数据库系统基础教程第二章答案
数据库系统基础教程第二章答案解析

For relation Accounts, the attributes are:acctNo, type, balanceFor relation Customers, the attributes are:firstName, lastName, idNo, accountExercise 2.2.1bFor relation Accounts, the tuples are:(12345, savings, 12000),(23456, checking, 1000),(34567, savings, 25)For relation Customers, the tuples are:(Robbie, Banks, 901-222, 12345),(Lena, Hand, 805-333, 12345),(Lena, Hand, 805-333, 23456)Exercise 2.2.1cFor relation Accounts and the first tuple, the components are:123456 → acctNosavings → type12000 → balanceFor relation Customers and the first tuple, the components are:Robbie → firstNameBanks → lastName901-222 → idNo12345 → accountExercise 2.2.1dFor relation Accounts, a relation schema is:Accounts(acctNo, type, balance)For relation Customers, a relation schema is:Customers(firstName, lastName, idNo, account) Exercise 2.2.1eAn example database schema is:Accounts (acctNo,type,balance)Customers (firstName,lastName,idNo,account)A suitable domain for each attribute:acctNo → Integertype → Stringbalance → IntegerfirstName → StringlastName → StringidNo → String (because there is a hyphen we cannot use Integer)account → IntegerExercise 2.2.1gAnother equivalent way to present the Account relation:Another equivalent way to present the Customers relation:Exercise 2.2.2Examples of attributes that are created for primarily serving as keys in a relation:Universal Product Code (UPC) used widely in United States and Canada to track products in stores.Serial Numbers on a wide variety of products to allow the manufacturer to individually track each product.Vehicle Identification Numbers (VIN), a unique serial number used by the automotive industry to identify vehicles.Exercise 2.2.3aWe can order the three tuples in any of 3! = 6 ways. Also, the columns can be ordered in any of 3! = 6 ways. Thus, the number of presentations is 6*6 = 36.Exercise 2.2.3bWe can order the three tuples in any of 5! = 120 ways. Also, the columns can be ordered in any of 4! = 24 ways. Thus, the number of presentations is 120*24 = 2880Exercise 2.2.3cWe can order the three tuples in any of m! ways. Also, the columns can be ordered in any of n! ways. Thus, the number of presentations is n!m!Exercise 2.3.1aCREATE TABLE Product (maker CHAR(30),model CHAR(10) PRIMARY KEY,type CHAR(15));CREATE TABLE PC (model CHAR(30),speed DECIMAL(4,2),ram INTEGER,hd INTEGER,price DECIMAL(7,2));Exercise 2.3.1cCREATE TABLE Laptop (model CHAR(30),speed DECIMAL(4,2),ram INTEGER,hd INTEGER,screen DECIMAL(3,1),price DECIMAL(7,2));Exercise 2.3.1dCREATE TABLE Printer (model CHAR(30),color BOOLEAN,type CHAR (10),price DECIMAL(7,2));Exercise 2.3.1eALTER TABLE Printer DROP color;Exercise 2.3.1fALTER TABLE Laptop ADD od CHAR (10) DEFAULT ‘none’; Exercise 2.3.2aCREATE TABLE Classes (class CHAR(20),type CHAR(5),country CHAR(20),numGuns INTEGER,bore DECIMAL(3,1),displacement INTEGER);Exercise 2.3.2bCREATE TABLE Ships (name CHAR(30),class CHAR(20),launched INTEGER);Exercise 2.3.2cCREATE TABLE Battles (name CHAR(30),date DATE);Exercise 2.3.2dCREATE TABLE Outcomes (ship CHAR(30),battle CHAR(30),result CHAR(10));Exercise 2.3.2eALTER TABLE Classes DROP bore;Exercise 2.3.2fALTER TABLE Ships ADD yard CHAR(30); Exercise 2.4.1aR1 := σspeed ≥ 3.00 (PC)R2 := πmodel(R1)Exercise 2.4.1bR1 := σhd ≥ 100 (Laptop)R2 := Product (R1)R3 := πmaker (R2)Exercise 2.4.1cR1 := σmaker=B (Product PC)R2 := σmaker=B (Product Laptop)R3 := σmaker=B (Product Printer)R4 := πmodel,price (R1)R5 := πmodel,price (R2)R6: = πmodel,price (R3)R7 := R4 R5 R6Exercise 2.4.1dR1 := σcolor = true AND type = laser (Printer)R2 := πmodel (R1)Exercise 2.4.1eR1 := σtype=laptop (Product)R2 := σtype=PC(Product)R3 := πmaker (R1) R4 := πmaker (R2) R5 := R3 – R4Exercise 2.4.1fR1 := ρPC1(PC)R2 := ρPC2(PC)R3 := R1 (PC1.hd = PC2.hd AND PC1.model <> PC2.model) R2R4 := πhd (R3)Exercise 2.4.1gR1 := ρPC1(PC)R2 := ρPC2(PC)R3 := R1 (PC1.speed = PC2.speed AND PC1.ram = PC2.ram AND PC1.model < PC2.model) R2 R4 := πPC1.model,PC2.model (R3)Exercise 2.4.1hR1 := πmodel (σspeed ≥ 2.80(PC)) πmodel (σspeed ≥ 2.80(Laptop))R2 := πmaker,model (R1 Product)R3 := ρR3(maker2,model2)(R2)R4 := R2 (maker = maker2 AND model <> model2) R3R5 := πmaker (R4)Exercise 2.4.1iR1 := πmodel,speed (PC)R2 := πmodel,speed(Laptop)R3 := R1 R2 R4 := ρR4(model2,speed2)(R3)R5 := πmodel,speed (R3 (speed < speed2 ) R4)R6 := R3 – R5(R6 Product)Exercise 2.4.1jR1 := πmaker,speed (Product PC)R2 := ρR2(maker2,speed2)(R1)R3 := ρR3(maker3,speed3)(R1)R4 := R1 (maker = maker2 AND speed <> speed2) R2R5 := R4 (maker3 = maker AND speed3 <> speed2 AND speed3 <> speed) R3R6 := πmaker (R5)Exercise 2.4.1kR1 := πmaker,model (Product PC)R2 := ρR2(maker2,model2)(R1)R3 := ρR3(maker3,model3)(R1)R4 := ρR4(maker4,model4)(R1)R5 := R1 (maker = maker2 AND model <> model2) R2R6 := R3(maker3 = maker AND model3 <> model2 AND model3 <> model) R5R7 := R4 (maker4 = maker AND (model4=model OR model4=model2 OR model4=model3)) R6 R8 := πmaker (R7)Exercise 2.4.2aπmodelσspeed≥3.00PCExercise 2.4.2bLaptopσhd ≥ 100 ProductπmakerExercise 2.4.2cσmaker=B πmodel,priceσmaker=B πmodel,price σmaker=Bπmodel,priceProduct PC Laptop Printer ProductProductExercise 2.4.2dPrinter σcolor = true AND type = laserπmodelExercise 2.4.2e σtype=laptop σtype=PC πmakerπmaker –Product ProductExercise 2.4.2fρPC1ρPC2 (PC1.hd = PC2.hd AND PC1.model <> PC2.model)πhdPC PCExercise 2.4.2gρPC1ρPC2PC PC(PC1.speed = PC2.speed AND PC1.ram = PC2.ram AND PC1.model < PC2.model)πPC1.model,PC2.modelExercise 2.4.2hPC Laptop σspeed ≥ 2.80σspeed ≥ 2.80πmodelπmodel πmaker,modelρR3(maker2,model2)(maker = maker2 AND model <> model2)makerExercise 2.4.2iPCLaptopProductπmodel,speed πmodel,speed ρR4(model2,speed2)πmodel,speed(speed < speed2 )–makerExercise 2.4.2jProduct PC πmaker,speed ρR3(maker3,speed3)ρR2(maker2,speed2)(maker = maker2 AND speed <> speed2)(maker3 = maker AND speed3 <> speed2 AND speed3 <> speed)πmakerExercise 2.4.2kπmaker(maker4 = maker AND (model4=model OR model4=model2 OR model4=model3)) (maker3 = maker AND model3 <> model2 AND model3 <> model)(maker = maker2 AND model <> model2)ρR2(maker2,model2)ρR3(maker3,model3)ρR4(maker4,model4)πmaker,modelProduct PCExercise 2.4.3aR1 := σbore ≥ 16 (Classes)R2 := πclass,country (R1)Exercise 2.4.3bR1 := σlaunched < 1921 (Ships)R2 := πname (R1)Exercise 2.4.3cR1 := σbattle=Denmark Strait AND result=sunk(Outcomes)R2 := πship (R1)Exercise 2.4.3dR1 := Classes ShipsR2 := σlaunched > 1921 AND displacement > 35000 (R1)R3 := πname (R2)Exercise 2.4.3eR1 := σbattle=Guadalcanal(Outcomes)R2 := Ships (ship=name) R1R3 := Classes R2R4 := πname,displacement,numGuns(R3)Exercise 2.4.3fR1 := πname(Ships)R2 := πship(Outcomes)R3 := ρR3(name)(R2)R4 := R1 R3Exercise 2.4.3gFrom 2.3.2, assuming that every class has one ship named after the class.R1 := πclass(Classes)R2 := πclass(σname <> class(Ships))R3 := R1 – R2Exercise 2.4.3hR1 := πcountry(σtype=bb(Classes))R2 := πcountry(σtype=bc(Classes))R3 := R1 ∩ R2Exercise 2.4.3iR1 := πship,result,date(Battles (battle=name) Outcomes)R2 := ρR2(ship2,result2,date2)(R1)R3 := R1 (ship=ship2 AND result=damaged AND date < date2) R2R4 := πship(R3)No results from sample data.Exercise 2.4.4aπclass,countryσbore ≥ 16ClassesExercise 2.4.4bπnameσlaunched < 1921ShipsExercise 2.4.4cπshipσbattle=Denmark Strait AND result=sunkOutcomesExercise 2.4.4dπnameσlaunched > 1921 AND displacement > 35000Classes Ships Exercise 2.4.4eσbattle=Guadalcanal Outcomes Ships(ship=name)πname,displacement,numGunsExercise 2.4.4f Ships Outcomesπnameπship ρR3(name)Exercise 2.4.4g Classes Shipsπclass σname <> class πclass–Exercise 2.4.4hClasses Classesσtype=bb σtype=bcπcountry πcountry∩Exercise 2.4.4iBattles Outcomes (battle=name)πship,result,dateρR2(ship2,result2,date2)(ship=ship2 AND result=damaged AND date < date2)πshipExercise 2.4.5The result of the natural join has only one attribute from each pair of equated attributes. On the other hand, the result of the theta-join has both columns of the attributes and their values are identical.Exercise 2.4.6UnionIf we add a tuple to the arguments of the union operator, we will get all of the tuples of the original result and maybe the added tuple. If the added tuple is a duplicate tuple, then the set behavior will eliminate that tuple.Thus the union operator is monotone.IntersectionIf we add a tuple to the arguments of the intersection operator, we will get all of the tuples of the originalresult and maybe the added tuple. If the added tuple does not exist in the relation that it is added but does exist in the other relation, then the result set will include the added tuple. Thus the intersection operator is monotone.DifferenceIf we add a tuple to the arguments of the difference operator, we may not get all of the tuples of the originalresult. Suppose we have relations R and S and we are computing R – S. Suppose also that tuple t is in R but not in S. The result of R – S would include tuple t. However, if we add tuple t to S, then the new result will not have tuple t. Thus the difference operator is not monotone.ProjectionIf we add a tuple to the arguments of the projection operator, we will get all of the tuples of the original result and the projection of the added tuple. The projection operator only selects columns from the relation and does not affect the rows that are selected. Thus the projection operator is monotone.SelectionIf we add a tuple to the arguments of the selection operator, we will get all of the tuples of the original result and maybe the added tuple. If the added tuple satisfies the select condition, then it will be added to the newresult. The original tuples are included in the new result because they still satisfy the select condition. Thusthe selection operator is monotone.Cartesian ProductIf we add a tuple to the arguments of the Cartesian product operator, we will get all of the tuples of the original result and possibly additional tuples. The Cartesian product pairs the tuples of one relation with the tuples ofanother relation. Suppose that we are calculating R x S where R has m tuples and S has n tuples. If we add a tuple to R that is not already in R, then we expect the result of R x S to have (m + 1) * n tuples. Thus the Cartesianproduct operator is monotone.Natural JoinsIf we add a tuple to the arguments of a natural join operator, we will get all of the tuples of the original result and possibly additional tuples. The new tuple can only create additional successful joins, not less. If, however, the added tuple cannot successfully join with any of the existing tuples, then we will have zero additionalsuccessful joins. Thus the natural join operator is monotone.Theta JoinsIf we add a tuple to the arguments of a theta join operator, we will get all of the tuples of the original result and possibly additional tuples. The theta join can be modeled by a Cartesian product followed by a selection onsome condition. The new tuple can only create additional tuples in the result, not less. If, however, the addedtuple does not satisfy the select condition, then no additional tuples will be added to the result. Thus the theta join operator is monotone.RenamingIf we add a tuple to the arguments of a renaming operator, we will get all of the tuples of the original result and the added tuple. The renaming operator does not have any effect on whether a tuple is selected or not. In fact, the renaming operator will always return as many tuples as its argument. Thus the renaming operator is monotone.Exercise 2.4.7aIf all the tuples of R and S are different, then the union has n + m tuples, and this number is the maximum possible.The minimum number of tuples that can appear in the result occurs if every tuple of one relation also appears in the other. Then the union has max(m , n) tuples.Exercise 2.4.7bIf all the tuples in one relation can pair successfully with all the tuples in the other relation, then the natural join has n * m tuples. This number would be the maximum possible.The minimum number of tuples that can appear in the result occurs if none of the tuples of one relation can pairsuccessfully with all the tuples in the other relation. Then the natural join has zero tuples.Exercise 2.4.7cIf the condition C brings back all the tuples of R, then the cross product will contain n * m tuples. This number would be the maximum possible.The minimum number of tuples that can appear in the result occurs if the condition C brings back none of the tuples of R. Then the cross product has zero tuples.Exercise 2.4.7dAssuming that the list of attributes L makes the resulting relation πL(R) and relation S schema compatible, then the maximum possible tuples is n. This happens when all of the tuples of πL(R) are not in S.The minimum number of tuples that can appear in the result occurs when all of the tuples in πL(R) appear in S. Then the difference has max(n–m , 0) tuples.Exercise 2.4.8Defining r as the schema of R and s as the schema of S:1.πr(R S)2.R δ(πr∩s(S)) where δ is the duplicate-elimination operator in Section 5.2 pg. 2133.R – (R –πr(R S))Exercise 2.4.9Defining r as the schema of R1.R - πr(R S)Exercise 2.4.10πA1,A2…An(R S)Exercise 2.5.1aσspeed < 2.00 AND price > 500(PC) = øModel 1011 violates this constraint.Exercise 2.5.1bσscreen < 15.4 AND hd < 100 AND price ≥ 1000(Laptop) = øModel 2004 violates the constraint.Exercise 2.5.1cπmaker(σtype = laptop(Product)) ∩ πmaker(σtype = pc(Product)) = øManufacturers A,B,E violate the constraint.Exercise 2.5.1dThis complex expression is best seen as a sequence of steps in which we define temporary relations R1 through R4 that stand for nodes of expression trees. Here is the sequence:R1(maker, model, speed) := πmaker,model,speed(Product PC)R2(maker, speed) := πmaker,speed(Product Laptop)R3(model) := πmodel(R1 R1.maker = R2.maker AND R1.speed ≤ R2.speed R2)R4(model) := πmodel(PC)The constraint is R4 ⊆ R3Manufacturers B,C,D violate the constraint.Exercise 2.5.1eπmodel(σLaptop.ram > PC.ram AND Laptop.price ≤ PC.price(PC × Laptop)) = øModels 2002,2006,2008 violate the constraint.Exercise 2.5.2aπclass(σbore > 16(Classes)) = øThe Yamato class violates the constraint.Exercise 2.5.2bπclass(σnumGuns > 9 AND bore > 14(Classes)) = øNo violations to the constraint.Exercise 2.5.2cThis complex expression is best seen as a sequence of steps in which we define temporary relations R1 through R5 that stand for nodes of expression trees. Here is the sequence:R1(class,name) := πclass,name(Classes Ships)R2(class2,name2) := ρR2(class2,name2)(R1)R3(class3,name3) := ρR3(class3,name3)(R1)R4(class,name,class2,name2) := R1 (class = class2 AND name <> name2) R2R5(class,name,class2,name2,class3,name3) := R4 (class=class3 AND name <> name3 AND name2 <> name3) R3The constraint is R5 = øThe Kongo, Iowa and Revenge classes violate the constraint.Exercise 2.5.2dπcountry(σtype = bb(Classes)) ∩ πcountry(σtype = bc(Classes)) = øJapan and Gt. Britain violate the constraint.Exercise 2.5.2eThis complex expression is best seen as a sequence of steps in which we define temporary relations R1 through R5 that stand for nodes of expression trees. Here is the sequence:R1(ship,bat tle,result,class) := πship,battle,result,class(Outcomes (ship = name) Ships)R2(ship,battle,result,numGuns) := πship,battle,result,numGuns(R1 Classes)R3(ship,battle) := πship,battle(σnumGuns < 9 AND result = sunk (R2))R4(ship2,battle2) := ρR4(ship2,battle2)(πship,battle(σnumGuns > 9(R2)))R5(ship2) := πship2(R3 (battle = battle2) R4)The constraint is R5 = øNo violations to the constraint. Since there are some ships in the Outcomes table that are not in the Ships table, we are unable to determine the number of guns on that ship.Exercise 2.5.3Defining r as the schema A1,A2,…,A n and s as the schema B1,B2,…,B n:πr(R) πs(S) = øwhere is the antisemijoinExercise 2.5.4The form of a constraint as E1 = E2 can be expressed as the other two constraints.Using the “equating an expression to the empty set” method, we can simply say:E1– E2 = øAs a containment, we can simply say:E1⊆ E2 AND E2⊆ E1Thus, the form E1 = E2 of a constraint cannot express more than the two other forms discussed in this section.。
数据库系统基础教程(第二版)课后习题答案

Database Systems: The Complete BookSolutions for Chapter 2Solutions for Section 2.1Exercise 2.1.1The E/R Diagram.Exercise 2.1.8(a)The E/R DiagramKobvxybzSolutions for Section 2.2Exercise 2.2.1The Addresses entity set is nothing but a single address, so we would prefer to make address an attribute of Customers. Were the bank to record several addresses for a customer, then it might make sense to have an Addresses entity set and make Lives-at a many-many relationship.The Acct-Sets entity set is useless. Each customer has a unique account set containing his or her accounts. However, relating customers directly to their accounts in a many-many relationship conveys the same information and eliminates the account-set concept altogether.Solutions for Section 2.3Exercise 2.3.1(a)Keys ssNo and number are appropriate for Customers and Accounts, respectively. Also, we think it does not make sense for an account to be related to zero customers, so we should round the edgeconnecting Owns to Customers. It does not seem inappropriate to have a customer with 0 accounts;they might be a borrower, for example, so we put no constraint on the connection from Owns to Accounts. Here is the The E/R Diagram,showing underlined keys and the numerocity constraint.Exercise 2.3.2(b)If R is many-one from E1 to E2, then two tuples (e1,e2) and (f1,f2) of the relationship set for R must be the same if they agree on the key attributes for E1. To see why, surely e1 and f1 are the same. Because R is many-one from E1 to E2, e2 and f2 must also be the same. Thus, the pairs are the same.Solutions for Section 2.4Exercise 2.4.1Here is the The E/R Diagram.We have omitted attributes other than our choice for the key attributes of Students and Courses. Also omitted are names for the relationships. Attribute grade is not part of the key for Enrollments. The key for Enrollements is studID from Students and dept and number from Courses.Exercise 2.4.4bHere is the The E/R Diagram Again, we have omitted relationship names and attributes other than our choice for the key attributes. The key for Leagues is its own name; this entity set is not weak. The key for Teams is its own name plus the name of the league of which the team is a part, e.g., (Rangers, MLB) or (Rangers, NHL). The key for Players consists of the player's number and the key for the team on which he or she plays. Since the latter key is itself a pair consisting of team and league names, the key for players is the triple (number, teamName, leagueName). e.g., JeffGarcia is (5, 49ers, NFL).Database Systems: The Complete BookSolutions for Chapter 3Solutions for Section 3.1Exercise 3.1.2(a)We can order the three tuples in any of 3! = 6 ways. Also, the columns can be ordered in any of 3! = 6 ways. Thus, the number of presentations is 6*6 = 36.Solutions for Section 3.2Exercise 3.2.1Customers(ssNo, name, address, phone)Flights(number, day, aircraft)Bookings(ssNo, number, day, row, seat)Being a weak entity set, Bookings' relation has the keys for Customers and Flights and Bookings' own attributes.Notice that the relations obtained from the toCust and toFlt relationships are unnecessary. They are:toCust(ssNo, ssNo1, number, day)toFlt(ssNo, number, day, number1, day1)That is, for toCust, the key of Customers is paired with the key for Bookings. Since both include ssNo, this attribute is repeated with two different names, ssNo and ssNo1. A similar situation exists for toFlt.Exercise 3.2.3Ships(name, yearLaunched)SisterOf(name, sisterName)Solutions for Section 3.3Exercise 3.3.1Since Courses is weak, its key is number and the name of its department. We do not havearelation for GivenBy. In part (a), there is a relation for Courses and a relation for LabCourses that has only the key and the computer-allocation attribute. It looks like:Depts(name, chair)Courses(number, deptName, room)LabCourses(number, deptName, allocation)For part (b), LabCourses gets all the attributes of Courses, as:Depts(name, chair)Courses(number, deptName, room)LabCourses(number, deptName, room, allocation)And for (c), Courses and LabCourses are combined, as:Depts(name, chair)Courses(number, deptName, room, allocation)Exercise 3.3.4(a)There is one relation for each entity set, so the number of relations is e. The relation for the root entity set has a attributes, while the other relations, which must include the key attributes, have a+k attributes.Solutions for Section 3.4Exercise 3.4.2Surely ID is a key by itself. However, we think that the attributes x, y, and z together form another key. The reason is that at no time can two molecules occupy the same point.Exercise 3.4.4The key attributes are indicated by capitalization in the schema below:Customers(SSNO, name, address, phone)Flights(NUMBER, DAY, aircraft)Bookings(SSNO, NUMBER, DAY, row, seat)Exercise 3.4.6(a)The superkeys are any subset that contains A1. Thus, there are 2^{n-1} such subsets, since each of the n-1 attributes A2 through An may independently be chosen in or out.Solutions for Section 3.5Exercise 3.5.1(a)We could try inference rules to deduce new dependencies until we are satisfied we have them all.A more systematic way is to consider the closures of all 15 nonempty sets of attributes.For the single attributes we have A+ = A, B+ = B, C+ = ACD, and D+ = AD. Thus, the only new dependency we get with a single attribute on the left is C->A.Now