决策树例题分析及解答_(1)
决策树例题分析

决策树例题分析决策树是一种常见的机器学习算法,它通过树形结构对数据进行分类和预测。
本文将基于一个例题,详细分析决策树的构建和应用过程。
例题描述:某公司想要根据客户的特征来判断他们是否会购买某个产品。
为了实现这个目标,公司收集了以下一些数据:客户的年龄、年收入和婚姻状况,以及他们最终购买与否的情况。
现要用这些数据建立一个决策树模型来预测客户是否会购买产品。
数据集准备:首先,我们需要对数据集进行准备和清洗。
将数据集划分为训练集和测试集,其中训练集用于建立决策树模型,测试集用于评估模型的性能。
然后,对于缺失值或异常值,可以根据具体情况进行处理,例如使用均值填充或删除异常样本。
特征选择:在决策树算法中,需要选择最佳的特征来构建决策树。
一个好的特征应该能够很好地区分不同类别的样本。
在本例中,我们可以使用信息增益或基尼系数作为特征选择的标准。
根据特征选择的结果,选择最佳的特征作为根节点。
决策树构建:在选择了根节点特征后,我们需要对数据集进行划分,并递归地构建决策树。
在每个节点上,根据选择的分裂特征和划分标准,将数据集分为更小的子集。
直到满足终止条件,例如节点中只包含同一类别的样本或达到了预定深度。
在构建过程中,可以使用剪枝技术来防止过拟合。
决策树预测:构建完决策树模型后,就可以用它来进行预测了。
对于一个新的样本,从根节点开始,根据节点的特征判断样本应该往哪个分支走,直到到达叶节点。
叶节点对应的类别就是预测的结果。
可以使用预测准确率、精确率、召回率等指标来评估模型的性能。
模型评估和优化:在预测的过程中,我们可以使用测试集来评估模型的性能。
根据评估结果,可以选择调整模型参数或选择其他特征,并再次训练模型。
一般来说,更好的特征和更合适的模型参数可以提高决策树的性能。
总结:决策树是一种常见而强大的分类和预测算法。
通过选择最佳特征、构建决策树和预测样本,可以实现对数据集的分类和预测。
在实际应用中,需要根据不同问题的特点选择合适的特征和模型参数,以达到更好的性能。
回归问题的决策树题目和解答

回归问题的决策树题目和解答(原创版)目录1.回归问题的决策树概述2.决策树的构建方法3.决策树在回归问题中的应用实例4.决策树的优缺点分析5.总结正文一、回归问题的决策树概述回归问题是指在给定一组输入变量和一个目标输出变量的情况下,通过构建一个数学模型来预测目标变量的值。
决策树是一种常用的回归分析方法,它通过一系列的问题对输入变量进行划分,从而得到不同的决策节点,最终得到目标变量的预测值。
二、决策树的构建方法决策树的构建过程主要包括以下步骤:1.特征选择:根据输入变量和目标变量的关系,选择一个最佳的特征进行划分。
2.决策节点:根据特征选择结果,将样本集划分为不同的子集,形成决策节点。
3.子集划分:对每个决策节点的子集,递归地重复步骤 1 和 2,直到满足停止条件。
4.叶子节点:当子集中的所有样本目标变量相同时,构建叶子节点,并返回目标变量的预测值。
三、决策树在回归问题中的应用实例假设有一个房价数据集,包含房屋面积、卧室数量、楼层等因素,目标是预测房价。
我们可以使用决策树方法,根据房屋面积、卧室数量等因素划分样本集,最终得到房价的预测值。
四、决策树的优缺点分析1.优点:(1)易于理解和实现:决策树方法简单直观,易于理解和实现。
(2)特征选择:决策树可以自动选择最优特征进行划分,有助于特征工程。
(3)泛化能力:决策树具有较强的泛化能力,能较好地处理未知数据。
2.缺点:(1)过拟合:决策树容易过拟合,导致在训练集上表现良好,但在测试集上性能下降。
(2)数据量要求高:决策树需要大量的数据进行训练,否则容易出现过拟合。
(3)剪枝策略:为了防止过拟合,需要对决策树进行剪枝,增加了计算复杂度。
五、总结决策树作为一种常用的回归分析方法,在实际应用中具有广泛的应用前景。
通过构建决策树模型,可以有效地对输入变量进行划分,从而得到目标变量的预测值。
决策树算法例题

决策树算法例题
一、决策树基本概念与原理
决策树是一种基于树结构的分类与回归模型。
