φ}{00,c K X c ααμμμ===-< 所以拒绝域为}{00K X c μ=-<13 设总体2(,)X N μσ根据假设检验的基本原理,对统计假设:(1)22220010:,:()H H σσσσμ=>已知;(2)22220010:,:()H H σσσσμ≤>未知试分析其拒绝域.解 由题意知 2~(,)X N μσ(1)假设统计假设为 22220010:=,:>H H σσσσ 其中μ已知当0H 成立时,拒绝域形式为 2020=>s K c σ⎧⎫⎪⎨⎬⎪⎭⎩由 222220=(n)ns ns χσσ,可得220=>ns P nc ασ⎧⎫⎪⎨⎬⎪⎭⎩所以 21-=()nc n αχ,由此可得拒绝域形式为2201-201=>()s K n n αχσ⎧⎫⎪⎨⎬⎪⎭⎩(2)假设统计假设为 22220010:<,:>H H σσσσ 其中μ未知当0H 成立时,选择拒绝域为 2020=>s K c σ⎧⎫⎪⎨⎬⎪⎭⎩,由222(-1)(1)n s n χσ-得 ()()()()222201111n s n s P n c Pn c ασσ⎧⎫⎧⎫--⎪⎪⎪⎪=>-≤>-⎨⎬⎨⎬⎪⎪⎪⎪⎩⎭⎩⎭所以21(1)(1)n c n αχ--=-,由此可得拒绝域形式为2201-201=>(1)1s K n n αχσ⎧⎫⎪-⎨⎬-⎪⎭⎩14 从甲、乙两煤矿各取若干样品,得其含灰率(%)为,甲:24.3, 20.8, 23.7, 21.3, 17.4, 乙:18.2, 16.9, 20.2, 16.7 .假定含灰率均服从正态分布且2212=σσ,问甲、乙两煤矿的含灰率有无显著差异 (=0.05α)?解 由题意知 2212(,),Y (,)X N N μσμσ设统计假设为 012112:=;:H H μμμμ≠ 其中12=5,=4n n当=0.05α时1/2122.3238,(2) 2.3646w s t n n α-==+-= 临界值1-212=(+2) 3.6861w c t n n s α-⋅= 拒绝域为}{0 3.6861K x y c =->=而 03.5,,.x y c H -=<接受认为没有差别15 设甲、乙两种零件彼此可以代替,但乙零件比甲零件制造简单,造价也低.经过试验获得它们的抗拉强度分别为(单位:kg/cm 2):甲:88,87,92,90,91 乙:89,89,90,84,88假定两种零件的抗拉强度都服从正态分布,且21σ =22σ.问甲种零件的抗拉强度是否比乙种的高(=0.05α)?解 由题意知 2212(,),Y (,)X N N μσμσ设统计假设为 012112:=;:H H μμμμ≠,其中12=5,=5n n当=0.05α时122.2136,(2) 1.86,w s t n n α==+-=- 临界值1-212=(+2) 2.2136w c t n n s α-⋅= 拒绝域为}{0 2.2136K x y c =->=而 1.6x y c -=<,所以接受0H ,认为甲的抗拉强度比乙的要高.16 甲、乙两车床生产同一种零件.现从这两车床产生的产品中分别抽取8个和9个,测得其外径(单位:mm )为:甲:15.0,14.5,15.2,15.5,14.8,15.1,15.2,14.8乙:15.2,15.0,14.8,15.2,15.0,15.0,14.8,15.1,14.8假定其外径都服从正态分布,问乙车床的加工精度是否比甲车床的高(=0.05α)?解 由题意知 2212(,),Y (,)X N N μσμσ设统计假设为 2222012112:;:H H σσσσ≥<,其中12=8,=9n n当=0.05α时 220.0955,0.0261x y s s ==,临界值12(1,1)0.2684c F n n α=--= 拒绝域为202x y s K c s ⎧⎫⎪⎪=<⎨⎬⎪⎪⎭⎩,而22 3.6588x y s F c s ==>,接受0H ,认为乙的精度高. 17 要比较甲、乙两种轮胎的耐磨性,现从甲、乙两种轮胎中各取8个,各取一个组成一对,再随机选取8架飞机,将8对轮胎磨损量(单位:mg )数据列表如下:试问这两种轮胎的耐磨性有无显著差异?(=0.05α). 假定甲、乙两种轮胎的磨损量分别满足2212(,),Y (,)X N N μσμσ且两个样本相互独立.解 由题意知 2212(,),Y (,)X N N μσμσ设统计假设为 012112:=;:H H μμμμ≠,其中12===8n n n当=0.05α时,令()221/211,320,102200,319.69,(1) 2.36461n ZZ i Z X Y z s z z s t n n α-==-==-==-=-∑ 拒绝域为}{0K z c =>,临界值 1-2=(1)2138Z c t n s α-⋅=而320z c =<,所以接受0H ,认为两种轮胎耐磨性无显著差异.18 设总体2212(,),Y (,)X N N μσμσ, 由两总体分别抽取样本X :4.4,4.0,2.0,4.8 Y :6.0,1.0,3.2,0.41)能否认为12μμ= (=0.05α)? 2)能否认为2212σσ= (=0.05α)?解 (1) 由题意知 2212(,),Y (,)XN N μσμσ设统计假设为 012112:=;:H H μμμμ≠,其中12==4=n n n令Z X Y =-,则有22111.15,()9.02331nzi z s z z n ===-=-∑, 当=0.05α时,1-2=(1) 3.1824c t n α-=,1-2=(1)/ 4.78Z c t n s α-⋅= 拒绝域为}{0K z c =>,而 1.15z c =<,所以012,.H μμ=接受认为 (2) 由题意知 2212(,),Y(,)XN N μσμσ设统计假设为 2222220111:=;:H H σσσσ≠,其中12==4=n n n 其中221.5467, 6.4367x y s s ==,拒绝域为2201222>x x y y s s K c c s s ⎧⎫⎪⎪=<⎨⎬⎪⎪⎭⎩或临界值 1/21221212(1,1)0.0648,(1,1)15.4392c F n n c F n n αα-=--==--=而22201220.2403,,.X Ys F H s σσ===接受认为19 从过去几年收集的大量记录发现,某种癌症用外科方法治疗只有2%的治愈率.一个主张化学疗法的医生认为他的非外科方法比外科方法更有效.为了用实验数据证 实他的看法,他用他的方法治疗200个癌症病人,其中有6个治好了.这个医生断 言这种样本中的3%治愈率足够证实他的看法.(1)试用假设检验方法检验这个医生的看法;(2)如果该医生实际得到了 4.5%治愈率,问检验将证实化学疗法比外科方法更有效的概率是多少?