1_1_C6000的体系结构和汇编语言详解
DSP2-3(c6000系列cpu结构和指令集)

2-3 2013.1主讲教师:任海鹏1. 8088CPU结构和240DSP流水线 2. C6000系列DSP的CPU结构 3. C6000系列DSP的指令基础 4. C6000系列DSP的流水线操作 5. 中断结构和中断响应《DSP原理及应用》2任海鹏CPU程序的执行顺序取指——PC控制 CPU上电PC=复位地址 第一条指令开始执行 随着节拍(时钟)顺 序(同步)执行下去 每一条指令的执行都是顺序安排好的。
问题:异步事件处理机制?《DSP原理及应用》3任海鹏中断的作用CPU按照节拍,将指令顺序地(或循环执行), 顺序执行的每一条操作是“同步”的。
如何来响应一些无法预知何时发生的操作或任 务呢? 两种可能的解决方法,一种是等待什么都不做; 一种是做其它事情,等到通知这个操作需要进行时, 在转到需要的操作。
《DSP原理及应用》4任海鹏中断的作用第二种方式就是中断方法,当有中断被响应 后,CPU停止当前的工作,去执行需要的操作,该 操作被执行后,需要返回原来的地方继续执行。
中断过程中存在两个操作的切换问题。
两个基本要求:被中断的程序执行到哪里要记住(保存)以便将来 返回; 到哪里去找要执行的中断操作要给出。
《DSP原理及应用》5任海鹏中断的入口和返回设计CPU的时候如何达到这两个要求呢?CPU中的中断返回指针寄存器IRP(NRP)来记忆当前程序 执行到哪里; CPU中的中断服务表指针寄存器ISTP用来指明中断发生后 到哪里去找要执行的程序。
《DSP原理及应用》6任海鹏中断的响应中断被响应以后发生的操作将要进入E1阶段的指令地址放入到中断返回寄存器IRP; 根据中断服务表指针中所指的地址去读取中断服务程序; 中断服务程序执行完后,一条B IRP指令可以使CPU从IRP 所指的地址开始重新执行被中断的程序。
《DSP原理及应用》7任海鹏中断的优先级一般需要执行的异步操作有多个,就需要设 置多个中断; 多个中断必要安排中断的优先级,使优先级 高的可以先响应; 同时中断服务表指针也要根据不同中断有所 不同; 中断源多了后,方便了应用,但对于简单应 用,要对不用的中断进行控制(屏蔽),需要一 些中断相关的一些控制寄存器。
第3章 C6000指令系统(1-2)

Dr. Naim Dahnoun, Bristol University, (c)
Texas Instruments 2002
12
32.2.2 延迟间隙(Delay Slots)
BK1
BK0
R
R,W
Mode select fields
15
14 13
12 11
10 9
87
6
B7 mode B6 mode B5 mode B4 mode A7 mode
5
4
A6 mode
R,W
3
2
A5 mode
1
0
A4 mode
R,W
00:线性寻址(复位后默认值)
各模式 01:循环寻址,使用BK0字段
Dr. Naim Dahnoun, Bristol University, (c)
Texas Instruments 2002
18
3.2.4 寻址方式及Load/Store类指令
一、寻址方式
寻址模式寄存器AMR各个位域的定义
Block size fields
31
26 25
21 20
16
ห้องสมุดไป่ตู้
Reserved
13
3.2.3 指令操作码映射图(Opcode Map)
C6000的每一条指令都是32位,都有自己的代码,详细指 明指令相关内容。
.L unit
31 29 28 27 23 22 18 17
13 12 11
54 3 2 10
C6000系列DSP的CPU结构概述

LD2a 32 MSB
• C64xx支持双字存储,还有第2个 ST2b 32LSB
32位存储通路,图中的ST1a和 ST2a 32MSB
ST2a。
TMS320C64x存储器读取通路
A组 寄存器
B组 寄存器
CPU数据通路与控制
2个数据地址通路 DA1,
ST1a 32MSB ST1b 32LSB
DA2
C6000系列CPU结构介绍
2 个对称的可进行数据处理的数据通路(A 和 B)
16个(C64x有32个)32位 通用寄存器
16个(C64x有32个)32位通 用寄存器
每个数据通路的4个功能单元有单一的 数据总线连接到 CPU 另一侧的寄存器上
4个功能单元 (.L、.S、.M和.D)
4个功能单元 (.L、.S、.M和.D)
C6000系列DSP的CPU结构概述
学习内容
TMS320C6000简介 C6000系列CPU结构介绍 CPU数据通路与控制 TMS320C6000公共指令集概述
TMS320C6000简介
美国TI公司发布的DSP芯片TMS320C6000 包括 TMS320C62xx和 TMS320C64xx两个定点系列和 TMS320C67xx 浮点系列,二个系列相互兼容。 C6000系列DSP主要特点:
32位加、减、线性及循环寻址计算 带5位常数偏移量的字读取与存储 带15位常数偏移量的字读取与存储 (仅.D2) 带5位常数偏移量的双字读取与存储 无边界调节的字读取与存储 5位常数产生 32位逻辑操作
带5位常数偏移量的双 字读取
CPU数据通路与控制
寄存器组交叉通路
CPU中有两个交叉通路1X和2X。 1X:允许A侧功能单元读取B组寄存 器数据。 2X:允许B侧功能单元读取A组寄存 器数据 每侧仅有一个交叉通路,在同一周 期内从另一侧寄存器组读操作数只 能一次,或者同时进行使用2个交 叉通路(1X和2X)的操作 .S,.M,.D功能单元仅src2可以使用 另一侧寄存器数据 仅C64系列的.D能使用交叉通路
basic汇编语言

basic汇编语言汇编语言是一种底层的计算机编程语言,它直接操作计算机的硬件资源。
在学习汇编语言之前,首先要了解计算机的基本组成部分和工作原理。
计算机由中央处理器(CPU)、内存、输入输出设备等组成,其中CPU是计算机的核心,负责执行程序的指令。
在汇编语言中,指令是以助记符的形式来表示的,比如MOV表示将数据从一个地方移动到另一个地方,ADD表示将两个数据相加。
汇编语言指令直接对应计算机的机器指令,因此汇编语言程序可以直接在计算机上执行。
汇编语言中的基本概念包括寄存器、内存、指令、标志位等。
寄存器是CPU 中的存储单元,用来存储数据和指令。
常见的寄存器包括通用寄存器(如AX、BX、CX、DX)、指令指针寄存器IP、堆栈指针寄存器SP等。
内存是用来存储程序和数据的地方,程序在执行时需要将数据加载到寄存器中进行操作。
指令是计算机执行的基本操作,汇编语言程序由一系列指令组成。
标志位是用来表示CPU运算结果的状态,比如进位标志CF、零标志ZF等。
在编写汇编语言程序时,需要考虑程序的逻辑结构和算法,合理地使用寄存器和内存,控制程序的执行流程。
汇编语言程序通常包括数据段、代码段和堆栈段。
数据段用来存储程序中的数据,代码段包括程序的指令,堆栈段用来存储函数的局部变量和返回地址。
汇编语言的编程风格通常是底层的、直接操作硬件的,因此在编写程序时需要考虑计算机的体系结构和指令集。
学习汇编语言可以帮助程序员更好地理解计算机的工作原理,提高编程的效率和性能。
总的来说,学习汇编语言需要对计算机的基本概念和工作原理有一定的了解,需要掌握汇编语言的基本语法和指令,需要练习编写简单的汇编语言程序。
通过学习汇编语言,可以更好地理解计算机的底层运作,提高编程的技能和水平。
C6000嵌入汇编C与汇编对照及功能说明