consider pairs of attributes:AB+ = ABCD, so we get new dependency AB->D. AC+ = ACD, and AC->D is nontrivial. AD+ = AD, so nothing new. BC+ = ABCD, so we get BC->A, and BC->D. BD+ = ABCD, giving usBD->A and BD->C. CD+ = ACD, giving CD->A.For the triples of attributes, ACD+ = ACD, but the closures of the other sets are each ABCD. Thus, we get new dependencies ABC->D, ABD->C, and BCD->A.Since ABCD+ = ABCD, we get no new dependencies.The collection of 11 new dependencies mentioned above is: C->A, AB->D, AC->D, BC->A, BC->D, BD->A, BD->C, CD->A, ABC->D, ABD->C, and BCD->A.Exercise 3.5.1(b)From the analysis of closures above, we find that AB, BC, and BD are keys. All other sets either do not have ABCD as the closure or contain one of these three sets.Exercise 3.5.1(c)The superkeys are all those that contain one of those three keys. That is, a superkey that is not a key must contain B and more than one of A, C, and D. Thus, the (proper) superkeys are ABC, ABD, BCD, and ABCD.Exercise 3.5.3(a)We must compute the closure of A1A2...AnC. Since A1A2...An->B is a dependency, surely B is in this set, proving A1A2...AnC->B.Exercise 3.5.4(a)Consider the relationThis relation satisfies A->B but does not satisfy B->A.Exercise 3.5.8(a)If all sets of attributes are closed, then there cannot be any nontrivial functional dependencies. For suppose A1A2...An->B is a nontrivial dependency. Then A1A2...An+ contains B and thus A1A2...An is not closed.Exercise 3.5.10(a)We need to compute the closures of all subsets of {ABC}, although there is no need to think about the empty set or the set of all three attributes. Here are the calculations for the remaining six sets: A+ = AB+ = BC+ = ACEAB+ = ABCDEAC+ = ACEBC+ = ABCDEWe ignore D and E, so a basis for the resulting functional dependencies for ABC are: C->A and AB->C. Note that BC->A is true, but follows logically from C->A, and therefore may be omitted from our list.Solutions for Section 3.6Exercise 3.6.1(a)In the solution to Exercise 3.5.1 we found that there are 14 nontrivial dependencies, including the three given ones and 11 derived dependencies. These are: C->A, C->D, D->A, AB->D, AB-> C, AC->D, BC->A, BC->D, BD->A, BD->C, CD->A, ABC->D, ABD->C, and BCD->A.We also learned that the three keys were AB, BC, and BD. Thus, any dependency above that does not have one of these pairs on the left is a BCNF violation. These are: C->A, C->D, D->A, AC->D, and CD->A.One choice is to decompose using C->D. That gives us ABC and CD as decomposed relations. CD is surely in BCNF, since any two-attribute relation is. ABC is not in BCNF, since AB and BC are its only keys, but C->A is a dependency that holds in ABCD and therefore holds in ABC. We must further decompose ABC into AC and BC. Thus, the three relations of the decomposition are AC, BC, and CD.Since all attributes are in at least one key of ABCD, that relation is already in 3NF, and no decomposition is necessary.Exercise 3.6.1(b)(Revised 1/19/02) The only key is AB. Thus, B->C and B->D are both BCNF violations. The derived FD's BD->C and BC->D are also BCNF violations. However, any other nontrivial, derived FD will have A and B on the left, and therefore will contain a key.One possible BCNF decomposition is AB and BCD. It is obtained starting with any of the four violations mentioned above. AB is the only key for AB, and B is the only key for BCD.Since there is only one key for ABCD, the 3NF violations are the same, and so is the decomposition.Solutions for Section 3.7Exercise 3.7.1Since A->->B, and all the tuples have the same value for attribute A, we can pair the B-value from any tuple with the value of the remaining attribute C from any other tuple. Thus, we know that R must have at least the nine tuples of the form (a,b,c), where b is any of b1, b2, or b3, and c is any of c1, c2, or c3. That is, we can derive, using the definition of a multivalued dependency, that each of the tuples (a,b1,c2), (a,b1,c3), (a,b2,c1), (a,b2,c3), (a,b3,c1), and (a,b3,c2) are also in R.Exercise 3.7.2(a)First, people have unique Social Security numbers and unique birthdates. Thus, we expect the functional dependencies ssNo->name and ssNo->birthdate hold. The same applies to children, so we expect childSSNo->childname and childSSNo->childBirthdate. Finally, an automobile has a unique brand, so we expect autoSerialNo->autoMake.There are two multivalued dependencies that do not follow from these functional dependencies. First, the information about one child of a person is independent of other information about that person. That is, if a person with social security number s has a tuple with cn,cs,cb, then if there isany other tuple t for the same person, there will also be another tuple that agrees with t except that it has cn,cs,cb in its components for the child name, Social Security number, and birthdate. That is the multivalued dependencyssNo->->childSSNo childName childBirthdateSimilarly, an automobile serial number and make are independent of any of the other attributes, so we expect the multivalued dependencyssNo->->autoSerialNo autoMakeThe dependencies are summarized below:ssNo -> name birthdatechildSSNo -> childName childBirthdateautoSerialNo -> autoMakessNo ->-> childSSNo childName childBirthdatessNo ->-> autoSerialNo autoMakeExercise 3.7.2(b)We suggest the relation schemas{ssNo, name, birthdate}{ssNo, childSSNo}{childSSNo, childName childBirthdate}{ssNo, autoSerialNo}{autoSerialNo, autoMake}An initial decomposition based on the two multivalued dependencies would give us {ssNo, name, birthDate}{ssNo, childSSNo, childName, childBirthdate}{ssNo, autoSerialNo, autoMake}Functional dependencies force us to decompose the second and third of these.Exercise 3.7.3(a)Since there are no functional dependencies, the only key is all four attributes, ABCD. Thus, each of the nontrvial multivalued dependencies A->->B and A->->C violate 4NF. We must separate out the attributes of these dependencies, first decomposing into AB and ACD, and then decomposing the latter into AC and AD because A->->C is still a 4NF violation for ACD. The final set of relations are AB, AC, and AD.Exercise 3.7.7(a)Let W be the set of attributes not in X, Y, or Z. Consider two tuples xyzw and xy'z'w' in the relation R in question. Because X ->-> Y, we can swap the y's, so xy'zw and xyz'w' are in R. Because X ->-> Z, we can take the pair of tuples xyzw and xyz'w' and swap Z's to get xyz'w and xyzw'. Similarly, we can take the pair xy'z'w' and xy'zw and swap Z's to get xy'zw' and xy'z'w.In conclusion, we started with tuples xyzw and xy'z'w' and showed that xyzw' and xy'z'w must also be in the relation. That is exactly the statement of the MVD X ->-> Y-union-Z. Note that the above statements all make sense even if there are attributes in common among X, Y, and Z.Exercise 3.7.8(a)Consider a relation R with schema ABCD and the instance with four tuples abcd, abcd', ab'c'd, and ab'c'd'. This instance satisfies the MVD A ->-> BC. However, it does not satisfy A ->-> B. For example, if it did satisfy A ->-> B, then because the instance contains the tuples abcd and ab'c'd, we would expect it to contain abc'd and ab'cd, neither of which is in the instance.Solutions for Chapter 4Solutions for Section 4.2Exercise 4.2.1class Customer {attribute string name;attribute string addr;attribute string phone;attribute integer ssNo;relationship Set<Account> ownsAcctsinverse Account::ownedBy;}class Account {attribute integer number;attribute string type;attribute real balance;relationship Set<Customer> ownedByinverse Customer::ownsAccts}Exercise 4.2.4class Person {attribute string name;relationship Person motherOfinverse Person::childrenOfFemalerelationship Person fatherOfinverse Person::childrenOfMalerelationship Set<Person> childreninverse Person::parentsOfrelationship Set<Person> childrenOfFemaleinverse Person::motherOfrelationship Set<Person> childrenOfMaleinverse Person::fatherOfrelationship Set<Person> parentsOfinverse Person::children}Notice that there are six different relationships here. For example, the inverse of the relationship that connects a person to their (unique) mother is a relationship that connects a mother (i.e., a female person) to the set of her children. That relationship, which we call childrenOfFemale, is different from the children relationship, which connects anyone -- male or female -- to their children.Exercise 4.2.7A relationship R is its own inverse if and only if for every pair (a,b) in R, the pair (b,a) is also in R. In the terminology of set theory, the relation R is ``symmetric.''Solutions for Section 4.3Exercise 4.3.1We think that Social Security number should me the key for Customer, and account number should be the key for Account. Here is the ODL solution with key and extent declarations.class Customer(extent Customers key ssNo){attribute string name;attribute string addr;attribute string phone;attribute integer ssNo;relationship Set<Account> ownsAcctsinverse Account::ownedBy;}class Account(extent Accounts key number){attribute integer number;attribute string type;attribute real balance;relationship Set<Customer> ownedByinverse Customer::ownsAccts}Solutions for Section 4.4Exercise 4.4.1(a)Since the relationship between customers and accounts is many-many, we should create a separate relation from that relationship-pair.Customers(ssNo, name, address, phone)Accounts(number, type, balance)CustAcct(ssNo, number)Exercise 4.4.1(d)Ther is only one attribute, but three pairs of relationships from Person to itself. Since motherOf and fatherOf are many-one, we can store their inverses in the relation for Person. That is, for each person, childrenOfMale and childrenOfFemale will indicate that persons's father and mother. The children relationship is many-many, and requires its own relation. This relation actually turns out to be redundant, in the sense that its tuples can be deduced from the relationships stored with Person. The schema:Persons(name, childrenOfFemale, childrenOfMale)Parent-Child(parent, child)Exercise 4.4.4You get a schema like:Studios(name, address, ownedMovie)Since name -> address is the only FD, the key is {name, ownedMovie}, and the FD has a left side that is not a superkey.Exercise 4.4.5(a,b,c)(a) Struct Card { string rank, string suit };(b) class Hand {attribute Set theHand;};For part (c) we have:Hands(handId, rank, suit)Notice that the class Hand has no key, so we need to create one: handID. Each hand has, in the relation Hands, one tuple for each card in the hand.Exercise 4.4.5(e)Struct PlayerHand { string Player, Hand theHand };class Deal {attribute Set theDeal;}Alternatively, PlayerHand can be defined directly within the declaration of attribute theDeal. Exercise 4.4.5(h)Since keys for Hand and Deal are lacking, a mechanical way to design the database schema is to have one relation connecting deals and player-hand pairs, and another to specify the contents of hands. That is:Deals(dealID, player, handID)Hands(handID, rank, suit)However, if we think about it, we can get rid of handID and connect the deal and the player directly to the player's cards, as:Deals(dealID, player, rank, suit)Exercise 4.4.5(i)First, card is really a pair consisting of a suit and a rank, so we need two attributes in a relation schema to represent cards. However, much more important is the fact that the proposed schema does not distinguish which card is in which hand. Thus, we need another attribute that indicates which hand within the deal a card belongs to, something like:Deals(dealID, handID, rank, suit)Exercise 4.4.6(c)Attribute b is really a bag of (f,g) pairs. Thus, associated with each a-value will be zero or more (f,g) pairs, each of which can occur several times. We shall use an attribute count to indicate the number of occurrences, although if relations allow duplicate tuples we could simply allow duplicate (a,f,g) triples in the relation. The proposed schema is:C(a, f, g, count)Solutions for Section 4.5Exercise 4.5.1(b)Studios(name, address, movies{(title, year, inColor, length,stars{(name, address, birthdate)})})Since the information about a star is repeated once for each of their movies, there is redundancy. To eliminate it, we have to use a separate relation for stars and use pointers from studios. That is: Stars(name, address, birthdate)Studios(name, address, movies{(title, year, inColor, length,stars{*Stars})})Since each movie is owned by one studio, the information about a movie appears in only one tuple of Studios, and there is no redundancy.Exercise 4.5.2Customers(name, address, phone, ssNo, accts{*Accounts})Accounts(number, type, balance, owners{*Customers})Solutions for Section 4.6Exercise 4.6.1(a)We need to add new nodes labeled George Lucas and Gary Kurtz. Then, from the node sw (which represents the movie Star Wars), we add arcs to these two new nodes, labeled directedBy and producedBy, respectively.Exercise 4.6.2Create nodes for each account and each customer. From each customer node is an arc to a node representing the attributes of the customer, e.g., an arc labeled name to the customer's name. Likewise, there is an arc from each account node to each attribute of that account, e.g., an arc labeled balance to the value of the balance.To represent ownership of accounts by customers, we place an arc labeled owns from each customer node to the node of each account that customer holds (possibly jointly). Also, we placean arc labeled ownedBy from each account node to the customer node for each owner of that account.Exercise 4.6.5In the semistructured model, nodes represent data elements, i.e., entities rather than entity sets. In the E/R model, nodes of all types represent schema elements, and the data is not represented at all. Solutions for Section 4.7Exercise 4.7.1(a)<STARS-MOVIES><STAR starId = "cf" starredIn = "sw, esb, rj"><NAME>Carrie Fisher</NAME><ADDRESS><STREET>123 Maple St.</STREET><CITY>Hollywood</CITY></ADDRESS><ADDRESS><STREET>5 Locust Ln.</STREET><CITY>Malibu</CITY></ADDRESS></STAR><STAR starId = "mh" starredIn = "sw, esb, rj"><NAME>Mark Hamill</NAME><ADDRESS><STREET>456 Oak Rd.<STREET><CITY>Brentwood</CITY></ADDRESS></STAR><STAR starId = "hf" starredIn = "sw, esb, rj, wit"><NAME>Harrison Ford</NAME><ADDRESS><STREET>whatever</STREET><CITY>whatever</CITY></ADDRESS></STAR><MOVIE movieId = "sw" starsOf = "cf, mh"><TITLE>Star Wars</TITLE><YEAR>1977</YEAR></MOVIE><MOVIE movieId = "esb" starsOf = "cf, mh"><TITLE>Empire Strikes Back</TITLE><YEAR>1980</YEAR></MOVIE><MOVIE movieId = "rj" starsOf = "cf, mh"><TITLE>Return of the Jedi</TITLE><YEAR>1983</YEAR></MOVIE><MOVIE movieID = "wit" starsOf = "hf"><TITLE>Witness</TITLE><YEAR>1985</YEAR></MOVIE></STARS-MOVIES>Exercise 4.7.2<!DOCTYPE Bank [<!ELEMENT BANK (CUSTOMER* ACCOUNT*)><!ELEMENT CUSTOMER (NAME, ADDRESS, PHONE, SSNO)><!A TTLIST CUSTOMERcustId IDowns IDREFS><!ELEMENT NAME (#PCDATA)><!ELEMENT ADDRESS (#PCDA TA)><!ELEMENT PHONE (#PCDATA)><!ELEMENT SSNO (#PCDA TA)><!ELEMENT ACCOUNT (NUMBER, TYPE, BALANCE)><!A TTLIST ACCOUNTacctId IDownedBy IDREFS><!ELEMENT NUMBER (#PCDA TA)><!ELEMENT TYPE (#PCDA TA)><!ELEMENT BALANCE (#PCDATA)>]>BookSolutions for Chapter 5Solutions for Section 5.2Exercise 5.2.1(a)PI_model( SIGMA_{speed >= 1000} ) (PC)Exercise 5.2.1(f)The trick is to theta-join PC with itself on the condition that the hard disk sizes are equal. That gives us tuples that have two PC model numbers with the same value of hd. However, these two PC's could in fact be the same, so we must also require in the theta-join that the model numbers be unequal. Finally, we want the hard disk sizes, so we project onto hd.The expression is easiest to see if we write it using some temporary values. We start by renaming PC twice so we can talk about two occurrences of the same attributes.R1 = RHO_{PC1} (PC)R2 = RHO_{PC2} (PC)R3 = R1 JOIN_{PC1.hd = PC2.hd AND PC1.model <> PC2.model} R2R4 = PI_{PC1.hd} (R3)Exercise 5.2.1(h)First, we find R1, the model-speed pairs from both PC and Laptop. Then, we find from R1 those computers that are ``fast,'' at least 133Mh. At the same time, we join R1 with Product to connect model numbers to their manufacturers and we project out the speed to get R2. Then we join R2 with itself (after renaming) to find pairs of different models by the same maker. Finally, we get our answer, R5, by projecting onto one of the maker attributes. A sequence of steps giving the desired expression is: R1 = PI_{model,speed} (PC) UNION PI_{model,speed} (Laptop)R2 = PI_{maker,model} (SIGMA_{speed>=700} (R1) JOIN Product)R3 = RHO_{T(maker2, model2)} (R2)R4 = R2 JOIN_{maker = maker2 AND model <> model2} (R3)R5 = PI_{maker} (R4)Exercise 5.2.2Here are figures for the expression trees of Exercise 5.2.1 Part (a)Part (f)Part (h). Note that the third figure is not really a tree, since it uses a common subexpression. We could duplicate the nodes to make it a tree, but using common subexpressions is a valuable form of query optimization. One of the benefits one gets from constructing ``trees'' for queries is the ability to combine nodes that represent common subexpressions.Exercise 5.2.7The relation that results from the natural join has only one attribute from each pair of equated attributes. The theta-join has attributes for both, and their columns are identical.Exercise 5.2.9(a)If all the tuples of R and S are different, then the union has n+m tuples, and this number is the maximum possible.The minimum number of tuples that can appear in the result occurs if every tuple of one relation also appears in the other. Surely the union has at least as many tuples as the larger of R and that is, max(n,m) tuples. However, it is possible for every tuple of the smaller to appear in the other, so it is possible that there are as few as max(n,m) tuples in the union.Exercise 5.2.10In the following we use the name of a relation both as its instance (set of tuples) and as its schema (set of attributes). The context determines uniquely which is meant.PI_R(R JOIN S) Note, however, that this expression works only for sets; it does not preserve the multipicity of tuples in R. The next two expressions work for bags.R JOIN DELTA(PI_{R INTERSECT S}(S)) In this expression, each projection of a tuple from S onto the attributes that are also in R appears exactly once in the second argument of the join, so it preserves multiplicity of tuples in R, except for those thatdo not join with S, which disappear. The DELTA operator removes duplicates, as described in Section 5.4.R - [R - PI_R(R JOIN S)] Here, the strategy is to find the dangling tuples of R and remove them.Solutions for Section 5.3Exercise 5.3.1As a bag, the value is {700, 1500, 866, 866, 1000, 1300, 1400, 700, 1200, 750, 1100, 350, 733}. The order is unimportant, of course. The average is 959.As a set, the value is {700, 1500, 866, 1000, 1300, 1400, 1200, 750, 1100, 350, 733}, and the average is 967. H3>Exercise 5.3.4(a)As sets, an element x is in the left-side expression(R UNION S) UNION Tif and only if it is in at least one of R, S, and T. Likewise, it is in the right-side expressionR UNION (S UNION T)under exactly the same conditions. Thus, the two expressions have exactly the same members, and the sets are equal.As bags, an element x is in the left-side expression as many times as the sum of the number of times it is in R, S, and T. The same holds for the right side. Thus, as bags the expressions also have the same value.Exercise 5.3.4(h)As sets, element x is in the left sideR UNION (S INTERSECT T)if and only if x is either in R or in both S and T. Element x is in the right side(R UNION S) INTERSECT (R UNION T)if and only if it is in both R UNION S and R UNION T. If x is in R, then it is in both unions. If x is in both S and T, then it is in both union. However, if x is neither in R nor in both of S and T, then it cannot be in both unions. For example, suppose x is not in R and not in S. Then x is not in R UNION S. Thus, the statement of when x is in the right side is exactly the same as when it is in the left side: x is either in R or in both of S and T.Now, consider the expression for bags. Element x is in the left side the sum of the number of times it is in R plus the smaller of the number of times x is in S and the number of times x is in T. Likewise, the number of times x is in the right side is the smaller ofThe sum of the number of times x is in R and in S.The sum of the number of times x is in R and in T.A moment's reflection tells us that this minimum is the sum of the number of times x is in R plus the smaller of the number of times x is in S and in T, exactly as for the left side.Exercise 5.3.5(a)For sets, we observe that element x is in the left side(R INTERSECT S) - T。
数据库第二章课后习题解答
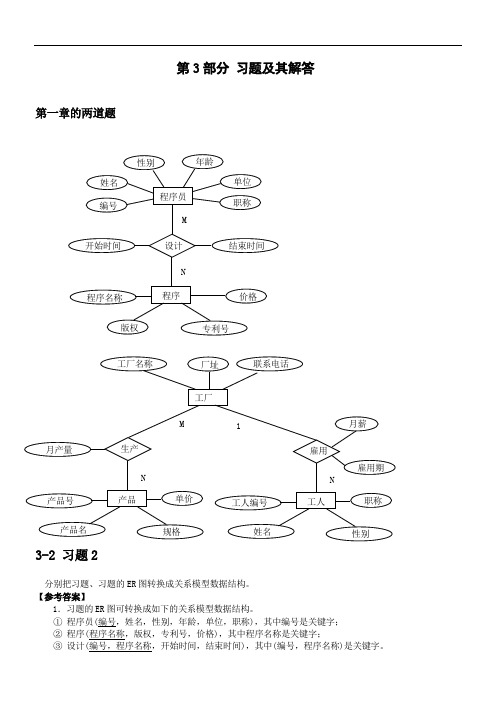
第3部分习题及其解答第一章的两道题3-2 习题2分别把习题、习题的ER图转换成关系模型数据结构。
【参考答案】1.习题的ER图可转换成如下的关系模型数据结构。
①程序员(编号,姓名,性别,年龄,单位,职称),其中编号是关键字;②程序(程序名称,版权,专利号,价格),其中程序名称是关键字;③设计(编号,程序名称,开始时间,结束时间),其中(编号,程序名称)是关键字。
2.习题的ER 图可转换成如下的关系模型数据结构。
① 工厂(工厂名称,厂址,联系电话),其中工厂名称是关键字; ② 产品(产品号,产品名,规格,单价),其中产品号是关键字;③ 工人(工人编号,姓名,性别,职称,工厂名称,雇用期,月薪),其中工人编号是关键字,工厂名称是外关键字,雇用期和月薪是联系属性;④ 生产(工厂名称,产品号,月产量),其中(工厂名称,产品号)是关键字,生产关系是表示联系的。
判断下列情况,分别指出它们具体遵循那一类完整性约束规则1.用户写一条语句明确指定月份数据在1~12之间有效。
2.关系数据库中不允许主键值为空的元组存在。
3.从A 关系的外键出发去找B 关系中的记录,必须能找到。
【解答】1.用户用语句指定月份数据在1~12之间有效,遵循用户定义的完整性约束规则。
2.关系数据库中不允许主键值为空的元组存在,遵循实体完整性约束规则;3.从A 关系的外键出发去找B 关系的记录,必须能找到,遵循引用完整性约束规则。
判断下列情况,分别指出他们是用DML 还是用DDL 来完成下列操作1.创建“学生”表结构。
2.对“学生”表中的学号属性,其数据类型由“整型”修改为“字符型”。
3.把“学生”表中学号“021”修改为“025”。
【解答】1.创建“学生”表结构,即定义一个关系模式,用DDL 完成。