解 (1) 记每个病人的治愈情况为X ,则有(1,) XB p设统计假设为 0010:=0.02;:0.02H p p H p p >≤=,其中200,0.05n α==拒绝域为}{00K x p c =-<,临界值10.0163c αμ-== 而 000.01,,0.02.x p c H p -=<>拒绝不能认为 (2) 不犯第二类错误的概率101 4.5%P X u p p β-⎧⎫⎪⎪-=>=⎨⎬⎪⎪⎭⎩由(1,) XB p ,可得 (1),p p EX p DX n-==由中心极限定理得1 4.5%10.72X P p β⎧⎫⎪-=>=⎬⎪⎭=-Φ=20 在某公路上,50min 之间,观察每15s 内通过的汽车数,得下表通过的汽车数量0 1 2 3 4 ≥5 次数f92 68 28 11 1 0问能否认为通过的汽车辆数服从泊松分布(=0.10α)?解 设统计假设为 0010:()(),()(),200.0.10H F x F x H F x F x n α====4001ˆ,0.805.j j H X j n λν====∑若成立 记 ˆ1,2,3,4ˆ(),!j j j p P x j ej λλ-==-=则有ˆ0.8050102143243500.8050.4471,0.805*0.3599,*0.144920.8050.805*0.0389,*0.0078,10.0014,34j j p e e p p p p p p p p p p λ--=============-=∑检验统计量的值为()2522210.9500 2.1596(1)(4)9.848,~(),0.805.j j n j jnp m r np H X P ανχχχλλ-=-==<--===∑不拒绝认为且21 对某厂生产的汽缸螺栓口径进行100次抽样检验,测得100数据分组列表如下:组限 10.93~10.95 10.95~10.97 10.97~10.99 10.99~11.01 频数582034 组限11.01~11.0311.03~11.0511.05~11.0711.07~11.09频数 17 6 6 4试对螺栓的口径X 的分布做假设检验(=0.05α).解 设X 表示螺栓的口径,2(,)XN μσ,分布函数为()F x ,统计假设为0010:()(),:()()H F x F x H F x F x =≠,其中100,0.05,2n r α===在0H 成立的情况下,计算得88221111ˆˆ11.0024,()0.00101888j j j j i i X x v x v μσμ====⋅==-⋅=∑∑ 由ˆ11.0024(0,1)ˆ0.00319X X N μσ--=得0810.9311.002411.0911.00242.2689,, 2.74520.003190.00319x x --==-==所以110887()()0.0386,,()()0.0140p x x p x x =Φ-Φ==Φ-Φ=检验统计量的值为2822210.951()13.825(1)(5)11.07j j nj jv np m r np αχχχ-=-==>--==∑由此应该20,~(,).H X N μσ拒绝不能认为22 检查产品质量时,每次抽取10个产品检验,共抽取100次,得下表:次品数 0 1 2 3 4 5 6 7 8 9 10 频数35 40 18 5 1 1 0 0 0 0 0问次品数是否服从二项分布(=0.05α)? 解 设X 表示抽取的次品数,2(,)XN μσ,分布函数为()F x ,统计假设为0010:()(),:()()H F x F x H F x F x =≠,其中10,0.05n α==在0H 成立的情况下,01ˆNjj X pjvN N===∑计算得00101192280101102103371010010*******(1),0,1,,10;ˆˆˆ(1)0.3487,(1)0.3874,(1)0.1937ˆˆ(1)0.0574,(1)10,jj N j j N p C p p j p C p p p C p p p C p p p C p pp C p p--=-==-==-==-==-==-= 检验统计量的值为0020()21022210.950 5.1295(1)(9)16.92j j n j jnp m r np ανχχχ-=-==<--==∑因此0,~(10,0.1).H X B 不拒绝认为23 请71人比较A 、B 两种型号电视机的画面好坏,认为A 好的有23人,认为B 好的有45人,拿不定主意的有3人,是否可以认为B 的画面比A 的好(=0.10α)?解 设X 表示A 种型号电视机的画面要好些,Y 表示B 中型号电视机画面要好些分布函数分别为()X F x ,()Y F x ,统计假设为01:()(),:()(),10,100.0.05X Y X Y H F x F x H F x F x N n α=≠===由题意知++=23=45,=+n n n n n --, 检验统计量 ,min()s n n +-=而23(68)25s s α=<=,所以0,.H B 拒绝认为的画面好24 为比较两车间(生产同一种产品)的产品某项指标的波动情况,各依次抽取12个产品进行测量,得下表 甲 1.13 1.26 1.16 1.41 0.86 1.39 1.21 1.22 1.20 0.62 1.18 1.34 乙 1.211.310.991.591.411.481.311.121.601.381.601.84问这两车间所生产的产品的该项指标分布是否相同(=0.05α)?解 设,X Y 分别表示甲乙两车间所生产产品的指标分布,分布函数分别()X F x ()Y F x ,统计假设为01:()(),:()(),.0.05,12,X Y X Y H F x F x H F x F x n m α=≠===检验统计量为秩和T ,易知T 的样本值为112T =且(150,300)T N拒绝域为012K u u α-⎧⎫⎪=>⎨⎬⎪⎭⎩而0.9752.194 1.96u u =>=,所以0,.H 拒绝认为指标分布不相同 25 观察两班组的劳动生产率(件/h),得下表:问两班组的劳动生产率是否相同(α=0.05)?解 设,X Y 分别表示两个组的劳动生产率,分布函数分别为(),X F x ()Y F x ,统计假设为01:()(),:()(),.0.05,9,9X Y X Y H F x F x H F x F x n m α=≠===检验统计量为秩和T ,易知T 的样本值为73T = 拒绝域形式为}{01212,<K T t T t t t =<>其中而12(9,9)=66,(9,9)105t t =,因此T K ∈, 所以0,.H 接受认为劳动生产率相同26 观观察得两样本值如下:Ⅰ 2.36 3.14 7.52 3.48 2.76 5.43 6.54 7.41 Ⅱ 4.38 4.25 6.54 3.28 7.21 6.54问这两样本是否来自同一总体(α=0.05)?