模式识别作业
模式识别作业三道习题

K7 ( X ) K6 ( X ) 1 第八步:取 X 4 w2 , K 7 ( X 4 ) 32 0 ,故 0 K8 ( X ) K 7 ( X ) 0 第九步:取 X 1 w1 , K8 ( X 1 ) 32 0 ,故 1 K 9 ( X ) K8 ( X ) 0 第十步:取 X 2 w1 , K9 ( X 2 ) 32 0 ,故 1 K10 ( X ) K9 ( X )
2
K ( X , X k ) exp{ || X X k || 2} exp{[( x 1 xk 1) 2 ( x 2 xk 2 ) 2]} x1 X = x2 ,训练样本为 X k 。 其中
北邮模式识别课堂作业答案(参考)

第一次课堂作业⏹ 1.人在识别事物时是否可以避免错识?⏹ 2.如果错识不可避免,那么你是否怀疑你所看到的、听到的、嗅到的到底是真是的,还是虚假的?⏹ 3.如果不是,那么你依靠的是什么呢?用学术语言该如何表示。
⏹ 4.我们是以统计学为基础分析模式识别问题,采用的是错误概率评价分类器性能。
如果不采用统计学,你是否能想到还有什么合理地分类器性能评价指标来替代错误率?1.知觉的特性为选择性、整体性、理解性、恒常性。
错觉是错误的知觉,是在特定条件下产生的对客观事物歪曲的知觉。
认知是一个过程,需要大脑的参与.人的认知并不神秘,也符合一定的规律,也会产生错误2.不是3.辨别事物的最基本方法是计算. 从不同事物所具有的不同属性为出发点认识事物. 一种是对事物的属性进行度量,属于定量的表示方法(向量表示法)。
另一种则是对事务所包含的成分进行分析,称为定性的描述(结构性描述方法)。
4.风险第二次课堂作业⏹作为学生,你需要判断今天的课是否点名。
结合该问题(或者其它你熟悉的识别问题,如”天气预报”),说明:⏹先验概率、后验概率和类条件概率?⏹按照最小错误率如何决策?⏹按照最小风险如何决策?ωi为老师点名的事件,x为判断老师点名的概率1.先验概率: 指根据以往经验和分析得到的该老师点名的概率,即为先验概率P(ωi )后验概率: 在收到某个消息之后,接收端所了解到的该消息发送的概率称为后验概率。
在上过课之后,了解到的老师点名的概率为后验概率P(ωi|x)类条件概率:在老师点名这个事件发生的条件下,学生判断老师点名的概率p(x| ωi )2.如果P(ω1|X)>P(ω2|X),则X归为ω1类别如果P(ω1|X)≤P(ω2|X),则X归为ω2类别3.1)计算出后验概率已知P(ωi)和P(X|ωi),i=1,…,c,获得观测到的特征向量X根据贝叶斯公式计算j=1,…,x2)计算条件风险已知: 后验概率和决策表计算出每个决策的条件风险3) 找出使条件风险最小的决策αk,则αk就是最小风险贝叶斯决策。
模式识别作业

(1)先用C-均值聚类算法程序,并用下列数据进行聚类分析。
在确认编程正确后,采用蔡云龙书的附录B中表1的Iris数据进行聚类。
然后使用近邻法的快速算法找出待分样本X (设X样本的4个分量x1=x2=x3=x4=6;子集数l=3)的最近邻节点和3-近邻节点及X与它们之间的距离。
并建议适当对书中所述算法进行改进。
并分别画出流程图、写出算法及程序。
x1=(0,0) x2=(1,0) x3=(0,1) x4=(1,1) x5=(2,1) x6=(1,2) x7=(2,2) x8=(3,2) x9=(6,6) x10=(7,6) x11=(8,6) x12=(6,7) x13=(7,7) x14=(8,7) x15=(9,7) x16=(7,8) x17=(8,8) x18=(9,8) x19=(8,9) x20=(9,9)
(2)写一篇论文。
内容可以包含下面四个方面中的一个:
①新技术(如数据挖掘等)在模式识别中的应用;
②模式识别最新的研究方向;
③一个相关系统的分析;
④一个算法的优化;
(3)书142页,描述近邻法的快速算法,写个报告。
模式识别习题及答案

模式识别习题及答案模式识别习题及答案【篇一:模式识别题目及答案】p> t,方差?1?(2,0)-1/2??11/2??1t,第二类均值为,方差,先验概率??(2,2)?122???1??1/21??-1/2p(?1)?p(?2),试求基于最小错误率的贝叶斯决策分界面。
解根据后验概率公式p(?ix)?p(x?i)p(?i)p(x),(2’)及正态密度函数p(x?i)?t(x??)?i(x??i)/2] ,i?1,2。
(2’) i?1基于最小错误率的分界面为p(x?1)p(?1)?p(x?2)p(?2),(2’) 两边去对数,并代入密度函数,得(x??1)t?1(x??1)/2?ln?1??(x??2)t?2(x??2)/2?ln?2(1) (2’)1?14/3-2/3??4/32/3??1由已知条件可得?1??2,?1,?2??2/34/3?,(2’)-2/34/31设x?(x1,x2)t,把已知条件代入式(1),经整理得x1x2?4x2?x1?4?0,(5’)二、(15分)设两类样本的类内离散矩阵分别为s1??11/2?, ?1/21?-1/2??1tt,各类样本均值分别为?1?,?2?,试用fisher准(1,0)(3,2)s2-1/21??(2,2)的类别。
则求其决策面方程,并判断样本x?解:s?s1?s2??t20?(2’) ??02?1/20??-2??-1?*?1w?s()?投影方向为12?01/22?1? (6’) ???阈值为y0?w(?1??2)/2??-1-13 (4’)*t2?1?给定样本的投影为y?w*tx??2-1?24?y0,属于第二类(3’) ??1?三、(15分)给定如下的训练样例实例 x0 x1 x2 t(真实输出) 1 1 1 1 1 2 1 2 0 1 3 1 0 1 -1 4 1 1 2 -1用感知器训练法则求感知器的权值,设初始化权值为w0?w1?w2?0;1 第1次迭代2 第2次迭代(4’)(2’)3 第3和4次迭代四、(15分)i. 推导正态分布下的最大似然估计;ii. 根据上步的结论,假设给出如下正态分布下的样本,估计该部分的均值和方差两个参数。
模式识别作业

第四章模式识别作业姓名:谢雪琴学号:20102220551、阐述线性判别函数的几何意义和用于分类的实用价值。
答:线性判别函数的几何意义:利用线性判别函数进行决策,它可以看成是两类数据沿着一个向量投影,在向量上存在一个超平面,能将两类数据分隔开,即两类数据能够完全被区别。
线性判别函数可以是最小错误率或最小风险意义下的最优分类器。
它利用一个超平面把特征空间分割成为两个决策区域,超平面的方向由权向量W确定,它的位置由阈权值w0确定,判别函数g(x)正比于x点到超平面的代数距离(带正负号),当x在H正侧时,g(x)>0,当在H负侧时,g(x)<0;使用价值:线性分类器是最简单的分类器,但是样本在某些分布情况时,线性判别函数可以成为最小错误率或最小风险意义下的最优分类器。
而在一般情况下,线性分类器只能是次优分类器,但是因为他简单而且在很多情况下效果接近最优,所以应用比较广发,在样本有限的情况下有时甚至能取得比复杂分类器更好地效果2、参考教材4.3,完成线性判别分析(LDA)的Matlab实现,并用Fisher's Iris Data【注】进行验证(考虑其中的2类即可)。
注:Fisher's Iris Data: Fisher's iris data consists of measurements on the sepal length, sepal width, petal length, and petal width of 150 iris specimens. There are 50 specimens from each of three species. 在Matlab中调用load fisheriris可以得到该数据,meas为150×4的数据矩阵,species为150×1的cell矩阵,含有类别信息。
3、试推导出感知器算法的迭代求解过程,尝试用Matlab实现,并用Fisher's Iris Data进行验证(考虑2类分类即可)。
模式识别练习题