C6000嵌入汇编C与汇编对照及功能说明1.求绝对值函数(1) _abs()C代码: int _abs(int src)汇编: ABS功能: 求32位数据的绝对值(2) _labs()C代码: int _labs(long src)汇编: ABS功能: 求40位数据的绝对值(3) _abs2()C代码: int _abs2(int src)汇编: ABS2功能:同时求高16位和低16位的绝对值,即return[31:16] = |src[31:16]|return[15: 0] = |src[15: 0]|2.运算指令(1) _add2()C代码: int _add2(int src1,int src2)汇编: ADD2功能: 同时进行src1,src2的高16位和src1,src2的低16位相加,忽略任何进位,即return[31:16] = src1[31:16] + src2[31:16]return[15: 0] = src1[15: 0] + src2[15: 0](2) _sadd()C代码: int _sadd(int src1,int src2)汇编: SADD功能:普通A+B的加法(3) _lsadd()C代码: long _lsadd(int src1,long src2)汇编: SADD功能: 32位数据加上40位数据,返回为40位数据(4) _add4()C代码: int _add4(int src1,int src2)汇编: ADD4功能: 同时进行src1和src2的每个对应Byte的4次加法,忽略任何进位,即 return[31:24] = src1[31:24] + src2[31:24]return[23:16] = src1[23:16] + src2[23:16]return[15: 8] = src1[15: 8] + src2[15: 8]return[ 7: 0] = src1[ 7: 0] + src2[ 7: 0]备注: src1,src2的每个8位数据当做signed数据使用(5) _sadd2()C代码: int _sadd2(int src1,int src2)汇编: SADD2功能:同时进行src1,src2的高16位和低16位相加,忽略任何进位.即return[31:16] = src1[31:16] + src2[31:16]return[15: 0] = src1[15: 0] + src2[15: 0]备注: src1,src2的每个16位数据被当做signed数据(6) _saddus2()C代码: int _saddus2(unsigned src1,int src2)汇编: SADDUS2功能: 执行和_sadd2一样的操作,但src1解释不同,见备注备注: src1的每个16位数据被当作unsigned数据,src2的每个16位数据被当作signed数据(7) _saddu4()C代码: unsigned _saddu4(unsigned src1,unsigned src2)汇编: SADDU4功能: 执行和_add4()一样的操作,但数据解释为unsigned,限值为0xff(8) _addsub()C代码: long long _addsub(int src1,int src2)汇编: ADDSUB功能:同时进行src1 + src2和src1 - src2操作,即hi32(return) = src1 + src2low32(return) = src - src2(9) _addsub2()C代码: long long _addsub2(int src1,int src2)汇编: ADDSUB2功能: 同时进行_add2()和_sub2()操作,即return[63:48] = hi16(src1) + hi16(src2)return[47:32] = low16(src1) + low16(src2)return[31:16] = hi16(src1) - hi16(src2)return[15:0] = low16(src1) - low16(src2)(10) _saddsub()C代码: long long _saddsub(unsigned src1,unsigned src2)汇编: SADDSUB功能: 同时执行add()和sub()操作,即return[63:32] = src1 + src2return[31:0] = src1 - src2(11) _saddsub2()C代码: long long _saddsub2(unsigned src1,unsigned src2)汇编: SADDSUB2功能:同时进行sadd2()和ssub2()操作,即return[63:48] = src1[31:16] + src2[31:16]return[47:32] = src1[15: 0] + src2[15: 0]return[31:16] = src1[31:16] - src2[31:16]return[15: 0] = src1[15: 0] - src2[15: 0](12) _ssub2()C代码: int _ssub2(unsigned src1,unsigned src2)汇编: SSUB2功能: 同时进行高16位和低16位的减法,即return[31:16] = src1[31:16] - src2[31:16]return[15: 0] = src1[15: 0] - src2[15: 0](13) _mpy2(),_mpy2llC代码: double(long long) _mpy2(int src1,int src2),long long _mpy2ll(intsrc1,int src2)汇编:功能:(15) _mpyhi(),_mpyhill()C代码: double _mpyhi(int src1,int src2),long long _mpyhill(int src1,int src2) 汇编: MPYHI功能: 执行16位* 32位操作,即return = src1[31:16] * src2[31: 0](15) _mpyli(),_mpylill()C代码: double _mpyli(int src1,int src2),long long _mpylill(int src1,int src2)汇编: MPYHI功能: 执行16位* 32位操作,即return = src1[15: 0] * src2[31: 0](16) _mpyhir()C代码: int _mpyhir(int src1,int src2)汇编: MPYHIR功能: 执行(16位* 32位>> 15)操作,即return = (src1[31:16] * src2[31: 0]) >> 15;备注: 结果看起来被四舍五入了,例如0x1122 * 0x55667788结果应该是0x0b6e4b17,但仿真结果为0x0b6e4b18(16) _mpylir()C代码: int _mpylir(int src1,int src2)汇编: MPYLIR功能: 执行(16位* 32位>> 15)操作,即return = (src1[15: 0] * src2[31: 0]) >> 15;备注: 结果看起来被四舍五入了,例如0x1122 * 0x55667788结果应该是0x0b6e4b17,但仿真结果为0x0b6e4b18(17) _mpy*u4(),_mpy*u4ll()C代码: double _mpysu4(int src1,int src2),long long _mpysull4(int src1,intsrc2)double _mpyu4(unsigned src1,unsigned src2),long long _mpyu4ll(unsigned src1,unsigned src2)汇编: MPYSU4MPYU4.M2X B4,A3,B5:A4功能:同时执行4个8位* 8位操作,即return[63:48] = src1[31:24] * src2[31:24];return[47:32] = src1[23:16] * src2[23:16];return[31:16] = src1[15: 8] * src2[15: 8];return[15: 0] = src1[ 7: 0] * src2[ 7: 0];(18) _smpy2(),_smpy2ll()C代码: double _smpy2(int src1,int src2),long long _smpy2ll(int src1,int src2) 汇编: SMPY2功能: 同时执行两个16位*16位操作,结果再左移1位,即return = ((src1[31:16] * src2[31:16] << 32) + (src1[15: 0] * src2[15: 0])) << 1;(19) _mpy32**()C代码: int _mpy32(int src1,int src2),long long _mpy32ll(int src1,int src2) long long _mpy32su(int src1,unsigned src2),long long_mpy32us(unsigned src1,int src2)long long _mpy32u(unsigned src1,unsigned src2)汇编: MPY32MPY32SU.M2X B4,A3,B5:A4MPY32US.M2X B4,A3,B5:A4MPY32U.M2X B4,A3,B5:A4功能: 执行32位* 32位操作(20) _mpy2ir()C代码: long long _mpy2ir(int src1,int src2)汇编: MPY2IR功能:返回如下结果return[63:32] = src1[31:16] * src2 >> 15return[31: 0] = src1[15: 0] * src2 >> 5备注: 每一部分可能被四舍五入(21) _gmpy()C代码: unsignd _gmpy(unsigned src1,unsigned src2)汇编: GMPY功能: 执行"Galois Field multiply"(22) _smpy**()C代码: int _smpy(int src1,int src2),int smpyh(int src1,int src2)int _smpyhl(int src1,int src2),int _smpylh(int src1,int src2)汇编: SMPY SMPYHSMPYHL SMPYLH功能: 执行16位*16位操作,结果再左移一位,限值结果为小于x80000000_smpy: return[31: 0] = src1[15: 0] * src2[15: 0] << 1_smpyh: return[31: 0] = src1[31:16] * src2[31:16] << 1_smpyhl:return[31: 0] = src1[31:16] * src2[15: 0] << 1_smpylh:return[31: 0] = src1[15: 0] * src2[31:16] << 1(23) _mpy**()C代码: int _mpy(int src1,int src2),int _mpyus(unsigned src1,int src2)int _mpysu(int src1,unsigned src2),unsigned _mpyu(unsigned src1,unsigned src2)汇编: MPY MPYUSMPYSU MPYU功能:返回src1[15: 0] * src2[15: 0]的结果(24) _mpyh**()C代码: int _mpyh(int src1,int src2),int _mpyhus(unsigned src1,int src2)int _mpyhsu(int src1,unsigned src2),int _mpyhu(unsigned src1,unsignedsrc2)汇编: MPYH MPYHUSMPYHSU MPYHU功能:返回src1[31:16] * src2[31:16]的结果(25) _mpyh*l*()C代码: int _mpyhl(int src1,int src2),int _mpyhuls(unsigned src1,int src2)int _mpyhslu(int src1,unsigned src2),int _mpyhlu(unsigned src1,unsigned src2)汇编: MPYHL MPYHULSMPYHSLU MPYHLU功能:返回src1[31:16] * src2[15: 0]的结果(26) _mpyl*h*()C代码: int _mpylh(int src1,int src2),int _mpyluhs(unsigned src1,int src2)int _mpylshu(int src1,unsigned src2),int _mpylhu(unsigned src1,unsigned src2)汇编: MPYLH MPYLUHSMPYLSHU MPYLHU功能:返回src1[15: 0] * src2[31: 16]的结果(27) _*ssub()C代码: int _ssub(int src1,int src2),long _lssub(int src1,int src2)汇编: SSUB.L2X B4,A3,B4功能: 执行src1 - src2操作,符号扩展为int或long(28) _subc()C代码:unsigned _subc(int src1,int src2)汇编: SUBC功能:未知!!(29) _sub2()C代码: int _sub2(int src1,int src2)汇编: SUB2功能:同时执行高16位和低16位减法,即return[31:16] = src1[31:16] - src2[31:16]return[15: 0] = src1[15: 0] - src2[15: 0](30) _sub4()C代码: int _sub4(int src1,int src2)汇编: SUB4功能:同时执行4个8位减法,即return[31:24] = src1[31:24] - src2[31:24]return[23:16] = src1[23:16] - src2[23:16]return[15: 8] = src1[15: 8] - src2[15: 8]return[ 7: 0] = src1[ 7: 0] - src2[ 7: 0](31) _subabs4()C代码: int _subabs4(int src1,int src2)汇编: SUBABS4功能:同时执行4个8位减法,再求绝对值,即 return[31:24] = |src1[31:24] - src2[31:24]|return[23:16] = |src1[23:16] - src2[23:16]|return[15: 8] = |src1[15: 8] - src2[15: 8]|return[ 7: 0] = |src1[ 7: 0] - src2[ 7: 0]|(32) _avg2()C代码: int _avg2(int src1,int src2)汇编: AVG2功能:计算两路16位平均值,四舍五入结果return[31:16] = (src1[31:16] + src2[31:16] + 1) / 2; return[15: 0] = (src1[15: 0] + src2[15: 0] + 1) / 2;(33) _avgu4()C代码: int _avgu4(int src1,int src2)汇编: AVGU4功能:计算四路8位平均值,四舍五入结果return[31:24] = (src1[31:24] + src2[31:24] + 1) / 2; return[23:16] = (src1[23:16] + src2[23:16] + 1) / 2; return[15: 8] = (src1[15: 8] + src2[15: 8] + 1) / 2; return[ 7: 0] = (src1[ 7: 0] + src2[ 7: 0] + 1) / 2;3.位操作指令(1) _clr()C代码: int _clr(unsined src,unsigned csta,unsigned cstb)汇编: CLR功能: 清除src上的位csta ~ 位cstb,即src[cstb:csta] = 0;备注: csta必须<= cstb,且保证< 32(2) _clrr()C代码: int _clrr(unsigned src,int shift)汇编: CLR功能: 清除src上的shift[ 9: 5] ~ shift[ 4: 0]位(3) _set()C代码: int _set(unsined src,unsigned csta,unsigned cstb)汇编: SET功能: 设置src上的位csta ~ 位cstb,即src[cstb:csta] = '1';备注: csta必须<= cstb,且保证< 32(4) _setr()C代码: int _setr(unsigned src,int shift)汇编: SET功能: 设置src上的shift[ 9: 5] ~ shift[ 4: 0]位为'1'(5) _sshl()C代码: int _sshl(int src,unsigned shift)汇编: SSHL功能: return[31: 0] = src << shift;备注: 有符号扩展功能(6) _rotl()C代码: int _rotl(unsigned src,unsigned shift汇编: ROTL功能: return[31: 0] = src << shift;备注:无符号扩展功能(7) __shlmb(),__shrmb()C代码: int _shlmb(int src1,int src2),int _shrmb(int src1,int src2) 汇编: SHLMB功能: shlmb-->return[31:0] = (src2 << 8) | src1[31:24]shrmb-->return[31:0] = (src2 >> 8) | (src1[7: 0] << 24)(8) __shr2(),_shru2()C代码: int _shr2(int src1,unsigned shift),int _shru2(unsigned src1,unsigned shift)汇编: SHR2功能: return[31: 16] = src1[31:16] >> shiftreturn[15: 0] = src1[15: 0] >> shift备注: 有符号数操作返回值会进行符号扩展(移出的位全部补1)(9) _sshvl(),_sshvr()C代码: int _sshvl(int src,int shift),int _sshvr(int src,int shift)汇编: SSHVL SSHVR功能: sshvl-->return[31: 0] = (src << shift) > MAX_INT?MAX_INT:(src << shift) sshvr-->return[31: 0] = (src >> shift) < MIN_INT?MIN_INT:(src >> shift)(10) _shfl()C代码: int _shfl(int src)汇编: SHFL功能:低16位嵌入到偶位,高16位嵌入到奇位,即return[31:0] = src[31]src[15]src[30]src[14]........src[16][src[0](11) _ext()C代码: int _ext(int src,unsigned lshift,unsigned rshift)汇编: EXT功能: return[31: 0] = (src << lshift) >> rshift;(12) _extr()C代码: int _extr(int src,int shift)汇编: EXT功能: return[31: 0] = (src << shift[ 9: 5]) >> shift[4: 0];(13) _extu()C代码: int _extu(int src,unsigned lshift,unsigned rshift)汇编: EXT功能: return[31: 0] = (src << lshift) >> rshift;(14) _extur()C代码: int _extur(int src,int shift)汇编: EXT功能: return[31: 0] = (src << shift[ 9: 5]) >> shift[4: 0];(15) _lmbd()C代码: unsigned _lmbd(int zero_or_one,int src)汇编: LMBD功能:从左到右查找该位是zero_or_one的位,返回该位置备注:zero_or_one必须为0或者1,为其他值无LMBD指令编译如src = 0x0fff0000,则_lmbd(0,src) == 0 /*D31为'0',所以返回0*/_lmbd(1,src) == 4 /*D27为'1',所以返回4*/(16) _*norm()C代码: unsigned _norm(int src),unsignd _lnorm(long src)汇编: NORM B4,B4功能: 未知(17) _bitc4()C代码: unsigned _bitc4(unsigned src)汇编: BITC4功能: 统计每个字节的'1'总数,4个总数合成unsigned返回备注:例如src = 0x01030507,因为4个字节分别有0x01,0x02,0x03,0x04个'1',所以返回为0x01020304(18) _bitr()C代码: unsigned _bitr(unsigned src)汇编: BITR功能: 反转所有的位,即return[31:0] = src[ 0:31]备注:例如src = '00010001000100010001000100010001',则返回值是'10001000100010001000100010001000'(19) _deal()C代码: unsigned _deal(unsigned src)汇编: DEAL功能: 所有偶位组合成一个16位数据,所有奇位组合成一个16位数据,返回该32位值,即return[31:16] = src[31,29,27, (1)return[15: 0] = src[30,28,26, 04.内存操作指令(1) _amem*()C代码: ushort& _amem2(void* ptr),const ushort _amem2_const(void* ptr) unsigned& _amem4(void* ptr),const unsigned& _amem4_const(void* ptr) long long _amem8(void* ptr),const long long& _amem8_const(void* ptr)double & _amemd8(void* ptr),const double& _amemd8_const(void* ptr)汇编: 略功能: 从对齐地址中读/写n字节数据,n = 以上的数字备注:读--->double val;char test[8] = {0,1,2,3,4,5,6,7};val = _amem2_const(&test) + _amem4_const(&test) +_amem8_const(&test);写--->_amem2(&test) = 0x0011;_amem4(&test) = 0x00112233;_amem8(&test) = 0x0011223344556677;(2) _mem*()C代码: ushort& _mem2(void* ptr),const ushort _mem2_const(void* ptr)unsigned& _mem4(void* ptr),const unsigned& _mem4_const(void* ptr)long long _mem8(void* ptr),const long long& _mem8_const(void* ptr)double & _memd8(void* ptr),const double& _memd8_const(void* ptr)汇编: 略功能: 从非对齐地址中读/写n字节数据,n = 以上的数字备注:读--->double val;char test[8] = {0,1,2,3,4,5,6,7};val = _mem2_const(&test) + _mem4_const(&test) + _mem8_const(&test); 写--->_mem2(&test) = 0x0011;_mem4(&test) = 0x00112233;_mem8(&test) = 0x0011223344556677;(3) _mvd()C代码: int _mvd(int src)汇编: MVD功能:利用4周期乘法流水线拷贝数据,return[31: 0] = src[31: 0]备注:这个需要和_mpy**()配合实现并行工作5.数据包装/转换指令(1) _hi**()C代码: unsigned _hi(double src),unsigned _hill(long long src)汇编:无功能:返回64位数据的高32位数据(2) _low**()C代码: unsigned _lo(double src),unsigned _loll(long long src)汇编:无功能:返回64位数据的低32位数据(3) _*to*()C代码: ulong _dtol(double src),unsigned _ftoi(float src)double _itod(unsigned hi32,unsigned low32),float _itof(unsigned src) long long _itoll(unsigned hi32,unsigned low32),double _ltod(long src) 汇编:无功能:各种数据类型互相转换(4) _sat()C代码: int _sat(long src2)汇编: SAT功能: 把40位long数据转成32位数据(5) _pack*2()C代码: unsigned _pack2(unsigned src1,unsigned src2),unsigned _packh2(unsigned src1,unsigned src2)汇编: PACK2 PACKH2功能: _pack2--->return[31:16] = src1[15: 0],return[15: 0] = src2[15: 0] _packh2-->return[31:16] = src1[31: 16],return[15: 0] = src2[31: 16](6) _pack*4()C代码: unsigned _packh4(unsigned src1,unsigned src2),unsigned _packl4(unsigned src1,unsigned src2)汇编: PACKH4 PACKL4功能:返回交替的4字节数据备注: 如src1 = 0x11223344,src2 = 0x55667788,则_packh4(src1,src2)返回0x11335577_packl4(src1,src2)返回0x22446688(7) _pack**2()C代码: unsigned _packhl2(unsigned src1,unsigned src2),unsigned _packlh2(unsigned src1,unsigned src2)汇编: PACKHL2 PACKLH2功能: _packhl2--->return[31:16] = src1[31: 16],return[15: 0] = src2[15: 0] _packlh2-->return[31:16] = src1[15: 0],return[15: 0] = src2[31: 16](8) _spack2()C代码: int _spack2(int src1,int src2)汇编: SPACK2功能:把两个32位数据格式化成16位数据,然后组合成32位数据备注: return[31: 16] = (int16_t)src1return[15: 0] = (int16_t)src2(9) _spacku4()C代码: unsigned _spacku4(int src1,int src2)汇编: SPACKU4功能:把4个16位数据格式化成4个8位数据,形成32位数据返回备注: return[31:24] = (unt8_t)src1[31:16]return[23:16] = (unt8_t)src1[15: 0]return[15: 8] = (unt8_t)src2[31:16]return[ 7: 0] = (unt8_t)src1[15: 0](10) _swap4()C代码: unsigned _swap(unsigned src)汇编: SWAP4功能:大小端数据转换备注: return[31:24] 和return[23:16] 交换return[15: 8] 和return[ 7: 0] 交换(11) _unpkhu4()C代码: unsigned _unpkhu4(unsigned src)汇编: UNPKHU4功能: 把两个高8位数据转成两个16位数据备注:return[31:16] = (uint16_t)src[31:24]return[15: 0] = (uint16_t)src[23:16](12) _unpklu4()C代码: unsigned _unpklu4(unsigned src)汇编: UNPKHU4功能: 把两个低8位数据转成两个16位数据备注:return[31:16] = (uint16_t)src[15: 8]return[15: 0] = (uint16_t)src[ 7: 0]6.比较/杂项指令(1) _cmpeq*() _cmpgt*()C代码: int _cmpeq2(int src1,int src2),int _cmpeq4(int src1,int src2)int _cmpgt2(int src1,int src2),int _cmpgtu4(unsigned src1,unsigned src2) 汇编: CMPEQ2 CMPEQ4CMPGT2 CMPGT4功能: 同时比较两个16位数据或者4个8位数据,比较结果在返回值的低2位或低四位中备注:_cmpeq2(0x11223344,0x11220000)返回为0x02_cmpeq4(0x11223344,0x00223344)返回为0x07_cmpgt2(0x00001111,0x0000ffff)返回为0x01_cmpgtu4(0x0000ffff,0x0000aaaa)返回0x03(2) _xpnd*()C代码: int _xpnd2(int src),int _xpnd4(int src)汇编: XPND2 XPND4功能: _xpnd2()把src的低2位逻辑值扩展为2个16位逻辑值_xpnd4()把src的低4位逻辑值扩展为4个8位逻辑值备注:_xpnd*()一般和_cmp*()配合实现逻辑扩展_xpnd2(0x01) = 0x0000ffff_xpnd2(0x03) = 0xffffffff_xpnd2(0x00) = 0x00000000_xpnd4(0x00) = 0x00000000_xpnd4(0x08) = 0xff000000_xpnd4(0x07) = 0x00ffffff_xpnd4(0x01) = 0x000000ff。
第2章C6000 硬件结构与指令集
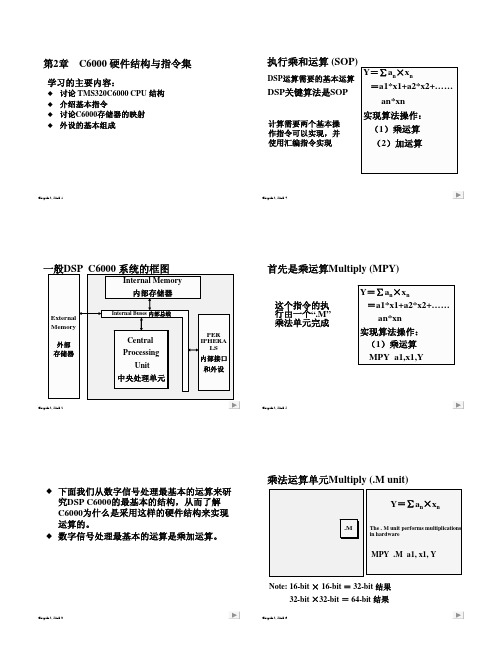
Chapter 2, Slide 1第2章C6000 硬件结构与指令集学习的主要内容:讨论TMS320C6000 CPU 结构 介绍基本指令讨论C6000存储器的映射外设的基本组成Chapter 2, Slide 2一般DSP C6000系统的框图PER IPHERA LS 内部接口和外设Central Processing Unit 中央处理单元Internal Memory 内部存储器Internal Buses 内部总线External Memory 外部存储器下面我们从数字信号处理最基本的运算来研究DSP C6000的最基本的结构,从而了解C6000为什么是采用这样的硬件结构来实现运算的。
数字信号处理最基本的运算是乘加运算。
Chapter 2, Slide 4执行乘和运算(SOP)DSP 运算需要的基本运算DSP 关键算法是SOPY =∑a n ×x n=a1*x1+a2*x2+……an*xn 实现算法操作:(1)乘运算(2)加运算计算需要两个基本操作指令可以实现,并使用汇编指令实现Chapter 2, Slide 5首先是乘运算Multiply (MPY)Y =∑a n ×x n=a1*x1+a2*x2+……an*xn 实现算法操作:(1)乘运算MPY a1,x1,Y这个指令的执行由一个“.M”乘法单元完成乘法运算单元Multiply (.M unit).MThe . M unit performs multiplications in hardwareMPY .M a1, x1, YNote: 16-bit ×16-bit =32-bit 结果32-bit ×32-bit =64-bit 结果Y =∑a n ×x nChapter 2, Slide 7加如何完成Addition (.?)?.M .?MPY .M a1, x1, prod ADD .? Y, prod, YY =∑a n ×x n =a 1*x 1+a 2*x 2+……a n *x nChapter 2, Slide 8采用.L 单元完成加运算Add (.L unit)C6000 使用寄存器保存操作数,Y =∑a n ×x n =a 1*x 1+a 2*x 2+……a n *x nMPY .M a1, x1, prod ADD .L Y, prod, Y.M.L寄存器文件A Register File –ALet us correct this by replacing a, x, prod and Y by theregisters as shown above.Y =∑a n ×x n =a 1*x 1+a 2*x 2+……a n *x nMPY .M a1, x1, prod ADD .L Y, prod, Y.M.La1x1prod 寄存器文件A 32位A0A1A2A15YChapter 2, Slide 10专用寄存器名字Specifying Register NamesThe registers A0, A1, A3 and A4 contain the values tobe used by the instructions.Y =∑a n ×x n =a 1*x 1+a 2*x 2+……a n *x nMPY .M A0, A1, A3ADD .L A4, A3, A4.M.La1x1prod寄存器文件A 32位A0A1A2A3A4A15Chapter 2, Slide 11专用寄存器名字Specifying Register Names寄存器文件A 包含16个32位寄存器(A0 -A15)。
1_2 C6000的体系结构和汇编语言(2).

