Linux-C-网卡抓包程序的实现
CDlinux抓取WPA握手包方法

CDlinux抓取WPA握手包方法
1、下载完CDlinux-0.9.6.1-se-wireless.iso 镜像文件后如果下图所示点开中文虚拟机或
无线路由检测工具
上图所示:1、打开虚拟机点击如图CD-ROM双击鼠标后跳出2
2、如图跳出窗口选择:使用ISM镜像内打点
3、点击浏览后制定路径:之前下载的CDLinux-0-9-6镜像包位置
上图所:1、点击播放后自动进入右图界面
2、记得加载网卡哦虚拟机-可移动设备-USB设备-鼠标左键点击RELTEK USB
3、加载网卡后点击桌面上蓝色图标minidwep-gtk文件
2、自动跳出提示窗口点击OK键
1、进入软件界面后-点击选项选择WPA/WPA2
2、点击选项选择注入速率:800
3、点击扫描扫描WPA/WPA2加密无线路由
2、点击启动键开始抓包
如下图所示开始抓取握手包模式
1、获取握手包后点击提示窗口NO
2、点击OK后自动跳出握手包位置
握手包寻找如下图所示:
1、查询字典位置-点击桌面蓝色图标-Home后自动跳出窗口
2、鼠标左键点击系统文件
3、点击系统文件内的tmp文件包
1、无线路由器WPA握手包文件-现在插移动U盘拷贝握手包-导出数据包
1、插入U盘后自动跳出窗口鼠标左键点击握手包然后点-复制
插入U盘U盘自动跳出从抓包工具中导出WPA握手包
2、自动跳出窗口点击-GENEAL USB FLASH DISK 安全拆除U盘。
抓包教程
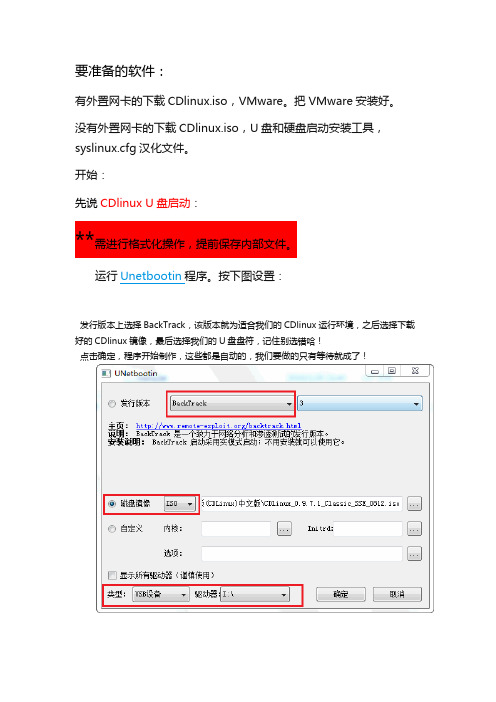
要准备的软件:有外置网卡的下载CDlinux.iso,VMware。
把VMware安装好。
没有外置网卡的下载CDlinux.iso,U盘和硬盘启动安装工具,syslinux.cfg汉化文件。
开始:先说CDlinux U盘启动:**需进行格式化操作,提前保存内部文件。
运行Unetbootin程序。
按下图设置:发行版本上选择BackTrack,该版本就为适合我们的CDlinux运行环境,之后选择下载好的CDlinux镜像,最后选择我们的U盘盘符,记住别选错哈!点击确定,程序开始制作,这些都是自动的,我们要做的只有等待就成了!制作完成后,会提示重启,这里我们点退出。
暂不重启。
2、中文语言设置这点做成后启动的时候让我头疼了下,因为源镜像是多国语言的,经过上面的工作做完后自动进入了英语,跳过了选择项,所以我们需要设置下。
设置方法很简单。
打开刚刚做好的U盘,找到下图syslinux.cfg文件,用记事本打开,将原有代码删除替换为红框内的。
附件会提供文件下载,到时大家直接覆盖即可!有外置网卡的:无外置网卡的朋友请直接跳过这一步下面说下有外置无线网卡的朋友该怎样不做U盘的情况下来安装镜像:首先我们需要一个虚拟机,安装完成后打开,点击‘创建新的虚拟机’,下一步下一步,这里选“稍后安装操作系统”,然后一直下一步到完成点击“编辑此虚拟机“选择“CD/DVD(SATA) “,选择”使用ISO映像文件“,点击”浏览“选择我们的CDlinux.iso文件,然后”确定“就可以开启破解系统了现在我们开始抓包让没有外置网卡的朋友久等了。
我们将制作好的U盘插入电脑,修改bios为U盘启动(或者按F12选择U盘启动,按键根据电脑而定):双击文件名为“minidwep-gtk”程序:每次运行都会弹出一个提示窗口:上面的说明,大家都懂的!切勿用于非法用户。
下面详细介绍下该工具的主界面:1)无线网卡 wlan0。
这里显示自己的无线网卡信息。
抓包工具的使用流程

抓包工具的使用流程什么是抓包工具抓包工具是一种网络分析工具,用于捕获和分析网络数据包。
通过抓包工具,用户可以查看和分析网络流量,从而帮助用户诊断和解决网络问题。
抓包工具的分类抓包工具按照使用方式和操作系统的不同可以分为以下几类: - 命令行工具:如Tcpdump、Tshark等,适用于Linux和Unix系统,可以通过命令行参数指定抓包的参数和过滤规则。
- 图形界面工具:如Wireshark、Fiddler等,适用于Windows、MacOS和Linux系统,提供用户友好的图形界面,方便用户进行抓包操作。
- 代理工具:如Burp Suite、Charles等,适用于Web应用程序的抓包,可以拦截和修改HTTP和HTTPS请求。
- 多协议支持工具:如Snort、Suricata等,适用于多种协议的抓包和分析,可以用于网络入侵检测和入侵防御等领域。
抓包工具的使用流程使用抓包工具进行网络分析一般包括以下几个步骤:步骤一:安装抓包工具根据操作系统的不同,选择对应的抓包工具,并进行下载和安装。
可以从官方网站或软件源进行安装,也可以选择独立安装包进行安装。
步骤二:打开抓包工具打开已安装的抓包工具,对于图形界面工具,可以直接在桌面或启动菜单中找到并点击打开。
对于命令行工具,可以通过终端或命令行界面来打开。
步骤三:设置抓包过滤规则抓包工具通常提供过滤规则功能,用户可以根据需要设置过滤规则,以便只捕获需要的网络数据包。
过滤规则通常包括协议类型、源IP地址、目的IP地址、端口号等参数。
步骤四:开始抓包在设置好过滤规则后,可以开始抓包操作。
对于图形界面工具,可以点击。
linux wireshark使用方法

linux wireshark使用方法# Linux Wireshark 使用方法Wireshark 是一个强大的网络协议分析工具,它在Linux 系统上得到广泛应用。
本文将介绍如何在 Linux 系统上安装和使用 Wireshark。
## 1. 安装 Wireshark在大多数常见的 Linux 发行版中,Wireshark 都可以通过包管理器进行安装。
以下是几个常见的发行版的安装命令:- Ubuntu/Debian:```sudo apt-get install wireshark```- Fedora/CentOS:```sudo dnf install wireshark```- Arch Linux:```sudo pacman -S wireshark```安装过程可能需要输入管理员密码,根据提示进行操作即可。
## 2. 配置 Wireshark 权限Wireshark 需要以 root 权限运行才能够监听网络接口。
为了避免直接使用 root用户运行 Wireshark,我们可以通过配置允许非特权用户捕获数据包的方法。
运行以下命令来配置:```sudo dpkg-reconfigure wireshark-common```在弹出的对话框中选择“是”,然后在下一个对话框中选择“确定”。
这将允许非特权用户进行数据包捕获。
## 3. 打开 Wireshark在命令行中运行以下命令来打开 Wireshark:```wireshark```Wireshark 将以图形界面的形式打开。
## 4. 选择网络接口在Wireshark 的界面中,可以看到一个网络接口列表。
选择要监听的网络接口,例如以太网或 Wi-Fi 接口。
点击该接口,然后点击“开始”按钮开始监控该接口上的网络流量。
## 5. 分析数据包一旦开始监控网络接口,Wireshark 将开始捕获数据包。
你将看到实时交换的网络流量。
你可以使用 Wireshark 的过滤器功能来仅显示感兴趣的数据包,以便更好地分析。
Linux命令高级技巧使用tcpdump进行网络抓包

Linux命令高级技巧使用tcpdump进行网络抓包TCPDump是一种常用的网络抓包工具,可以在Linux系统中使用。