一、试问“模式”与“模式类”的含义。
如果一位姓王的先生是位老年人,试问“王先生”和“老头”谁是模式,谁是模式类?答:在模式识别学科中,就“模式”与“模式类”而言,模式类是一类事物的代表,概念或典型,而“模式”则是某一事物的具体体现,如“老头”是模式类,而王先生则是“模式”是“老头”的具体化。
二、试说明Mahalanobis距离平方的定义,到某点的Mahalanobis距离平方为常数的轨迹的几何意义,它与欧氏距离的区别与联系。
答:Mahalanobis距离的平方定义为:其中x,u为两个数据,是一个正定对称矩阵(一般为协方差矩阵)。
根据定义,距某一点的Mahalanobis距离相等点的轨迹是超椭球,如果是单位矩阵Σ,则Mahalanobis距离就是通常的欧氏距离。
三、试说明用监督学习与非监督学习两种方法对道路图像中道路区域的划分的基本做法,以说明这两种学习方法的定义与它们间的区别。
答:监督学习方法用来对数据实现分类,分类规则通过训练获得。
该训练集由带分类号的数据集组成,因此监督学习方法的训练过程是离线的。
非监督学习方法不需要单独的离线训练过程,也没有带分类号(标号)的训练数据集,一般用来对数据集进行分析,如聚类,确定其分布的主分量等。
就道路图像的分割而言,监督学习方法则先在训练用图像中获取道路象素与非道路象素集,进行分类器设计,然后用所设计的分类器对道路图像进行分割。
使用非监督学习方法,则依据道路路面象素与非道路象素之间的聚类分析进行聚类运算,以实现道路图像的分割。
四、试述动态聚类与分级聚类这两种方法的原理与不同。
答:动态聚类是指对当前聚类通过迭代运算改善聚类;分级聚类则是将样本个体,按相似度标准合并,随着相似度要求的降低实现合并。
五、如果观察一个时序信号时在离散时刻序列得到的观察量序列表示为,而该时序信号的内在状态序列表示成。
如果计算在给定O 条件下出现S 的概率,试问此概率是何种概率。
如果从观察序列来估计状态序列的最大似然估计,这与Bayes 决策中基于最小错误率的决策有什么关系。
模式识别_作业1

作业一:作业二:对如下5个6维模式样本,用最小聚类准则进行系统聚类分析: x 1: 0, 1, 3, 1, 3, 4 x 2: 3, 3, 3, 1, 2, 1 x 3: 1, 0, 0, 0, 1, 1 x 4: 2, 1, 0, 2, 2, 1 x 5: 0, 0, 1, 0, 1, 01、 计算D (0)=⎪⎪⎪⎪⎪⎪⎪⎪⎭⎫ ⎝⎛0 12 3 5 2612 0 7 15 243 7 0 24 55 15 24 0 2326 24 5 23 0,因为x3与x5的距离最近,则将x3与x5分为一类。
同时可以求出x1,x2,x4与x3,5的距离,如x1到x3,5的距离为x1到x3的距离与x1与x5的距离中取最小的一个距离。
2、 则D (1)=⎪⎪⎪⎪⎪⎪⎭⎫ ⎝⎛0 7 15 2470 24 515 24 0 2324 5 23 0,同样现在该矩阵中x4与x3,5的距离最近,则可以将x3,4,5分为一类,这样分类结束,总共可以将x1,x2,x3,x4,x5分为三类,其中:x1为第一类;x2为第二类;x3和x4和x5为第三类。
• 作业三:(K-均值算法)• 选k=2,z 1(1)=x 1,z 2(1)=x 10,用K-均值算法进行聚类分析由图可以看出这二十个点的坐标:x1(0,0),x2(1,0),x3(0,1),x4(1,1),x5(2,1),x6(1,2),x7(2,2),x8( 3,2),x9(6,6),x10(7,6),x11(8,6),x12(6,7),x13(7,7),x14(8,7),x 15(9,7),x16(7,8),x17(8,8),x18(9,8),x19(8,9),x20(9,9)。
1、选2个初始聚类中心,z1(1)=x1,z2(1)=x10.2、求取其它十八个点分别到x1与x10的距离:x2到x1的距离为1;x2到x10的距离为6x3到x1的距离为1;x3到x10的距离为x4到x1的距离为;x4到x10的距离为x5到x1的距离为;x5到x10的距离为5x6到x1的距离为;x6到x10的距离为x7到x1的距离为2;x7到x10的距离为x8到x1的距离为;x8到x10的距离为4x9到x1的距离为6;x9到x10的距离为1x11到x1的距离为10;x11到x10的距离为1x12到x1的距离为;x12到x10的距离为x13到x1的距离为7;x13到x10的距离为1x14到x1的距离为;x14到x10的距离为x15到x1的距离为;x15到x10的距离为x16到x1的距离为;x16到x10的距离为2x17到x1的距离为8;x17到x10的距离为x18到x1的距离为;x18到x10的距离为2x19到x1的距离为;x19到x10的距离为x20到x1的距离为9;x20到x10的距离为所以其中x2到x8距离x1近些,则可以将x2到x8与x1分为一类,而x9与x11到x20与x10分为另一类;3、通过将第一类中的所有x1到x8的坐标求取平均来计算该类别的中心坐标,求取新的类别的中心坐标z1(2)= (5/4,9/8),同理可以求出另一类的中心坐标z2(2)= (92/12,22/3)4、然后重新计算各点距离这二点中心坐标的距离,最后可以得出x1到x8仍然为第一类,x9到x20仍然为第二类。
模式识别习题及答案

模式识别习题及答案模式识别习题及答案模式识别是人类智能的重要组成部分,也是机器学习和人工智能领域的核心内容。
通过模式识别,我们可以从大量的数据中发现规律和趋势,进而做出预测和判断。
本文将介绍一些模式识别的习题,并给出相应的答案,帮助读者更好地理解和应用模式识别。
习题一:给定一组数字序列,如何判断其中的模式?答案:判断数字序列中的模式可以通过观察数字之间的关系和规律来实现。
首先,我们可以计算相邻数字之间的差值或比值,看是否存在一定的规律。
其次,我们可以将数字序列进行分组,观察每组数字之间的关系,看是否存在某种模式。
最后,我们还可以利用统计学方法,如频率分析、自相关分析等,来发现数字序列中的模式。
习题二:如何利用模式识别进行图像分类?答案:图像分类是模式识别的一个重要应用领域。
在图像分类中,我们需要将输入的图像分为不同的类别。
为了实现图像分类,我们可以采用以下步骤:首先,将图像转换为数字表示,如灰度图像或彩色图像的像素矩阵。
然后,利用特征提取算法,提取图像中的关键特征。
接下来,选择合适的分类算法,如支持向量机、神经网络等,训练模型并进行分类。
最后,评估分类结果的准确性和性能。
习题三:如何利用模式识别进行语音识别?答案:语音识别是模式识别在语音信号处理中的应用。
为了实现语音识别,我们可以采用以下步骤:首先,将语音信号进行预处理,包括去除噪声、降低维度等。
然后,利用特征提取算法,提取语音信号中的关键特征,如梅尔频率倒谱系数(MFCC)。
接下来,选择合适的分类算法,如隐马尔可夫模型(HMM)、深度神经网络(DNN)等,训练模型并进行语音识别。
最后,评估识别结果的准确性和性能。
习题四:如何利用模式识别进行时间序列预测?答案:时间序列预测是模式识别在时间序列分析中的应用。
为了实现时间序列预测,我们可以采用以下步骤:首先,对时间序列进行平稳性检验,确保序列的均值和方差不随时间变化。
然后,利用滑动窗口或滚动平均等方法,将时间序列划分为训练集和测试集。
(完整word版)模式识别题目及答案(word文档良心出品)

