(完整word版)图像编码基本方法
变换系数编码过程

变换系数编码过程
变换系数编码是一种无损压缩算法,常用于图像和音频的编码过程。
下面是变换系数编码的步骤:
1. 将原始数据分成若干个块,通常使用2D的块状分割。
2. 对每个块进行变换。
常用的变换有离散余弦变换(DCT)和离散小波变换(DWT)。
变换后的块将得到频域系数。
3. 对频域系数进行量化。
通常使用固定或可变的量化步长对频域系数进行量化,以减少数据的冗余,同时牺牲一定的精度。
4. 对量化后的系数进行编码。
常见的编码方法有无序编码(如哈夫曼编码)和有序编码(如游程编码和算术编码)。
编码后的系数可以使用更少的位数进行表示。
5. 对编码后的系数进行熵编码。
熵编码是对编码后的系数进行进一步压缩的技术,常见的方法有霍夫曼编码和算术编码。
6. 将编码后的数据进行存储或传输。
编码解码过程中使用的变换和量化方法会影响压缩效率和重构质量。
常用的变换系数编码算法有JPEG、JPEG2000和MPEG等。
计算机等级考试选择题(全含答案)

库一1、下列对信息的描述,错误的是(A )。
数据就是信息信息是用数据作为载体来描述和表示的客观现象信息可以用数值、文字、声音、图形、影像等多种形式表示信息是具有含义的符号或消息,数据是计算机内信息的载体2、以下关于图灵机的说法,错误的是(B)。
在图灵机的基础上发展了可计算性理论图灵机是最早作为数学运算的计算机图灵机是一种数学自动机器,包含存储程序的思想图灵机是一种抽象计算模型,用来精确定义可计算函数3、用32位二进制补码表示带符号的十进制整数的范围是(C)。
-4294967296~+4294967295-4294967296~+4294967296-2147483648~+2147483647-2147483647~+21474836484、某微型机的CPU中含有32条地址线、28位数据线及若干条控制信号线,对内存按字节寻址,其最大内存空间应是(A)。
A、4GBB、4MBC、256MBD、2GB5、下面关于计算机语言的叙述中,正确的是(D )。
汇编语言程序是在计算机中能被直接执行的语言机器语言是与计算机的型号无关的语言C语言是最早出现的高级语言高级语言是与计算机型号无关的算法语言6、中文Windows XP操作系统是一个(B )。
用户多任务操作系统单用户多任务操作系统多用户单任务操作系统单用户单任务操作系统7、中文WindowsXP中的"剪贴板"是(A )。
内存中的一块区域硬盘中的一块区域软盘中的一块区域高速缓存中的一块区域8、以下对WindowsXP的系统工具的叙述,错误的是(D )。
磁盘备份是防止硬盘的损坏或错误操作而造成数据丢失"磁盘清理"是将磁盘上的文件以某种编码格式压缩存储"磁盘碎片整理程序"可以将零散的可用空间组织成连续的可用空间"任务计划"不能清理硬盘9、下列关于WordXP各种视图的叙述中(C)是错误的。
数字图像处理实验报告 (图像编码)

实验三图像编码一、实验内容:用Matlab语言、C语言或C++语言编制图像处理软件,对某幅图像进行时域和频域的编码压缩。
二、实验目的和意义:1. 掌握哈夫曼编码、香农-范诺编码、行程编码2.了解图像压缩国际标准三、实验原理与主要框架:3.1实验所用编程环境:Visual C++6.0(简称VC)3.2实验处理的对象:256色的BMP(BIT MAP )格式图像BMP(BIT MAP )位图的文件结构:(如图3.1)图3.1 位图的文件结构具体组成图:单色DIB 有2个表项16色DIB 有16个表项或更少 256色DIB 有256个表项或更少 真彩色DIB 没有调色板每个表项长度为4字节(32位) 像素按照每行每列的顺序排列每一行的字节数必须是4的整数倍biSize biWidth biHeight biPlanes biBitCount biCompression biSizeImagebiXPelsPerMeter biYPelsPerMeter biClrUsedbiClrImportantbfType=”BM ” bfSizebfReserved1 bfReserved2 bfOffBits BITMAPFILEHEADER位图文件头 (只用于BMP 文件)BITMAPINFOHEADER位图信息头Palette 调色板DIB Pixels DIB 图像数据3.3 数字图像基本概念数字图像是连续图像(,)f x y 的一种近似表示,通常用由采样点的值所组成的矩阵来表示:(0,0)(0,1)...(0,1)(1,0)(1,1)...(1,1).........(1,0)(1,1)...(1,1)f f f M f f f M f N f N f N M -⎡⎤⎢⎥-⎢⎥⎢⎥⎢⎥----⎣⎦每一个采样单元叫做一个像素(pixel ),上式(2.1)中,M 、N 分别为数字图像在横(行)、纵(列)方向上的像素总数。
数字图像处理简答题复习重点word版本