控制/状态寄存器: 模式设置和状态标识
存储器的结构的学习:
目的:如何更快的取数
远见品质
控制/状态寄存器:CSR
远见品质
控制/状态寄存器:CSR
CPU版本
远见品质
Powerdown逻辑
远见品质
Powerdown逻辑
远见品质
大小端位
Little-endian ordering, in which bytes are ordered from right to left, the most significant byte having the highest address
两个16 × 16bit->2个32bit 一个16×32bit-> 64bit 一个16×32bit ->32bit 舍入并右移运 算 4个8×8->4个16bit
远见品质
C64xx的其它运算指令
求极值运算指令:MAX2、MAXU4、 MIN2、MINU4 16-16比;8-8-8-8比
Galois域多项式生成函数寄存器与乘法指 令GMPY4 算法的硬件实现; 工程应用-要求->芯片设计实现
中断使能寄存器(IER):使能或禁止中断处理。
中断标志寄存器(IFR):示出有中断请求、尚未得到服 务的中断。
中断设置寄存器(ISR):人工设置IFR中的标志位。
中断清零寄存器(ICR):人工清除IFR中的标志位。
中断服务表指针(ISTP):指向中断服务表的起始地址。
不可屏蔽中断返回指针(NRP):包含从不可屏蔽中断返 回的地址,该中断返回通过B NRP指令完成。
C6000