它通过一系列的问题对数据进行划分,最终得到叶子节点对应的分类结果或预测值。
决策树的构建过程通常采用自上而下、递归划分的方法。
二、决策树算法实例解析
以一个简单的决策树为例,假设我们要预测一个人是否喜欢户外运动。
已知特征:性别、年龄、是否喜欢晒太阳。
可以通过以下决策树划分:
1.根据性别划分,男性为喜欢户外运动,女性为不喜欢户外运动。
2.若性别为男性,再根据年龄划分,年龄小于30分为喜欢户外运动,大于30分为不喜欢户外运动。
3.若性别为女性,无论年龄如何,均分为喜欢户外运动。
通过这个决策树,我们可以预测一个人是否喜欢户外运动。
三、决策树算法应用场景及优缺点
1.应用场景:分类问题、回归问题、关联规则挖掘等。
2.优点:易于理解、可解释性强、泛化能力较好。
3.缺点:容易过拟合、对噪声敏感、构建过程耗时较长。
四、实战演练:构建决策树解决实际问题
假设我们要预测房价,已知特征:面积、卧室数量、卫生间数量、距市中心距离。
可以通过构建决策树进行预测:
1.选择特征:根据相关性分析,选择距市中心距离作为最佳划分特征。
2.划分数据集:将数据集划分为训练集和测试集。
3.构建决策树:采用递归划分方法,自上而下构建决策树。
4.模型评估:使用测试集评估决策树模型的预测性能。
通过以上步骤,我们可以运用决策树算法解决实际问题。
决策树算法例题

决策树算法例题【原创版】目录1.决策树算法概述2.决策树算法的基本原理3.决策树算法的例题解析4.决策树算法的应用场景与优缺点正文【决策树算法概述】决策树算法是一种常见的基于特征的分类与回归方法,通过将数据集分成许多子集,每个子集对应一个决策节点,直到最终得到叶子节点为止。
这种树形结构可以用来预测新数据的分类或回归值。
【决策树算法的基本原理】决策树算法基于以下两个原则:1.信息增益:选择一个特征,使得信息增益最大,即信息熵增加,从而选择最佳特征进行分裂。
2.基尼指数:在构建分类树时,使用基尼指数来评估特征的选择,目标是最小化基尼指数,从而得到最优特征。
【决策树算法的例题解析】假设有一个数据集,包含以下几个特征:身高、体重、是否购买衬衫。
目标是预测用户是否购买衬衫。
首先,根据信息增益原则,选择身高作为最佳特征进行分裂。
将数据集按照身高分为两部分,一部分是身高小于 170 的用户,另一部分是身高大于等于 170 的用户。
然后,针对身高小于 170 的用户,再根据信息增益原则选择体重作为最佳特征进行分裂。
将这部分数据集按照体重分为两部分,一部分是体重小于 60 的用户,另一部分是体重大于等于 60 的用户。
接着,针对身高大于等于 170 的用户,再根据信息增益原则选择体重作为最佳特征进行分裂。
将这部分数据集按照体重分为两部分,一部分是体重小于 70 的用户,另一部分是体重大于等于 70 的用户。
最后,针对身高小于 170 且体重小于 60 的用户,以及身高大于等于 170 且体重大于等于 70 的用户,可以判断他们很可能不会购买衬衫。
而其他用户则可能会购买衬衫。
通过以上步骤,我们可以构建一个简单的决策树,用于预测用户是否购买衬衫。
【决策树算法的应用场景与优缺点】决策树算法广泛应用于数据挖掘、机器学习、生物信息学等领域。
其优点包括易于理解和解释、特征选择能力强等。
然而,决策树算法也存在过拟合、容易受到噪声干扰等缺点。
决策树例题(详细分析“决策树”共10张)

• 第四步:确定决策方案:在比较方案考虑的是收益值 时,那么取最大期望值;假设考虑的是损失时,那么 取最小期望值。
• 根据计算出的期望值分析,此题采取开工方案较 好。
第7页,共10页。
决策树例题
第1页,共10页。
决策树的画法
• A、先画一个方框作为出发点,又称决策节点; • B、从出发点向右引出假设干条直线,这些直线叫做方案
枝;
• C、在每个方案枝的末端画一个圆圈,这个圆圈称为 概率分叉点,或自然状态点;
• D、从自然状态点引出代表各自然状态的分枝,称 为概率分枝;
• E、如果问题只需要一级决策,那么概率分枝末端画 三角形,表示终点 。