1、数字图像处理的主要研究内容包含很多方面,请列出并简述其中的4种。
2、什么是图像识别与理解?5、简述图像几何变换与图像变换的区别。
6、图像的数字化包含哪些步骤?简述这些步骤。
7、图像量化时,如果量化级比较小会出现什么现象?为什么?8、简述二值图像与彩色图像的区别。
9、简述二值图像与灰度图像的区别。
10、简述灰度图像与彩色图像的区别。
11、简述直角坐标系中图像旋转的过程。
13、举例说明使用邻近行插值法进行空穴填充的过程。
14、举例说明使用均值插值法进行空穴填充的过程。
15、均值滤波器对高斯噪声的滤波效果如何?试分析其中的原因。
16、简述均值滤波器对椒盐噪声的滤波原理,并进行效果分析。
17、中值滤波器对椒盐噪声的滤波效果如何?试分析其中的原因。
18、使用中值滤波器对高斯噪声和椒盐噪声的滤波结果相同吗?为什么会出现这种现象?19、使用均值滤波器对高斯噪声和椒盐噪声的滤波结果相同吗?为什么会出现这种现象?20、写出腐蚀运算的处理过程。
21、写出膨胀运算的处理过程。
22、为什么YUV表色系适用于彩色电视的颜色表示?23、简述白平衡方法的主要原理。
24、YUV表色系的优点是什么?25、请简述快速傅里叶变换的原理。
26、傅里叶变换在图像处理中有着广泛的应用,请简述其在图像的高通滤波中的应用原理。
27、傅里叶变换在图像处理中有着广泛的应用,请简述其在图像的低通滤波中的应用原理。
28、小波变换在图像处理中有着广泛的应用,请简述其在图像的压缩中的应用原理。
29、什么是图像的无损压缩?给出2种无损压缩算法。
2、对于扫描结果:aaaabbbccdeeeeefffffff,若对其进行霍夫曼编码之后的结果是:f=01e=11 a=10 b=001 c=0001 d=0000。
若使用行程编码和霍夫曼编码的混合编码,压缩率是否能够比单纯使用霍夫曼编码有所提高?31、DCT变换编码的主要思想是什么?32、简述DCT变换编码的主要过程。
(完整word版)信息论与编码选择题

单项选择题1.下面表达式中正确的是(A )。
A.∑=j i j x y p 1)/( B.∑=i i j x y p 1)/( C.∑=j j j iy y x p )(),(ω D.∑=ii j i x q y x p )(),( 2.彩色电视显像管的屏幕上有5×105 个像元,设每个像元有64种彩色度,每种彩度又有16种不同的亮度层次,如果所有的彩色品种和亮度层次的组合均以等概率出现,并且各个组合之间相互独立。
每秒传送25帧图像所需要的信道容量(C )。
A. 50⨯106B. 75⨯106C. 125⨯106D. 250⨯1063.已知某无记忆三符号信源a,b,c 等概分布,接收端为二符号集,其失真矩阵为d=⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡1 21 12 1,则信源的最大平均失真度max D 为( D )。
A. 1/3B. 2/3C. 3/3D. 4/34.线性分组码不具有的性质是( C )。
A.任意多个码字的线性组合仍是码字B.最小汉明距离等于最小非0重量C.最小汉明距离为3D.任一码字和其校验矩阵的乘积c m H T =05.率失真函数的下限为( B )。
A .H(U) B.0 C.I(U; V) D.没有下限6.纠错编码中,下列哪种措施不能减小差错概率( D )。
A. 增大信道容量B. 增大码长C. 减小码率D. 减小带宽7.一珍珠养殖场收获240颗外观及重量完全相同的特大珍珠,但不幸被人用外观相同但重量仅有微小差异的假珠换掉1颗。
一人随手取出3颗,经测量恰好找出了假珠,不巧假珠又滑落进去,那人找了许久却未找到,但另一人说他用天平最多6次能找出,结果确是如此,这一事件给出的信息量( A )。
A. 0bitB. log6bitC. 6bitD. log240bit8.下列陈述中,不正确的是( D )。
A.离散无记忆信道中,H (Y )是输入概率向量的凸函数B.满足格拉夫特不等式的码字为惟一可译码C.一般地说,线性码的最小距离越大,意味着任意码字间的差别越大,则码的检错、纠错能力越强D.满足格拉夫特不等式的信源是惟一可译码9.一个随即变量x 的概率密度函数P(x)= x /2,V 20≤≤x ,则信源的相对熵为( C )。
(完整word版)数字图像处理_胡学龙_许开宇_课后答案
胡学龙、许开宇编著《数字图像处理》思考题与习题参考答案第1 章概述1。
1 连续图像和数字图像如何相互转换?答:数字图像将图像看成是许多大小相同、形状一致的像素组成。
这样,数字图像可以用二维矩阵表示.将自然界的图像通过光学系统成像并由电子器件或系统转化为模拟图像(连续图像)信号,再由模拟/数字转化器(ADC)得到原始的数字图像信号。
图像的数字化包括离散和量化两个主要步骤。
在空间将连续坐标过程称为离散化,而进一步将图像的幅度值(可能是灰度或色彩)整数化的过程称为量化。
1。
2 采用数字图像处理有何优点?答:数字图像处理与光学等模拟方式相比具有以下鲜明的特点:1.具有数字信号处理技术共有的特点。
(1)处理精度高。
(2)重现性能好.(3)灵活性高。
2.数字图像处理后的图像是供人观察和评价的,也可能作为机器视觉的预处理结果.3.数字图像处理技术适用面宽。
4.数字图像处理技术综合性强。
1。
3 数字图像处理主要包括哪些研究内容?答:图像处理的任务是将客观世界的景象进行获取并转化为数字图像、进行增强、变换、编码、恢复、重建、编码和压缩、分割等处理,它将一幅图像转化为另一幅具有新的意义的图像。
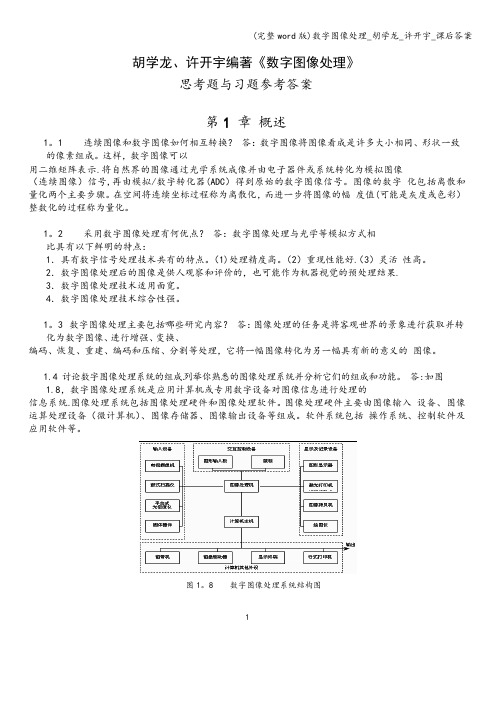
1.4 讨论数字图像处理系统的组成.列举你熟悉的图像处理系统并分析它们的组成和功能。
答:如图1.8,数字图像处理系统是应用计算机或专用数字设备对图像信息进行处理的信息系统.图像处理系统包括图像处理硬件和图像处理软件。
图像处理硬件主要由图像输入设备、图像运算处理设备(微计算机)、图像存储器、图像输出设备等组成。
软件系统包括操作系统、控制软件及应用软件等。
图1。
8 数字图像处理系统结构图11。
5 常见的数字图像处理开发工具有哪些?各有什么特点?答.目前图像处理系统开发的主流工具为 Visual C++(面向对象可视化集成工具)和 MATLAB 的图像处理工具箱(Image Processing Tool box)。
两种开发工具各有所长且有相互间的软件接口。
(word完整版)产品编码规则