PI-脉冲量输入 PI0 无 PI1 1路 PI2 2路 PI3 3路 PI4 4路 FC-运算表达式 FC0 无 FC1 有
PW-配电输出 PW0 无 PW1 有
M0 M2 M4
C0 C2 C4
C-通讯接口 无 RS-232C RS-485
E0 E1
E-以太网 无 有
FL0 FL1 FL2
FL-流量运算 无 流量累积 温压补偿 与流量累积
概述
C6000 过程控制器是一款采用 7 英寸触摸屏的可编程多回路过程控制器。 C6000 过程控制器内部包含 8 个单回路 PID 控制模块、3 个程序控制模块、8 个 ON/OFF 控制模块、RLZ 温度专用算法,可实 现单回路控制、多回路控制。每个回路除可以作为普通的 PID 回路外还可以结合运算功能,设置成三冲量、串级、比率、分程、自 动选择、非线性控制、位式控制及用户定制等多种复杂的控制方案,其控制输出信号可以通过继电器触点、直流电流模拟信号输出 给 执行器。 C6000 过程控制器按照 IEC61010-1:2001 设计,前方面板防护等级符合 IP65 的要求。
数据外部存储
CF 卡: 通过 CF 卡可手动或自动转存历史数据,也 可保存组态数据、累积报表、报警信息、操 作信息、故障信息、监控画面,以便在 PC 机上进行分析。
控制功能
控制类型
PID 控制: 最多支持 8 个 PID 回路。 针对流程工业,PID 模块与表达式功能相结 合可配置为单回路、串级、比值、分程、前 馈、均匀、三冲量、自动选择、非线性控制 等复杂控制方案; 针对设备自动化控制,可配置为位式、逻辑、 批量、定时等控制模式。 为满足复杂控制要求,提供 10 组 PID 参数 自动切换功能。 可通过外部信号实现手自动切换、内外给定 切换。 可预先设定故障 MV 输出值、控制器上电时 的 SV 初始值、MV 初始值。 可实现内/外给定切换和无扰动切换,具有参 数自整定和死区非线性增益功能。 RLZ 算法: 程序控制: 针对温度对象设计。通过设定与过程相匹配 的上、 下过冲值及保温输出值进行温度控制。 在程序控制模块中,可同时设置 3 条随时间 变化的曲线,它们可直接输出去控制其他仪 表,也可供内部 PID 控制模块使用。可同时 应用在不同的被控对象及回路中。 有同步模式和异步模式两种方式,最多可同 时运行 3 条曲线,最多支持 600 个程 序 段 。 同步模式下,所有曲线操作同步进行;异步 模式下,各条曲线操作相对独立。 以太网: 串口:
C6000芯片(C64x)构架