一、(15分)设有两类正态分布的样本集,第一类均值为T1μ=(2,0),方差11⎡⎤∑=⎢⎥⎣⎦11/21/2,第二类均值为T2μ=(2,2),方差21⎡⎤∑=⎢⎥⎣⎦1-1/2-1/2,先验概率12()()p p ωω=,试求基于最小错误率的贝叶斯决策分界面。
解 根据后验概率公式()()()()i i i p x p p x p x ωωω=, (2’)及正态密度函数11/21()exp[()()/2]2T i i i i nip x x x ωμμπ-=--∑-∑ ,1,2i =。
(2’) 基于最小错误率的分界面为1122()()()()p x p p x p ωωωω=, (2’) 两边去对数,并代入密度函数,得1111112222()()/2ln ()()/2ln T T x x x x μμμμ----∑--∑=--∑--∑ (1) (2’)由已知条件可得12∑=∑,114/3-⎡⎤∑=⎢⎥⎣⎦4/3-2/3-2/3,214/3-⎡⎤∑=⎢⎥⎣⎦4/32/32/3,(2’)设12(,)Tx x x =,把已知条件代入式(1),经整理得1221440x x x x --+=, (5’)二、(15分)设两类样本的类内离散矩阵分别为11S ⎡⎤=⎢⎥⎣⎦11/21/2, 21S ⎡⎤=⎢⎥⎣⎦1-1/2-1/2,各类样本均值分别为T 1μ=(1,0),T2μ=(3,2),试用fisher 准则求其决策面方程,并判断样本Tx =(2,2)的类别。
解:122S S S ⎡⎤=+=⎢⎥⎣⎦200 (2’) 投影方向为*112-2-1()211/2w S μμ-⎡⎤⎡⎤⎡⎤=-==⎢⎥⎢⎥⎢⎥--⎣⎦⎣⎦⎣⎦1/200 (6’)阈值为[]*0122()/2-1-131T y w μμ⎡⎤=+==-⎢⎥⎣⎦(4’)给定样本的投影为[]*0-12241T y w x y ⎡⎤===-<⎢⎥-⎣⎦, 属于第二类 (3’)三、 (15分)给定如下的训练样例实例 x0 x1 x2 t(真实输出) 1 1 1 1 1 2 1 2 0 1 3 1 0 1 -1 4 1 1 2 -1用感知器训练法则求感知器的权值,设初始化权值为0120w w w ===;1 第1次迭代(4’)2 第2次迭代(2’)3 第3和4次迭代四、 (15分)i. 推导正态分布下的最大似然估计;ii. 根据上步的结论,假设给出如下正态分布下的样本{}1,1.1,1.01,0.9,0.99,估计该部分的均值和方差两个参数。
模式识别_作业2

作业一:在一个10类的模式识别问题中,有3类单独满足多类情况1,其余的类别满足多类情况2。
问该模式识别问题所需判别函数的最少数目是多少?答案:将10类问题可看作4类满足多类情况1的问题,可将3类单独满足多类情况1的类找出来,剩下的7类全部划到4类中剩下的一个子类中。
再在此子类中,运用多类情况2的判别法则进行分类,此时需要7*(7-1)/2=21个判别函数。
故共需要4+21=25个判别函数。
作业二:一个三类问题,其判别函数如下:d1(x)=-x1, d2(x)=x1+x2-1, d3(x)=x1-x2-11. 设这些函数是在多类情况1条件下确定的,绘出其判别界面和每一个模式类别的区域。
2. 设为多类情况2,并使:d12(x)= d1(x), d13(x)= d2(x), d23(x)=d3(x)。
绘出其判别界面和多类情况2的区域。
3. 设d1(x), d2(x)和d3(x)是在多类情况3的条件下确定的,绘出其判别界面和每类的区域。
答案:123作业三:两类模式,每类包括5个3维不同的模式,且良好分布。
如果它们是线性可分的,问权向量至少需要几个系数分量?假如要建立二次的多项式判别函数,又至少需要几个系数分量?(设模式的良好分布不因模式变化而改变。
)答案:如果它们是线性可分的,则至少需要4个系数分量;如果要建立二次的多项式判别函数,则至少需要个系数分量。
作业四:用感知器算法求下列模式分类的解向量w:ω1: {(0 0 0)T, (1 0 0)T, (1 0 1)T, (1 1 0)T}ω2: {(0 0 1)T, (0 1 1)T, (0 1 0)T, (1 1 1)T}答案:将属于ω2的训练样本乘以(-1),并写成增广向量的形式。
x①=(0 0 0 1)T,x②=(1 0 0 1)T,x③=(1 0 1 1)T,x④=(1 1 0 1)Tx⑤=(0 0 -1 -1)T,x⑥=(0 -1 -1 -1)T,x⑦=(0 -1 0 -1)T,x⑧=(-1 -1 -1 -1)T第一轮迭代:取C=1,w(1)=(0 0 0 0)T因wT(1)x① =(0 0 0 0)(0 0 0 1)T=0≯0,故w(2)=w(1)+x①=(0 0 0 1)因wT(2)x②=(0 0 0 1)(1 0 0 1)T =1>0,故w(3)=w(2)=(0 0 0 1)T因wT(3)x③=(0 0 0 1)(1 0 1 1)T=1>0,故w(4)=w(3)=(0 0 0 1)T因wT(4)x④=(0 0 0 1)(1 1 0 1)T=1>0,故w(5)=w(4)=(0 0 0 1)T因wT(5)x⑤=(0 0 0 1)(0 0 -1 -1)T=-1≯0,故w(6)=w(5)+x⑤=(0 0 -1 0)T因wT(6)x⑥=(0 0 -1 0)(0 -1 -1 -1)T=1>0,故w(7)=w(6)=(0 0 -1 0)T因wT(7)x⑦=(0 0 -1 0)(0 -1 0 -1)T=0≯0,故w(8)=w(7)+x⑦=(0 -1 -1 -1)T因wT(8)x⑧=(0 -1 -1 -1)(-1 -1 -1 -1)T=3>0,故w(9)=w(8)=(0 -1 -1 -1)T因为只有对全部模式都能正确判别的权向量才是正确的解,因此需进行第二轮迭代。
模式识别大作业
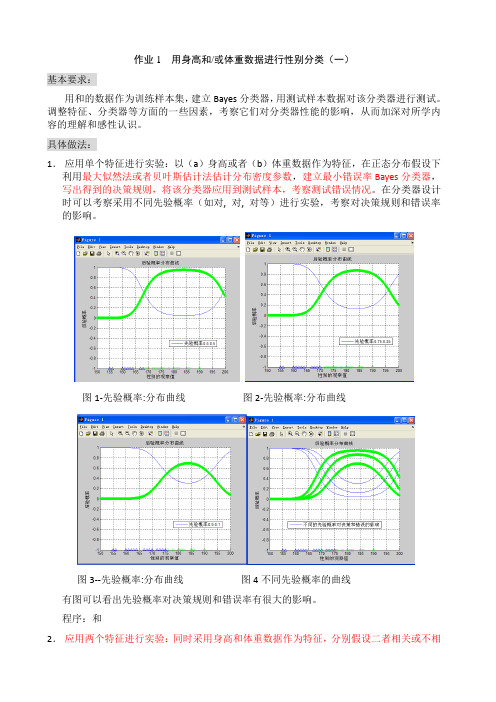
作业1 用身高和/或体重数据进行性别分类(一)基本要求:用和的数据作为训练样本集,建立Bayes分类器,用测试样本数据对该分类器进行测试。
调整特征、分类器等方面的一些因素,考察它们对分类器性能的影响,从而加深对所学内容的理解和感性认识。
具体做法:1.应用单个特征进行实验:以(a)身高或者(b)体重数据作为特征,在正态分布假设下利用最大似然法或者贝叶斯估计法估计分布密度参数,建立最小错误率Bayes分类器,写出得到的决策规则,将该分类器应用到测试样本,考察测试错误情况。
在分类器设计时可以考察采用不同先验概率(如对, 对, 对等)进行实验,考察对决策规则和错误率的影响。
图1-先验概率:分布曲线图2-先验概率:分布曲线图3--先验概率:分布曲线图4不同先验概率的曲线有图可以看出先验概率对决策规则和错误率有很大的影响。
程序:和2.应用两个特征进行实验:同时采用身高和体重数据作为特征,分别假设二者相关或不相关(在正态分布下一定独立),在正态分布假设下估计概率密度,建立最小错误率Bayes 分类器,写出得到的决策规则,将该分类器应用到训练/测试样本,考察训练/测试错误情况。
比较相关假设和不相关假设下结果的差异。
在分类器设计时可以考察采用不同先验概率(如vs. , vs. , vs. 等)进行实验,考察对决策和错误率的影响。
训练样本female来测试图1先验概率vs. 图2先验概率vs.图3先验概率vs. 图4不同先验概率对测试样本1进行试验得图对测试样本2进行试验有图可以看出先验概率对决策规则和错误率有很大的影响。
程序和3.自行给出一个决策表,采用最小风险的Bayes决策重复上面的某个或全部实验。
W1W2W10W20close all;clear all;X=120::200; %设置采样范围及精度pw1=;pw2=; %设置先验概率sample1=textread('') %读入样本samplew1=zeros(1,length(sample1(:,1)));u1=mean(sample1(:,1));m1=std(sample1(:,1));y1=normpdf(X,u1,m1); %类条件概率分布figure(1);subplot(2,1,1);plot(X,y1);title('F身高类条件概率分布曲线');sample2=textread('') %读入样本samplew2=zeros(1,length(sample2(:,1)));u2=mean(sample2(:,1));m2=std(sample2(:,1));y2=normpdf(X,u2,m2); %类条件概率分布subplot(2,1,2);plot(X,y2);title('M身高类条件概率分布曲线');P1=pw1*y1./(pw1*y1+pw2*y2);P2=pw2*y2./(pw1*y1+pw2*y2);figure(2);subplot(2,1,1);plot(X,P1);title('F身高后验概率分布曲线');subplot(2,1,2);plot(X,P2);title('M身高后验概率分布曲线');P11=pw1*y1;P22=pw2*y2;figure(3);subplot(3,1,1);plot(X,P11);subplot(3,1,2);plot(X,P22);subplot(3,1,3);plot(X,P11,X,P22);sample=textread('all ') %读入样本[result]=bayes(sample1(:,1),sample2(:,1),pw1,pw2);%bayes分类器function [result] =bayes(sample1(:,1),sample2(:,1),pw1,pw2);error1=0;error2=0;u1=mean(sample1(:,1));m1=std(sample1(:,1));y1=normpdf(X,u1,m1); %类条件概率分布u2=mean(sample2(:,1));m2=std(sample2(:,1));y2=normpdf(X,u2,m2); %类条件概率分布P1=pw1*y1./(pw1*y1+pw2*y2);P2=pw2*y2./(pw1*y1+pw2*y2);for i = 1:50if P1(i)>P2(i)result(i)=0;pe(i)=P2(i);elseresult(i)=1;pe(i)=P1(i);endendfor i=1:50if result(k)==0error1=error1+1;else result(k)=1error2=error2+1;endendratio = error1+error2/length(sample); %识别率,百分比形式sprintf('正确识别率为%.2f%%.',ratio)作业2 用身高/体重数据进行性别分类(二)基本要求:试验直接设计线性分类器的方法,与基于概率密度估计的贝叶斯分离器进行比较。
模式识别_作业3