它可以捕获网络数据包,并提供详细的分析和监测功能。
本文将介绍一些高级技巧,帮助您更好地使用tcpdump工具进行网络抓包。
1. 安装和基本使用要使用tcpdump,首先需要在Linux系统上安装它。
在终端中输入以下命令来安装tcpdump:```sudo apt-get install tcpdump```安装完成后,输入以下命令来开始抓包:```sudo tcpdump -i <interface>```其中,<interface>是要抓取网络流量的网络接口,如eth0或wlan0。
2. 抓取指定端口的数据包有时候,我们只对某个特定端口的网络流量感兴趣。
您可以使用以下命令来抓取指定端口的数据包:```sudo tcpdump -i <interface> port <port_number>```其中,<port_number>是您感兴趣的端口号。
3. 根据源IP或目标IP过滤数据包如果您只想抓取特定源IP或目标IP的数据包,可以使用以下命令进行过滤:```sudo tcpdump -i <interface> src <source_IP>```或```sudo tcpdump -i <interface> dst <destination_IP>```其中,<source_IP>是源IP地址,<destination_IP>是目标IP地址。
4. 保存抓包结果为文件您可以将抓到的数据包保存到文件中,以便稍后分析。
使用以下命令将数据包保存到文件:```sudo tcpdump -i <interface> -w <output_file>```其中,<output_file>是保存数据包的文件名。
小议Linux系统下如何实现抓包

一般我们都能够通过一些好的抓包工具,在windows操作系统下进行抓包分析,这些工具很多,常见的有sniffer、wireshark等。
但是在linux环境下,特别是在远程支持的时候,只能通过如SSH工具远程连到linux服务器上进行问题分析,一旦涉及到需要抓包分析的时候,就特别麻烦,因为远程连上去的都是文本界面。
下面就linux下常用的抓包及分析方法进行介绍,并介绍一种非常实用的方法。
在Linux操作系统下,常见的抓包工具有tcpdump 和wireshark。
1、Tcpdumptcpdump采用命令行方式,它的命令格式为:tcpdump [ -adeflnNOpqStvx ] [ -c 数量] [ -F 文件名][ -i 网络接口] [ -r 文件名] [ -s snaplen ][ -T 类型] [ -w 文件名] [表达式]1.1 tcpdump的选项介绍-a 将网络地址和广播地址转变成名字;-d 将匹配信息包的代码以人们能够理解的汇编格式给出;-dd 将匹配信息包的代码以c语言程序段的格式给出;-ddd 将匹配信息包的代码以十进制的形式给出;-e 在输出行打印出数据链路层的头部信息;-f 将外部的Internet地址以数字的形式打印出来;-l 使标准输出变为缓冲行形式;-n 不把网络地址转换成名字;-t 在输出的每一行不打印时间戳;-v 输出一个稍微详细的信息,例如在ip包中可以包括ttl和服务类型的信息;-vv 输出详细的报文信息;-c 在收到指定的包的数目后,tcpdump就会停止;-F 从指定的文件中读取表达式,忽略其它的表达式;-i 指定监听的网络接口;-r 从指定的文件中读取包(这些包一般通过-w选项产生);-w 直接将包写入文件中,并不分析和打印出来;-s 每一包的最大字节数,默认是96个字节;-T 将监听到的包直接解释为指定的类型的报文,常见的类型有rpc(远程过程调用)和snmp(简单网络管理协议;)1.2. tcpdump的表达式介绍表达式是一个正则表达式,tcpdump利用它作为过滤报文的条件,如果一个报文满足表达式的条件,则这个报文将会被捕获。
linux(Red Hat)抓包及ethereal抓包工具的使用方法

linux抓包及ethereal抓包工具的使用方法1.Linux抓包(1)一般抓包命令tcpdump -s0 -c 包数量-i 网卡名-w 文件名其中:-s0表示应用层的size不受限制,用于详细分析。
否则将被截断,即应用层消息可能不完整)-c 包数量到达某个数量后自动停止抓包,防止文件太大-i 只抓某个网卡的消息,不抓其他网卡的消息-w抓到的消息自动存入文件中,但消息不再在显示器上显示了例:tcpdump -s0 –c 10000 -i eth0 -w /tmp/1.cap抓取本机eth0网卡上所有进出的消息,且应用层的消息是完整的,并存入/tmp目录下的1.cap文件(.cap是ethereal消息包文件的后缀名),如果在抓包过程中用户不使用ctrl+c来中断的话,抓到10000条消息后自动停止抓包。
如果中途被中断,文件中存放的是中断之前的消息。
(2)指定交互双方的抓包命令tcpdump host 192.168.0.2 and 192.168.0.3 –s0 –w /tmp/2-3.cap只抓这2台主机之间交互的消息,其它消息被过滤掉。
由于ethereal工具功能强大,所以尽管tcpdump命令有许多参数可以达到许多过滤条件,但把这些事交给ethereal来做,我们就更省力。
2.ethereal抓包工具的使用方法把xxx.cap文件下载后,就可以使用ethereal工具来分析了。
当然也可在linux 机器上直接使用ethereal来抓包(需要安装rpm)而不用使用tcpdump命令。
现在介绍的是在windows电脑上启动ethereal程序,见下图:选择菜单“file”-open选择消息包文件:打开:选择菜单“statistics”-conversation list-tcp通过对IP地址的排序找到所关心的一次交互过程,在该条目上使用右键:该次交互过程中的所有消息便显示出来,可以认真分析了。
linux c 抓取二层数据的方法

linux c 抓取二层数据的方法Linux下使用C语言抓取二层数据的方法一、引言在网络通信中,二层数据是指以太网帧中的数据部分,也是我们在网络抓包分析中最常接触到的数据。
本文将介绍如何使用C语言在Linux系统下抓取二层数据的方法。
二、准备工作在开始编写代码之前,我们需要先安装libpcap库,该库提供了一组用于网络抓包的API函数。
在Ubuntu系统下,可以使用以下命令进行安装:```sudo apt-get install libpcap-dev```三、编程实现1. 包含头文件我们需要包含pcap.h头文件,该头文件定义了libpcap库中的函数和数据结构。
```c#include <pcap.h>```2. 打开网络接口使用pcap_open_live()函数打开网络接口,该函数接受三个参数:网络接口名、数据包最大长度和是否设置为混杂模式。
```cchar *dev = "eth0"; // 网络接口名pcap_t *handle;char errbuf[PCAP_ERRBUF_SIZE];handle = pcap_open_live(dev, BUFSIZ, 1, 1000, errbuf);if (handle == NULL) {fprintf(stderr, "Couldn't open device %s: %s\n", dev, errbuf); return 2;}```3. 设置过滤器可以使用pcap_compile()和pcap_setfilter()函数设置过滤器,以便只捕获我们感兴趣的数据包。