CPU
L2 Unified
(1MB)
EMIF
Auto via EDMA
L1 Data
(16KB)
PDF 文件使用 "pdfFactory Pro" 试用版本创建
两级缓存的访问逻辑
CPU requests data
No Is data in L1? Is data in L2?
n n n n
Offset是字偏移地址 行容量: 64字节 Word字段选择组中相应的字 Set Index确定该组在L1D中的位置 Tag使该地址数据的一个唯一标记
PDF 文件使用 "pdfFactory Pro" 试用版本创建
L1D的访问描述
n
n
n
CPU的数据访问如果命中L1D,将单周期返 回需要的数据。 如果没有命中L1D,命中的是L2,对于 C621x/C671x,CPU将被阻塞4个时钟周 期;对于C64x,CPU将被阻塞2~8个时钟 周期。 如果也没有命中L2,CPU将被阻塞,直到 L2从外部存储空间取得相应数据,送入 L1D,再送入CPU。
CPU
P E R I P H E R A L S
PDF 文件使用 "pdfFactory Pro" 试用版本创建
TMS320C62xx/64xx/67xx结构框图
程序读入及 指令译码、 分配机构 芯片测试和 仿真端口及 其控制逻辑
程序执行机构
PDF 文件使用 "pdfFactory Pro" 试用版本创建
1 3 2 4
5
PDF 文件使用 "pdfFactory Pro" 试用版本创建
5分钟看懂汇编语言C语言