作业一:设以下模式类别具有正态概率密度函数: ω1:{(0 0)T , (2 0)T , (2 2)T , (0 2)T }ω2:{(4 4)T , (6 4)T , (6 6)T , (4 6)T }(1)设P(ω1)= P(ω2)=1/2,求这两类模式之间的贝叶斯判别界面的方程式。
(2)绘出判别界面。
答案:(1)模式的均值向量m i 和协方差矩阵C i 可用下式估计:2,111==∑=i x N m i N j ij i i2,1))((11=--=∑=i m x m x N C i N j Ti ij i ij i i 其中N i 为类别ωi 中模式的数目,x ij 代表在第i 个类别中的第j 个模式。
由上式可求出:T m )11(1= T m )55(2= ⎪⎪⎭⎫ ⎝⎛===1 00 121C C C ,⎪⎪⎭⎫⎝⎛=-1 00 11C 设P(ω1)=P(ω2)=1/2,因C 1=C 2,则判别界面为:24442121)()()(2121211112121=+--=+--=----x x m C m m C m x C m m x d x d T T T(2)作业二:编写两类正态分布模式的贝叶斯分类程序。
程序代码:#include<iostream>usingnamespace std;void inverse_matrix(int T,double b[5][5]){double a[5][5];for(int i=0;i<T;i++)for(int j=0;j<(2*T);j++){ if (j<T)a[i][j]=b[i][j];elseif (j==T+i)a[i][j]=1.0;elsea[i][j]=0.0;}for(int i=0;i<T;i++){for(int k=0;k<T;k++){if(k!=i){double t=a[k][i]/a[i][i];for(int j=0;j<(2*T);j++){double x=a[i][j]*t;a[k][j]=a[k][j]-x;}}}}for(int i=0;i<T;i++){double t=a[i][i];for(int j=0;j<(2*T);j++)a[i][j]=a[i][j]/t;}for(int i=0;i<T;i++)for(int j=0;j<T;j++)b[i][j]=a[i][j+T];}void get_matrix(int T,double result[5][5],double a[5]) {for(int i=0;i<T;i++){for(int j=0;j<T;j++){result[i][j]=a[i]*a[j];}}}void matrix_min(int T,double a[5][5],int bb){for(int i=0;i<T;i++){for(int j=0;j<T;j++)a[i][j]=a[i][j]/bb;}}void getX(int T,double res[5],double a[5],double C[5][5]) {for(int i=0;i<T;i++)double sum=0.0;for(int j=0;j<T;j++)sum+=a[j]*C[j][i];res[i]=sum;}}int main(){int T;int w1_num,w2_num;double w1[10][5],w2[10][5],m1[5]={0},m2[5]={0},C1[5][5]={0},C2[5][5]={0};cin>>T>>w1_num>>w2_num;for(int i=0;i<w1_num;i++){for(int j=0;j<T;j++){cin>>w1[i][j];m1[j]+=w1[i][j];}}for(int i=0;i<w2_num;i++){for(int j=0;j<T;j++){cin>>w2[i][j];m2[j]+=w2[i][j];}}for(int i=0;i<w1_num;i++)m1[i]=m1[i]/w1_num;for(int i=0;i<w2_num;i++)m2[i]=m2[i]/w2_num;for(int i=0;i<w1_num;i++){double res[5][5],a[5];for(int j=0;j<T;j++)a[j]=w1[i][j]-m1[j];get_matrix(T,res,a);for(int j=0;j<T;j++){for(int k=0;k<T;k++)C1[j][k]+=res[j][k];}matrix_min(T,C1,w1_num);for(int i=0;i<w2_num;i++){double res[5][5],a[5];for(int j=0;j<T;j++)a[j]=w2[i][j]-m2[j];get_matrix(T,res,a);for(int j=0;j<T;j++){for(int k=0;k<T;k++)C2[j][k]+=res[j][k];}}matrix_min(T,C2,w2_num);inverse_matrix(T,C1);inverse_matrix(T,C2);double XX[5]={0},C_C1[5]={0},C_C2[5]={0};double m1_m2[5];for(int i=0;i<T;i++){m1_m2[i]=m1[i]-m2[i];}getX(T,XX,m1_m2,C1);getX(T,C_C1,m1,C1);getX(T,C_C2,m2,C1);double resultC=0.0;for(int i=0;i<T;i++)resultC-=C_C1[i]*C_C1[i];for(int i=0;i<T;i++)resultC+=C_C2[i]*C_C2[i];resultC=resultC/2;cout<<"判别函数为:"<<endl;cout<<"d1(x)-d2(x)=";for(int i=0;i<T;i++)cout<<XX[i]<<"x"<<i+1;if(resultC>0)cout<<"+"<<resultC<<endl;elseif(resultC<0)cout<<resultC<<endl;return 0;}运行截图:。
模式识别作业(全)