产品编码规则版本记录:1 目的使全体员工了解公司产品编码规则及编码中相应代码含义,便于产品编码的统一管理。
2 参考文件《产品标识和可追溯性控制程序》3 适用范围公司内部用于产品方面的所有整机、单机、包装、组件、原材料及外加工产品。
4 产品编码规则4。
1 产品编号构成(特征:第1位代码3)①②③④①前2位数字表示结构类别代码(整机、单机、包装)具体如下:30代表:整机31代表:单机32代表:包装XX代表:为可拓展码段,暂时留用。
②第3位数字表示名称类别代码(如:氧气机,呼吸机)具体如下:1代表:氧气机2代表:呼吸机X:为可拓展码段,暂时留用。
③第4、5位的XX表示第三分类号(例如:整机中的某种型号或组件中的某一特征)XX具体含义如下:oo机:XX代表最大流量,例如03代表3LPM,05代表5LPM.aa机:XX代表最大压力,例如20代表20cmH2O,25代表25cmH2O。
XX代表:为可拓展码段,暂时留用.④最后4位的XXXX表示产品设计序列号4.2 组件编号构成(特征:第1位代码为4)①②③④①前2位数字表示结构类别代码(组件)具体如下:40代表:生产组件41代表:售后组件XX代表:为可拓展码段,暂时留用。
②第3位数字表示名称类别代码,(如:oo,aa)具体如下:1代表:oo2代表:aaX:为可拓展码段,暂时留用.③第4、5位的XX表示第三分类号(例如:表示组件中的某一特征组件)01代表:oo机分子筛罐组件02代表:oo机储氧罐组件03代表:压缩机组件05代表:机加气控阀组件06代表:前壳组件07代表:后壳粘贴组件08代表:底座组件09代表:进气罐组件10代表:、排气罐组件11代表:罩壳组件21代表:风扇组件22代表:分子筛罐组件24代表:反吹管路组件25代表:线路板组件XX:为可拓展码段,暂时留用④最后4位的XXXX表示:序列号.4.3 原材料编码规则(特征:第1位代码为5,6或7)XX X XX XXXX (9位数字组成)①②③④①前2位数字表示结构类别代码(专用原材料,常规采购原材料或外协加工件)具体如下:50代表:专用原材料60代表:常规采购原材料70代表:外协加工原材料XX代表:为可拓展码段,暂时留用②前3位数字表示:原材料第一分类后更细化的第二分类序号501表示:oo机专用件;601表示:电器;602表示:超领核销;604表示:接头;605表示:塑料件;606表示:其它材料;具体实例如下:③前五位数字表示:更细化的第三分类序号50专用件细分如下:其它为可拓展码段,暂时留用;60常规采购原材料细分如下:其它为可拓展码段,暂时留用;70外协加工原材料细分如下:其它为可拓展码段,暂时留用;具体详细内容可参考《料代码清单》④最后4位的XXXX表示:序列号5 产品、组件和原材料编码举例例1:301030005表示:产品设计序列号为0005的3LPMoo机整机例2:301050020表示:产品设计序列号为0020的5LPMoo机整机例3:311030006表示:产品设计序列号为0006的3LPMoo机单机。
(完整word版)《多媒体技术》测试题及答案