解 设,X Y 分别表示Ⅰ,Ⅱ两个样本,分布函数分别是(),X F x ()Y F x ,统计假设为01:()(),:()(),.0.05,6,8,X Y X Y H F x F x H F x F x n m α=≠===检验统计量为秩和T ,易知T 的样本值为49T = 拒绝域形式为}{01212,<K T t T t t t =<>其中而12(6,8)=32,(6,8)58t t =,因此0T K ∈, 所以0,.H 接受认为来自同一总体 27 某种动物配偶的后代按体格的属性分为三类,各类的数目是:10,53,46,按照某种遗传模型其比率之比应为:22)1(:)1(2:p p p p --,问数据与模型是否相符(05.0=α)?解 设体格的属性为样本X ,由题意知(2,1)X B p -其密度函数为()f x ,其中22(,)(1)0,1,2xxx f x p C p p x -=-=统计假设为0010:()(),:()()H F x F x H F x F x =≠似然函数为222211(1)(1)i iii nnx x x x n nxnxi i L C pp pp C --===-=-∏∏ 解得最大似然统计量为 ˆ12xp=- 则220ˆˆ 1.330.1121p p ===1ˆˆˆ2(1)0.4454pp p =-= 22ˆˆ(1)0.4424pp =-= 拒绝域为}{2201(1)K m r αχχ-=>--而 ()21022210.950ˆ0.9134(1)(9) 3.8414ˆjj n j j np m r npανχχχ-=-==<--==∑所以0,.H 不拒绝认为与模型相符28 在某地区的人口调查中发现:15729245个男人中有3497个是聋哑人.16799031个女人中有3072个是聋哑人.试检验“聋哑人与性别无关”的假设(05.0=α).解 设X 表示男人中聋哑人的个数,Y 表示女人中聋哑人的个数,其分布函数分别表示为()X F x ,()Y F x . 统计假设为01:(,)()(),:(,)()()X Y X Y H F x y F x F x H F x y F x F x =≠拒绝域为}{2201(1)K m r αχχ-=>--而21022210.950ˆ()62.64(1)(1) 3.84ˆj j nj jv np m r np αχχχ-=-==>--==∑ 所以0,.H 拒绝认为聋哑与性别相关 29 下表为某药治疗感冒效果的联列表:试问该药疗效是否与年龄有关(α=0.05)?解 设X 表示该药的疗效与年龄有关,Y 表示该药的疗效与年龄无关,其分布函数分别表示为(),X F x ()Y F x . 统计假设为01:(,)()(),:(,)()(),3,3,0.05,X Y X Y H F x y F x F x H F x y F x F x r s α=≠===拒绝域为}{2201(1)K m r αχχ-=>--而 ()21022210.950ˆ13.59(1)(4)9.488ˆj j n j j np m r npανχχχ-=-==>--==∑所以0,.H 拒绝认为疗效与年龄相关30 某电子仪器厂与协作的电容器厂商定,当电容器厂提供的产品批的不合格率不超过3%时以高于95%的概率接受,当不合格率超过12%时,将以低于10%的概率接受.试为验收者制订验收抽样方案.解 由题意知,010.03,0.12,0.05,0.1p p αβ====代入式子 01()1()L p L p αβ=-⎧⎨=⎩()L p 选用式子()()()(1)(1)L P X d P U np p np p φ=≤=≤≈--计算求得 66,4n d ==,于是抽查方案是:抽查66件产品,如果抽得的不合格产品4X ≤,则接受这批产品,否则拒绝这批产品.31 假设一批产品的质量指标2(,)XN μσ(2σ已知),要求质量指标值越小越好.试给出检验抽样方案(,n c )的计算公式.若2σ未知,又如何确定检验抽样方案(,n c )?若质量高时指质量指标在一个区间时,又如何确定检验抽样方案(,n c )?解 (1) 解方程组01()1()L L μαμβ=-⎧⎨=⎩ 得 ()201u u n αβσμμ⎛⎫+⎪= ⎪-⎝⎭10u u c u u αβαβμμ+=+ (2) 若2σ未知,用*2M 估计2σ,从而得出公式()2*201u u M n αβμμ⎛⎫+⎪= ⎪-⎝⎭10u u c u u αβαβμμ+=+习题四1 下表数据是退火温度x (C 0)对黄铜延性η效应的试验结果,η是以延伸率计算的,且设为正态变量,求η对x 的样本线性回归方程.x (C 0)300 400 500 600 700 800 y (%)40 50 55 60 67 70 解 利用回归系数的最小二估计:101ˆˆˆxyxx l l y x βββ⎧=⎪⎨⎪=-⎩其中2211,n nxy i i xx i i i l x y nxy l x nx ===-=-∑∑ 代入样本数据得到:10ˆˆ0.0589,24.6286ββ== 样本线性回归方程为:ˆ24.62860.0589yx =+ 2 证明线性回归函数中(1)回归系数1β的置信水平为α-1的置信区间为211ˆˆ(2)n αβ--; (2)回归系数0β的置信水平为α-1的置信区间为2ˆ(2)n αβ-±-.证 (1) 由于211ˆ,xx N l σββ⎛⎫ ⎪⎝⎭()0,1N222(2)ES n χσ-又因为:,()222ˆ2(2)n nσχσ--故所以()2t n -易知 {}11ˆ1pc ββα-<=-,1P α<=-⎪⎭⎩其中()122n α--所以1β的置信水平为α-1的置信区间为211ˆˆ(2)n αβ-- (2) 由0ˆβ~2201(,())xxn x N l βσ+,得 ()0,1N ,()222ˆ2(2)n n σχσ--,0ˆβ与2ˆσ相互独立,所以:()2T t n ==-根据11221(2)(2)P T t n P t n ααα--⎫⎪⎛⎫⎪-=<-=<- ⎪⎪⎝⎭⎪⎪⎭()()0001122ˆˆ22P n n ααβββ--⎛⎫ ⎪ ⎪=--<<+- ⎪ ⎪ ⎪⎝⎭得到0β的置信度为1α-的置信区间()012ˆ2n αβ--.3 某河流溶解氧浓度(以百万分之一计)随着水向下游流动时间加长而下降.现测得8组数据如下表所示.求溶解氧浓度对流动时间的样本线性回归方程,并以α=0.05对回归显著性作检验.流动时间t (天) 0.5 1.0 1.6 1.8 2.6 3.2 3.8 4.7 溶解氧浓度(百万分之一)0.28 0.29 0.29 0.18 0.17 0.18 0.10 0.12解 利用101ˆˆˆtyttl l y t βββ⎧=⎪⎨⎪=-⎩其中2211,n n ty i i tt i i i l t y nty l t nt ===-=-∑∑ 代入样本数据得到: 10ˆˆ0.0472,0.3145ββ=-= 所以,样本线性回归方程为:ˆ0.31450.0472yt =- 拒绝域形式为:{}21ˆc β> ()20.95ˆ1,6,0.0058ttF c c l σ==>而21ˆ0.0022β=,所以回归模型不显著.4 假设X 是一可控制变量,Y 是一随机变量,服从正态分布.