5分钟看懂汇编语言C语言汇编语言和C语言是计算机编程中非常重要的两种语言。
汇编语言是一种低级语言,它与计算机硬件直接相连,能够直接访问和控制计算机的各种资源。
而C语言是一种高级语言,它是一种更接近自然语言的编程语言,可以编写更容易理解和维护的代码。
在学习汇编语言和C语言之前,我们首先需要了解计算机的基本结构。
计算机由硬件和软件两部分组成。
硬件是计算机的物理部分,包括中央处理器(CPU)、内存、硬盘、显示器等。
软件是计算机的程序和数据,包括操作系统、应用程序、编程语言等。
汇编语言是一种与计算机硬件相对应的语言。
它使用符号代表不同的指令和数据,通过汇编器将汇编语言代码转换成机器语言代码,再由计算机执行。
汇编语言相对于高级语言来说,更加底层,更加直接地操作计算机的硬件资源。
因此,熟练掌握汇编语言对于理解计算机底层工作原理以及进行系统级编程是非常重要的。
与汇编语言相对的是C语言,它是一种高级编程语言。
C语言由贝尔实验室的Dennis Ritchie于1972年设计开发,已经成为一种广泛使用的编程语言。
C语言更加接近自然语言,使用更加方便、简洁,可以编写出易于理解和维护的代码。
C语言是系统级编程和嵌入式开发的首选语言,也是其他高级编程语言的基础。
在学习汇编语言和C语言时,我们需要掌握它们的基本语法和特性。
汇编语言的语法与具体的硬件平台相关,不同的平台有不同的指令集和寻址方式。
因此,在学习汇编语言时,需要首先选择一个特定的平台进行学习,比如x86平台或者ARM平台等。
汇编语言的基本语法包括汇编指令、寄存器、内存访问、运算操作等。
汇编指令是汇编语言的核心部分,它们与机器指令一一对应,用于控制计算机的执行流程和操作数据。
寄存器是计算机的高速存储器,用于暂时存放数据或者指令。
内存是计算机的主存储器,用于存放程序和数据。
在汇编语言中,我们可以使用不同的寻址方式来访问内存中的数据。
C语言的基本语法包括变量、数据类型、运算符、控制语句、函数等。
汇编语言第二章计算机组织结构

PPT文档演模板
汇编语言第二章计算机组织结构
•第二•第章一章计算基机础组知织识结构
•机器规定:从0地址开始,每16个字节为一小段。
•段地址的选取不是任意的,计算机规定:20位二进制的地址值 中,只有低4位地址值为0的地址才能作为段地址使用。在1M空 间中,可以有以下的地址作为段地址使用:
•00000H
PPT文档演模板
汇编语言第二章计算机组织结构
•第二•第章一章计算基机础组知织识结构
•每一个操作系统都必须定义一个GDT,而每一个正在运行的任务都会有 一个相应的LDT。每一个描述符的长度是8个字节,格式如下图所示。
• GDT和LDT是在内存中的,由OS设置。
PPT文档演模板
汇编语言第二章计算机组织结构
• 微处理器就是由控制器和算术逻辑部件组成 的中央处理器(即CPU)。它的作用是自动地执行各 条指令,协调整个系统的工作。
• 存储器是计算机的记忆装置,用于存储计算 机当前的数据和程序,我们通常接触的是RAM,它是 一种随机存取存储器,它的数据在重启或关机后会 丢失,而且在计算机运行时还需不断刷新。
汇编语言第二章计算机 组织结构
PPT文档演模板
2020/11/22
汇编语言第二章计算机组织结构
•第二•第章一章计算基机础组知织识结构
•2.1 计算机系统的概述
•计算机系统包括硬件与软件两部分 •一、计算机硬件 •二、计算机软件
•2.1.1 硬件
• 硬件是指计算机的物理实体(如CPU,显卡等) 我们在这里将它分为微处理器,存储器,接口电路, 外部设备和系统总线等。(如左图所示)
PPT文档演模板
汇编语言第二章计算机组织结构
•第二•第章一章计算基机础组知织识结构
汇编语言概述范文