专科《多媒体技术》测试题一、判断题目(正确的在后面写“T”错误的写“F" ,每题1分)1.帧动画是对每一个活动的对象分别进行设计,并构造每一个对象的特征,然后用这些对象组成完整的画面. ( F)2.软件性能评价是指在规定时间和年件下,软件完成规定功能的能力。
(F)3、若CD—ROM光盘存储的内容是文本(程序和数字),则对误码率的要求较,若对于声音和图像的存储,误码率要求就较高。
(F)4、寻道时间反映了DVD驱动器接受系统指令到指定的位置读出数据的快慢.(T)5、美国的“原版”DVD光盘,在标有中国区码的DVD-ROM驱动器上能读出。
(F)6、。
声卡可支持11.025Hz、22.05Hz、44.1Hz三种采样频率。
11。
025KHz、22.05KHz、44。
1KHz7、在扫描照片图像时,为获得最佳的效果,往往选择最大的分辨率,这是正确的选择。
(F)8、激光打印机是用受主机中图像信息调制的激光束直接照射在纸张上成像。
(F)9、红外线式触摸屏价格便宜,但分辨率低,适合室外,用属低档产品.(F)10、电容式触摸屏分辨率高,寿命长、抗腐蚀、耐磨损,紧贴显像管安装于显示器壳内,不易损坏,属低档产品。
(F)11.多媒体数据的特点是数据量巨大、数据类型少、数据类型间区别大和输入输出复杂.(F)12.对于位图来说,采用一位位图时每个像素可以有黑白两种颜色,而用二位位图时每个像素则可以有三种颜色。
(F)13.在CD-ROM的设计中应考虑四个因素:数据文件的命名和定位、存储能力、数据传输速率和平均查找时间。
(T)14.音频(Audio)指的是大约在20Hz~20kHz频率范围的声音。
(T)15.预测编码是一种只能针对空间冗余进行压缩的方法。
(F)16.熵压缩法可以无失真地恢复原始数据。
(F)17.音频卡是按声道数分类的。
(F)18.在CD—ROM的设计中应考虑四个因素:数据文件的命名和定位、存储能力、数据传输速率和平均查找时间. (T )19.红外触摸屏必须用手等导电物体触摸。
bmp编码规则

BMP(Bitmap Image File)是一种位图图像文件格式,它的编码规则如下:
1. BMP文件格式由文件头、位图信息头、颜色表和位图数据四部分组成。
2. 文件头包括两个字节的文件类型标识和四个字节的文件大小。
其中,文件类型标识固定为0x4d42,即"BM"。
3. 位图信息头包括14个字节的信息,包括位图宽度、位图高度、像素位数、压缩方式等。
4. 颜色表用于存储位图中的颜色信息,它由若干个RGBQUAD结构组成。
每个RGBQUAD结构包含红色、绿色、蓝色和保留字段,其中保留字段用于填充位图数据中的空隙。
5. 位图数据是位图中每个像素值的序列,按照扫描行内从左到右、扫描行之间从下到上的顺序记录。
需要注意的是,BMP文件的编码方式有多种,包括不压缩、RLE压缩等。
不同的编码方式会影响到BMP文件的存储大小和显示效果。
编码 的知识 -回复

编码的知识-回复编码是一种将信息从一种形式转换为另一种形式的过程。
在信息技术领域,编码通常指的是将文本、图像、音频和视频等媒体数据转换为计算机可以理解和处理的二进制数据。
这篇文章将一步一步回答关于编码的知识。
第一步:了解编码的概念和原理编码是将信息转换为特定规则下的序列的过程。
在计算机科学中,编码是将字符、数字、图像、音频和视频等多媒体数据转换为二进制数值的过程。
编码的目的是提供一种统一的标准,便于数据的存储、传输和处理。
第二步:了解常见的编码方式在计算机领域,有许多常见的编码方式,包括ASCII码、Unicode、UTF-8和Base64等。
ASCII码是最早的字符编码系统,它将字符映射到一个7位二进制数值。
Unicode是一种支持全球范围内字符的编码标准,使用16位或32位二进制数表示字符。
UTF-8是Unicode的一种变体,通过变长编码来节省存储空间。
Base64是一种将二进制数据转换为可打印字符的编码方式,常用于电子邮件和数据传输。
第三步:了解图像编码图像编码是将图像数据转换为计算机可识别的二进制数据的过程。
常见的图像编码方式包括JPEG、PNG和GIF等。
JPEG是一种有损压缩编码方式,具有高压缩率和较低的图像质量损失。
PNG是一种无损压缩编码方式,保留了更高质量的图像数据。
GIF是一种使用LZW算法进行压缩的编码方式,适用于简单的动画和图形。
第四步:了解音频编码音频编码是将音频数据转换为计算机可识别的二进制数据的过程。
常见的音频编码方式包括MP3、AAC和FLAC等。
MP3是一种有损压缩编码方式,通过减少音频数据中的冗余和无关信息来实现高压缩率。
AAC是一种更先进的音频压缩编码方式,具有更好的声音质量和较低的比特率。
FLAC 是一种无损压缩编码方式,保留了完整的音频数据。
第五步:了解视频编码视频编码是将视频数据转换为计算机可识别的二进制数据的过程。
常见的视频编码方式包括MPEG-2、H.264和HEVC等。
医学图像处理重点知识概要