现在不同的X 值下分别对Y 进行观测,得如下数据i x0.25 0.37 0.44 0.55 0.60 0.62 0.68 0.70 0.73 i y2.57 2.31 2.12 1.92 1.75 1.71 1.60 1.51 1.50 i x 0.75 0.82 0.84 0.87 0.88 0.90 0.95 1.00 i y1.41 1.33 1.31 1.25 1.20 1.19 1.15 1.00(1)假设X 与Y 有线性相关关系,求Y 对X 样本回归直线方程,并求2σ=DY 的无偏估计;(2)求回归系数210σββ、、的置信度为95%的置信区间; (3)检验Y 和X 之间的线性关系是否显著(=0.05α); (4)求Y 置信度为95%的预测区间;(5)为了把Y 的观测值限制在)68.1,08.1(,需把x 的值限制在什么范围?(=0.05α)解 (1) 利用101ˆˆˆxyxx l l y x βββ⎧=⎪⎨⎪=-⎩其中2211,n nxy i i xx i i i l x y nxy l x nx ===-=-∑∑计算得10ˆˆ2.0698, 3.0332ββ=-= 所以,样本线性回归方程为:ˆ 3.0332 2.0698yx =-,22ˆ0.002015ES σ== (2) 根据第二题,1β的置信区间为()112ˆˆ2n αβ--,代入值计算得到: ()1 2.1825, 1.9571β∈--,0β的置信区间为()02ˆ2n αβσ-±-,代入数值计算得到:()0 2.95069,3.1160β∈.(3) 根据F 检验法,其拒绝域形式为 }{201ˆK c β=> 而 12ˆ(2),xxc tn l ασ-=- 显然10K β∈,所以Y 和X 之间具有显著的线性关系.(4)()221(0,(1))xxx x yN l nσ-++,()2ˆ1()1(0,1)xxx x s x N l n -=++令222ˆ(2)(2),(2)ˆ()n nt n s x σχσσ---则有 1122ˆˆˆ((2),(2))y yt nyt n αα--∈--(5) 根据(4)的结论,令 22ˆˆ1.68 1.08yyαα--+=-=,解得 (0.7802,0.8172)x ∈5 证明对一元线性回归系数0ˆβ,1ˆβ相互独立的充分必要条件是0=x . 证 ""⇒()()()()()010011111ˆˆˆˆˆˆcov ,E y x ββββββββββ=--=---2110111101ˆˆˆˆ()E y x y x βββββββββ=---++2211011101ˆy xE y x ββββββββ=---++ ()2211ˆx E ββ=-- 222221111ˆˆˆ()xxE D E l σββββ=+=+若要()01ˆˆcov ,0ββ=,那么0x =.反之显然也成立,命题的证.6 设n 组观测值),...,2,1)(,(n i y x i i =之间有关系式:i i i i x x y εεββ,+-+=)(10~),...,2,1)(,0(2n i N =σ(其中∑==ni i x n x 11),且n εεε,...,,21相互独立.(1) 求系数10,ββ的最小二乘估计量10ˆ,ˆββ; (2) 证明∑∑∑===-+-=-ni in i i i n i i y y y y y y 121212)ˆ()ˆ()(,其中∑==n i i y n y 11 (3) 求10ˆ,ˆββ的分布. 解 (1) 最小化残差平方和:2201[()]Ei i S y x x ββ=---∑01ββ求,的偏导数[][]220101012()02()()0E Ei i i i i S S y x x y x x x x ββββββ∂∂=----==-----=∂∂∑∑, 01ˆˆ,xy xxl y l ββ==得到:(2) 易知()()()22221111ˆˆˆˆˆˆ()()2()nnnniiiiiii i i i i i i i y y y yy y y y yy y y y y ====-=-+-=-+-+--∑∑∑∑ 其中01ˆˆˆ()()xy i ii xxl y x x y x x l ββ=+-=+-,将其代入上式可得1ˆˆ()()0niiii y yy y =--=∑ 所以,∑∑∑===-+-=-ni i n i i i ni iy y yy y y121212)ˆ()ˆ()( (3)20ˆ~(0,),i N y εσβ=,200ˆ~(,)N nσββ∴同理,易得211ˆ~(,)xxN l σββ∴7 某矿脉中13个相邻样本点处某种金属的含量Y 与样本点对原点的距离X 有如下观测值 ix 2 3 4 5 7 8 10 i y 106.42 108.20 109.58 109.50 110.00 109.93 110.49 ix 11 14 15 16 18 19 i y 110.59 110.60 110.90 110.76 111.00 111.20分别按(1)x b a y +=;(2)x b a y ln +=;(3)xba y +=. 建立Y 对X 的回归方程,并用相关系数221TES S R -=指出其中哪一种相关最大.解 (1)令v y a bv ==+,根据最小二乘法得到,正规方程:101ˆˆˆvy vv l l y vβββ⎧=⎪⎨⎪=-⎩,最后得到10ˆˆ1.1947,106.3013ββ==所以:样本线性回归方程为:ˆ106.3013y=+10.8861R = (2) 令ln ,v x y a bv ==+101ˆˆˆvyvv l l y vβββ⎧=⎪⎨⎪=-⎩,得到10ˆˆ1.714,106.3147ββ== 所以:样本线性回归方程为:ˆ106.3147 1.714ln yx =+,20.9367R = (3) 令1,v y a bv x==+ 101ˆˆˆvy vv l l y vβββ⎧=⎪⎨⎪=-⎩,得到10ˆˆ111.4875,9.833ββ==- 所以:样本线性回归方程为:ˆ111.48759.833yx =-,30.987R = 综上,123R R R <<,所以第三种模型所表示的X Y 与的相关性最大. 8 设线性模型⎪⎩⎪⎨⎧++=+-=+=3213221211122εββεββεβy y y其中i ε~),0(2σN (1,2,3.i =)且相互独立,试求1β、2β的LS 估计.