```cstruct bpf_program fp;char filter_exp[] = "tcp port 80"; // 过滤器表达式bpf_u_int32 net;if (pcap_compile(handle, &fp, filter_exp, 0, net) == -1) {fprintf(stderr, "Couldn't parse filter %s: %s\n", filter_exp, pcap_geterr(handle));return 2;}if (pcap_setfilter(handle, &fp) == -1) {fprintf(stderr, "Couldn't install filter %s: %s\n", filter_exp, pcap_geterr(handle));return 2;}```4. 抓取数据包使用pcap_loop()函数循环捕获数据包,可以在回调函数中对数据包进行处理。
Linux下编写网络抓包程序

以下实例代码实现捕获并显示 3 个 ARP 包 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <pcap.h>
pcap_loop(descr, 3, ProcessPacket, (u_char *)&count);
华清远见嵌入式学院:
return 0; }
资源分享:
1、华清远见精品图书专区:
/FarsightBooks/home.html
printf("%02x ", (unsigned int)packet[i]);
if ( (i%16 = = 15 && i != 0) || (i = = pkthdr->len -1)) {
printf("\n"); } } printf("\n\n************************************************\n"); return; }
华清远见嵌入式学院:
ห้องสมุดไป่ตู้
华清远见嵌入式学院:
int pcap_compile(pcap_t *p, struct bpf_program *fp, char *str, int optimize, bpf_u_int32 netmask); 功能:创建过滤器 p :接口描述符 fp:指向保存过滤器的结构体的指针 str:要转化的过滤规则 optimize: 过滤器是否要优化 netmask:网络掩码 返回值:成功时返回 0;出错时返回-1
linux wireshark使用方法

linux wireshark使用方法Wireshark是一款功能强大的网络协议分析工具,可以用于监视和分析网络流量。
它在Linux系统上的使用方法与其他操作系统类似,但在安装和配置方面可能有所不同。
下面是一份关于Linux上Wireshark的简要使用方法参考内容:首先,使用以下命令在Linux系统上安装Wireshark:```sudo apt-get updatesudo apt-get install wireshark```安装完成后,需要以root权限或具有特定用户组权限的用户来运行Wireshark。
可以通过以下命令将Wireshark添加到用户组:```sudo usermod -aG wireshark $USER```然后,需要在Linux上配置网络接口以允许Wireshark进行数据包捕获。
可以使用以下命令来查看可用的网络接口:```ifconfig -a```选择要监视的网络接口,然后使用以下命令将其设置为“promisc”模式:```sudo ifconfig [interface name] promisc```接下来,可以通过以下命令以图形界面启动Wireshark:```wireshark```启动Wireshark后,可以看到一个主要的捕获窗口,用于显示捕获到的数据包。
可以选择要捕获的特定接口,也可以使用“Capture Options”菜单进行进一步的配置。
在捕获过程中,可以通过点击红色的圆形按钮或选择“Capture”菜单中的“Start”选项开始捕获数据包。
捕获的数据包将会在主窗口中以列表形式显示,并且可以通过点击每个数据包来查看详细信息。
此外,Wireshark还提供了一些过滤器,用于对捕获的数据包进行筛选。
用户可以使用显示过滤器和捕获过滤器来仅显示感兴趣的数据包。
可以使用菜单栏中的“Filter”选项来进行设置。
有了捕获的数据包,用户可以进行各种分析操作。
抓包操作流程

抓包操作流程抓包操作流程是网络分析和网络故障排查中必不可少的一环,在网络管理员、网络安全专业人员、开发人员等领域具有广泛的应用。
本文将从以下三个方面介绍抓包操作流程——第一、准备工作1.1、安装抓包软件:需要安装类似Wireshark、tcpdump、Fiddler等抓包软件,这些软件都是开源、免费的。
1.2、了解所监控的网络环境,包括网络拓扑、网络设备的配置等信息,这可以帮助我们更好的分析和理解网络流量。
1.3、根据需要,配置好抓包软件的过滤器,过滤掉那些不需要的数据包,提高流量质量。
第二、开始抓包2.1、启动抓包软件,并开始进行抓包操作。
一般情况下,我们都需要知道所关注的设备或IP地址,以及设备或IP地址与其他设备或IP地址之间的通信流程。
为了实现这一目标,我们可以通过设置过滤器,只抓取满足条件的数据包,如以下三个过滤器:tcp.port == 80:仅抓取TCP协议下端口为80的数据包,一般情况下它是用来传输HTTP协议的数据。
ip.src == 10.0.0.1:仅抓取来源IP地址为10.0.0.1的数据包,通过这个过滤器可以查看该IP地址与其他设备之间的通信流程。
2.2、停止抓包并保存数据。
在已经完成了必要的抓包操作后,我们需要停止抓包,并将抓取下来的数据保存到本地,以便我们后期的分析和处理。
第三、数据分析3.1、打开抓包软件中已经保存的数据文件,进入数据分析模式。
3.2、清晰地展示数据包的详细信息,如协议、源地址、目的地址、源端口、目标端口、数据长度等信息,以便我们在学习分析时进行参考。
3.3、跟踪数据包的传输流程,在网络环境中分析数据的各种代表性事件,如连接、请求、回复、响应等事件,以便我们更好地理解和分析故障原因。
3.4、综合分析,利用各种分析工具对数据进行统计和分析,以便我们更好地分析数据的其他特征,如分析三次握手流程、分析传输性能等等。
3.5、通过分析得到的数据,我们可以更好地了解网络端到端性能,以便监控和诊断网络故障。
抓包的操作流程

抓包的操作流程
抓包是网络分析的重要工具之一,可以用来查看网络传输过程中的数据包信息。
下面是抓包的操作流程:
1. 准备工作:安装抓包工具,例如Wireshark,在打开抓包工具前,最好关闭其他网络应用程序,以免干扰抓包。
2. 选择网卡:在抓包工具中选择要抓包的网卡,如果有多个网卡,需要选择正确的网卡。
3. 过滤数据包:通过设置过滤器,只捕捉需要的数据包,避免捕捉到无用的数据包,从而节省空间和分析时间。
4. 开始抓包:点击“开始抓包”按钮,等待一段时间,让抓包工具收集足够多的数据包。
5. 分析数据包:在抓包过程中,可以实时查看抓到的数据包,也可以保存数据包以便后续分析。
分析数据包时,需要了解协议格式和具体的网络应用程序。
6. 结束抓包:在分析完数据包后,可以停止抓包。
如果抓包过程中产生了大量数据包,需要及时清理数据包,以免影响系统性能。
7. 总结分析结果:分析数据包后,需要总结分析结果,得出结论,并根据需要采取相应的措施,从而改善网络性能和安全。