模式识别大作业一.K均值聚类(必做,40分)1.K均值聚类的基本思想以及K均值聚类过程的流程图;2.利用K均值聚类对Iris数据进行分类,已知类别总数为3。
给出具体的C语言代码,并加注释。
例如,对于每一个子函数,标注其主要作用,及其所用参数的意义,对程序中定义的一些主要变量,标注其意义;3.给出函数调用关系图,并分析算法的时间复杂度;4.给出程序运行结果,包括分类结果(只要给出相对应的数据的编号即可)以及循环迭代的次数;5.分析K均值聚类的优缺点。
二.贝叶斯分类(必做,40分)1.什么是贝叶斯分类器,其分类的基本思想是什么;2.两类情况下,贝叶斯分类器的判别函数是什么,如何计算得到其判别函数;3.在Matlab下,利用mvnrnd()函数随机生成60个二维样本,分别属于两个类别(一类30个样本点),将这些样本描绘在二维坐标系下,注意特征值取值控制在(-5,5)范围以内;4.用样本的第一个特征作为分类依据将这60个样本进行分类,统计正确分类的百分比,并在二维坐标系下将正确分类的样本点与错误分类的样本点用不同标志(正确分类的样本点用“O”,错误分类的样本点用“X”)画出来;5.用样本的第二个特征作为分类依据将这60个样本再进行分类,统计正确分类的百分比,并在二维坐标系下将正确分类的样本点与错误分类的样本点用不同标志画出来;6.用样本的两个特征作为分类依据将这60个样本进行分类,统计正确分类的百分比,并在二维坐标系下将正确分类的样本点与错误分类的样本点用不同标志画出来;7.分析上述实验的结果。
8.60个随即样本是如何产生的的;给出上述三种情况下的两类均值、方差、协方差矩阵以及判别函数;三.特征选择(选作,15分)1.经过K均值聚类后,Iris数据被分作3类。
从这三类中各选择10个样本点;2.通过特征选择将选出的30个样本点从4维降低为3维,并将它们在三维的坐标系中画出(用Excell);3.在三维的特征空间下,利用这30个样本点设计贝叶斯分类器,然后对这30个样本点利用贝叶斯分类器进行判别分类,给出分类的正确率,分析实验结果,并说明特征选择的依据;。
模式识别大作业许萌1306020

第一题 对数据进行聚类分析用、和/或test2.txt 的数据作为本次实验利用的样本集,利用C 均值聚类法和层次聚类法对样本集进行聚类分析,对结果进行分析,从而加深对所学内容的明白得和感性熟悉。
2.1 C 均值聚类法原理C 均值算法第一取定C 个类别数量并对这C 个类别数量选取C 个聚类中心,按最小距离原那么将各模式分派到C 类中的某一类,以后不断地计算类心和调整各模式的类别,最终使各模式到其对应的判属类别中心的距离平方之和最小。
2.2 C 均值聚类算法流程图N图1.1 C 均值聚类算法流程图2.3 层次聚类算法原理N 个初始模式样本自成一类,即成立N 类,以后依照以下步骤运算:Step1:计算各类之间(即各样本间)的距离,得一个维数为N ×N 的距离矩阵D(0)。
“0”表示初始状态。
Step2:假设已求得距离矩阵D (n )(n 为逐次聚类归并的次数),找出D (n )中的最小元素,将其对应的两类归并为一类。
由此成立新的分类:),1(),1(21++n G n GStep3:计算归并后所取得的新类别之间的距离,得D(n+1)。
Step4:跳至第2步,重复计算及归并。
直到知足以下条件时即可停止计算:①取距离阈值T,当D(n)的最小分量超过给定值T 时,算法停止。
所得即为聚类结果。
②或不设阈值T,一直到将全数样本聚成一类为止,输出聚类的分级树。
初始化分类找出D(n)中的最小元素将其对应的两类合并为一类N计算合并后新类别之间的距离是否满足停止条件Y结束程序图1.2层次聚类算法流程图3 验结果分析对数据文件、进行C均值聚类的聚类结果如以下图所示:图1.3 C均值聚类结果的二维平面显示将两种样本即进行聚类后的样本中心进行比较,如下表:从下表能够纵向比较能够看出,C越大,即聚类数量越多,聚类之间不同越小,他们的聚类中心也越接近。
横向比较用FEMALE,MALE中数据作为样本和用FEMALE,MALE,test2中数据作为样本时,由于引入了新的样本,能够发觉后者的聚类中心比前者都稍大。
模式识别大作业