解 令()()1231212310,,,21,(,),,,12T TT Y y y y X βββεεεε⎡⎤⎢⎥==-==⎢⎥⎢⎥⎣⎦则线性模型可转化为 Y X βε=+ 根据 222TTTTES Y X Y Y Y X X X ββββ=-=-+, 令 20ES β∂=∂ 可得 ()1ˆTT X X X Y β-=即 112322311ˆˆ(23),(2)66Y Y Y Y Y ββ=++=--+ 9 养猪场为估算猪的毛重,随机抽测了14头猪的身长1x (cm),肚围2x (cm)与体重y (kg),得数据如下表所示,试求一个22110x b x b b y ++=型的经验公式.解由多元线性模型得:()2140,Y X I βεεσ=+⎧⎪⎨=⎪⎩()()()0121212,,,,,,TTTn n Y y y y ββββεεεε===()114149145581516215271159621627416971ˆ172741787918084190851929419891110395T T X X X X Y β-⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥==⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦代入数值得到:12ˆ15.93840.52230.4738yx x =-++ 同样得到:12ˆ15.93840.52230.4738yx x =-++ 10 某种商品的需求量y ,消费者的平均收入1x 和商品价格2x 的统计数据如下表所示.试求y 对1x 、2x 的线性回归方程. 1i x1000 600 1200 500 300 400 1300 1100 1300 300 2i x 5 7 6 6 8 7 5 4 3 9 y解 建立回归模型201122=+++(0,)Y x x N βββεεσ其中根据2()=0E S ββ∂∂,可求得β的LS 估计为 -1ˆ=(X X)T T X Y β代入x ,得0=111.6918,β 1=0.0143,β 2=7.1882,β- 则回归方程为:12ˆ111.69180.01437.1882yx x =+-11 设n 组观测值),...,2,1)(,(n i y x i i =之间有如下关系:i i i i i x x y εεβββ,+++=2210~),...,2,1)(,0(2n i N =σ,且n εεε,...,,21相互独立.(1)求系数210,,βββ的最小二乘估计量21ˆ,ˆ,ˆβββ; (2)设n i x x y i i i ,...,2,1,ˆˆˆˆ2210=++=βββ,∑==n i i y n y 11,证明:∑∑∑===-+-=-ni i ni i i ni i y y y y y y 121212)ˆ()ˆ()(解 (1) ()()()0121212,,,,,,TTTn n Y y y y ββββεεεε===1222211111Tn n X x x x x x x ⎛⎫ ⎪= ⎪ ⎪⎝⎭()1ˆT T X X X Y β-=(2)()()()22221111ˆˆˆˆˆˆ()()2()nnnniiiiiii i i i i i i i y y y yy y y y yy y y y y ====-=-+-=-+-+--∑∑∑∑()()11ˆˆˆˆ()0nT T i i i i x x x x y yy y β-==--=∑其中:y=x ,将其代入,得到 ()22211ˆˆ()()nni i i i i i y y y yy y ==∴-=-+-∑∑ 12(1)求形如210的回归方程;(2)对上述回归方程的显著性作检验; (3)求当x =5.5时Y 的估计值.解 (1) 令212,xx x x ==,求得回归方程为:2ˆ 3.4167 2.72620.3905yx x =+- (2) 拒绝域形式为:{}21ˆc β> ()20.9521ˆ1,6ˆxxF c l σβ=>而,所以回归方程具有显著性 (3)将5.5x =代入回归方程,得到ˆ 6.5982y=13 设y 和变量12,x x 有形为ε++=2211x b x b y ,2(0,)N εσ的回归方程模型,试用最小二乘法求出12b b 和的估计.解 令 ()()()121212,,,,,TT Tn Y y y y βββεεε===1112121222Tn n x x x X x x x ⎛⎫=⎪⎝⎭残差平方和为 222T T T T E S Y X Y Y Y X X X ββββ=-=-+令 20E S β∂=∂,得到 112ˆ(,)()T T T X X X Y βββ-==.友情提示:本资料代表个人观点,如有帮助请下载,谢谢您的浏览!。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
习题五1试检验不同日期生产的钢锭的平均重量有无显著差异?(=0.05) 解 根据问题,因素A 表示日期,试验指标为钢锭重量,水平为5.假设样本观测值(1,2,3,4)ij y j =来源于正态总体2~(,),1,2,...,5i i Y N i μσ= .检验的问题:01251:,:i H H μμμμ===不全相等 .计算结果:表5.1 单因素方差分析表‘*’ .查表0.95(4,15) 3.06F =,因为0.953.9496(4,15)F F =>,或p = 0.02199<0.05,所以拒绝0H ,认为不同日期生产的钢锭的平均重量有显著差异.2 考察四种不同催化剂对某一化工产品的得率的影响,在四种不同催化剂下分别做试验 试检验在四种不同催化剂下平均得率有无显著差异?(=0.05)解根据问题,设因素A 表示催化剂,试验指标为化工产品的得率,水平为4 .假设样本观测值(1,2,...,)ij i y j n =来源于正态总体2~(,),1,2,...,5i i Y N i μσ= .其中样本容量不等,i n 分别取值为6,5,3,4 . 检验的问题:012341:,:i H H μμμμμ===不全相等 .计算结果:表5.2 单因素方差分析表查表0.95(3,14) 3.34F =,因为0.952.4264(3,14)F F =<,或p = 0.1089 > 0.05,所以接受0H ,认为在四种不同催化剂下平均得率无显著差异 .3 试验某种钢的冲击值(kg ×m/cm2),影响该指标的因素有两个,一是含铜量A ,试检验含铜量和试验温度是否会对钢的冲击值产生显著差异?(=0.05) 解 根据问题,这是一个双因素无重复试验的问题,不考虑交互作用.设因素,A B 分别表示为含铜量和温度,试验指标为钢的冲击力,水平为12.假设样本观测值(1,2,3,1,2,3,4)ij y i j ==来源于正态总体2~(,),1,2,3,ij ij Y N i μσ=1,2,3,4j = .