- 1 -。
linux_pcap实现原理_概述及解释说明

linux pcap实现原理概述及解释说明1. 引言1.1 概述引言部分的目的是为读者提供对后续内容的整体了解。
本文将从概念、工作原理、应用案例等多个方面探讨Linux pcap实现原理。
通过深入研究pcap在Linux 系统中的应用,并结合实际案例,展示它在网络流量分析和安全领域的重要性。
1.2 文章结构本文分为五个主要部分:引言、Linux pcap实现原理概述、pcap数据包捕获过程解释、pcap实现原理的实际应用案例分析以及结论与展望。
每个部分都围绕着特定主题展开,逐步深入介绍和讨论相关内容。
1.3 目的本文旨在系统概述和解释Linux pcap实现原理,帮助读者全面了解pcap技术在网络数据包捕获和分析中的重要作用。
通过对pcap工作原理和应用案例的探究,读者能够深入理解其功能和特点,并有助于进一步研究和应用该技术。
以上是《linux pcap实现原理概述及解释说明》文章中“1. 引言”部分内容的详细清晰描述。
2. Linux pcap实现原理概述2.1 pcap概念和作用PCAP(Packet Capture)是一种在计算机网络中进行数据包捕获的技术。
它可以实时获取网络上的数据包,并将其存储在文件中供进一步分析和处理。
PCAP 主要用于网络分析、协议研究、安全监测等领域。
2.2 pcap的工作原理PCAP工作原理主要涉及两个重要组件:内核模块和用户态库。
在Linux系统中,内核模块负责从网络接口处获取数据包,并将其传递给用户态库进行处理。
具体来说,当一个数据包从物理网卡到达内核后,内核会通过驱动程序将数据包复制到内核缓冲区。
然后,内核会通知用户态应用程序(通过信号、文件描述符或其他方式)有新的数据包到达。
用户态应用程序通过调用pcap库函数,以合适的方式获取内核缓冲区中的数据包。
这些函数可能是阻塞式或非阻塞式的,具体取决于应用程序的需求。
2.3 pcap在Linux系统中的应用PCAP广泛应用于Linux系统下对网络流量进行捕获和分析的场景。
linux常用抓包命令

linux常用抓包命令在Linux系统中,抓包是网络诊断和分析的常见操作。
以下是一些常用的Linux抓包命令:1. tcpdump:一款常用的网络抓包工具,可以捕获和显示网络数据包。
例如:`sudo tcpdump -i eth0`,其中`eth0`是网络接口。
2. wireshark:图形界面抓包工具,功能强大,可以以图形方式显示抓取的数据包。
可以使用命令`wireshark`或者`sudo wireshark`来启动。
3. tshark:Wireshark的命令行版本,可以在没有图形界面的情况下进行抓包分析。
例如:`tshark -i eth0`。
4. tcpflow:根据TCP连接抓取数据流,更方便分析通信内容。
例如:`sudo tcpflow -c -i eth0`。
5. ngrep:类似于grep的网络抓包工具,可以根据正则表达式搜索网络数据。
例如:`sudo ngrep -q 'GET|POST' port 80`。
6. dumpcap:Wireshark的命令行抓包工具,可以捕获数据包并保存为pcap文件。
例如:`sudo dumpcap -i eth0 -w capture.pcap`。
7. ss:显示当前网络套接字信息,可以用于查看网络连接状态。
例如:`ss -tuln`。
8. netstat:显示网络连接、路由、接口信息。
例如:`netstat -tuln`。
9. dstat:显示实时系统资源使用情况,包括网络流量。
例如:`dstat -n`。
10. iftop:实时监控网络流量,显示当前连接的带宽使用情况。
例如:`sudo iftop -i eth0`。
这些命令可以帮助您在Linux系统中抓包并分析网络数据,用于网络故障排除、安全审计等。
请注意,在使用这些命令时,需要有足够的权限,有些命令可能需要以超级用户权限(使用`sudo`)运行。
linux抓包方法

linux抓包方法
在Linux系统中,有多种工具可以用来抓包,以下是其中常用
的几种方法:
1. tcpdump:这是一个命令行工具,可以捕获网络数据包并将
其输出到终端窗口。
使用tcpdump时,可以指定要抓取的网络接口、抓取的数据包数量和过滤条件等选项。
2. Wireshark:Wireshark是一个功能强大的网络协议分析工具,可以在图形界面下捕获和分析网络数据包。
Wireshark可以显
示抓取到的数据包的详细信息,包括源IP地址、目标IP地址、协议类型、数据长度等。
3. tshark:tshark是Wireshark的命令行版本,与Wireshark具
有相似的功能,可以用来捕获和分析网络数据包。
tshark可以
以不同的格式输出抓包数据,如文本、CSV、JSON等。
4. ngrep:ngrep是一个强大的网络数据包搜索工具,可以根据
指定的正则表达式搜索网络数据包,并将匹配的数据包输出到终端。
ngrep支持TCP、UDP和ICMP等协议。
这些工具在Linux系统中都可以通过包管理器(如apt、yum 等)进行安装。
根据具体需要,选择适合自己的工具来进行抓包操作。
使用tcpdump命令在Linux中抓取指定端口的网络数据包

使用tcpdump命令在Linux中抓取指定端口的网络数据包在Linux中使用tcpdump命令抓取指定端口的网络数据包在网络通信中,数据包的抓取和分析是非常重要的,它能帮助我们了解网络流量、问题排查、安全性分析等方面的情况。
在Linux系统中,我们可以使用tcpdump命令来实现抓取指定端口的网络数据包。
本文将介绍如何使用tcpdump命令在Linux系统中抓取指定端口的网络数据包。
一、什么是tcpdump命令tcpdump是一个在Unix和Linux系统下的用于抓取网络数据包的命令行工具。
它能够监听网络接口上的网络流量,并将数据包内容以及相关的信息进行输出。
tcpdump命令可以根据用户的需求,对网络数据包进行过滤、解析和保存。
二、安装tcpdump在开始使用tcpdump之前,我们需要先确保系统已经安装了该命令。
可以通过以下命令来检查是否已经安装了tcpdump:```$ tcpdump -h```如果系统没有安装tcpdump,可以使用以下命令来安装:```$ sudo apt-get install tcpdump```三、tcpdump命令的基本用法tcpdump命令的基本语法如下:```$ tcpdump [选项] [表达式]```其中,选项用于指定tcpdump命令的具体行为,而表达式用于过滤所抓取的网络数据包。
下面介绍一些常用的选项和表达式:1. 选项- -i:指定网络接口,如eth0、wlan0等。
- -c:指定抓取数据包的数量。
- -v:输出详细的数据包信息。
- -X:以16进制和ASCII格式显示数据包内容。
2. 表达式- host:按照主机进行过滤,如host 192.168.0.1。
- port:按照端口进行过滤,如port 80。
- src/dst:按照源地址或目的地址进行过滤,如src 192.168.0.1或dst 192.168.0.2。
- and/or/not:用于进行逻辑运算,如host 192.168.0.1 and port 80。
基于Linux C实现的网卡抓包程序