模式识别大作业1.最近邻/k近邻法一.基本概念:最近邻法:对于未知样本x,比较x与N个已知类别的样本之间的欧式距离,并决策x与距离它最近的样本同类。
K近邻法:取未知样本x的k个近邻,看这k个近邻中多数属于哪一类,就把x归为哪一类。
K取奇数,为了是避免k1=k2的情况。
二.问题分析:要判别x属于哪一类,关键要求得与x最近的k个样本(当k=1时,即是最近邻法),然后判别这k个样本的多数属于哪一类。
可采用欧式距离公式求得两个样本间的距离s=sqrt((x1-x2)^2+(y1-y2)^2)三.算法分析:该算法中任取每类样本的一半作为训练样本,其余作为测试样本。
例如iris中取每类样本的25组作为训练样本,剩余25组作为测试样本,依次求得与一测试样本x距离最近的k 个样本,并判断k个样本多数属于哪一类,则x就属于哪类。
测试10次,取10次分类正确率的平均值来检验算法的性能。
四.MATLAB代码:最近邻算实现对Iris分类clc;totalsum=0;for ii=1:10data=load('iris.txt');data1=data(1:50,1:4);%任取Iris-setosa数据的25组rbow1=randperm(50);trainsample1=data1(rbow1(:,1:25),1:4);rbow1(:,26:50)=sort(rbow1(:,26:50));%剩余的25组按行下标大小顺序排列testsample1=data1(rbow1(:,26:50),1:4);data2=data(51:100,1:4);%任取Iris-versicolor数据的25组rbow2=randperm(50);trainsample2=data2(rbow2(:,1:25),1:4);rbow2(:,26:50)=sort(rbow2(:,26:50));testsample2=data2(rbow2(:,26:50),1:4);data3=data(101:150,1:4);%任取Iris-virginica数据的25组rbow3=randperm(50);trainsample3=data3(rbow3(:,1:25),1:4);rbow3(:,26:50)=sort(rbow3(:,26:50));testsample3=data3(rbow3(:,26:50),1:4);trainsample=cat(1,trainsample1,trainsample2,trainsample3);%包含75组数据的样本集testsample=cat(1,testsample1,testsample2,testsample3);newchar=zeros(1,75);sum=0;[i,j]=size(trainsample);%i=60,j=4[u,v]=size(testsample);%u=90,v=4for x=1:ufor y=1:iresult=sqrt((testsample(x,1)-trainsample(y,1))^2+(testsample(x,2) -trainsample(y,2))^2+(testsample(x,3)-trainsample(y,3))^2+(testsa mple(x,4)-trainsample(y,4))^2); %欧式距离newchar(1,y)=result;end;[new,Ind]=sort(newchar);class1=0;class2=0;class3=0;if Ind(1,1)<=25class1=class1+1;elseif Ind(1,1)>25&&Ind(1,1)<=50class2=class2+1;elseclass3=class3+1;endif class1>class2&&class1>class3m=1;ty='Iris-setosa';elseif class2>class1&&class2>class3m=2;ty='Iris-versicolor';elseif class3>class1&&class3>class2m=3;ty='Iris-virginica';elsem=0;ty='none';endif x<=25&&m>0disp(sprintf('第%d组数据分类后为%s类',rbow1(:,x+25),ty));elseif x<=25&&m==0disp(sprintf('第%d组数据分类后为%s类',rbow1(:,x+25),'none'));endif x>25&&x<=50&&m>0disp(sprintf('第%d组数据分类后为%s类',50+rbow2(:,x),ty));elseif x>25&&x<=50&&m==0disp(sprintf('第%d组数据分类后为%s类',50+rbow2(:,x),'none'));endif x>50&&x<=75&&m>0disp(sprintf('第%d组数据分类后为%s类',100+rbow3(:,x-25),ty));elseif x>50&&x<=75&&m==0disp(sprintf('第%d组数据分类后为%s类',100+rbow3(:,x-25),'none'));endif (x<=25&&m==1)||(x>25&&x<=50&&m==2)||(x>50&&x<=75&&m==3)sum=sum+1;endenddisp(sprintf('第%d次分类识别率为%4.2f',ii,sum/75));totalsum=totalsum+(sum/75);enddisp(sprintf('10次分类平均识别率为%4.2f',totalsum/10));测试结果:第3组数据分类后为Iris-setosa类第5组数据分类后为Iris-setosa类第6组数据分类后为Iris-setosa类第7组数据分类后为Iris-setosa类第10组数据分类后为Iris-setosa类第11组数据分类后为Iris-setosa类第12组数据分类后为Iris-setosa类第14组数据分类后为Iris-setosa类第16组数据分类后为Iris-setosa类第18组数据分类后为Iris-setosa类第19组数据分类后为Iris-setosa类第20组数据分类后为Iris-setosa类第23组数据分类后为Iris-setosa类第24组数据分类后为Iris-setosa类第26组数据分类后为Iris-setosa类第28组数据分类后为Iris-setosa类第30组数据分类后为Iris-setosa类第31组数据分类后为Iris-setosa类第34组数据分类后为Iris-setosa类第37组数据分类后为Iris-setosa类第39组数据分类后为Iris-setosa类第41组数据分类后为Iris-setosa类第44组数据分类后为Iris-setosa类第45组数据分类后为Iris-setosa类第49组数据分类后为Iris-setosa类第53组数据分类后为Iris-versicolor类第54组数据分类后为Iris-versicolor类第55组数据分类后为Iris-versicolor类第57组数据分类后为Iris-versicolor类第58组数据分类后为Iris-versicolor类第59组数据分类后为Iris-versicolor类第60组数据分类后为Iris-versicolor类第61组数据分类后为Iris-versicolor类第62组数据分类后为Iris-versicolor类第68组数据分类后为Iris-versicolor类第70组数据分类后为Iris-versicolor类第71组数据分类后为Iris-virginica类第74组数据分类后为Iris-versicolor类第75组数据分类后为Iris-versicolor类第77组数据分类后为Iris-versicolor类第79组数据分类后为Iris-versicolor类第80组数据分类后为Iris-versicolor类第84组数据分类后为Iris-virginica类第85组数据分类后为Iris-versicolor类第92组数据分类后为Iris-versicolor类第95组数据分类后为Iris-versicolor类第97组数据分类后为Iris-versicolor类第98组数据分类后为Iris-versicolor类第99组数据分类后为Iris-versicolor类第102组数据分类后为Iris-virginica类第103组数据分类后为Iris-virginica类第105组数据分类后为Iris-virginica类第106组数据分类后为Iris-virginica类第107组数据分类后为Iris-versicolor类第108组数据分类后为Iris-virginica类第114组数据分类后为Iris-virginica类第118组数据分类后为Iris-virginica类第119组数据分类后为Iris-virginica类第124组数据分类后为Iris-virginica类第125组数据分类后为Iris-virginica类第126组数据分类后为Iris-virginica类第127组数据分类后为Iris-virginica类第128组数据分类后为Iris-virginica类第129组数据分类后为Iris-virginica类第130组数据分类后为Iris-virginica类第133组数据分类后为Iris-virginica类第135组数据分类后为Iris-virginica类第137组数据分类后为Iris-virginica类第142组数据分类后为Iris-virginica类第144组数据分类后为Iris-virginica类第148组数据分类后为Iris-virginica类第149组数据分类后为Iris-virginica类第150组数据分类后为Iris-virginica类k近邻法对wine分类:clc;otalsum=0;for ii=1:10 %循环测试10次data=load('wine.txt');%导入wine数据data1=data(1:59,1:13);%任取第一类数据的30组rbow1=randperm(59);trainsample1=data1(sort(rbow1(:,1:30)),1:13);rbow1(:,31:59)=sort(rbow1(:,31:59)); %剩余的29组按行下标大小顺序排列testsample1=data1(rbow1(:,31:59),1:13);data2=data(60:130,1:13);%任取第二类数据的35组rbow2=randperm(71);trainsample2=data2(sort(rbow2(:,1:35)),1:13);rbow2(:,36:71)=sort(rbow2(:,36:71));testsample2=data2(rbow2(:,36:71),1:13);data3=data(131:178,1:13);%任取第三类数据的24组rbow3=randperm(48);trainsample3=data3(sort(rbow3(:,1:24)),1:13);rbow3(:,25:48)=sort(rbow3(:,25:48));testsample3=data3(rbow3(:,25:48),1:13);train_sample=cat(1,trainsample1,trainsample2,trainsample3);%包含89组数据的样本集test_sample=cat(1,testsample1,testsample2,testsample3);k=19;%19近邻法newchar=zeros(1,89);sum=0;[i,j]=size(train_sample);%i=89,j=13[u,v]=size(test_sample);%u=89,v=13for x=1:ufor y=1:iresult=sqrt((test_sample(x,1)-train_sample(y,1))^2+(test_sample(x ,2)-train_sample(y,2))^2+(test_sample(x,3)-train_sample(y,3))^2+( test_sample(x,4)-train_sample(y,4))^2+(test_sample(x,5)-train_sam ple(y,5))^2+(test_sample(x,6)-train_sample(y,6))^2+(test_sample(x ,7)-train_sample(y,7))^2+(test_sample(x,8)-train_sample(y,8))^2+( test_sample(x,9)-train_sample(y,9))^2+(test_sample(x,10)-train_sa mple(y,10))^2+(test_sample(x,11)-train_sample(y,11))^2+(test_samp le(x,12)-train_sample(y,12))^2+(test_sample(x,13)-train_sample(y, 13))^2); %欧式距离newchar(1,y)=result;end;[new,Ind]=sort(newchar);class1=0;class 2=0;class 3=0;for n=1:kif Ind(1,n)<=30class 1= class 1+1;elseif Ind(1,n)>30&&Ind(1,n)<=65class 2= class 2+1;elseclass 3= class3+1;endendif class 1>= class 2&& class1>= class3m=1;elseif class2>= class1&& class2>= class3m=2;elseif class3>= class1&& class3>= class2m=3;endif x<=29disp(sprintf('第%d组数据分类后为第%d类',rbow1(:,30+x),m));elseif x>29&&x<=65disp(sprintf('第%d组数据分类后为第%d类',59+rbow2(:,x+6),m));elseif x>65&&x<=89disp(sprintf('第%d组数据分类后为第%d类',130+rbow3(:,x-41),m));endif (x<=29&&m==1)||(x>29&&x<=65&&m==2)||(x>65&&x<=89&&m==3) sum=sum+1;endenddisp(sprintf('第%d次分类识别率为%4.2f',ii,sum/89));totalsum=totalsum+(sum/89);enddisp(sprintf('10次分类平均识别率为%4.2f',totalsum/10));第2组数据分类后为第1类第4组数据分类后为第1类第5组数据分类后为第3类第6组数据分类后为第1类第8组数据分类后为第1类第10组数据分类后为第1类第11组数据分类后为第1类第14组数据分类后为第1类第16组数据分类后为第1类第19组数据分类后为第1类第20组数据分类后为第3类第21组数据分类后为第3类第22组数据分类后为第3类第26组数据分类后为第3类第27组数据分类后为第1类第28组数据分类后为第1类第30组数据分类后为第1类第33组数据分类后为第1类第36组数据分类后为第1类第37组数据分类后为第1类第43组数据分类后为第1类第44组数据分类后为第3类第45组数据分类后为第1类第46组数据分类后为第1类第49组数据分类后为第1类第54组数据分类后为第1类第56组数据分类后为第1类第57组数据分类后为第1类第60组数据分类后为第2类第61组数据分类后为第3类第63组数据分类后为第3类第65组数据分类后为第2类第66组数据分类后为第3类第67组数据分类后为第2类第71组数据分类后为第1类第72组数据分类后为第2类第74组数据分类后为第1类第76组数据分类后为第2类第77组数据分类后为第2类第79组数据分类后为第3类第81组数据分类后为第2类第82组数据分类后为第3类第83组数据分类后为第3类第84组数据分类后为第2类第86组数据分类后为第2类第87组数据分类后为第2类第88组数据分类后为第2类第93组数据分类后为第2类第96组数据分类后为第1类第98组数据分类后为第2类第99组数据分类后为第3类第102组数据分类后为第2类第104组数据分类后为第2类第105组数据分类后为第3类第106组数据分类后为第2类第110组数据分类后为第3类第113组数据分类后为第3类第114组数据分类后为第2类第115组数据分类后为第2类第116组数据分类后为第2类第118组数据分类后为第2类第122组数据分类后为第2类第123组数据分类后为第2类第124组数据分类后为第2类第133组数据分类后为第3类第134组数据分类后为第3类第135组数据分类后为第2类第136组数据分类后为第3类第140组数据分类后为第3类第142组数据分类后为第3类第144组数据分类后为第2类第145组数据分类后为第1类第146组数据分类后为第3类第148组数据分类后为第3类第149组数据分类后为第2类第152组数据分类后为第2类第157组数据分类后为第2类第159组数据分类后为第3类第161组数据分类后为第2类第162组数据分类后为第3类第163组数据分类后为第3类第164组数据分类后为第3类第165组数据分类后为第3类第167组数据分类后为第3类第168组数据分类后为第3类第173组数据分类后为第3类第174组数据分类后为第3类2.Fisher线性判别法Fisher 线性判别是统计模式识别的基本方法之一。
模式识别大作业