记i α⋅为对应于i A 的主效应;记j β⋅为对应于j B 的主效应;检验的问题:(1)10:i H α⋅全部等于零,11:i H α⋅不全等于零; (2)20:j H β⋅全部等于零,21:j H β⋅不全等于零; 计算结果:表5.3 双因素无重复试验的方差分析表查表0.95(2,6) 5.143F =,0.95(3,6) 4.757F =,显然计算值,A B F F 分别大于查表值,或p = 0.0005,0.0009 均显著小于0.05,所以拒绝1020,H H ,认为含铜量和试验温度都会对钢的冲击值产生显著影响作用.4 下面记录了三位操作工分别在四台不同的机器上操作三天的日产量:设每个工人在每台机器上的日产量都服从正态分布且方差相同 .试检验:(=0.05)1) 操作工之间的差异是否显著? 2) 机器之间的差异是否显著?3) 它们的交互作用是否显著?解 根据问题,这是一个双因素等重复(3次)试验的问题,要考虑交互作用.设因素,A B 分别表示为机器和操作,试验指标为日产量,水平为12. 假设样本观测值(1,2,3,1,2,3,4)ijk y i j ==来源于正态总体2~(,),1,2,3,ij ij Y N i μσ= 1,2,3,4j =,1,2,3k = .记i α⋅为对应于i A 的主效应;记j β⋅为对应于j B 的主效应;记ij γ为对应于交互作用A B ⨯的主效应; 检验的问题:(1)10:i H α⋅全部等于零,11:i H α⋅不全等于零; (2)20:j H β⋅全部等于零,21:j H β⋅不全等于零; (3)30:ij H γ全部等于零,31:ij H γ不全等于零;计算结果:表5.4 双因素无重复试验的方差分析表查表0.95(3,24) 3.01F =,0.95(2,24) 3.4F =,0.95(6,24) 2.51F =,计算值 3.01,A F <3.4, 2.51B A B F F ⨯>>,或0.05A p >>,而,B A B p p ⨯均显著小于0.05,所以拒绝2030,H H ,接受10H ,认为操作工之间的差异显著,机器之间的差异不显著,它们之间的交互作用显著 . 5 某轴承厂为了提高轴承圈退火的质量,制定因素水平分级如下表所示因素 上升温度℃ 保温时间(h)出炉温度℃水平1 800 6 400 水平28208500试填好正交试验结果分析表并对试验结果进行直观分析和方差分析 .解 根据题意,这是一个3因素2水平的试验问题 .试验指标为硬度的合格率 .应选择正方差来源 自由度 平方和 均方 F 值 P 值 因素A 因素B 相互效应A ×B误差 总和3 2 6 24 352.750 27.167 73.5 41.333 144.750.917 13.583 12.250 1.7220.5323 7.8871 7.11290.6645 0.00233** 0.00192**交表44(2)L 来安排试验,随机生成正交试验表如下:由此可见第三号试验条件为:上升温度800℃、保温时间6h 、出炉温度500℃ . 直观分析需要计算K 值,计算结果如下:直观分析 由计算的K 值知,因素A 、B 、C 的极差分别为70,40,40,因此主次关系为A B C >=,B ,C 相当 .由于试验指标为硬度的合格率,应该是越大越好,所以各确定因素的水平分别是121,,A B C ,即最佳的水平组合是121A B C ,即最佳搭配为:上升温度800℃、保温时间8h 、出炉温度400℃.采用方差分析法,计算得下表:表5.7 方差分析表方差来源平方和 自由度 均方差 F 值 A 1225 1 1225 1 B 400 1 400 0.33 C 400 1 400 0.33 误差 1225 1 1225 总和32504如果显著性检验水平取0.1α=,则查表得0.9(1,1)39.9F =,显然计算的F 值1,0.33A B C F F F ===均小于查表值,所以认为三个因素对结果影响都显著 .6问应选用哪正交表安排试验,并写出第8号试验的条件;如果9组试验结果为(单位:kg/100m 2):62.925,57.075,51.6,55.05,58.05,56.55,63.225,50.7,54.45,试对该正交试验结果进行直观分析和方差分析.解 该问题属于3因素3水平的试验问题,试验指标为水稻产量 .根据题意应选择正交表49(3)L 来安排试验,随机生成正交表如下:由表可知,第8号试验的条件:品种(A 3)珍珠矮11号,插值密度(B 2)3.75棵/100m 2 ,施肥量(C 1)0.75kg/100m 2纯氨; 直观分析需要计算K 值,计算结果如下:同上题进行直观分析,得出K 值的大小关系为:111312212223333132,,K K K K K K K K K >>>>>>由直观分析看出:本例较好的水平搭配是:113A B C 采用方差分析法,计算得下表:表5.10 方差分析表方差来源平方和自由度 均方差F 值A 1.759 2 0.879 0.0223B 65.861 2 32.931 0.8361C 6.660 2 3.330 0.0845 误差78.776 239.388 39.3880.9(2,2)9F =,所以认为三个因素对结果影响都不显著.7 在阿酸的合成工艺考察中,为了提高产量,选取了原料配比A ,吡啶量B 和反应时间C 三个因素,它们各取了7个水平如下:原料配比A :1.0,1.4,1.8,2.2,2.6,3.0,3.4 吡啶量B :10,13,16,19,22,25,28 反应时间C :0.5,1.0,1.5,2.0,2.5,3.0,3.5试选用合适的均匀设计表安排试验,并写出第7号试验的条件;如果7组试验的结果(收率)为:0.33,0.336,0.294,0.476,0.209,0.451,0.482,试对该均匀试验结果进行直观分析并通过回归分析发现可能更好的工艺条件.解 根据题意选择均匀设计表47(7)U 来安排试验,有3个因素,根据使用表,实验安排如:表5.11 试验安排表6 6 5 4 0.4517 7 7 7 0.482 所以第7号实验的条件为:原配料比3.4,吡啶量28ml,反应时间3.5h.通过直观分析,最好的实验条件是:原配料比3.4,吡啶量28ml,反应时间3.5h. 通过回归分析,最合适的实验条件是:原配料比2.6,吡啶量16ml,反应时间0.5h.习题六1 从某中学高二女生中随机选取8名,测得其升高、体重如下:1 2 3 4 5 6 78身高(cm)160 159 160 157 169 162 165 154体重(kg)49 46 53 41 49 50 48 43在绝对距离下,试用最短距离法和离差平方和法对其进行聚类分析.