第四步:确定决策方案:在比较方案考虑的是收益值时,那么取最大期望值;
B、从出发点向右引出假设干条直线,这些直线叫做方案枝;
天气好 0.3 根据计算出的期望值分析,此题采取开工方案较好。
假设考虑的是损失时,那么取最小期望值。 A、先画一个方框作为出发点,又称决策节点;
40000
-1000
天气坏
0.7
-10000
第8页,共10页。
【例题9】
方案 A高 A低 B高 B低
效果
优 一般 赔 优 一般 赔 优 一般 赔 优 一般 赔
可能的利润(万元)
5000 1000 -3000 4000 500 -4000 7000 2000 -3000 6000 1000 -1000
概率
0.3 0.5 0.2 0.2 0.6 0.2 0.3 0.5 0.2 0.3 0.6 0.1
决策树例题分析及解答分解课件

目录
CONTENTS
• 决策树与其他机器学习算法的比 • 决策树未来发展方向
01
决策树简 介
决策树的定义
决策树是一种监督学习算法,用于解决分类和回归问题。
它通过递归地将数据集划分成更纯的子集来构建决策树,每个内部节点表示一个 特征属性上的判断条件,每个分支代表一个可能的属性值,每个叶子节点表示一 个类别。
03
决策树例题分析
题目描述
题目
预测一个学生是否能够被大学录 取
数据集
包含学生的个人信息、成绩、活动 参与情况等
目标变量
是否被大学录取(0表示未录取,1 表示录取)
数据预处理
01
02
03
数据清洗
处理缺失值、异常值和重 复值
数据转换
将分类变量转换为虚拟变 量,将连续变量进行分箱 处理
数据归一化
将特征值缩放到0-1之间, 以便更好地进行模型训练
结果解读与优化建议
结果解读
根据模型输出的结果,分析决策树 的构建情况,理解各节点的划分依据。
优化建议
根据模型评估结果和业务需求,提出 针对性的优化建议,如调整特征选择、 调整模型参数等。
05
决策树与其他机器
学习算法的比 较
与逻辑回归的比较
总结词
逻辑回归适用于连续和二元分类问题,而决策树适用于多元分类问题。
建立决策树模型
选择合适的决策树算 法:ID3、C4.5、 CART等
构建决策树模型并进 行训练
确定决策树的深度和 分裂准则
模型评估与优化
使用准确率、召回率、F1分数等指标 评估模型性能
对模型进行优化:剪枝、调整参数等
进行交叉验证,评估模型的泛化能力
决策树例题分析及解答_(1)
状
益损值 态
方案
需求 需求 量较 量一
高般
甲
600 400
乙
800 350
丙
350 220
丁
400 250
需求 量较
低
-150
-350
50
需求量 很低
max
min
-350 -700 -100
600 -350 800 -700 350 -100
a=0.7
315 350 215
90 -50 400 -50 265
自然状态 概率 建大厂(投资25 建小厂(投资10
万元)
万元)
原料800担 0.8 原料2000担 0.2
13.5 25.5
15.0 15.0
4
补充: 风险型决策方法——决策树方法
• 风险决策问题的直观表示方法的图示法。因为图的形状 像树,所以被称为决策树。
• 决策树的结构如下图所示。图中的方块代表决策节点, 从它引出的分枝叫方案分枝。每条分枝代表一个方案, 分枝数就是可能的相当方案数。圆圈代表方案的节点, 从它引出的概率分枝,每条概率分枝上标明了自然状态 及其发生的概率。概率分枝数反映了该方案面对的可能 的状态数。末端的三角形叫结果点,注有各方案在相应 状态下的结果值。
600×0.7+(--350 ×0.3)=315
28
决策准则小结
不同决策者甚至同一决策者在不同决 策环境下对同一个问题的决策可能截 然不同,并没有所谓的“正确答案” 。决策准则的选取主要取决于决策者 对于决策的性格和态度,以及制定决 策时的环境
所有的准则都不能保证所选择的方案 在实际情况发生时会成为最佳方案
• 试用决策树法选出合理的决策方案。 经过市场调查, 市场销路好的概率为0.7,销路不好的概率为0.3。
决策树案例及答案