汇编语言概述范文汇编语言是一种底层的计算机语言,它直接与计算机硬件相对应。
它使用符号和助记符来代替二进制代码,使程序员能够更容易地编写和理解机器语言指令。
汇编语言通常与特定的处理器架构相关联,因此不同的机器和处理器可能有不同的汇编语言。
汇编语言是高级语言和机器语言之间的一个桥梁。
与高级语言相比,汇编语言更接近机器语言,提供了更多底层的控制和操作选项。
它可以直接访问计算机硬件资源,如寄存器、内存和I/O设备,使程序员能够更好地优化代码的性能和效率。
汇编语言的编程通常涉及以下几个方面:1.汇编语言的语法:汇编语言中的指令由助记符、操作数和注释组成。
助记符表示特定的指令,操作数指定指令的操作数据,而注释用于提供代码的解释和说明。
汇编语言还具有丰富的控制结构,如条件分支和循环,可以实现复杂的程序逻辑。
2.寄存器:寄存器是计算机内部的快速存储区域,可以存储指令和数据。
汇编语言使用寄存器来执行算术和逻辑操作,存储中间结果,并控制程序流程。
不同的机器和处理器有不同的寄存器集,每个寄存器具有特定的功能和使用规则。
3.内存管理:汇编语言直接访问计算机的物理内存,可以读写内存中的数据。
程序员需要使用内存地址和指针来操作内存,如存储变量、定义数组和字符串,并进行数据的加载和保存。
汇编语言还提供了一些特殊的指令来管理内存的分配和释放。
4.I/O操作:汇编语言可以通过I/O指令来读写外部设备,如键盘、显示器、硬盘和网络接口。
这使得程序员能够与用户交互,输入和输出数据。
汇编语言还可以通过中断处理程序来处理硬件中断和异常。
5.程序调用和堆栈:汇编语言通过跳转指令和子程序调用来实现程序的模块化和代码重用。
子程序是一段具有特定功能的代码块,可以被其他程序调用。
汇编语言使用堆栈来保存子程序的返回地址和局部变量,以便在子程序结束后能够正确返回到调用者。
汇编语言相对于高级语言具有一些优点和局限性。
优点包括更高的执行效率、更精确的控制和更好的硬件资源访问能力。
C6000体系结构与汇编语言4--存储器

C620x/C670x Cache的结构
直接映射式: cache的行(line)容量256-bit,可容纳8条32bit的指令。Cache中每一行对应一个取指包, 直接映射外存中某个地址的内容。
C6201/C6204/C6205/C6701 Cache地址的解析
C6202(B)/C6203(B) Cache地址的解析
C621x/C671x/C64x的L1D
双路组联想结构
6BIT,64组
5BIT,32字节
128组
访问L1D cache 阻塞: CPU的数据访问如果命中L1D,将单周期返回需要的数据。如果 没有命中L1D,但是命中L2,对于C621x/C671x,CPU将被阻塞4 个周期;对于C64x,CPU将被阻塞2~8个周期。
Cache存储系统组成
Cache系统组成原理
Cache系统工作原理
Cache和主存储器都划分成相同大小的 块(有的地方也称行,line) 块(Block)的大小是2的整次幂,一块 包含若干字,字可分为字节。 Cache与主存储器之间以块为单位进行 数据交换。 主存储器的块可以采用某种地址映象和 地址变换映射到Cache上的块。
C620x/C670x的片内数据存储器
C6201/C6204/C6205片内数据存储器的 组织结构: 思考:为什 么分为多个 bank?2个 block?
C6701片内数据存储器的组织结构
思考:为什 么C67的bank 数为8?C62 为4?
C620x/C670x对片内数据存储器的访问
数据访问的格式控制: 边界限制 DMA数据传输 优先级
Cache系统工作原理(全相联)
C6000系列教程一解析

ST2
A组 寄存器
.D1
.D2
B组 寄存器
BIT/TI
第一讲TMS320C62xx/C67xx结构概述
38
2.控制寄存器
控制寄存器缩写 AMR
CSR
IFR ISR ICR IER ISTP IRP NRP
PCE1
控制寄存器名称 寻址模式寄存器
控制状态寄存器
中断标志寄存器 中断设置寄存器 中断清除寄存器 中断使能寄存器 中断服务表指针 中断返回指针 不可屏蔽中断返回 指针 程序计数器
描述 指定是否使用线性或循环寻址,也包括 循环寻址的尺寸 包括全局中断使能位、高速缓冲存储器 控制位和其它各种控制和状态位 显示中断状态 允许软件控制挂起的中断 允许软件清除挂起的中断 允 许 使 能 /禁 止 个 别 中 断 指向中断服务表的开始 保存从可屏蔽中断返回时的地址 保存从不可屏蔽中断返回时的地址
23
关于指针
第1次循环后,A4为: 第2次循环如何访问a(1)和x(1)?
BIT/TI
第一讲TMS320C62xx/C67xx结构概述
24
递增指针
BIT/TI
第一讲TMS320C62xx/C67xx结构概述
25
另一套功能单元和寄存器(B侧)
BIT/TI
第一讲TMS320C62xx/C67xx结构概述
21
读取/存入(.D单元)
BIT/TI
第一讲TMS320C62xx/C67因此使用指令MVK:
• MVK指令所移的位数:16 bit • 表示一个完整地址的位数:32 bit • 一个地址读入寄存器必须使用两条指令:
例如:
BIT/TI
第一讲TMS320C62xx/C67xx结构概述
第三章_CCSC6000程序基本结构

4.1 软件开发流程和开发工具 4.2 集成开发环境CCS(code composer studio) 4.3 实时操作系统DSP/BIOS
1
4.1 TMS320C6000 软件开发流程和开发工具
4.1.1 TMS320C6000软件开发流程 4.1.2 连接命令文件(.cmd)的编写 4.1.3 C语言编程常见问题 4.1.4 汇编代码结构 4.1.5 线性汇编语言结构 4.1.6 C语言和线性汇编语言的混合编程
2
3
4
(1)准备工作:7个需要复制的文件
文件名 main.c
Load. asm Vectors.asm Volume.h Volume.cmd
Sine.dat Volume.gel Rts6700.lib
文件说明
实验用源文件(C主函数);必须包含一个main()函 数作为C程序的入口点 实验用源文件(汇编子函数) 实验用源文件(中断向量表)
0190 0000~0193 FFFF
保留
EDMA RAM 和EDMA寄 存器 保留
516B~ 256KB 256KB
768KB
019C 0204 ~019F FFFF 01A0 0000~01A3 FFFF 01A4 0000~01AF FFFF
GPIO寄存 器
保留
1.C6000的存储器映射 2. C6000编译器的C环境实现和COFF文件格式 3. 连接器linker 的使用
10
1. C6000的存储器映射
SEED_DEC6713的存储器扩展总线,包含4个存储空间 XCE[3:0],每个存储空间有20位地址线、32位数据线。 SEED_DEC6713的这4个存储空间被XCE[3:0]被映射到 C6713的CE2和CE3空间中,具体的映射关系
第2章 TMS320C6000系列的硬件结构-244

2.4.3 片内2级(L2)高速缓存的结构 1) C621x/C671x的L2容量为64KB,C64x 的L2容量为1024KB;
2)可以工作在5种模式下,由CCFG中的 L2MODE控制
L2的五种模式
高速缓存访问逻辑
2.4.4 片内高速缓存的控制
控制寄存器 除了前面提到的多个cache控制寄存器,C621x/ C671x
C621x/C671x/C64x2级高速缓存结构
C621x/C671x 2级存储器结构
2.4.1 片内1级程序(L1P)高速缓存的结构
1)C621x/C671x和C64x 区别 C621x/C671x的L1P行大小为64 B ,缓存64组 C64x L1P的行大小为32 B,缓存512组
2.4.1 片内1级程序(L1P)高速缓存的结构
/C64x还提供了一组存储器属性寄存器(Memory Atribute Registers,MAR),用于控制外存某一段空间 的高速缓存使能。
本章小结
1 C6000系列DSP处理器组成 CPU内核、外设和存储器
2 C6000DSP芯片的CPU结构 CPU数据通路和控制
3 片内存储器和二级内部存储器 结构原理、寄存器和应用
习题
1 cache —地址的解析
2 对片内数据存储器的访问
假设源地址xxxxxx00h中预先存放的数据为A8A76543h
不同endian模式下数据访问结果 LDH(地址位:00h) 大端: 小端:
第2章 TMS320C6000系列的硬件结构
本章内容提要: Biblioteka 芯片的设计角度出发,利用简单的汇编指令实现经典的
数字信号处理算法-点积运算,同时引出C6000DSP芯片 的结构。
soft3-代码产生工具及C6000程序结构