解由R软件,用最短距离(左)和差离平方和法(右)对题目进行聚类分析如下图6.1,表6.1和表6.2:最短距离法离差平方和法图6.1 聚类树形图表6.1 聚类附表(最短距离法)步骤聚类合并系数首次出现的阶段类别下一步组1 组2 组1 组21 1 6 5.000 0 0 22 1 2 10.000 1 0 43 4 8 13.000 0 0 74 1 7 13.000 2 0 55 1 3 13.000 4 0 6表6.2 聚类附表(离差平方和法)2 已知五个变量的距离矩阵为03674012340444401592343331).;2);3)036034022020401000⎛⎫⎛⎫⎛⎫⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭试用最短距离法和最长距离法对这些变量进行聚类,并画出聚类图和二分树.解 针对距离矩阵1),采用两种方法计算如下. ①最短距离法的聚类步骤如下:12345036740159036020w w w w w ⎛⎫ ⎪⎪ ⎪ ⎪⎪⎪⎝⎭a )将()236,1w w f h =合并为一类,,{}11456,,,,H w w w h =距离矩阵如下0743023060⎛⎫ ⎪⎪ ⎪ ⎪⎝⎭ {}()457457),,,2b w w h w w f h ==合并为一类,{}2167,,,H w h h =距离矩阵如下:034030⎛⎫ ⎪⎪ ⎪⎝⎭{}()()1681689),,3,3c w h h w h f h f h ===合并为一类,最后,,聚类图和树状图如图6.2:图6.2 聚类图(左)与树状图(右)②最长距离法与最短距离法类似,步骤如下: a )()236,1w w f h =合并为一类,{}11456,,,,H w w w h =距离矩阵如下0746025090⎛⎫ ⎪⎪ ⎪ ⎪⎝⎭{}(){}4574572167),,,2,,,b w w h w w f h H w h h ===合并为一类,距离矩阵如下:067090⎛⎫⎪⎪ ⎪⎝⎭{}()()1681689),,69c w h h w h f h f h ===合并为一类,最后,,,聚类图和树状图如图6.3:图6.3 聚类图(左)与树状图(右)(2)针对距离矩阵2)012340234034040⎛⎫ ⎪⎪ ⎪ ⎪⎪⎪⎝⎭①最短距离法的聚类步骤如下 a )()216,1w w f h =合并为一类,{}13456,,,,0342043040H w w w h =⎛⎫⎪⎪ ⎪ ⎪⎝⎭距离矩阵如下{}()367367),,,2b w h h w h f h ==合并为一类,{}24567,,,,H w w h h =聚类矩阵如下:043040⎛⎫⎪⎪ ⎪⎝⎭{}(){}()4784789879),,3,,4c w h h w h f h h w h f h ====合并为一类,最后,,聚类图和树状图如图6.4:图6.4 聚类图(左)与树状图(右)②由于本题数据的特殊性,最长距离法与最短距离法结果相同(略). (3)044440333022010⎛⎫ ⎪⎪ ⎪ ⎪⎪⎪⎝⎭最短距离法的聚类步骤如下a ) ()456,1w w f h =合并为一类,{}11236,,,,H w w w h =距离矩阵如下0444033020⎛⎫ ⎪⎪ ⎪ ⎪⎝⎭{}(){}36736724567),,,2,,,,b w h h w h f h H w w h h ===合并为一类,距离矩阵如下:044030⎛⎫⎪⎪ ⎪⎝⎭{}(){}()4784789879),,3,,4c w h h w h f h h w h f h ====合并为一类,最后,,,聚类图和树状图如图6.5:123454123h9h812h73h645图6.5 聚类图(左)与树状图(右)由于本题数据的特殊性,最长距离法与最短距离法结果相同(略).3在一项关于作物对土壤营养的反应的研究中,要测定土壤的总磷量和总氮量(占干物质重的百分比),今对10份土样测得数据如下:土样变量1 2 3 4 5 6 7 8 9 10总磷量(%)总氮量(%)0.12 0.15 0.36 0.17 0.14 0.06 0.10 0.11 0.110.120.63 1.19 2.30 1.29 0.73 0.52 0.33 0.61 0.470.66在绝对距离下,试用重心法对其进行聚类分析.解由R软件得到重心法聚类分析的结果如图6.6与表6.3:图6.6 聚类树形图表6.3 聚类过程记录表步骤聚类合并系数首次出现的阶段类别下一步组1 组2 组1 组21 1 8 .001 0 0 22 1 10 .002 1 0 43 6 9 .005 0 0 64 15 .010 2 0 75 2 4 .010 0 0 84 1975年Dagnelie 收集了11年的气象数据资料如下表其中:x 1—前一年11月12日的降水量;x 2—7月均温;x 3—7月降雨量;x 4—月日辐射,试对这四个气象因子进行主成分分析. 解 由R 软件分析得到如下表6.4,6.5:表6.4 各主成分的重要性:主成分1 主成分2 主成分3 主成分4 标准差 1.6103349 0.9890848 0.53407741 0.37854199 方差贡献率 0.6482947 0.2445722 0.07130967 0.03582351 累积贡献率0.64829470.89286680.964176491.00000000表6.5 因子荷载:主成分1 主成分2 主成分3 主成分4 X1 0.291 0.871 0.332 -0.214 X2 -0.506 0.425 -0.742 -0.111 X3 0.577 0.136 -0.418 0.688 X4-0.5710.2050.4040.685由于前两个主成分对应的累积贡献率已经达到89.287,因此选取主成分的数目为2.5 对某初中12岁的女生进行体检,测量其身高x 1、体重x 2、胸围x 3和坐高x 4,共测得58个样本,并算得1234(,,,)x x x x x ='的样本协方差为19.9410.5023.566.5919.7120.958.637.97 3.937.55S ⎛⎫ ⎪⎪= ⎪ ⎪ ⎪⎝⎭试进行样本主成分分析.解 首先计算样本的相关系数矩阵:10.484410.32240.887210.70330.59760.31251⎛⎫ ⎪ ⎪ ⎪ ⎪⎝⎭设相关系数矩阵的特征值和特征向量分别为d 和v 阵,计算得到0.0546000 0 0.312600= 000.96470 000 2.6681d ⎛⎫ ⎪ ⎪ ⎪ ⎪⎝⎭即四个特征值依次为:2.6681,0.9647,0.3126,0.0546,前两个主成分的累计贡献率为:90.8471%,因此提取主成分为2.四个特征根相应的特征向量为0.06000.70600.5333 0.4620 0.7317 0.17430.34040.5642=0.60570.19320.60400.48060.30690.65870.48460.4870v -⎛⎫ ⎪-⎪ ⎪--- ⎪-⎝⎭因此,两个主成分的表达式为:112340.060.73170.60570.3069z x x x x =+-- 212340.7060.17430.19320.6587z x x x x =-+-+6 比较因子分析和主成分分析模型的异同,阐明两者的关系. 