案例:假设有一工程项目,管理人员要根据天气状况决定开工方案。
如果开工后天气好,可以给国家创收30000元;如果开工后天气差,将给国家带来损失10000元;如果不开工,讲给国家带来损失1000元,。
已知开工后天气好的概率是0.6,开工后天气差的概率是0.4.请用
决策树方案进行决策。
状方、、态案天气好天气坏
0.60.4
开工30000 (期望收益=30000*0.6 )-10000 (期望收益=-10000*0.4 )爪开工-1000 (期望收益=-1000*0.6 )-1000 (期望收益=-1000*0.4 )第二步,绘制决策树
(1) 计算期望收益并标注在决策树上
开工方案下,预期收益值=30000*0.6+ (-10000) *0.4=14000
不开工方案下,预期损失值=-1000
(2) 比较两个方案并减去期望收益较小的方案枝
30000*0. 6
概率枝-10000*0-4
-1000*0.6
-1 000*0.4
概率枝▲18000 .▲-4000▲-600
A-400。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
h
5
状态节点
2 方案分枝
1 决策结点
方案分枝
3
状态节点
概率分枝 4 结果节点
概率分枝 5 结果节点
概率分枝 6
结果节点
概率分枝 7
结果节点
h
6
• 应用决策树来作决策的过程,是从右向 左逐步后退进行分析。根据右端的损益
值和概率枝的概率,计算出期望值的大
小,确定方案的期望结果,然后根据不 同方案的期望结果作出选择。
h
9
决策过程如下:画图,即绘制决策树
• A1的净收益值=[300×0.7+(-60)×0.3] ×5-450=510万 • A2的净收益值=(120×0.7+30×0.3)×5-240=225万 • 选择:因为A1大于A2,所以选择A1方案。 • 剪枝:在A2方案枝上打杠,表明舍弃。
h
10
例题
• 为了适应市场的需要,某地提出了扩大电视机生产的 两个方案。一个方案是建设大工厂,第二个方案是建 设小工厂。
h
11
680万元 2
建大厂
销路好(0.7) 销路差(0.3)
200万元 -40万元
1 719万元
建小厂
扩建 5 销路好(0.7) 930万元
销路好(0.7) 4 不扩建
930万元
6 销路好(0.7)
3
560万元
719万元
销路差(0.3)
前3年,第一次决策
后7年,第二次决策h Nhomakorabea190万元
80万元 60万元
• 建设大工厂需要投资600万元,可使用10年。销路好 每年赢利200万元,销路不好则亏损40万元。
• 建设小工厂投资280万元,如销路好,3年后扩建,扩 建需要投资400万元,可使用7年,每年赢利190万元。 不扩建则每年赢利80万元。如销路不好则每年赢利60 万元。
• 试用决策树法选出合理的决策方案。 经过市场调查, 市场销路好的概率为0.7,销路不好的概率为0.3。
h
7
• 计算完毕后,开始对决策树进行剪枝, 在每个决策结点删去除了最高期望值以 外的其他所有分枝,最后步步推进到第 一个决策结点,这时就找到了问题的最 佳方案
• 方案的舍弃叫做修枝,被舍弃的方案用 “≠”的记号来表示,最后的决策点留下 一条树枝,即为最优方案。
h
8
• A1、A2两方案投资分别为450万和240 万,经营年限为5年,销路好的概率为 0.7,销路差的概率为0.3,A1方案销 路好、差年损益值分别为300万和负60 万;A2方案分别为120万和30万。
➢ 把点⑤的930万元移到点4来,可计算出点③的期望利 润值:
• 点③:0.7×80×3+0.7×930+0.3×60×(3+7)-280 = 719(万元)
h
13
➢最后比较决策点1的情况:
• 由于点③(719万元)与点②(680万元) 相比,点③的期望利润值较大,因此取 点③而舍点②。这样,相比之下,建设 大工厂的方案不是最优方案,合理的策 略应采用前3年建小工厂,如销路好,后 7年进行扩建的方案。
玉米 棉花 花生
忙季需 工作日数
60 105 45