2.修改“学生”表中学号属性的数据类型,即修改关系模式的定义,用DDL 完成。
3.修改“学生”表中学号属性的数据值,即对表中的数据进行操作,用DML 完成。
数据库第2章习题(答案)

第二章习题一、单项选择题1、对关系模式的任何属性:A:不可再分B:可再分C:命名在该关系模式中可以不唯一D:以上都不是答案:A2、在关系R(R#,RN,S#)和S(S#,SN,SD)中,R的主键是R#,S的主键是S#,则S#在R中称为:A:外键B:候选键C:主键D:以上都不是答案:A3、取出关系的某些列,并取消重复元组的关系代数运算称为:A:取列运算B:投影运算C:连接运算D:选择运算答案:B4、关系数据库管理系统应能实现的专门关系运算包括:A:排序、索引、统计B:选择、投影、连接C:关联、更新、排序D:显示、打印、制表答案:B5、根据关系模式的实体完整性规则,一个关系的“主键”:A:不能有两个B:不能成为另一个关系的外键C:不允许为空D:可以取值答案:C6、参加差运算的两个关系:A:属性个数可以不相同B:属性个数必须相同C:一个关系包含另一个关系的属性D:属性名必须相同答案:B7、在基本的关系中,下列说法是正确的()。
A:行列顺序有关B:属性名允许重名C:任意两个元组不允许重复D:列是非同质的答案:C8、σ4<‘4’(S)表示()。
A.从S关系中挑选4的值小于第4个分量的元组B.从S关系中挑选第4个分量值小于4的元组C.从S关系中挑选第4个分量值小于第4个分量的元组D.σ4<‘4’(S)是向关系垂直方向运算答案:B9、在连接运算中如果两个关系中进行比较的分量必须是相同的属性组,那么这个连接是:A:有条件的连接B:等值连接C:自然连接D:完全连接答案:C10、关系R与S做连接运算,选取R中A的属性值和S中B的属性值相等的那些元组,则R与S的连接是:A:有条件的连接B:等值连接C:自然连接D:完全连接答案:B11、关系a1的象集是:A:{(b1), (c1), (d1) } B:{(b1, c1), (b2, c3) }C:{(b1, c1, d1), (b2, c3, d4) } D:{(a1, b1, c1, d1), (a1, b2, c3, d4) }答案:C12、关系(a3,b1)的象集是:A:{(d2), (d4) } B:{(c2), (c3) }C:{(c2, d2), (c3, d4) } D:{(b1, c2, d2), (b1, c3, d4) }答案:C13、在通常情况下,下面的关系中不可以作为关系数据库的关系是:A:R1(学生号,学生名,性别) B:R2(学生号,学生名,班级号)C:R3(学生号,学生名,宿舍名) D:R4(学生号,学生名,简历)答案:D14、“年龄在15至30岁之间”这种约束属于DBS的()功能。
数据库系统基础教程(第二版)课后习题答案2

Database Systems: The Complete BookSolutions for Chapter 2Solutions for Section 2.1Exercise 2.1.1The E/R Diagram.Exercise 2.1.8(a)The E/R DiagramKobvxybzSolutions for Section 2.2Exercise 2.2.1The Addresses entity set is nothing but a single address, so we would prefer to make address an attribute of Customers. Were the bank to record several addresses for a customer, then it might make sense to have an Addresses entity set and make Lives-at a many-many relationship.The Acct-Sets entity set is useless. Each customer has a unique account set containing his or her accounts. However, relating customers directly to their accounts in a many-many relationship conveys the same information and eliminates the account-set concept altogether.Solutions for Section 2.3Exercise 2.3.1(a)Keys ssNo and number are appropriate for Customers and Accounts, respectively. Also, we think it does not make sense for an account to be related to zero customers, so we should round the edge connecting Owns to Customers. It does not seem inappropriate to have a customer with 0 accounts;they might be a borrower, for example, so we put no constraint on the connection from Owns to Accounts. Here is the The E/R Diagram,showing underlined keys andthe numerocity constraint.Exercise 2.3.2(b)If R is many-one from E1 to E2, then two tuples (e1,e2) and (f1,f2) of the relationship set for R must be the same if they agree on the key attributes for E1. To see why, surely e1 and f1 are the same. Because R is many-one from E1 to E2, e2 and f2 must also be the same. Thus, the pairs are the same.Solutions for Section 2.4Exercise 2.4.1Here is the The E/R Diagram.We have omitted attributes other than our choice for the key attributes of Students and Courses. Also omitted are names for the relationships. Attribute grade is not part of the key for Enrollments. The key for Enrollements is studID from Students and dept and number from Courses.Exercise 2.4.4bHere is the The E/R Diagram Again, we have omitted relationship names and attributes other than our choice for the key attributes. The key for Leagues is its own name; this entity set is not weak. The key for Teams is its own name plus the name of the league of which the team is a part, e.g., (Rangers, MLB) or (Rangers, NHL). The key for Players consists of the player's number and the key for the team on which he or she plays. Since the latter key is itself a pair consisting of team and league names, the key for players is the triple (number, teamName, leagueName). e.g., JeffGarcia is (5, 49ers, NFL).Database Systems: The Complete BookSolutions for Chapter 3Solutions for Section 3.1Exercise 3.1.2(a)We can order the three tuples in any of 3! = 6 ways. Also, the columns can be ordered in any of 3! = 6 ways. Thus, the number of presentations is 6*6 = 36.Solutions for Section 3.2Exercise 3.2.1Customers(ssNo, name, address, phone)Flights(number, day, aircraft)Bookings(ssNo, number, day, row, seat)Being a weak entity set, Bookings' relation has the keys for Customers and Flights and Bookings' own attributes.Notice that the relations obtained from the toCust and toFlt relationships are unnecessary. They are:toCust(ssNo, ssNo1, number, day)toFlt(ssNo, number, day, number1, day1)That is, for toCust, the key of Customers is paired with the key for Bookings. Since both include ssNo, this attribute is repeated with two different names, ssNo and ssNo1. A similar situation exists for toFlt.Exercise 3.2.3Ships(name, yearLaunched)SisterOf(name, sisterName)Solutions for Section 3.3Exercise 3.3.1Since Courses is weak, its key is number and the name of its department. We do not have arelation for GivenBy. In part (a), there is a relation for Courses and a relation for LabCourses that has only the key and the computer-allocation attribute. It looks like:Depts(name, chair)Courses(number, deptName, room)LabCourses(number, deptName, allocation)For part (b), LabCourses gets all the attributes of Courses, as:Depts(name, chair)Courses(number, deptName, room)LabCourses(number, deptName, room, allocation)And for (c), Courses and LabCourses are combined, as:Depts(name, chair)Courses(number, deptName, room, allocation)Exercise 3.3.4(a)There is one relation for each entity set, so the number of relations is e. The relation for the root entity set has a attributes, while the other relations, which must include the key attributes, have a+k attributes.Solutions for Section 3.4Exercise 3.4.2Surely ID is a key by itself. However, we think that the attributes x, y, and z together form another key. The reason is that at no time can two molecules occupy the same point.Exercise 3.4.4The key attributes are indicated by capitalization in the schema below:Customers(SSNO, name, address, phone)Flights(NUMBER, DAY, aircraft)Bookings(SSNO, NUMBER, DAY, row, seat)Exercise 3.4.6(a)The superkeys are any subset that contains A1. Thus, there are 2^{n-1} such subsets, since each of the n-1 attributes A2 through An may independently be chosen in or out.Solutions for Section 3.5Exercise 3.5.1(a)We could try inference rules to deduce new dependencies until we are satisfied we have them all.A more systematic way is to consider the closures of all 15 nonempty sets of attributes.For the single attributes we have A+ = A, B+ = B, C+ = ACD, and D+ = AD. Thus, the only new dependency we get with a single attribute on the left is C->A.Now consider pairs of attributes:AB+ = ABCD, so we get new dependency AB->D. AC+ = ACD, and AC->D is nontrivial. AD+ = AD, so nothing new. BC+ = ABCD, so we get BC->A, and BC->D. BD+ = ABCD, giving usBD->A and BD->C. CD+ = ACD, giving CD->A.For the triples of attributes, ACD+ = ACD, but the closures of the other sets are each ABCD. Thus, we get new dependencies ABC->D, ABD->C, and BCD->A.Since ABCD+ = ABCD, we get no new dependencies.The collection of 11 new dependencies mentioned above is: C->A, AB->D, AC->D, BC->A, BC->D, BD->A, BD->C, CD->A, ABC->D, ABD->C, and BCD->A.Exercise 3.5.1(b)From the analysis of closures above, we find that AB, BC, and BD are keys. All other sets either do not have ABCD as the closure or contain one of these three sets.Exercise 3.5.1(c)The superkeys are all those that contain one of those three keys. That is, a superkey that is not a key must contain B and more than one of A, C, and D. Thus, the (proper) superkeys are ABC, ABD, BCD, and ABCD.Exercise 3.5.3(a)We must compute the closure of A1A2...AnC. Since A1A2...An->B is a dependency, surely B is in this set, proving A1A2...AnC->B.Exercise 3.5.4(a)Consider the relationThis relation satisfies A->B but does not satisfy B->A.Exercise 3.5.8(a)If all sets of attributes are closed, then there cannot be any nontrivial functional dependenc ies. For suppose A1A2...An->B is a nontrivial dependency. Then A1A2...An+ contains B and thus A1A2...An is not closed.Exercise 3.5.10(a)We need to compute the closures of all subsets of {ABC}, although there is no need to think about the empty set or the set of all three attributes. Here are the calculations for the remaining six sets: A+ = AB+ = BC+ = ACEAB+ = ABCDEAC+ = ACEBC+ = ABCDEWe ignore D and E, so a basis for the resulting functional dependencies for ABC are: C->A and AB->C. Note that BC->A is true, but follows logically from C->A, and therefore may be omitted from our list.Solutions for Section 3.6Exercise 3.6.1(a)In the solution to Exercise 3.5.1 we found that there are 14 nontrivial dependencies, including the three given ones and 11 derived dependencies. These are: C->A, C->D, D->A, AB->D, AB-> C, AC->D, BC->A, BC->D, BD->A, BD->C, CD->A, ABC->D, ABD->C, and BCD->A.We also learned that the three keys were AB, BC, and BD. Thus, any dependency above that does not have one of these pairs on the left is a BCNF violation. These are: C->A, C->D, D->A, AC->D, and CD->A.One choice is to decompose using C->D. That gives us ABC and CD as decomposed relations. CD is surely in BCNF, since any two-attribute relation is. ABC is not in BCNF, since AB and BC are its only keys, but C->A is a dependency that holds in ABCD and therefore holds in ABC. We must further decompose ABC into AC and BC. Thus, the three relations of the decomposition are AC, BC, and CD.Since all attributes are in at least one key of ABCD, that relation is already in 3NF, and no decomposition is necessary.Exercise 3.6.1(b)(Revised 1/19/02) The only key is AB. Thus, B->C and B->D are both BCNF violations. The derived FD's BD->C and BC->D are also BCNF violations. However, any other nontrivial, derived FD will have A and B on the left, and therefore will contain a key.One possible BCNF decomposition is AB and BCD. It is obtained starting with any of the four violations mentioned above. AB is the only key for AB, and B is the only key for BCD.Since there is only one key for ABCD, the 3NF violations are the same, and so is the decomposition.Solutions for Section 3.7Exercise 3.7.1Since A->->B, and all the tuples have the same value for attribute A, we can pair the B-value from any tuple with the value of the remaining attribute C from any other tuple. Thus, we know that R must have at least the nine tuples of the form (a,b,c), where b is any of b1, b2, or b3, and c is any of c1, c2, or c3. That is, we can derive, using the definition of a multivalued dependency, that each of the tuples (a,b1,c2), (a,b1,c3), (a,b2,c1), (a,b2,c3), (a,b3,c1), and (a,b3,c2) are also in R.Exercise 3.7.2(a)First, people have unique Social Security numbers and unique birthdates. Thus, we expect the functional dependencies ssNo->name and ssNo->birthdate hold. The same applies to children, so we expect childSSNo->childname and childSSNo->childBirthdate. Finally, an automobile has a unique brand, so we expect autoSerialNo->autoMake.There are two multivalued dependencies that do not follow from these functional dependencies. First, the information about one child of a person is independent of other information about that person. That is, if a person with social security number s has a tuple with cn,cs,cb, then if there isany other tuple t for the same person, there will also be another tuple that agrees with t except that it has cn,cs,cb in its components for the child name, Social Security number, and birthdate. That is the multivalued dependencyssNo->->childSSNo childName childBirthdateSimilarly, an automobile serial number and make are independent of any of the other attributes, so we expect the multivalued dependencyssNo->->autoSerialNo autoMakeThe dependencies are summarized below:ssNo -> name birthdatechildSSNo -> childName childBirthdateautoSerialNo -> autoMakessNo ->-> childSSNo childName childBirthdatessNo ->-> autoSerialNo autoMakeExercise 3.7.2(b)We suggest the relation schemas{ssNo, name, birthdate}{ssNo, childSSNo}{childSSNo, childName childBirthdate}{ssNo, autoSerialNo}{autoSerialNo, autoMake}An initial decomposition based on the two multivalued dependencies would give us {ssNo, name, birthDate}{ssNo, childSSNo, childName, childBirthdate}{ssNo, autoSerialNo, autoMake}Functional dependencies force us to decompose the second and third of these.Exercise 3.7.3(a)Since there are no functional dependencies, the only key is all four attributes, ABCD. Thus, each of the nontrvial multivalued dependencies A->->B and A->->C violate 4NF. We must separate out the attributes of these dependencies, first decomposing into AB and ACD, and then decomposing the latter into AC and AD because A->->C is still a 4NF violation for ACD. The final set of relations are AB, AC, and AD.Exercise 3.7.7(a)Let W be the set of attributes not in X, Y, or Z. Consider two tuples xyzw and xy'z'w' in the relation R in question. Because X ->-> Y, we can swap the y's, so xy'zw and xyz'w' are in R. Because X ->-> Z, we can take the pair of tuples xyzw and xyz'w' and swap Z's to get xyz'w and xyzw'. Similarly, we can take the pair xy'z'w' and xy'zw and swap Z's to get xy'zw' and xy'z'w.In conclusion, we started with tuples xyzw and xy'z'w' and showed that xyzw' and xy'z'w must also be in the relation. That is exactly the statement of the MVD X ->-> Y-union-Z. Note that the above statements all make sense even if there are attributes in common among X, Y, and Z.Exercise 3.7.8(a)Consider a relation R with schema ABCD and the instance with four tuples abcd, abcd', ab'c'd, and ab'c'd'. This instance satisfies the MVD A->-> BC. However, it does not satisfy A->-> B. For example, if it did satisfy A->-> B, then because the instance contains the tuples abcd and ab'c'd, we would expect it to contain abc'd and ab'cd, neither of which is in the instance.Database Systems: The Complete BookSolutions for Chapter 4Solutions for Section 4.2Exercise 4.2.1class Customer {attribute string name;attribute string addr;attribute string phone;attribute integer ssNo;relationship Set<Account> ownsAcctsinverse Account::ownedBy;}class Account {attribute integer number;attribute string type;attribute real balance;relationship Set<Customer> ownedByinverse Customer::ownsAccts}Exercise 4.2.4class Person {attribute string name;relationship Person motherOfinverse Person::childrenOfFemalerelationship Person fatherOfinverse Person::childrenOfMalerelationship Set<Person> childreninverse Person::parentsOfrelationship Set<Person> childrenOfFemaleinverse Person::motherOfrelationship Set<Person> childrenOfMaleinverse Person::fatherOfrelationship Set<Person> parentsOfinverse Person::children}Notice that there are six different relationships here. For example, the inverse of the relationship that connects a person to their (unique) mother is a relationship that connects a mother (i.e., a female person) to the set of her children. That relationship, which we call childrenOfFemale, is different from the children relationship, which connects anyone -- male or female -- to their children.Exercise 4.2.7A relationship R is its own inverse if and only if for every pair (a,b) in R, the pair (b,a) is also in R. In the terminology of set theory, the relation R is ``symmetric.''Solutions for Section 4.3Exercise 4.3.1We think that Social Security number should me the key for Customer, and account number should be the key for Account. Here is the ODL solution with key and extent declarations.class Customer(extent Customers key ssNo){attribute string name;attribute string addr;attribute string phone;attribute integer ssNo;relationship Set<Account> ownsAcctsinverse Account::ownedBy;}class Account(extent Accounts key number){attribute integer number;attribute string type;attribute real balance;relationship Set<Customer> ownedByinverse Customer::ownsAccts}Solutions for Section 4.4Exercise 4.4.1(a)Since the relationship between customers and accounts is many-many, we should create a separate relation from that relationship-pair.Customers(ssNo, name, address, phone)Accounts(number, type, balance)CustAcct(ssNo, number)Exercise 4.4.1(d)Ther is only one attribute, but three pairs of relationships from Person to itself. Since motherOf and fatherOf are many-one, we can store their inverses in the relation for Person. That is, for each person, childrenOfMale and childrenOfFemale will indicate that persons's father and mother. The children relationship is many-many, and requires its own relation. This relation actually turns out to be redundant, in the sense that its tuples can be deduced from the relationships stored with Person. The schema:Persons(name, childrenOfFemale, childrenOfMale)Parent-Child(parent, child)Exercise 4.4.4Y ou get a schema like:Studios(name, address, ownedMovie)Since name -> address is the only FD, the key is {name, ownedMovie}, and the FD has a left side that is not a superkey.Exercise 4.4.5(a,b,c)(a) Struct Card { string rank, string suit };(b) class Hand {attribute Set theHand;};For part (c) we have:Hands(handId, rank, suit)Notice that the class Hand has no key, so we need to create one: handID. Each hand has, in the relation Hands, one tuple for each card in the hand.Exercise 4.4.5(e)Struct PlayerHand { string Player, Hand theHand };class Deal {attribute Set theDeal;}Alternatively, PlayerHand can be defined directly within the declaration of attribute theDeal. Exercise 4.4.5(h)Since keys for Hand and Deal are lacking, a mechanical way to design the database schema is to have one relation connecting deals and player-hand pairs, and another to specify the contents of hands. That is:Deals(dealID, player, handID)Hands(handID, rank, suit)However, if we think about it, we can get rid of handID and connect the deal and the player directly to the player's cards, as:Deals(dealID, player, rank, suit)Exercise 4.4.5(i)First, card is really a pair consisting of a suit and a rank, so we need two attributes in a relation schema to represent cards. However, much more important is the fact that the proposed schema does not distinguish which card is in which hand. Thus, we need another attribute that indicates which hand within the deal a card belongs to, something like:Deals(dealID, handID, rank, suit)Exercise 4.4.6(c)Attribute b is really a bag of (f,g) pairs. Thus, associated with each a-value will be zero or more (f,g) pairs, each of which can occur several times. We shall use an attribute count to indicate the number of occurrences, although if relations allow duplicate tuples we could simply allow duplicate (a,f,g) triples in the relation. The proposed schema is:C(a, f, g, count)Solutions for Section 4.5Exercise 4.5.1(b)Studios(name, address, movies{(title, year, inColor, length,stars{(name, address, birthdate)})})Since the information about a star is repeated once for each of their movies, there is redundancy. To eliminate it, we have to use a separate relation for stars and use pointers from studios. That is: Stars(name, address, birthdate)Studios(name, address, movies{(title, year, inColor, length,stars{*Stars})})Since each movie is owned by one studio, the information about a movie appears in only one tuple of Studios, and there is no redundancy.Exercise 4.5.2Customers(name, address, phone, ssNo, accts{*Accounts})Accounts(number, type, balance, owners{*Customers})Solutions for Section 4.6Exercise 4.6.1(a)We need to add new nodes labeled George Lucas and Gary Kurtz. Then, from the node sw (which represents the movie Star Wars), we add arcs to these two new nodes, labeled direc tedBy and producedBy, respectively.Exercise 4.6.2Create nodes for each account and each customer. From each customer node is an arc to a node representing the attributes of the customer, e.g., an arc labeled name to the customer's name. Likewise, there is an arc from each account node to each attribute of that account, e.g., an arc labeled balance to the value of the balance.To represent ownership of accounts by customers, we place an arc labeled owns from each customer node to the node of each account that customer holds (possibly jointly). Also, we placean arc labeled ownedBy from each account node to the customer node for each owner of that account.Exercise 4.6.5In the semistructured model, nodes represent data elements, i.e., entities rather than entity sets. In the E/R model, nodes of all types represent schema elements, and the data is not represented at all. Solutions for Section 4.7Exercise 4.7.1(a)<STARS-MOVIES><STAR starId = "cf" starredIn = "sw, esb, rj"><NAME>Carrie Fisher</NAME><ADDRESS><STREET>123 Maple St.</STREET><CITY>Hollywood</CITY></ADDRESS><ADDRESS><STREET>5 Locust Ln.</STREET><CITY>Malibu</CITY></ADDRESS></STAR><STAR starId = "mh" starredIn = "sw, esb, rj"><NAME>Mark Hamill</NAME><ADDRESS><STREET>456 Oak Rd.