1. 灰度直方图
定义:图象中象素灰度分布的概率密度函数;是灰度级的函数,描述的是图像中各灰度 级的像素个数,即横坐标表示灰度级,纵坐标表示图像中该灰度级出现的个数;
性质:①反映图像灰度分布情况,丢失了像素的位置信息,不包含图象灰度分布的空间信 息,因此无法解决目标形状问题;②具有不唯一性,不同图象可能对应相同的直方图;③具 有可加性,即图象总体直方图等于切分的各个子图象的直方图之和;
(u,
v)
=
1 1+[D(u, v)
/
D10
]2n
n 为滤波器的阶次,D0 为截止频率
3)巴特沃斯高通滤波器:H (u , v ) = 1 + [ D0 / D (u , v )] 2n 通过高频分量,削弱低频分量
4)同态滤波:图像 f(x,y)是由光源产生的照度场 i(x,y)和目标的反射系数场 r(x,y)的共
1 I×J
I i =1
J
[x(i, j) − x(i, j)]2 归一化后: NMSE
j =1
=
i =1
[x(i, j) − x(i,
j =1
IJ
x2 (i, j)
j )] 2
i =1 j =1
∑ ∑ 绝对误差: MAE = 1
IJ
x(i, j) − x(i, j)
I × J i=1 j=1
1
∑ ∑ 峰值信噪比: PSNR = 10lg
1
x2 max
IJ
[x(i, j) − x(i, j)]2
I ⋅ J i=1 j=1
第二章 图像文件的格式
BMP 文件,不压缩形式(WORD 类型 2 个字节,DWOR、DLONG 4 个字节)
(完整word版)MPEG4压缩编码算法简介

MPEG4压缩编码算法简介视频压缩:MPEG4视频压缩编码后包括三种元素:I帧(I-frames)、P帧(P-frames)和B帧(B-frames)。
在MPEG编码的过程中,部分视频帧序列压缩成为I帧;部分压缩成P帧;还有部分压缩成B帧。
I帧法是帧内压缩法,也称为“关键帧”压缩法。
I帧法是基于离散余弦变换DCT(Discrete Cosine Transform )的压缩技术,这种算法与JPEG压缩算法类似。
采用I帧压缩可达到1/6的压缩比而无明显的压缩痕迹。
在保证图像质量的前提下实现高压缩的压缩算法,仅靠帧内压缩是不能实现的,MPEG采用了帧间和帧内相结合的压缩算法。
P帧法是一种前向预测算法,它考虑相邻帧之间的相同信息或数据,也即考虑运动的特性进行帧间压缩。
P帧法是根据本帧与相邻的前一帧(I帧或P帧)的不同点来压缩本帧数据。
采取P帧和I帧联合压缩的方法可达到更高的压缩且无明显的压缩痕迹。
然而,只有采用B帧压缩才能达到200:1的高压缩。
B帧法是双向预测的帧间压缩算法。
当把一帧压缩成B帧时,它根据相邻的前一帧、本帧以及后一帧数据的不同点来压缩本帧,也即仅记录本帧与前后帧的差值。
B帧数据只有I帧数据的百分之十五、P帧数据的百分之五十以下。
MPEG标准采用类似4:2:2的采用格式,压缩后亮度信号的分辨率为352×240,两个色度信号分辨率均为176×120,这两种不同分辨率信息的帧率都是每秒30帧。
其编码的基本方法是在单位时间内,首先采集并压缩第一帧的图像为I帧。
然后对于其后的各帧,在对单帧图像进行有效压缩的基础上,只存储其相对于前后帧发生变化的部分。
帧间压缩的过程中也常间隔采用帧内压缩法,由于帧内(关键帧)的压缩不基于前一帧,一般每隔15帧设一关键帧,这样可以减少相关前一帧压缩的误差积累。
MPEG编码器首先要决定压缩当前帧为I帧或P帧或B帧,然后采用相应的算法对其进行压缩。
一个视频序列经MPEG全编码压缩后可能的格式为:IBBPBBPBBPBBPBBIBBPBBPBBPBBPBBI......压缩成B帧或P帧要比压缩成I帧需要多得多的计算处理时间。
(完整word版)数字电视技术考试题(参考)(word文档良心出品)