/* 绑定物理网卡 */ stLocal.sll_family = PF_PACKET; stLocal.sll_ifindex = stIf.ifr_ifindex; stLocal.sll_protocol = htons(ETH_P_ALL); iRet = bind(fd, (struct sockaddr *)&stLocal, sizeof(stLocal)); if (0 > iRet) {
/* 输出MAC地址 */ static void ethdump_showMac(const int iType, const char acHWAddr[]) {
int i = 0;
if (0 == iType) {
printf("SMAC=["); } e ls e {
printf("DMAC=["); }
return 0; }
/* 获取L2帧封装的协议类型 */ static char *ethdump_getProName(const int iProNum) {
int iIndex = 0;
for(iIndex = 0; iIndex < sizeof(g_iEthProId) / sizeof(g_iEthProId[0]); iInd e x++)
0.基础知识 在Linux环境下,可以使用raw socket,即原始套接字,接收本机网卡上的数据帧或者数据包,实
现对与监听网络的流量和分析是很有作用的。一共可以有3种方式创建这种s o cke t: 1.socket(AF_INET, SOCK_RAW, IPPROTO_TCP|IPPROTO_UDP|IPPROTO_ICMP)发送 接收ip数据包 2.socket(PF_PACKET, SOCK_RAW, htons(ETH_P_IP|ETH_P_ARP|ETH_P_ALL))发送 接收以太网数据帧
Linux下Wireshark的网络抓包使用方法

Linux下Wireshark的⽹络抓包使⽤⽅法Wireshark是世界上最流⾏的⽹络分析⼯具。
这个强⼤的⼯具可以捕捉⽹络中的数据,并为⽤户提供关于⽹络和上层协议的各种信息。
与很多其他⽹络⼯具⼀样,Wireshark也使⽤pcap network library来进⾏封包捕捉。
Wireshark的优势:- 安装⽅便。
- 简单易⽤的界⾯。
- 提供丰富的功能。
Wireshark的原名是Ethereal,新名字是2006年起⽤的。
当时Ethereal的主要开发者决定离开他原来供职的公司,并继续开发这个软件。
但由于Ethereal这个名称的使⽤权已经被原来那个公司注册,Wireshark这个新名字也就应运⽽⽣了。
Wireshark⽬前世界上最受欢迎的协议分析软件,利⽤它可将捕获到的各种各样协议的⽹络⼆进制数据流翻译为⼈们容易读懂和理解的⽂字和图表等形式,极⼤地⽅便了对⽹络活动的监测分析和教学实验。
它有⼗分丰富和强⼤的统计分析功能,可在Windows,Linux 和UNIX等系统上运⾏。
此软件于1998年由美国Gerald Combs⾸创研发,原名Ethereal,⾄今世界各国已有100多位⽹络专家和软件⼈员正在共同参与此软件的升级完善和维护。
它的名称于2006年5⽉由原Ethereal改为Wireshark。
⾄今它的更新升级速度⼤约每2~3个⽉推出⼀个新的版本,2007年9⽉时的版本号为0.99.6。
但是升级后软件的主要功能和使⽤⽅法保持不变。
它是⼀个开源代码的免费软件,任何⼈都可⾃由下载,也可参与共同开发。
Wireshark⽹络协议分析软件可以⼗分⽅便直观地应⽤于计算机⽹络原理和⽹络安全的教学实验,⽹络的⽇常安全监测,⽹络性能参数测试,⽹络恶意代码的捕获分析,⽹络⽤户的⾏为监测,⿊客活动的追踪等。
因此它在世界范围的⽹络管理专家,信息安全专家,软件和硬件开发⼈员中,以及美国的⼀些知名⼤学的⽹络原理和信息安全技术的教学、科研和实验⼯作中得到⼴泛的应⽤。
Linux抓包工具tcpdump命令详解

Linux抓包⼯具tcpdump命令详解1、简介⽤简单的话来定义tcpdump,就是:dump the traffic on a network,根据使⽤者的定义对⽹络上的数据包进⾏截获的包分析⼯具。
tcpdump可以将⽹络中传送的数据包的“头”完全截获下来提供分析。
它⽀持针对⽹络层、协议、主机、⽹络或端⼝的过滤,并提供and、or、not等逻辑语句来帮助你去掉⽆⽤的信息。
2、实⽤命令实例1)默认启动tcpdump普通情况下,直接启动tcpdump将监视第⼀个⽹络接⼝上所有流过的数据包。
2)监视指定⽹络接⼝的数据包 tcpdump -i eth1如果不指定⽹卡,默认tcpdump只会监视第⼀个⽹络接⼝,⼀般是eth0,下⾯的例⼦都没有指定⽹络接⼝。
3)监视指定主机的数据包打印所有进⼊或离开sundown的数据包:tcpdump host sundown也可以指定ip,例如截获所有210.27.48.1的主机收到的和发出的所有的数据包:tcpdump host 210.27.48.1打印helios与hot或者与ace之间通信的数据包:tcpdump host helios and \( hot or ace \)截获主机210.27.48.1 和主机210.27.48.2或210.27.48.3的通信:tcpdump host 210.27.48.1 and \ (210.27.48.2 or 210.27.48.3 \)打印ace与任何其他主机之间通信的IP数据包, 但不包括与helios之间的数据包:tcpdump ip host ace and not helios如果想要获取主机210.27.48.1除了和主机210.27.48.2之外所有主机通信的ip包,使⽤命令:tcpdump ip host 210.27.48.1 and ! 210.27.48.2截获主机hostname发送的所有数据:tcpdump -i eth0 src host hostname监视所有送到主机hostname的数据包:tcpdump -i eth0 dst host hostname4)监视指定主机和端⼝的数据包如果想要获取主机210.27.48.1接收或发出的telnet包,使⽤如下命令:tcpdump tcp port 23 host 210.27.48.1对本机的udp 123 端⼝进⾏监视123为ntp的服务端⼝:tcpdump udp port 1235)监视指定⽹络的数据包打印本地主机与Berkeley⽹络上的主机之间的所有通信数据包(nt: ucb-ether, 此处可理解为'Berkeley⽹络'的⽹络地址,此表达式最原始的含义可表达为: 打印⽹络地址为ucb-ether的所有数据包):tcpdump net ucb-ether打印所有通过⽹关snup的ftp数据包:(注意,表达式被单引号括起来了,这可以防⽌shell对其中的括号进⾏错误解析)tcpdump 'gateway snup and (port ftp or ftp-data)'6)监视指定协议的数据包打印TCP会话中的的开始和结束数据包,并且数据包的源或⽬的不是本地⽹络上的主机:(nt: localnet, 实际使⽤时要真正替换成本地⽹络的名字)tcpdump 'tcp[tcpflags] & (tcp-syn|tcp-fin) != 0 and not src and dst net localnet'打印所有源或⽬的端⼝是80,⽹络层协议为IPv4,并且含有数据,⽽不是SYN,FIN以及ACK-only等不含数据的数据包:(ipv6的版本的表达式可做练习)tcpdump 'tcp port 80 and (((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)'(nt: 可理解为, ip[2:2]表⽰整个ip数据包的长度, (ip[0]&0xf)<<2)表⽰ip数据包包头的长度(ip[0]&0xf代表包中的IHL域, ⽽此域的单位为32bit, 要换算成字节数需要乘以4,即左移2.(tcp[12]&0xf0)>>4 表⽰tcp头的长度, 此域的单位也是32bit, 换算成⽐特数为 ((tcp[12]&0xf0) >> 4) << 2, 即((tcp[12]&0xf0)>>2).((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0 表⽰: 整个ip数据包的长度减去ip头的长度,再减去tcp头的长度不为0,这就意味着, ip数据包中确实是有数据。