<STREET><CITY>Brentwood</CITY></ADDRESS></STAR><STAR starId = "hf" starredIn = "sw, esb, rj, wit"><NAME>Harrison Ford</NAME><ADDRESS><STREET>whatever</STREET><CITY>whatever</CITY></ADDRESS></STAR><MOVIE movieId = "sw" starsOf = "cf, mh"><TITLE>Star Wars</TITLE><YEAR>1977</YEAR></MOVIE><MOVIE movieId = "esb" starsOf = "cf, mh"><TITLE>Empire Strikes Back</TITLE><YEAR>1980</YEAR></MOVIE><MOVIE movieId = "rj" starsOf = "cf, mh"><TITLE>Return of the Jedi</TITLE><YEAR>1983</YEAR></MOVIE><MOVIE movieID = "wit" starsOf = "hf"><TITLE>Witness</TITLE><YEAR>1985</YEAR></MOVIE></STARS-MOVIES>Exercise 4.7.2<!DOCTYPE Bank [<!ELEMENT BANK (CUSTOMER* ACCOUNT*)><!ELEMENT CUSTOMER (NAME, ADDRESS, PHONE, SSNO)> <!A TTLIST CUSTOMERcustId IDowns IDREFS><!ELEMENT NAME (#PCDA TA)><!ELEMENT ADDRESS (#PCDA TA)><!ELEMENT PHONE (#PCDA TA)><!ELEMENT SSNO (#PCDA TA)><!ELEMENT ACCOUNT (NUMBER, TYPE, BALANCE)><!A TTLIST ACCOUNTacctId IDownedBy IDREFS><!ELEMENT NUMBER (#PCDA TA)><!ELEMENT TYPE (#PCDA TA)><!ELEMENT BALANCE (#PCDA TA)>]>Database Systems: The CompleteBookSolutions for Chapter 5Solutions for Section 5.2Exercise 5.2.1(a)PI_model( SIGMA_{speed >= 1000} ) (PC)Exercise 5.2.1(f)The trick is to theta-join PC with itself on the condition that the hard disk sizes are equal. That gives us tuples that have two PC model numbers with the same value of hd. However, these two PC's could in fact be the same, so we must also require in the theta-join that the model numbers be unequal. Finally, we want the hard disk sizes, so we project onto hd.The expression is easiest to see if we write it using some temporary values. We start by renaming PC twice so we can talk about two occurrences of the same attributes.R1 = RHO_{PC1} (PC)R2 = RHO_{PC2} (PC)R3 = R1 JOIN_{PC1.hd = PC2.hd AND PC1.model <> PC2.model} R2R4 = PI_{PC1.hd} (R3)Exercise 5.2.1(h)First, we find R1, the model-speed pairs from both PC and Laptop. Then, we find from R1 those computers that are ``fast,'' at least 133Mh. At the same time, we join R1 with Product to connect model numbers to their manufacturers and we project out the speed to get R2. Then we join R2 with itself (after renaming) to find pairs of different models by the same maker. Finally, we get our answer, R5, by projecting onto one of the maker attributes. A sequence of steps giving the desired expression is: R1 = PI_{model,speed} (PC) UNION PI_{model,speed} (Laptop)R2 = PI_{maker,model} (SIGMA_{speed>=700} (R1) JOIN Product)R3 = RHO_{T(maker2, model2)} (R2)R4 = R2 JOIN_{maker = maker2 AND model <> model2} (R3)R5 = PI_{maker} (R4)Exercise 5.2.2Here are figures for the expression trees of Exercise 5.2.1 Part (a)Part (f)Part (h). Note that the third figure is not really a tree, since it uses a common subexpression. We could duplicate the nodes to make it a tree, but using common subexpressions is a valuable form of query optimization. One of the benefits one gets from constructing ``trees'' for queries is the ability to combine nodes that represent common subexpressions.Exercise 5.2.7The relation that results from the natural join has only one attribute from each pair of equated attributes. The theta-join has attributes for both, and their columns are identical.Exercise 5.2.9(a)If all the tuples of R and S are different, then the union has n+m tuples, and this number is the maximum possible.The minimum number of tuples that can appear in the result occurs if every tuple of one relation also appears in the other. Surely the union has at least as many tuples as the larger of R and that is, max(n,m) tuples. However, it is possible for every tuple of the smaller to appear in the other, so it is possible that there are as few as max(n,m) tuples in the union.Exercise 5.2.10In the following we use the name of a relation both as its instance (set of tuples) and as its schema (set of attributes). The context determines uniquely which is meant.PI_R(R JOIN S) Note, however, that this expression works only for sets; it does not preserve the multipicity of tuples in R. The next two expressions work for bags.R JOIN DELTA(PI_{R INTERSECT S}(S)) In this expression, each projection of a tuple from S onto the attributes that are also in R appears exactly once in the second argument of the join, so it preserves multiplicity of tuples in R, except for those thatdo not join with S, which disappear. The DELTA operator removes duplicates, as described in Section 5.4.R - [R - PI_R(R JOIN S)] Here, the strategy is to find the dangling tuples of R and remove them.Solutions for Section 5.3Exercise 5.3.1As a bag, the value is {700, 1500, 866, 866, 1000, 1300, 1400, 700, 1200, 750, 1100, 350, 733}. The order is unimportant, of course. The average is 959.As a set, the value is {700, 1500, 866, 1000, 1300, 1400, 1200, 750, 1100, 350, 733}, and the average is 967. H3>Exercise 5.3.4(a)As sets, an element x is in the left-side expression(R UNION S) UNION Tif and only if it is in at least one of R, S, and T. Likewise, it is in the right-side expressionR UNION (S UNION T)under exactly the same conditions. Thus, the two expressions have exactly the same members, and the sets are equal.As bags, an element x is in the left-side expression as many times as the sum of the number of times it is in R, S, and T. The same holds for the right side. Thus, as bags the expressions also have the same value.Exercise 5.3.4(h)As sets, element x is in the left sideR UNION (S INTERSECT T)if and only if x is either in R or in both S and T. Element x is in the right side(R UNION S) INTERSECT (R UNION T)if and only if it is in both R UNION S and R UNION T. If x is in R, then it is in both unions. If x is in both S and T, then it is in both union. However, if x is neither in R nor in both of S and T, then it cannot be in both unions. For example, suppose x is not in R and not in S. Then x is not in R UNION S. Thus, the statement of when x is in the right side is exactly the same as when it is in the left side: x is either in R or in both of S and T.Now, consider the expression for bags. Element x is in the left side the sum of the number of times it is in R plus the smaller of the number of times x is in S and the number of times x is in T. Likewise, the number of times x is in the right side is the smaller ofThe sum of the number of times x is in R and in S.The sum of the number of times x is in R and in T.A moment's reflection tells us that this minimum is the sum of the number of times x is in R plus the smaller of the number of times x is in S and in T, exactly as for the left side.Exercise 5.3.5(a)For sets, we observe that element x is in the left side(R INTERSECT S) - T。
(完整版)数据库系统基础教程第二章答案解析

For relation Accounts, the attributes are:acctNo, type, balanceFor relation Customers, the attributes are:firstName, lastName, idNo, accountExercise 2.2.1bFor relation Accounts, the tuples are:(12345, savings, 12000),(23456, checking, 1000),(34567, savings, 25)For relation Customers, the tuples are:(Robbie, Banks, 901-222, 12345),(Lena, Hand, 805-333, 12345),(Lena, Hand, 805-333, 23456)Exercise 2.2.1cFor relation Accounts and the first tuple, the components are:123456 → acctNosavings → type12000 → balanceFor relation Customers and the first tuple, the components are:Robbie → firstNameBanks → lastName901-222 → idNo12345 → accountExercise 2.2.1dFor relation Accounts, a relation schema is:Accounts(acctNo, type, balance)For relation Customers, a relation schema is:Customers(firstName, lastName, idNo, account) Exercise 2.2.1eAn example database schema is:Accounts (acctNo,type,balance)Customers (firstName,lastName,idNo,account)A suitable domain for each attribute:acctNo → Integertype → Stringbalance → IntegerfirstName → StringlastName → StringidNo → String (because there is a hyphen we cannot use Integer)account → IntegerExercise 2.2.1gAnother equivalent way to present the Account relation:Another equivalent way to present the Customers relation:Exercise 2.2.2Examples of attributes that are created for primarily serving as keys in a relation:Universal Product Code (UPC) used widely in United States and Canada to track products in stores.Serial Numbers on a wide variety of products to allow the manufacturer to individually track each product.Vehicle Identification Numbers (VIN), a unique serial number used by the automotive industry to identify vehicles.Exercise 2.2.3aWe can order the three tuples in any of 3! = 6 ways. Also, the columns can be ordered in any of 3! = 6 ways. Thus, the number of presentations is 6*6 = 36.Exercise 2.2.3bWe can order the three tuples in any of 5! = 120 ways. Also, the columns can be ordered in any of 4! = 24 ways. Thus, the number of presentations is 120*24 = 2880Exercise 2.2.3cWe can order the three tuples in any of m! ways. Also, the columns can be ordered in any of n! ways. Thus, the number of presentations is n!m!Exercise 2.3.1aCREATE TABLE Product (maker CHAR(30),model CHAR(10) PRIMARY KEY,type CHAR(15));CREATE TABLE PC (model CHAR(30),speed DECIMAL(4,2),ram INTEGER,hd INTEGER,price DECIMAL(7,2));Exercise 2.3.1cCREATE TABLE Laptop (model CHAR(30),speed DECIMAL(4,2),ram INTEGER,hd INTEGER,screen DECIMAL(3,1),price DECIMAL(7,2));Exercise 2.3.1dCREATE TABLE Printer (model CHAR(30),color BOOLEAN,type CHAR (10),price DECIMAL(7,2));Exercise 2.3.1eALTER TABLE Printer DROP color;Exercise 2.3.1fALTER TABLE Laptop ADD od CHAR (10) DEFAULT ‘none’; Exercise 2.3.2aCREATE TABLE Classes (class CHAR(20),type CHAR(5),country CHAR(20),numGuns INTEGER,bore DECIMAL(3,1),displacement INTEGER);Exercise 2.3.2bCREATE TABLE Ships (name CHAR(30),class CHAR(20),launched INTEGER);Exercise 2.3.2cCREATE TABLE Battles (name CHAR(30),date DATE);Exercise 2.3.2dCREATE TABLE Outcomes (ship CHAR(30),battle CHAR(30),result CHAR(10));Exercise 2.3.2eALTER TABLE Classes DROP bore;Exercise 2.3.2fALTER TABLE Ships ADD yard CHAR(30); Exercise 2.4.1aR1 := σspeed ≥ 3.00 (PC)R2 := πmodel(R1)model100510061013Exercise 2.4.1bR1 := σhd ≥ 100 (Laptop)R2 := Product (R1)R3 := πmaker (R2)makerEABFGExercise 2.4.1cR1 := σmaker=B (Product PC)R2 := σmaker=B (Product Laptop)R3 := σmaker=B (Product Printer)R4 := πmodel,price (R1)R5 := πmodel,price (R2)R6: = πmodel,price (R3)R7 := R4 R5 R6model price1004 6491005 6301006 10492007 1429Exercise 2.4.1dR1 := σcolor = true AND type = laser (Printer)R2 := πmodel (R1)model30033007Exercise 2.4.1eR1 := σtype=laptop (Product)R2 := σtype=PC(Product)R3 := πmaker(R1)R4 := πmaker(R2)R5 := R3 – R4Exercise 2.4.1fR1 := ρPC1(PC)R2 := ρPC2(PC)R3 := R1 (PC1.hd = PC2.hd AND PC1.model <> PC2.model) R2R4 := πhd(R3)Exercise 2.4.1gR1 := ρPC1(PC)R2 := ρPC2(PC)R3 := R1 (PC1.speed = PC2.speed AND PC1.ram = PC2.ram AND PC1.model < PC2.model) R2R4 := πPC1.model,PC2.model(R3)Exercise 2.4.1hR1 := πmodel(σspeed ≥ 2.80(PC)) πmodel(σspeed ≥ 2.80(Laptop))R2 := πmaker,model(R1 Product)R3 := ρR3(maker2,model2)(R2)R4 := R2 (maker = maker2 AND model <> model2) R3R5 := πmaker(R4)Exercise 2.4.1iR1 := πmodel,speed(PC)R2 := πmodel,speed(Laptop)R3 := R1 R2R4 := ρR4(model2,speed2)(R3)R5 := πmodel,speed (R3 (speed < speed2 ) R4)R6 := R3 – R5makerBExercise 2.4.1jR1 := πmaker,speed(Product PC)R2 := ρR2(maker2,speed2)(R1)R3 := ρR3(maker3,speed3)(R1)R4 := R1 (maker = maker2 AND speed <> speed2) R2R5 := R4 (maker3 = maker AND speed3 <> speed2 AND speed3 <> speed) R3R6 := πmaker(R5)makerFGhd25080160PC1.model PC2.model1004 1012makerBEmakerADEExercise 2.4.1kR1 := πmaker,model(Product PC)R2 := ρR2(maker2,model2)(R1)R3 := ρR3(maker3,model3)(R1)R4 := ρR4(maker4,model4)(R1)R5 := R1 (maker = maker2 AND model <> model2) R2R6 := R3 (maker3 = maker AND model3 <> model2 AND model3 <> model) R5R7 := R4 (maker4 = maker AND (model4=model OR model4=model2 OR model4=model3)) R6R8 := πmaker(R7)makerABDEExercise 2.4.2aπmodelσspeed≥3.00PCExercise 2.4.2bπmakerσhd ≥ 100 ProductLaptopExercise 2.4.2cσmaker=B πmodel,priceσmaker=B πmodel,price σmaker=Bπmodel,priceProduct PC Laptop Printer ProductProductExercise 2.4.2dPrinter σcolor = true AND type = laserπmodelExercise 2.4.2e σtype=laptop σtype=PC πmakerπmaker –Product ProductExercise 2.4.2fρPC1ρPC2 (PC1.hd = PC2.hd AND PC1.model <> PC2.model)πhdPC PCExercise 2.4.2gρPC1ρPC2PC PC(PC1.speed = PC2.speed AND PC1.ram = PC2.ram AND PC1.model < PC2.model)πPC1.model,PC2.modelExercise 2.4.2hPC Laptop σspeed ≥ 2.80σspeed ≥ 2.80πmodelπmodel πmaker,modelρR3(maker2,model2)(maker = maker2 AND model <> model2)makerExercise 2.4.2iPCLaptopProductπmodel,speed πmodel,speed ρR4(model2,speed2)πmodel,speed(speed < speed2 )–makerExercise 2.4.2jProduct PC πmaker,speed ρR3(maker3,speed3)ρR2(maker2,speed2)(maker = maker2 AND speed <> speed2)(maker3 = maker AND speed3 <> speed2 AND speed3 <> speed)πmakerExercise 2.4.2kπmaker(maker4 = maker AND (model4=model OR model4=model2 OR model4=model3)) (maker3 = maker AND model3 <> model2 AND model3 <> model)(maker = maker2 AND model <> model2)ρR2(maker2,model2)ρR3(maker3,model3)ρR4(maker4,model4)πmaker,modelProduct PCExercise 2.4.3aR1 := σbore ≥ 16 (Classes)R2 := πclass,country (R1)Exercise 2.4.3bR1 := σlaunched < 1921 (Ships)R2 := πname (R1)KirishimaKongoRamilliesRenownRepulseResolutionRevengeRoyal OakRoyal SovereignTennesseeExercise 2.4.3cR1 := σbattle=Denmark Strait AND result=sunk(Outcomes)R2 := πship (R1)shipBismarckHoodExercise 2.4.3dR1 := Classes ShipsR2 := σlaunched > 1921 AND displacement > 35000 (R1)R3 := πname (R2)nameIowaMissouriMusashiNew JerseyNorth CarolinaWashingtonWisconsinYamatoExercise 2.4.3eR1 := σbattle=Guadalcanal(Outcomes)R2 := Ships (ship=name) R1R3 := Classes R2R4 := πname,displacement,numGuns(R3)name displacement numGuns Kirishima 32000 8Washington 37000 9Exercise 2.4.3fR1 := πname(Ships)R2 := πship(Outcomes)R3 := ρR3(name)(R2)R4 := R1 R3nameCaliforniaHarunaHieiIowaKirishimaKongoMissouriMusashiNew JerseyExercise 2.4.3gFrom 2.3.2, assuming that every class has one ship named after the class.R1 := πclass (Classes) R2 := πclass (σname <> class (Ships)) R3 := R1 – R2Exercise 2.4.3hR1 := πcountry (σtype=bb (Classes)) R2 := πcountry (σtype=bc (Classes)) R3 := R1 ∩ R2Exercise 2.4.3iR1 := πship,result,date (Battles (battle=name) Outcomes)R2 := ρR2(ship2,result2,date2)(R1)R3 := R1 (ship=ship2 AND result=damaged AND date < date2) R2R4 := πship (R3)No results from sample data.Exercise 2.4.4aσbore ≥ 16πclass,countryClassesExercise 2.4.4bNorth Carolina Ramillies Renown Repulse Resolution Revenge Royal Oak Royal Sovereign Tennessee Washington Wisconsin Yamato Arizona Bismarck Duke of York Fuso Hood King George V Prince of Wales Rodney Scharnhorst South Dakota West Virginia Yamashiro class Bismarck country Japan Gt. Britainπnameσlaunched < 1921ShipsExercise 2.4.4cπshipσbattle=Denmark Strait AND result=sunkOutcomesExercise 2.4.4dπnameσlaunched > 1921 AND displacement > 35000Classes Ships Exercise 2.4.4eσbattle=Guadalcanal Outcomes Ships(ship=name)πname,displacement,numGunsExercise 2.4.4f Ships Outcomesπnameπship ρR3(name)Exercise 2.4.4g Classes Shipsπclass σname <> class πclass–Exercise 2.4.4hClasses Classesσtype=bb σtype=bcπcountry πcountry∩Exercise 2.4.4iBattles Outcomes (battle=name)πship,result,dateρR2(ship2,result2,date2)(ship=ship2 AND result=damaged AND date < date2)πshipExercise 2.4.5The result of the natural join has only one attribute from each pair of equated attributes. On the other hand, the result of the theta-join has both columns of the attributes and their values are identical.Exercise 2.4.6UnionIf we add a tuple to the arguments of the union operator, we will get all of the tuples of the original result and maybe the added tuple. If the added tuple is a duplicate tuple, then the set behavior will eliminate that tuple.Thus the union operator is monotone.IntersectionIf we add a tuple to the arguments of the intersection operator, we will get all of the tuples of the originalresult and maybe the added tuple. If the added tuple does not exist in the relation that it is added but does exist in the other relation, then the result set will include the added tuple. Thus the intersection operator is monotone.DifferenceIf we add a tuple to the arguments of the difference operator, we may not get all of the tuples of the originalresult. Suppose we have relations R and S and we are computing R – S. Suppose also that tuple t is in R but not in S. The result of R – S would include tuple t. However, if we add tuple t to S, then the new result will not have tuple t. Thus the difference operator is not monotone.ProjectionIf we add a tuple to the arguments of the projection operator, we will get all of the tuples of the original result and the projection of the added tuple. The projection operator only selects columns from the relation and does not affect the rows that are selected. Thus the projection operator is monotone.SelectionIf we add a tuple to the arguments of the selection operator, we will get all of the tuples of the original result and maybe the added tuple. If the added tuple satisfies the select condition, then it will be added to the newresult. The original tuples are included in the new result because they still satisfy the select condition. Thusthe selection operator is monotone.Cartesian ProductIf we add a tuple to the arguments of the Cartesian product operator, we will get all of the tuples of the original result and possibly additional tuples. The Cartesian product pairs the tuples of one relation with the tuples ofanother relation. Suppose that we are calculating R x S where R has m tuples and S has n tuples. If we add a tuple to R that is not already in R, then we expect the result of R x S to have (m + 1) * n tuples. Thus the Cartesianproduct operator is monotone.Natural JoinsIf we add a tuple to the arguments of a natural join operator, we will get all of the tuples of the original result and possibly additional tuples. The new tuple can only create additional successful joins, not less. If, however, the added tuple cannot successfully join with any of the existing tuples, then we will have zero additionalsuccessful joins. Thus the natural join operator is monotone.Theta JoinsIf we add a tuple to the arguments of a theta join operator, we will get all of the tuples of the original result and possibly additional tuples. The theta join can be modeled by a Cartesian product followed by a selection onsome condition. The new tuple can only create additional tuples in the result, not less. If, however, the addedtuple does not satisfy the select condition, then no additional tuples will be added to the result. Thus the theta join operator is monotone.RenamingIf we add a tuple to the arguments of a renaming operator, we will get all of the tuples of the original result and the added tuple. The renaming operator does not have any effect on whether a tuple is selected or not. In fact, the renaming operator will always return as many tuples as its argument. Thus the renaming operator is monotone.Exercise 2.4.7aIf all the tuples of R and S are different, then the union has n + m tuples, and this number is the maximum possible.The minimum number of tuples that can appear in the result occurs if every tuple of one relation also appears in the other. Then the union has max(m , n) tuples.Exercise 2.4.7bIf all the tuples in one relation can pair successfully with all the tuples in the other relation, then the natural join has n * m tuples. This number would be the maximum possible.The minimum number of tuples that can appear in the result occurs if none of the tuples of one relation can pairsuccessfully with all the tuples in the other relation. Then the natural join has zero tuples.Exercise 2.4.7cIf the condition C brings back all the tuples of R, then the cross product will contain n * m tuples. This number would be the maximum possible.The minimum number of tuples that can appear in the result occurs if the condition C brings back none of the tuples of R. Then the cross product has zero tuples.Exercise 2.4.7dAssuming that the list of attributes L makes the resulting relation πL(R) and relation S schema compatible, then the maximum possible tuples is n. This happens when all of the tuples of πL(R) are not in S.The minimum number of tuples that can appear in the result occurs when all of the tuples in πL(R) appear in S. Then the difference has max(n–m , 0) tuples.Exercise 2.4.8Defining r as the schema of R and s as the schema of S:1.πr(R S)2.R δ(πr∩s(S)) where δ is the duplicate-elimination operator in Section 5.2 pg. 2133.R – (R –πr(R S))Exercise 2.4.9Defining r as the schema of R1.R - πr(R S)Exercise 2.4.10πA1,A2…An(R S)Exercise 2.5.1aσspeed < 2.00 AND price > 500(PC) = øModel 1011 violates this constraint.Exercise 2.5.1bσscreen < 15.4 AND hd < 100 AND price ≥ 1000(Laptop) = øModel 2004 violates the constraint.Exercise 2.5.1cπmaker(σtype = laptop(Product)) ∩ πmaker(σtype = pc(Product)) = øManufacturers A,B,E violate the constraint.Exercise 2.5.1dThis complex expression is best seen as a sequence of steps in which we define temporary relations R1 through R4 that stand for nodes of expression trees. Here is the sequence:R1(maker, model, speed) := πmaker,model,speed(Product PC)R2(maker, speed) := πmaker,speed(Product Laptop)R3(model) := πmodel(R1 R1.maker = R2.maker AND R1.speed ≤ R2.speed R2)R4(model) := πmodel(PC)The constraint is R4 ⊆ R3Manufacturers B,C,D violate the constraint.Exercise 2.5.1eπmodel(σLaptop.ram > PC.ram AND Laptop.price ≤ PC.price(PC × Laptop)) = øModels 2002,2006,2008 violate the constraint.Exercise 2.5.2aπclass(σbore > 16(Classes)) = øThe Yamato class violates the constraint.Exercise 2.5.2bπclass(σnumGuns > 9 AND bore > 14(Classes)) = øNo violations to the constraint.Exercise 2.5.2cThis complex expression is best seen as a sequence of steps in which we define temporary relations R1 through R5 that stand for nodes of expression trees. Here is the sequence:R1(class,name) := πclass,name(Classes Ships)R2(class2,name2) := ρR2(class2,name2)(R1)R3(class3,name3) := ρR3(class3,name3)(R1)R4(class,name,class2,name2) := R1 (class = class2 AND name <> name2) R2R5(class,name,class2,name2,class3,name3) := R4 (class=class3 AND name <> name3 AND name2 <> name3) R3The constraint is R5 = øThe Kongo, Iowa and Revenge classes violate the constraint.Exercise 2.5.2dπcountry(σtype = bb(Classes)) ∩ πcountry(σtype = bc(Classes)) = øJapan and Gt. Britain violate the constraint.Exercise 2.5.2eThis complex expression is best seen as a sequence of steps in which we define temporary relations R1 through R5 that stand for nodes of expression trees. Here is the sequence:R1(ship,bat tle,result,class) := πship,battle,result,class(Outcomes (ship = name) Ships)R2(ship,battle,result,numGuns) := πship,battle,result,numGuns(R1 Classes)R3(ship,battle) := πship,battle(σnumGuns < 9 AND result = sunk (R2))R4(ship2,battle2) := ρR4(ship2,battle2)(πship,battle(σnumGuns > 9(R2)))R5(ship2) := πship2(R3 (battle = battle2) R4)The constraint is R5 = øNo violations to the constraint. Since there are some ships in the Outcomes table that are not in the Ships table, we are unable to determine the number of guns on that ship.Exercise 2.5.3Defining r as the schema A1,A2,…,A n and s as the schema B1,B2,…,B n:πr(R) πs(S) = øwhere is the antisemijoinExercise 2.5.4The form of a constraint as E1 = E2 can be expressed as the other two constraints.Using the “equating an expression to the empty set” method, we can simply say:E1– E2 = øAs a containment, we can simply say:E1⊆ E2 AND E2⊆ E1Thus, the form E1 = E2 of a constraint cannot express more than the two other forms discussed in this section.。