A卷填空题(每个1分, 共20分)1、通信系统由三大部分组成: (信源)、(信道)、(信宿)。
32.我国数字电视按信号传输方式分为(地面无线传输数字电视)(卫星传输数字电视)其标准为(DVB-S)和(有线传输数字电视)其标准为(DVB-C)和(地面数字电视标准)其标准为(DVB-T/DMB-T/DTTB)。
63、在数字复用中, SPTS的含义为单节目流, 而MPTS的含义为多节目流。
24.节目专用信息PSI表由PAT表、(PMT表)、(CA T表)和(NIT表)组成。
35.图像的4个级别(低级(LL))、(主级(ML: Main level))、(高1440级(H14L))和(高级(HL))。
41、6、数字电视中用于显示的设备有: 阴极射线管显示器(CRT)、(液晶显示器(LCD))、(等离子体显示器(PDP))、投影显示(包括前投、背投)等。
2、选择题(每个1分, 共12分)3、在数字传输系统中, 通常 B 用于地面传输, E 用于卫星传输。
4、A.DSB-SC B、QAM C、PDM D、PSM E、QPSK5、在数字广播电视系统选用的编解码设备一般采用 B 标准。
6、A.MPEG-1 B.MPEG-2 C.JPEG D.MPEG-47、在MPEG–2中图像分成三种编码类型:I帧为(C)、B帧为(B )和P 帧(A)。
其中(B)的压缩比最高, ( C )的压缩比最低。
8、A.双向预测编码的图像 B.前向预测编码的图像 C.帧内编码的图像9、PSI 表中的CAT 表是(B ), PMT表(C )。
A.节目关联表B.条件接收表C.节目映射表D.网络信息表调制误差率MER值越大说明调制的准确率越(C), 码流出现的误码越(B), 图象质量越好。
A.大B、小C、高D、低三、简述题和计算题1.什么是数字电视?与模拟电视比有哪些优点?10分2.请说明电视信号数字化的3个步骤。
10分3.什么是复合编码?什么是分量编码, 它们各有什么特点?5分视频信号的编码方式:复合编码(composite video): 将彩色全电视信息直接编成PCM码, 变成一个数字复合电视信号分量编码(component video):将亮度信号Y, 色差信号R- Y和B-Y分别编码成三个数字分量电视信号二者比较:“复合编码”与电视制式有关。
(word完整版)ENVI使用手册

第一章:ENVI 概述如何使用本手册本手册包括若干章节;每章描述 ENVI 提供的一系列处理程序。
多数章节遵循 ENVI 的菜单结构。
例如,第 4 章的标题为“Basic Tools",它描述的功能可以在 ENVI 的Basic Tools下拉菜单下找到。
5 个附录分别针对:ENVI基本功能、文件格式、波谱库、地图投影以及描述 ENVI 该版本的新特征.该介绍性章节包括与 ENVI 图形用户界面(GUI)的交互,使用 ENVI 窗口,及其它介绍性材料。
新的 ENVI 用户使用前务必认真阅读本手册,以及附带的 ENVI 教程.对于章节中的每个主题,功能描述之后给出了实现它的一步步向导.向导中描述了参数,通常还附有建议和例子。
大多数功能(除了交互的功能) 从 ENVI 的下拉主菜单启动。
出现包含接受用户输入参数的对话框。
许多参数包含系统默认值并且有一些是可选的。
当功能运行时,出现一个处理状态窗口。
运行功能的一步步向导被编号并且用粗体显示。
鼠标控制菜单选项与用斜体字印刷的下拉菜单一同出现。
子菜单用“〉" 连接。
每个步骤内的选项用项目符号显示。
按钮名用引号标明,对话框标题以大写字母开头。
一些对话框内部有下拉菜单。
每个下拉菜单下的选项通常在以该下拉菜单名为标题的一节中描述.例如,这些是如何对一个文件进行中值滤波的向导:1. 从 ENVI 主菜单,选择Filters > Convolutions > Median .将出现一个文件选择对话框,允许你交互地改变目录并选定需要的输入文件。
2. 通过点击文件名,再点击“OK” 或“Open",来选择所需要的文件。
若有必要,使用任意空间和/或波谱的构造子集(subsetting)。
3。
当出现 Convolution Parameters 对话框,在“Size” 文本框中,输入所需要的滤波器大小.4。
选择输出到“File” 或“Memory",若需要,键入一个输出文件名.5. 点击“OK”,开始处理.ENVI 图形用户界面( GUI )要有效地使用 ENVI,你必须熟悉图形用户界面(GUI)的概念。
(完整word版)数字图像处理期末考试试题

数字图像处理期末考试试题一、单项选择题(每小题1分,共10分)( d )1。
一幅灰度级均匀分布的图象,其灰度范围在[0,255],则该图象的信息量为:a。
0 b.255 c。
6 d.8( b )2.图象与灰度直方图间的对应关系是:a.一一对应b.多对一c。
一对多 d.都不对( d )3.下列算法中属于局部处理的是:a.灰度线性变换b。
二值化 c.傅立叶变换d。
中值滤波( b )4。
下列算法中属于点处理的是:a.梯度锐化b。
二值化 c.傅立叶变换 d.中值滤波( d ) 5.一曲线的方向链码为12345,则曲线的长度为a。
5 b。
4 c.5。
83 d.6。
24( c )6. 下列算法中属于图象平滑处理的是:a.梯度锐化b.直方图均衡c. 中值滤波placian增强( b )7。
下列图象边缘检测算子中抗噪性能最好的是:a。
梯度算子 b.Prewitt算子c。
Roberts算子d。
Laplacian算子( c )8.采用模板[-1 1]主要检测____方向的边缘。
a。
水平 b.45°c。
垂直d。
135°( d )9.二值图象中分支点的连接数为:a.0b.1c.2d.3( a )10。
对一幅100´100像元的图象,若每像元用8bit表示其灰度值,经霍夫曼编码后压缩图象的数据量为40000bit,则图象的压缩比为:a。
2:1 b.3:1 c.4:1 d。
1:2二、填空题(每空1分,共15分)1。
图像锐化除了在空间域进行外,也可在频率域进行。
2。
图像处理中常用的两种邻域是 4-邻域和 8—邻域。
3。
直方图修正法包括直方图均衡和直方图规定化两种方法。
4.常用的灰度内插法有最近邻元法、双线性内插法和(双)三次内插法。
5。
多年来建立了许多纹理分析法,这些方法大体可分为统计分析法和结构分析法两大类. 6。
低通滤波法是使高频成分受到抑制而让低频成分顺利通过,从而实现图像平滑.7。
检测边缘的Sobel算子对应的模板形式为和。
(完整word版)信封中邮政编码位置的定位