linux抓包原理

linux抓包原理【最新版】目录一、Linux 抓包原理概述二、抓包工具的使用1.tcpdump2.sockraw三、抓包技术的发展1.第一代抓包工具:BPF2.第二代抓包工具:ebpf四、结论正文一、Linux 抓包原理概述在 Linux 系统中,抓包是指捕捉网络数据包并将其分析的过程。
网络数据包是在网络中传输的数据单元,包含了发送方和接收方的信息以及数据内容。
抓包技术可以帮助我们了解网络流量、分析网络问题和优化网络性能。
Linux 系统提供了多种抓包工具,如 tcpdump 和 sockraw,可以实现对网络数据包的捕捉和分析。
二、抓包工具的使用1.tcpdumptcpdump 是一款强大的网络包捕获和分析工具,可以捕捉经过指定网卡的数据包。
使用 tcpdump 抓包时,需要先确定数据包会通过哪个网卡,然后使用-i 选项指定网卡,接着使用-s 选项设置数据包截断长度,-x 选项告诉 tcpdump 显示协议头和包内容,-vvv 选项显示最详细的报文信息,最后使用-w 选项将捕获的数据包写入文件。
例如,要在 ens1f1 网卡上抓取 TCP 协议的数据包,可以使用以下命令:```tcpdump -i ens1f1 -s 0 -x -vvv -w 1.pcap```2.sockrawsockraw 是一款基于原始套接字的抓包工具,可以通过建立原始套接字并接收包来实现抓包。
使用 sockraw 抓包需要了解 Linux 下 socket 编程的基本知识和网络协议细节。
在使用 sockraw 抓包时,需要包含以下头文件:stdio.h、stdlib.h、unistd.h、sys/socket.h、sys/types.h、netinet/ifether.h。
三、抓包技术的发展1.第一代抓包工具:BPFBPF(Berkeley Packet Filter)是第一代抓包工具,它诞生于 1992 年。
BPF 是一种用户级抓包工具,通过在内核中实现过滤器,可以高效地捕捉网络数据包。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
目录一、课程设计目的 (2)二、开发环境、运行方式 (5)1、开发环境 (5)2、运行方式 (5)3、测试结果截图 (6)三、流程的说明 (8)四、帧封装的过程 (10)1、填充帧头部字段 (10)2、填充数据字段 (10)3、CRC校验 (10)4、主程序设计 (12)五、帧封装方法的相关扩展 (21)1、比特型算法 (22)2、字节型算法 (22)六、课程设计心得与体会 (23)七、参考文献 (23)一、课程设计目的帧是网络通信的基本传输单元,熟悉帧结构对于理解网络协议的概念、协议执行过程以及网络层次结构具有重要的意义。
本次作业的目的是应用数据链路层与介质访问控制子层的知识,根据数据链路层的基本原理,通过封装和解析Ethernet 帧,了解Ethernet 帧结构中各个字段的含义,从而深入理解Internet 协议族中的最底层协议——数据链路层协议。
网络节点间发送数据都要将它放在帧的有效部分,分为一个或多个帧进行传送。
节点之间可靠的帧传输不仅是通信的保障,而且还可以实现网络控制等各种功能。
1980年,Xerox、DEC与Intel等三家公司合作,第一次公布了Ethernet的物理层、数据链路层规范;1981年Ethernet V2.0规范公布;IEEE 802.3 标准是在Ethernet V2.0规范的基础上制定的,IEEE 802.3针对整个CSMA/CD网络,它的制定推动了Ethernet 技术的发展和广泛应用。
Ethernet V2.0规范和IEEE802.3标准中的Ethernet帧结构有一些差别,这里我们按Ethernet V2.0的帧结构进行讨论。
图 1.1 IEEE802.3标准Ethernet帧结构802.3标准中Ethernet帧结构由以下几个部分组成:(1)前导码和帧前定界符前导码由56位(7Byte)的10101010…1010比特序列组成,帧前定界符由一个8位的字节组成,其比特序列位10101011。
前导码用于使接收端同步,不计入帧头长度。
帧前定界符也不计入帧头长度。
(2)目的地址和源地址目的地址与源地址均分别表示帧的接收结点与发送结点的硬件地址。
硬件地址一般称作MAC 地址或物理地址。
在Ethernet 帧中,目的地址和源地址字段长度可以是2B 或6B。
早期的Ethernet 曾经使用过2B 长度的地址,但是目前所有的Ethernet 都使用6B(即48 位)长度的地址。
为了方便起见,通常使用16 进制数书写(例如,00-13-d3-a2-42-a8)。
为了保证MAC地址的唯一性,世界上由一个专门的组织负责为网卡的生产厂家分配MAC地址。
Ethernet帧的目的地址可以分为以下3种。
●单播地址(unicast address):目的地址的第一位为0表示单播地址。
目的地址是单播地址,则表示该帧只被与目的地址相同的结点所接收。
●多播地址(multicast address):目的地址的第一位为1表示多播地址。
目的地址是多播地址,则表示该帧被一组结点所接接收。
●广播地址(broadcast address):目的地址为全1则表示广播地址。
目的地址是广播地址,则表示该帧被所有结点接收。
(3)数据长度字段802.3标准中的帧用2B定义LLC数据字段包含的字节数。
描述了LLC数据的实际长度。
(4)数据字段IEEE802.3 协议规定LLC 数据的长度在46B 与1500B 之间。
如果数据的长度少于46B,需要加填充字节,补充到46B。
填充字段是任意的,不计入长度字段值中。
帧头部分长度为18B,包括6B 的目的地址字段、6B 的源地址字段、2B 的长度字段、4B 的帧校验和字段,而前导码与帧前界定符不计入帧头长度中,那么,Ethernet 帧的最小长度为64B,最大长度为1518B。
设置最小帧长度的一个目的是使每个接收结点能够有足够的时间检测到冲突。
(5) 帧校验字段帧校验字段FCS 采用32位CRC 校验。
校验的范围包括目的地址字段、源地址字段、长度字段、LLC 数据字段。
在接收端进行校验,如果发现错误,帧将被丢弃。
在本次作业中,为了简便起见,采用8位的CRC 校验。
8位CRC 校验的生成多项式为:1)(128+++=x x x x GCRC 校验的工作原理是:将要发送的数据比特序列当作一个多项式f(x)的系数,在发送端用收发双方预先约定的生成多项式G(x)去除,求得一个余数多项式。