数据库系统基础教程(第二版)课后习题答案

Database Systems: The Complete BookSolutions for Chapter 2Solutions for Section 2.1Exercise 2.1.1The E/R Diagram.Exercise 2.1.8(a)The E/R DiagramKobvxybzSolutions for Section 2.2Exercise 2.2.1The Addresses entity set is nothing but a single address, so we would prefer to make address an attribute of Customers. Were the bank to record several addresses for a customer, then it might make sense to have an Addresses entity set and make Lives-at a many-many relationship.The Acct-Sets entity set is useless. Each customer has a unique account set containing his or her accounts. However, relating customers directly to their accounts in a many-many relationship conveys the same information and eliminates the account-set concept altogether.Solutions for Section 2.3Exercise 2.3.1(a)Keys ssNo and number are appropriate for Customers and Accounts, respectively.Also, we think it does not make sense for an account to be related to zero customers, so we should round the edge connecting Owns to Customers. It does not seem inappropriate to have a customer with 0 accounts; they might be a borrower, for example, so we put no constraint on the connection from Owns to Accounts. Here is the The E/R Diagram,showing underlined keys and the numerocity constraint.Exercise 2.3.2(b)If R is many-one from E1 to E2, then two tuples (e1,e2) and (f1,f2) of the relationship set for R must be the same if they agree on the key attributes for E1. To see why, surely e1 and f1 are the same. Because R is many-one from E1 to E2, e2 and f2 must also be the same. Thus, the pairs are the same. Solutions for Section 2.4Exercise 2.4.1Here is the The E/R Diagram.We have omitted attributes other than our choice for the key attributes of Students and Courses. Also omitted are names for the relationships. Attribute grade is not part of the key for Enrollments. The key for Enrollements is studID from Students and dept and number from Courses.Exercise 2.4.4bHere is the The E/R Diagram Again, we have omitted relationship names and attributes other than our choice for the key attributes. The key for Leagues is itsown name; this entity set is not weak. The key for Teams is its own name plus the name of the league of which the team is a part, e.g., (Rangers, MLB) or (Rangers, NHL). The key for Players consists of the player's number and the key for the team on which he or she plays. Since the latter key is itself a pair consisting of team and league names, the key for players is the triple (number, teamName, leagueName).e.g., Jeff Garcia is (5, 49ers, NFL).Database Systems: The Complete BookSolutions for Chapter 3Solutions for Section 3.1Exercise 3.1.2(a)We can order the three tuples in any of 3! = 6 ways. Also, the columns can be ordered in any of 3! = 6 ways. Thus, the number of presentations is 6*6 = 36. Solutions for Section 3.2Exercise 3.2.1Customers(ssNo, name, address, phone)Flights(number, day, aircraft)Bookings(ssNo, number, day, row, seat)Being a weak entity set, Bookings' relation has the keys for Customers and Flights and Bookings' own attributes.Notice that the relations obtained from the toCust and toFlt relationships are unnecessary. They are:toCust(ssNo, ssNo1, number, day)toFlt(ssNo, number, day, number1, day1)That is, for toCust, the key of Customers is paired with the key for Bookings. Since both include ssNo, this attribute is repeated with two different names, ssNo and ssNo1. A similar situation exists for toFlt.Exercise 3.2.3Ships(name, yearLaunched)SisterOf(name, sisterName)Solutions for Section 3.3Exercise 3.3.1Since Courses is weak, its key is number and the name of its department. We do not have a relation for GivenBy. In part (a), there is a relation for Courses and a relation for LabCourses that has only the key and the computer-allocation attribute. It looks like:Depts(name, chair)Courses(number, deptName, room)LabCourses(number, deptName, allocation)For part (b), LabCourses gets all the attributes of Courses, as:Depts(name, chair)Courses(number, deptName, room)LabCourses(number, deptName, room, allocation)And for (c), Courses and LabCourses are combined, as:Depts(name, chair)Courses(number, deptName, room, allocation)Exercise 3.3.4(a)There is one relation for each entity set, so the number of relations is e. The relation for the root entity set has a attributes, while the other relations, which must include the key attributes, have a+k attributes.Solutions for Section 3.4Exercise 3.4.2Surely ID is a key by itself. However, we think that the attributes x, y, and z together form another key. The reason is that at no time can two molecules occupy the same point.Exercise 3.4.4The key attributes are indicated by capitalization in the schema below: Customers(SSNO, name, address, phone)Flights(NUMBER, DAY, aircraft)Bookings(SSNO, NUMBER, DAY, row, seat)Exercise 3.4.6(a)The superkeys are any subset that contains A1. Thus, there are 2^{n-1} such subsets, since each of the n-1 attributes A2 through An may independently be chosen in or out.Solutions for Section 3.5Exercise 3.5.1(a)We could try inference rules to deduce new dependencies until we are satisfied we have them all. A more systematic way is to consider the closures of all 15 nonempty sets of attributes.For the single attributes we have A+ = A, B+ = B, C+ = ACD, and D+ = AD. Thus, the only new dependency we get with a single attribute on the left is C->A.Now consider pairs of attributes:AB+ = ABCD, so we get new dependency AB->D. AC+ = ACD, and AC->D is nontrivial. AD+ = AD, so nothing new. BC+ = ABCD, so we get BC->A, and BC->D. BD+ = ABCD, giving us BD->A and BD->C. CD+ = ACD, giving CD->A.For the triples of attributes, ACD+ = ACD, but the closures of the other sets are each ABCD. Thus, we get new dependencies ABC->D, ABD->C, and BCD->A. Since ABCD+ = ABCD, we get no new dependencies.The collection of 11 new dependencies mentioned above is: C->A, AB->D, AC->D, BC->A, BC->D, BD->A, BD->C, CD->A, ABC->D, ABD->C, and BCD->A. Exercise 3.5.1(b)From the analysis of closures above, we find that AB, BC, and BD are keys. All other sets either do not have ABCD as the closure or contain one of these three sets.Exercise 3.5.1(c)The superkeys are all those that contain one of those three keys. That is, a superkey that is not a key must contain B and more than one of A, C, and D. Thus, the (proper) superkeys are ABC, ABD, BCD, and ABCD.Exercise 3.5.3(a)We must compute the closure of A1A2...AnC. Since A1A2...An->B is a dependency, surely B is in this set, proving A1A2...AnC->B.Exercise 3.5.4(a)Consider the relationExercise 3.5.8(a)If all sets of attributes are closed, then there cannot be any nontrivial functional dependencies. For suppose A1A2...An->B is a nontrivial dependency. Then A1A2...An+ contains B and thus A1A2...An is not closed.Exercise 3.5.10(a)We need to compute the closures of all subsets of {ABC}, although there is no need to think about the empty set or the set of all three attributes. Here are thecalculations for the remaining six sets:A+ = AB+ = BC+ = ACEAB+ = ABCDEAC+ = ACEBC+ = ABCDEWe ignore D and E, so a basis for the resulting functional dependencies for ABC are: C->A and AB->C. Note that BC->A is true, but follows logically from C->A, and therefore may be omitted from our list.Solutions for Section 3.6Exercise 3.6.1(a)In the solution to Exercise 3.5.1 we found that there are 14 nontrivial dependencies, including the three given ones and 11 derived dependencies. These are: C->A, C->D, D->A, AB->D, AB-> C, AC->D, BC->A, BC->D, BD->A, BD->C, CD->A, ABC->D, ABD->C, and BCD->A.We also learned that the three keys were AB, BC, and BD. Thus, any dependency above that does not have one of these pairs on the left is a BCNF violation. These are: C->A, C->D, D->A, AC->D, and CD->A.One choice is to decompose using C->D. That gives us ABC and CD as decomposed relations. CD is surely in BCNF, since any two-attribute relation is. ABC is not in BCNF, since AB and BC are its only keys, but C->A is a dependency that holds in ABCD and therefore holds in ABC. We must further decompose ABC into AC and BC. Thus, the three relations of the decomposition are AC, BC, and CD.Since all attributes are in at least one key of ABCD, that relation is already in 3NF, and no decomposition is necessary.Exercise 3.6.1(b)(Revised 1/19/02) The only key is AB. Thus, B->C and B->D are both BCNF violations. The derived FD's BD->C and BC->D are also BCNF violations. However, any other nontrivial, derived FD will have A and B on the left, and therefore will contain a key.One possible BCNF decomposition is AB and BCD. It is obtained starting with any of the four violations mentioned above. AB is the only key for AB, and B is the only key for BCD.Since there is only one key for ABCD, the 3NF violations are the same, and so is the decomposition.Solutions for Section 3.7Exercise 3.7.1Since A->->B, and all the tuples have the same value for attribute A, we can pair the B-value from any tuple with the value of the remaining attribute C from any other tuple. Thus, we know that R must have at least the nine tuples of the form (a,b,c), where b is any of b1, b2, or b3, and c is any of c1, c2, or c3. That is, we can derive, using the definition of a multivalued dependency, that each of the tuples (a,b1,c2), (a,b1,c3), (a,b2,c1), (a,b2,c3), (a,b3,c1), and (a,b3,c2) are also in R. Exercise 3.7.2(a)First, people have unique Social Security numbers and unique birthdates. Thus, we expect the functional dependencies ssNo->name and ssNo->birthdate hold. The same applies to children, so we expect childSSNo->childname and childSSNo->childBirthdate. Finally, an automobile has a unique brand, so we expect autoSerialNo->autoMake.There are two multivalued dependencies that do not follow from these functional dependencies. First, the information about one child of a person is independent of other information about that person. That is, if a person with social security number s has a tuple with,cs,cb, then if there is any other tuple t for the same person, there will also be another tuple that agrees with t except that it has,cs,cb in its components for the child name, Social Security number, and birthdate. That is the multivalued dependencyssNo->->childSSNo childName childBirthdateSimilarly, an automobile serial number and make are independent of any of the other attributes, so we expect the multivalued dependencyssNo->->autoSerialNo autoMakeThe dependencies are summarized below:ssNo -> name birthdatechildSSNo -> childName childBirthdateautoSerialNo -> autoMakessNo ->-> childSSNo childName childBirthdatessNo ->-> autoSerialNo autoMakeExercise 3.7.2(b)We suggest the relation schemas{ssNo, name, birthdate}{ssNo, childSSNo}{childSSNo, childName childBirthdate}{ssNo, autoSerialNo}{autoSerialNo, autoMake}An initial decomposition based on the two multivalued dependencies would give us{ssNo, name, birthDate}{ssNo, childSSNo, childName, childBirthdate}{ssNo, autoSerialNo, autoMake}Functional dependencies force us to decompose the second and third of these.Exercise 3.7.3(a)Since there are no functional dependencies, the only key is all four attributes, ABCD. Thus, each of the nontrvial multivalued dependencies A->->B and A->->C violate 4NF. We must separate out the attributes of these dependencies, first decomposing into AB and ACD, and then decomposing the latter into AC and AD because A->->C is still a 4NF violation for ACD. The final set of relations are AB, AC, and AD.Exercise 3.7.7(a)Let W be the set of attributes not in X, Y, or Z. Consider two tuples xyzw and xy'z'w' in the relation R in question. Because X ->-> Y, we can swap the y's, so xy'zw and xyz'w' are in R. Because X ->-> Z, we can take the pair of tuples xyzw and xyz'w' and swap Z's to get xyz'w and xyzw'. Similarly, we can take the pair xy'z'w' and xy'zw and swap Z's to get xy'zw' and xy'z'w.In conclusion, we started with tuples xyzw and xy'z'w' and showed that xyzw' and xy'z'w must also be in the relation. That is exactly the statement of the MVD X ->-> Y-union-Z. Note that the above statements all make sense even if there are attributes in common among X, Y, and Z.Exercise 3.7.8(a)Consider a relation R with schema ABCD and the instance with four tuples abcd, abcd', ab'c'd, and ab'c'd'. This instance satisfies the MVD A ->-> BC. However, it does not satisfy A ->-> B. For example, if it did satisfy A ->-> B, then because the instance contains the tuples abcd and ab'c'd, we would expect it to contain abc'd and ab'cd, neither of which is in the instance.Database Systems: The Complete BookSolutions for Chapter 4Solutions for Section 4.2Exercise 4.2.1class Customer {attribute string name;attribute string addr;attribute string phone;attribute integer ssNo;relationship Set<Account> ownsAcctsinverse Account::ownedBy;}class Account {attribute integer number;attribute string type;attribute real balance;relationship Set<Customer> ownedByinverse Customer::ownsAccts}Exercise 4.2.4class Person {attribute string name;relationship Person motherOfinverse Person::childrenOfFemalerelationship Person fatherOfinverse Person::childrenOfMalerelationship Set<Person> childreninverse Person::parentsOfrelationship Set<Person> childrenOfFemaleinverse Person::motherOfrelationship Set<Person> childrenOfMaleinverse Person::fatherOfrelationship Set<Person> parentsOfinverse Person::children}Notice that there are six different relationships here. For example, the inverse of the relationship that connects a person to their (unique) mother is a relationship that connects a mother (i.e., a female person) to the set of her children. That relationship, which we call childrenOfFemale, is different from the children relationship, which connects anyone -- male or female -- to their children. Exercise 4.2.7A relationship R is its own inverse if and only if for every pair (a,b) in R, the pair (b,a) is also in R. In the terminology of set theory, the relation R is ``symmetric.'' Solutions for Section 4.3Exercise 4.3.1We think that Social Security number should me the key for Customer, and account number should be the key for Account. Here is the ODL solution with key and extent declarations.class Customer(extent Customers key ssNo){attribute string name;attribute string addr;attribute string phone;attribute integer ssNo;relationship Set<Account> ownsAcctsinverse Account::ownedBy;}class Account(extent Accounts key number){attribute integer number;attribute string type;attribute real balance;relationship Set<Customer> ownedByinverse Customer::ownsAccts}Solutions for Section 4.4Exercise 4.4.1(a)Since the relationship between customers and accounts is many-many, we should create a separate relation from that relationship-pair.Customers(ssNo, name, address, phone)Accounts(number, type, balance)CustAcct(ssNo, number)Exercise 4.4.1(d)Ther is only one attribute, but three pairs of relationships from Person to itself. Since motherOf and fatherOf are many-one, we can store their inverses in the relation for Person. That is, for each person, childrenOfMale and childrenOfFemale will indicate that persons's father and mother. The children relationship is many-many, and requires its own relation. This relation actually turns out to be redundant, in the sense that its tuples can be deduced from the relationships stored with Person. The schema:Persons(name, childrenOfFemale, childrenOfMale)Parent-Child(parent, child)Exercise 4.4.4You get a schema like:Studios(name, address, ownedMovie)Since name -> address is the only FD, the key is {name, ownedMovie}, and the FD has a left side that is not a superkey.Exercise 4.4.5(a,b,c)(a) Struct Card { string rank, string suit };(b) class Hand {attribute Set theHand;};For part (c) we have:Hands(handId, rank, suit)Notice that the class Hand has no key, so we need to create one: handID. Each hand has, in the relation Hands, one tuple for each card in the hand. Exercise 4.4.5(e)Struct PlayerHand { string Player, Hand theHand };class Deal {attribute Set theDeal;}Alternatively, PlayerHand can be defined directly within the declaration of attribute theDeal.Exercise 4.4.5(h)Since keys for Hand and Deal are lacking, a mechanical way to design the database schema is to have one relation connecting deals and player-hand pairs, and another to specify the contents of hands. That is:Deals(dealID, player, handID)Hands(handID, rank, suit)However, if we think about it, we can get rid of handID and connect the deal and the player directly to the player's cards, as:Deals(dealID, player, rank, suit)Exercise 4.4.5(i)First, card is really a pair consisting of a suit and a rank, so we need two attributes in a relation schema to represent cards. However, much more important is the fact that the proposed schema does not distinguish which card is in which hand. Thus, we need another attribute that indicates which hand within the deal a card belongs to, something like:Deals(dealID, handID, rank, suit)Exercise 4.4.6(c)Attribute b is really a bag of (f,g) pairs. Thus, associated with each a-value will be zero or more (f,g) pairs, each of which can occur several times. We shall use an attribute count to indicate the number of occurrences, although if relations allow duplicate tuples we could simply allow duplicate (a,f,g) triples in the relation. The proposed schema is:C(a, f, g, count)Solutions for Section 4.5Exercise 4.5.1(b)Studios(name, address, movies{(title, year, inColor, length,stars{(name, address, birthdate)})})Since the information about a star is repeated once for each of their movies, there is redundancy. To eliminate it, we have to use a separate relation for stars and use pointers from studios. That is:Stars(name, address, birthdate)Studios(name, address, movies{(title, year, inColor, length,stars{*Stars})})Since each movie is owned by one studio, the information about a movie appears in only one tuple of Studios, and there is no redundancy.Exercise 4.5.2Customers(name, address, phone, ssNo, accts{*Accounts})Accounts(number, type, balance, owners{*Customers})Solutions for Section 4.6Exercise 4.6.1(a)We need to add new nodes labeled George Lucas and Gary Kurtz. Then, from the node sw (which represents the movie Star Wars), we add arcs to these two new nodes, labeled directedBy and producedBy, respectively.Exercise 4.6.2Create nodes for each account and each customer. From each customer node is an arc to a node representing the attributes of the customer, e.g., an arc labeled name to the customer's name. Likewise, there is an arc from each account node to each attribute of that account, e.g., an arc labeled balance to the value of the balance.To represent ownership of accounts by customers, we place an arc labeled owns from each customer node to the node of each account that customer holds (possibly jointly). Also, we place an arc labeled ownedBy from each account node to the customer node for each owner of that account.Exercise 4.6.5In the semistructured model, nodes represent data elements, i.e., entities rather than entity sets. In the E/R model, nodes of all types represent schema elements, and the data is not represented at all.Solutions for Section 4.7Exercise 4.7.1(a)<STARS-MOVIES><STAR starId = "cf" starredIn = "sw, esb, rj"><NAME>Carrie Fisher</NAME><ADDRESS><STREET>123 Maple St.</STREET><CITY>Hollywood</CITY></ADDRESS><ADDRESS><STREET>5 Locust Ln.</STREET><CITY>Malibu</CITY></ADDRESS></STAR><STAR starId = "mh" starredIn = "sw, esb, rj"><NAME>Mark Hamill</NAME><ADDRESS><STREET>456 Oak Rd.