模式识别专业:电子信息工程班级:电信****班学号:********** 姓名:艾依河里的鱼一、贝叶斯决策(一)贝叶斯决策理论 1.最小错误率贝叶斯决策器在模式识别领域,贝叶斯决策通常利用一些决策规则来判定样本的类别。
最常见的决策规则有最大后验概率决策和最小风险决策等。
设共有K 个类别,各类别用符号k c ()K k ,,2,1 =代表。
假设k c 类出现的先验概率()k P c以及类条件概率密度()|k P c x 是已知的,那么应该把x 划分到哪一类才合适呢?若采用最大后验概率决策规则,首先计算x 属于k c 类的后验概率()()()()()()()()1||||k k k k k Kk k k P c P c P c P c P c P P c P c ===∑x x x x x然后将x 判决为属于kc ~类,其中()1arg max |kk Kk P c ≤≤=x若采用最小风险决策,则首先计算将x 判决为k c 类所带来的风险(),k R c x ,再将x 判决为属于kc ~类,其中()min ,kkk R c =x可以证明在采用0-1损失函数的前提下,两种决策规则是等价的。
贝叶斯决策器在先验概率()k P c 以及类条件概率密度()|k P c x 已知的前提下,利用上述贝叶斯决策规则确定分类面。
贝叶斯决策器得到的分类面是最优的,它是最优分类器。
但贝叶斯决策器在确定分类面前需要预知()k P c 与()|k P c x ,这在实际运用中往往不可能,因为()|k P c x 一般是未知的。
因此贝叶斯决策器只是一个理论上的分类器,常用作衡量其它分类器性能的标尺。
最小风险贝叶斯决策可按下列步骤进行: (1)在已知)(i P ω,)(i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率:∑==cj iii i i P X P P X P X P 1)()()()()(ωωωωω j=1,…,x(2)利用计算出的后验概率及决策表,按下面的公式计算出采取i a ,i=1,…,a 的条件风险∑==cj j j i i X P a X a R 1)(),()(ωωλ,i=1,2,…,a(3)对(2)中得到的a 个条件风险值)(X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的决策k a ,即()()1,min k i i aR a x R a x ==则k a 就是最小风险贝叶斯决策。
模式识别习题及答案

第一章 绪论1.什么是模式?具体事物所具有的信息。
模式所指的不是事物本身,而是我们从事物中获得的___信息__。
2.模式识别的定义?让计算机来判断事物。
3.模式识别系统主要由哪些部分组成?数据获取—预处理—特征提取与选择—分类器设计/ 分类决策。
第二章 贝叶斯决策理论1.最小错误率贝叶斯决策过程? 答:已知先验概率,类条件概率。
利用贝叶斯公式得到后验概率。
根据后验概率大小进行决策分析。
2.最小错误率贝叶斯分类器设计过程?答:根据训练数据求出先验概率类条件概率分布 利用贝叶斯公式得到后验概率如果输入待测样本X ,计算X 的后验概率根据后验概率大小进行分类决策分析。
3.最小错误率贝叶斯决策规则有哪几种常用的表示形式? 答:4.贝叶斯决策为什么称为最小错误率贝叶斯决策?答:最小错误率Bayes 决策使得每个观测值下的条件错误率最小因而保证了(平均)错误率 最小。
Bayes 决策是最优决策:即,能使决策错误率最小。
5.贝叶斯决策是由先验概率和(类条件概率)概率,推导(后验概率)概率,然后利用这个概率进行决策。
6.利用乘法法则和全概率公式证明贝叶斯公式答:∑====mj Aj p Aj B p B p A p A B p B p B A p AB p 1)()|()()()|()()|()(所以推出贝叶斯公式7.朴素贝叶斯方法的条件独立假设是(P(x| ωi) =P(x1, x2, …, xn | ωi)⎩⎨⎧∈>=<211221_,)(/)(_)|()|()(w w x w p w p w x p w x p x l 则如果∑==21)()|()()|()|(j j j i i i w P w x P w P w x P x w P 2,1),(=i w P i 2,1),|(=i w x p i ∑==21)()|()()|()|(j j j i i i w P w x P w P w x P x w P ∑===Mj j j i i i i i A P A B P A P A B P B P A P A B P B A P 1)()|()()|()()()|()|(= P(x1| ωi) P(x2| ωi)… P(xn| ωi))8.怎样利用朴素贝叶斯方法获得各个属性的类条件概率分布?答:假设各属性独立,P(x| ωi) =P(x1, x2, …, xn | ωi) = P(x1| ωi) P(x2| ωi)… P(xn| ωi) 后验概率:P(ωi|x) = P(ωi) P(x1| ωi) P(x2| ωi)… P(xn| ωi)类别清晰的直接分类算,如果是数据连续的,假设属性服从正态分布,算出每个类的均值方差,最后得到类条件概率分布。
模式识别作业