燕山大学课程设计说明书题目:信封中邮政编码位置的定位学院(系):电气工程学院年级专业:学号:学生姓名:指导教师教师职称:讲师讲师燕山大学课程设计(论文)任务书年月日摘要图像是一种重要的信息源,通过图像处理可以帮助人们了解信息的内涵。
数字图像处理是一门综合性很强的边缘性学科。
如今其理论体系已十分完善,且其实践应用很广泛,在医学、军事、艺术、遥感等都有广泛且成熟的应用。
MATLAB是一种高效的工程计算语言,在数值计算、数据处理、图像处理等方面都有广泛的应用。
MATLAB是一种向量语言,它非常适合于进行图像处理。
本文主要研究对信封图片中邮政编码位置的定位的方法。
利用MATLAB寸图片进行相关处理,使彩色图片变成灰度图像。
将灰度图像通过适当的阈值选取而获得可以反映图像整体和局部特征的二值图像。
根据投影法得到的位置信息实现对信封中邮政编码位置的定位,从而提取出仅包含有手写邮政编码的数字图像。
当有手写数字超出红色方框时,最后进行区域定位时可以扩大定位范围,将超出部分包含在定为区域内。
关键字:图像处理邮政编码定位二值化目录第一章彩色图像的二值化 ................................ 4 1、 ................................. 彩色图像变为灰度图像 42、 灰度图像二值化 (4)第二章邮政编码的定位和提取1、 邮政编码位置的定位....2、 ..................... 手写邮政编码提取 ................3、 ..................... 超出红方框的情况 ................ 第三章matlab 程序 .......... 第四章课程设计总结 ......... 参考文献资料 ...............第一章彩色图像的二值化1彩色图像变为灰度图像使用MATLAB 进行处理时,所读入的信封图像是 RGB 三维矩阵,在以后的处理中用到的是 灰度图像和二值图像,因此,必须经过处理变成灰度图像。
吸色像素编码