<STREET><CITY>Brentwood</CITY></ADDRESS></STAR><STAR starId = "hf" starredIn = "sw, esb, rj, wit"><NAME>Harrison Ford</NAME><ADDRESS><STREET>whatever</STREET><CITY>whatever</CITY></ADDRESS></STAR><MOVIE movieId = "sw" starsOf = "cf, mh"><TITLE>Star Wars</TITLE><YEAR>1977</YEAR></MOVIE><MOVIE movieId = "esb" starsOf = "cf, mh"><TITLE>Empire Strikes Back</TITLE><YEAR>1980</YEAR></MOVIE><MOVIE movieId = "rj" starsOf = "cf, mh"><TITLE>Return of the Jedi</TITLE><YEAR>1983</YEAR></MOVIE><MOVIE movieID = "wit" starsOf = "hf"><TITLE>Witness</TITLE><YEAR>1985</YEAR></MOVIE></STARS-MOVIES>Exercise 4.7.2<!DOCTYPE Bank [<!ELEMENT BANK (CUSTOMER* ACCOUNT*)><!ELEMENT CUSTOMER (NAME, ADDRESS, PHONE, SSNO)> <!ATTLIST CUSTOMERcustId IDowns IDREFS><!ELEMENT NAME (#PCDATA)><!ELEMENT ADDRESS (#PCDATA)><!ELEMENT PHONE (#PCDATA)><!ELEMENT SSNO (#PCDATA)><!ELEMENT ACCOUNT (NUMBER, TYPE, BALANCE)><!ATTLIST ACCOUNTacctId IDownedBy IDREFS><!ELEMENT NUMBER (#PCDATA)><!ELEMENT TYPE (#PCDATA)><!ELEMENT BALANCE (#PCDATA)>]>Database Systems: TheComplete BookSolutions for Chapter 5Solutions for Section 5.2Exercise 5.2.1(a)PI_model( SIGMA_{speed >= 1000} ) (PC)Exercise 5.2.1(f)The trick is to theta-join PC with itself on the condition that the hard disk sizes are equal. That gives us tuples that have two PC model numbers with the same value of hd. However, these two PC's could in fact be the same, so we must also require in the theta-join that the model numbers be unequal. Finally, we want the hard disk sizes, so we project onto hd.The expression is easiest to see if we write it using some temporary values. We start by renaming PC twice so we can talk about two occurrences of the same attributes.R1 = RHO_{PC1} (PC)R2 = RHO_{PC2} (PC)R3 = R1 JOIN_{PC1.hd = PC2.hd AND PC1.model <> PC2.model} R2R4 = PI_{PC1.hd} (R3)Exercise 5.2.1(h)First, we find R1, the model-speed pairs from both PC and Laptop. Then, we find from R1 those computers that are ``fast,'' at least 133Mh. At the same time, we join R1 with Product to connect model numbers to their manufacturers and we project out the speed to get R2. Then we join R2 with itself (after renaming) to find pairs of different models by the same maker. Finally, we get our answer, R5, by projecting onto one of the maker attributes. A sequence of steps giving the desired expression is: R1 = PI_{model,speed} (PC) UNION PI_{model,speed} (Laptop)R2 = PI_{maker,model} (SIGMA_{speed>=700} (R1) JOIN Product)R3 = RHO_{T(maker2, model2)} (R2)R4 = R2 JOIN_{maker = maker2 AND model <> model2} (R3)R5 = PI_{maker} (R4)Exercise 5.2.2Here are figures for the expression trees of Exercise 5.2.1 Part (a)Part (f) Part (h). Note that the third figure is not really a tree, since it uses a common subexpression. We could duplicate the nodes to make it a tree, but using common subexpressions is a valuable form of queryoptimization. One of the benefits one gets from constructing ``trees'' for queries is the ability to combine nodes that represent common subexpressions.Exercise 5.2.7The relation that results from the natural join has only one attributefrom each pair of equated attributes. The theta-join has attributes for both, and their columns are identical.Exercise 5.2.9(a)If all the tuples of R and S are different, then the union has n+m tuples, and this number is the maximum possible.The minimum number of tuples that can appear in the result occurs if every tuple of one relation also appears in the other. Surely the union has at least as many tuples as the larger of R and that is, max(n,m) tuples. However, it is possible for every tuple of the smaller to appear in the other, so it is possible that there are as few as max(n,m) tuples in the union.Exercise 5.2.10In the following we use the name of a relation both as its instance (set of tuples) and as its schema (set of attributes). The context determines uniquely which is meant.PI_R(R JOIN S) Note, however, that this expression works only for sets; it does not preserve the multipicity of tuples in R. The next two expressions work for bags.R JOIN DELTA(PI_{R INTERSECT S}(S)) In this expression, each projection of a tuple from S onto the attributes that are also in R appears exactly once in the second argument of the join, so it preserves multiplicity of tuples in R, except for those that do not join with S,which disappear. The DELTA operator removes duplicates, as described in Section 5.4.R - [R - PI_R(R JOIN S)] Here, the strategy is to find the dangling tuples of R and remove them.Solutions for Section 5.3Exercise 5.3.1As a bag, the value is {700, 1500, 866, 866, 1000, 1300, 1400, 700, 1200, 750, 1100, 350, 733}. The order is unimportant, of course. The average is 959.As a set, the value is {700, 1500, 866, 1000, 1300, 1400, 1200, 750, 1100, 350, 733}, and the average is 967. H3>Exercise 5.3.4(a)As sets, an element x is in the left-side expression(R UNION S) UNION Tif and only if it is in at least one of R, S, and T. Likewise, it is in the right-side expressionR UNION (S UNION T)under exactly the same conditions. Thus, the two expressions have exactly the same members, and the sets are equal.As bags, an element x is in the left-side expression as many times as the sum of the number of times it is in R, S, and T. The same holds for the right side. Thus, as bags the expressions also have the same value. Exercise 5.3.4(h)As sets, element x is in the left sideR UNION (S INTERSECT T)if and only if x is either in R or in both S and T. Element x is in the right side(R UNION S) INTERSECT (R UNION T)if and only if it is in both R UNION S and R UNION T. If x is in R, then it is in both unions. If x is in both S and T, then it is in both union. However, if x is neither in R nor in both of S and T, then it cannot be in both unions. For example, suppose x is not in R and not in S. Then x is not in R UNION S. Thus, the statement of when x is in the right side is exactly the same as when it is in the left side: x is either in R or in both of S and T.Now, consider the expression for bags. Element x is in the left side the sum of the number of times it is in R plus the smaller of the number of times x is in S and the number of times x is in T. Likewise, the number of times x is in the right side is the smaller ofThe sum of the number of times x is in R and in S.The sum of the number of times x is in R and in T.A moment's reflection tells us that this minimum is the sum of the number of times x is in R plus the smaller of the number of times x is in S and in T, exactly as for the left side.Exercise 5.3.5(a)。
数据库课后答案 第二章(数据库系统基本原理)

《数据库技术及应用基础教程》第二章参考答案--责任人:袁圆、董婧灵、娄振霞一、选择题1~5:CDCCD 6~10:BDCCA 11~15:AD,ABCA 16:B二、填空题:1.数据库、数据库系统软件、数据库系统用户2. 关系名(属性名1,属性名2,属性名3,…)3.列4. 能标识独一实体的属性或属性组5.一张或几张表(或视图),结构,数据6. 使关系中的每一个属性为不可再分的单纯形域(消除“表中表”),使关系中所有非主属性对任意一个侯选关键字不存在部分函数依赖(使关系中所有非主属性都完全函数依赖于任意一个侯选关键字),使关系中所有非主属性对任意一个侯选关键字不存在传递函数依赖7.需求分析阶段,概念结构设计阶段,逻辑结构设计阶段,数据库物理设计阶段,数据库实施阶段,数据库运行和维护阶段8.数据库应用系统(DBAS)9.安全性、完整性、并发控制和数据恢复10.发生故障后,故障前状态11.授权12.事务13.事务中包括的各个操作一旦开始执行,则一定要全部完成14.封锁,共享锁,排他锁15. 一致性,正确性16.系统自动完成三、简答题1、试述数据模型的概念、数据模型的作用和数据模型的三个要素。
答:数据模型是现实世界数据特征的一种抽象,一种表示实体类型及实体类型间联系的模型。
数据模型可以抽象、表示、处理现实中的数据和信息。
数据模型的三要素分别是:(1)数据结构:是所研究的对象类型的集合,是对系统静态特性的描述。
(2)数据操作:对数据库中各种对象(型)的实例(值)允许执行的操作的集合,操作及操作规则。
(3)数据的约束条件:是一组完整性规则的集合。
也就是说,对于具体的应用娄必须遵循特定的语义约束条件,以保证数据的正确、有效和相容。
2、试述网状、层次数据库的优缺点。
答:网状数据库的优点:(1)能更直接的描述现实世界;(2)具有良好的性能,存取效率更好。
网状数据库缺点:(1)结构复杂,应用系统越大数据库结构越复杂;(2)用法复杂,用户不易理解。
(完整版)数据库系统基础教程第二章答案

(Lena, Hand,805-333, 12345),
(Lena, Hand,805-333, 23456)
Exercise 2.2.1c
For relation Accounts and the first tuple, the components are:
idNo
firstName
lastName
account
805-333
Lena
Hand
23456
805-333
Lena
Hand
12345
901-222
Robbie
Banks
12345
Exercise 2.2.2
Examples of attributes that are created for primarily serving as keys in a relation:
Vehicle Identification Numbers (VIN), a unique serial number used by the automotive industry to identify vehicles.
Exercise 2.2.3a
We can order the three tuples in any of 3! = 6 ways. Also, the columns can be ordered in any of 3! = 6 ways. Thus, the number of presentations is 6*6 = 36.
CREATE TABLE Outcomes (
ship CHAR(30), battle CHAR(30), result CHAR(10)
数据库系统基础教程第二章答案终审稿)

数据库系统基础教程第二章答案文稿归稿存档编号:[KKUY-KKIO69-OTM243-OLUI129-G00I-FDQS58-For relation Accounts, the attributes are:acctNo, type, balanceFor relation Customers, the attributes are:firstName, lastName, idNo, accountFor relation Accounts, the tuples are:(12345, savings, 12000),(23456, checking, 1000),(34567, savings, 25)For relation Customers, the tuples are:(Robbie, Banks, 901-222, 12345),(Lena, Hand, 805-333, 12345),(Lena, Hand, 805-333, 23456)For relation Accounts and the first tuple, the components are: 123456 acctNosavings type12000 balanceFor relation Customers and the first tuple, the components are: Robbie firstNameBanks lastName901-222 idNo12345 accountFor relation Accounts, a relation schema is:Accounts(acctNo, type, balance)For relation Customers, a relation schema is:Customers(firstName, lastName, idNo, account)An example database schema is:Accounts (acctNo,type,balance)Customers (firstName,lastName,idNo,account)A suitable domain for each attribute:acctNo Integertype Stringbalance IntegerfirstName StringlastName StringidNo String (because there is a hyphen we cannot use Integer)account IntegerExamples of attributes that are created for primarily serving as keys in a relation:Universal Product Code (UPC) used widely in United States and Canada to track products in stores.Serial Numbers on a wide variety of products to allow the manufacturer to individually track each product.Vehicle Identification Numbers (VIN), a unique serial number used by the automotive industry to identify vehicles.We can order the three tuples in any of 3! = 6 ways. Also, the columns can be ordered in any of 3! = 6 ways. Thus, the number of presentations is 6*6 = 36. We can order the three tuples in any of 5! = 120 ways. Also, the columns can be ordered in any of 4! = 24 ways. Thus, the number of presentations is 120*24 = 2880We can order the three tuples in any of m! ways. Also, the columns can be ordered in any of n! ways. Thus, the number of presentations is n!m!CREATE TABLE Product (maker CHAR(30),model CHAR(10) PRIMARY KEY,type CHAR(15));CREATE TABLE PC (model CHAR(30),speed DECIMAL(4,2),ram INTEGER,hd INTEGER,price DECIMAL(7,2));CREATE TABLE Laptop (model CHAR(30),speed DECIMAL(4,2),ram INTEGER,hd INTEGER,screen DECIMAL(3,1),price DECIMAL(7,2));CREATE TABLE Printer (model CHAR(30),color BOOLEAN,type CHAR (10),price DECIMAL(7,2));ALTER TABLE Printer DROP color;ALTER TABLE Laptop ADD od CHAR (10) DEFAULT ‘none’; CREATE TABLE Classes (class CHAR(20),type CHAR(5),country CHAR(20),numGuns INTEGER,bore DECIMAL(3,1),displacement INTEGER);CREATE TABLE Ships (name CHAR(30),class CHAR(20),launched INTEGER);CREATE TABLE Battles (name CHAR(30),date DATE);CREATE TABLE Outcomes (ship CHAR(30),battle CHAR(30),result CHAR(10));ALTER TABLE Classes DROP bore;ALTER TABLE Ships ADD yard CHAR(30);R1 := σspeed ≥ 3.00(PC)R2 := πmodel(R1)R1 := σhd ≥ 100(Laptop)R2 := Product (R1)R3 := πmaker (R2)model100510061013 makerEAR1 := σmaker=B(Product PC)R2 := σmaker=B(Product Laptop)R3 := σmaker=B(Product Printer)model,priceR5 := πmodel,price(R2)R6: = πmodel,price(R3)R7 := R4 R5 R6model price100464910056301006104920071429R1 := σcolor = true AND type = laser(Printer)R2 := πmodel(R1)R1 := σtype=laptop(Product)R2 := σtype=PC(Product)R3 := πmaker(R1)R4 := πmaker(R2)R5 := R3 – R4R1 := ρPC1(PC)R2 := ρPC2(PC)R3 := R1(PC1.hd = PC2.hd AND PC1.model <> PC2.model)R2R4 := πhd(R3)R1 := ρPC1(PC)R2 := ρPC2(PC)R3 := R1(PC1.speed = PC2.speed AND PC1.ram = PC2.ram AND PC1.model < PC2.model)R2R4 := πPC1.model,PC2.model(R3)R1 := πmodel (σspeed ≥ 2.80(PC)) πmodel(σspeed≥ 2.80(Laptop))R2 := πmaker,model(R1 Product)R3 := ρR3(maker2,model2)(R2)R4 := R2(maker = maker2 AND model <> model2)R3R5 := πmaker(R4)R1 := πmodel,speed(PC)R2 := πmodel,speed(Laptop)R3 := R1 R2R4 := ρR4(model2,speed2)(R3)R5 := πmodel,speed (R3(speed < speed2 )R4)R6 := R3 – R5(R6 Product) makerBmaker,speed (Product PC)BFGmodel30033007makerFGhd25080160PC1.model PC2.model 10041012makerBER2 := ρR2(maker2,speed2)(R1) R3 := ρR3(maker3,speed3)(R1)R4 := R1 (maker = maker2 AND speed <> speed2) R2R5 := R4 (maker3 = maker AND speed3 <> speed2 AND speed3 <> speed) R3 R6 := πmaker (R5)R1 := πmaker,model (Product PC)R2 := ρR2(maker2,model2)(R1)R3 := ρR3(maker3,model3)(R1)R4 := ρR4(maker4,model4)(R1)R5 := R1 (maker = maker2 AND model <> model2) R2R6 := R3 (maker3 = maker AND model3 <> model2 AND model3 <> model) R5R7 := R4 (maker4 = maker AND (model4=model OR model4=model2 OR model4=model3)) R6R8 := πmaker (R7)R1 := σbore ≥ 16 (Classes)R2 := πclass,country (R1)class countryIowa USA North Carolina USA Yamato Japanlaunched < 1921nameHaruna HieiKirishima KongoRamillies Renown RepulseResolution Revenge Royal Oak Royal Sovereign Tennesseebattle=Denmark Strait AND result=sunk (Outcomes)ship Bismarck HoodmakerADEmakerA B D ER1 := Classes Ships(R1) R2 := σlaunched > 1921 AND displacement > 35000(R2)R3 := πnamenameIowaMissouriMusashiNew JerseyNorthCarolinaWashingtonWisconsinYamato(Outcomes)R1 := σbattle=GuadalcanalR1R2 := Ships(ship=name)R3 := Classes R2numGuns name displacementKirishima320008 Washingto370009nname(Outcomes)R2 := πshipR3 := ρ(R2)R3(name)R4 := R1 R3nameCaliforniaHarunaHieiIowaKirishimaKongoMissouriMusashiNew JerseyNorth CarolinaRamilliesRenownRepulseResolutionRevengeFrom 2.3.2, assuming that every class has one ship named after the class. R1 := πclass (Classes) R2 := πclass (σname <> class (Ships)) R3 := R1 – R2 R1 := πcountry (σtype=bb (Classes)) R2 := πcountry (σtype=bc (Classes)) R3 := R1 ∩ R2 R1 := πship,result,date (Battles (battle=name) Outcomes)R2 := ρR2(ship2,result2,date2)(R1)R3 := R1 (ship=ship2 AND result=damaged AND date < date2) R2R4 := πship (R3)No results from sample data. Exercise 2.4.5 The result of the natural join has only one attributefrom each pair of equated attributes. On the other hand,the result of the theta-join has both columns of theattributes and their values are identical.Exercise 2.4.6UnionIf we add a tuple to the arguments of the unionoperator, we will get all of the tuples of the original result and maybe the added tuple. If the added tuple is a duplicate tuple, then the set behavior will eliminate that tuple. Thus the union operator is monotone.IntersectionIf we add a tuple to the arguments of the intersection operator, we will get all of the tuples of the original result and maybe the added tuple. If the added tuple does not exist in the relation that it is added but does exist in the other relation, then the result set will include the added tuple. Thus the intersection operator is monotone.DifferenceIf we add a tuple to the arguments of the difference operator, we may not get all of the tuples of the original result. Suppose we haverelations R and S and we are computing R – S. Suppose also that tuple t is in R but not in S. The result of R – S would include tuple t .However, if we add tuple t to S, then the new result will not have tuple t . Thus the difference operator is not monotone.ProjectionIf we add a tuple to the arguments of the projection operator, we will get all of the tuples of the original result and the projection of the added tuple. The projection operator only selects columns from the relation and does not affect the rows that are selected. Thus the projection operator is monotone.SelectionRoyal OakRoyalSovereignTennesseeWashingtonWisconsin Yamato ArizonaBismarck Duke of York FusoHoodKing George V Prince of WalesRodneyScharnhorstSouth DakotaWest VirginiaYamashiroclassBismarck countryJapanGt. BritainIf we add a tuple to the arguments of the selection operator, we willget all of the tuples of the original result and maybe the added tuple.If the added tuple satisfies the select condition, then it will be added to the new result. The original tuples are included in the new resultbecause they still satisfy the select condition. Thus the selectionoperator is monotone.Cartesian ProductIf we add a tuple to the arguments of the Cartesian product operator, we will get all of the tuples of the original result and possiblyadditional tuples. The Cartesian product pairs the tuples of onerelation with the tuples of another relation. Suppose that we arecalculating R x S where R has m tuples and S has n tuples. If we add atuple to R that is not already in R, then we expect the result of R x S to have (m + 1) * n tuples. Thus the Cartesian product operator ismonotone.Natural JoinsIf we add a tuple to the arguments of a natural join operator, we willget all of the tuples of the original result and possibly additionaltuples. The new tuple can only create additional successful joins, notless. If, however, the added tuple cannot successfully join with any of the existing tuples, then we will have zero additional successful joins.Thus the natural join operator is monotone.Theta JoinsIf we add a tuple to the arguments of a theta join operator, we will get all of the tuples of the original result and possibly additional tuples.The theta join can be modeled by a Cartesian product followed by aselection on some condition. The new tuple can only create additionaltuples in the result, not less. If, however, the added tuple does notsatisfy the select condition, then no additional tuples will be added to the result. Thus the theta join operator is monotone.RenamingIf we add a tuple to the arguments of a renaming operator, we will getall of the tuples of the original result and the added tuple. Therenaming operator does not have any effect on whether a tuple isselected or not. In fact, the renaming operator will always return asmany tuples as its argument. Thus the renaming operator is monotone.If all the tuples of R and S are different, then the union has n + m tuples, and this number is the maximum possible.The minimum number of tuples that can appear in the result occurs if every tuple of one relation also appears in the other. Then the union has max(m , n) tuples.If all the tuples in one relation can pair successfully with all the tuples in the other relation, then the natural join has n * m tuples. This number wouldbe the maximum possible.The minimum number of tuples that can appear in the result occurs if none of the tuples of one relation can pair successfully with all the tuples in the other relation. Then the natural join has zero tuples.If the condition C brings back all the tuples of R, then the cross productwill contain n * m tuples. This number would be the maximum possible.The minimum number of tuples that can appear in the result occurs if the condition C brings back none of the tuples of R. Then the cross product has zero tuples.Assuming that the list of attributes L makes the resulting relation πL(R) and relation S schema compatible, then the maximum possible tuples is n. Thishappens when all of the tuples of πL(R) are not in S.The minimum number of tuples that can appear in the result occurs when all ofthe tuples in πL(R) appear in S. Then the difference has max(n–m , 0) tuples.Exercise 2.4.8Defining r as the schema of R and s as the schema of S:1.πr(R S)2.R δ(πr∩s(S)) where δ is the duplicate-elimination operator inSection 5.2 pg. 2133.R – (R –πr(R S))Exercise 2.4.9Defining r as the schema of R1.R - πr(R S)πA1,A2…An(R S)σspeed < 2.00 AND price > 500(PC) =Model 1011 violates this constraint.σscreen < 15.4 AND hd < 100 AND price ≥ 1000(Laptop) =Model 2004 violates the constraint.πmaker (σtype = laptop(Product)) ∩ πmaker(σtype = pc(Product)) =Manufacturers A,B,E violate the constraint.This complex expression is best seen as a sequence of steps in which we define temporary relations R1 through R4 that stand for nodes of expression trees. Here is the sequence:R1(maker, model, speed) := πmaker,model,speed(Product PC)R2(maker, speed) := πmaker,speed(Product Laptop)R3(model) := πmodel (R1R1.maker = R2.maker AND R1.speed ≤ R2.speedR2)R4(model) := πmodel(PC)The constraint is R4 R3Manufacturers B,C,D violate the constraint.πmodel (σLaptop.ram > PC.ram AND Laptop.price ≤ PC.price(PC × Laptop)) =Models 2002,2006,2008 violate the constraint.πclass (σbore > 16(Classes)) =The Yamato class violates the constraint.πclass (σnumGuns > 9 AND bore > 14(Classes)) =No violations to the constraint.This complex expression is best seen as a sequence of steps in which we define temporary relations R1 through R5 that stand for nodes of expression trees. Here is the sequence:R1(class,name) := πclass,name(Classes Ships)R2(class2,name2) := ρR2(class2,name2)(R1)R3(class3,name3) := ρR3(class3,name3)(R1)R4(class,name,class2,name2) := R1(class = class2 AND name <> name2)R2R5(class,name,class2,name2,class3,name3) := R4(class=class3 AND name <> name3 AND name2 <> name3)R3The constraint is R5 =The Kongo, Iowa and Revenge classes violate the constraint.πcountry (σtype = bb(Classes)) ∩ πcountry(σtype = bc(Classes)) =Japan and Gt. Britain violate the constraint.This complex expression is best seen as a sequence of steps in which we define temporary relations R1 through R5 that stand for nodes of expression trees. Here is the sequence:R1(ship,battle,result,class) := πship,battle,result,class (Outcomes(ship = name)Ships)R2(ship,battle,result,numGuns) := πship,battle,result,numGuns(R1 Classes)R3(ship,battle) := πship,battle (σnumGuns < 9 AND result = sunk(R2))R4(ship2,battle2) := ρR4(ship2,battle2)(πship,battle(σnumGuns > 9(R2)))R5(ship2) := πship2(R3(battle = battle2)R4)The constraint is R5 =No violations to the constraint. Since there are some ships in the Outcomes table that are not in the Ships table, we are unable to determine the number of guns on that ship.Exercise 2.5.3Defining r as the schema A1,A2,…,Anand s as the schema B1,B2,…,Bn:πr (R) πs(S) =where is the antisemijoinExercise 2.5.4The form of a constraint as E1 = E2can be expressed as the other twoconstraints.Using the “equating an expression to the empty set” method, we can simply say:E 1– E2=As a containment, we can simply say:E1 E2AND E2E1Thus, the form E1 = E2of a constraint cannot express more than the two otherforms discussed in this section.。
数据库系统基础教程(第二版)课后习题答案