解(1)提取公因子的方法主要有主成分法和公因子法.若采取主成分法,则主成分分析和因子分析基本等价,该法从解释变量的变异的角度出发,尽量使变量的方差能被主成分解释;而公因子法主要从解释变量的相关性角度,尽量使变量的相关程度能被公因子解释,当因子分析目的重在确定结构时则用到该法.(2)主成分分析和因子分析都是在多个原始变量过他们之间的部相关性来获得新的变量,达到既减少分析指标个数,又能概括原始指标主要信息的目的.但他们各有其特点:主成分分析是将n 个原始变量提取m 个支配原始变量的公因子,和1个特殊因子,各因子之间可以相关或不相关.(3)统用降维的方法,但差异也很明显:主成分分析把方差划分为不同的正交成分,而因子分析则把方差化分为不同的起因因子;因子分析中的特征值的计算只能从相关系数矩阵出发,且必须把主成分划分为因子.(4)因子分析提取的公因子比主成分分析提取的主成分更具有可解释性.(5)两者分析的实质及重点不同.主成分的数学模型为Y AX =,因子分析的数学模型为X AF ε=+.因而可知主成分分析是实际上是线性变换,无假设检验,而因子分析是统计模型,某些因子模型是可以得到假设检验的;主成分分析主要综合原始数据的信息,而因子分析重在解释原始变量之间的关系.(6)SPSS 数据的实现:两者都通过“analyze data reduction Factor···”过程实现,但主成分分析主要使用“descriptires ”,“extraction ”,“stores ”对话框,而因子分析处使用这些外,还可使用“rotaction ”对话框进行因子旋转.7 试对第4题的变量作因子分析,并将结果和上面的结果进行比较. 解 用SPSS 分析,计算结果如下表6.6-6.8:表6.6 反应压缩比情况表计算的相关系数矩阵的特征值和方差贡献率:表6.7 方差解释度表6.8 主成分矩阵8 为研究某一树种的叶片形态,选取50片叶测量其长度x 1(mm )和宽度x 2(mm ),按样本数据求得其平均值和协方差矩阵为:129048134,92,4845x x S ⎛⎫=== ⎪⎝⎭求出相关系数阵R ,并由R 出发作因子分析;解1)求相关系数矩阵:904810.7303,48900.73031S R ⎛⎫⎛⎫== ⎪ ⎪⎝⎭⎝⎭ 2)用R 软件求R 的特征根及其相应的特征向量,软件输出结果如下:$values[1] 2.99393809 0.07273809 $vectors[,1] [,2] [1,] 0.7071068 -0.7071068 [2,] 0.7071068 0.7071068122.9939,0.0727,λλ∴==12(),()0.7071,0.7071-0.7071,0.7071T Tηη==3) 求载荷矩阵A :1.22350.19071.22350.1907A -⎛⎫= ⎪⎝⎭4)22121.5333, 1.5333,h h == 0.98810.154*0.98810.154A -⎛⎫=⎪⎝⎭12121,1,0.3043,0.3043u u v v ===-=,222222000011112,0,()0.9074,20i i iii i i i i i A u B v C u v D u v =========-===∑∑∑∑9 1981年,生物学家Grogan 和Wirth 对两种蠓虫Af 和Apf 根据其触角长度x 1和翼长x 2进行了分类,分类的数据资料如下:Af 1 2 3 4 5 6 7 8 x 1 1.24 1.36 1.38 1.38 1.38 1.40 1.48 1.54 x 2 1.27 1.74 1.64 1.82 1.90 1.70 1.82 1.82 Apf 1 2 3 4 5 6 x 1 1.14 1.18 1.20 1.26 1.28 1.30 x 2 1.78 1.96 1.86 2.00 2.00 1.96(1)试建立Af 和Apf 的Fisher 判别模型;(2)对样本(1.24,1.80),(1.28,1.84),(1.40,2.04)进行判别分类.解 (1)建立Fisher 判别模型991122121111(,)(1.42,1.75),(,)(1.23,1.93)99T TT T i i i i i i x x y y μμ======∑∑120.08480.1490.01980.0218,0.1490.39120.02180.039A A ⎛⎫⎛⎫== ⎪ ⎪⎝⎭⎝⎭12120.0080.0130.0130.0332A A n n ⎛⎫+== ⎪+-⎝⎭∑()120.19,0.18Tμμ-=-,()()121 1.325,1.842Tμμ+= 1345.05135.42135.4283.33--⎛⎫= ⎪-⎝⎭∑, 带入Fisher 判别函数 ()12345.05135.42[(,)(1.325,1.84)]0.19,0.18135.4283.33Tx x -⎛⎫-- ⎪-⎝⎭1291.301741.336944.534x x =--(2)把三个样本(1.24,1.80),(1.28,1.84),(1.4,2.04)带入模型,得到结果:三个样本均属于Apf 类.10 在两个玉米品种之间进行判别:137玉米G 1和甜玉米G 2,选取的两个变量是:x 1—玉米果穗长;x 2—玉米果穗直径,两个类的样本容量为n 1=n 2=40,实际算得两个类的样本均值和样本协方差为:121218.5625.348.120 4.4589.661 3.720,,,5.98 4.12 4.458 4.350 3.720 3.410x x S S ⎛⎫⎛⎫⎛⎫⎛⎫==== ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭⎝⎭试建立G 1,G 2的Bayes 类线性判别函数.解 因为已知两类的样本均值和样本协方差为:12(18.56,5.98),(25.34,4.12)T T x x ==,128.120 4.4589.661 3.720,4.458 4.350 3.720 3.410S S ⎛⎫⎛⎫== ⎪ ⎪⎝⎭⎝⎭可计算得到修正的公共协方差矩阵和逆矩阵12120.2280.1450.1450.0992A A n n ⎛⎫+== ⎪+-⎝⎭∑,1 5.6393.738.25147.38--⎛⎫= ⎪-⎝⎭∑()()()121216.78,1.86,21.95,5.052TT μμμμ-=-+= 带入Fisher 判别函数()112121(())()2T W x x μμμμ-=-+-∑ ()()12 5.6393.73[(,)21.95,5.05] 6.78,1.868.25147.38Tx x -⎛⎫=-- ⎪-⎝⎭1274.396.951141.29x x =-+-。