模式识别作业2.6给出K-均值算法的程序框图,编写程序,自选一组分别属于三类的三维模式样本,并对它们进行聚类分析。
开始输入样本矩阵绘制样本数据的散点图输入聚类数目k 得到样本矩阵的大小聚类数目大于样本个数随机选取k 个样本作为初始聚类中心N 迭代次数=1计算各点到聚类中心的距离输出迭代次数,聚类中心,聚类结果按最短距离原则分配各点迭代次数+1计算各聚类中心的新向量值判断前后两次聚类中心是否变化结束N Y 输入错误,要求重新输入kYMATLAB程序代码clear all;clc;data=input('请输入样本数据矩阵:');X=data(:,1);Y=data(:,2);figure(1);plot(X,Y,'r*','LineWidth',3);axis([0 9 0 8])xlabel('x');ylabel('y');hold on;grid on;m=size(data,1);n=size(data,2);counter=0;k=input('请输入聚类数目:');if k>mdisp('输入的聚类数目过大,请输入正确的k值');k=input('请输入聚类数目:');endM=cell(1,m);for i=1:kM{1,i}=zeros(1,n);endMold=cell(1,m);for i=1:kMold{1,i}=zeros(1,n);end%随机选取k个样本作为初始聚类中心%第一次聚类,使用初始聚类中心p=randperm(m);%产生m个不同的随机数for i=1:kM{1,i}=data(p(i),:);while truecounter=counter+1;disp('第');disp(counter);disp('次迭代');count=zeros(1,k);%初始化聚类CC=cell(1,k);for i=1:kC{1,i}=zeros(m,n);end%聚类for i=1:mgap=zeros(1,k);for d=1:kfor j=1:ngap(d)=gap(d)+(M{1,d}(j)-data(i,j))^2;endend[y,l]=min(sqrt(gap));count(l)=count(l)+1;C{1,l}(count(l),:)=data(i,:);endMold=M;disp('聚类中心为:');for i=1:kdisp(M{1,i});enddisp('聚类结果为:');for i=1:kdisp(C{1,i});sumvar=0;for i=1:kE=0;disp('单个误差平方和为:');for j=1:count(i)for h=1:nE=E+(M{1,i}(h)-C{1,i}(j,h))^2;endenddisp(E);sumvar=sumvar+E;enddisp('总体误差平方和为:');disp(sumvar);%计算新的聚类中心,更新M,并保存旧的聚类中心for i=1:kM{1,i}=sum(C{1,i})/count(i);end%检查前后两次聚类中心是否变化,若变化则继续迭代;否则算法停止;tally=0;for i=1:kif abs(Mold{1,i}-M{1,i})<1e-5*ones(1,n)tally=tally+1;continue;elsebreak;endendif tally==kbreak;endEnd3.11给出感知器算法程序框图,编写算法程序.MATLAB 程序代码clear all;clc; disp('感知器算法求解两类训练样本的判别函数'); Data1=input('请输入第一类样本数据:'); Data2=input('请输入第二类样本数据:'); 开始输入两类样本数据及初始权向量值写成增广向量形式并进行规范化处理迭代次数=0校正增量系数=1计算判别函数判别函数>0校正权向量迭代次数+1输出权向量N Y 绘制判别函数结束W=input('请输入权向量初始值W(1)='); Expand=cat(1,Data1,Data2);ExpandData1=cat(2,Data1,ones(4,1));ExpandData2=cat(2,Data2.*-1,ones(4,1).*-1);ExpandData=cat(1,ExpandData1,ExpandData2); X=Expand(:,1);Y=Expand(:,2);Z=Expand(:,3);[ro,co]=size(ExpandData);Step=0;CountError=1;while CountError>0;CountError=0;for i=1:roTemp=W*ExpandData(i,:)';if Temp<=0W=W+ExpandData(i,:);disp(W)CounterError=CountError+1;endendStep=Step+1;enddisp(W)figure(1)plot3(X,Y,Z,'ks','LineWidth',2);grid on;hold on;xlabel('x');ylabel('y');zlabel('z');f=@(x,y,z)W(1)*x+W(2)*y+W(3)*z+W(4); [x,y,z]=meshgrid(-1:.2:1,-1:.2:1,0:.2:1);v=f(x,y,z);h=patch(isosurface(x,y,z,v ));isonormals(x,y,z,v,h)set(h,'FaceColor','r','EdgeColor','none');。
模式识别练习题

模式识别练习题模式识别练习题模式识别是一种认知能力,是人类大脑的重要功能之一。
通过模式识别,我们能够从复杂的信息中抽取出有用的模式,并进行分类、归纳和推理。
模式识别在日常生活中无处不在,无论是辨认人脸、理解语言还是解读图像,都离不开模式识别的帮助。
在这里,我将给大家提供一些模式识别练习题,帮助大家锻炼和提高自己的模式识别能力。
这些题目涵盖了不同的领域,包括数字、形状和图案等,旨在让大家在娱乐中提升自己的认知水平。
1. 数字序列请观察以下数字序列:2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, ...请问下一个数字是多少?答案:2048解析:观察数字序列,可以发现每个数字都是前一个数字的2倍。
因此,下一个数字是1024的2倍,即2048。
2. 形状序列请观察以下形状序列:▲, □, ○, △, ▢, ◇, ...请问下一个形状是什么?答案:□解析:观察形状序列,可以发现每个形状都是按照一定的规律交替出现。
▲和○是封闭的形状,□和▢是开放的形状,△和◇是封闭的形状。
因此,下一个形状应该是开放的形状,即□。
3. 图案序列请观察以下图案序列:A, AB, ABA, ABAC, ABACA, ...请问下一个图案是什么?答案:ABACABAC解析:观察图案序列,可以发现每个图案都是在前一个图案的基础上添加一个新的元素。
第一个图案是A,第二个图案是在A的基础上添加B,第三个图案是在ABA的基础上添加C,依此类推。
因此,下一个图案是在ABACABAC的基础上添加ABAC,即ABACABAC。
通过这些练习题,我们可以锻炼自己的观察力和逻辑思维能力。
模式识别不仅仅是一种认知能力,也是一种解决问题的思维方式。
通过不断地练习和思考,我们可以提高自己的模式识别能力,更好地应对各种复杂的情境和挑战。
除了以上的练习题,我们还可以通过观察自然界、阅读文学作品和解决日常问题等方式来锻炼模式识别能力。