Database Systems: The Complete BookSolutions for Chapter 2Solutions for Section 2.1Exercise 2.1.1The E/R Diagram.Exercise 2.1.8(a)The E/R DiagramKobvxybzSolutions for Section 2.2Exercise 2.2.1The Addresses entity set is nothing but a single address, so we would prefer to make address an attribute of Customers. Were the bank to record several addresses for a customer, then it might make sense to have an Addresses entity set and make Lives-at a many-many relationship.The Acct-Sets entity set is useless. Each customer has a unique account set containing his or her accounts. However, relating customers directly to their accounts in a many-many relationship conveys the same information and eliminates the account-set concept altogether.Solutions for Section 2.3Exercise 2.3.1(a)Keys ssNo and number are appropriate for Customers and Accounts, respectively. Also,we think it does not make sense for an account to be related to zero customers, so we should round the edge connecting Owns to Customers. It does not seem inappropriate to have a customer with 0 accounts; they might be a borrower, for example, so we put no constraint on the connection from Owns to Accounts. Here is the The E/R Diagram,showing underlined keys and the numerocity constraint.Exercise 2.3.2(b)If R is many-one from E1 to E2, then two tuples (e1,e2) and (f1,f2) of the relationship set for R must be the same if they agree on the key attributes for E1. To see why, surely e1 and f1 are the same. Because R is many-one from E1 to E2, e2 and f2 must also be the same. Thus, the pairs are the same.Solutions for Section 2.4Exercise 2.4.1Here is the The E/R Diagram.We have omitted attributes other than our choice for the key attributes of Students and Courses. Also omitted are names for the relationships. Attribute grade is not part of the key for Enrollments. The key for Enrollements is studID from Students and dept and number from Courses.Exercise 2.4.4bHere is the The E/R Diagram Again, we have omitted relationship names and attributes other than our choice for the key attributes. The key for Leagues is its own name;this entity set is not weak. The key for Teams is its own name plus the name of the league of which the team is a part, e.g., (Rangers, MLB) or (Rangers, NHL). The key for Players consists of the player's number and the key for the team on which he or she plays. Since the latter key is itself a pair consisting of team and league names, the key for players is the triple (number, teamName, leagueName). e.g., Jeff Garcia is (5, 49ers, NFL).Database Systems: The Complete BookSolutions for Chapter 3Solutions for Section 3.1Exercise 3.1.2(a)We can order the three tuples in any of 3! = 6 ways. Also, the columns can be ordered in any of 3! = 6 ways. Thus, the number of presentations is 6*6 = 36. Solutions for Section 3.2Exercise 3.2.1Customers(ssNo, name, address, phone)Flights(number, day, aircraft)Bookings(ssNo, number, day, row, seat)Being a weak entity set, Bookings' relation has the keys for Customers and Flights and Bookings' own attributes.Notice that the relations obtained from the toCust and toFlt relationships are unnecessary. They are:toCust(ssNo, ssNo1, number, day)toFlt(ssNo, number, day, number1, day1)That is, for toCust, the key of Customers is paired with the key for Bookings. Since both include ssNo, this attribute is repeated with two different names, ssNo and ssNo1. A similar situation exists for toFlt.Exercise 3.2.3Ships(name, yearLaunched)SisterOf(name, sisterName)Solutions for Section 3.3Exercise 3.3.1Since Courses is weak, its key is number and the name of its department. We do not have a relation for GivenBy. In part (a), there is a relation for Courses and a relation for LabCourses that has only the key and the computer-allocation attribute. It looks like:Depts(name, chair)Courses(number, deptName, room)LabCourses(number, deptName, allocation)For part (b), LabCourses gets all the attributes of Courses, as:Depts(name, chair)Courses(number, deptName, room)LabCourses(number, deptName, room, allocation)And for (c), Courses and LabCourses are combined, as:Depts(name, chair)Courses(number, deptName, room, allocation)Exercise 3.3.4(a)There is one relation for each entity set, so the number of relations is e. The relation for the root entity set has a attributes, while the other relations, which must include the key attributes, have a+k attributes.Solutions for Section 3.4Exercise 3.4.2Surely ID is a key by itself. However, we think that the attributes x, y, and z together form another key. The reason is that at no time can two molecules occupy the same point.Exercise 3.4.4The key attributes are indicated by capitalization in the schema below:Customers(SSNO, name, address, phone)Flights(NUMBER, DAY, aircraft)Bookings(SSNO, NUMBER, DAY, row, seat)Exercise 3.4.6(a)The superkeys are any subset that contains A1. Thus, there are 2^{n-1} such subsets, since each of the n-1 attributes A2 through An may independently be chosen in or out.Solutions for Section 3.5Exercise 3.5.1(a)We could try inference rules to deduce new dependencies until we are satisfied we have them all. A more systematic way is to consider the closures of all 15 nonempty sets of attributes.For the single attributes we have A+ = A, B+ = B, C+ = ACD, and D+ = AD. Thus, the only new dependency we get with a single attribute on the left is C->A.Now consider pairs of attributes:AB+ = ABCD, so we get new dependency AB->D. AC+ = ACD, and AC->D is nontrivial. AD+ = AD, so nothing new. BC+ = ABCD, so we get BC->A, and BC->D. BD+ = ABCD, giving us BD->A and BD->C. CD+ = ACD, giving CD->A.For the triples of attributes, ACD+ = ACD, but the closures of the other sets are each ABCD. Thus, we get new dependencies ABC->D, ABD->C, and BCD->A.Since ABCD+ = ABCD, we get no new dependencies.The collection of 11 new dependencies mentioned above is: C->A, AB->D, AC->D, BC->A, BC->D, BD->A, BD->C, CD->A, ABC->D, ABD->C, and BCD->A.Exercise 3.5.1(b)From the analysis of closures above, we find that AB, BC, and BD are keys. All other sets either do not have ABCD as the closure or contain one of these three sets.Exercise 3.5.1(c)The superkeys are all those that contain one of those three keys. That is, a superkey that is not a key must contain B and more than one of A, C, and D. Thus, the (proper) superkeys are ABC, ABD, BCD, and ABCD.Exercise 3.5.3(a)We must compute the closure of A1A2...AnC. Since A1A2...An->B is a dependency, surely B is in this set, proving A1A2...AnC->B.Exercise 3.5.4(a)Consider the relationThis relation satisfies A->B but does not satisfy B->A.Exercise 3.5.8(a)If all sets of attributes are closed, then there cannot be any nontrivial functional dependencies. For suppose A1A2...An->B is a nontrivial dependency. Then A1A2...An+ contains B and thus A1A2...An is not closed.Exercise 3.5.10(a)We need to compute the closures of all subsets of {ABC}, although there is no need to think about the empty set or the set of all three attributes. Here are the calculations for the remaining six sets:A+ = AB+ = BC+ = ACEAB+ = ABCDEAC+ = ACEBC+ = ABCDEWe ignore D and E, so a basis for the resulting functional dependencies for ABC are: C->A and AB->C. Note that BC->A is true, but follows logically from C->A, and therefore may be omitted from our list.Solutions for Section 3.6Exercise 3.6.1(a)In the solution to Exercise 3.5.1 we found that there are 14 nontrivial dependencies, including the three given ones and 11 derived dependencies. These are: C->A, C->D, D->A, AB->D, AB-> C, AC->D, BC->A, BC->D, BD->A, BD->C, CD->A, ABC->D, ABD->C, and BCD->A.We also learned that the three keys were AB, BC, and BD. Thus, any dependency above that does not have one of these pairs on the left is a BCNF violation. These are: C->A, C->D, D->A, AC->D, and CD->A.One choice is to decompose using C->D. That gives us ABC and CD as decomposed relations. CD is surely in BCNF, since any two-attribute relation is. ABC is not in BCNF, since AB and BC are its only keys, but C->A is a dependency that holds in ABCD and therefore holds in ABC. We must further decompose ABC into AC and BC. Thus, the three relations of the decomposition are AC, BC, and CD.Since all attributes are in at least one key of ABCD, that relation is already in 3NF, and no decomposition is necessary.Exercise 3.6.1(b)(Revised 1/19/02) The only key is AB. Thus, B->C and B->D are both BCNF violations. The derived FD's BD->C and BC->D are also BCNF violations. However, any other nontrivial, derived FD will have A and B on the left, and therefore will contain a key.One possible BCNF decomposition is AB and BCD. It is obtained starting with any of the four violations mentioned above. AB is the only key for AB, and B is the only key for BCD.Since there is only one key for ABCD, the 3NF violations are the same, and so is the decomposition.Solutions for Section 3.7Exercise 3.7.1Since A->->B, and all the tuples have the same value for attribute A, we can pair the B-value from any tuple with the value of the remaining attribute C from any othertuple. Thus, we know that R must have at least the nine tuples of the form (a,b,c), where b is any of b1, b2, or b3, and c is any of c1, c2, or c3. That is, we can derive, using the definition of a multivalued dependency, that each of the tuples (a,b1,c2), (a,b1,c3), (a,b2,c1), (a,b2,c3), (a,b3,c1), and (a,b3,c2) are also in R.Exercise 3.7.2(a)First, people have unique Social Security numbers and unique birthdates. Thus, we expect the functional dependencies ssNo->name and ssNo->birthdate hold. The same applies to children, so we expect childSSNo->childname and childSSNo->childBirthdate. Finally, an automobile has a unique brand, so we expect autoSerialNo->autoMake.There are two multivalued dependencies that do not follow from these functional dependencies. First, the information about one child of a person is independent of other information about that person. That is, if a person with social security number s has a tuple with,cs,cb, then if there is any other tuple t for the same person, there will also be another tuple that agrees with t except that it has,cs,cb in its components for the child name, Social Security number, and birthdate. That is the multivalued dependencyssNo->->childSSNo childName childBirthdateSimilarly, an automobile serial number and make are independent of any of the other attributes, so we expect the multivalued dependencyssNo->->autoSerialNo autoMakeThe dependencies are summarized below:ssNo -> name birthdatechildSSNo -> childName childBirthdateautoSerialNo -> autoMakessNo ->-> childSSNo childName childBirthdatessNo ->-> autoSerialNo autoMakeExercise 3.7.2(b)We suggest the relation schemas{ssNo, name, birthdate}{ssNo, childSSNo}{childSSNo, childName childBirthdate}{ssNo, autoSerialNo}{autoSerialNo, autoMake}An initial decomposition based on the two multivalued dependencies would give us {ssNo, name, birthDate}{ssNo, childSSNo, childName, childBirthdate}{ssNo, autoSerialNo, autoMake}Functional dependencies force us to decompose the second and third of these.Exercise 3.7.3(a)Since there are no functional dependencies, the only key is all four attributes,ABCD. Thus, each of the nontrvial multivalued dependencies A->->B and A->->C violate 4NF. We must separate out the attributes of these dependencies, first decomposing into AB and ACD, and then decomposing the latter into AC and AD because A->->C is still a 4NF violation for ACD. The final set of relations are AB, AC, and AD.Exercise 3.7.7(a)Let W be the set of attributes not in X, Y, or Z. Consider two tuples xyzw and xy'z'w' in the relation R in question. Because X ->-> Y, we can swap the y's, so xy'zw and xyz'w' are in R. Because X ->-> Z, we can take the pair of tuples xyzw and xyz'w' and swap Z's to get xyz'w and xyzw'. Similarly, we can take the pair xy'z'w' and xy'zw and swap Z's to get xy'zw' and xy'z'w.In conclusion, we started with tuples xyzw and xy'z'w' and showed that xyzw' and xy'z'w must also be in the relation. That is exactly the statement of the MVD X ->-> Y-union-Z. Note that the above statements all make sense even if there are attributes in common among X, Y, and Z.Exercise 3.7.8(a)Consider a relation R with schema ABCD and the instance with four tuples abcd, abcd', ab'c'd, and ab'c'd'. This instance satisfies the MVD A ->-> BC. However, it does not satisfy A ->-> B. For example, if it did satisfy A ->-> B, then because the instance contains the tuples abcd and ab'c'd, we would expect it to contain abc'd and ab'cd, neither of which is in the instance.Database Systems: The Complete BookSolutions for Chapter 4Solutions for Section 4.2Exercise 4.2.1class Customer {attribute string name;attribute string addr;attribute string phone;attribute integer ssNo;relationship Set<Account> ownsAcctsinverse Account::ownedBy;}class Account {attribute integer number;attribute string type;attribute real balance;relationship Set<Customer> ownedByinverse Customer::ownsAccts}Exercise 4.2.4class Person {attribute string name;relationship Person motherOfinverse Person::childrenOfFemalerelationship Person fatherOfinverse Person::childrenOfMalerelationship Set<Person> childreninverse Person::parentsOfrelationship Set<Person> childrenOfFemaleinverse Person::motherOfrelationship Set<Person> childrenOfMaleinverse Person::fatherOfrelationship Set<Person> parentsOfinverse Person::children}Notice that there are six different relationships here. For example, the inverse of the relationship that connects a person to their (unique) mother is a relationship that connects a mother (i.e., a female person) to the set of her children. That relationship, which we call childrenOfFemale, is different from the children relationship, which connects anyone -- male or female -- to their children.Exercise 4.2.7A relationship R is its own inverse if and only if for every pair (a,b) in R, the pair (b,a) is also in R. In the terminology of set theory, the relation R is ``symmetric.''Solutions for Section 4.3Exercise 4.3.1We think that Social Security number should me the key for Customer, and account number should be the key for Account. Here is the ODL solution with key and extent declarations.class Customer(extent Customers key ssNo){attribute string name;attribute string addr;attribute string phone;attribute integer ssNo;relationship Set<Account> ownsAcctsinverse Account::ownedBy;}class Account(extent Accounts key number){attribute integer number;attribute string type;attribute real balance;relationship Set<Customer> ownedByinverse Customer::ownsAccts}Solutions for Section 4.4Exercise 4.4.1(a)Since the relationship between customers and accounts is many-many, we should create a separate relation from that relationship-pair.Customers(ssNo, name, address, phone)Accounts(number, type, balance)CustAcct(ssNo, number)Exercise 4.4.1(d)Ther is only one attribute, but three pairs of relationships from Person to itself. Since motherOf and fatherOf are many-one, we can store their inverses in the relation for Person. That is, for each person, childrenOfMale and childrenOfFemale will indicate that persons's father and mother. The children relationship is many-many, and requires its own relation. This relation actually turns out to be redundant, in the sense that its tuples can be deduced from the relationships stored with Person. The schema:Persons(name, childrenOfFemale, childrenOfMale)Parent-Child(parent, child)Exercise 4.4.4You get a schema like:Studios(name, address, ownedMovie)Since name -> address is the only FD, the key is {name, ownedMovie}, and the FD has a left side that is not a superkey.Exercise 4.4.5(a,b,c)(a) Struct Card { string rank, string suit };(b) class Hand {attribute Set theHand;};For part (c) we have:Hands(handId, rank, suit)Notice that the class Hand has no key, so we need to create one: handID. Each hand has, in the relation Hands, one tuple for each card in the hand.Exercise 4.4.5(e)Struct PlayerHand { string Player, Hand theHand };class Deal {attribute Set theDeal;}Alternatively, PlayerHand can be defined directly within the declaration of attribute theDeal.Exercise 4.4.5(h)Since keys for Hand and Deal are lacking, a mechanical way to design the database schema is to have one relation connecting deals and player-hand pairs, and another to specify the contents of hands. That is:Deals(dealID, player, handID)Hands(handID, rank, suit)However, if we think about it, we can get rid of handID and connect the deal and the player directly to the player's cards, as:Deals(dealID, player, rank, suit)Exercise 4.4.5(i)First, card is really a pair consisting of a suit and a rank, so we need two attributes in a relation schema to represent cards. However, much more important is the fact that the proposed schema does not distinguish which card is in which hand. Thus, we need another attribute that indicates which hand within the deal a card belongs to, something like:Deals(dealID, handID, rank, suit)Exercise 4.4.6(c)Attribute b is really a bag of (f,g) pairs. Thus, associated with each a-value will be zero or more (f,g) pairs, each of which can occur several times. We shall use an attribute count to indicate the number of occurrences, although if relations allow duplicate tuples we could simply allow duplicate (a,f,g) triples in the relation. The proposed schema is:C(a, f, g, count)Solutions for Section 4.5Exercise 4.5.1(b)Studios(name, address, movies{(title, year, inColor, length,stars{(name, address, birthdate)})})Since the information about a star is repeated once for each of their movies, there is redundancy. To eliminate it, we have to use a separate relation for stars anduse pointers from studios. That is:Stars(name, address, birthdate)Studios(name, address, movies{(title, year, inColor, length,stars{*Stars})})Since each movie is owned by one studio, the information about a movie appears in only one tuple of Studios, and there is no redundancy.Exercise 4.5.2Customers(name, address, phone, ssNo, accts{*Accounts})Accounts(number, type, balance, owners{*Customers})Solutions for Section 4.6Exercise 4.6.1(a)We need to add new nodes labeled George Lucas and Gary Kurtz. Then, from the node sw (which represents the movie Star Wars), we add arcs to these two new nodes, labeled directedBy and producedBy, respectively.Exercise 4.6.2Create nodes for each account and each customer. From each customer node is an arc to a node representing the attributes of the customer, e.g., an arc labeled name to the customer's name. Likewise, there is an arc from each account node to each attribute of that account, e.g., an arc labeled balance to the value of the balance. To represent ownership of accounts by customers, we place an arc labeled owns from each customer node to the node of each account that customer holds (possibly jointly). Also, we place an arc labeled ownedBy from each account node to the customer node for each owner of that account.Exercise 4.6.5In the semistructured model, nodes represent data elements, i.e., entities rather than entity sets. In the E/R model, nodes of all types represent schema elements, and the data is not represented at all.Solutions for Section 4.7Exercise 4.7.1(a)<STARS-MOVIES><STAR starId = "cf" starredIn = "sw, esb, rj"><NAME>Carrie Fisher</NAME><ADDRESS><STREET>123 Maple St.</STREET><CITY>Hollywood</CITY></ADDRESS><ADDRESS><STREET>5 Locust Ln.</STREET><CITY>Malibu</CITY></ADDRESS></STAR><STAR starId = "mh" starredIn = "sw, esb, rj"><NAME>Mark Hamill</NAME><ADDRESS><STREET>456 Oak Rd.