存储器模式
小存储器模式和大存储器模式。区别在 于为.bss段分配存储空间方式。
小存储器模式: LDW *+DP(0x7),B5
.bss 32KByte,使用DP(B14)访问全局数据
大存储器模式:
不限制.bss段的大小
3. 初始化全局的变量,这是通过将.cinit 段中的初始化表复制给.bss段中为变量 分配的存储空间来完成的。如果是在加 载时初始化变量(–cr选项),加载器 (loader)在程序运行之前就完成了这 个步骤(它不是通过引导程序执行的)
4. 调用main函数来运行C/C++程序
C_int_00源码 1
并行指令安排 指令延迟 寄存器使用
效率可达汇编语言代码的 95%~100%
汇编器
产生可重新分配地址的机器语言目标文 件
输入:
C编译器产生的汇编文件 汇编优化器输出的汇编文件 文档管理器管理的宏库内的宏
输出:
目标代码是TI的COFF格式 汇编代码内除机器指令外,还有汇编伪指令
C代码产生器也可以完成一些优化工作 C优化器最重要的优化处理-软件流水 -pm
把一个程序所有的C文件合成一个模块进 行优化处理
效率可达汇编语言代码的 70%~80%
汇编优化器
对线性汇编代码(.sa文件)进行优化 输入:用户编写的线性汇编代码 输出:标准汇编代码.asm文件 编程过程不需考虑:
寄存器使用规范
在C/C++环境下,一些具体的操作要使 用哪些的寄存器来完成,是有严格的规 范的。
寄存器使用规范规定了编译器使用寄存 器的方法以及函数调用过程中数值保存 的方法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Register File - A
Register File A A0 A1 A2 A3 A4 a1 x1 prod Y . . .
40
Y =
n = 1
an * xn
.M .L
MPY ADD
.M .L
a1, x1, prod Y, prod, Y
A15
32-bits
Let us correct this by replacing a, x, prod and Y by the registers as shown above.
C6000 体系结构和汇编语言
田黎育
Why DSP?
DSP: What kind of 对大量数据作
Algorithm driven
Algorithm?
相同的运算
典型DSP算法: 乘法累加 。 For循环, 20%-80%现象 DSP就是为了 缩短这样类型 的运算的时间 ,DSP是如何 做到的呢?
A15
32-bits
Data Memory
Load Instructions (LDB, LDH,LDW,LDDW)
Register File A A0 a1 x1 prod Y . . .
A1
A2 A3
Q: Which instruction(s) can be used for loading operands from the memory to the registers? .M .L .D A: The load instructions.
General DSP System Block Diagram
Internal Memory
Internal Buses
External Memory
Central Processing Unit
P E R I P H E R A L S
C6000 CPU Architecture
VLIW, Very Long Instruction word
This instruction is performed by a multiplier unit that is called “.M”
Multiply (.M unit)
40
Y =
n = 1
an * xn
.M
The . M unit performs multiplications in hardware
A15
32-bits
Data Memory
Load Unit “.D”
Register File A A0 a1 x1 prod Y . . .
A1
A2 A3
.M .L .D
It is worth noting at this stage that the only way to access memory is through the .D unit.
对比:TigerShare101 Architecture
C6201/04/05 片内存储器
C6701片内存储器
C64x 片内2级存储器
C64的 L1D的存储 体结构:8×32bit 。(32B)
L1D行:64B。 共128组(4K字)
程序员角度的DSP结构:存储器的层次
片外存储器
片内存储器
对比:8086的ADD指令
8086/8088 一条指令长1~6字节
8086 ADD CX,DX CX和DX相加放到CX
000000 0 1 11 001 010;寻址方式和立即数,这里没有 ADD (1) (2) (3) (4)(5)
(1)0 reg为目的,
(2)1 字处理(8086的字为16bit), 表示操作的是CX,DX不是 CL,DL。
address
Rn is a register that contains the address of the operand to be loaded
and Rm is the destination register.
00000000 00000002 00000004 00000006 00000008
Data loading
Register File A A0 A1 A2 A3 A4 a1 x1 prod Y . . .
Q: How do we load the operands into the registers? .M .L
A15
32-bits
Load Unit “.D”
Register File A A0 a1 x1 prod Y . . .
Specifying Register Names
Register File A A0 A1 A2 A3 A4 a1 x1 prod Y . . .
40
Y =
n = 1
an * xn
.M .L
MPY ADD
.M .L
A0, A1, A3 A4, A3, A4
A15
32-bits
Register File A contains 16 registers (A0 -A15) which are 32-bits wide.
数据寄存器
处理 单元
C62xx CPU Core
C67xx CPU Core
C64xx CPU Core
一条C6000的指令和其机器码
C6000: ADD .D2 B5,B4,B4 ADD (.D2 or.D1) src2,src1,dst1 00000010000101001000100001000010 000 0 00100 00101 00100 010000 10000 1 0 (1) (2) (3) (4) (5) (6) (7)(8)(9) (1) 条件寄存器: A1,A2,B0~2; C64添加A0 (2) z,指定条件寄存器的判断条件 (3) dst,目的 (4) src2,源2 (5) src1, 源1 (6) 操作码:设定唯一指令的码,sint,2个源和目标都为有符 号整数且功能单元为D时的操作码就是010000 ; (7) 固定值 (8) s,选择A边寄存器还是B边寄存器 (9) p,是否并行
N
Y =
n = 1
an * xn
So let’s write the code for this algorithm and at the same time learn the C6000 architecture.
= a1 * x1 + a2 * x2 +... + aN * xN
Two basic operations are required for this algorithm. (1) Multiplication
N
Y =
n = 1
an * xn
= a1 * x1 + a2 * x2 +... + aN * xN
Two basic operations are required for this algorithm. (1) Multiplication
(2) Addition
Therefore two basic instructions are required
Specifying Register Names
Register File A A0 A1 A2 A3 A4 a1 x1 prod Y . . .
40
Y =
n = 1
an * xn
.M .L
MPY ADD
.M .L
A0, A1, A3 A4, A3, A4
A15
32-bits
The registers A0, A1, A3 and A4 contain the values to be used by the instructions.
FFFFFFFF 16-bits
Using the Load Instructions
The syntax for the load instruction is: LD *Rn,Rm The question now is how many bytes are going to be loaded into the destination register? Data a1 x1 prod Y
an * xn
.M .?
MPY ADD
.M .?
a1, x1, prod Y, prod, Y
Add (.L unit)
40
Y =
n = 1
an * xn
.M .L
MPY ADD
.M .L
a1, x1, prod Y, prod, Y
RISC processors such as the C6000 use registers to hold the operands, so lets change this code.
A15
32-bits
Data Memory
Using the Load Instructions
Before using the load unit you have to be aware that this processor is byte addressable, which means that each byte is represented by a unique address. Also the addresses are 32-bit wide. Data
Multiply (MPY)
N
Y =
n = 1
an * xn
= a1 * x1 + a2 * x2 +... + aN * xN