灌水需要量 (立方米)
2250 2250 750
产量 (公斤)
8250 750 1500
利润 (元)
1500 1800 1650
h
1
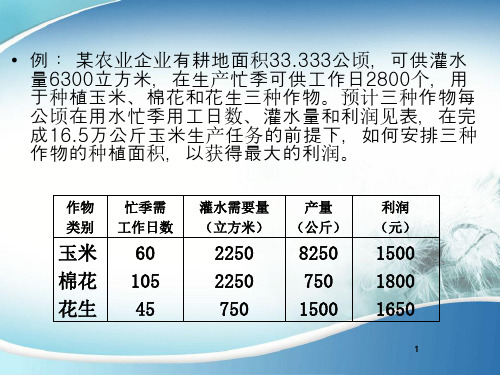
解:玉米、棉花、花生和种植面积分别为X1,X2,X3公顷,依 题意列出线性规划模型。
目标函数:S=1500X1+1800X2+1650X3——极大值 约束条件:X1+X2+X3≤33.333 60X1+105X2+45X3≤2800 2250X1+2250X2+750X3≤63000 8250X1≤165000 X1,X2,X3≥0 采用单纯形法求出决策变量值:
• 例: 某农业企业有耕地面积33.333公顷,可供灌水量 6300立方米,在生产忙季可供工作日2800个,用于 种植玉米、棉花和花生三种作物。预计三种作物每公 顷在用水忙季用工日数、灌水量和利润见表,在完成 16.5万公斤玉米生产任务的前提下,如何安排三种作 物的种植面积,以获得最大的利润。
作物 类别
自然状态 概率 建大厂(投资25 建小厂(投资10
万元)
万元)
原料800担 0.8 原料2000担 0.2
13.5 25.5
15.0 15.0
h
4
补充: 风险型决策方法——决策树方法
• 风险决策问题的直观表示方法的图示法。因为图的形状 像树,所以被称为决策树。
• 决策树的结构如下图所示。图中的方块代表决策节点, 从它引出的分枝叫方案分枝。每条分枝代表一个方案, 分枝数就是可能的相当方案数。圆圈代表方案的节点, 从它引出的概率分枝,每条概率分枝上标明了自然状态 及其发生的概率。概率分枝数反映了该方案面对的可能 的状态数。末端的三角形叫结果点,注有各方案在相应 状态下的结果值。
12
➢ 计算各点的期望值:
• 点②:0.7×200×10+0.3×(-40)×10-600(投资) =680(万元)
• 点⑤:1.0×190×7-400=930(万元)
• 点⑥:1.0×80×7=560(万元)
➢ 比较决策点4的情况可以看到,由于点⑤(930万元) 与点⑥(560万元)相比,点⑤的期望利润值较大, 因此应采用扩建的方案,而舍弃不扩建的方案。
X1=20公顷 X2=5.333公顷 X3=8公顷
h
2
决策方案评价
作物类别
玉米 棉花 花生 合计 资源供给量 资源余缺量
占用耕 忙季耗用 灌水用量 地面积 工日数 (立方米) (公顷)
20
1200
45000
5.333
560
12000
8
360
6000
33.333
2120
63000
33.333
2800
63000
0
680
0
总产量 (千瓦)
165000 40000
120000
利润量 (元)
30000 9600
13200 52800
在生产出16.5万公顷玉米的前提下,将获得 5.28万元的利润,在忙劳动力资源尚剩余680 个工日可用于其他产品生产。
h
3
例 : 设某茶厂计划创建精制茶厂,开始有两个方案,方案 一是建年加工能力为800担的小厂,方案二是建年加工能 力为2000担的大厂。两个厂的使用期均为10年,大厂投 资25万元,小厂投资10万元。产品销路没有问题,原料来 源有两种可能(两种自然状态):一种为800担,另一种为 2000担。两个方案每年损益及两种自然状态的概率估计值 见下表
h
14
决策树法的一般程序是: (1)画出决策树图形 决策树指的是某个决策问题未来发展情 况的可能性和可能结果所做的估计,在图纸上的描绘决策树 (2)计算效益期望值 两个行动方案的效益期望值计算过程: 行动方案A1(建大厂)的效益期望值: 13.5×0.8×10+25.5×0.2×10-25=134万元 行动方案A2(建小厂)的效益期望值: 15×0.8×10+15×0.2×10-10=140万元 (3)将效益期望值填入决策树图 首先在每个结果点后面填上 相应的效益期望值;其次在每个方案节点上填上相应的期望值, 最后将期望值的角色分支删减掉。只留下期望值最大的决策分 支,并将此数值填入决策点上面,至此决策方案也就相应选出