<STREET><CITY>Brentwood</CITY></ADDRESS></STAR><STAR starId = "hf" starredIn = "sw, esb, rj, wit"> <NAME>Harrison Ford</NAME><ADDRESS><STREET>whatever</STREET><CITY>whatever</CITY></ADDRESS></STAR><MOVIE movieId = "sw" starsOf = "cf, mh"><TITLE>Star Wars</TITLE><YEAR>1977</YEAR></MOVIE><MOVIE movieId = "esb" starsOf = "cf, mh"><TITLE>Empire Strikes Back</TITLE><YEAR>1980</YEAR></MOVIE><MOVIE movieId = "rj" starsOf = "cf, mh"><TITLE>Return of the Jedi</TITLE><YEAR>1983</YEAR></MOVIE><MOVIE movieID = "wit" starsOf = "hf"><TITLE>Witness</TITLE><YEAR>1985</YEAR></MOVIE></STARS-MOVIES>Exercise 4.7.2<!DOCTYPE Bank [<!ELEMENT BANK (CUSTOMER* ACCOUNT*)><!ELEMENT CUSTOMER (NAME, ADDRESS, PHONE, SSNO)> <!ATTLIST CUSTOMERcustId IDowns IDREFS><!ELEMENT NAME (#PCDATA)><!ELEMENT ADDRESS (#PCDATA)><!ELEMENT PHONE (#PCDATA)><!ELEMENT SSNO (#PCDATA)><!ELEMENT ACCOUNT (NUMBER, TYPE, BALANCE)><!ATTLIST ACCOUNTacctId IDownedBy IDREFS><!ELEMENT NUMBER (#PCDATA)><!ELEMENT TYPE (#PCDATA)><!ELEMENT BALANCE (#PCDATA)>]>Database Systems: The CompleteBookSolutions for Chapter 5Solutions for Section 5.2Exercise 5.2.1(a)PI_model( SIGMA_{speed >= 1000} ) (PC)Exercise 5.2.1(f)The trick is to theta-join PC with itself on the condition that the hard disk sizes are equal. That gives us tuples that have two PC model numbers with the same value of hd. However, these two PC's could in fact be the same, so we must also require in the theta-join that the model numbers be unequal. Finally, we want the hard disk sizes, so we project onto hd. The expression is easiest to see if we write it using some temporary values. We start by renaming PC twice so we can talk about two occurrences of the same attributes.R1 = RHO_{PC1} (PC)R2 = RHO_{PC2} (PC)R3 = R1 JOIN_{PC1.hd = PC2.hd AND PC1.model <> PC2.model} R2R4 = PI_{PC1.hd} (R3)Exercise 5.2.1(h)First, we find R1, the model-speed pairs from both PC and Laptop. Then, we find from R1 those computers that are ``fast,'' at least 133Mh. At the same time, we join R1 with Product to connect model numbers to their manufacturers and we project out the speed to get R2. Then we join R2 with itself (after renaming) to find pairs of different models by the same maker. Finally, we get our answer, R5, by projecting onto one of the maker attributes. A sequence of steps giving the desired expression is:R1 = PI_{model,speed} (PC) UNION PI_{model,speed} (Laptop)R2 = PI_{maker,model} (SIGMA_{speed>=700} (R1) JOIN Product)R3 = RHO_{T(maker2, model2)} (R2)R4 = R2 JOIN_{maker = maker2 AND model <> model2} (R3)R5 = PI_{maker} (R4)Exercise 5.2.2Here are figures for the expression trees of Exercise 5.2.1 Part (a)Part (f)Part (h). Note that the third figure is not really a tree, since it uses a common subexpression. We could duplicate the nodes to make it a tree, but using common subexpressions is a valuable form of query optimization. One of the benefits one gets from constructing ``trees'' for queries is the ability to combine nodes that represent common subexpressions.Exercise 5.2.7The relation that results from the natural join has only one attribute from each pair of equated attributes. The theta-join has attributes for both, and their columns are identical.Exercise 5.2.9(a)If all the tuples of R and S are different, then the union has n+m tuples, and this number is the maximum possible.The minimum number of tuples that can appear in the result occurs if every tuple of one relation also appears in the other. Surely the union has at least as many tuples as the larger of R and that is, max(n,m) tuples. However, it is possible for every tuple of the smaller to appear in the other, so it is possible that there are as few as max(n,m) tuples in the union.Exercise 5.2.10In the following we use the name of a relation both as its instance (set of tuples) and as its schema (set of attributes). The context determines uniquely which is meant.PI_R(R JOIN S) Note, however, that this expression works only for sets; it does not preserve the multipicity of tuples in R. The next two expressions work for bags.R JOIN DELTA(PI_{R INTERSECT S}(S)) In this expression, each projection of a tuple from S onto the attributes that are also in R appears exactly once in the second argument of the join, so it preserves multiplicity of tuples in R, except for those that do not join with S, which disappear. The DELTA operator removes duplicates, as described in Section 5.4. R - [R - PI_R(R JOIN S)] Here, the strategy is to find the dangling tuples of R and remove them.Solutions for Section 5.3Exercise 5.3.1As a bag, the value is {700, 1500, 866, 866, 1000, 1300, 1400, 700, 1200, 750, 1100, 350, 733}. The order is unimportant, of course. The average is 959.As a set, the value is {700, 1500, 866, 1000, 1300, 1400, 1200, 750, 1100, 350, 733}, and the average is 967. H3>Exercise 5.3.4(a)As sets, an element x is in the left-side expression(R UNION S) UNION Tif and only if it is in at least one of R, S, and T. Likewise, it is in the right-side expressionR UNION (S UNION T)under exactly the same conditions. Thus, the two expressions have exactly the same members, and the sets are equal.As bags, an element x is in the left-side expression as many times as the sum of the number of times it is in R, S, and T. The same holds for the right side. Thus, as bags the expressions also have the same value. Exercise 5.3.4(h)As sets, element x is in the left sideR UNION (S INTERSECT T)if and only if x is either in R or in both S and T. Element x is in the right side(R UNION S) INTERSECT (R UNION T)if and only if it is in both R UNION S and R UNION T. If x is in R, then it is in both unions. If x is in both S and T, then it is in both union. However, if x is neither in R nor in both of S and T, then it cannot be in both unions. For example, suppose x is not in R and not in S. Then x is not in R UNION S. Thus, the statement of when x is in the right side is exactly the same as when it is in the left side: x is either in R or in both of S and T.Now, consider the expression for bags. Element x is in the left side the sum of the number of times it is in R plus the smaller of the number of times x is in S and the number of times x is in T. Likewise, the number of times x is in the right side is the smaller ofThe sum of the number of times x is in R and in S.The sum of the number of times x is in R and in T.A moment's reflection tells us that this minimum is the sum of the number of times x is in R plus the smaller of the number of times x is in S and in T, exactly as for the left side.Exercise 5.3.5(a)For sets, we observe that element x is in the left side(R INTERSECT S) - Tif and only if it is in both R and S and not in T. The same holds for the right side。
数据库系统教程课后答案(施伯乐)(第三版)

第1章数据库概论1.1 基本内容分析1.1.1 本章的重要概念(1)DB、DBMS和DBS的定义(2)数据管理技术的发展阶段人工管理阶段、文件系统阶段、数据库系统阶段和高级数据库技术阶段等各阶段的特点。
(3)数据描述概念设计、逻辑设计和物理设计等各阶段中数据描述的术语,概念设计中实体间二元联系的描述(1:1,1:N,M:N)。
(4)数据模型数据模型的定义,两类数据模型,逻辑模型的形式定义,ER模型,层次模型、网状模型、关系模型和面向对象模型的数据结构以及联系的实现方式。
(5)DB的体系结构三级结构,两级映像,两级数据独立性,体系结构各个层次中记录的联系。
(6)DBMSDBMS的工作模式、主要功能和模块组成。
(7)DBSDBS的组成,DBA,DBS的全局结构,DBS结构的分类。
1.1.2本章的重点篇幅(1)教材P23的图1.24(四种逻辑数据模型的比较)。
(2)教材P25的图1.27(DB的体系结构)。
(3)教材P28的图1.29(DBMS的工作模式)。
(4)教材P33的图1.31(DBS的全局结构)。
1.2 教材中习题1的解答1.1 名词解释·逻辑数据:指程序员或用户用以操作的数据形式。
·物理数据:指存储设备上存储的数据。
·联系的元数:与一个联系有关的实体集个数,称为联系的元数。
·1:1联系:如果实体集E1中每个实体至多和实体集E2中的一个实体有联系,反之亦然,那么E1和E2的联系称为“1:1联系”。
·1:N联系:如果实体集E1中每个实体可以与实体集E2中任意个(零个或多个)实体有联系,而E2中每个实体至多和E1中一个实体有联系,那么E1和E2的联系是“1:N联系”。
·M:N联系:如果实体集E1中每个实体可以与实体集E2中任意个(零个或多个)实体有联系,反之亦然,那么E1和E2的联系称为“M:N联系”。
·数据模型:能表示实体类型及实体间联系的模型称为“数据模型”。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Exercise 2.2.1aFor relation Accounts, the attributes are:acctNo, type, balanceFor relation Customers, the attributes are:firstName, lastName, idNo, accountExercise 2.2.1bFor relation Accounts, the tuples are:(12345, savings, 12000),(23456, checking, 1000),(34567, savings, 25)For relation Customers, the tuples are:(Robbie, Banks, 901-222, 12345),(Lena, Hand, 805-333, 12345),(Lena, Hand, 805-333, 23456)Exercise 2.2.1cFor relation Accounts and the first tuple, the components are: 123456 acctNosavings type12000 balanceFor relation Customers and the first tuple, the components are: Robbie firstNameBanks lastName901-222 idNo12345 accountExercise 2.2.1dFor relation Accounts, a relation schema is:Accounts(acctNo, type, balance)For relation Customers, a relation schema is:Customers(firstName, lastName, idNo, account) Exercise 2.2.1eAn example database schema is:Accounts (acctNo,type,balanceCustomers (firstName,lastName,idNo,account)Exercise 2.2.1fA suitable domain for each attribute:acctNo Integertype Stringbalance IntegerfirstName StringlastName StringidNo String (because there is a hyphen we cannot use Integer)account IntegerExercise 2.2.1gAnother equivalent way to present the Account relation:acctNo balance type34567 25 savings23456 1000 checking12345 12000 savingsAnother equivalent way to present the Customers relation:idNo firstName lastName account805-333 Lena Hand 23456805-333 Lena Hand 12345901-222 Robbie Banks 12345Exercise 2.2.2Examples of attributes that are created for primarily serving as keys in a relation:Universal Product Code (UPC) used widely in United States and Canada to track products in stores.Serial Numbers on a wide variety of products to allow the manufacturer to individually track each product.Vehicle Identification Numbers (VIN), a unique serial number used by the automotive industry to identify vehicles.Exercise 2.2.3aWe can order the three tuples in any of 3! = 6 ways. Also, the columns can be ordered in any of 3! = 6 ways. Thus, the number of presentations is 6*6 = 36.Exercise 2.2.3bWe can order the three tuples in any of 5! = 120 ways. Also, the columns can be ordered in any of 4! = 24 ways. Thus, the number of presentations is 120*24 = 2880Exercise 2.2.3cWe can order the three tuples in any of m! ways. Also, the columns can be ordered in any of n! ways. Thus, the number of presentations is n!m!Exercise 2.3.1aCREATE TABLE Product (maker CHAR(30),model CHAR(10) PRIMARY KEY,type CHAR(15));Exercise 2.3.1bCREATE TABLE PC (model CHAR(30),speed DECIMAL(4,2),ram INTEGER,hd INTEGER,price DECIMAL(7,2));Exercise 2.3.1cCREATE TABLE Laptop (model CHAR(30),speed DECIMAL(4,2),ram INTEGER,hd INTEGER,screen DECIMAL(3,1),price DECIMAL(7,2));Exercise 2.3.1dCREATE TABLE Printer (model CHAR(30),color BOOLEAN,type CHAR (10),price DECIMAL(7,2));Exercise 2.3.1eALTER TABLE Printer DROP color;Exercise 2.3.1fALTER TABLE Laptop ADD od CHAR (10) DEFAULT ‘none’;Exercise 2.3.2aCREATE TABLE Classes (class CHAR(20),type CHAR(5),country CHAR(20),numGuns INTEGER,bore DECIMAL(3,1),displacement INTEGER);Exercise 2.3.2bCREATE TABLE Ships (name CHAR(30),class CHAR(20),launched INTEGER);Exercise 2.3.2cCREATE TABLE Battles (name CHAR(30),date DATE);Exercise 2.3.2dCREATE TABLE Outcomes (ship CHAR(30),battle CHAR(30),result CHAR(10));Exercise 2.3.2eALTER TABLE Classes DROP bore; Exercise 2.3.2fALTER TABLE Ships ADD yard CHAR(30); Exercise 2.4.1aR1 := σspeed ≥ 3.00 (PC)R2 := πmodel(R1)Exercise 2.4.1bR1 := σhd ≥ 100 (Laptop)R2 := Product (R1)R3 := πmaker (R2)Exercise 2.4.1c R1 := σmaker=B (Product PC)R2 := σmaker=B (Product Laptop) R3 := σmaker=B (Product Printer) R4 := πmodel,price (R1) R5 := πmodel,price (R2) R6: = πmodel,price (R3) R7 := R4 R5 R6Exercise 2.4.1d R1 := σcolor = true AND type = laser (Printer)R2 := πmodel (R1)Exercise 2.4.1e R1 := σtype=laptop (Product)R2 := σtype=PC (Product) R3 := πmaker (R1) R4 := πmaker (R2) R5 := R3 –R4Exercise 2.4.1f R1 := ρPC1(PC) R2 := ρPC2(PC) R3 := R1 (PC1.hd = PC2.hd AND PC1.model <> PC2.model) R2 R4 := πhd(R3)Exercise 2.4.1gR1 := ρPC1(PC) R2 := ρPC2(PC) R3 := R1 (PC1.speed = PC2.speed AND PC1.ram = PC2.ram AND PC1.model < PC2.model) R2 R4 := πPC1.model,PC2.model (R3)Exercise 2.4.1h R1 := πmodel (σspeed ≥ 2.80(PC )) πmodel (σspeed ≥ 2.80(Laptop)) R2 := πmaker,model (R1 Product) R3 := ρR3(maker2,model2)(R2)R4 := R2 (maker = maker2 AND model <> model2) R3 R5 := πmaker (R4)Exercise 2.4.1i R1 := πmodel,speed (PC) R2 := πmodel,speed (Laptop) R3 := R1 R2 R4 := ρR4(model2,speed2)(R3)R5 := πmodel,speed (R3 (speed < speed2 ) R4) R6 := R3 –R5Exercise 2.4.1j R1 := πmaker,speed (Product PC) R2 := ρR2(maker2,speed2)(R1) R3 := ρR3(maker3,speed3)(R1) R4 := R1 (maker = maker2 AND speed <> speed2) R2R5 := R4 (maker3 = maker AND speed3 <> speed2 AND speed3 <> speed) R3 R6 := πmaker (R5)Exercise 2.4.1k R1 := πmaker,model (Product PC) R2 := ρR2(maker2,model2)(R1) R3 := ρR3(maker3,model3)(R1) R4 := ρR4(maker4,model4)(R1) R5 := R1 (maker = maker2 AND model <> model2) R2 R6 := R3 (maker3 = maker AND model3 <> model2 AND model3 <> model) R5 R7 := R4 (maker4 = maker AND (model4=model OR model4=model2 OR model4=model3)) R6 R8 := πmaker (R7)Exercise 2.4.2aExercise 2.4.2bLaptopσhd ≥ 100ProductπmakerExercise 2.4.2cσmaker=Bπmodel,price σmaker=B πmodel,priceσmaker=B πmodel,priceProduct PC Laptop PrinterProductProductExercise 2.4.2dExercise 2.4.2eσtype=laptopσtype=PC πmakerπmaker–ProductProductExercise 2.4.2fρPC1ρPC2 (PC1.hd = PC2.hd AND PC1.model <> PC2.model)πhdPCPCExercise 2.4.2gρPC1ρPC2PCPC (PC1.speed = PC2.speed AND PC1.ram = PC2.ram AND PC1.model < PC2.model)πPC1.model,PC2.modelExercise 2.4.2hPCLaptopσspeed ≥ 2.80σspeed ≥ 2.80πmodelπmodelπmaker,modelρR3(maker2,model2)(maker = maker2 AND model <> model2)πmakerExercise 2.4.2iPCLaptopProductπmodel,speedπmodel,speed ρR4(model2,speed2)πmodel,speed(speed < speed2 )–πmakerExercise 2.4.2jProduct PC πmaker,speed ρR3(maker3,speed3)ρR2(maker2,speed2)(maker = maker2 AND speed <> speed2)(maker3 = maker AND speed3 <> speed2 AND speed3 <> speed)πmakerExercise 2.4.2kπmaker(maker4 = maker AND (model4=model OR model4=model2 OR model4=model3)) (maker3 = maker AND model3 <> model2 AND model3 <> model)(maker = maker2 AND model <> model2)ρR2(maker2,model2)ρR3(maker3,model3)ρR4(maker4,model4)πmaker,modelProduct PCExercise 2.4.3aR1 := σbore ≥ 16 (Classes)R2 := πclass,country (R1)Exercise 2.4.3bR1 := σlaunched < 1921 (Ships)R2 := πname (R1)Exercise 2.4.3cR1 := σbattle=Denmark Strait AND result=sunk(Outcomes)R2 := πship (R1)Exercise 2.4.3dR1 := Classes ShipsR2 := σlaunched > 1921 AND displacement > 35000 (R1)R3 := πname (R2)Exercise 2.4.3eR1 := σbattle=Guadalcanal(Outcomes)R2 := Ships (ship=name) R1R3 := Classes R2R4 := πname,displacement,numGuns(R3)Exercise 2.4.3fR1 := πname(Ships)R2 := πship(Outcomes)R3 := ρR3(name)(R2)R4 := R1 R3Exercise 2.4.3gFrom 2.3.2, assuming that every class has one ship named after the class.R1 := πclass(Classes)R2 := πclass(σname <> class(Ships))R3 := R1 – R2Exercise 2.4.3hR1 := πcountry(σtype=bb(Classes))R2 := πcountry(σtype=bc(Classes))R3 := R1 ∩ R2Exercise 2.4.3iR1 := πship,result,date(Battles (battle=name) Outcomes)R2 := ρR2(ship2,result2,date2)(R1)R3 := R1 (ship=ship2 AND result=damaged AND date < date2) R2R4 := πship(R3)No results from sample data.Exercise 2.4.4aExercise 2.4.4bExercise 2.4.4cExercise 2.4.4dClasses Ships σlaunched > 1921 AND displacement > 35000πnameExercise 2.4.4e σbattle=Guadalcanal Outcomes Classes(ship=name)πname,displacement,numGunsExercise 2.4.4f Ships Outcomes πnameπship ρR3(name)Exercise 2.4.4gClassesShipsπclass σname <> class πclass –Exercise 2.4.4hClasses Classes σtype=bb σtype=bcπcountry πcountry∩Exercise 2.4.4iπship(ship=ship2 AND result=damaged AND date < date2)ρR2(ship2,result2,date2)πship,result,date(battle=name)Battles OutcomesExercise 2.4.5The result of the natural join has only one attribute from each pair of equated attributes. On the other hand, the result of the theta-join has both columns of the attributes and their values are identical.Exercise 2.4.6UnionIf we add a tuple to the arguments of the union operator, we will get all of the tuples of the original result and maybe the added tuple. If the added tuple is a duplicate tuple, then the set behavior will eliminate that tuple. Thus theunion operator is monotone.IntersectionIf we add a tuple to the arguments of the intersection operator, we will get all of the tuples of the original result and maybe the added tuple. If the added tuple does not exist in the relation that it is added but does exist in the otherrelation, then the result set will include the added tuple. Thus the intersection operator is monotone.DifferenceIf we add a tuple to the arguments of the difference operator, we may not get all of the tuples of the original result.Suppose we have relations R and S and we are computing R – S. Suppose also that tuple t is in R but not in S. The result of R – S would include tuple t. However, if we add tuple t to S, then the new result will not have tuple t. Thus the difference operator is not monotone.ProjectionIf we add a tuple to the arguments of the projection operator, we will get all of the tuples of the original result and the projection of the added tuple. The projection operator only selects columns from the relation and does not affect the rows that are selected. Thus the projection operator is monotone.SelectionIf we add a tuple to the arguments of the selection operator, we will get all of the tuples of the original result andmaybe the added tuple. If the added tuple satisfies the select condition, then it will be added to the new result. The original tuples are included in the new result because they still satisfy the select condition. Thus the selectionoperator is monotone.Cartesian ProductIf we add a tuple to the arguments of the Cartesian product operator, we will get all of the tuples of the original result and possibly additional tuples. The Cartesian product pairs the tuples of one relation with the tuples of anotherrelation. Suppose that we are calculating R x S where R has m tuples and S has n tuples. If we add a tuple to R that is not already in R, then we expect the result of R x S to have (m + 1) * n tuples. Thus the Cartesian product operator is monotone.Natural JoinsIf we add a tuple to the arguments of a natural join operator, we will get all of the tuples of the original result andpossibly additional tuples. The new tuple can only create additional successful joins, not less. If, however, the added tuple cannot successfully join with any of the existing tuples, then we will have zero additional successful joins. Thus the natural join operator is monotone.Theta JoinsIf we add a tuple to the arguments of a theta join operator, we will get all of the tuples of the original result andpossibly additional tuples. The theta join can be modeled by a Cartesian product followed by a selection on somecondition. The new tuple can only create additional tuples in the result, not less. If, however, the added tuple doesnot satisfy the select condition, then no additional tuples will be added to the result. Thus the theta join operator is monotone.RenamingIf we add a tuple to the arguments of a renaming operator, we will get all of the tuples of the original result and the added tuple. The renaming operator does not have any effect on whether a tuple is selected or not. In fact, therenaming operator will always return as many tuples as its argument. Thus the renaming operator is monotone. Exercise 2.4.7aIf all the tuples of R and S are different, then the union has n + m tuples, and this number is the maximum possible.The minimum number of tuples that can appear in the result occurs if every tuple of one relation also appears in the other. Then the union has max(m , n) tuples.Exercise 2.4.7bIf all the tuples in one relation can pair successfully with all the tuples in the other relation, then the natural join has n * m tuples. This number would be the maximum possible.The minimum number of tuples that can appear in the result occurs if none of the tuples of one relation can pair successfully with all the tuples in the other relation. Then the natural join has zero tuples.Exercise 2.4.7cIf the condition C brings back all the tuples of R, then the cross product will contain n * m tuples. This number would be the maximum possible.The minimum number of tuples that can appear in the result occurs if the condition C brings back none of the tuples of R. Then the cross product has zero tuples.Exercise 2.4.7dAssuming t hat the list of attributes L makes the resulting relation πL(R) and relation S schema compatible, then the maximum possible tuples is n. This happens when all of the tuples of πL(R) are not in S.The minimum number of tuples that can appear in the result occurs when all of the tuples in πL(R) appear in S. Then the difference has max(n–m , 0) tuples.Exercise 2.4.8Defining r as the schema of R and s as the schema of S:1.πr(R S)2.R δ(πr∩s(S)) where δ is the duplicate-elimination operator in Section 5.2 pg. 2133.R – (R –πr(R S))Exercise 2.4.9Defining r as the schema of R1.R - πr(R S)Exercise 2.4.10πA1,A2…An(R S)Exercise 2.5.1aσspeed < 2.00 AND price > 500(PC) = øModel 1011 violates this constraint.Exercise 2.5.1bσscreen < 15.4 AND hd < 100 AND price ≥ 1000(Laptop) = øModel 2004 violates the constraint.Exercise 2.5.1cπmaker(σtype = laptop(Product)) ∩ πmaker(σtype = pc(Product)) = øManufacturers A,B,E violate the constraint.Exercise 2.5.1dThis complex expression is best seen as a sequence of steps in which we define temporary relations R1 through R4 that stand for nodes of expression trees. Here is the sequence:R1(maker, model, speed) := πmaker,model,speed(Product PC)R2(maker, speed) := πmaker,speed(Product Laptop)R3(model) := πmodel(R1 R1.maker = R2.maker AND R1.speed ≤ R2.speed R2)R4(model) := πmodel(PC)The constraint is R4 ⊆ R3Manufacturers B,C,D violate the constraint.Exercise 2.5.1eπmodel(σLaptop.ram > PC.ram AND Laptop.price ≤ PC.pric e(PC × Laptop)) = øModels 2002,2006,2008 violate the constraint.Exercise 2.5.2aπclass(σbore > 16(Classes)) = øThe Yamato class violates the constraint.Exercise 2.5.2bπclass(σnumGuns > 9 AND bore > 14(Classes)) = øNo violations to the constraint.Exercise 2.5.2cThis complex expression is best seen as a sequence of steps in which we define temporary relations R1 through R5 that stand for nodes of expression trees. Here is the sequence:R1(class,name) := πclass,name(Classes Ships)R2(class2,name2) := ρR2(class2,name2)(R1)R3(class3,name3) := ρR3(class3,name3)(R1)R4(class,name,class2,name2) := R1 (class = class2 AND name <> name2) R2R5(class,name,class2,name2,class3,name3) := R4 (class=class3 AND name <> name3 AND name2 <> name3) R3The constraint is R5 = øThe Kongo, Iowa and Revenge classes violate the constraint.Exercise 2.5.2dπcountry(σtype = bb(Classes)) ∩ πcountry(σtype = bc(Classes)) = øJapan and Gt. Britain violate the constraint.Exercise 2.5.2eThis complex expression is best seen as a sequence of steps in which we define temporary relations R1 through R5 that stand for nodes of expression trees. Here is the sequence:R1(ship,battle,result,class) := πship,battle,result,class(Outcomes (ship = name) Ships)R2(ship,battle,result,numGuns) := πship,battle,result,numGuns(R1 Classes)R3(ship,battle) := πship,battle(σnumGuns < 9 AND result = sunk (R2))R4(ship2,battle2) := ρR4(ship2,battle2)(πship,battle(σnumGuns > 9(R2)))R5(ship2) := πship2(R3 (battle = battle2) R4)The constraint is R5 = øNo violations to the constraint. Since there are some ships in the Outcomes table that are not in the Ships table, we are unable to determine the number of guns on that ship.Exercise 2.5.3Defining r as the schema A1,A2,…,A n and s as the schema B1,B2,…,B n:πr(R) πs(S) = øwhere is the antisemijoinExercise 2.5.4The form of a constraint as E1 = E2 can be expressed as the other two constraints.Using the “equating an expression to the empty set” method, we can simply say:E1– E2= øAs a containment, we can simply say:E1⊆ E2 AND E2⊆ E1Thus, the form E1 = E2 of a constraint cannot express more than the two other forms discussed in this section.。