将余数多项式附在数据多项式之后发送到接收端。
在接收端用同样的生成多项是G(x)去除接受数据多项式f(x),得到计算余数多项式。
如果计算余数多项式与接受余数多项式不相同,则表示传输有差错;否则数据认为正确而被接受。
CRC 编码实际上是一个循环移位的模2运算,在加法中不进位,在减法中不借位,等价于操作数的按位异或(XOR )。
CRC 校验的实现:为了简便起见,我们在程序中采用8 位的CRC 校验。
8 位CRC 校验的生成多项式如式1 :G(x) = x8 + x2 + x1 +1 (1)图1.2 CRC ‐8 的基本实现就是一个用来计算CRC ‐8(x8 + x2 + x1 +1)的硬件电路实现方法,它由8 个移位寄存器和3 个加法器(异或单元)组成。
计算过程如下:(1) 编码或解码前将所有寄存器清零;2) 输入位作为最右边异或操作的输入之一,8 个寄存器上的移位操作同时进行,均为左移一位;3) 最左边寄存器中位作为所有三个异或操作的输入之一;4) 每次移位时,最右边的寄存器作为中间异或操作的输入之一,中间的寄存器作为最左边异或操作输入之一;5) 各个异或操作的结果作为它左边那个寄存器的移入位;6) 重复步骤 2 到6,每输入一个bit 就做一次移位操作,直到输入了所有要计算的数据为止。
这时这个寄存器组中的数据就是CRC-8 的结果。
二.程序的执行环境、运行方式、测试结果截图1、开发环境平台:Windows编程环境:VC 6.0语言:C++2、运行方式1)开始→运行→输入cmd→进入DOS界面2)改变当前目录到可执行程序所在的文件夹下3)用户输入命令,程序包含帧封装和帧解析两个部分的功能。
帧封装格式:[可执行文件名] –p [数据帧文件名]其中 -p 表示帧封装,数据帧文件名由用户自己拟定。
帧封装可以让用户输入任意一段信息,以两个回车作为结束,然后程序将这段信息作为帧的数据字段封装到数据帧文件中。
帧封装格式[可执行文件名] –u [数据帧文件路径]其中 -u 表示帧解析,数据帧文件路径表示要进行解析的数据帧文件路径,比如input1 文件和input2 文件的路径。
帧解析可以将包含帧的数据文件作为数据,从这些文件中读出帧,并对其各字段进行解析。
并通过重新计算CRC 校验和,判断该帧是否接受。
若校验和正确,则接受;否则,丢弃。
3、测试结果截图1)帧解析图2.3.1 帧解析图1图2.3.2 帧解析图2图2.3.3 帧解析图3图2.3.4帧解析图4 2)封装与发送图2.3. 5 帧封装与发送图5图2.3.6帧封装与发送图6图2.3.7 帧封装与发送图7四、帧封装与解析过程1、帧封装在封装过程中需要注意的是如果所封装的数据长度小于46B的时候,需要填充字符,使其整体长度等于46B,但是需要注意的是当对其进行校验和显示的时候并不需要填充的字符串,此时需要将其剔除。
if (data_length<46){向其填充46-data_length个字符;}package(start,data_length,data,fp);封装其中start为起始位置,data为数据存储的数组,fp为文件指针;for(data中前data_length个数据)crc=CRC(data[i],crc);for中将填充字符剔除。
2、帧解析在解析中需要注意,当数据长度小于46B的时候,在读完数据之后,需要读取46-data_length个字符之后的字符作为校验码。
for(等待46-data_length个字符)file.get();crc=file.get();3、CRC校验函数在图1.2中,CRC-8 的计算过程是,当寄存器R7 的移出位为1 时,寄存器组才和00000111进行XOR运算;移出位为0 时,不做运算。
每次寄存器中的数据左移后就需要从输入数据中读入一位新的数据,如果读入的新数据为1,则需要把寄存器R0 置为1,然后再判断寄存器组是否需要与00000111 进行XOR 操作。
具体实现的伪代码如下://register_8是一个8位的寄存器把register_8中的值置为0;在原始数据input后添加8各0;while(数据未处理完){if(register_8首位是1){register_8中的数据左移1位;if(从input中读入的新的数据为1){将register_8的最低位置1;}register_8 = register_8 XOR 00000111;}else{register_8中的数据左移1位;if(从input中读入的新的数据为1){将register_8的最低位置1;}}}在程序中我构造了一个函数CRC(unsigned char a,unsigned char b);其中a为所要计算校验码的字符,b为此时crc的值。
变量b可以看成一个寄存器,它的值为初始寄存器的值;a为这个寄存器变换的输入。
4、主程序的设计void main(int argc, char* argv[]){// 检测命令行参数的正确性if (argc != 2){cout << "请以帧封装包文件为参数重新执行程序" << endl;exit(0);}// 检测输入文件是否存在,并可以按所需的权限和方式打开ifstream file(argv[1], ios::in|ios::binary|ios::nocreate);if (!file.is_open()){cout << "无法打开帧封装包文件,请检查文件是否存在并且未损坏" << endl;exit(0);}// 变量声明及初始化int nSN = 1; // 帧序号int nCheck = 0; // 校验码int nCurrDataOffset = 22; // 帧头偏移量int nCurrDataLength = 0; // 数据字段长度bool bParseCont = true; // 是否继续对输入文件进行解析int nFileEnd = 0; // 输入文件的长度// 计算输入文件的长度file.seekg(0, ios::end); // 把文件指针移到文件的末尾nFileEnd = file.tellg(); // 取得输入文件的长度file.seekg(0, ios::beg); // 文件指针位置初始化cout.fill('0'); // 显示初始化cout.setf(ios::uppercase); // 以大写字母输出// 定位到输入文件中的第一个有效帧// 从文件头开始,找到第一个连续的“AA-AA-AA-AA-AA-AA-AA-AB”while ( true ){for (int j = 0; j < 7; j++) // 找7个连续的0xaa{if (file.tellg() >= nFileEnd) // 安全性检测{cout<<"没有找到合法的帧"<<endl;file.close();exit(0);}// 看当前字符是不是0xaa,如果不是,则重新寻找7个连续的0xaa if (file.get() != 0xaa){j = -1;}}if (file.tellg() >= nFileEnd) // 安全性检测{cout<<"没有找到合法的帧"<<endl;file.close();exit(0);}if (file.get() == 0xab) // 判断7个连续的0xaa之后是否为0xab {break;}}// 将数据字段偏移量定位在上述二进制串之后14字节处,并准备进入解析阶段nCurrDataOffset = file.tellg() + 14;file.seekg(-8,ios::cur);// 