吸色像素编码
吸色像素编码通常是指在数字图像处理中,从一个图像中吸取颜色并将其应用于另一个图像或像素的过程。
这个过程涉及到颜色空间的转换和像素值的计算。
在数字图像处理中,颜色通常由三个或四个分量表示,如RGB (红、绿、蓝)或RGBA(红、绿、蓝、透明度)。
每个分量通常是一个8位的整数,范围从0到255。
因此,一个像素的颜色可以用一个三元组(RGB)或四元组(RGBA)表示。
吸色像素编码的过程通常包括以下步骤:
1、从源图像中吸取颜色。
这可以通过在源图像上选择一个像素点并获取其颜色值来实现。
2、将吸取的颜色转换为所需的颜色空间。
例如,如果源图像使用RGB颜色空间,而目标图像使用CMYK颜色空间,那么就需要将RGB颜色转换为CMYK颜色。
3、将转换后的颜色应用于目标图像的像素。
这可以通过计算目标像素与吸取的像素之间的差值,并将该差值添加到目标像素的颜色值中来实现。
需要注意的是,吸色像素编码可能会导致图像的颜色失真或变形,因为它忽略了像素之间的空间关系和颜色分布。
因此,在实际应用中,需要根据具体情况选择合适的颜色吸取方法和像素编码算法,以达到最佳的效果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、霍夫曼编码(Huffman Codes)
最佳编码定理:在变长编码中,对于出现概率大的信息符号编以短字长的码,对于出现概率小的信息符号编以长字长的码,如果码字长度严格按照符号出现概率大小的相反的顺序排列,则平均码字长度一定小于按任何其他符号顺序排列方式的平均码字长度。
霍夫曼编码已被证明具有最优变长码性质,平均码长最短,接近熵值。
霍夫曼编码步骤:设信源X 有m 个符号(消息)⎭⎬⎫⎩⎨⎧=m m p x p p x x X ΛΛ2121
,
1. 1. 把信源X 中的消息按概率从大到小顺序排列,
2. 2. 把最后两个出现概率最小的消息合并成一个消息,从而使信源的消息数减少,并同时再按信源符号(消息)出现的概率从大到小排列;
3. 3. 重复上述2步骤,直到信源最后为⎭⎬⎫⎩⎨⎧=o o o o o p p x x X 212
1为止;
4. 4. 将被合并的消息分别赋予1和0,并对最后的两个消息也相应的赋予1和0;
通过上述步骤就可构成最优变长码(Huffman Codes)。
例:
110005.0010010.000015.01120.00125.01025.065
4
3
2
1
x x x x x x P X
i 码字编码过程
则平均码长、平均信息量、编码效率、冗余度为分别为:
%
2%
9842
.2)05.0log 05.01.0log 1.015.0log 15.02.0log 2.025.0log 25.02(45
.205.041.0415.0320.0225.022===⨯+⨯+⨯+⨯+⨯⨯-==⨯+⨯+⨯+⨯+⨯⨯=Rd H N η
二 预测编码(Predictive encoding )
在各类编码方法中,预测编码是比较易于实现的,如微分(差分)脉冲编码调制(DPCM )方法。
在这种方法中,每一个象素灰度值,用先前扫描过的象素灰度值去减,求出他们的差值,此差值称为预测误差,预测误差被量化和编码与传送。
接收端再将此差值与预测值相加,重建原始图像象素信号。
由于量化和传送的仅是误差信号,根据一般扫描图像信号在空间及时间邻域内个象素的相关性,预测误差分布更加集中,即熵值比原来图象小,可用较少的单位象素比特率进行编码,使得图象数据得以压缩。
当输入图象信号是模拟信号时,“量化”过程中的信息损失不可避免的。
预测器预测值 ∑-=-=111
ˆN i N i X Q X
其中 i Q 应适当选择使预测误差最小,即使 N N N X X e ˆ-=最小。
然后,非均匀量化此预测误差 N e ,就能产生最小均方误差的最佳 N e ˊ,经编码后发送。
接收端解码得到的 N e 加上预测值就能再现
N X ,它与原始图象的存在误差为 'N N N X X g -=。
这里关键的问题是选择适当的 i Q ,使预测效果最好,即预测差值的方差最小。
对于隔行扫描的电视图象通常有
)1,1(81)1,1(81),1(41)1,(21),()1,1(4
1),1(41)1,(21),(+-+--+-+-=--+-+-=
y x f y x f y x f y x f y x f y x f y x f y x f y x f 或 其它预测方法有:
1. 1. 前值预测,用()y x f ,同一行中临近前面一象素预测,即
()()1,,^
-=y x f y x f 2. 2. 一维预测,用同一行中前面若干象素预测;
3. 3. 二维预测,用几行内象素预测;
4. 4. 三维预测,利用相邻两帧图像信号的相关性预测。
三 变换编码(Transform encoding )
前面图象变换章节已经说明图象变换会使图象信号能量在空间重新分布,其中低频成分占据能量的绝大部分,而高频成分所占比重很小,根据统计编码的原理,能量分布集中,熵值最小,可实现平均码长最短。
变换编码的基本原理是将原来在空域描述的图象信号,变换到另外一些正交空间中去,用变换系数来表示原始图象,并对变换系数进行编码。
一般来说在变换域里描述要比在空域简单,因为图象的相关性明显下降。
尽管变换本身并不带来数据压缩,但由于变换图象的能量大部分只集中于少数几个变换系数上,采用量化和熵编码则可以有效地压缩图象的编码比特率。
根据上面的原理变换编码的一般过程如下: 输入图象 变换 量化 编码器 -- - 译码器 逆变换 输出
常用的变换编码所使用的变换有离散余弦变换(DCT )和沃尔什--哈达玛变换(WHT )。
变换后图象能量更加集中,在量化和编码时,结合人类视觉心理因素等,采用“区域取样”或“阈值取样”等方法,保留变换系数中幅值较大的元素,进行量化编码,而大多数幅值小或某些特定区域的变换系数将全部当作零处理。
四 方块编码(Block encoding)
方块编码是静态图像编码的一种方法,它可将某一帧图象得以压缩而不致使图象质量有明显的下降。
它是将图象()y x f ,划分成n n N ⨯=大小互不重叠的子块,由于子块内各临近象素间具有灰度相关性,可选用两个适当的灰度级来近似代表子块内各象素原来的灰度。
通常可以利用均方误差最小的方法来逐个求出各子块的这两个代表灰度级,然后指明子块内各个象素分别属于哪个代表性灰级。
这两个代表性灰级称为灰度分量,而指明某象素属哪个代表性灰级的信息称为分辨率分量。
设子块内共有 N 个象素,其中第 i 个象素 i p 的灰值为 i x ,编码后子块有两个代表性灰度分量 10,a a ,用 i ϕ表示象素 i p 的分辨率分量, r x 为方块内阈值,则编码后 i p 象素的灰度级为 i y ,
10a a y i i i ⨯+⨯=-
ϕϕ ⎩⎨⎧<≥=T i T
i i x x if x x if
01ϕ
子块内象素编码后为 {}N y y y Λ,,21可以由 {}10,a a 和 {}N ϕϕϕ,,,21Λ的组合来表示。
这种编码方法每个象素所用比特数,比各象素独立编码所用比特数有大幅度降低。
设 10,a a 各用 P 比特, i ϕ用1比特,则每个象素的比特数 B 为: N P B 21+=。
当 N 取值 Y 越大, B 越小,压缩比越大,但图像质量也会相应下降,因为方块越大,该方块内个象素间的相关性也就越小,只用两个灰度级当然逼真度越差。
通常方块尺寸选为 44⨯=N 较好。
当 44⨯=N 时, 8=P 比特,则方块编码的每个象素的比特数 比特2=B ,压缩比为 4。
适当选择10,a a 和r x ,使编码后方块灰度值和方差与原始图象的灰度相同或近似相同,其中一种方法是设灰度阈值为x ,则有
∑=-==N i i T x
N x x 11
∑<=T i x x i N x a 00 ∑≥=T i x x i N x a 11
即r x 为方块内象素的平均灰度,把象素分成比平均值r x 大和小的两组,0a 是方块中灰度级低于X T 的组内象素灰级的平均值,1a 为灰度级高于r x 的一组各象素灰级的平均值。