主控循环while ( bParseCont ) // 当仍然可以继续解析输入文件时,继续解析{// 检测剩余文件是否可能包含完整帧头if (file.tellg() + 14 > nFileEnd){cout<<endl<<"没有找到完整帧头,解析终止"<<endl;file.close();exit(0);}int c; // 读入字节int i = 0; // 循环控制变量int EtherType = 0; // 由帧中读出的类型字段bool bAccept = true; // 是否接受该帧// 输出帧的序号cout << endl << "序号:\t\t" << nSN;// 输出前导码,只输出,不校验cout << endl << "前导码:\t";for (i = 0; i < 7; i++) // 输出格式为:AA AA AA AA AA AA AA {cout.width(2);cout << hex << file.get() << dec << " ";}// 输出帧前定界符,只输出,不校验cout << endl << "帧前定界符:\t";cout.width(2); // 输出格式为:ABcout << hex << file.get();// 输出目的地址,并校验cout << endl << "目的地址:\t";for (i = 0; i < 6; i++) // 输出格式为:xx-xx-xx-xx-xx-xx {c = file.get();cout.width(2);cout<< hex << c << dec << (i==5 ? "" : "-");if (i == 0) // 第一个字节,作为“余数”等待下一个bit {nCheck = c;}else // 开始校验{checkCRC(nCheck, c);}}// 输出源地址,并校验cout << endl << "源地址:\t";for (i = 0; i < 6; i++) // 输出格式为:xx-xx-xx-xx-xx-xx {c = file.get();cout.width(2);cout<< hex << c << dec << (i==5 ? "" : "-");checkCRC(nCheck, c); // 继续校验}// 输出类型字段,并校验cout<<endl<<"类型字段:\t";cout.width(2);// 输出类型字段的高8位c = file.get();cout<< hex << c << dec << " ";checkCRC(nCheck, c); // CRC校验EtherType = c;// 输出类型字段的低8位c = file.get();cout.width(2);cout<< hex << c;checkCRC(nCheck,c); // CRC校验EtherType <<= 8; // 转换成主机格式EtherType |= c;// 定位下一个帧,以确定当前帧的结束位置while ( bParseCont ){for (int i = 0; i < 7; i++) //找下一个连续的7个0xaa {if (file.tellg() >= nFileEnd) //到文件末尾,退出循环 {bParseCont = false;break;}// 看当前字符是不是0xaa,如果不是,则重新寻找7个连续的0xaaif (file.get() != 0xaa){i = -1;}}// 如果直到文件结束仍没找到上述比特串,将终止主控循环的标记bParseCont置为truebParseCont = bParseCont && (file.tellg() < nFileEnd);// 判断7个连续的0xaa之后是否为0xabif (bParseCont && file.get() == 0xab){break;}}// 计算数据字段的长度nCurrDataLength =bParseCont ? // 是否到达文件末尾(file.tellg() - 8 - 1 - nCurrDataOffset) : // 没到文件末尾:下一帧头位置- 前导码和定界符长度 - CRC校验码长度 - 数据字段起始位置(file.tellg() - 1 - nCurrDataOffset); // 已到达文件末尾:文件末尾位置- CRC校验码长度 - 数据字段起始位置// 以文本格式数据字段,并校验cout << endl << "数据字段:\t";unsigned char* pData = new unsigned char[nCurrDataLength]; // 创建缓冲区 file.seekg(bParseCont ? (-8 - 1 -nCurrDataLength) : ( -1 - nCurrDataLength), ios::cur);file.read(pData, nCurrDataLength); // 读入数据字段int nCount = 50; // 每行的基本字符数量for (i = 0; i < nCurrDataLength; i++) // 输出数据字段文本{nCount--;cout << pData[i]; // 字符输出checkCRC(nCheck, (int)pData[i]); // CRC校验if ( nCount < 0) // 换行处理{// 将行尾的单词写完整if ( pData[i] == ' ' ){cout << endl << "\t\t";nCount = 50;}// 处理过长的行尾单词:换行并使用连字符if ( nCount < -10){cout<< "-" << endl << "\t\t";nCount = 50;}}}delete[] pData; //释放缓冲区空间// 输出CRC校验码,如果CRC校验有误,则输出正确的CRC校验码cout << endl <<"CRC校验";c = file.get(); // 读入CRC校验码int nTmpCRC = nCheck;checkCRC(nCheck, c); // 最后一步校验if ((nCheck & 0xff) == 0) // CRC校验无误{cout.width(2);cout<<"(正确):\t"<< hex << c;}else // CRC校验有误{cout.width(2);cout<< "(错误):\t" << hex << c;checkCRC(nTmpCRC, 0); // 计算正确的CRC校验码cout<< "\t应为:" << hex << (nTmpCRC & 0xff);bAccept = false; // 将帧的接收标记置为false}// 如果数据字段长度不足46字节或数据字段长度超过1500字节,则将帧的接收标记置为falseif (nCurrDataLength < 46 || nCurrDataLength > 1500 ){bAccept = false;}// 输出帧的接收状态cout<< endl << "状态:\t\t" << (bAccept ? "Accept" : "Discard") << endl <<endl; nSN++; // 帧序号加1nCurrDataOffset = file.tellg() + 22; // 将数据字段偏移量更新为下一帧的帧头结束位置}// 关闭输入文件file.close();}五、帧封装方法的相关扩展除了上面介绍的方法之外,还有其它一些算法可以完成CRC校验。